データサイエンティスト協会 構造化データ前処理 100 本ノック with Exploratory
問21〜問30 の答案
答案全体を通して
Exploratory では R 言語が動いていますが, 解答やコード参照の説明では Python言語 のものでやります。
SQL的な視点や考え方が入るときもその都度書きたいと思います。枠の色使いは以下のような形を意識しています。
オレンジ枠 :
あか枠 :
あお枠 :
みどり枠 :
問21 : データの件数をカウントする

答案・解説はこちら
これは何かの操作をすることはないです。
df_receipt のデータをサイドバーから選べば、テーブル・ビューの上に行数が書いてありますので既にカウントされています。
解答も確認してみましょう。 
Python 解答コードはこちら
解答コードはこのようになっています。
len(df_receipt)
データの件数をカウントすることの意味
データの件数とはつまり、データの行数であることは理解してもらえたでしょう。
では、どうしてデータの件数をカウントしたのでしょうか?
その意味はなんだと思いますか?
実はここに問題のキーポイントがあります。
まず、データを扱う人は必ずしています。
すごく大事なことなので、今回のデータでイメージを再現してみました。
まずは見てください。 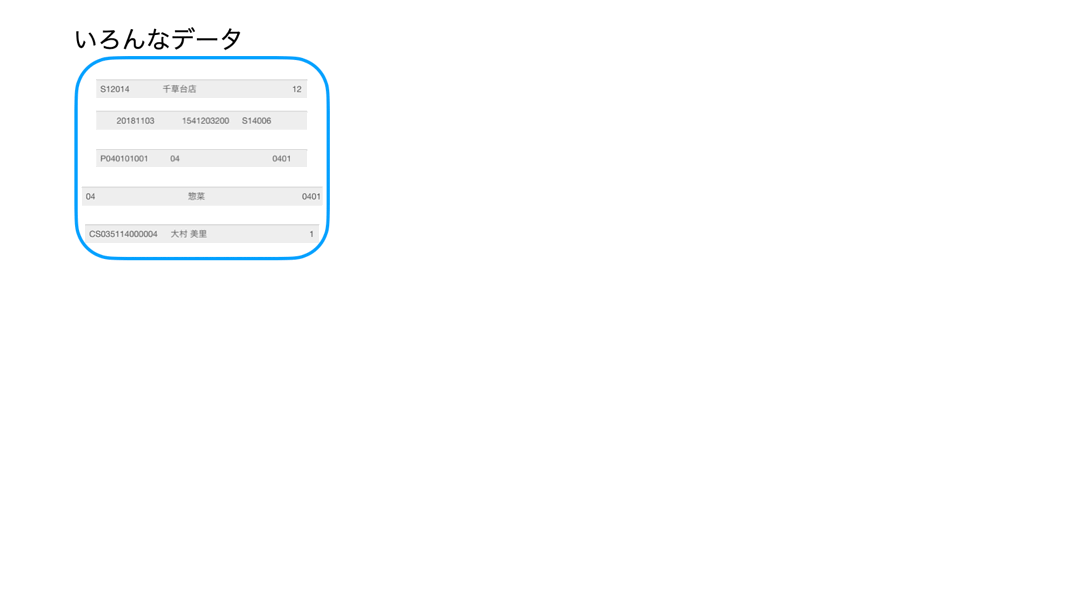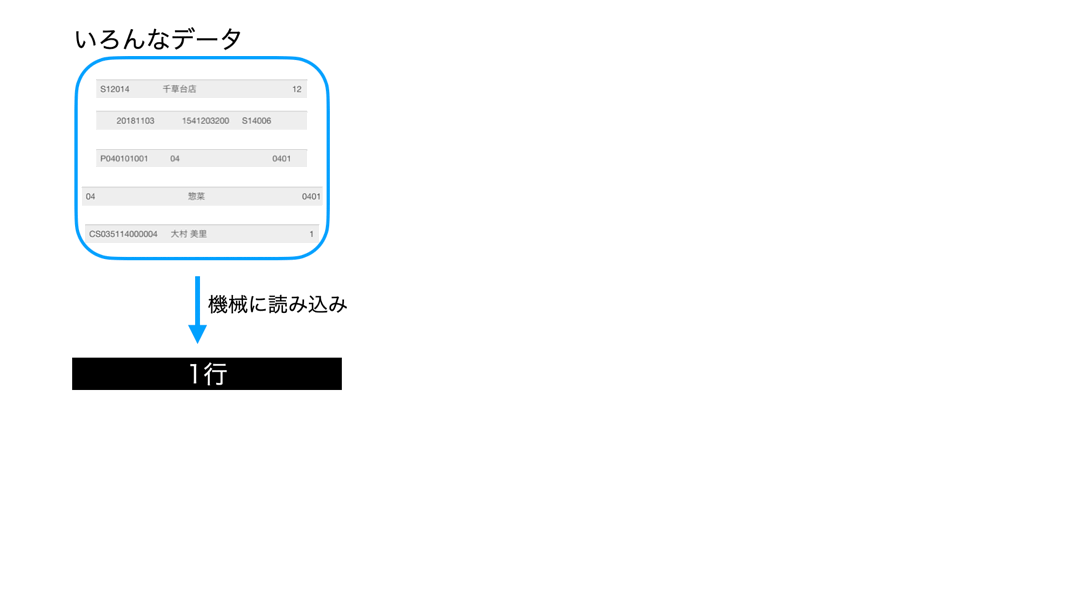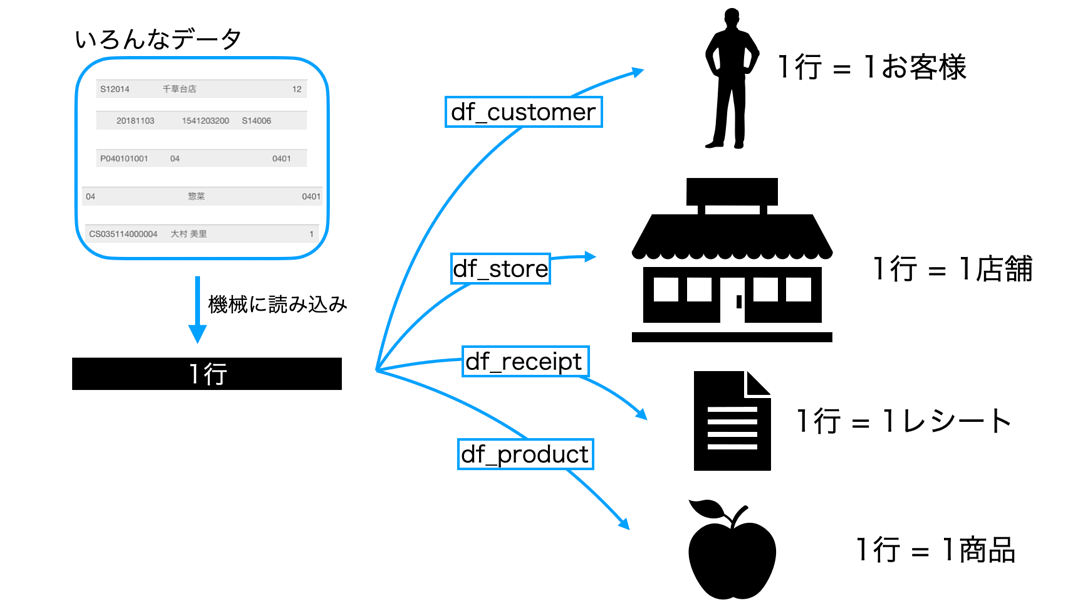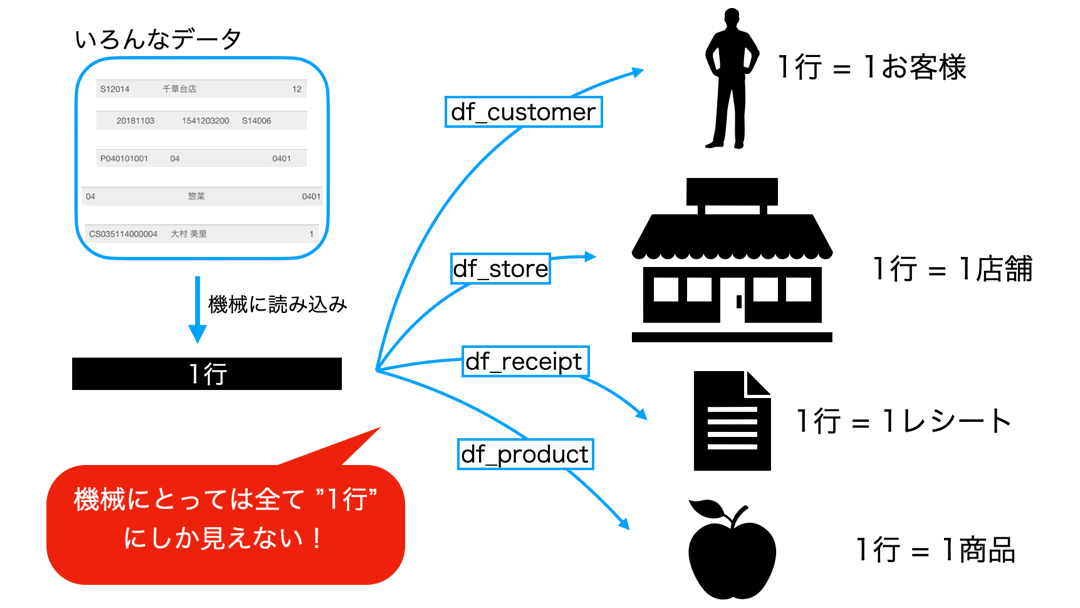
今回のデータ(df_〇〇)はたくさんあります。
いろんなデータがあって、それらを最初に全て機械に読み込みましたよね。
もうその時点で全て同じ1行です。
しかし、それぞれのデータで1行に書いてある情報は異なります。
例えば
- df_customer : IDがあって名前があって...
- df_store : 店舗名があって住所があって...
- df_receipt : 購入数があって支払いがあって...
- df_product : 原価があって単価があって...
といった具合です。
しかし それでも機械にとっては同じ1行でしかない のです。
ということは、データ分析する人間が、1行=1△△の意味を考えながらデータを操作するしかないということです。
モデルを作るにしたって、このことが根底にないものは本当に何も生み出しません。
だからこそ、データ分析を始めるどの場面であっても、話し合いの初期段階で飛んでくる質問は「1行=1△△?(1行ってなんだっけ?)」なのです。
そして次の段階はおそらく「じゃあそれ何個あるの?」でしょう。
レシート(購買履歴)なら10万枚くらい、店なら50店舗くらい、お客様(カスタマー)なら2万人くらい...そのくらいは流れるように実際やっています。 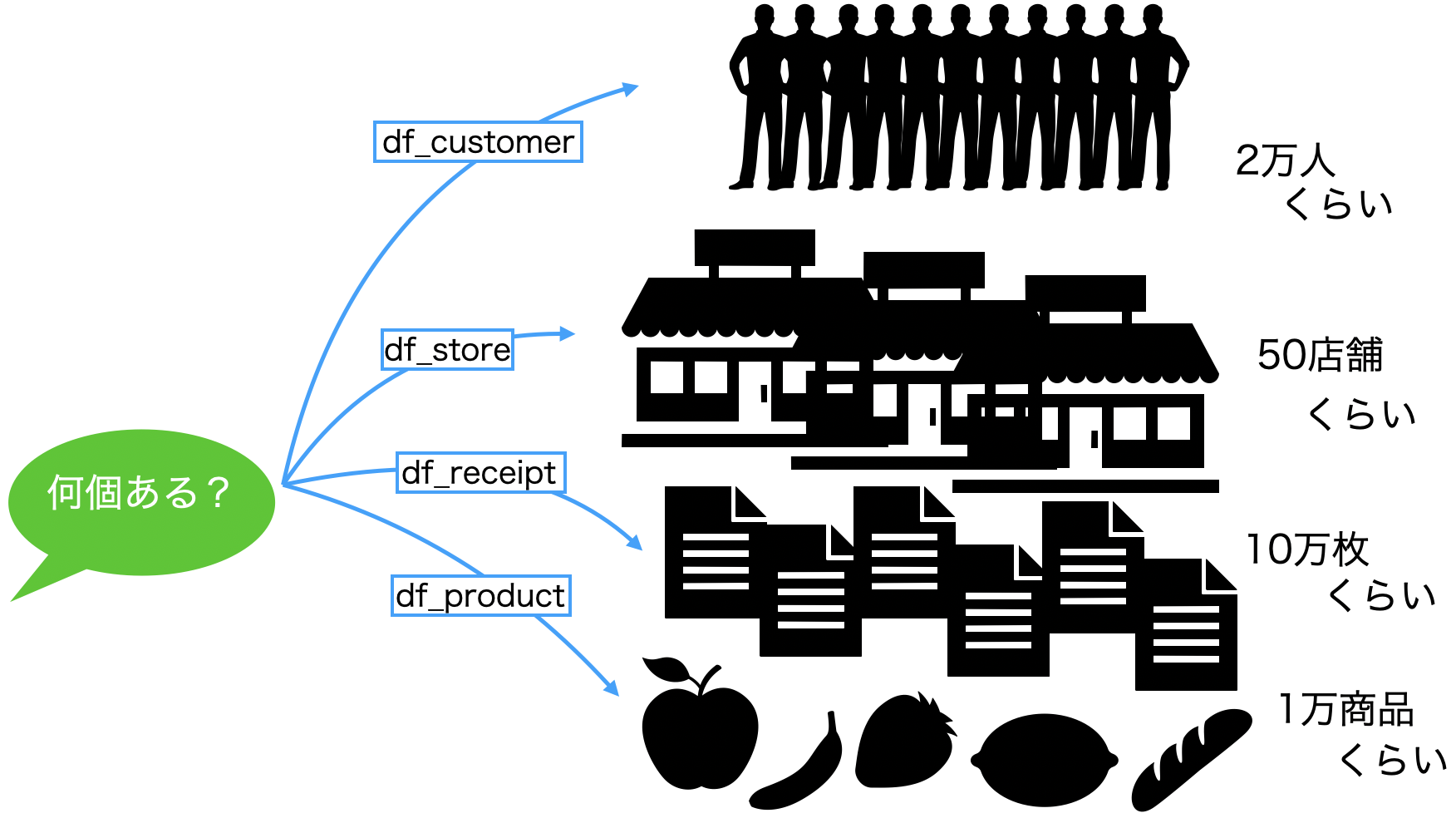
そしてデータと向き合う際に、想像をいちばん鮮明にできた人が最後に勝ちます。
この問題でデータの件数をカウントした理由は、その想像を鮮明にする材料のひとつを得るためということだったのです。
実はこの参考書の影響を受けています
「シン・ニホン」という著書をご存知でしょうか。
著者はヤフー株式会社CSOの安宅和人さんという方です。 
この著書の中では「想像力が富を生む時代」であることを語っています。
データから想像してそれを少しずつ何らかの形にしていくことが現代の新しい価値であることを、そろそろ真剣に考える必要があるようです。
問22 : データのユニーク件数をカウントする

答案・解説はこちら
これも Exploratory では何もすることは無いです。
df_receipt のサマリー・ビューに書いてあります。解答も確認してみましょう。 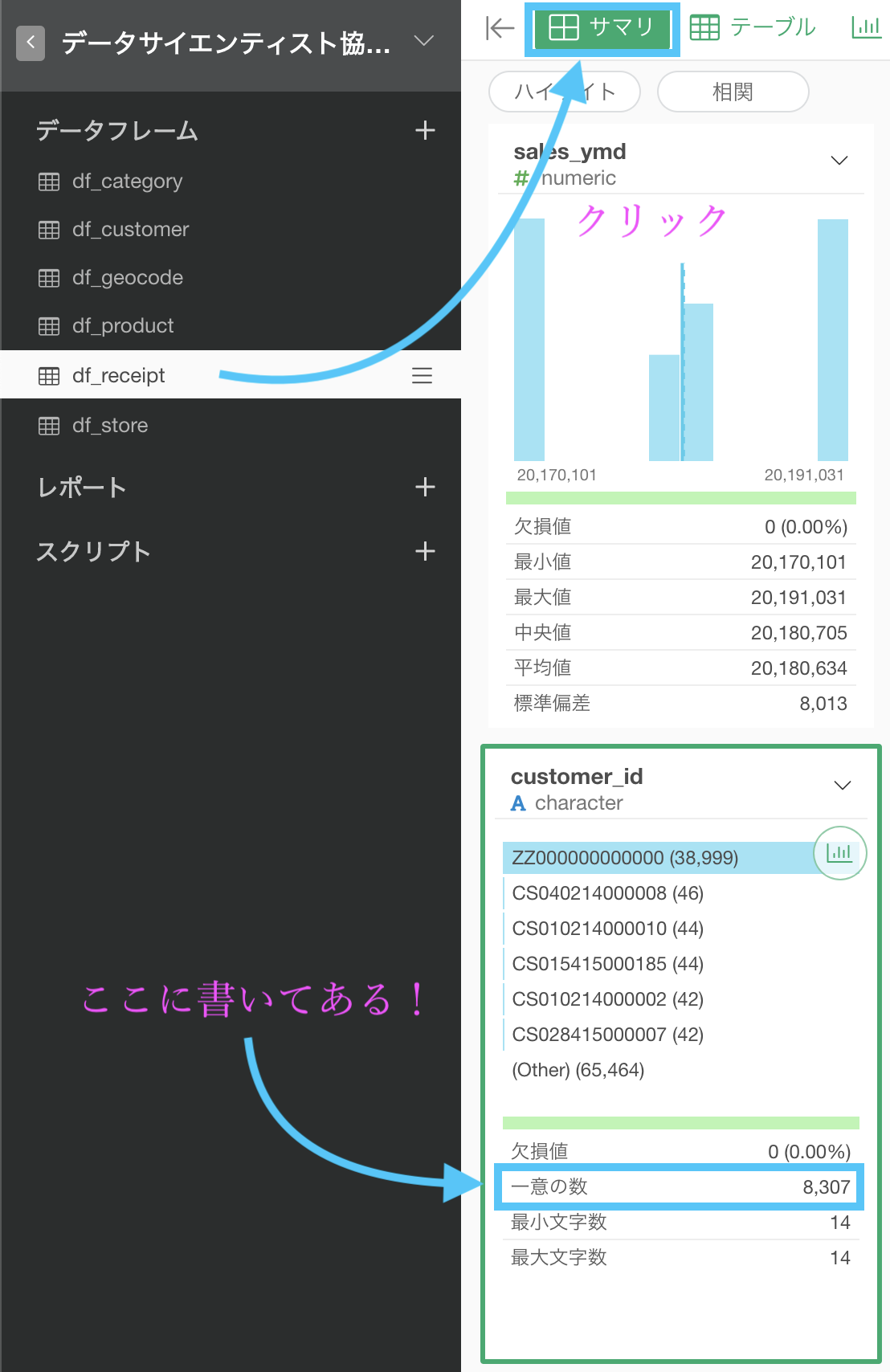
ユニーク件数(一意の数)とはなんなのか
一意的...あまり使わない言葉だと思います。
「ユニークな人だね!」は使うと思いますが「一意な人だね!」という人は少ないでしょう。
良くも悪くも「他と違うね!」と言いたいことに変わりないです。
ということです。
イメージが沸きやすいように、図を書いてみました。 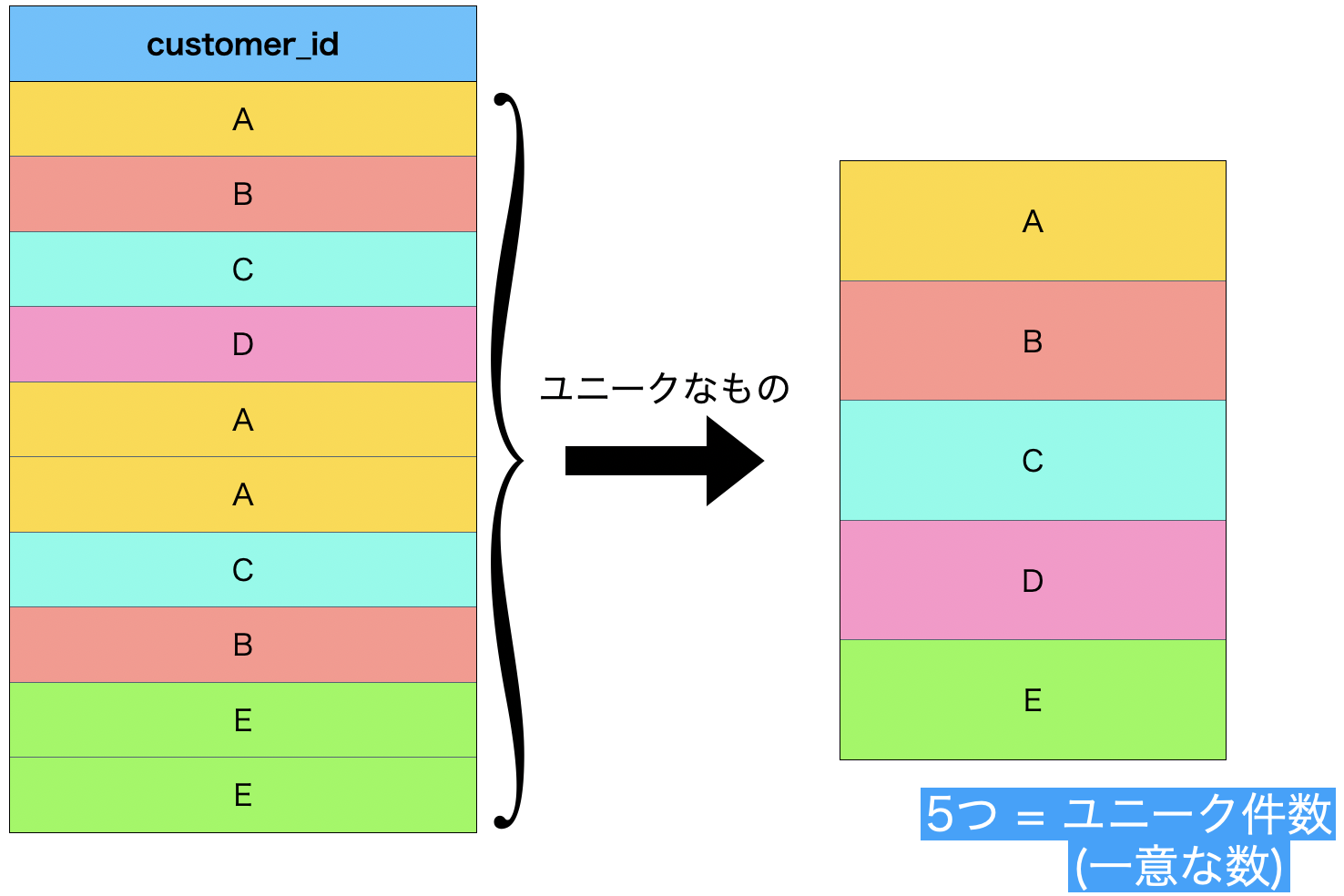
基本的に
- データは繰り返す
- データは散らばる
ということを知っておくと良いでしょう。
そしてどちらも悪いことではありませんし、好都合なことです。
繰り返さないデータは...散らばってないデータは...と想像してもらえれば、あるいは自分で作って読み込ませるとわかってくると思います。
どうしてユニーク件数を調べたのか
ユニーク件数というものがわかった上で、なぜ調べたのでしょう?
今回の問題に限って言えば明確なので一緒に調べていこうと思います。
df_receipt の列に customer_id がありますが、df_customer の列にも customer_id がありました。
ユニーク件数(一意の数)はそれぞれこのようになっているでしょう。 
これは一体どういうことなのか、説明できますか?
ヒント
問21で話した、1行=1△△ の視点です。
解答例
- df_receipt の customer_id : 買いにきたお客様だけ
- df_customer の customer_id : 登録しているお客様の一覧
一方で df_customer は 1行=1お客様なので、全てのお客様が載っているため、ユニーク件数は異なっていたという訳です。
これではっきりしたでしょうか。
データを鮮明に想像できていない場合は、今の解答例を読んでも「え?」となるかもしれません。
しかし、お客様がお店に買いに来てレシートを受け取るその様子と、データを取っていた期間にお店に来なかったお客様の様子まで想像すればたどり着く答えだと思います。
同じデータを扱う・コードを書く・学ぶ...いずれにしても、
- コードを書いて、ちゃんと動けば満足する人
- データサイエンティストを目指している人・既に成っている人
両者の最大の違いは、いまこの瞬間です。
Python 解答コードはこちら
解答コードはこのようになっています。
len(df_receipt['customer_id'].unique())
問23 : 対象データの合計値を算出する

答案・解説はこちら
やりたいことをまず確認します。
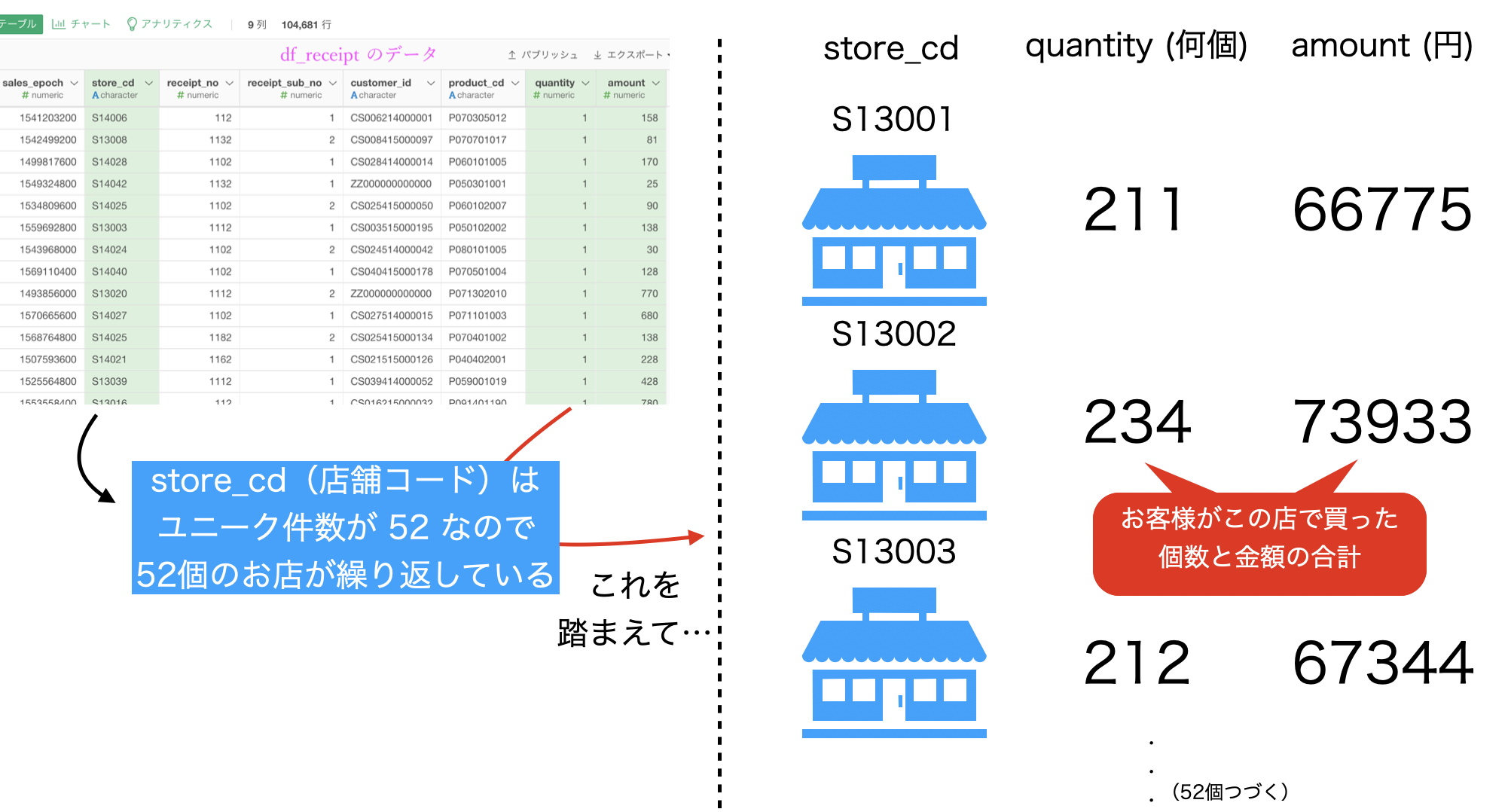
ということになります。
まぁつべこべ言わず、一度やってみましょう。
Exploratory にはそのままが用意されています。 
よく使う機能の1つなので、集計 (Summarize) 機能と言ったらこのことだと思ってください。
この画面を使いこなせれば、実はどんな集計でもできてしまいます。 
集計 (Summarize) 機能については早く慣れて欲しいのでいろいろ話してしまいますが...まず先に今回の問題を解いてしまいましょう。 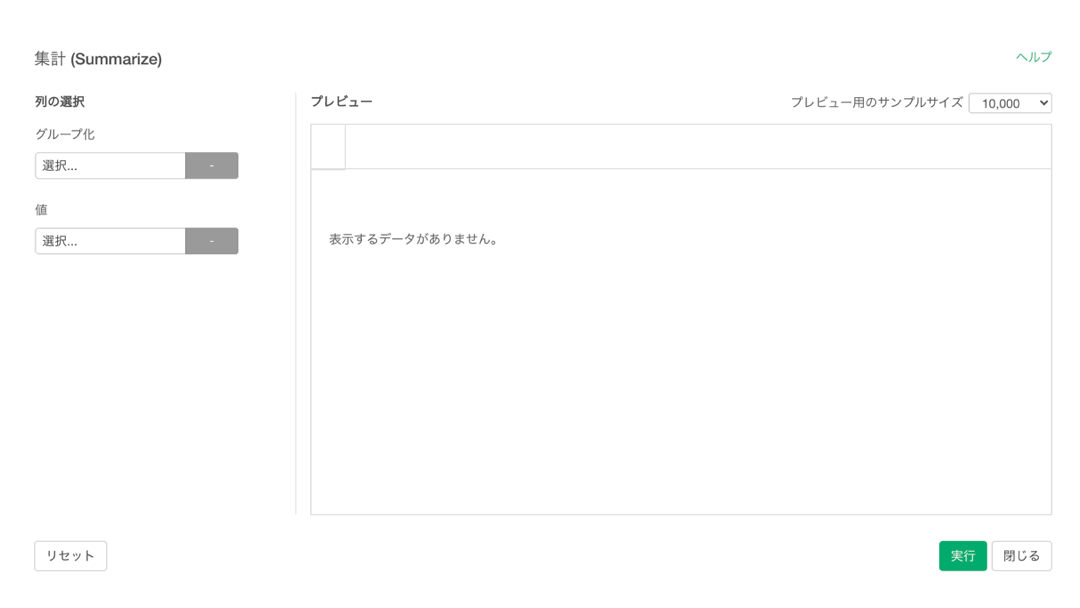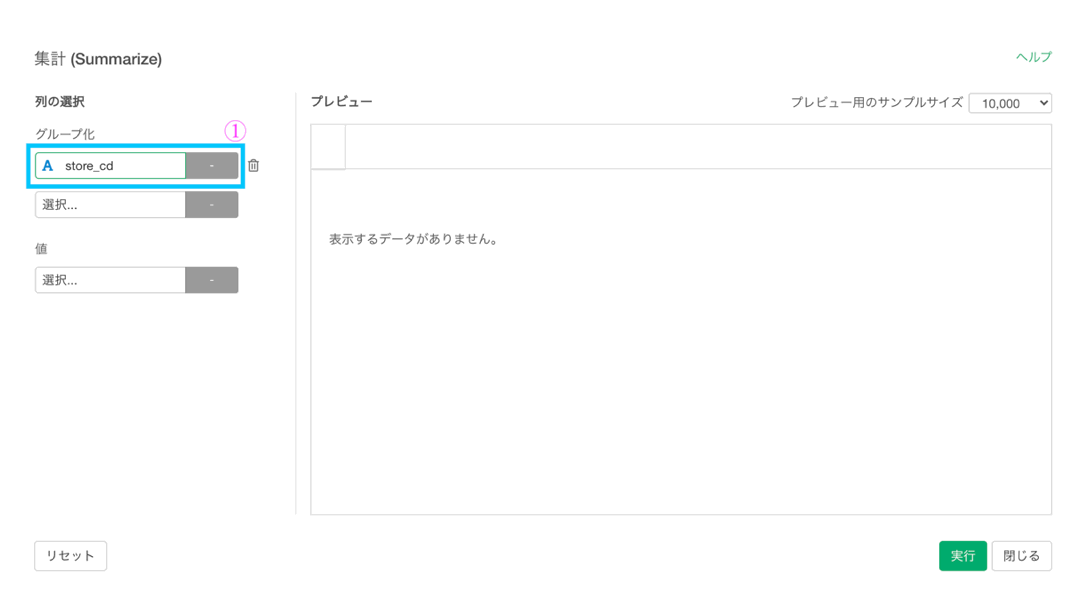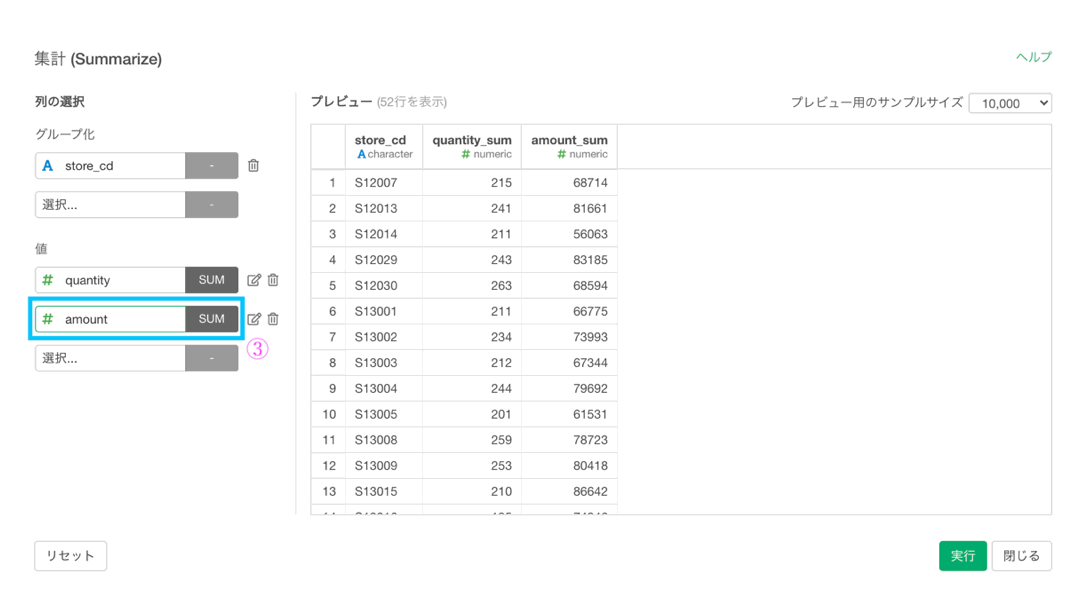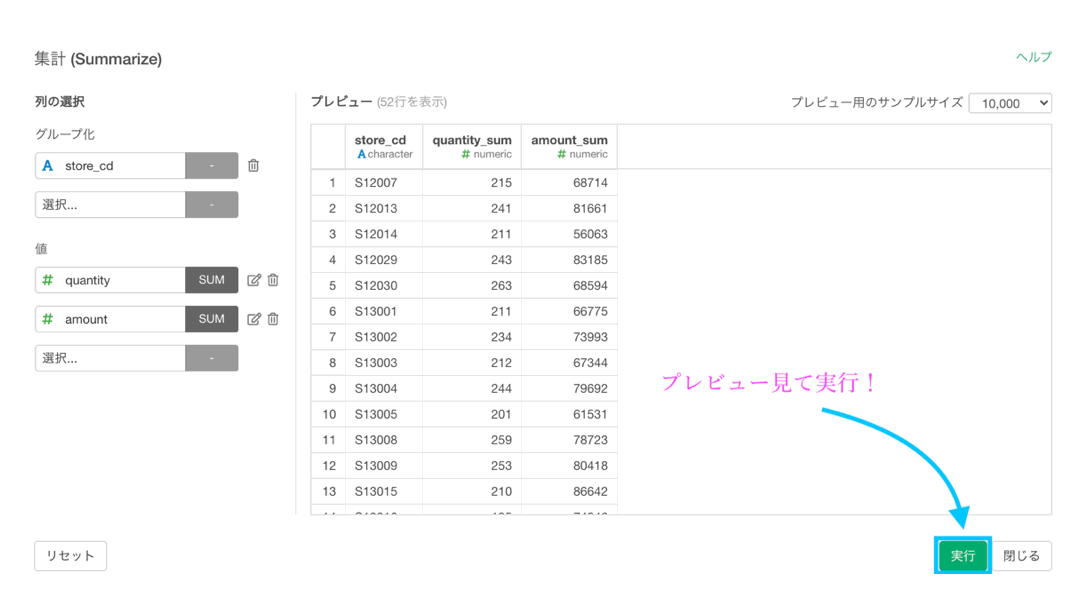
集計 (Summarize) 機能の画面に書かれている通りに書くと、
- グループ化 : store_cd
- 値 : quantity と amount
という具合に説明できますが、この時点ではまだ完全ではありません(説明は後述)。
しかし、今回の問題はカンタンのため、このまま実行でOKです。
こんな感じになったと思います。解答と確認して見ましょう。 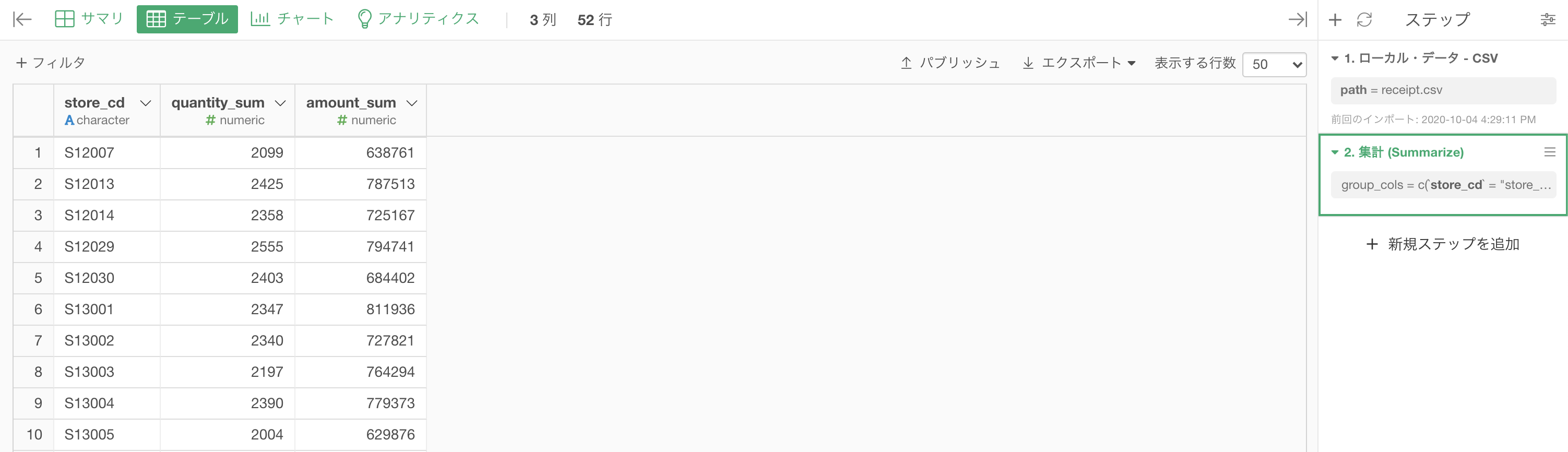
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.groupby('store_cd').agg({'amount':'sum',
'quantity':'sum'}).reset_index()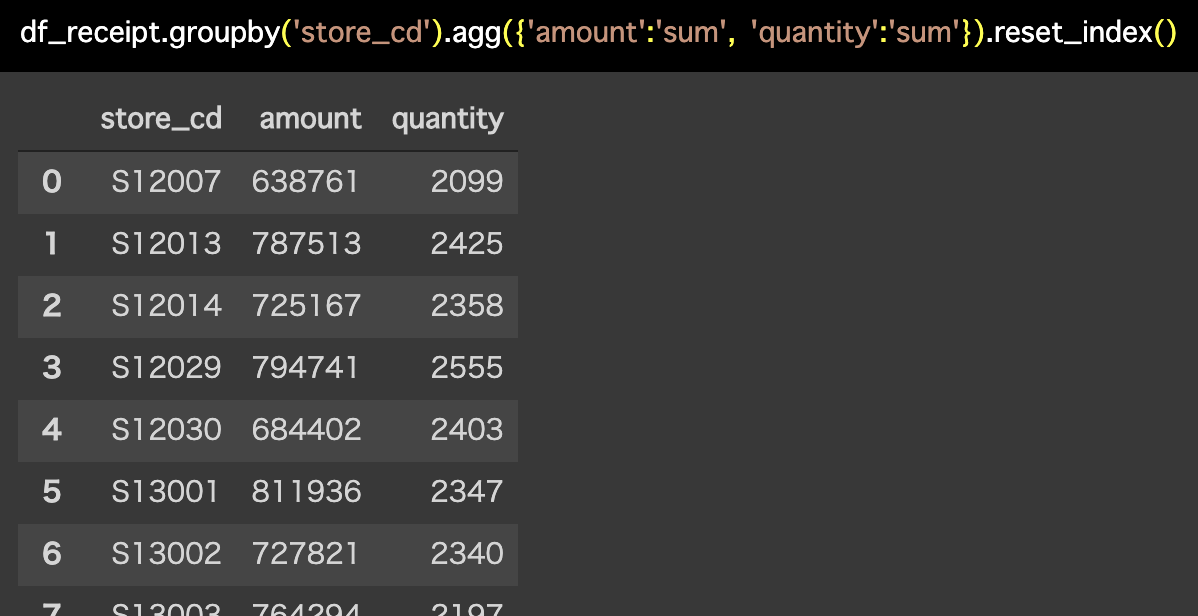
groupby は、データ分析をする最初の関門みたいなものです。
reset_index()とかも Exploratory で自動で機能しているところが素晴らしいですよね。要するに store_cd がきちんと順番に並んでいるということです。
そんなことより次の折りたたみの中身は、この記事で一番大事ですよ。
集計 (Summarize) 機能に関して(イメージが大事!)
です。
えー?またか〜と思うかもしれませんが、とにかくもう一度答案のデータをよく見てください。 
しかし、集計 (Summarize) 機能で 1行=1店舗 に変わっています!
データにとって、1行=1△△ は最も基本的な情報です。
それを変えてしまえるほどの機能なので、データをよく見てねということなのです。
では集計 (Summarize) 機能について、なんでこんなこと起きるのかも含めてもう少し深く掘り下げていきたいと思います。
集計 (Summarize) 機能のイメージ
データ分析では特に過程・結果をイメージすることが非常に大切です。
それができなければ、単にコードで動けば満足な人と同じです。
集計 (Summarize) 機能のイメージは結構あっさりしていますが、今回は SQL 的な観点に触れた時でも同じようなイメージで通用するような説明と図にしたいと思います。
まずデータ(df_receipt)をこんな感じでイメージしてみましょう。
SQL 的な観点(あるいは数学的な観点)では、集合と呼ばれるものです。 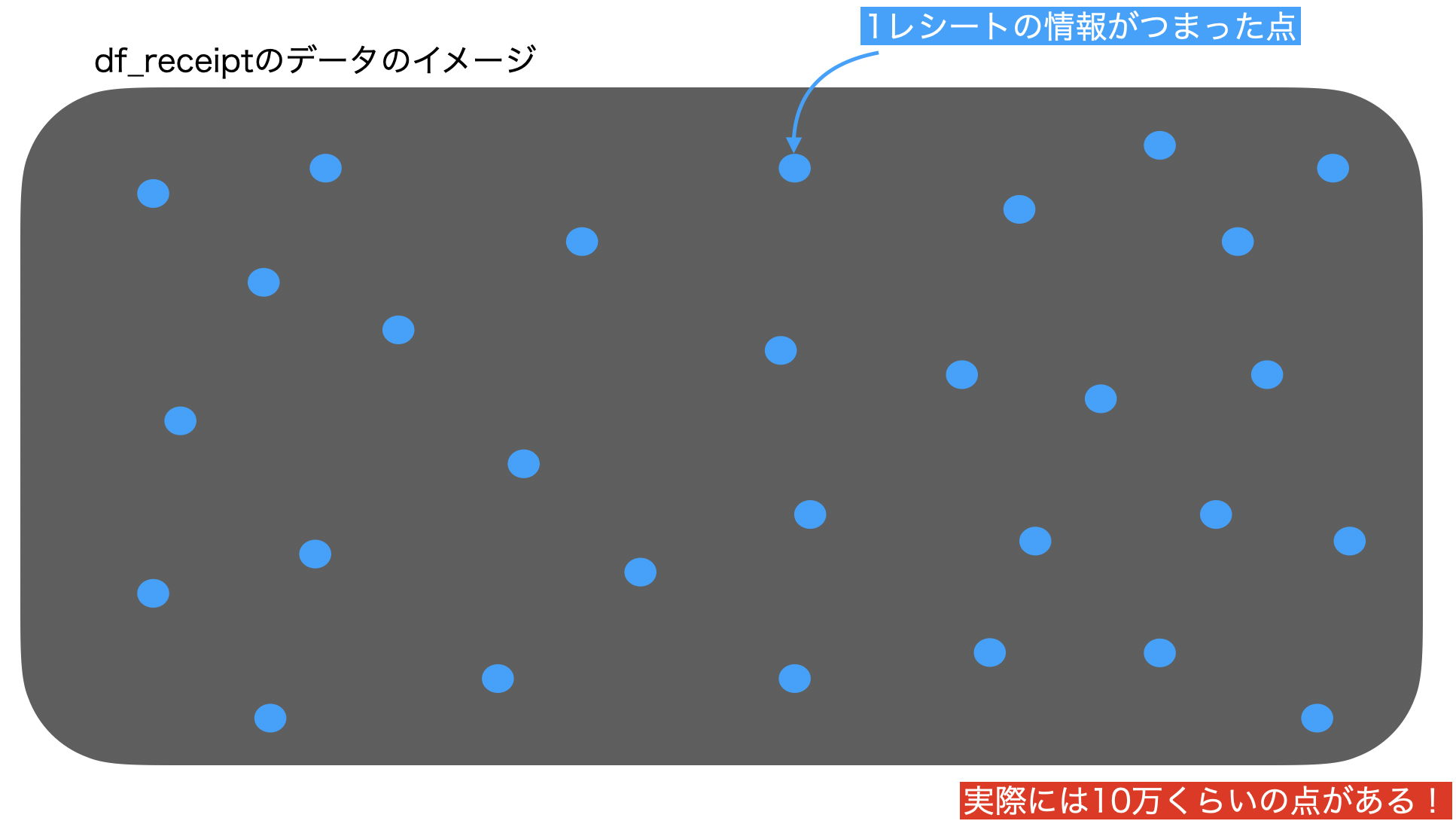
さっきの問題では、store_cd ごとに分割したのです(結果からもわかると思います)。
こんな感じです。 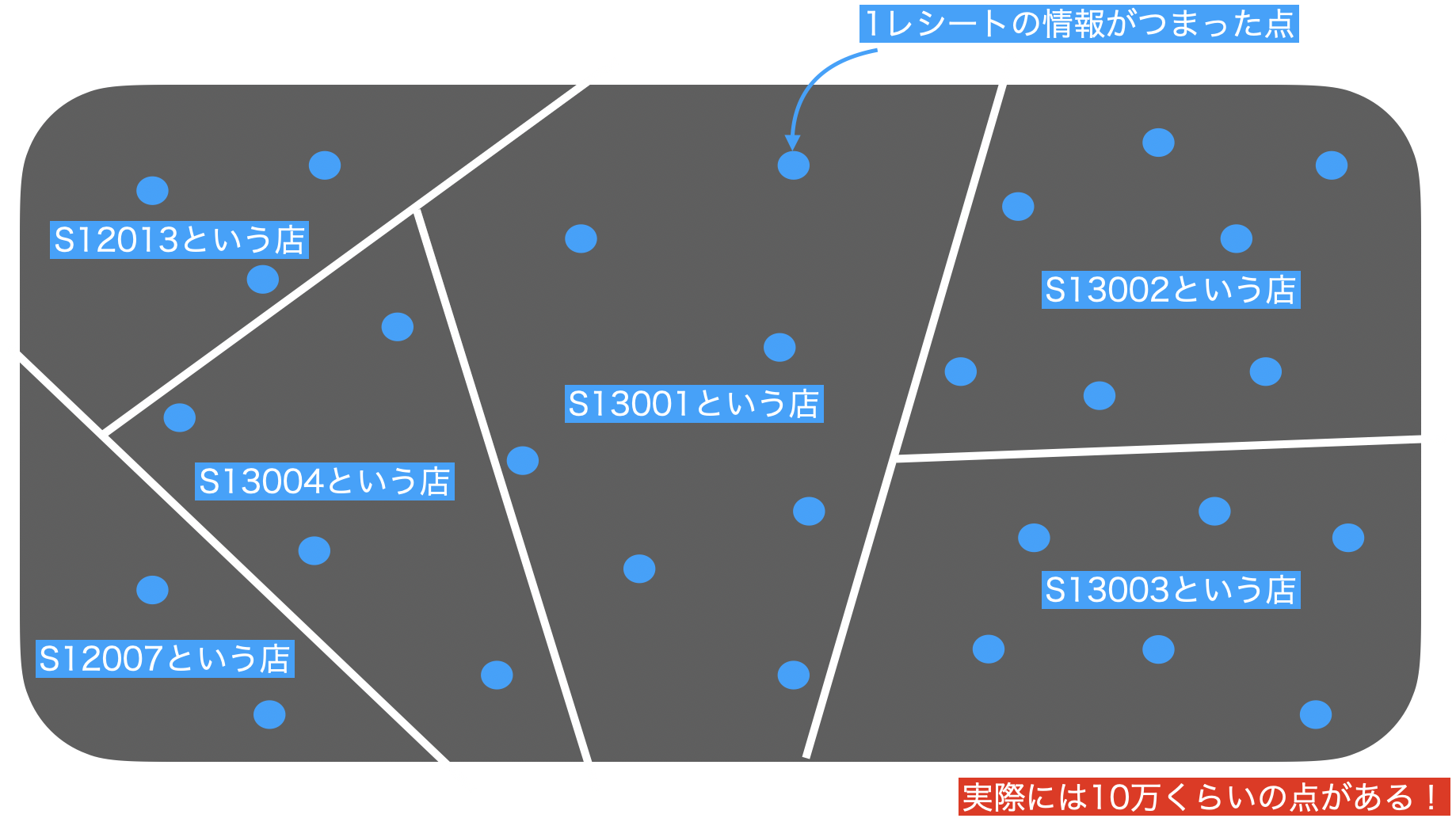
そこで、データをこのように分割したのは良いのですが、それぞれのお店に何個もレシートがありますよね。
S12007とS13001の2つのお店でレシートの数も違えば金額も違うはずです。
「集計する」の考え方では、その過程でまずこのようにデータを集めています。 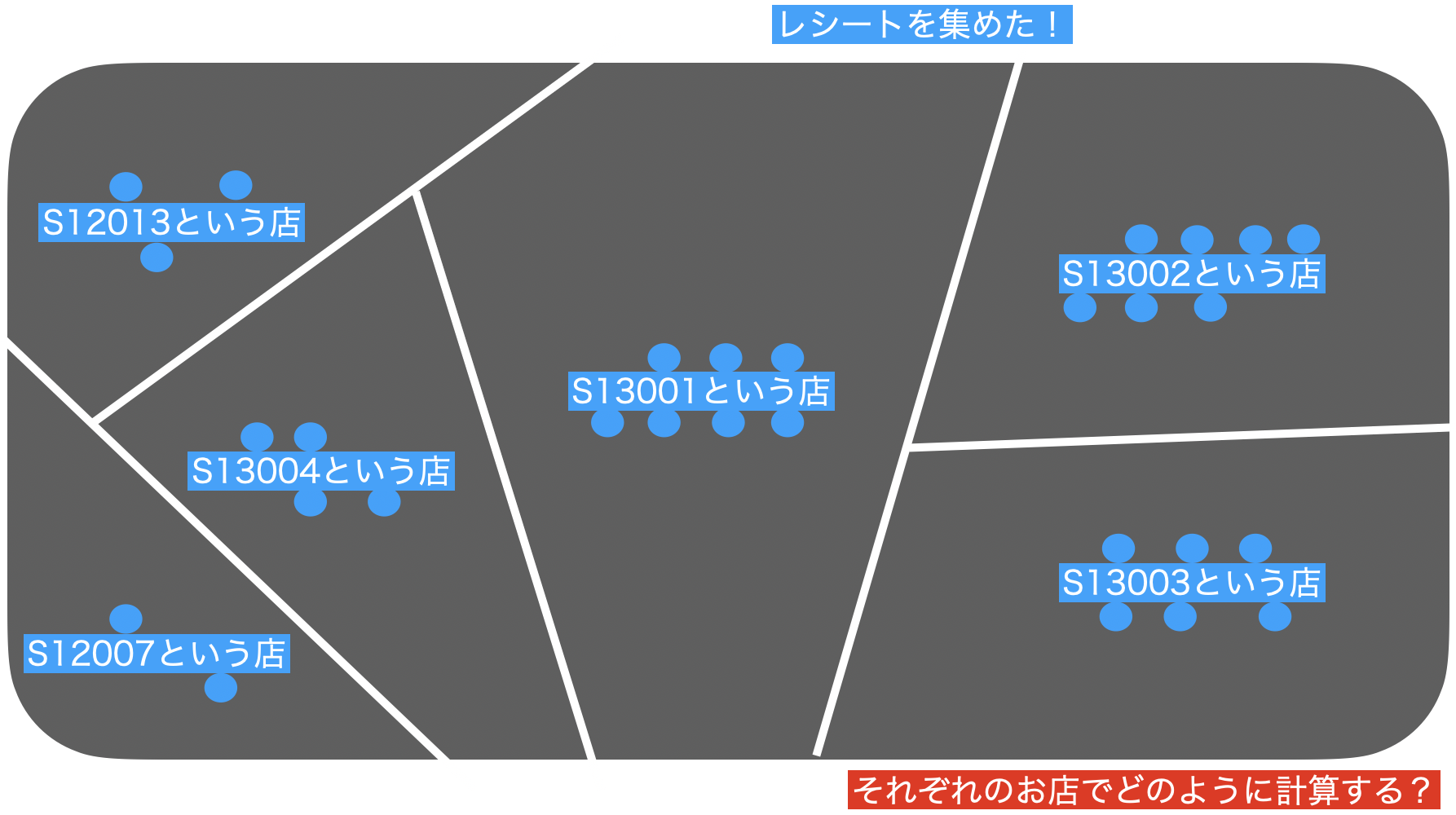
さて、それぞれの場所で何やら計算することができそうです。
それぞれのお店を1つの値で表現したい ...例えば amount(金額)を合計すると1つの値になりますし、quantity(数量)もそうです。イメージなので、要は見やすくなるからやっているんだなぁと思ってくれて構いません。 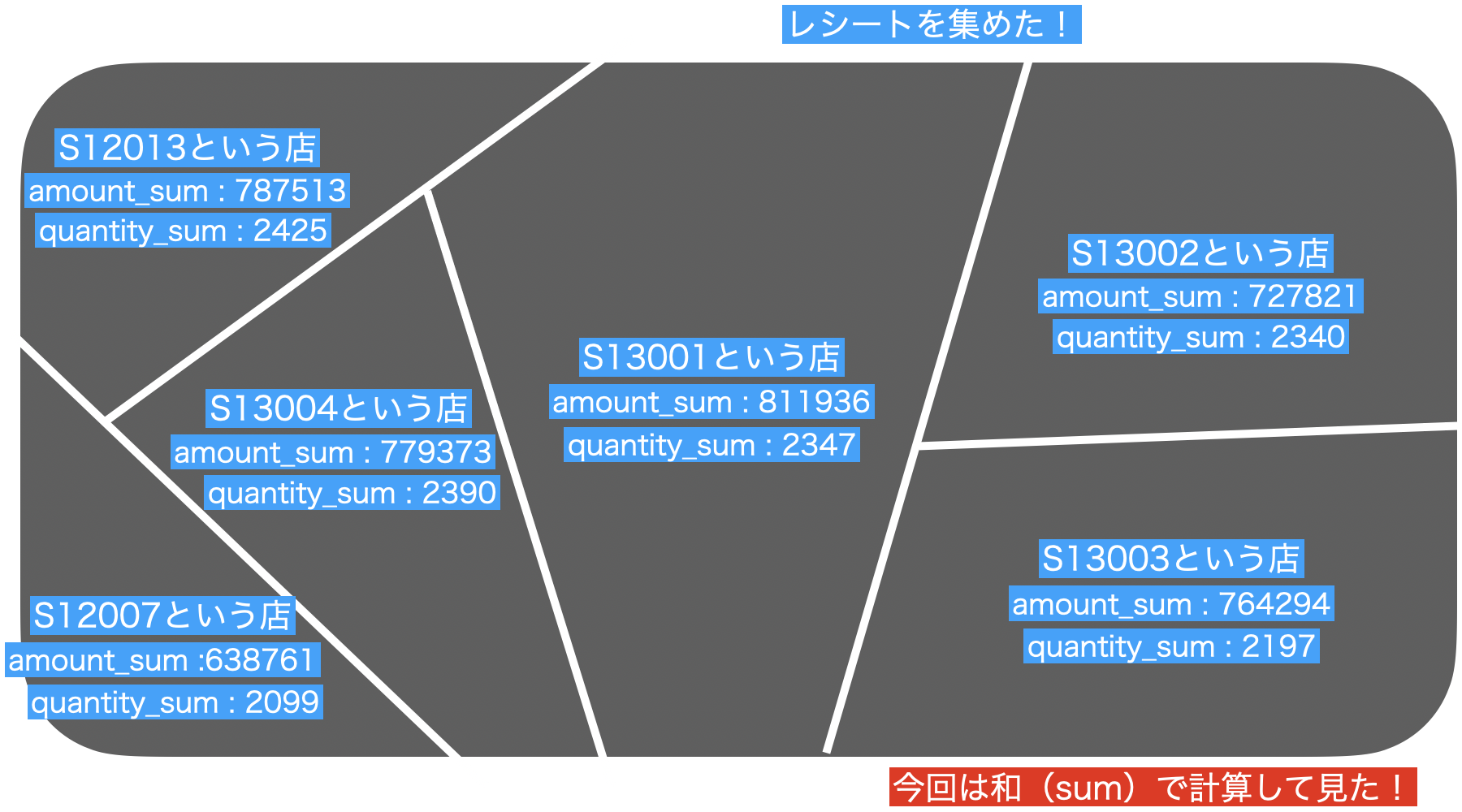
なので、これは1つの点で表現できそうです。 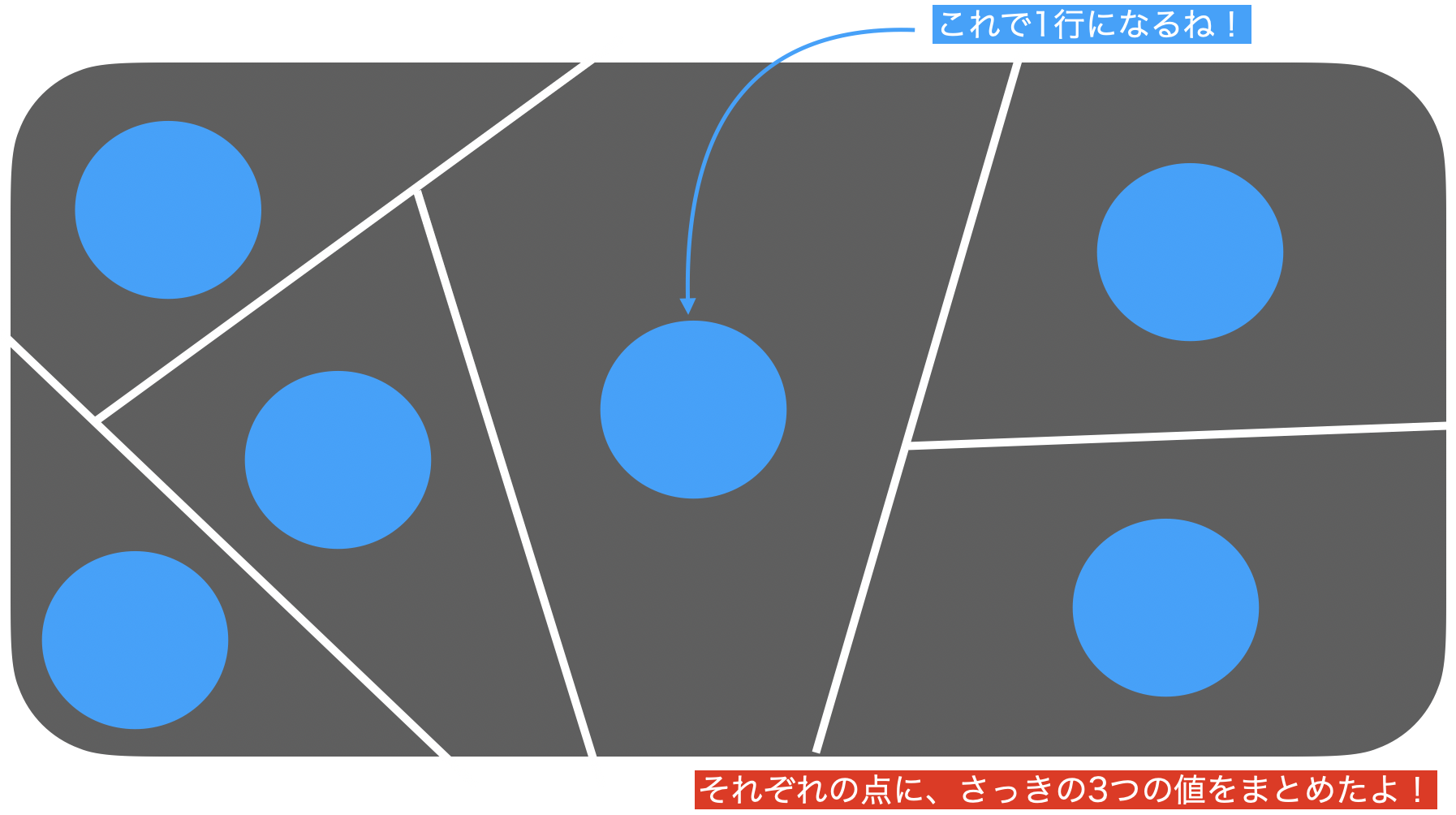
この点は 52個しかない はずです。
なので、結果も52行しかないデータになっていたのです。
しかも、背景には df_receipt のデータが残っています(グレーのところ)。
集計するとは、データにする
ということだったのです!
どうでしょうか?イメージはついて来ましたか?
集計のイメージの流れを動かしてみるとこんな感じになります。 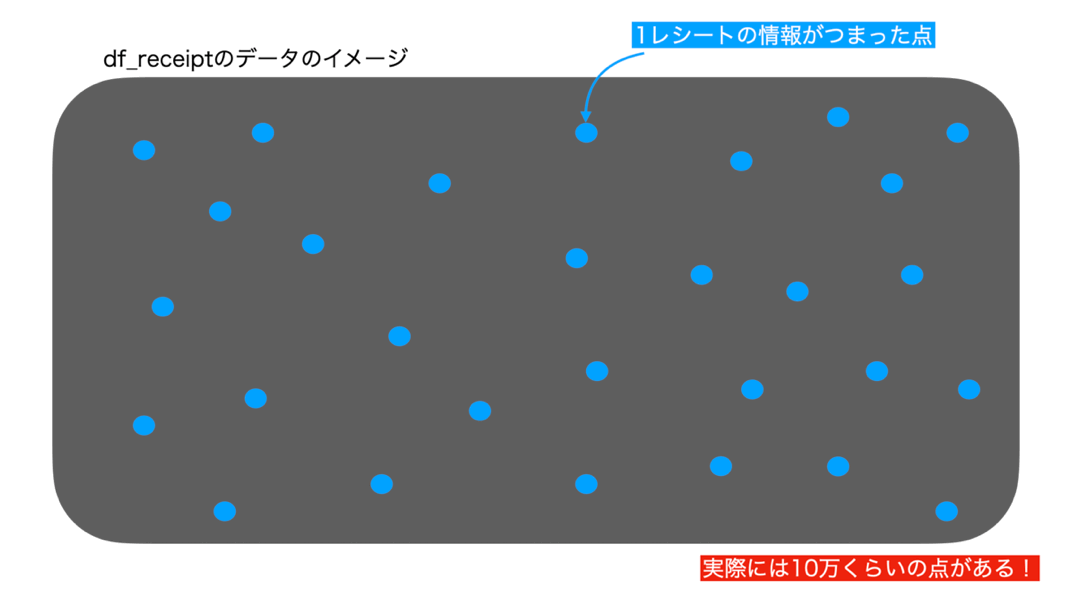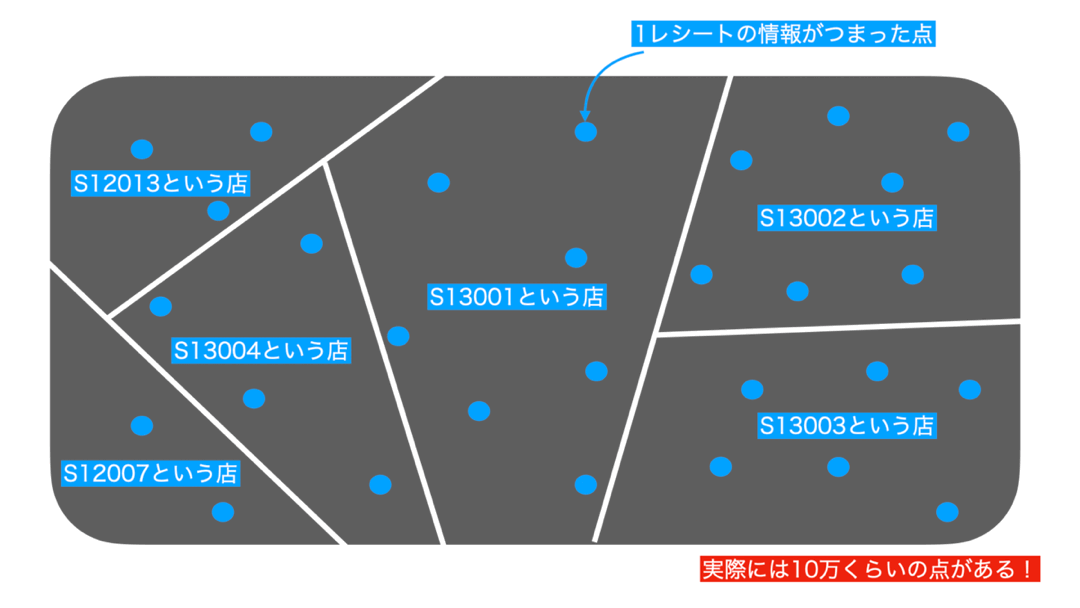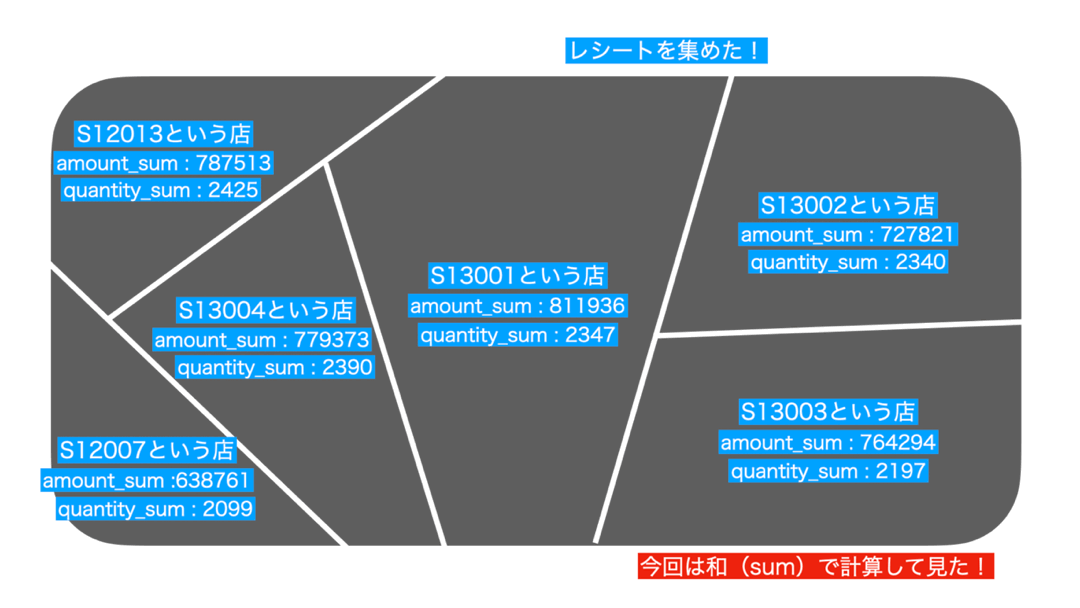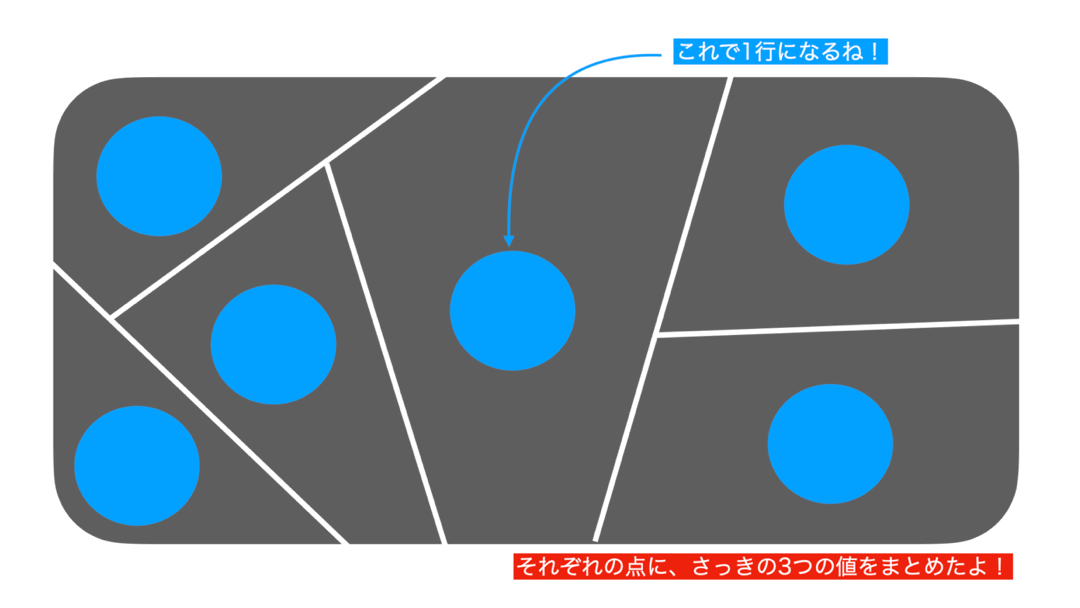
Exploratory で集計すると、イメージしながらすぐに実現できるはずです(選ぶだけだし)。
集計 (Summarize) 機能の使い方
せっかくここまでイメージを膨らませたので、ぜひ実現化させたいですよね。
そこでイメージと機能の使い方を対応させることで「ここのイメージがここの機能で、ここはこうして...」をイメージしながらできるようになるので、望んだ結果も得られやすくなるでしょう。
でもイメージは言葉にすると意思疎通をしやすいため、少しずつ言葉にしていこうと思います。
- グループ化
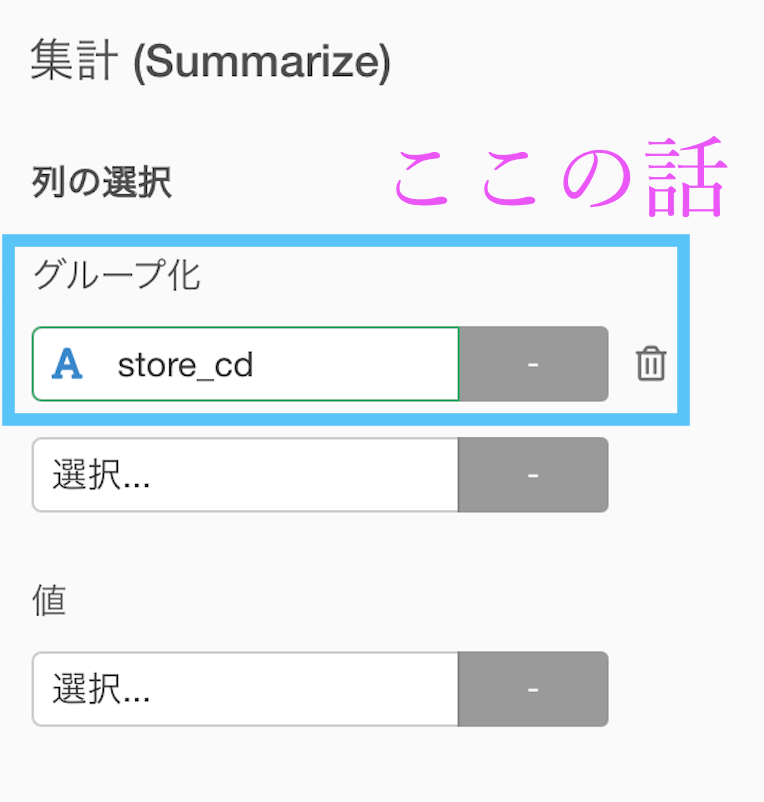
グループ化のところに store_cd を入れることは、イメージで言うと「何で分けるか?」の部分です。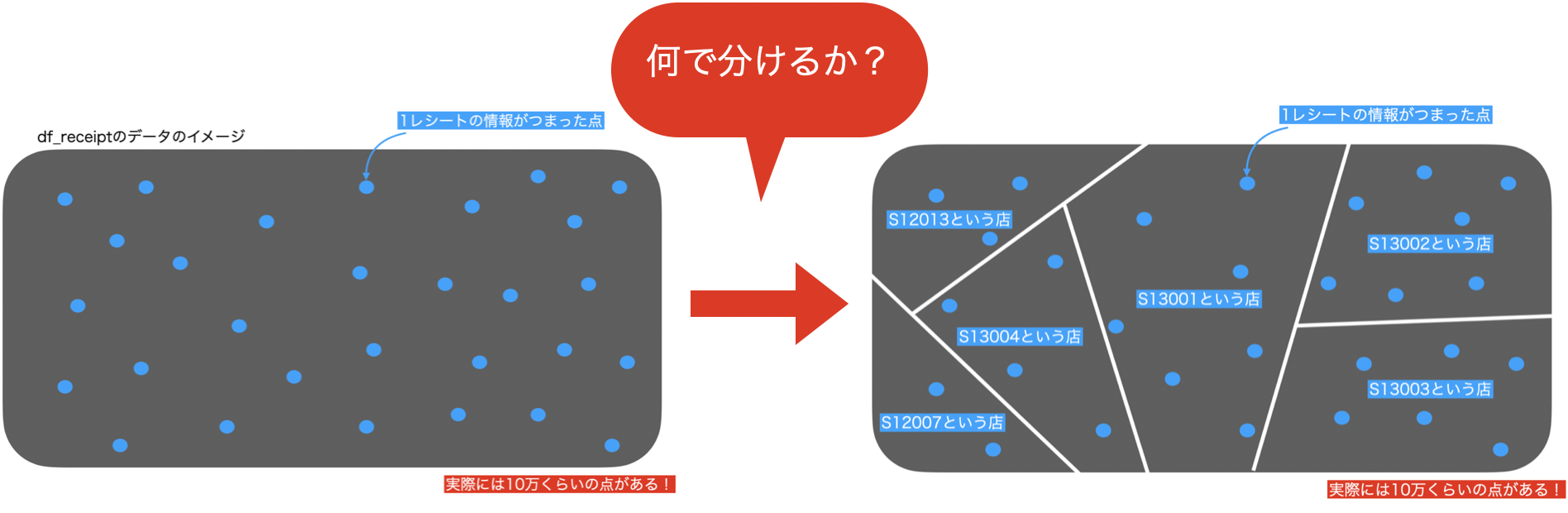
store_cd でグループ化したので、分け方は store_cd のユニーク件数(52)だけあります。なので、集計結果も52行のデータになります。 - 値
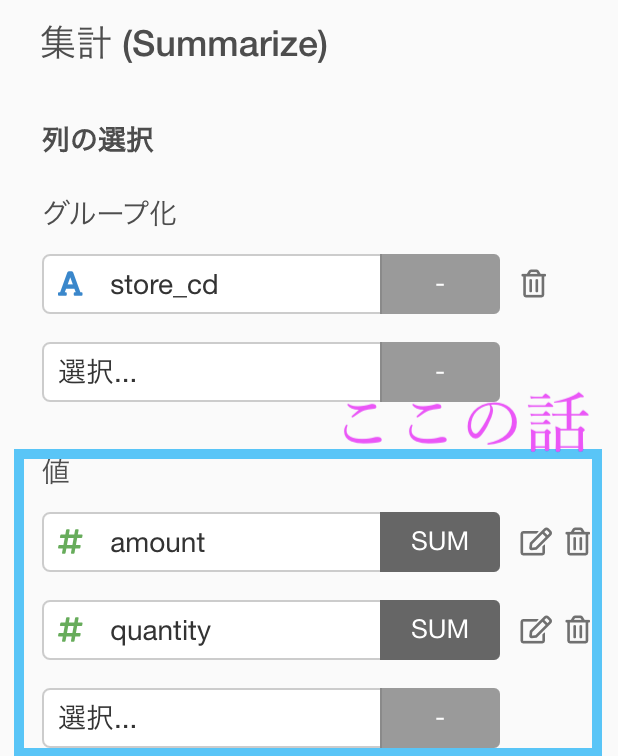 集計 (Summarize) 機能で列を入れるところは グループ化 するか 値 にするかどちらかしか選べません。値に何を選ぶかは、問題文にも書いてありました。
集計 (Summarize) 機能で列を入れるところは グループ化 するか 値 にするかどちらかしか選べません。値に何を選ぶかは、問題文にも書いてありました。
値のところに amount や quantity を入れることはイメージで言うと「どの列を使うか?」の部分です。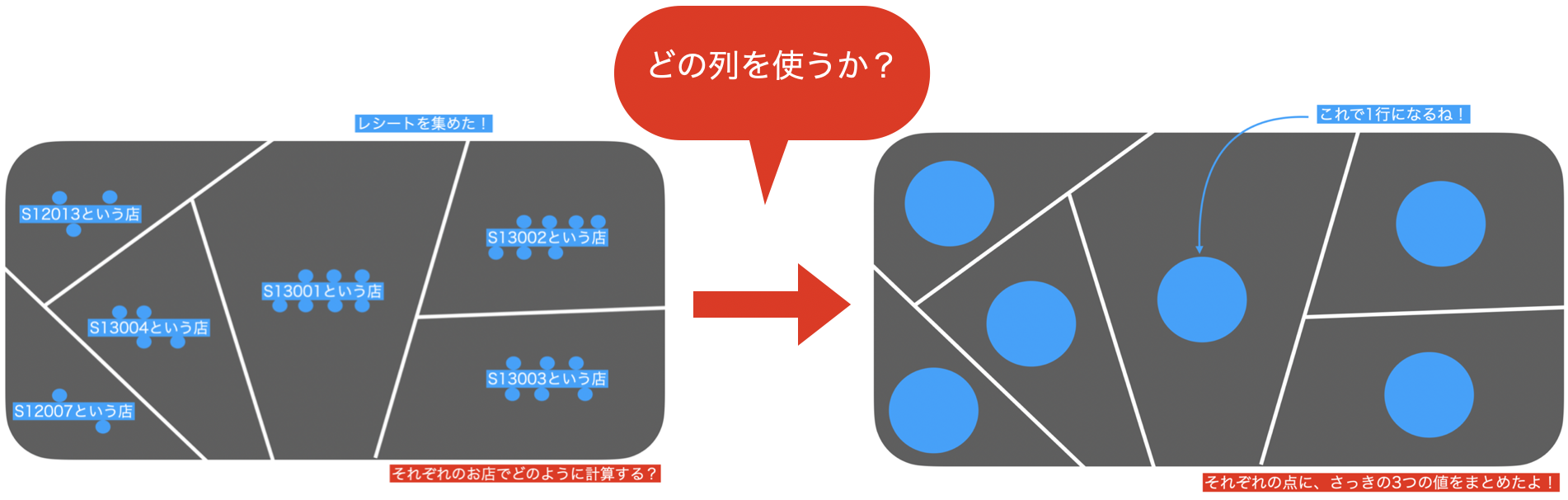
- 計算
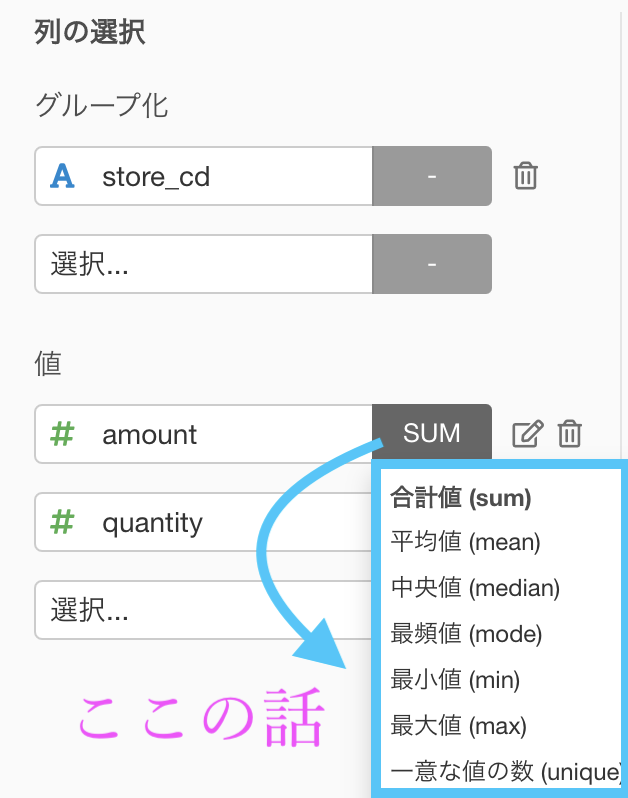 実はここ、押せるんです。データをグループ化で分けると、小さな集まりがいくつもできることになります。それらを1つの値で表現する(ギュ〜!ってする)から集計と呼ぶのです。
実はここ、押せるんです。データをグループ化で分けると、小さな集まりがいくつもできることになります。それらを1つの値で表現する(ギュ〜!ってする)から集計と呼ぶのです。
計算のところを選ぶのはイメージで言うと「どう計算するか?」の部分です。
いったん、集計 (Summarize) 機能のおさらいをしておきましょう。
- グループ化 : 何で分けるか? → store_cd
- 値 : どの列を使うか? → amount と quantity
- 計算 : どう計算するか? → 和(sum)
(グループ化)ごとに(値)を(計算)せよ
となります。
合計するところは、平均を取るとか、レシートの数を数えるとか、最大値・最小値だけにするとか...とにかく1つの値になる計算の仕方になるものならなんでもOKなのです。
計算の仕方は Exploratory に搭載されていて、メニューから選ぶだけなので大丈夫です!
集計 (Summarize) 機能の小ネタ
値の計算をしたら、列名が変更されてしまいます。
好きな名前に変更することが可能です。もちろん後から変更することもできますが、ステップが1つ増えるだけです。 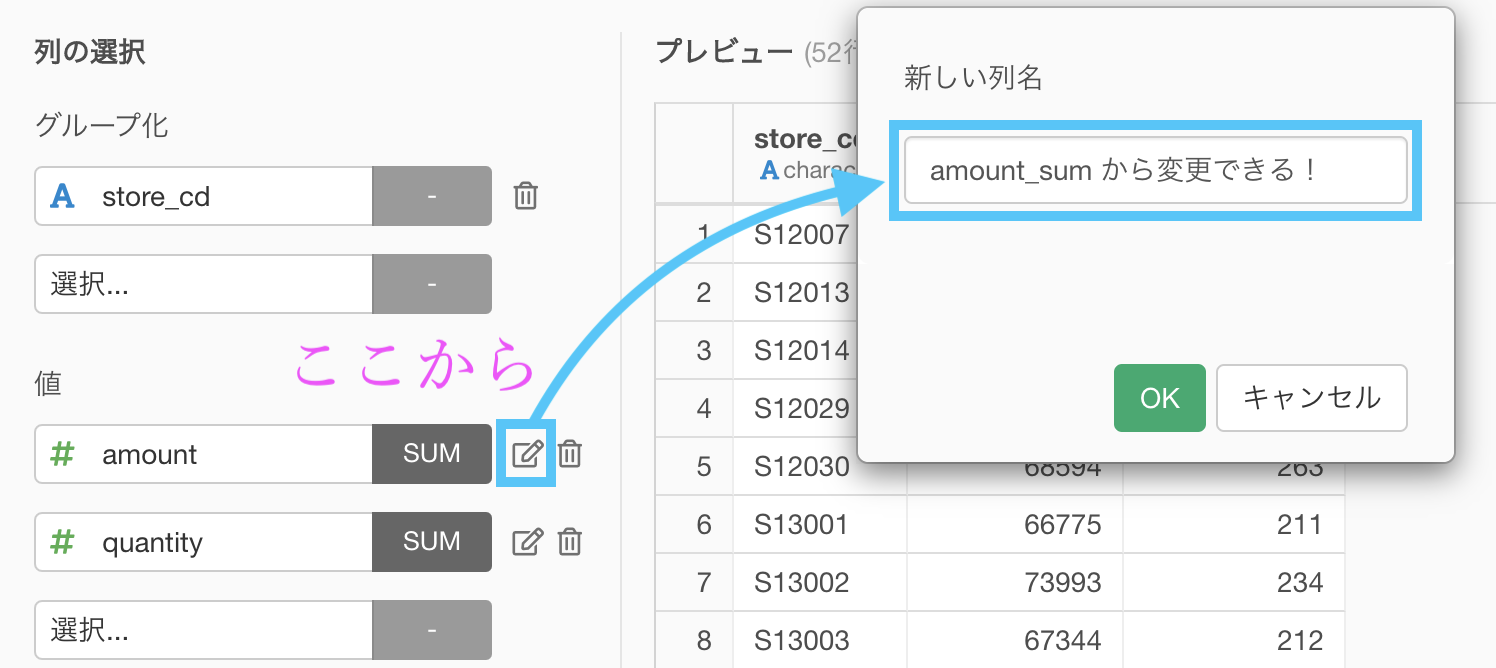
集計 (Summarize) 機能はぜひ使いこなして欲しいので、これからの問題を通していろいろ学んでいきましょう!(グループ化のところに2列選んだら?計算の仕方のところを最大値・最小値にしたら?順番に並べたら?etc...)
これに慣れるとクロス集計やろうとか、コレスポンデンス分析やろうとか、これ使ってからのアレもやって〜からの...?ってなったりしますよ。たくさん練習 しましょう。
大丈夫です。ただ列名とかを選ぶだけなので。
問24 : 対象データの最大値を求める

答案・解説はこちら
イメージもつけながらやれると very good です!
(グループ化)ごとに(値)の(計算)をせよ
ということで、まずは集計 (Summarize) 機能を起動しましょう。 
この画面になれば、もうあとはカンタンです。 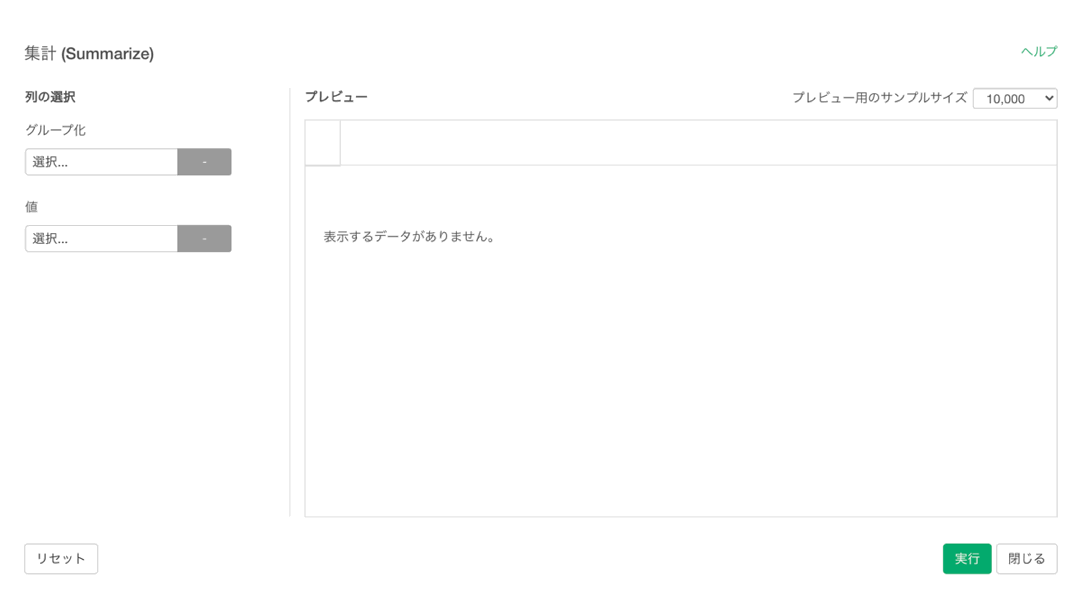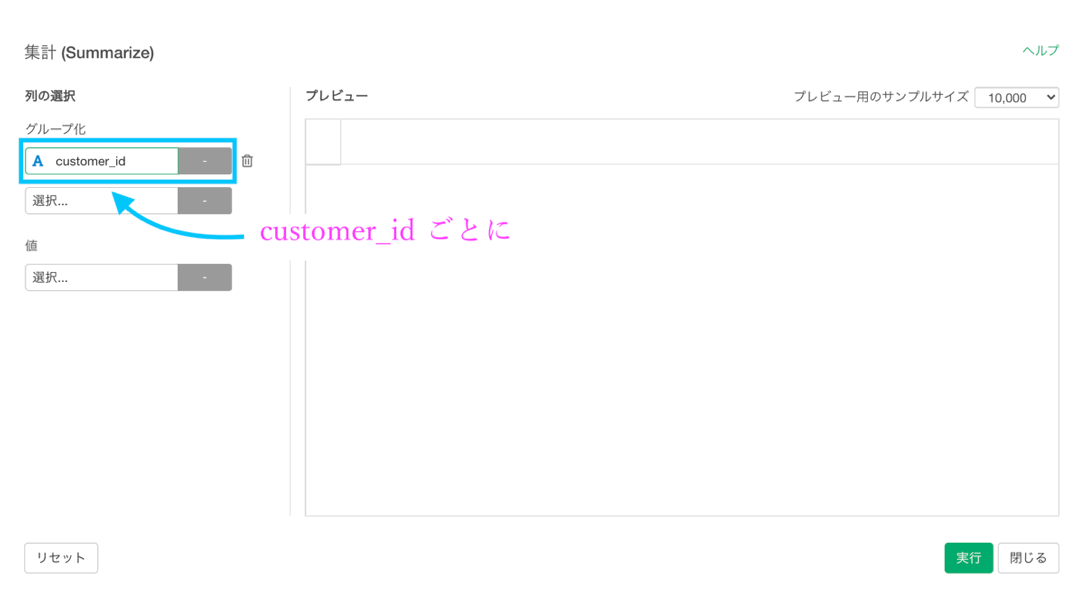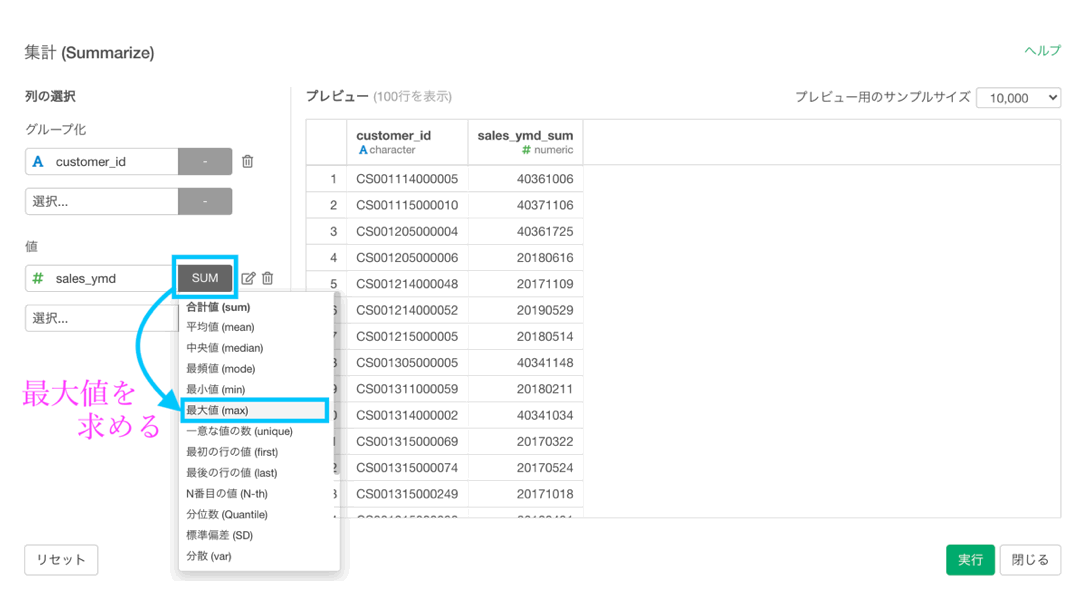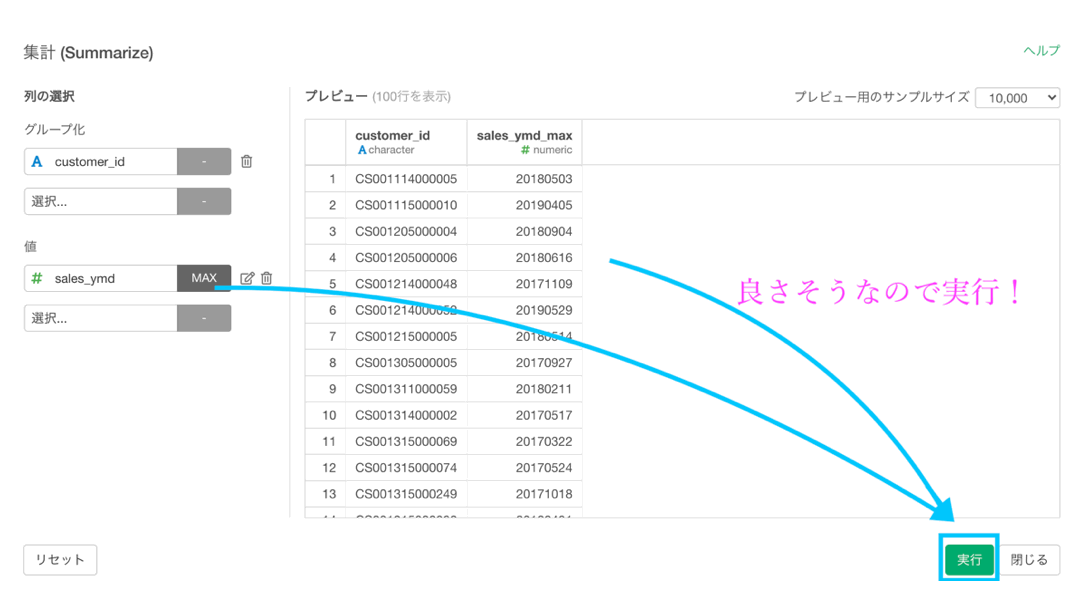
まとめるとこんな感じです。
- グループ化 : customer_id(ユニーク件数 8307)
- 値 : sales_ymd(レシートのお買い上げ日)
- 計算 : 最大値(max)
以下のような結果になったと思います。解答を確認すると同時に、結果のデータをよくみてイメージをきちんと再確認しましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.groupby('customer_id').sales_ymd.max().reset_index().head(10)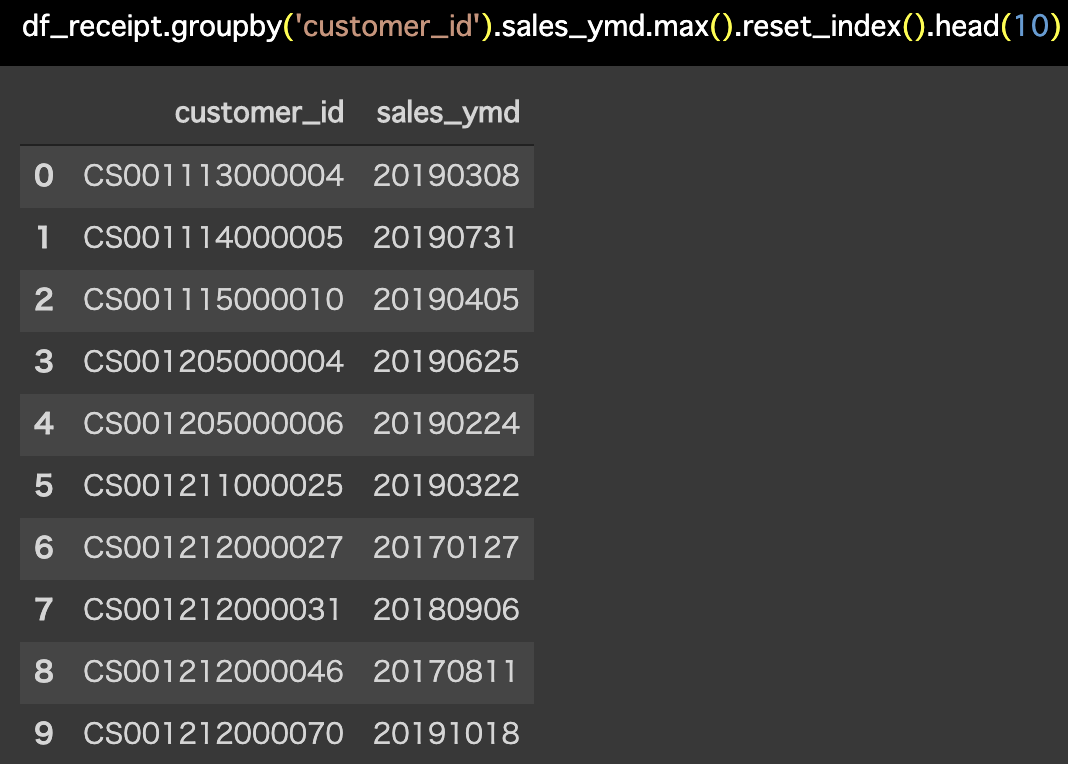
計算の仕方 (MAX) で疑問を抱くべき!
理由がないとおそらく実務でデータ分析しようと思っても動けません。
ただやった・問題を解いただけ ・・・楽しくないと思いますし、それで終わったらデータ分析をやる意味は失くなると思います。
sales_ymd という今回のデータに限定してしか最大値を出せないようでは、集計する意味がないでしょう。
つまり、たまたま sales_ymd だから最大値を出したという理由は全く役に立たない根拠です。だって、列名を変更すればなんでも最大値だといっているわけですからね。
もう一度聞きます。なんで最大値なの?
ヒント
問題文をよく見て、何かの言葉に引っかかってください。
解答例
と読みます。ymd は、Year(年)Month(月)Day(日)の頭文字です。
こういう命名の仕方はよくやります。今更ながら、cd は code(コード)だし、id は identity(アイデンティティー)です。
さて「最も新しい」とはつまり「最新の日付」のことです。
つまりそれは「数値で言えば最大値」ということなのです。
つまり、最新の日付 & 数値のデータだから最大値 として計算するんだ!という思考回路なのです。  「どうすれば?」を周りの人と議論する・必死に考えることで、データ分析の経験値もどんどん積めるはずです!
「どうすれば?」を周りの人と議論する・必死に考えることで、データ分析の経験値もどんどん積めるはずです!
同じ集計 (Summarize) 機能を使っても全然違う
問23 と 問24 はどちらも集計 (Summarize) 機能で解きました。
だからそれ以上のことはできないかも?...と考える人もいると思います。
だって(列名だけ違うけど)同じコードや関数で動いてるんですよ?
それは変わらない事実です。しかも同じ df_receipt を集計しています。
では比べてみましょう。
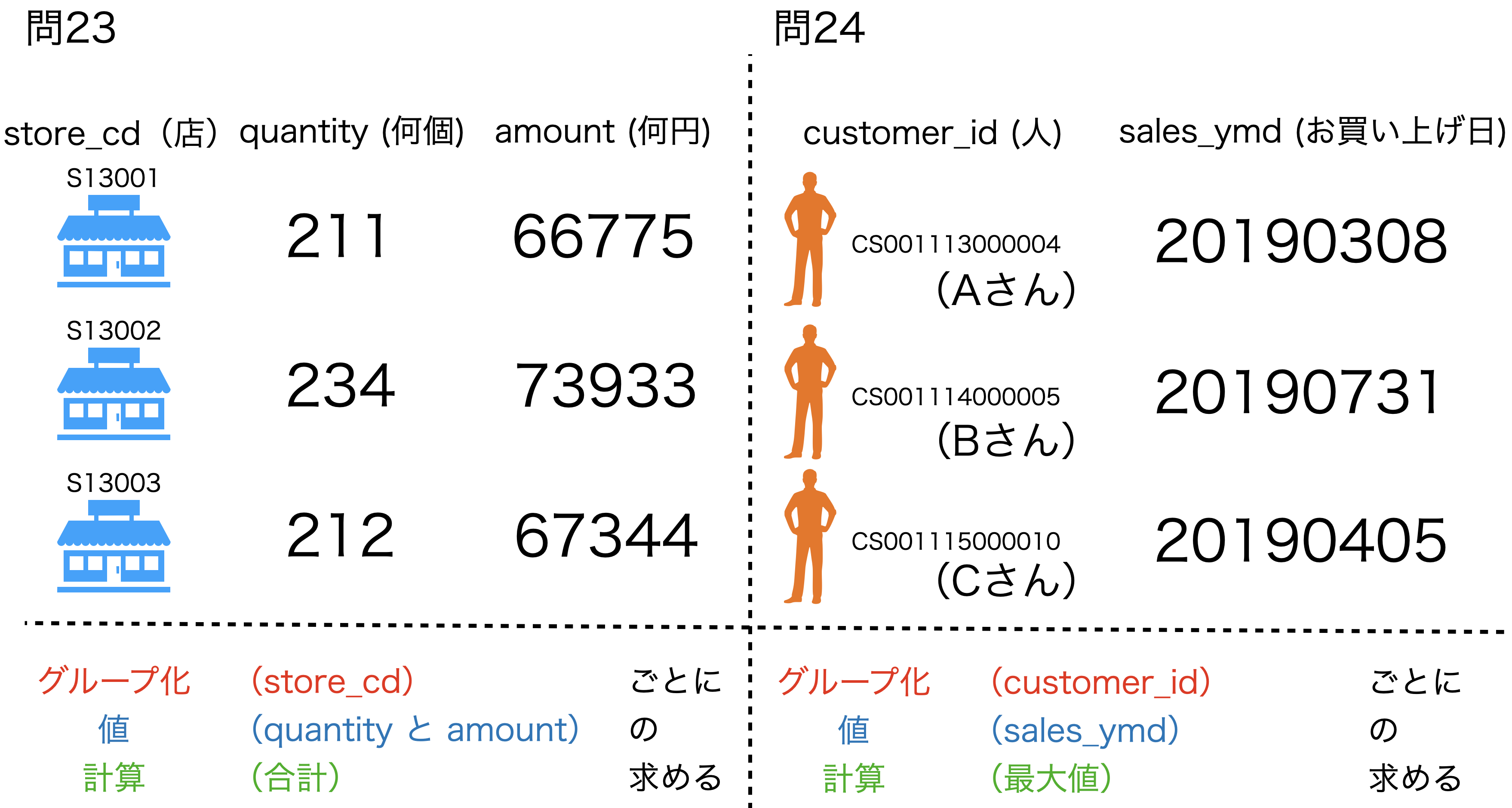
さて、同じ集計 (Summarize) 機能を使っても、2つのデータでは例えば次のように異なります。
- 店舗ごとの売上 → 売れてる・売れてないお店とかはここからわかりそう!
- お客様ごとのお買い上げ日 → 最近来てないお客様はここからわかりそう!
お分かりでしょうか?
同じ集計 (Summarize) 機能で、同じ df_receipt から作られたデータですが、たった3つの要素「グループ化・値・計算 を意識するだけでここまで違う」のです。
集計 (Summarize) 機能だけでも可能性を感じてきますよね。
このあとも集計 (Summarize) 機能たくさん練習するので、頑張りましょう。
問25 : 対象データの最小値を求める

答案・解説はこちら
問題文に「最も古い売上日」と書いてあるので、計算の仕方は最小値です。
さっきが最大値だったから...という理由でも良いですが、それがなくてもこの問題が解けるようにするためには、やはりイメージすることが大切だと思います。
とはいっても、実装することはカンタンです。
問24と同様にして、計算の仕方を最小値 (min) にしましょう。
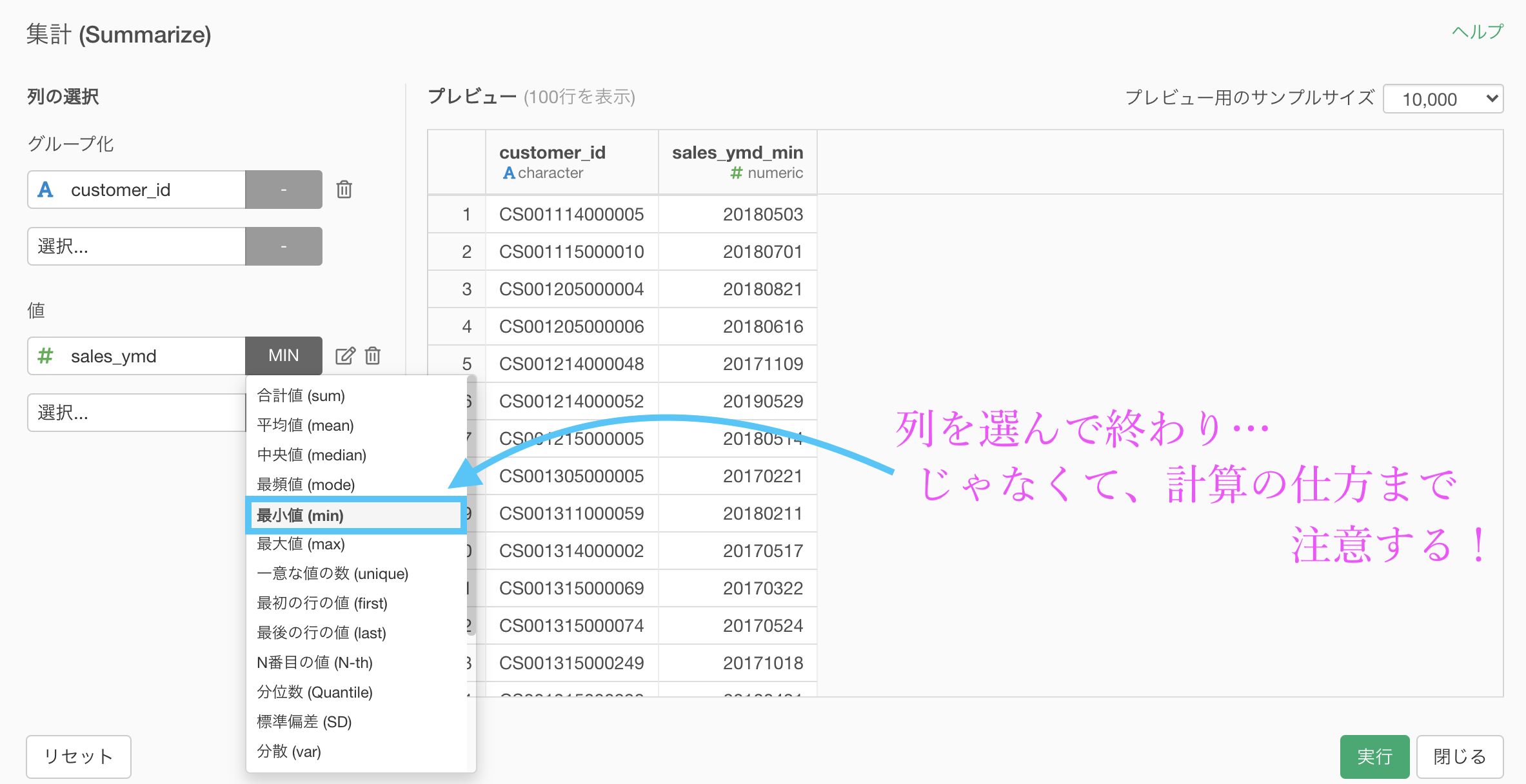
結果は以下のようになっていると思います。解答を確認してみましょう。 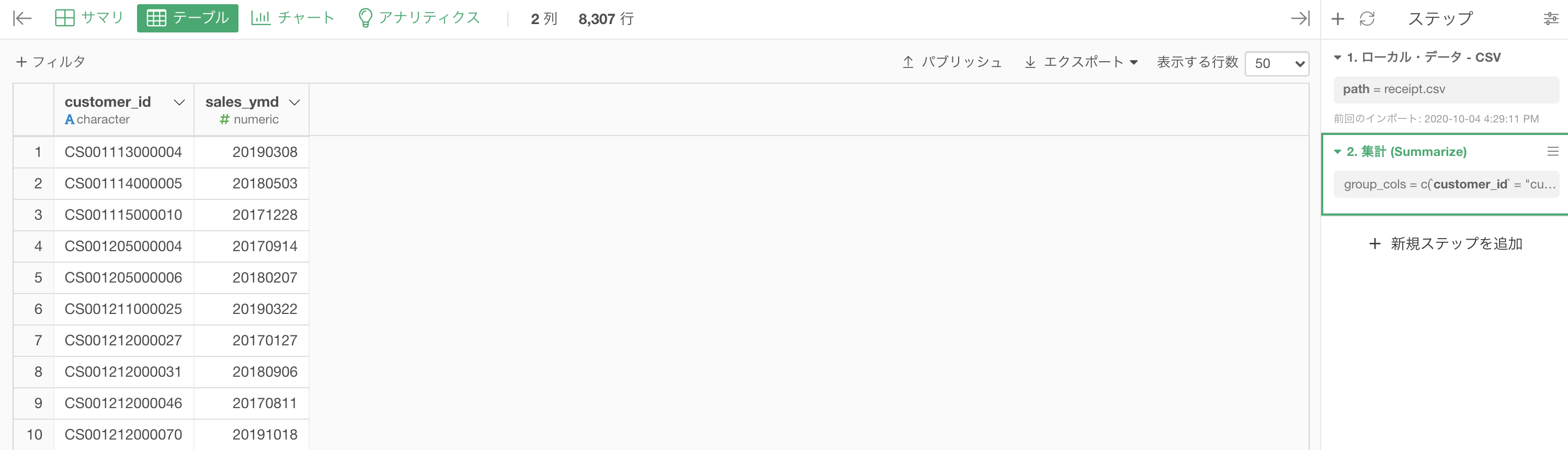
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.groupby('customer_id').agg({'sales_ymd':'min'}).head(10)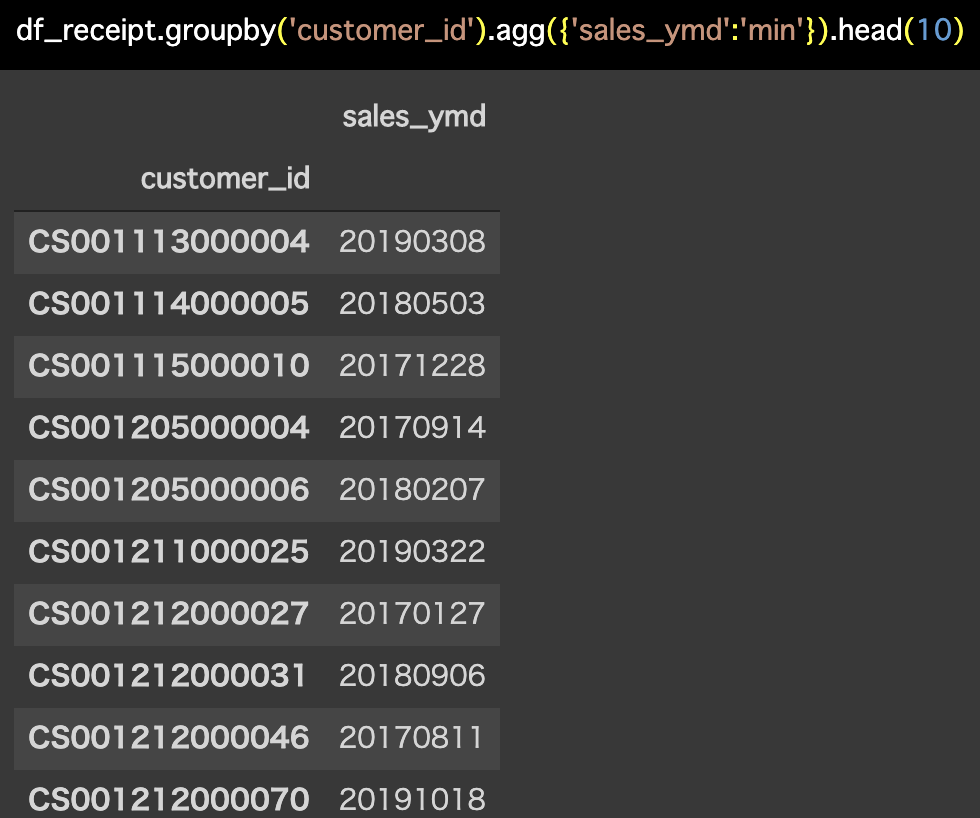
臨場感のために
お買い上げ日の最大値から最小値をみる...例えば点から点を繋げて線にしたり、日数を数えたり...ということはよくされますが、何を見たいのかがはっきりしているからこそです。
もしかしたら最近来ていないお客様は特に主婦が多いのかもしれないし、最近来るようになったお客様はシニアの方かもしれませんよね。
つまりお客様の動きを見たいという動機です。
このような動機がなくては、本当に何もできません。
ただやってみただけになります。
問26 : 集計結果に対する条件指定で絞り込む

答案・解説はこちら
具体的には
1. 集計
グループ化 : customer_id
値 : sales_ymd 計算 : 最大値・最小値
2. フィルター
sales_ymd_max(最大値) と sales_ymd_min(最小値) が異なるものという2つの処理をすれば良さそうです。
では、まずは 集計 からやってみましょう。
集計 (Summarize) 機能で、以下のように入力していきます。 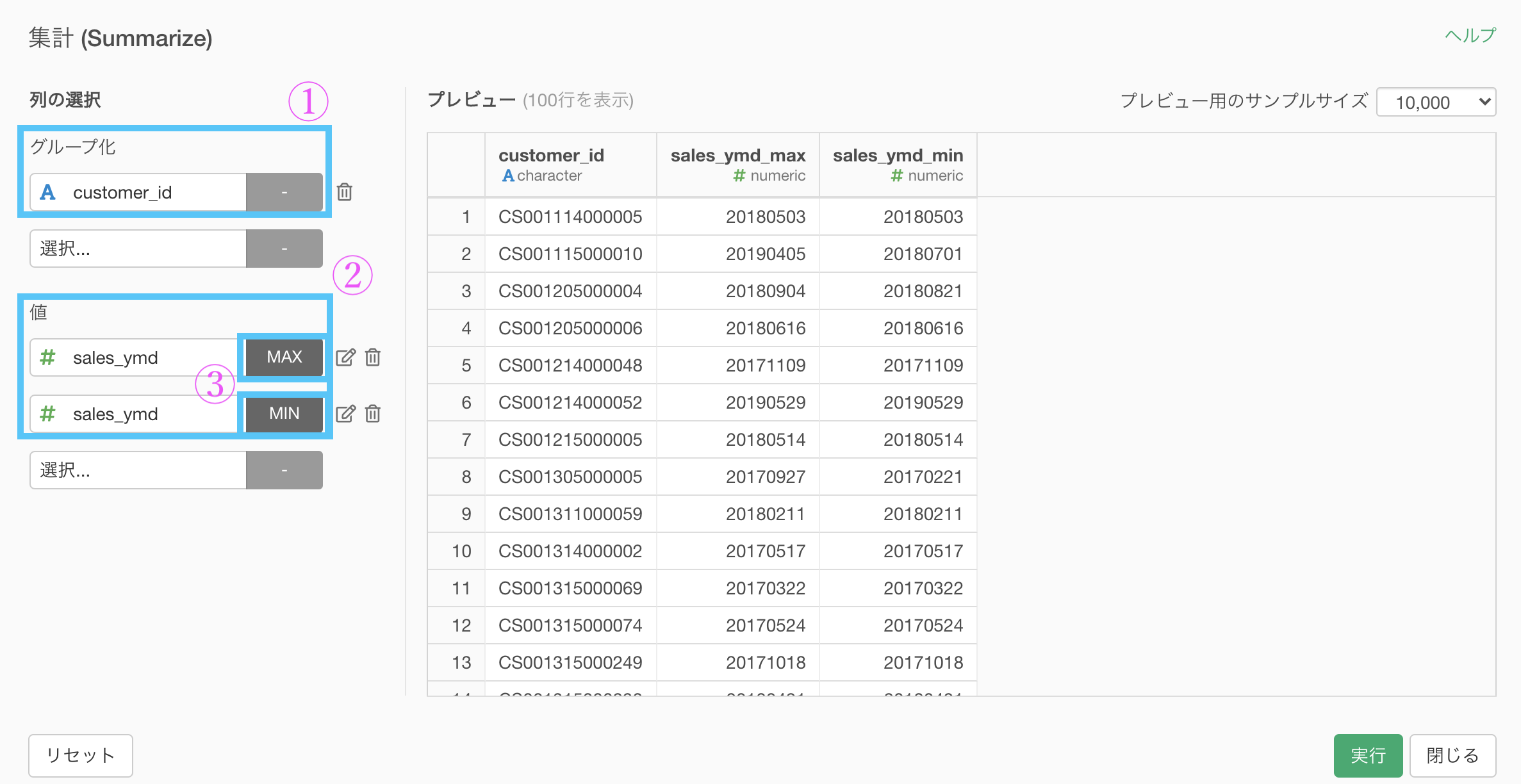
実行できたらこのような画面になったかと思います。 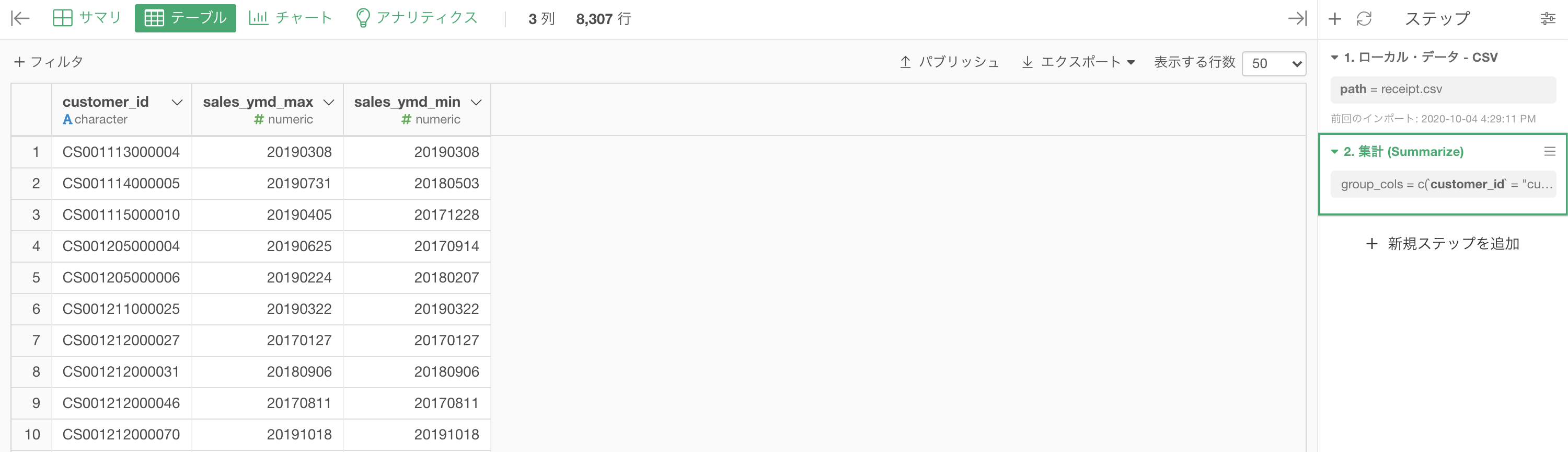
さて、ここからは フィルター です。
今回は2通りの方法を紹介しますが、どちらも思い付いて欲しい方法です。
ワンステップあるけど動きがきちんと追える方法
集計した後は、新しいステップを追加 → 「計算を作成(Mutate)」を選択しましょう。 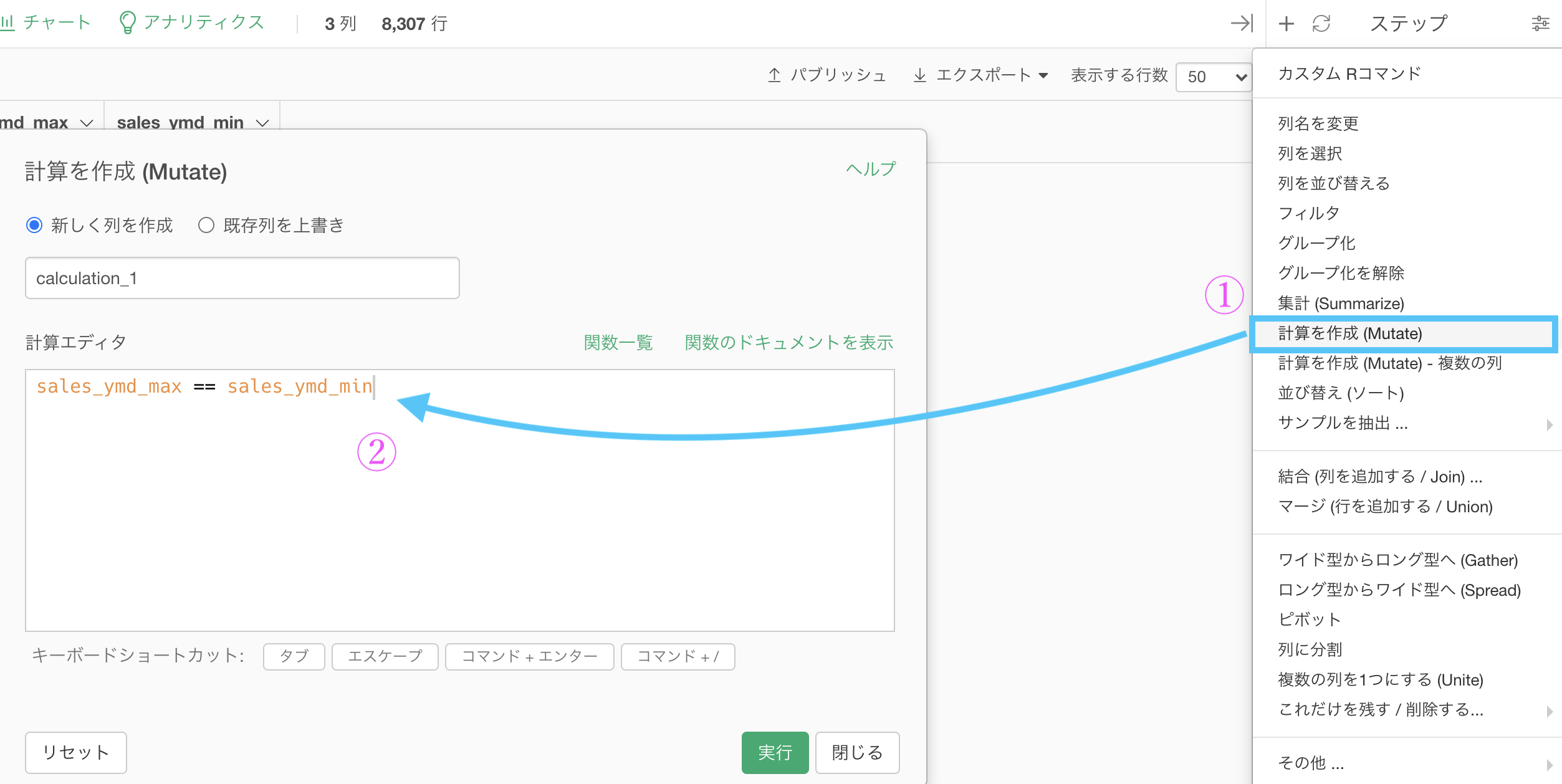 計算エディタの中には
計算エディタの中には
sales_ymd_max == sales_ymd_minとします。等しい場合は TRUE、等しくない場合は FALSE になる列(calculation_1)を作成するわけです。
そして、この列にフィルターをかけましょう。 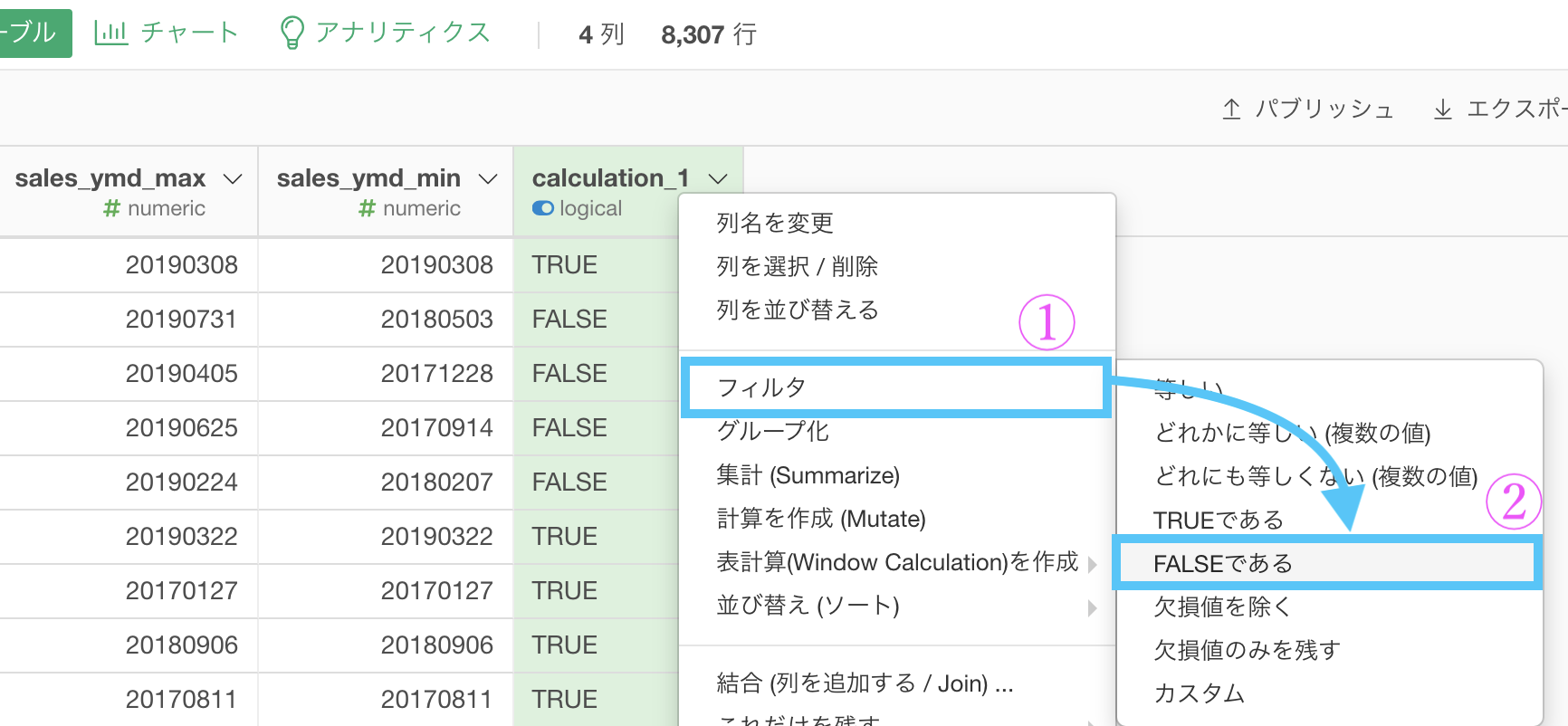
このまま実行します。 
結果はこのようになります。解答と確認してみましょう。 
一発でやる方法
やはり一発でやるためにはある程度のコマンドに頼る方が良さそうです。
しかし、ここまでの問題をやってきたならば、この程度のコマンドなら書けるはず(であってほしい!)ので、あえて紹介します。
集計した後は、フィルター →「カスタム」を選択します。 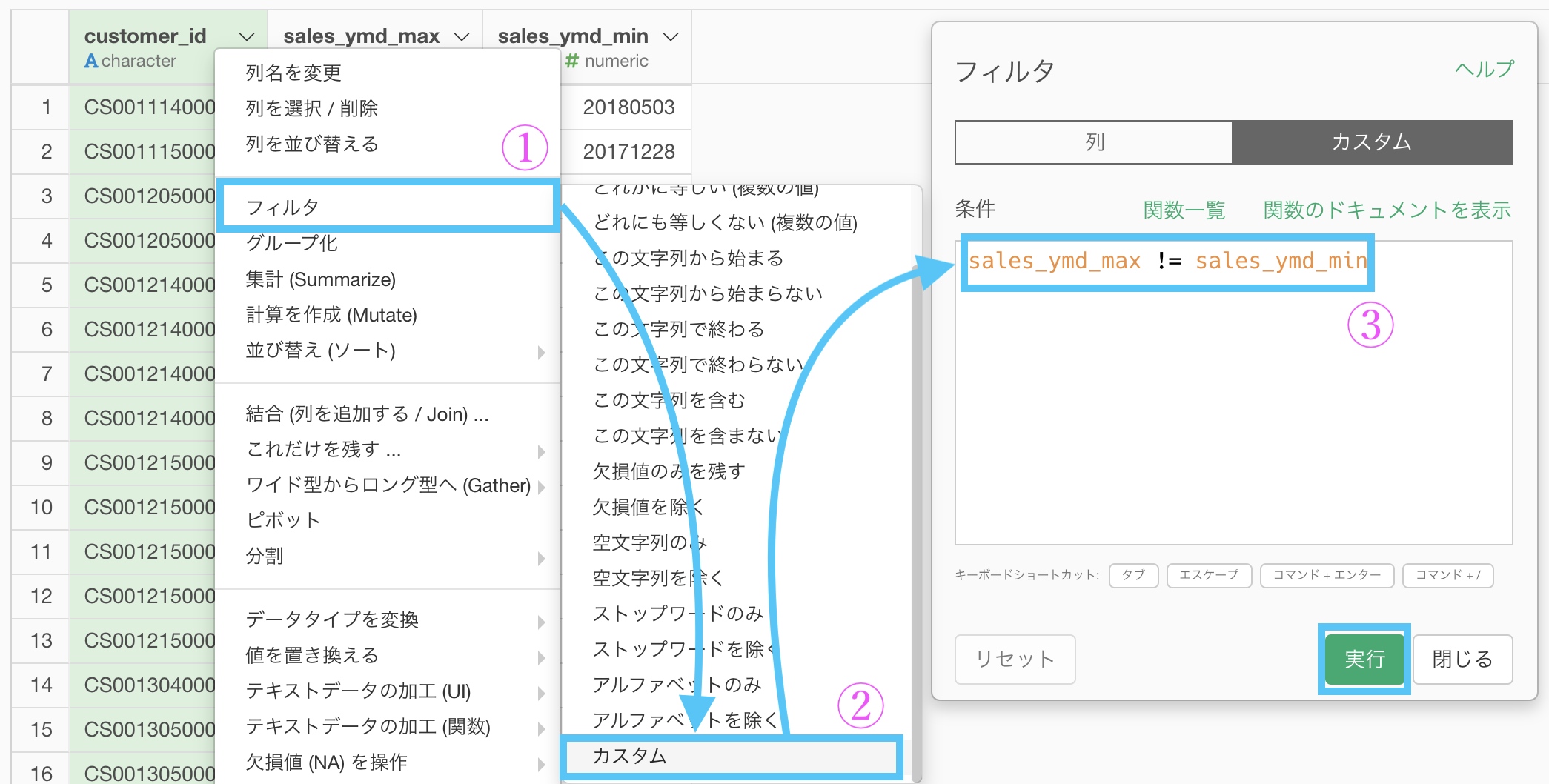
後はそのカスタムする計算式の中には
sales_ymd_max != sales_ymd_minを書いて実行するだけです。
結果はこのようになります。解答と確認してみましょう。 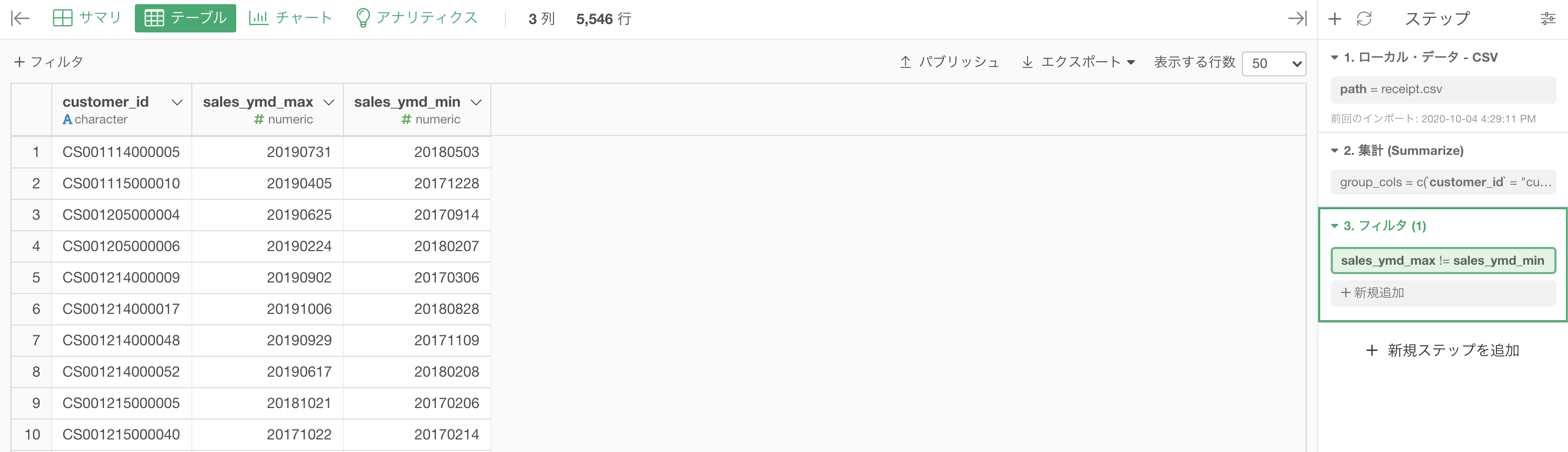
Python 解答コードはこちら
解答コードはこのようになっています。
df_tmp = df_receipt.groupby('customer_id').agg(
{'sales_ymd':['max','min']}).reset_index()
df_tmp.columns = ["_".join(pair) for pair in df_tmp.columns]
df_tmp.query('sales_ymd_max != sales_ymd_min').head(10)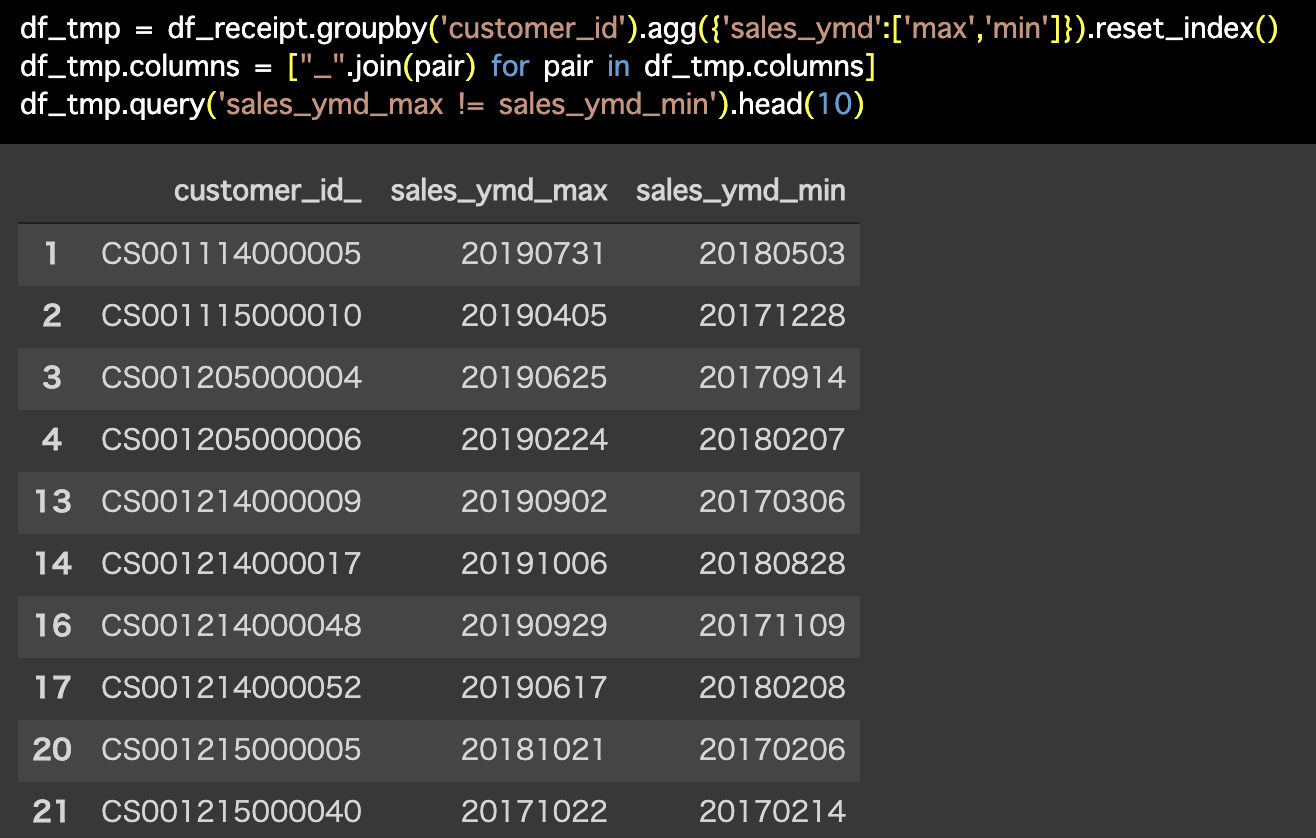
この問題をやった理由
やった理由は2つあります。
- データ分析は集計して終わりじゃない、その先の方が大事
- 2回以上来ているお客様をみたかった
上の理由の方が大切だと思うでしょう。
しかし実は下の理由も同じくらい大事です。
なぜなら、動機だから です。
もっとカンタンに噛み砕きましょう。その先が大事って...じゃあそれは何なの? となる
というのが理由です。
つまり上の理由は抽象的なので、言ってみれば「空っぽだけど大事」なのです。
それを下の理由で具体的に「例えばこんなふうに大事!」と言っていたということになります。
他の問題(問27とか問28とか)を差し置いて、途中で挟んでも申し分のない理由があった上での 問26 でした。
問27 : 対象データの平均値を求める

答案・解説はこちら
なので安心してください。
さて、今回の問題でやるべきをことを整理すると
特に各グループでの平均の集計です。
まず 集計 です。
集計 (Summarize) 機能で、以下のように入力していきます。
グループ化 : store_id 値 : amount 計算 : 平均値(mean)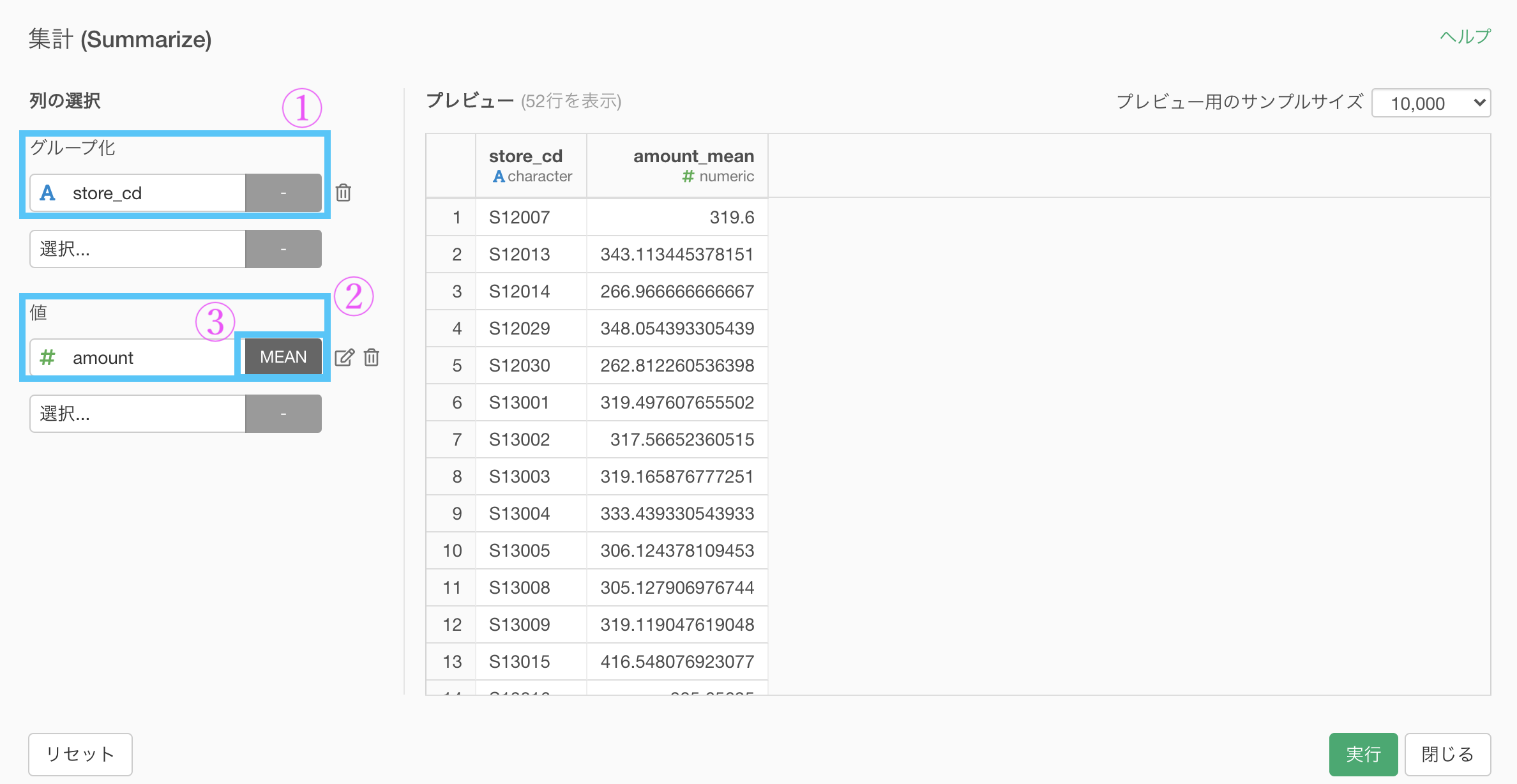
集計が終わったら次は TOP5 に並べることでした。
とは言え、今までの知識でなんとかなります。
集計 (Summarize) 機能 でできた amount_mean の列にソート → 降順をかけましょう。 
結果はこのようになります。解答と確認しましょう。 
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.groupby('store_cd').agg(
{'amount':'mean'}).reset_index().sort_values(
'amount', ascending=False).head(5)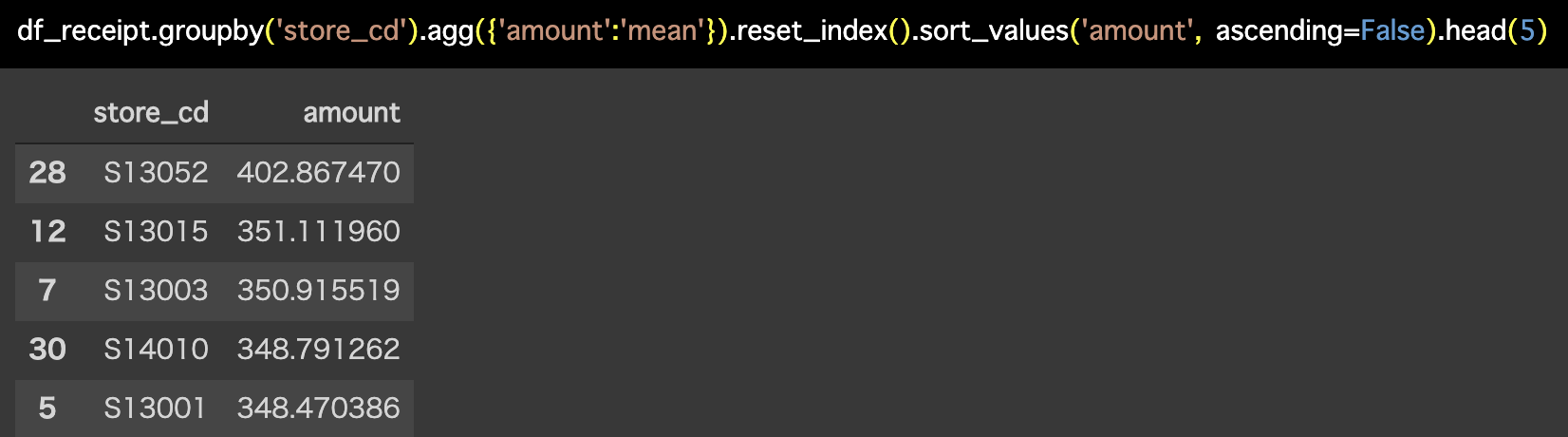
列名が amount_mean になっていませんが、それは後で or 集計 (Summarize) 機能の時点で変えれば良い話です。
個人的には amount_mean の方が好きです。
数値だけを見ても平均で計算したことはおそらくわからないと思うので。
問28 : 対象データの中央値を求める

答案・解説はこちら
特に各グループでの中央値の集計です。
まず 集計 です。
集計 (Summarize) 機能で、以下のように入力していきます。
グループ化 : store_id 値 : amount 計算 : 中央値(median)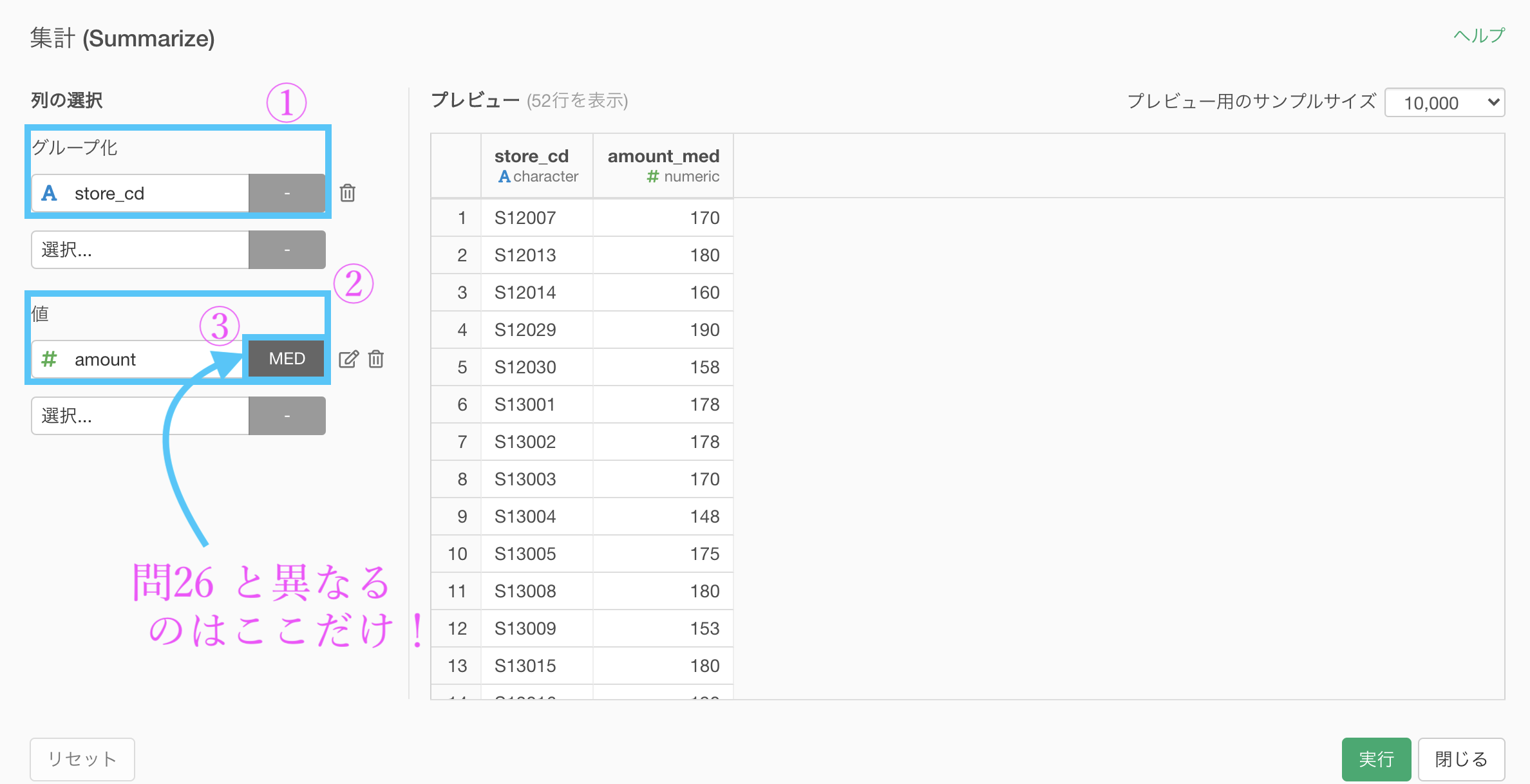
集計が終わったら次は TOP5 に並べることでした。
とは言え、前問の問26 と全く同じやり方です。
集計 (Summarize) 機能 でできた amount_med の列にソート → 降順をかけましょう。 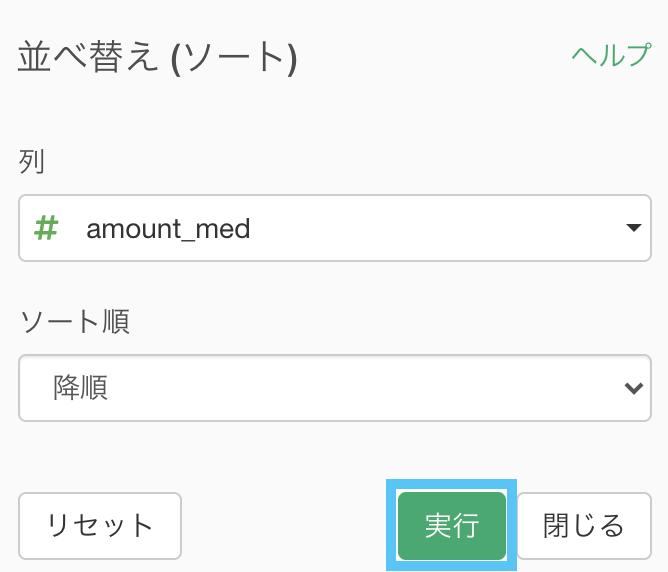
結果はこのようになります。解答と確認してください。 
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.groupby('store_cd').agg(
{'amount':'median'}).reset_index().sort_values(
'amount', ascending=False).head(5)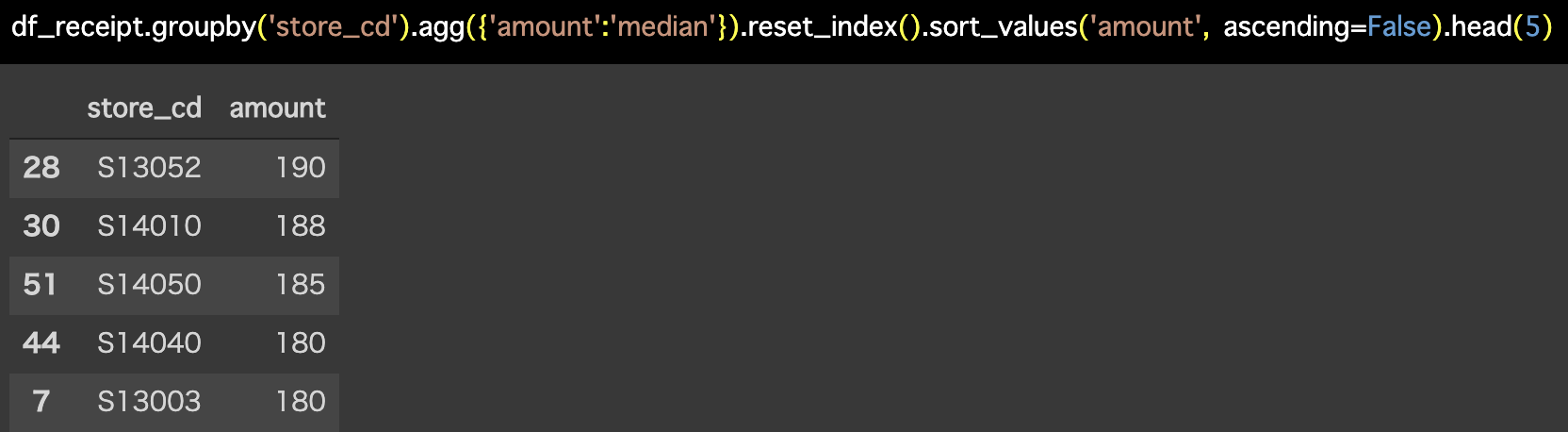
例えば amount で平均値と中央値でそれぞれ TOP5 を並べるとなったら、そのときはどのように表示するのが良いのでしょうか。
おそらく、amount だと数値の出力で平均値(小数点がある方)か中央値(小数点がない・0.5までの方)だと思いますが、流石に列名が不親切でしょう。
問29 : 対象データの最頻値を求める

答案・解説はこちら
よくよく考えてみたら、最頻値のTOP5って、最初から1位を出してるのだから日本語的にはどうなのかとは思いますが、実は論理的にも誤りです。
そのため、今回のような問題文になっています。
この問題では、一旦 amount の代わりに product_cd(商品コード)を用います。
今回は2通りの答案を用意しましたが、一方のは正解な回答ではありません。間違っているといわれても文句は言えないでしょう。その代わりわかりやすいです。
もう一方は正解な回答です。これは解答コードを実行した解答データとも一致します。
いままでと同じやり方で R の方に解答があるやり方
これを書いたのは、こうする人は普通に大勢で居ると思ったからです。
まず今までと同じように集計 (Summarize) 機能で、 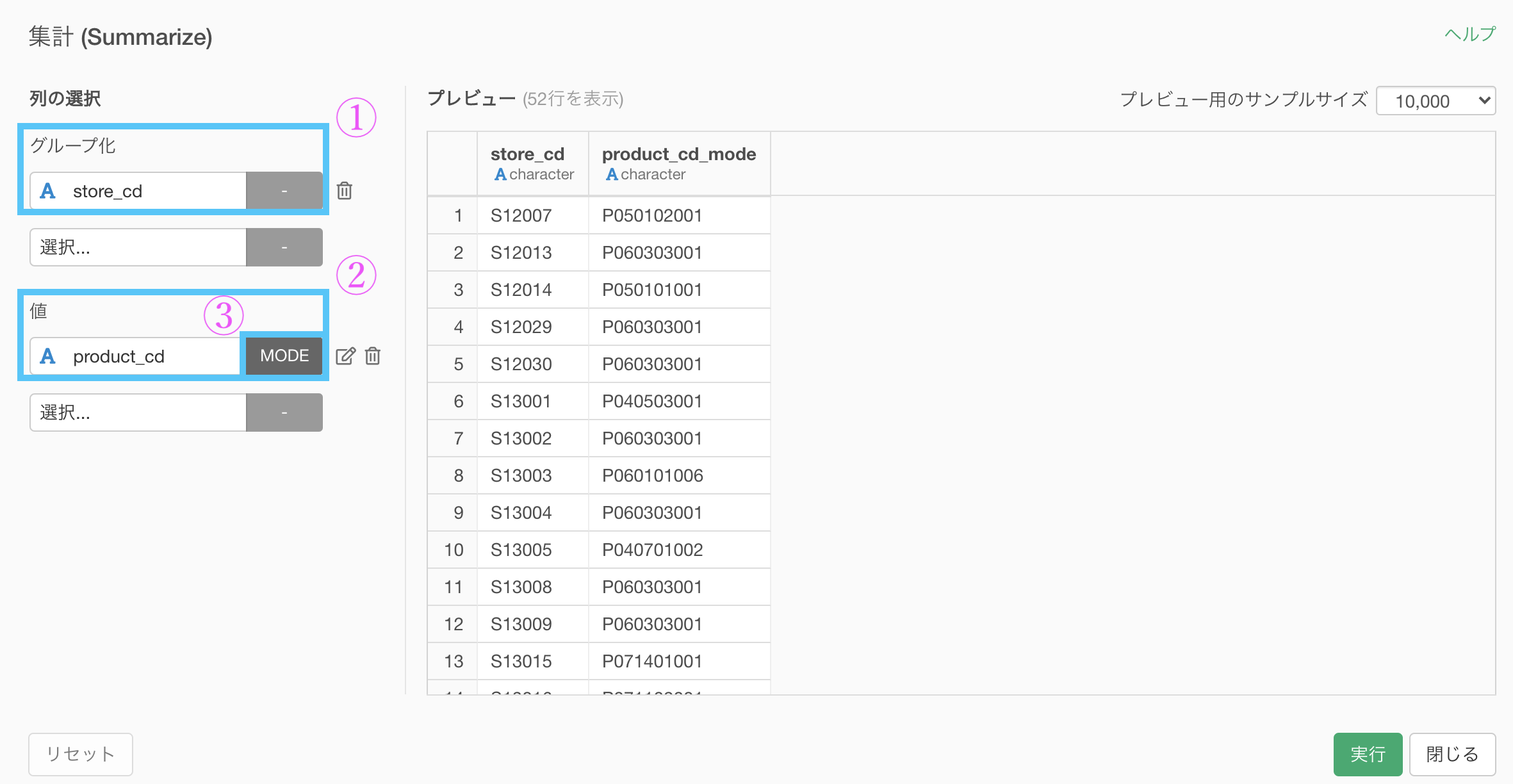
やっていることは今までと同じように、
グループ化 : store_id 値 : product_cd 計算 : 最頻値(mode)です。
これで実行すればこのような結果になっていると思います。 
ちなみにRの解答はこちら
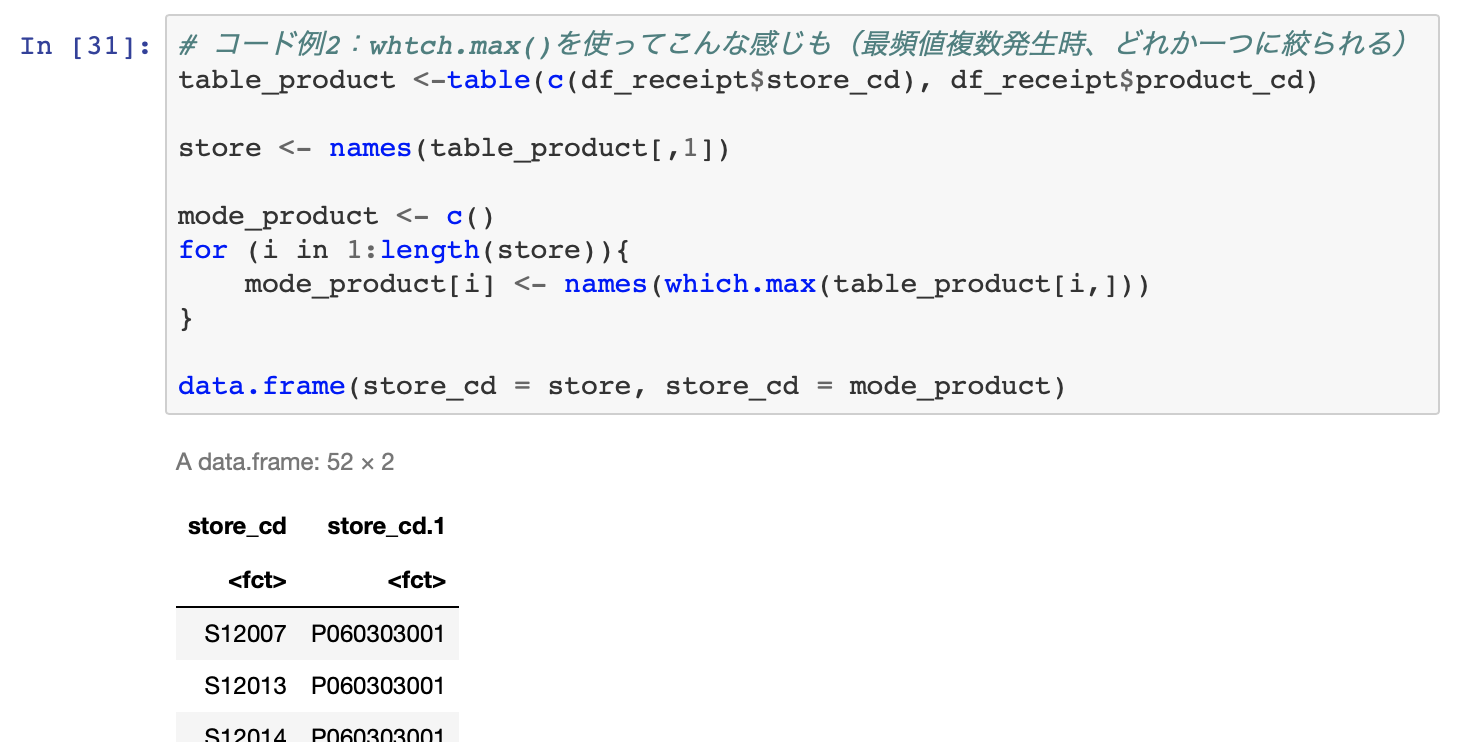
解答のテーブルだけ見れば同じものなので大丈夫です。
難しいかも知れないけど Python の方に解答があるやり方
要するに、頻度が同順位のものは1つしか表記されていない問題を、Exploratory でも解決する方法です。
まずはいつも通り 集計 (Summarize) 機能 を開きます。 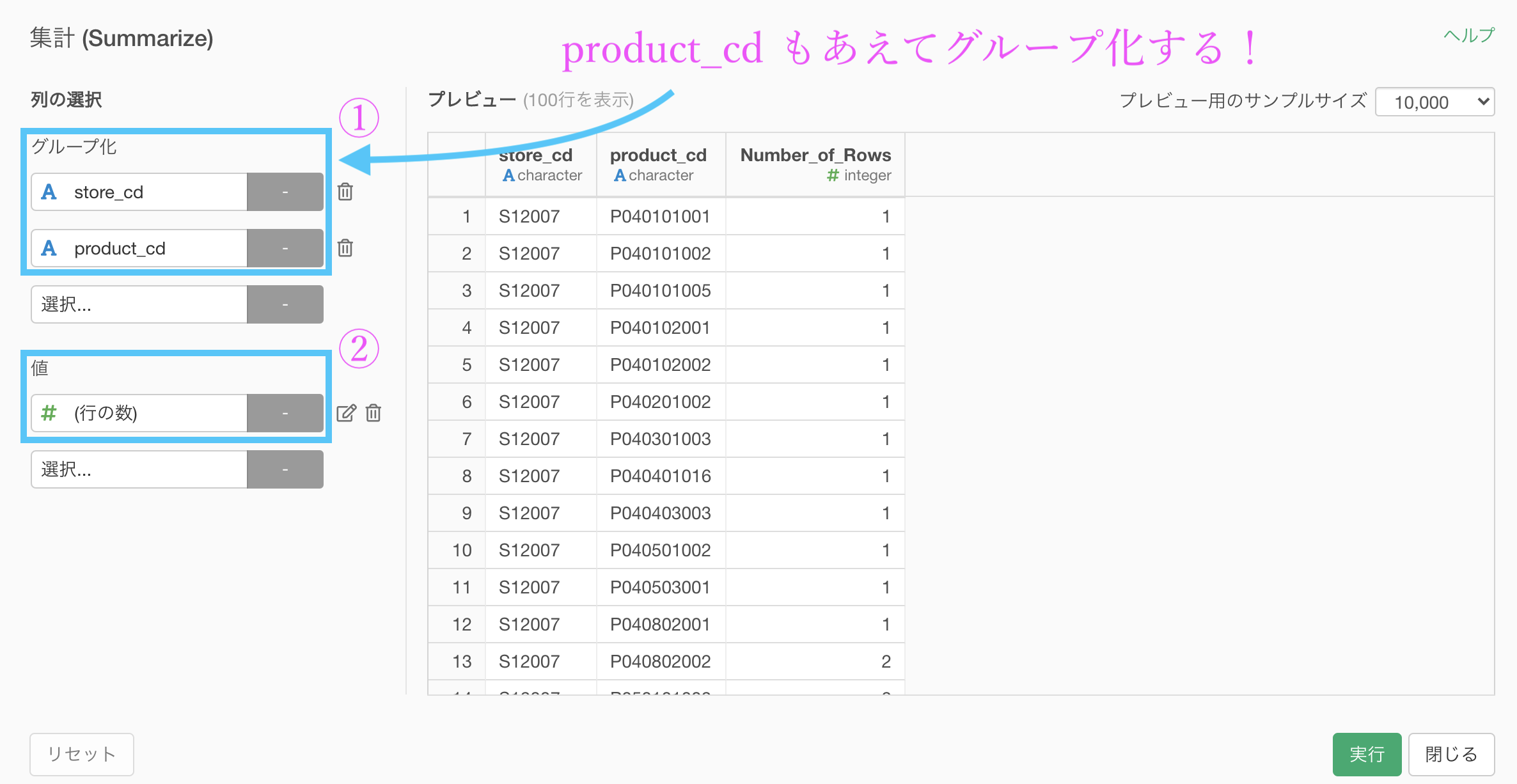
やっていることは
グループ化 : store_cd と product_cd
値 : 行の数 計算 : (そもそも選べない)です。ポイントは、store_cd と product_cd を一緒にグループ化のところに入れたというところです。
実行する際には少し処理が重くなります(グループの数が多いので)。
このようになったはずです。 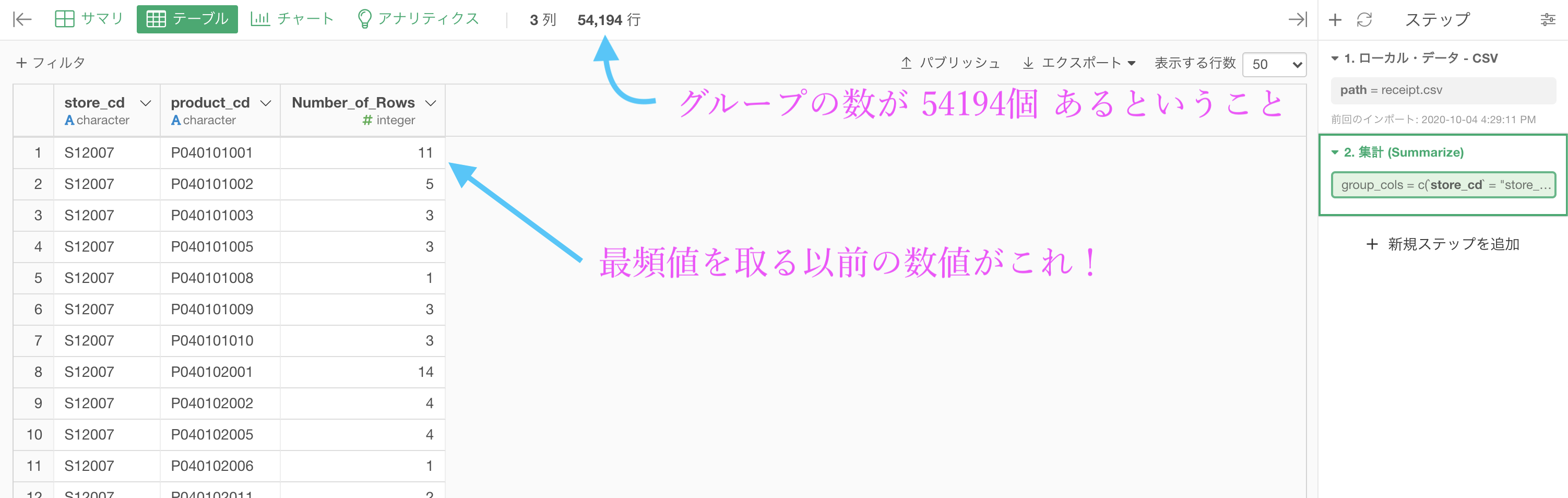
説明は上の通りで、グループ化のところをよく考えると、行の数(Number of Rows)は最頻値を取る前の数値です。
そのお店(S12007)の中でその商品(P040101001)が11個買われた
(例) 千葉の佐倉店でお寿司の惣菜が11個買われた...みたいな感じ!次にやることは、store_cd だけをグループとしてみます。 
色がついたはずです。 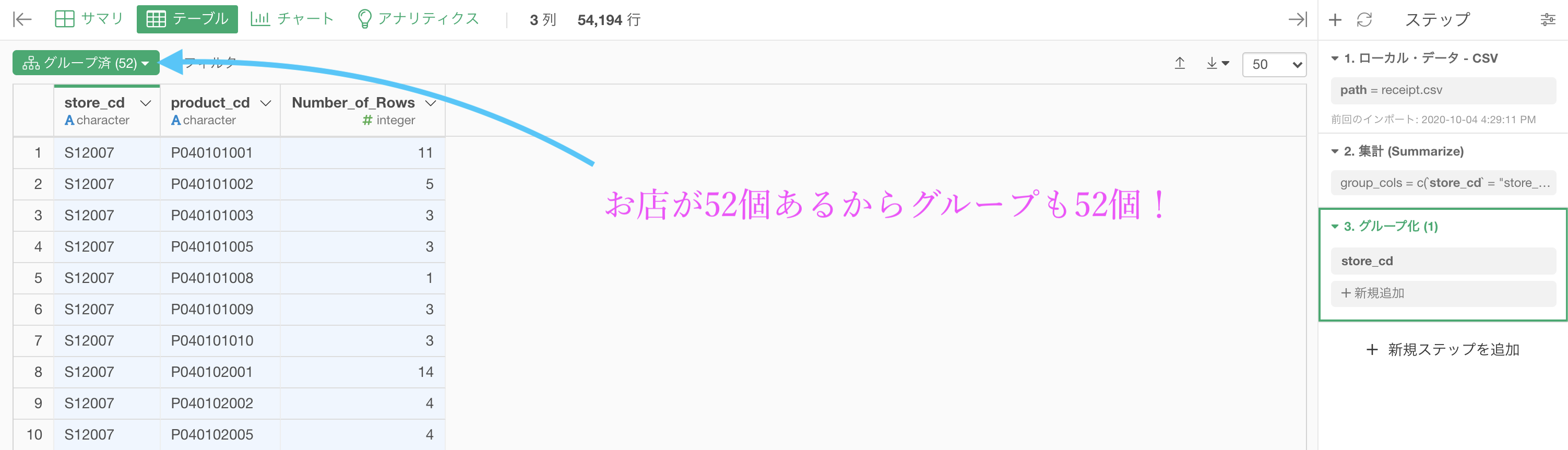
つまり、テーブルの中に小さなテーブルが52個(グループの数)ある!
ということです。
SQLがわかる人は、
PARTITION BY : 今やったグループ化
GROUP BY : 今までやっていた集計 (Summarize) 機能という具合です。知らない人であっても、ただ分けてるだけなのが上、分けてから値を計算するのが下と覚えておきましょう。
とにかく、テーブルの中にテーブルがたくさんあるので、色がついている間(グループ化している間)は、処理がそれぞれのテーブル(色の中)で行われます。
それが本当かどうかやってみましょう!
色がついた状態(今の状態)で、Number of Rows の列に、これだけを残す... → 「上位N」を押します。 
あとは N に相当する数値(=順位)を 1 にします。
つまり、各グループで上位1 の Number of Rows が多いものだけを残します。 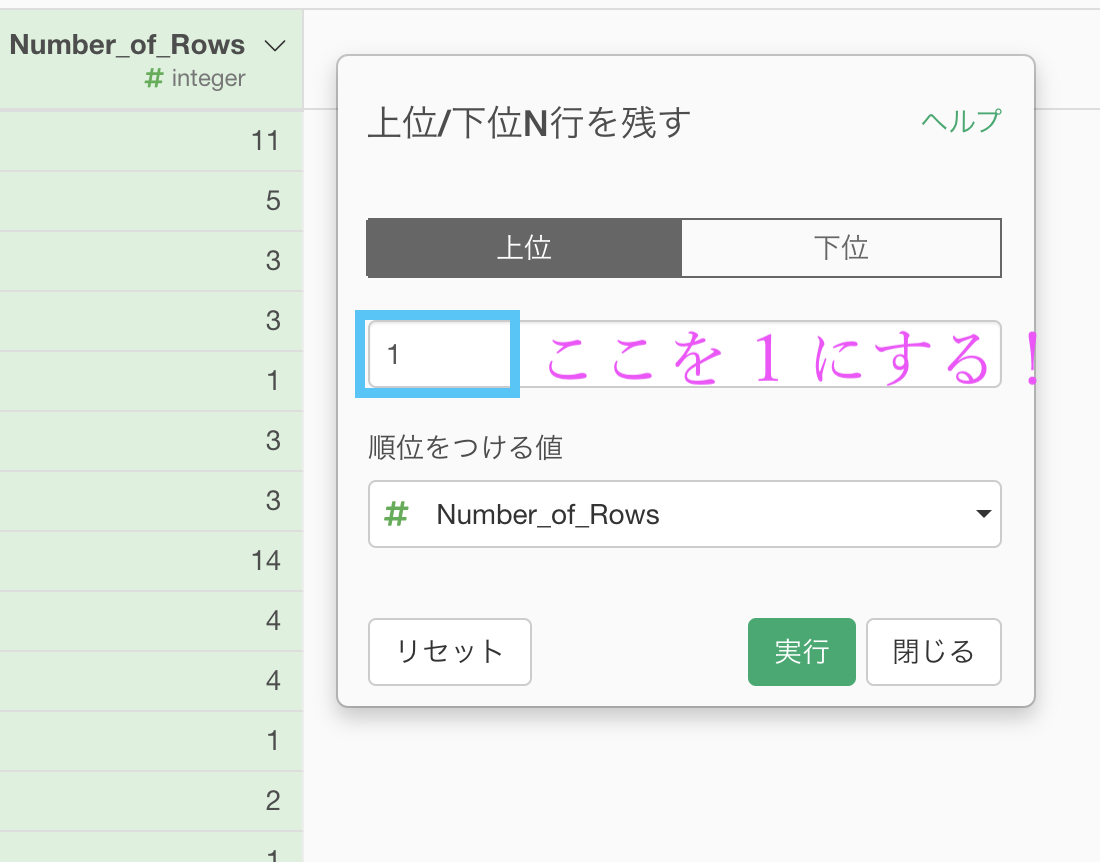
するとこのようになったと思います。
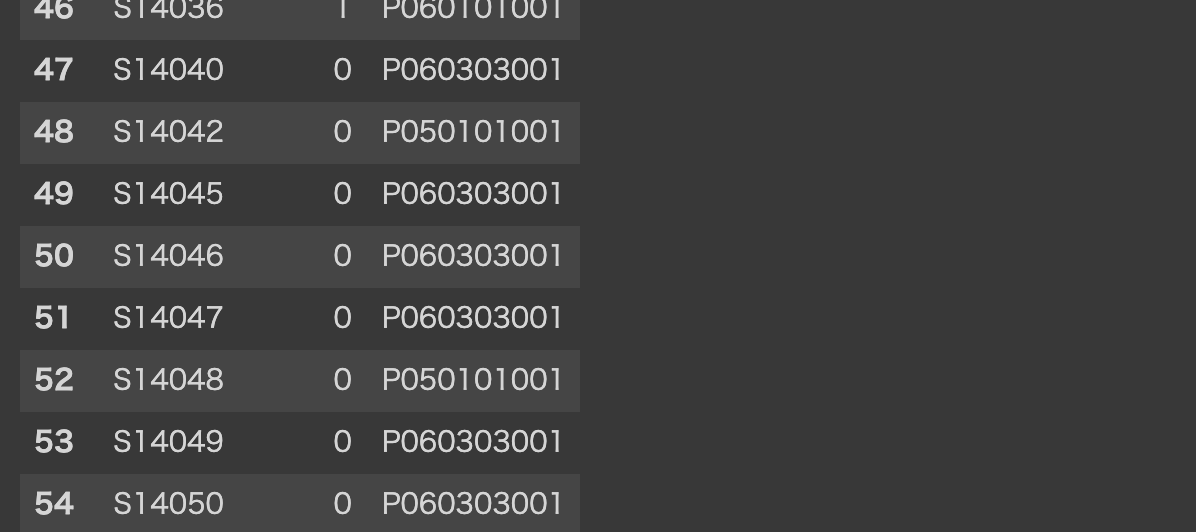
目がチカチカしますが、注目して欲しいのは、この時点での行数です。 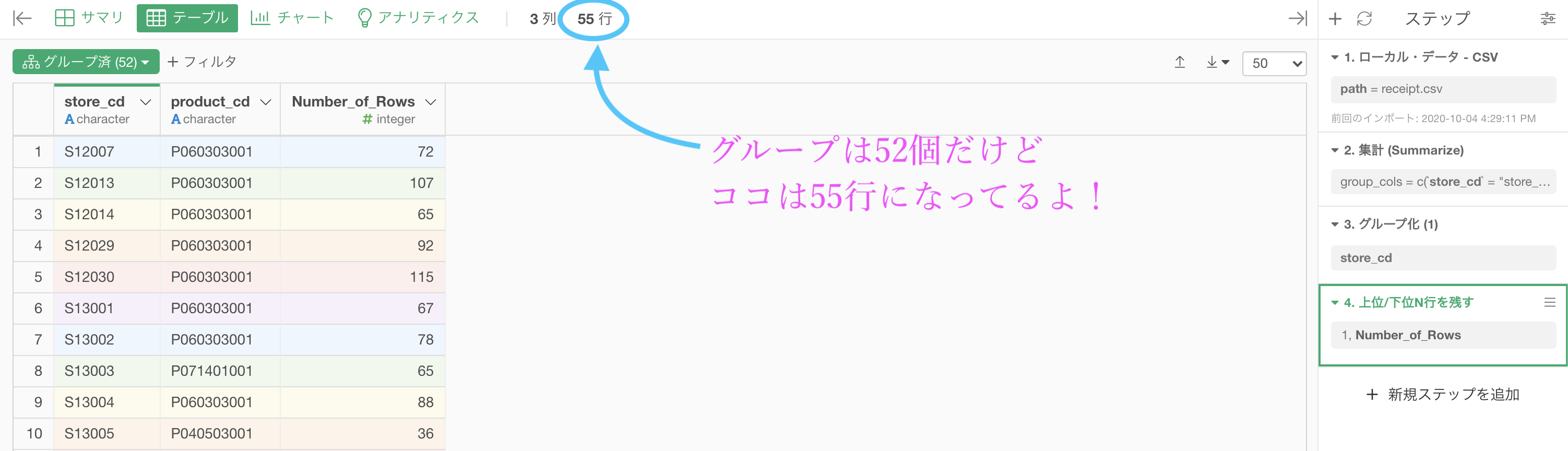
グループ(お店の数)は52個しかないのは、グループ化(52) と書いてあるところからもわかりますが、上位1 を抜き出したのに行数が55です。
つまり
上位1 のダブリが、全体で 3 つある!ということです。最頻値が被っているのですね。
実際に探してみました。 
これで答案は実質的に終わっています。
...が、Pythonの解答の表示では、同じところにある順位は 0,1,2...とつけているようです。
解答をチェックしてみましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.groupby('store_cd').product_cd.apply(
lambda x: x.mode()).reset_index()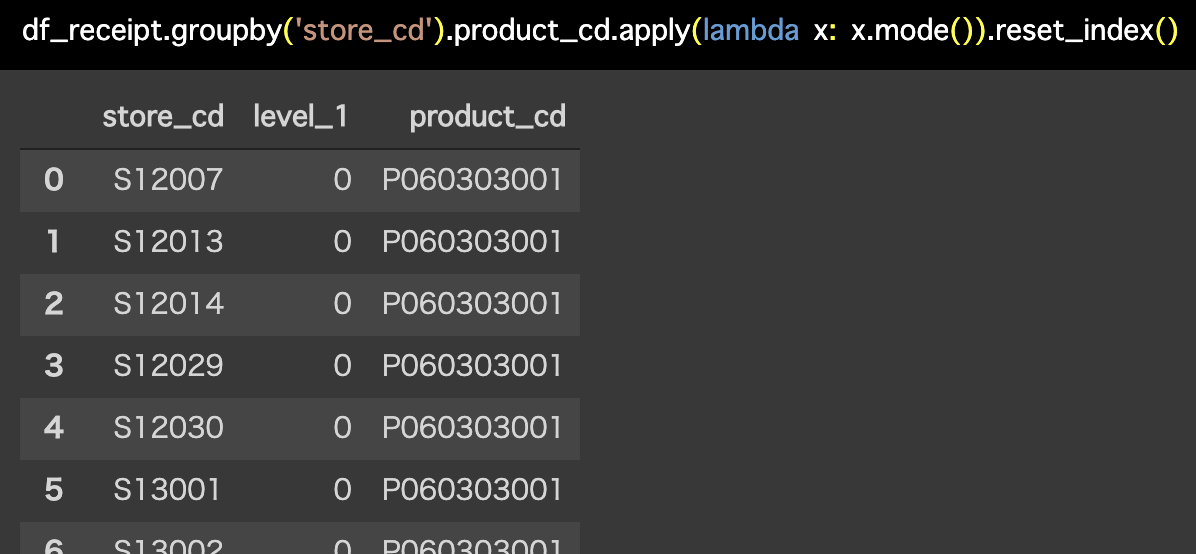
拘っている人のために
伏線回収です。
Python の解答と合わせたい!という人もいると思いますし、これも1つのトレーニングとして紹介してみます。
グループ化をそのままにしていると思いますので、このまま Number of Rows に上書きする形で計算を作成(Mutate)したいと思います。 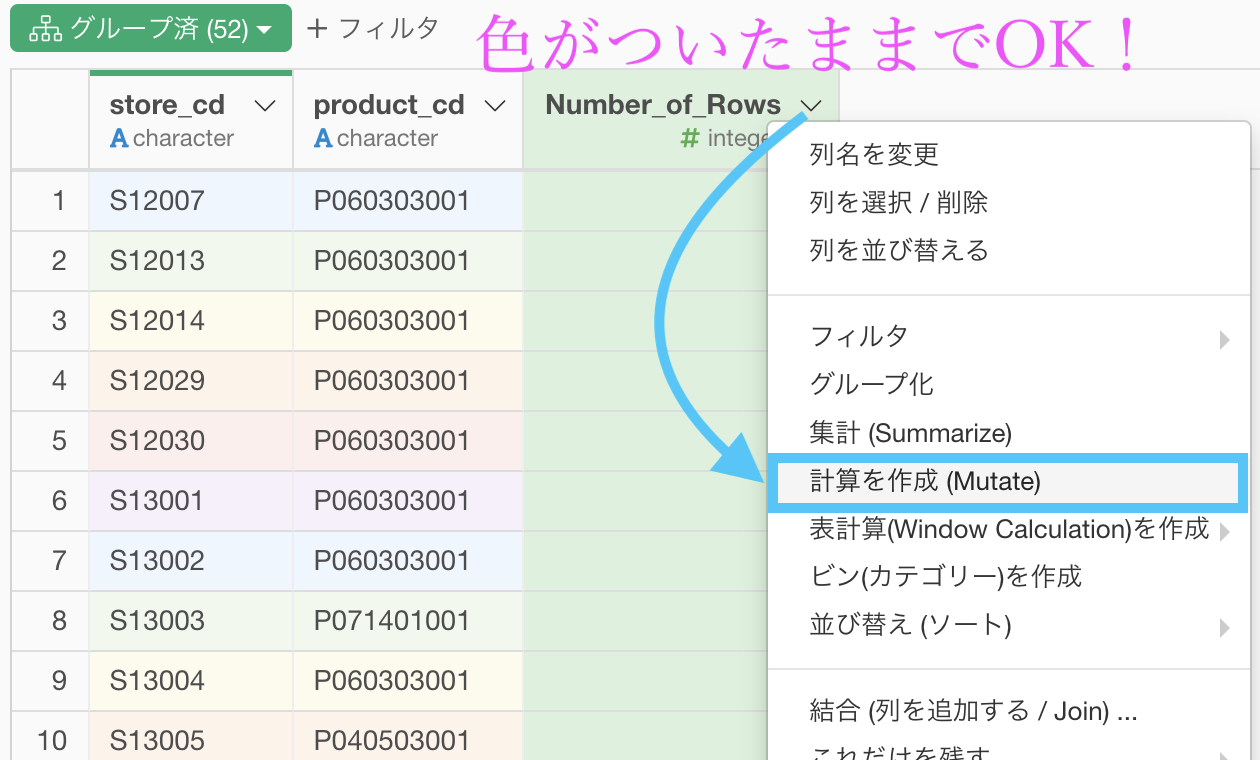
計算エディタにはこのように設定して書きましょう。 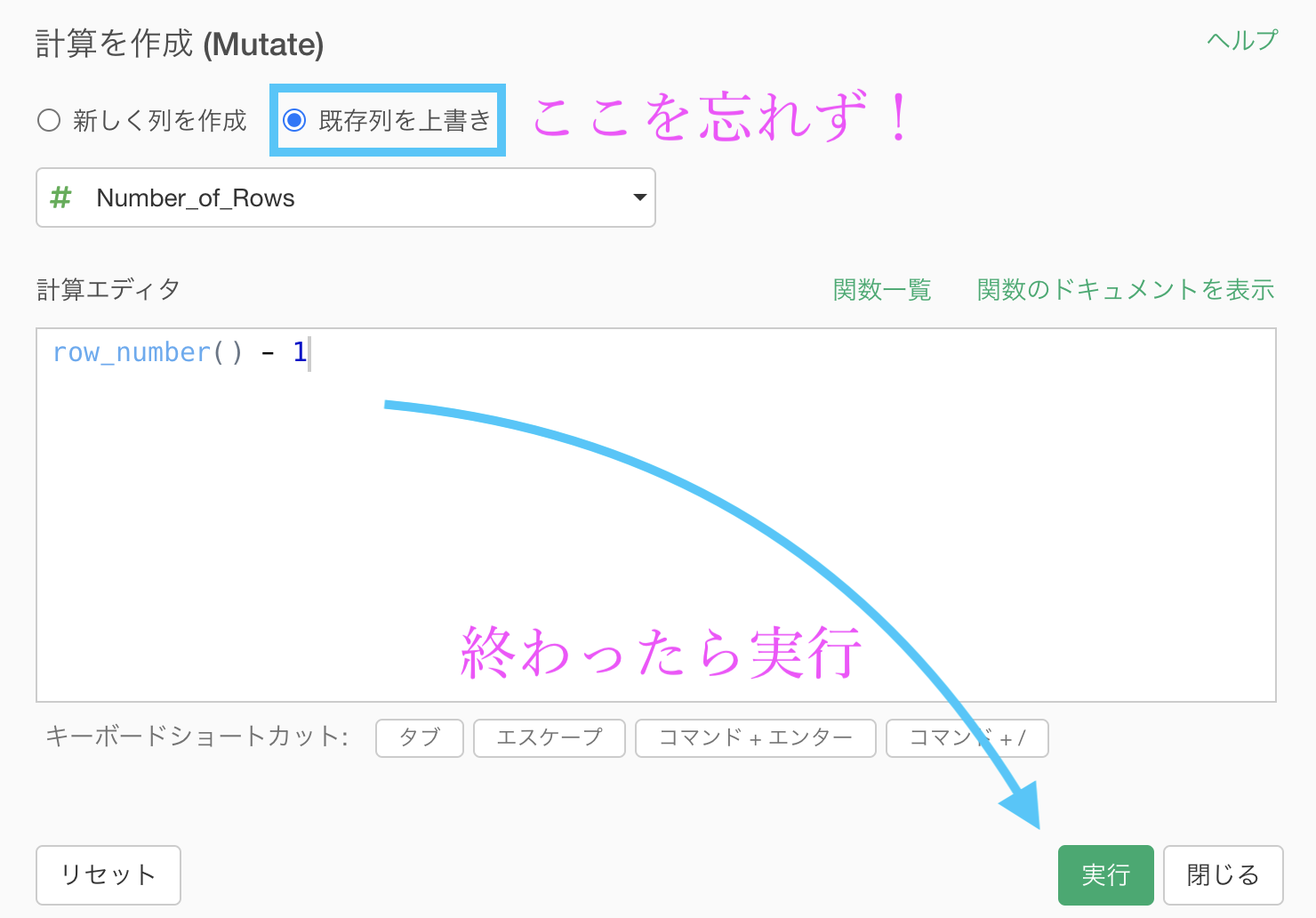
row_number() - 1と書いています。コピペして使うなどしてください。
これでもうグループ化は必要ないので、解除しておきましょう。 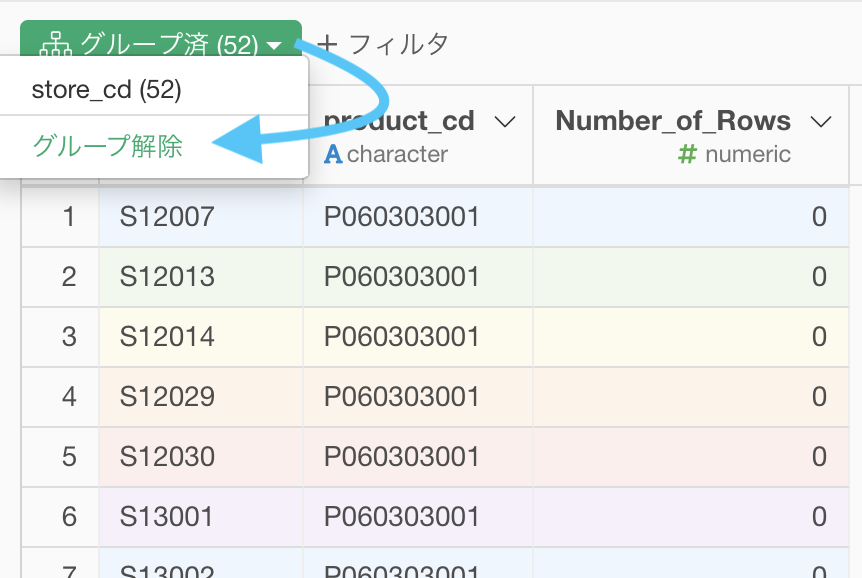
下のほうに行くと、このような結果になっているので Python の解答と一致するはずです。 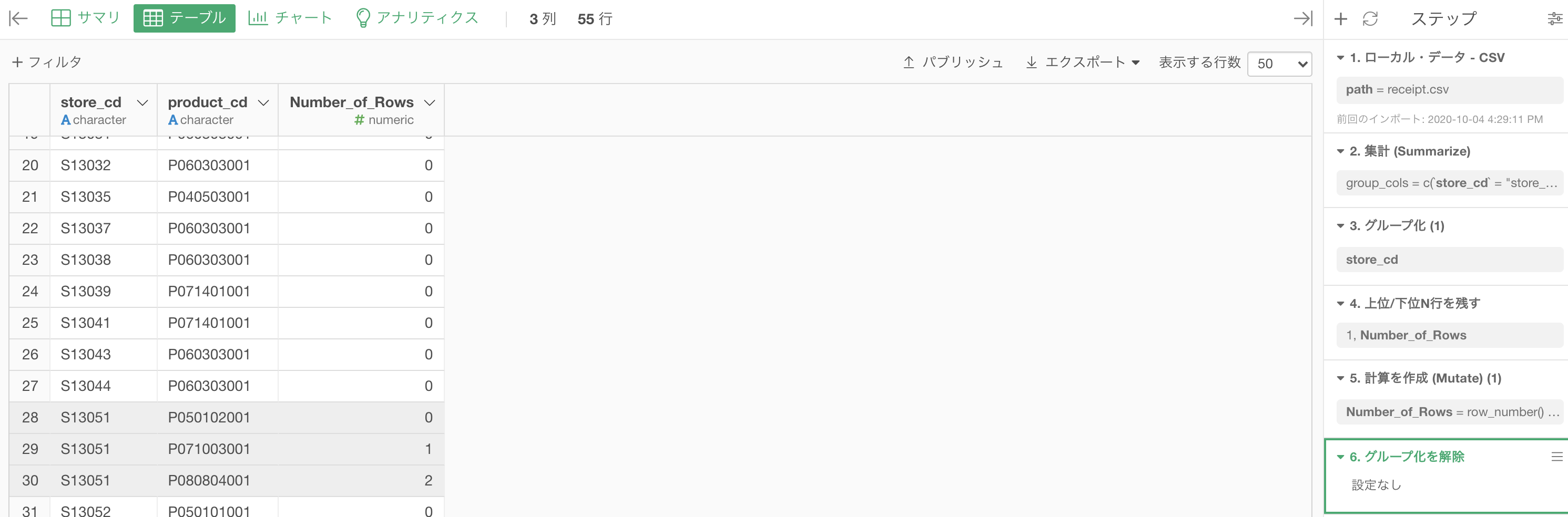
最頻値は拘りましたが、どうせ順位が一緒ならいいや...という方は、単に 集計 (Summarize) 機能 を使うだけでも良いですが、1度はこのくらいしっかりトレーニングを経験しておくことも良いことだと思います。
グループ化の機能を使い慣れておくと、実務であろうとも強い武器になります。
問30 : 対象データの分散を求める

答案・解説はこちら
特に各グループでの分散の集計です。
まず 集計 です。
集計 (Summarize) 機能で、以下のように入力していきます。
グループ化 : store_id 値 : amount 計算 : 分散(var)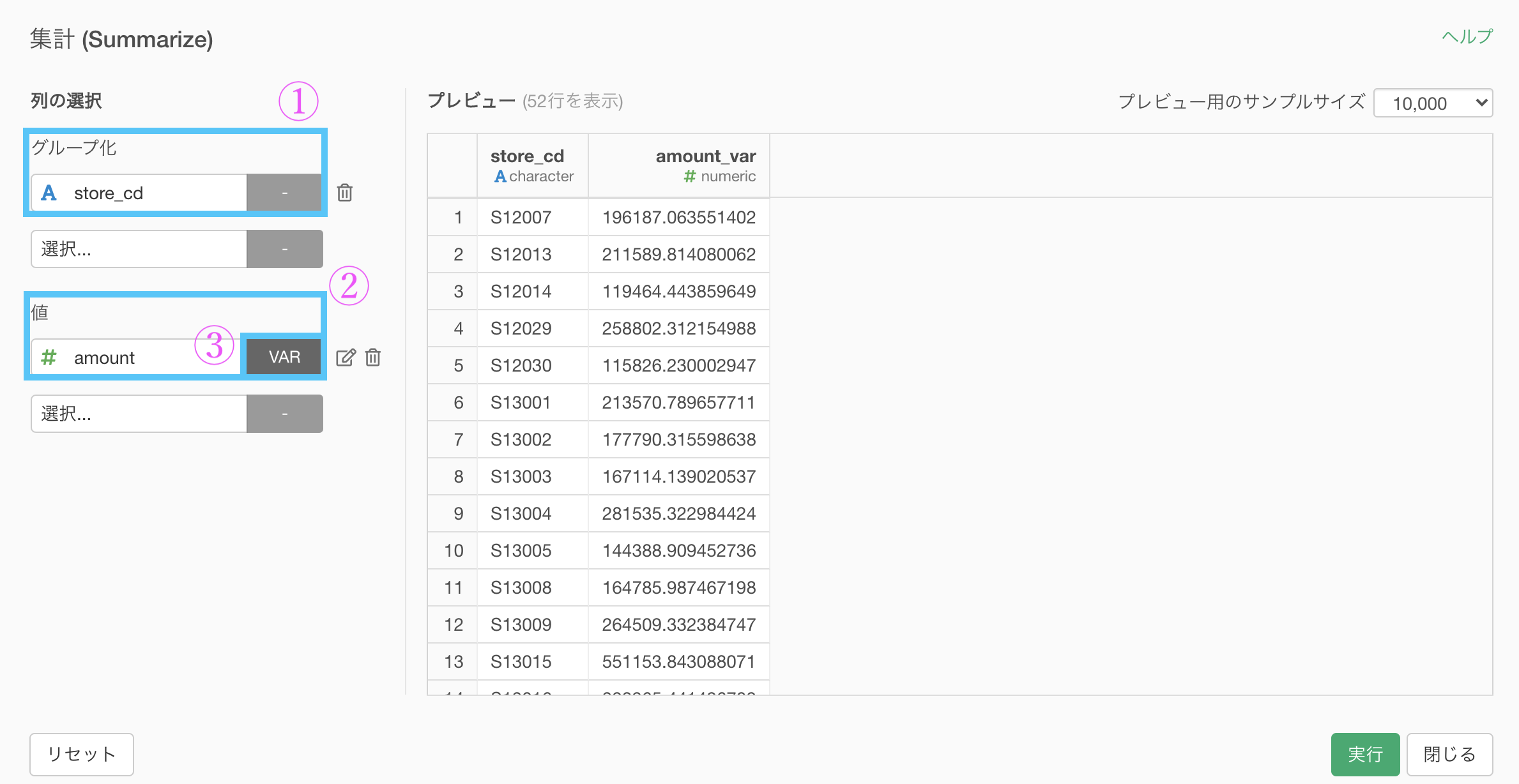
集計が終わったら次は TOP5 に並べることでした。
とは言え、平均値や中央値のときと全く同じやり方です。
集計 (Summarize) 機能 でできた amount_var の列にソート → 降順をかけましょう。 
結果はこのようになります。解答と確認してください。 
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.groupby('store_cd').amount.var(ddof=0).reset_index().sort_values(
'amount', ascending=False).head(5)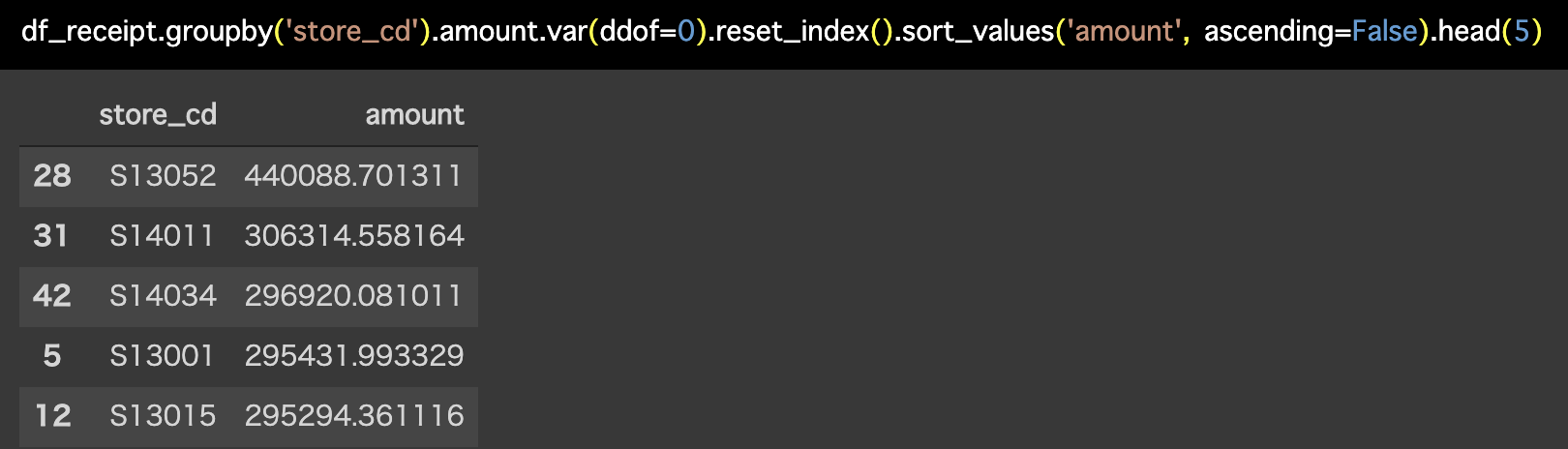
よくみたら値が違う!そう思った鋭い方へ
これで詐欺グラフを作る・見破るセンスがありそうですが、今回の場合はサンプルサイズが大きくなるにつれてほとんど 0 になります。
冗長な話はさておき、解答コードの問31の中に Tips と書かれたこのような記載があるはずです。 
ddof = 0 と ddof = 1 では、分散の計算で nで割ったのか n-1 で割ったのかが異なります。
ddof = 0 : n で割る
ddof = 1 : n-1 で割る1 が立つと -1 したもので割るということですね。
さて、困ったことに実は
R言語では n-1 で割った分散だけで、n で割った分散は自分で作るしかないのです。n-1 で割った分散からすぐに作れるのですが、Python と同じようにしてくれればよかったのに...と考える方もいるかも知れませんね。
見方を変えると、考える良い機会になっていると思うので、一長一短かと思います。
R言語で自分で作るしかないなら Exploratory でももちろん自分で作るしかないです。
今回の場合では、集計 (Summarize) 機能で、行の数(Number_of_Rows)も追加してみしょう。 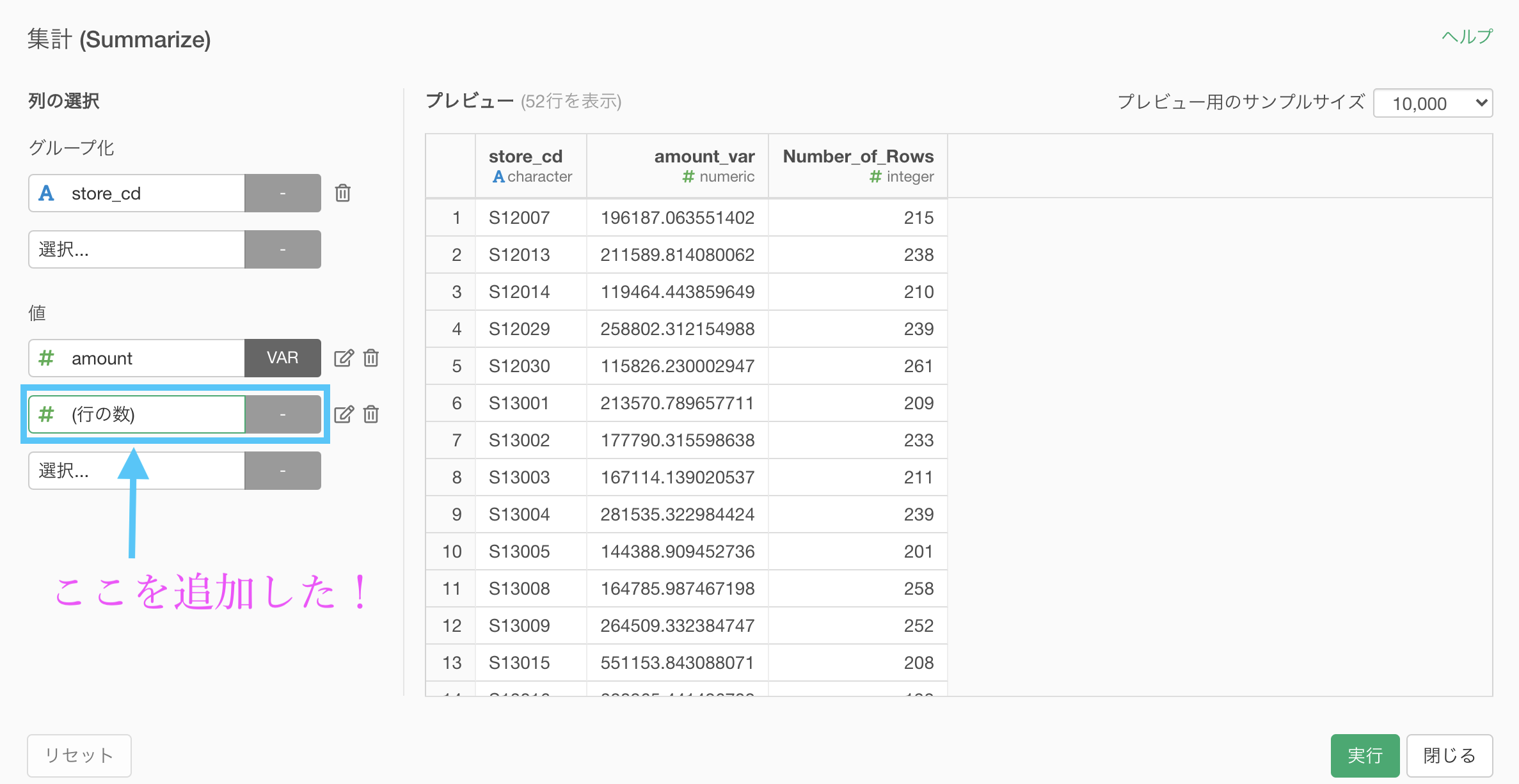
そして、amount_var に対して計算を作成(Mutate)します。 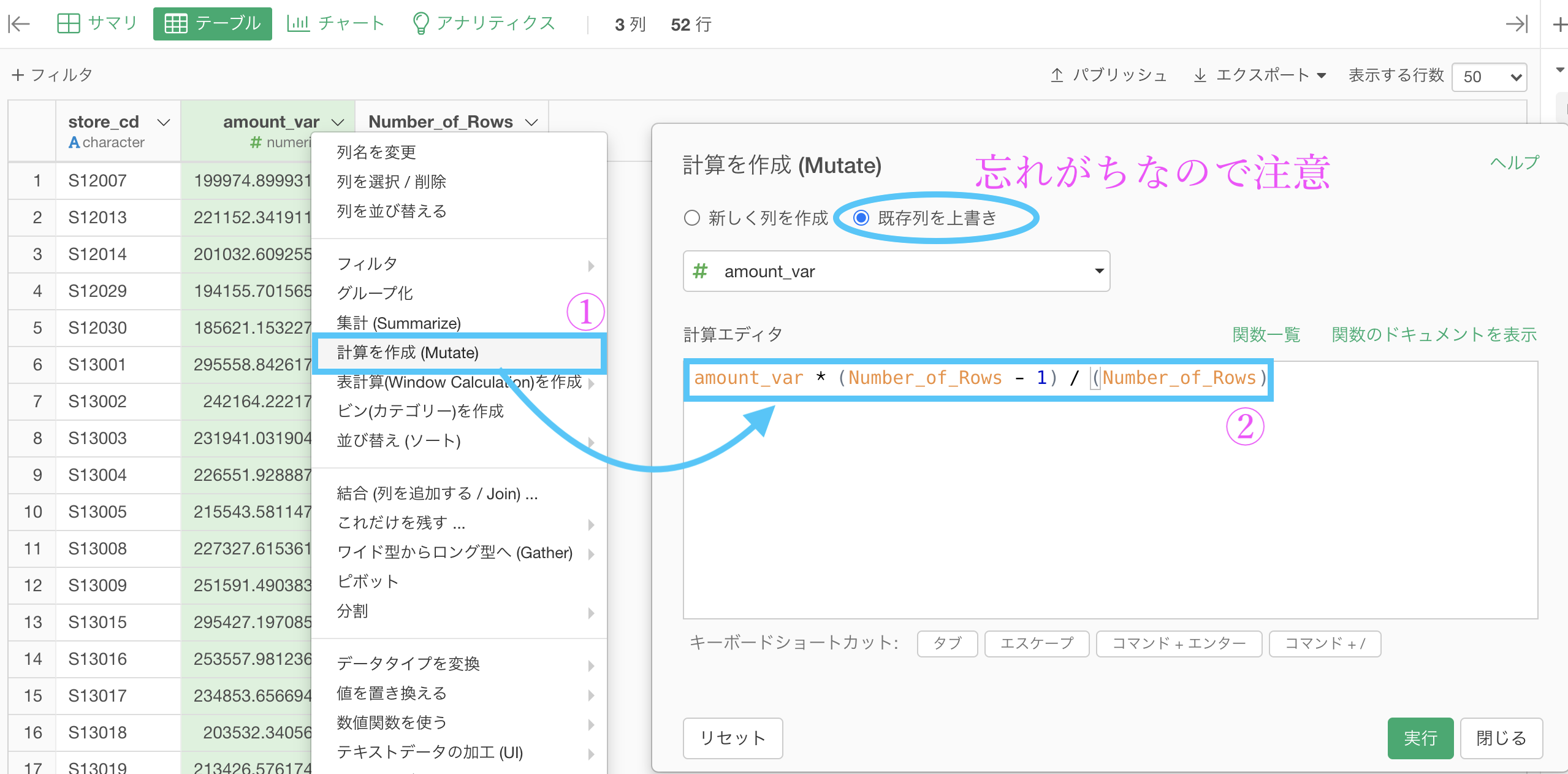 計算エディタには
計算エディタには
amount_var * (Number_of_Rows - 1) / (Number_of_Rows)と入力し、既存列を上書きを押しておきましょう。
後はさっきと同じように「ソート → 降順」をかけるとこのような結果になります。
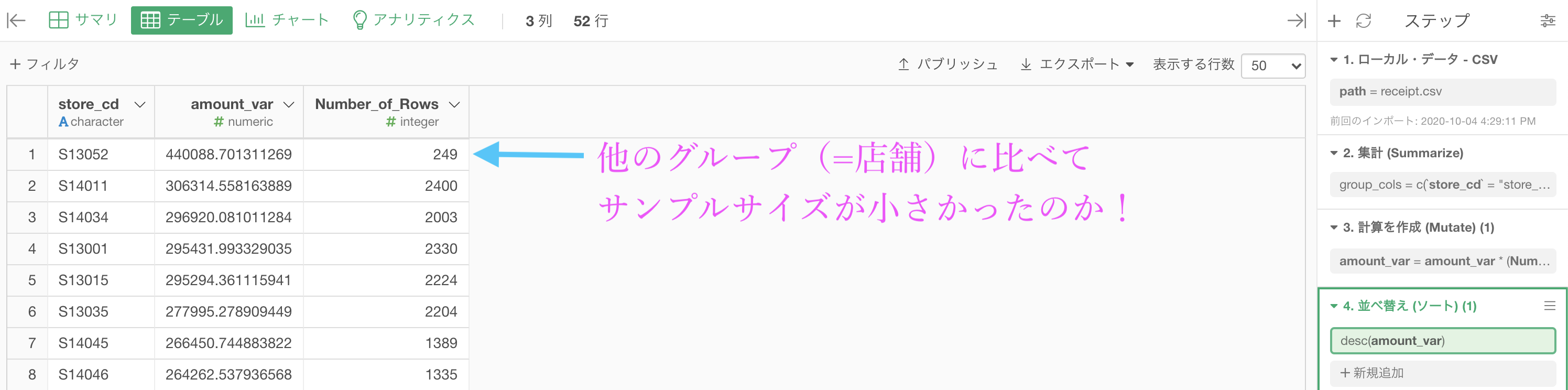
さて、このようにすることで、どうして S13052店 の分散が大きかったのかがわかってきました。
まず分散が最も大きい S13052店 では、サンプルサイズが他の店舗と1桁少ない(=10倍のレシート数が違うということなので相当)ということがわかります。
サンプルサイズが1桁も異なって居ることも問題ですが、それ以上に「全体として3桁と4桁の差が大きい」のです。これが例えば9桁と10桁ならば全く気にしていなかったと思います。
250個集まったデータと2400個集まったデータならば、その信憑性も明らかに異なります。
こういうことまで見えるので、n-1 で割った分散から n で割った分散を作ることは色々と考える・発見するきっかけになるはずです。
おまけ : 問題を合体させた答案を作ってみる
問題としてはここで区切りが良いですし、今までの問題での集計で
グループ化 : store_id, 値 : amount, 計算 : いろいろをやってきました。
問題26にて、値 : sales_ymd が2回も選べたことを覚えているでしょうか。
これを amount にも適応させてみましょう。
つまり、何回も値のところに amount を選んで、それぞれで計算の仕方を変えれば、面白いことが起きそう です。
やってみましょう。 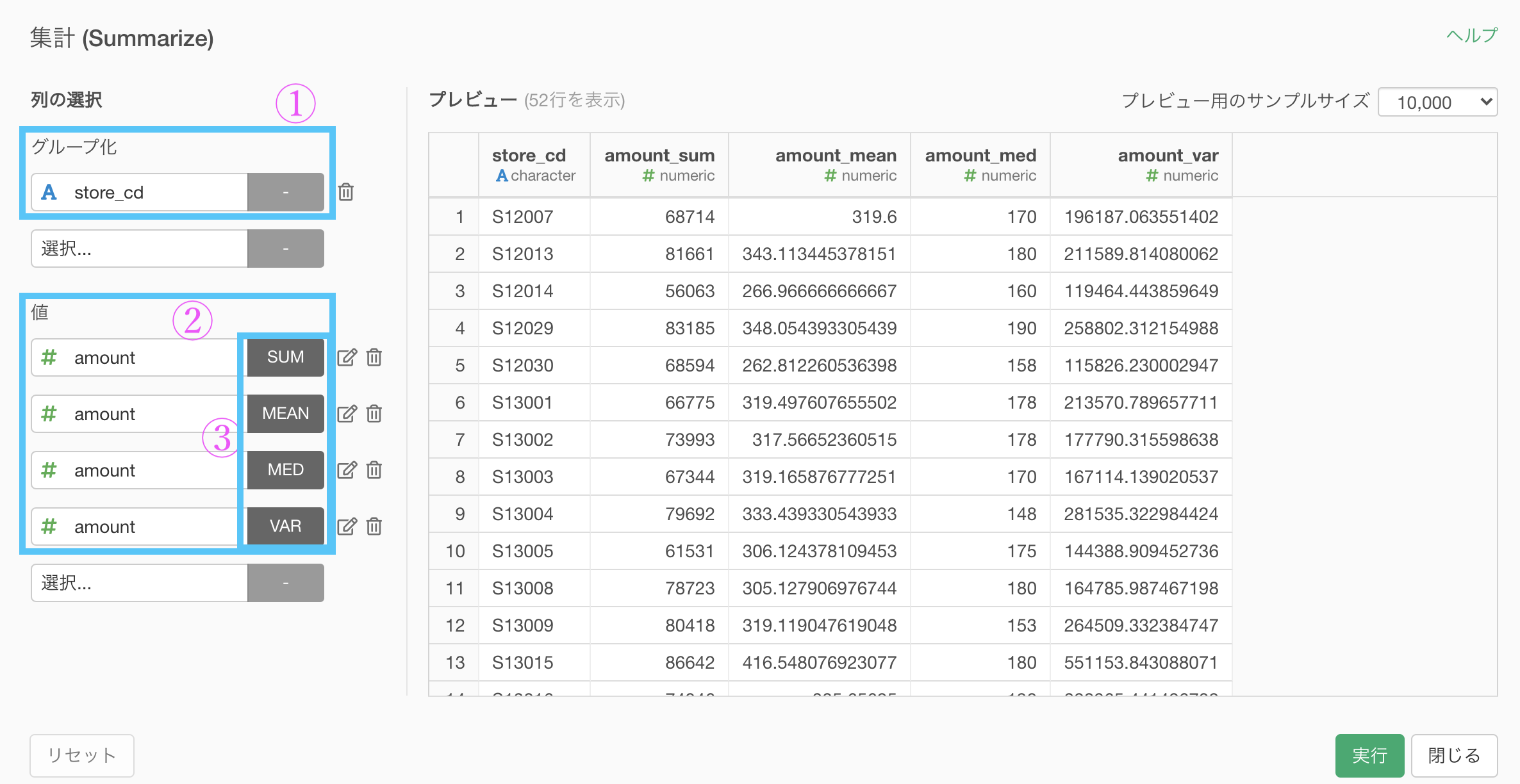
実行するとこのような結果が得られたはずです。 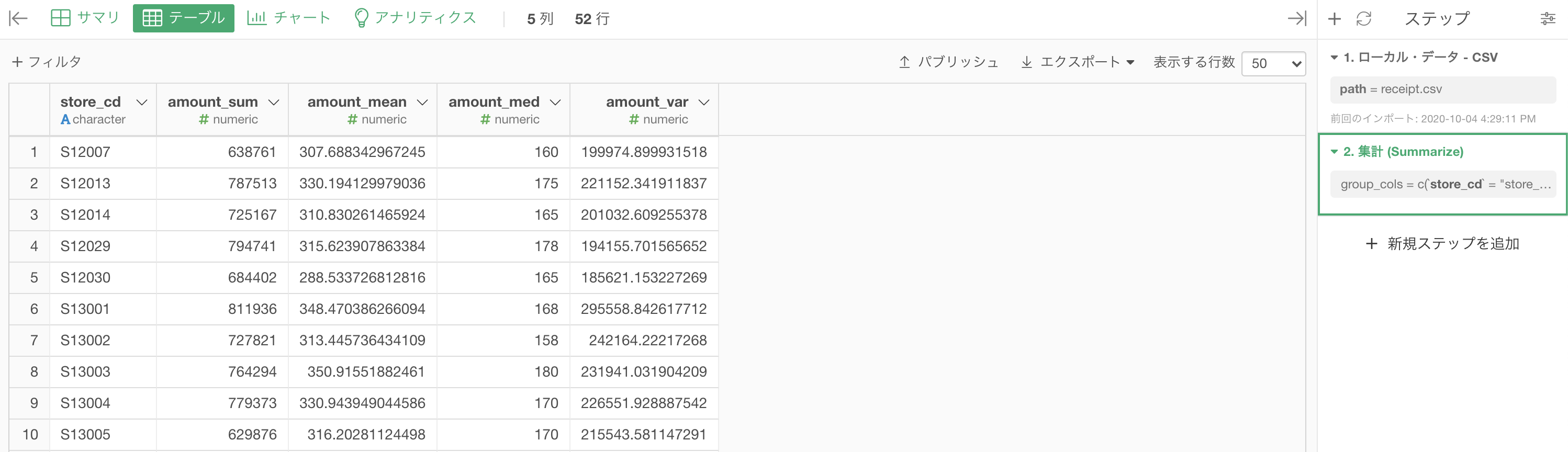
さて、これをどのように使うかはそれぞれの状況次第ですが、イメージは次のようなものなのでカンタンです。
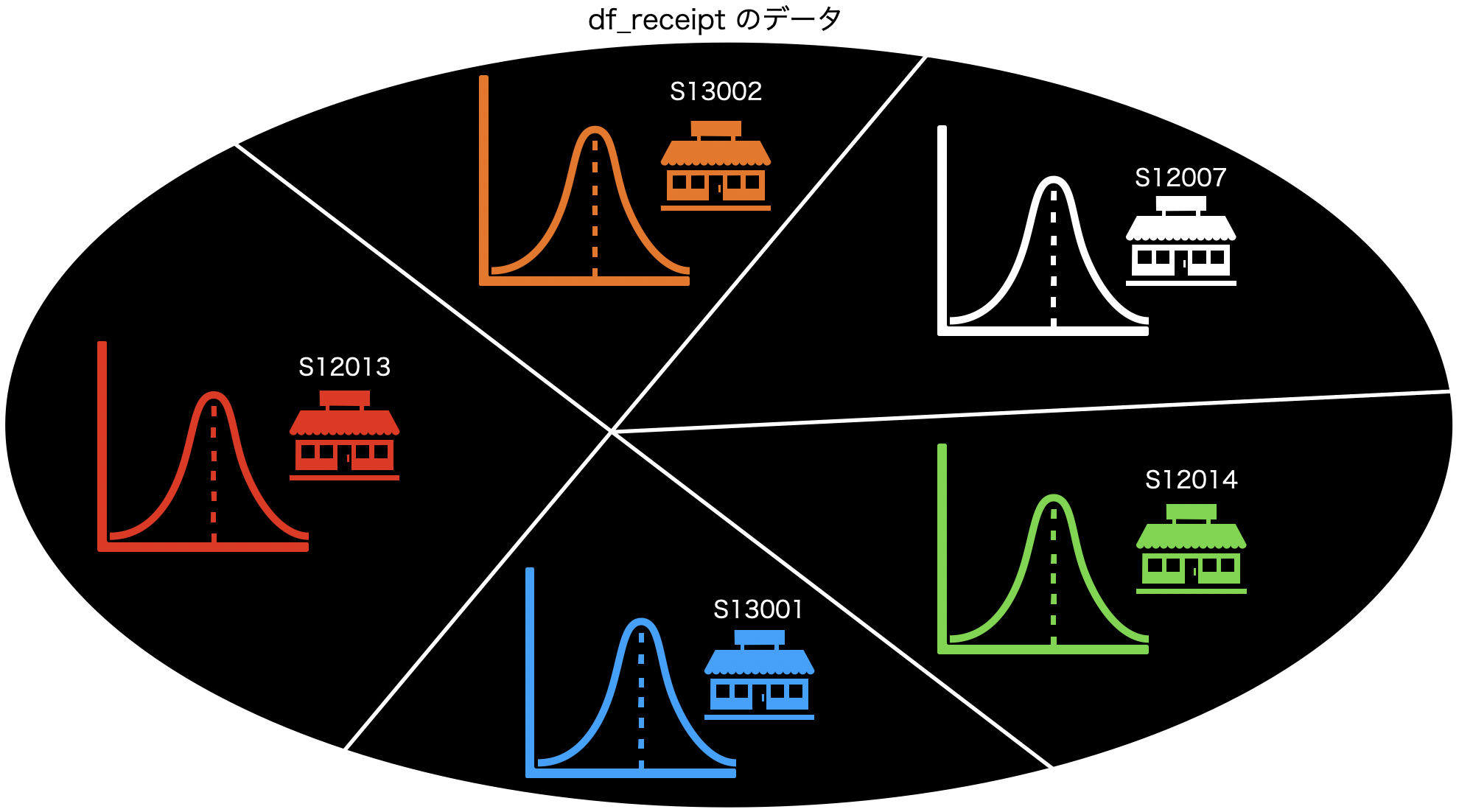
その分布たちの統計量...合計とか平均とか分散とか中央値とかを算出したのがこの集計でやったことなのです。
各グループで分布を背景に考えることができているのは、分析するときにとても大事だと思います。