データサイエンティスト協会 構造化データ前処理 100 本ノック with Exploratory
問31〜問40 の答案
答案全体を通して
Exploratory では R 言語が動いていますが, 解答やコード参照の説明では Python言語 のものでやります。
SQL的な視点や考え方が入るときもその都度書きたいと思います。枠の色使いは以下のような形を意識しています。
オレンジ枠 :
あか枠 :
あお枠 :
みどり枠 :
問31 : 対象データの標準偏差を求める

答案・解説はこちら
特に各グループでの標準偏差の集計です。
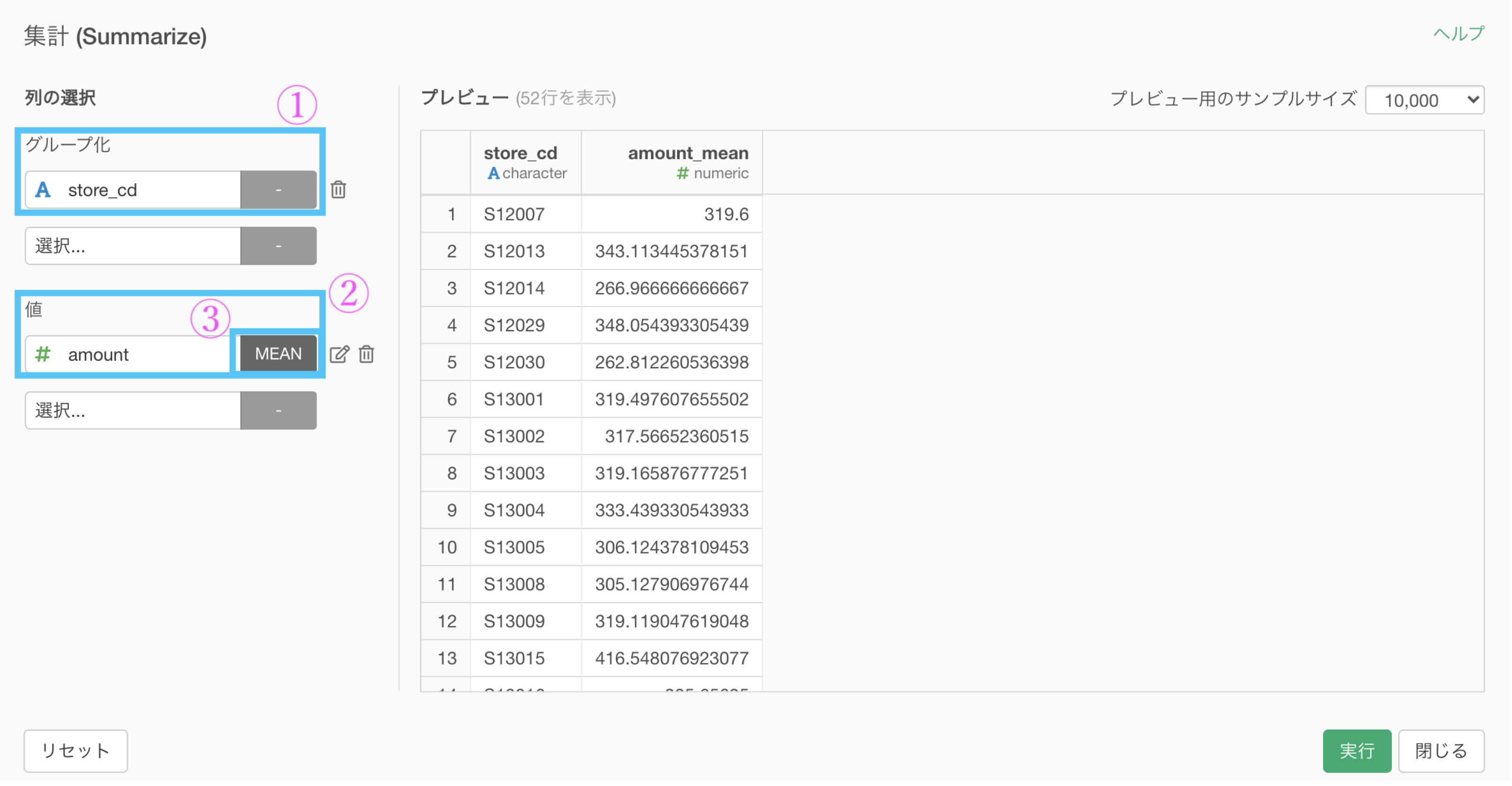
まず 集計 です。
集計 (Summarize) 機能で、以下のように入力していきます。
グループ化 : store_id, 値 : amount, 計算 : 標準偏差(sd)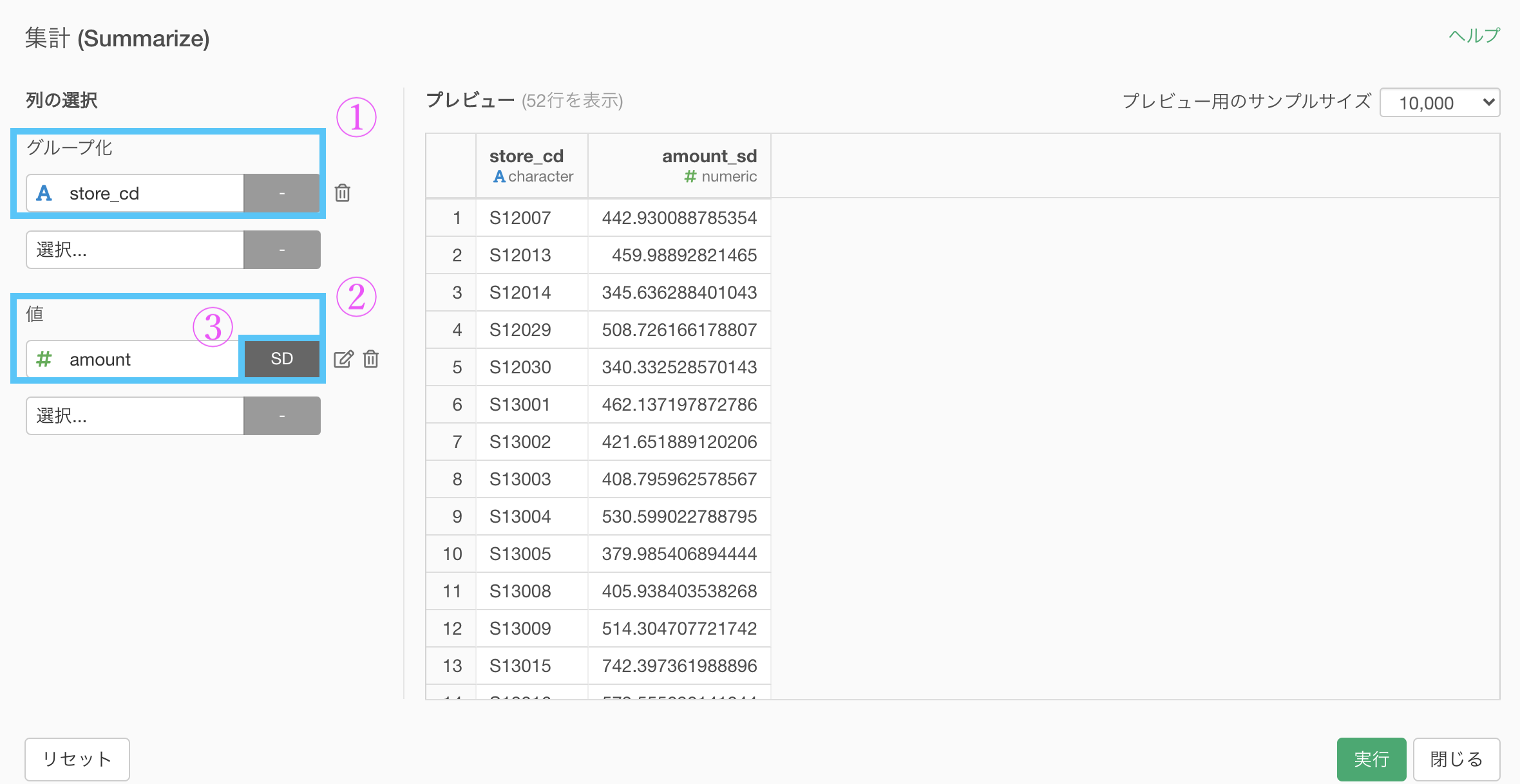
集計が終わったら次は TOP5 に並べることでした。
とは言え、並べ替えは今までと同じやり方です。
集計 (Summarize) 機能 でできた amount_sd の列にソート → 降順をかけましょう。 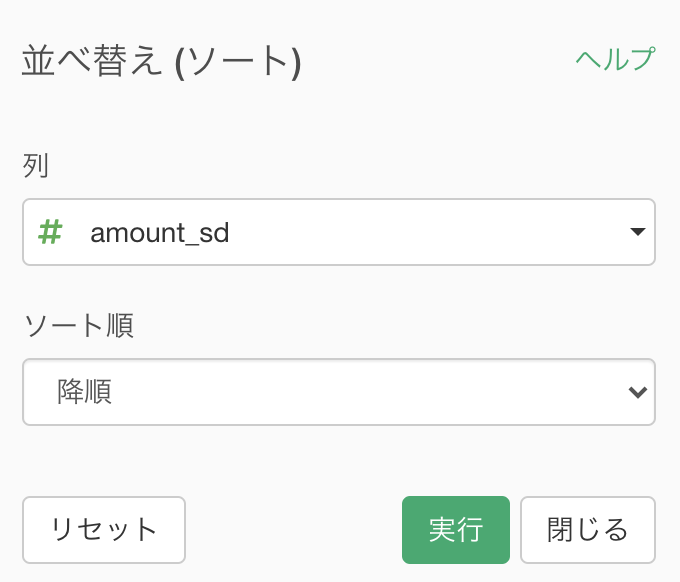
結果はこのようになります。解答と確認してください。 
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.groupby('store_cd').amount.std(ddof=0).reset_index().sort_values(
'amount', ascending=False).head(5)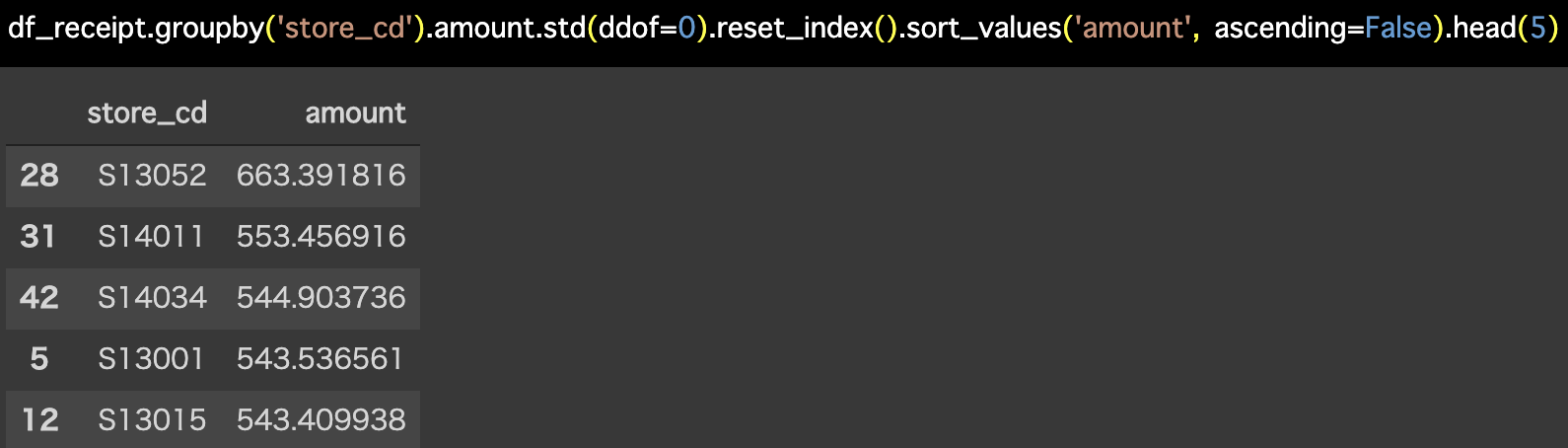
よく見ると値が違う!という鋭い方へ(デジャヴ)
Python コードの資料をみると  と書いてあります。
と書いてあります。
・・・的な下りは、すでに問30でやっているので、その続きです。
とは言っても、問30は分散、問31は標準偏差なので、分散を出してからルートを取れば良いだけです。
つまり、問30の続きという形でやればよくて、それはルートをとるだけです。
問30の続きからスタートして、amount_var を選択して 計算を作成(Mutate) します。 既存列の上書きを忘れずチェックしましょう。 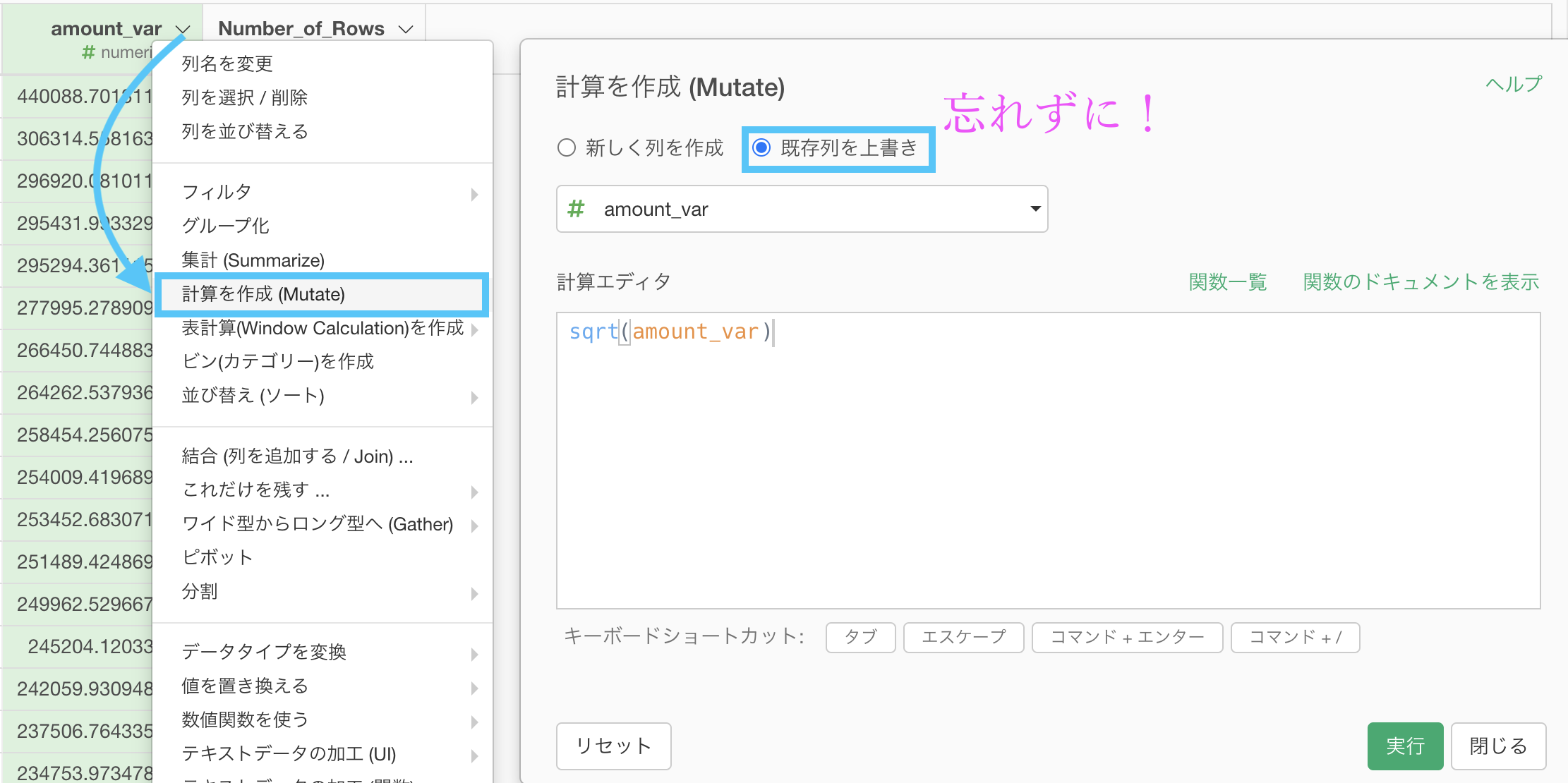 計算エディタの中には
計算エディタの中には
sqrt(amount_var)と書いてあります。
sqrt とは、square root(スクエアルート)のことで、2乗根...日常的にルートと呼ばれるものです。
結果はこのようになります。 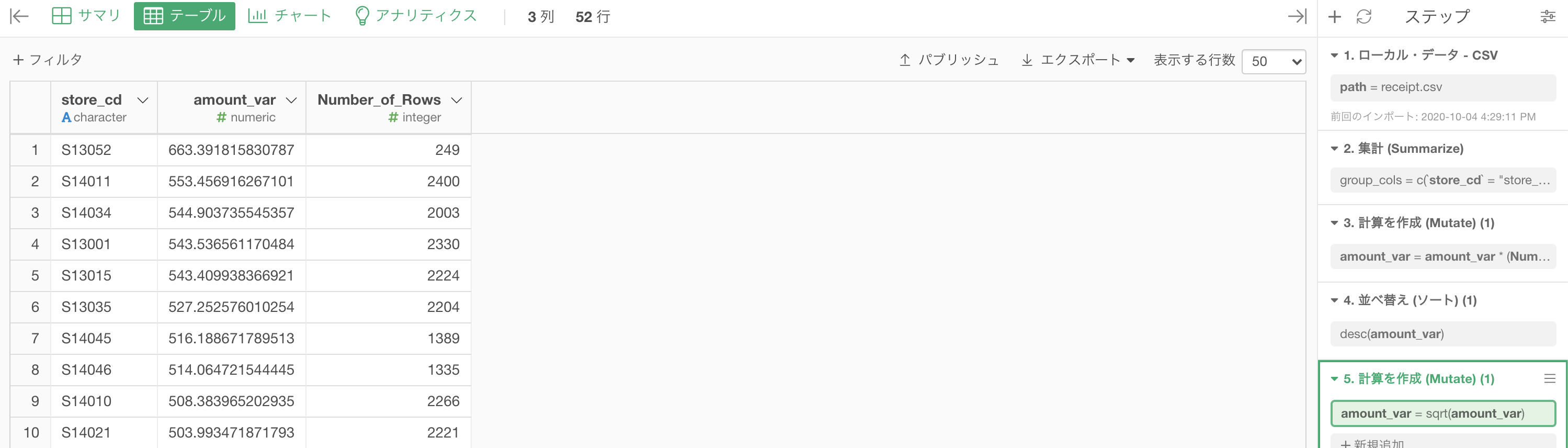
Python の解答コードと一致していますね。
ちなみに3乗根は cubic root(キュービックルート)というそうです。
問32 : データのパーセンタイル値を求める

答案・解説はこちら
25%刻みでパーセンタイル値を求めよ!
と言われても、なんのこっちゃ?となる方のための最初のわかりやすい答案は、箱ヒゲ図を描くことです。
実際に書いてみましょう。
まずはいつものテーブルからチャートにいき、箱ヒゲ図を選択します。 
次に、y軸の方にだけ amount を選択しましょう。 
選択するとすぐに箱ヒゲ図が描かれたと思いますが、実は外れ値などが既に除外されています。
チェックをつけてもう一度やってみましょう。 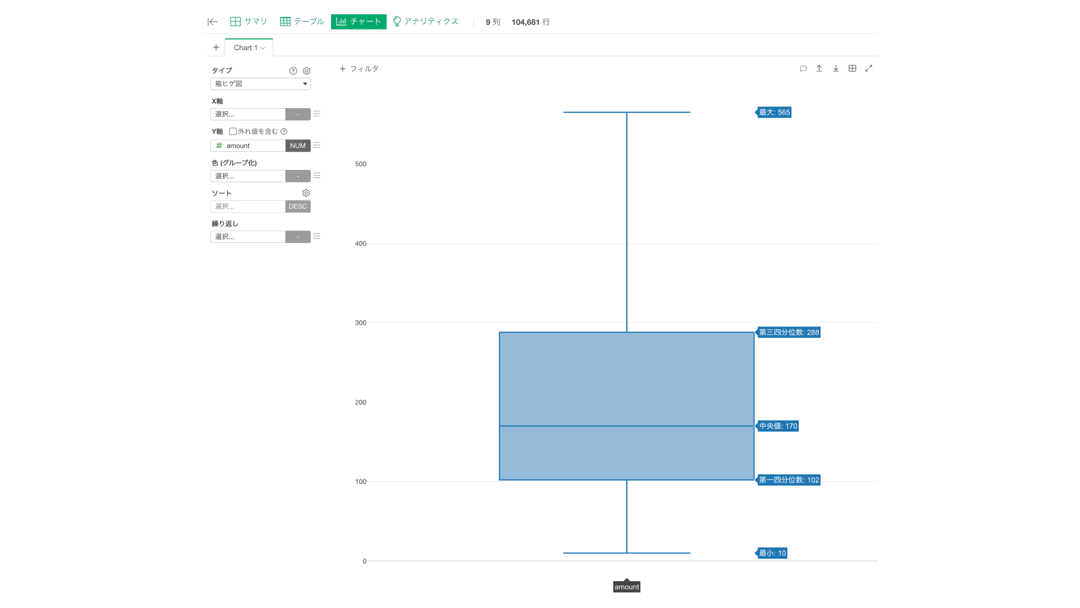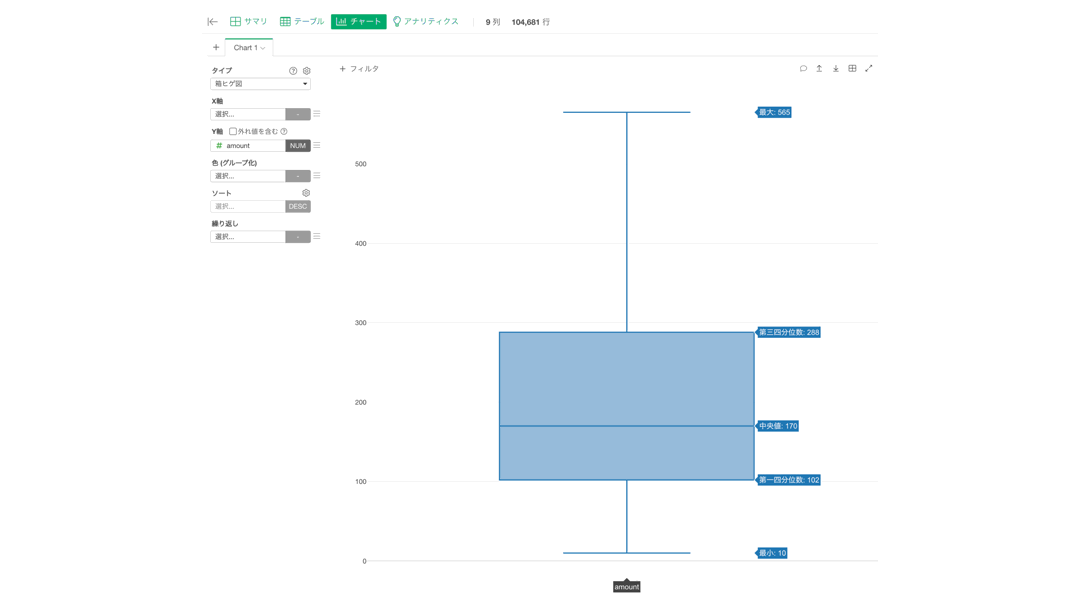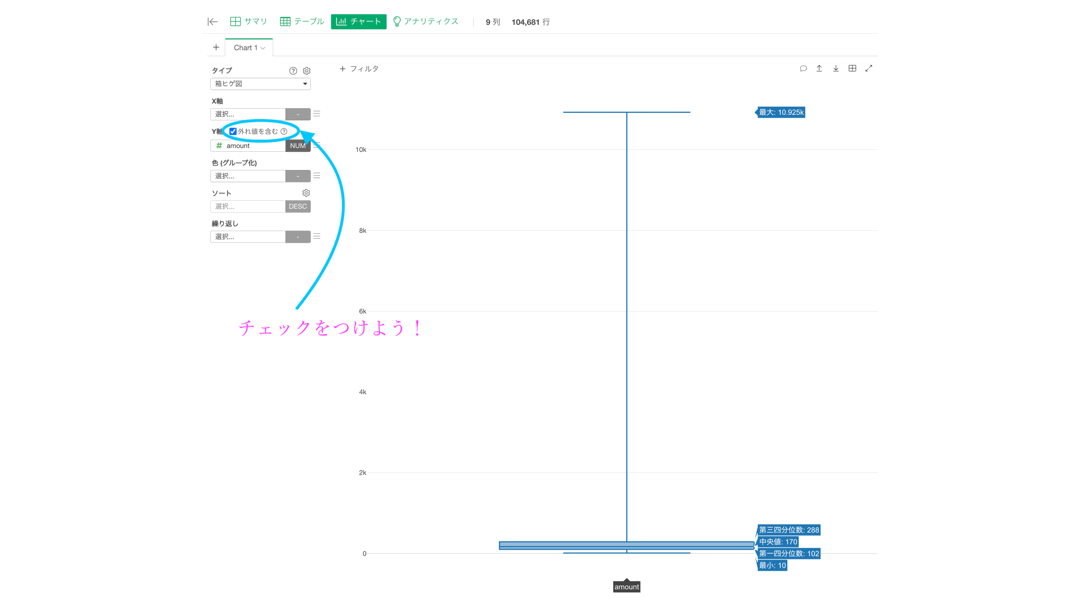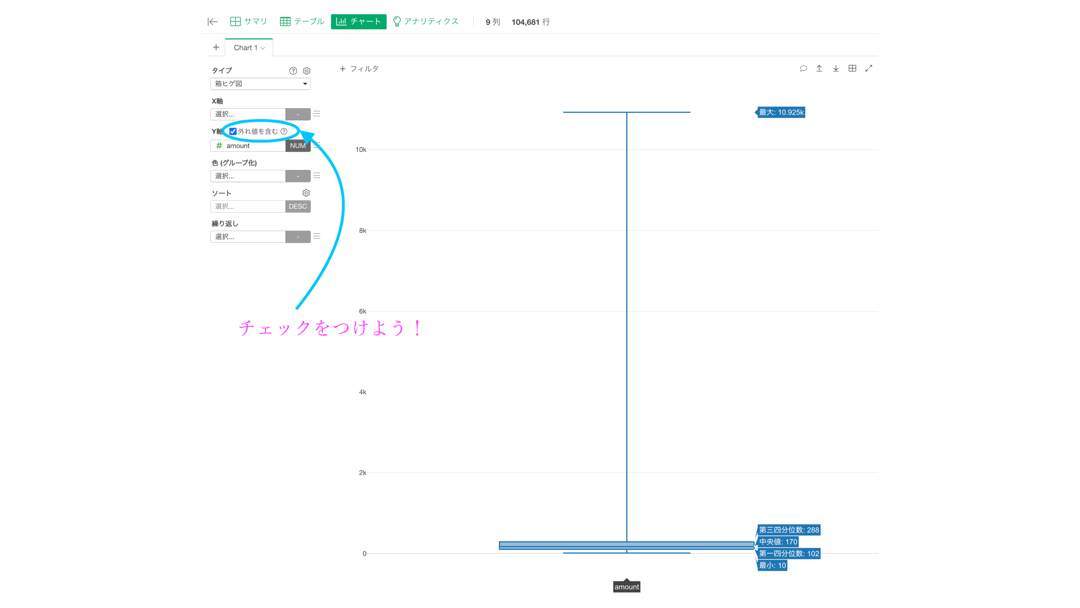
外れ値を含むとやはり形が歪になりますが、実は問題の答えは全てここに入っています。
一番上 : 最大値 = 100% のところ ... 10925
その下 : 第3四分位数(Q3) = 75% のところ ... 288
真ん中 : 中央値(Q2) = 50% のところ ... 102
その上 : 第1四分位数(Q1) = 25% のところ ... 170
一番下 : 最小値 = 0% のところ ... 10となっています。
解答と確認してみましょう。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
np.percentile(df_receipt['amount'], q=[25, 50, 75,100])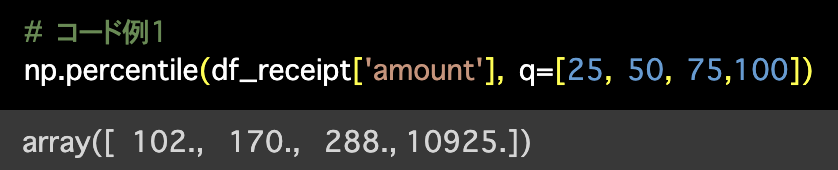
2つ目の解答のコードはこのようになっています。
# コード例2
df_receipt.amount.quantile(q=np.arange(5)/4)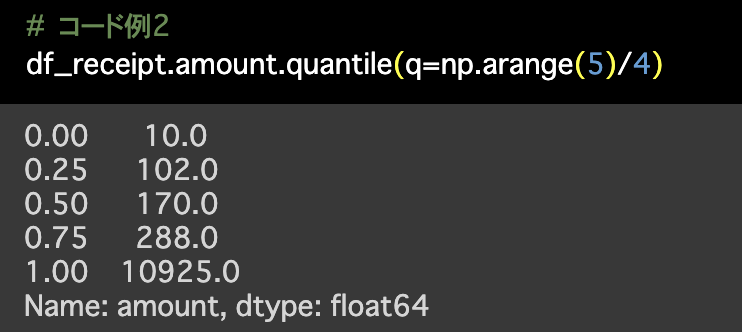
数値だけ見せられてもなかなかそのデータのイメージはつかないかも知れませんが、可視化してみるとその姿は意外なほどに酷いものだったということはよくあります。
しかし、データを順に並べた個数で分けて考えるというのは大切な考え方です。
これで終わらないための豆知識
普通、0%〜100%って、確率に対していうものですよね?
なんでデータの個数で25%とか行っているのでしょうか?
データの割合が25%だからでしょうか?
実はきちんと、確率の意味での25% なのです。
累積分布関数を描いたときの50%点...つまり、その値(図を参照)が中央値(Q2)の数学的な定義なのです。
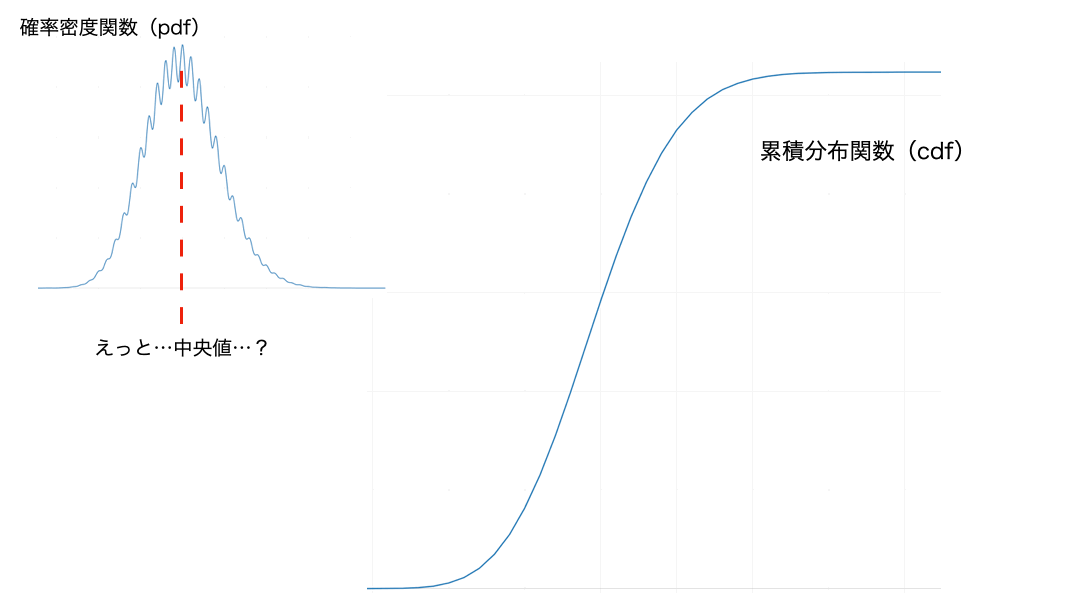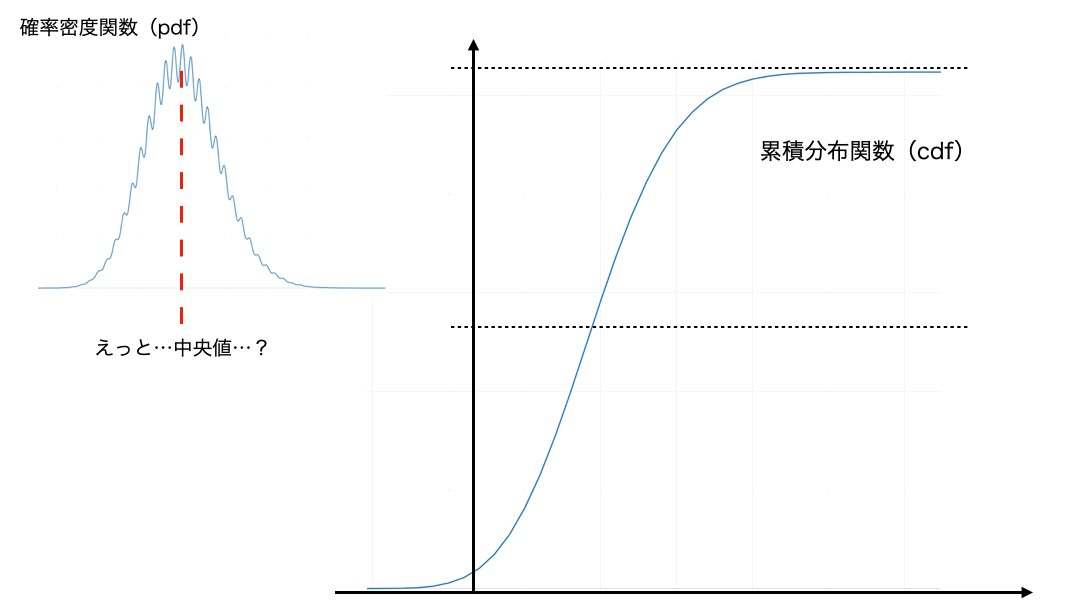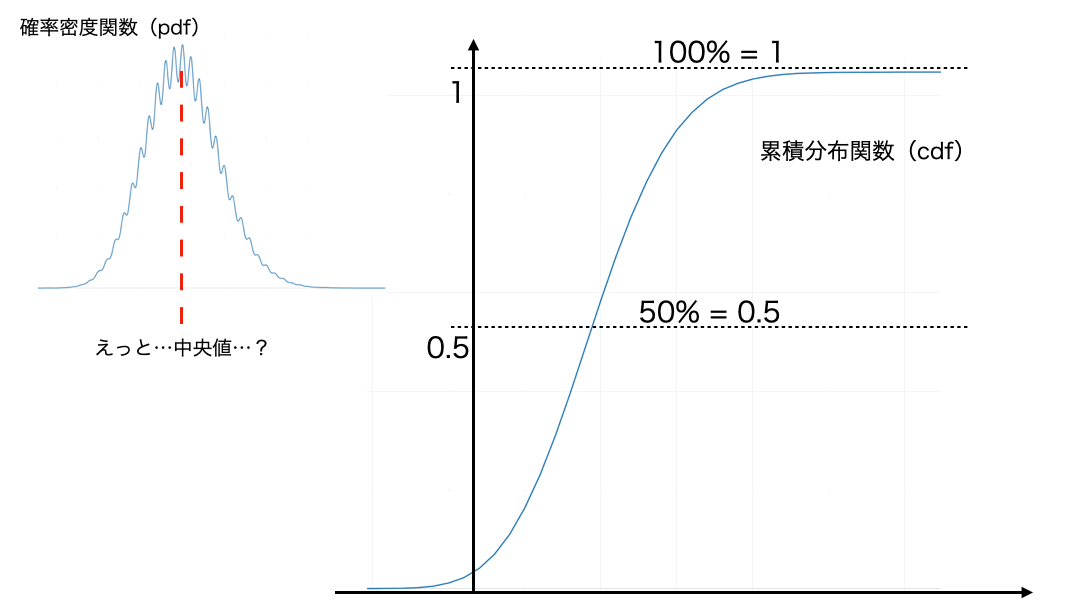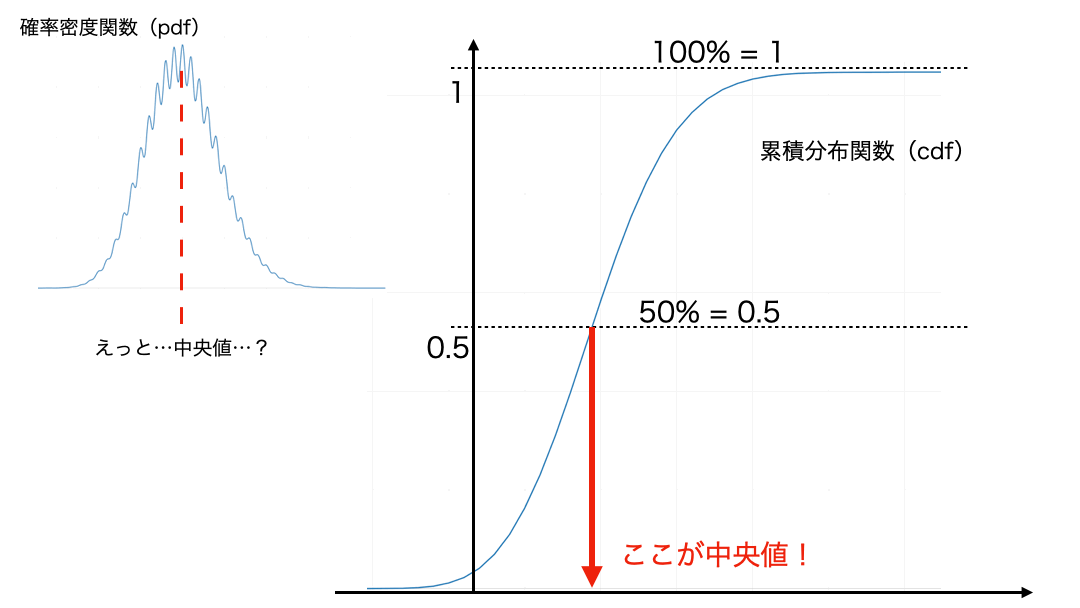 難しいことはそこまで好きじゃない!という方のために、その定義を説明するよりも「どこが中央値なのか?」を知ってもらうために作りました。
難しいことはそこまで好きじゃない!という方のために、その定義を説明するよりも「どこが中央値なのか?」を知ってもらうために作りました。
確率密度関数(pdf) : いつもヒストグラムで近似しているもの。直感的に中央値を調べるのが難しいような例(図の左上みたいなもの)をいまは考えれば良い。
累積分布関数(cdf) : 縦軸が0〜1までで、pdfの累積を1点ずつ調べたもの。パレート図でも使われている。
中央値 : cdf の 0.5(=50%) のラインにぶつかったときの値。ということさえわかっておけば、大丈夫でしょう。
正確な説明ではないかも知れませんが、正確な定義の本質的な気持ちは逃していないと思います。
こういう話と、データを順に並べた個数で分けて考えるということまでどのように対応しているのかを調べるのはここではやらないことにしますが、今のことをわかっていれば少なくとも、どうして50%という言い方をするのかは理解できたかと思います。
問33 : 集計結果に対する条件指定で絞り込む

答案・解説はこちら
実は似たようなことを 問26 で既にやっています。
まずやりたいこと・やるべきことを整理すると
具体的には
1. 集計
グループ化 : store_cd
値 : amount 計算 : 平均(mean)
2. フィルター
amount_mean が 330 以上のものという2つの処理をすれば良さそうです。
しかも最初の処理は、問27 と同じ処理でした。
次の処理は、amount_mean にフィルターするだけなので簡単です。 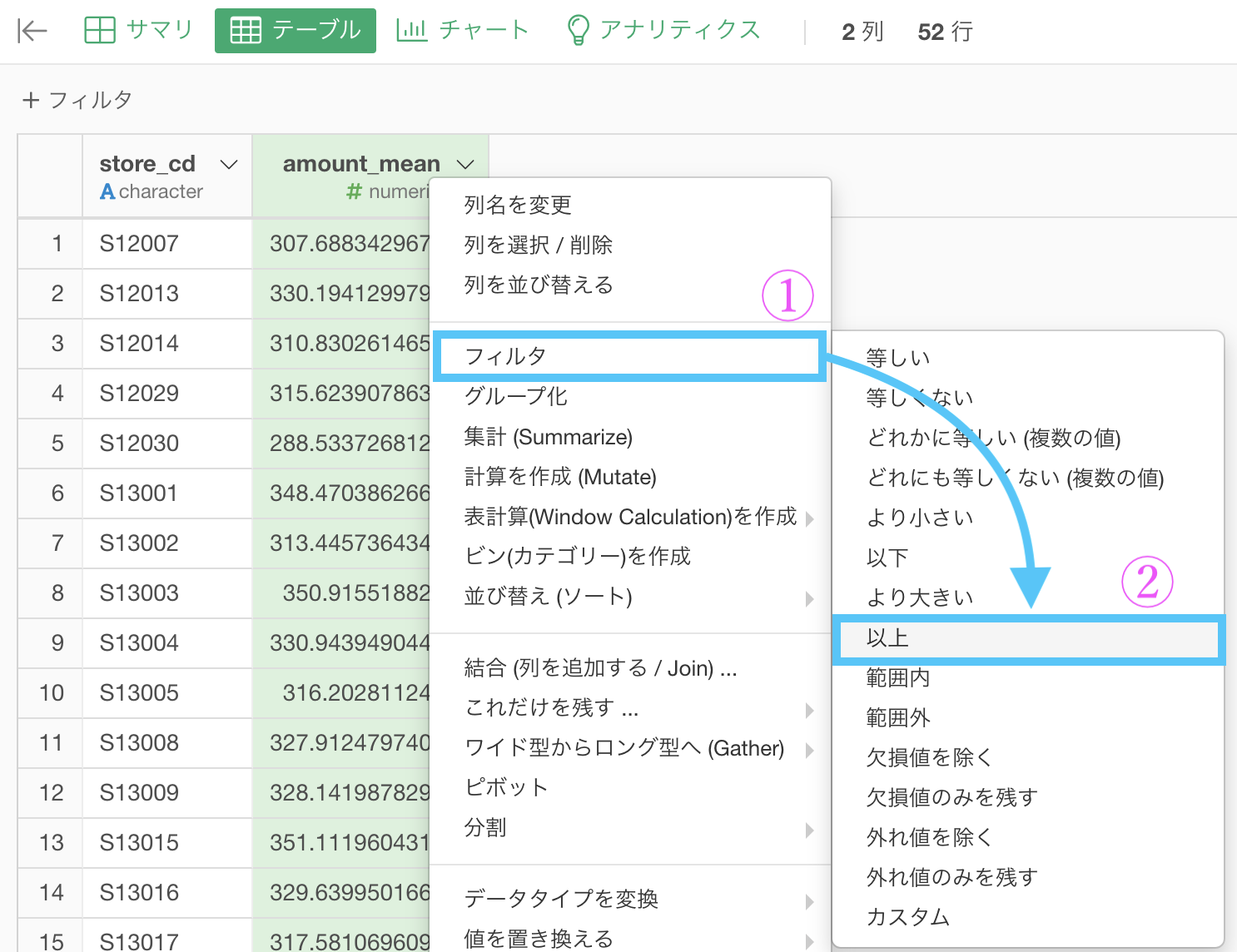
330 と入力しましょう。 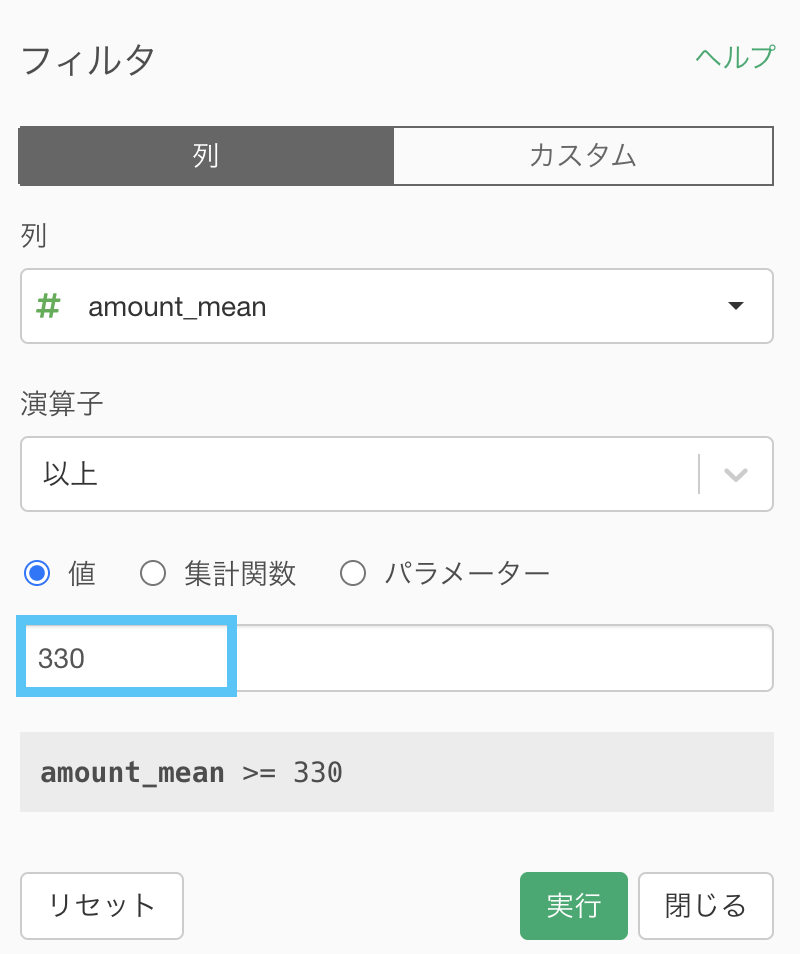
結果はこのようになります。解答と確認しましょう。 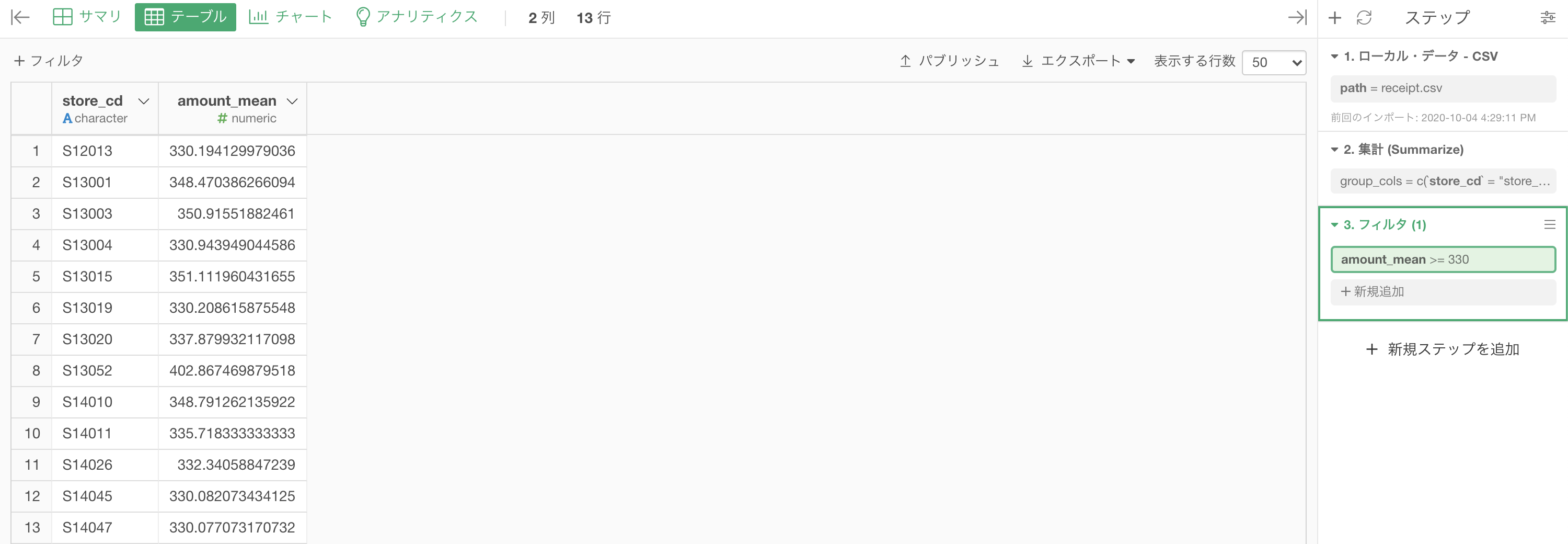
Python 解答コードはこちら
解答コードはこのようになっています。
df_receipt.groupby('store_cd').amount.mean().reset_index().query(
'amount >= 330')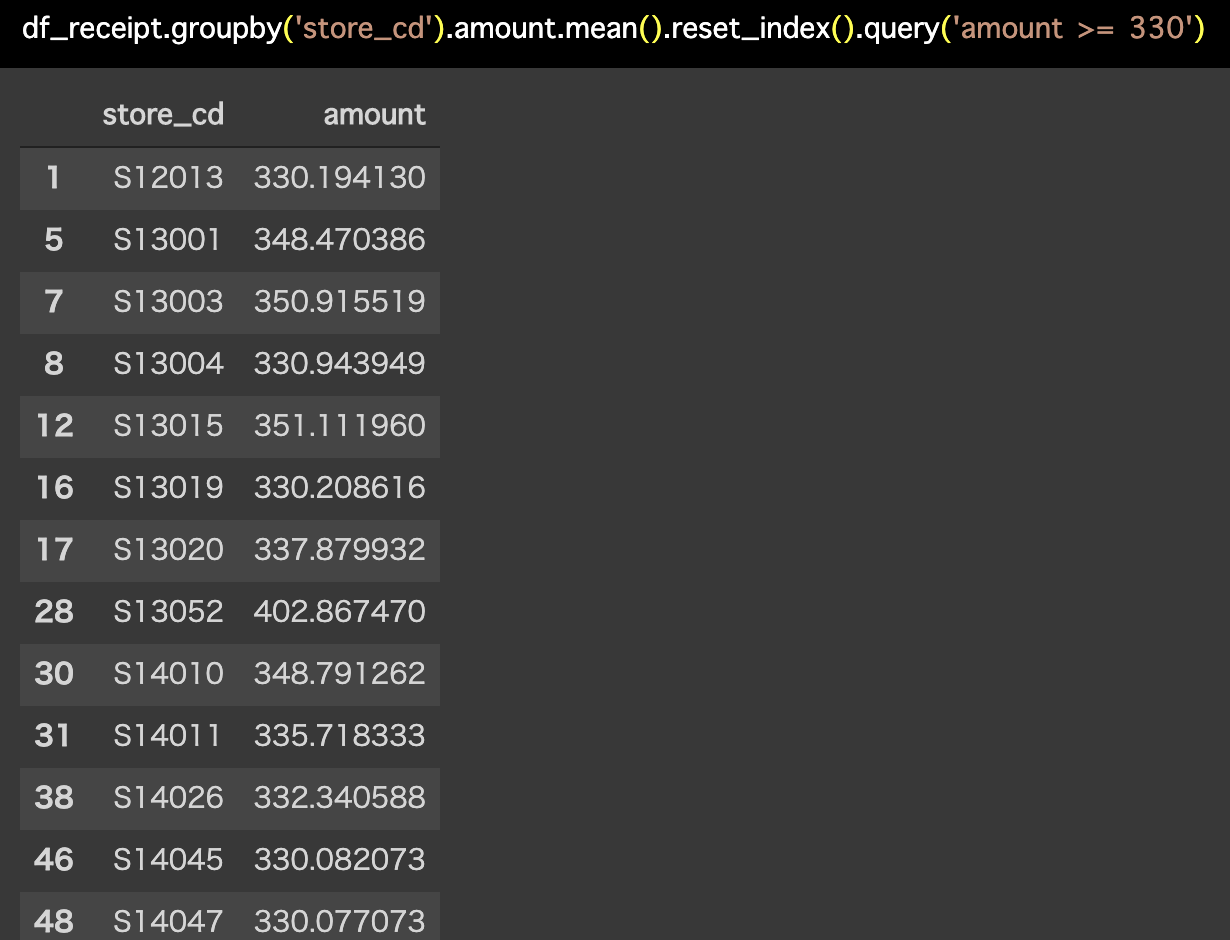
問34 : 検索結果から集計する

答案・解説はこちら
ついに非会員の顧客(customer_id が Z から始まる行のこと)が消え去るときがきました。
いつも通りフィルター → 「この文字列から始まらない」を選択します。 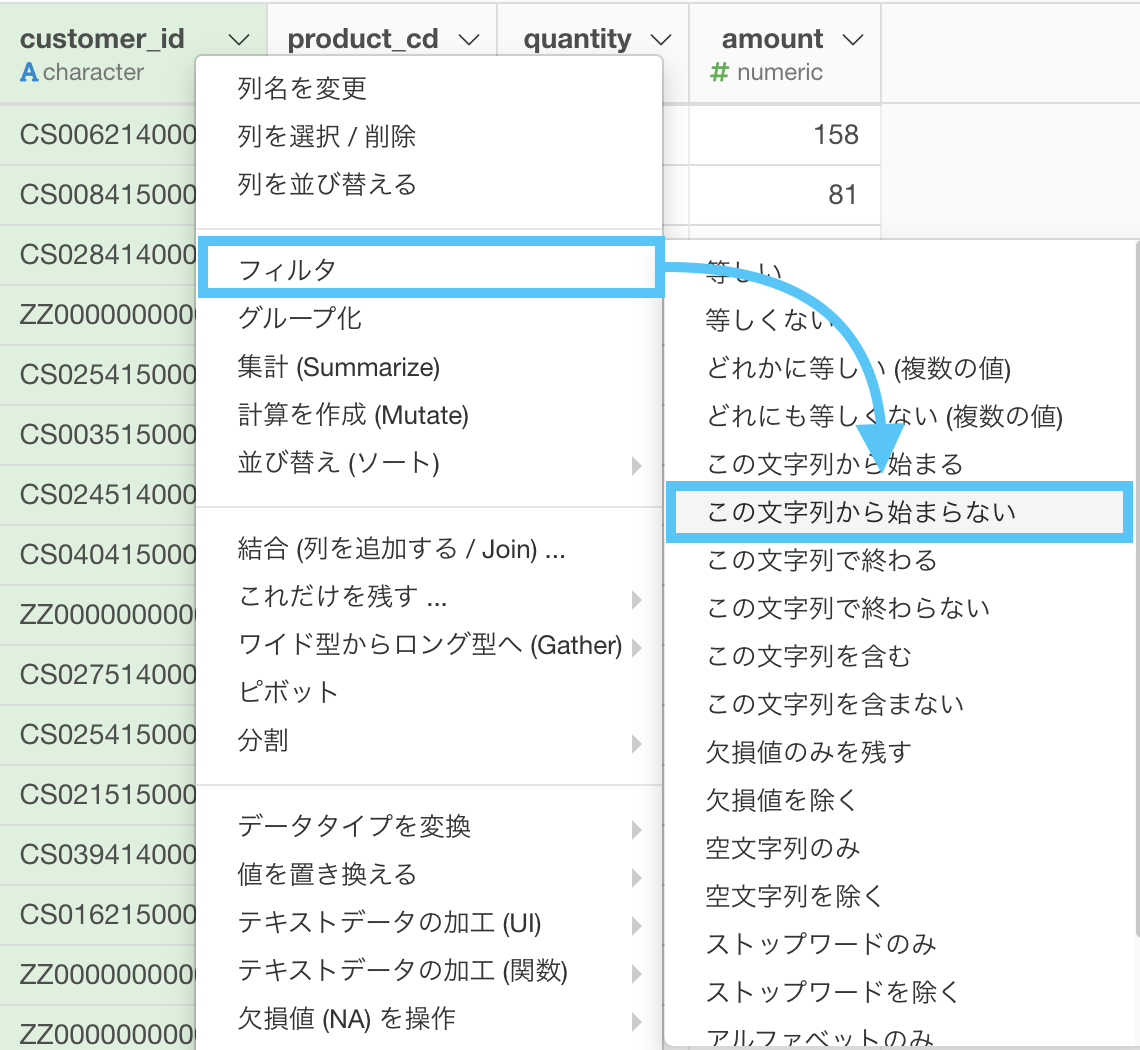
フィルター画面に半角で Z と入力するだけでOKです。 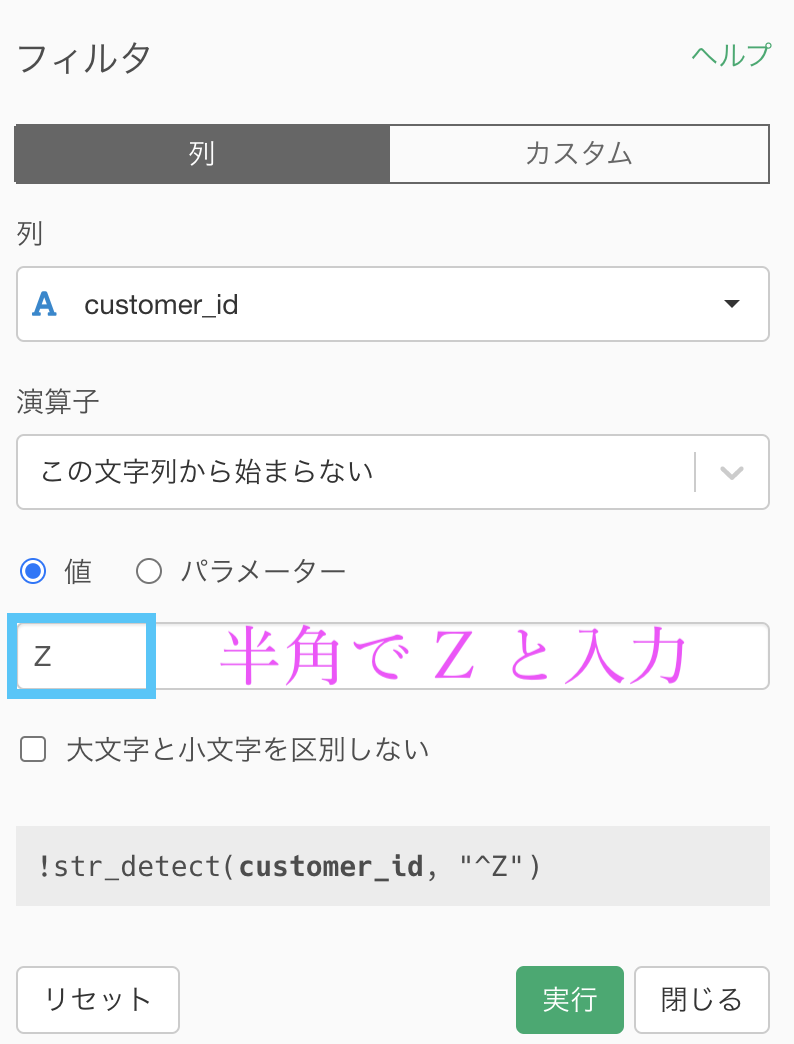
65,682行 になっていれば良いです。 
問題文には「顧客ID(customer_id)ごとに売上金額(amount)を合計して...」とあるので、いつも通り集計しましょう。 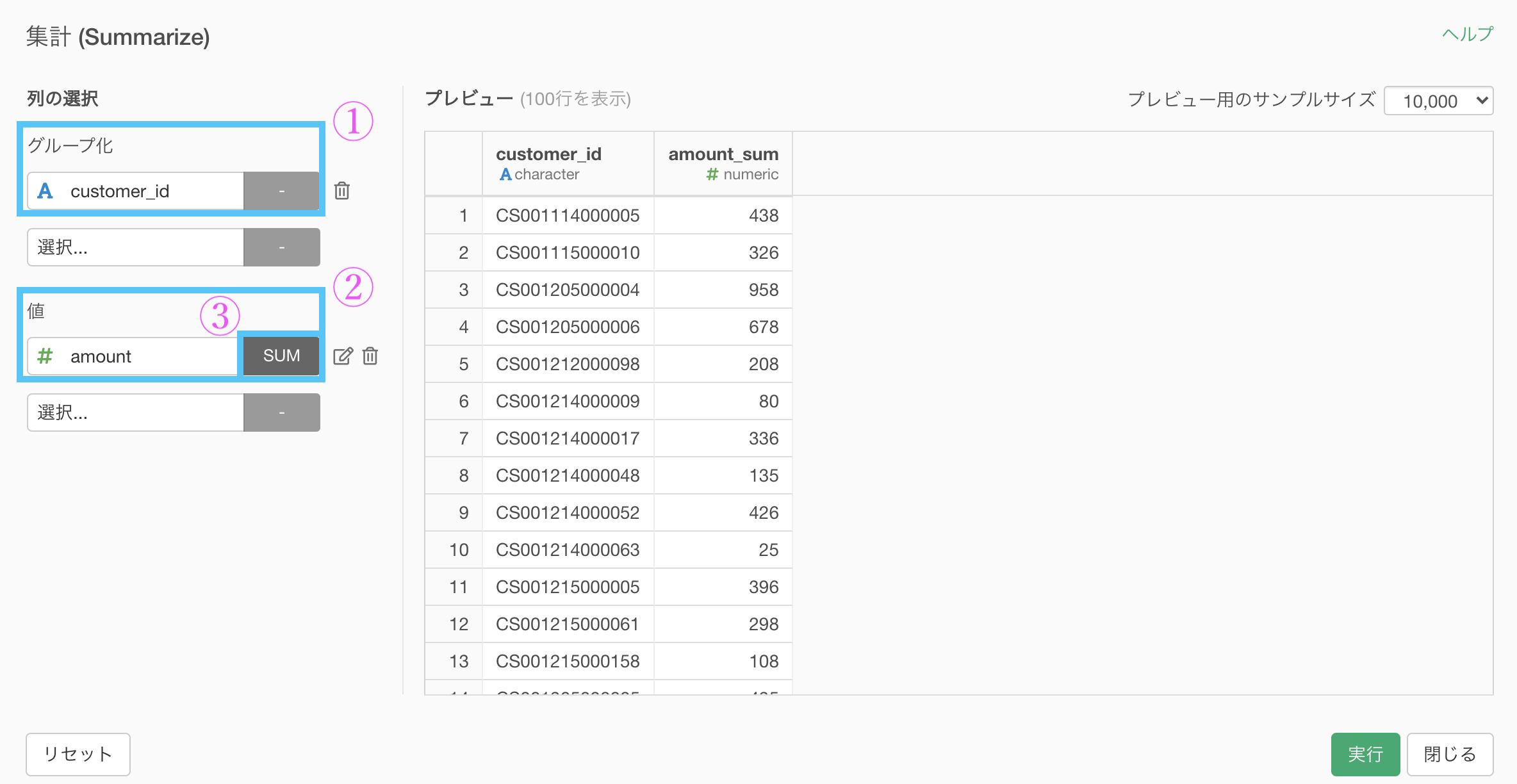
グループ化 : customer_id 値 : amount 計算 : 合計(sum)結果はこのようになったと思います。 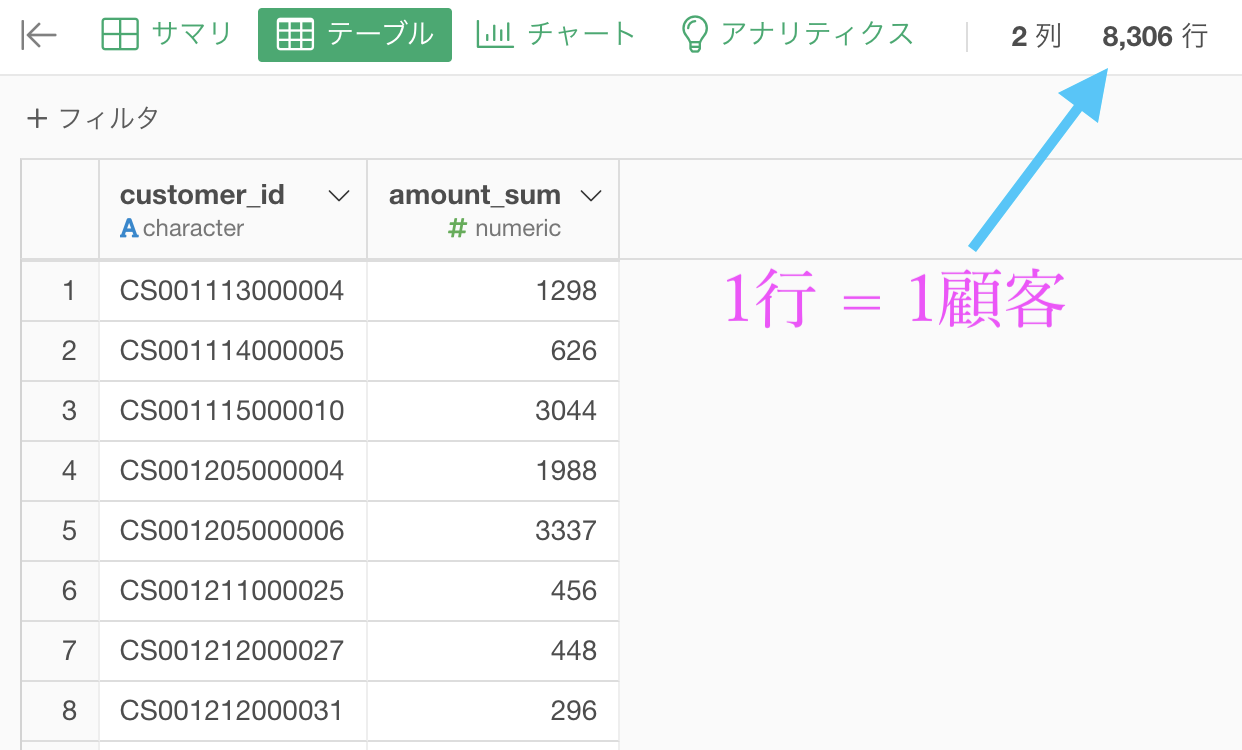
この amount_sum 列は、1顧客がお会計したレシートの合計です。
ちなみに全部の期間でなので、2回来店した場合も合計されています。
amount_sum の平均を知れれば、今回の問題の答えになります。
集計 (Summarize) 機能 をもう一度使いましょう。
グループ化のところに何もいれないところがポイントで、計算を平均値 (mean) にすれば大丈夫です. 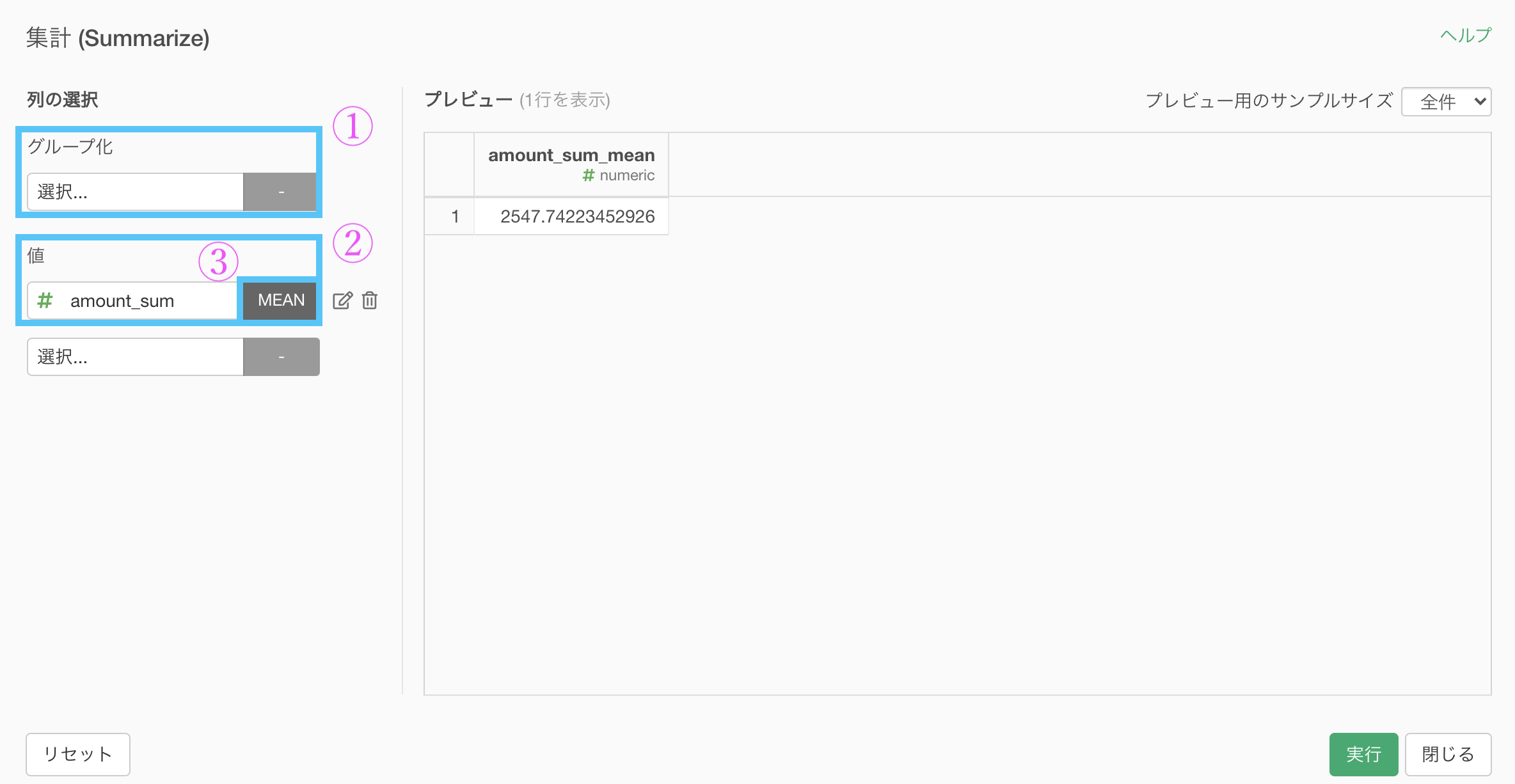
結果はこのようになったと思います。解答と確認してください。 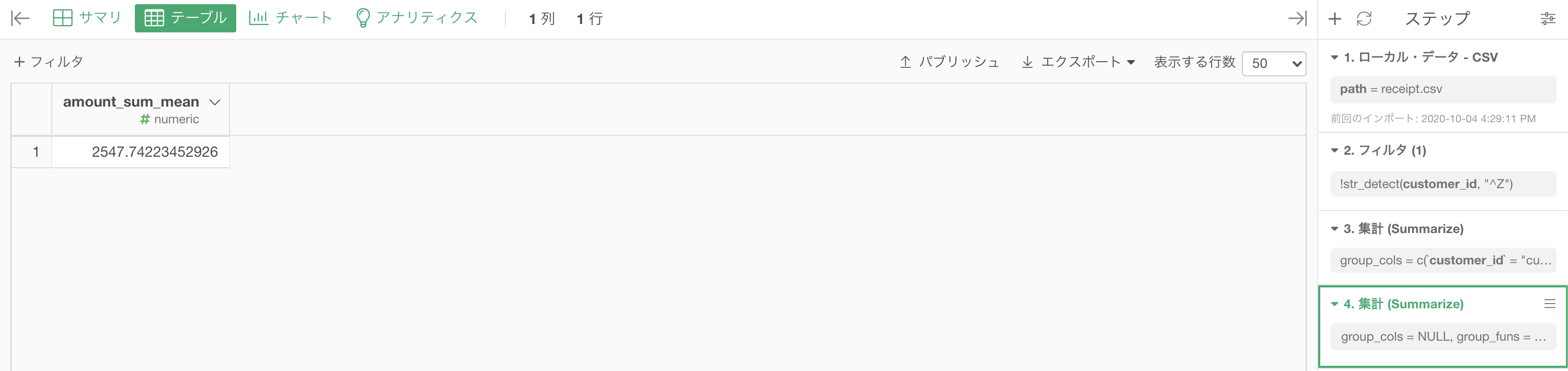
サマリーを見るという別解
1度集計した後にもう1度集計したというのは少し変に感じた人のための答案です。
1行 = 1顧客の時点で、サマリーを見てしまえば平均値はわかります。 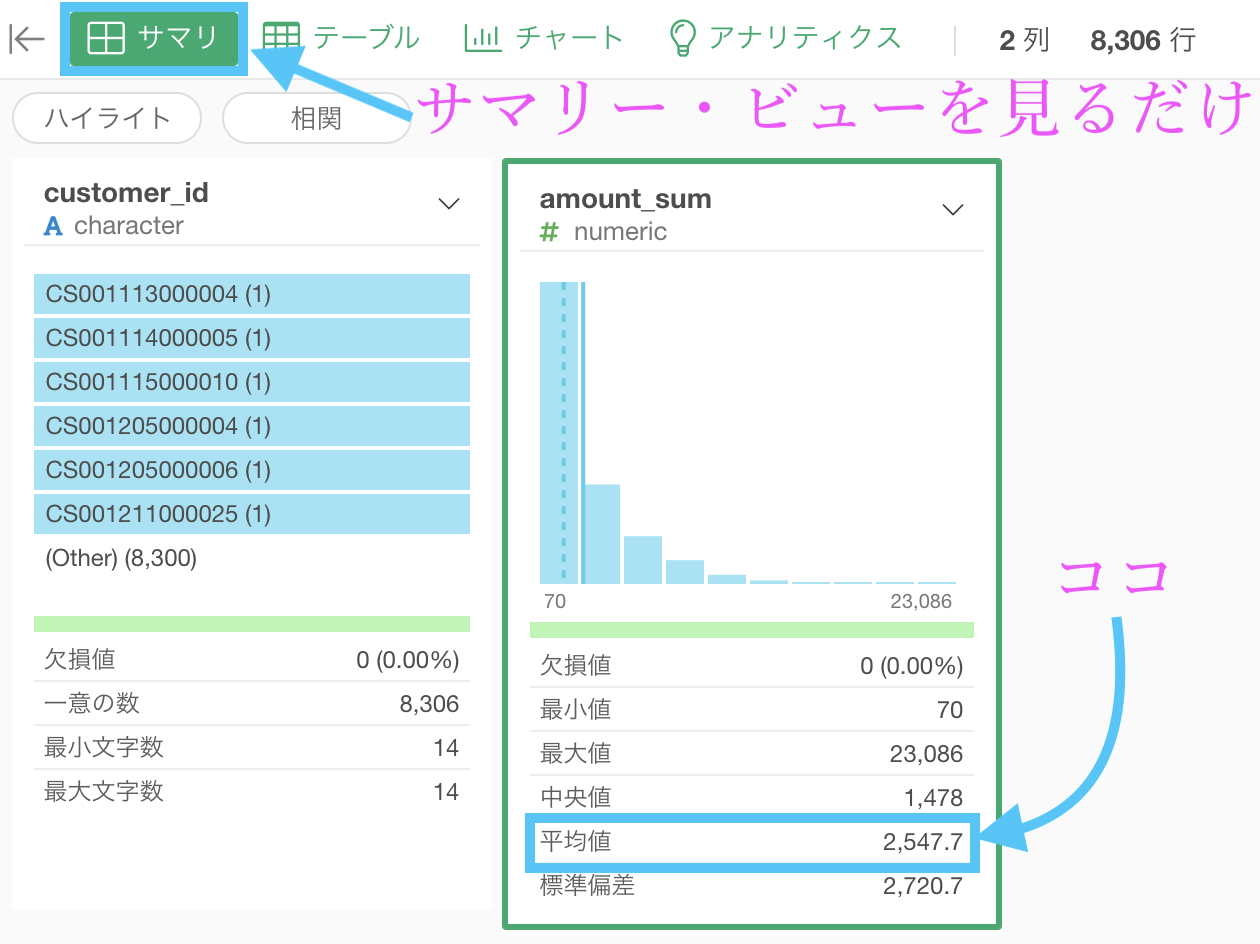
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# queryを使わない書き方
df_receipt[~df_receipt['customer_id'].str.startswith("Z")].groupby(
'customer_id').amount.sum().mean()
2つ目の解答コードはこのようになっています。
# queryを使う書き方
df_receipt.query('not customer_id.str.startswith("Z")',
engine='python').groupby('customer_id').amount.sum().mean()
合計してから平均する??
今回の作業は、顧客ID(customer_id)ごとに売上金額(amount)を 合計してから平均する ことでした。
一瞬「あれ?」と思うかも知れません。
文を読んだだけだと、最初から平均をとったら良さそうに思えるからです。
でも違います。
何も考えずに(非会員顧客を抜いてから直後に)平均を計算するとこのようになります。 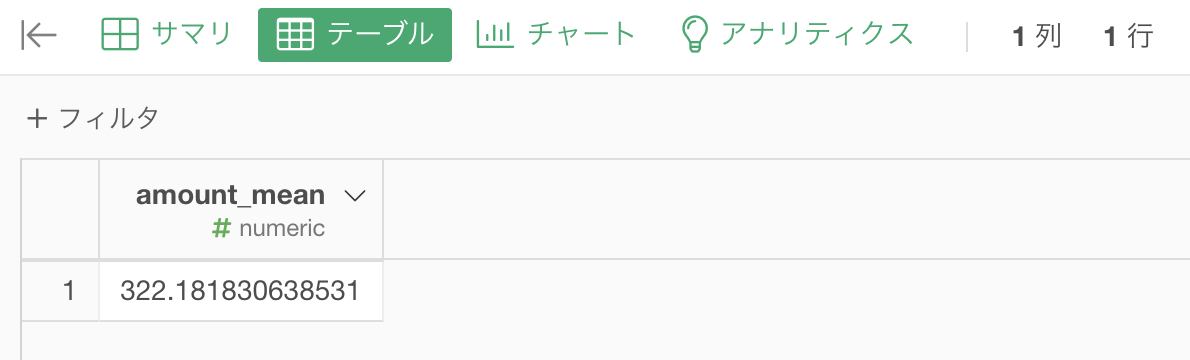
どうして今回の結果と違うかを解釈するためにデータをよく見て欲しくて、いろいろ考えて欲しいので、ここではあえて説明しないことにします。
問35 : 検索結果を条件指定に使った副問合せを行う

答案・解説はこちら
問34の続き(1行 = 1顧客の段階)から行きます。 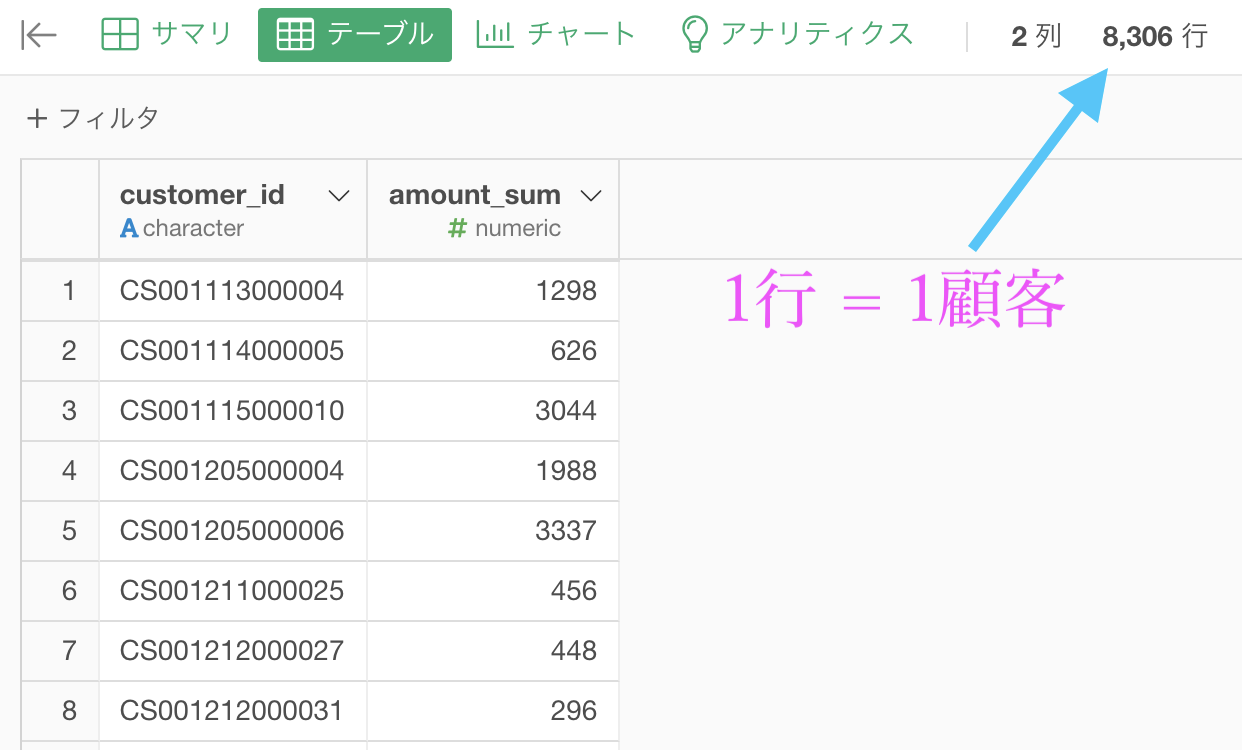
ちなみにここでいう平均値とはまさに、問34 の答えの数値です。
今回は正確にやりたいので、フィルター → 「カスタム」でこのように打ち込みましょう。 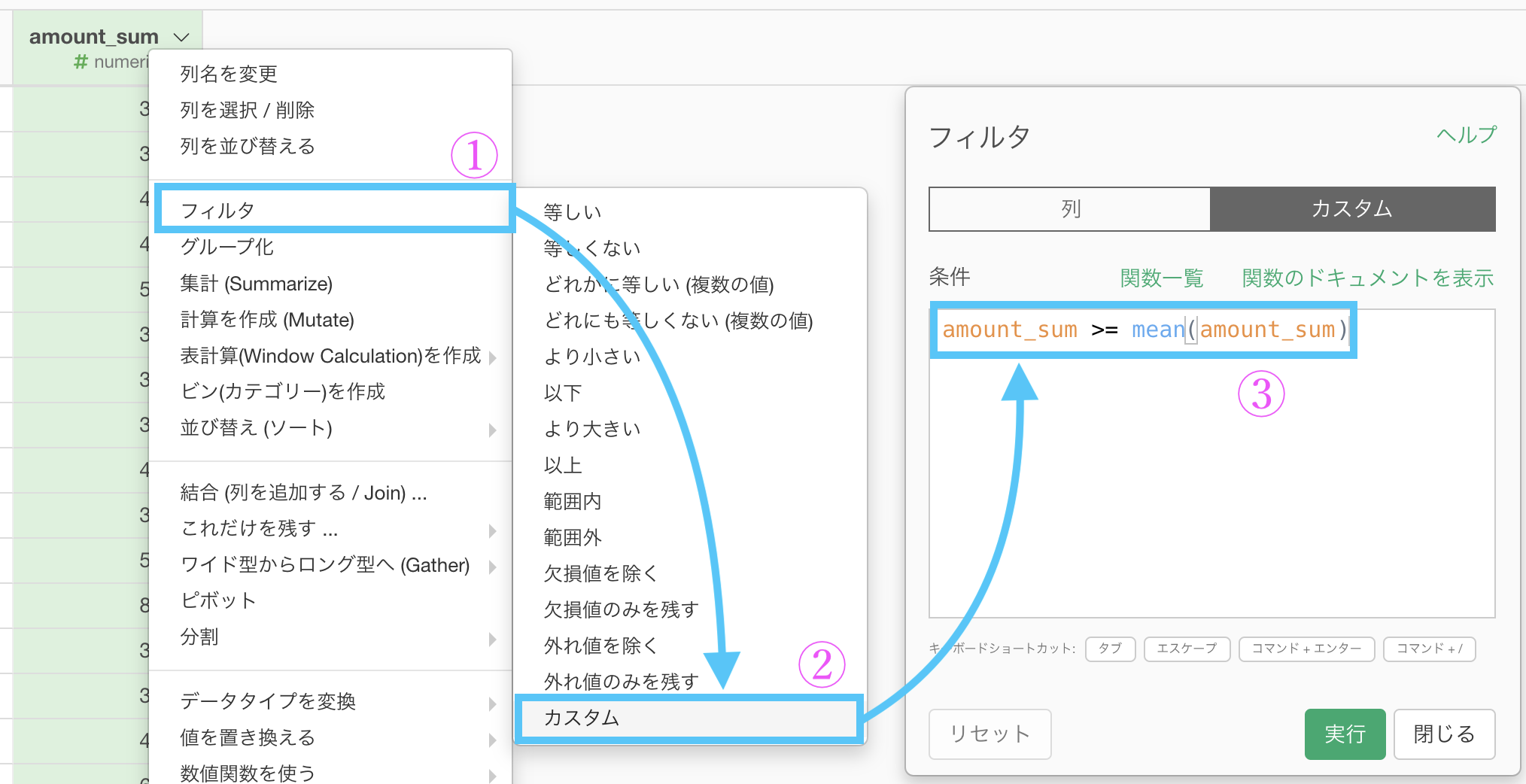
amount_sum >= mean(amount_sum)「amount_sum の平均値(mean)以上の amount_sum」みたいに読めるかと思います。
結果はこのようになったと思います。解答と確認しましょう。 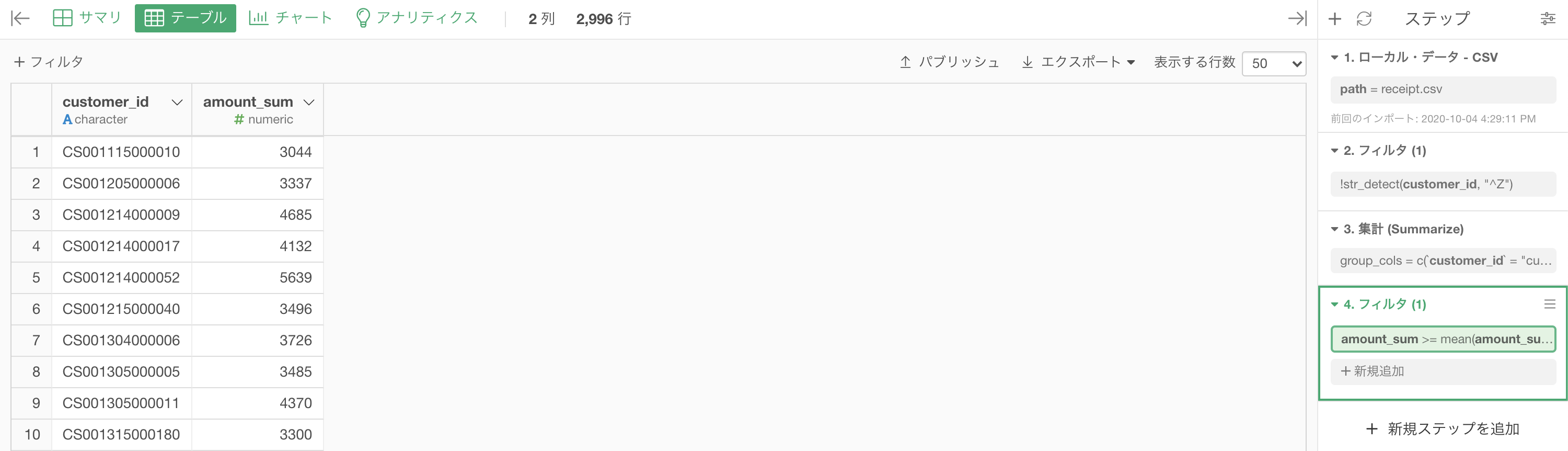
Python 解答コードはこちら
解答コードはこのようになっています。
amount_mean = df_receipt[~df_receipt['customer_id'].str.startswith("Z")].groupby('customer_id').amount.sum().mean()
df_amount_sum = df_receipt.groupby('customer_id').amount.sum().reset_index()
df_amount_sum[df_amount_sum['amount'] >= amount_mean].head(10)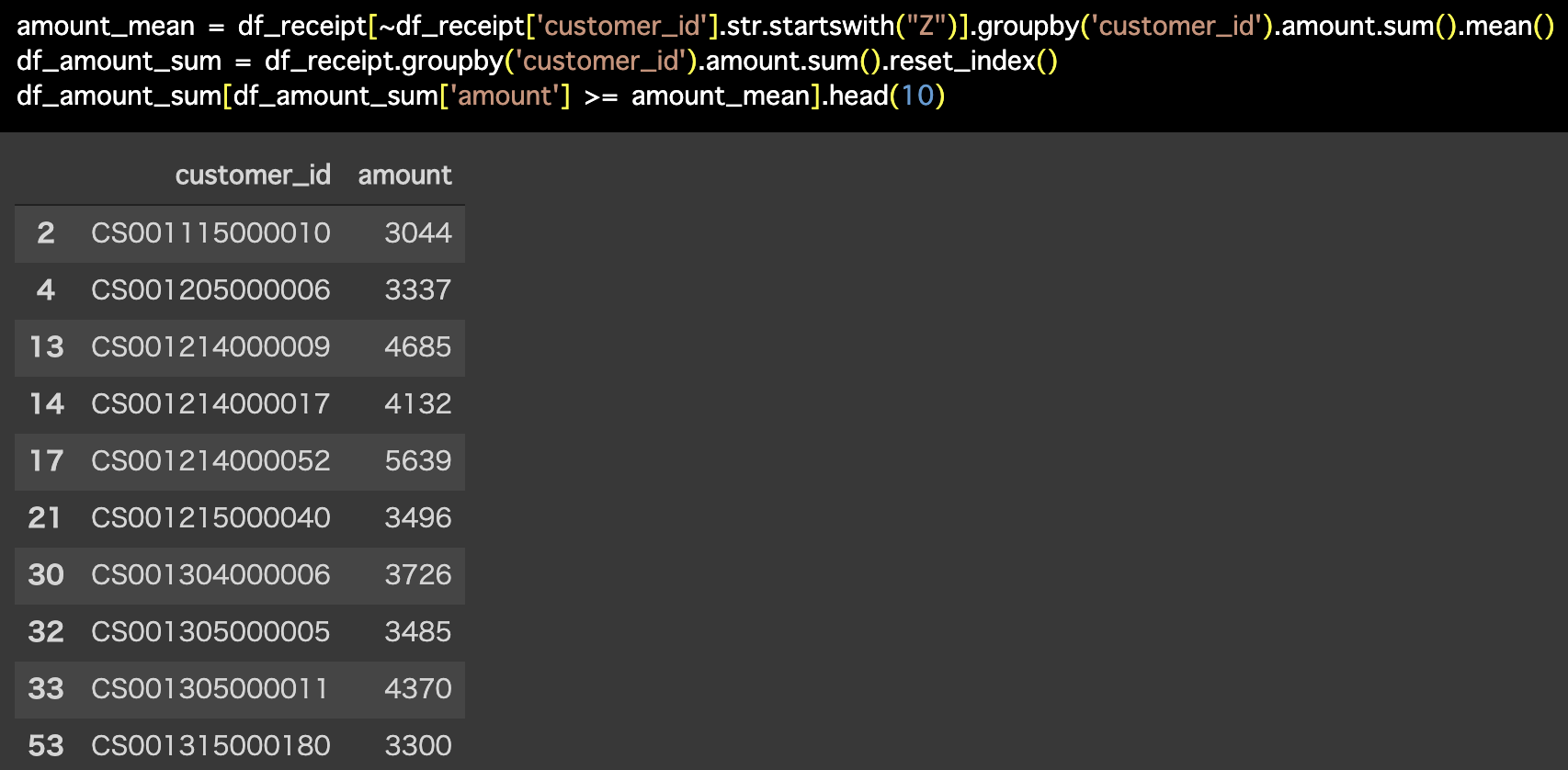
もちろん、問34 の値を覚えておいて(記録して)からフィルターしても良いといえば良いのですが、少しでもプログラムの心得や教養を持っている人はしないと思います。
しかし、一方でデータをきちんと見ている人ならば、2547.7 以上でフィルターすれば十分だということがすぐにわかります。
amount_sum が全て整数値だからです。
問36 : トランザクションとマスタを内部結合する

答案・解説はこちら
要するに、情報が分割されているので1つにまとめて復元しようということです。
なぜそんなことをしなくてはならないのかは Python の解答コードの折りたたみの中に書いておきました。
今までの問題と決定的に異なるのは、データが2つあった上での処理をしようとしている ことです。
さて、やりたいことの概念図を示してみます。
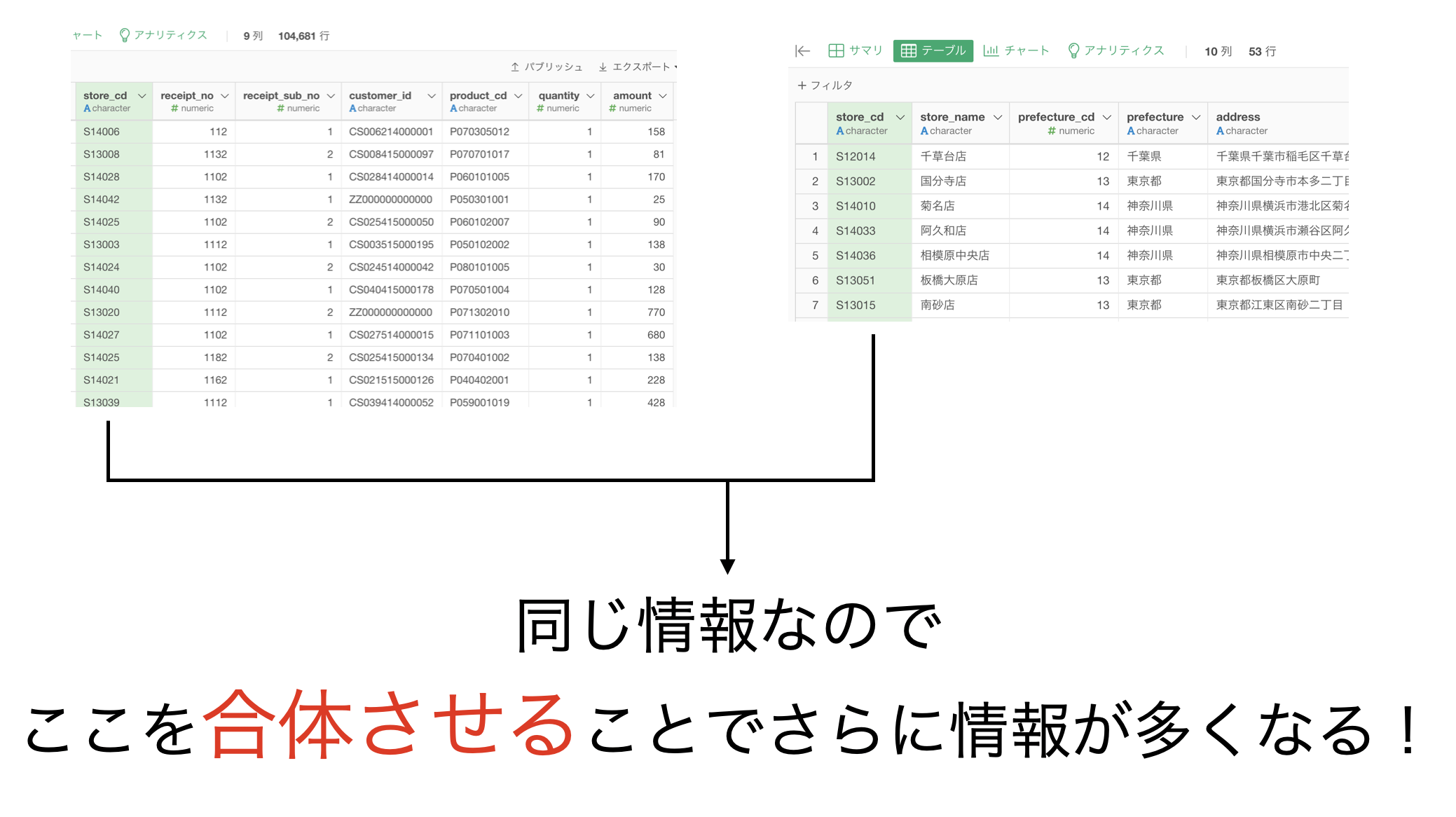
これをするにはどう実装したら良いのでしょうか?ということを Exploratory でやりたいと思います。
まず前段階として問題文にあるように、df_receipt に store_name(店名)を表示させたいので、df_store の列を store_cd(店舗コード) と store_name(店名)の2列だけにしましょう。
ちなみに列を選択するのは 問2 で既にやっていますので参考にしてください。
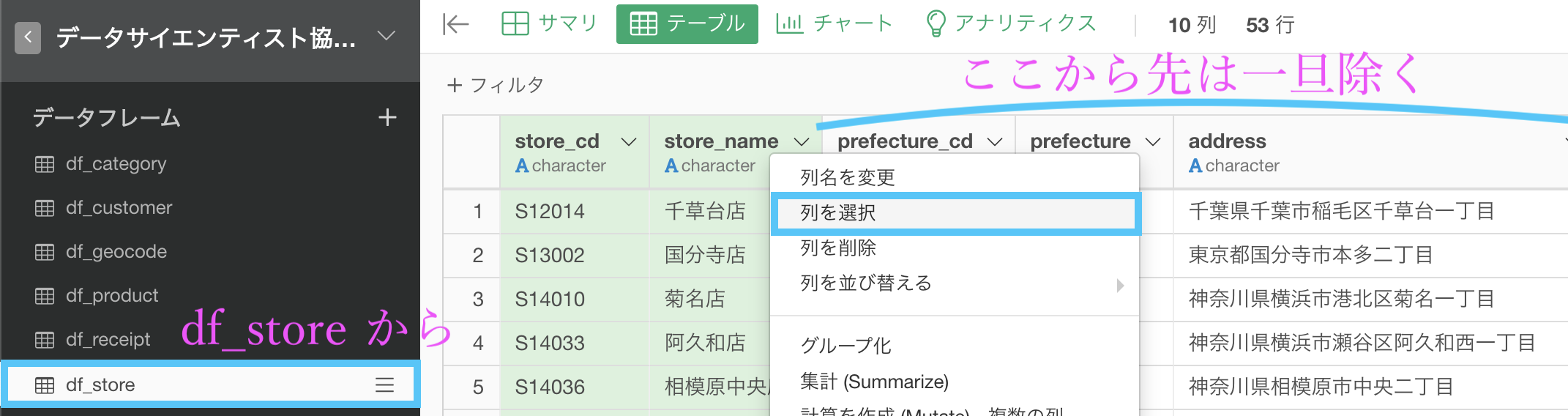
そのあと、df_receipt の中にある store_cd を選択して、「結合 (列を追加する/Join) 」を選択します。
これを選択すると、次の様な画面が出てきますので、一緒に操作してみましょう。なお、先に提示した概念図を想像しながらやれると良いと思います。 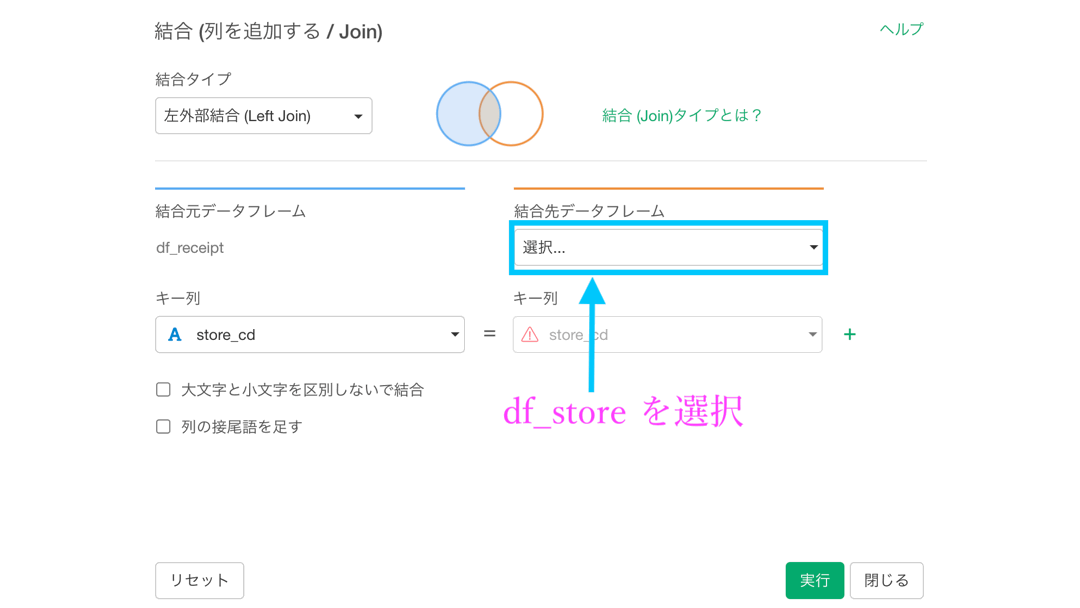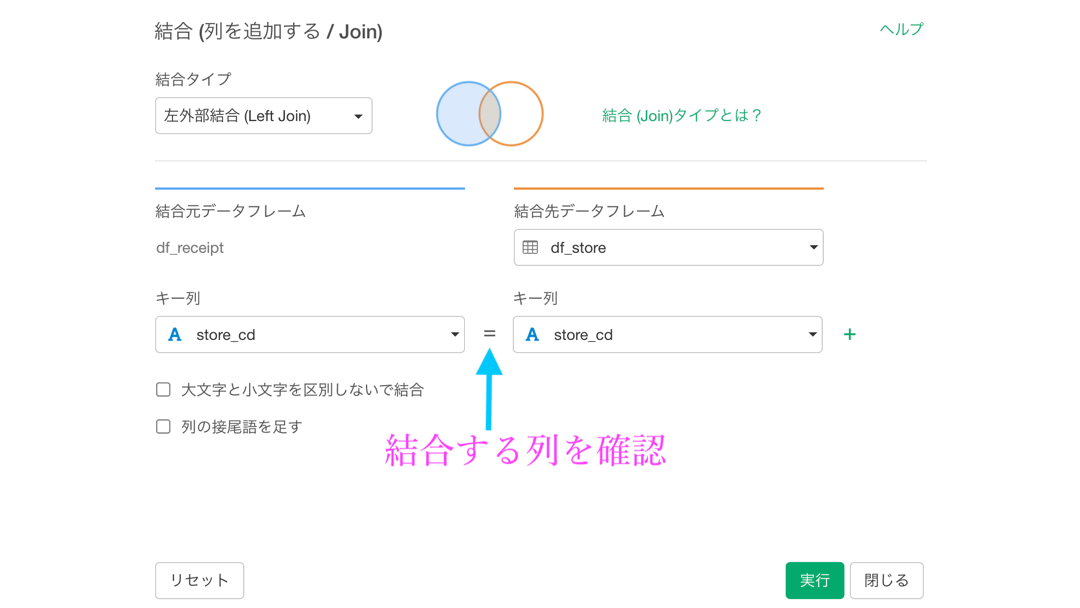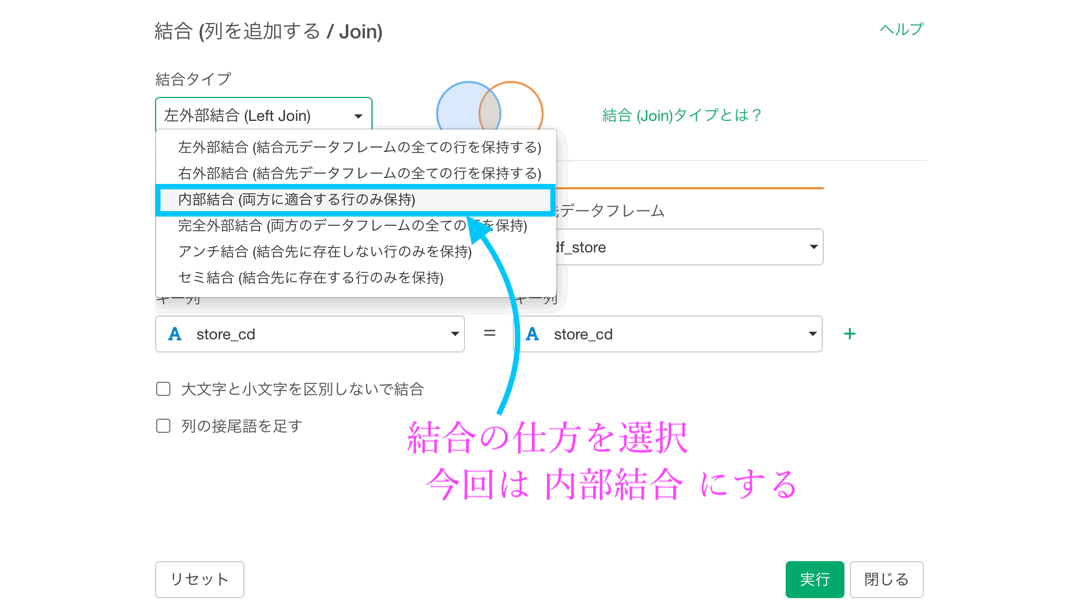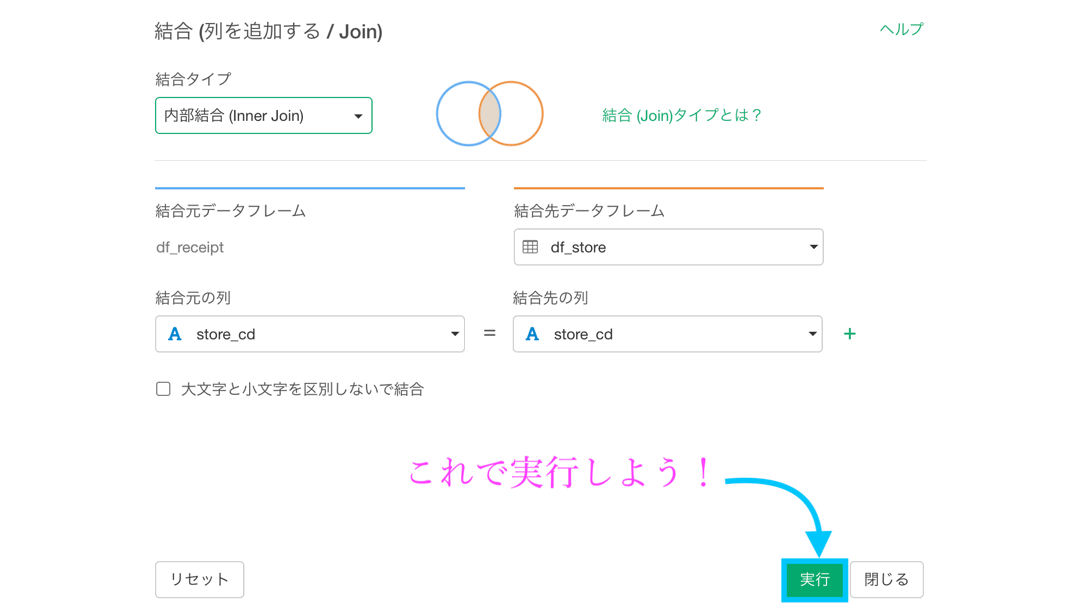
結果はこのようになります。解答と確認しましょう。 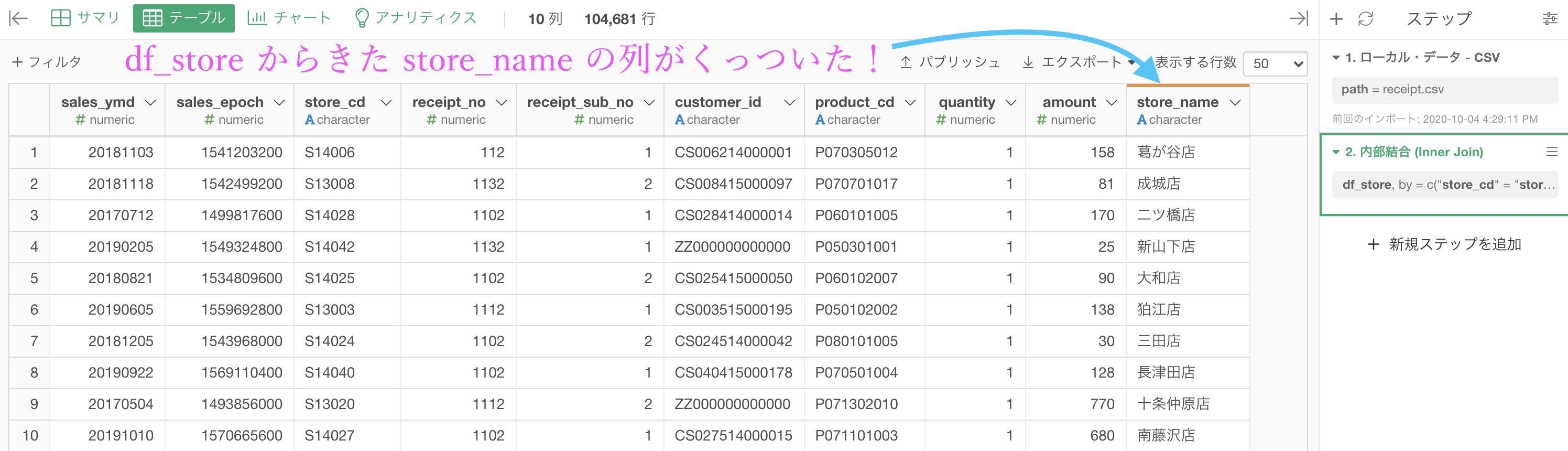
Python 解答コードはこちら
解答コードはこのようになっています。
pd.merge(df_receipt, df_store[['store_cd','store_name']], how='inner',
on='store_cd').head(10)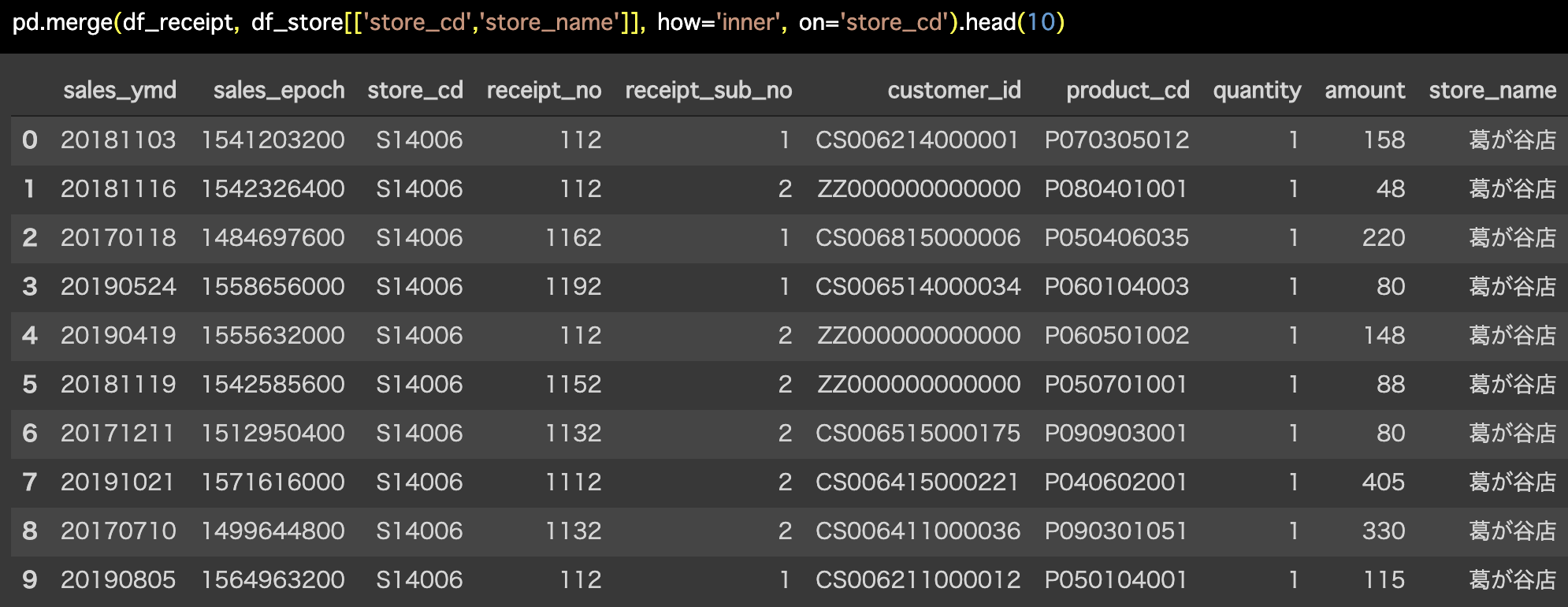
データの結合の仕方(合体のさせ方)は、実は1つではなく沢山あります。
特撮ヒーローもので合体のさせ方が沢山あるのと同じようなものです。
Exploratory のメニューに上がっているものでも(覚えなくて良いですが)
左外部結合、右外部結合、内部結合、完全外部結合、アンチ結合、セミ結合の6つありました。合体のさせ方の中でも、普通にイメージしていたのはおそらく内部結合(または左外部結合)のことでしょう。
つまりはその結合の仕方を最もよく使いますが、問38 では左外部結合を使ったり 問39 では完全外部結合を使ったりしますので、名前は覚えなくともデータがどのような動き方をするのかは理解しておく必要があるでしょう。
それをすぐにでも学びたいというのであれば、問題・例題を通して一度やってみる & 結果のデータをよく見ることをすれば良いと思います。
データベースのことも少し知っておくと良いと思います。
これは今回の問題をやる意味を考えることでもあります。
100本ノックのフォルダーのなかに、100knocks_ER.pdf というファイルがあります。 
中身はこんな感じです。 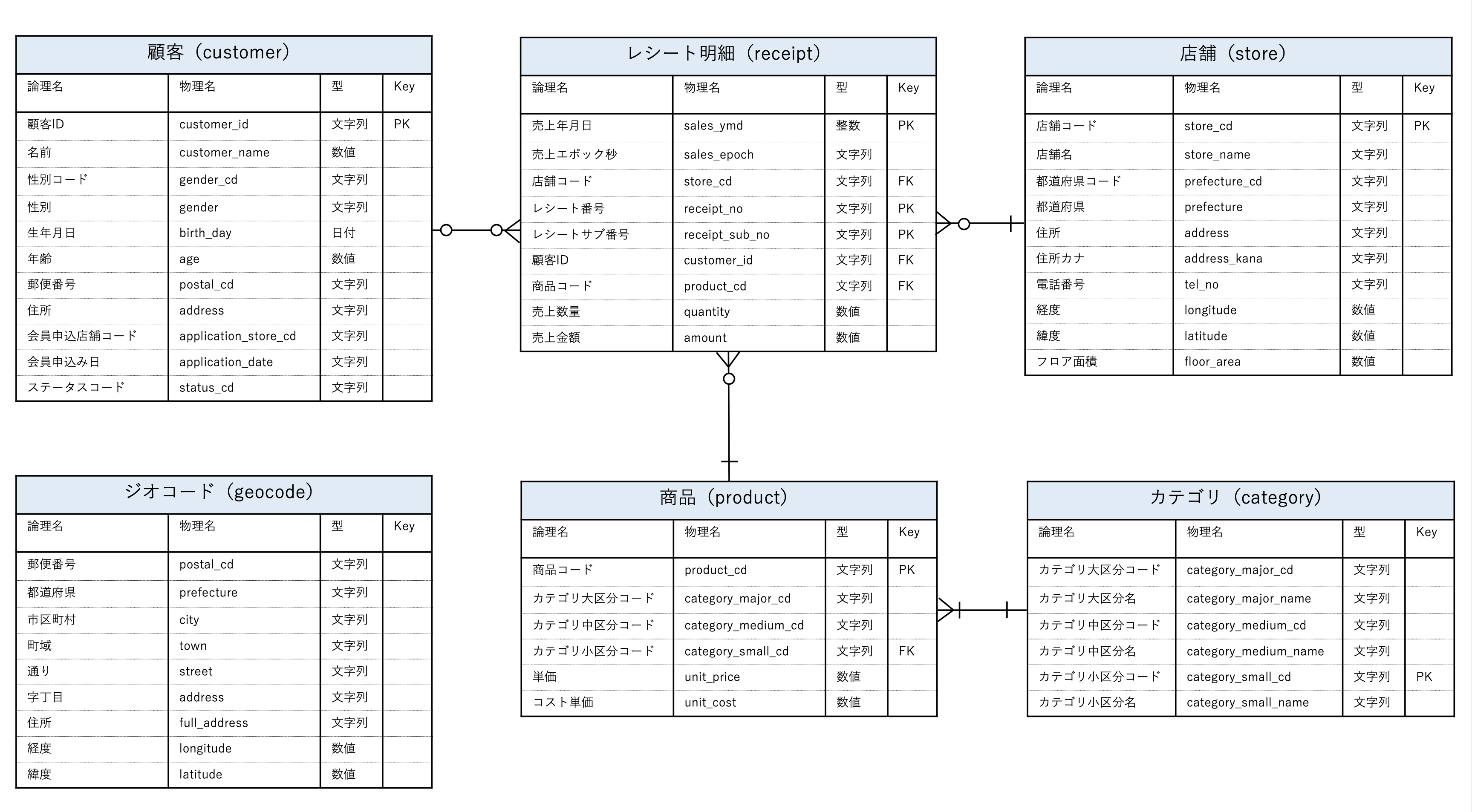
これは ER図 といって、今回の疑問を解決するヒントみたいなものです。
この図は何者なのか?をカンタンに説明するとというものです。
よく見ると、それぞれの四角い枠は、今回配布されている csvデータ です。
例えば、こんなふうに最初は見ます。 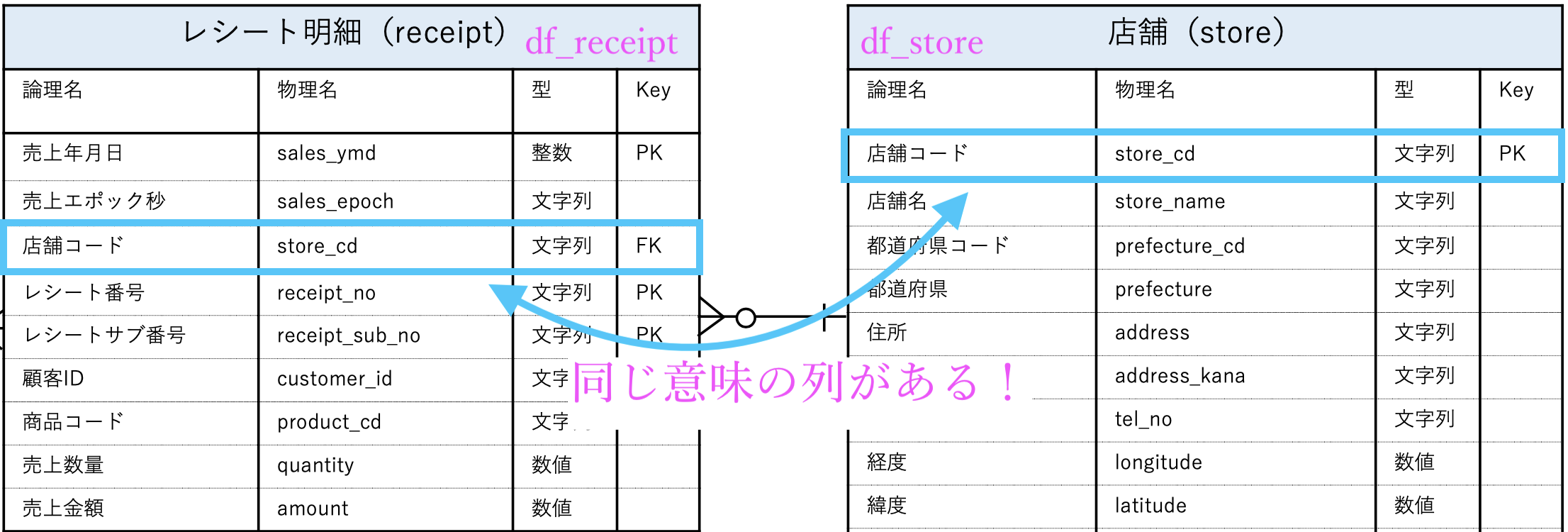
この四角い枠の右端にはそれぞれ Key という列があって
PK : 主キー、Primary Key
FK : 外部キー、Foreign Keyと書いてある所と、書いていない所があります。
それぞれの意味はよくわからないにしても、問36 でやったことと対応づけると 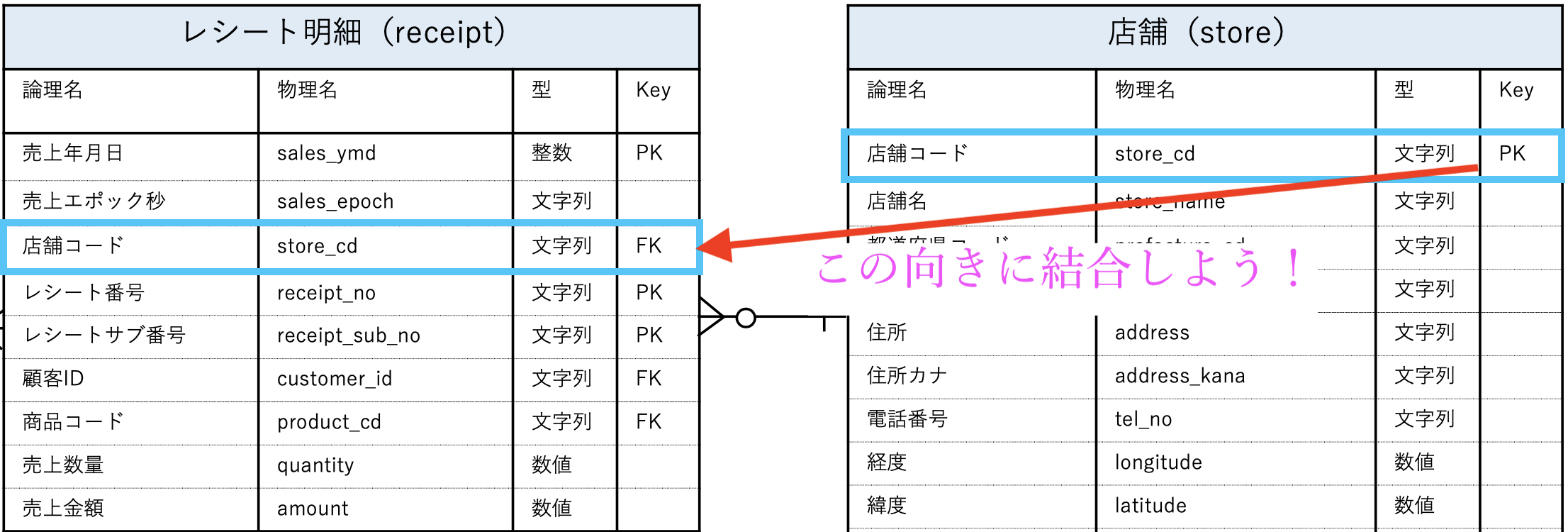
と見ることができます。
結局、問36でやったことと同じことを言っています。
データベースの話では、よくこの ER図 が登場します。
とは言っても、どの列とどの列をつなげると良いよ!というメモ書きみたいなもので、例え列名が違っていたとしても間違えることなく結合することができます。
「どうしてデータを結合するのか?」という疑問は「じゃあどうしてデータは分解されているのか?」という話題にすり替えても同じことです。
その理由は例えば、
- データを1つだけにしてしまうと、そもそも重たくて動かしにくいから
- 繰り返すデータは別々にして、ユニークにすることで全体として圧縮できるから
といった具合です。
例えば、store_name はせいぜい 52個 しかないのに、df_receipt と結合すると 52個 が10万回も不規則に繰り返された1列(10万行)がある!ということが想像できます。
でもそれはデータを分割して、別データの 52行 にした方が良いじゃん!というだけの話だったのです。
これが データを結合する・分解することの理由 です。
ER図は、分解したデータを復元するための設計図だった のです。
ここから問40までは、データベース的な事情が背景にありつつ処理をすることになりますが、そう大してキツくなるわけではありません。
実質、データベースと何かやりとりをするということはなく、今まで通り Exploratory で選んで処理し続けるだけのことですから。
イメージはこのような感じです。 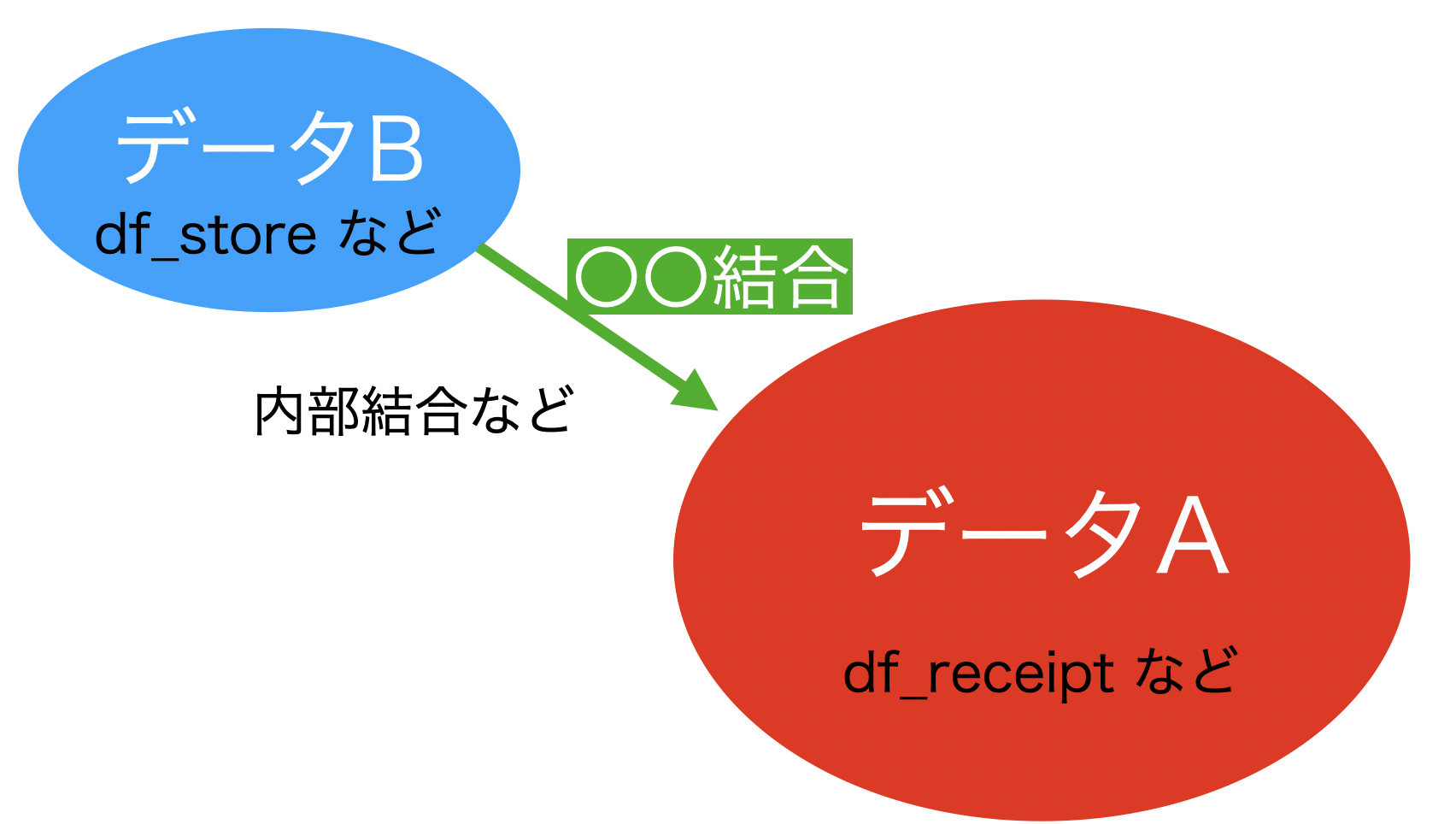
基本的には、データBの方が行数も列数も小さい時が多いです。
問37 : マスタ同士を内部結合する

答案・解説はこちら
列を絞らずに結合するとそれなりに大きなデータになってしまうので、結合するときにはいらない列を消して、必要なものだけ残してからやる方が良いと思います。
df_category のなかの、category_small_cd(小カテゴリコード) と category_small_name(小カテゴリ名)の2列を残します。 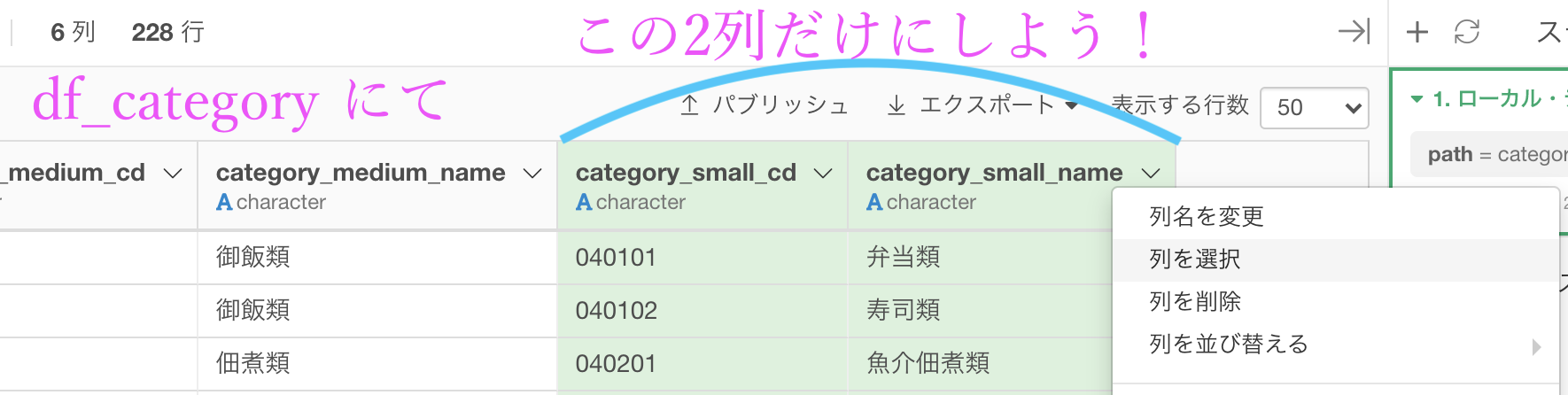
このようになれば大丈夫です。 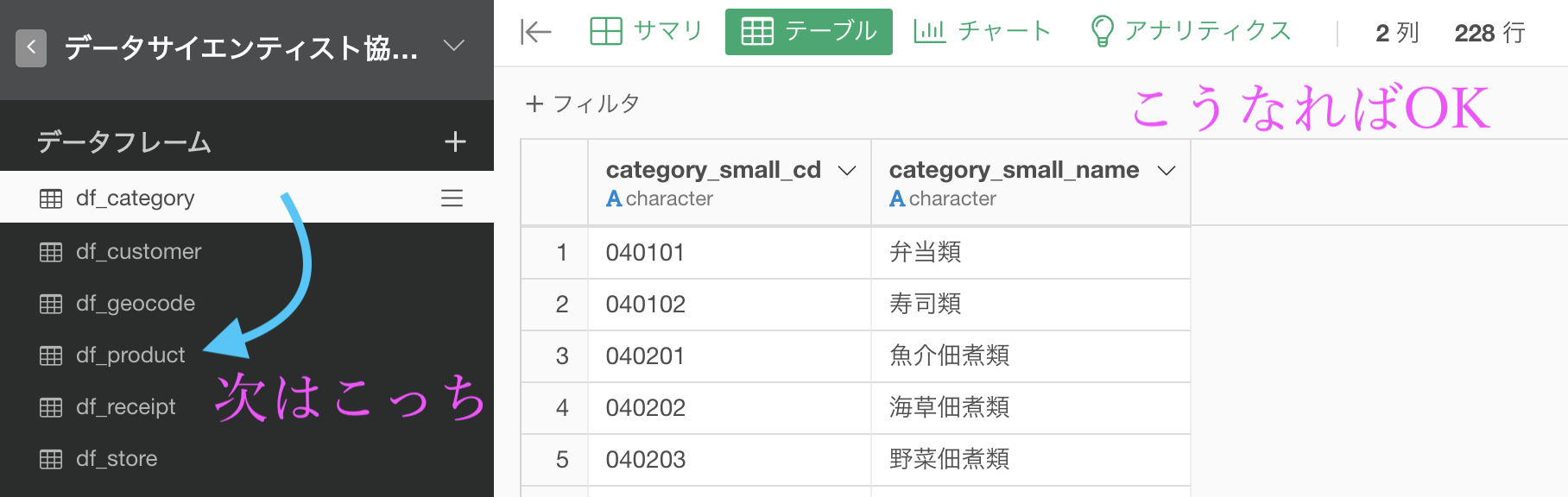
次は df_product の方を開きます。こちらの方では結合するだけなので、問36と同じようにします。
category_small_cd を選択 →「結合 (列を追加する/Join) 」を選択します。 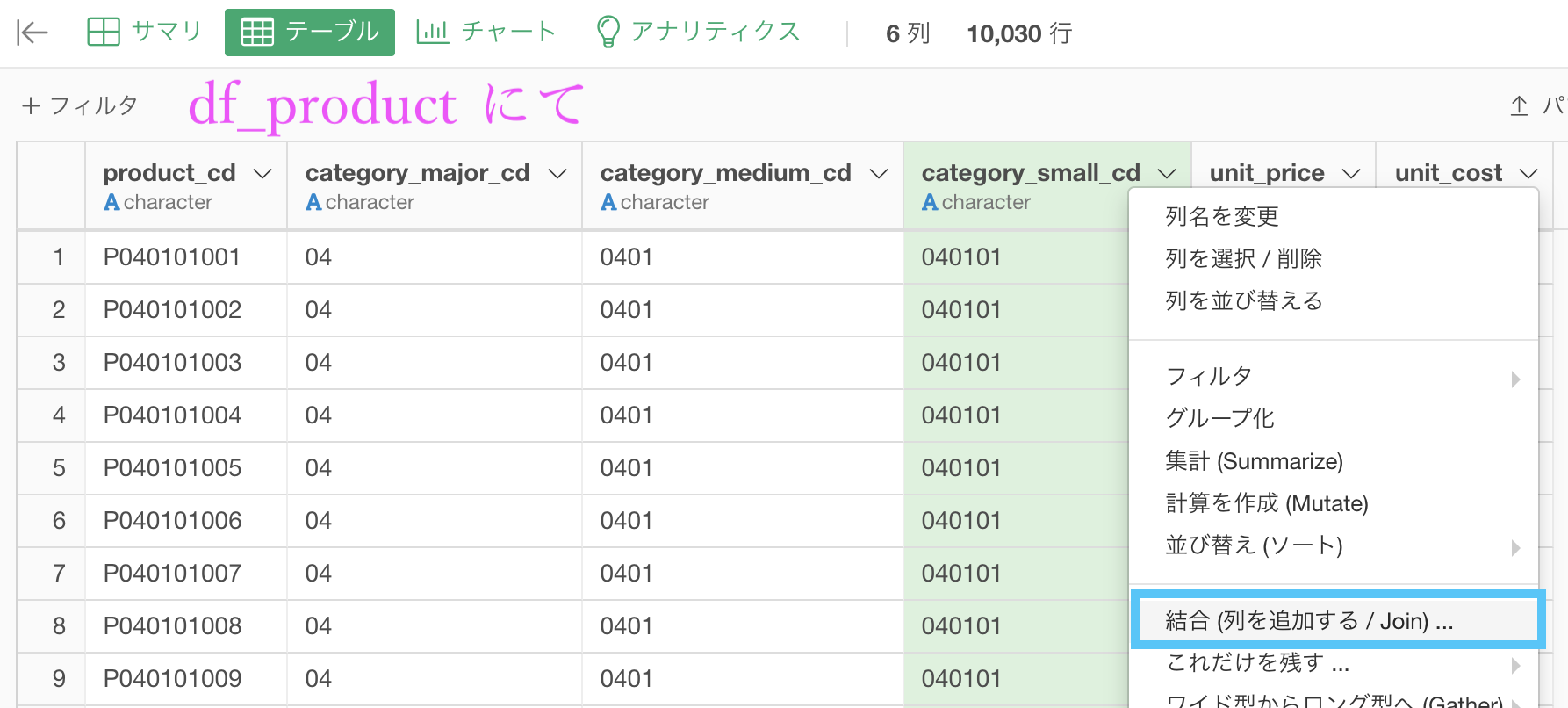
このような画面からデータを選択し、結合の仕方を「内部結合」にしましょう。 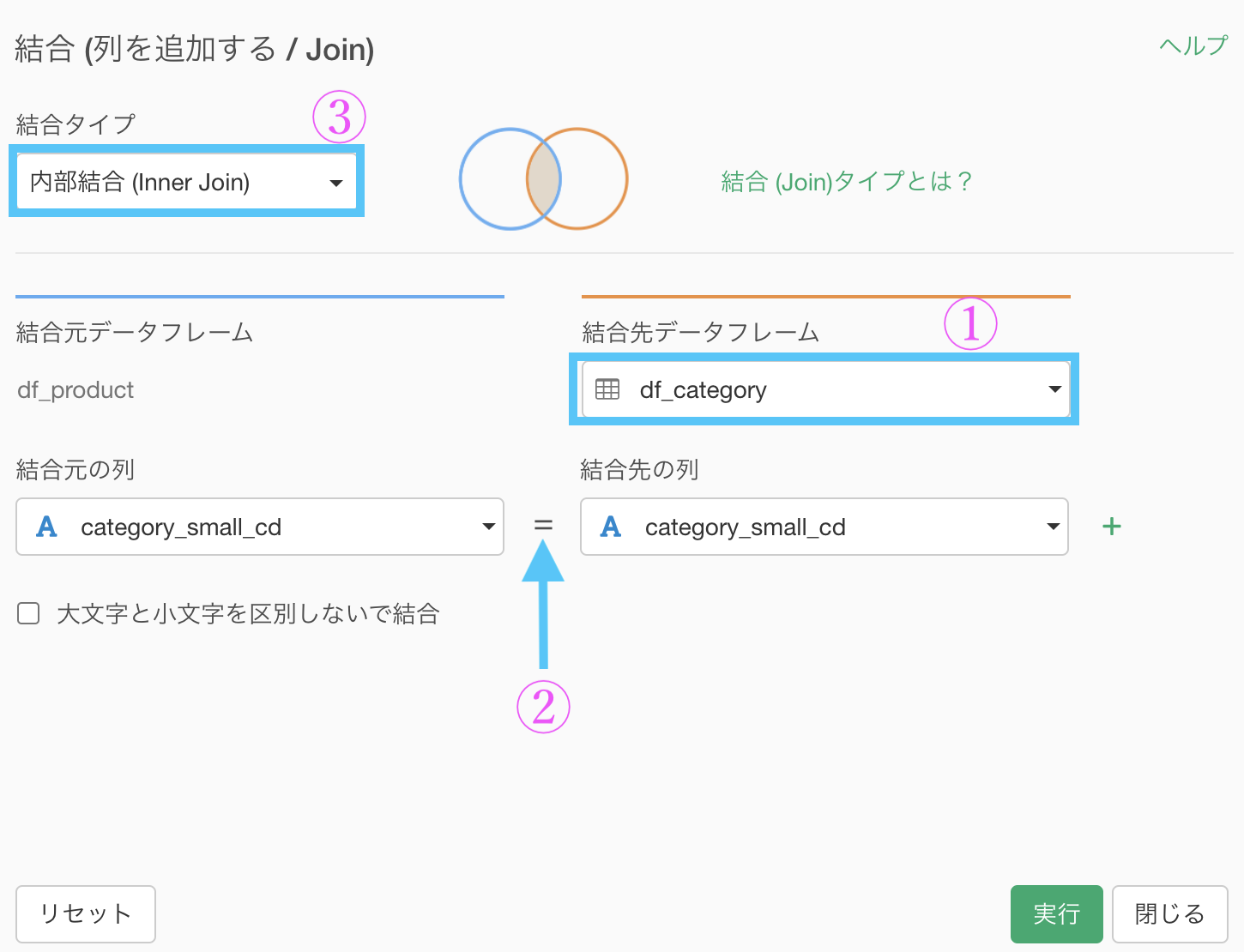
データ : df_category を選択
列 : 結合する列が一致していることを確認 (実質は何もしない)
結合 : 内部結合 を選択これで実行しましょう。
結果はこのようになったと思います。解答と確認してください。 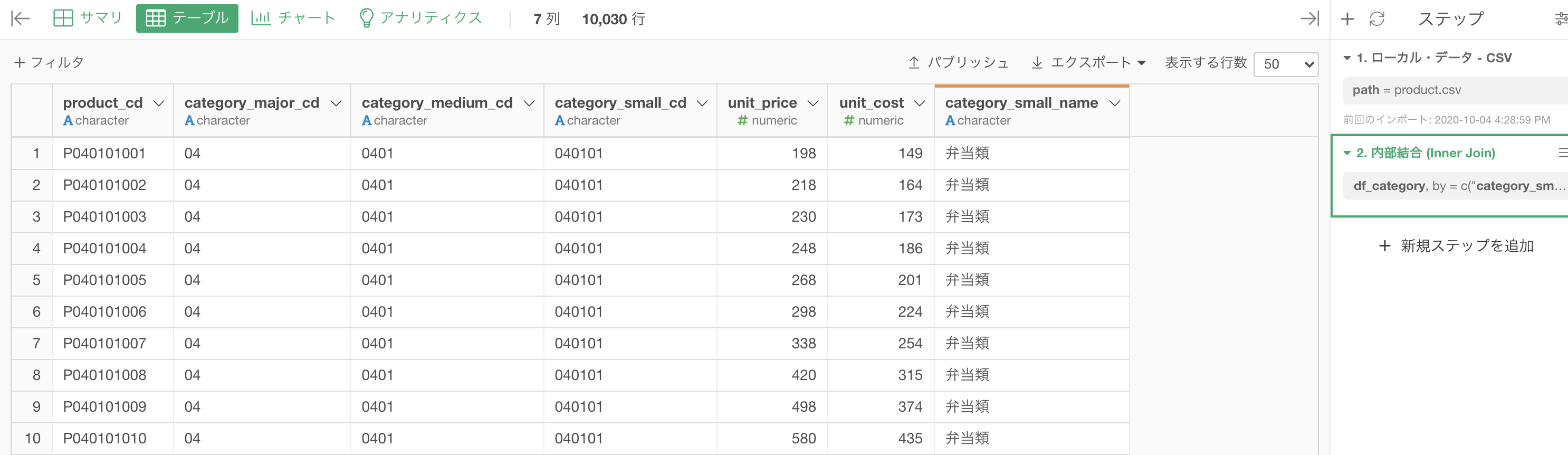
Python 解答コードはこちら
解答コードはこのようになっています。
pd.merge(df_product
, df_category[['category_small_cd','category_small_name']]
, how='inner', on='category_small_cd').head(10)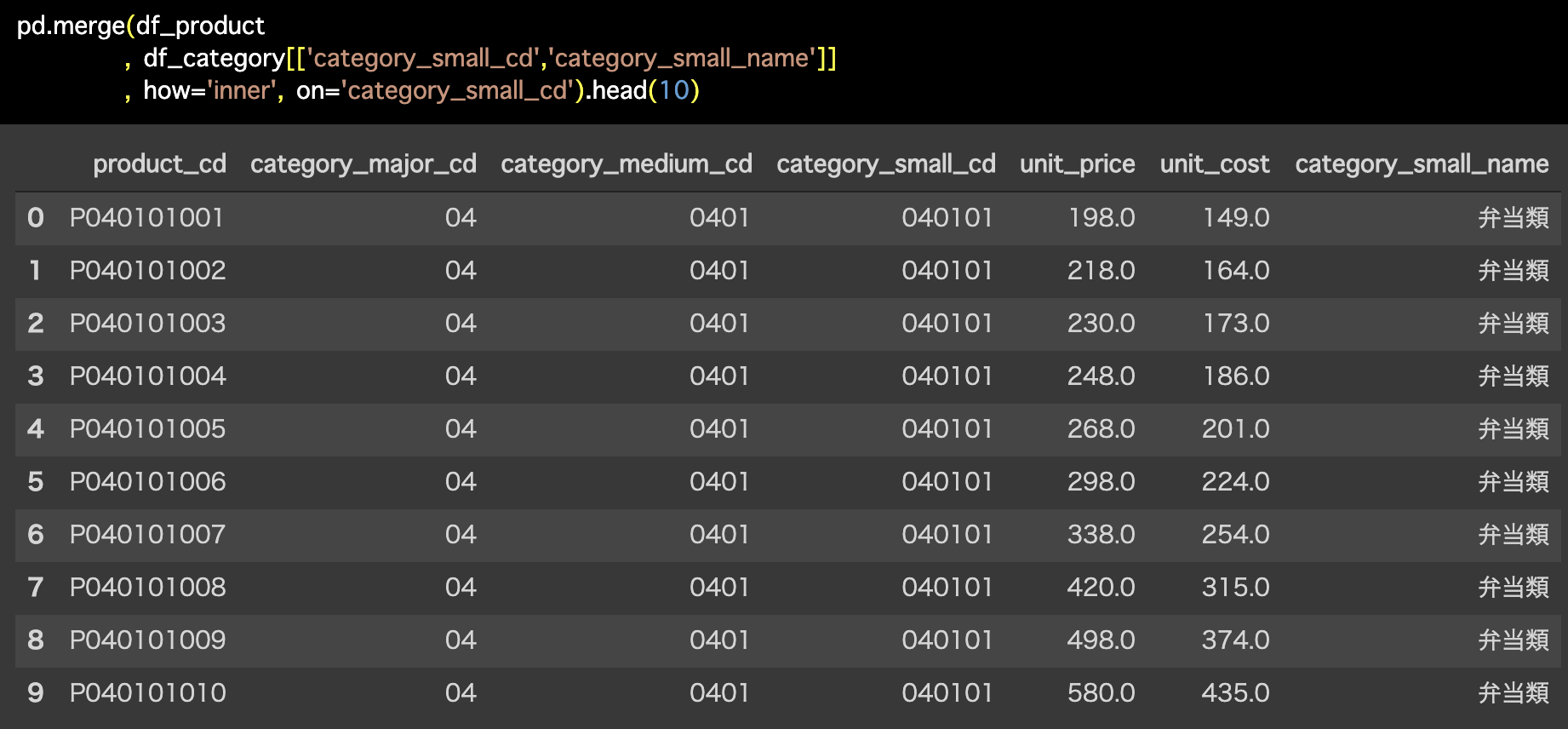
問38 : 左外部結合でデータを残す

答案・解説はこちら
まず df_receipt から非会員顧客(customer_id が Z から始まる人)をフィルターで削除します。 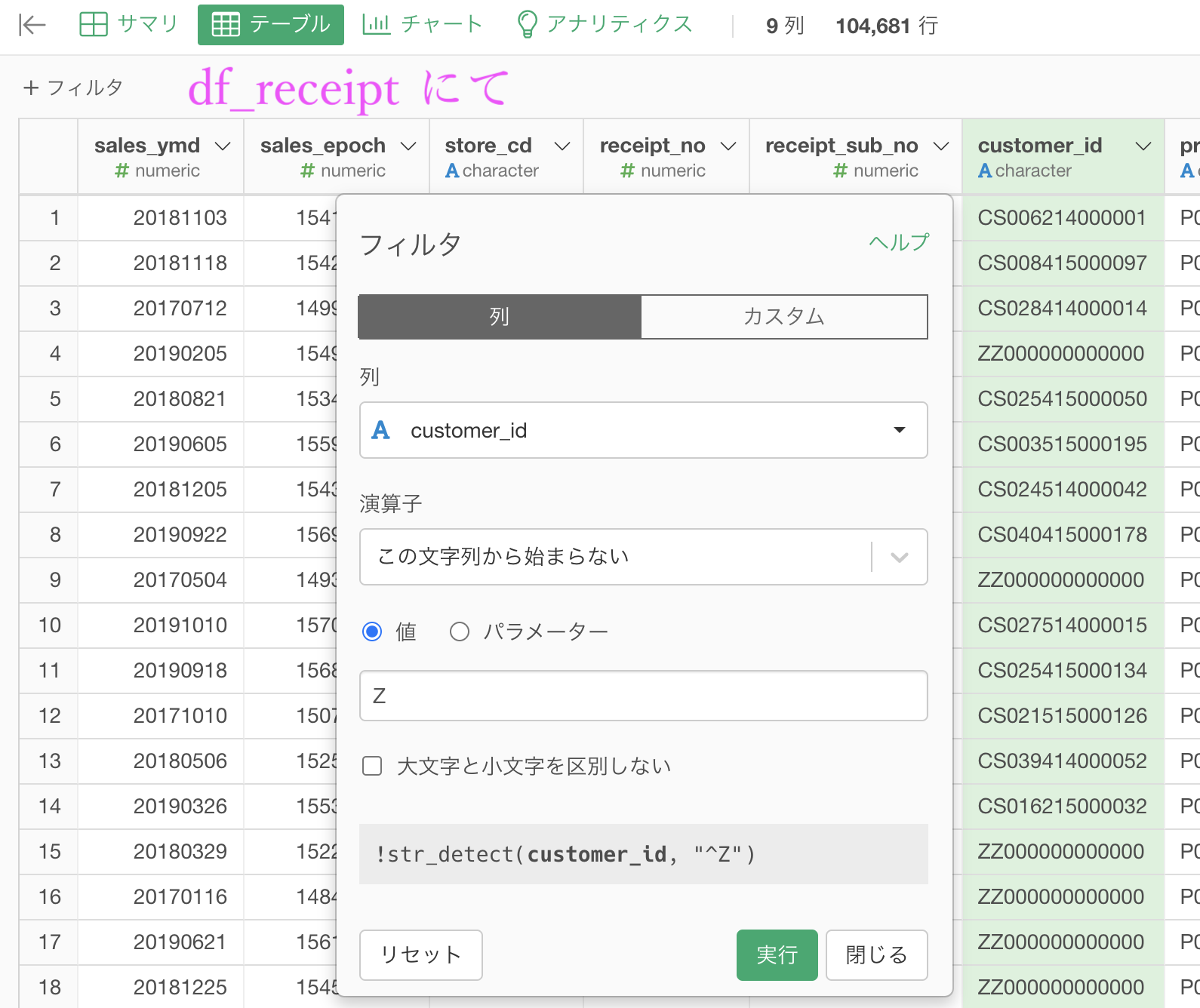
まずは販売実績のデータである df_receipt の集計からしましょう。
集計 (Summarize) 機能 の画面です。 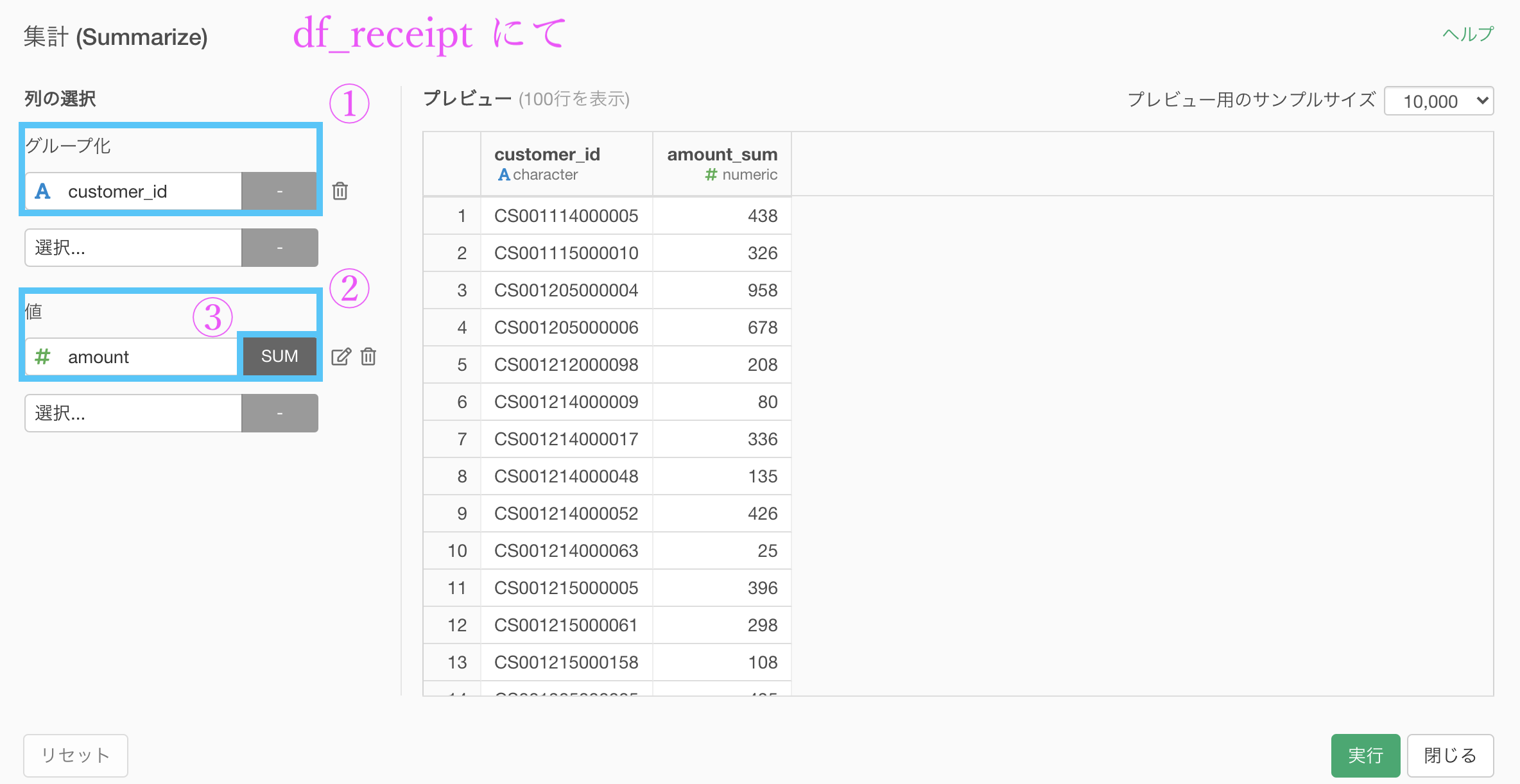
グループ化 : customer_id 値 : amount 計算 : 合計(sum)として集計しました。
次に df_ customer にて gender_cd が 1 だけのもの(女性だけにするので)をフィルターで行います。 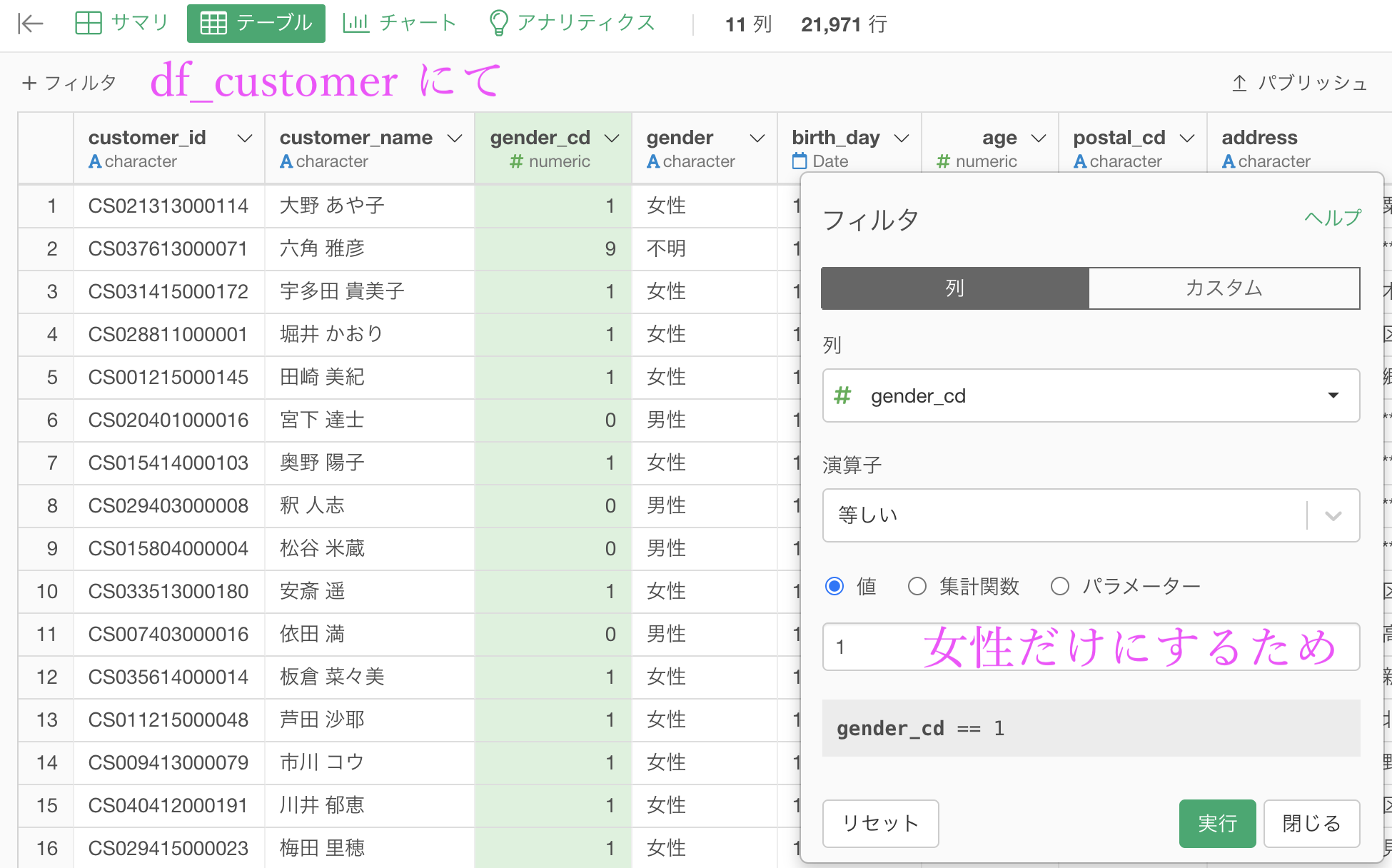
ということをしましょう。
解答とは少しそれますが、せっかくなので customer_id と customer_name を残しました(本当は customer_name は必要ありませんがわかりやすく)。
現在での2つのデータの様子はこのようになっています。
あとは、df_customer に df_receipt を 左外部結合 します。
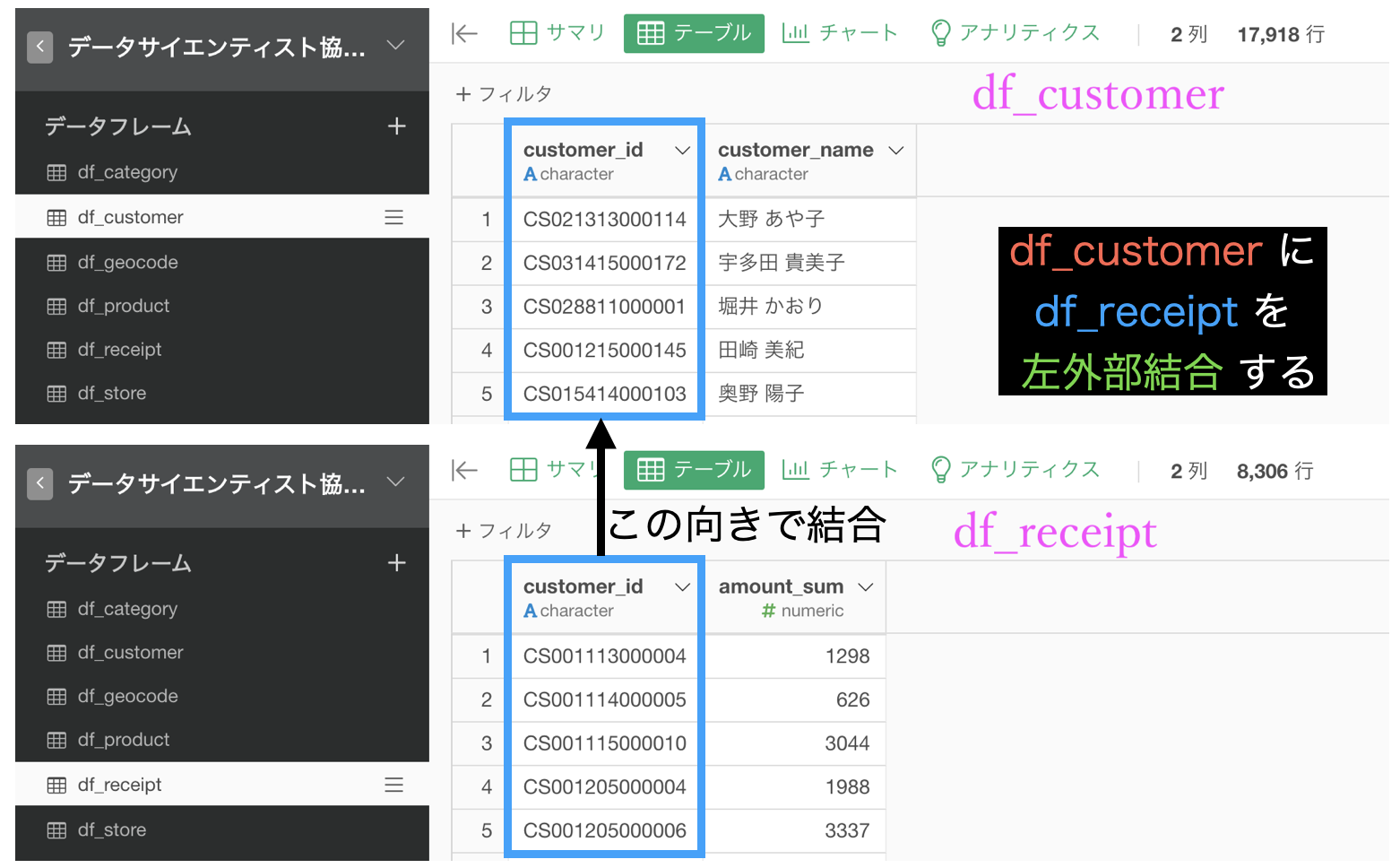
df_customer の customer_id を選択して、結合 (列を追加する/Join) をします。
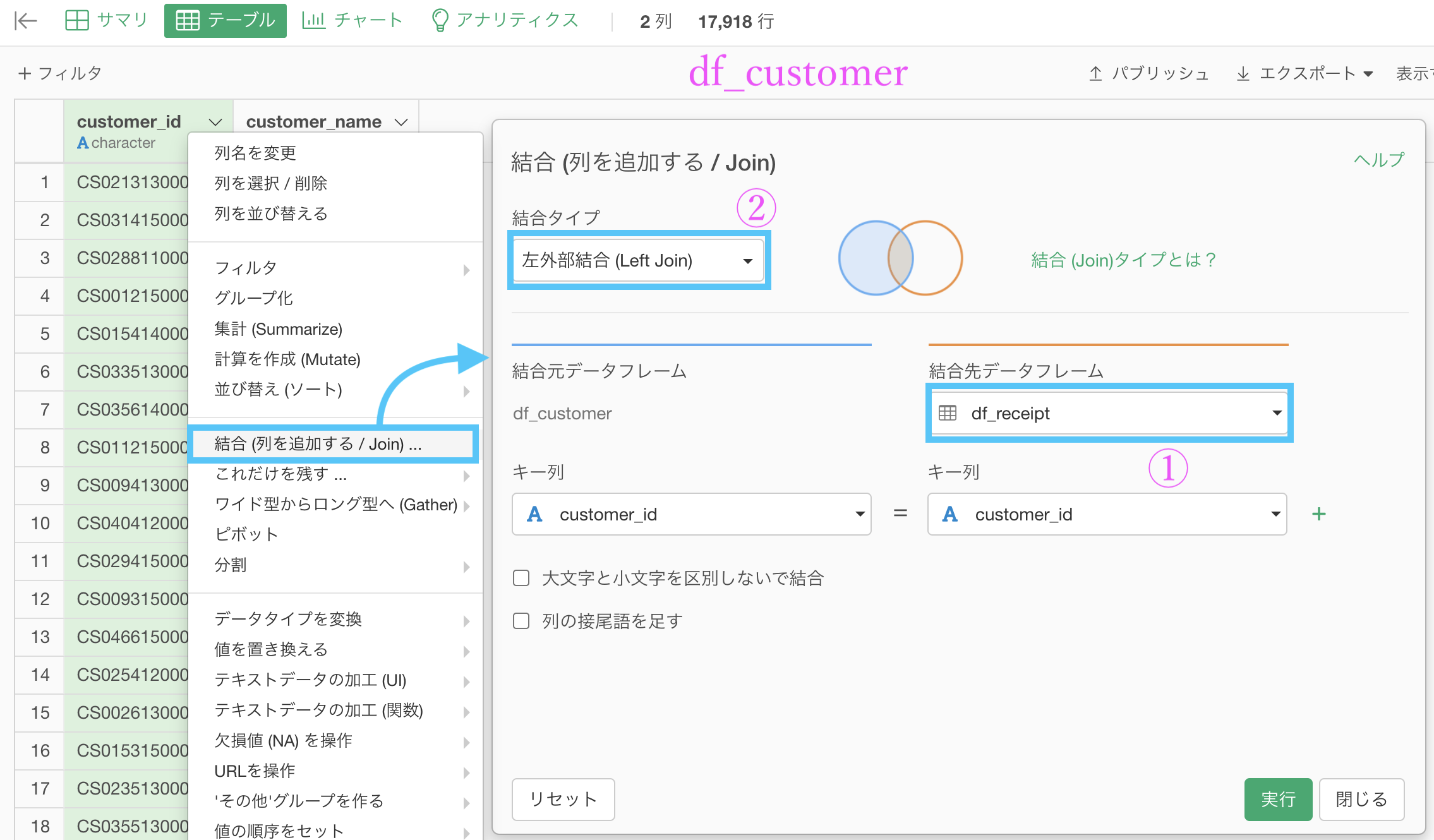
データ : df_receipt を選択
列 : 自動で列名が同じものが選択されるので実質何もしない
結合 : 左外部結合 を選択(デフォルトなので実質何もしない)結果はこのようになります。
df_receipt の amount_sum がくっつきましたが、欠損値(NA)が含まれています。
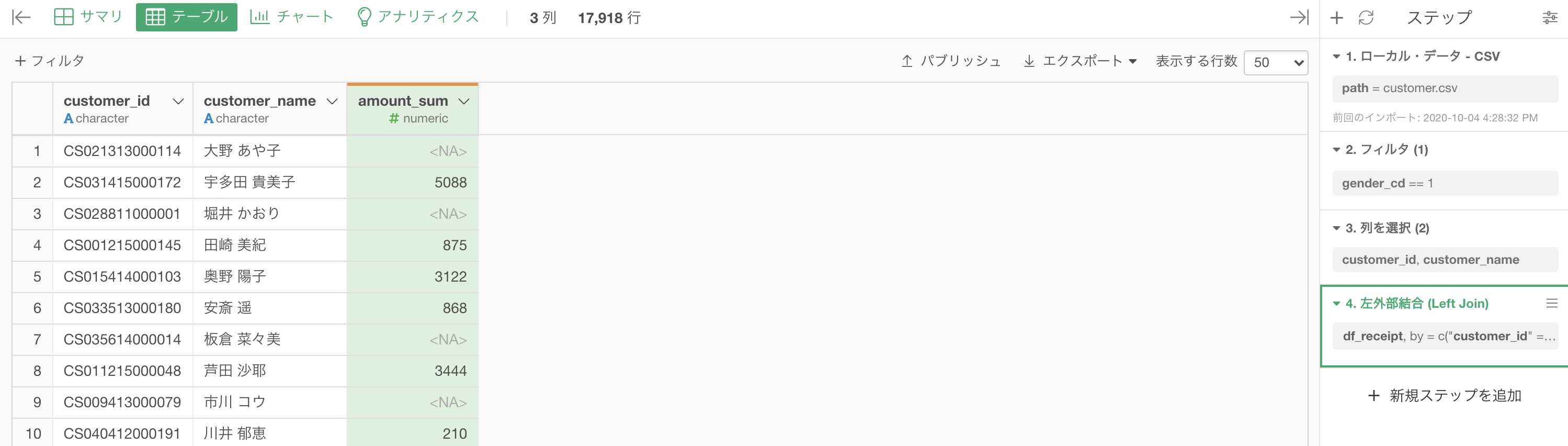
この欠損値(NA)の解釈は簡単で
販売実績のデータを顧客データに結合したら観測されなかった
= もともと顧客のリストには載っているけど, 単に買いに来なかっただけということです。
問題文にあるように、買い物の実績がない顧客については売上金額を 0 として表示させるように言われているので、欠損値に 0 を代入します。
これについては初めての操作なので丁寧にやっていきますが、もう既に問題の本質的なところは終わっていますので飛ばしても構いません。
まずは amount_sum の列を選択して、欠損値 (NA) を扱う → 欠損値 (NA) を ... で埋める →「特定の値」を選択します。
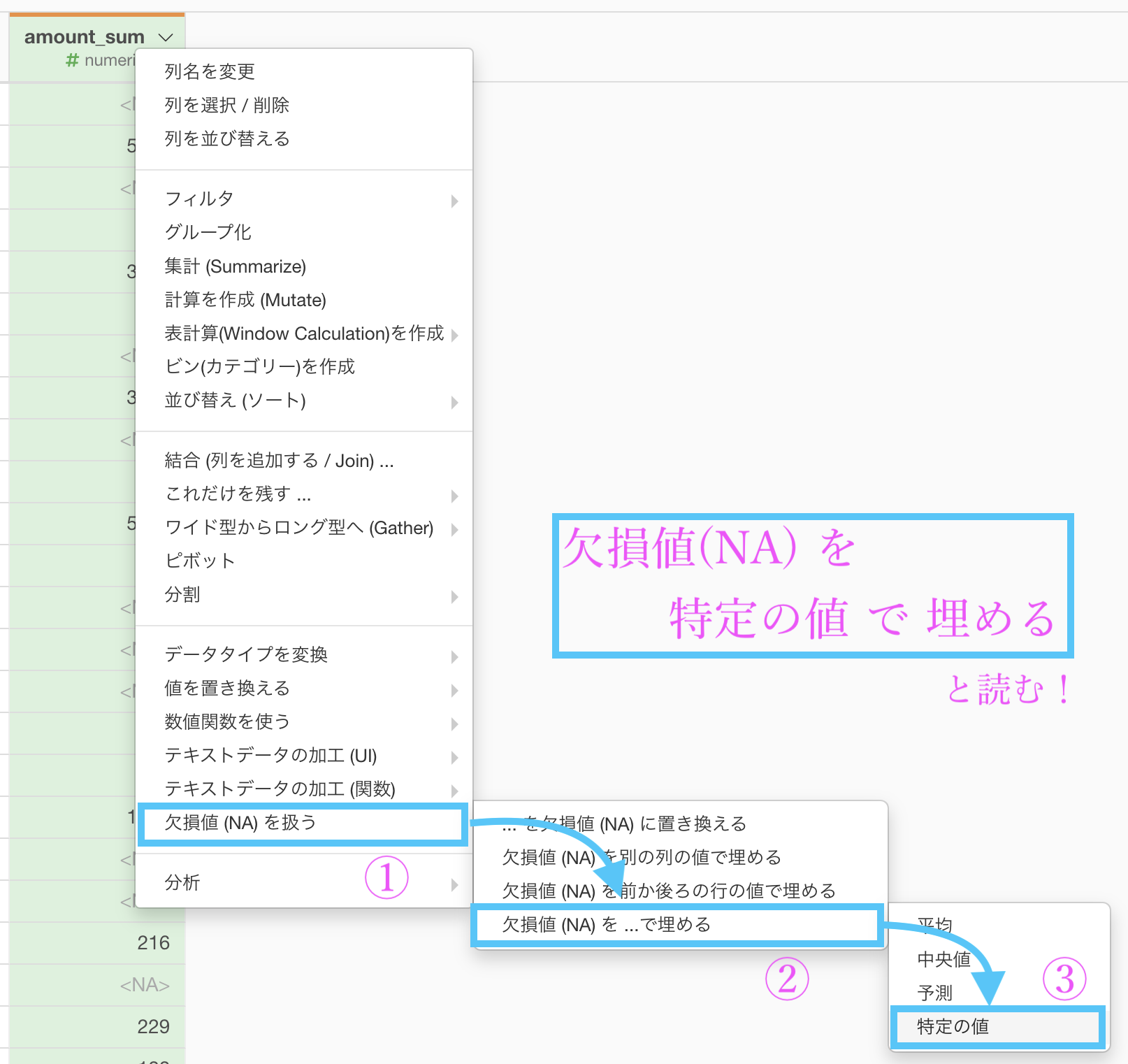
そのあとこのような計算エディタが出てきますので、0 とだけ入力すれば同じようになります。終わったら実行しましょう。
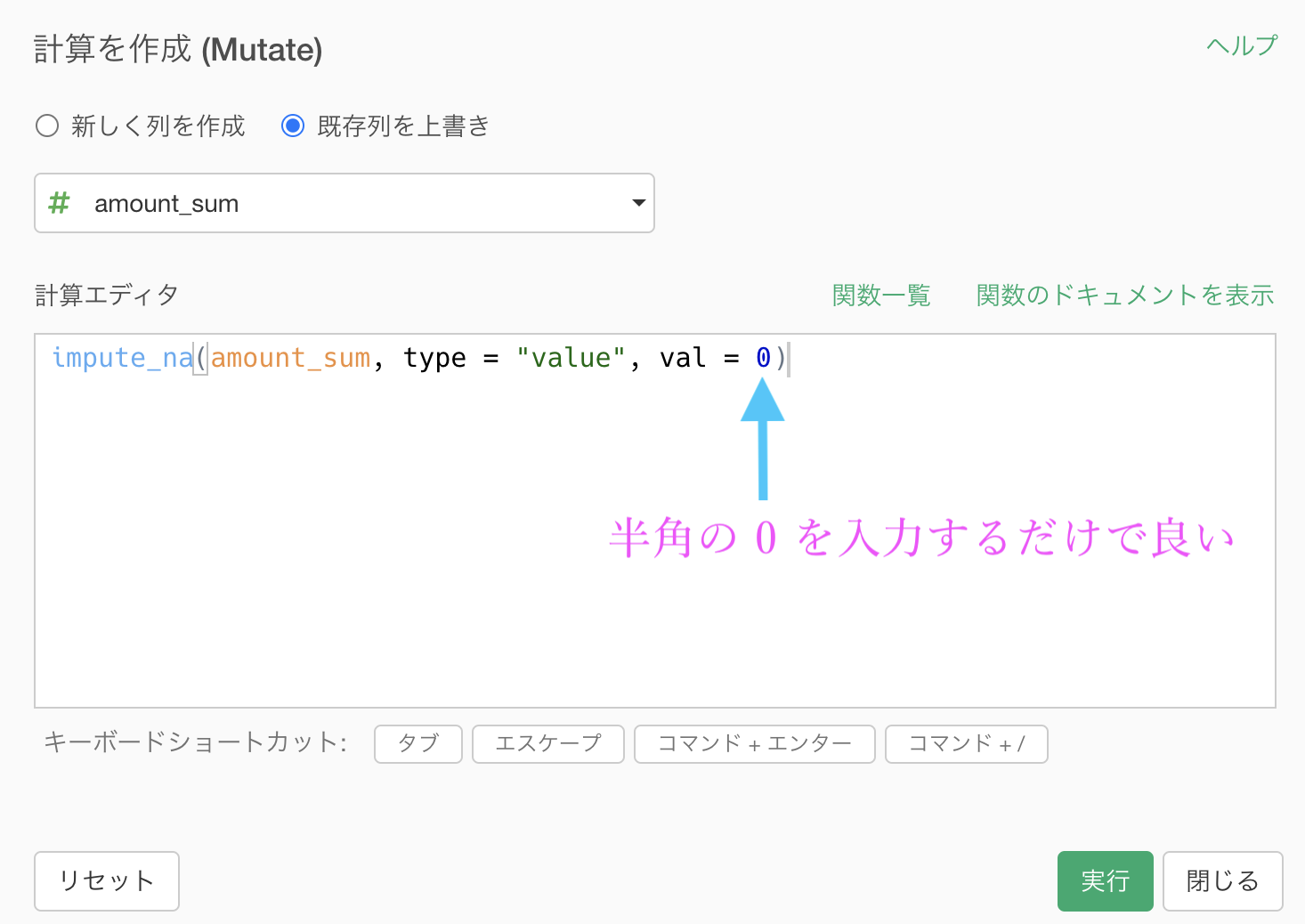
念のためコードも提示しておきます(不祥事の際のコピペなどに)。
impute_na(amount_sum, type = "value", val = 0)結果はこのようになります。解答を確認しましょう。 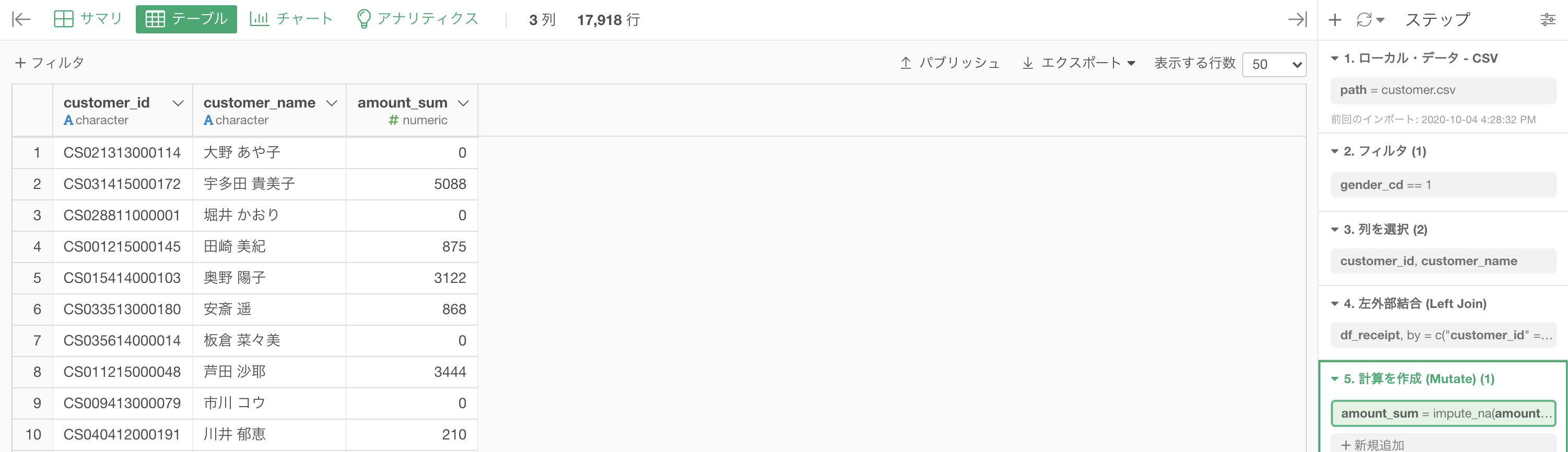
Python 解答コードはこちら
解答コードはこのようになっています。
df_amount_sum = df_receipt.groupby('customer_id').amount.sum().reset_index()
df_tmp = df_customer.query('gender_cd == "1" and not customer_id.str.startswith("Z")', engine='python')
pd.merge(df_tmp['customer_id'], df_amount_sum, how='left', on='customer_id').fillna(0).head(10)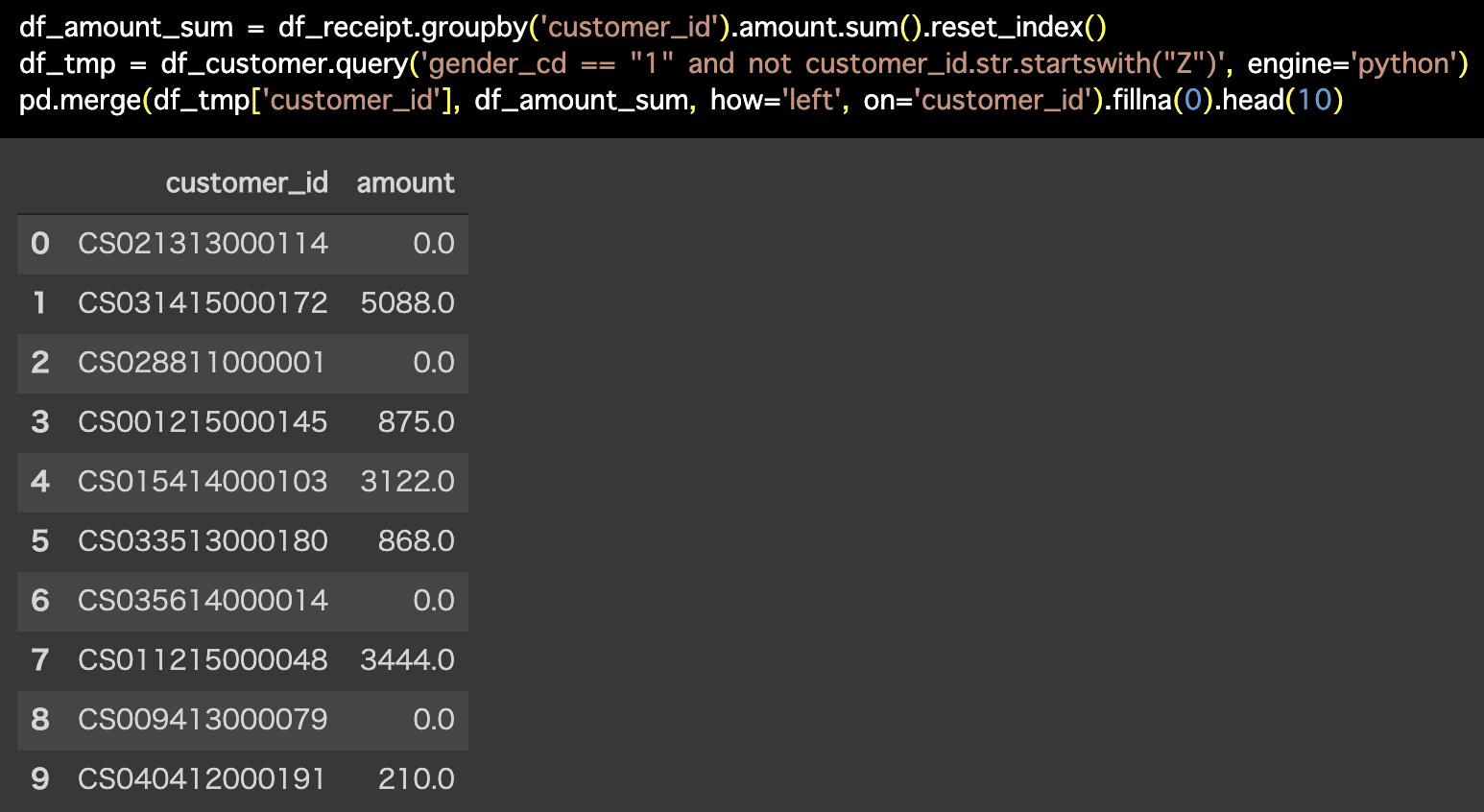
途中 NA を 0 で埋める処理がありましたが、そこは今回の問題ではあまり本質ではないので気にしなくて良いです。
むしろ、左外部結合で NA になったけど、今まで使ってた内部結合にしたらどうなるのか?などを試す方がデータの動きが理解できて、よっぽど本質的な活動になると思います。
問39 : 完全外部結合ですべてのレコードを残す

答案・解説はこちら
まず df_receipt から非会員顧客(customer_id が Z から始まる人)をフィルターで削除します。
- df_receipt から売上金額の多い顧客を上位20件
- df_receipt から売上日数の多い顧客を上位20件
まず、df_receipt を加工して2つのデータを作ろうとしているため、df_receipt のデータは2つ必要です。
そこで便利な機能として、 ブランチ の機能を紹介します。
概念としては簡単で、今までのステップから枝分かれするだけです。
ブランチ(branch)とは枝を意味しています。お昼の朝食ではありません。
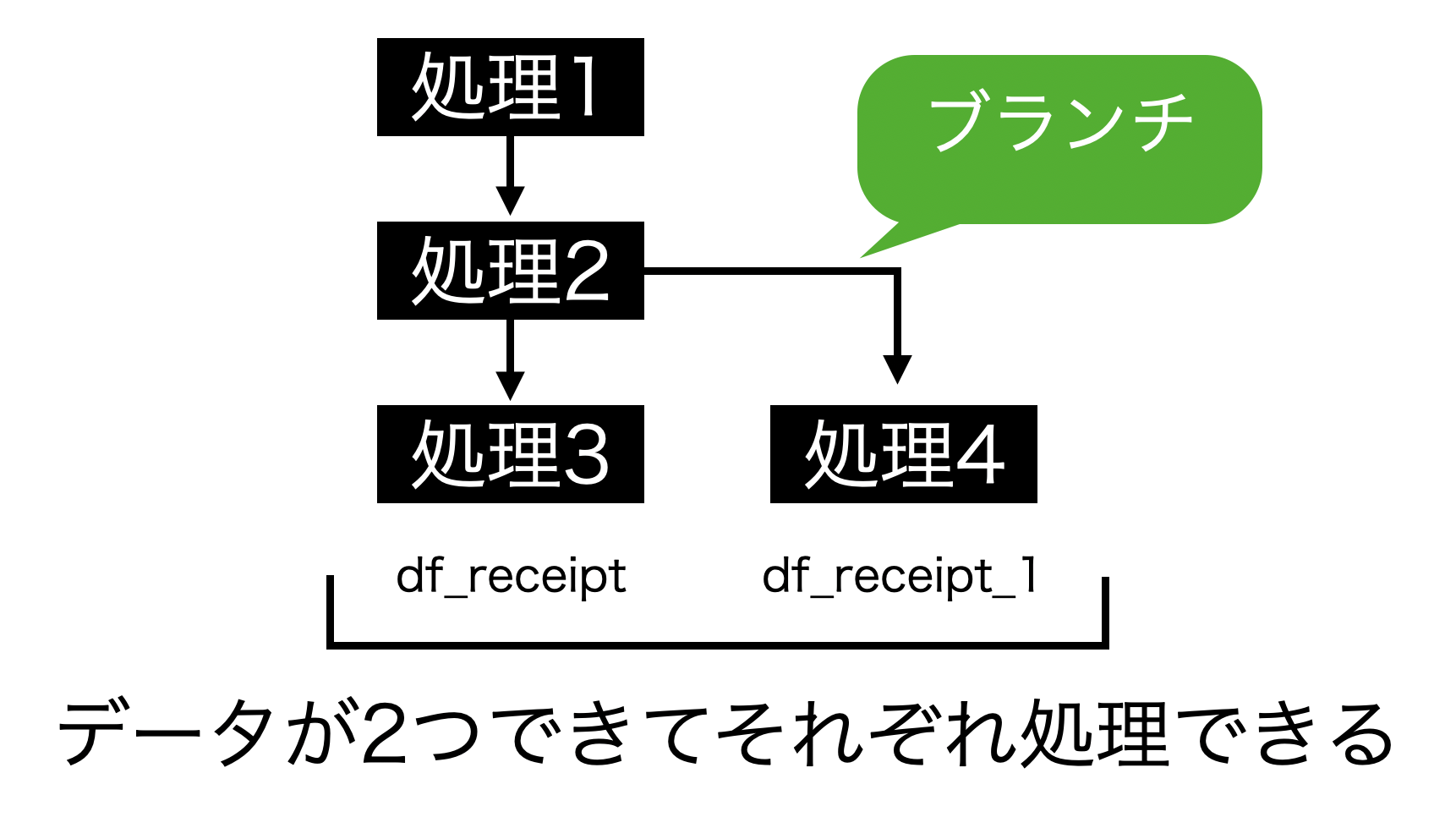
こんな感じのことを Exploratory でやってみましょう。
まずはブランチの作成です。ボタンを押しましょう。 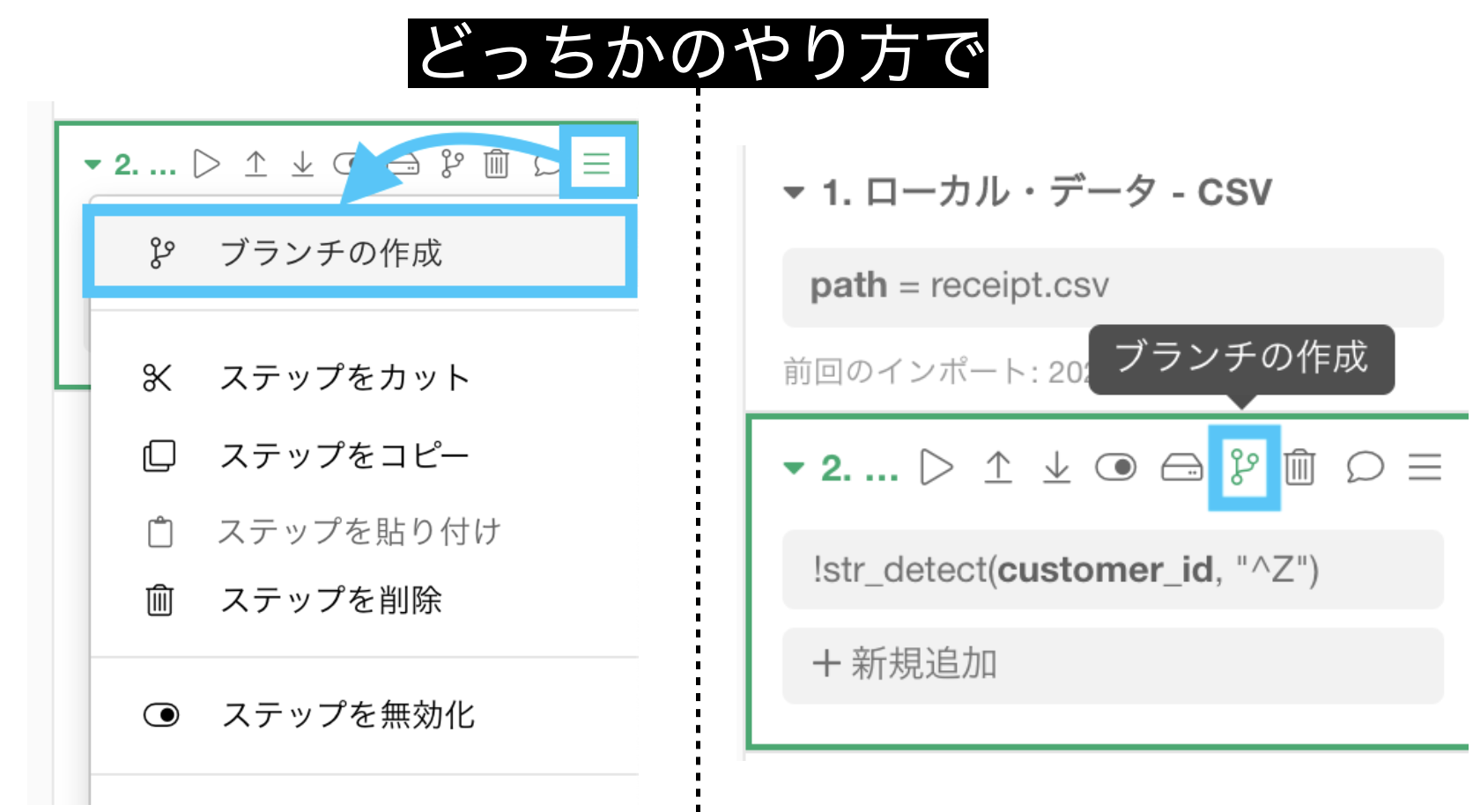
するとこのようにブランチの名前を決められますので、今回はそのまま作成しましょう。

これでブランチが作られました。何もしないとただのコピーですが、処理を元のデータと違うようにしたいという場合はオススメです。

ちなみに高度な処理・試験的な処理などをするときはブランチを使うととても便利だと思います。
さて、本題に入りましょう。
df_receipt(本体の方)に戻って df_receipt から売上金額の多い顧客を上位20件 取り出したデータを作りましょう。
まずは集計 (Summarize) 機能を使います。
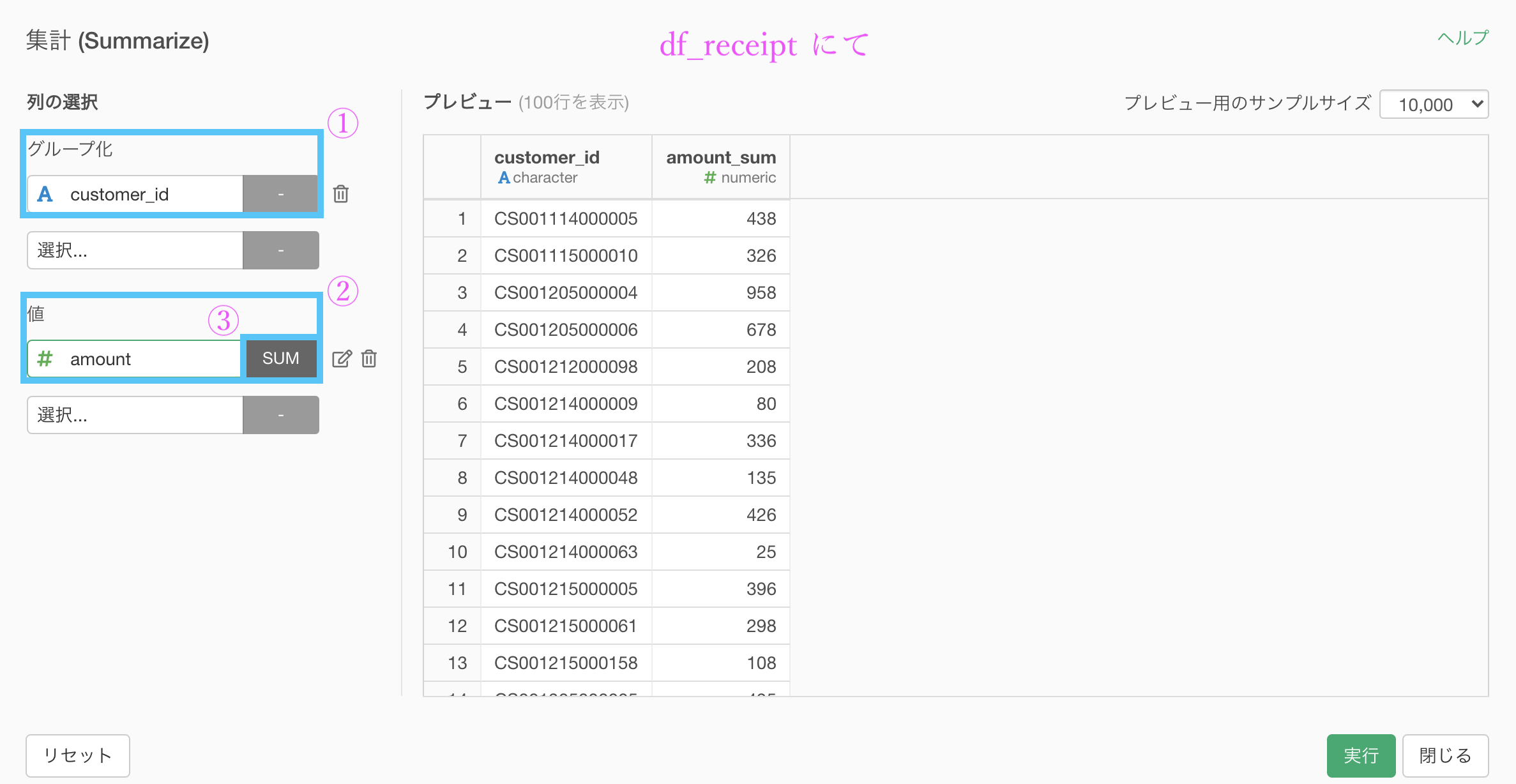
グループ化 : customer_id 値 : amount 計算 : 合計(sum)あとは、これだけ残す...→ 上位N を選択して
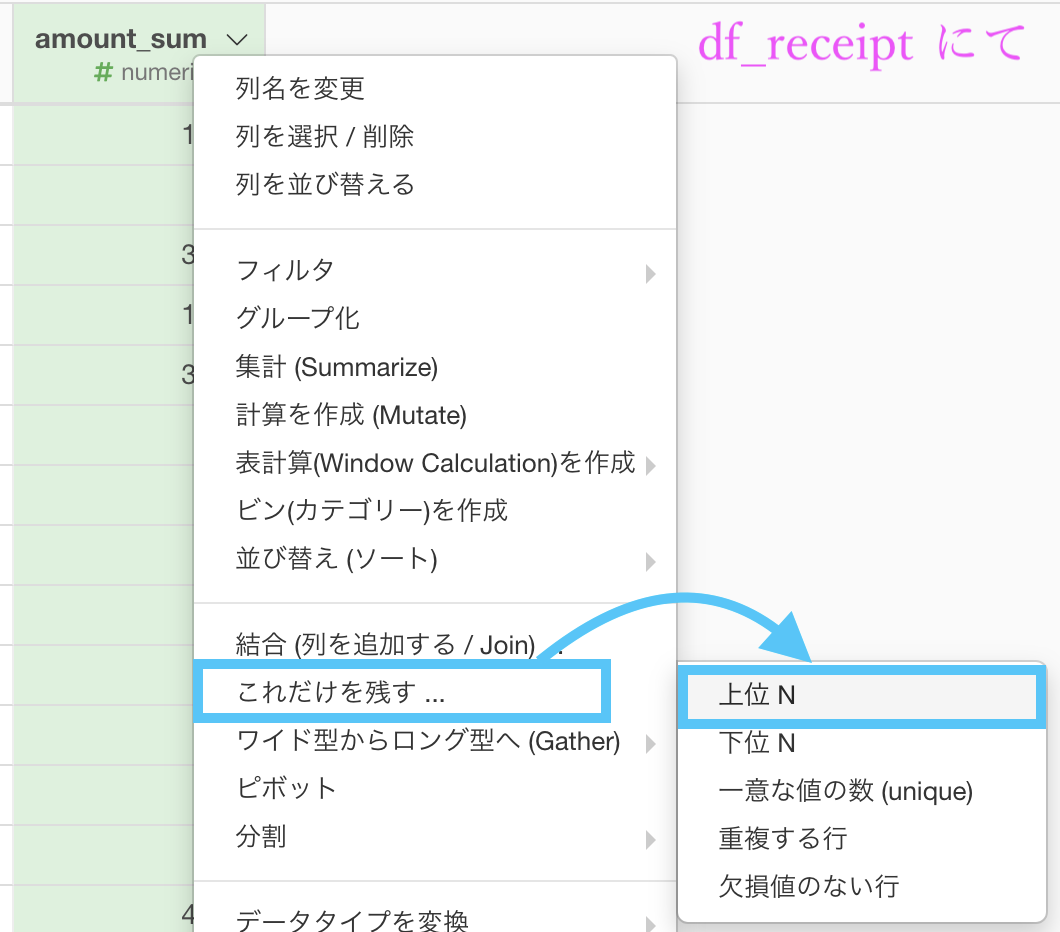
この画面で 20 を入力するだけです。
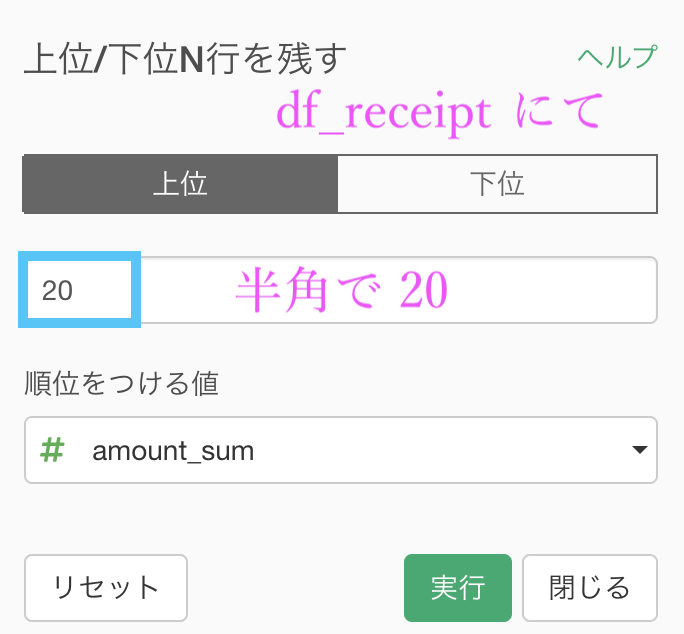
これで売上金額の多い顧客を上位20件で残すことができました。
さらにおまけでせっかくなのでソート(降順)もしましょう。
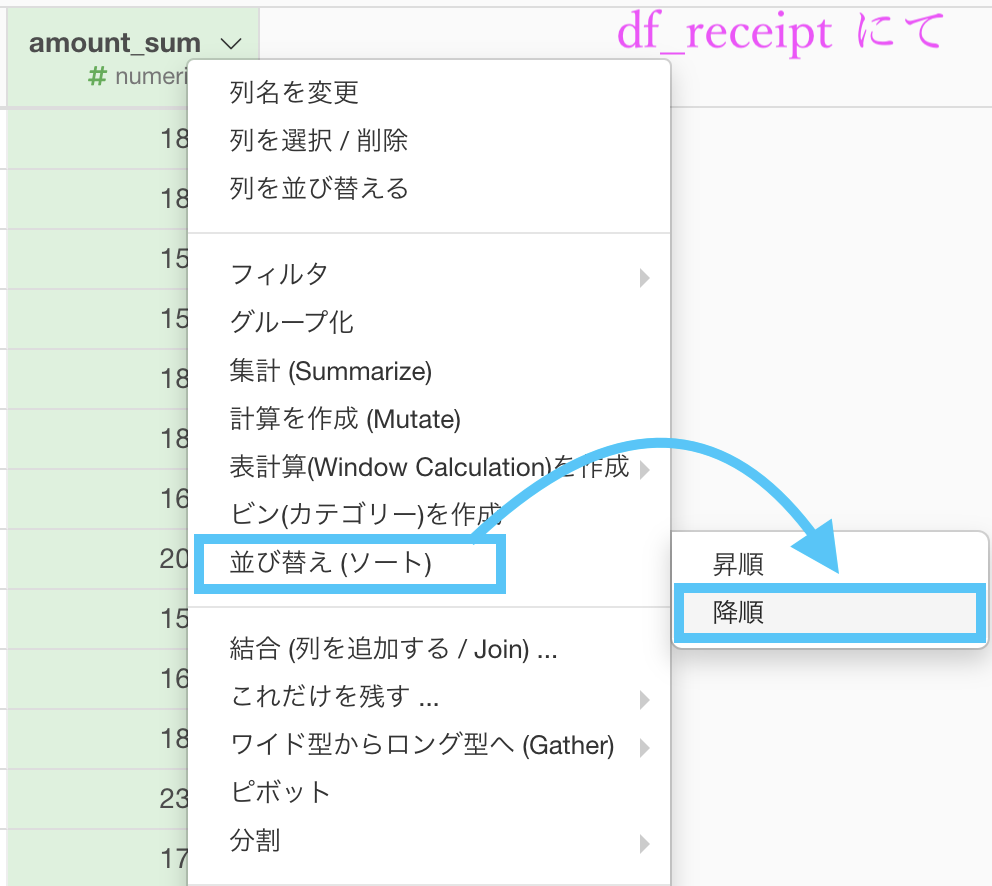
このまま実行します。
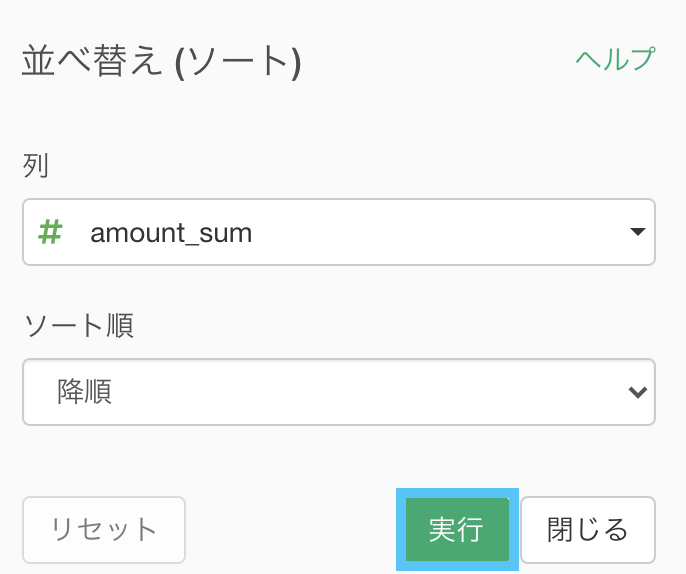
次に、df_receipt_1(ブランチの方)で df_receipt_1 から売上金額の多い顧客を上位20件 取り出したデータを作りましょう。
とは言っても、今さっきやったことと同じようなことをするだけです。
まずは集計 (Summarize) 機能を使います。
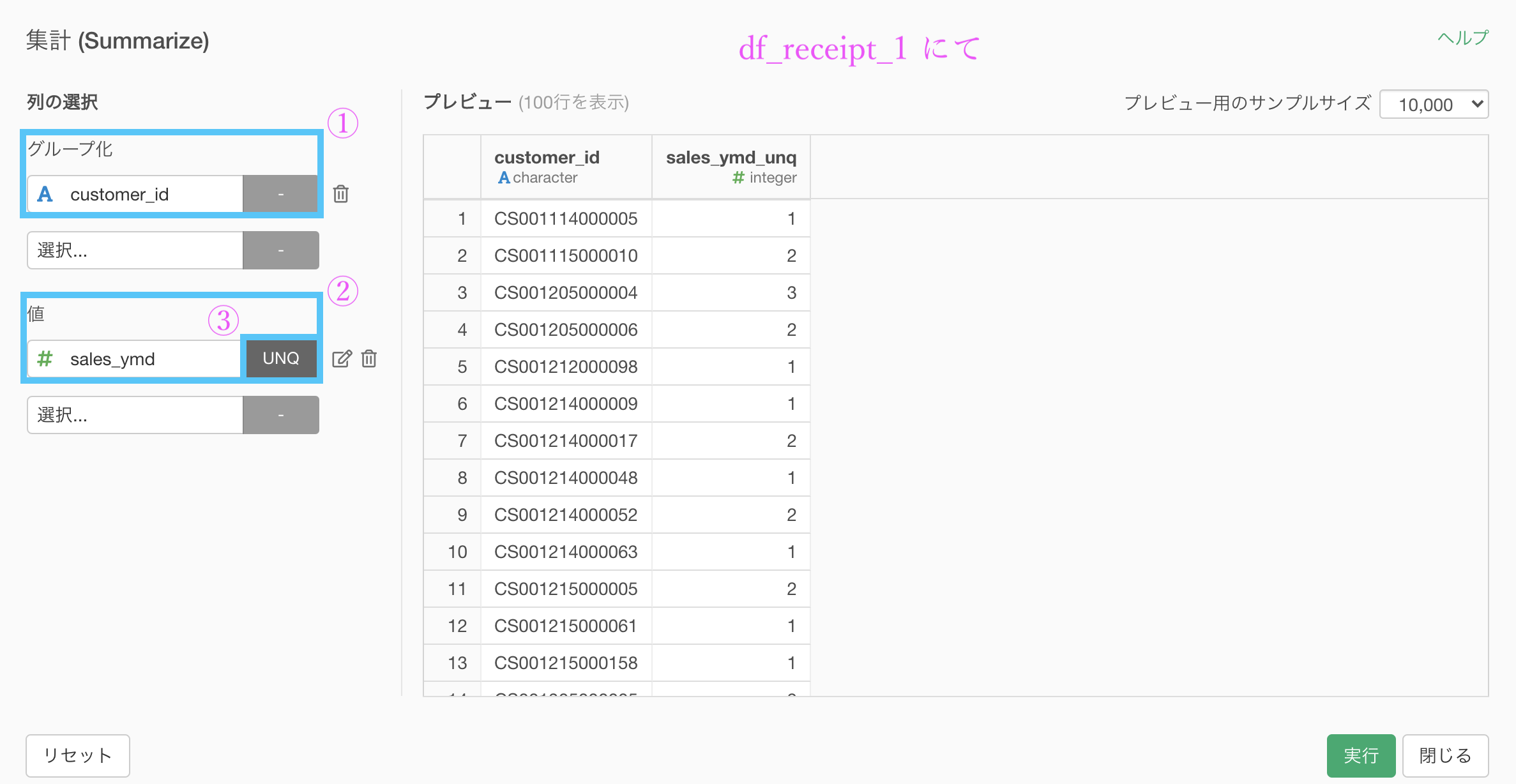
グループ化 : customer_id 値 : amount 計算 : 一意な値の数(unique)あとは、これだけ残す...→ 上位N を選択して、この画面で 20 を入力するだけです。
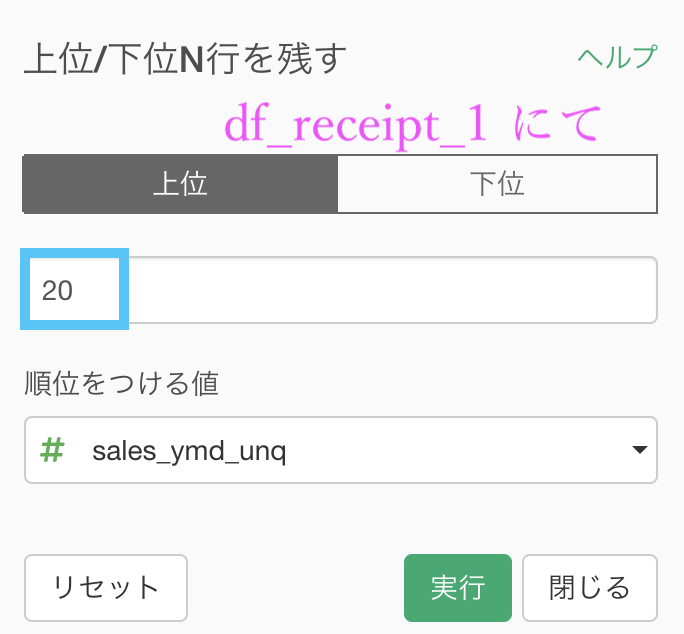
さらにおまけでせっかくなのでソート(降順)もしておくと良いでしょう。
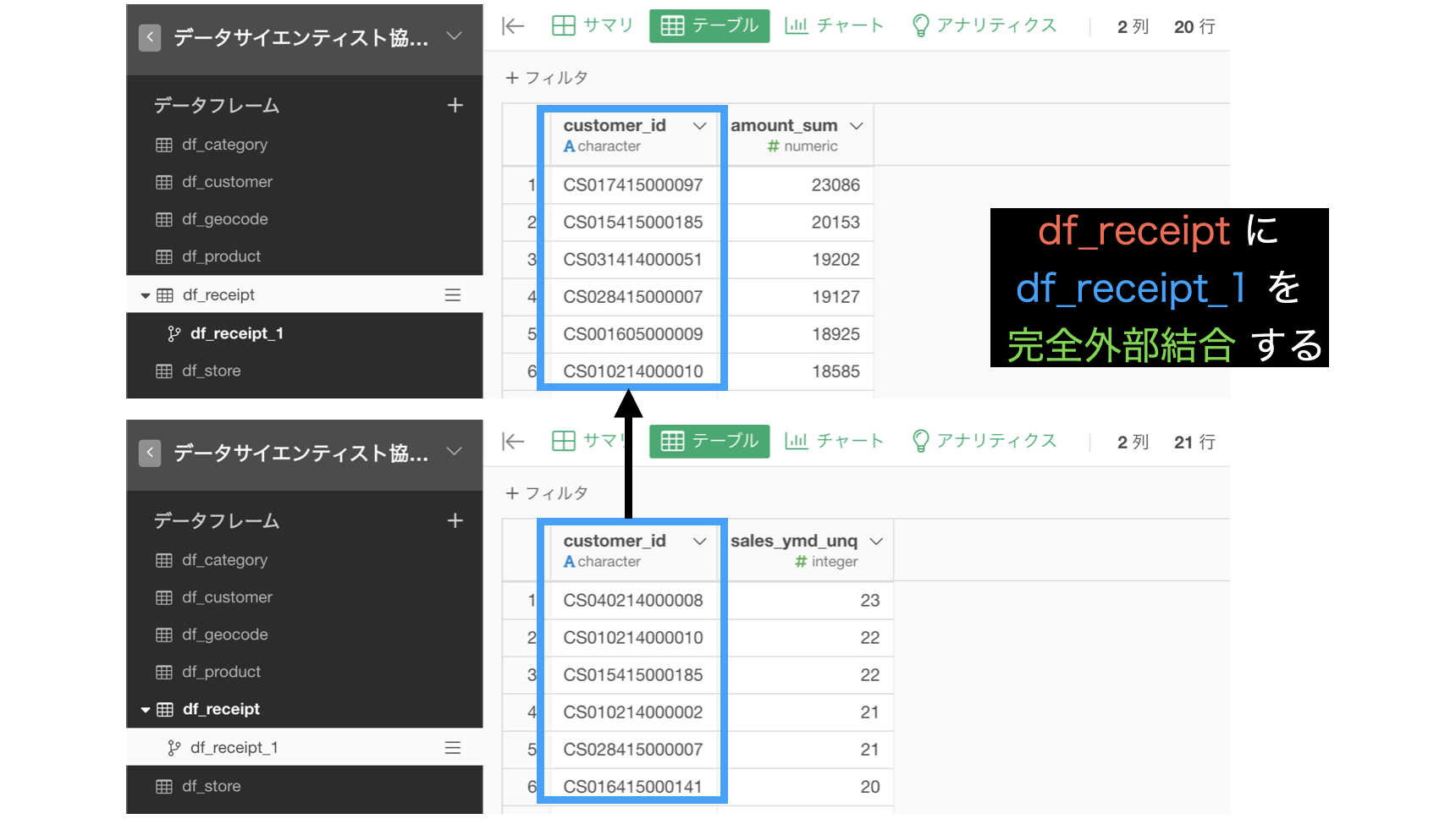
最終的に、df_receipt と df_receipt_1 の2つのデータが完成しました。
df_receipt に df_receipt_1 を 完全外部結合しましょう。
df_receipt の customer_id から結合するため、いつもの画面を開きます。 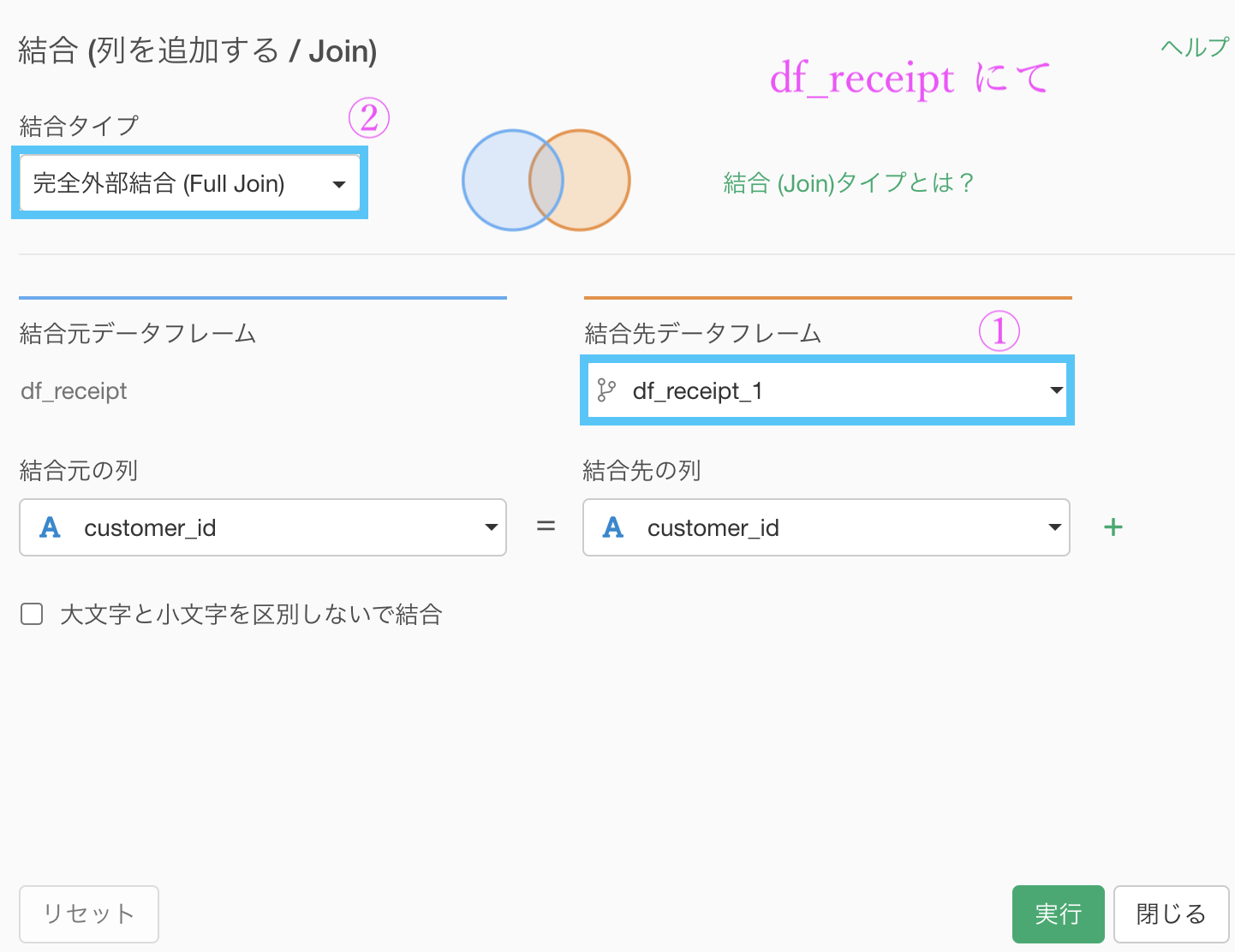
データ : df_receipt_1 を選択
列 : 自動で列名が同じものが選択されるので実質何もしない
結合 : 完全外部結合を選択結果はこのようになったと思います。解答を確認しましょう。
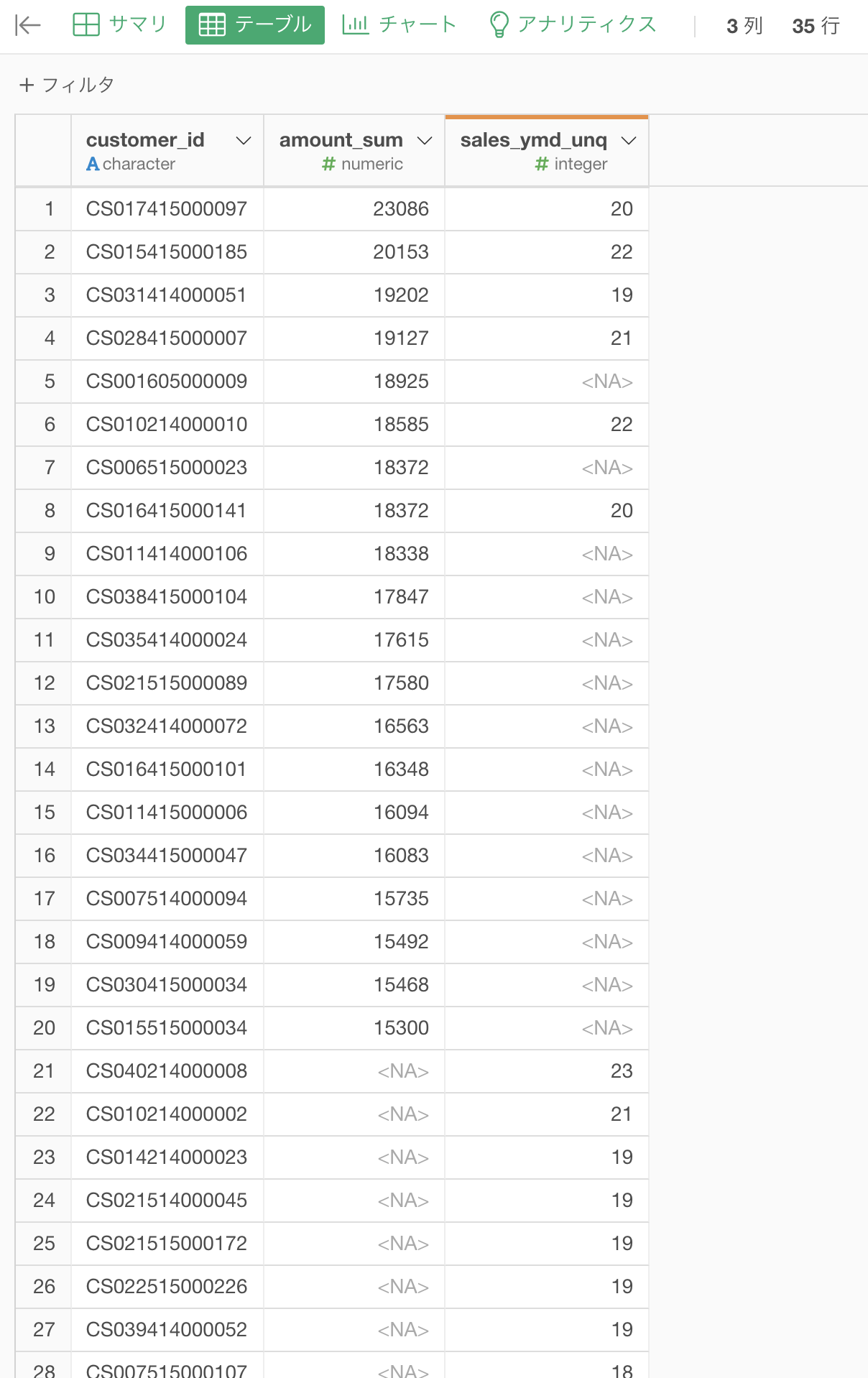
ちなみに結果の解釈の仕方はこのようになります。
amount_sum : 売上金額の合計
sales_ymd_unq : 売上日数(=来店回数のこと)
amount_sum で NA : この顧客は 売上金額 で 上位20位 じゃなかった
sales_ymd_unq で NA : この顧客は 売上日数 で 上位20位 じゃなかった表示されていない顧客は、両方とも上位20位じゃなかったということです。
Python 解答コードはこちら
解答コードはこのようになっています。
df_sum = df_receipt.groupby('customer_id').amount.sum().reset_index()
df_sum = df_sum.query('not customer_id.str.startswith("Z")', engine='python')
df_sum = df_sum.sort_values('amount', ascending=False).head(20)
df_cnt = df_receipt[~df_receipt.duplicated(subset=['customer_id', 'sales_ymd'])]
df_cnt = df_cnt.query('not customer_id.str.startswith("Z")', engine='python')
df_cnt = df_cnt.groupby('customer_id').sales_ymd.count().reset_index()
df_cnt = df_cnt.sort_values('sales_ymd', ascending=False).head(20)
pd.merge(df_sum, df_cnt, how='outer', on='customer_id')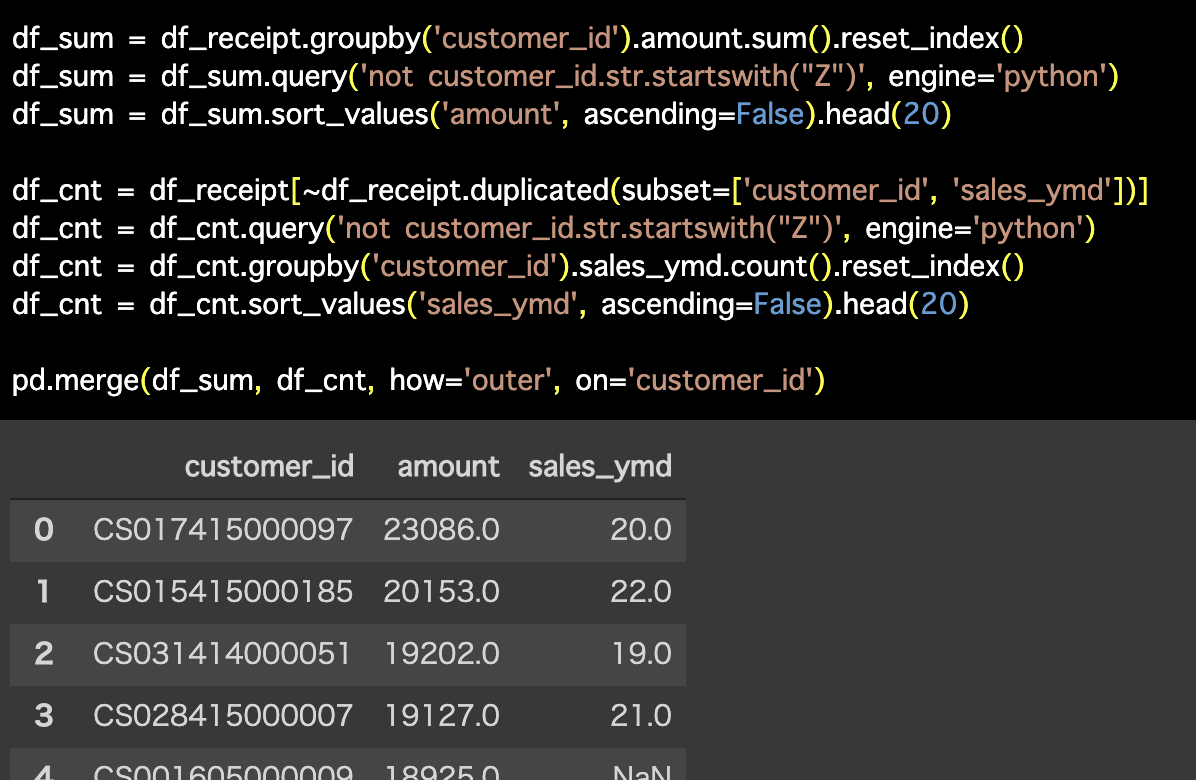
流石にこのコードで目を逸らしたくなった人が居たかもしれません(汗)
そろそろ結合って何者なんだろう?結局どんな動きをしているんだろう?となってくる頃合いだと思いますので、ここでまとめて紹介したいと思います。
結合オールスターズ
結合には6つの種類があることは、Exploratory のメニューからわかります。
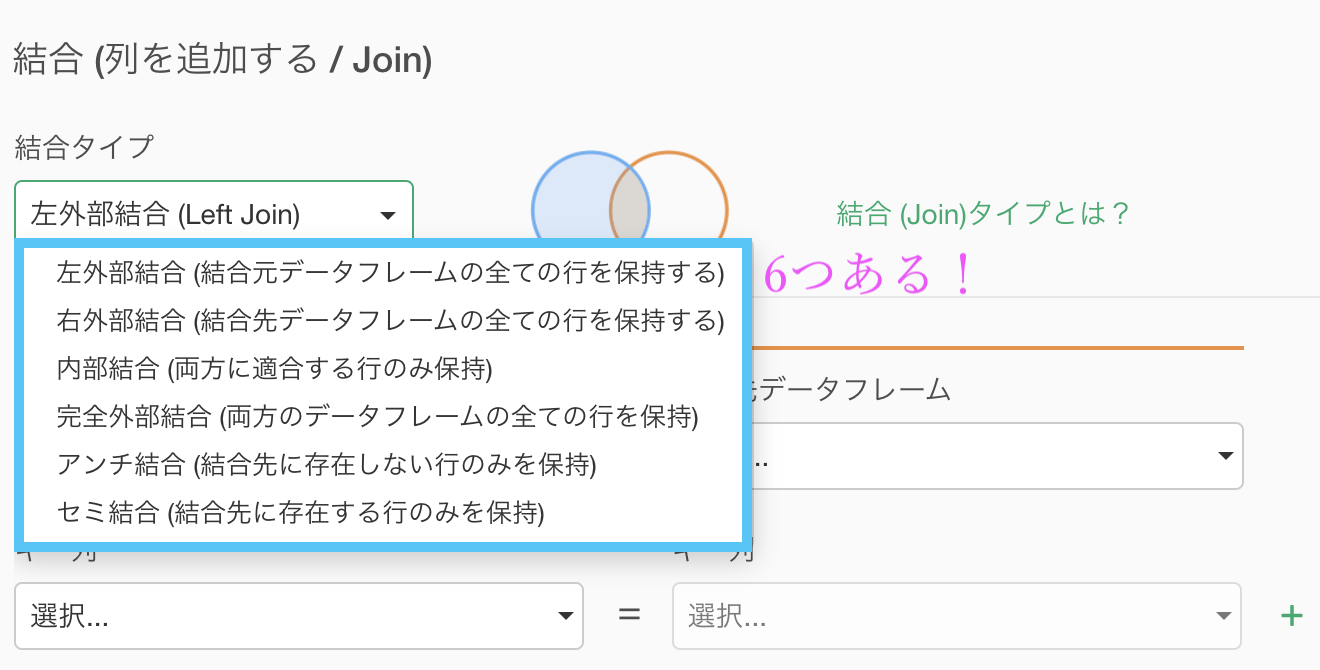
残りの2つは、4つのうちのどれかを使って説明できるからです。
このことも踏まえながら説明します。
0 : 結合の取扱説明書
まずはじめに...という具合に書きました。
まず 結合元 と 結合先 の2つのデータを区別 するところからです。 1〜6の結合まで、同じように考えていることはこのようなことです。
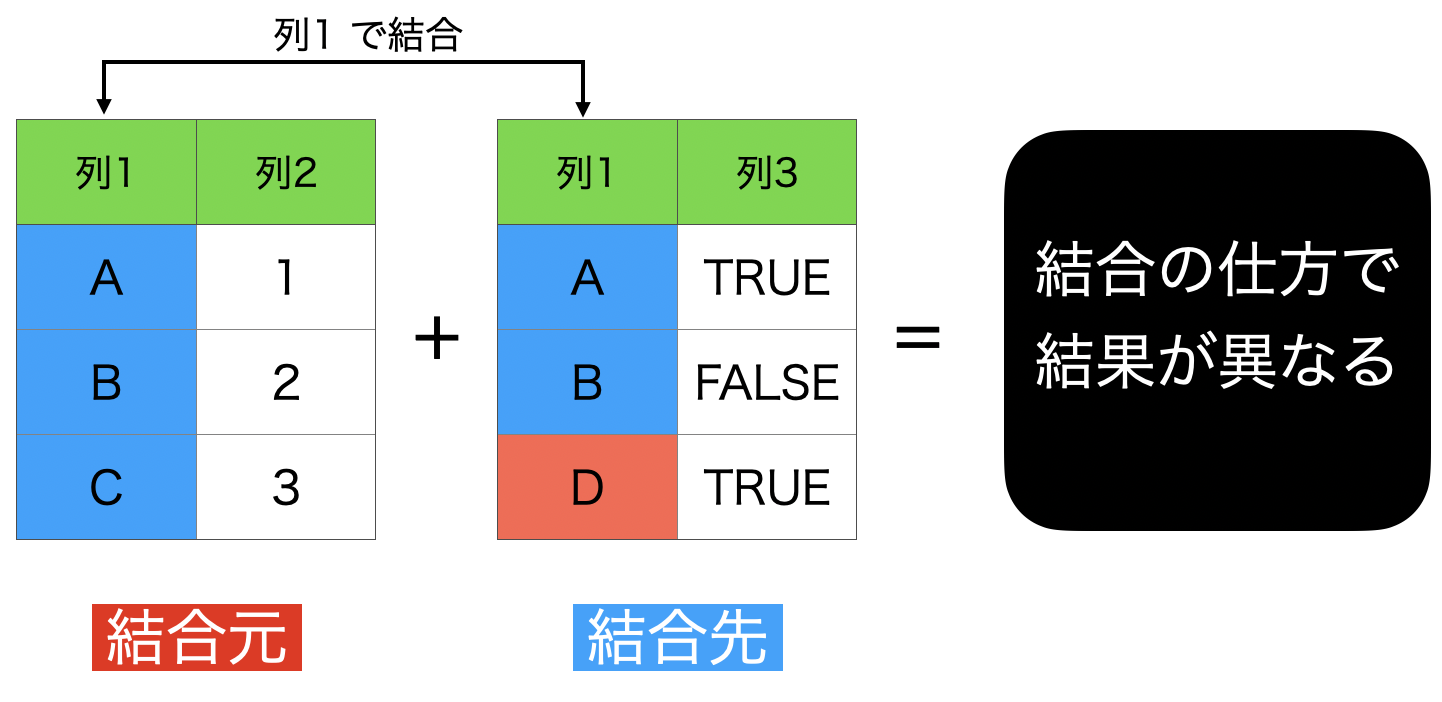
結合先のデータ はいま Exploratory で開いているデータで、結合先のデータ はいつも結合するときの画面から選んでいたものです。
いま、列1 同士で結合しようと考えています。
これから6つの結合の仕方を紹介しますが、全て結果が異なります。
1 : 左外部結合 (結合元データフレームの全ての行を保持)
左外部結合をするとどうなるかを見たものです。
そのイメージはこのようなものです。
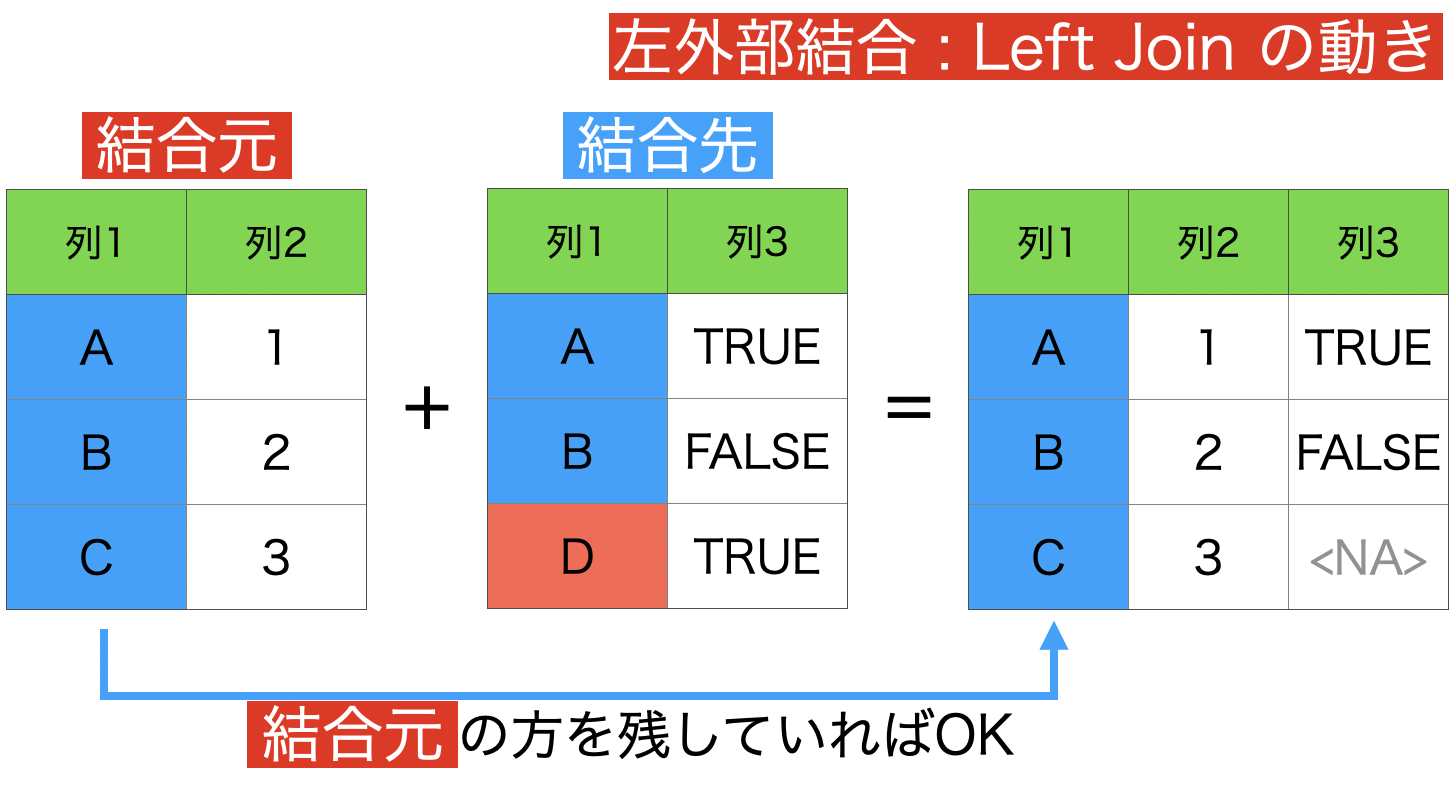
これに関しては、結合先のデータ が優先的に残され、結果のところに残ります。
ここで注意してもらいたいのは、欠損値(NA)の意味です。
結合元 の C に 列3 (TRUE か FALSE) の情報はもともとないから NAとなっているだけです。C は TRUE か FALSE のどっち?と言われても、答えることはできないから NA なのです。
2 : 右外部結合 (結合先データフレームの全ての行を保持)
これは左外部結合を使って説明できるので本質的ではありません。
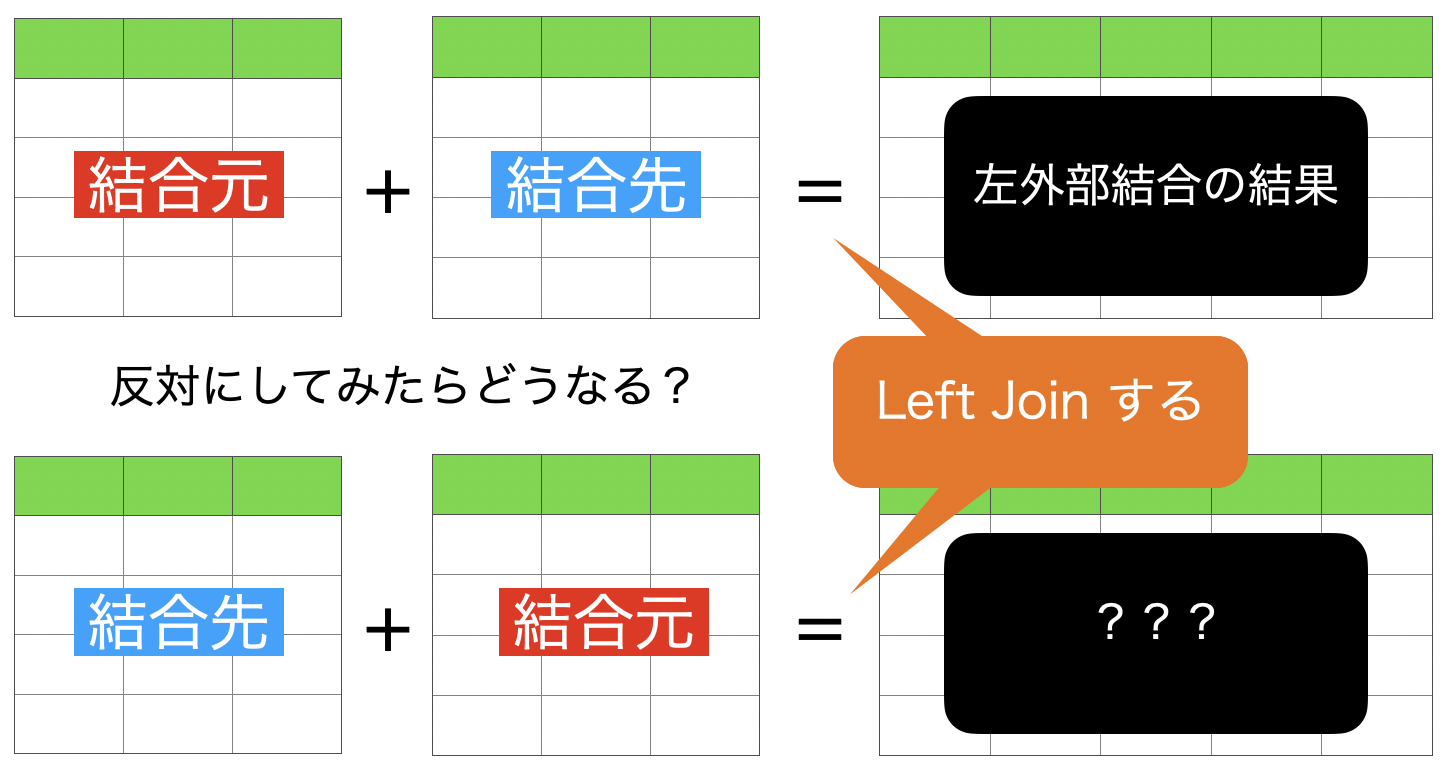
この「???」にあるものが 右外部結合の結果 ということになります。 つまり、左外部結合からひっくり返すだけで、右外部結合になります。
一応動きを見ておきますが、左外部結合の動きがわかっていれば使う場面は少ないとおもいます。 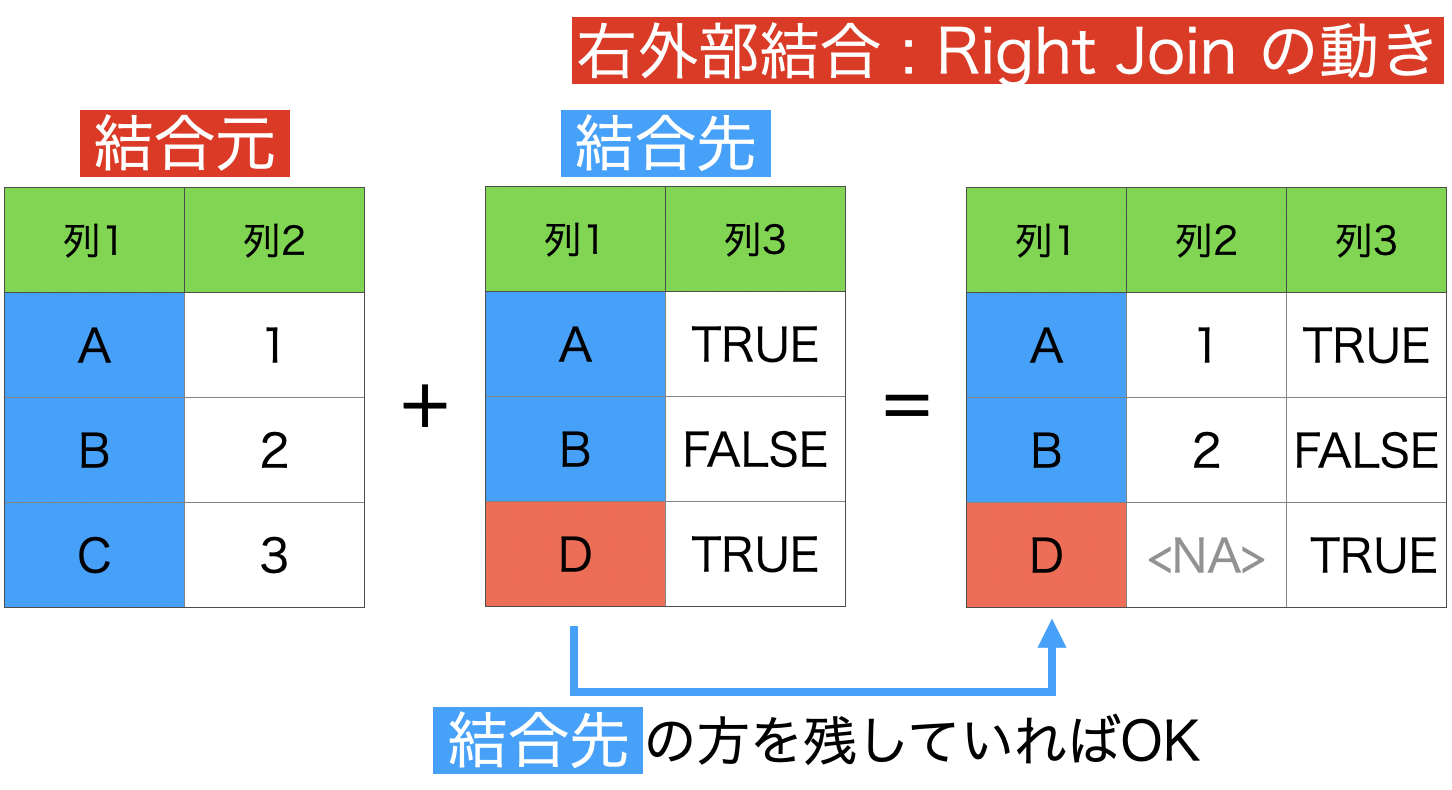
欠損値の意味は左外部結合のときと同様です。
3 : 内部結合 (両方に適合する行のみを保持)
今回この100本ノックでは、一番よく使うかもしれない結合の仕方です。
イメージはこのようなものです。 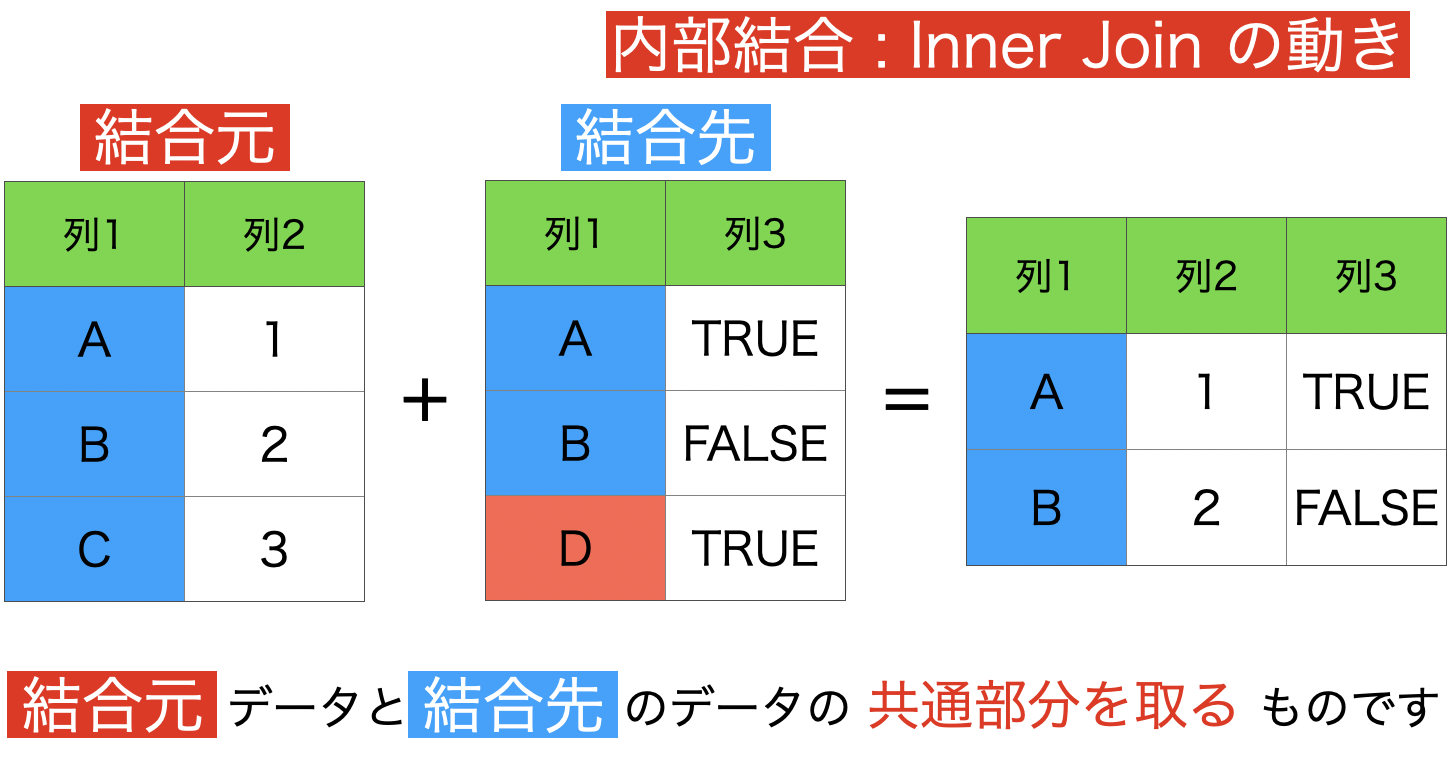
左(右)外部結合では、結合元の 列1 と結合先の 列1 をつなげる際に、NA がある時がありました。
内部結合では、その NA となるものが排除され、NA とならないものだけをとってきます。
SQL 的な視点(あるいは数学の立場)から言うと、共通部分をとっているイメージ を持つのが良いと思います。
まぁ行数が増える時もあるので、微妙に違うといえば違うのですが...。
その微妙な違いは是非とも体験して欲しいので、ぜひ今回の100本ノックで、内部結合をわざと左外部結合にしたらどうなるのか?あるいはその逆をした場合にどのような挙動を示すのか?をやってみると良いと思います。
4 : 完全外部結合 (両方のデータフレームの全ての行を保持)
完全外部結合は、左外部結合と右外部結合を掛け合わせたような 考え方です。
イメージはこのように、とにかく全部が残ります。
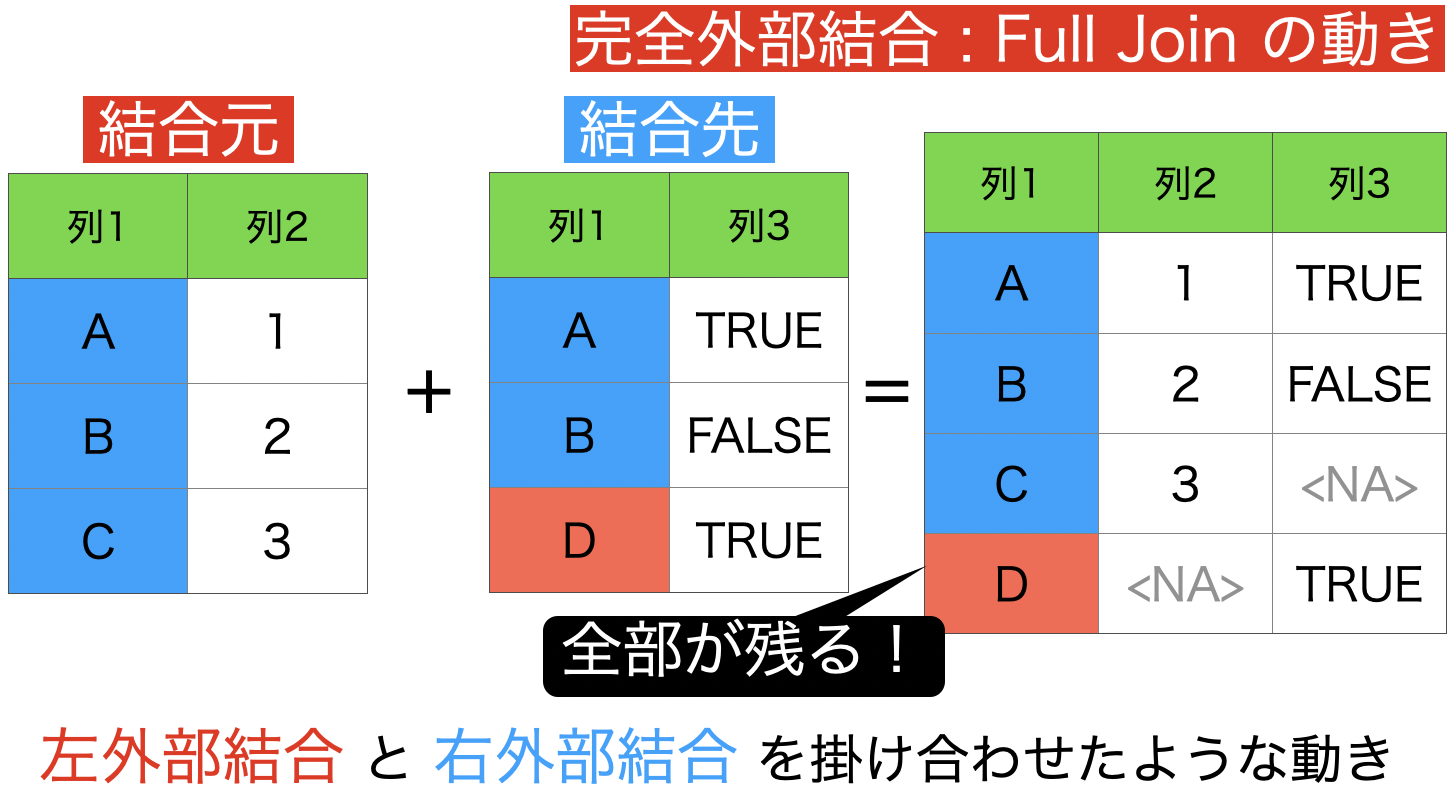
NA がたくさん出ることを覚悟でやるには相当の肝が座っていないとできませんが、使いこなせる人は差がつくと思います。
その代わり、この結合が6つの中で最もデータのサイズが大きくなるので、いきなり大きなデータで完全外部結合しようするのは、本当にやめた方が良いと思います。
5 : アンチ結合 (結合先に存在しない行のみを保持)
アンチ結合のイメージはこのようなものです。
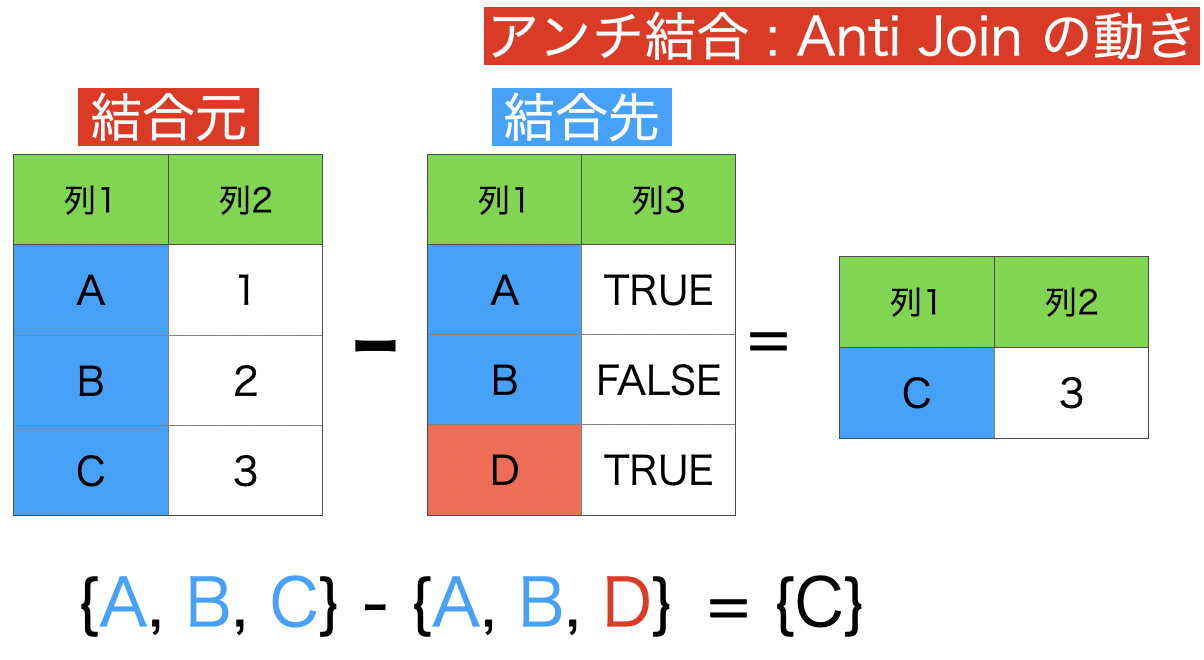
差集合 という言葉を聞いたことがある人は、このアンチ結合がまさに差集合の操作です。
差集合とは簡単で、次のようにベン図を描けばわかりやすいと思います。
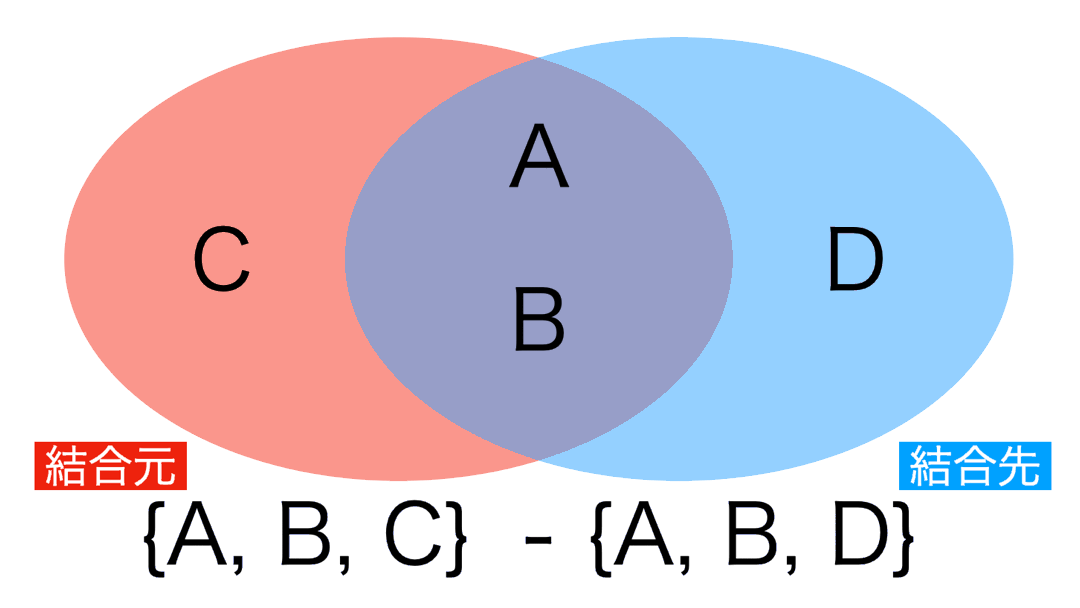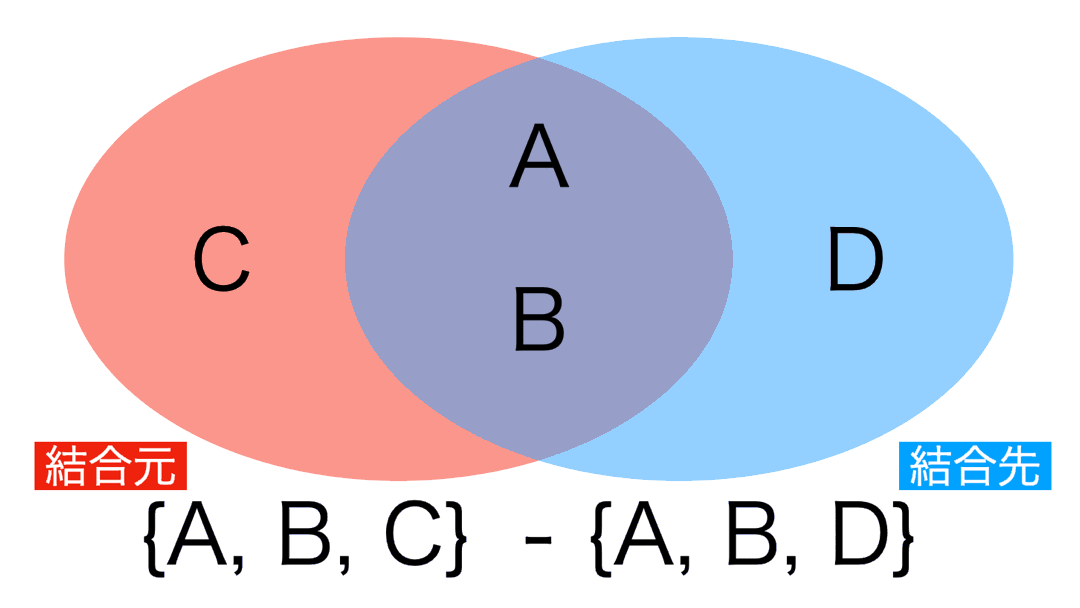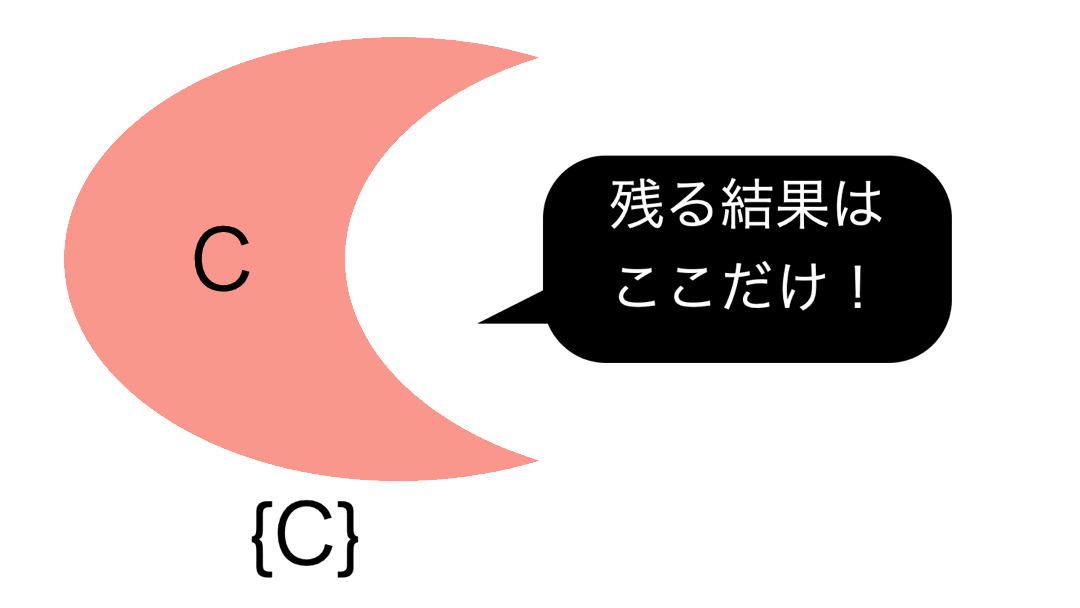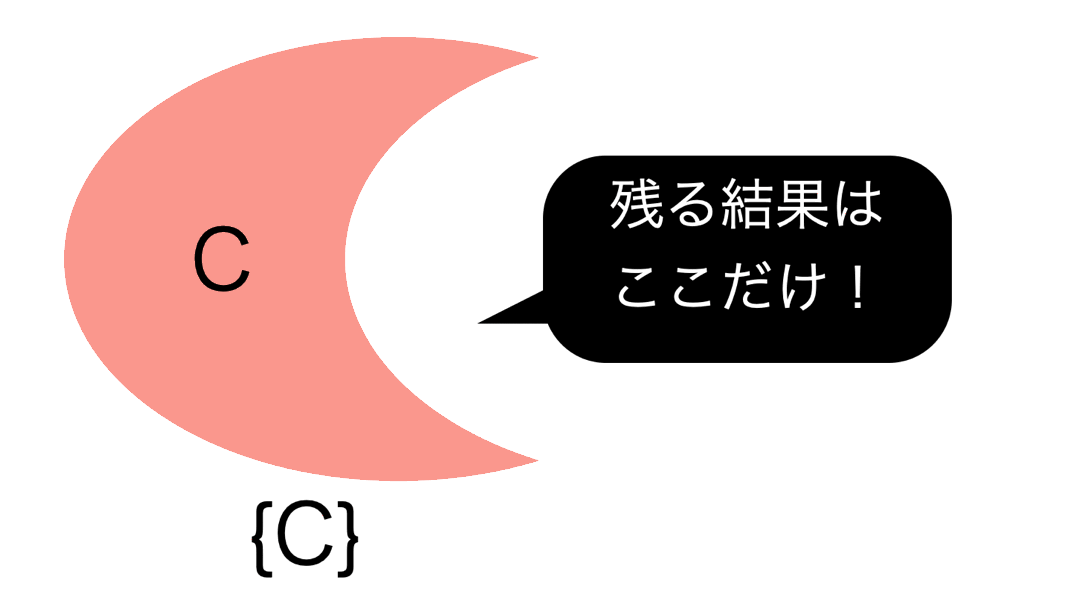
結合先に存在しない行とは、言い換えれば結合元だけにしかない行 を意味します。
なので、左側が残るというわけだったのです。
今までの結合とは異なり、列が増えない(ケースが多い)のが特徴 です。
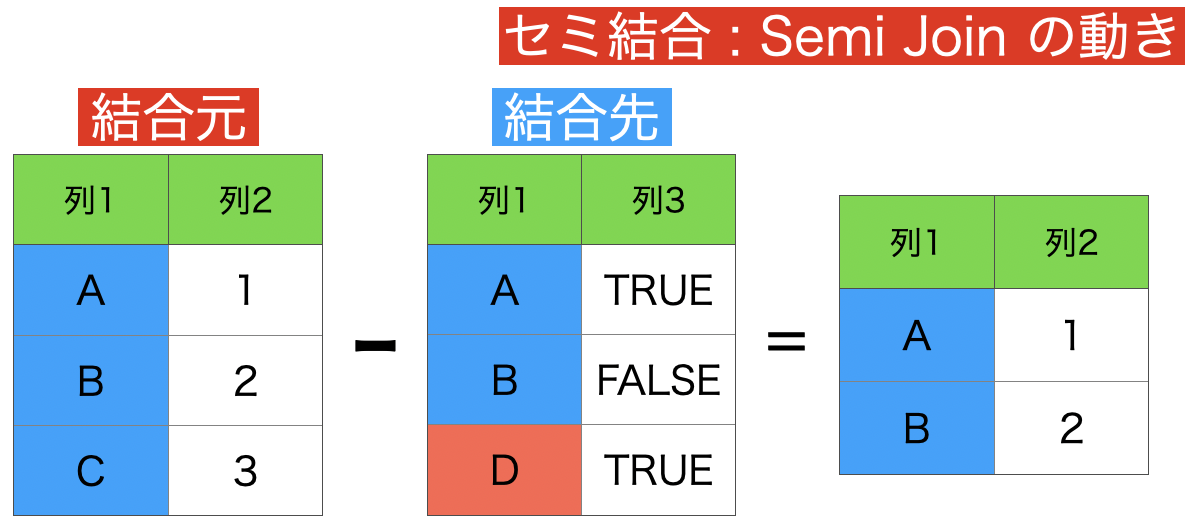
6 : セミ結合 (結合先に存在する行のみを保持)
これはアンチ結合を使って説明できるので本質的ではありません。
アンチのアンチがセミ結合 の結果です。今いったことを、きちんとイメージとして確認しておきましょう。
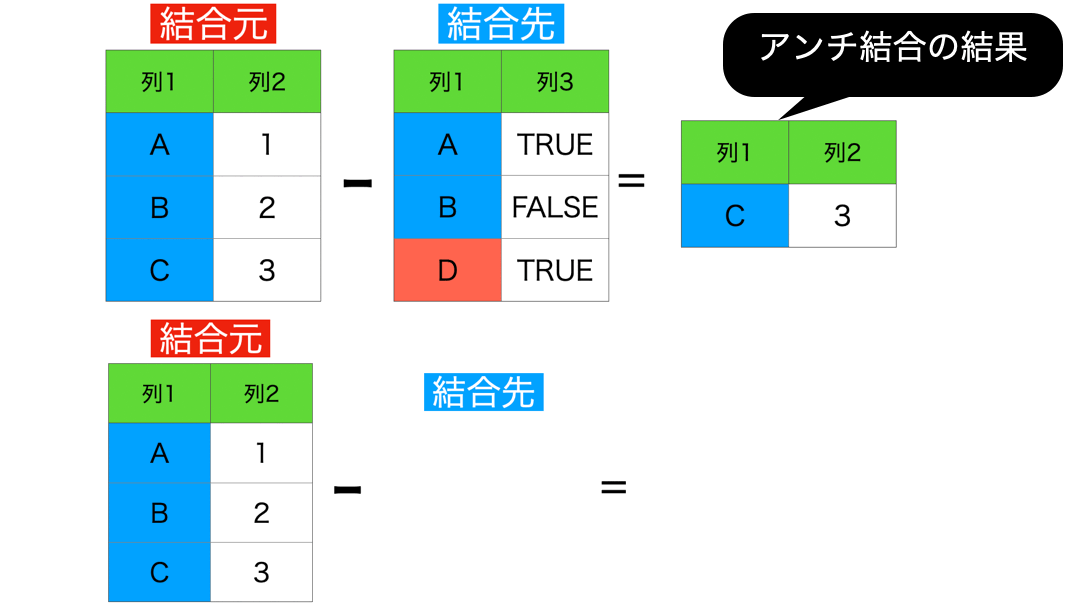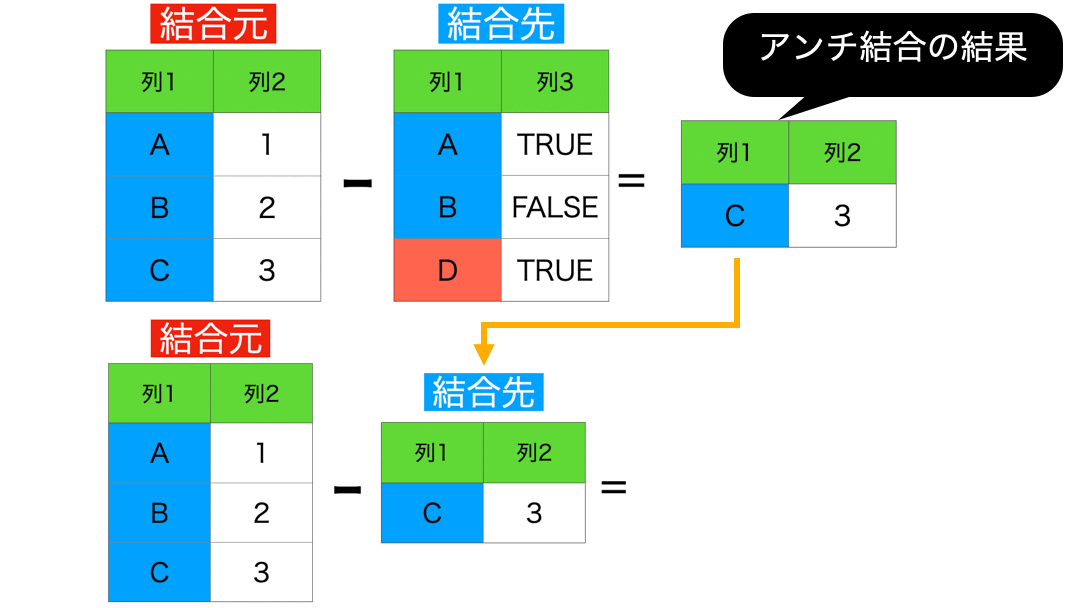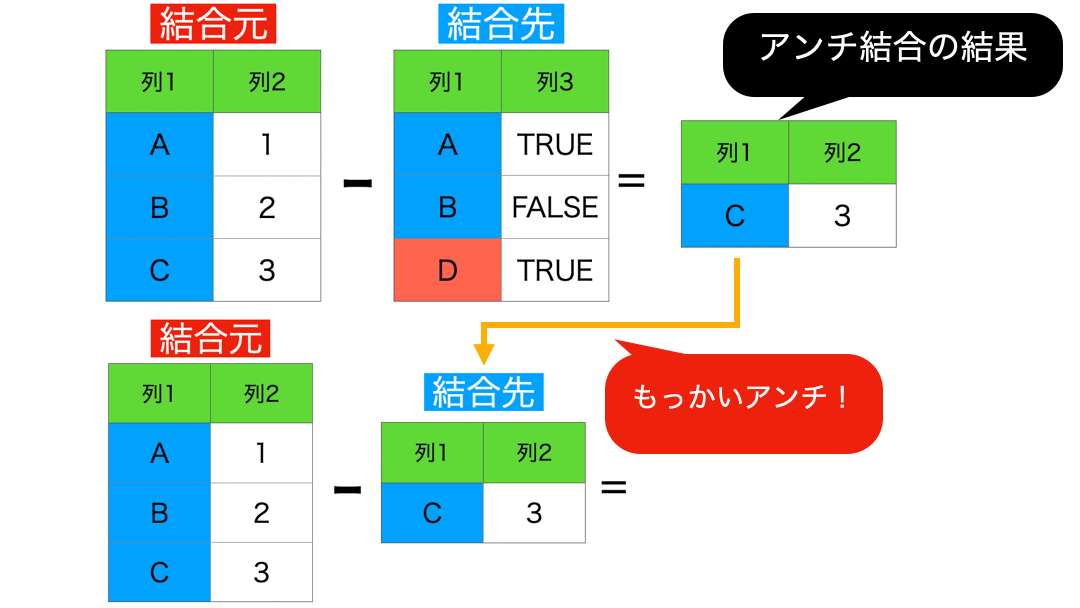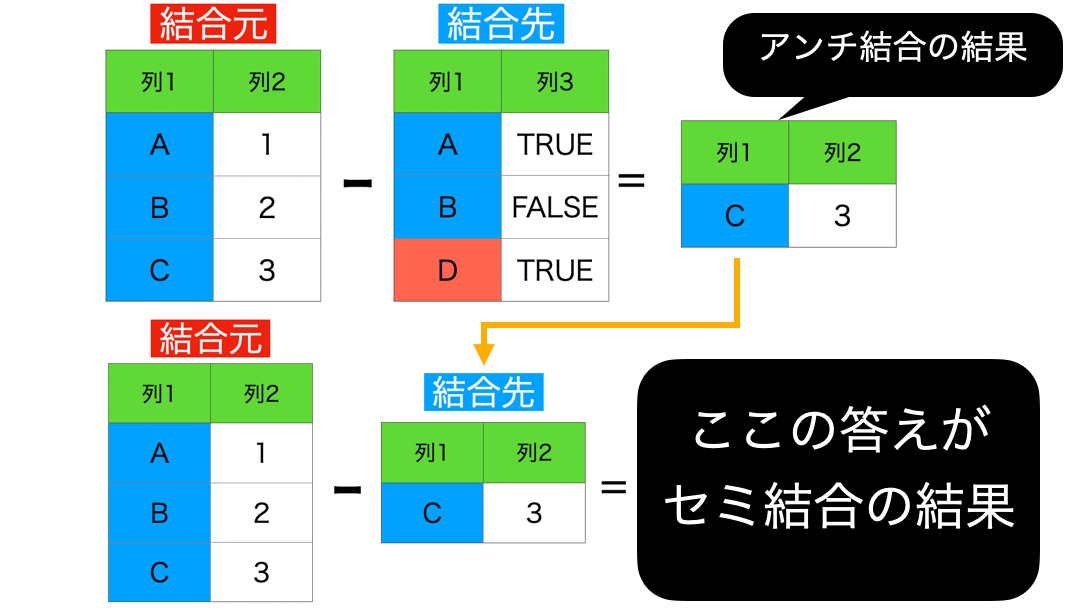
ちなみに答えはこのようになります。
内部結合と答えが似ているように思えますが、よく見ると違います。
取扱説明書のところで言ったように、結合の結果は全て異なります。
アンチ結合の結果とセミ結合の結果を足す(マージする)と結合元のデータに戻ります。
問40 : クロス結合ですべてのレコードの組合せを作成する

答案・解説はこちら
クロス結合とは名ばかりで、この問題では単に完全外部結合するだけです。
完全外部結合は下手に触ると行数が多くなって処理落ちするかもしれないので、今回の問題で知りたいことのみに焦点を当てたデータにしてから、完全外部結合(Full Join)します。
まずやりたいことを確認します。→ 完全外部結合をして、その行数を見れば答えになる
とにかくまずは、df_product にて計算を作成 (Mutate) しましょう。
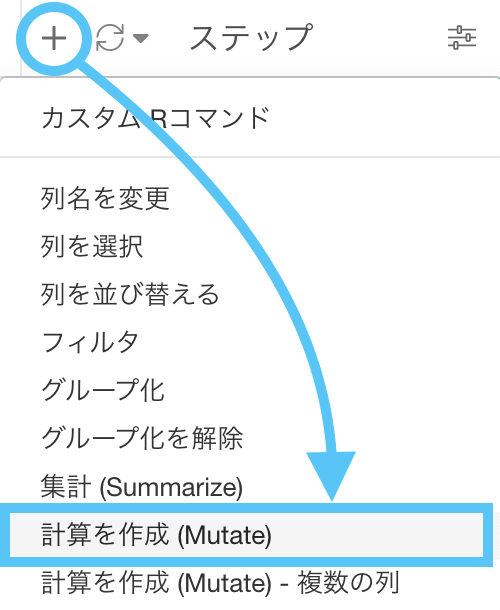
計算エディタのなかは「0」とだけ入れましょう。
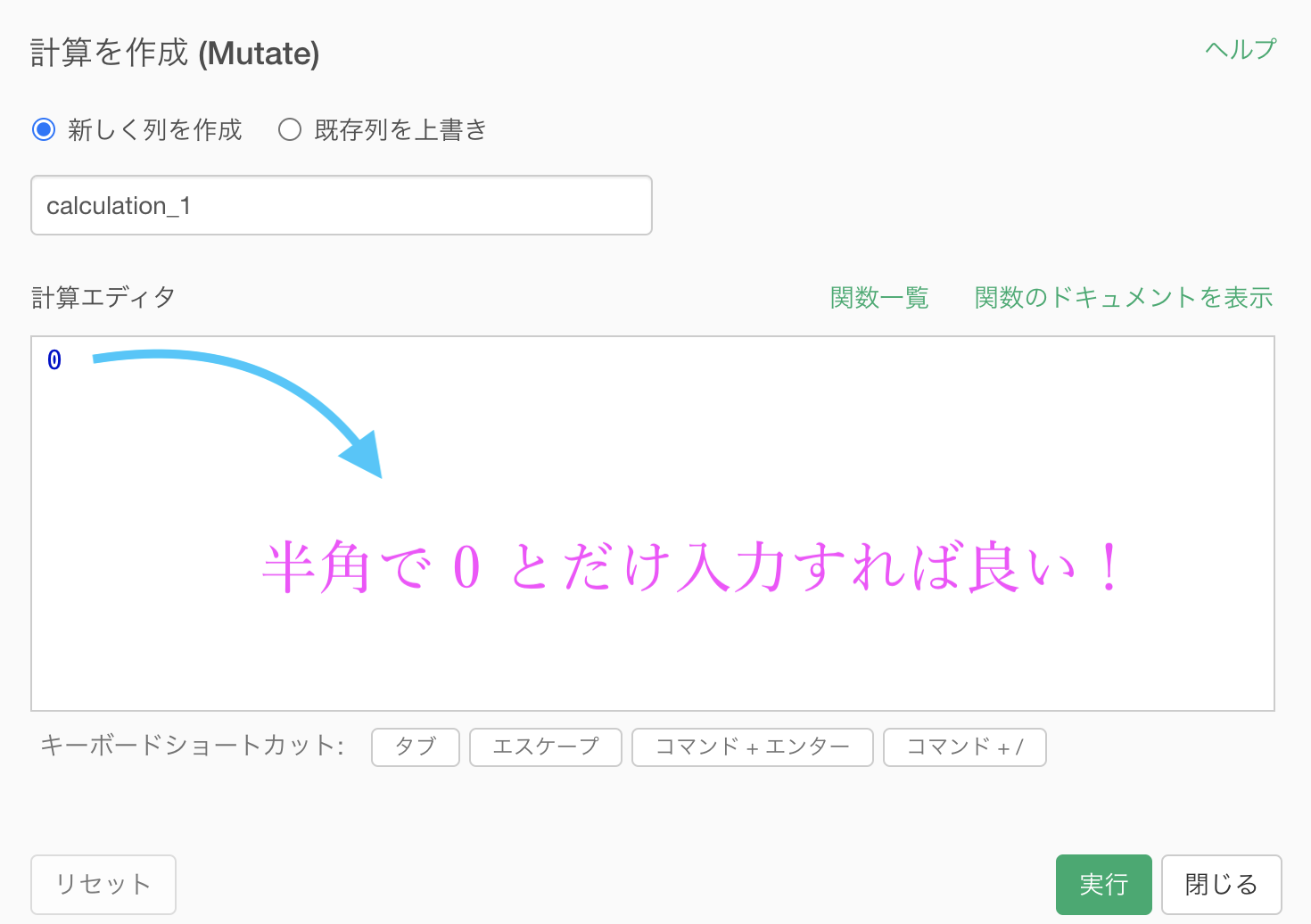
あとは列を選択するだけ( 0 の列だけにする)です。
この流れを df_store でも全く同じようにやります。
ここまででデータを作る作業は終わりで、あとは完全外部結合するだけです。
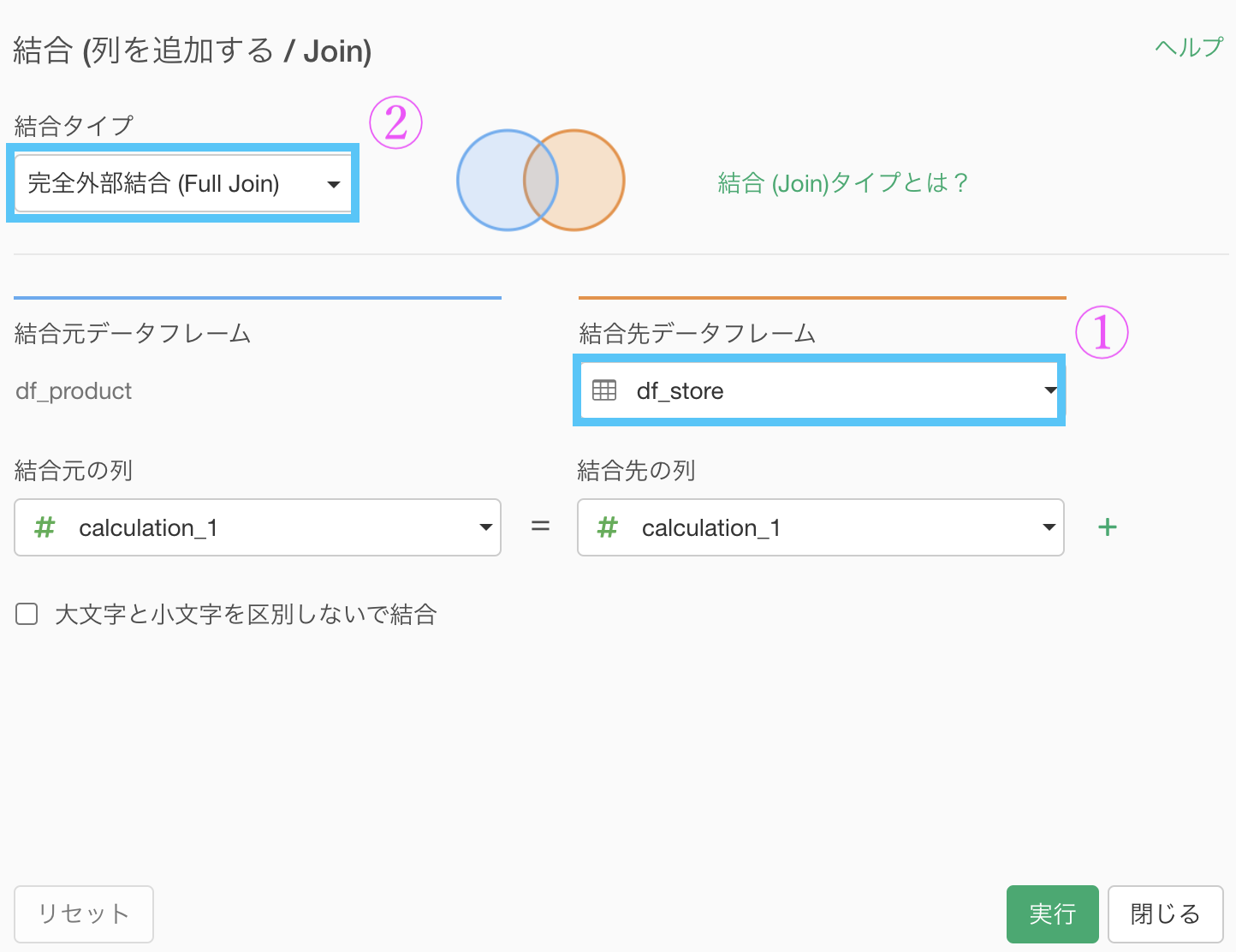
結果はこのようになります。解答と確認しましょう。

ちなみにこの行数(531590行)は、(df_productの行数) × (df_storeの行数) のことです。
問題は手計算でも解くことができます。
Python 解答コードはこちら
解答コードはこのようになっています。
df_store_tmp = df_store.copy()
df_product_tmp = df_product.copy()
df_store_tmp['key'] = 0
df_product_tmp['key'] = 0
len(pd.merge(df_store_tmp, df_product_tmp, how='outer', on='key'))
個人的には、データの件数だけではなくて、完全外部結合した(直積した)データの中身までみる必要があると思っています。
データに目を通すことによって、何をやっていたのかイメージが付きやすいと思うからです。
幸いにも、今回のような小さなデータに対しては完全外部結合をしても処理落ちせずに表示できます。
試す価値とデータを見る価値は十分にあると思います(実質、列を選択するステップを無くすだけですので)。
ここまでで一旦ブレイク挟むと良いかもしれません
知識の整理は大切です