データサイエンティスト協会 構造化データ前処理 100 本ノック with Exploratory
問41〜問50 の答案
答案全体を通して
Exploratory では R 言語が動いていますが, 解答やコード参照の説明では Python言語 のものでやります。
SQL的な視点や考え方が入るときもその都度書きたいと思います。枠の色使いは以下のような形を意識しています。
オレンジ枠 :
あか枠 :
あお枠 :
みどり枠 :
問41 : n件前のデータを結合する

答案・解説はこちら
しかし、やらなくてはならないことはいくつかあるはず です。
思いつくものを列挙するところから始めて、それらを結びつけるという流れで思考 しても良いと思います。こんな感じに。
- 「sales_ymd ごとに集計...」だから、集計(Summarize)機能を使う
- 「前日からの売上...」と言っているので、期間をズラす必要がある
- 「増減を計算...」なので、差を取るんだな
思いつく順番は人それぞれだと思います。それらを整理してつなげた結果が以下の答案です。
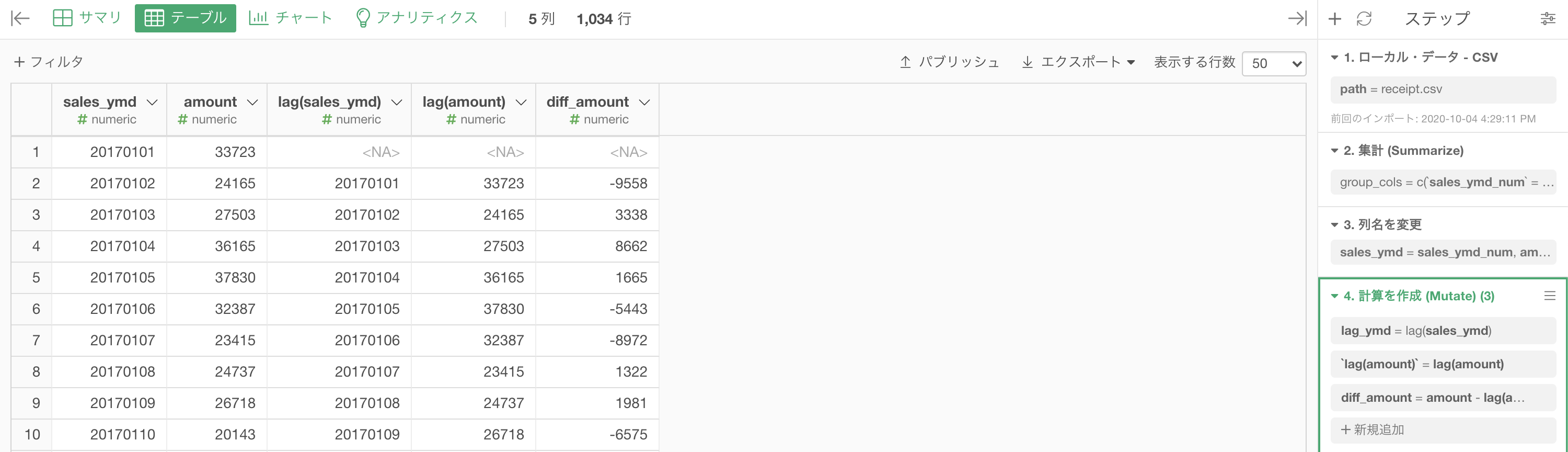
まずは df_receipt を集計 (Summarize) 機能で以下のように集計します。
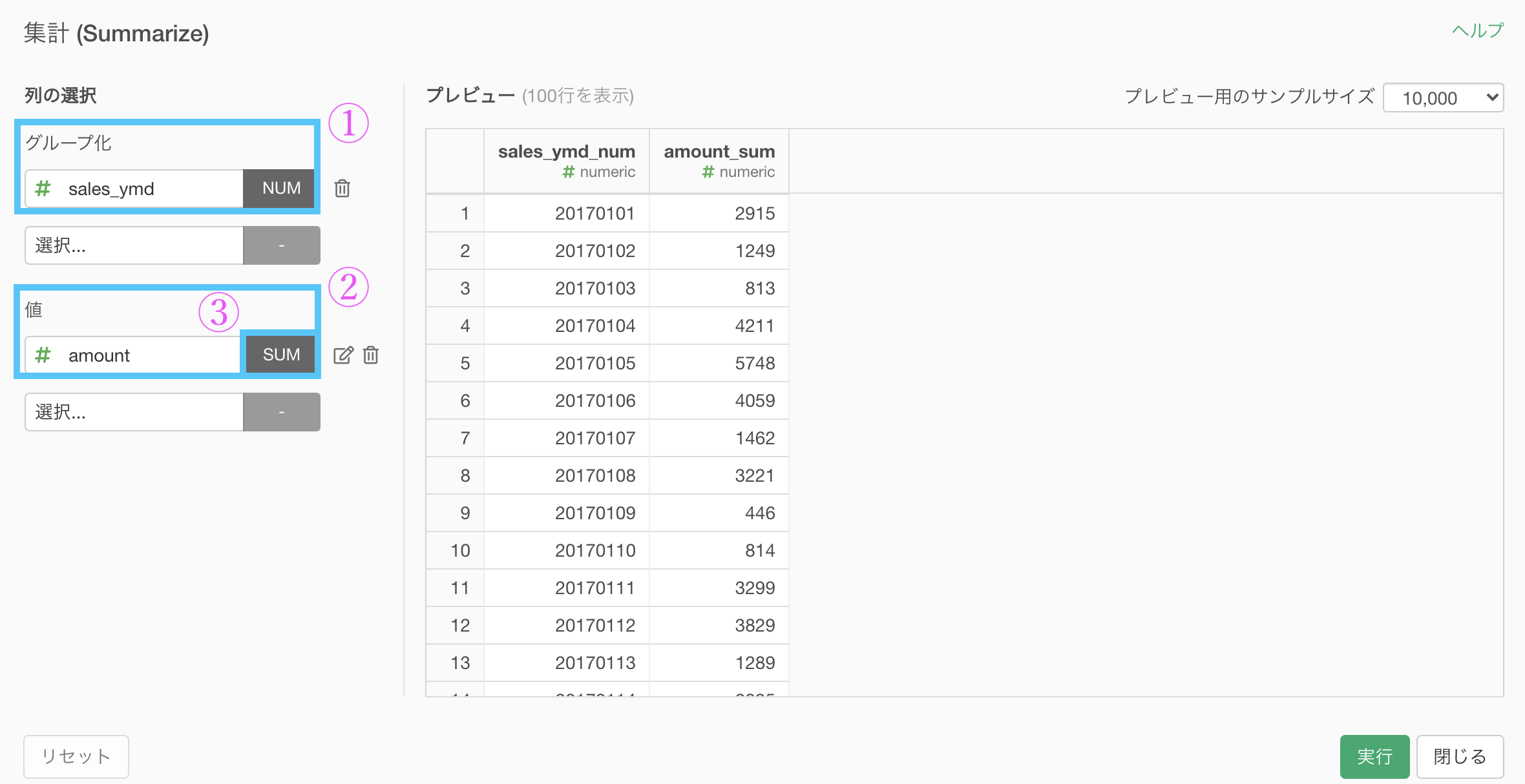
グループ化 : sales_ymd 値 : amount 計算 : 合計(sum)結果はこのようになります。
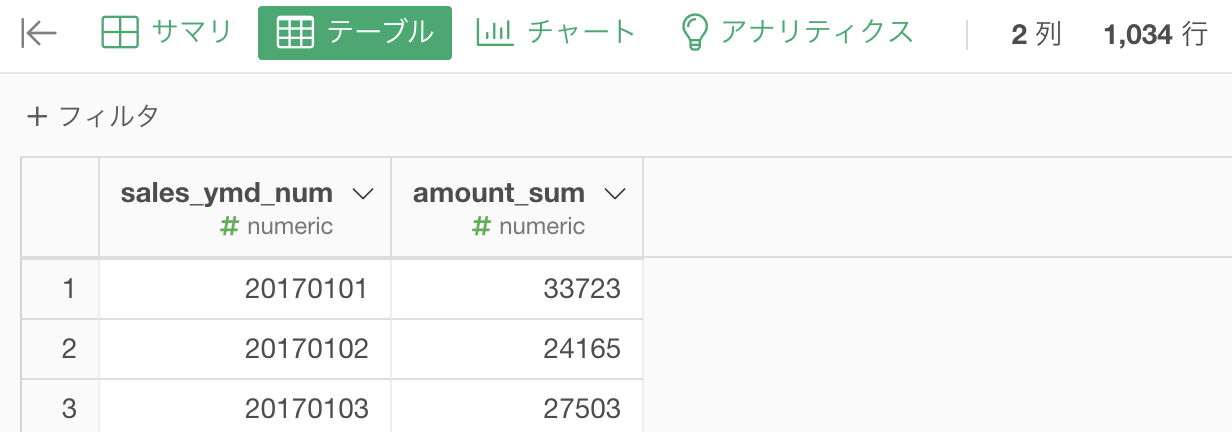
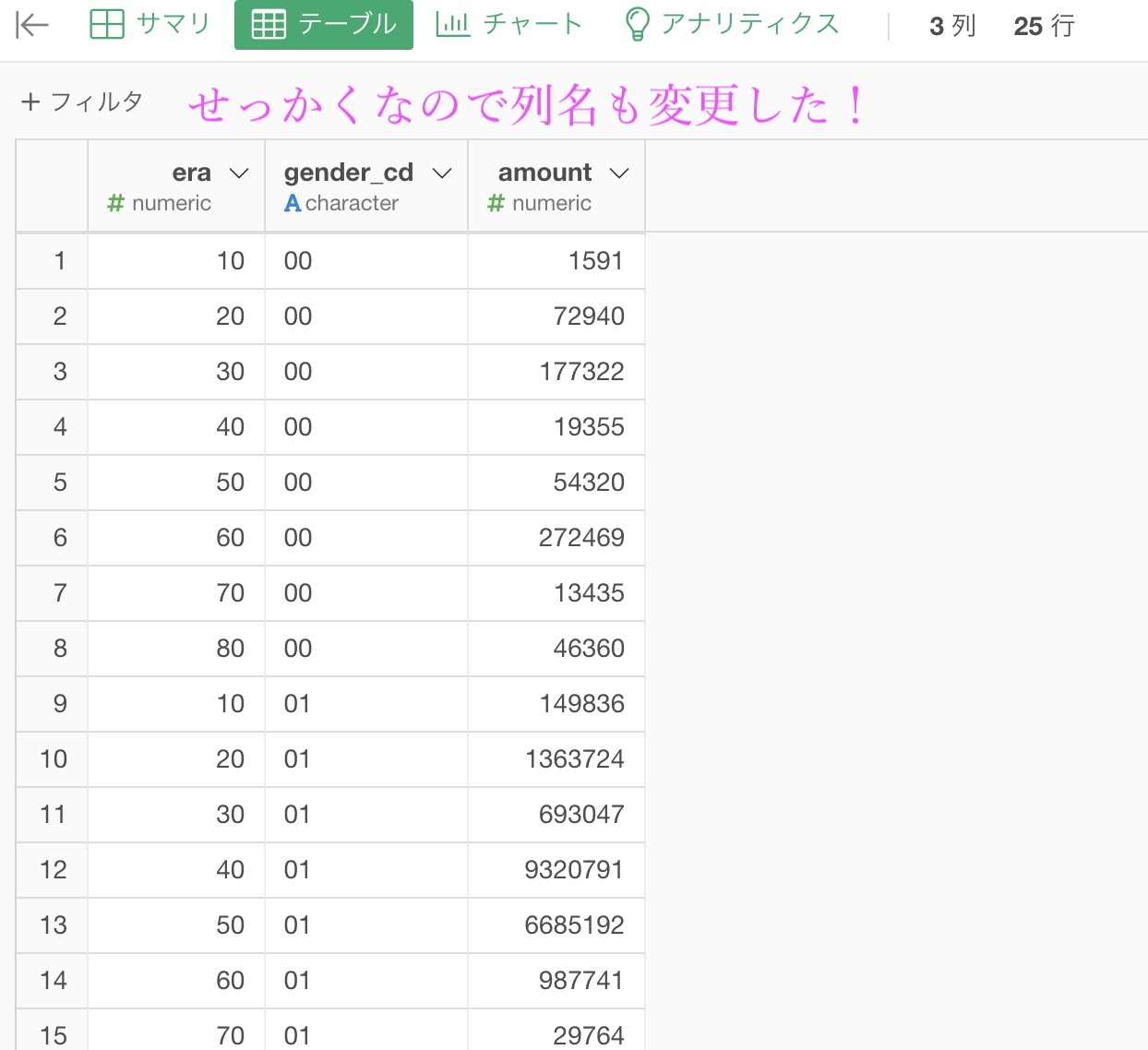
気になる方は列名を変更しておきましょう。
今後、列名が煩雑になっても仕方ないので変更しておくのをオススメします。
ここまでの結果はこのようになります。

集計は一旦終わりで、次は 期間をズラす 作業をしましょう。
計算を作成 (Mutate) して、計算エディタを開きましょう。
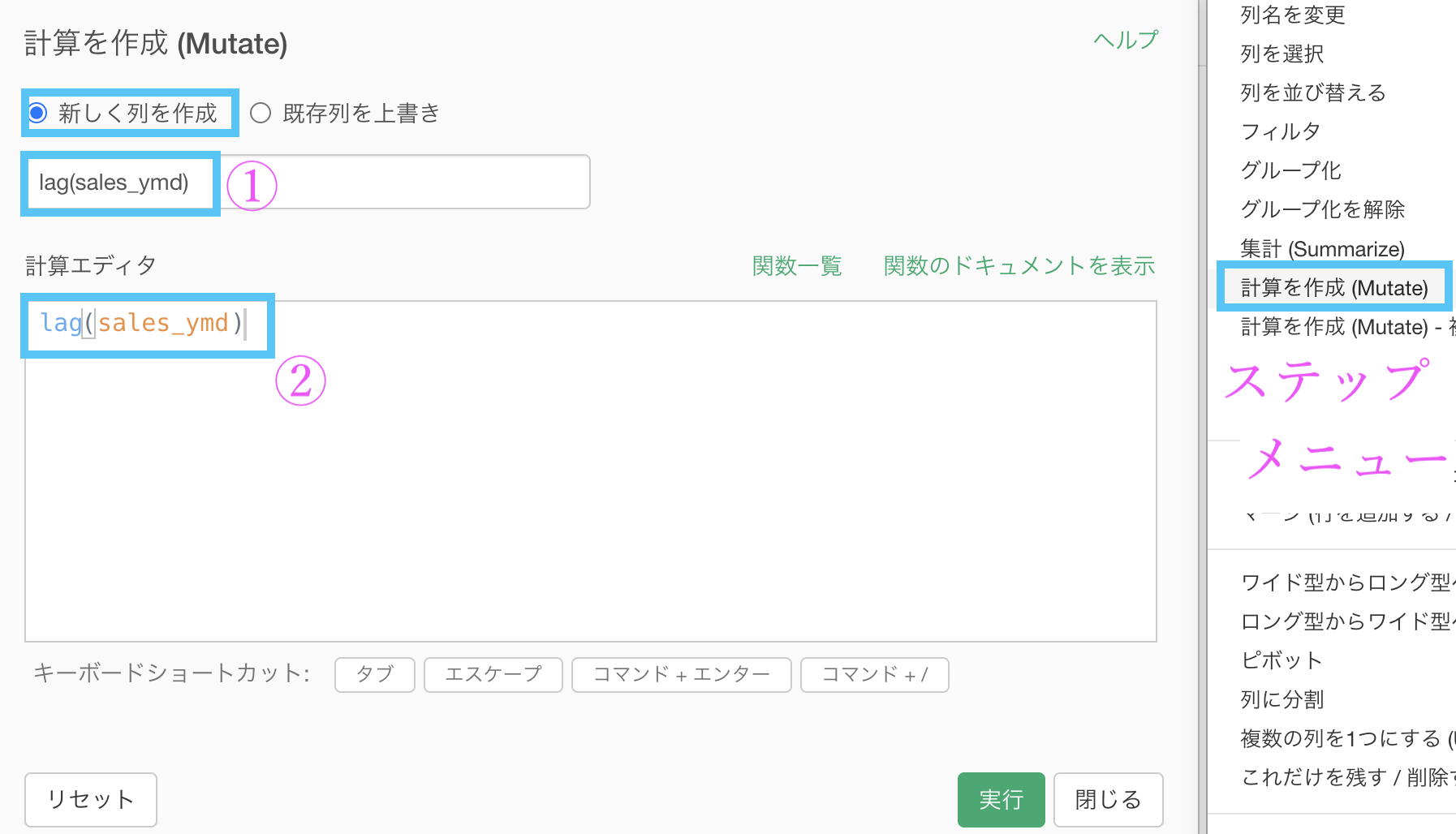
列名 : lag(sales_ymd) ... これは「lag_ymd」や「前日売上」と変更してもOK
計算エディタ : lag(sales_ymd) ... これは変えちゃダメ列名は人間が読むところだからなんでも良い(わかりやすいのがオススメ)ですが、計算エディタは機械が読むところだから変えちゃダメなわけです。
amount の列についても同じようにします。
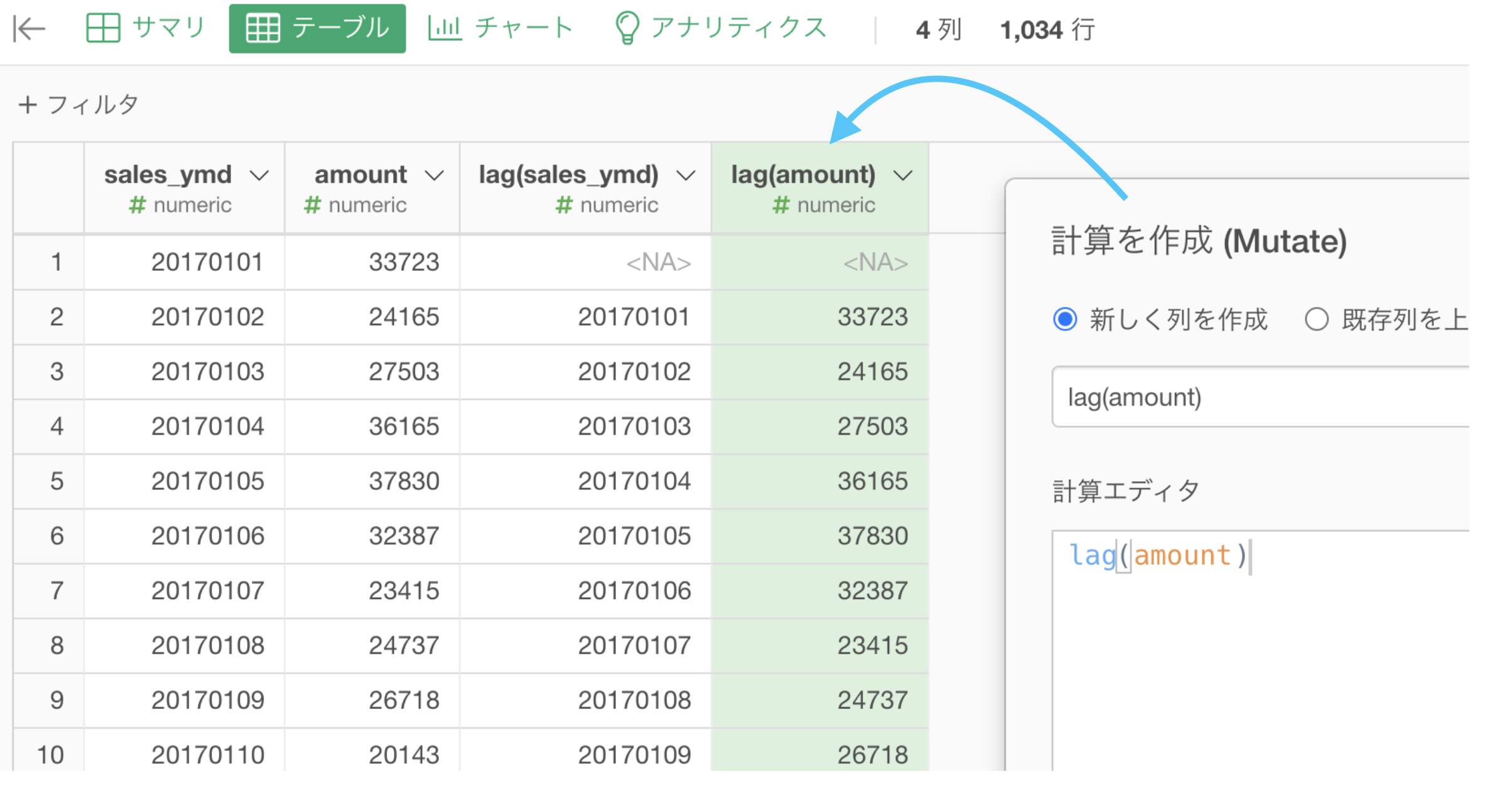
NA になっているのは簡単で、一番古いデータの日付が 2017年01月01日 なのでその前日はデータにないから NA です。
期間をズラす作業はここまでです。
実際に、期間がズレている事を確認しましょう。ちなみに lag はタイムラグのラグで「遅れ」を意味することから覚えられると思います。
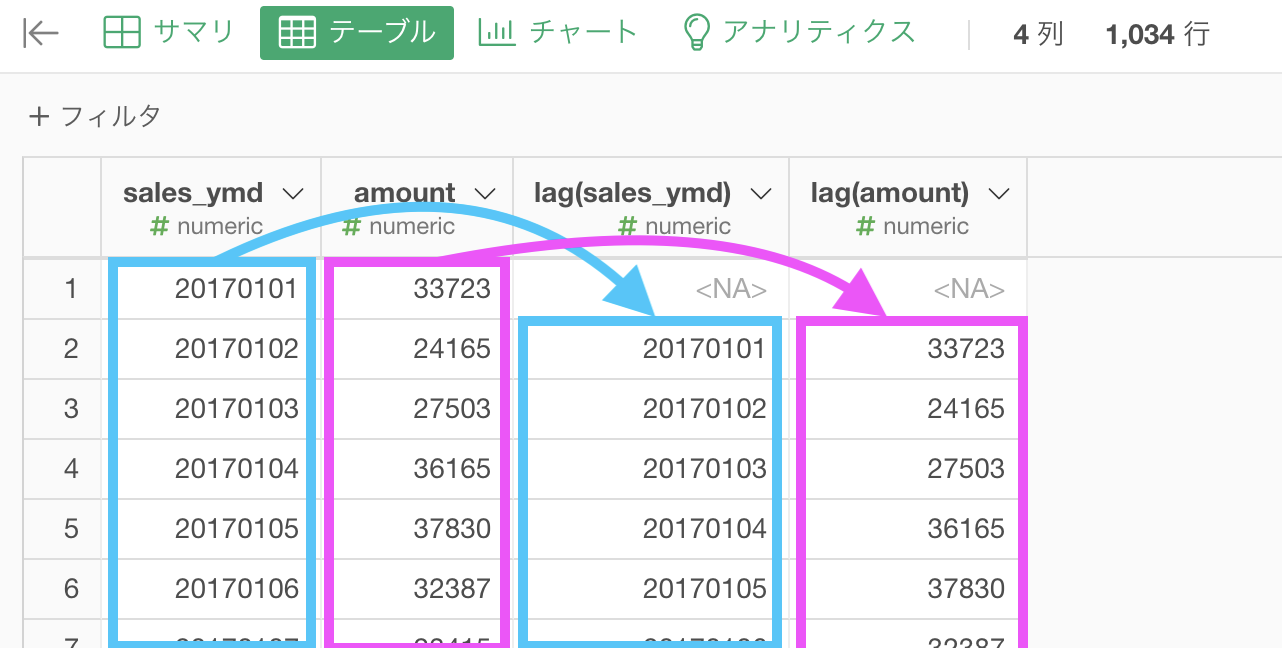
列名はなんでも良いのですが、後の計算に関わってくるためわかりやすくするのがオススメです。
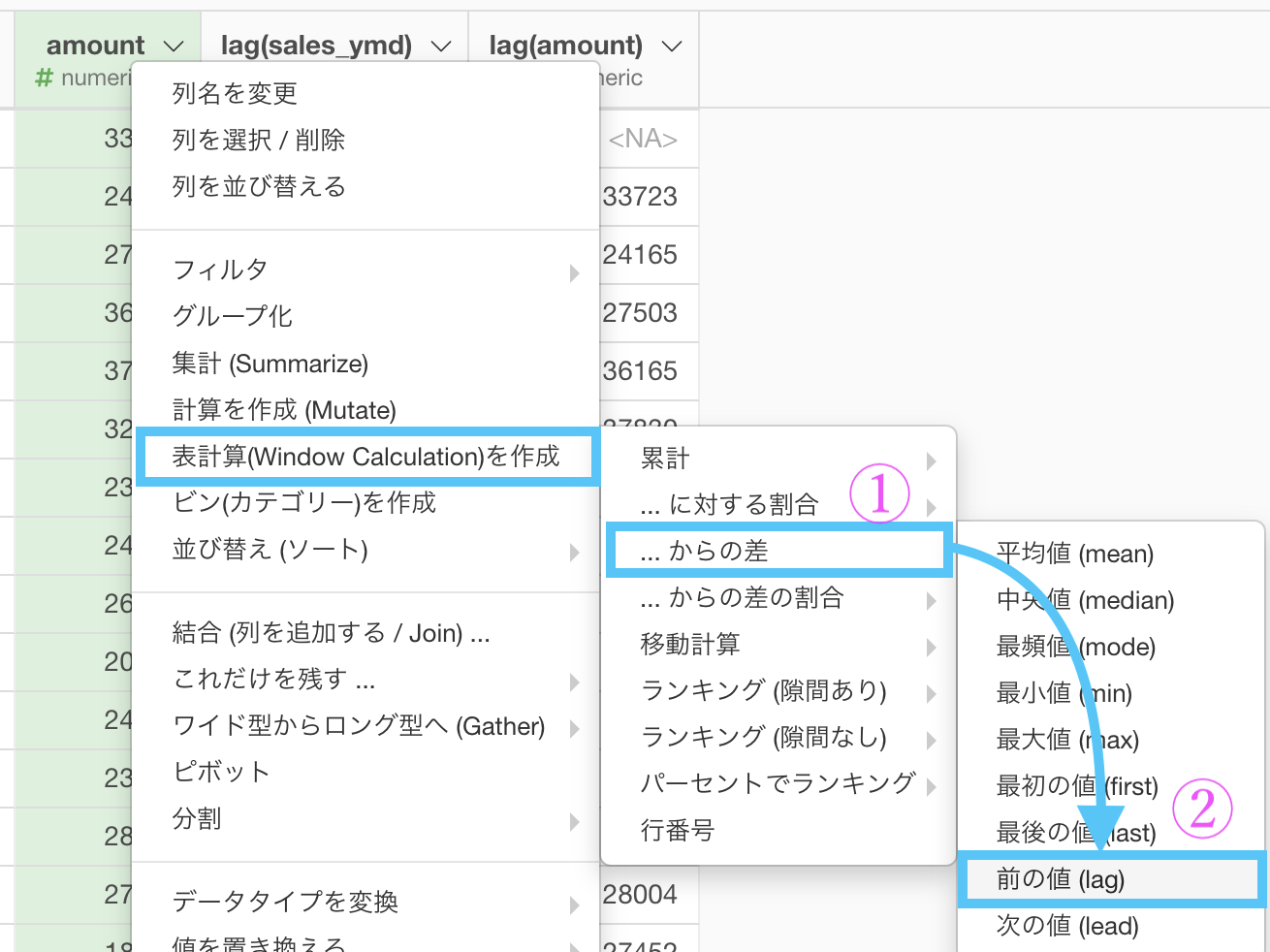
最後は 差を取る 作業です。
amount について差を取るので、次のように選びましょう。
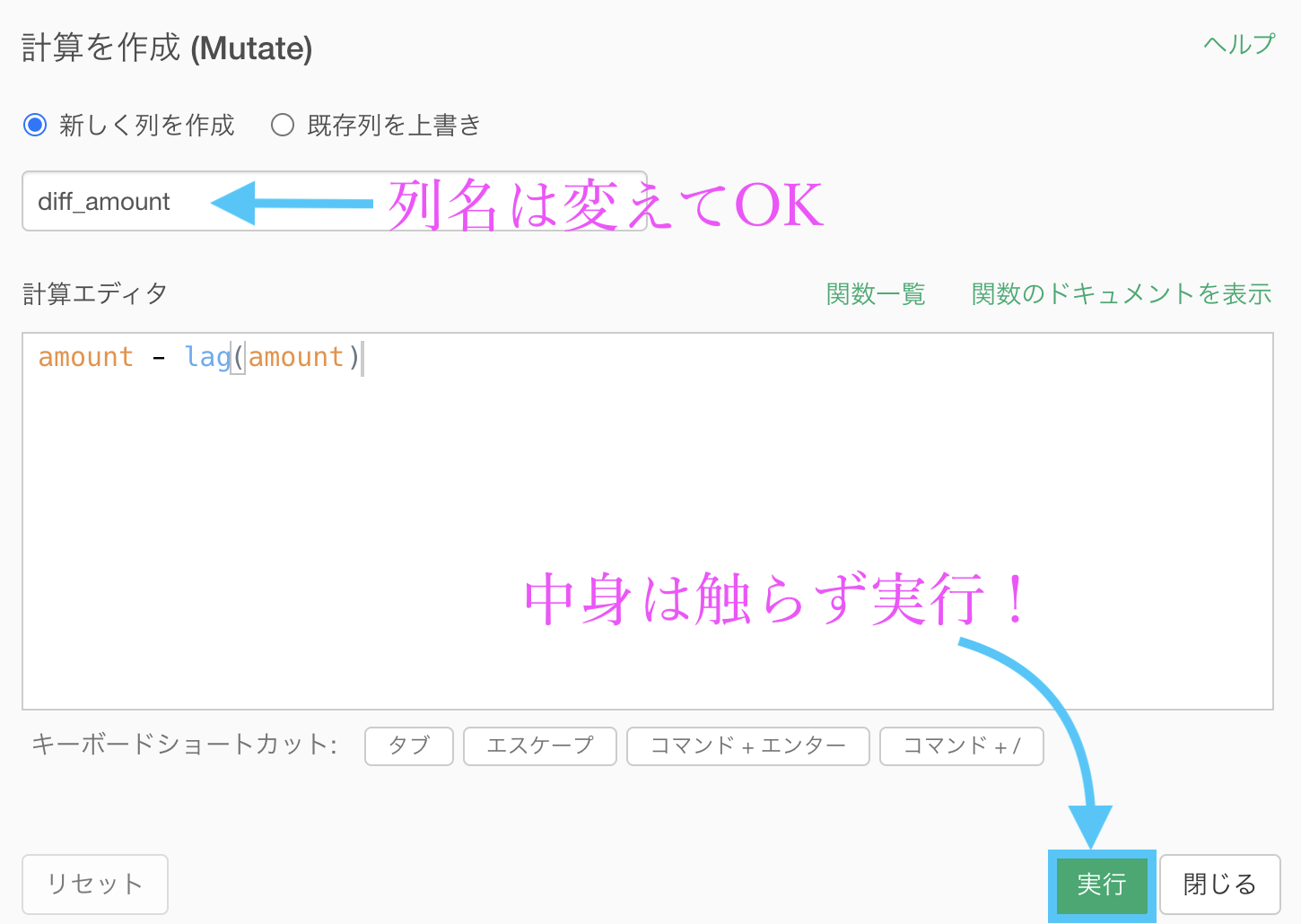
列名は「diff_amount」としています。
意味は difference「差」で、当日の amount と 前日の amount の差分です。
結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
df_sales_amount_by_date
= df_receipt[['sales_ymd',
'amount']].groupby('sales_ymd').sum().reset_index()
df_sales_amount_by_date
= pd.concat([df_sales_amount_by_date,df_sales_amount_by_date.shift()],
axis=1)
df_sales_amount_by_date.columns
= ['sales_ymd','amount','lag_ymd','lag_amount']
df_sales_amount_by_date['diff_amount']
= df_sales_amount_by_date['amount'] - df_sales_amount_by_date['lag_amount']
df_sales_amount_by_date.head(10)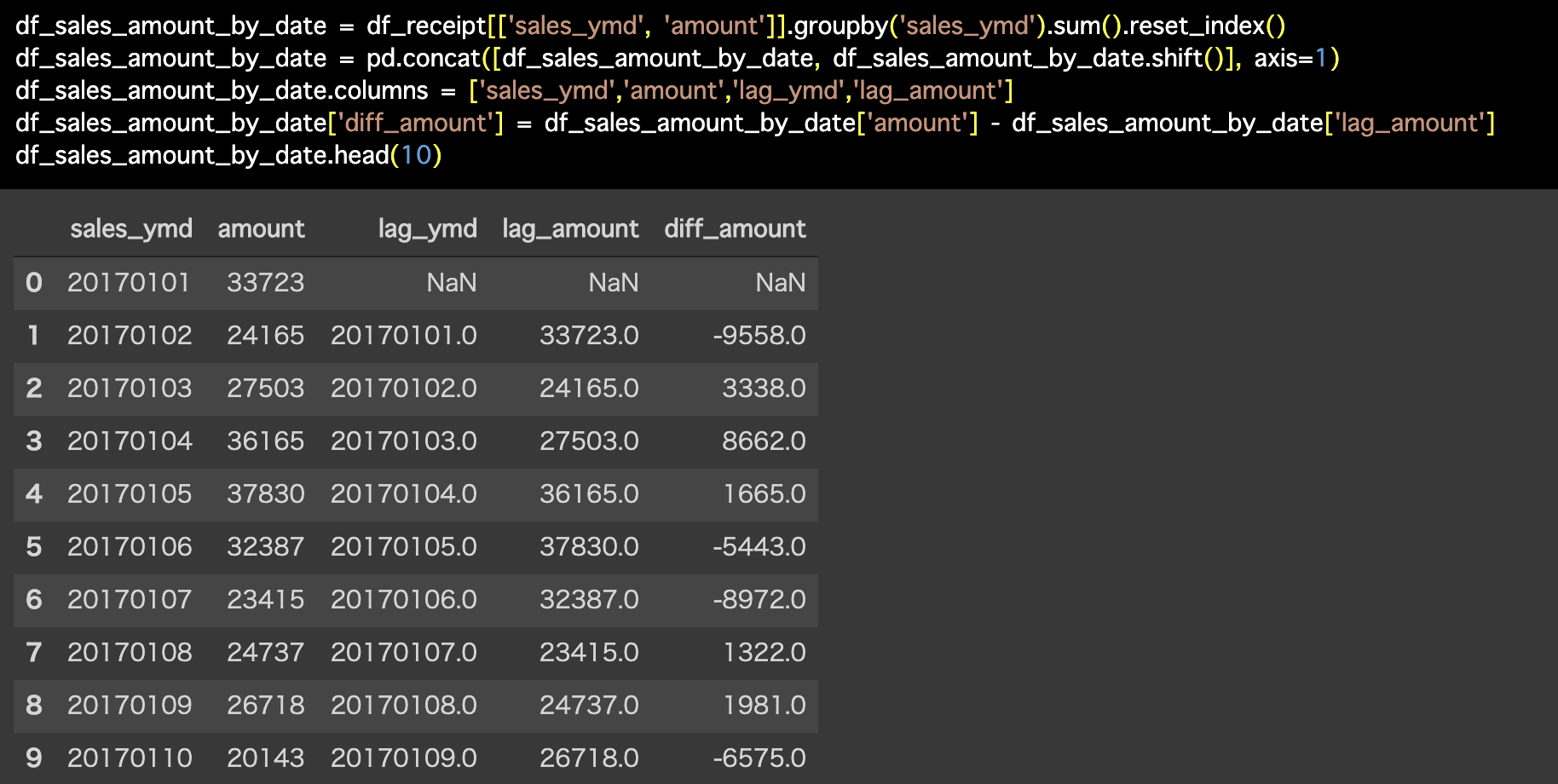
Exploratory が R言語 で動くことを利用したい方へ
この時点(列名を変更したあと)で カスタムRコマンド をします。
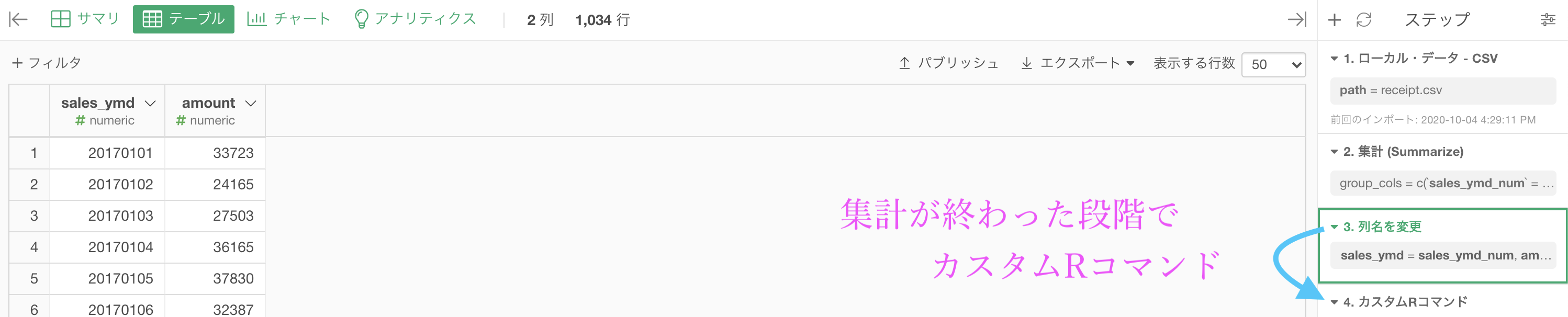
コマンドは下の方からコピペできるようにしました。
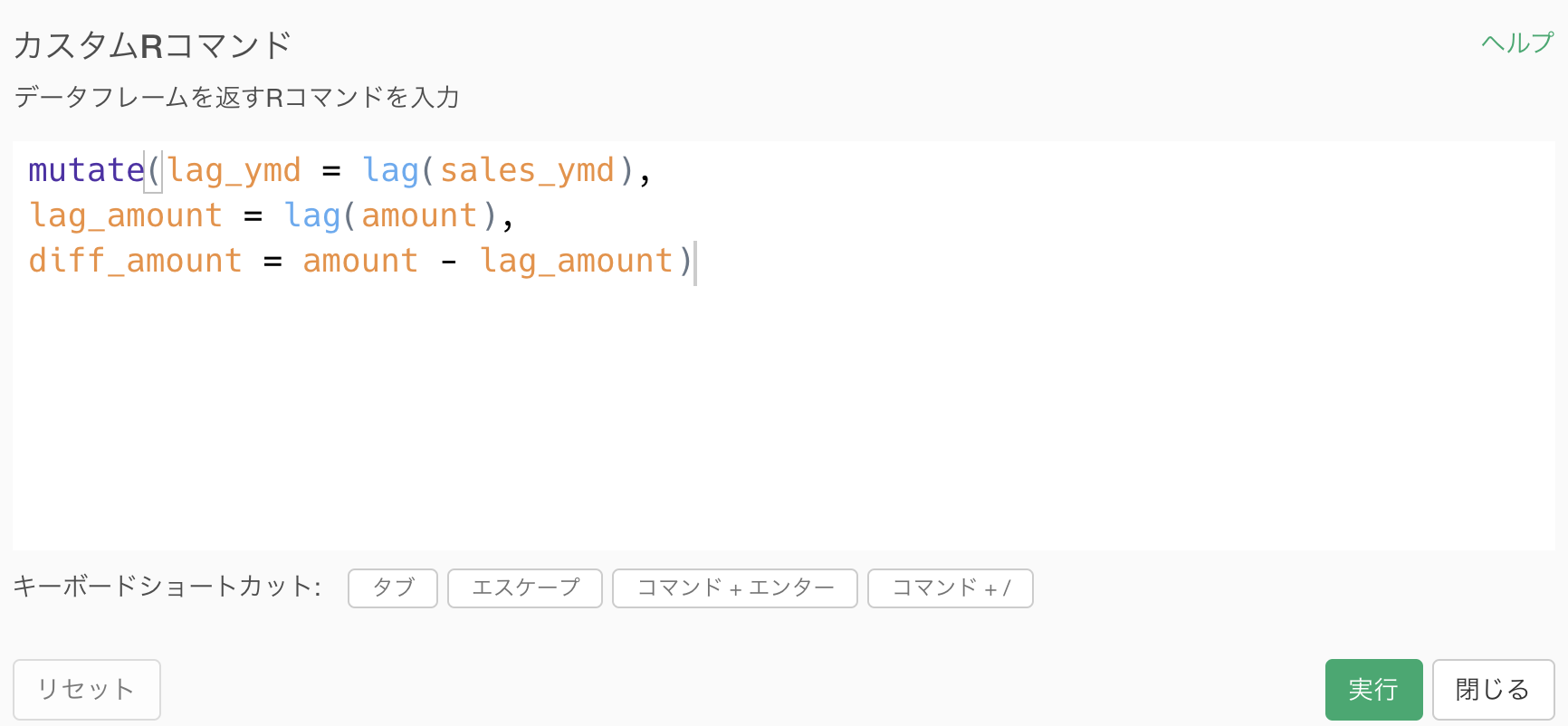
mutate(lag_ymd = lag(sales_ymd),
lag_amount = lag(sum_amount),
diff_amount = sum_amount - lag_amount)こうすることで一気に答えにたどり着きますが、実は私たちはすでにこれを打ち込まなくても打ち込んでいます。
まず、最後のステップに行って、ステップメニュー →「Rコマンドへ変換」を押します。
実際はステップメニューを押したら一番下に出てきます。

するとこのようなコマンドが出てきたと思います。
見やすくするために、カンマのところで改行を加えています。
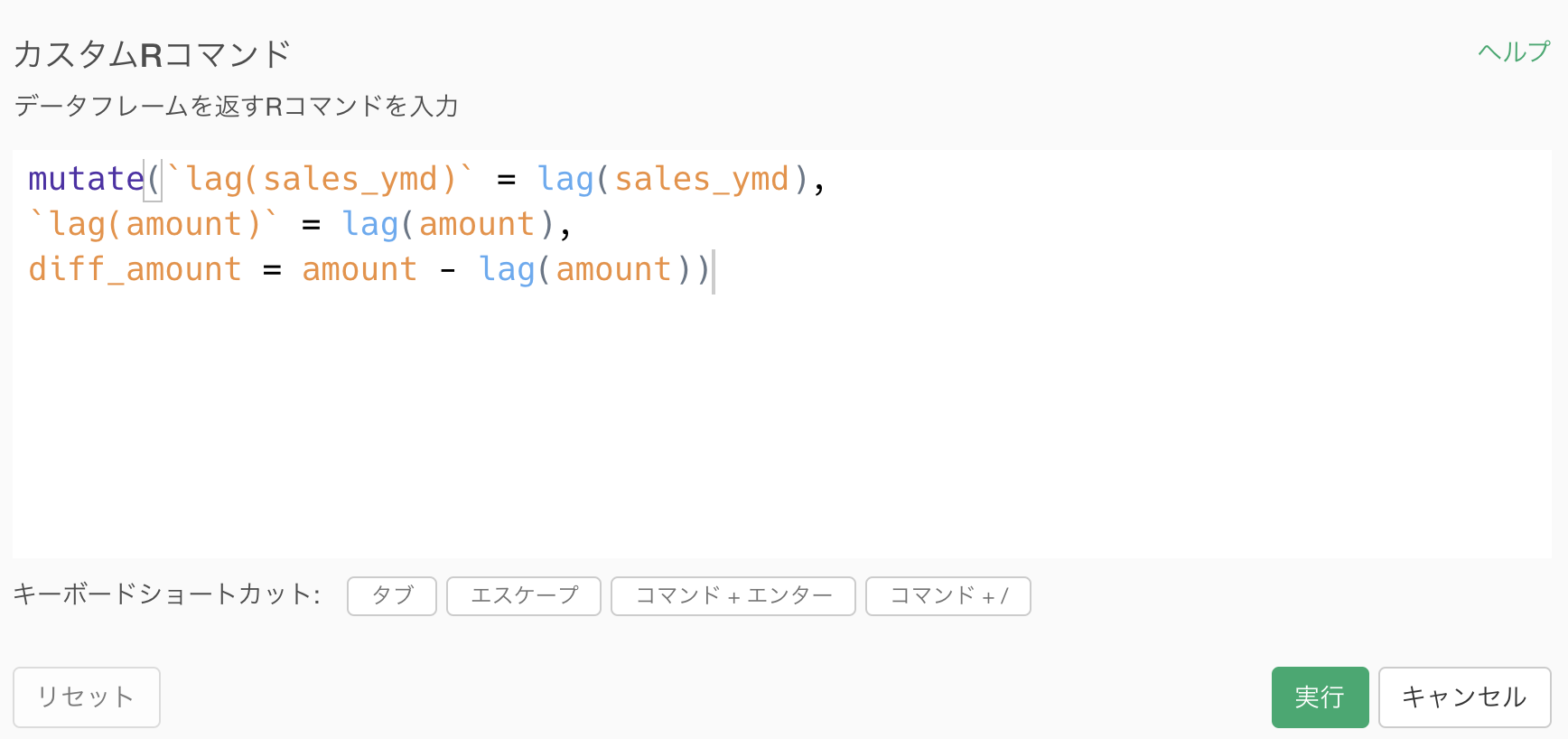
これは単にステップをRコマンドに変換しただけなので、私たちが今まで操作したものは R言語 でいうとこのコマンドを実行しましたという記録です。
最初に紹介したコマンドとほとんど同じですよね?
雑談というかなんというか
Python のコードを見てもとにかく長いという印象だろうし、Exploratory でもちょっと長いなぁと感じた人もいるかもしれません。
もし Excel を使い慣れている方なら「こんなの Excel でやった方が早いよ!」と思ったことでしょう。
ですが、残念なことに Excel だとデータが大きいとき(とは言ってもせいぜい100MBは小さな方ですけど...)は開くどころじゃないかもしれませんし、開いたところで挙動はガタガタです。むしろ遅いです。
さらに追い討ちをかけるようで申し訳ないのですが、Excel でやるということは、人間にとってわかりやすさを得るのと引き換えに、単純作業の自動化を捨てることを無意識に選んでいます。
複雑な関数を将来自分たちで組み立て自動化するプロジェクトのようなものが発足したとき、そこに Excel の力は必要ないということです。
問42 : 過去n件のデータを結合する

答案・解説はこちら
わかりやすく for 文を使わずにやります。問題の本質がわかっている人にはには本当にごめんなさい。「できる」ということを優先します。
問41 のここからスタートします。
差を取る直前までですね。
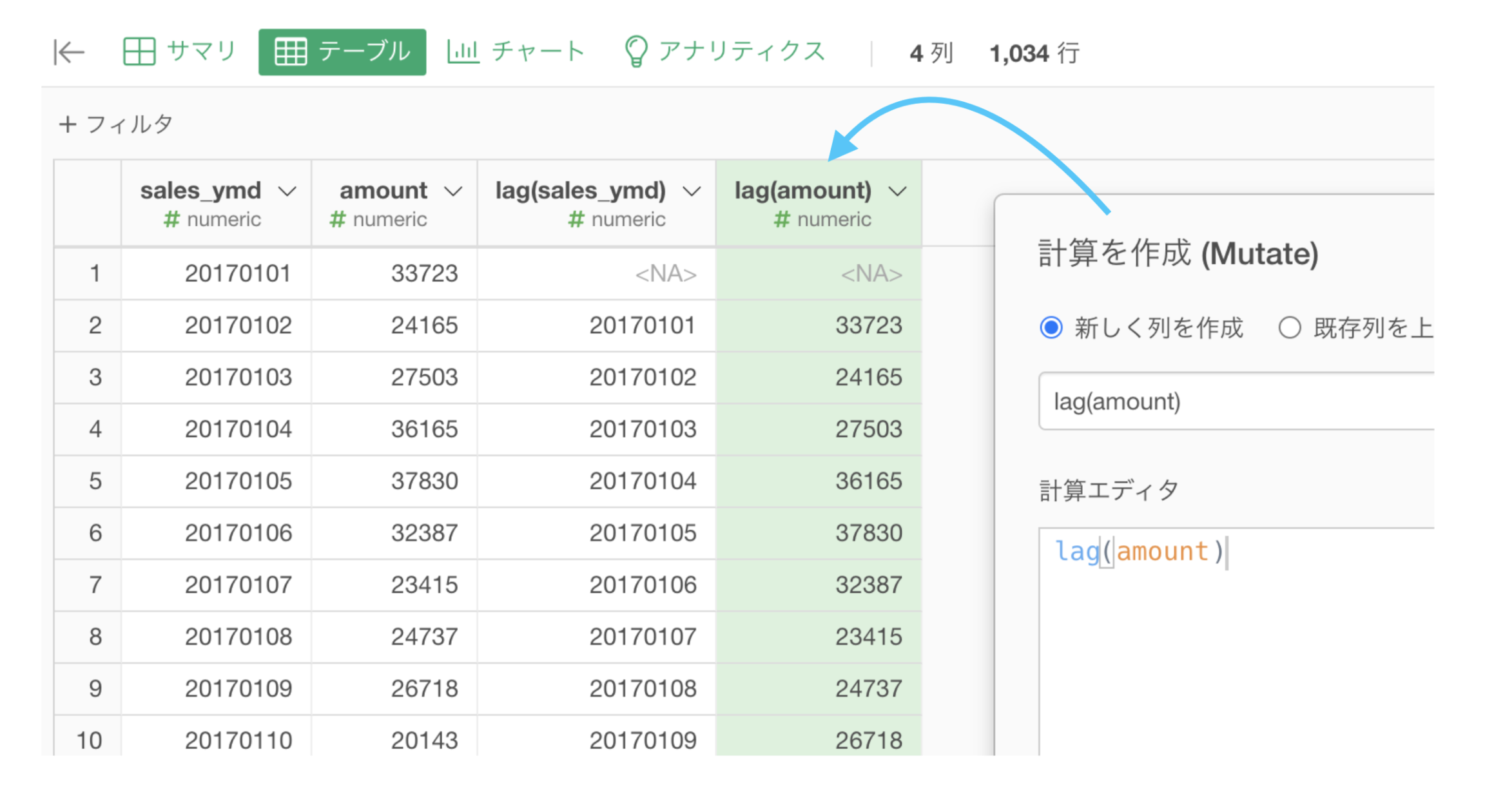
このように lag(amount) としたときは1つ前へズラす操作をするわけです。ということは、2つ前、3つ前へズラすのは、これを何度も繰り返せば良いということになります。
以上のことから、このようにすれば良いでしょう。
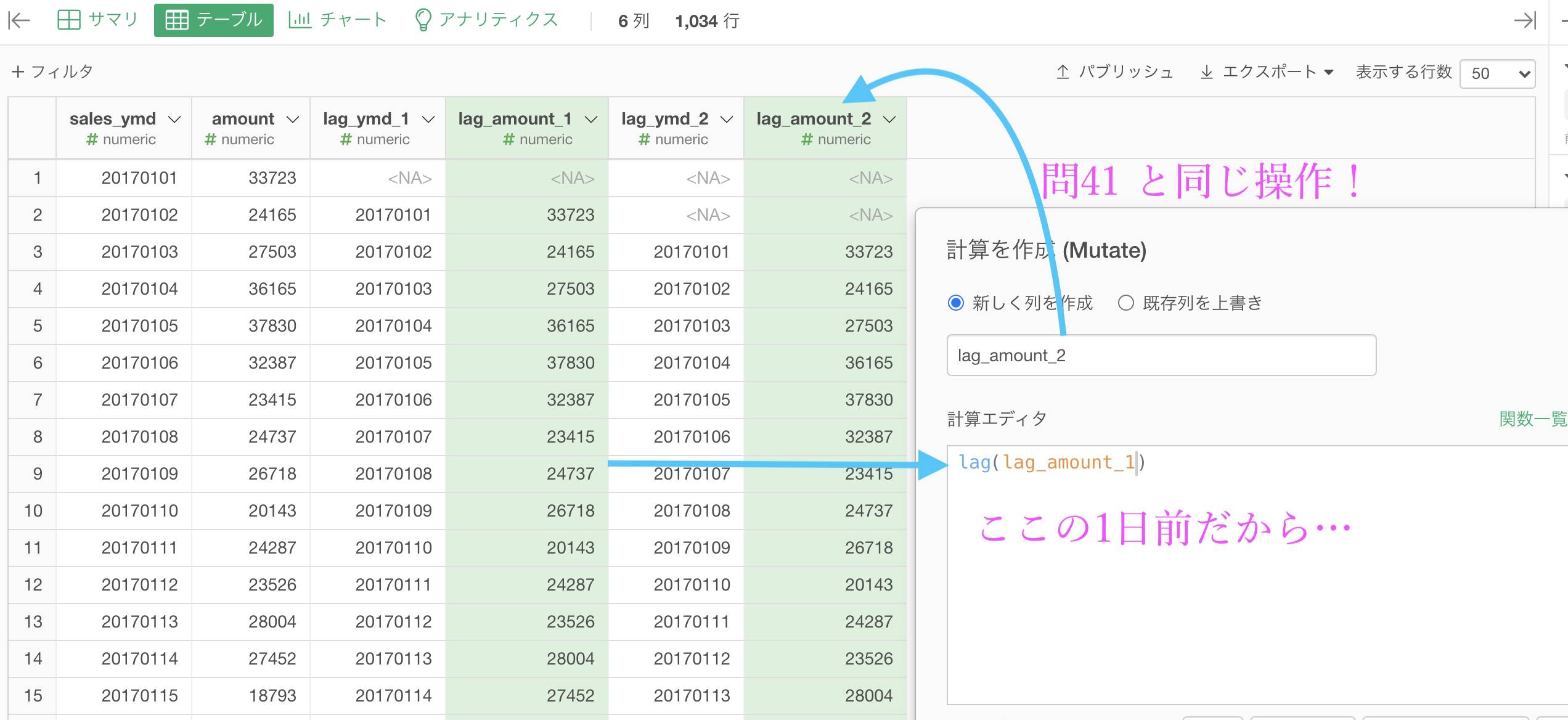
見てわかったかもしれませんが、わかりやすさのために列名は変更してあります。各自わかりやすい列名にすることをオススメします。
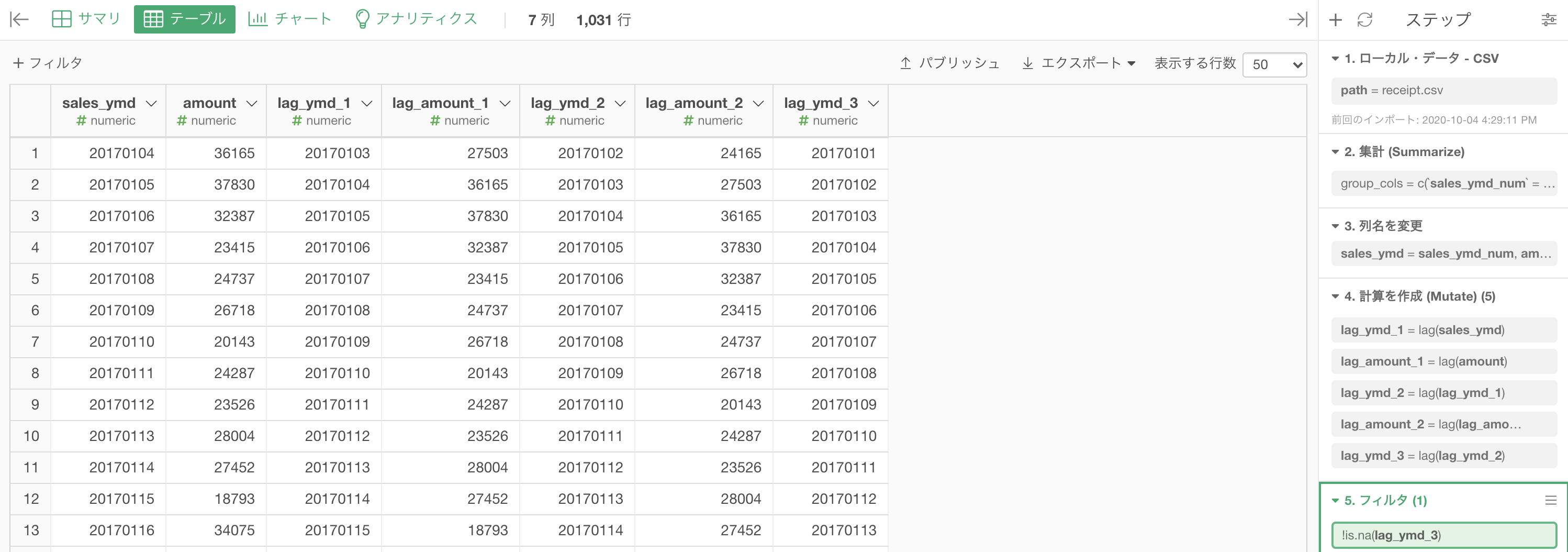
これを3日分まで続ければこのような結果になります。
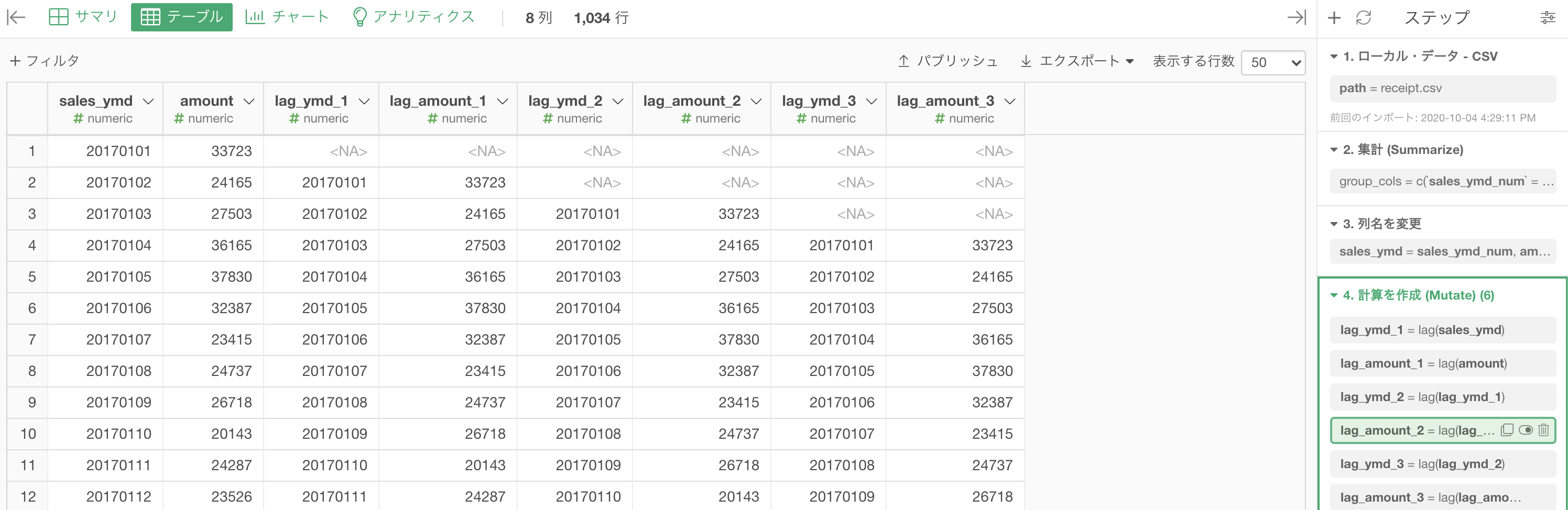
あとはフィルターで欠損値を取り除きます。 
実行すると以下のような結果になったと思います。解答(2つ目の解答の方)を確認してみましょう。
いろいろなやり方があるので、あえて最も簡単で誰でも思い付きやすいような方法を取りました。
本番に立ったときにはきっと、こんなもんじゃレベル差があってどうしようもなくなります。
でもそうなる前に、ワンステップ下の段階を経験しておくことも必要だと思っています。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1:縦持ちケース
df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index()
for i in range(1, 4):
if i == 1:
df_lag = pd.concat([df_sales_amount_by_date,
df_sales_amount_by_date.shift(i)],axis=1)
else:
df_lag = df_lag.append(pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(i)],axis=1))
df_lag.columns = ['sales_ymd', 'amount', 'lag_ymd', 'lag_amount']
df_lag.dropna().sort_values(['sales_ymd','lag_ymd']).head(10)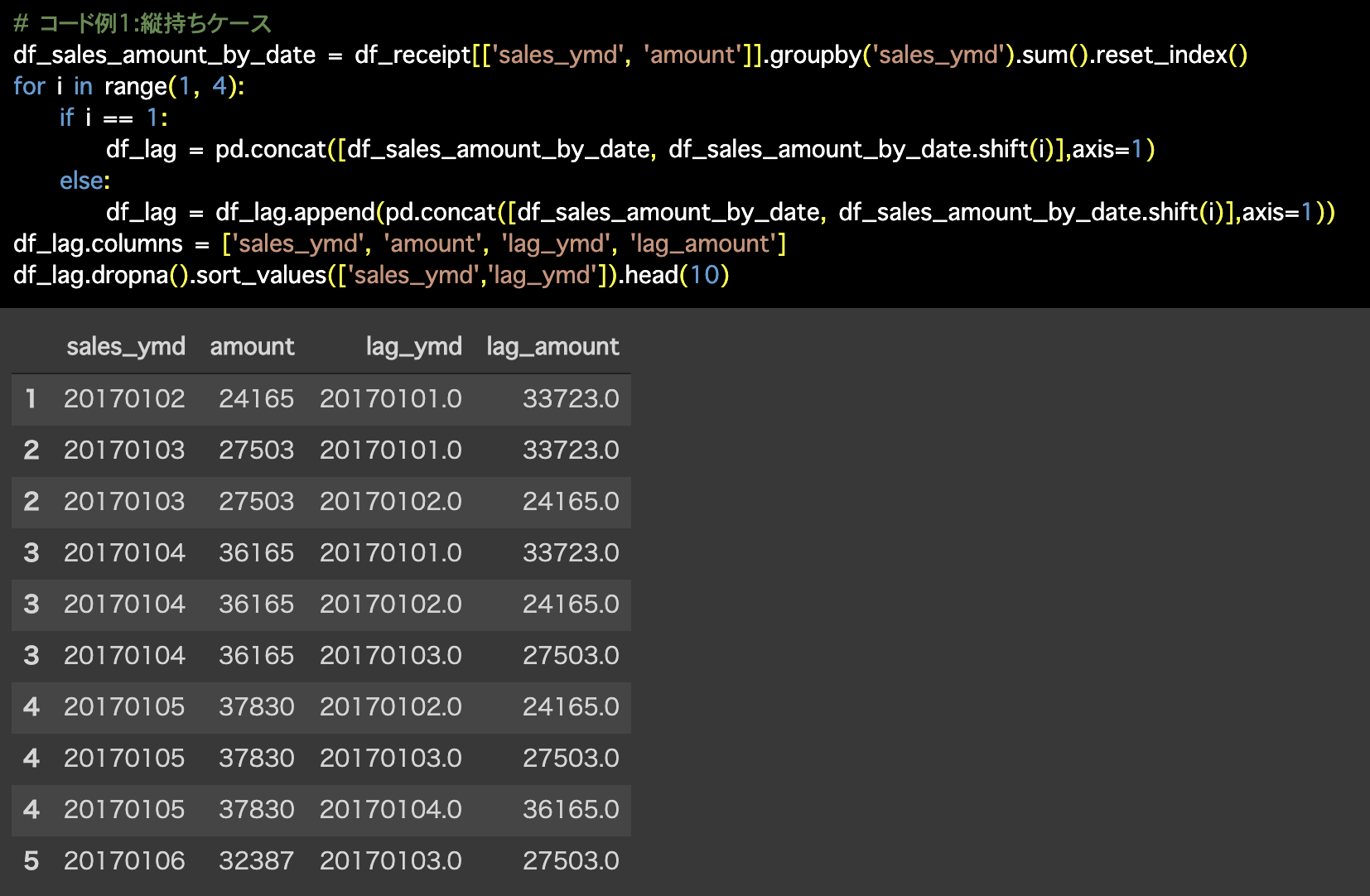
2つ目の解答コードはこのようになっています。
# コード例2:横持ちケース
df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index()
for i in range(1, 4):
if i == 1:
df_lag = pd.concat([df_sales_amount_by_date,
df_sales_amount_by_date.shift(i)],axis=1)
else:
df_lag = pd.concat([df_lag, df_sales_amount_by_date.shift(i)],axis=1)
df_lag.columns = ['sales_ymd', 'amount', 'lag_ymd_1', 'lag_amount_1', 'lag_ymd_2', 'lag_amount_2', 'lag_ymd_3', 'lag_amount_3']
df_lag.dropna().sort_values(['sales_ymd']).head(10)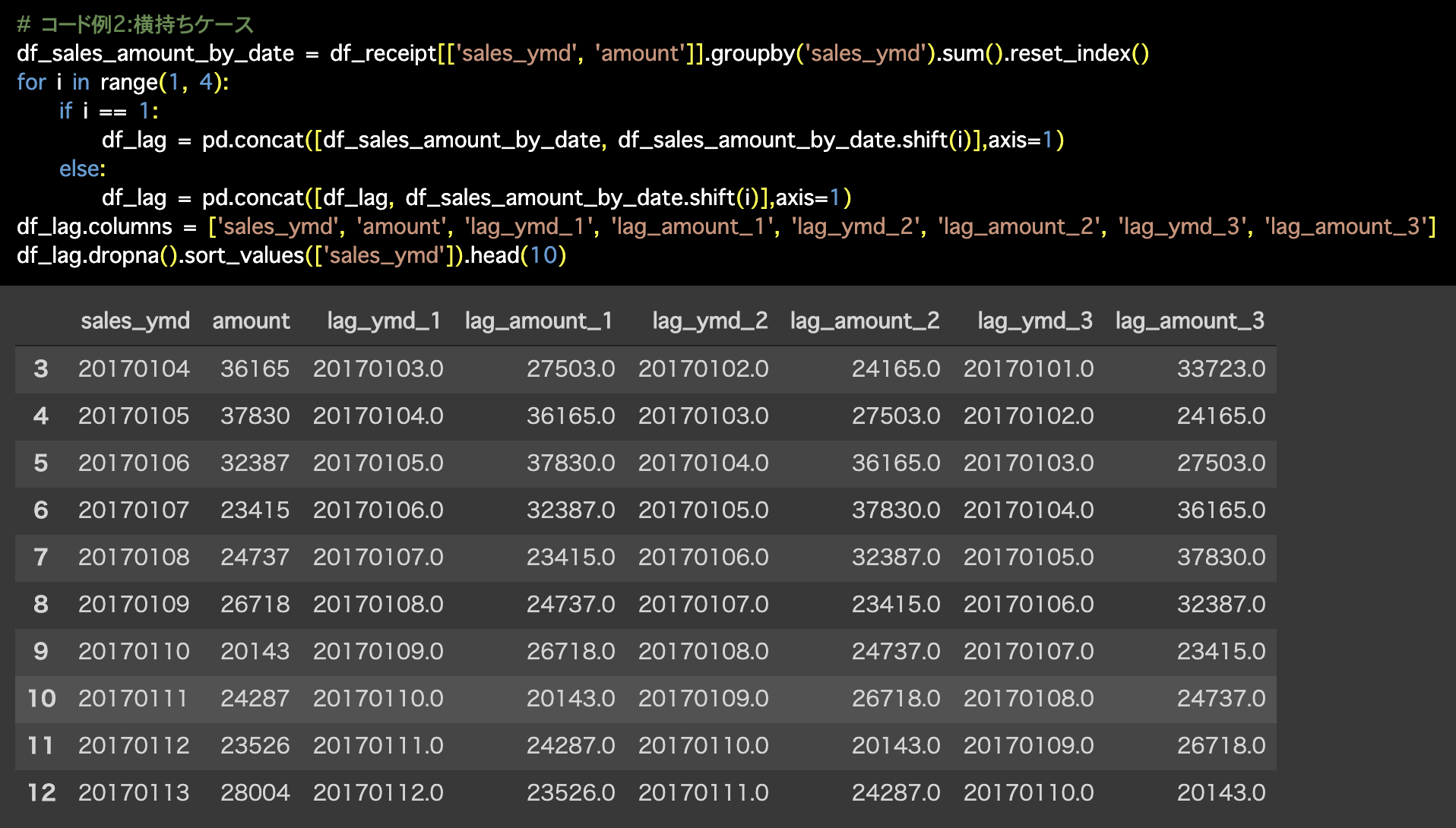
説明がわかりにくくなるため、今回ではあえて for 文を使わずに説明しました。
しかし、問42 の本質は for 文を組み立てられることにあるのは、実はいうまでもないことなのです。
だから最初に謝りました ... m(_ _ ;)m
ちなみに計算エディタの中身を
lag(amount, n=3)とすると、一気に3日前(NAが2つ)になります。
1つ目の解答コードについて
今回は2つ目の解答コードしかできていません。1つ目は Exploratory ではできないのか?と言われると、そうではありません。
ですが、問43 をやっていないから、今はやらなくて良い という理解をするのが先に進みやすい方法です。
問43 : 縦持ちデータを横持ちデータに変換する

答案・解説はこちら
まずは
です。
しかし、まずは縦持ちのデータを、df_receipt を処理してから用意する必要があります。そっちはサクサクいきたいので、細かい説明は後に回します。
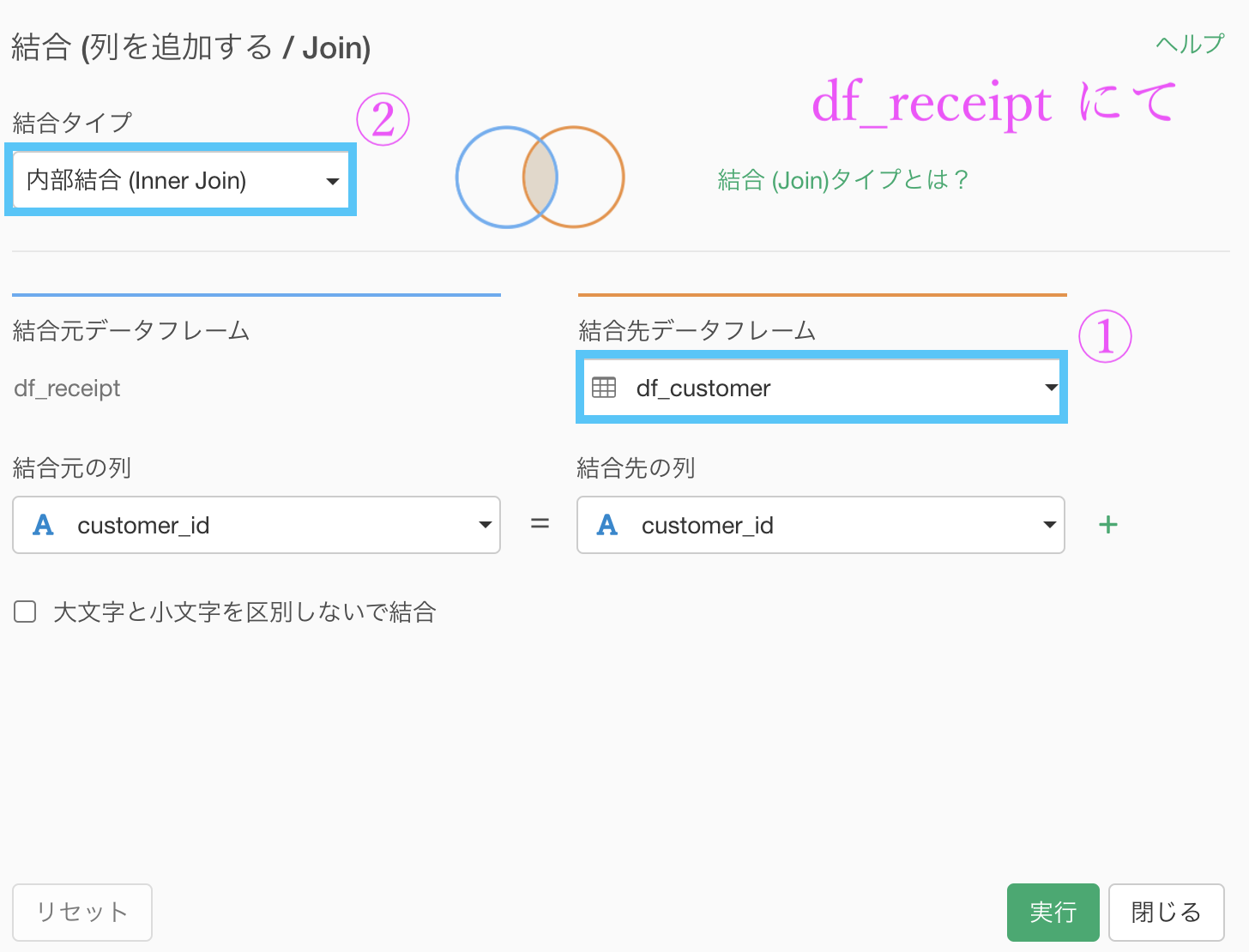
df_receipt を df_customer と結合する。
何もせずいきなり結合します。列が多くなりますが少し我慢してください(本番だとタブーな操作かも)。
age を年代(10代, 20代, ...)にする。
この計算式については、解答を確認してからにしましょう。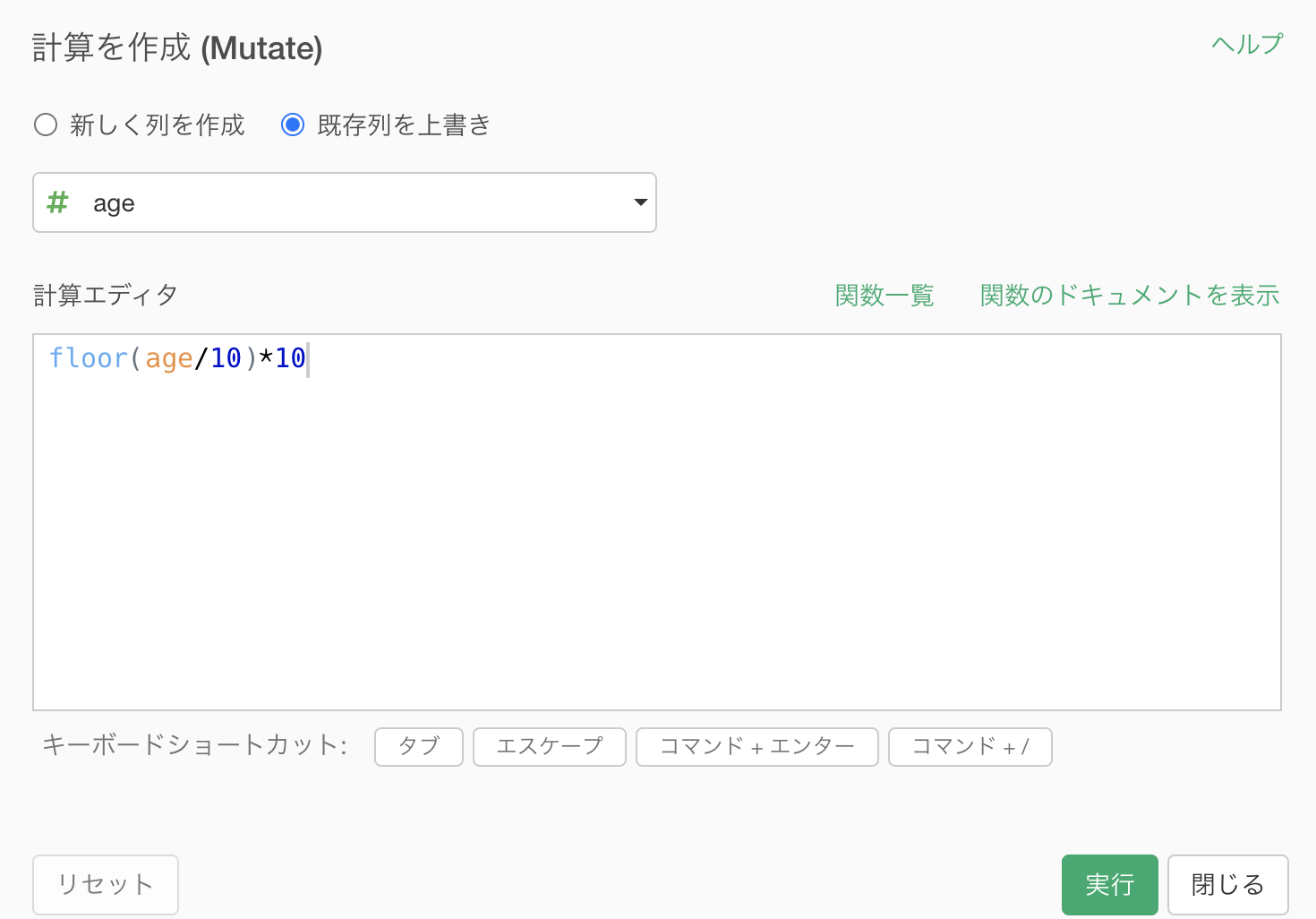
floor(age/10)*10 # コピペ用集計 (Summarize) 機能で次のように設定します。
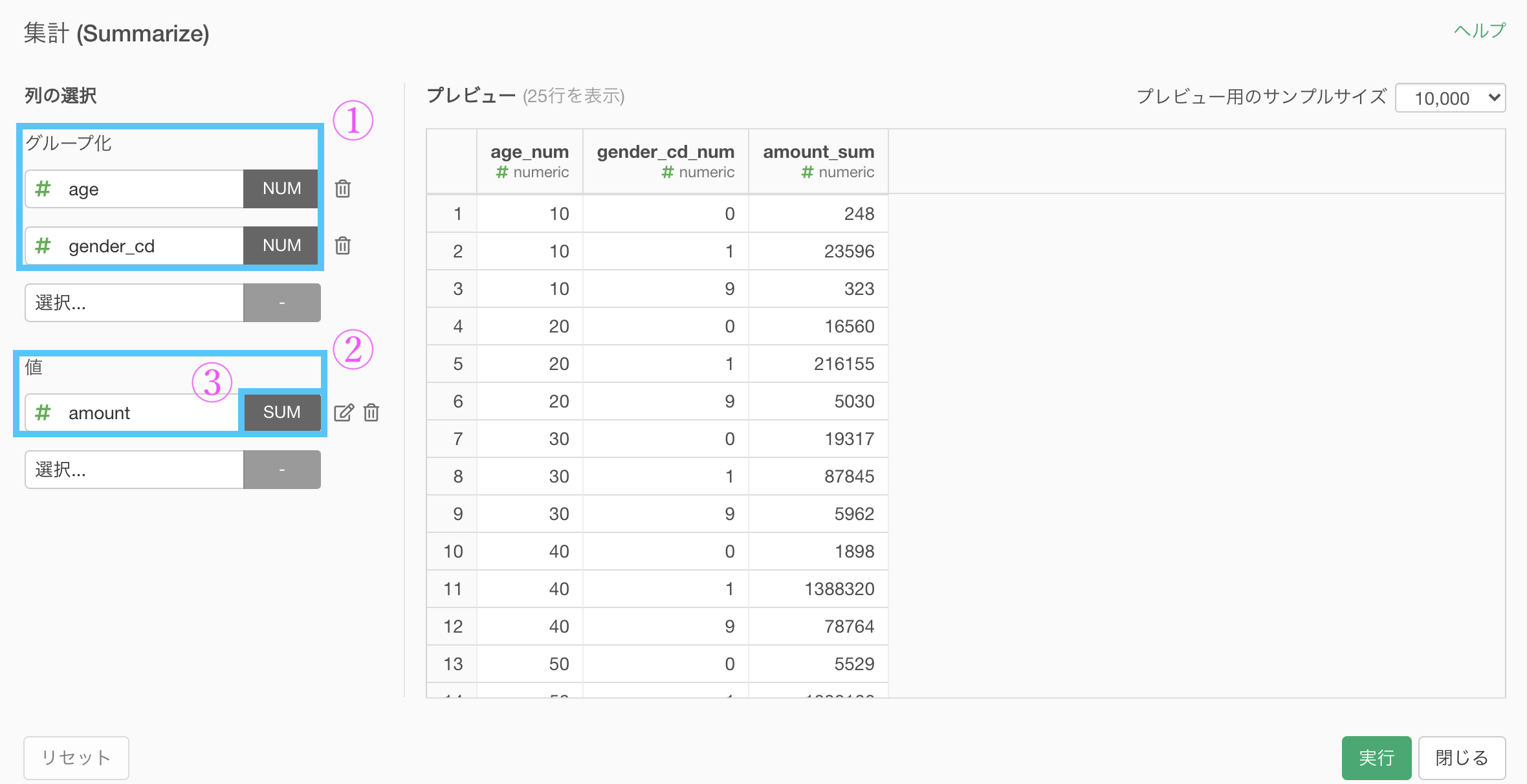
グループ化 : age と gender_cd 値 : amount 計算 : 合計(sum)
ここまででこのような結果になったと思います。
気になる場合は、列名を変更しておいても良いでしょう。
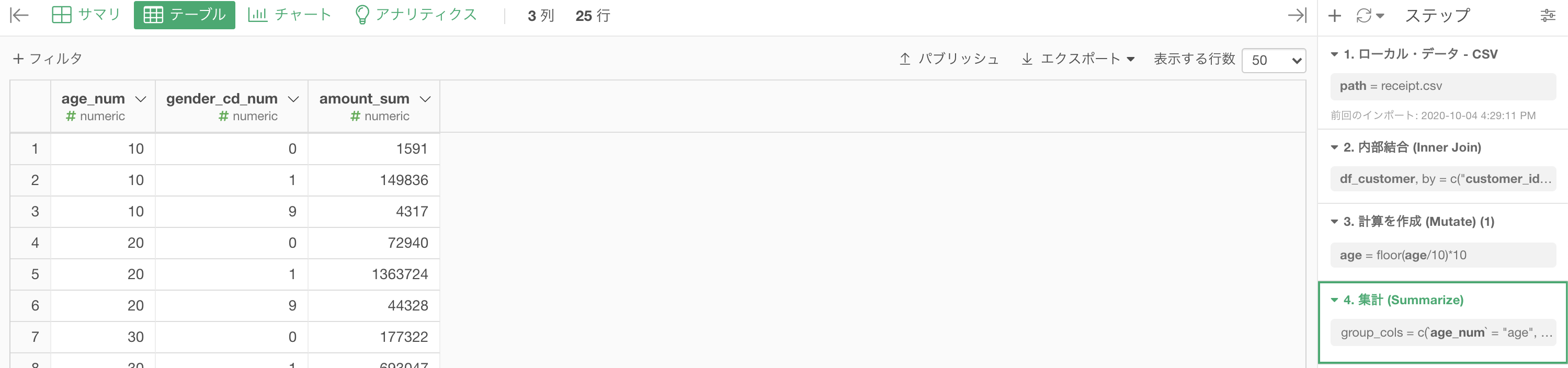
さて、データが用意できたので、ここからが本番です。
縦持ちのデータになっているところは、gender_cd(性別コード)のところです。
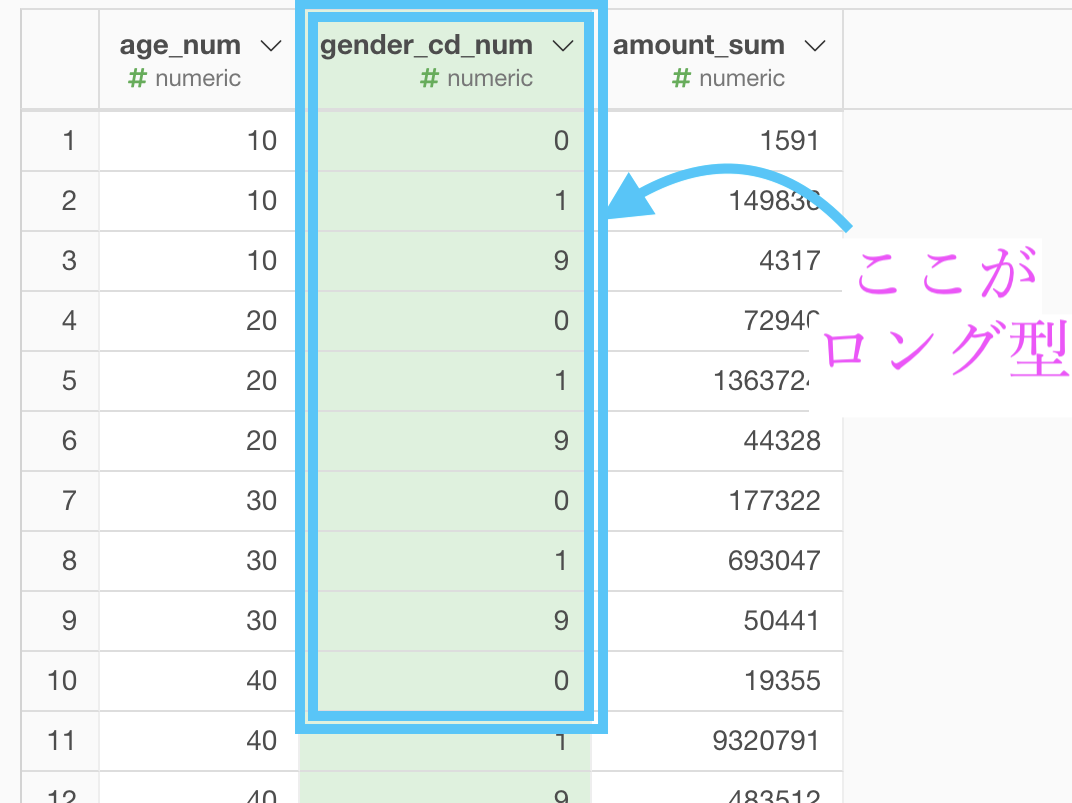
というところから気付くことができると思います。
なぜなら、age は 10, 20, 30, ... としたいはずだから です。
そういう場合にこの 問43 をやる意味があるのです。
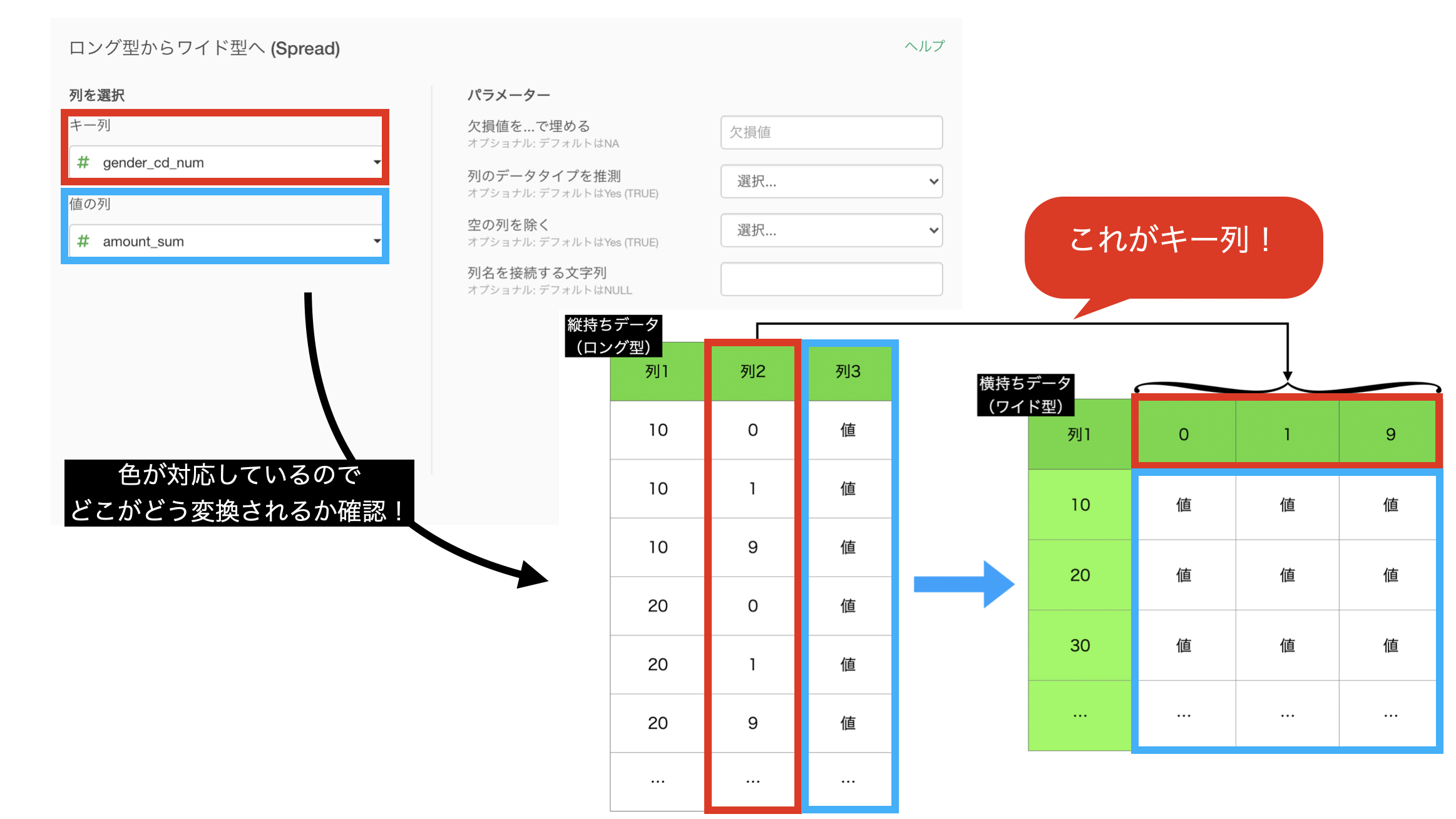
整理として、縦持ちデータ(ロング型)→ 横持ちデータ(ワイド型)で結局のところ何をしたいのか、イメージをつかんでおきましょう。
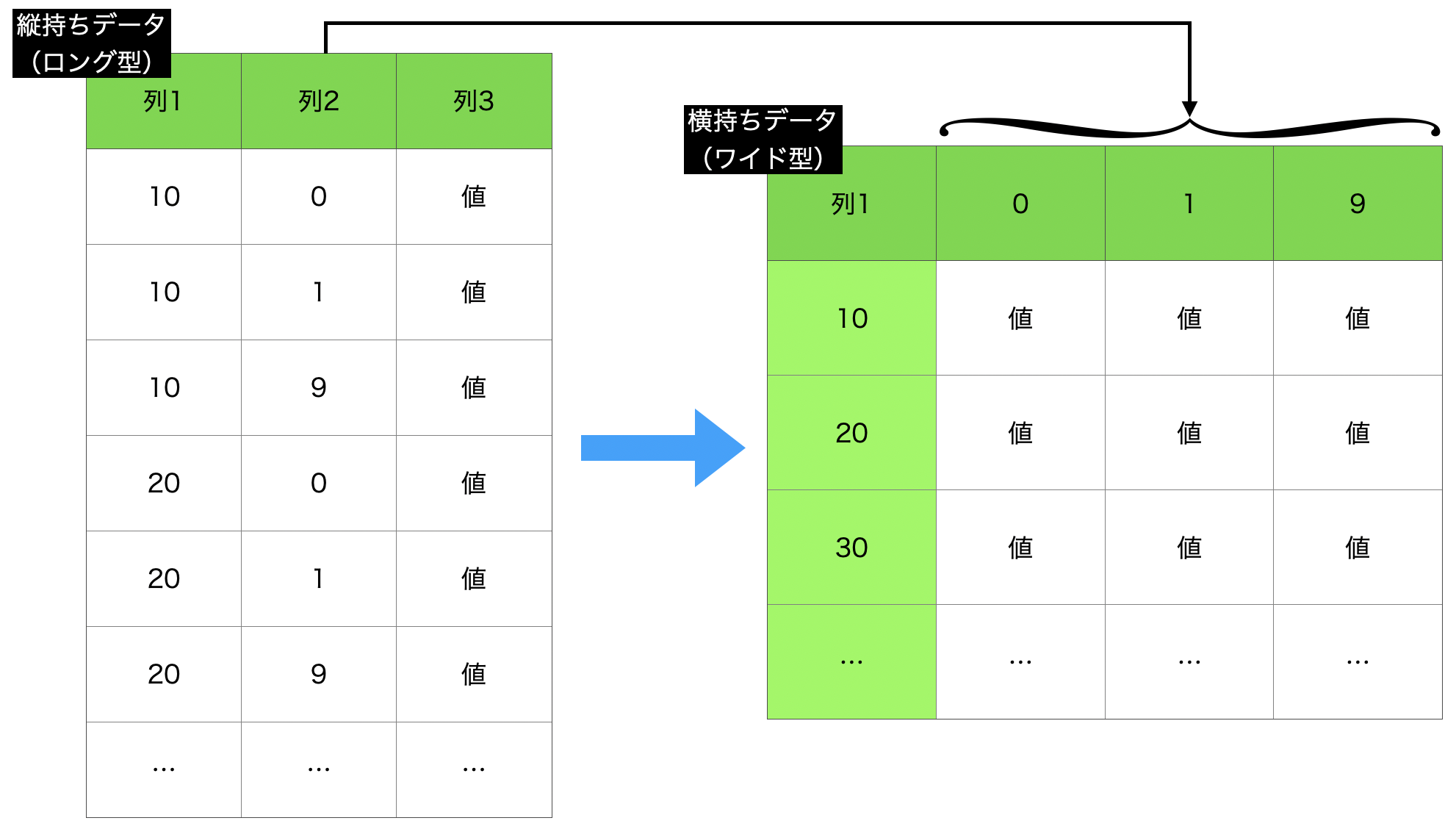
こうすると、横持ちのデータが見やすくてたまりませんよね。
Exploratory で実装しましょう。
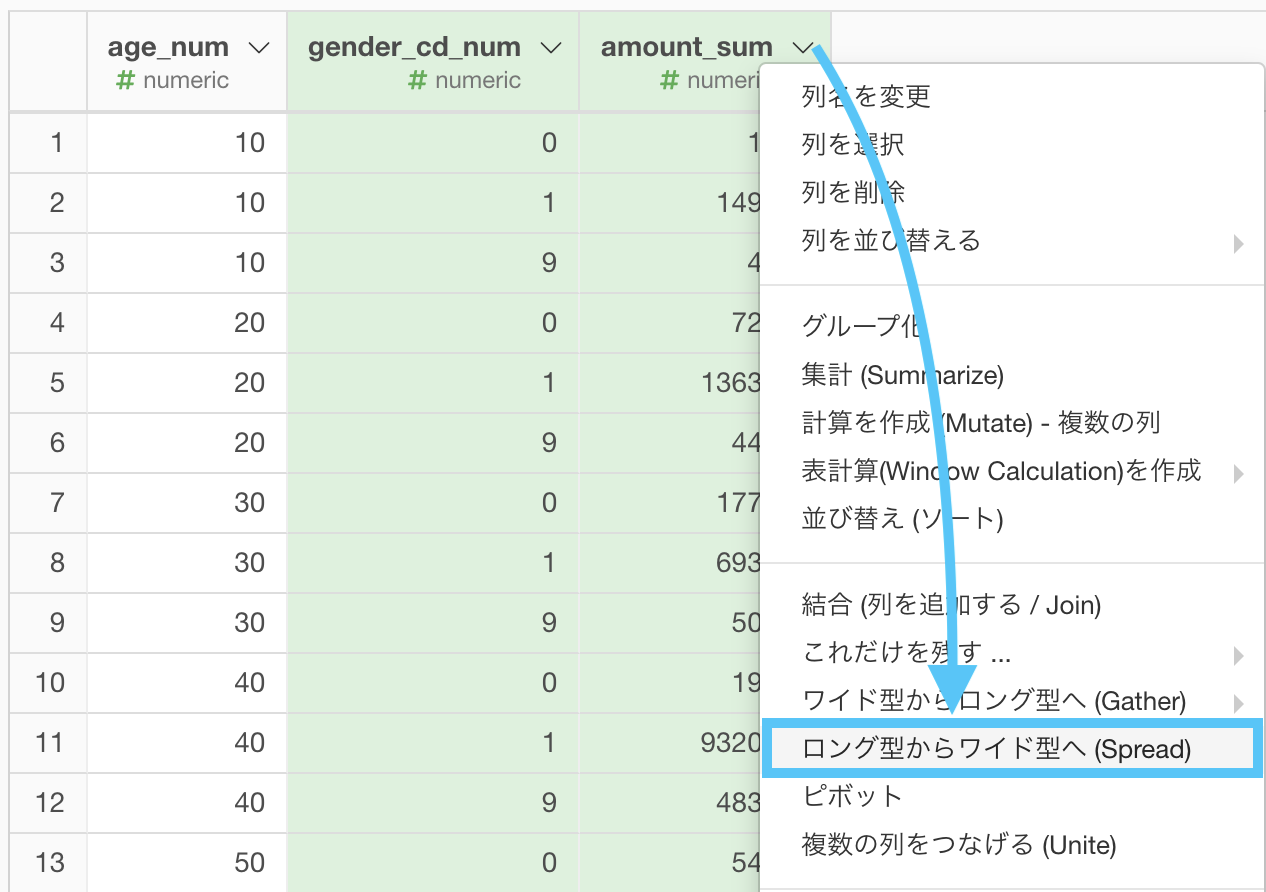
ロング型からワイド型へ (Spread) と書いてありますが、実際にR言語で Spread という関数があります。
このような画面が出てきたと思います。
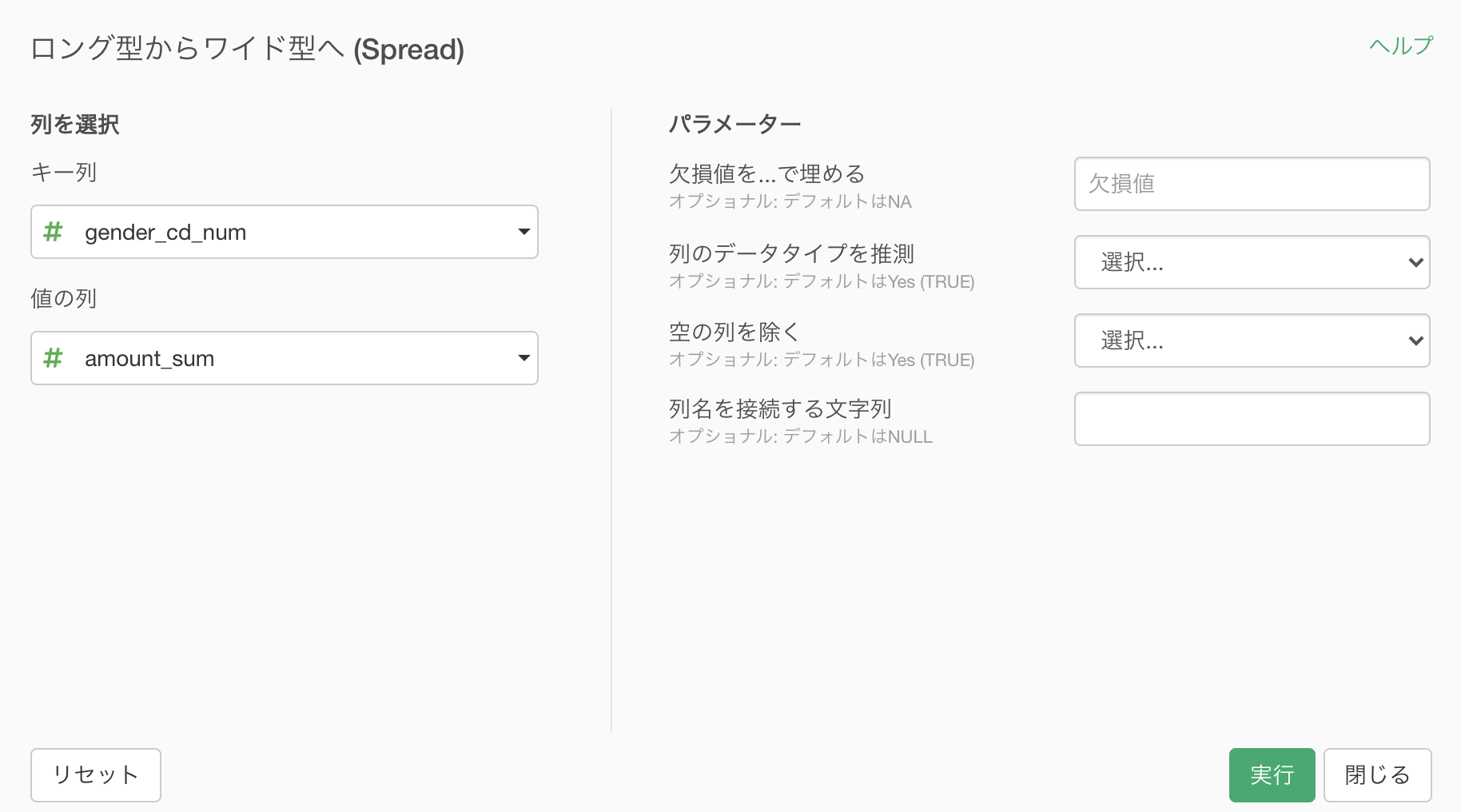
そのまま実行すれば良いです。
せっかくイメージをもったので、対応させます。
このような結果になったと思います。
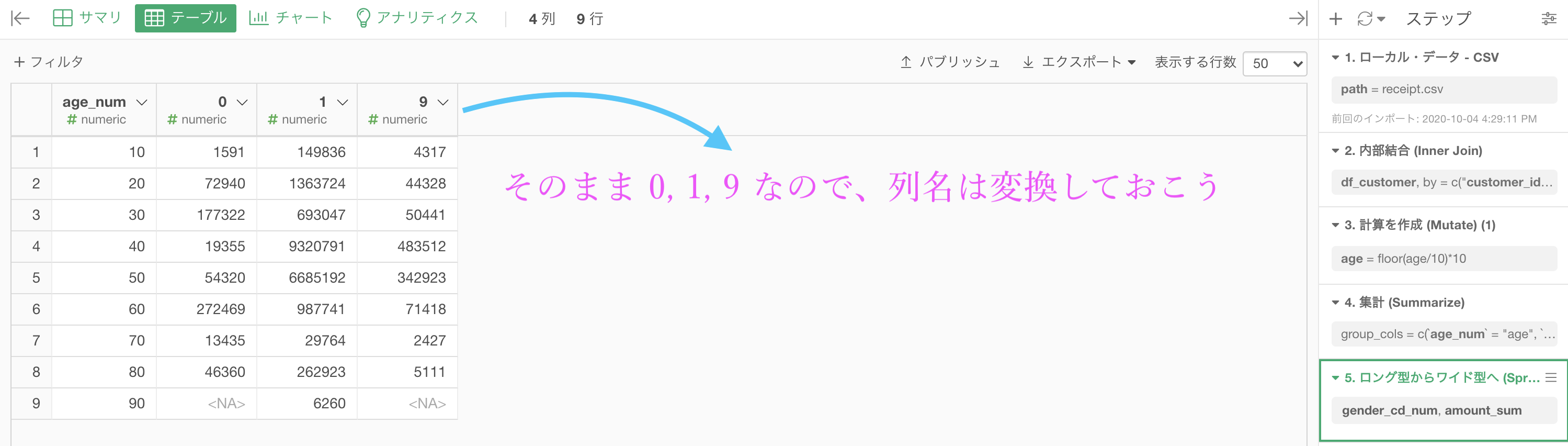
あとは列名を変更するだけで良いので、そこまで問題ではないでしょう。ここでは age も era にしてみました。
結果はこのようになります。解答と確認しましょう。
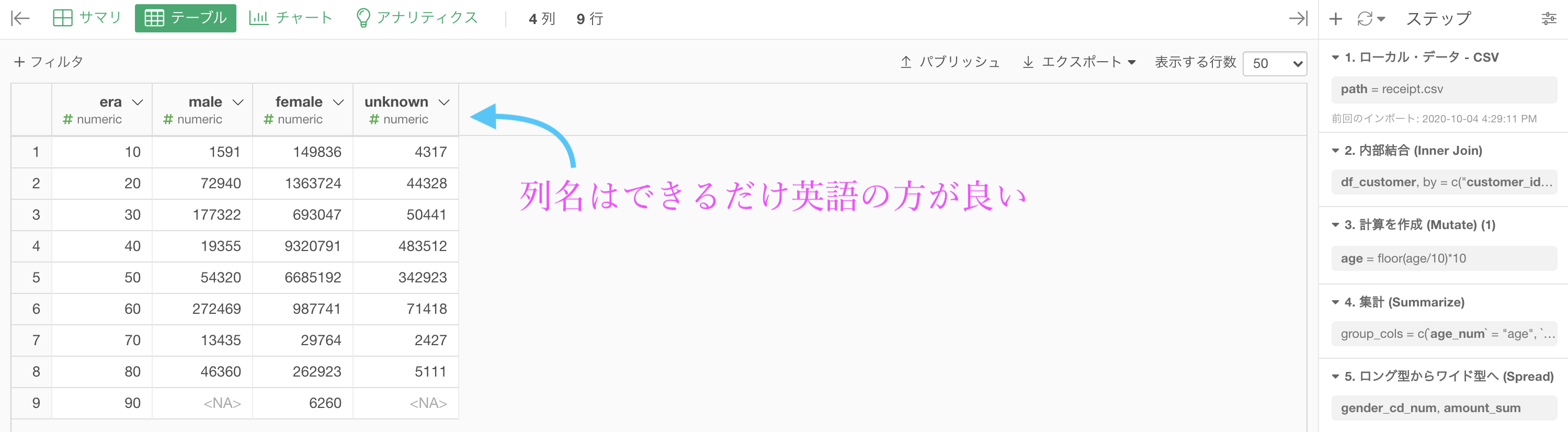
列名を英語で書いてあったり、それを推奨したりしている場合は、コードが英語で書いてあるからだと思うと良いと思います。
実際はコードで動くので、エラー防止のための工夫というわけです。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
df_tmp = pd.merge(df_receipt, df_customer, how ='inner', on="customer_id")
df_tmp['era'] = df_tmp['age'].apply(lambda x: math.floor(x / 10) * 10)
df_sales_summary = pd.pivot_table(df_tmp, index='era', columns='gender_cd',
values='amount', aggfunc='sum').reset_index()
df_sales_summary.columns = ['era', 'male', 'female', 'unknown']
df_sales_summary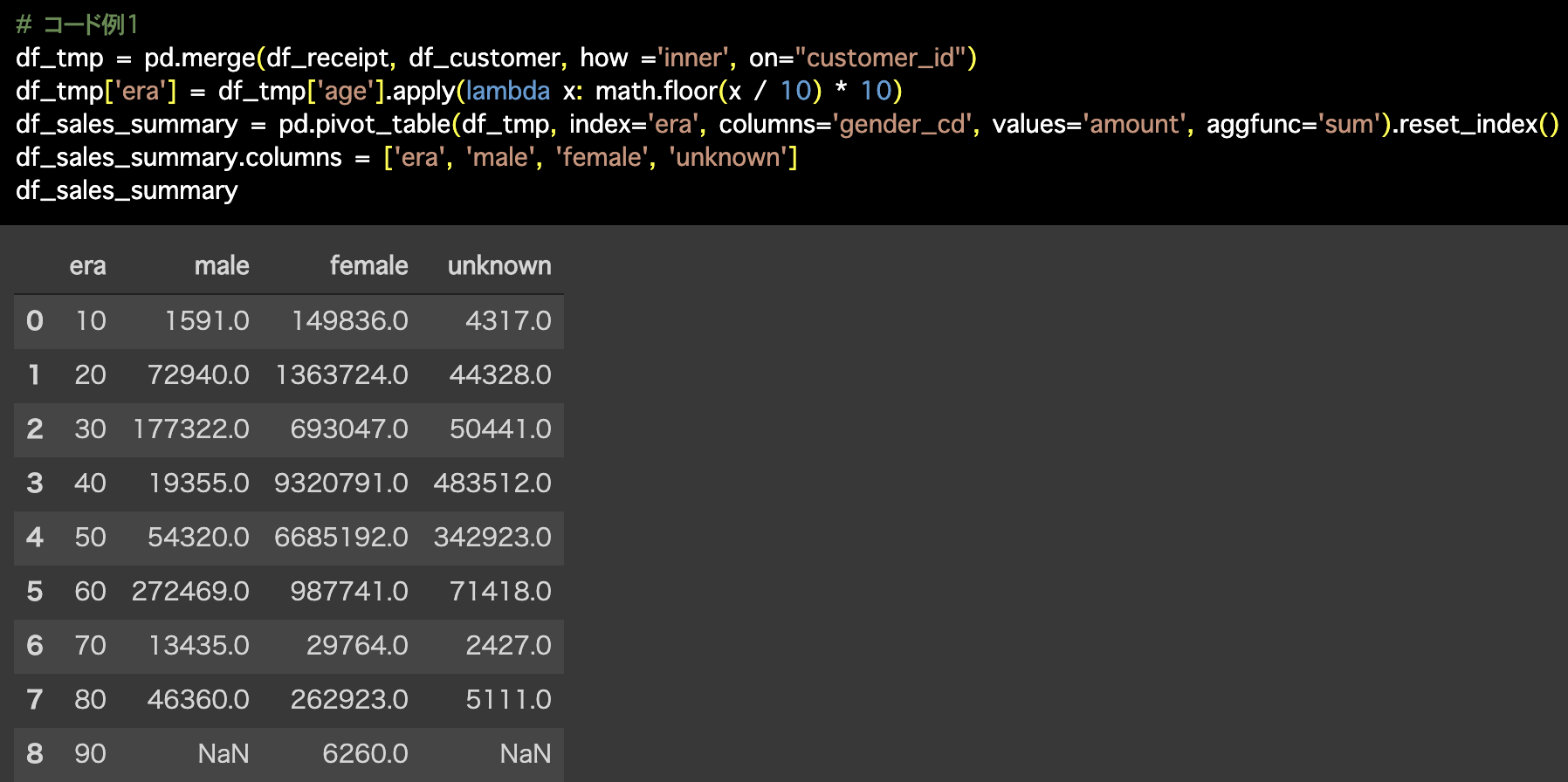
2つ目の解答コードはこのようになっています。
# コード例2
df_tmp = pd.merge(df_receipt, df_customer, how ='inner', on="customer_id")
df_tmp['era'] = np.floor(df_tmp['age'] / 10).astype(int) * 10
df_sales_summary = pd.pivot_table(df_tmp, index='era', columns='gender_cd',
values='amount', aggfunc='sum').reset_index()
df_sales_summary.columns = ['era', 'male', 'female', 'unknown']
df_sales_summary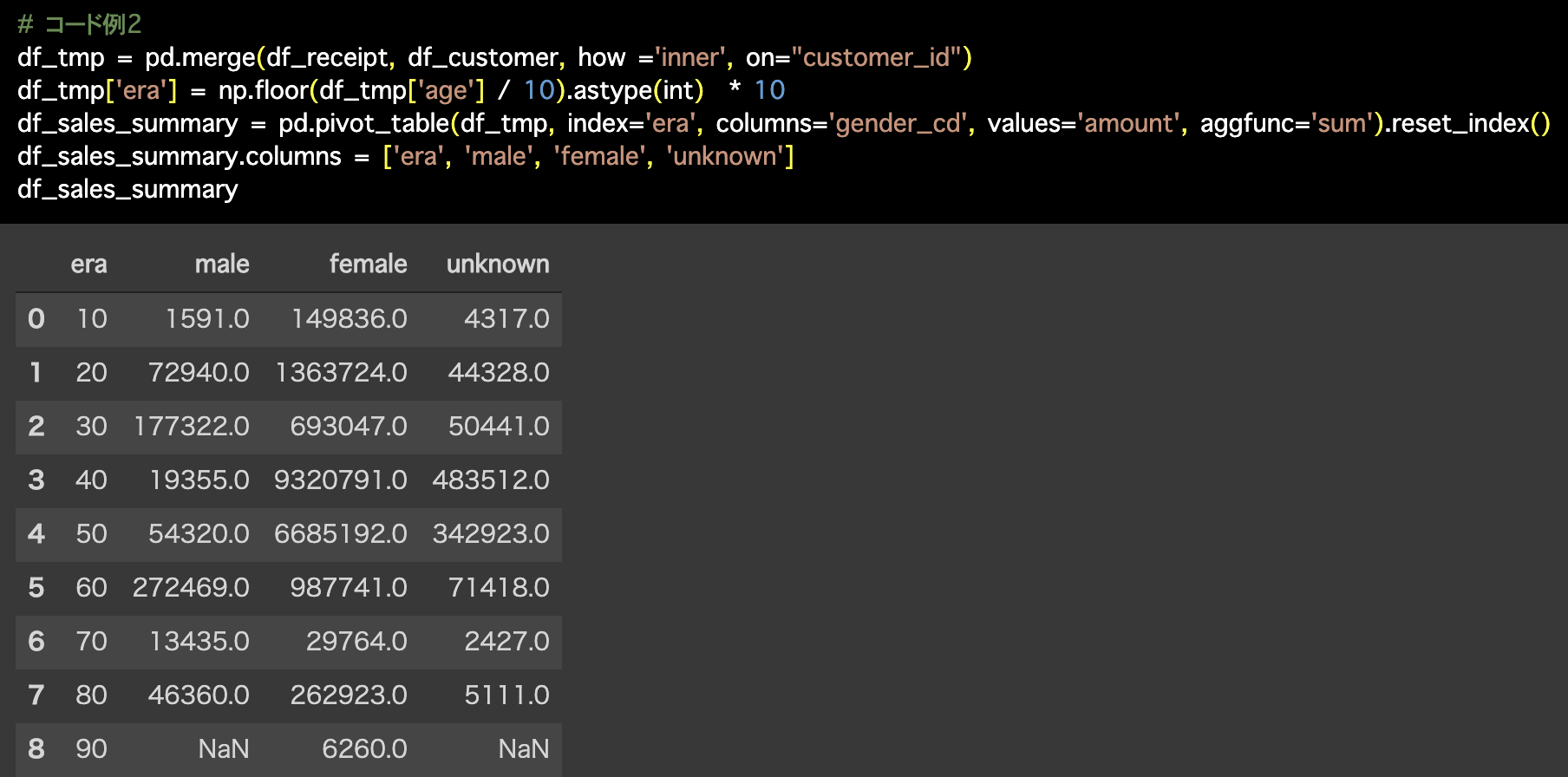
年齢を年代にした操作
データを処理している途中、このような式が出てきました。
floor(age/10)*10これは次のように計算がされているので、イメージしながら考えるとわかりやすいと思います。 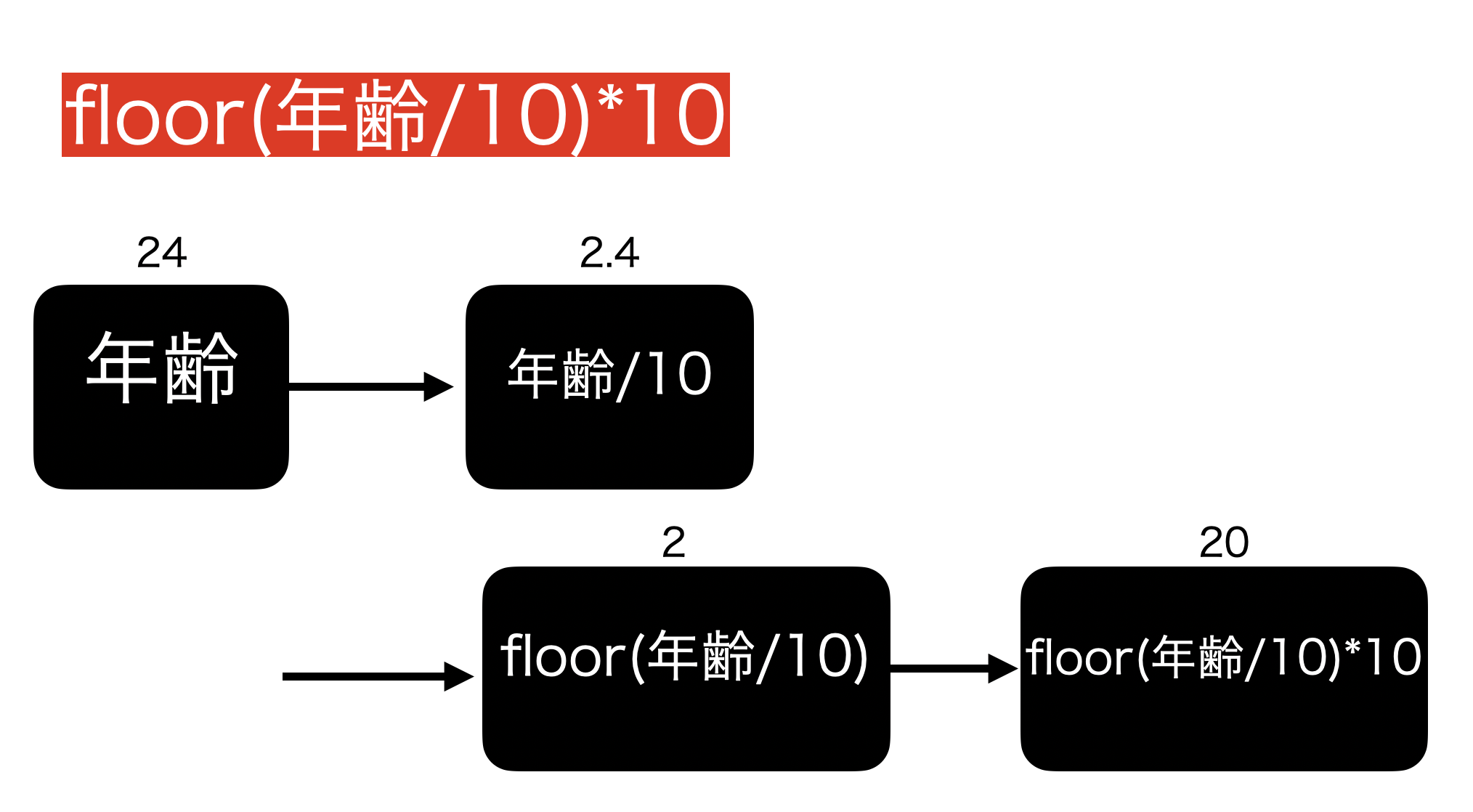
わかりやすいように、age は 年齢 と書いていますが、大事なのは数値の流れです。
途中にある floor(フロア)というのは、整数部分だけ取り出す関数(ガウス記号のこと)です。
floor(2.4) = 2 : 整数部分だけ取り出す
floor(3.1415) = 3 : 小数点のところは無視!という具合で考えれば良いと思います.
問43 の結果そのままの状態で 問44 に行きましょう。
問44 : 横持ちデータを縦持ちデータに変換する

答案・解説はこちら
をやってみましょう。
予告通り、問43 の処理をほぼそのまま引き継ぎます。
やりたいことはこのように、横持ちのデータ(ワイド型)→ 縦持ちのデータ(ロング型)にすることです。
問43 の逆変換のことなので、イメージは付きやすいかと思います。 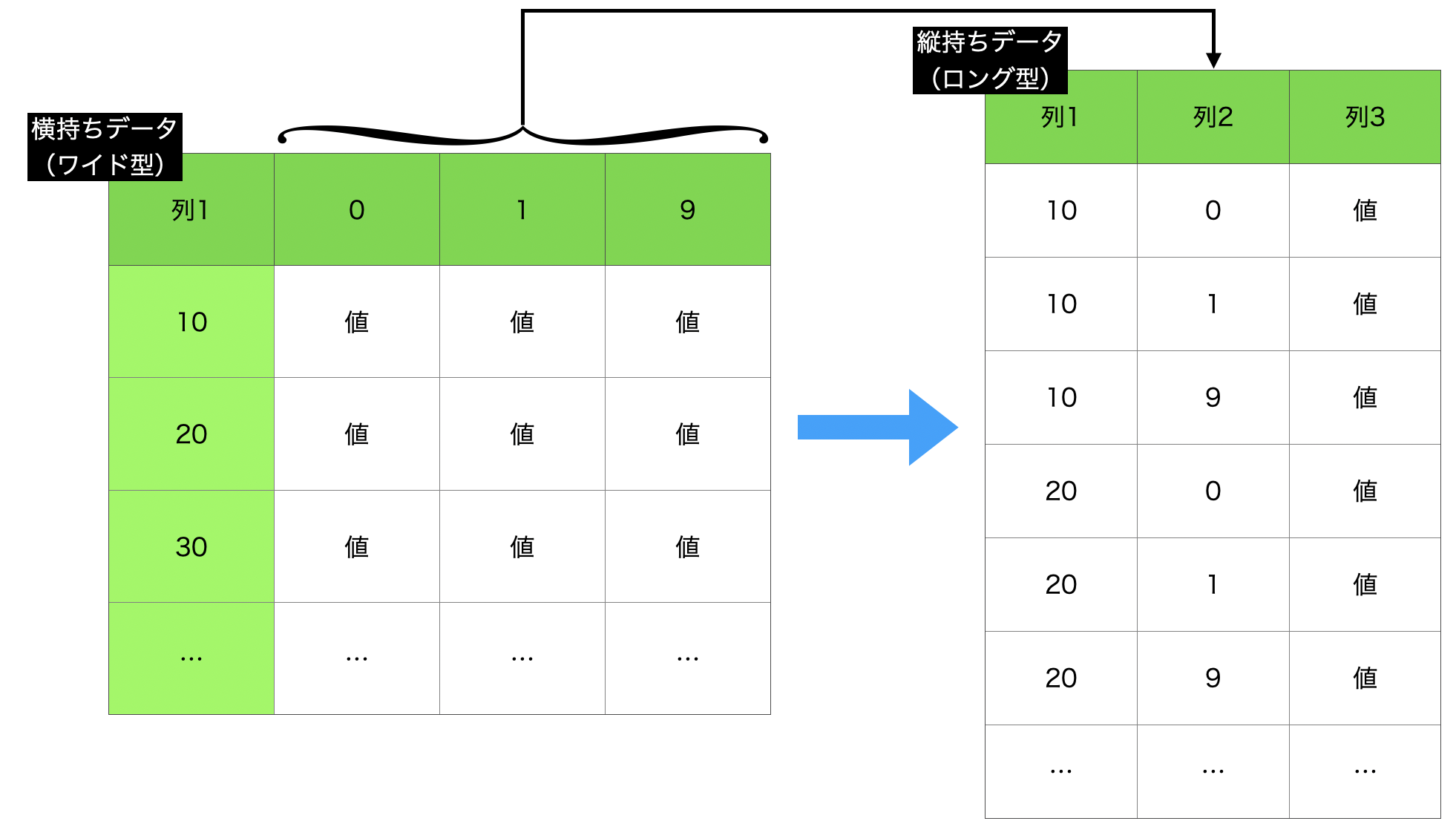
Exploratory で実装するときには、3つの列を同時選択して「ワイド型からロング型へ (Gather) → 選択された列」をクリックします。
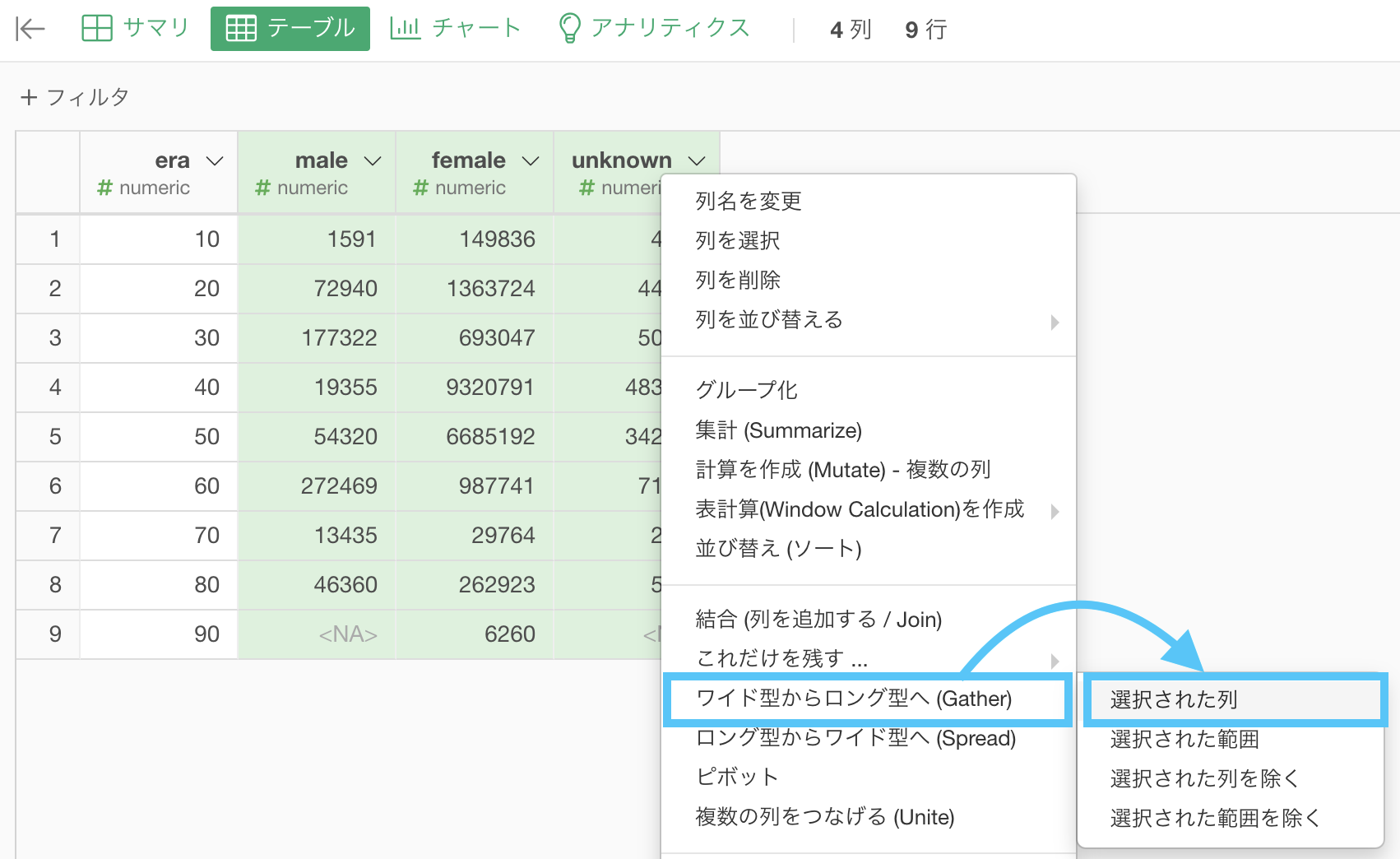
このような画面が出てきたと思います。
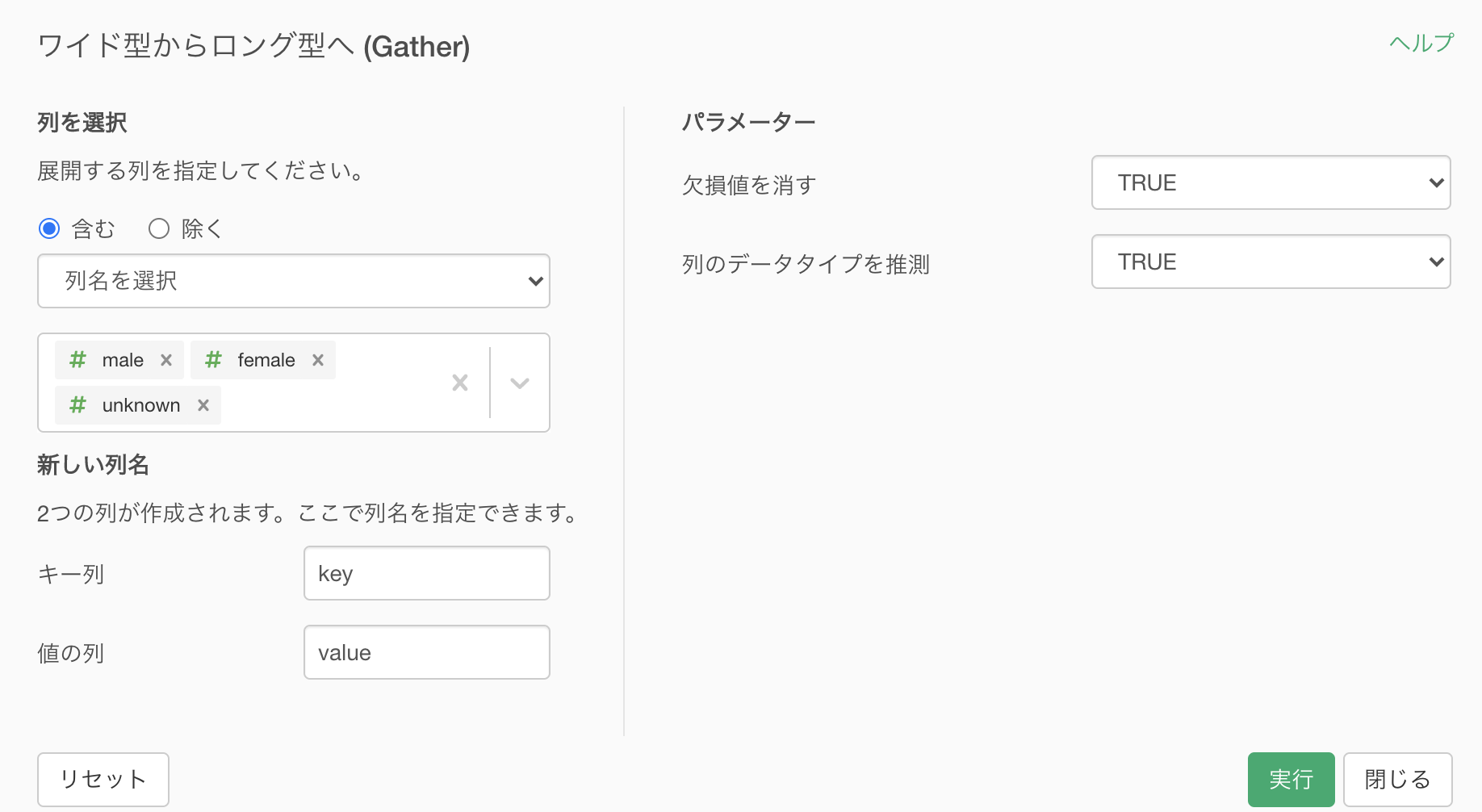
こちらも、何もせず実行すれば良いです。
せっかくイメージをもったので、対応させます。
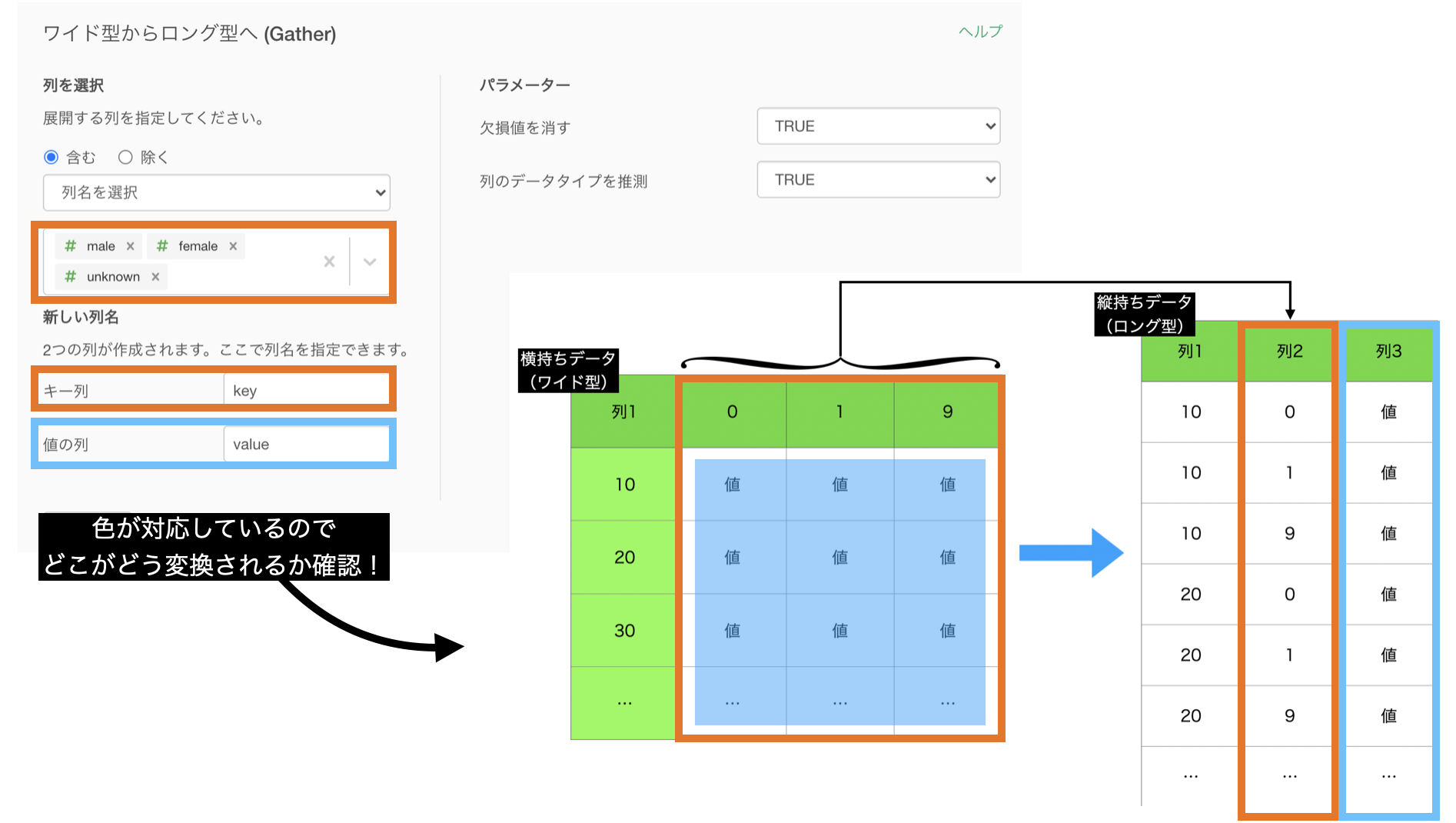
結果はこのようになったと思います。
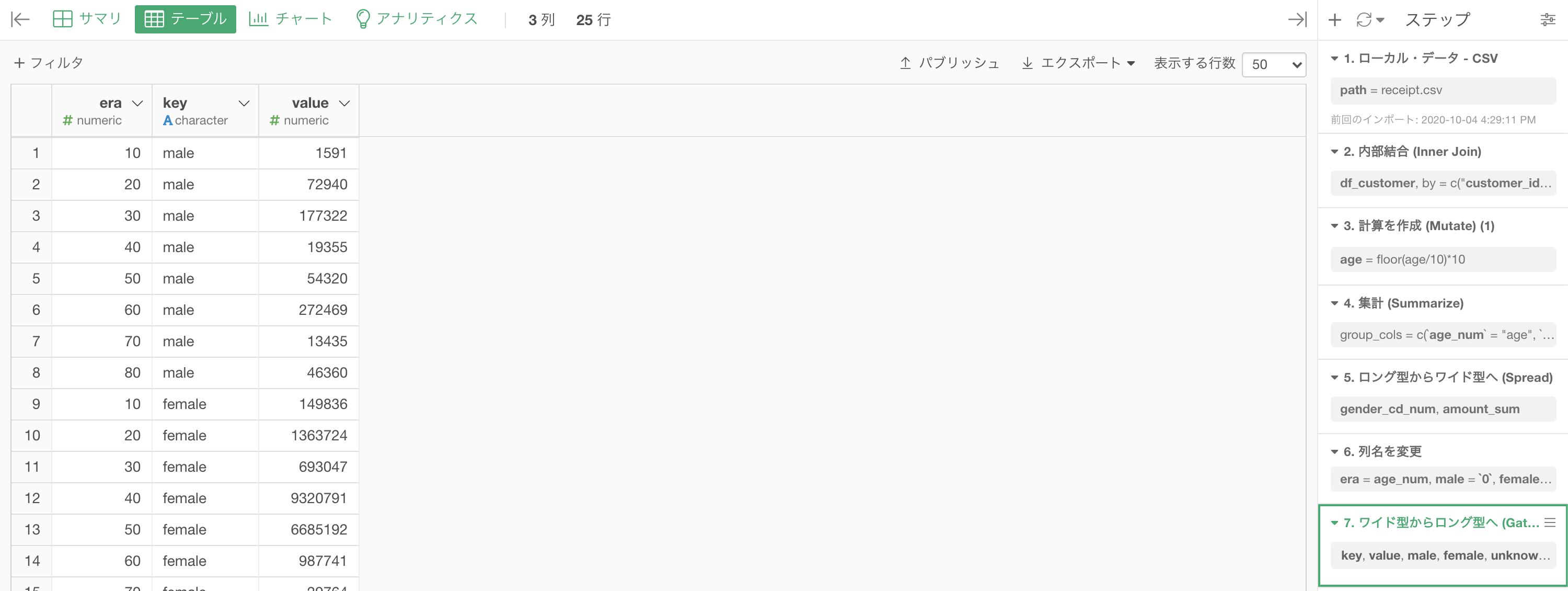
せっかくここまできたからキレイにしたい人へ
あとは問題文にあるように、性別コードは
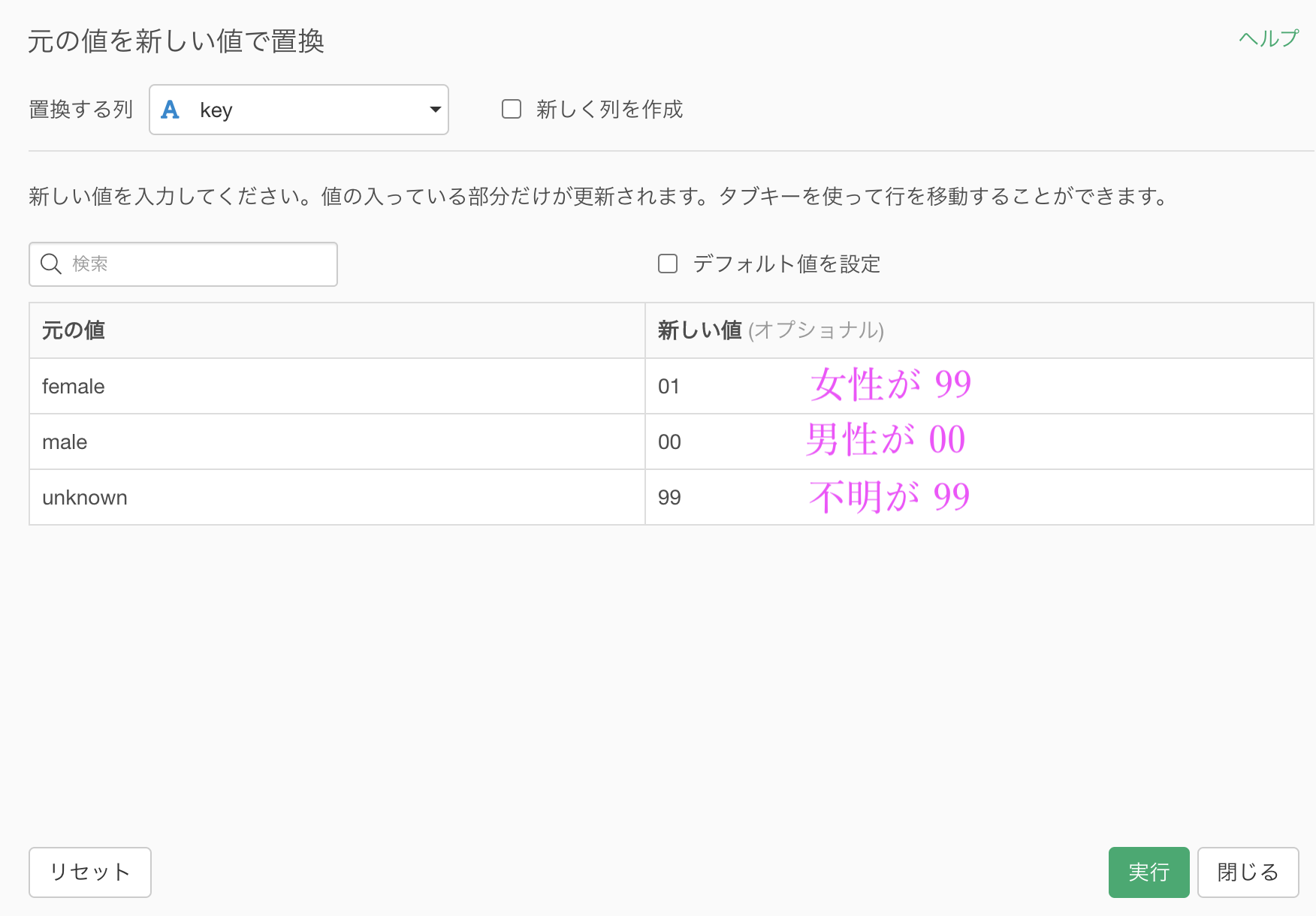
男性(male)が 00, 女性(female)が 01, 不明(unknown)が 99にします。
「値を置き換える → 新しい値を指定」とします。
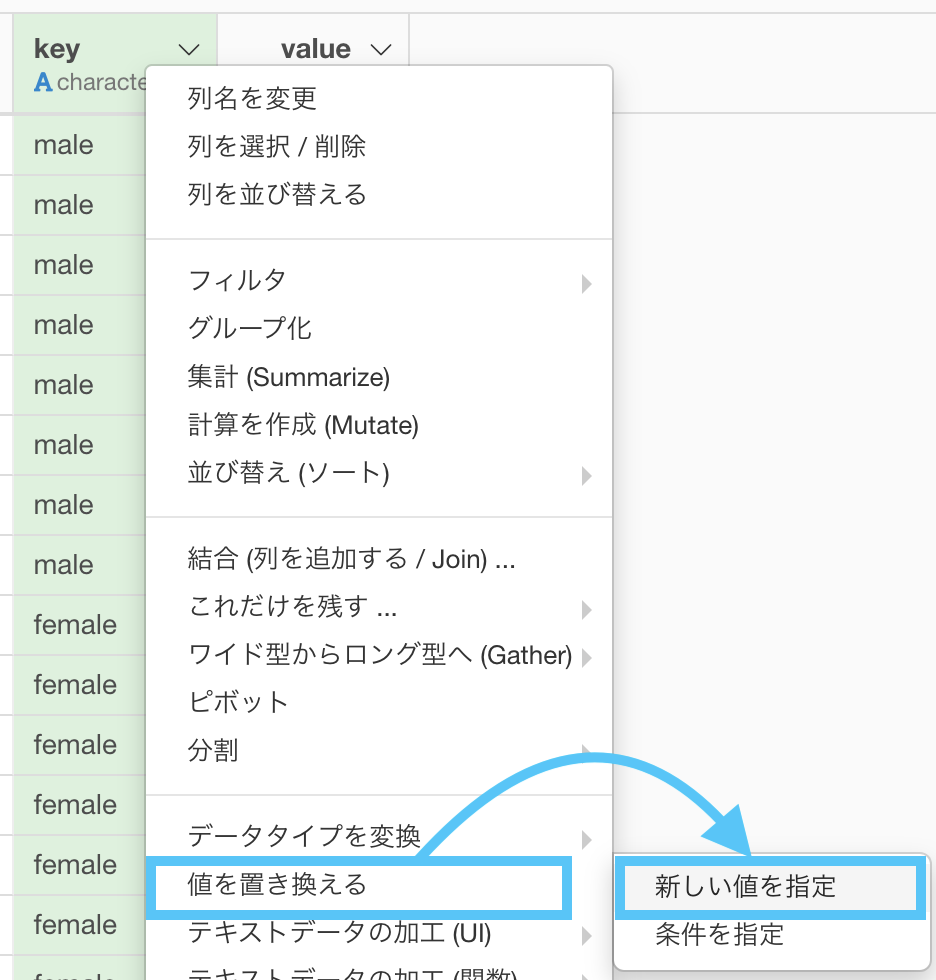
このように対応させたら、あとは実行するだけです。
あとは列名を変更するだけで以下のような結果にこのようになります。
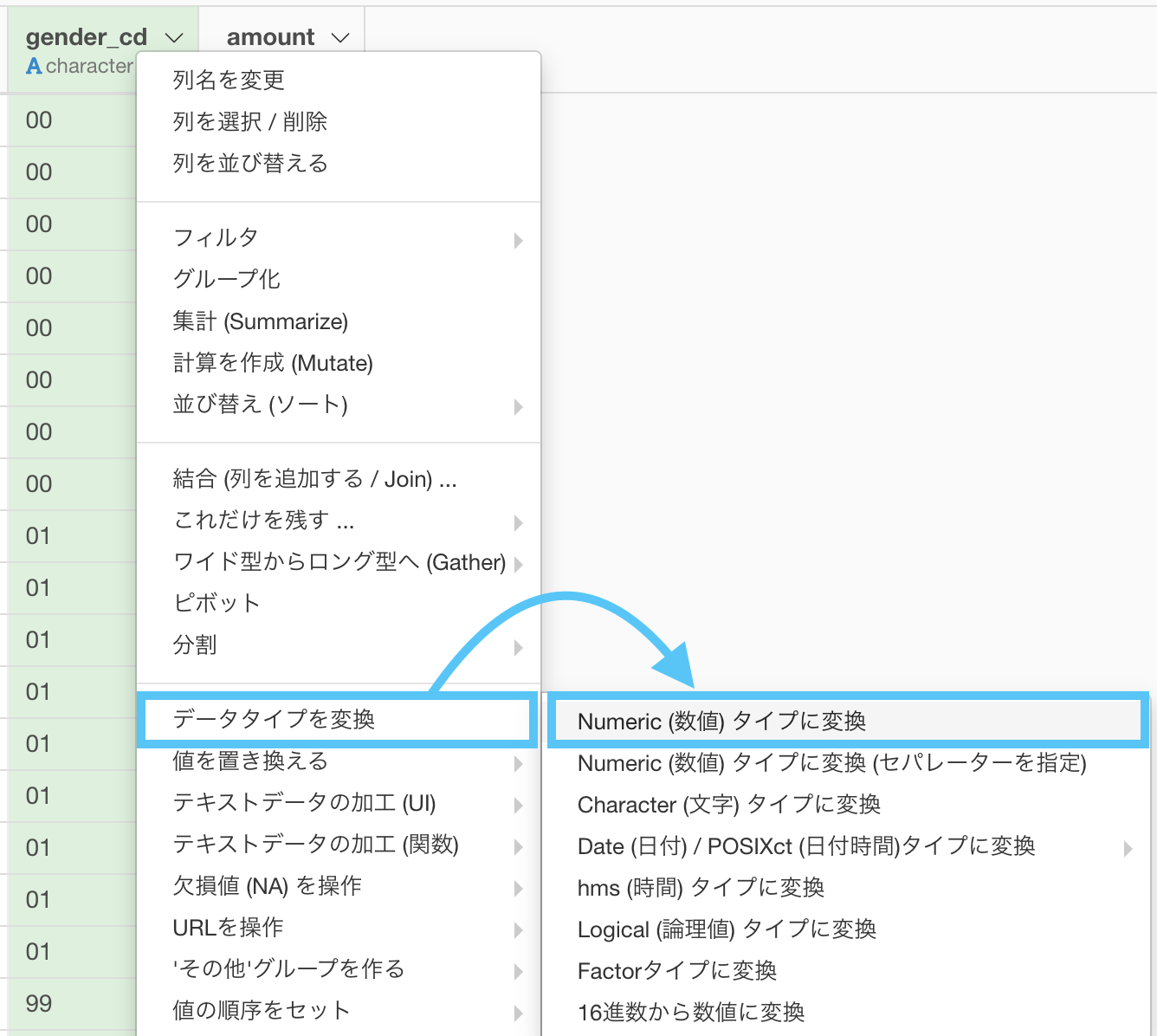
また、データタイプも気になる方は気になります(気にしないとこれからが大変です!)ので、変更しましょう。
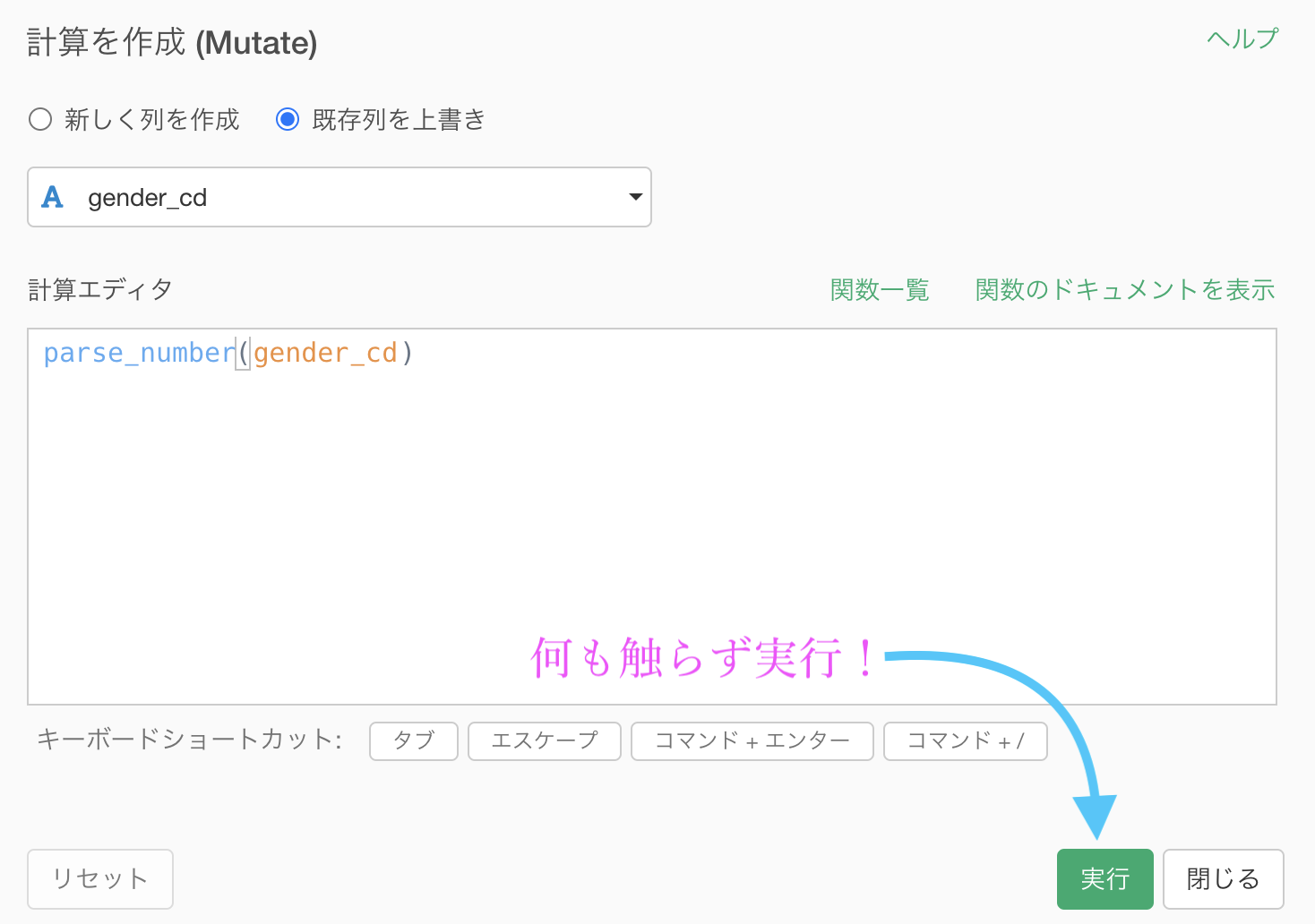
出てきた計算エディタは何も触らず実行します。
これで元通り...と思いきや、ソートも必要でした(R言語の解答の方はここまでで良いですが、Python言語の解答の方は表示が異なっていましたので)。
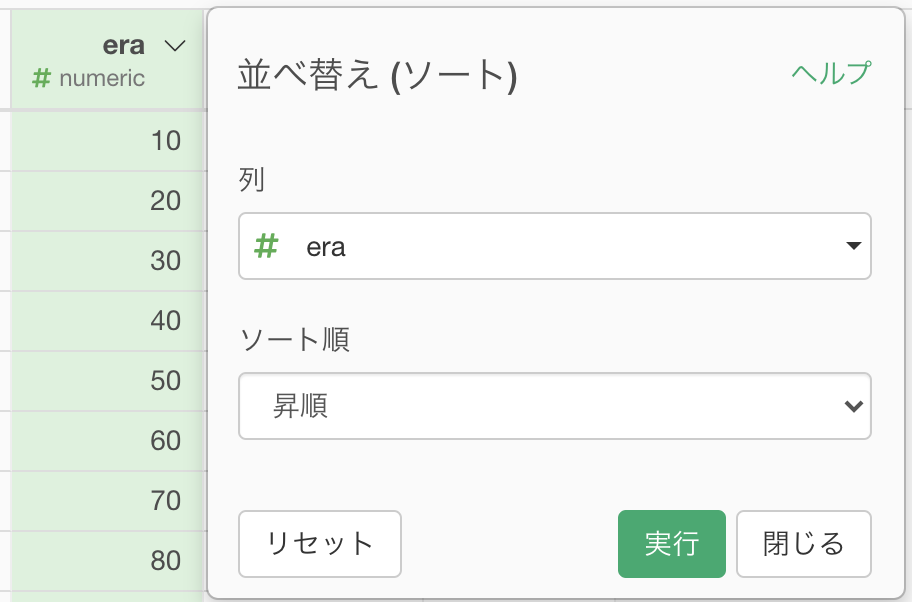
これまでの処理は全て既出ですので、詳しく説明しませんでしたが大丈夫でしょうか。
問44 自体は既にワイド型からロング型へ処理したときに既に終わっていますので、横道にそれていただけですが、どれも復習にしてはちょうど良いと思います。
結果はこのようになります。解答と確認してください。
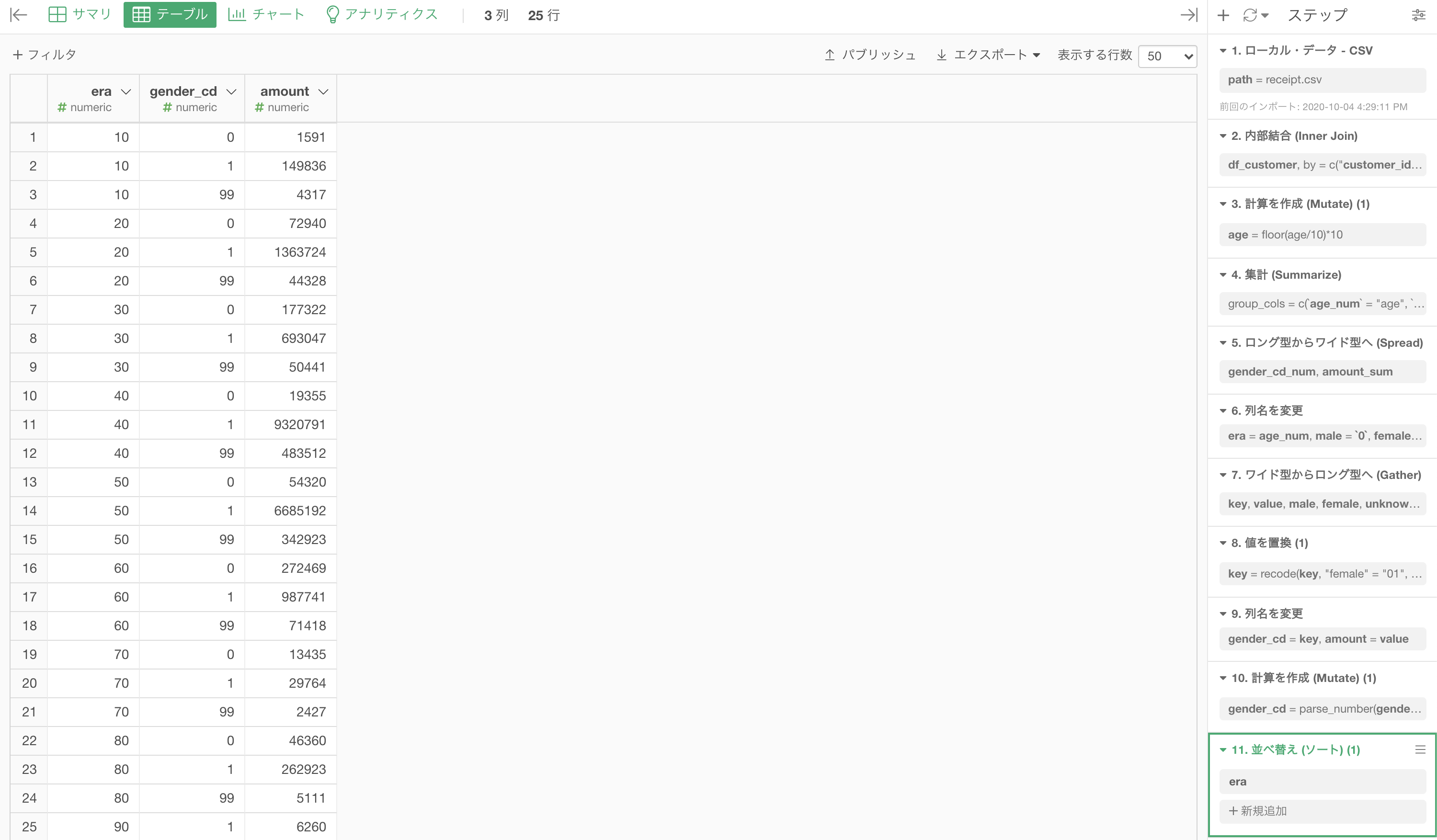
Python 解答コードはこちら
解答コードはこのようになっています。
df_sales_summary = df_sales_summary.set_index('era'). \
stack().reset_index().replace({
'female':'01',
'male':'00',
'unknown':'99'}).rename(columns={'level_1':'gender_cd', 0: 'amount'})df_sales_summary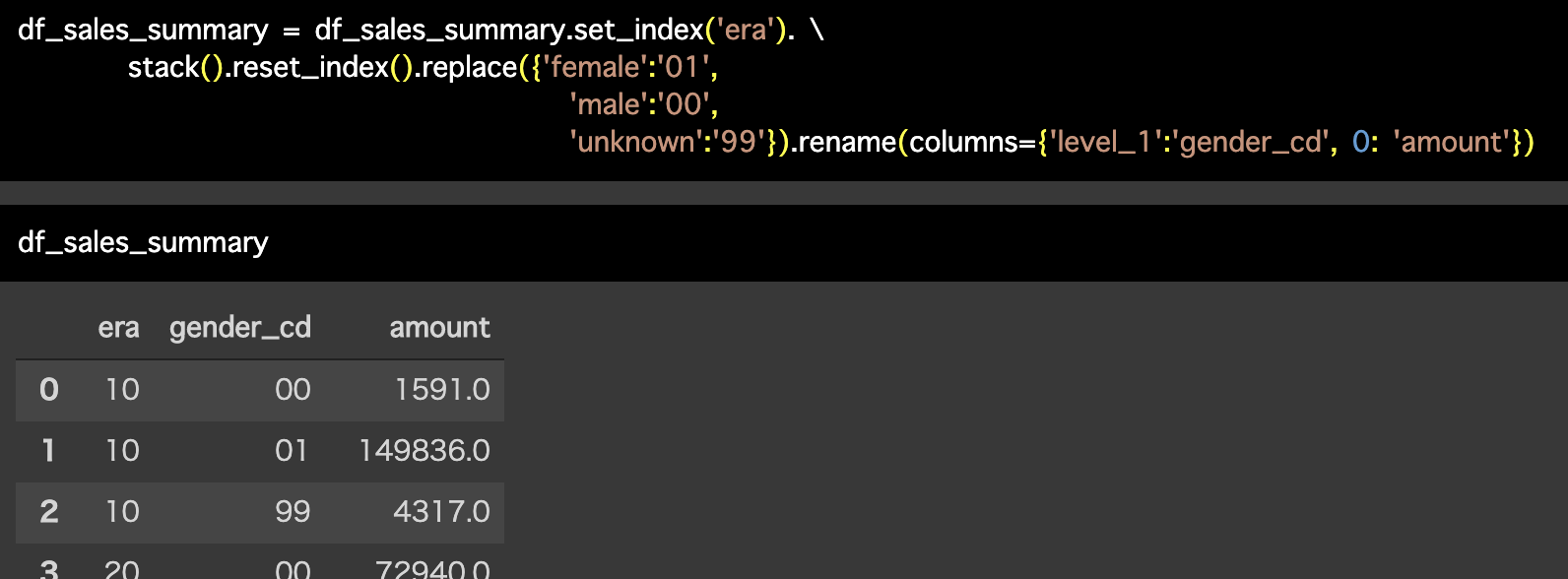

ワイド型とロング型の雑談
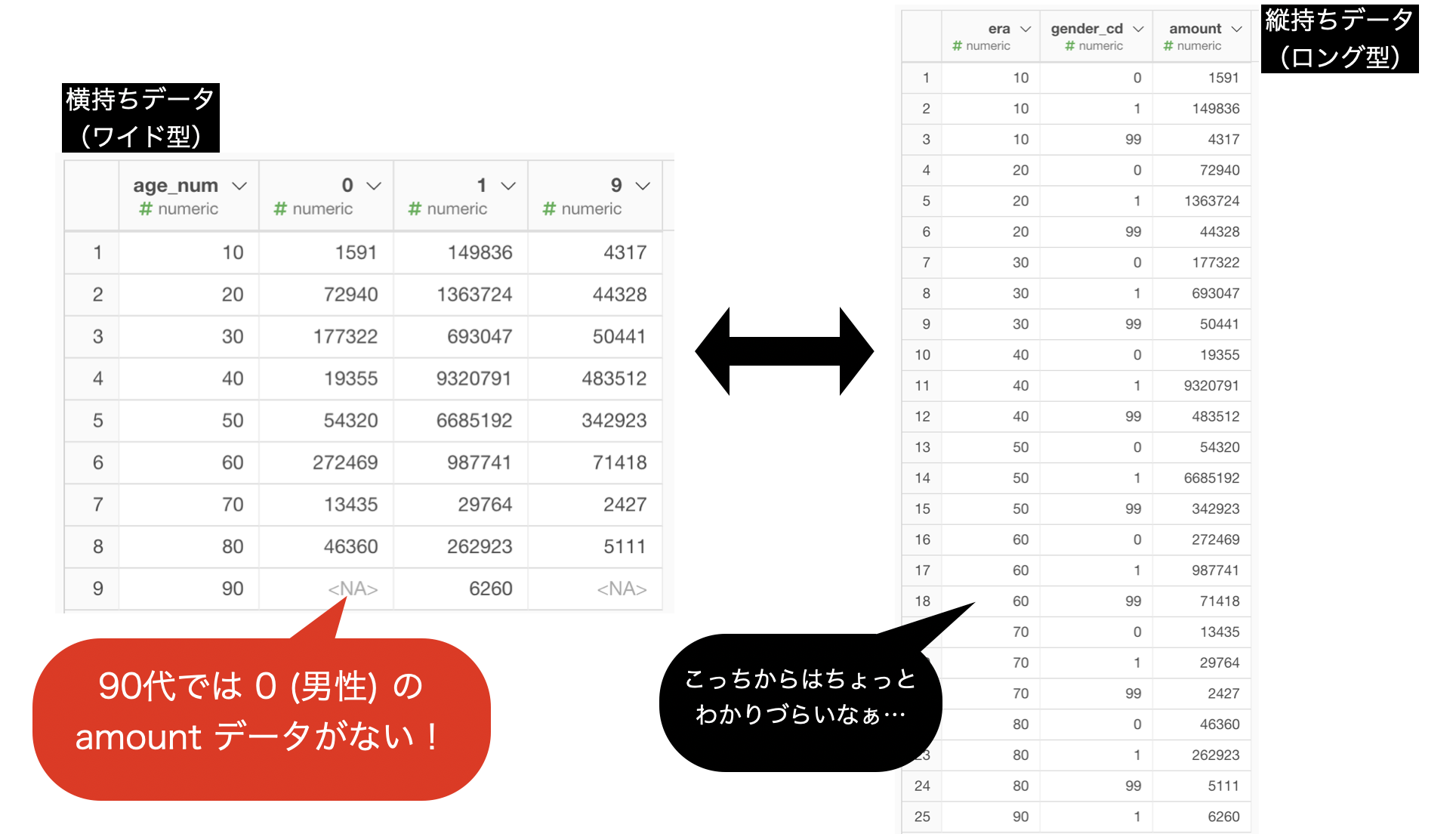
横道が長くなりましたが、ワイド型からロング型にしたときに NA が消えていること に気付いたでしょうか(ステップをクリックして移動し、確認しましょう!)。
NA になっているところは、組み合わせ自体は理論的にあるんだけれども、そこにデータがなかったということです。
今回で言えばつまり、以下のようなことに気付けた人はワイド型とロング型の心が芽生え始めていると思います。
問45 : 日付型データを文字列データに変換する

答案・解説はこちら
まずここでやることは
です。
ちなみに文字型(character)にすると、テキストデータに使える関数をほぼ全て味方につけたことと同じだと思って良いです。
まず df_customer を開いて、customer_id と birth_dayの 2列 にします。

次にbirth_day を選んで、データタイプを変換する →「Character(文字)タイプに変換」します。
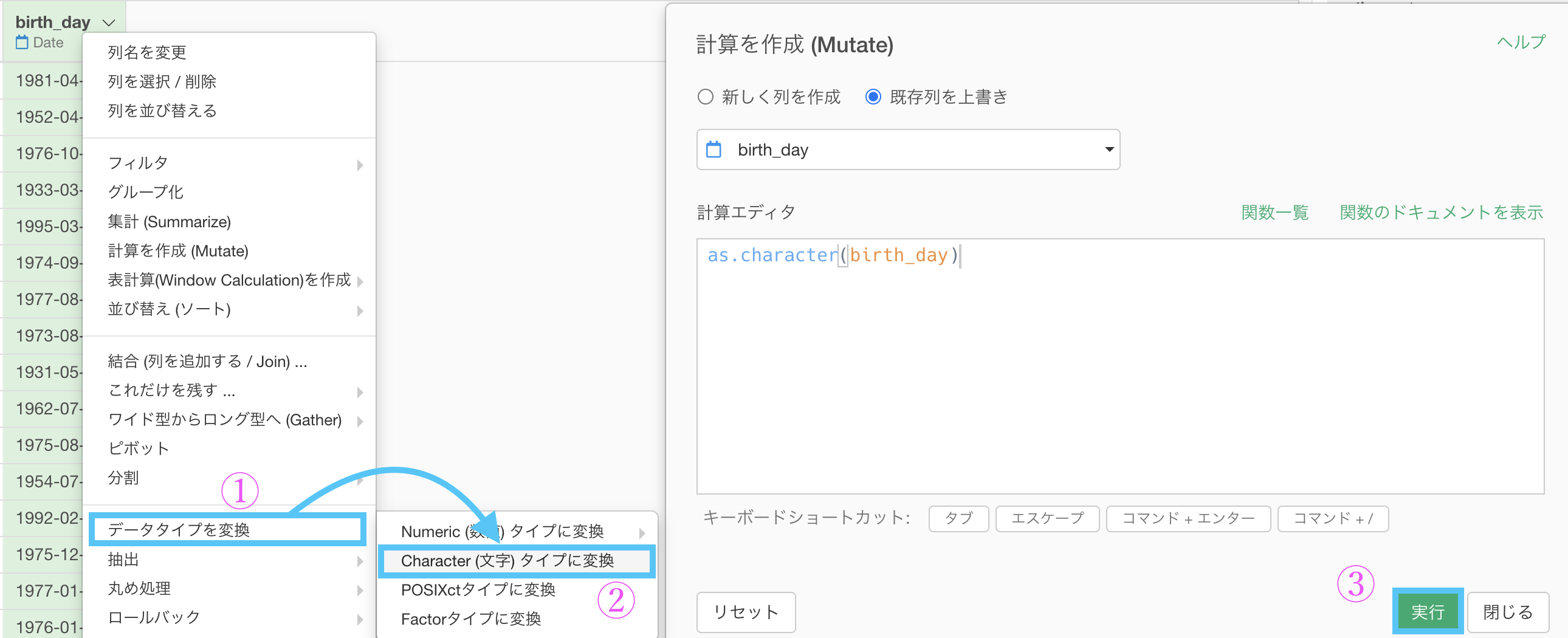
これだけではハイフンが取り除かれていないので、テキストデータの加工 (UI) → 「取り除く」を選択します。
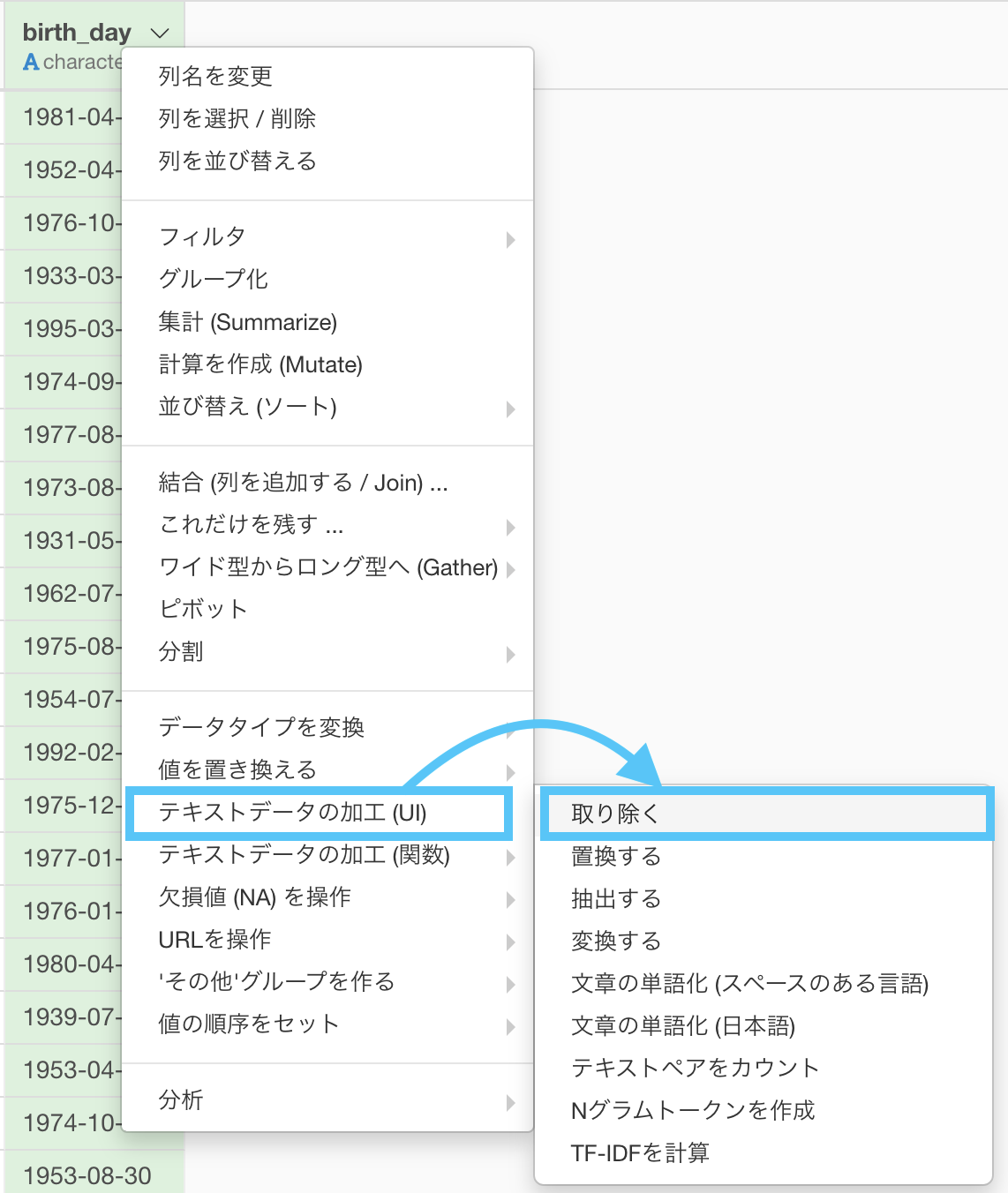
するとこのような画面が出てきたと思います。
1, 2 の手順で設定します。
1 : テキスト(全て) を選択する
2 : ハイフン(-)を入力する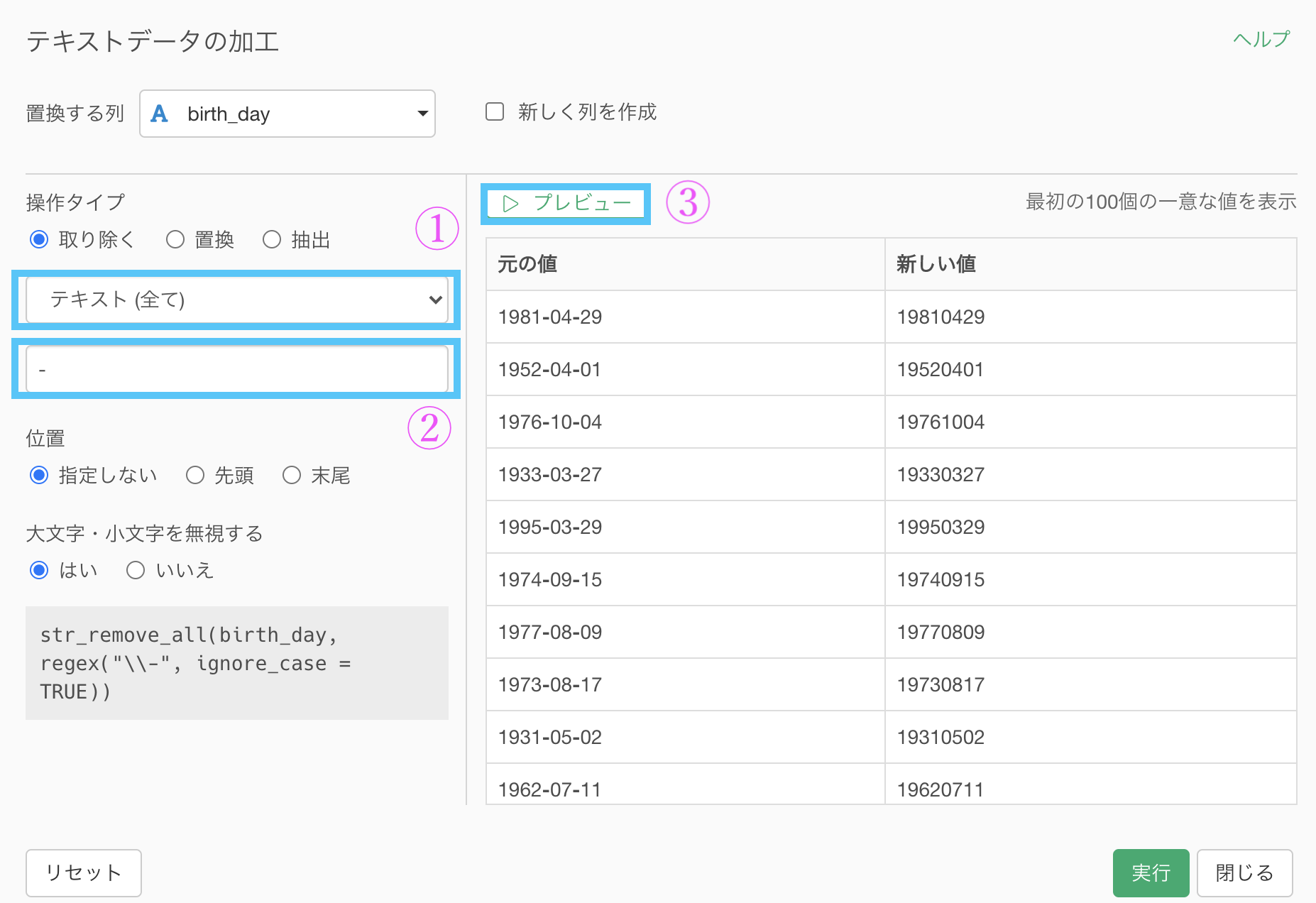
3 を押してプレビューしてOKだったら実行しましょう。
結果はこのようになります。解答と確認しましょう。
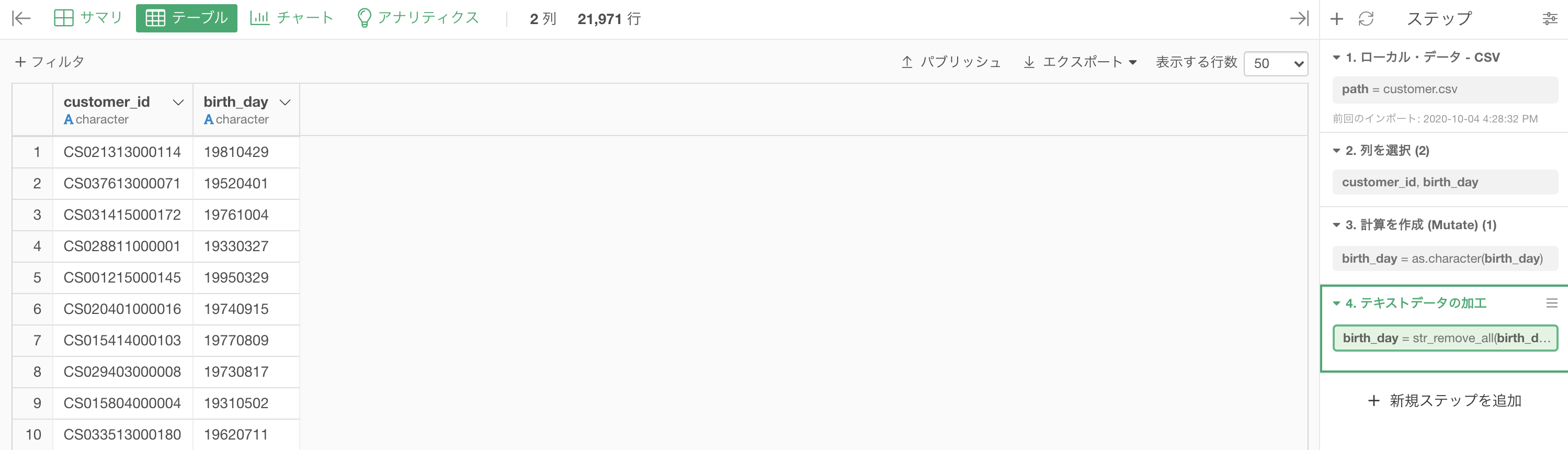
Python 解答コードはこちら
解答コードはこのようになっています。
pd.concat([df_customer['customer_id'],
pd.to_datetime(df_customer['birth_day']).dt.strftime('%Y%m%d')],
axis = 1).head(10)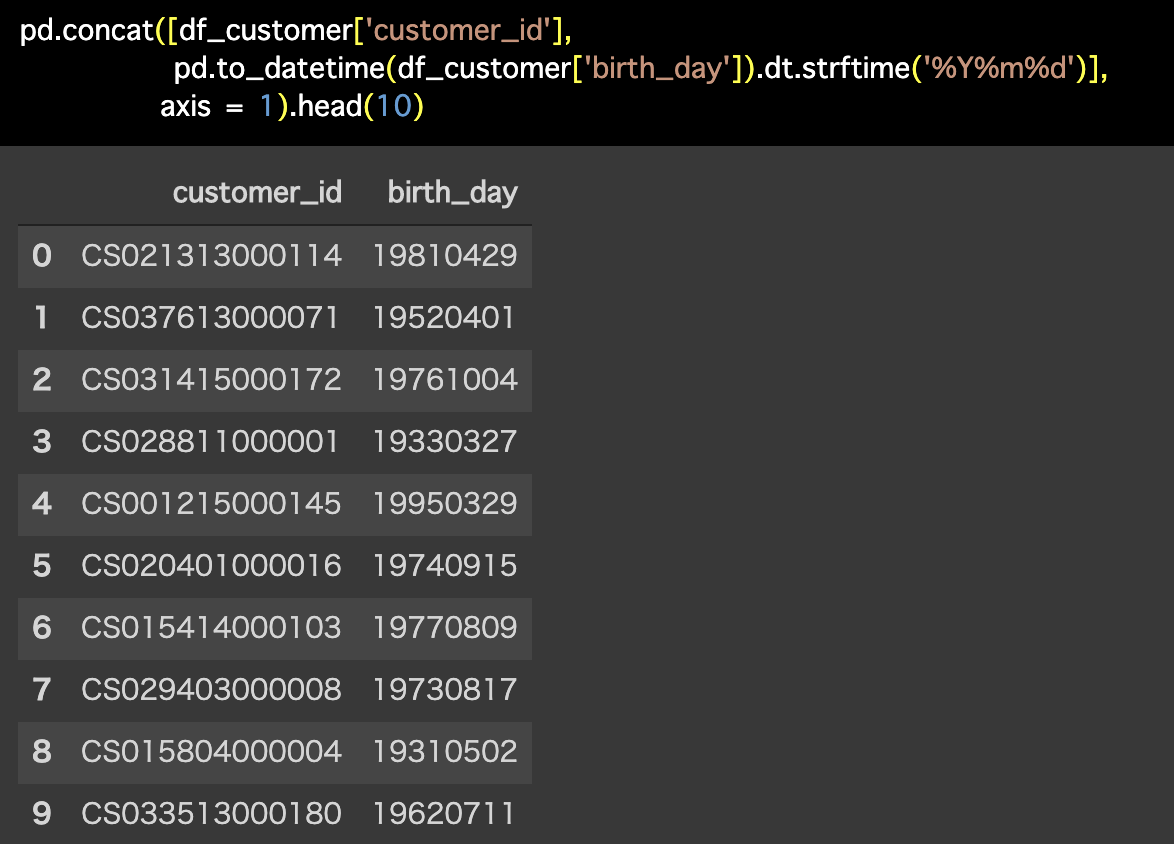
せっかくなのでちょっとした豆知識
問題文に書いてあった YYYMMDD形式とは...
YYYYMMDD形式 : Yはyear(月), Month(火曜), DD(日) の略称のことです。
また話は少し変わりますが、別解も載せておきます。
最後の処理(ハイフンを取り除く処理)はテキストデータの加工 (関数) → 「数値を取り出す」とします。
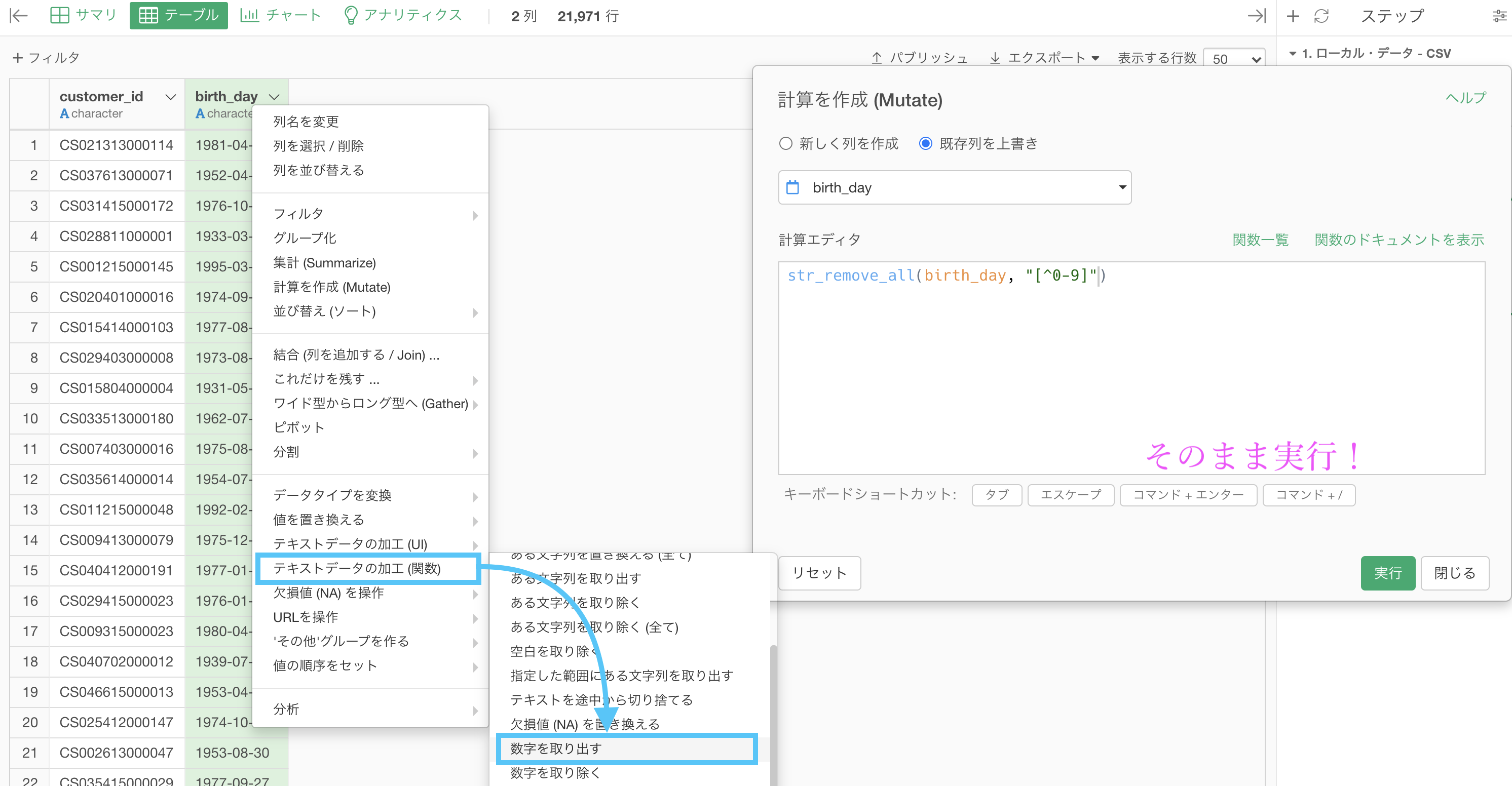
何も触らず実行することで、答案と同じ結果同じ結果が得られるはずです。
これは単に数値にしか残さないという処理なので、他のテキストデータにする場合は結果が違ってきます。
今回のデータは数値の他にハイフンしかないからたまたま一致するというだけです。
ちなみにコマンドの中にある [^0-9] の部分に、あれ?これどこかで見たことあるなぁ...と思ったら、よく勉強している証拠だと思います。
フィルターの問題でこの書き方は出てきていますので、もう一度やってみるのも良いかと思います。
問46 : 文字データを日付型データに変換する

答案・解説はこちら
よくよくみると application_data のところは numeric (数値)タイプになっていて、文字データになっていません。
問題文と整合性が取れていないような気がするのですが、それに関しては解答コードの中にある折りたたみに書いておきましたので参照ください。
です。
データタイプの変換についての話で、変換前のデータタイプが何であるかはぶっちゃけそこまで本質ではなかったりします。
とりあえず変換できるのかできないのか....そして変換の仕方はどうするのか?
ぶっちゃけこの2つしか考慮に無いのです。
まぁ暴論はこの辺にして、早速 application_date(申し込み日) のデータタイプを日付型に変換してしまいましょう!
まず application_date のデータをきちんと見ます。
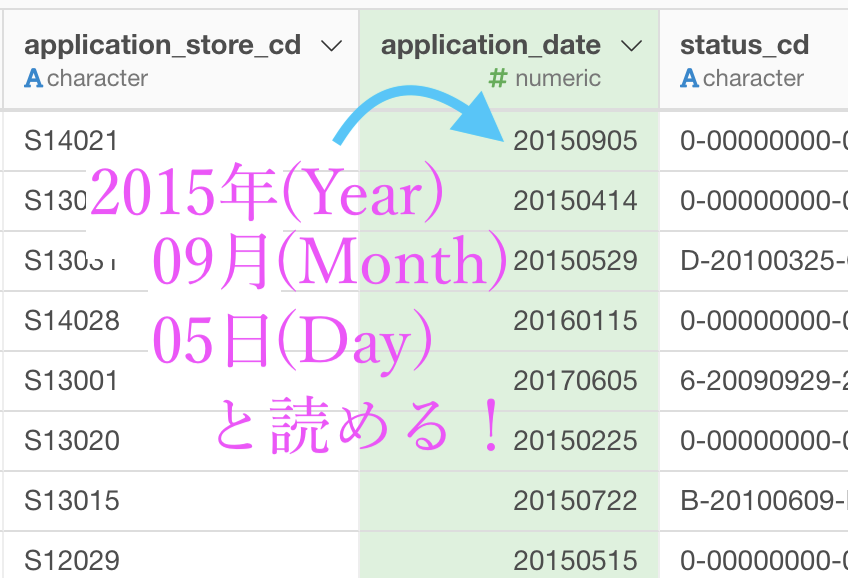
20150905 : 2015年 09月 05日 と読める. 他の数値も全部そう1という場合にはぜひ、日付型に変換だな!と思った方が良いです。
あとは簡単です。
データタイプを変換 → Date (日付) ... タイプに変換 → Year, Month, Day を選択します。最後の最後で読み方が効いてきます。
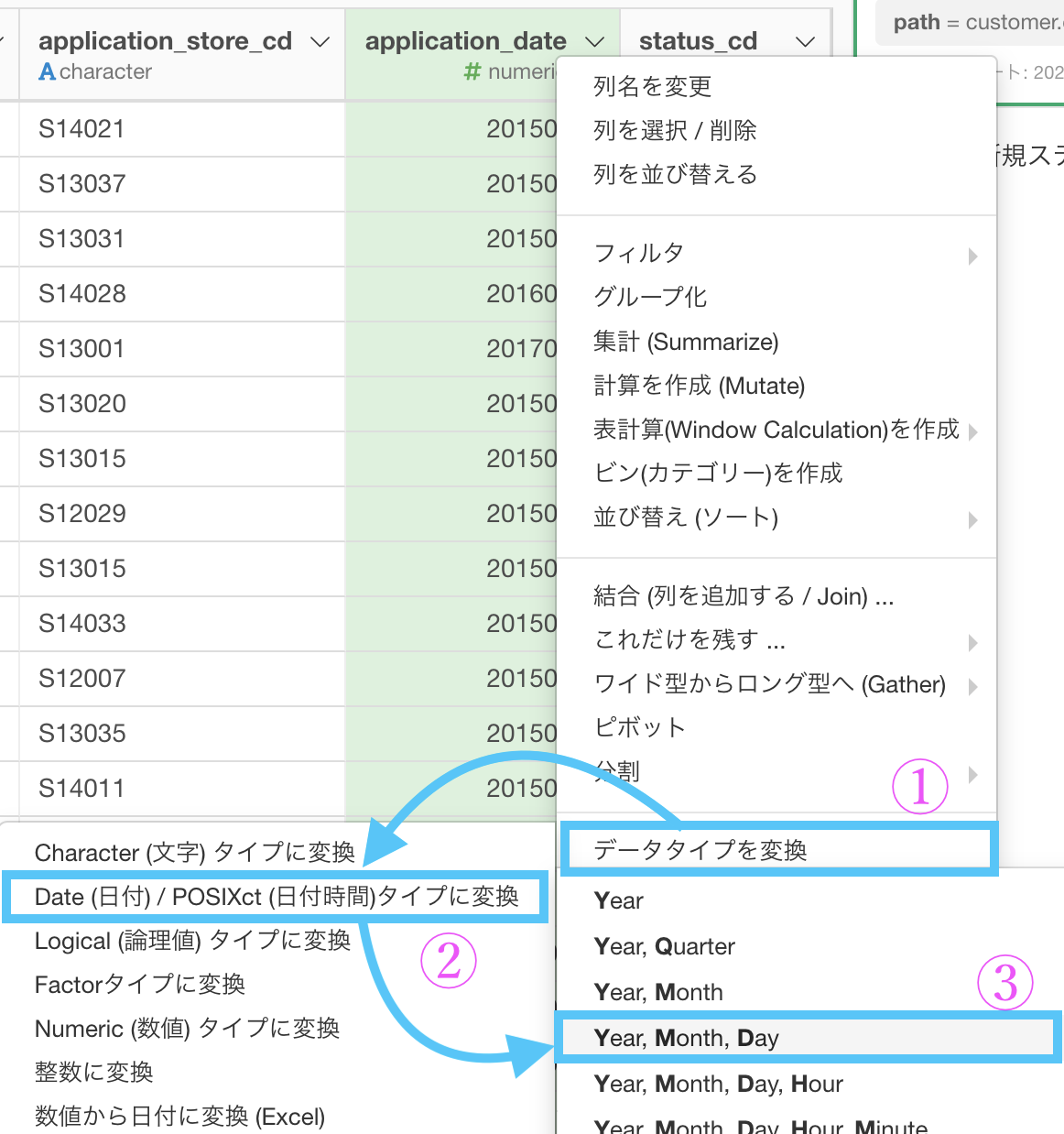
ここまでいくと、計算エディタが出てきます。
これは何もせずに実行しましょう。
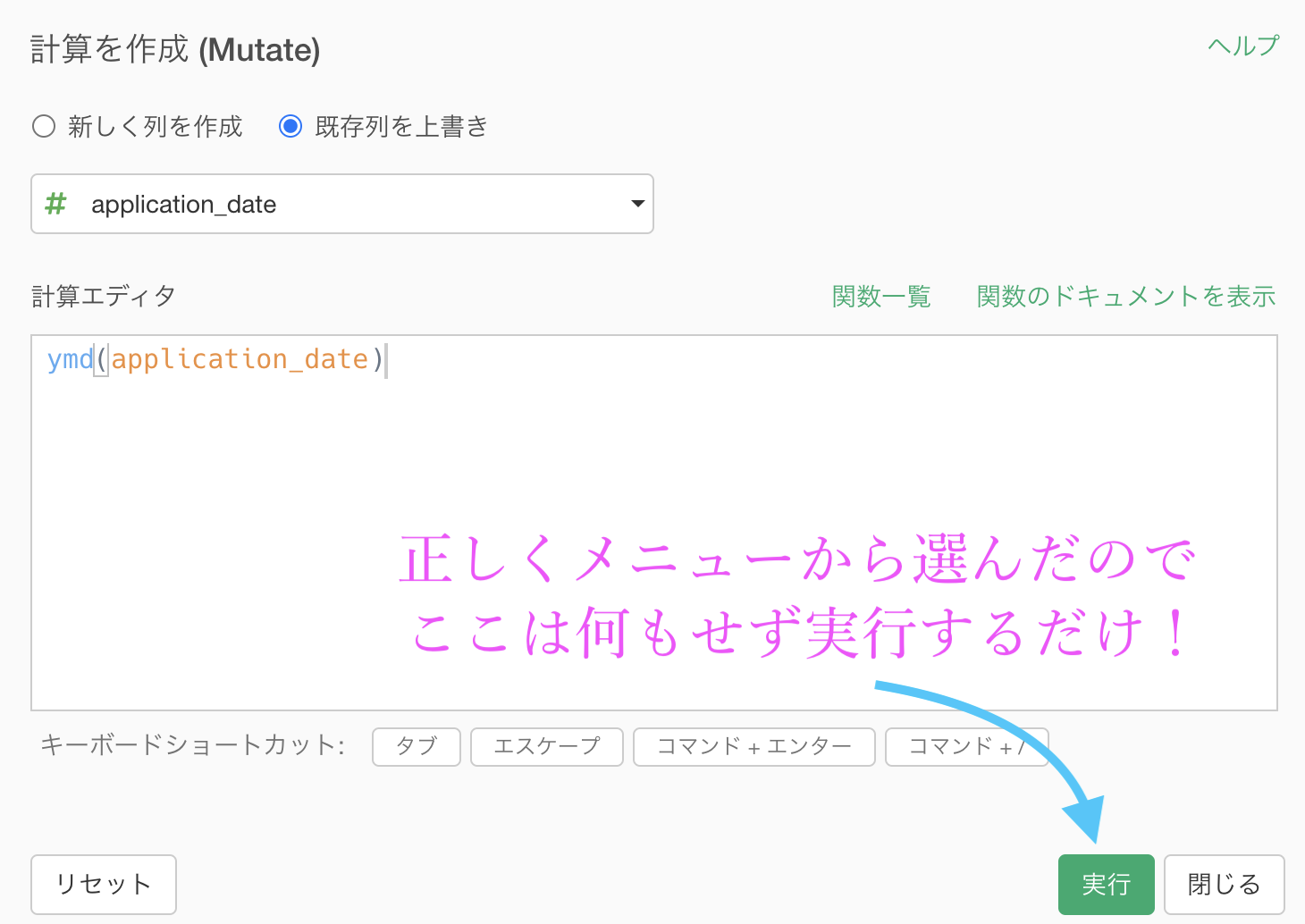
ちなみに ymd() もR言語の関数で、year・month・day の頭文字をとって ymd です。単純ですね。
この時点での結果はこのようになっているかと思います。
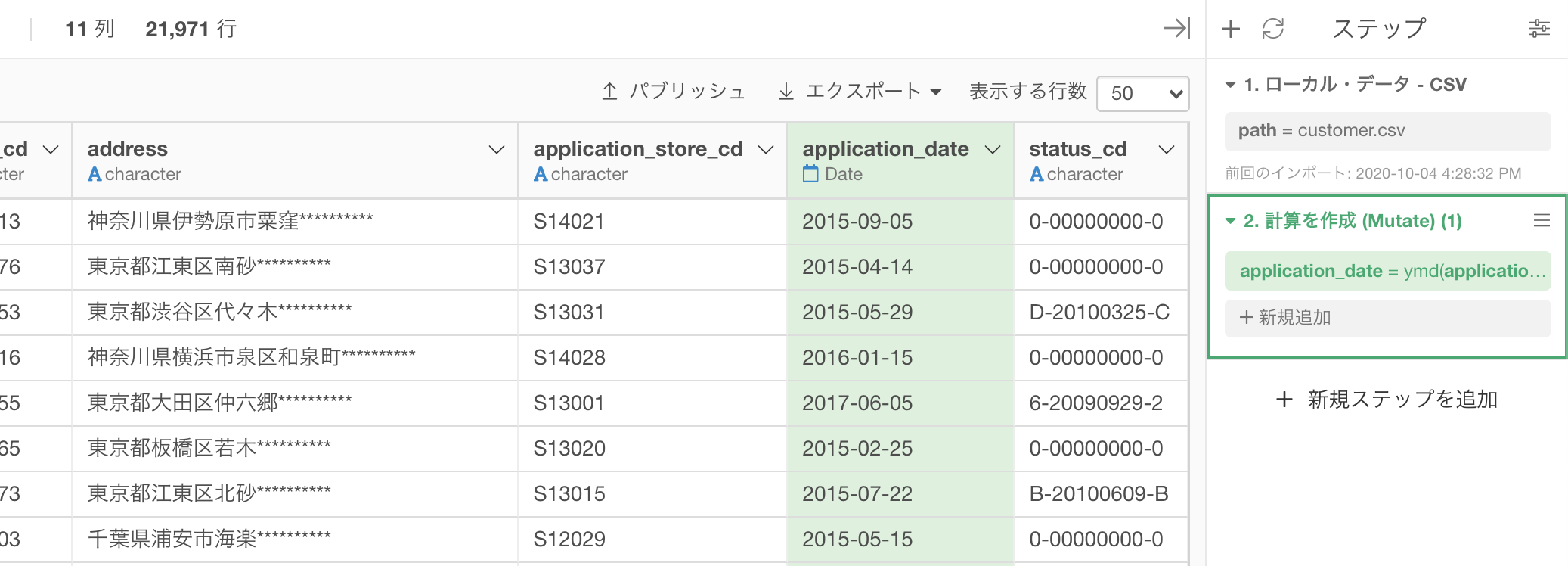
あとは列を customer_id と application_date に絞って表示させましょう。
結果はこのようになります。解答と確認しましょう。
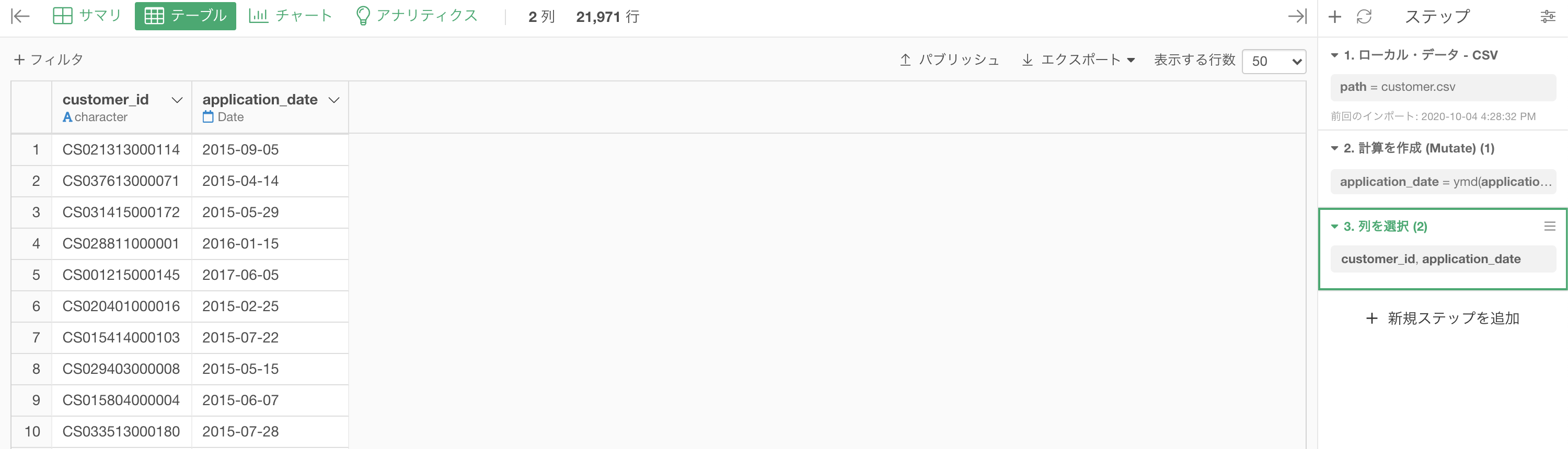
Python 解答コードはこちら
解答コードはこのようになっています。
pd.concat([df_customer['customer_id'],pd.to_datetime(
df_customer['application_date'])], axis=1).head(10)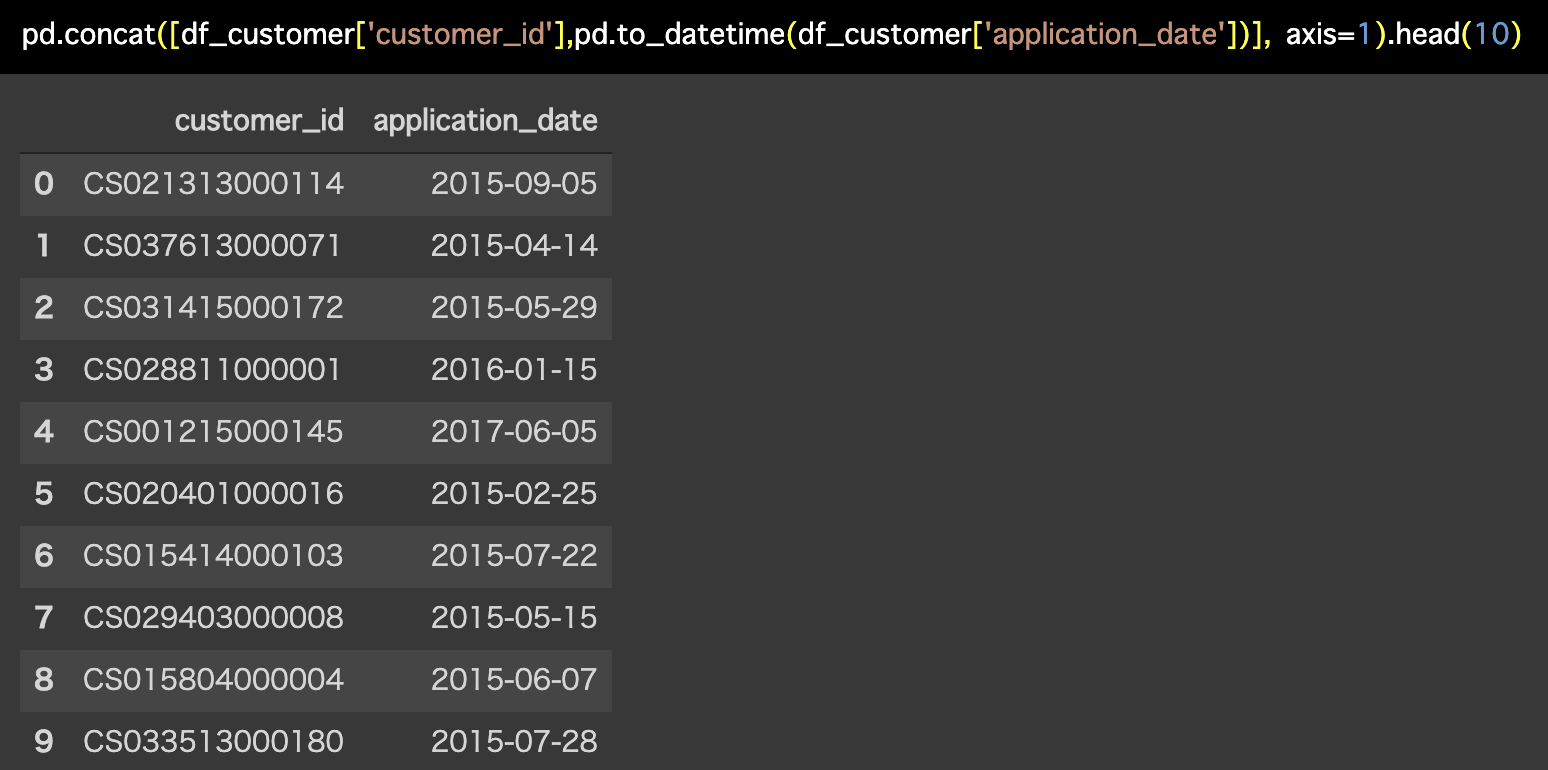
解答は 2列(customer_id と application_date)にしていますし、問題文にも 2列 で表示せよと書いてあります。
しかし、問題の本質的な処理はデータタイプの変換ですので、今後は2列にする処理は最初か最後に行うと思います。
説明の流れを見ながらある程度の判断はつくと思いますし、一言入れますので、そういうわけでご容赦ください。
application_date が数値型だった理由
Exploratory は使う側にとても優しいデザインをしているので、最初からデータタイプをある程度認識してからデータを取り込みます。
矢印が2本出ている根元のチェックボックスのところです。
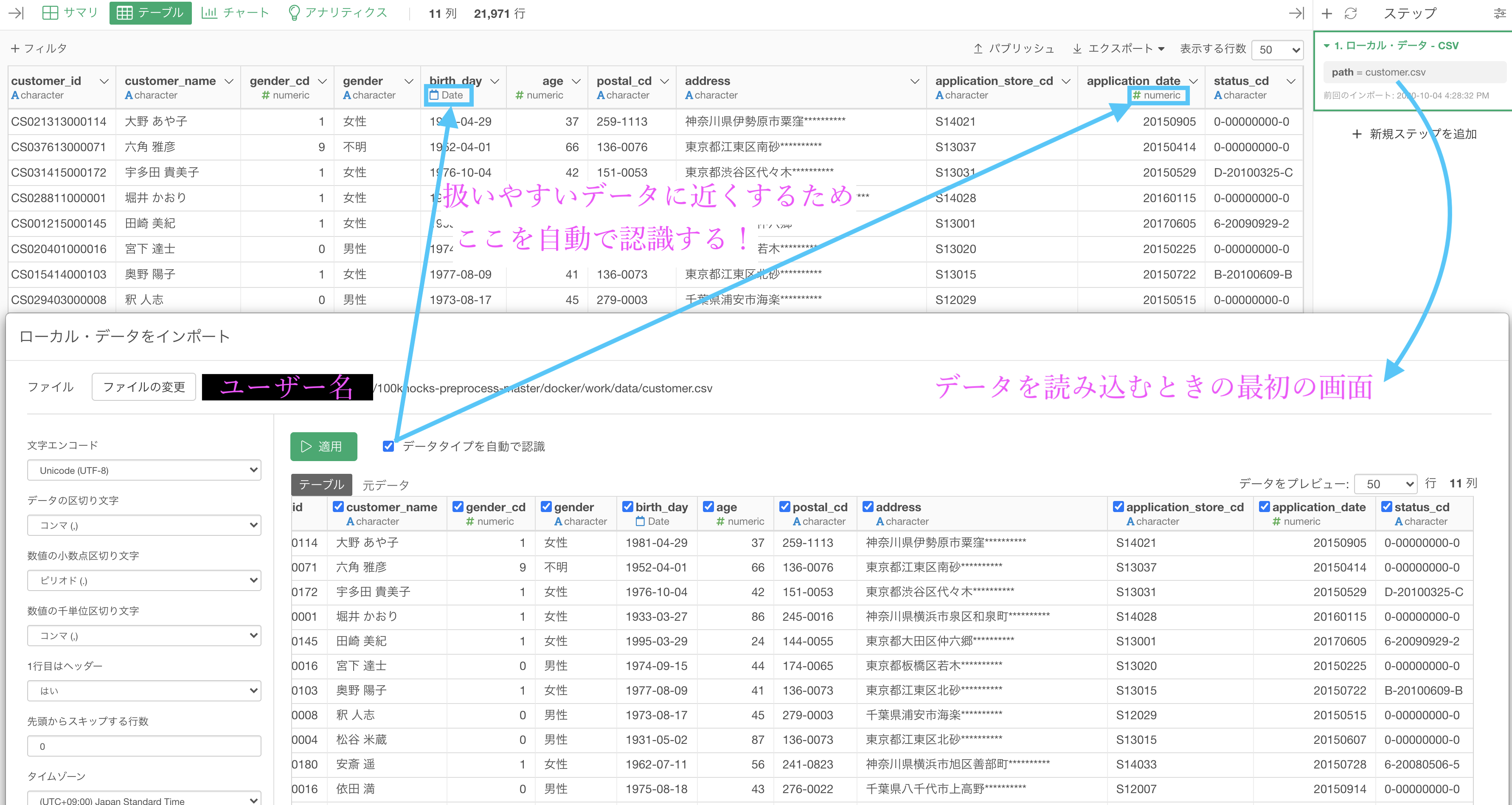
例えば R言語 や Python言語 でデータを読み込むと「ここは数値しかないからテキストデータよりも数値データになとしておいた方が良いな」とか、あるいは「これは明らかに日付でしょ!」というときも データタイプを変換することさえ、全てコマンドで(つまりまっさらな紙の上にイチから英語を)打ち込み ます。
また、チェックが入っているからデータタイプの認識はされていて大丈夫!というわけではありません。
数値型にした方が良いか日付型にした方が良いかは人間ほど確実な認識ではないから(正確には機械ができるかどうかも怪しいから)です。
2020年01月01日 → 202001010 は機械にとっては数値(テキストよりも)であって、日付だと認識するようにはできていません。
例えば 0003年01月01日 → 30101 にしたときに、日付だ!と常に認識させたら、30101円のお買い上げレシートは日付になってしまいますからね。正確に判断できるかどうかは結構怪しいところです。
そういうわけなので「データタイプを自動で認識する」というところにチェックがついているのは、機械が認識しやすいようなデータになっていますよ ということで、あとのカスタマイズ(これは日付って思って欲しいな〜とか)は自分たちでしなくてはなりません。
ここのチェックを外すと、application_date が文字データに なって、問46 の問題文で言っていたことの整合性が取れます。
まぁでもそこまで心配することはないですよ。
データタイプを変換するときは変換前がこれの時はこれしか選べませんよ〜ってメニューに書いてありますからね。
問47 : 数値データを日付型データに変換する

答案・解説はこちら
これは 問46 と全く同じ方法です。
df_receipt のデータにて、sales_ymd(売上日)は numeric(数値)タイプなので変換しましょう。
「データタイプを変換 → Date (日付) ... タイプに変換 → Year, Month, Day」を選択します。最後の最後で読み方が効いてくるのでした。
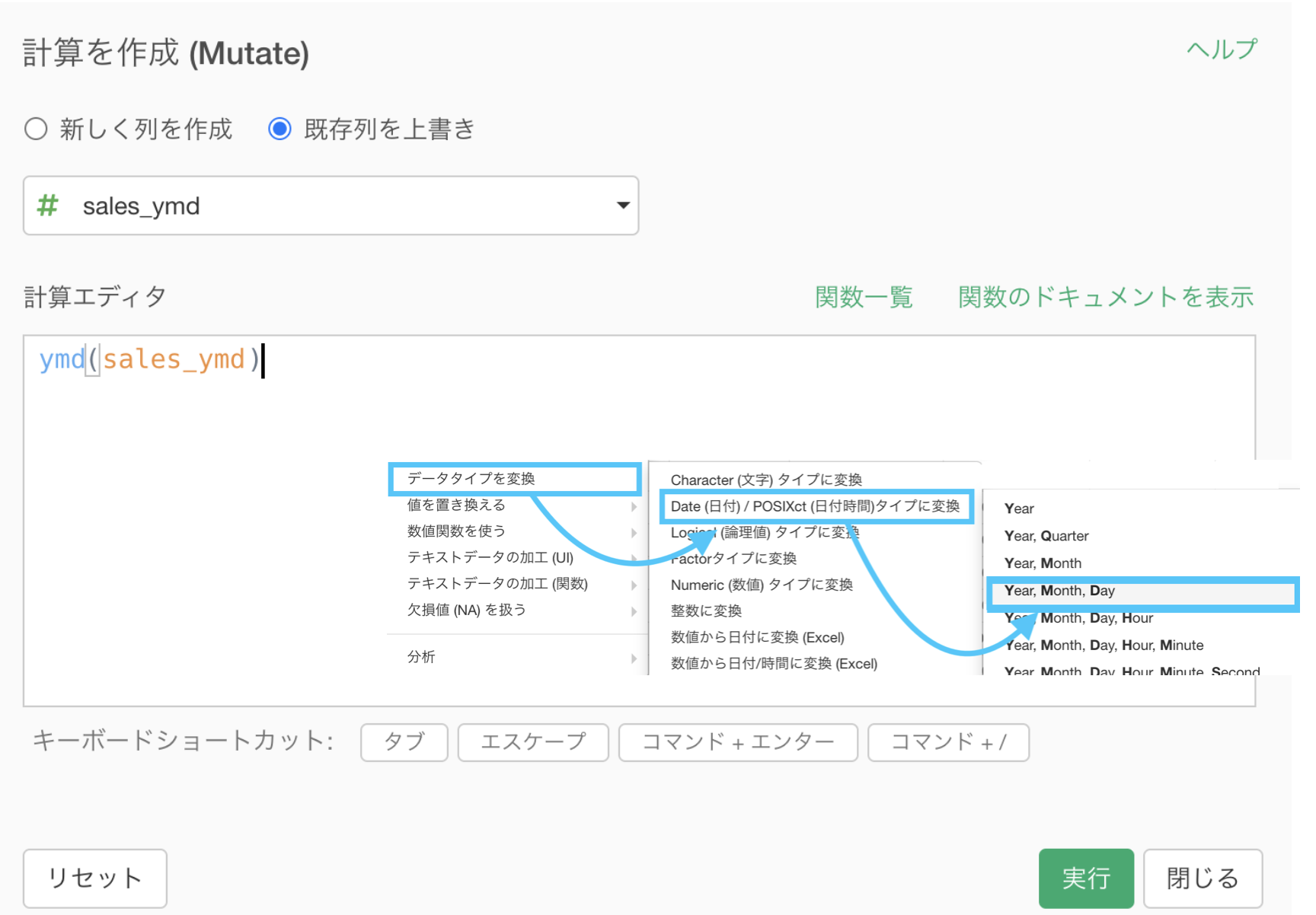
これをそのまま実行するだけです。
あとは問題文のように、列を sales_ymd, receipt_no, receipt_sub_no の 3列 にして、必要ならば列の順番を変えましょう。
結果はこのようになります。解答と確認しましょう(列の順番変えました)。
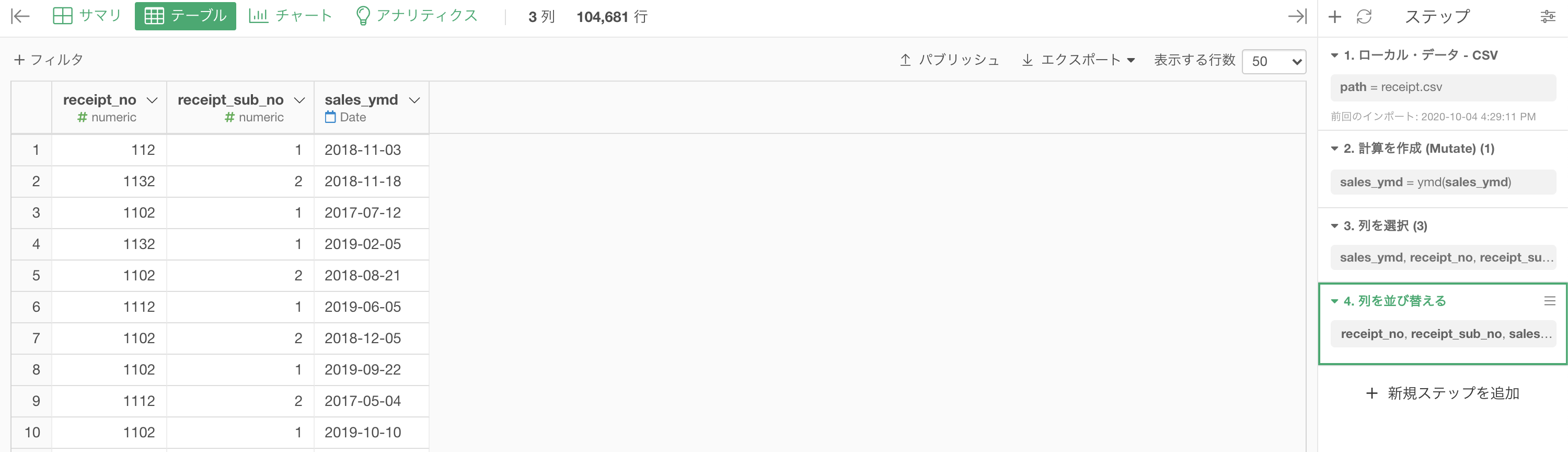
データタイプを変換するところはとても重要なのですが、ステップ 1つ でほとんど完結してしまうので楽といえば楽です。
細かいところまで説明すると楽どころか、人によっては二度と考えたくなくなるかもしれません。
Python 解答コードはこちら
解答コードはこのようになっています。
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_ymd'].astype('str'))],axis=1).head(10)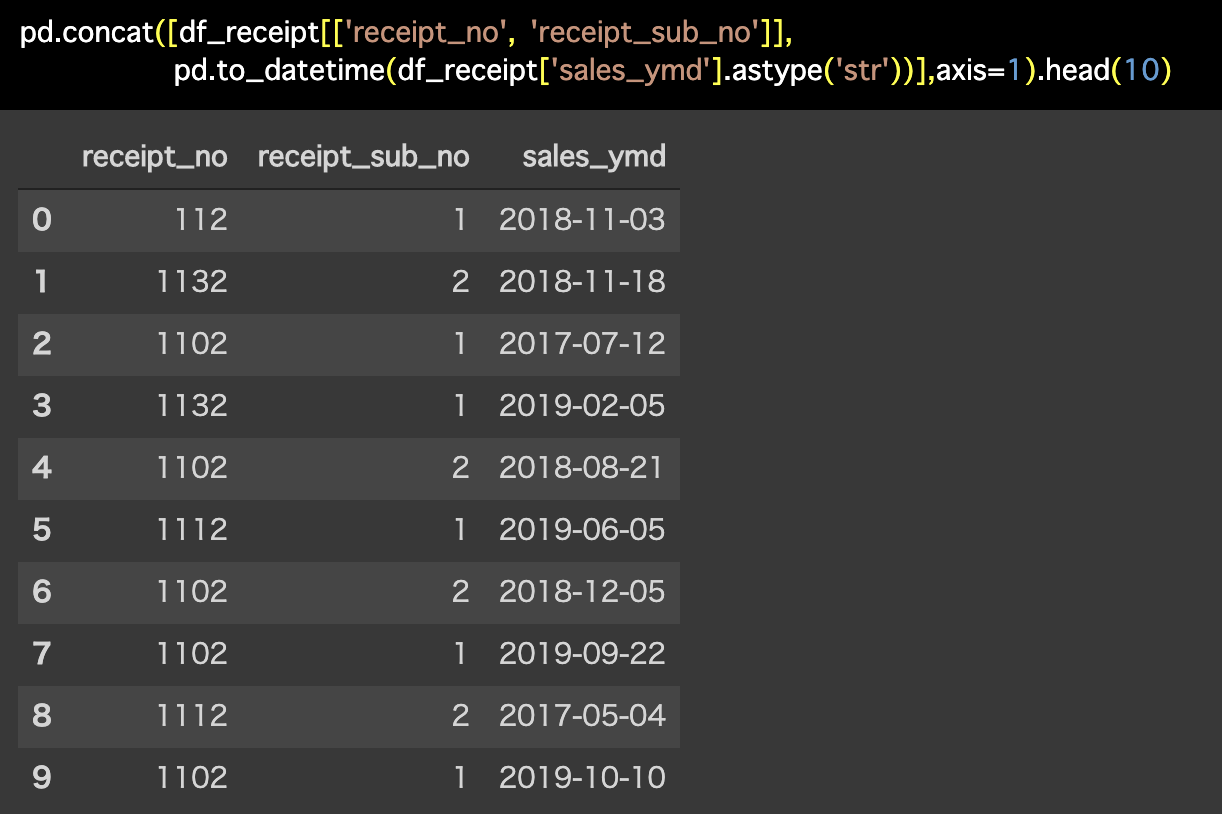
ちなみにほとんどの関数で、データタイプが違うものは最初から受け付けない...つまり、データタイプでのエラーじゃなければ、とりあえず解決の第一歩は踏み出したと思って良い...という話を聞いたことがあります。
とりあえずそのくらい大事な事情がデータタイプなのですが、実装するにあたってはそこまで身の詰まったことをやるわけではありません。
むしろ実装するときは、1ステップ...対面で説明するときは、30秒くらいで終わる話題(知っているかどうかの違い) です。
なんで列の順番まで変えたの?(余談です)
どうして receipt_no と receipt_sub_no が先に来て、sales_ymd が後に来たのか?という話 です。
ぶっちゃけどっちでもいいですよ、列なんてどこにあっても本質的ではないです。もう開き直りのノリです。
しかし...一般的に、行番号は、後(右側)じゃなくて先(左側) ですよね。このことを受けて、次のように考えてみることもできるはずです。
という説明です。
これは、初めの方で何度か強調したはずの 1行 = 1△△ の心が基盤 にあるからこその考え方 なのです。
どうでしょうか?なんかこういうことを聞いちゃうと「あぁやっぱり...処理したら右側になってた...気にしなかったけど、左側にしようかなぁ」という気が起きなくもないような...?という感じの人もいらっしゃるかと思います。
まぁ、今はそんな程度で良いと思います。
ただチームでやるときは、そういう小さな拘りを気にする方がいらっしゃるかもしれませんね(え?お呼びですか?)。
問48 : エポック秒(UNIX時間)を日付型データに変換する

答案・解説はこちら
見たいことはこれです。
ということです。
この話を、いったん文字ではなくイメージとしてみるとこのようになります。 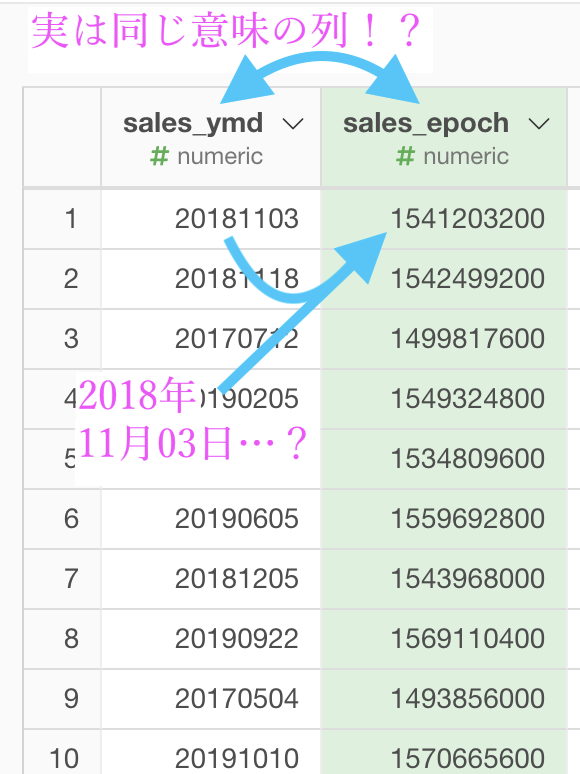
1541203200エポック秒 = 2018年11月03日なんだよ、知ってました?...そんなの知るわけないやろ。
これは早急に処理する必要がありそうです。
ちなみにエポック秒とは、UNIX(ユニックス)という時間表記の仕方で、人間には理解し難い表記の1つです。
これも Exploratory のメニュー(「データタイプを変換」のところ)を探せば、ちゃんとあります。
探せばある...理由は簡単で、Exploratory が R言語 で動いているからです。100本ノックがR言語バージョンもあるということは、Exploratory でできない訳がないのです。
早速実装しましょう。ここまで書いておいて、実装は10秒でできます。
今回は見やすいように列を先に操作して、receipt_no, receipt_sub_no, sales_epoch, sales_ymd の順番にしてから処理しています。
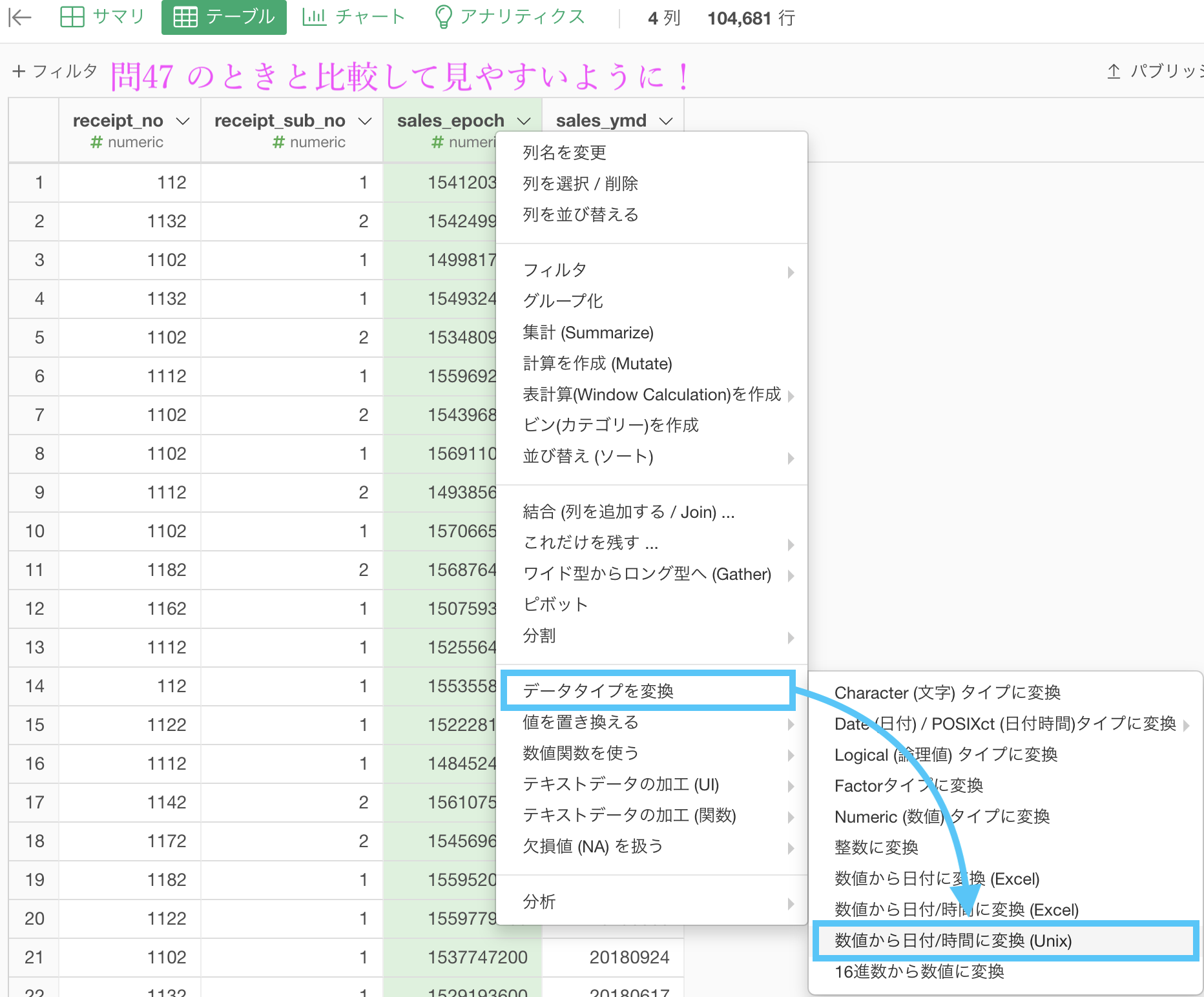
上の画面のように 「データタイプを変換 → 数値から日付/時間に変換 (Unix)」を選択 します。
ちなみに1つ上にあるように、Excel にも Unix と同じ類の時間表記の仕方がありますので、そちらも変更可能です(やりませんが)。
いつものように、このような画面が出てきたはずです。
何もせず実行しましょう。
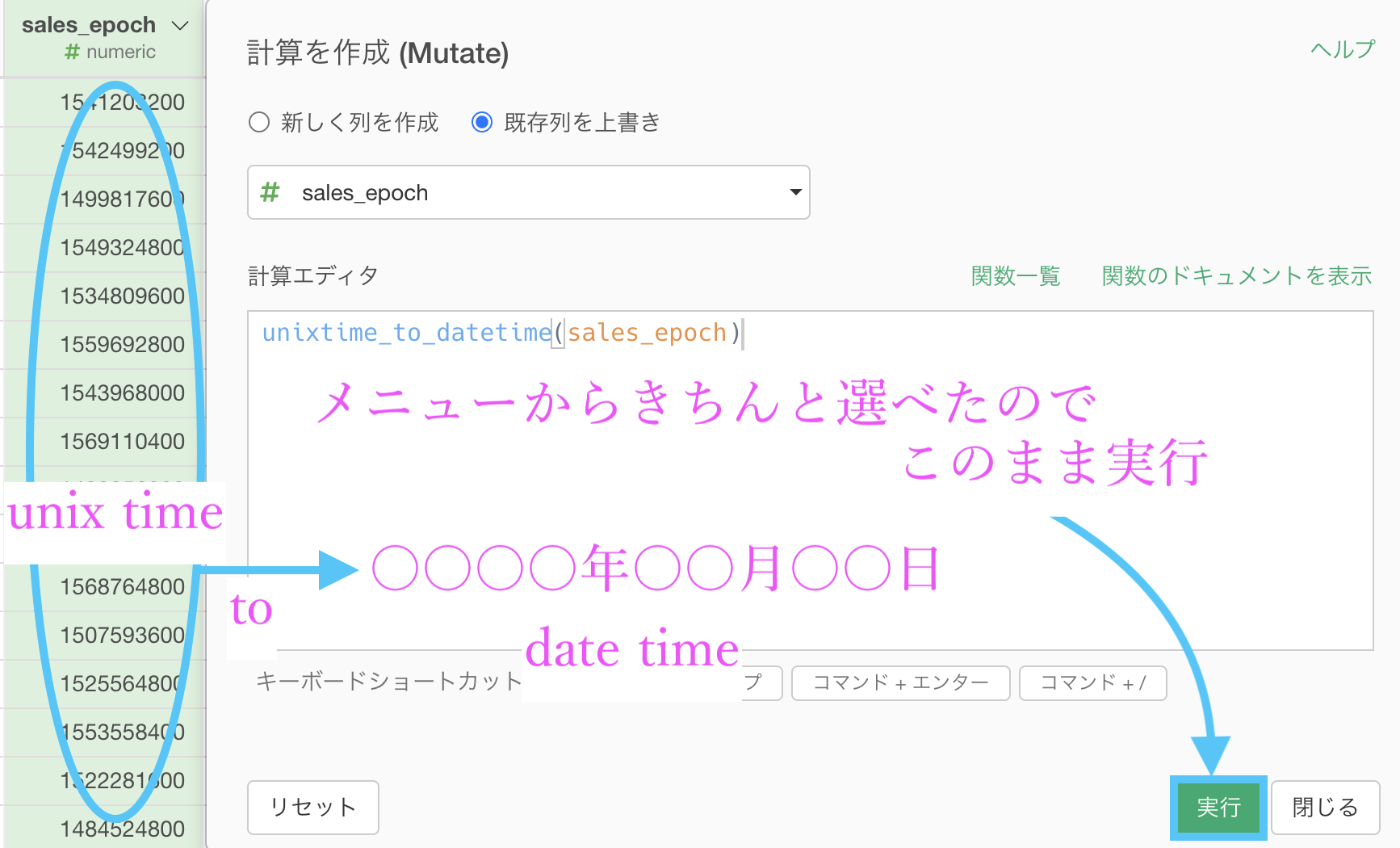
ちなみに、R言語の関数なのですが unixtime_to_datetime() という関数の名前は unix 時間(time) から(to) date 時間(time) へ と読むことができます。
前処理するときは、読みやすい関数が結構あるので、コードを英語で読んでみようとするのもオススメです。
結果はこのようになります。
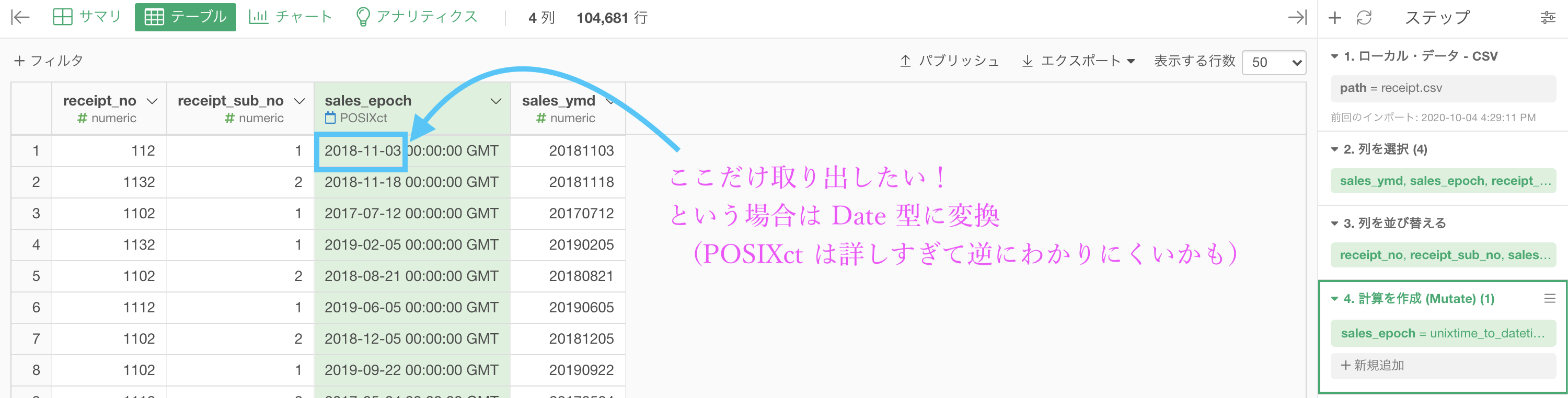
データタイプは POSIXct なので、詳しい時間表記までされてしまいます(タイムゾーンといって、国ごとの時差まで考慮していますし)。
データは詳し過ぎてもひたすらにわからなくなるだけですので、ちょうど良いところで留めて おきたいところです。
ということで、これを Date型(前問の sales_ymd と同じ型) に変換します。
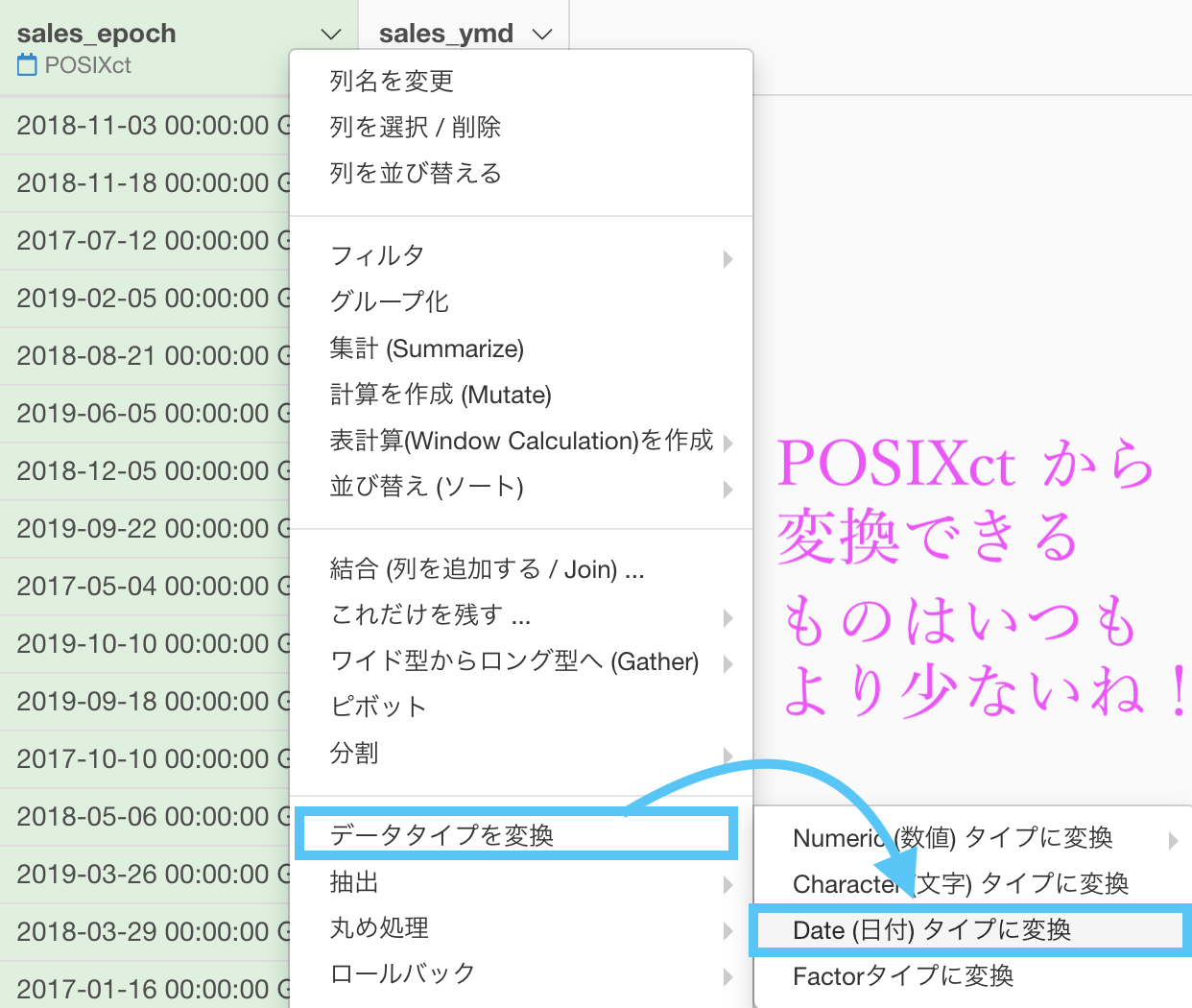
メニューが少なくなったことから受ける恩恵とは
実装やりながら気が付くこととしては、POSIXct を変換するときって、今までよりもデータタイプの変換の中にあるメニューが少ないよね? ということです。
これがデータタイプを変換するときに覚えることを一気に減らしてくれます!
だって、イチからコマンドを書く場合には、やったことのあるコマンドしか基本的にできないはず です...。
しかし Exploratory では、今までやったことのない「時間のデータをテキストデータに変換する」などのことも、メニューから選ぶことだけで、経験したことなくてもできるはずです!(しかも、できない変換は事前に選べないので、エラーになることもないのです!)
これが Exploratory の最高のメリットだなと思います。
だってR言語の本からコマンドの経験を積まなくても、データタイプくらいなら誰でも変換できちゃうわけですからね。
余談はさておき、きちんとメニューから「Date型 (日付) タイプに変換」を選べているので、何もせずこのまま実行します。
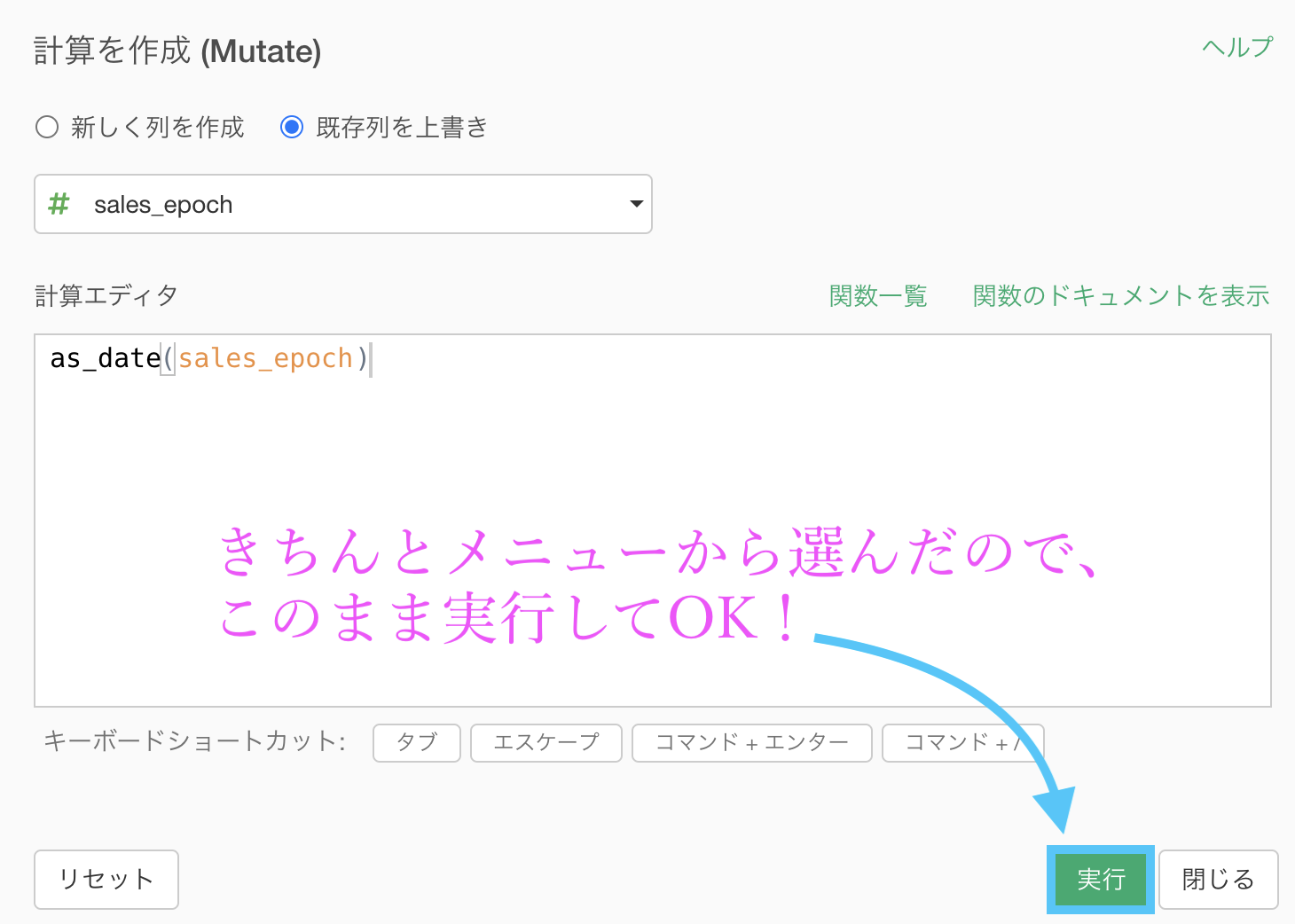
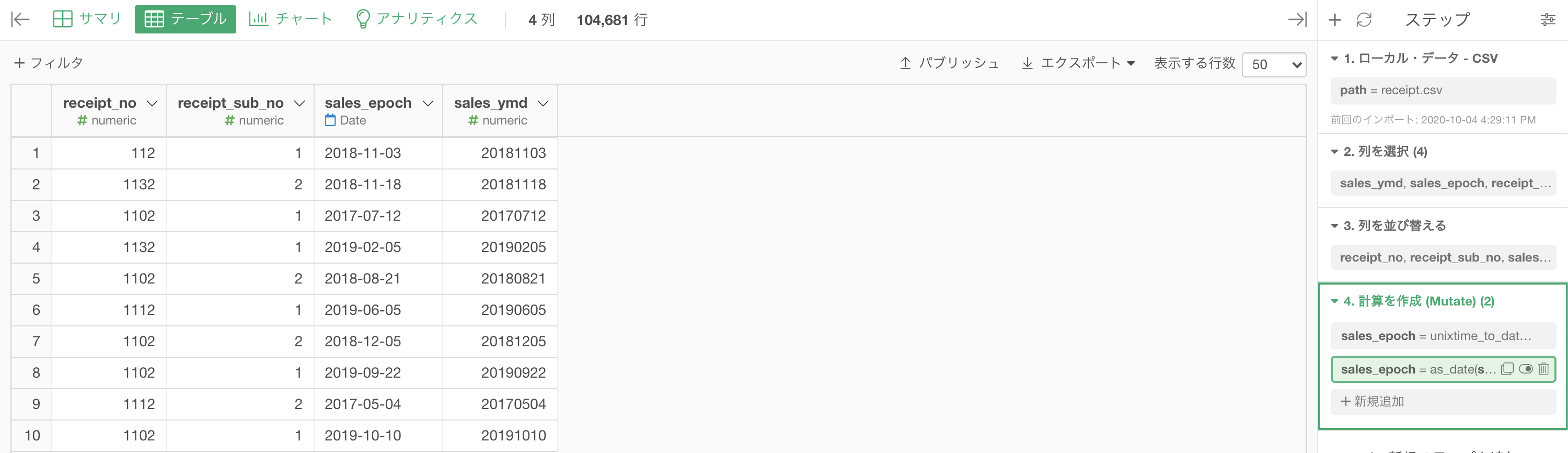
結果はこのようになります。解答と確認しましょう。
この問題の最初に言っていた「sales_ymd と sales_epoch は同じ意味の列だった」ということは、ご理解いただけたはず です。
...長々と説明していますが、問45 からずっと、本質的に手を動かしている部分は「データタイプを変換 → ... → 出てきたものをそのまま実行するだけ」という簡単なことだけ です。
つまらない説明は流し読みして構いません。最終的に本番で実装できるかどうかなのです。そのために必要なことだと思った説明を書いているだけに過ぎません。
Python 解答コードはこちら
解答コードはこのようになっています。
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'],
unit='s')],axis=1).head(10)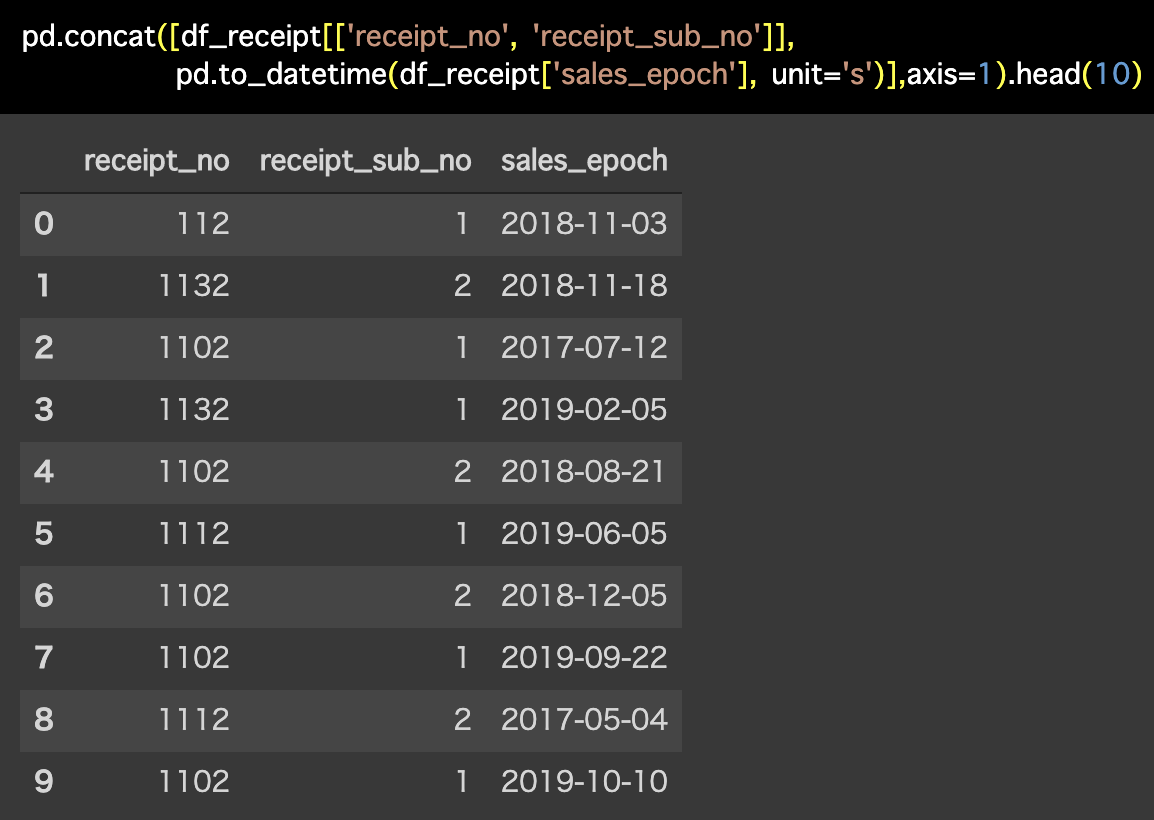
コマンド見て、unit = 's' のところを覚えている人なんて、残念ながらそこまで多くないのが現状だと思います。
更に深刻なことに、それを身に付けることができる機会は「失敗して、エラーを真剣に検索して、頑張って解決したときくらいしかない」でしょう。
いくらコマンドに慣れ、教えることに慣れていても、unit = 's' のオプションを、一体誰がきちんと説明して相手に経験させようという機会を作れるのでしょうか?...多分、そんな説明をする側も(ぶっちゃけ)恥ずかしいし「聞かれなかったから答えなかった」という流れになって当然だと思います。
問49 : 日付データから特定の年だけ取り出す

答案・解説はこちら
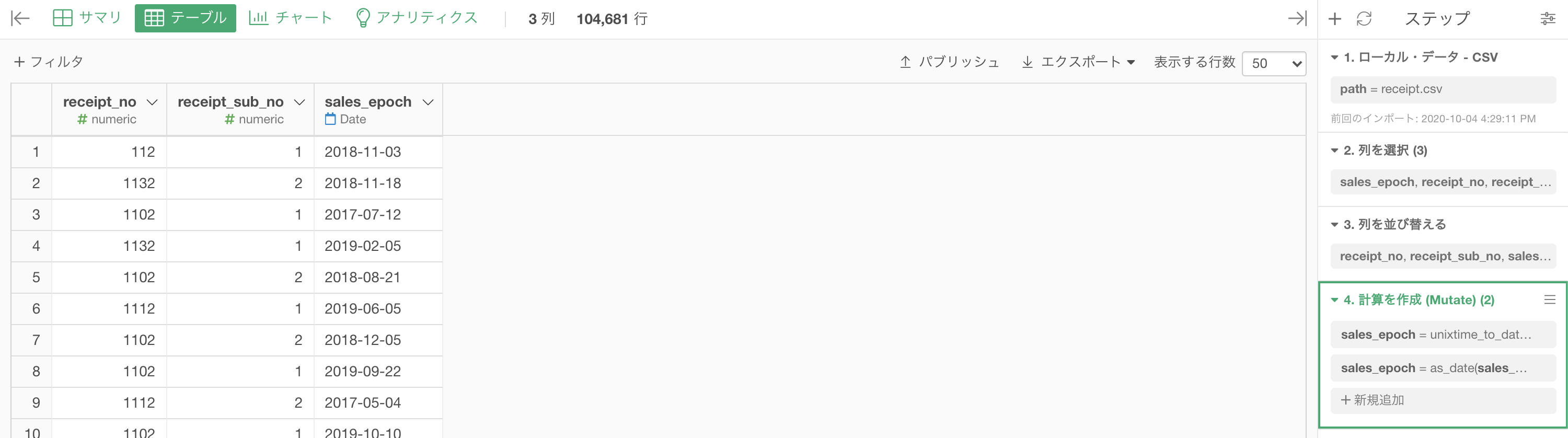
問48 では、比較して見やすいように sales_ymd を付与していましたが、単純にそれを付与していない状態からスタートします。
今回は多少、列の選択と並び替えのステップをいじりましたが、問48 の結果をそのまま引き継いで sales_ymd の列を消去すればOK です。
そのような状態からスタートしたいと思います(結局のところ、問48 ほぼそのままです)。
ということです。
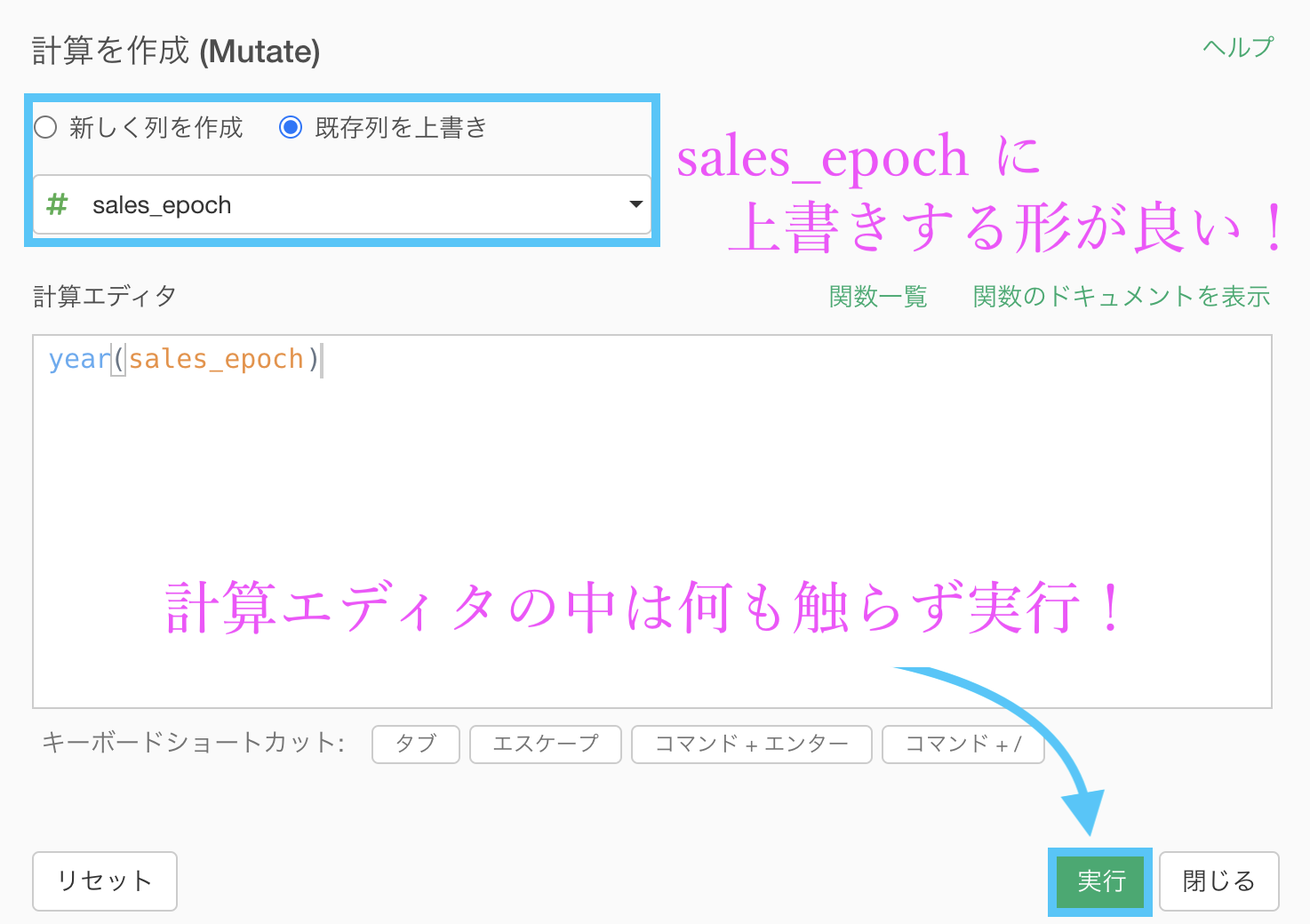
これも Exploratory ですぐできますので早速実装しましょう。
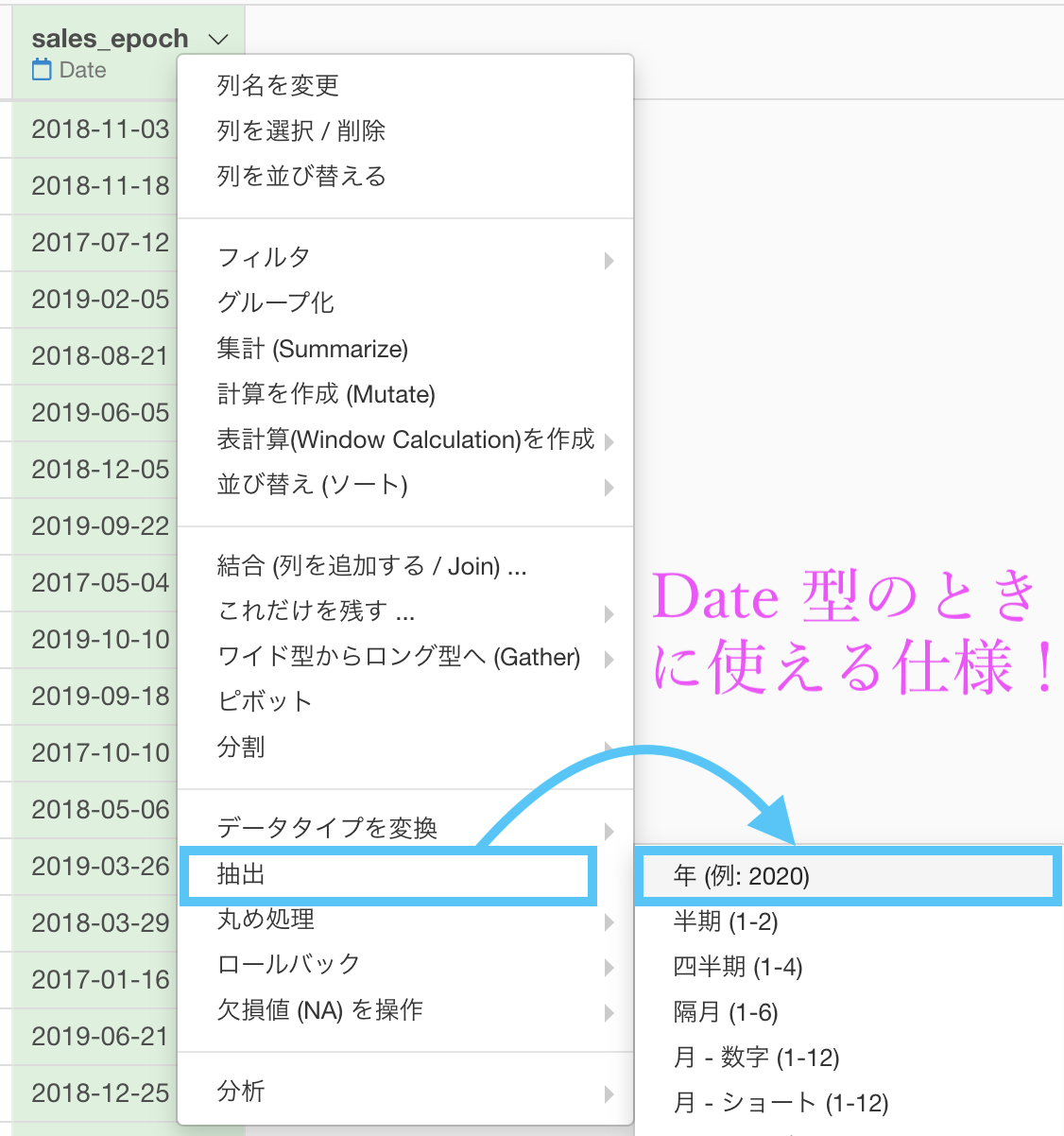
sales_epoch は 問48 で既に Date 型にしていますので、ステップメニューを開くと「抽出 → 年 (例 : 2020) 」が選択できます。
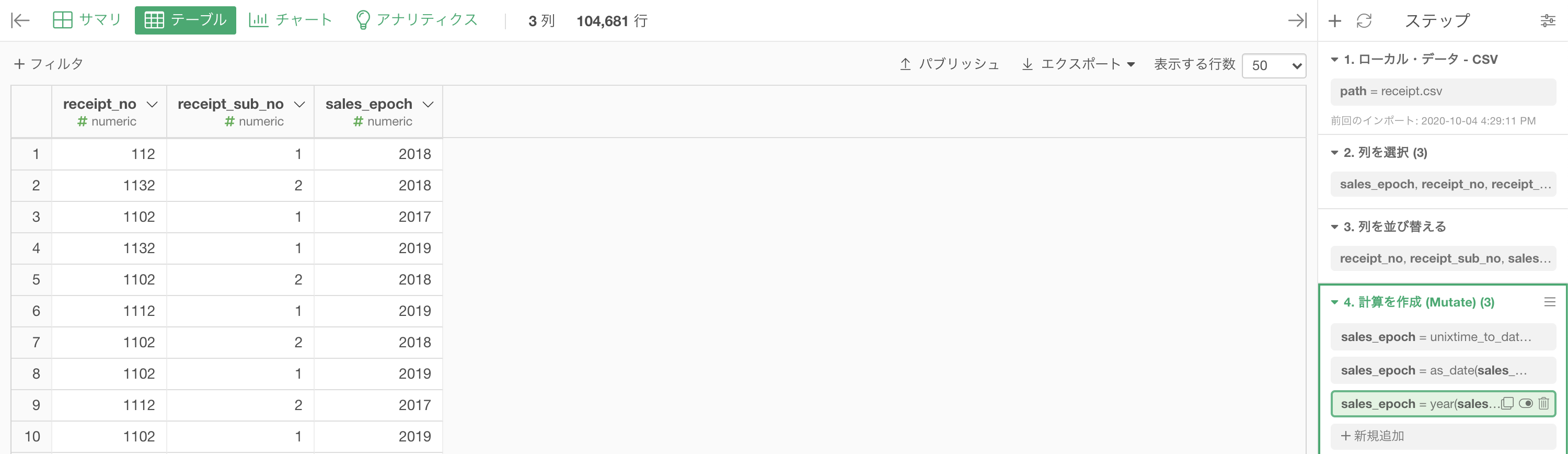
結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'],
unit='s').dt.year],axis=1).head(10)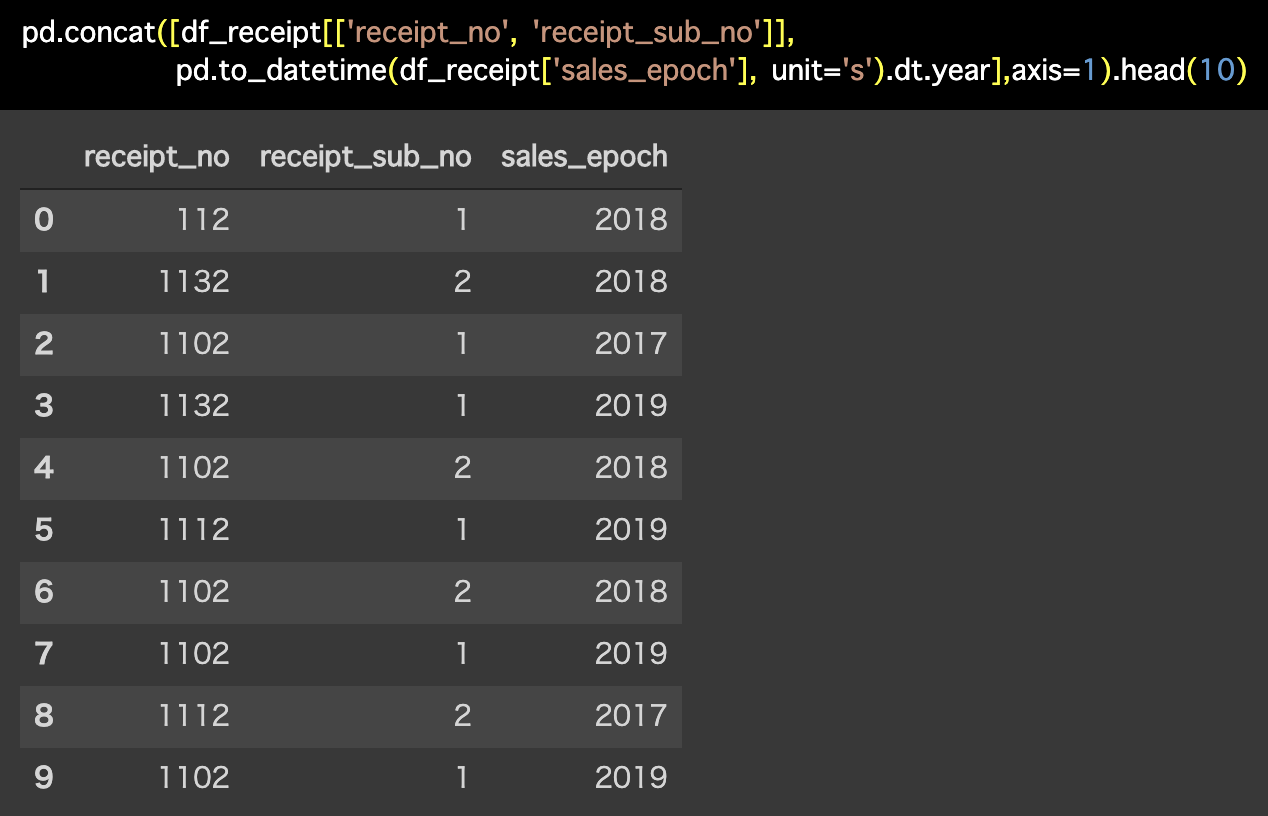
以前の問題と計算エディターの中身を比較してみよう
application_date(問46)や sales_ymd(問47)のデータタイプを変換したときと、今回のときで比べてみましょう。
問46 や 問47 での計算エディタの中身との違いはこんな感じです。

ymd(...) : 問46 や 問47 >> year month day の頭文字で ymd
year(...) : 今回の問題 >> 西暦だけ取り出すので year だけ関数の名前がそれなりだと、理解する際にも楽かと思います。
Exploratory を使っているとはいえ、コマンドの理解をしなくて良いことにはなりません。理解できるものは少しでも多く理解しておくのが良いと思います(R言語が裏で動いているからです!)。
もちろん、初めての Exploratory での前処理だという方もいらっしゃると思いますので、カンタン & 直感的にわかりやすい関数の名前から 少しずつ紹介しているつもりです。
問50 : 日付データから特定の月だけ取り出す

答案・解説はこちら
以下は完全な答案ではありません。しかし、答案としては妥協できる範囲でありながら、処理のわかりやすさを優先しています。
まず今回でやるべきことはです。
早速やっていきましょう。
問48 から引き継ぎで(あるいは 問49 でのステップを消すことによって)ここからスタートします。
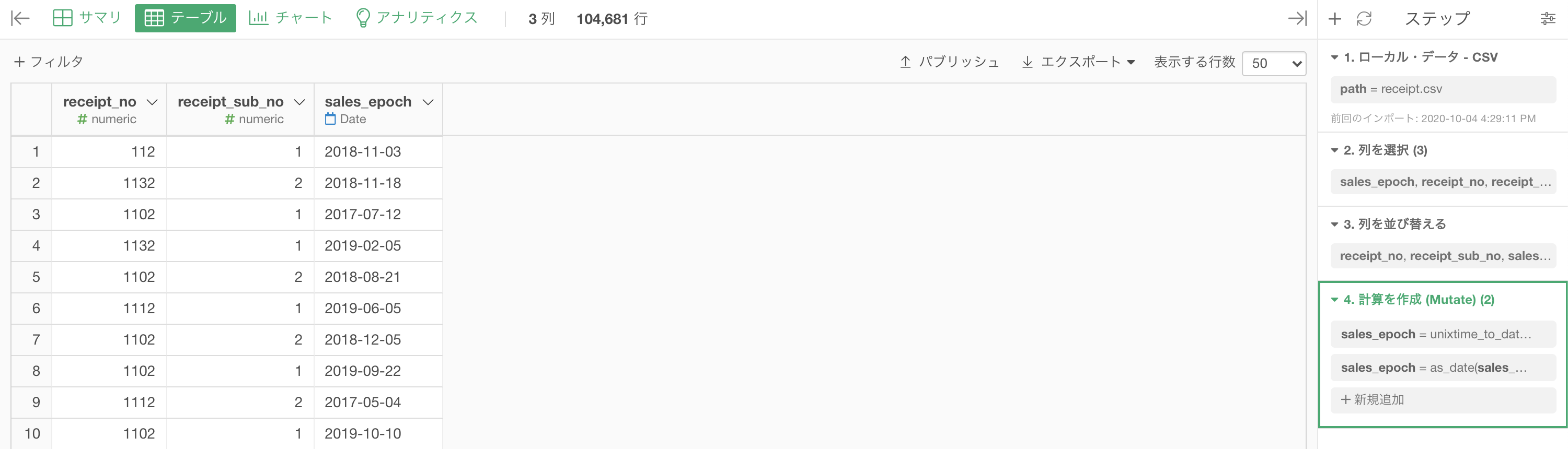
問49 では「抽出 → 年」だったところを、今回では「抽出 → 月」に選択するだけです。
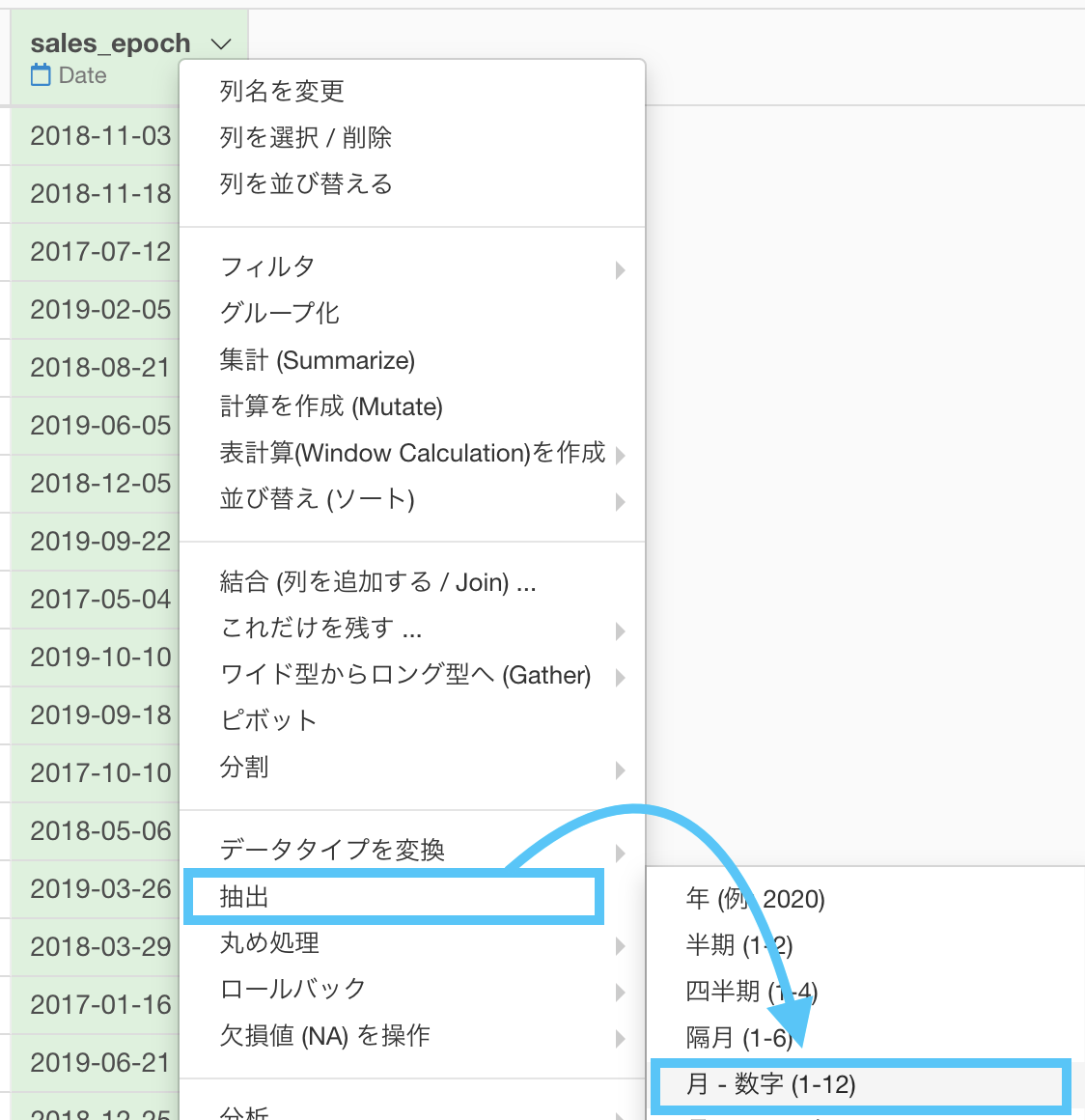
するとこのような画面が出てきます。
問49 で年は year(...) だったので、今回は月ですから month(...) です。
列も sales_epoch に上書きする設定をします。
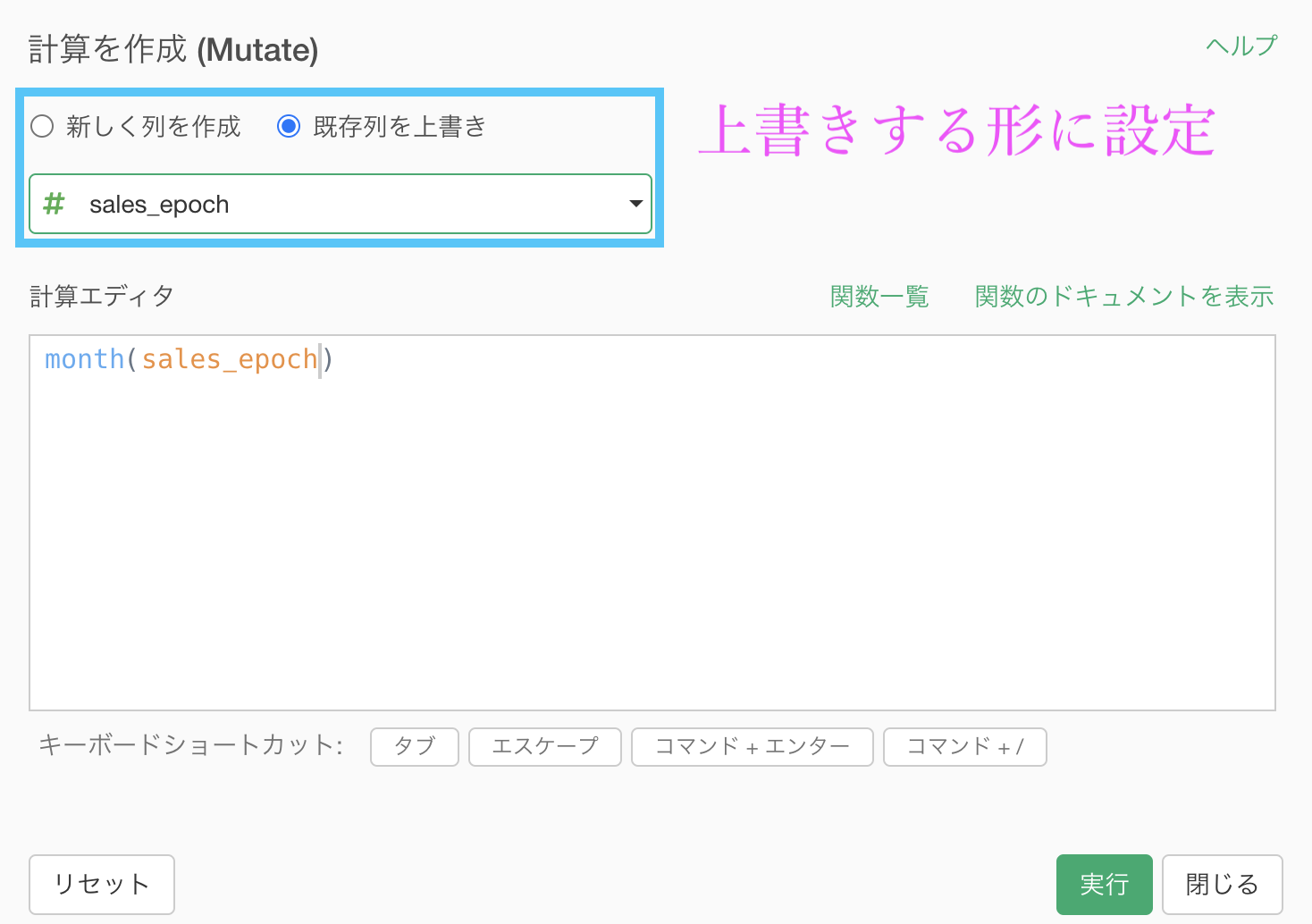
結果はこのようになります。解答と確認しましょう。
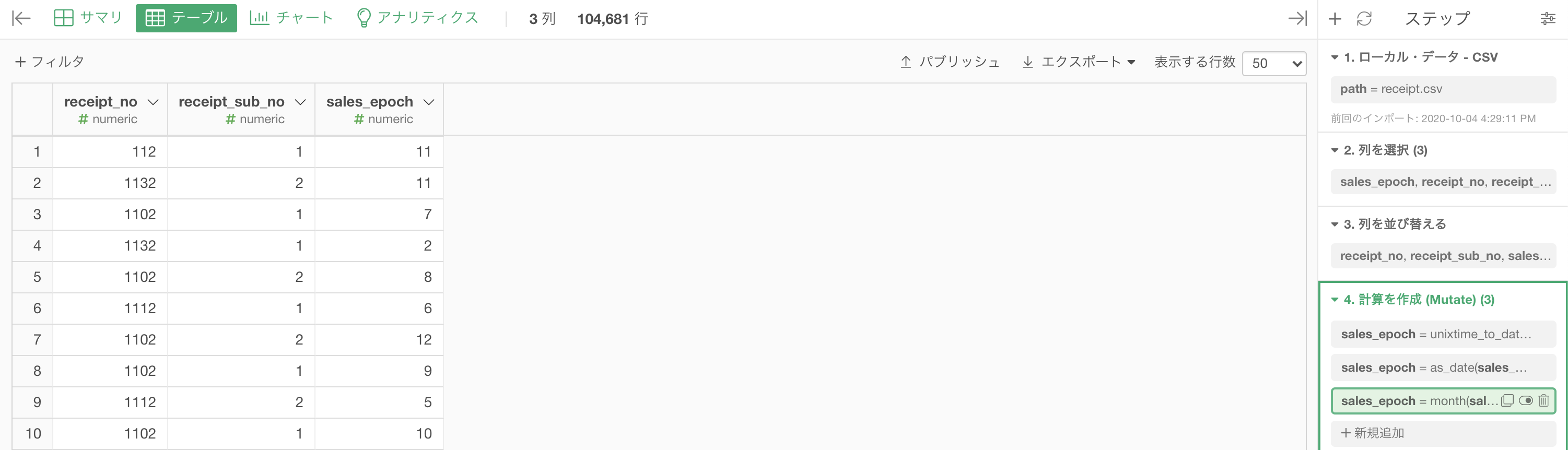
Python 解答コードはこちら
解答コードはこのようになっています。
# dt.monthでも月を取得できるが、ここでは0埋め2桁で取り出すためstrftimeを利用している
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'],
unit='s').dt.strftime('%m')],axis=1).head(10)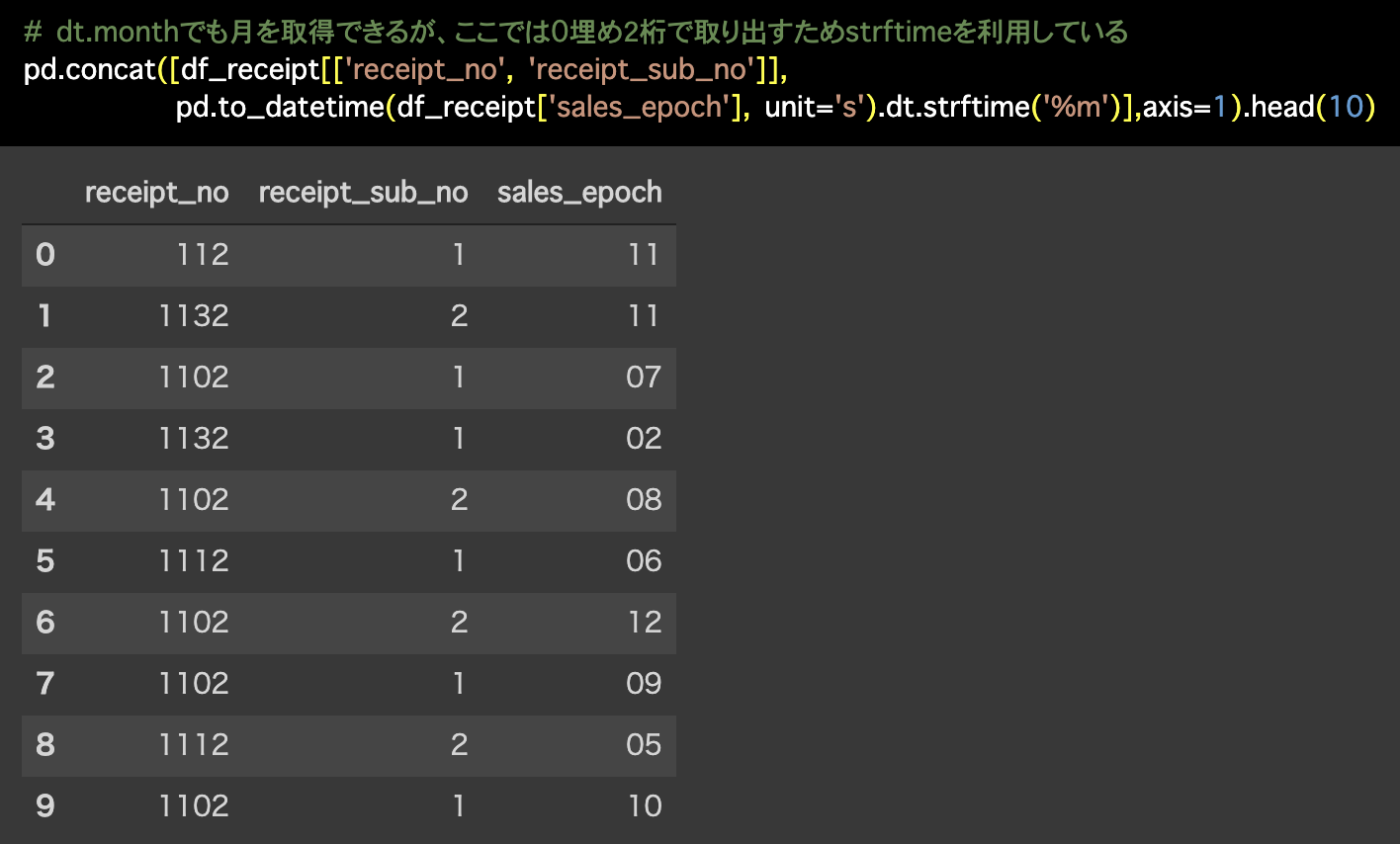
結果に妥協できないあなたへ
問50 のはじめに断っておきましたが、不完全な答案です。 問題を正確に解くことよりも、わかることを優先しているからです。
しかし、ここまできたあなたには問題を正確に解くことの方を求めているのかもしれません。そのような方のために折りたたみました。
とは言ってもこの折りたたみを読まないと、もしかしたら 問51 で書いてあることの全ては理解できない可能性があります。
さて、どこが妥協するかしないかの境目かというとということです。
ちなみに問題文からは 01 にせよという旨が書いてありますが、ソートで見やすい・桁が揃っているなどの理由による 01月 の表記なので、本質的な問題ではないのです。
だからわかりやすさのため、最初の答案ではカバーしませんでした。
しかし、この折りたたみを見ている方は妥協できなかった人 なのできちんとカバーさせていただきます。
まず気持ちとしては、numeric(数値)タイプで 01 は絶対に不可能 です。
だとするならば、そこは Character(文字)タイプでの 01 だな!ということがわかるかと思います。
そこから派生すれば、Character(文字)のデータはテキスト関数を全て味方につけている のだから、何か都合の良い関数はないかなぁと探してみることもできます。
まず、問50 のスタートから始めます。
次に、sales_epoch に「データタイプを変換 → Character (文字) 」を選択します。
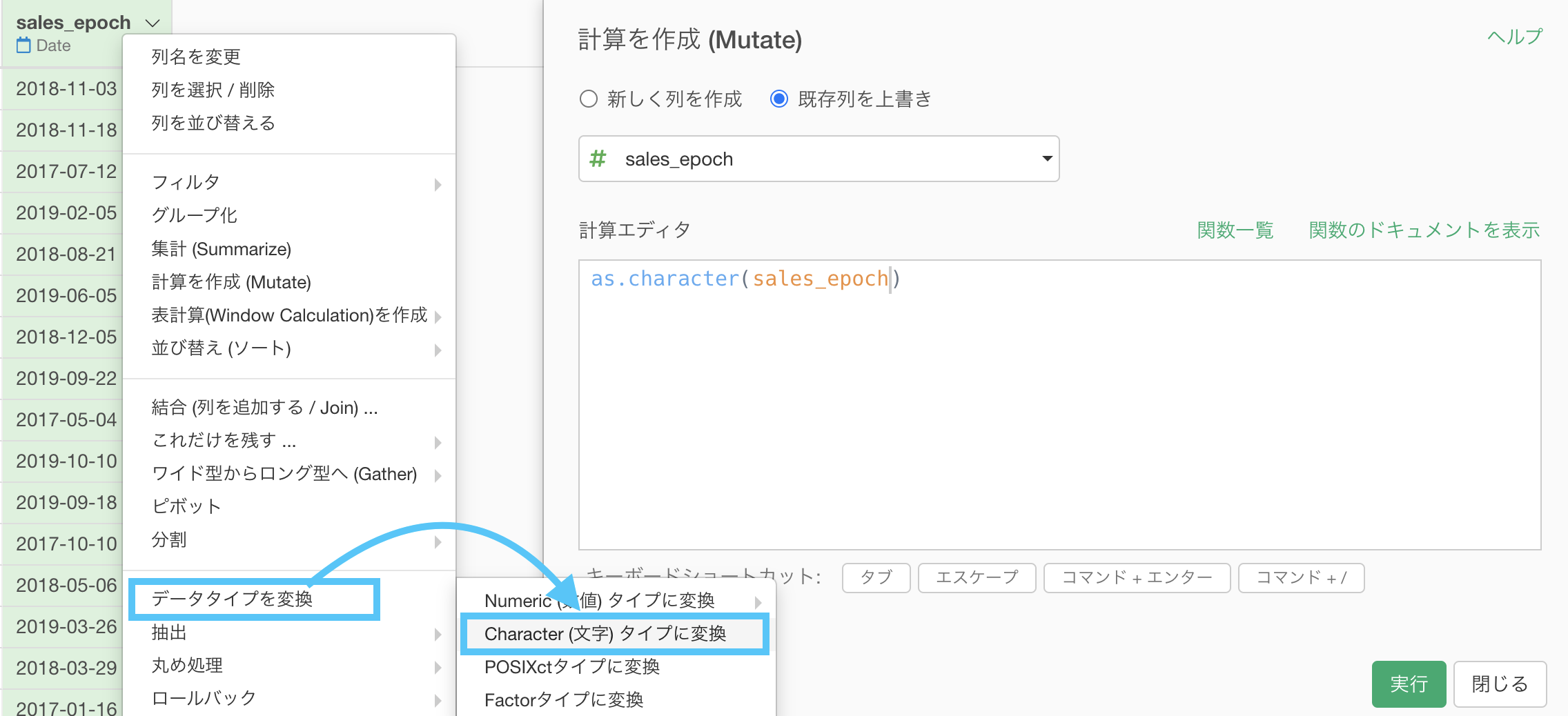
見た目は全く変わりませんが、これでデータタイプは変換されています。
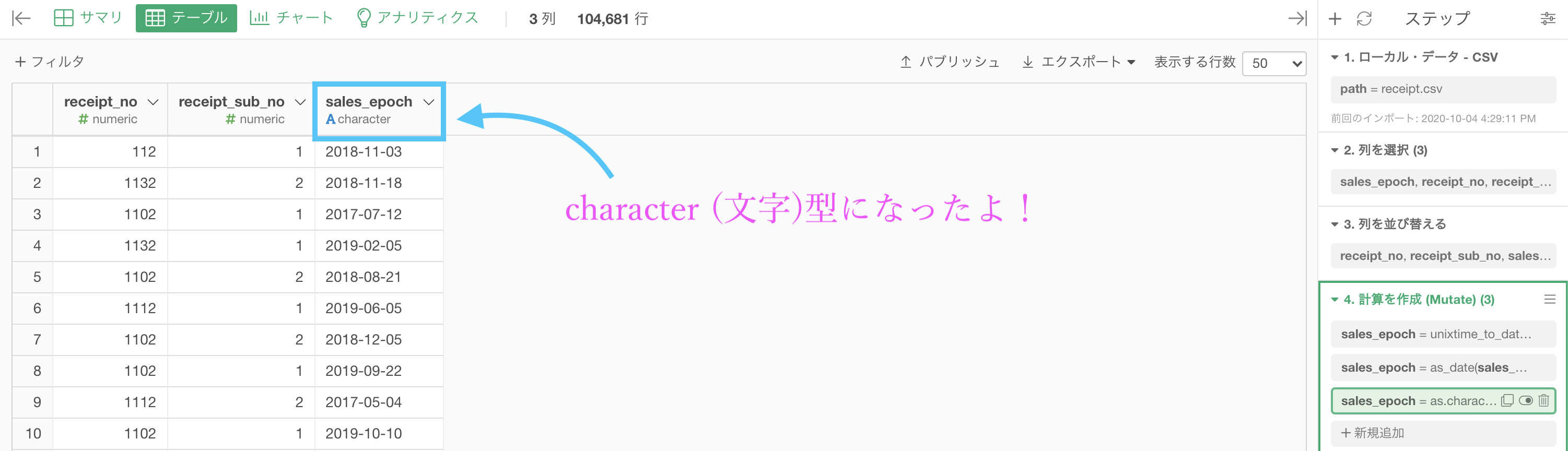
大きく変わるのは、ステップメニュー です。
見た目は同じデータであったとしてもためです。character (文字) 型にしたということは、テキストデータの関数をほぼ全て味方につけたことだと思って良い ということは何度か言ってきました。
それは今話していることにドンピシャです。実装の話に戻りましょう。
ステップメニューから「テキストデータの加工 → 抽出する → 指定した範囲にある文字列」を選択します。
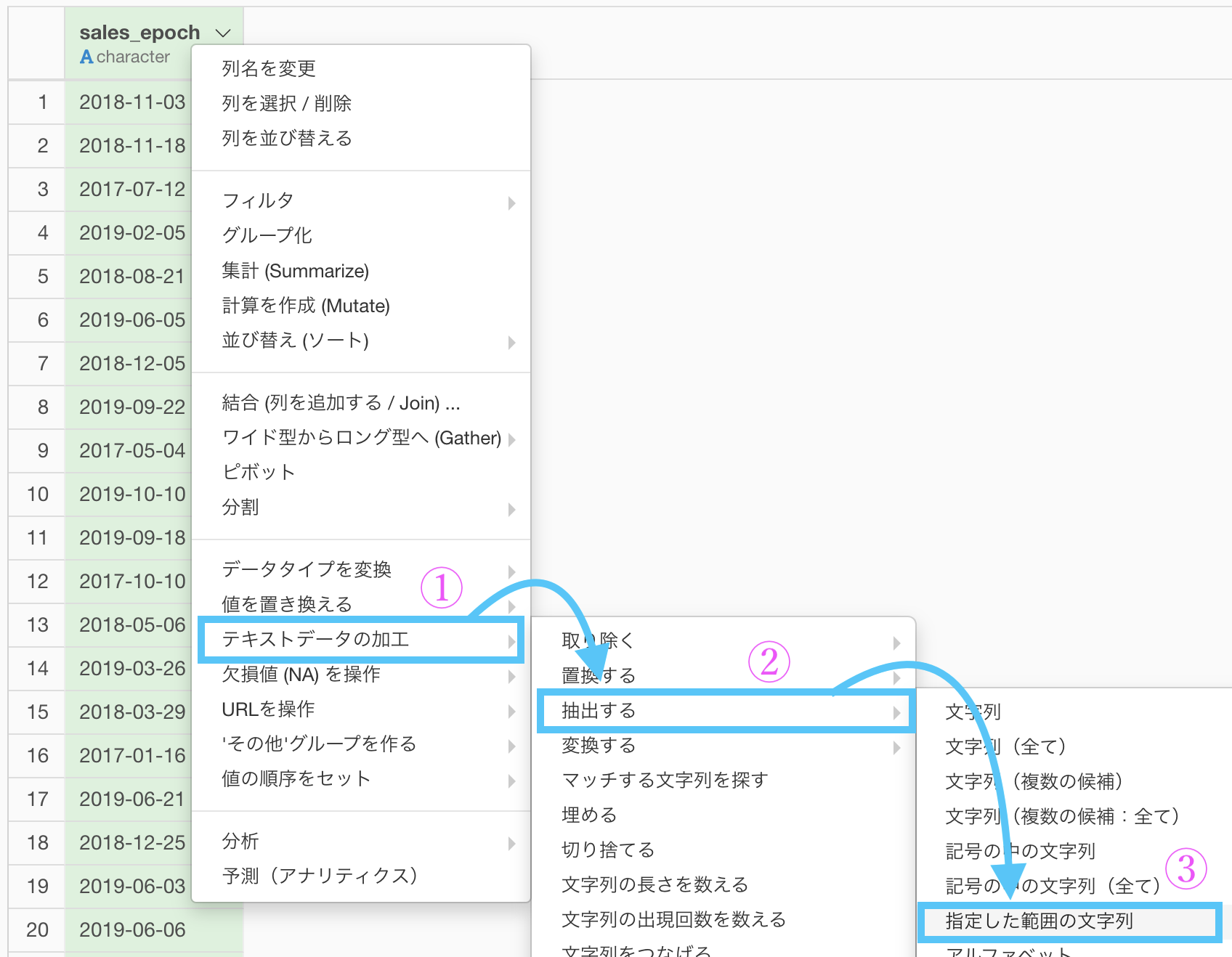
するとこのような画面が出てきたと思います。
以下のように操作しましょう。
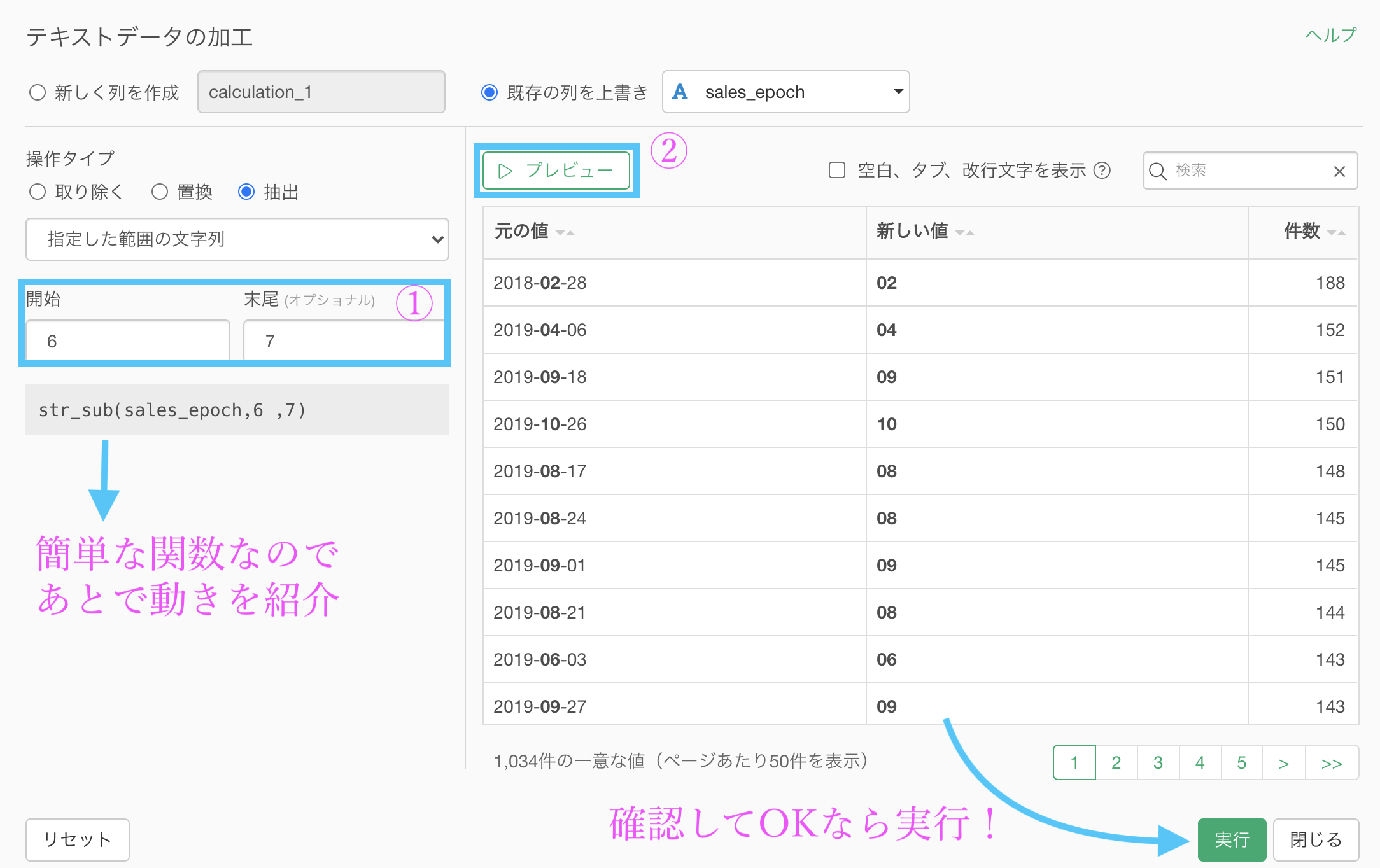
実行した結果がこちらです。答案と一致しているはずです。
最後にコマンド(指定した範囲にある文字列を抽出する)の説明をしておきます。
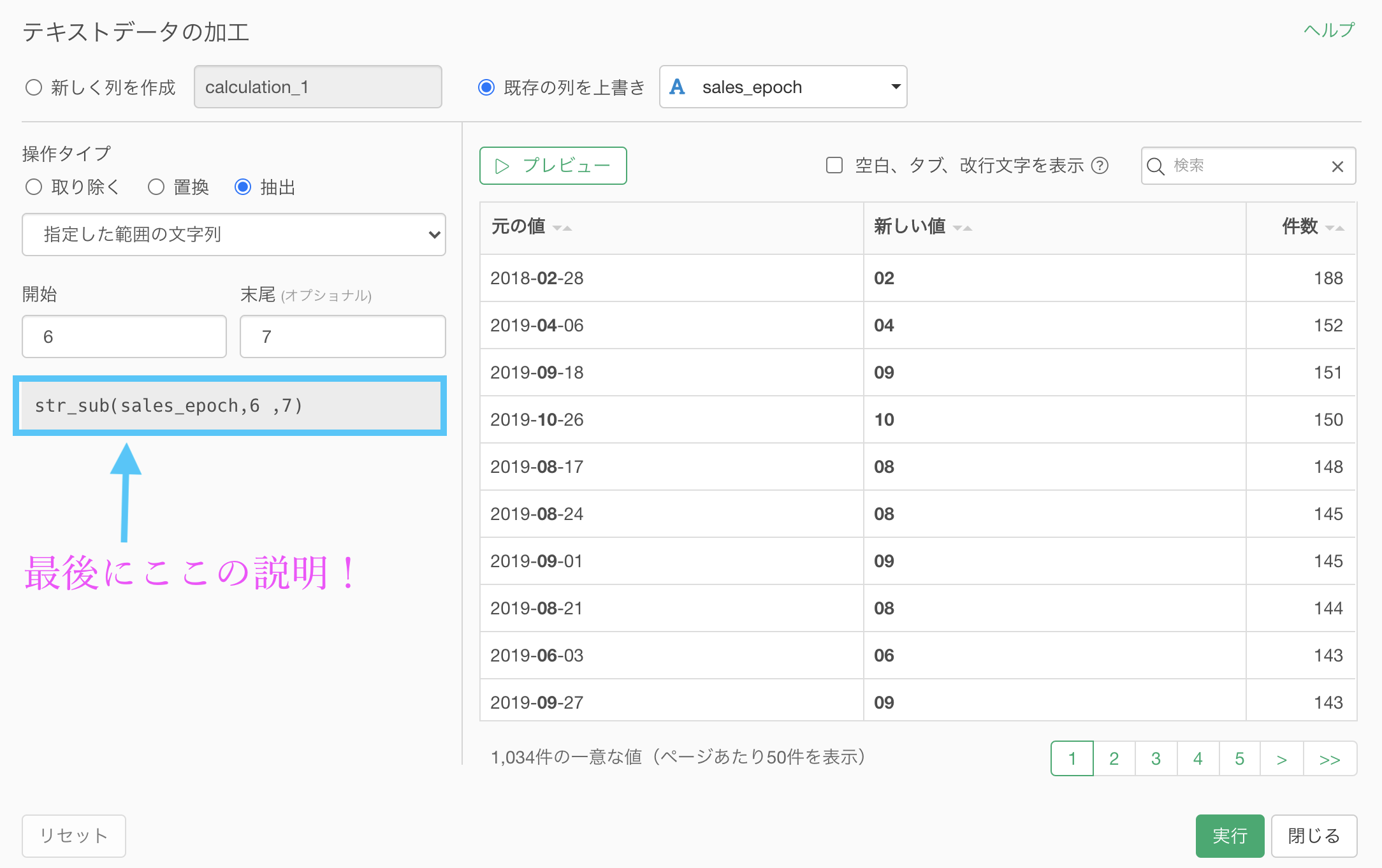
「指定した範囲の文字列を抽出する」ということですので、範囲を指定するのは分析する側がやることです。
str_sub(列名, )まで予め打ち込んでありますので、あとは
str_sub(列名, 開始, 末尾) # 開始 と 末尾 のところには 数値 を入れるとすれば完成です。
開始 と 終了 は数値なので、イメージして範囲をきちんと指定できるようになりましょう。

今回は
2017-07-12 >> 07 のところは 開始,終了 が 6,7 だから
str_sub(列名, 6, 7)と打ち込めば、結果的に 月(7月 は 07月 などとして)を取り出すことに成功 しています。
このように、関数の動き・効果をイメージによって知っていれば、もともと str_sub がそういう用途で使うつもりなく設計されていたとしても、今回のように 柔軟に応用することが可能 です。
どうでしょうか?実は今回で 問50 が終わり
100本ノックがちょうど半分です。
ここまでの内容をきちんとやってこれた人は
折り返しても良いスタートダッシュが切れると思います!