データサイエンティスト協会 構造化データ前処理 100 本ノック with Exploratory
問51〜問60 の答案
答案全体を通して
Exploratory では R 言語が動いていますが, 解答やコード参照の説明では Python言語 のものでやります。
SQL的な視点や考え方が入るときもその都度書きたいと思います。枠の色使いは以下のような形を意識しています。
オレンジ枠 :
あか枠 :
あお枠 :
みどり枠 :
問51 : 日付データから特定の日だけ取り出す

答案・解説はこちら
これは 問50 とほとんど同じやり方なのでサクサクいきます。
まずは 問48の引き継ぎでここからスタートです(問50 と同じスタートの仕方)。
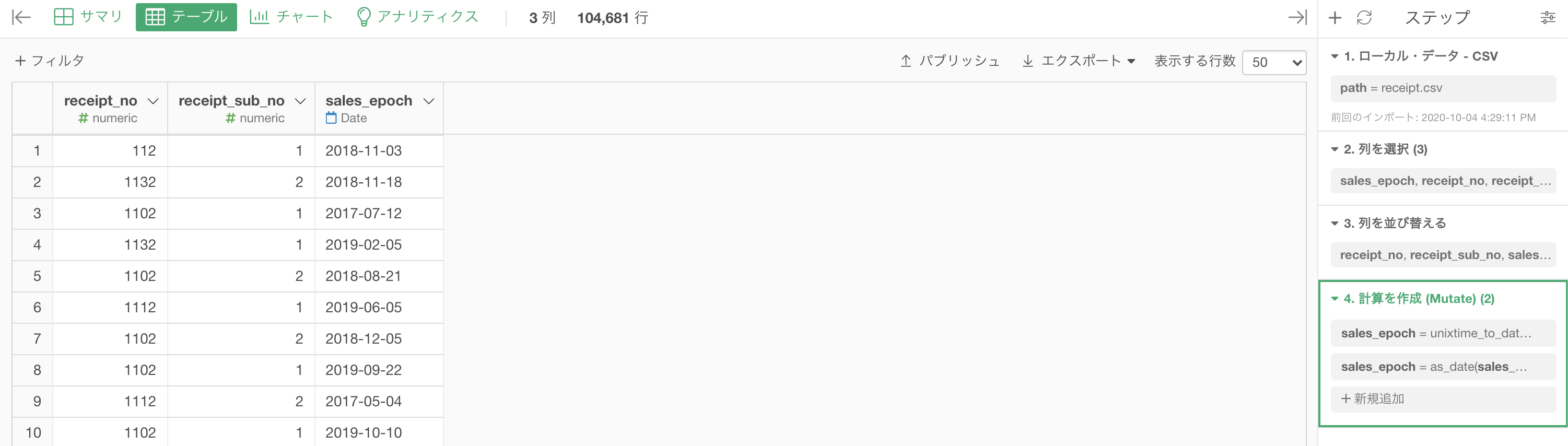
問50 では「抽出 → 月」だったところを、ここでは「抽出 → 日 - 月の日 (1-31) 」に選択するだけです。
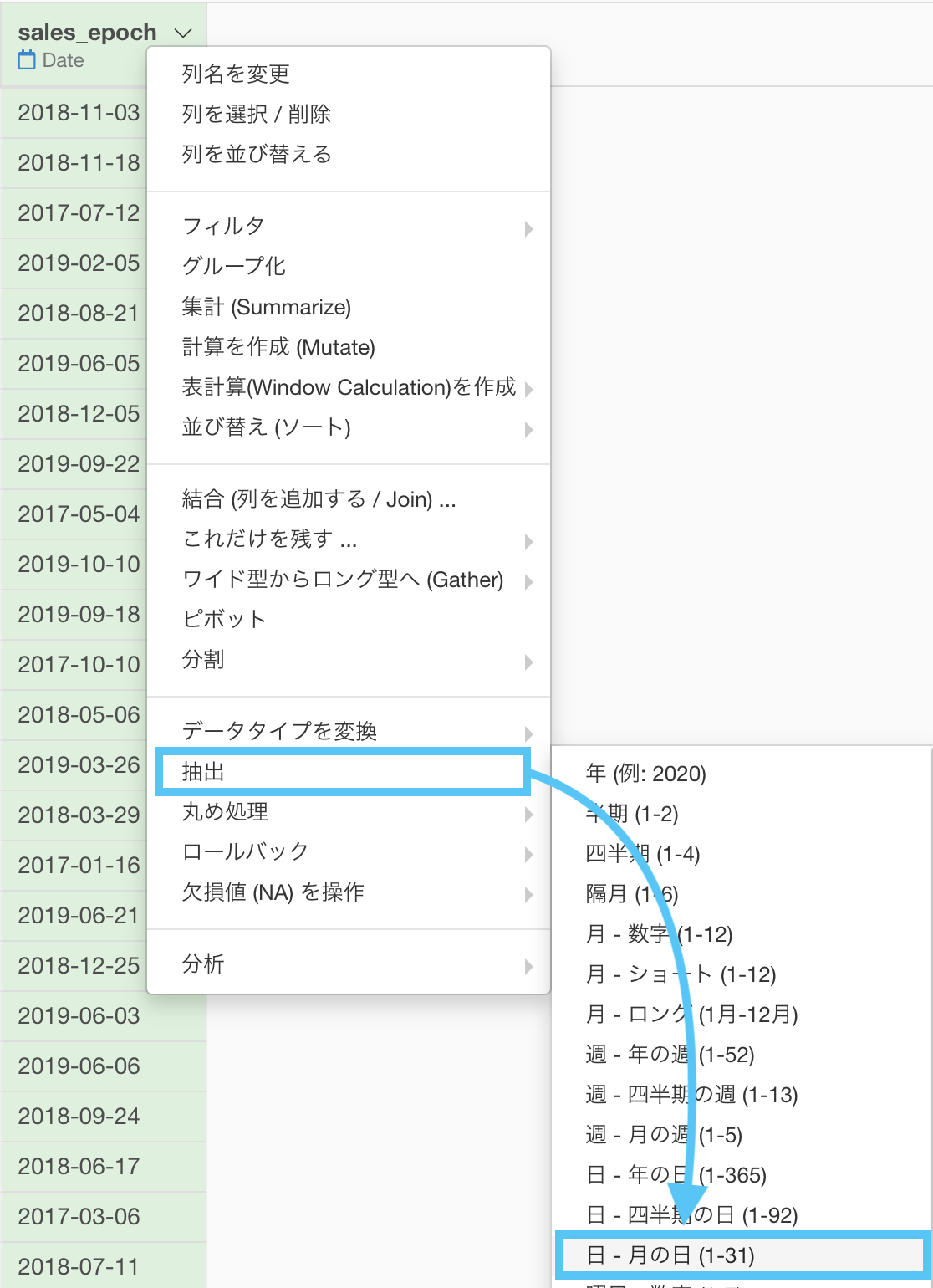
関数も、 day(...) となっていることから、これは日付を取り出すんだなということがわかると思います。
操作の流れは 問50 と同じです。
既存列を上書き(sales_epoch を選択)にして実行しましょう。
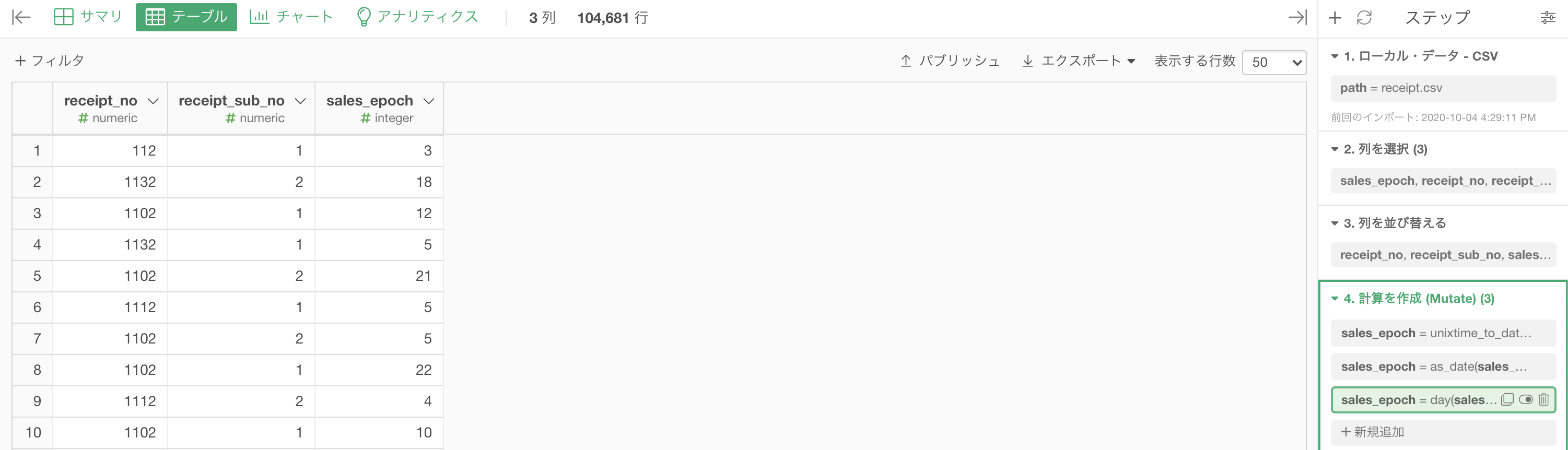
結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
# dt.dayでも日を取得できるが、ここでは0埋め2桁で取り出すためstrftimeを利用している
pd.concat([df_receipt[['receipt_no', 'receipt_sub_no']],
pd.to_datetime(df_receipt['sales_epoch'],
unit='s').dt.strftime('%d')],axis=1).head(10)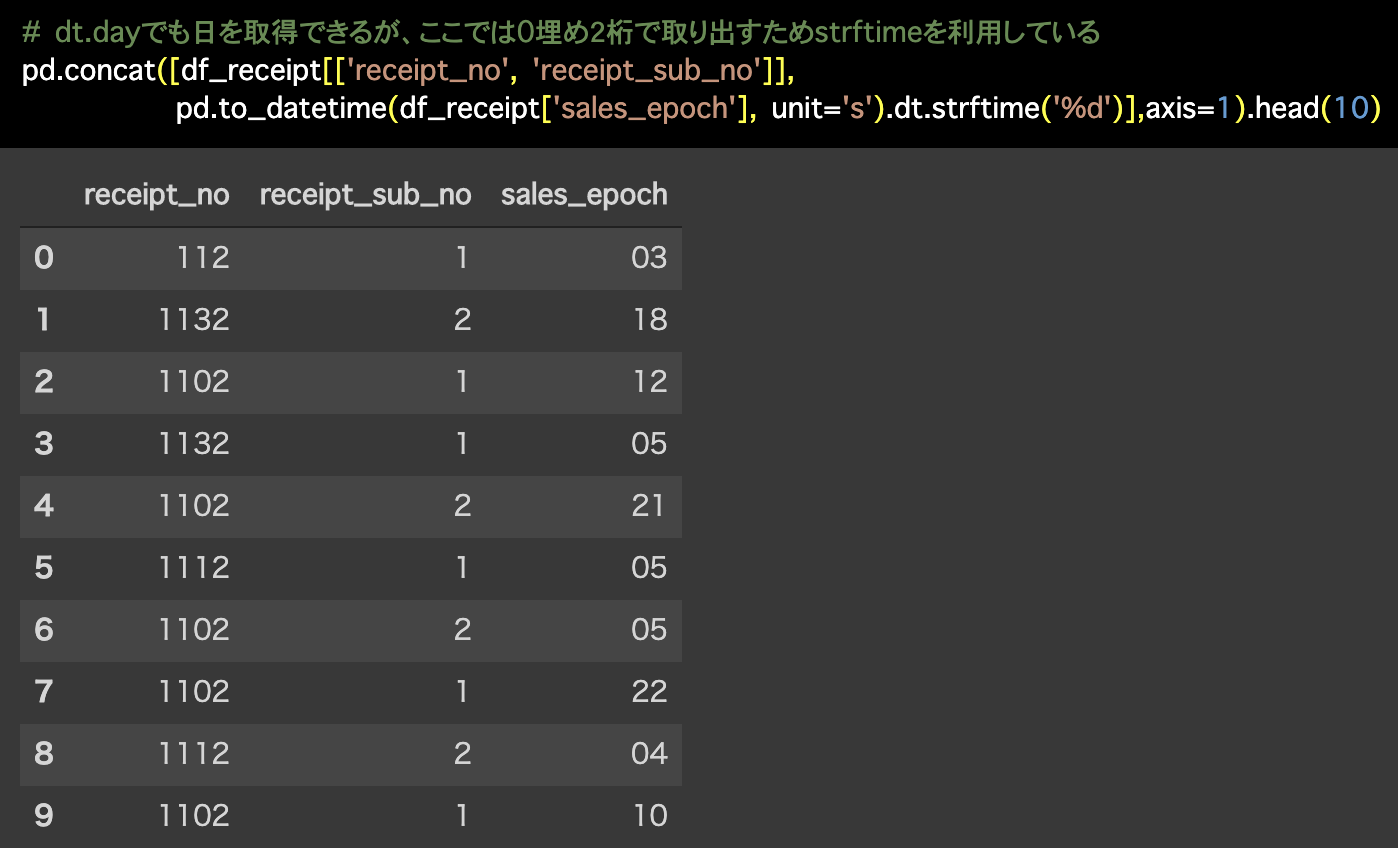
妥協できない方はこちら
基本的に 問50 のときのやり方と同じですので、多少の詳しい説明は省略させていただきます。
スタートは sales_epoch が Date 型になっているところ(問51 のスタート)からです。
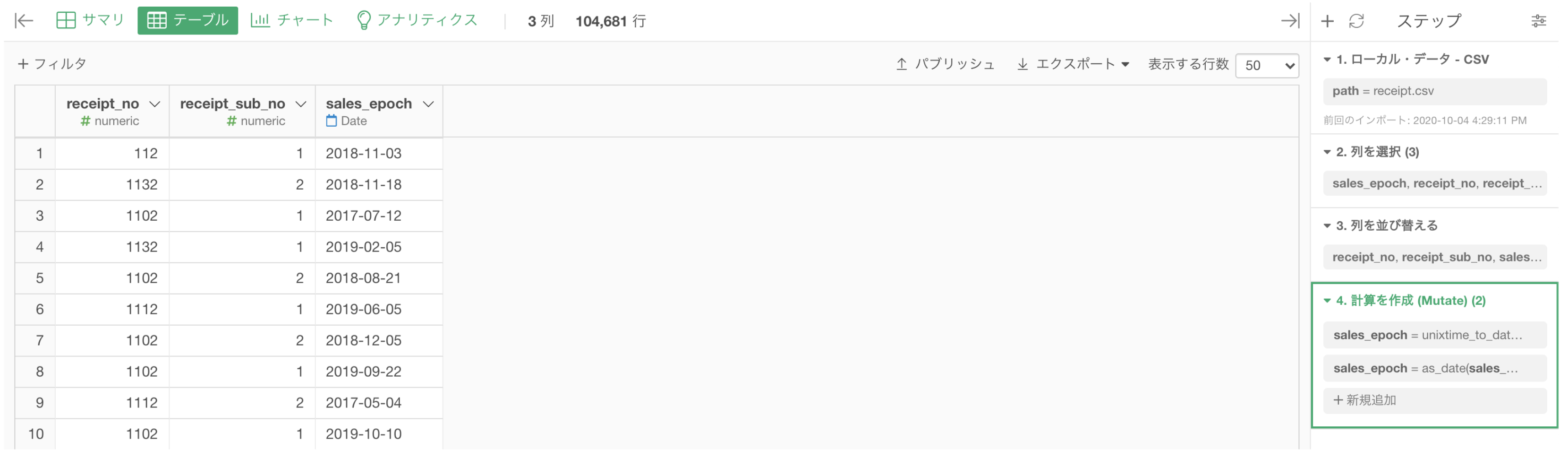
numeric(数値)タイプで 01 は絶対に不可能 です。
だとするならば、そこは Character(文字)タイプでの 01 だな!ということに目をつけて、sales_epoch を Character(文字)タイプへ変換し、テキスト関数を味方に つけましょう。
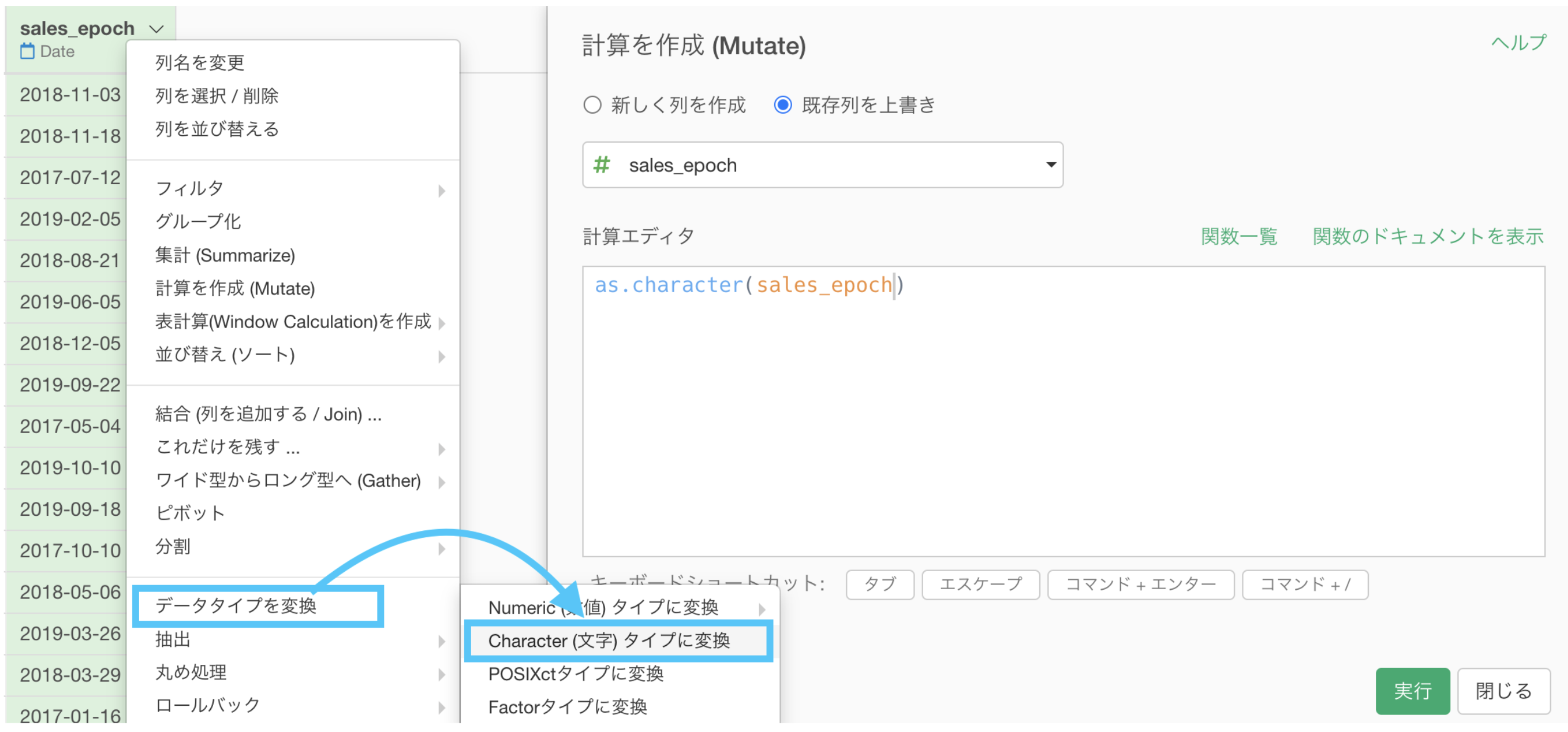
テキスト関数を味方につけている(という意識の想定をしている)ので、早速使っていきましょう。
「テキストデータの加工 → 抽出する →指定した範囲にある文字列」を選択します。
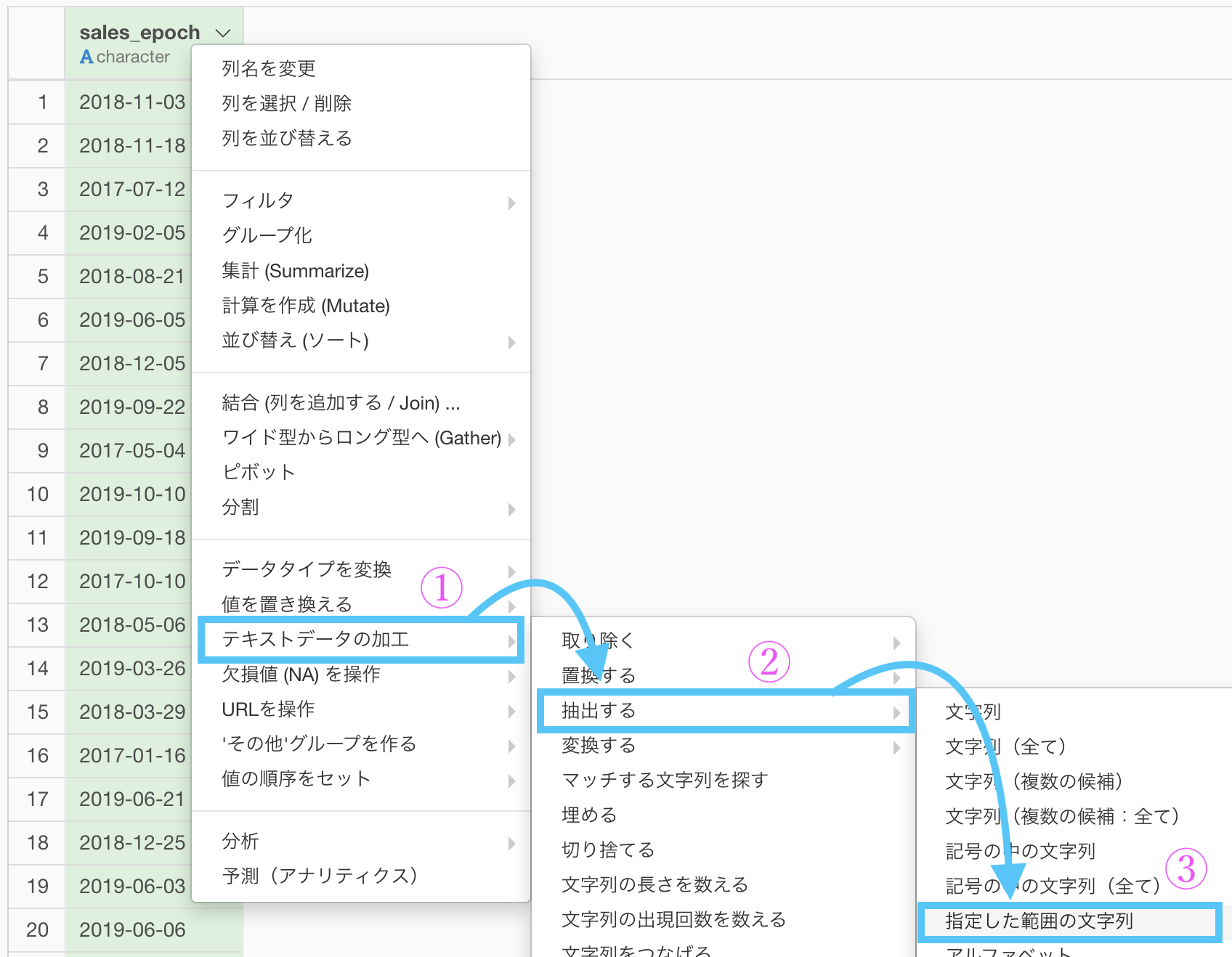
9〜10番目の文字がちょうど日付の文字になっている場所です(ハイフンも1文字と数えます)。
イメージ付きの詳しい説明は 問50(の同じような折りたたみ)をみていただければわかるかと思います。
以下のように操作しましょう。
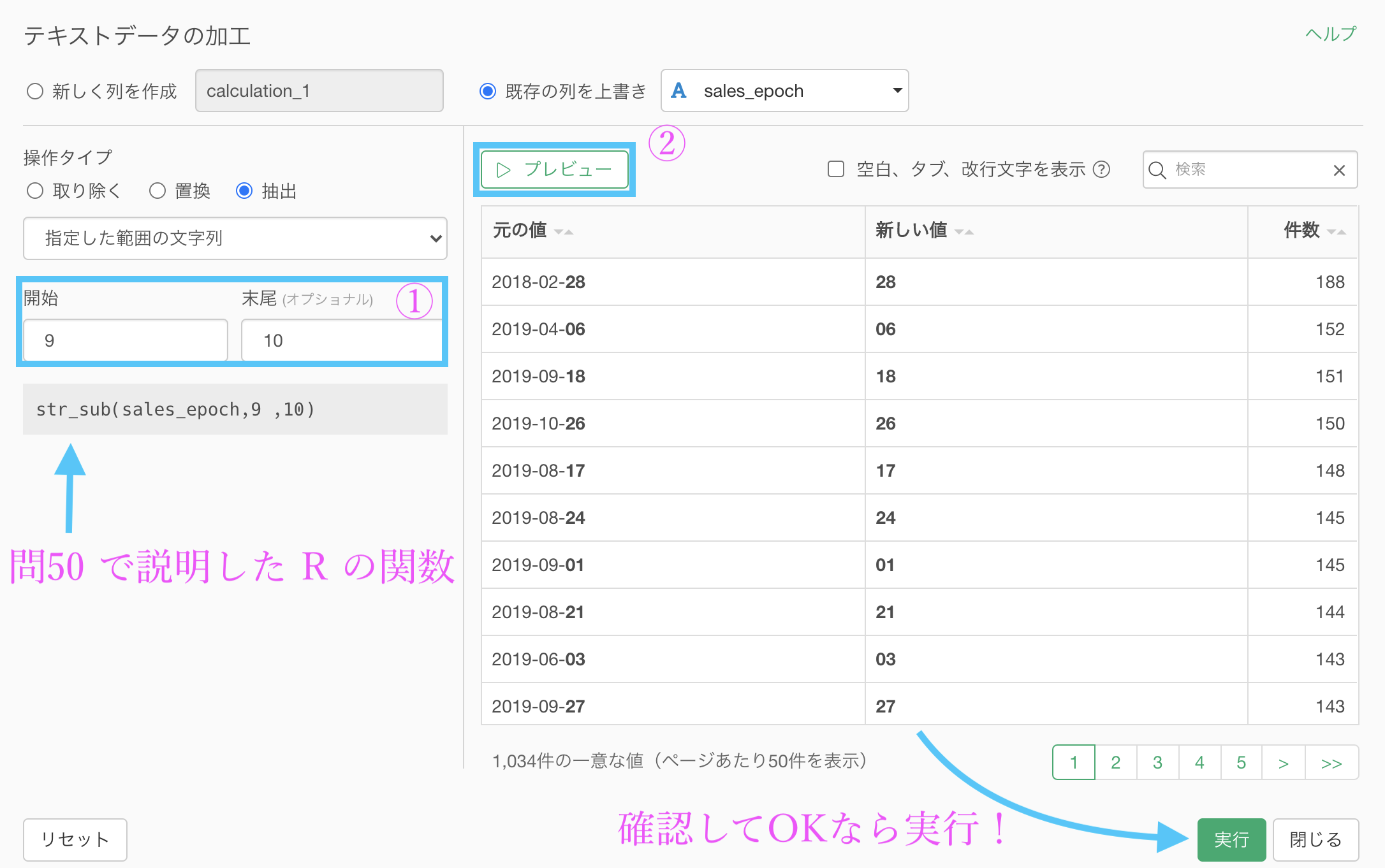
結果はこのようになります。解答を確認しましょう。
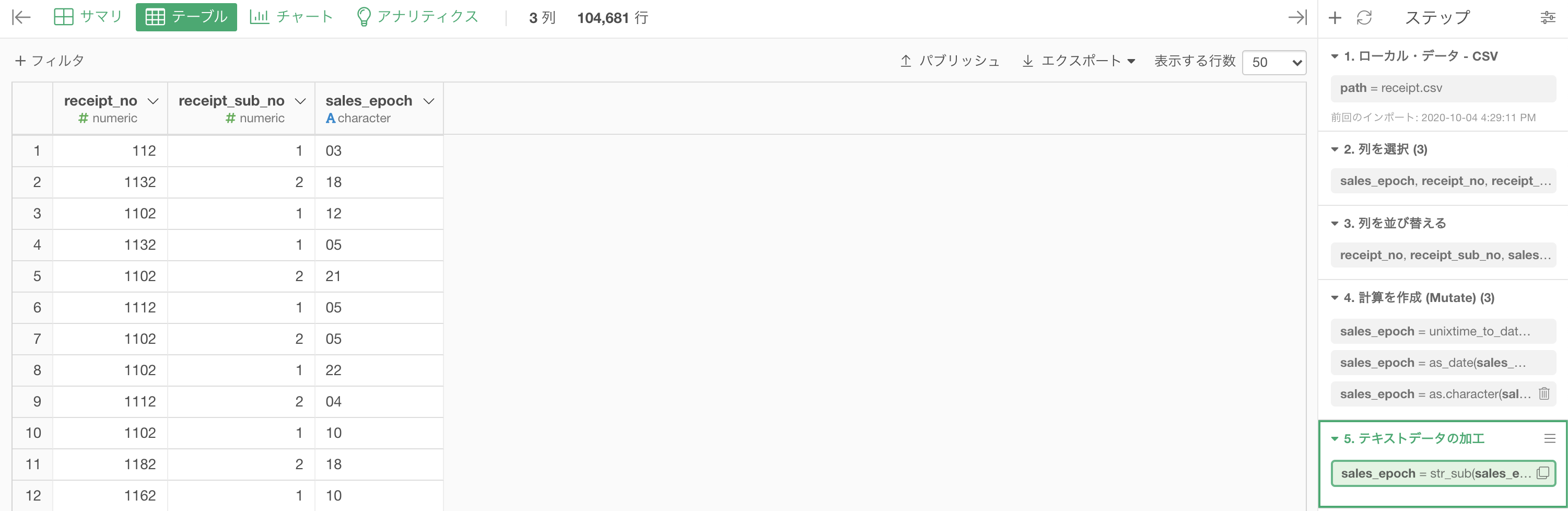
ちなみに余談ですが、sales_epoch が Date 型の時点で 無理矢理にでも 計算を作成 (Mutate) をして、str_sub(...) を同じように打ち込むと一発でゴールまで辿り着きます。
Date型であっても、結局は文字に順番(時間の情報)がついただけのものだから、テキスト関数が使えているという考え方で良いと思います。
この場合はイチからコマンドを打ち込む(できる範囲で良い)ことになりますが、経験値がものを言う部分もやっぱりありますので少しずつ慣れていきましょう。
ここまでで データタイプの変換 の問題は終わり です。
次から(問58 まで)は カテゴリ化 の問題に取り組み ます。
問52 : 数値データを二値(0/1)データに変換する

答案・解説はこちら
です。
具体的にどういうことをしているのか?というのはざっくり問題のタイトルを流し読みしていただけると良いかと思います。
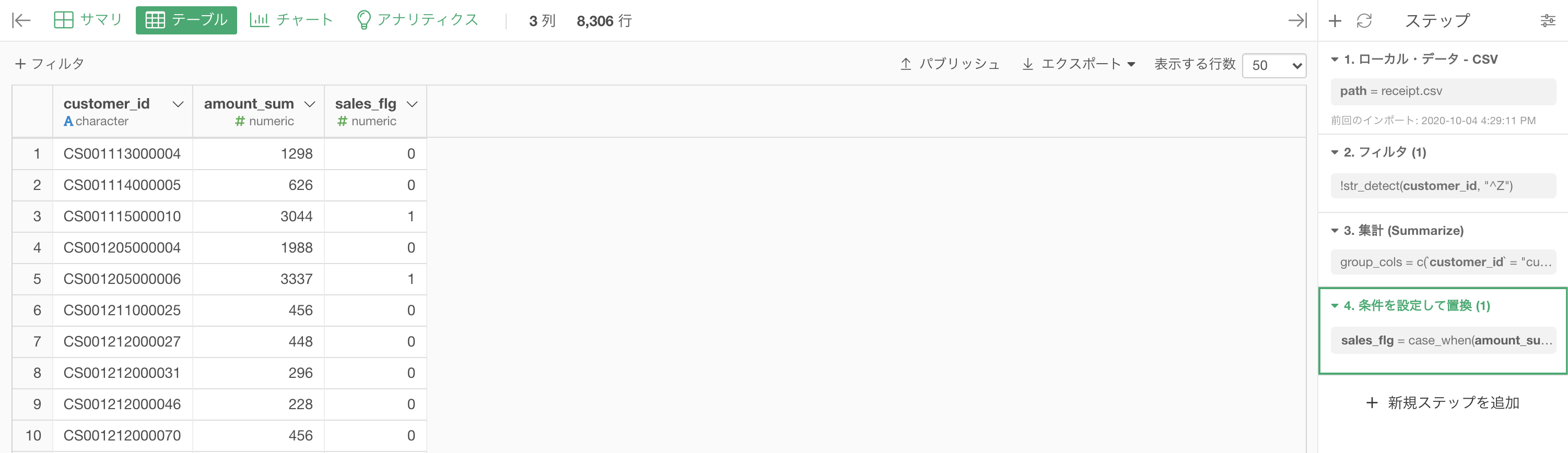
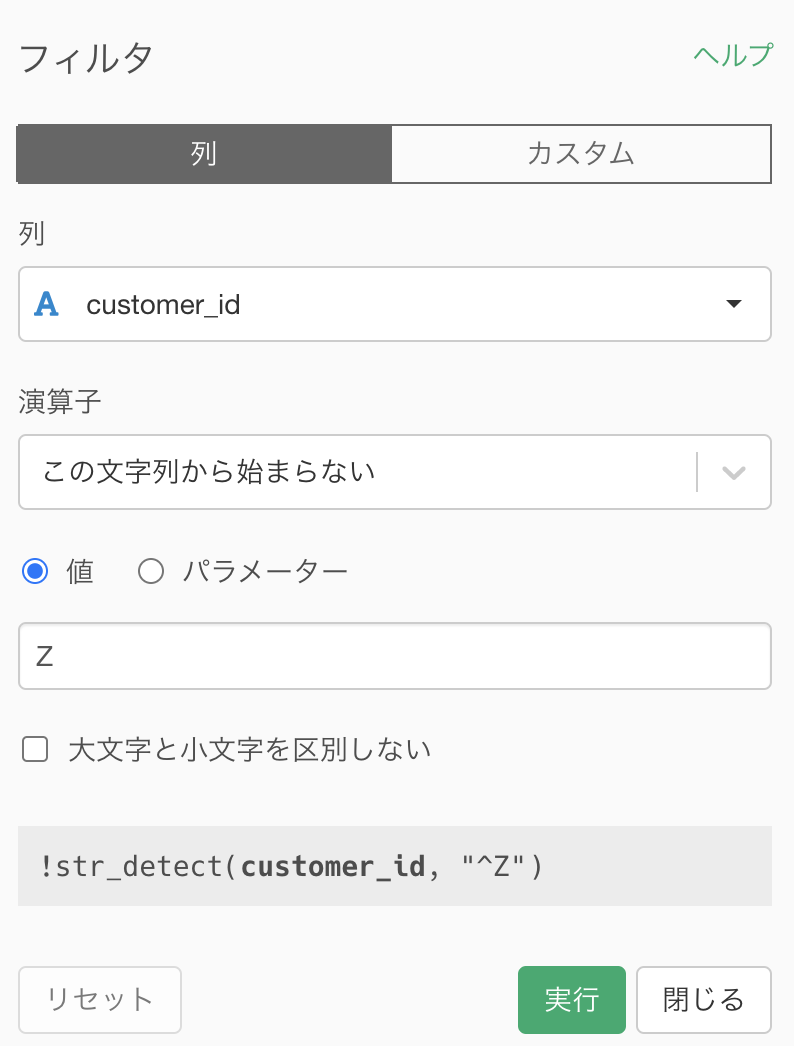
それではまず問題文に書いてあるように、customer_id が Z から始まる顧客(非会員顧客)はフィルターした後に
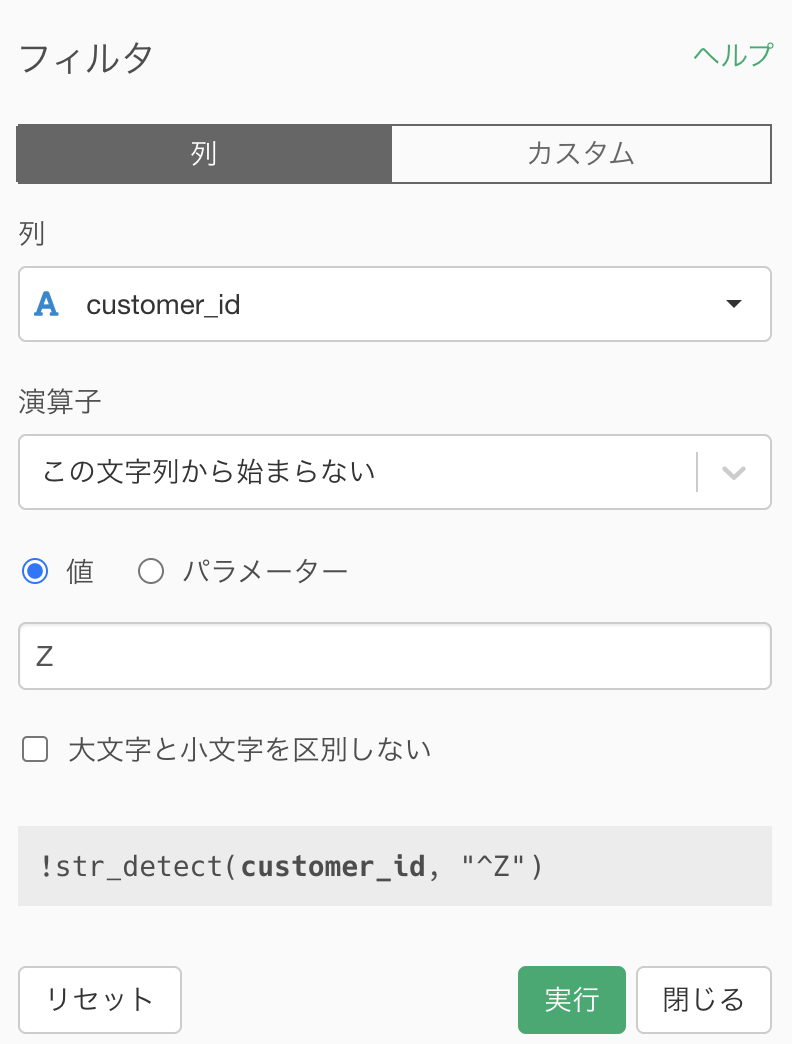
以下のように集計しましょう。
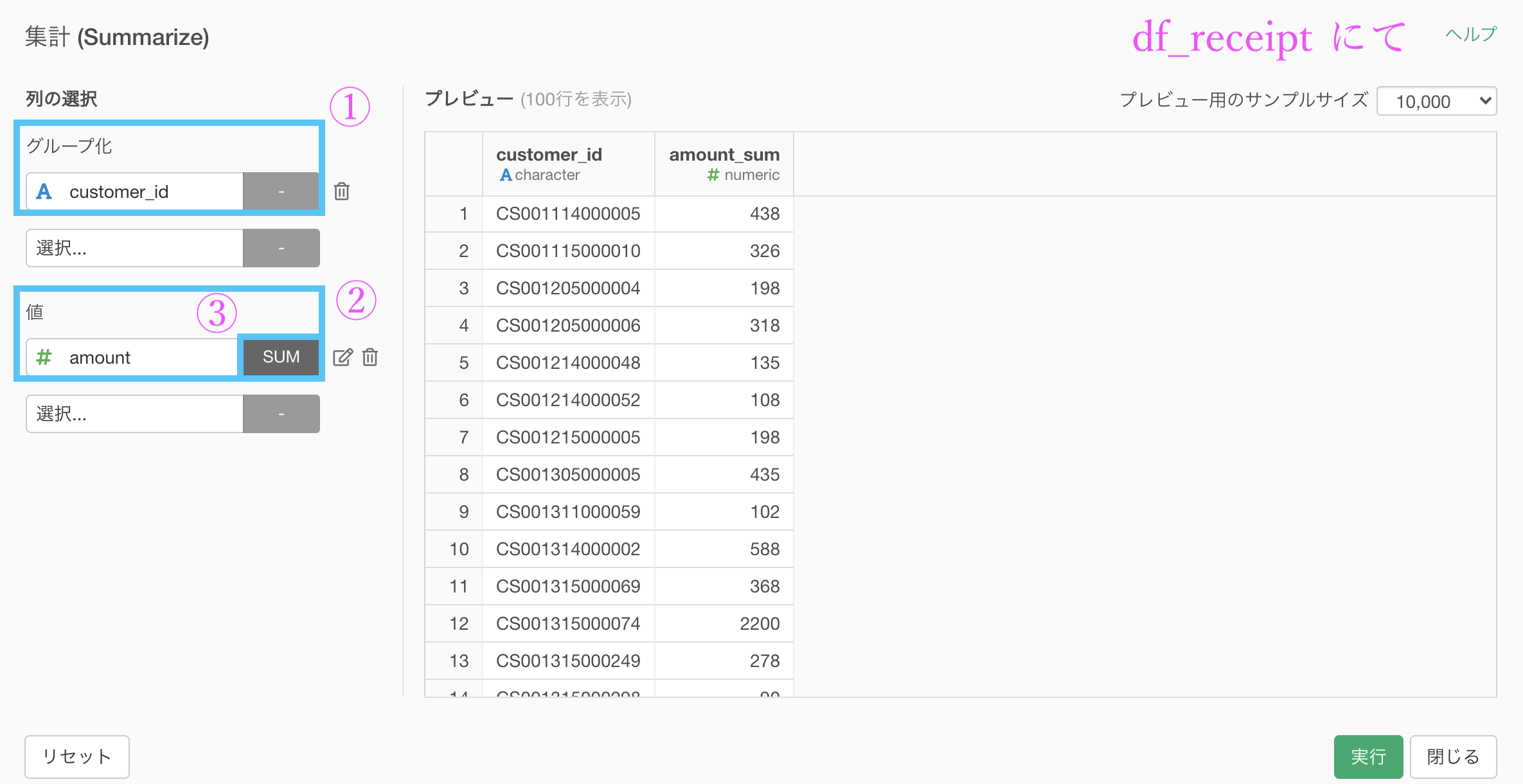
ここまではできたでしょうか。今までの話を振り返りながらでもたどり着けて欲しいところです。
このあとやりたいことはです。
0 か 1 かというのは、FALSE か TRUE かということとほとんど同じ です。
イメージとしては次のようなことです。
さて、Exploratory でやっていきましょう。
ステップメニューから「値を置き換える → 条件を指定」とします。
このような画面が出てきたと思います。
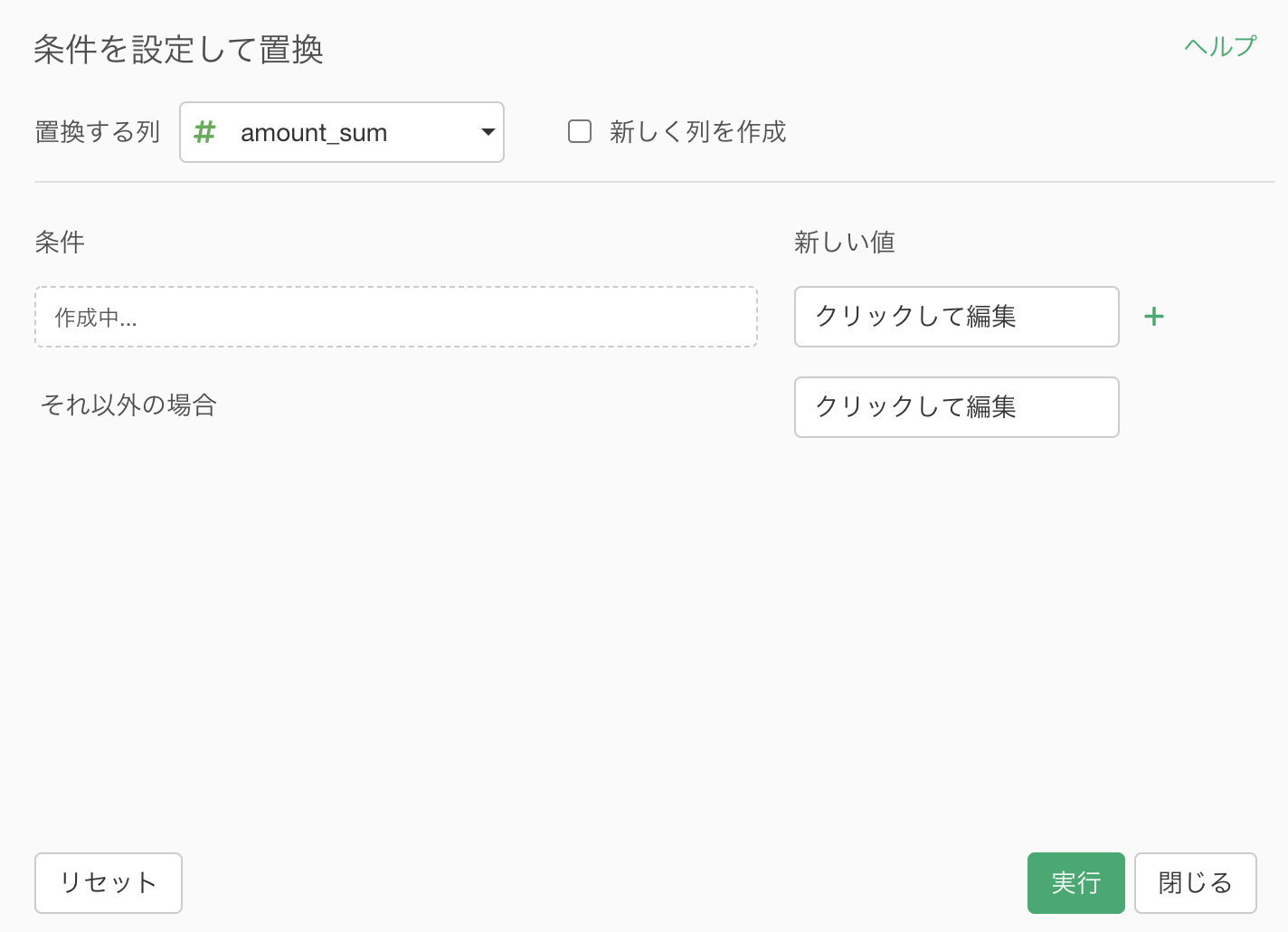
少し手を止めて、画面とイメージを対応させましょう!
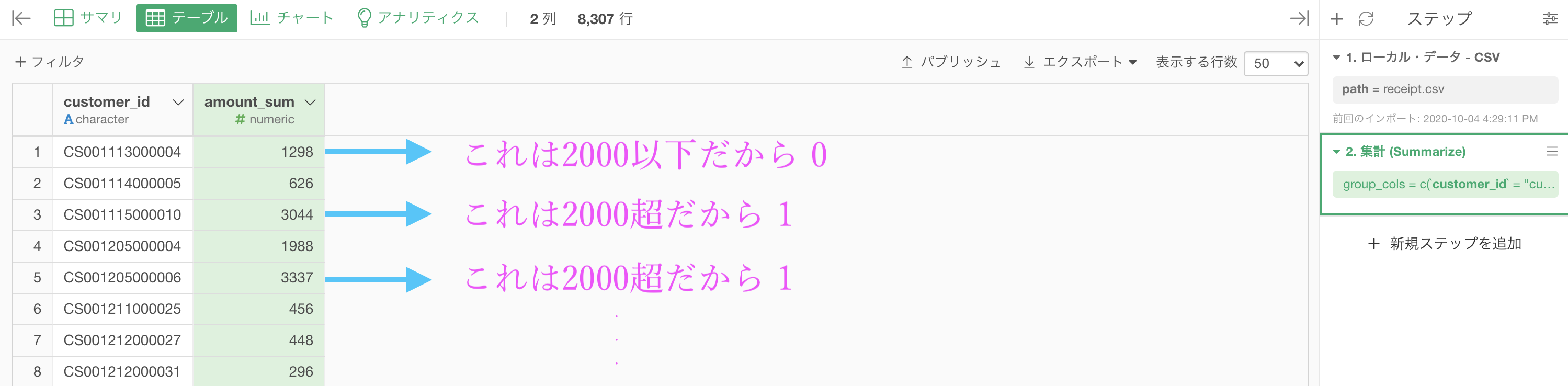
今やりたいことは
- 2000 以下 なら 0
- 2000 超 なら 1
ということでした。
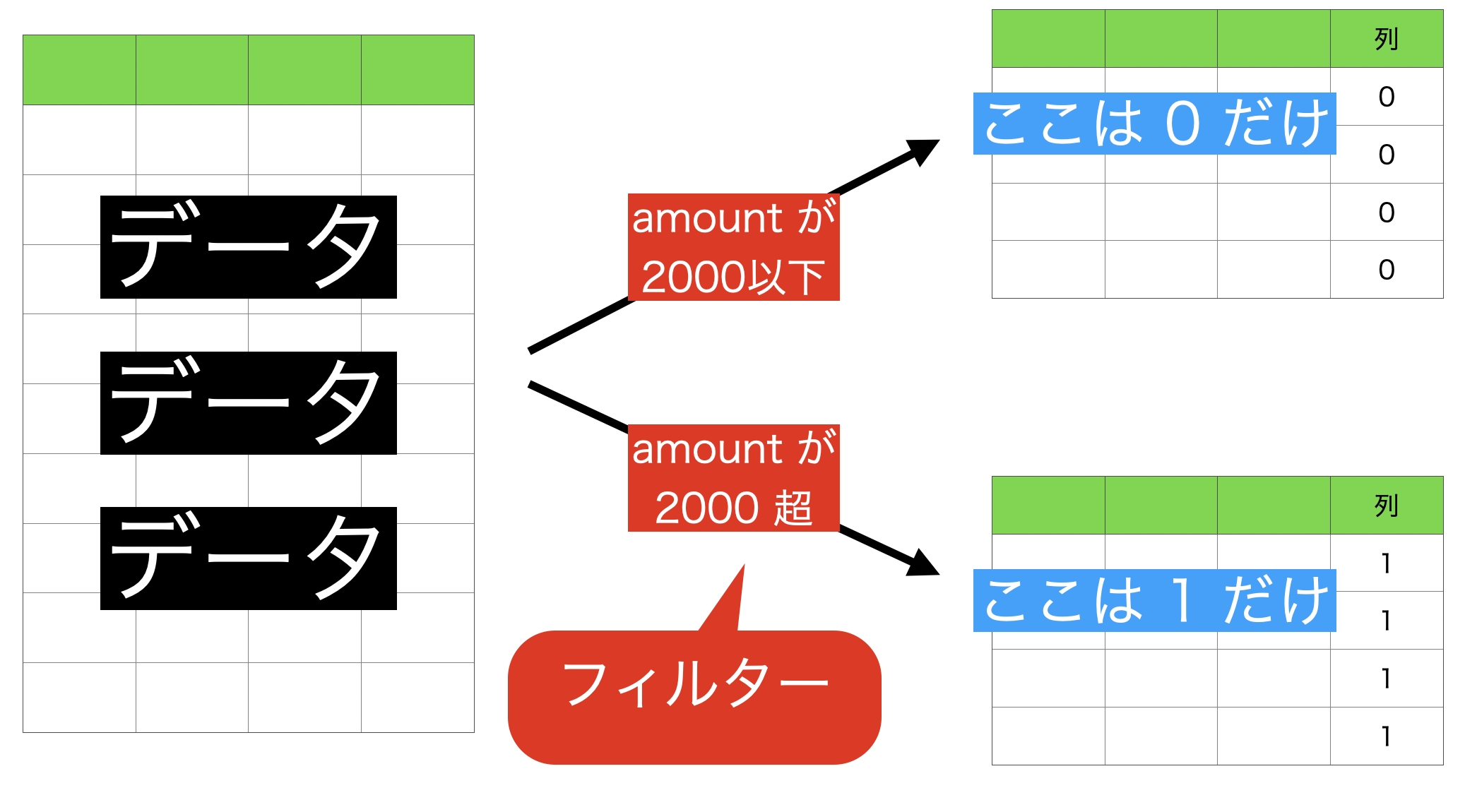
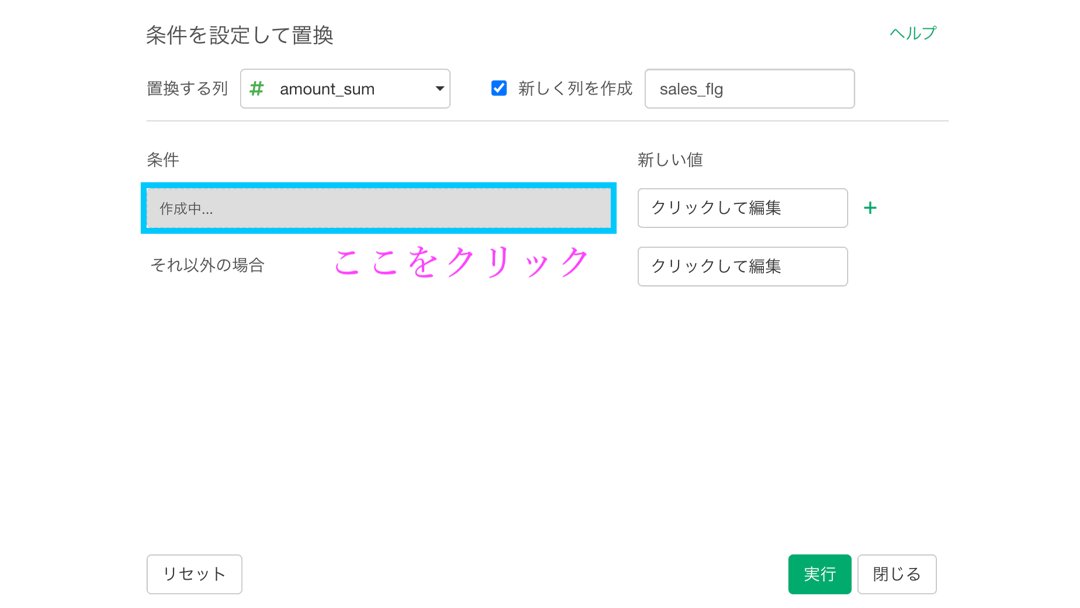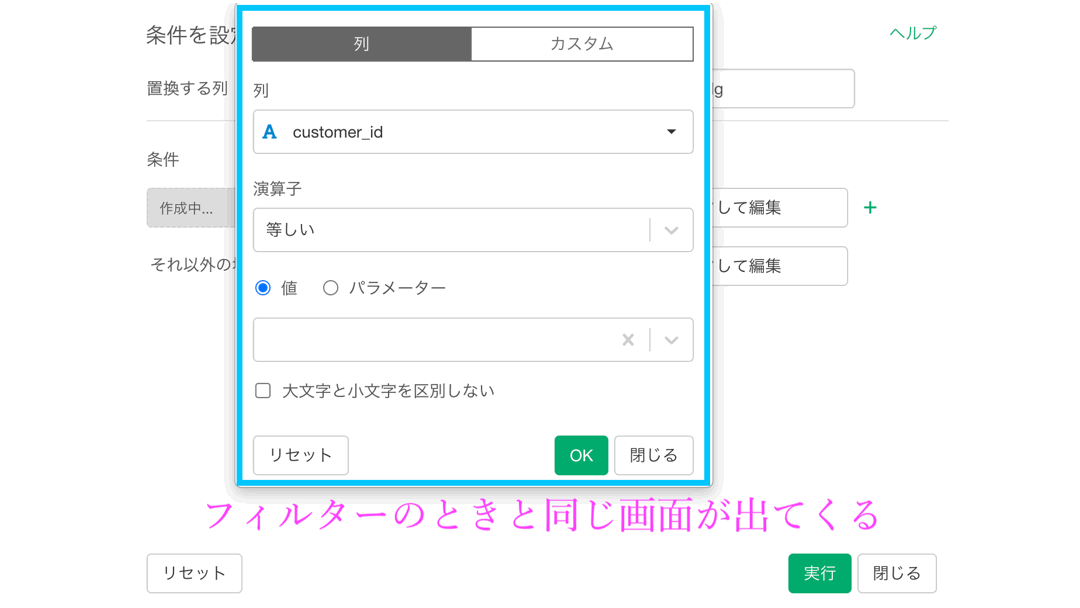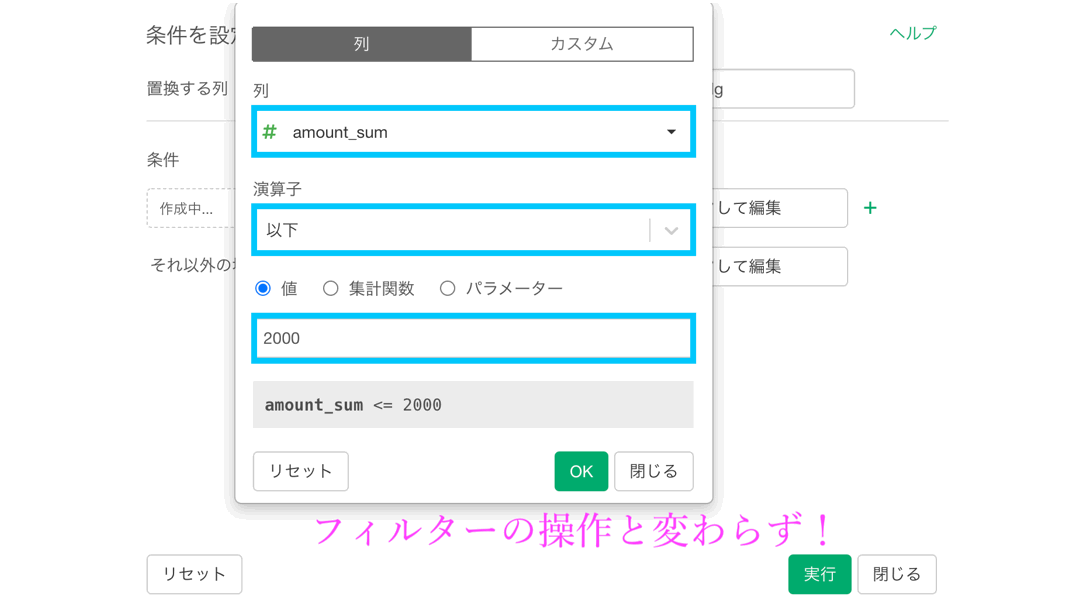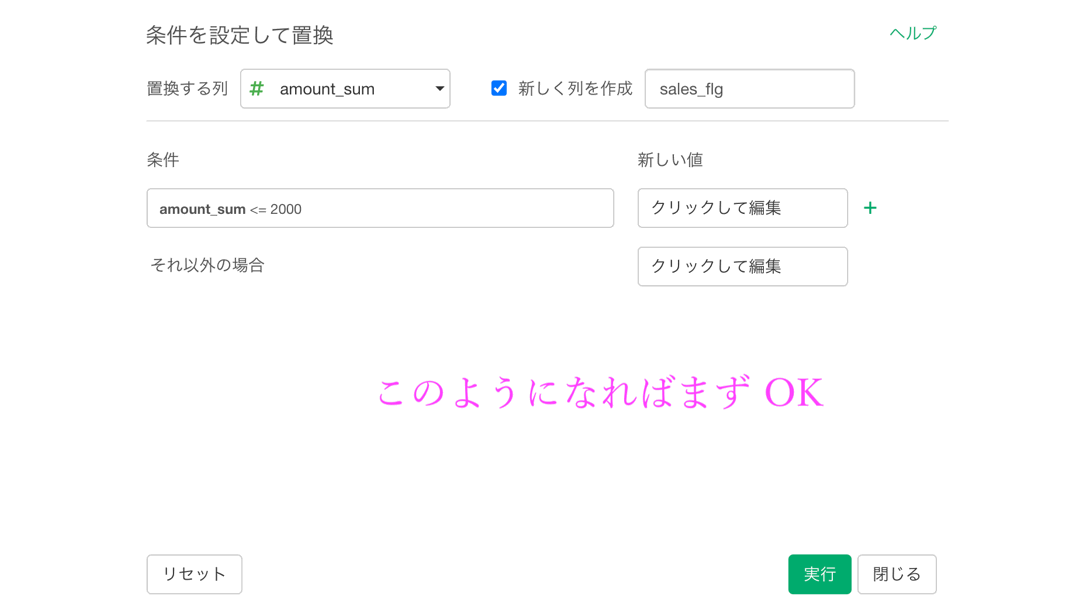
これをそのまま Exploratory の画面と対応させるとこのようになります。
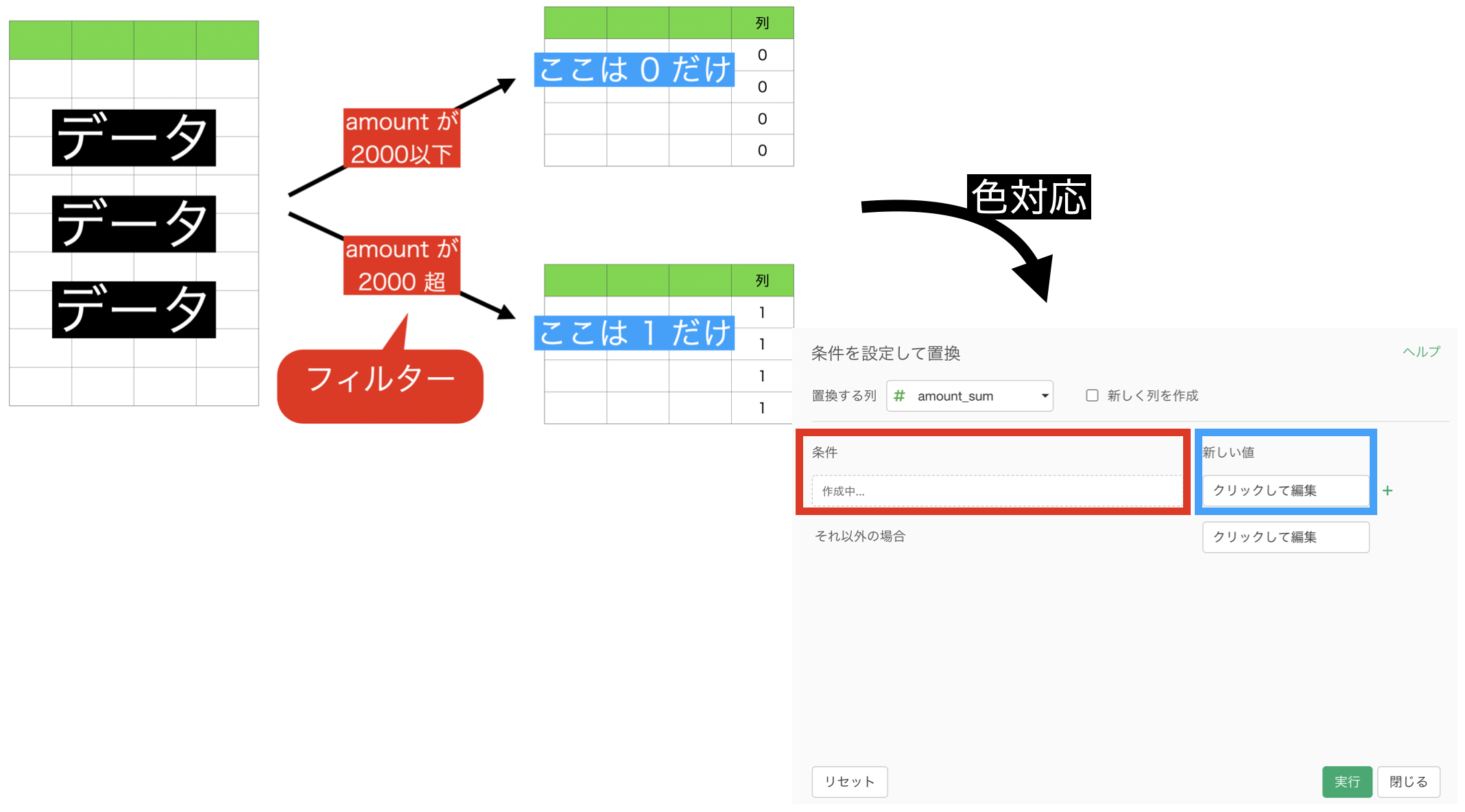
これをイメージしながら、画面だけみても操作ができるように 説明するとこんな感じになります。
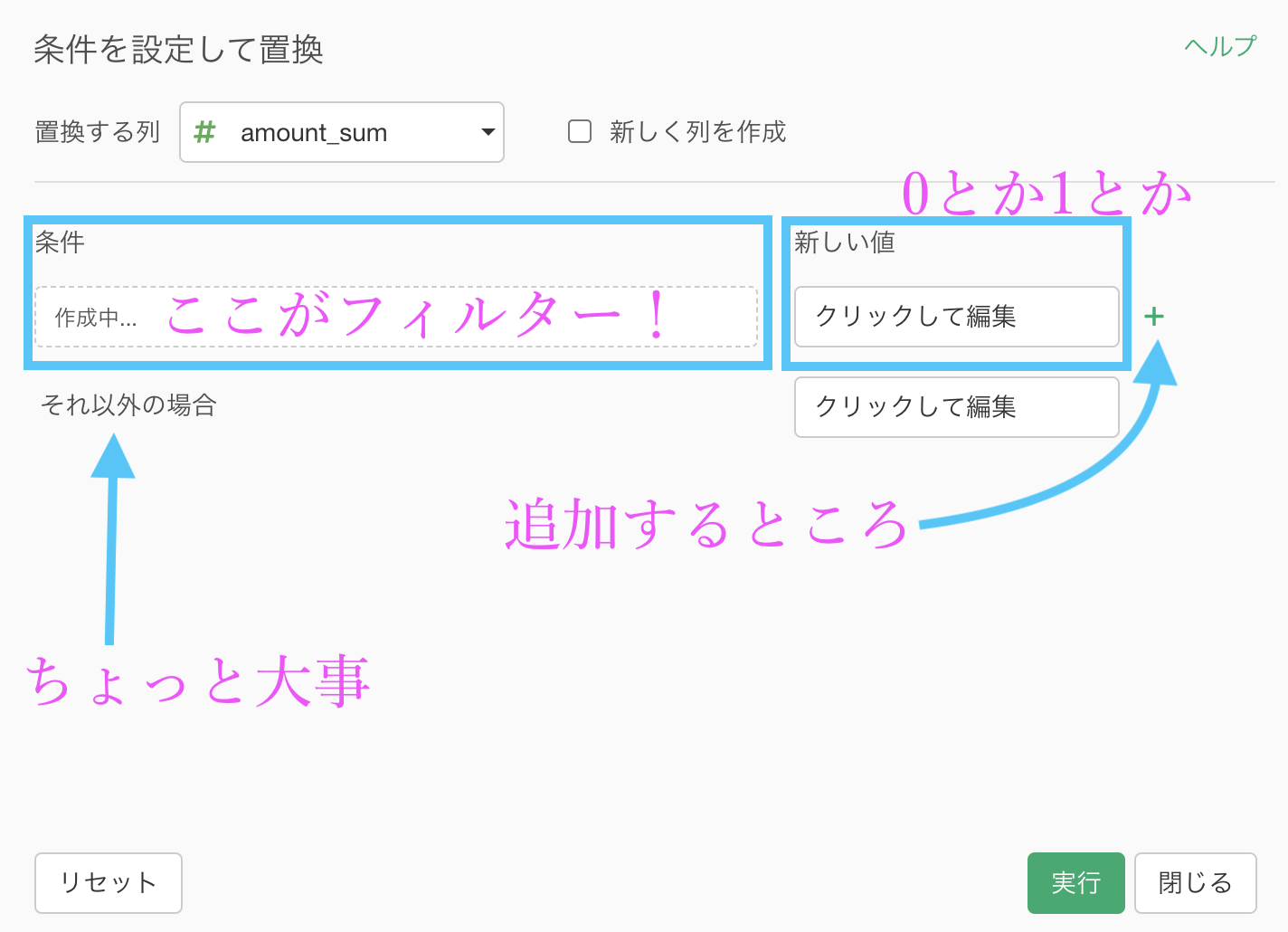
では実際に操作をやっていきましょう。
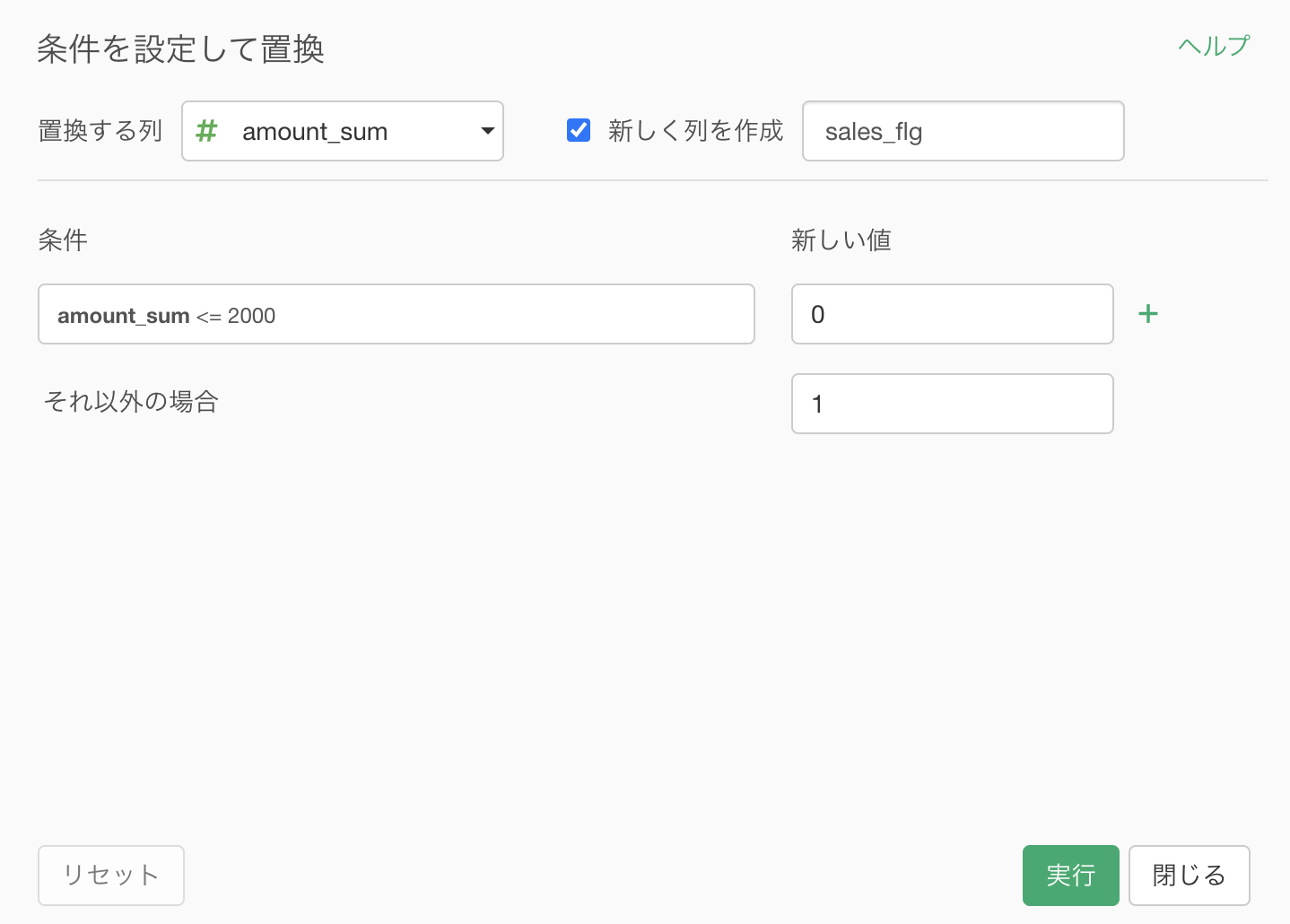
まずは「新しく列を作成」にチェックを入れて、0 とか 1 とかの列の名前を「sales_flg」(セールスフラグ)とします。
ここまでできれば、あとは新しい値(0とか1とか)を指定するだけ です。
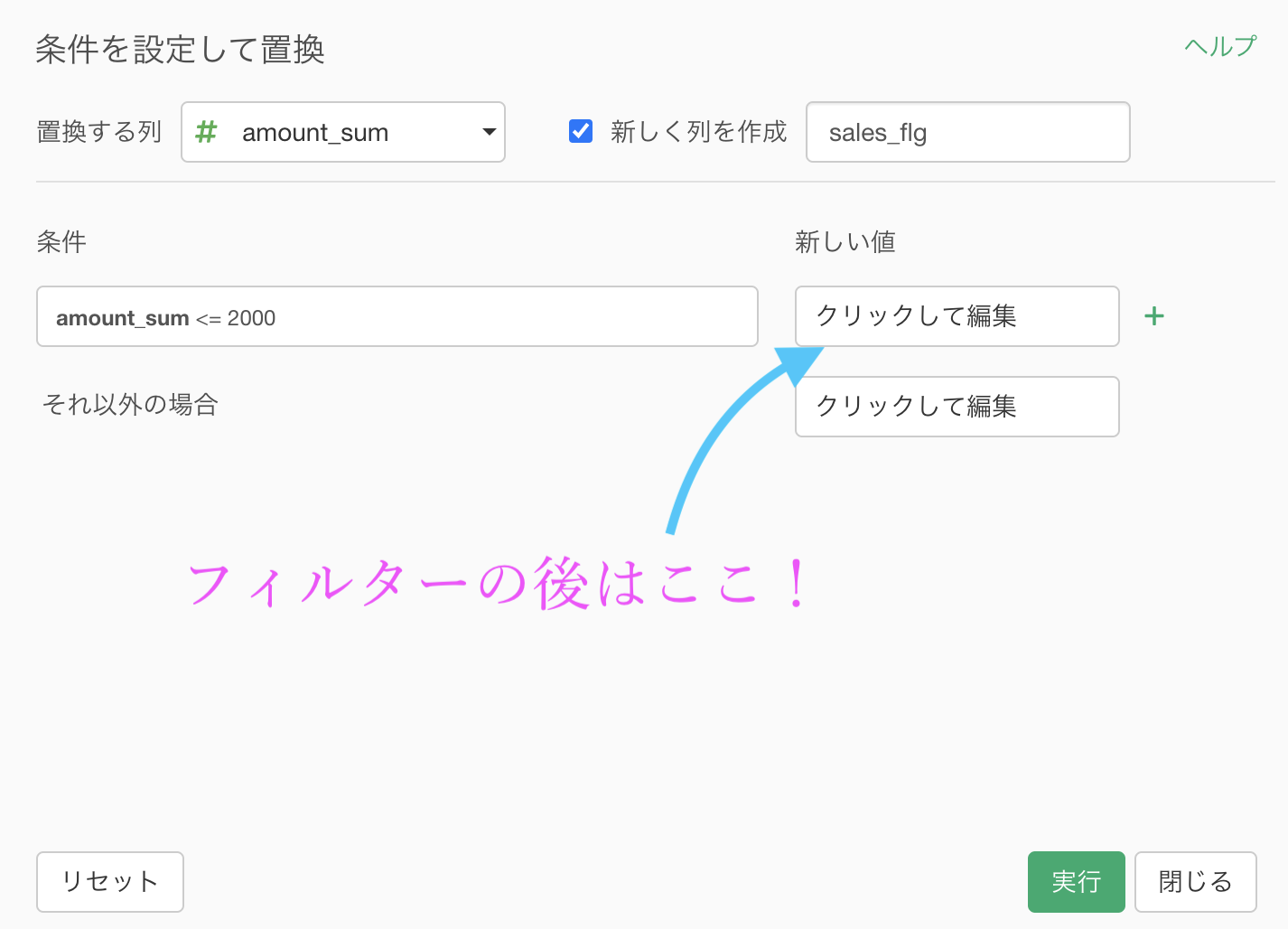
新しい値のところにクリックして編集します。
このとき出てくる白紙の中に 0 と打ち込めば「amount_sum が 2000 以下なら 0」と読めます よね。
計算式も打ち込めますし、計算を作成 (Mutate) と同じ感覚で操作するので非常に便利です。

忘れがちなので本当に注意してください。
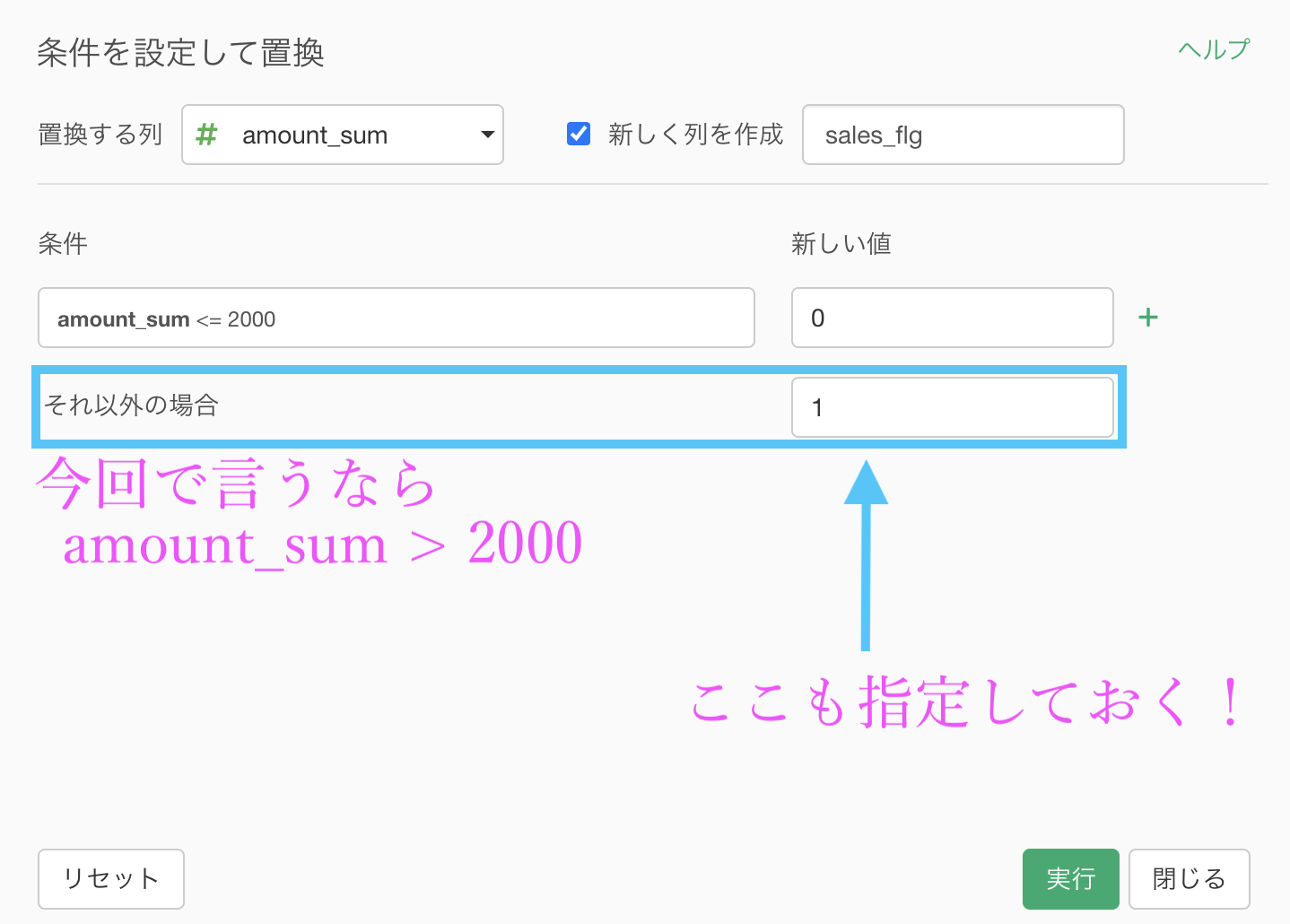
このようになったら実行します。
結果はこのようになります。解答を確認しましょう。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python')
df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index()
df_sales_amount['sales_flg'] = df_sales_amount['amount'].apply(lambda x: 1 if x > 2000 else 0)
df_sales_amount.head(10)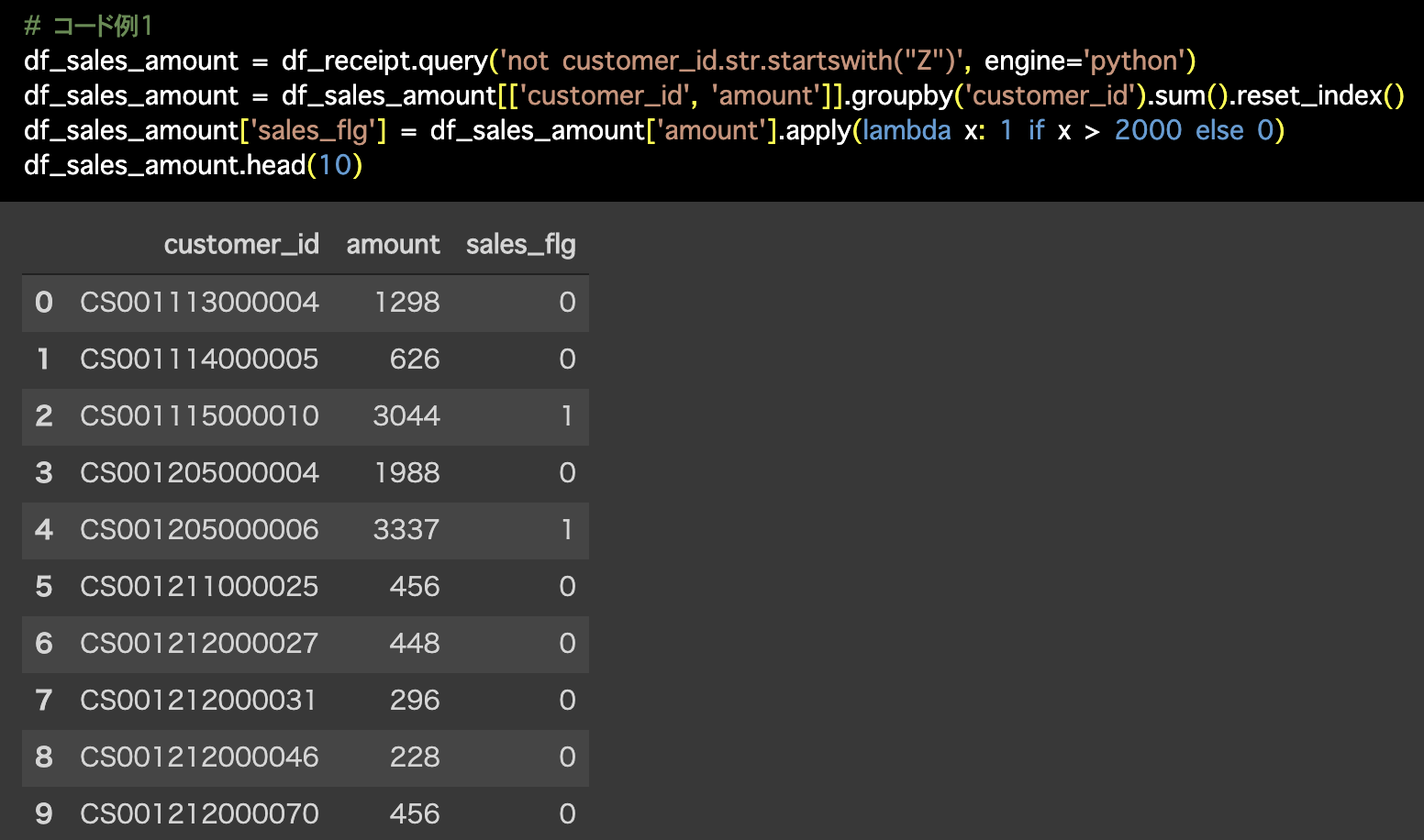 2つ目の解答コードはこのようになっています。
2つ目の解答コードはこのようになっています。
# コード例2(np.whereの活用)
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python')
df_sales_amount = df_sales_amount[['customer_id', 'amount']].groupby('customer_id').sum().reset_index()
df_sales_amount['sales_flg'] = np.where(df_sales_amount['amount'] > 2000, 1, 0)
df_sales_amount.head(10)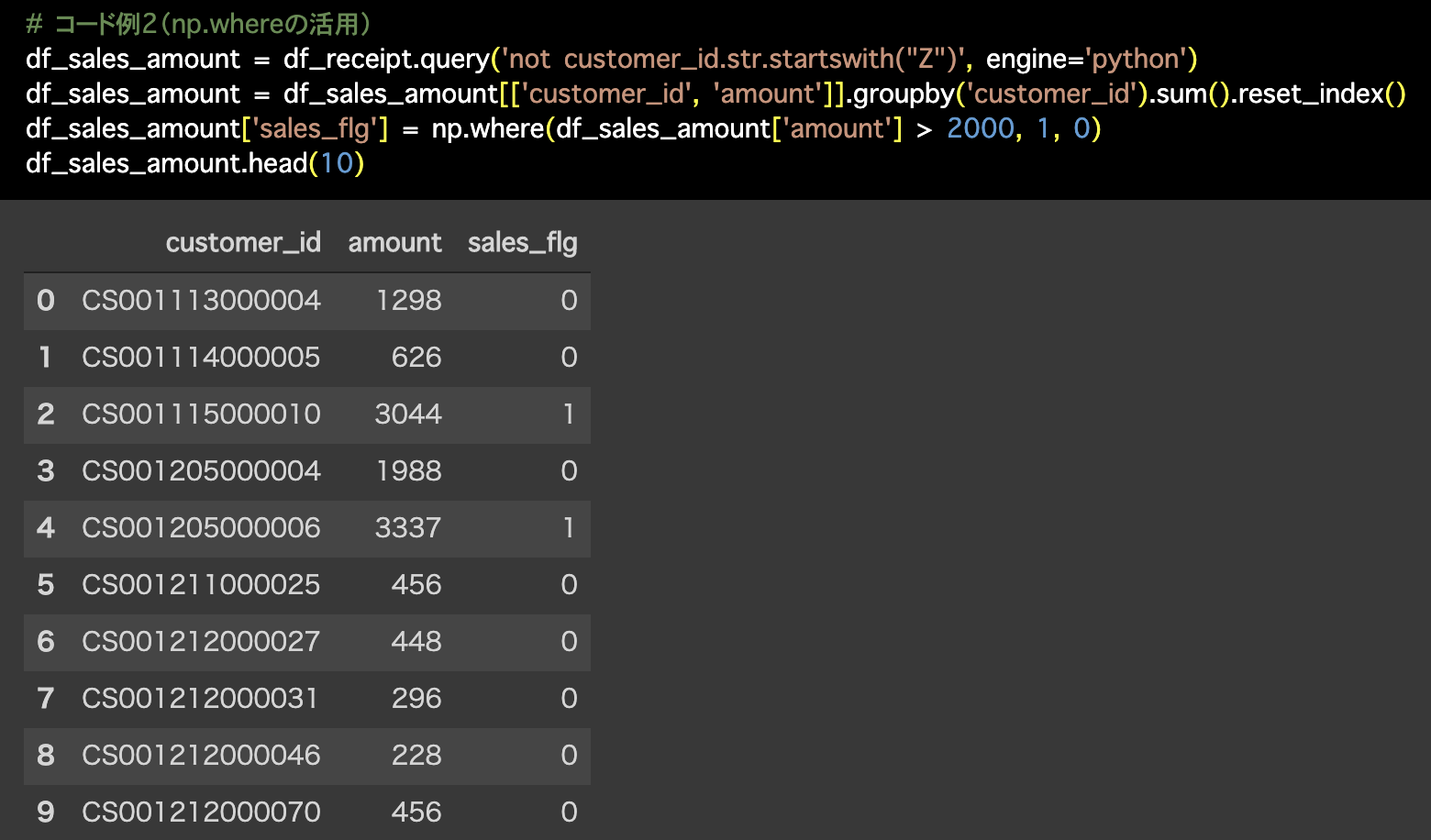
次の折りたたみは Exploratory の中身の話なので、コマンドの話も多くなりますが SQL も絡めた話なので読み物としてどうぞ。
せっかく出てきたのでこのタイミングで見ておきます
今回の操作はR言語だとこのようなコマンドになります。
これが Exploratory の中身で自動生成された R コマンドということでもあります。 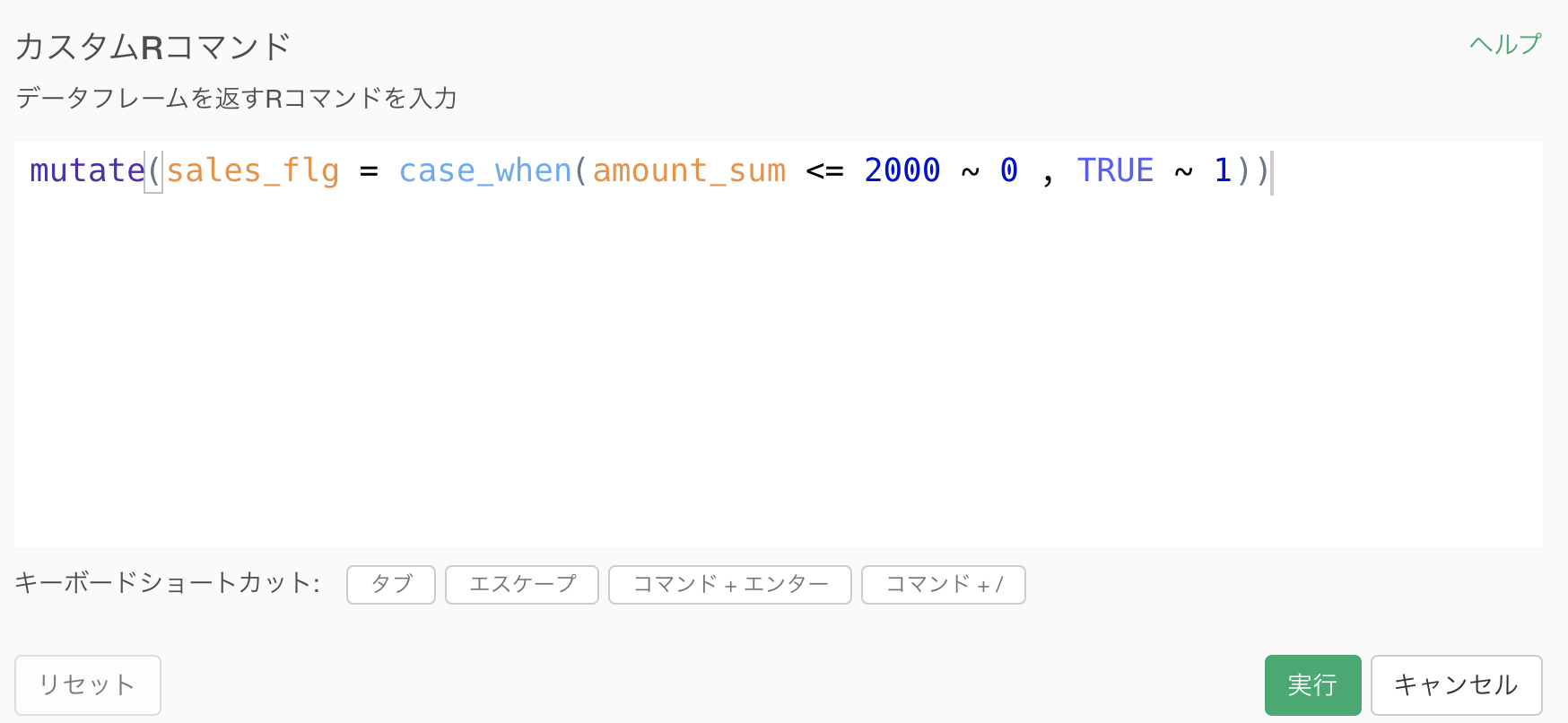
少々見づらいかと思いますが、以前のバージョン(2020年の夏とか)では、実はこの機能を選択すると計算を作成 (Mutate) からくる次のような雛形が用意されていました(同じメニューから選んだ結果、過去はこんな感じでした)。
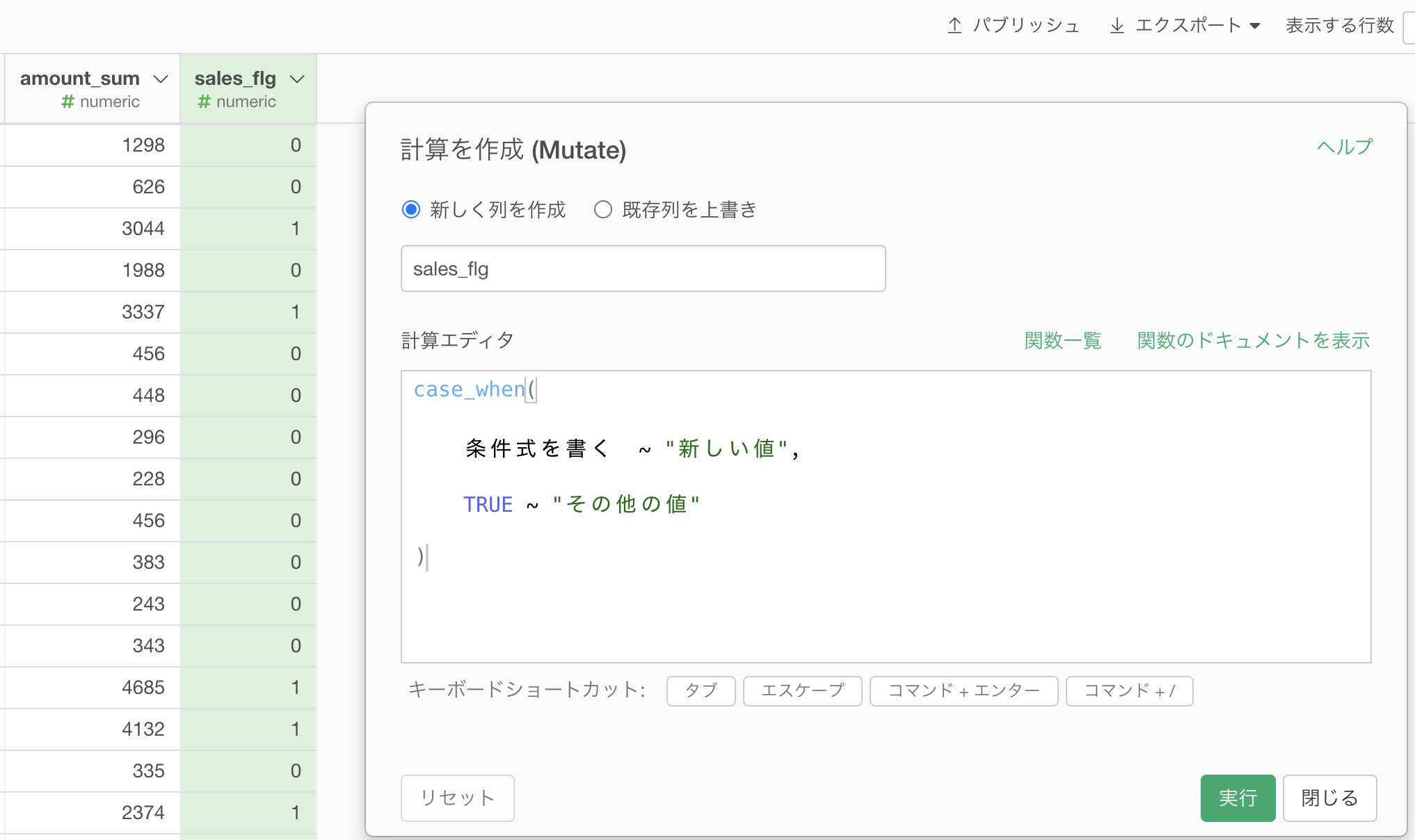
case_when の雛形は用意されていましたが、Exploratory ではフィルターを画面操作でやっているので、中身の条件式(フィルターの式)まできちんとかける人は次のようにサクサク 書いていました。
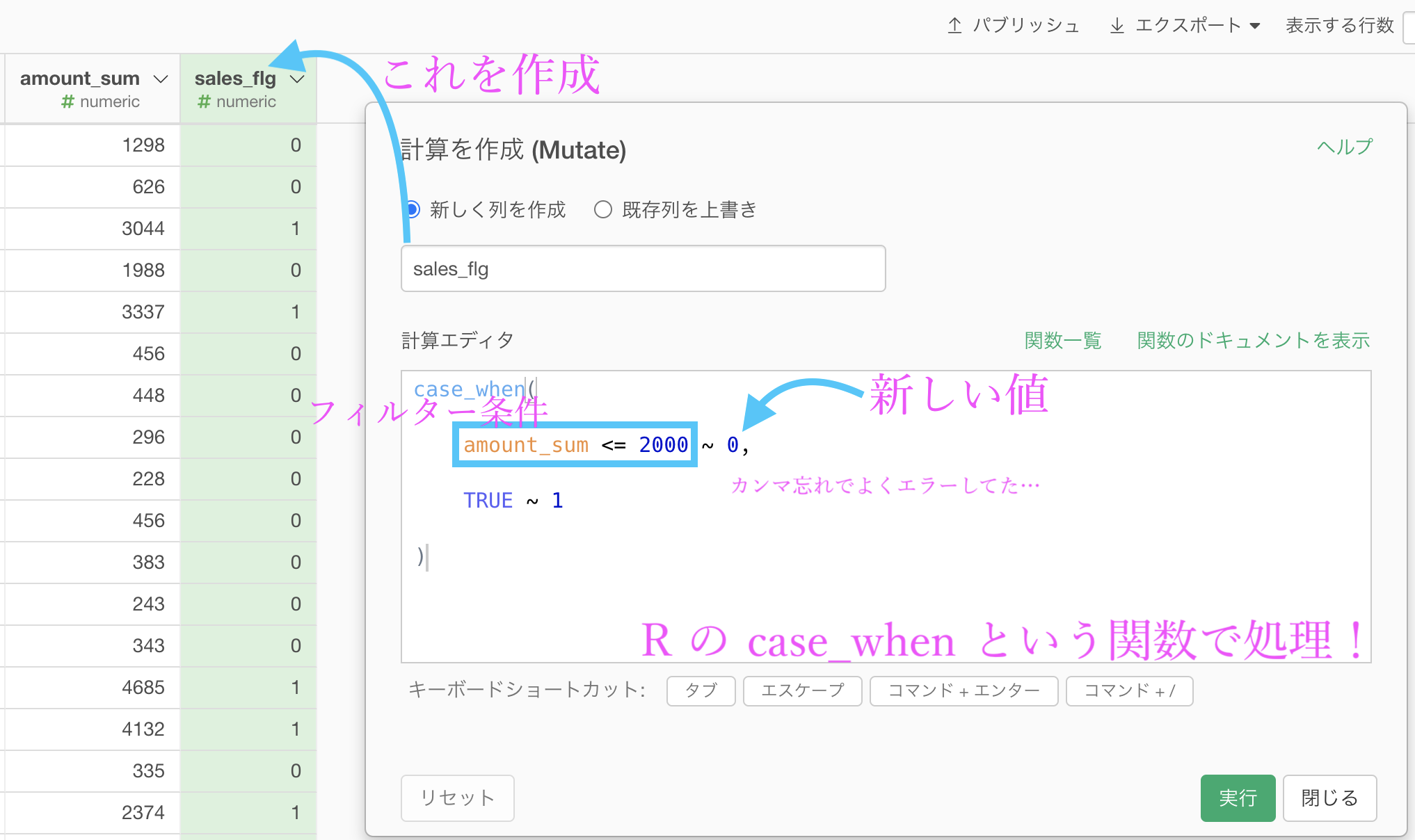
しかし、そのようなことがサクサクできる人たちは、最初から R言語についてバリバリやっていた人くらいしかいません。
例えそうでなかったとしても、ある程度の知識を備えて使っていたはずで、よりきちんと使えていたならばもうそれはR言語ができる人なのです(世間から見れば)。
Exploratory ではそのようなR言語をバリバリできる人も対象にしていますが、そうでない人たちもカバーしたいからこその優しい設計をしているところが多々見受けられます。
小難しいSQLの話(飛ばしてOKです!)
case_when という関数は是非使えるようになっておくと良いと思います。
大きな理由は2つあります。
・一目惚れするかのように、処理していることがわかりやすく書いてあるから
・SQL にも同じ使い方をする関数があるからです。
1つ目の理由については、例えば今回の Python 解答コードではそれがひと目見てもわかりづらいといったことです。
なぜなら「どこで本題のカテゴリ化をしているか、コードから探さないと読めないから」です。
case_when ではそこをきちんと書きます し、Exploratory の画面でも ひと目見ただけで何をどうやってカテゴリ化(0 と 1 に)しようとしているかわかりますよね。
さて、2つ目の理由にあげた「SQL でも同じ使い方をする関数」とは一体何でしょうか?
それは CASE という句(関数)です(同じような名前です)。
SQLではこんなふうに使われています
CASE 列名
WHEN 条件式1 THEN 新しい値
WHEN 条件式2 THEN 新しい値
ELSE その他の値 ENDSQL なんか知らないよ!という方でも、もうここまで説明を読んでくださった方は、書いてあることは何となくわかるはず かと思います。
ちなみに以前に紹介した 「達人に学ぶSQL徹底指南書(第2版)」 という本(著 : ミック氏)では CASE の話が2ページ目(目次などの後)から書いてあります。
それくらい重要で使い勝手の良いものだから、最初に学んで欲しかったという気持ちが伝わってきますよね。
問53 : 文字データを二値(0/1)データに変換する

答案・解説はこちら
ですので、今回はまずきちんと東京を 1、それ以外を 0 とできるところをやりましょう(解答は集計が終わったというところまでしか見られませんのできちんとやります)。
まず df_customer を確認しましょう。
postal_cd(緑の列)の先頭3桁が 100〜209 のものは東京都になっていることが確認できるかと思います。
それらを 1、他の県は 0 とする列を作る処理をしましょう。

わかりやすさのため、customer_id と postal_cd の 2列 しておきます。
postal_cd 文字型で、ハイフンより後ろの数値は必要ないので、切ってしまいましょう(テキストデータはフィルターしにくいからです)。
以前にも紹介した「指定した範囲にある文字列を取り出す」を選択しましょう。
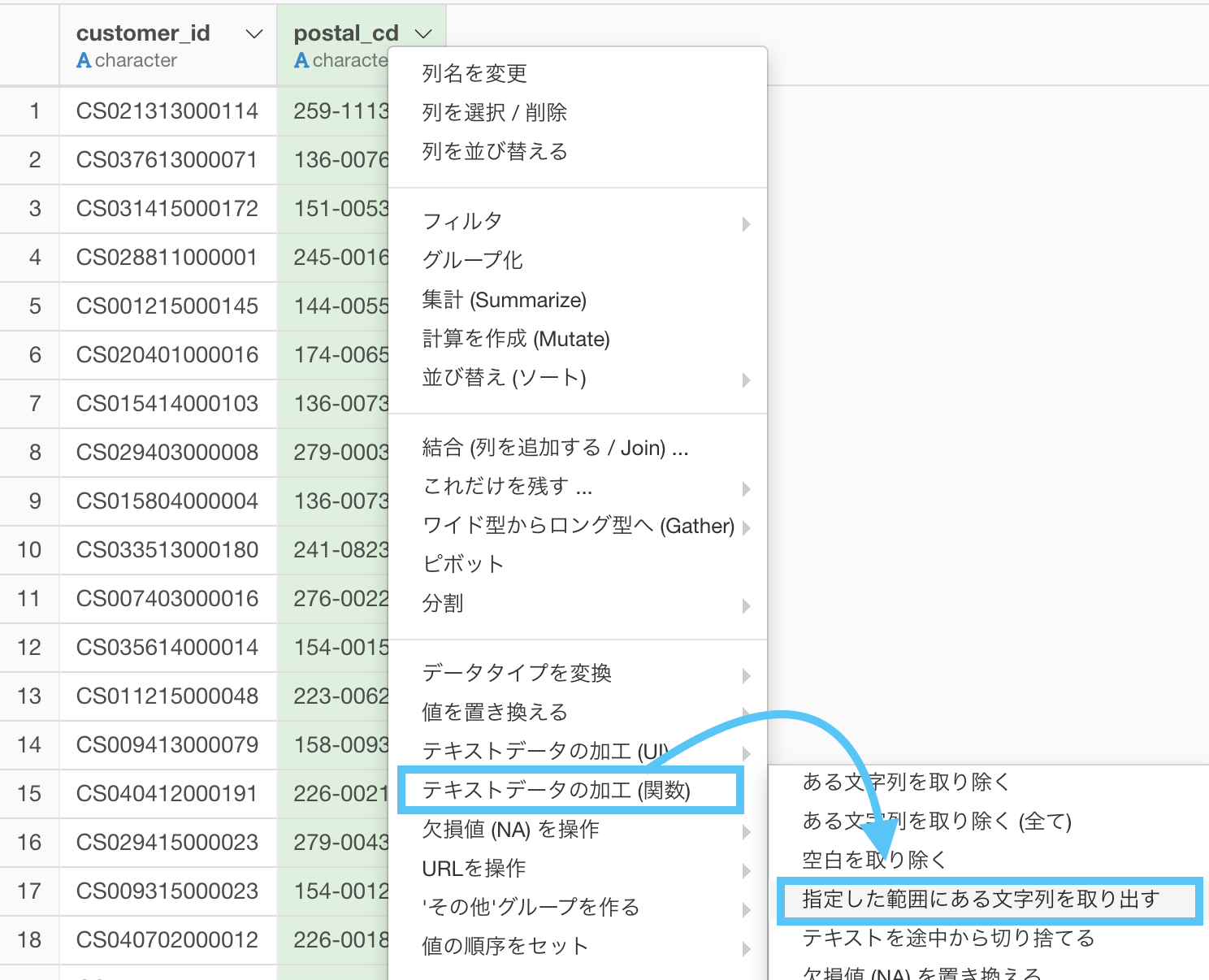
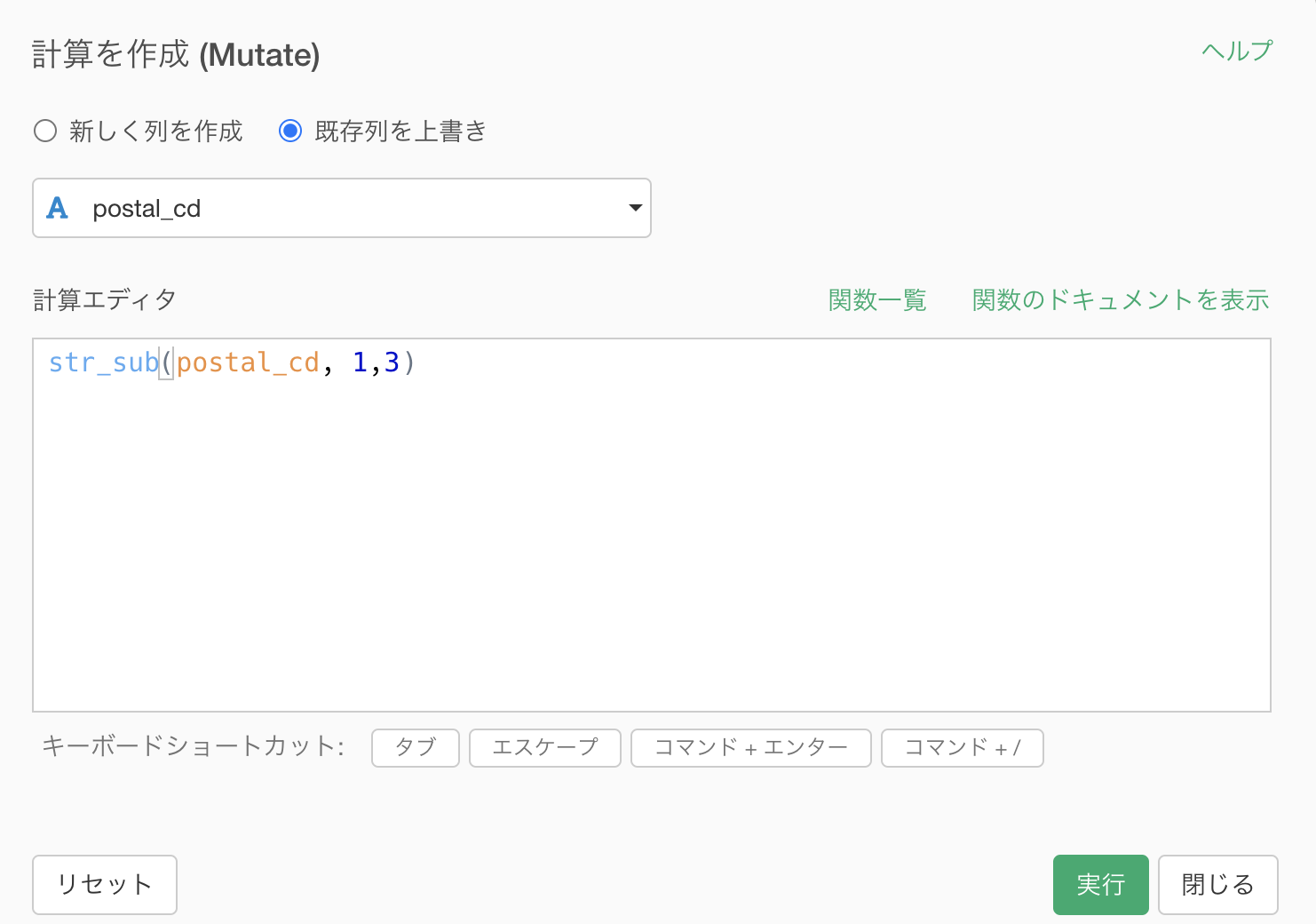
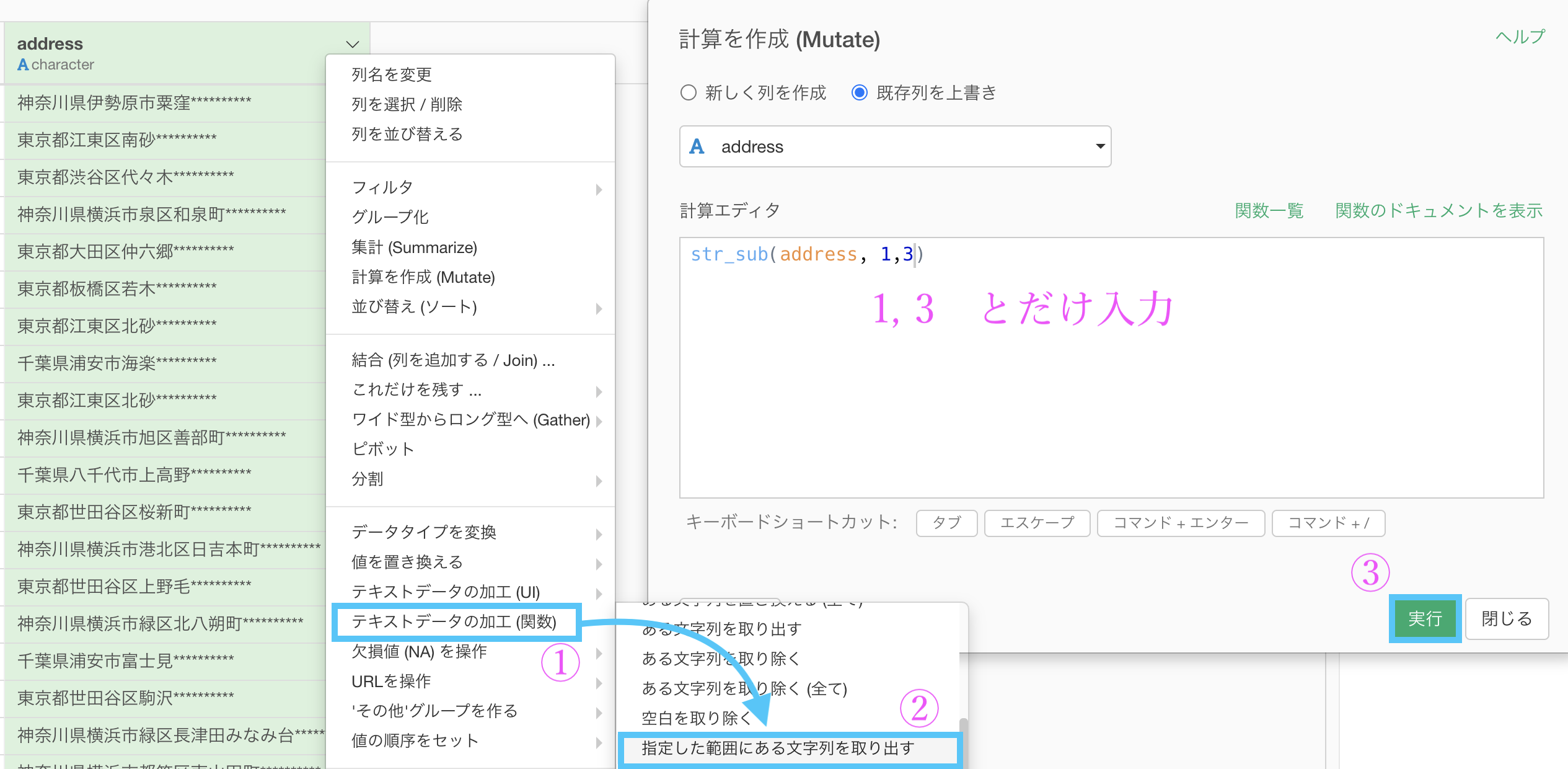
欲しいところは先頭3桁なので、「1, 3」と入力するだけです。
このままでは postal_cd が character(文字)型なので、数値に変換します。
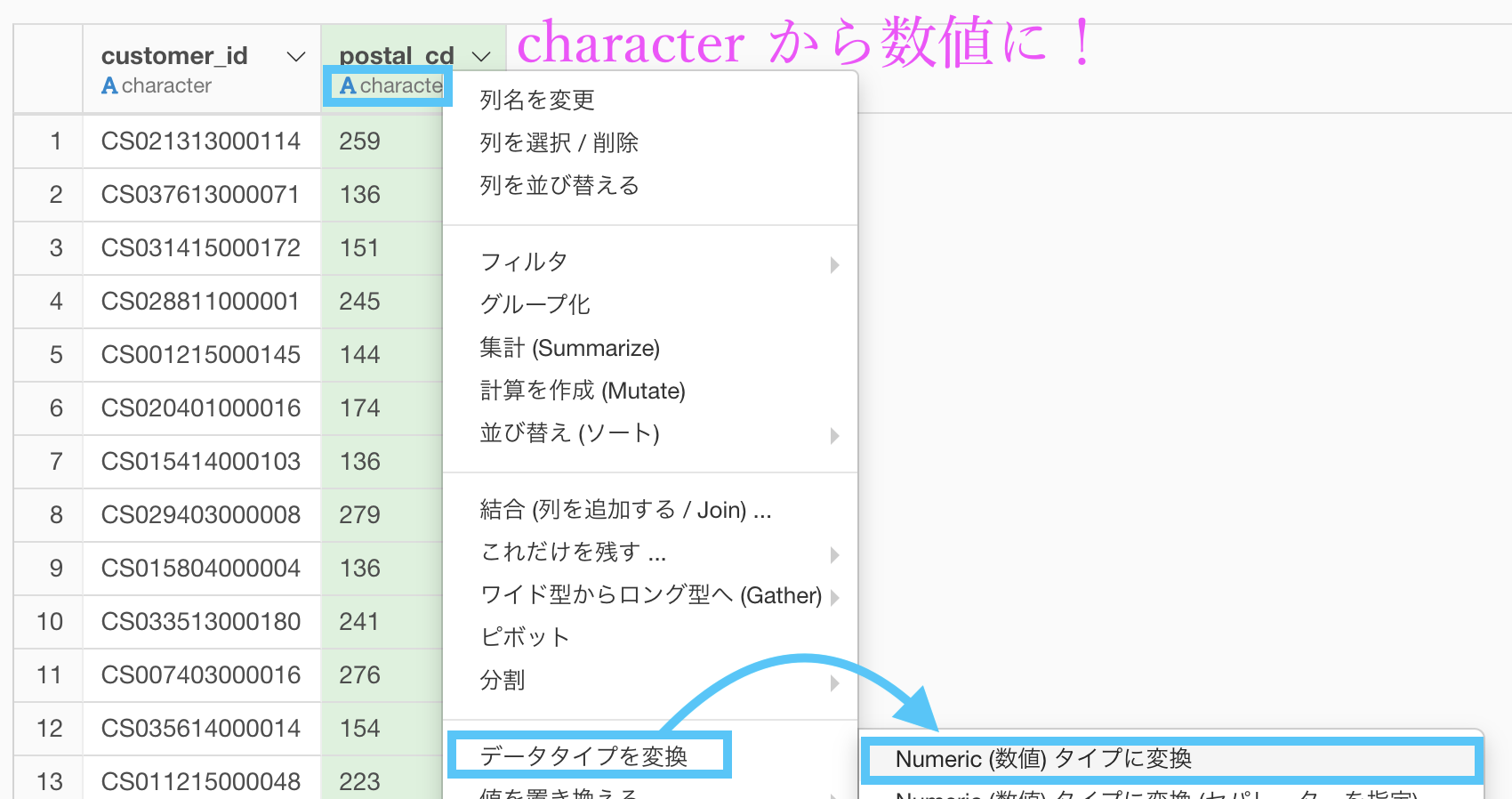
そのまま実行すれば、numeric(数値)型になったと思います。
と思います。
一緒に操作していきましょう。
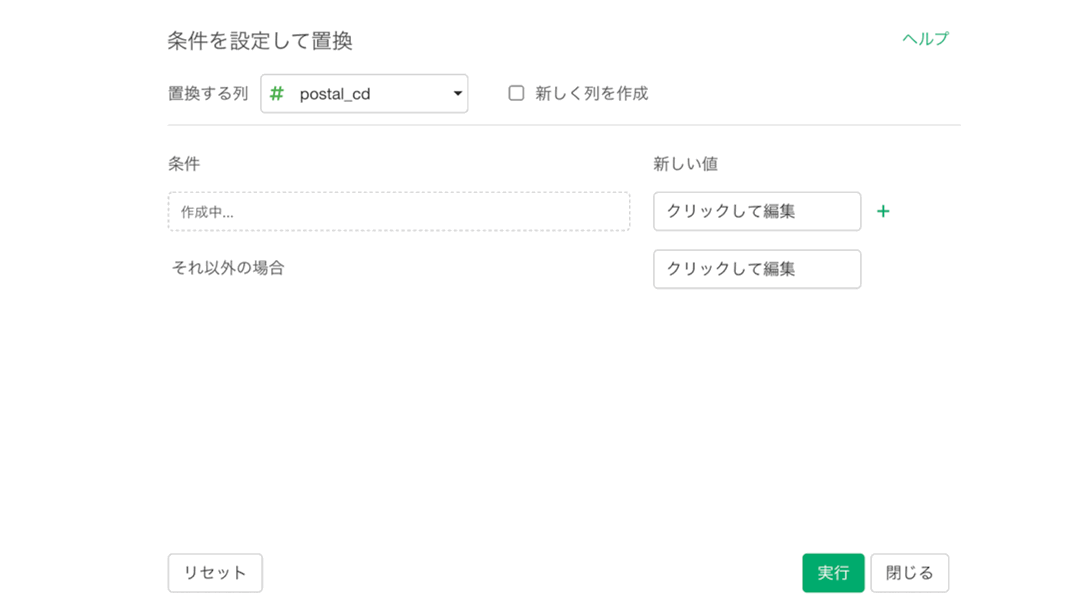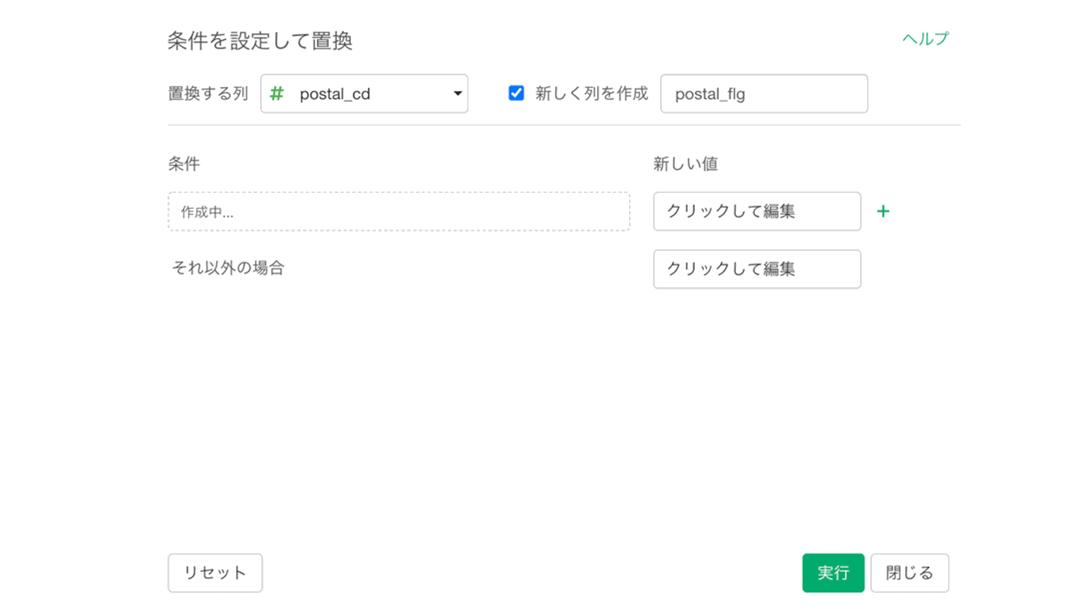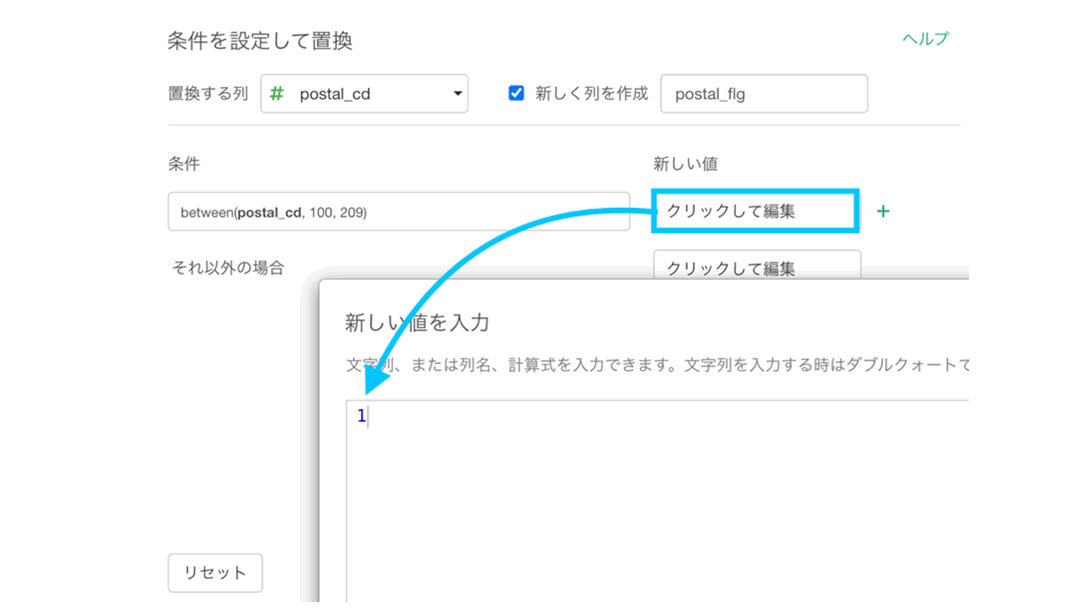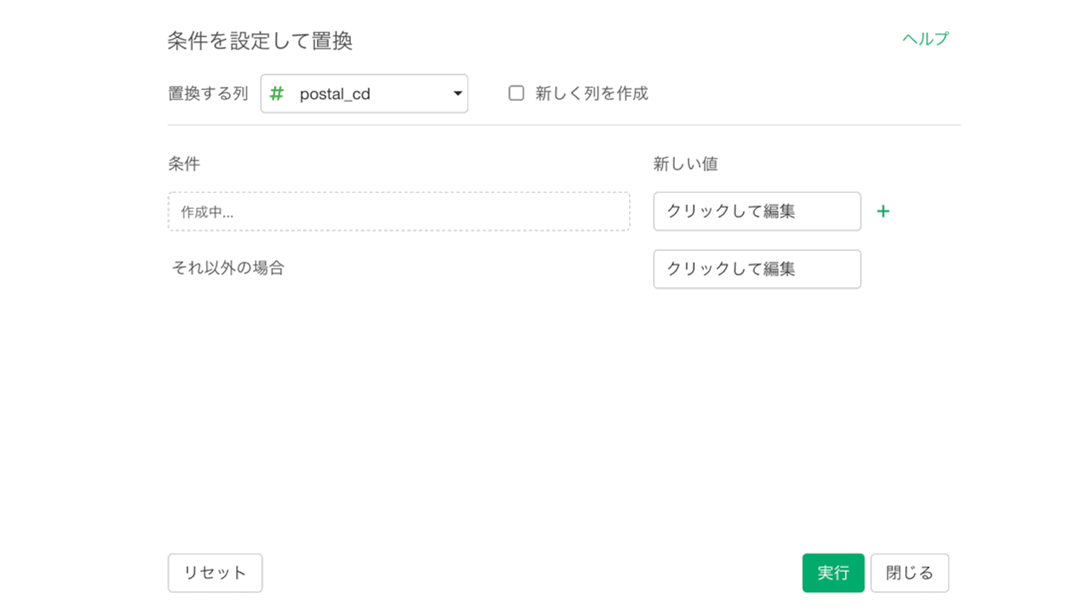
このようになったら実行しましょう。
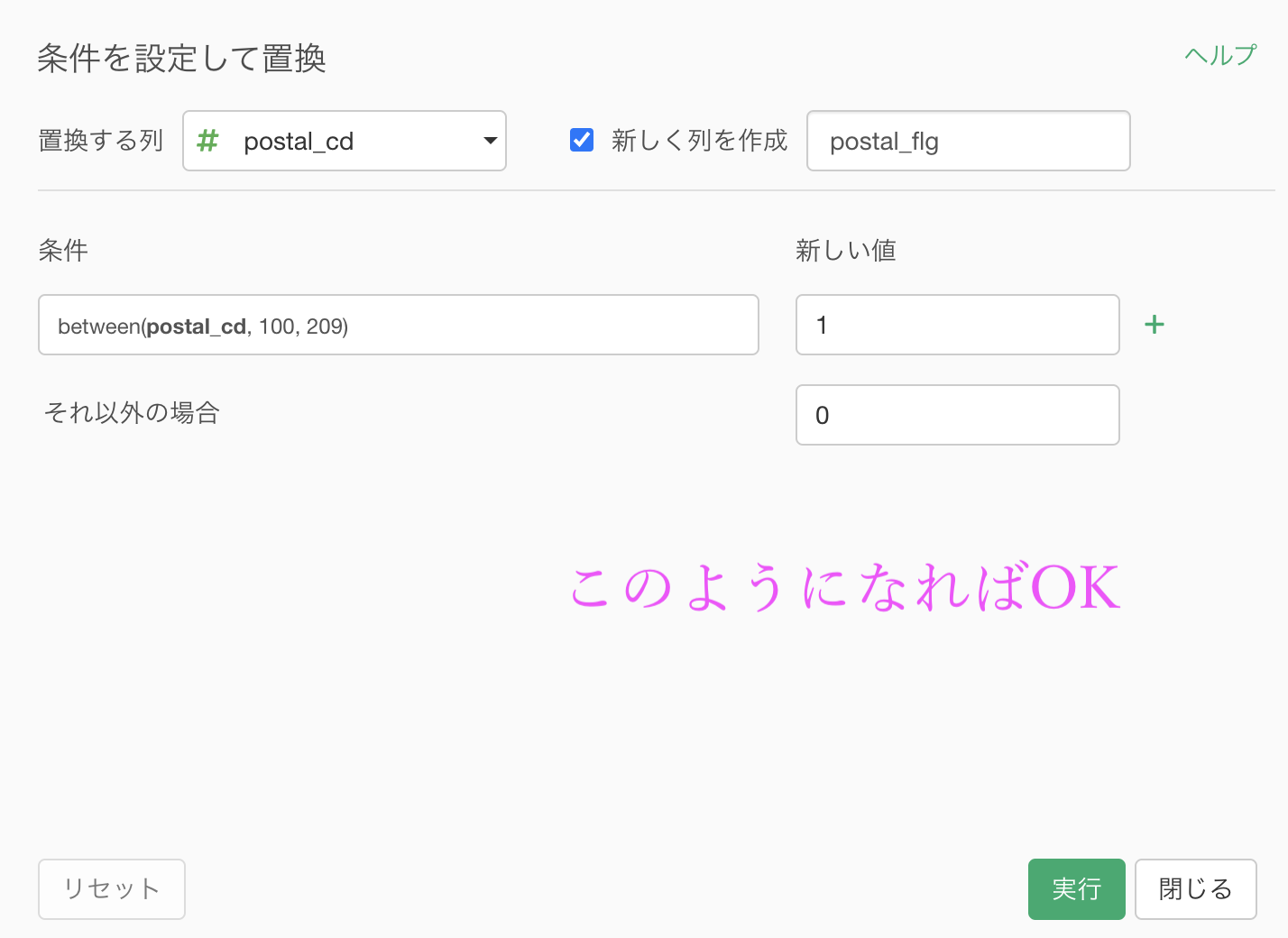
ニ値化した結果、このようになったかと思います。
前半はここまでで、カテゴリ化(メインにしたかった所)の処理は終わりました。
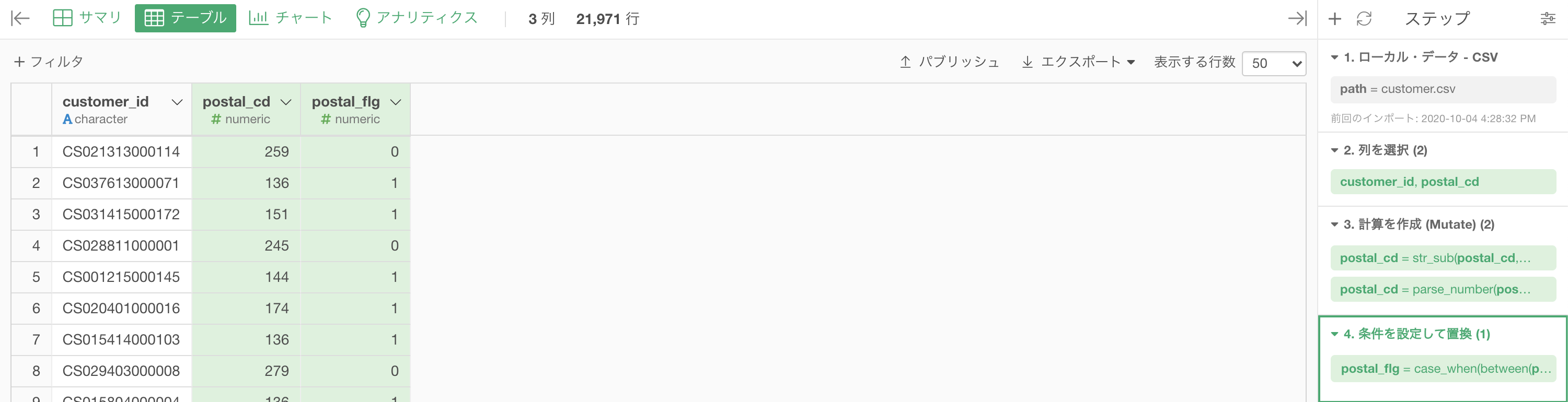
さて後半です。
postal_flg は全顧客に対してのニ値化(東京 1 かそうでない 0 か)をしたものでした。
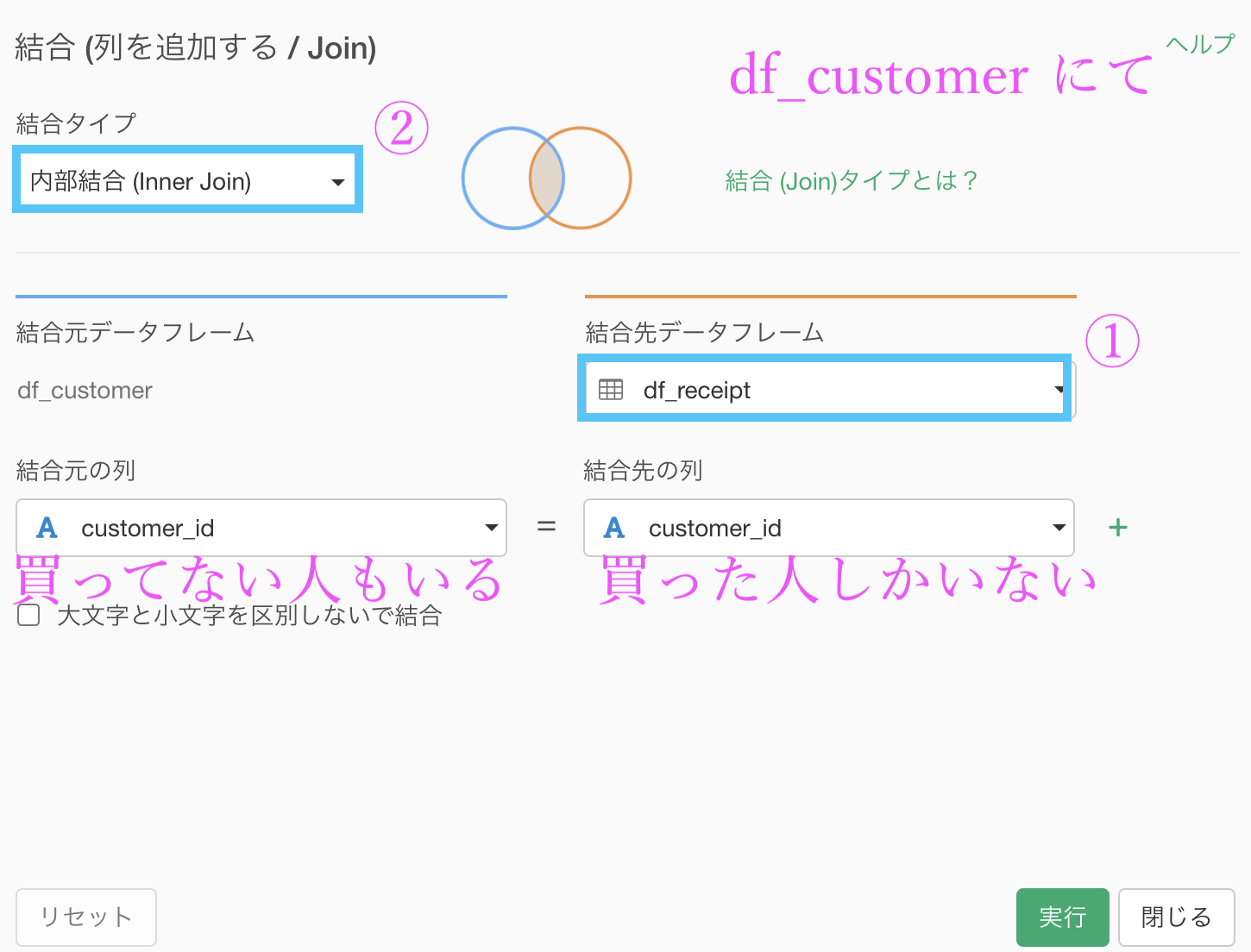
問題文(の後半)にあるように、買い物実績のある顧客だけに焦点を当てたいのですが、買い物をしたというデータは df_receipt の customer_idであって、df_customer の customer_id ではなかった ということことを以前の問題で説明したと思います。
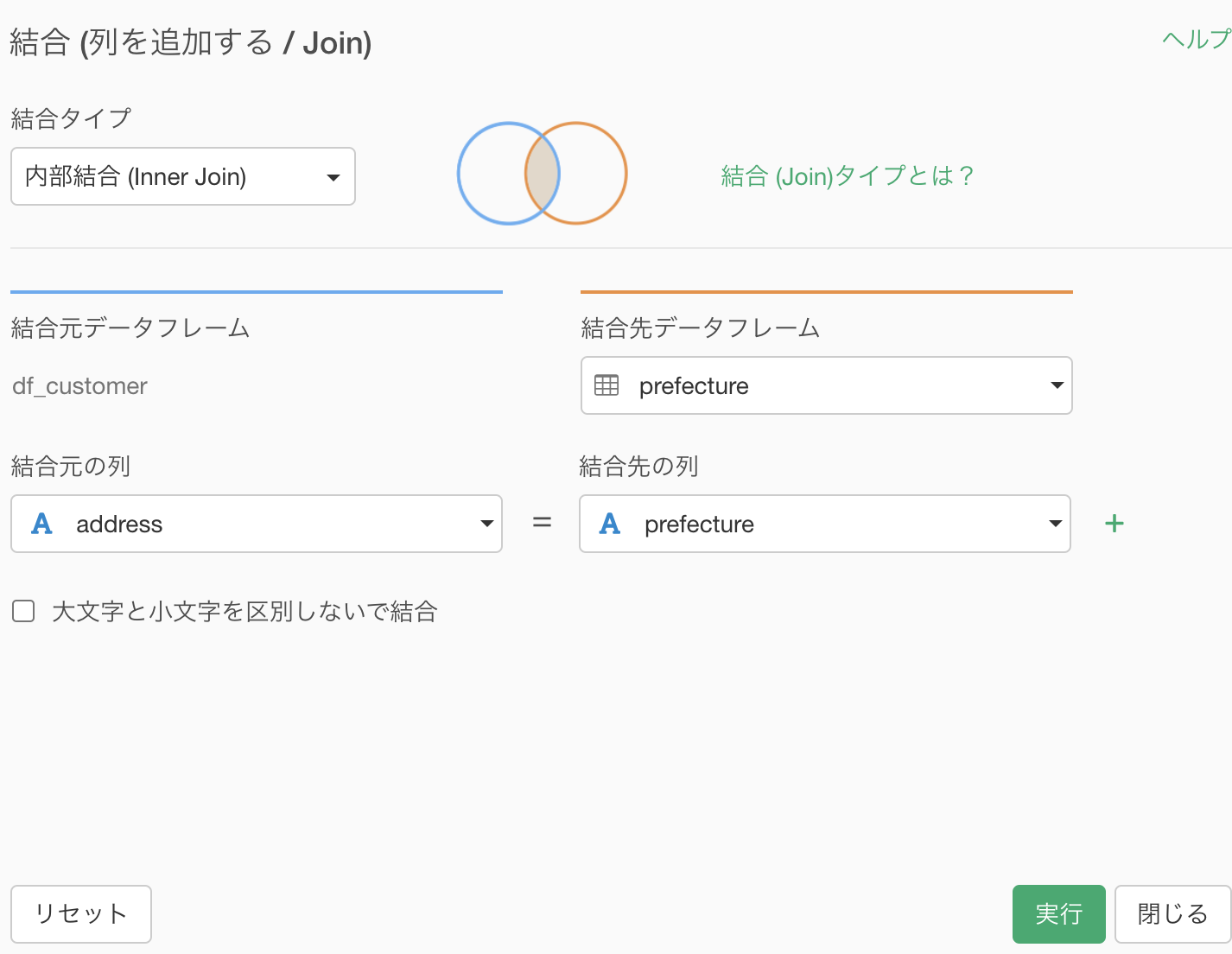
このことを考慮すれば、df_receipt の customer_id と内部結合する必要がありそう です。
早速やりましょう。結合の仕方についてはすでにやっていますので、操作画面だけ見せます。
これで実行すると一旦数字がたくさん出てきますが、今回の問題ではほとんど見る必要ありません。
それよりも、前のデータ(特に行数とか postal_cd とか)がどのように変わったのかを見ることの方が大切です。
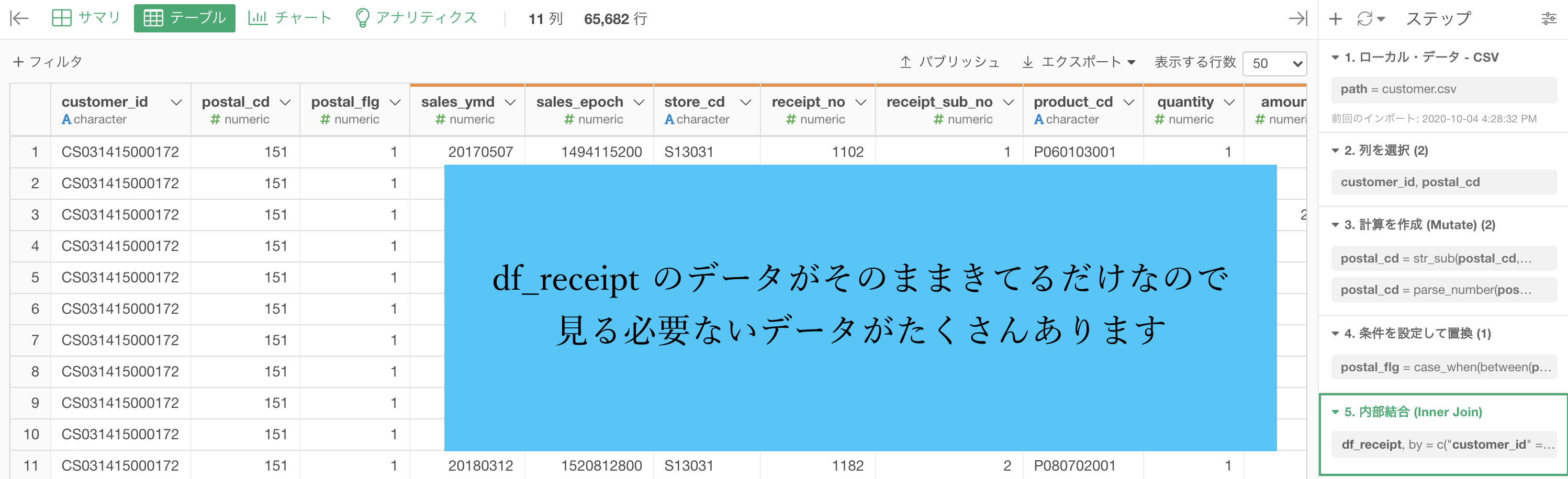
この時点で起きていることをイメージでまとめますと、次のような感じです(内部結合はよく使うので復習して下さい)。
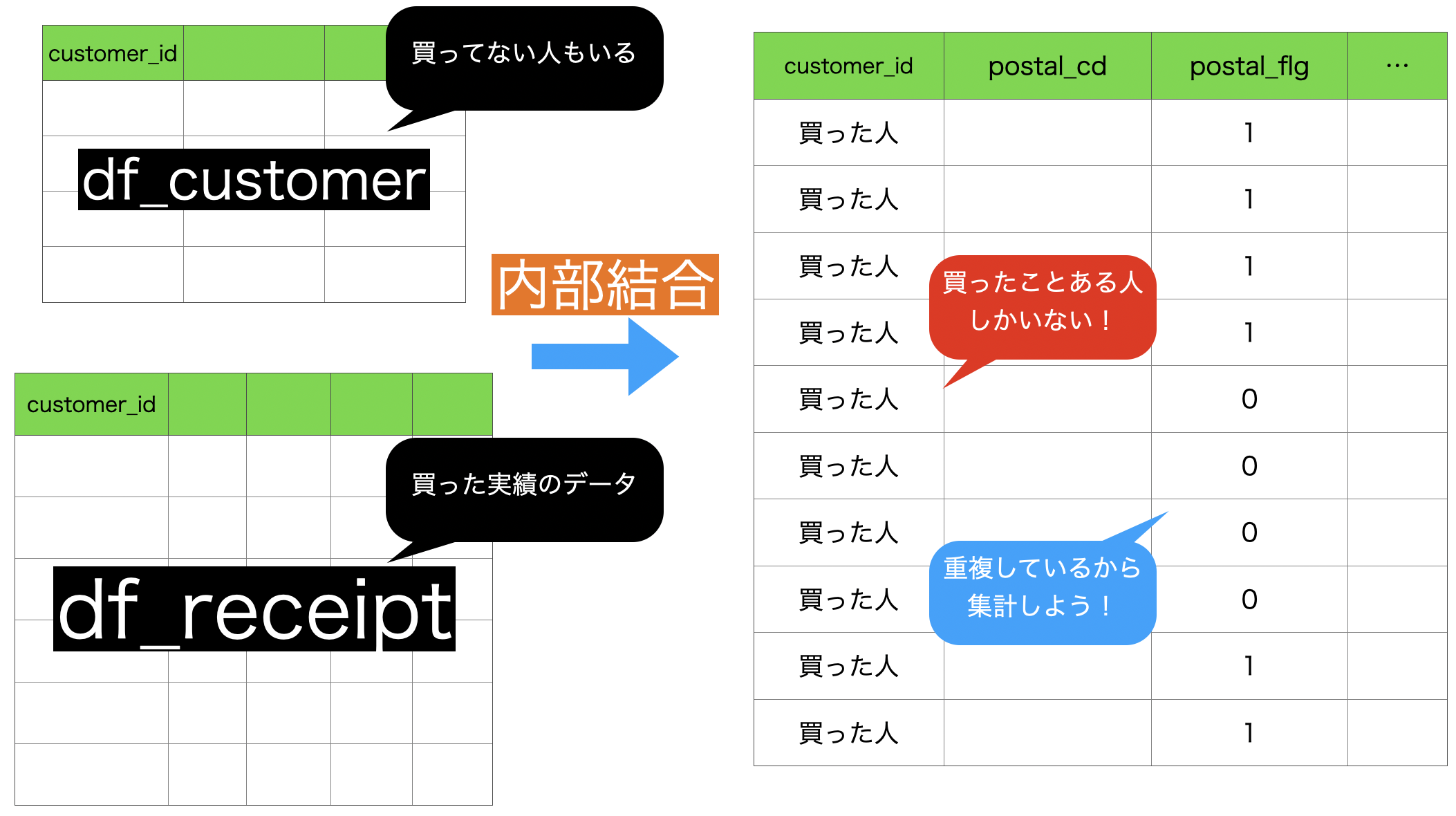
前のデータに焦点を当てたイメージです(くっついてきたデータは今回の問題に関係ないので)。
df_customer の中には、データをとった期間中に買いに来てない人もいいますが、df_receipt には買いに来た人しかいないので、その情報を共有するべく内部結合したと考えても良いでしょう。
結局、postal_flg(東京かそうでないか)というところが、重複してレシート枚数まで増えているから集計する必要があるんだ! というところまでいけば、今回の問題は終わったようなものです。
今回の問題の最終結果で欲しいのは
- postal_flg が 1(東京) の(買いに来た)顧客は何人いるか?
- postal_flg が 0(他県) の(買いに来た)顧客は何人いるか?
だったので、集計するときは
グループ化 : postal_flg 値 : customer_id 計算 : 一意な値の数(UNQ)とします。
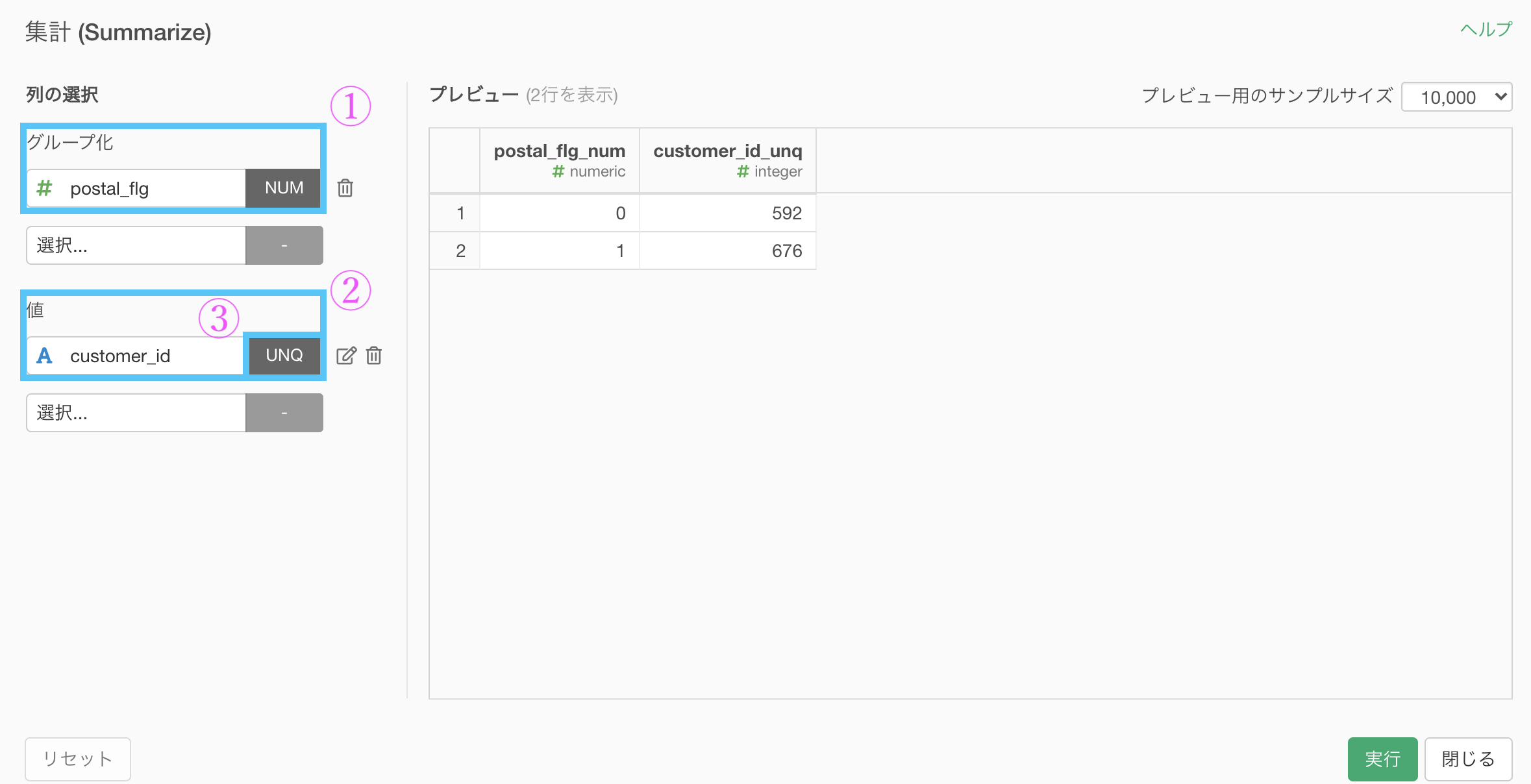
結果はこのようになります。解答を確認しましょう。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
df_tmp = df_customer[['customer_id', 'postal_cd']].copy()
df_tmp['postal_flg'] = df_tmp['postal_cd'].apply(lambda x: 1 if 100 <= int(x[0:3]) <= 209 else 0)
pd.merge(df_tmp, df_receipt, how='inner', on='customer_id'). \
groupby('postal_flg').agg({'customer_id':'nunique'})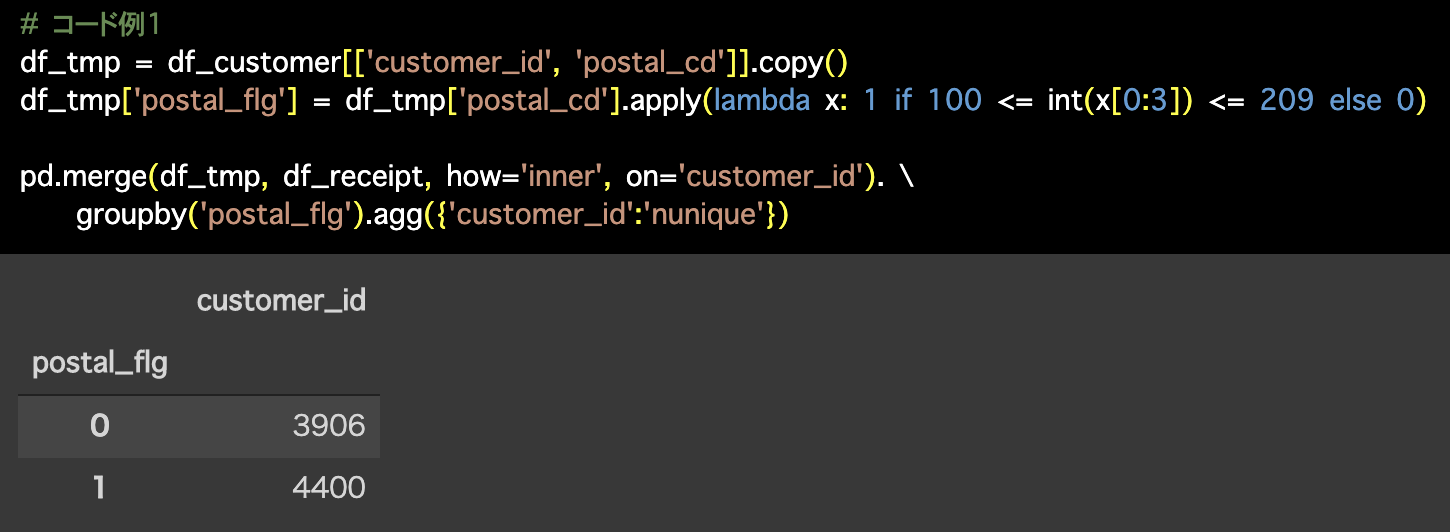 2つ目の解答コードはこのようになっています。
2つ目の解答コードはこのようになっています。
# コード例2(np.where、betweenの活用)
df_tmp = df_customer[['customer_id', 'postal_cd']].copy()
df_tmp['postal_flg'] = np.where(df_tmp['postal_cd'].str[0:3].astype(int)
.between(100, 209), 1, 0)
pd.merge(df_tmp, df_receipt, how='inner', on='customer_id'). \
groupby('postal_flg').agg({'customer_id':'nunique'})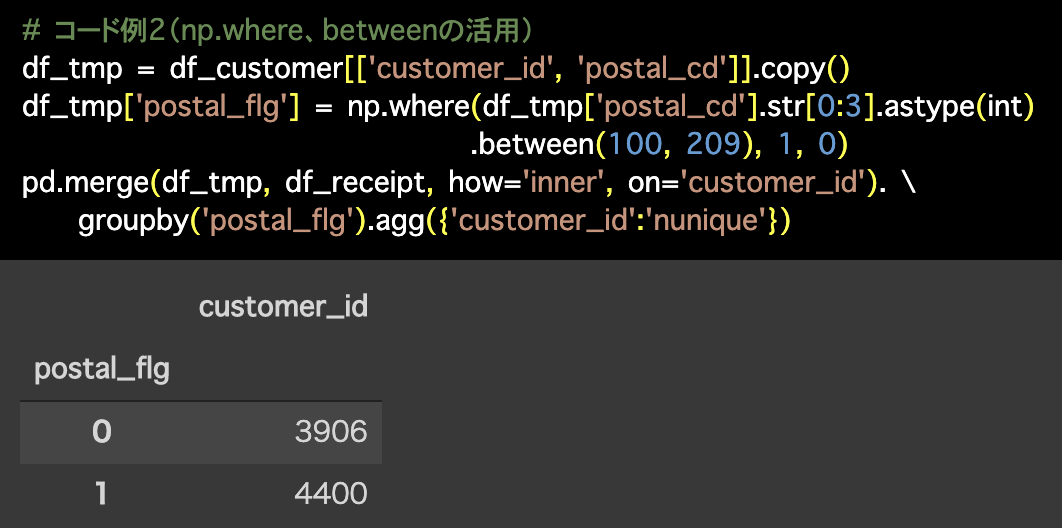
一発で postal_cd の先頭3桁をとってくる方法
Exploratory(およびR)で最適解だと思うものは一見して複雑なものばかりだと思うかもしれませんが、そうでもなかったりすることもあります。
postal_cd は文字型のデータとしてもかなりわかりやすいもので、単にハイフンがあるから文字型になっているだけ です。
こういうときに面白いを使ってみましょう。
postal_cd が 3桁-4桁 の状況で「データタイプを変換 → Numeric (数値) タイプに変換 (セパレータを指定) 」とします。
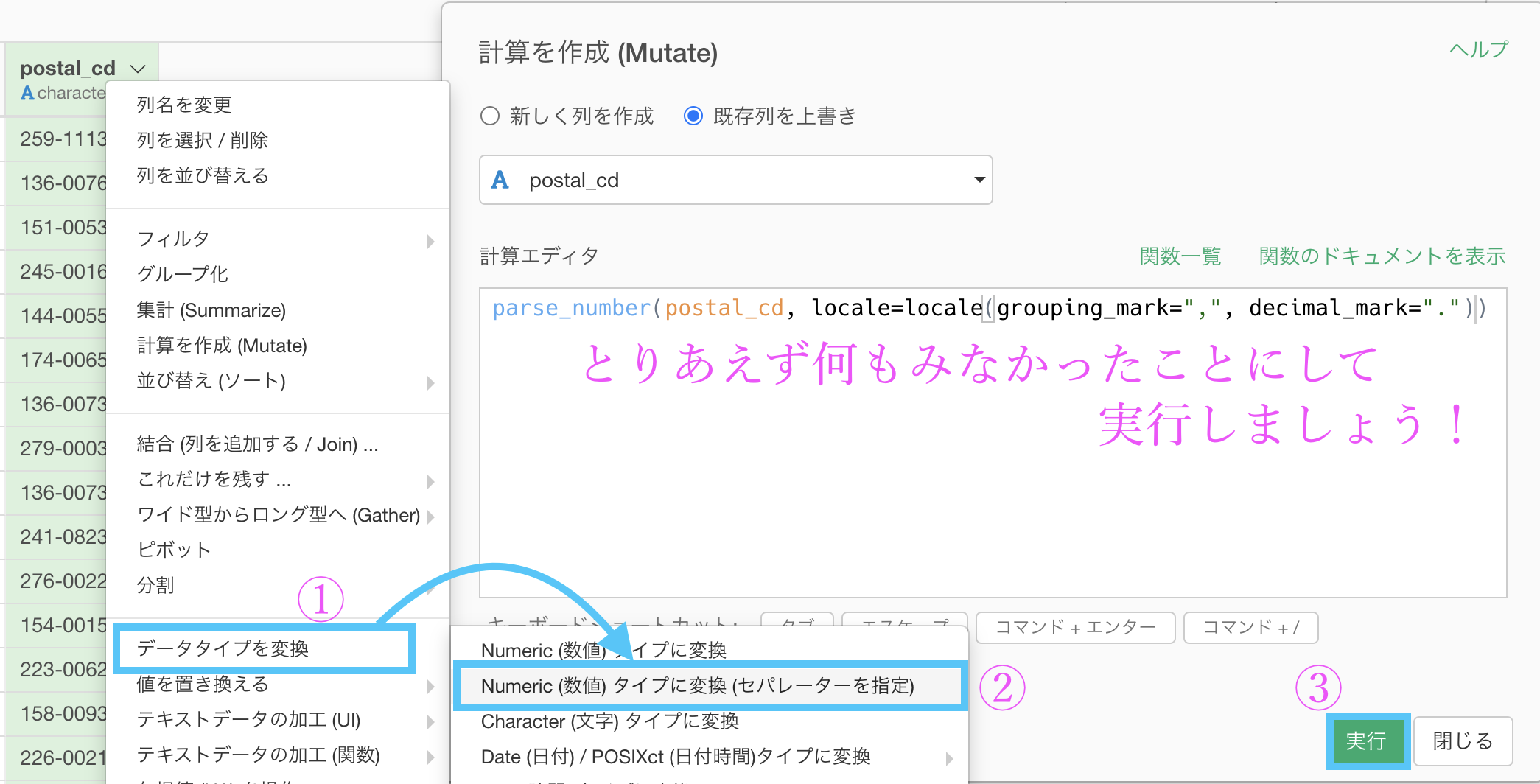
そのあと出てきた訳のわからないコードは一旦置いておき、このまま実行すると、3桁だけ & 数値タイプに一気に変換されています。
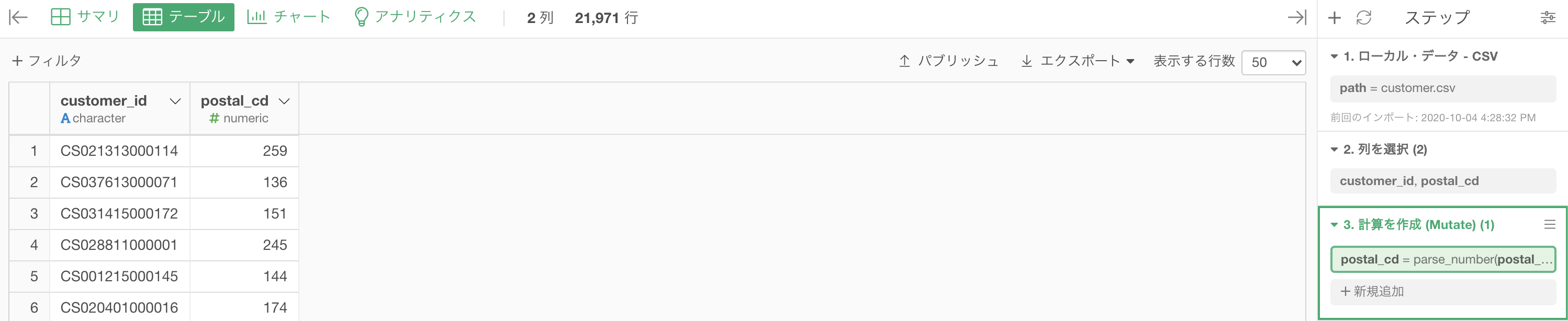
関数の検索機能はここから
Rの関数についていま一度調べたいけど、いちいち Google 検索しては多くの記事をみるというのも辛いと思います。
そこで、計算を作成する時にその場で R の関数の一覧から検索することが可能です。
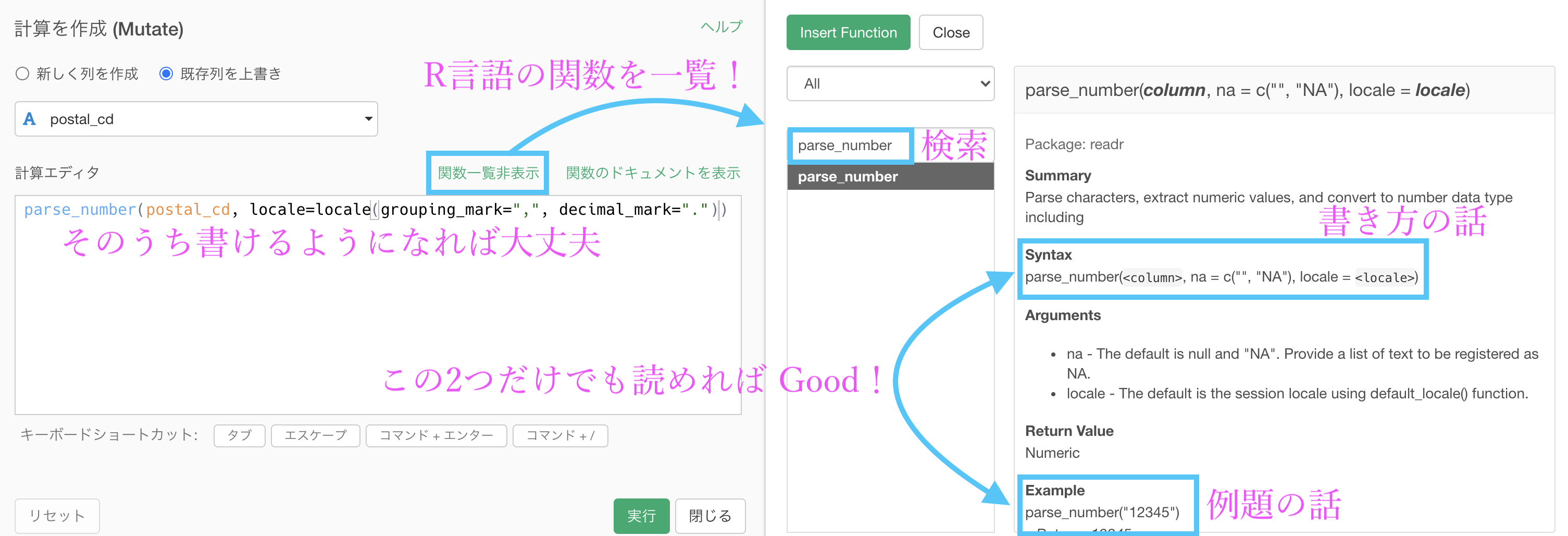
この機能は非常に便利ですが、英語で書いてあるため頑張って翻訳する必要があります。
ここは頑張って英語を読むか、Google 翻訳などで頑張りましょう。
本当にさらっとしか書いていませんので、Syntax(書き方)と Example(例題)の2つを参考にする程度が良い と思います。
詳しいことはさらに Google 検索することができますので「parse_number の使い方」ではなく「parse_number の locale の書き方(英語をコピペするのも可)」などから検索しはじめると、よりリッチで高級な情報を手に入れることができると思います。
問54 : テキストラベルからカテゴリデータを作成する

答案・解説はこちら
df_customer のなかでcustomer_id と adress(住所)の2列にしました。
この問題でやりたいことはこのようなことです。

しかし、テキストデータというのはこういうときに扱いづらいです。
「神奈川県横浜市〇〇」と「神奈川県横浜市△△」と「東京都江東区 X X 」ではそれぞれ等間隔に異なっているので、フィルターするにしても難しいからです。
ということで、こういうときに便利なのがカテゴリ化 というわけなのです。
「値を置き換える → 条件を指定」から、いつものように出します。
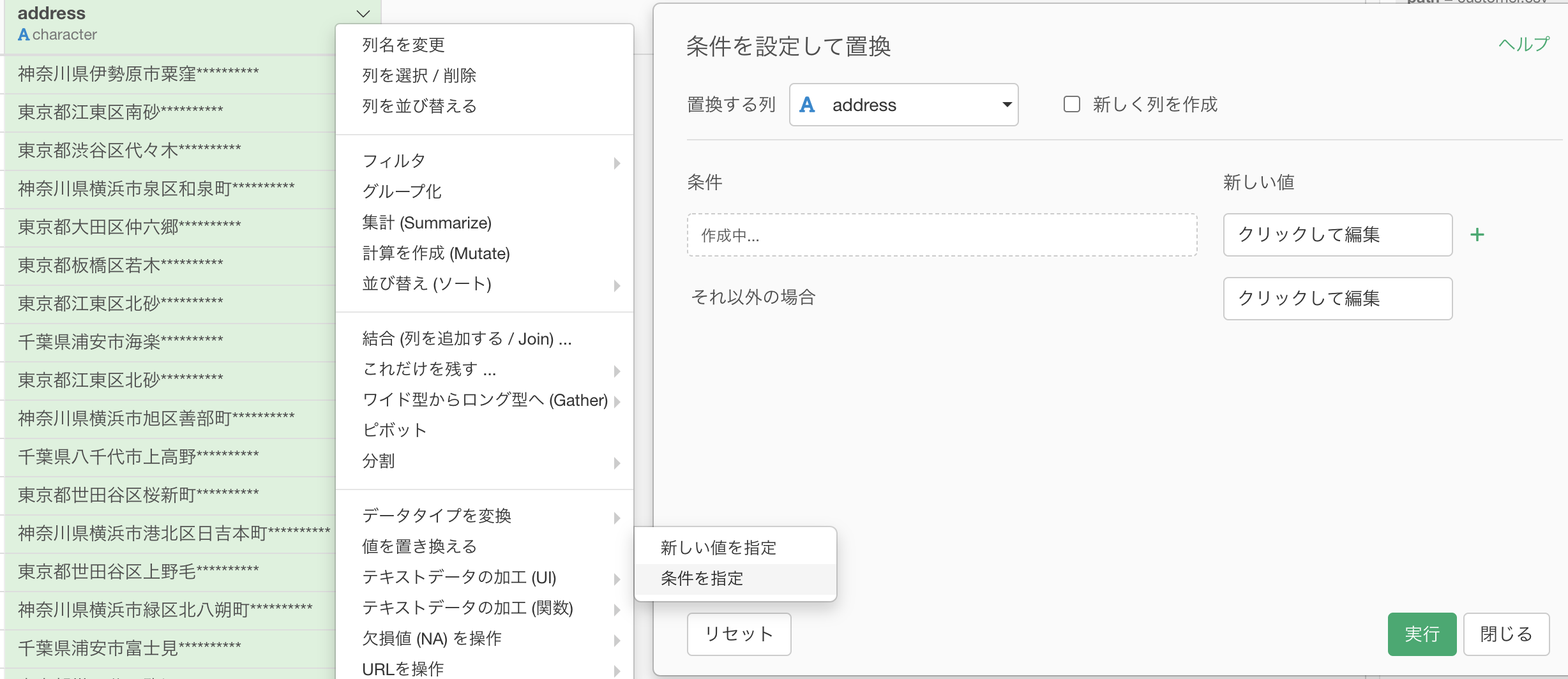
もうこれに関しては結局 フィルター + 計算を作成 (Mutate) みたいなもの で、扱いもそうなのです。
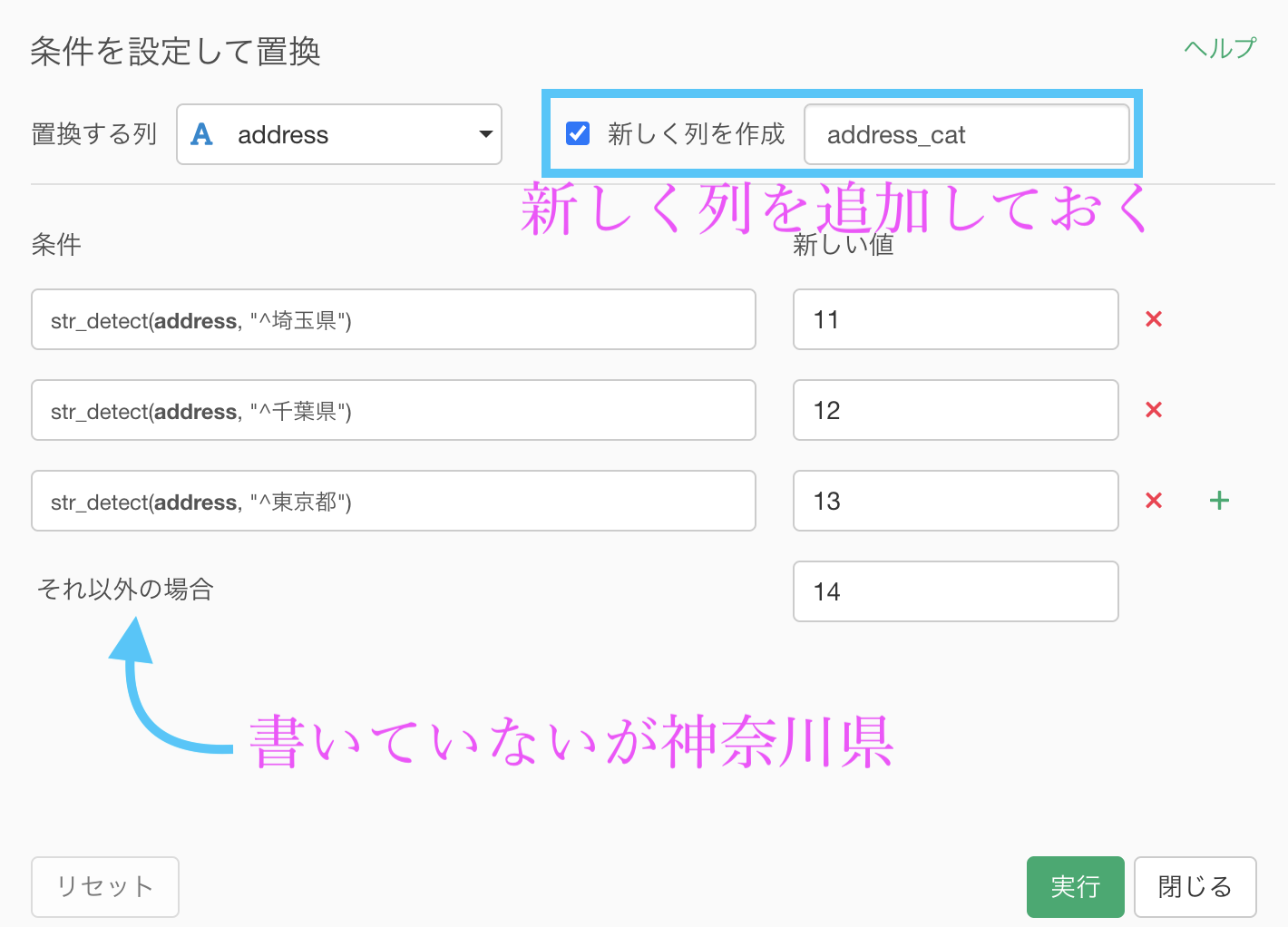
そういうわけなので、文字列に関するフィルターで学んだ「この文字列から始まる」というところから、埼玉県 〜 神奈川県まで設定します。
今回では、神奈川県を「それ以外の場合」としています。
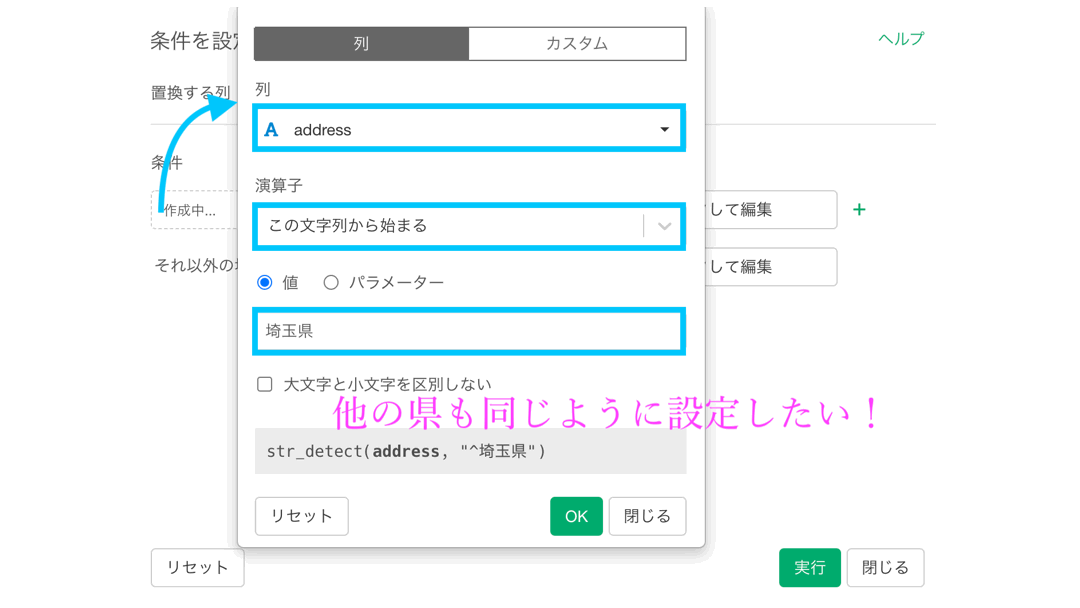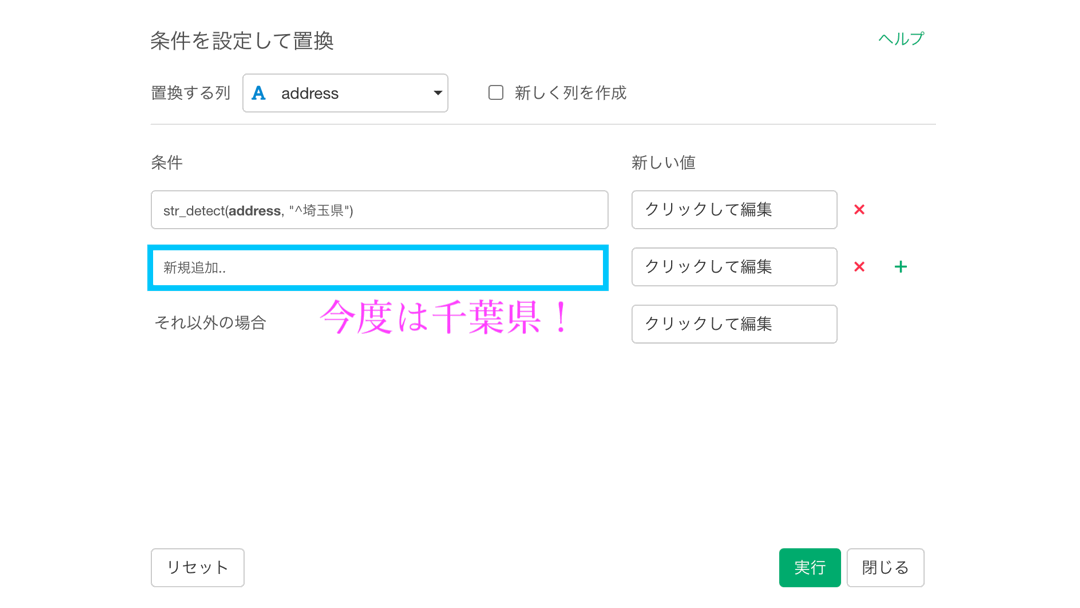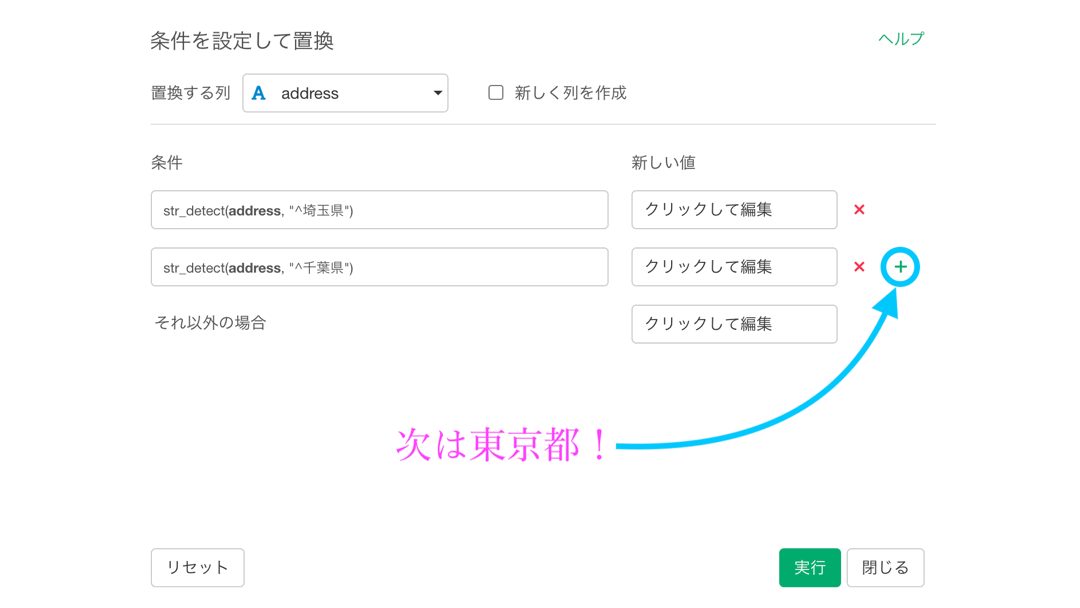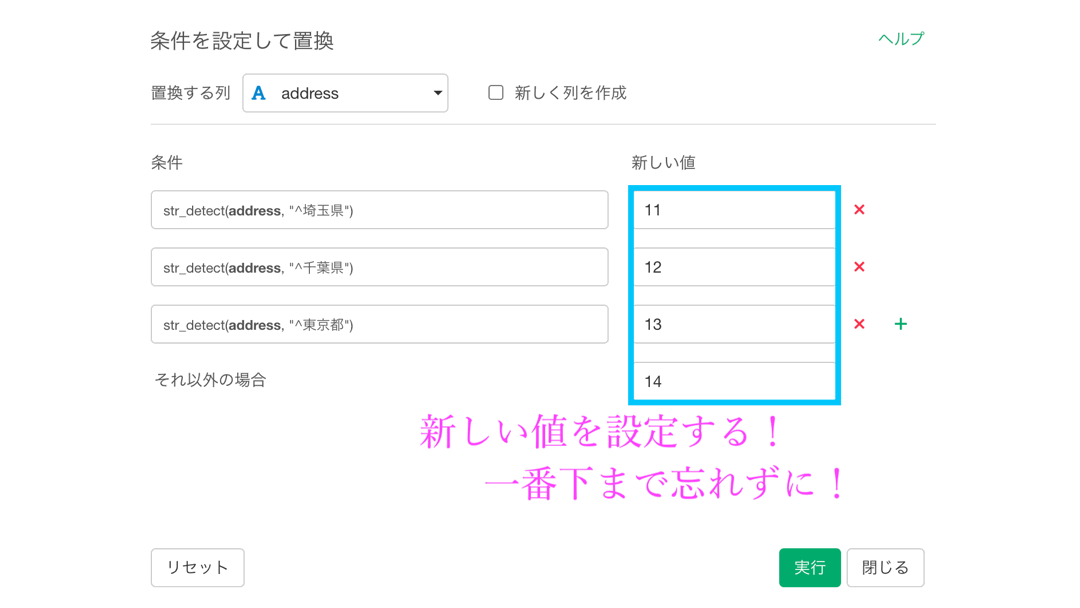
新しい列を作成して、比較できるようにしておきます。
その他の場合のところも抜かりなくチェックしないと NA になりますので注意してください(普段から)。
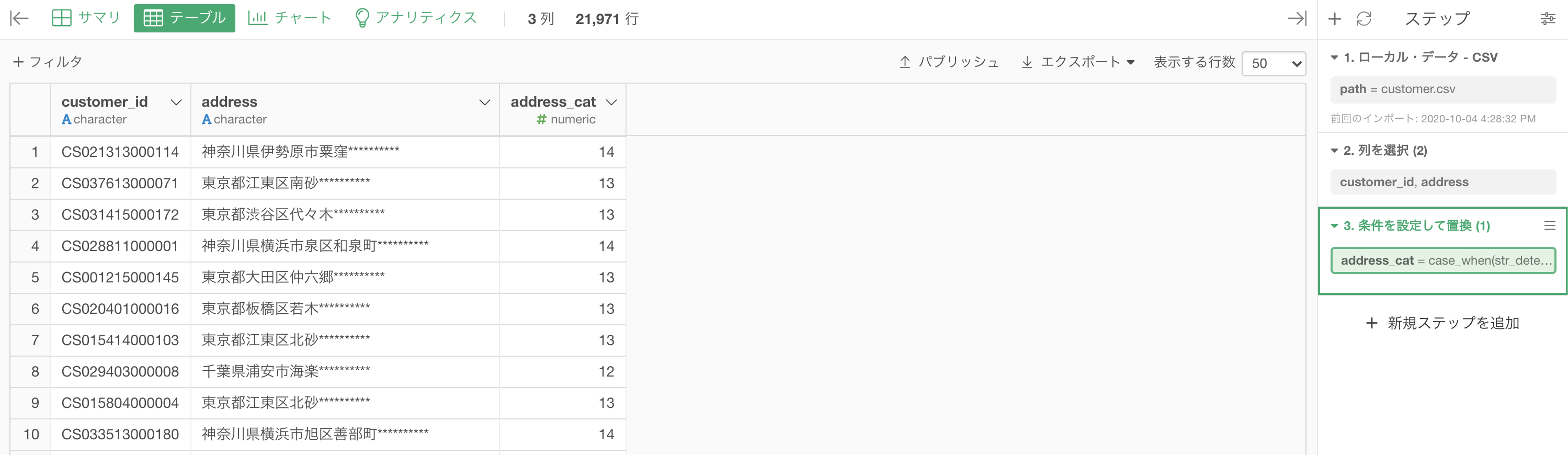
結果はこのようになります。解答を確認しましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
pd.concat([df_customer[['customer_id', 'address']], df_customer['address'].str[0:3].map({'埼玉県': '11',
'千葉県':'12',
'東京都':'13',
'神奈川':'14'})], axis=1).head(10)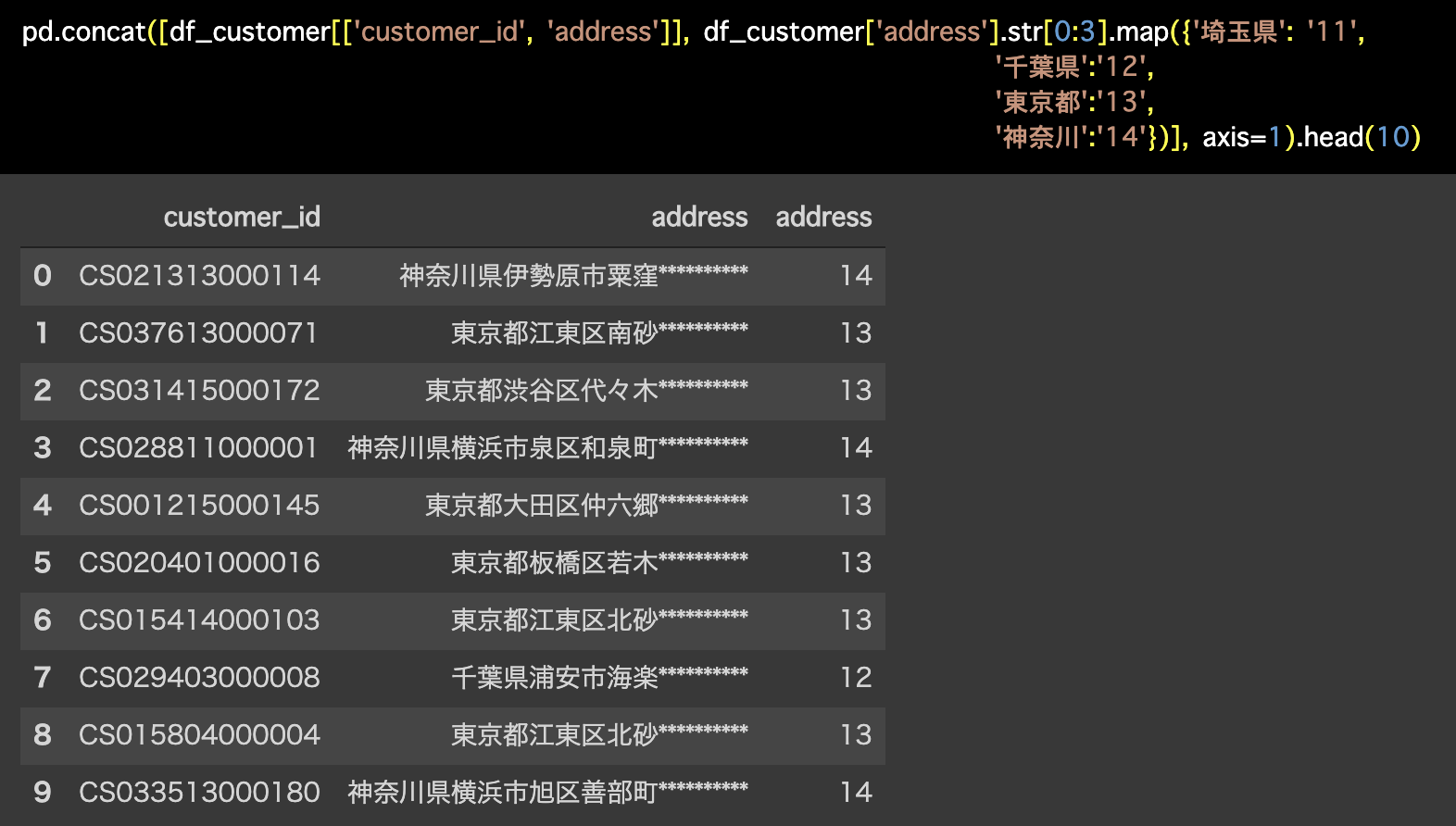
県の数がもっと増えたらどうするか?
ただし、コードのデータはあるとします。
...こんなことを平気で突きつけて来ます。
しかし、別解を考えておくことで、こういうことが出てきてもきちんと効率よく対処することができます。
例えばそのような場合だったら
- テキスト関数 → 指定した範囲にある文字列を取り出す
- 1,3 と入力(
str_sub(列名, 1, 3)ということ) - 都道府県コードのデータ(2列47行)を別でとってきて、2番と同じ処理
- 持ってきたコードのデータと内部結合する
という流れが考えられます。
実際にやってみようとしても、都道府県コードのデータがないのでできませんが(実践ではどこかにありますから心配せず)、イメージとしてはこのような感じです。
まずいつものように1番と2番の処理を行います。
このようになりました。ここまでは実装できますね。 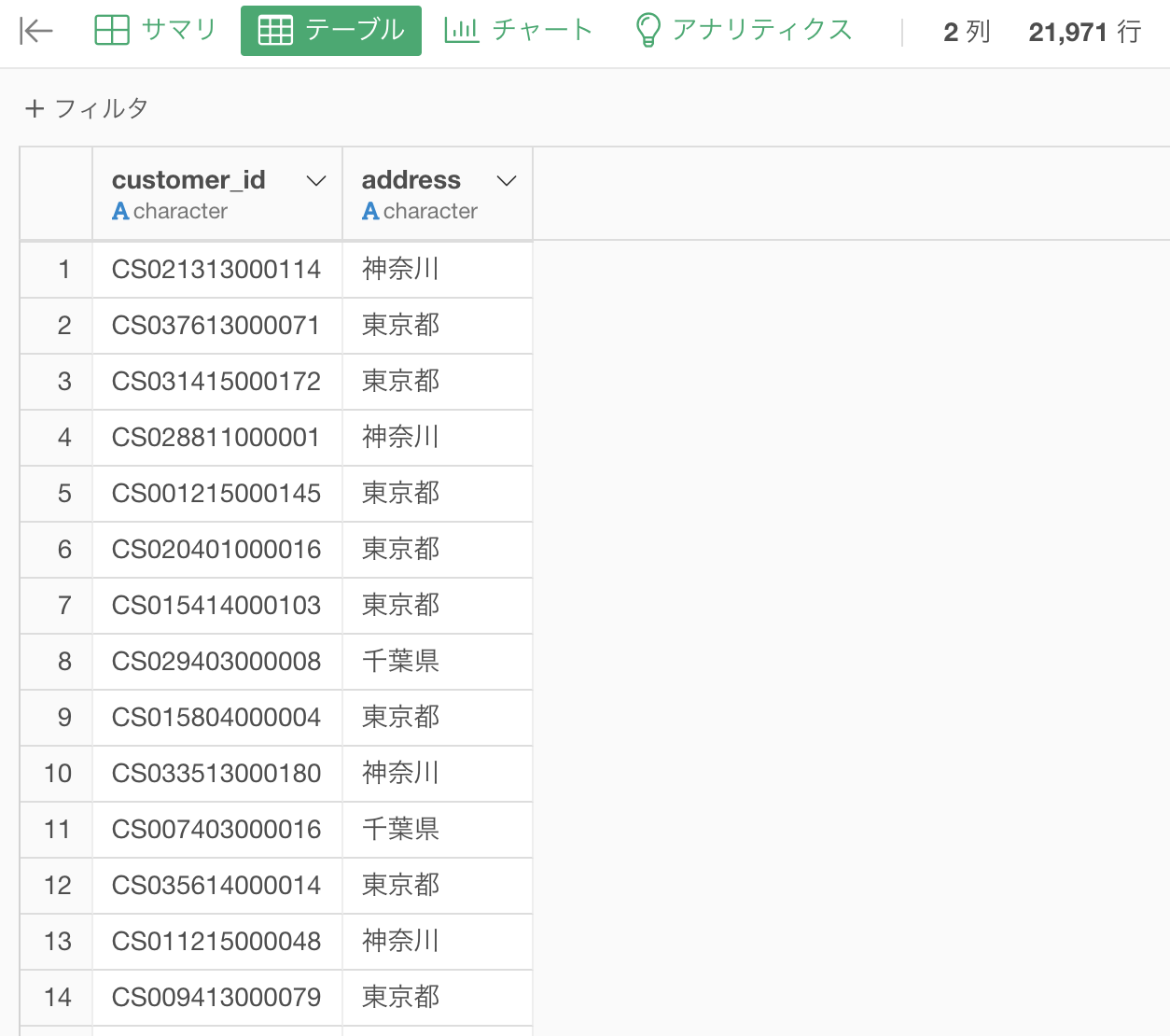
ここからはデータがないので実装できませんが、読みながらイメージしてください(やり方をすぐに思いつかなかった人は特に!)。
次にやることは、コードのデータをインポートすることです。
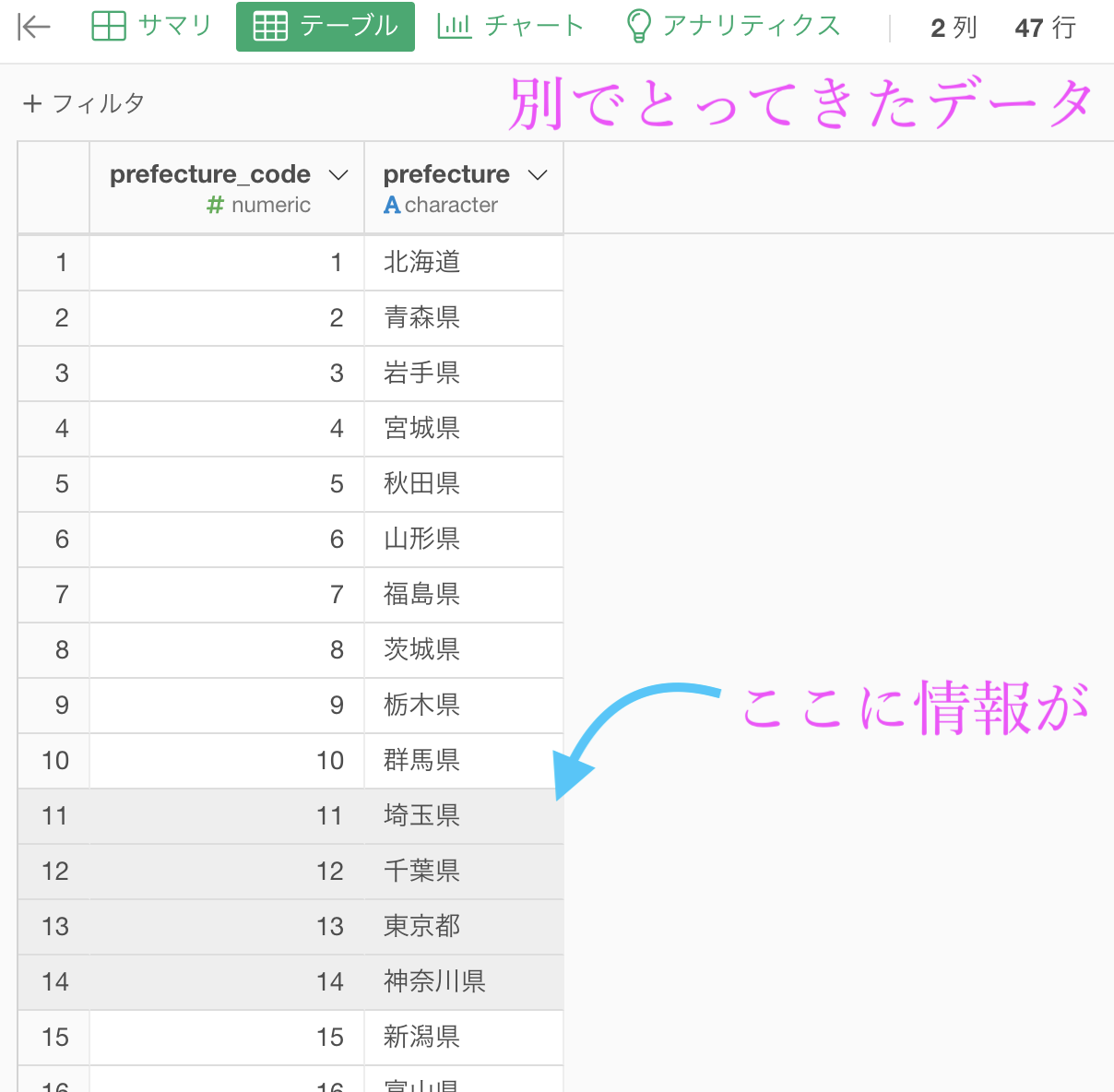
そして、prefecture(都道府県)の列に1番と2番の処理をかけます。
すると、神奈川県は4文字なので神奈川と3文字になりますが、両方のデータで同じ処理をしているので、きちんとコードが結合できるという仕組みです。
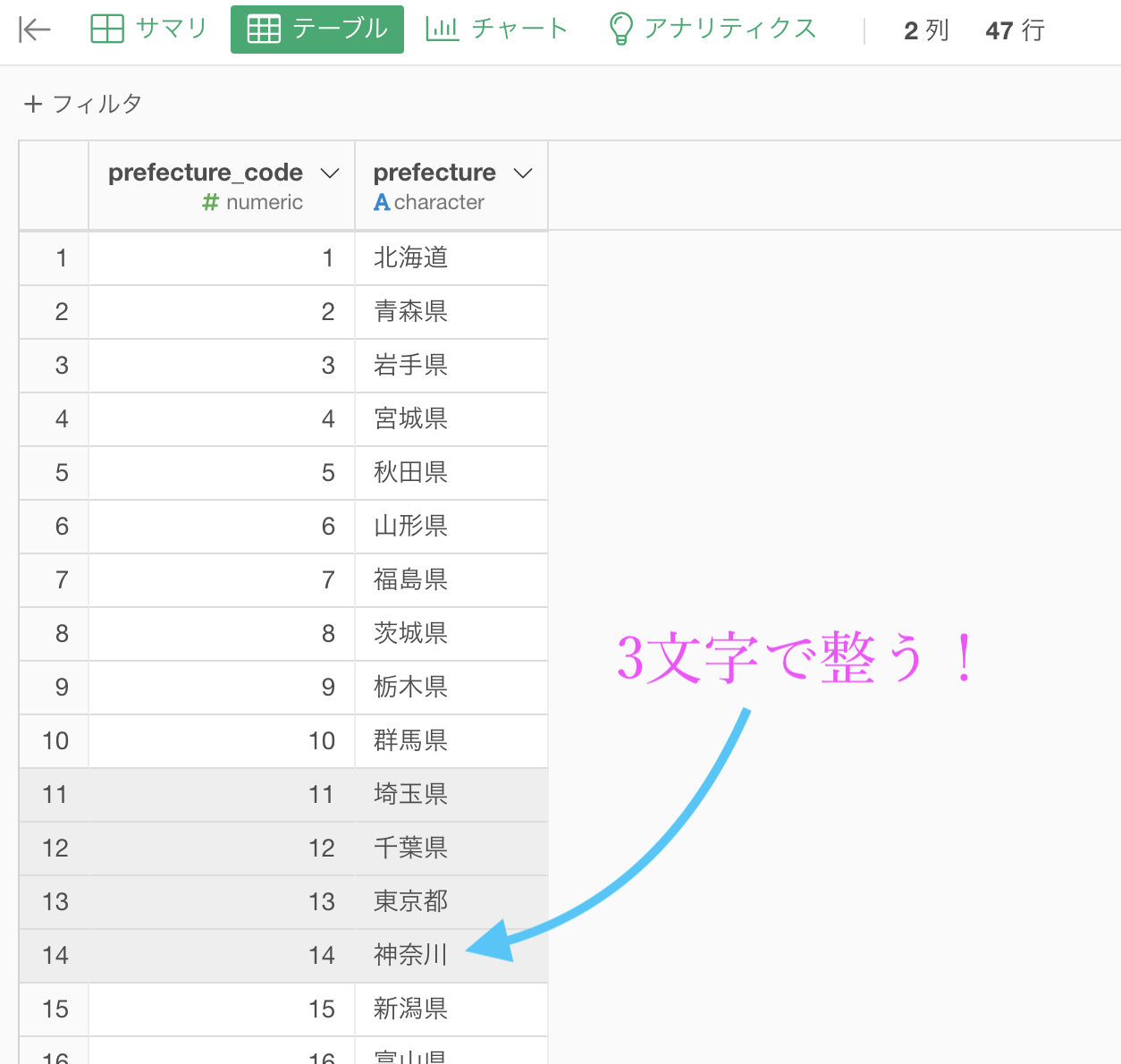
こういう工夫がエラーを防ぎます。
最後に内部結合すれば全ての都道府県がきても望んだ結果が得られるということになります。
結果はこのようになりました。
このやり方をそのものを実務で使おうとするのは標準ですが、考え方や柔軟な思考をもっと求めるモチベーションに繋がってくることを楽しみにしています。
ちなみに、R や Python 解答コードではきちんと、先頭の3文字を切り出すコマンドを書いています。
全ての都道府県まで考えるきっかけになる良いコマンドだと思いますが、Exploratory で実装しようとするとステップが増えるのでやらなかっただけのことです。
問55 : 数値からカテゴリデータを作成する
答案・解説はこちら
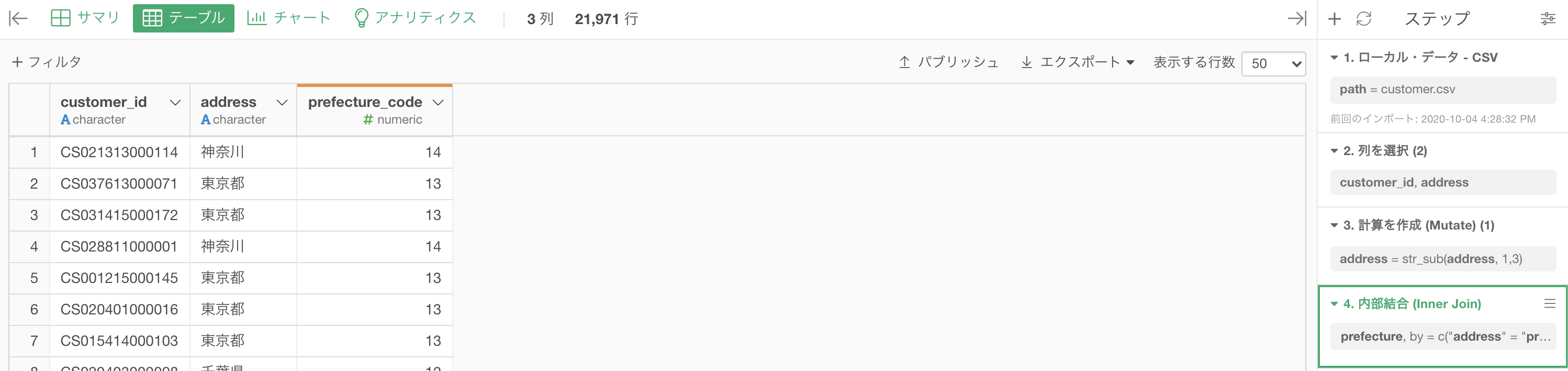
まずは df_receipt を集計しましょう。
グループ化 : customer_id 値 : amount 計算 : 合計(sum)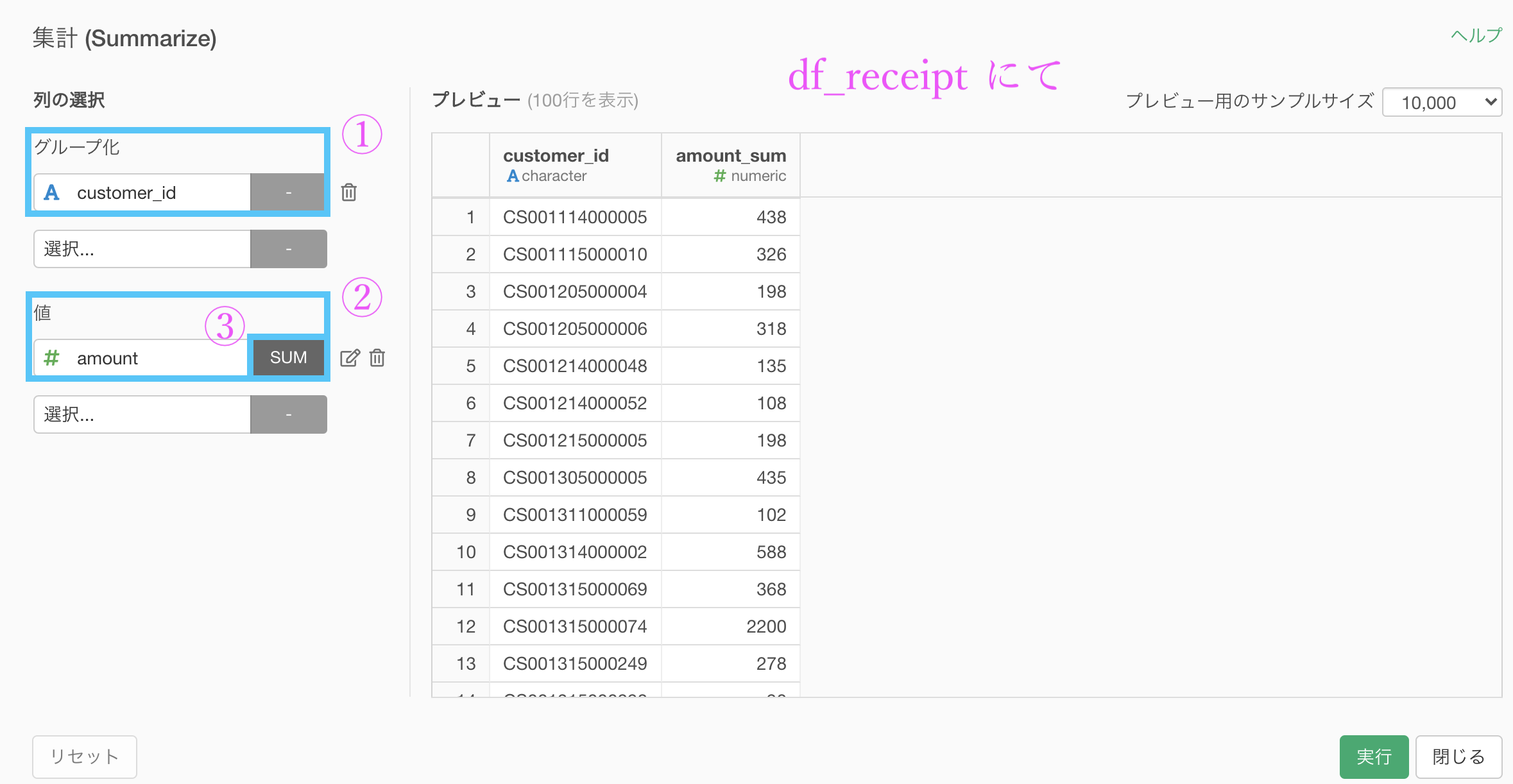
です。amount_sum の列を第1四分位数 〜 第3四分位数を使って4分割するのが今回の実装です。
今回ではいつものように条件を指定しても良いのですが、数値をカテゴリ化するにあたってはもっと簡単なやり方があります。
ビン (カテゴリー) を作成を選択しましょう。
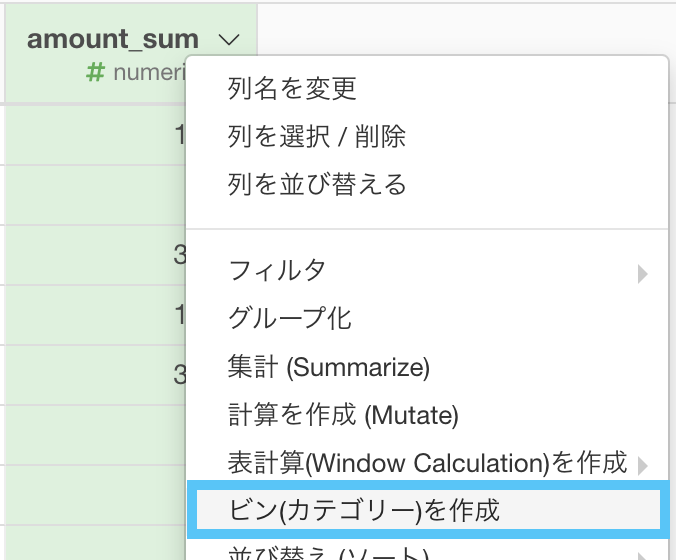
このような画面が出てきたと思います。
ちなみに ビンというのは、ヒストグラムの階級(の個数)のことです。
これが大きくなれば、カテゴリ(分け方)も多くなるということです。
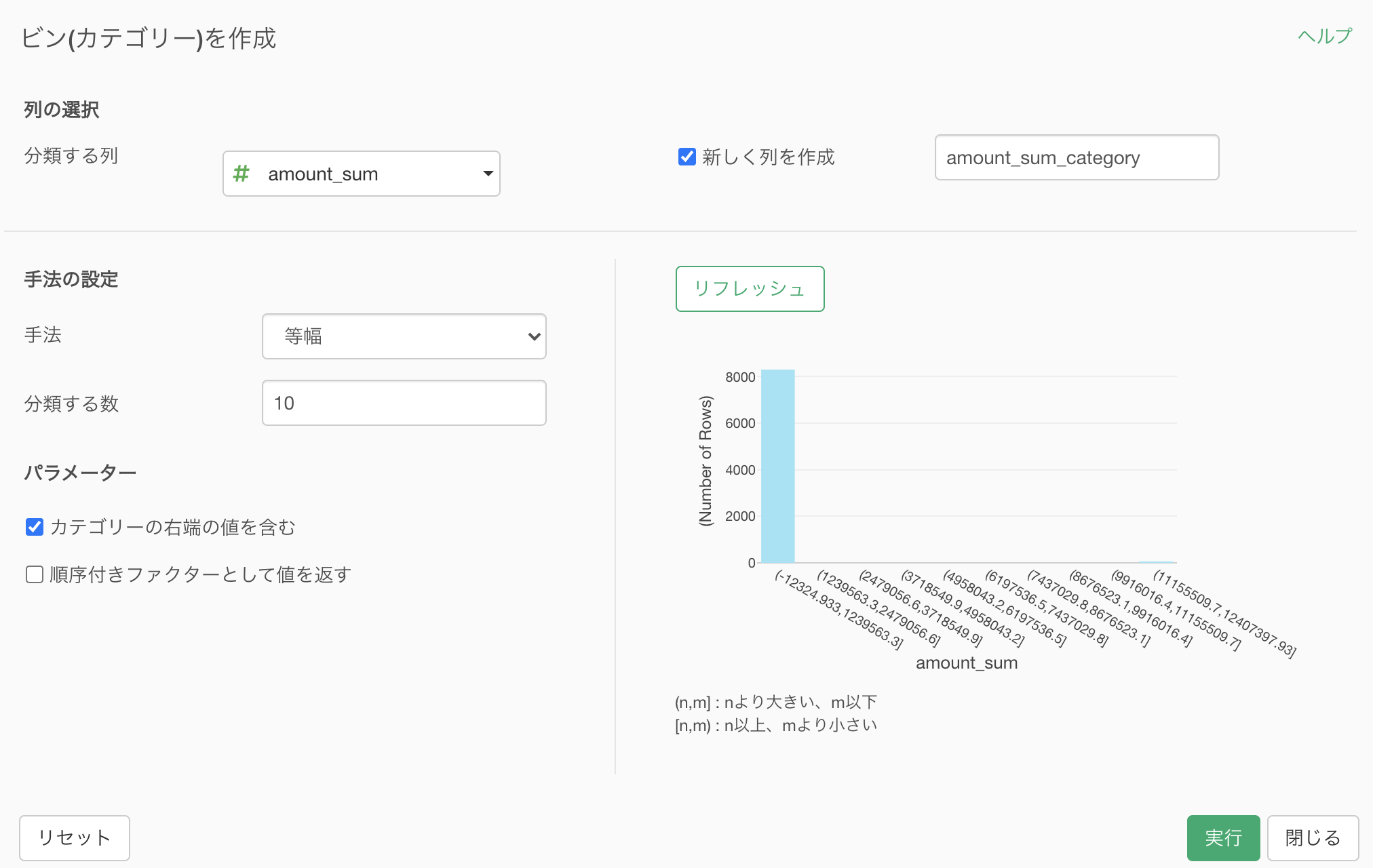
読み方はこのようになっています。
右側のヒストグラムを作成するイメージで作成していきたいと思います。
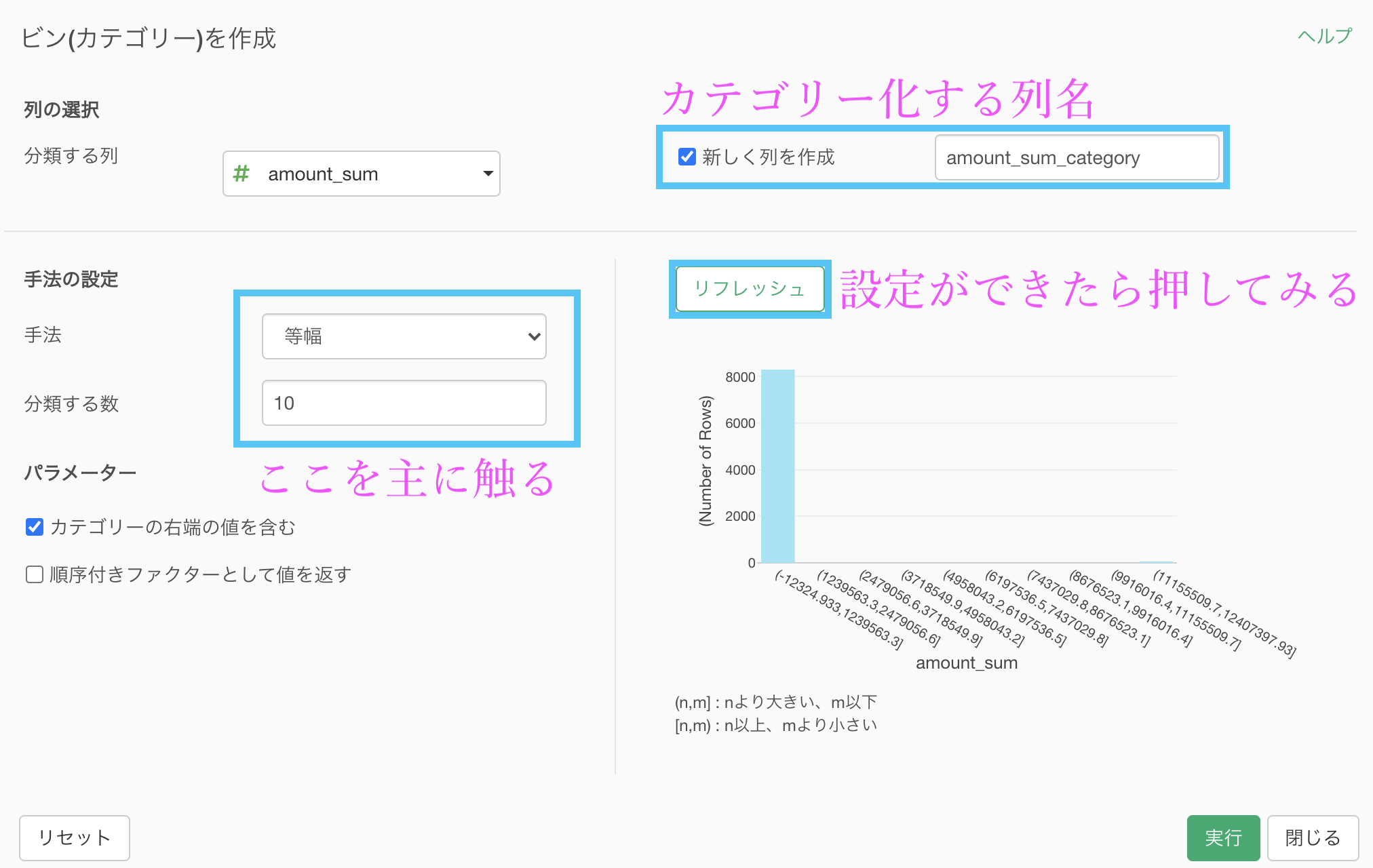
とは言っても、実際に触るところは2箇所だけです。
手法 : 等頻度(分位数)
分類する数 : 4リフレッシュされているようであれば実行しましょう。 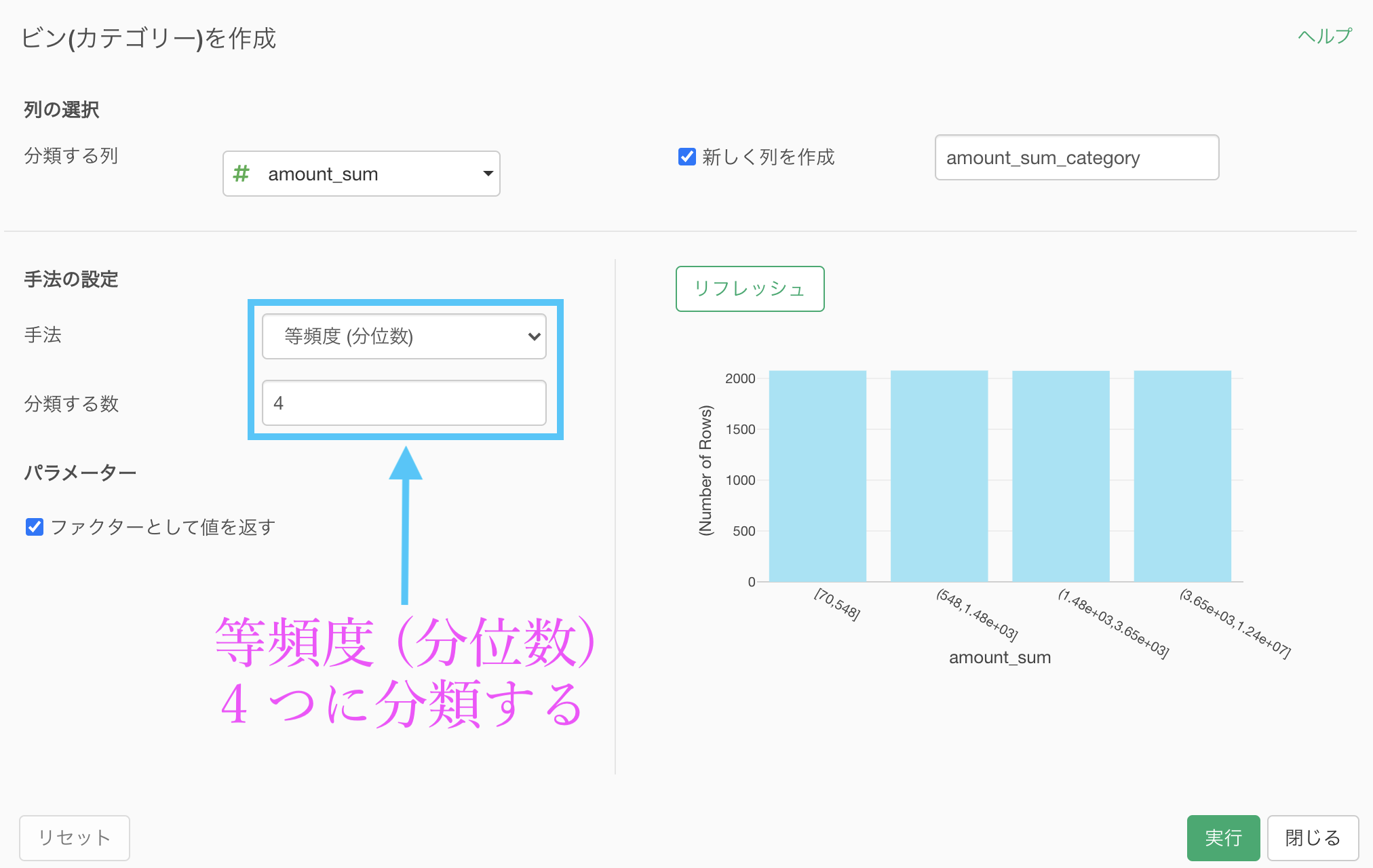
結果はこのようになります。解答を確認しましょう。
 1.48e+03 の読み方は 上のように 1480 です。電卓で遊んだことのある方はこの表記を知っている方も多いのではないでしょうか。
1.48e+03 の読み方は 上のように 1480 です。電卓で遊んだことのある方はこの表記を知っている方も多いのではないでしょうか。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
df_sales_amount = df_receipt[['customer_id', 'amount']].groupby('customer_id').sum().reset_index()
pct25 = np.quantile(df_sales_amount['amount'], 0.25)
pct50 = np.quantile(df_sales_amount['amount'], 0.5)
pct75 = np.quantile(df_sales_amount['amount'], 0.75)
def pct_group(x):
if x < pct25:
return 1
elif pct25 <= x < pct50:
return 2
elif pct50 <= x < pct75:
return 3
elif pct75 <= x:
return 4
df_sales_amount['pct_group'] = df_sales_amount['amount'].apply(lambda x: pct_group(x))
df_sales_amount.head(10)# 確認用
print('pct25:', pct25)
print('pct50:', pct50)
print('pct75:', pct75)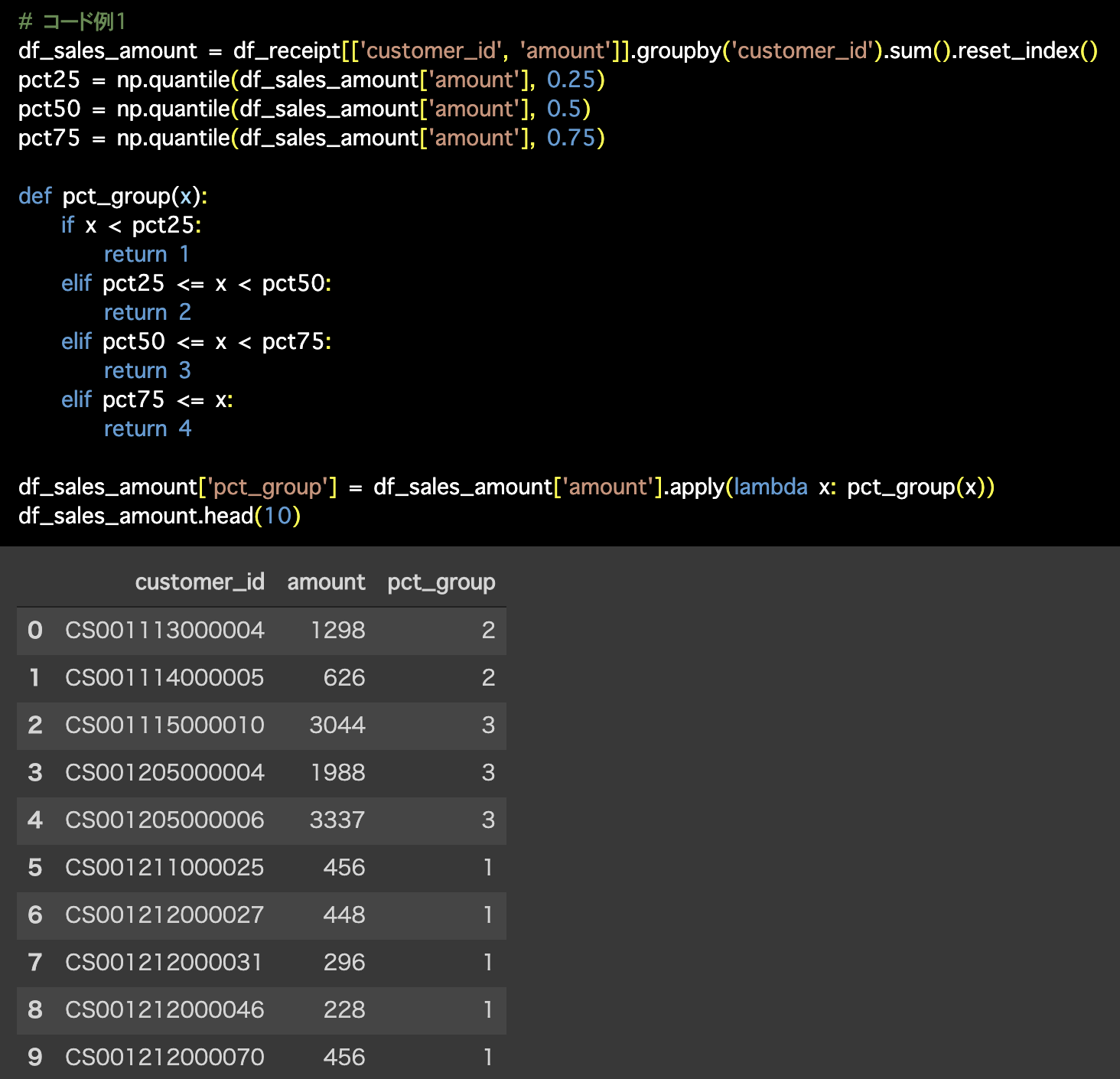

2つ目の解答コードはこのようになっています。
# コード例2
df_temp = df_receipt.groupby('customer_id')[['amount']].sum()
df_temp['quantile'], bins = pd.qcut(df_receipt.groupby('customer_id')['amount'].sum(), 4, retbins=True)
display(df_temp.head())
print('quantiles:', bins)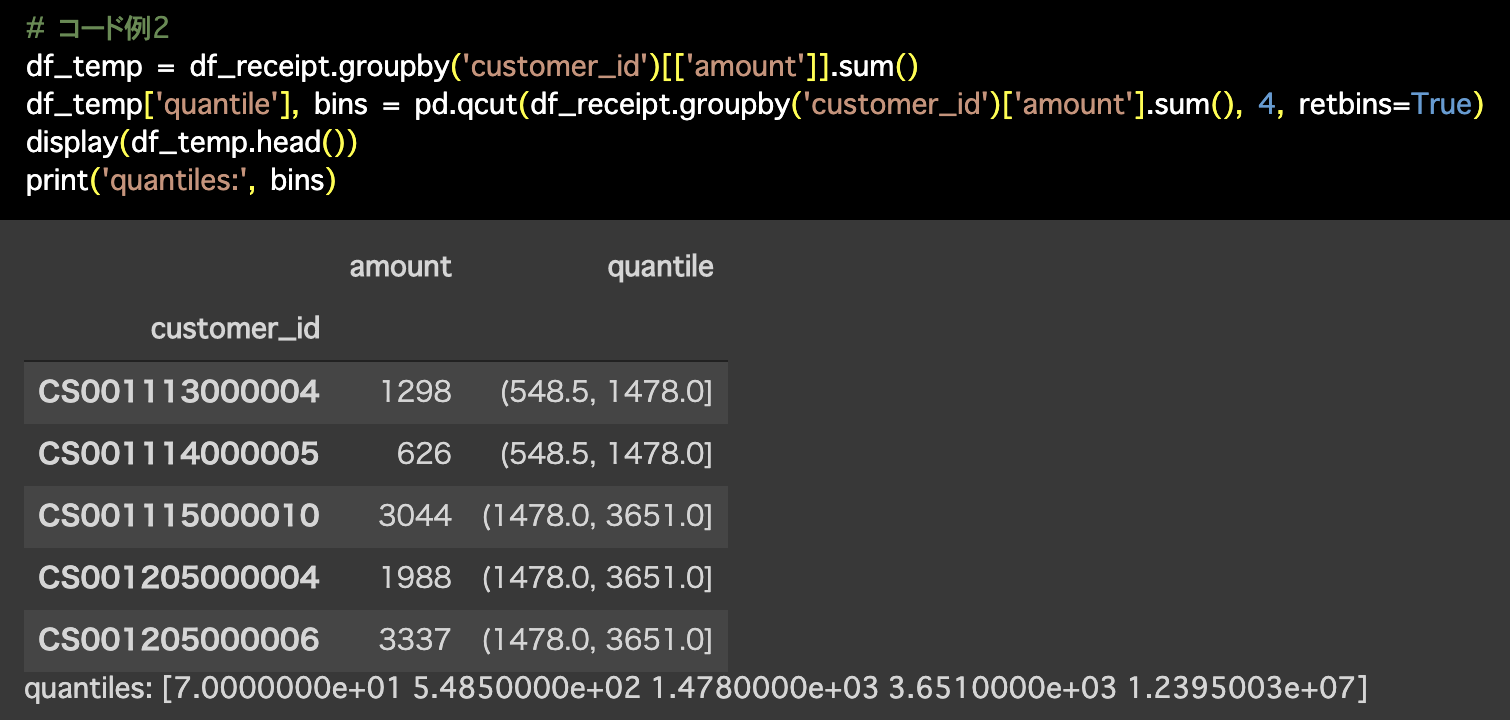
今回は(コード例2のように)区間で分けるカテゴリーにしましたが、それぞれに 1〜4 を割り当てることはそこまで難しいことではないはずです。
ぜひやってみると良いと思います。
今回のことでぜひ注意したいこと
おもむろにサクサクやって分割しましたが、読み方って
(548.5 , 1480] を「548.5 以上 1480 未満」と読んでいませんか?これ誤りですよ。
実際に正しいのは
(548.5 , 1480] は「548.5 より大きく 1480 以下」と読みますので、注意してください。
数学の表記ですが、丸いカッコは「より大きい・小さい」で四角いカッコは「以上・以下」ですので、その値を含むか含まないかの違いがあります。
ということは、例えば整数値だった場合はこれがかなり左右してきます のでその時は本気で注意する必要があります。
変換する方法はカスタムRコマンド(実質的に Exploratory の中身)をいじる方法が挙げられます。
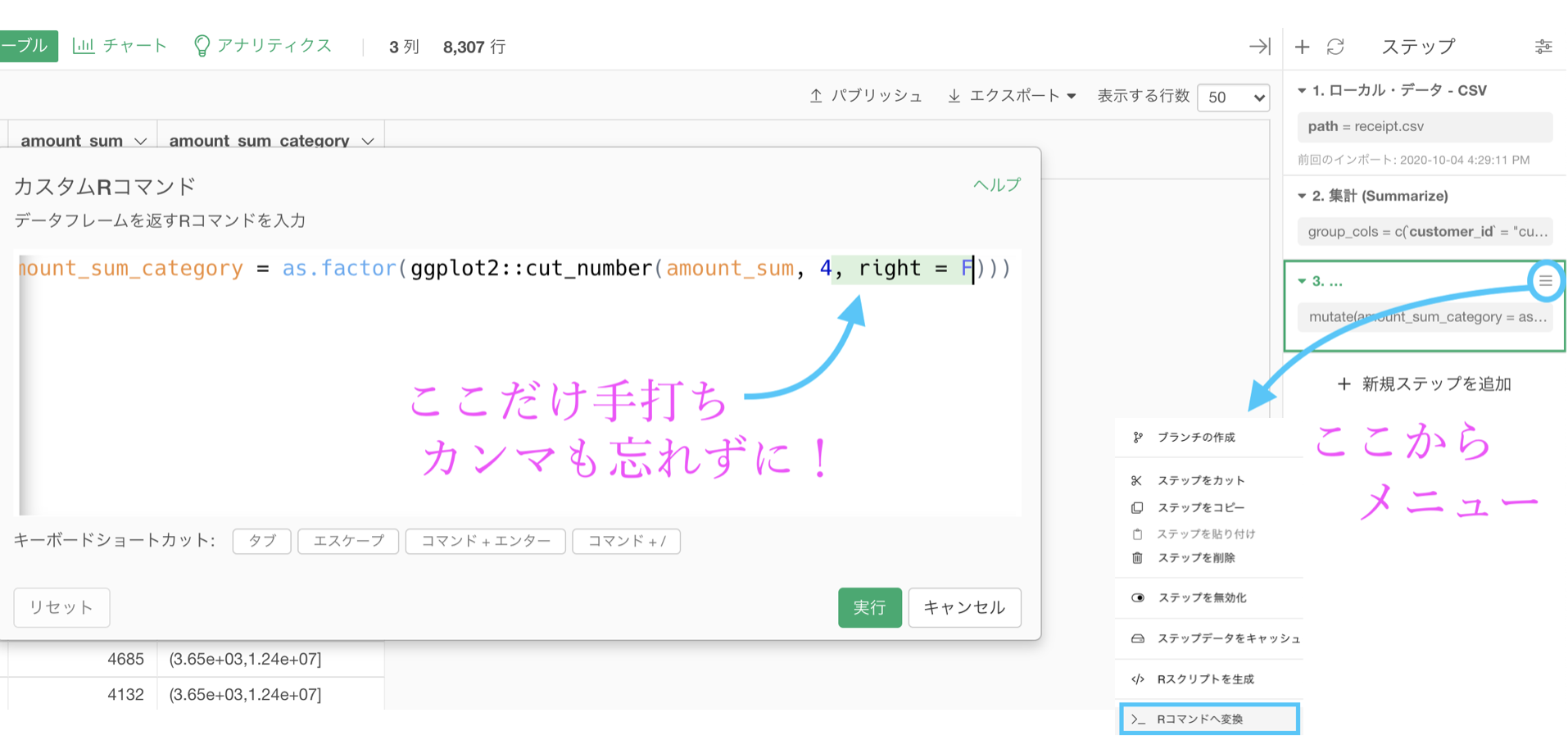
カンマも忘れずに、4 のとなりに , right = F と打ち込むだけです。
一応、コピペ用にコマンドを書いておきます。
mutate(amount_sum_category = as.factor(ggplot2::cut_number(amount_sum, 4, right = F)))なお、right = F の意味は「右端はFALSE(含めない)ことにする」という意味です。
意外とコードって単純に記述されるので、時々こじ付けで覚えたりすると本当にそうだったということもよくあります。
問56 : 件数の少ないカテゴリを適切なカテゴリに寄せる

答案・解説はこちら
です。
慣れていないとはじめは、この操作はデータのすり替えで詐称になってしまうのではないか と感じる方もいらっしゃるかもしれません。
なぜなら、80代の方も60代と年齢詐称しているわけ ですから。
確かにそうなのですが、実はこの前処理はよくやることだったりします。
例えば年齢に応じて amount(購入額)に変化はあるか?と考えたときに、80代の人たちは件数も少ないし、60代と対して変化に差はないだろうと判断 できることがあります。
いっそのこと、60代(以上)というカテゴリの中に入れてしまって、まとめてしまおうという訳なのです。
というわけで前置きが長くなりましたが実装の方をやっていきましょう。
まずは age(年齢)→ era(年代)にします。
これについては以前に説明した通り、 floor 関数を用いるのでした。
df_customer を customer_id、birthday、age の3列にして計算を作成 (Mutate) をしましょう。
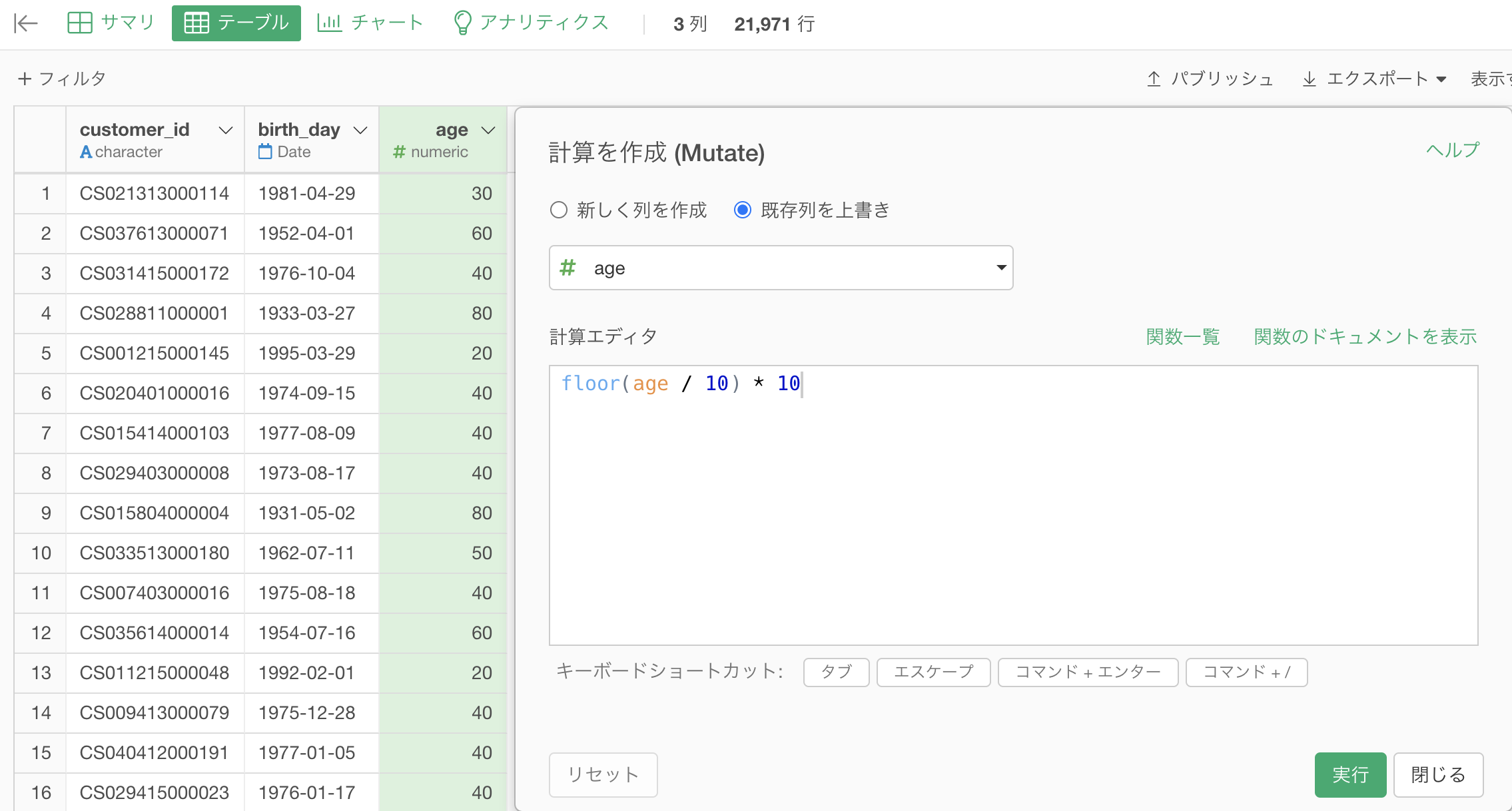
floor(age / 10) * 10と入力して実行します(よく使うので覚えておいて損はないと思います)。
ちなみに列名は era(年代)にしておきますが、ここはわかりやすくしているだけなのでやらなくても大丈夫です。
ここまできたら、今回の問題もカテゴリ化の枠組みで処理することができます。
いつものように「値を置き換える → 条件を指定」とした画面を出して、フィルター(条件)の部分はこのように「60 以上」とします。
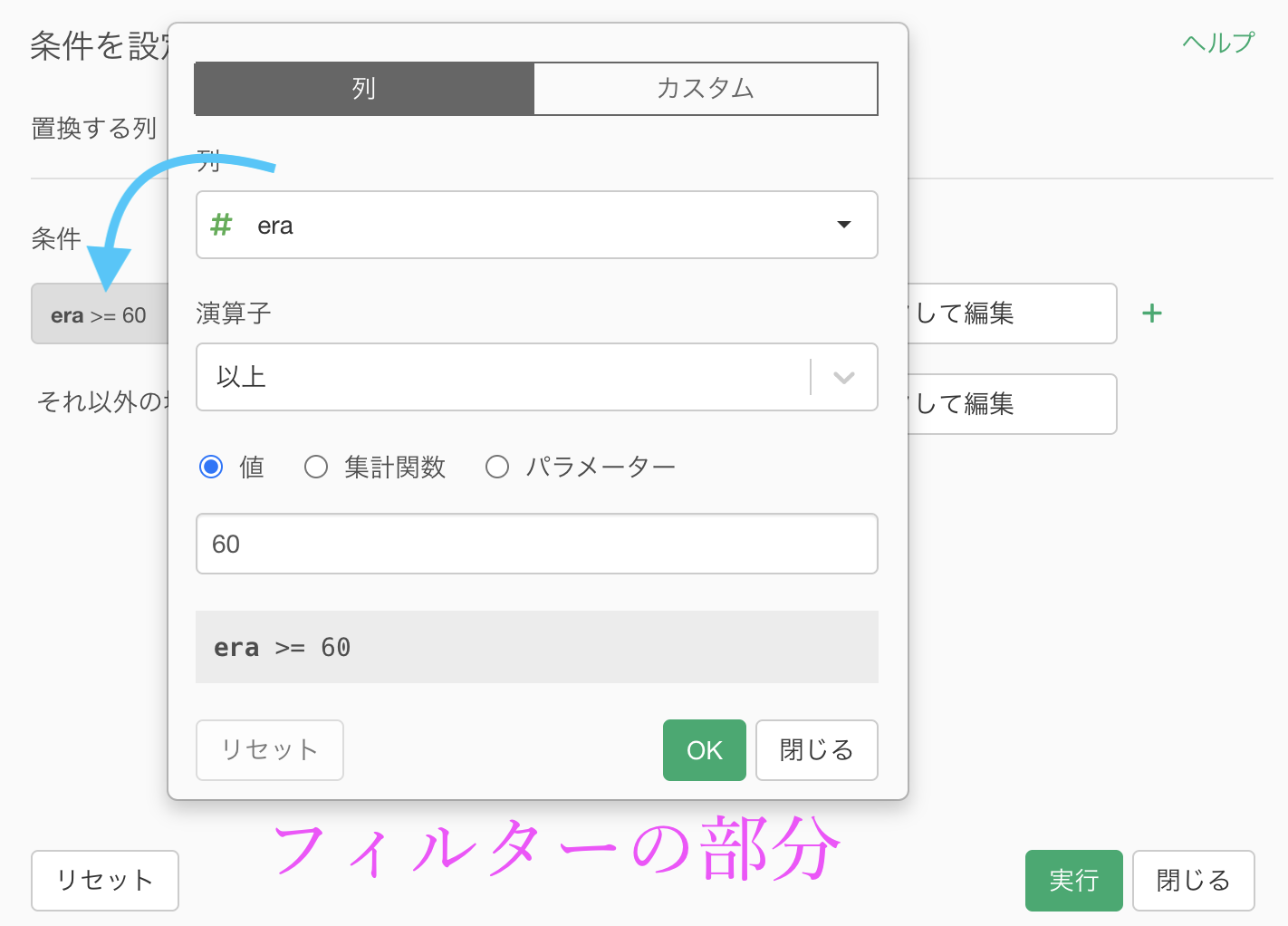
フィルター(条件)の部分は今回は終わりです。
次に新しい値の部分に入りまして、このように「60以上 → 60」「それ以外の場合 → era(列名そのまま!)」と入力しましょう。
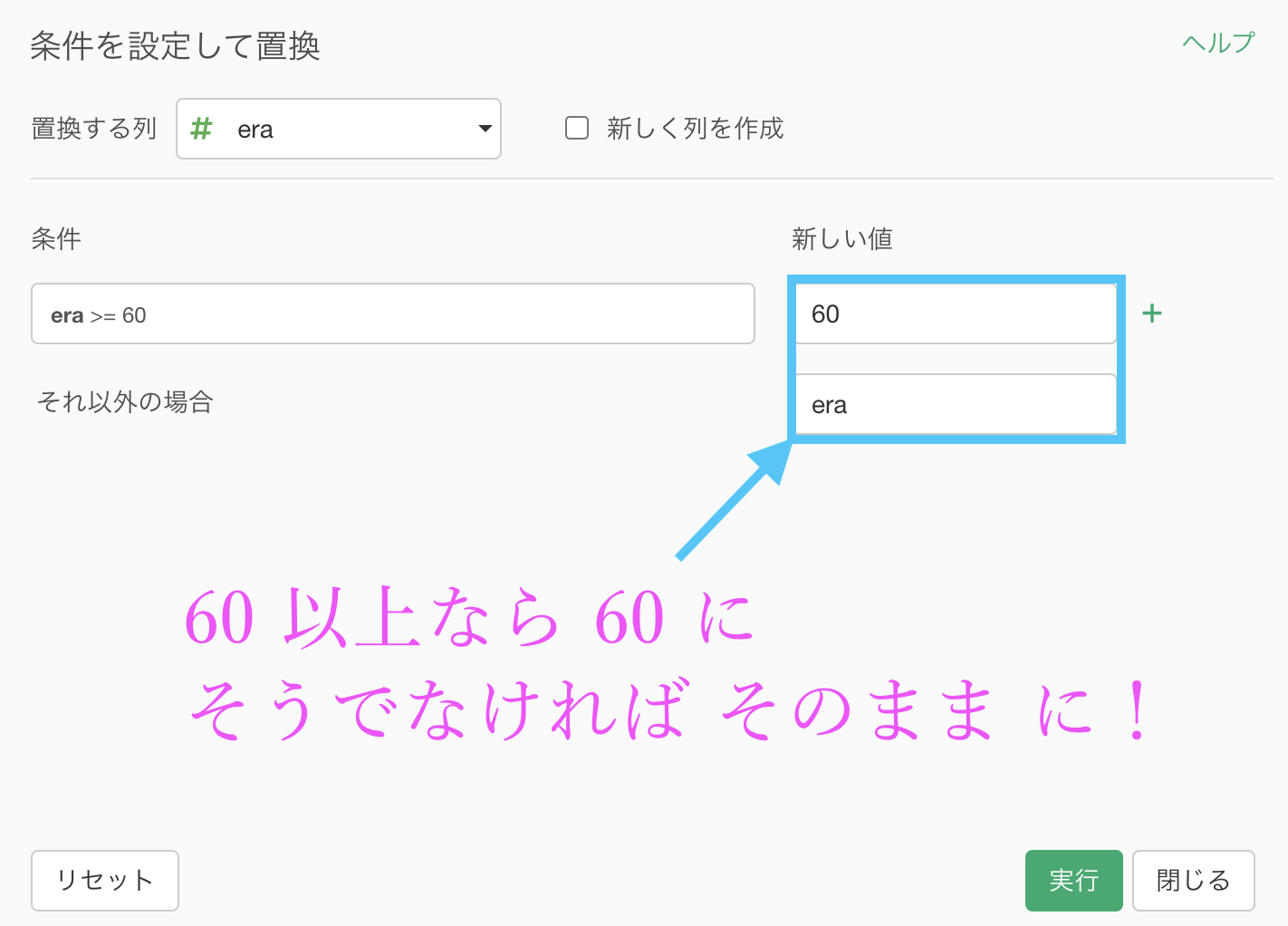
新しい値の中は計算を作成する (Mutate) と同じデザイン になっていますので、列名をそのまま書き込んでも良いのです(もちろん計算式を書いても大丈夫です)。
というわけなのでこのまま実行しましょう(変わったことを比較したい場合は、新しく列を作成するところにチェック)。
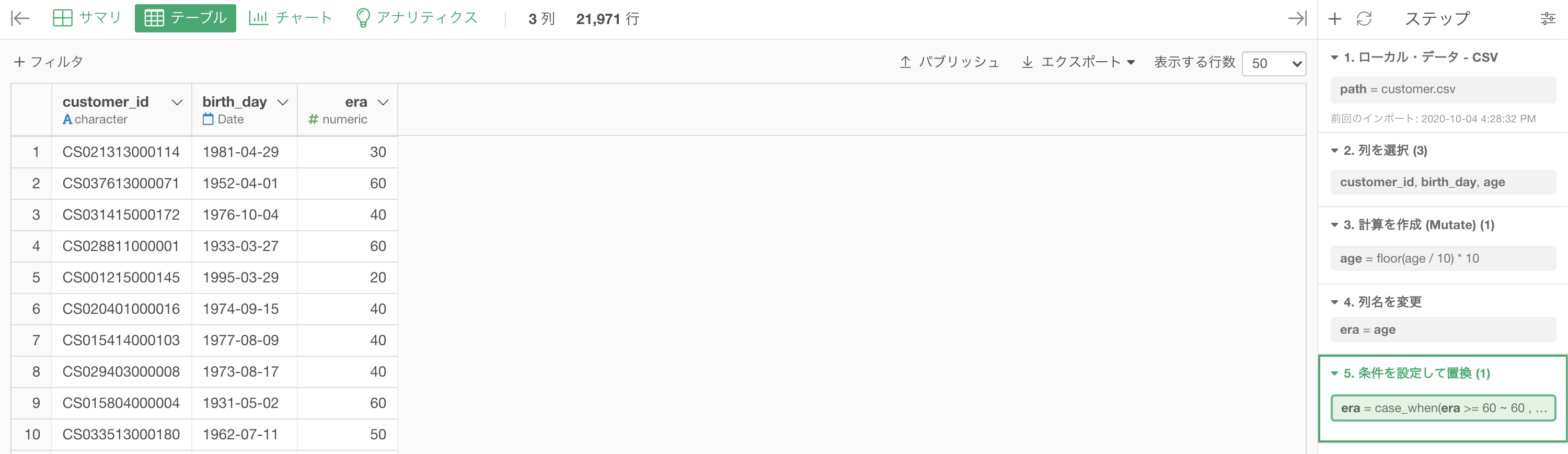
結果はこのようになります。解答を確認しましょう。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
df_customer_era = pd.concat([df_customer[['customer_id', 'birth_day']],
df_customer['age'].apply(lambda x: min(math.floor(x / 10) * 10, 60))],
axis=1)
df_customer_era.head(10)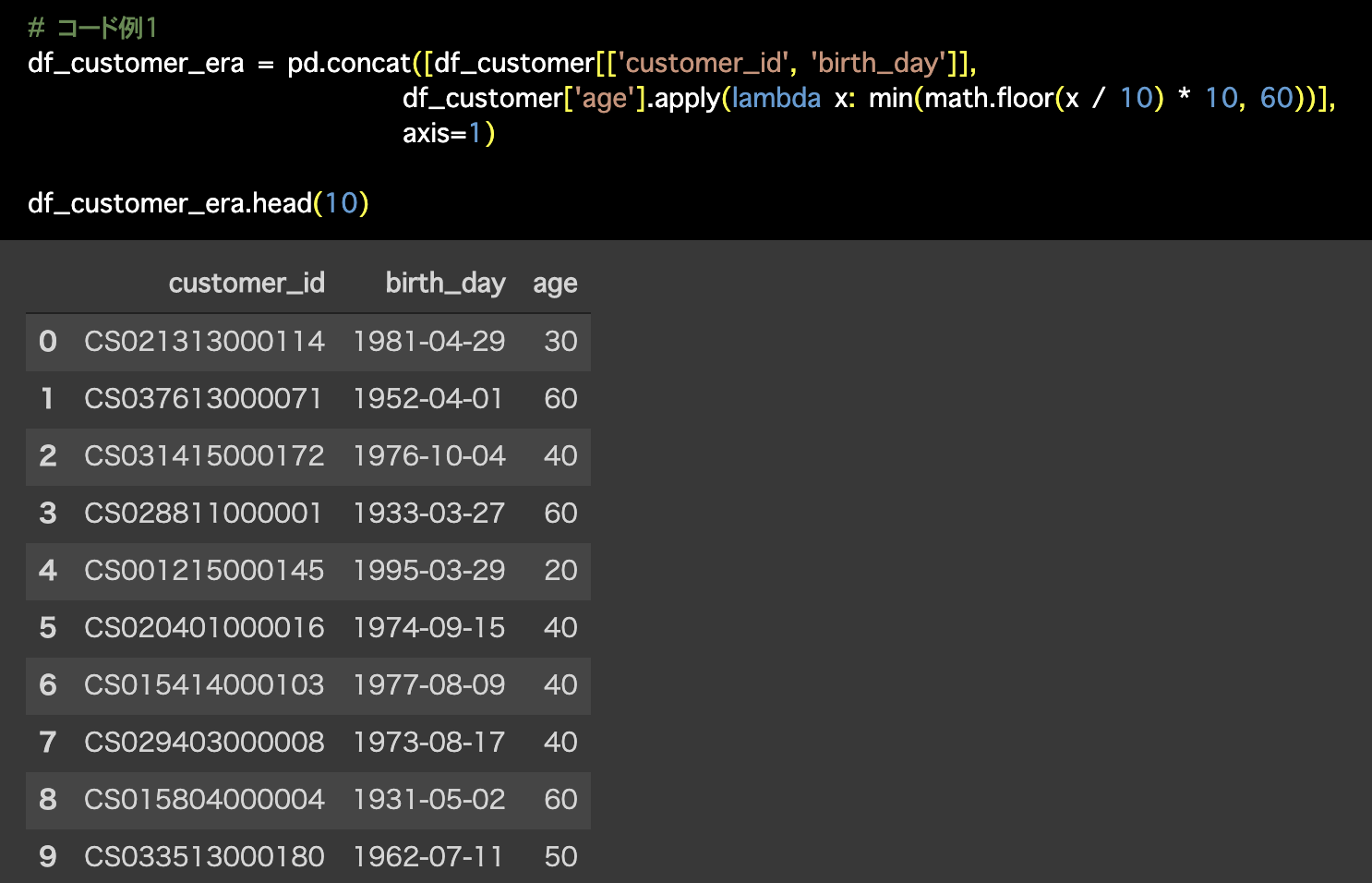
2つ目の解答コードはこのようになっています。
# コード例2
df_customer['age_group'] = pd.cut(df_customer['age'], bins=[0, 10, 20, 30, 40, 50, 60, np.inf], right=False)
df_customer[['customer_id', 'birth_day', 'age_group']].head(10)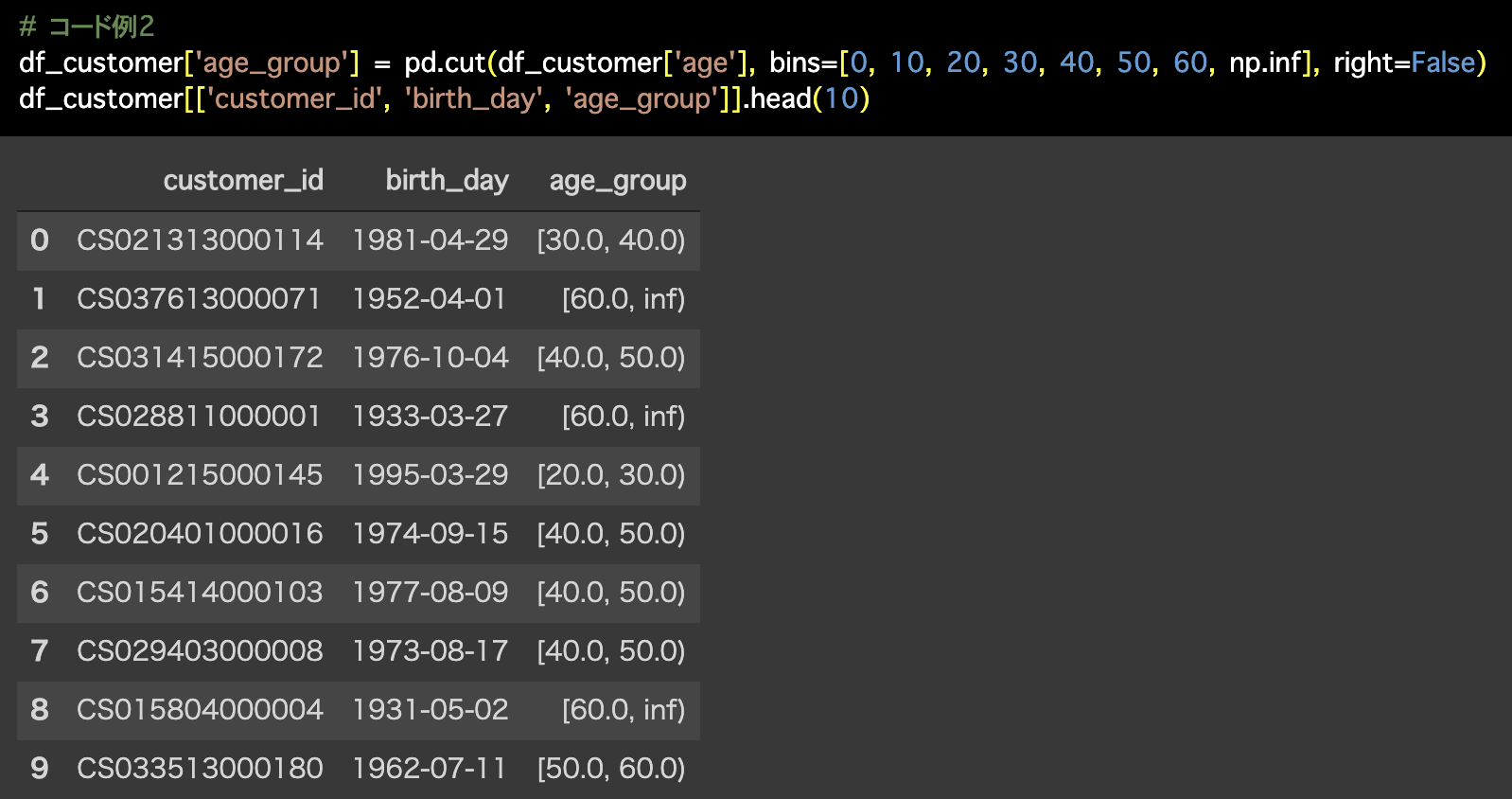
2つ目の解答コードは 問55 のときと同じく区間で分割していますが、これもぜひ Exploratory で実装してみてくださいね!
やってみようと思えばなんとかなると思います(Inf は Infinity で無限大という意味なので、それを出すのは妥協する or 他の大きな値にしてから後で変換するという手もあります)。
次の問題は 今回の結果をそのまま引き継ぎます ので、消さないでおくと良いと思います。
ブランチなどを作るなどして工夫してください。
問57 : カテゴリ同士を組合せた新たなカテゴリを作成する

答案・解説はこちら
メインの話題は終わっていますので、ここでやることの確認をすると
です。
これも前処理でよく使う方法なのでやっていきましょう。(特にテキストデータでも使えて便利!)
その前にまずは前回の結果のなかで、gender_cd の列がないので復活させましょう。
きちんとデータをみて処理することは前処理の鉄則 です。
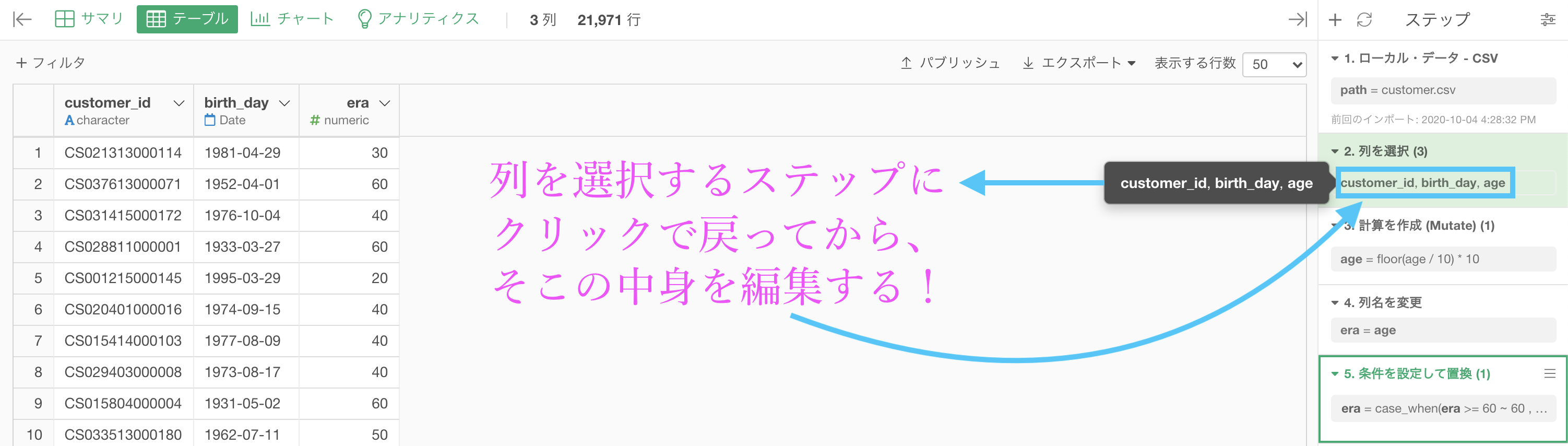
ステップの中身を開いたら、gender_cd を追加しましょう。
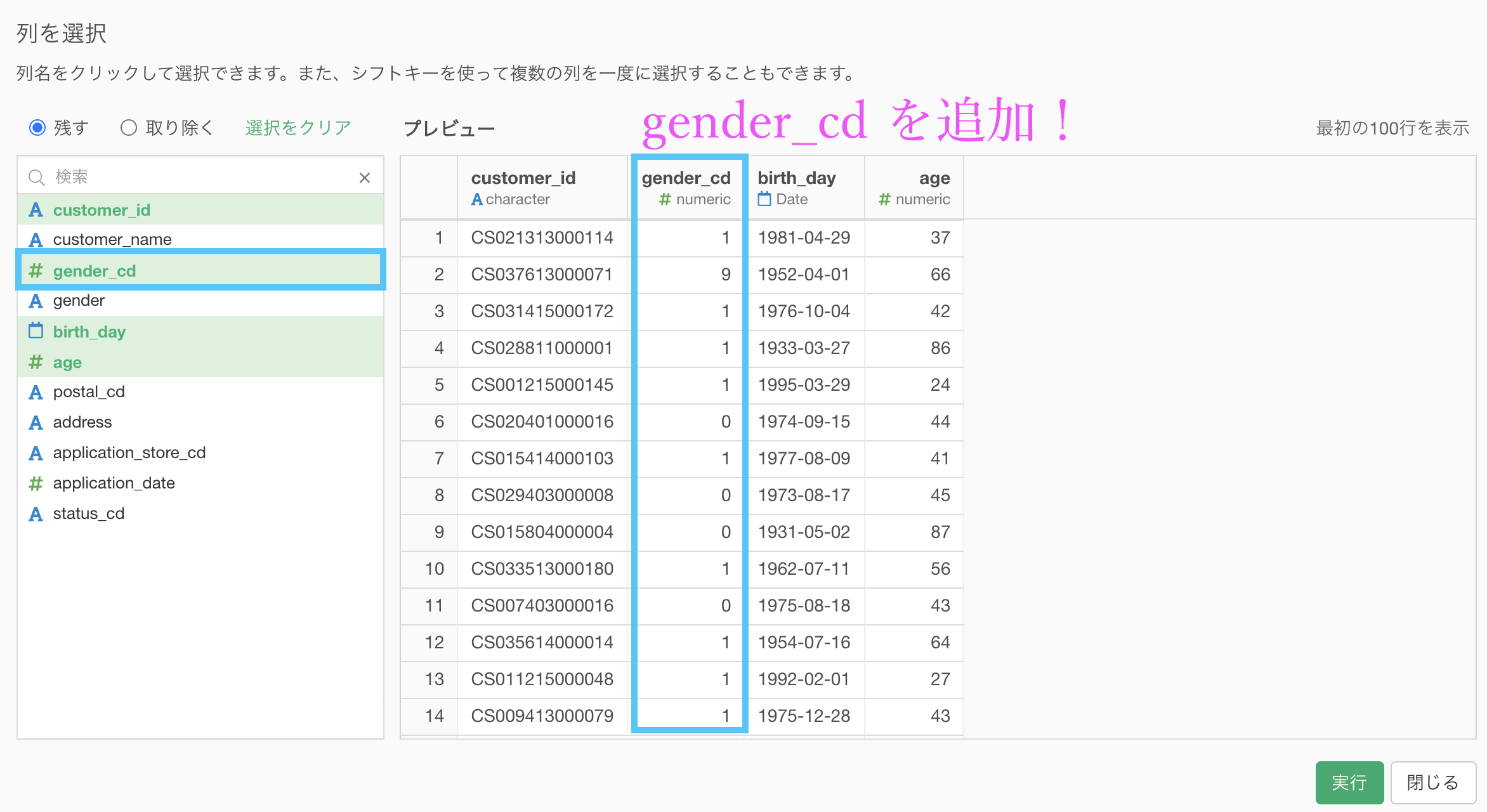
そして再び一番下のステップに戻ると、そのまま gender_cd が引き継がれます。
gender_cd についてはそれまで何も処理されていなかったので、一番下のステップに行ってもそのままが残ります。

これで gender_cd を復活させる作業は終了です。
ようやく次に、gender_cd(性別コード)と era(年齢)を合体して、1列に しましょう。
gender_cd をクリックしてから、Ctrl(または Cmd)キーを押しながらera をクリックします。
そのあと、era からステップメニューを出して「複数の列をつなげる (Unite) 」を選択しましょう。
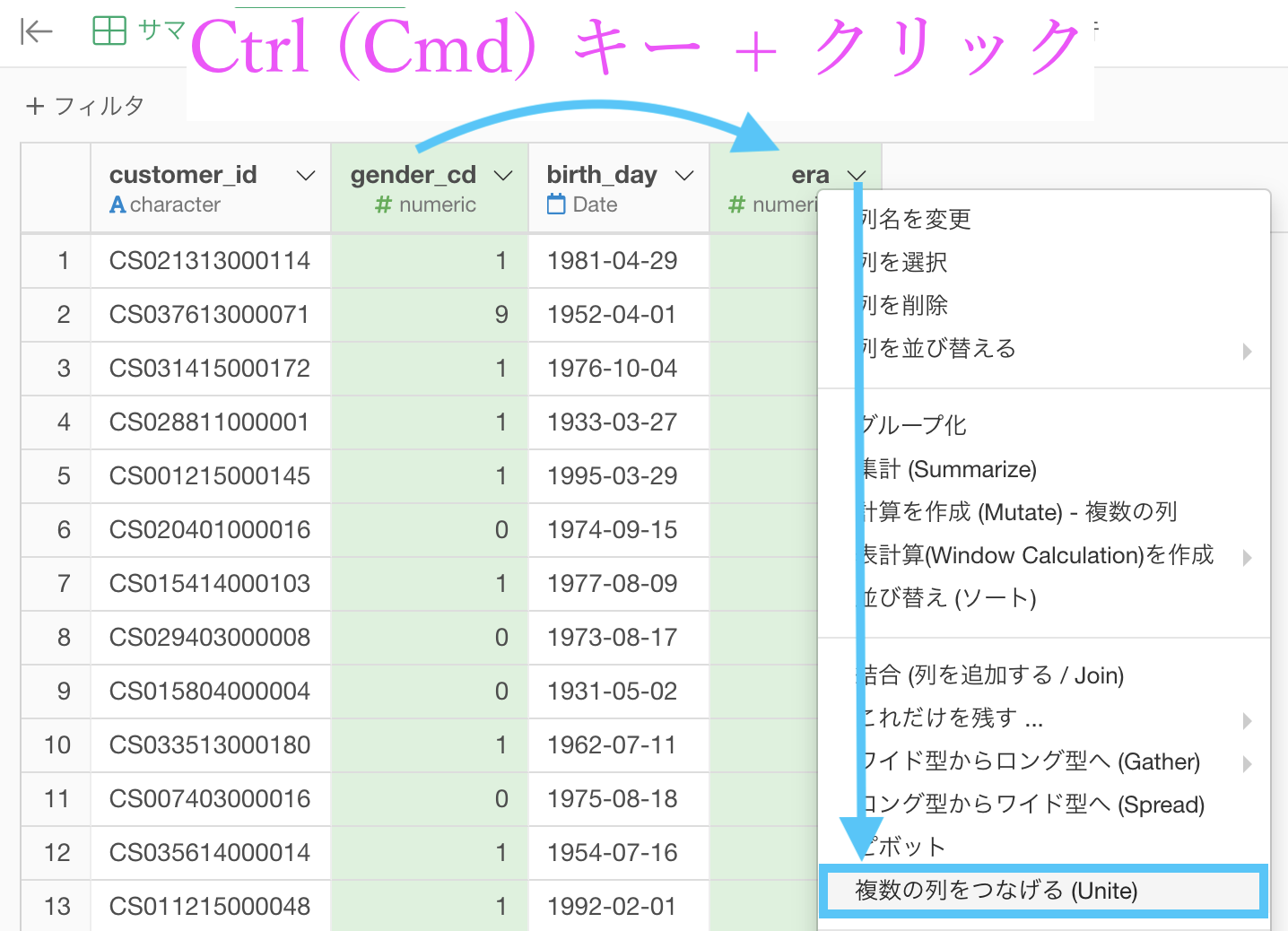
このような画面が出たと思いますので説明します。
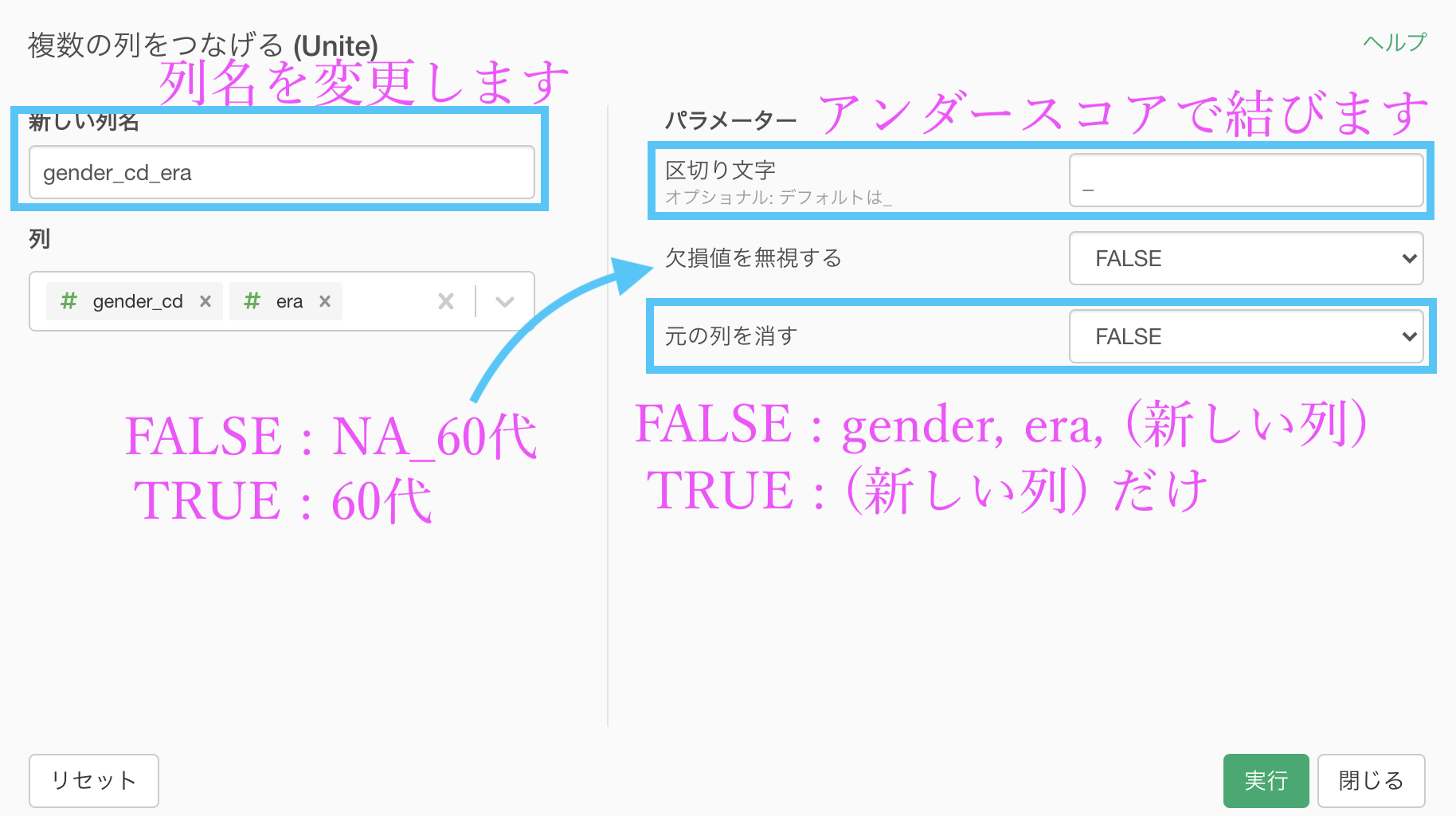
説明が終わったところで、今回はこのように編集して実行しましょう。
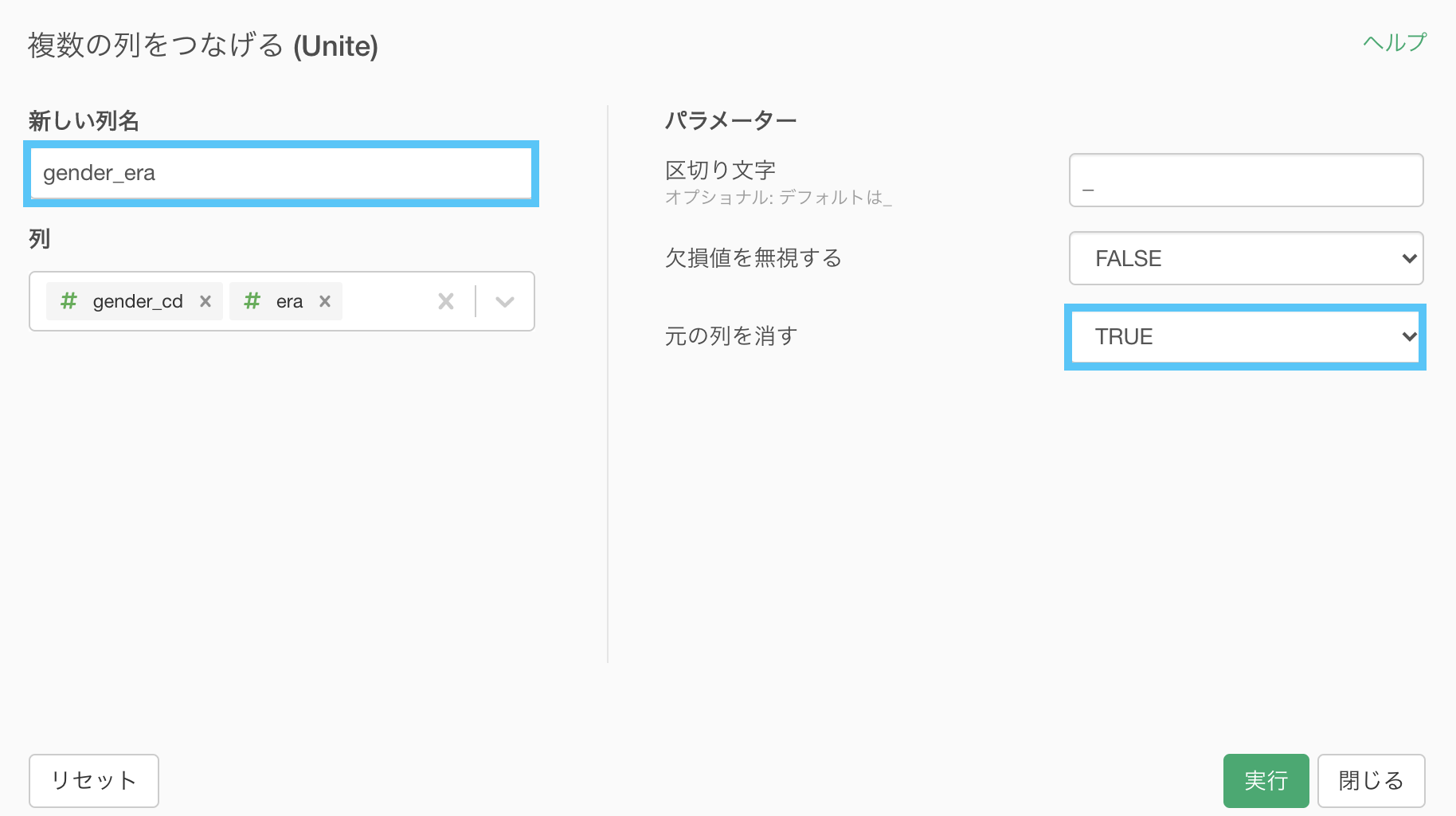
結果はこのようになります。解答と確認しましょう。
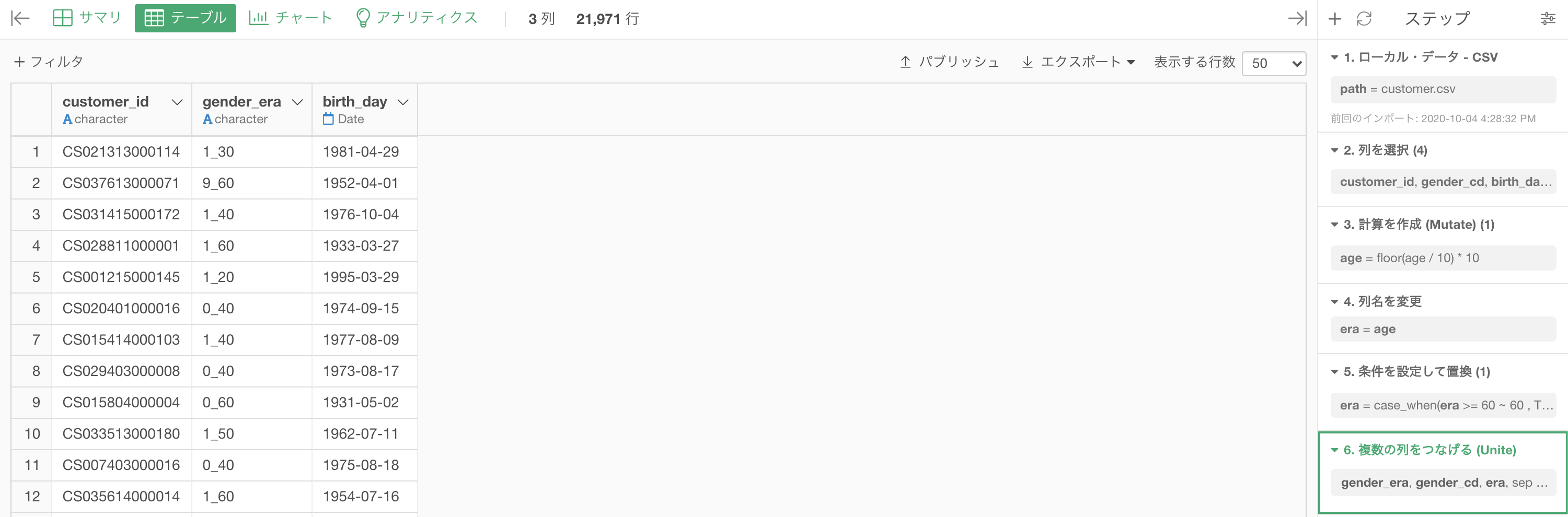
Python 解答コードはこちら
解答コードはこのようになっています。
df_customer_era['era_gender'] = df_customer['gender_cd'] + df_customer_era['age'].astype('str')
df_customer_era.head(10)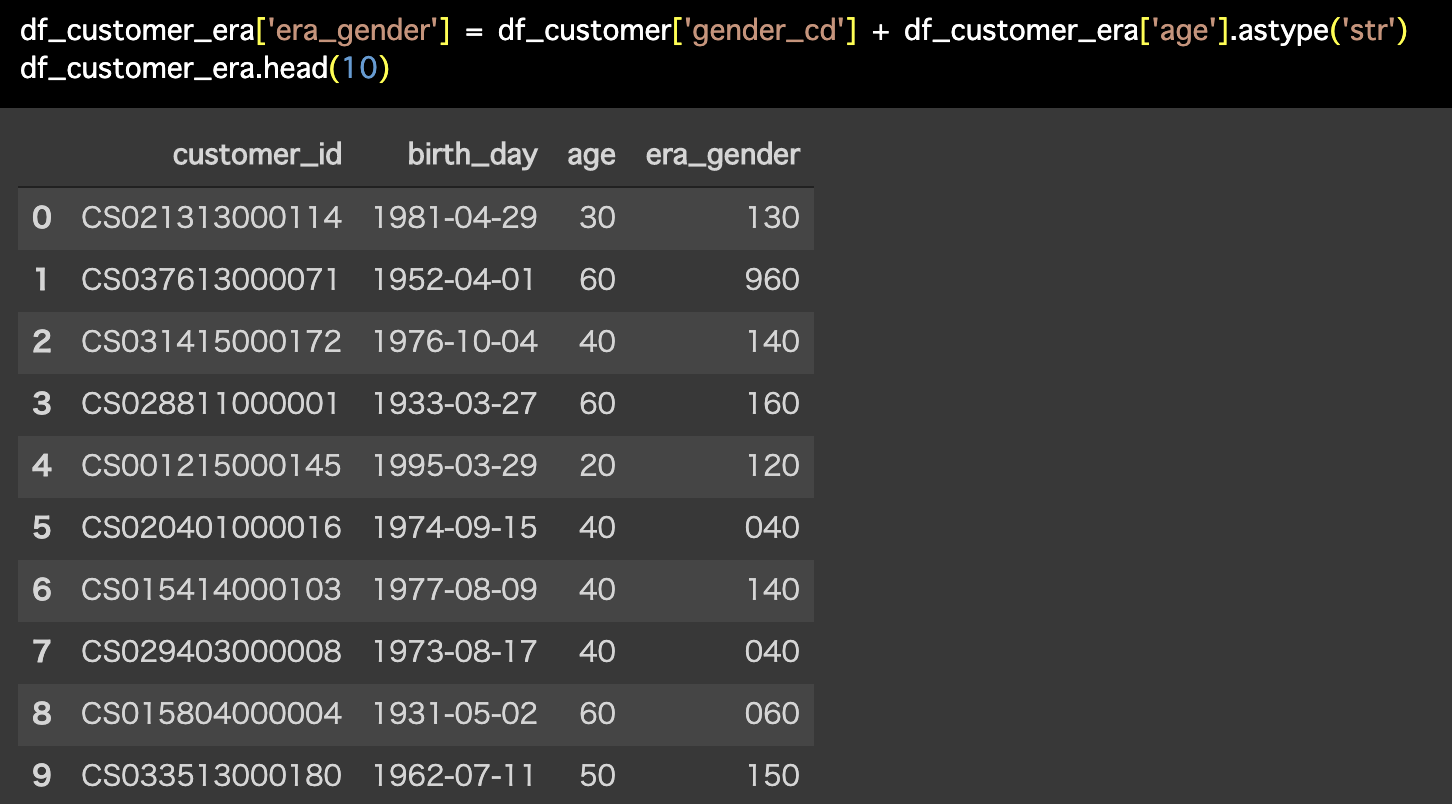
今回に限っての賢いやり方を紹介
今回は、いわば汎用的なやり方でした。
テキストデータにも複数の列を1列にする (Unite) は使えるから です。
しかし、今回の問題はもう少し賢くやることができます。
なぜ賢いかというと
- テキストデータよりも数値データの方が軽いからできれば数値データのままで処理したい ... これを実現
- 解答と同じようにしたい ... これも同時に実現
できるからです。
Python 解答コードをみるとわかるかと思いますが、足し算で書いたものです。
しかし、単なる足し算ではないことがわかるかと思います。
1 + 60 >> 150 ... 女性 (1) で 50 代普通に足すと 61 ですからね。
そこで astype('str') (str : 文字のタイプとして)足すというのが効いてきていますが、その感覚を近づけるために答案のようにやっていました。
でもそんなことをしなくても、数学をちょっと得意とするならば 1 と 60 から 160 を作ることは R言語 でも Python言語 でも共通の考え方で実装することが可能 です。
そのやり方がこちら
ステップメニューを開いて(あるいは新規ステップを追加して)計算を作成 (Mutate) し、計算式を次のように書きます。
gender_cd * 100 + era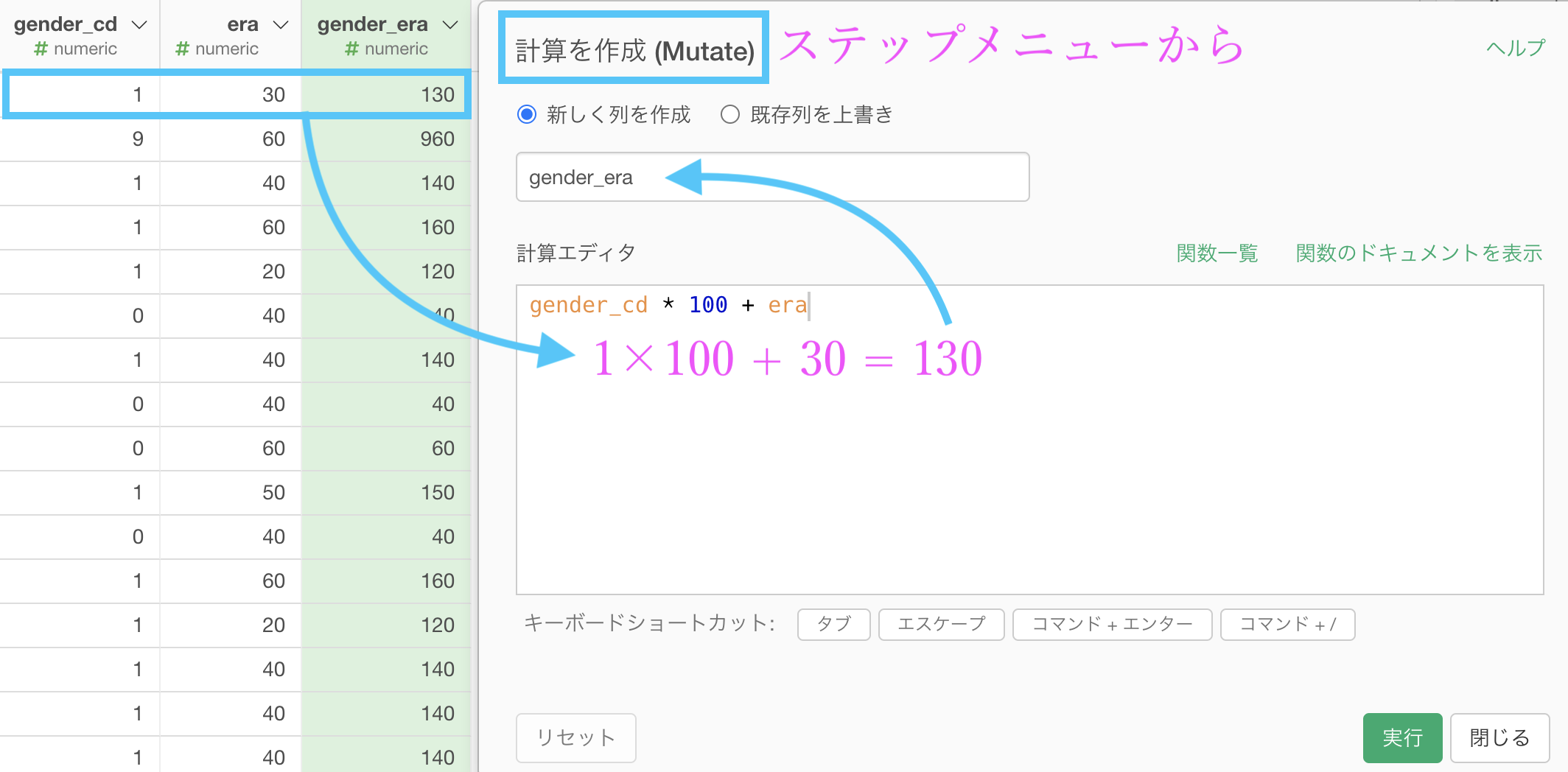
これだけで本質的な処理は終わりです。
なお、numeric(数値)型はデータが軽い分、先頭に 0 がついていないので「0(男性) + 40(代) >> 040」と表記されません。
そういう場合は、女性を1、男性を2、不明を9(実質、男性の 0 を 2 にする)として操作した後で同じように計算式を作れば全て3桁で揃います。
です。
10進数 というのは、10 の △乗(1乗, 2乗...)で桁が次へ次へと進んでいく世界ですね。2進数ならば 2 を掛け算する(2倍する)と次の桁へ進む世界です。
問58 : ダミー変数(0/1)に変換する(カテゴリ型→ダミー変数)

答案・解説はこちら
ちなみに one-hot-encoding でもダミー変数でも言葉の使い方の問題程度でやりたいことは同じです。
初めて聞く方もいらっしゃると思いますし、ワンホットってなんだっけ?1だけ暑くするエンコーディング(コード化する)こと?となっているかも知れませんので共通認識として図で説明したいと思います。
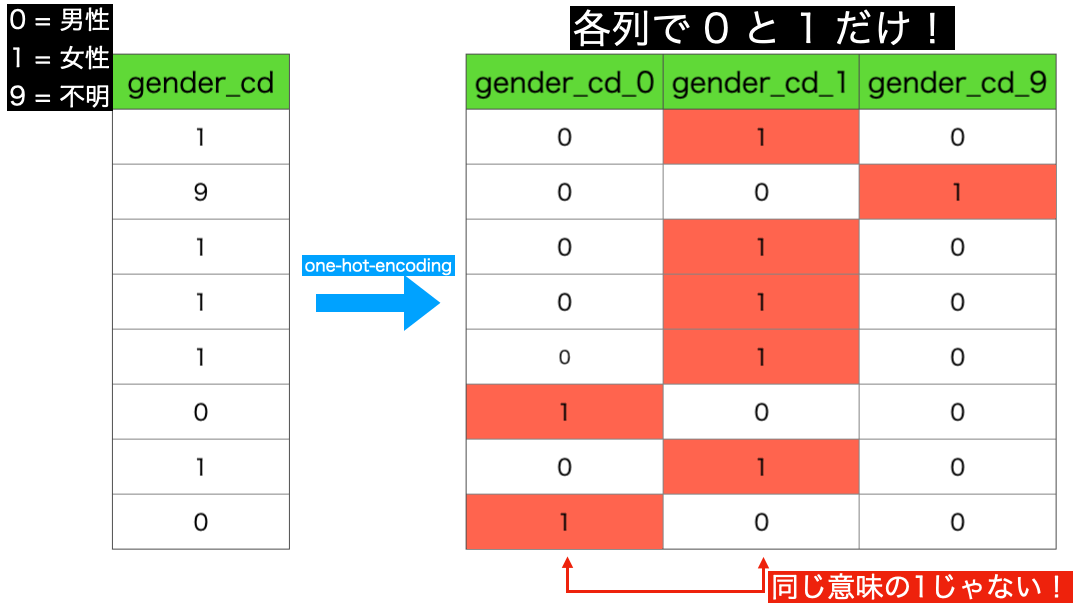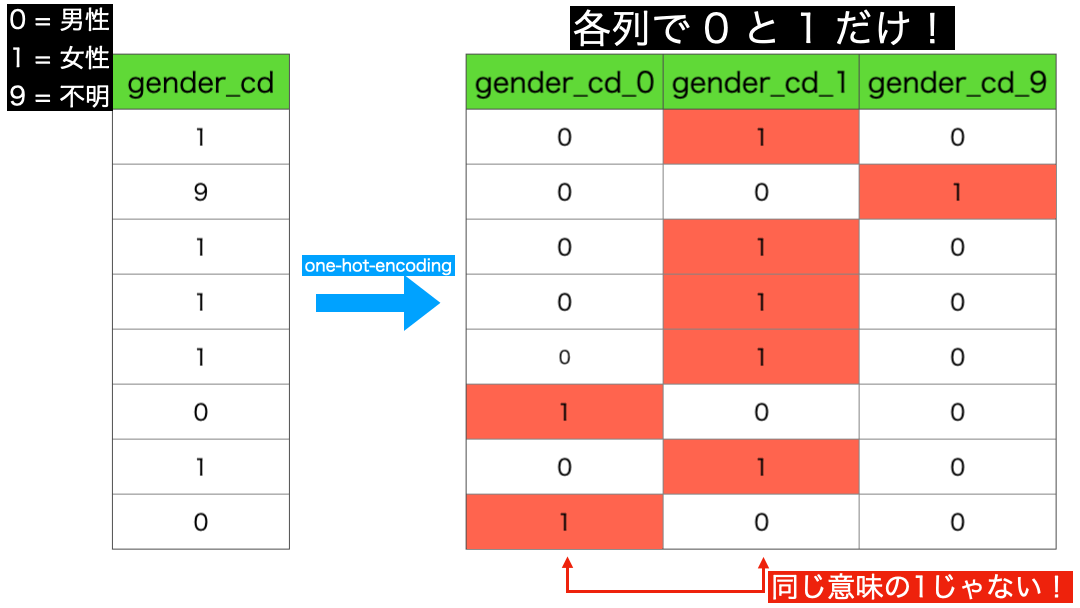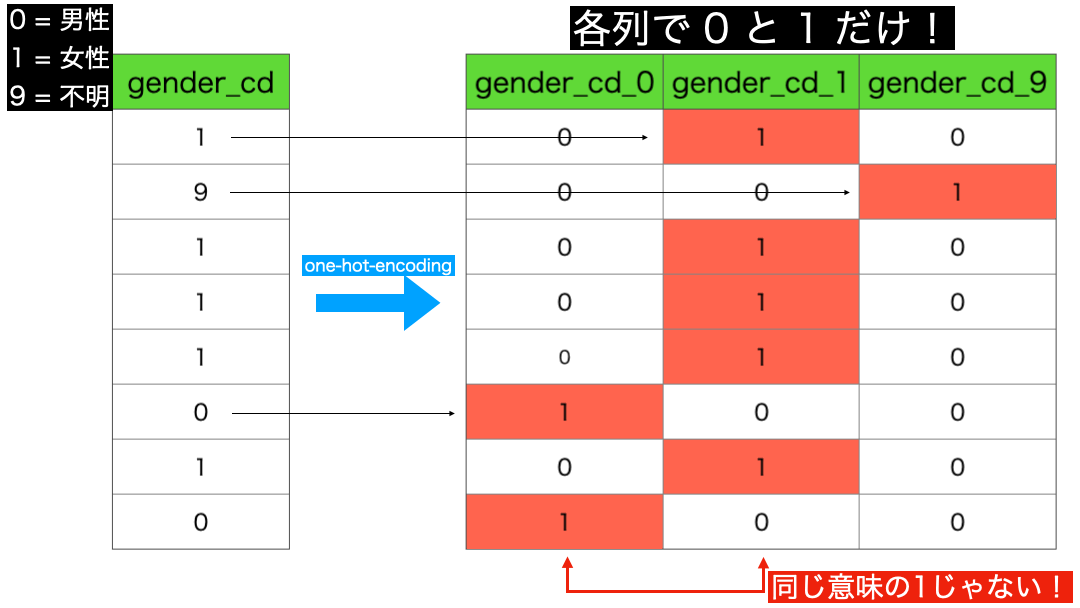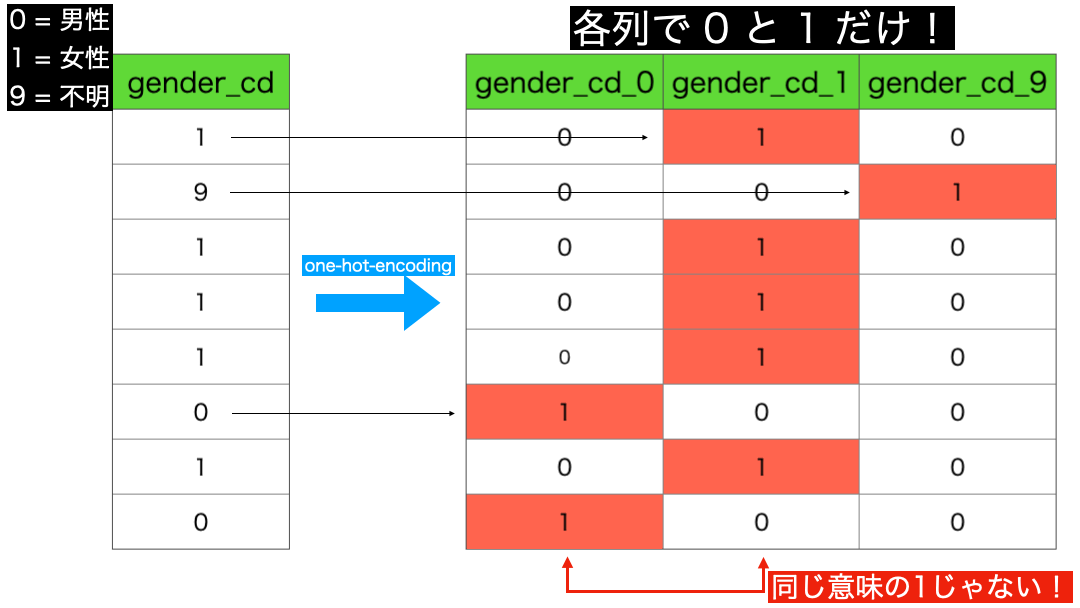
図で見ればわかるかと思いますが、gender_cd には 3 種類の値(男性と女性と不明)があるから、3列 にしてそれぞれの列で 0 と 1 だけの表現にすることが one-hot-encoding です。
つまり、それぞれの列で 1 の意味が異なっている ことがわかります。
one-hot...の方がニュアンスとしても個人的には好きです。名は体を表すということも魅力(ダミーよりかは)です。
これも(モデルや分野によっては)よく使う前処理ですので Exploratory で実装しましょう。
まず customer_id と gender_cd の 2列 にします。
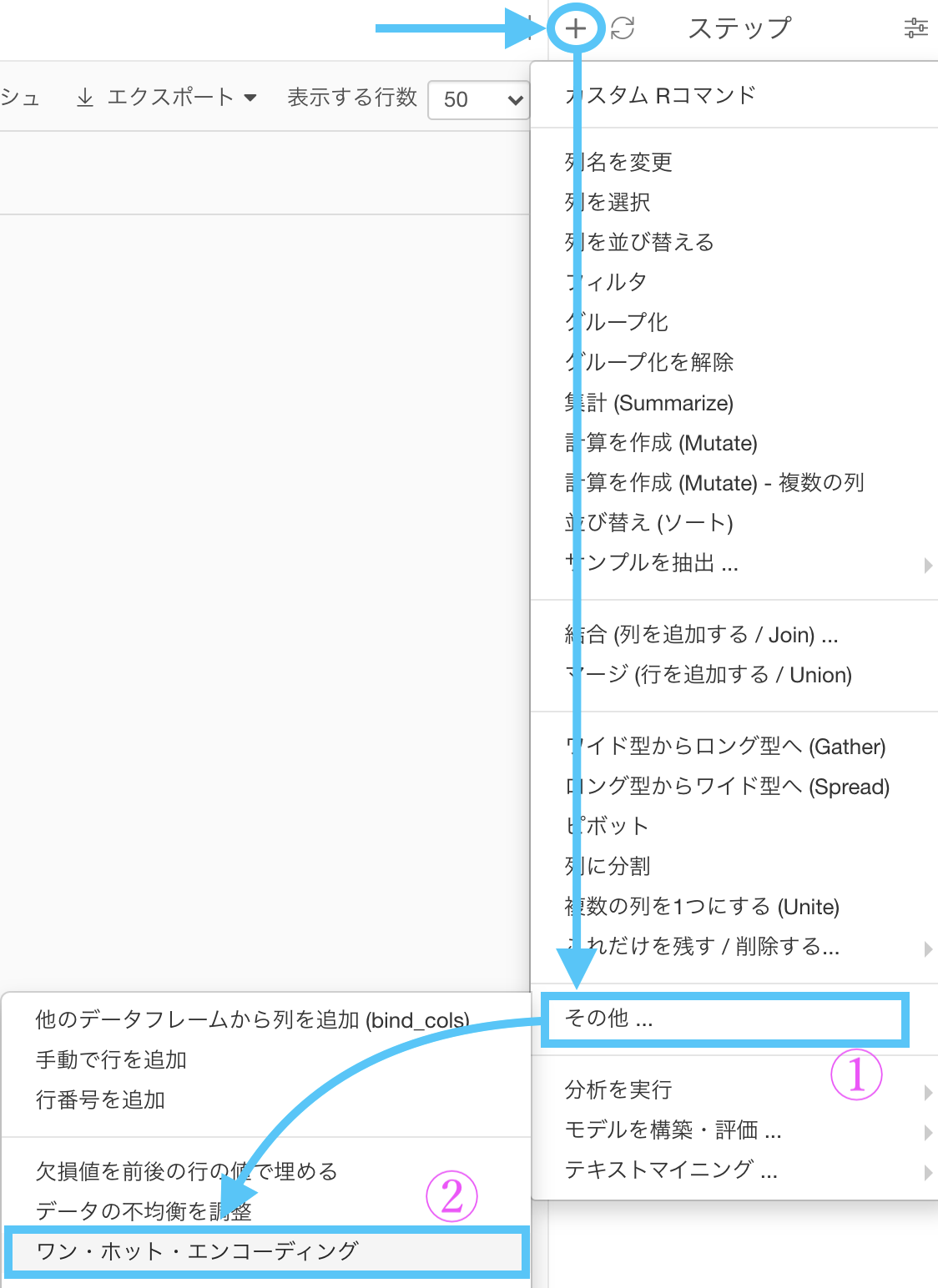
「新規ステップを追加 → その他... → ワン・ホット・エンコーディング」と選択しましょう。
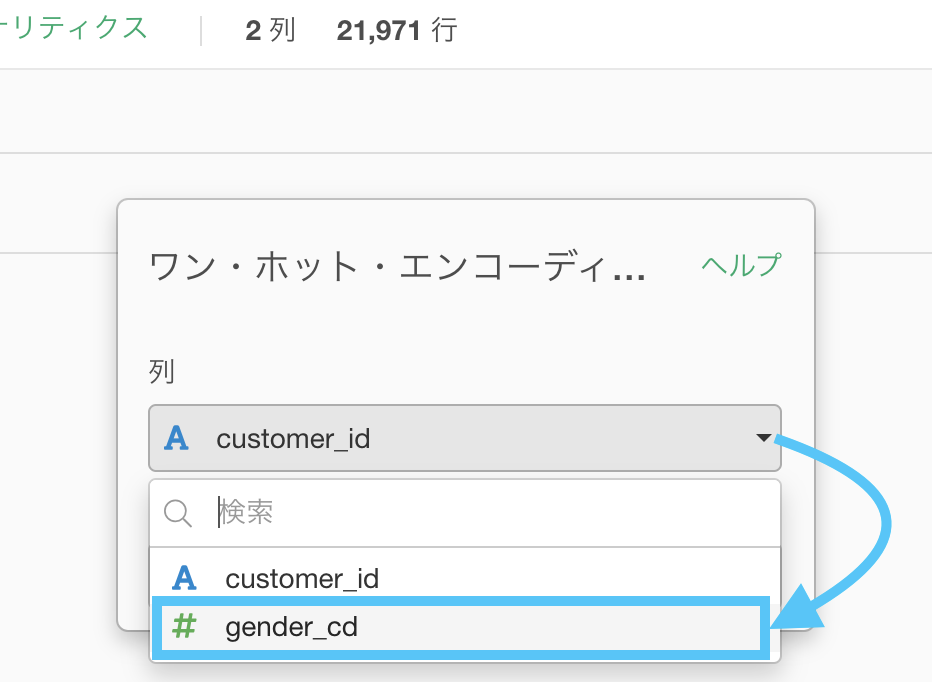
このような画面が出てきたと思いますので、gender_cd を選択して実行しましょう。
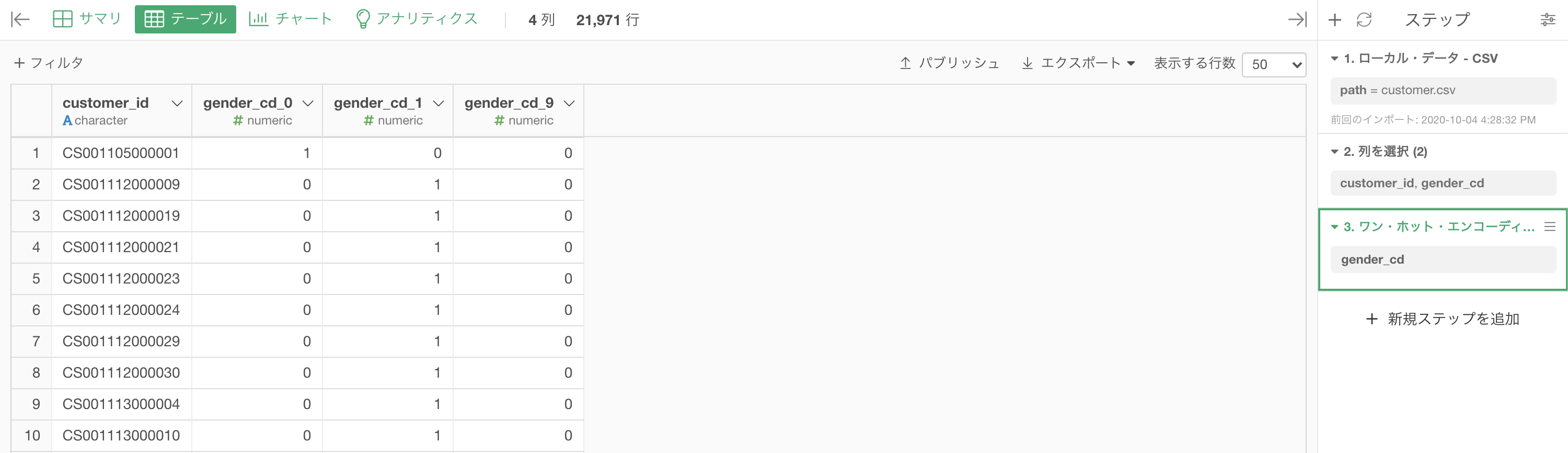
結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
pd.get_dummies(df_customer[['customer_id', 'gender_cd']], columns=['gender_cd']).head(10)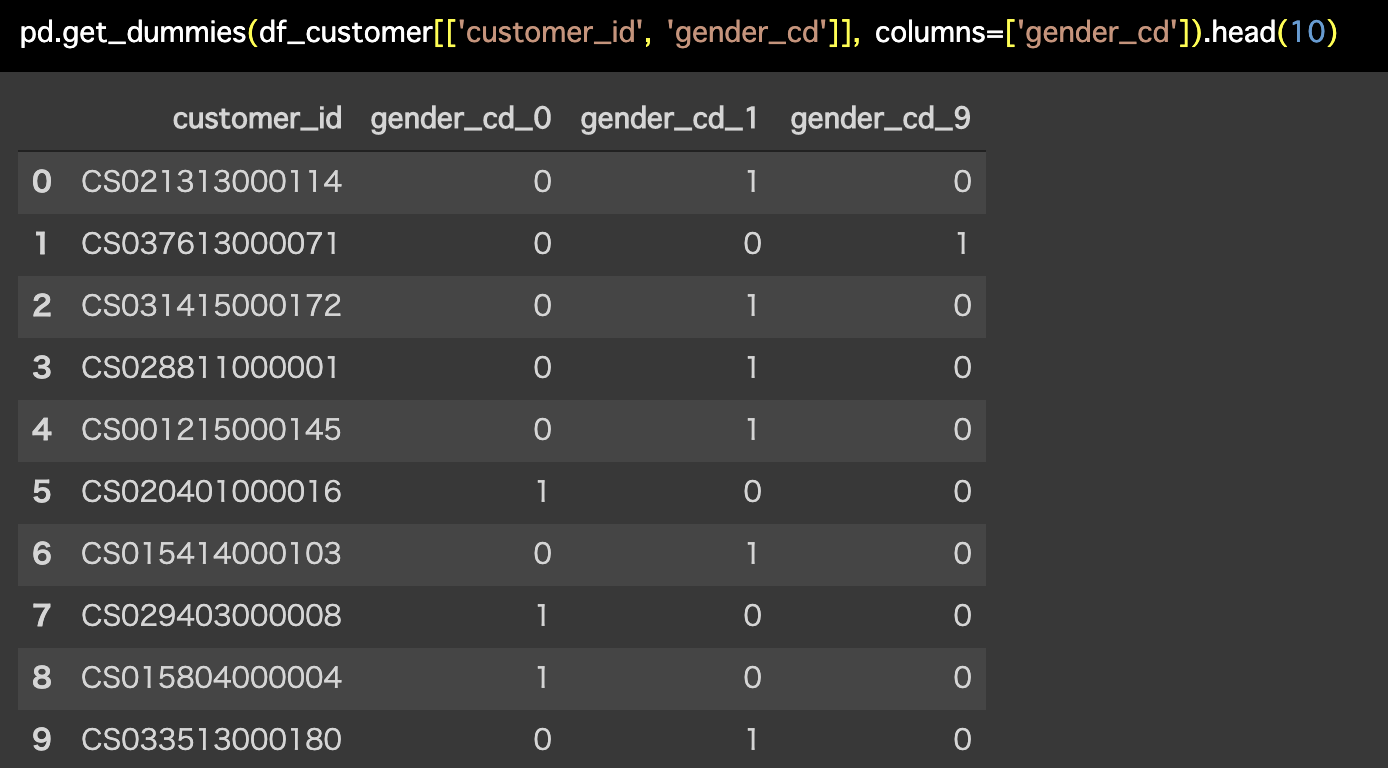
中身はどのように動いているのか?
one_hot という exploratory パッケージの関数を使っています。
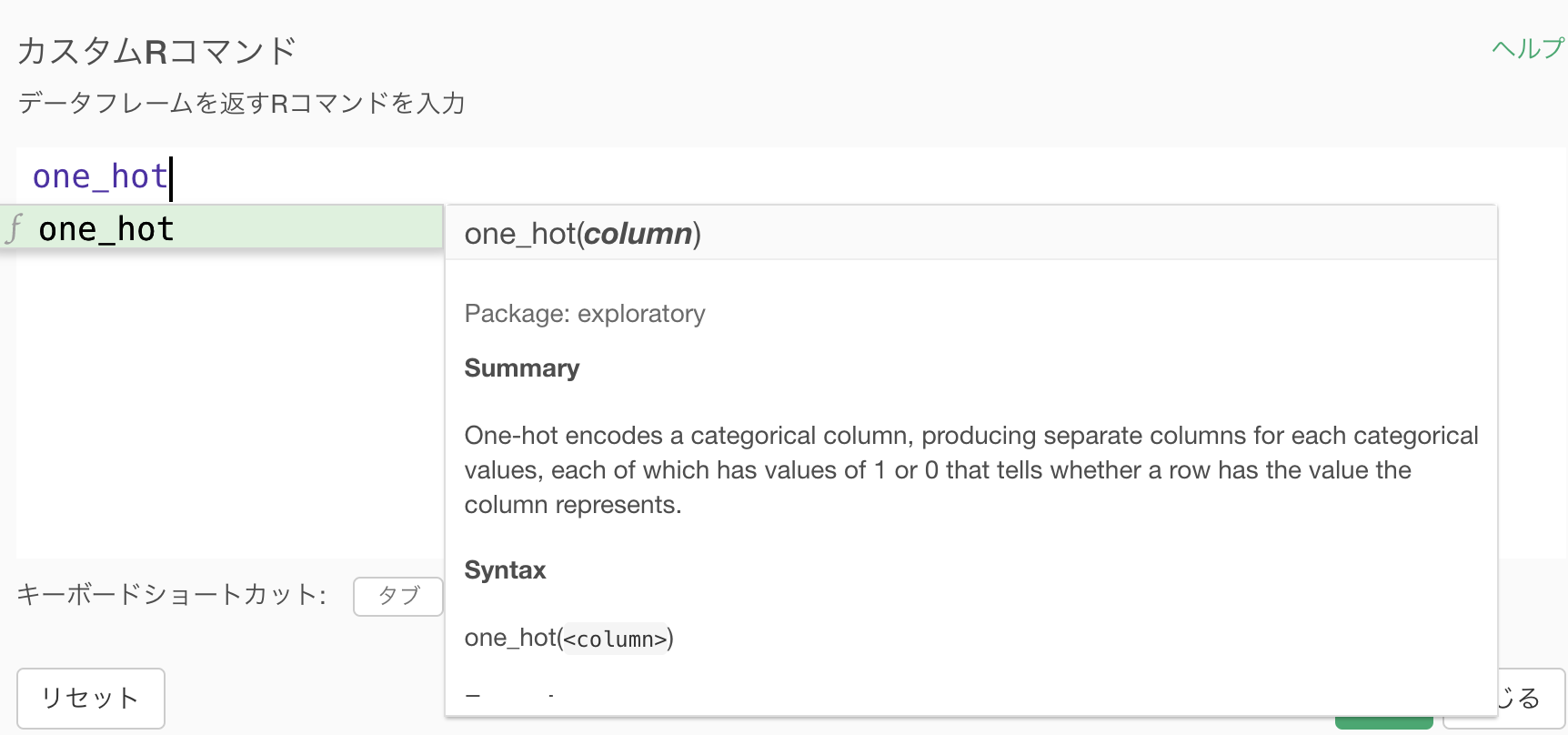
one_hot(gender_cd)をカスタムRコマンド(計算を作成 (Mutate) の方ではない)で打ち込むと今回と同じ結果が得られます。
ちなみに Exploratory が提供する exploratory という R のパッケージのなかに入っているのが one_hot です。R Studio をお使いの方は、このパッケージをインストールすることができません(つまり今の時点では R だと one_hot が使えません)のでご注意ください。
R で one_hot を使いたい方はこちら(興味のある興味のある方のみ)
あまりガチガチにコードを提示すると拒否反応を示してしまうかも知れないので折りたたみにしました。
画像は R Studio でやったものです。(今回ではあえて Exploratory を使わないでやることに価値があります)
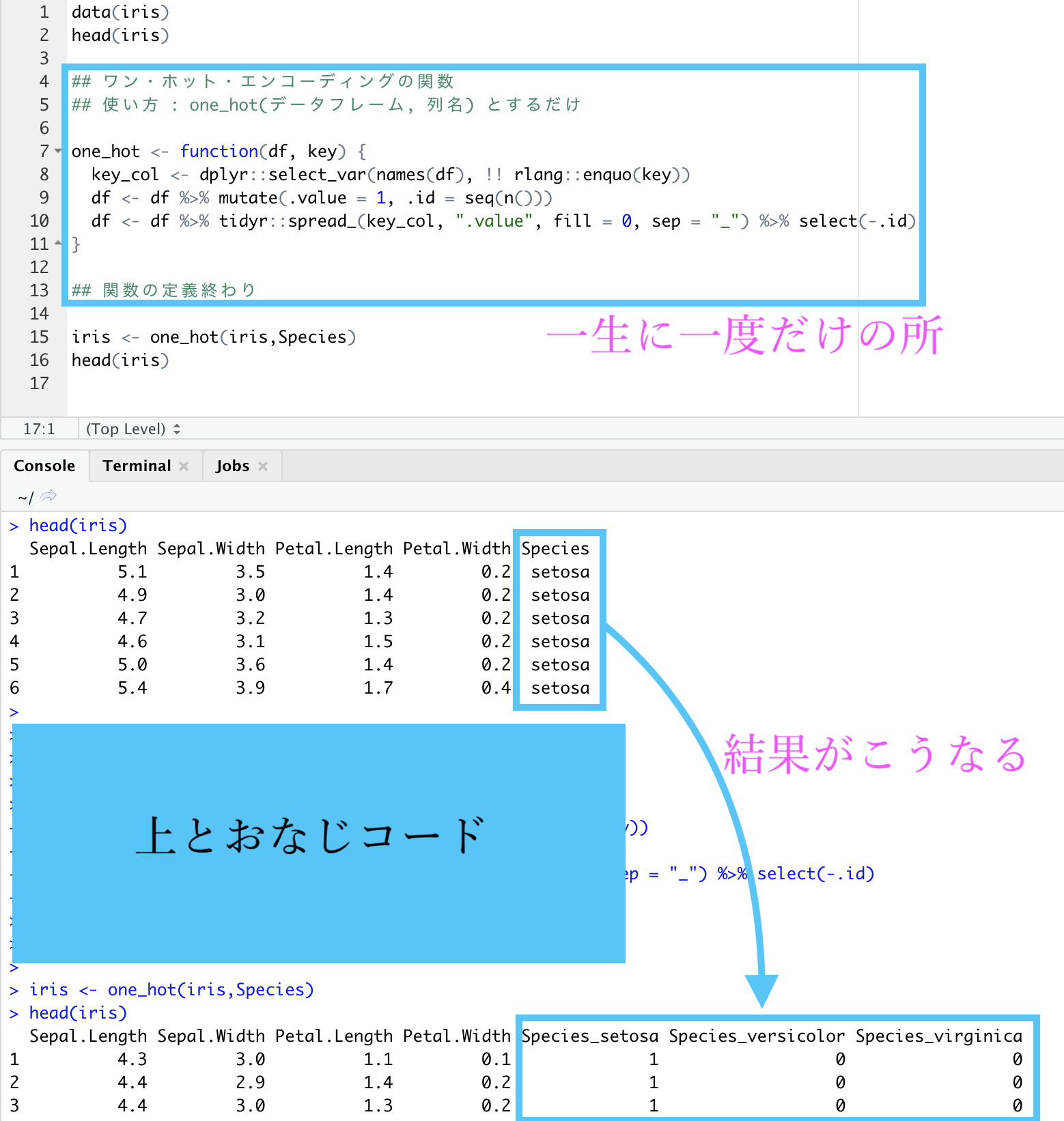
コードはこちらです
data(iris)
head(iris)
## ワン・ホット・エンコーディングの関数
## 使い方 : one_hot(データフレーム, 列名) とするだけ
one_hot <- function(df, key) {
key_col <- dplyr::select_var(names(df), !! rlang::enquo(key))
df <- df %>% mutate(.value = 1, .id = seq(n()))
df <- df %>% tidyr::spread_(key_col, ".value", fill = 0, sep = "_") %>% select(-.id)
}
## 関数の定義終わり
iris <- one_hot(iris,Species)
head(iris)実際に setosa だけでなく他の種(versicolor や virginica)も 1 になっていることを確かめておきました。
最初と最後と真ん中らへんの行を取ってきています。
| Species_setosa | Species_versicolor | Species_virginica |
|---|---|---|
| 1 | 0 | 0 |
| 1 | 0 | 0 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 1 |
| 0 | 0 | 1 |
参考資料はこちらです。
Exploratory のバージョンがかなり前のものになっていますのでご注意ください。
問59 : 平均0、分散1に変換する

答案・解説はこちら
ということをやっていきましょう。
まず問題を解くまえにやっておくべきことが 2つ あります。
1つ目は非会員顧客(customer_id が Z から始まるレシート)は取り除きたいのでフィルターします。
2つ目は集計です。これも今まで何度かやりました。
グループ化 : customer_id 値 : amount 計算 : 合計(sum)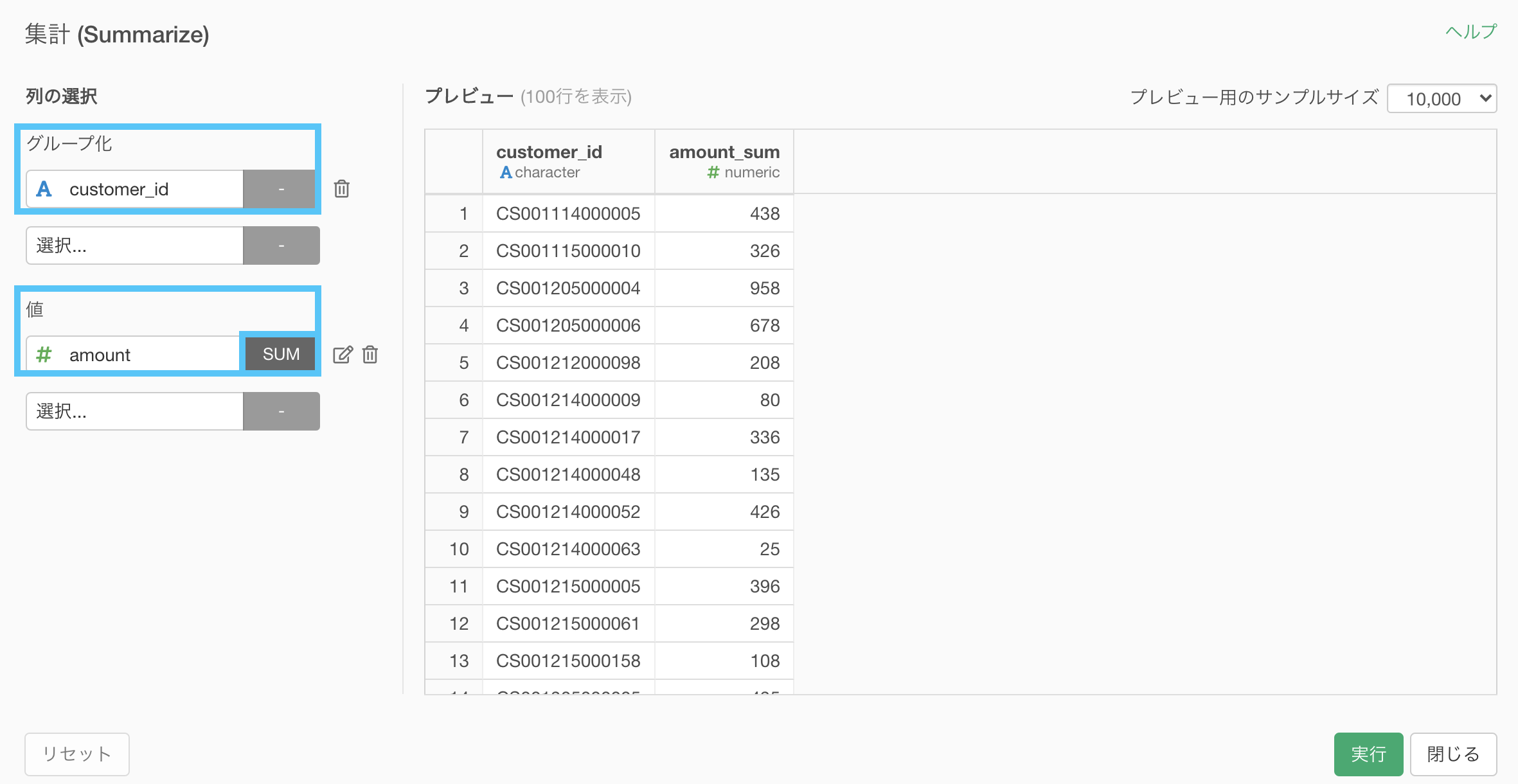
ここまでやったら以下のような結果になっていると思います。
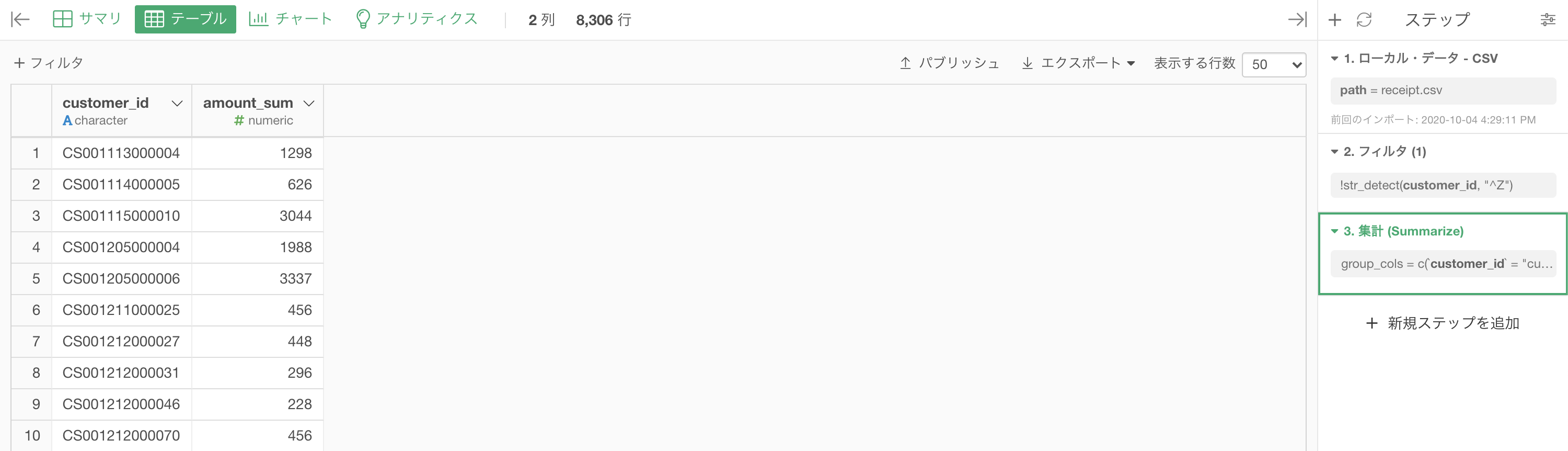
ここからが 問59 のスタートみたいなものです。
今回やることはというものです。
amount_sum を選択して「数値関数を使う → normalize」を選択します。
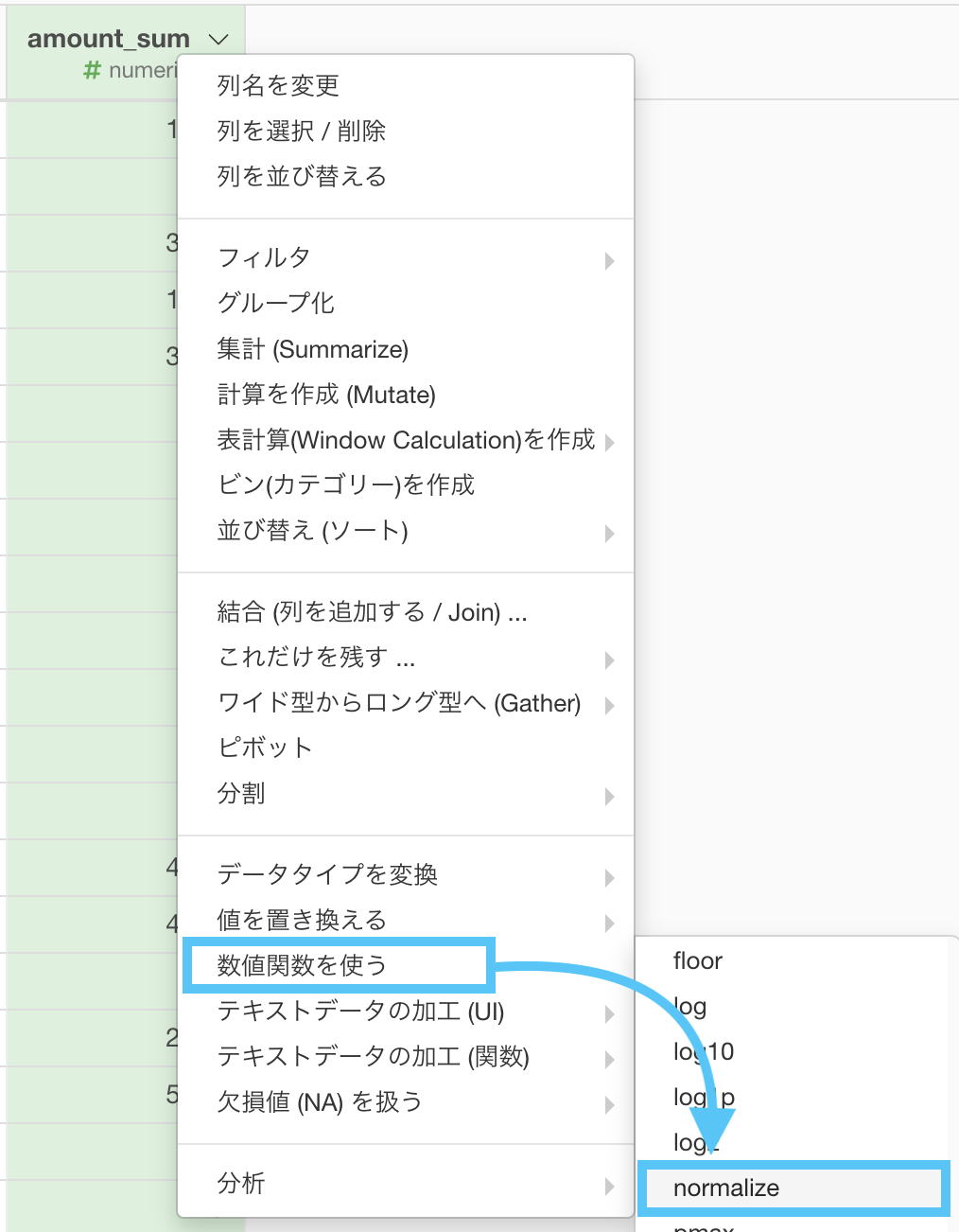
このような画面になったと思いますので、「新しく列を作成にチェック」しておきましょう。列名はわかりやすければなんでも良いです。
結果はこのようになります。解答と確認しましょう。
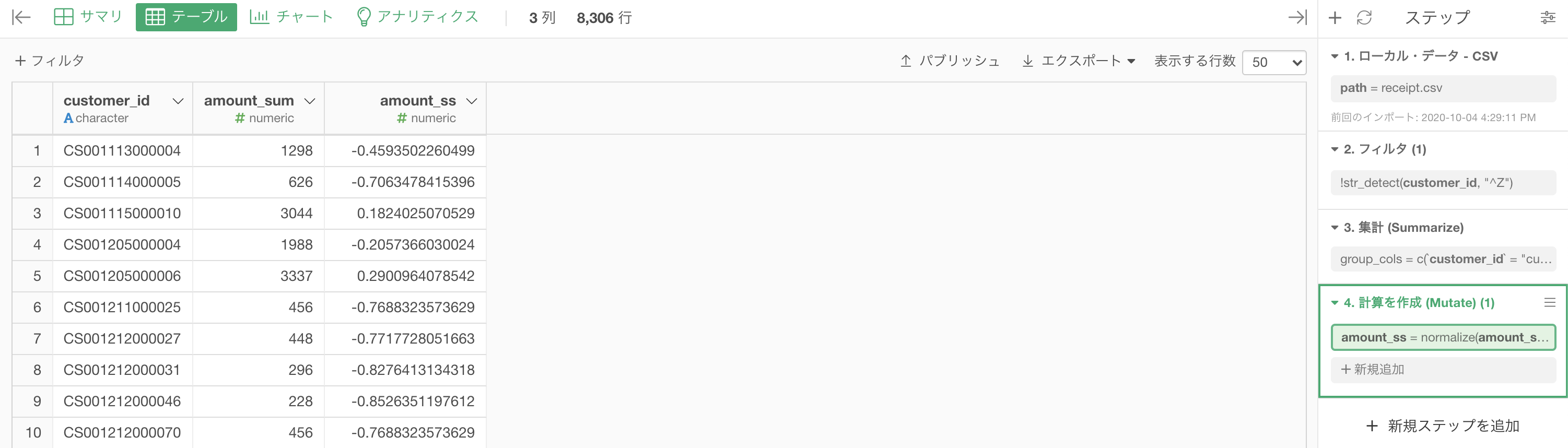
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1(sklearnのpreprocessing.scaleを利用するため、標本標準偏差で計算されている)
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \
groupby('customer_id').agg({'amount':'sum'}).reset_index()
df_sales_amount['amount_ss'] = preprocessing.scale(df_sales_amount['amount'])
df_sales_amount.head(10)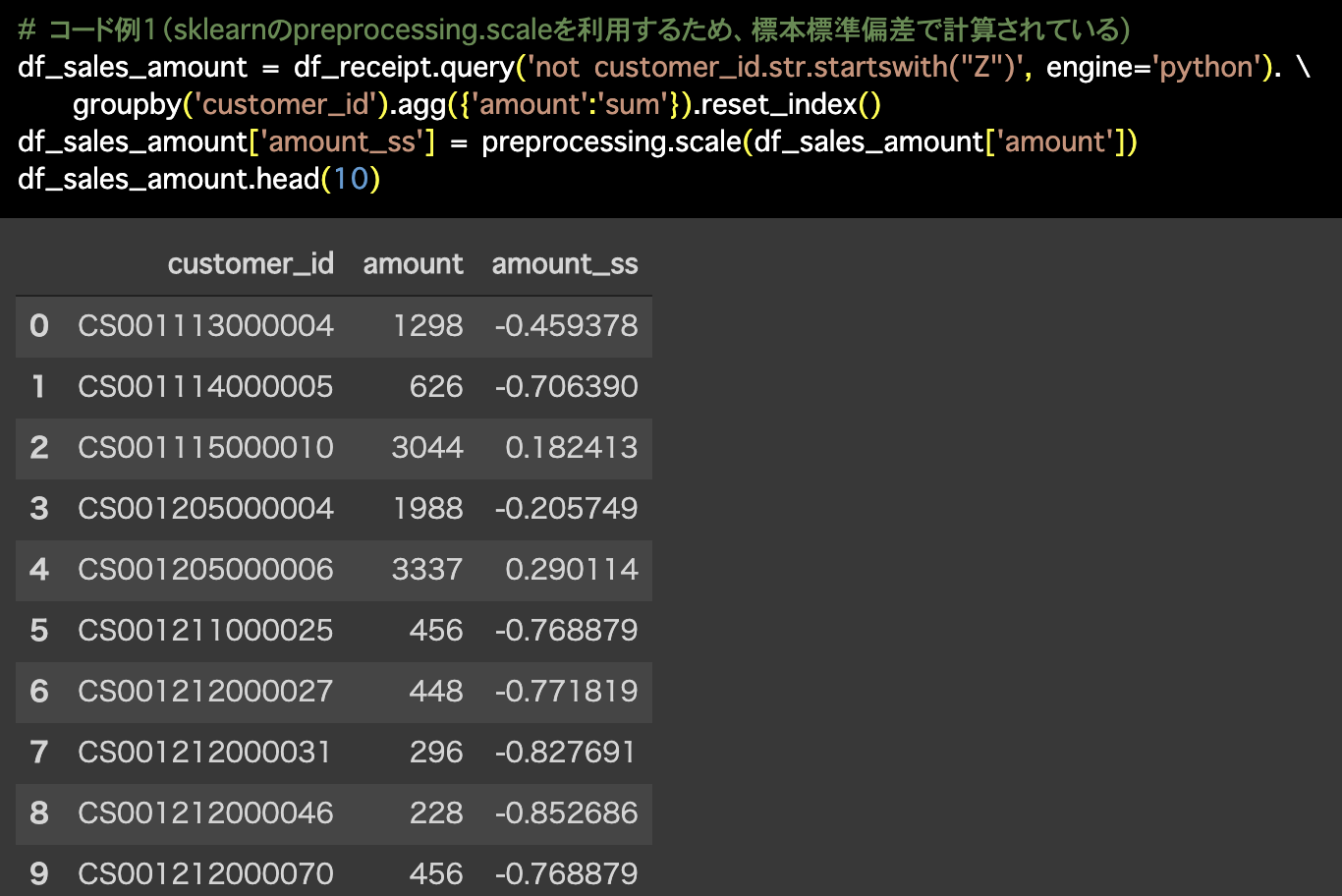
2つ目の解答コードはこのようになっています。
# コード例2(fitを行うことで、別のデータでも同じの平均・標準偏差で標準化を行える)
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \
groupby('customer_id').agg({'amount':'sum'}).reset_index()
scaler = preprocessing.StandardScaler()
scaler.fit(df_sales_amount[['amount']])
df_sales_amount['amount_ss'] = scaler.transform(df_sales_amount[['amount']])
df_sales_amount.head(10)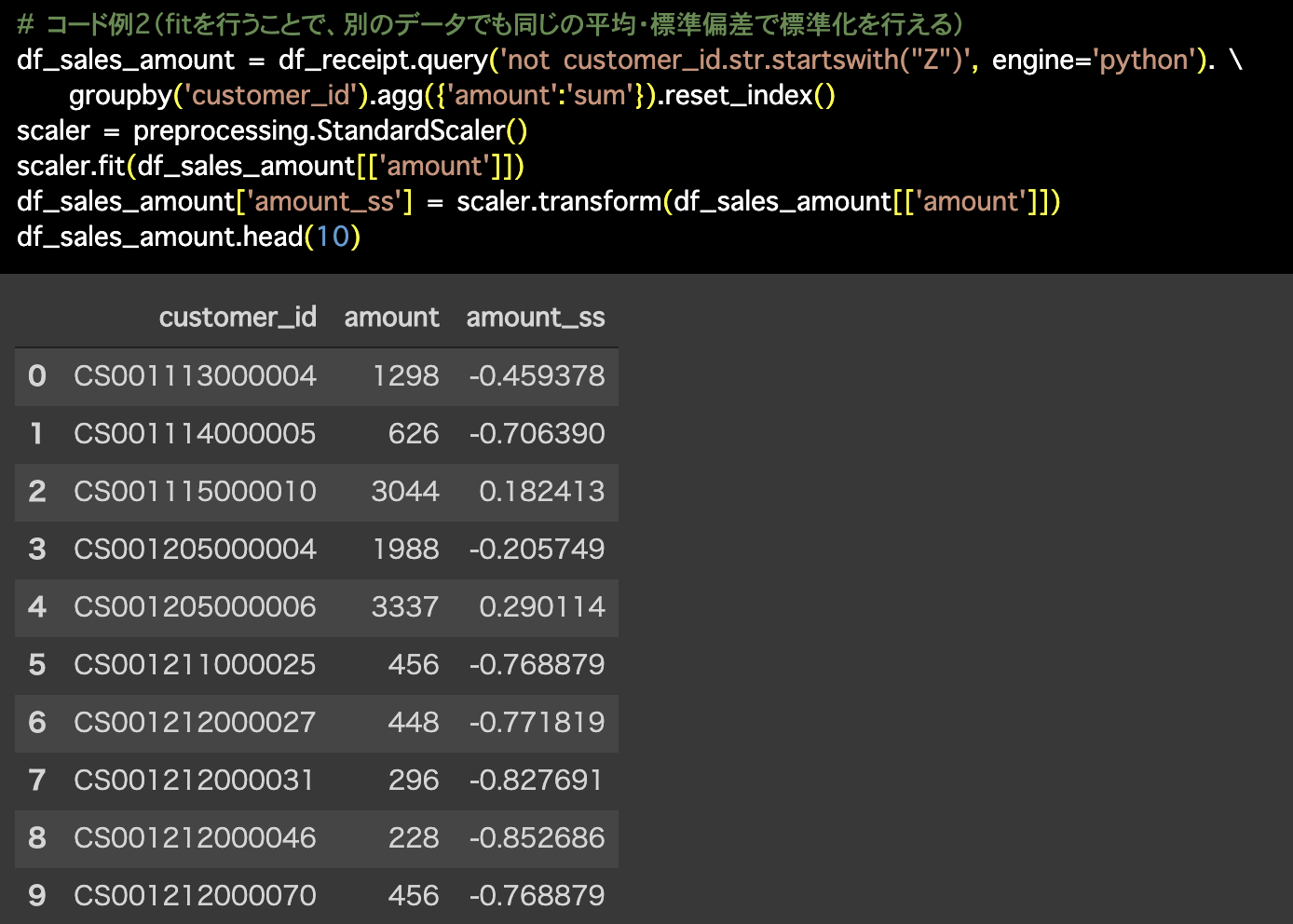
画像と数字が違う!と思った方は鋭いですが、その原因は以前にも(問30で)紹介しました。
分散には N(=行数)で割るか N-1 で割るかは、たまに悩みの種になります。
R言語では N で割った分散しかないですが、もう1つは自分で作る(分母分子を考えながら)しかないですのでこのようなことが起きています。
コマンド出るけど scale 関数が気になる方へ
実は normalize の他に scale という関数もR言語には用意されています。
これは 問60 まででやると少しわかるようになるのですが、要するに書き方を統一したい などのことがあります。
とりあえずあれこれ考えずに、scale を使ってみましょう。
こんな感じに使います。
scale(amount_sum,
center = mean(amount_sum), # center = TRUE でも良い
scale = sd(amount_sum) # scale = TRUE でも良い
) 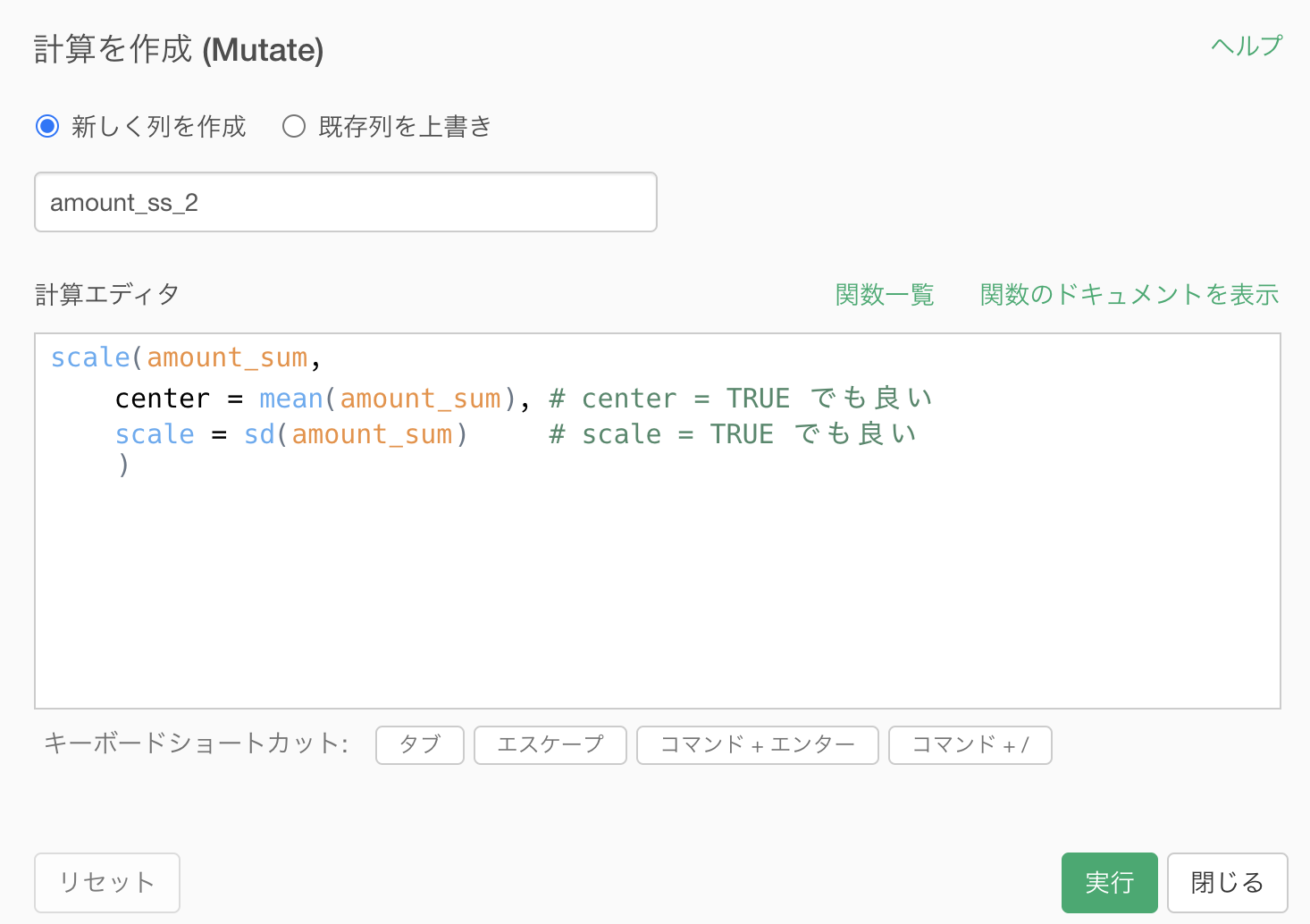
- center とは中心を意味します ので、何で引き算するか? を考えます。
- scale とは尺度を意味します ので、何で割り算するか? を考えます。
scale 関数のイメージとしてはこんな感じです。
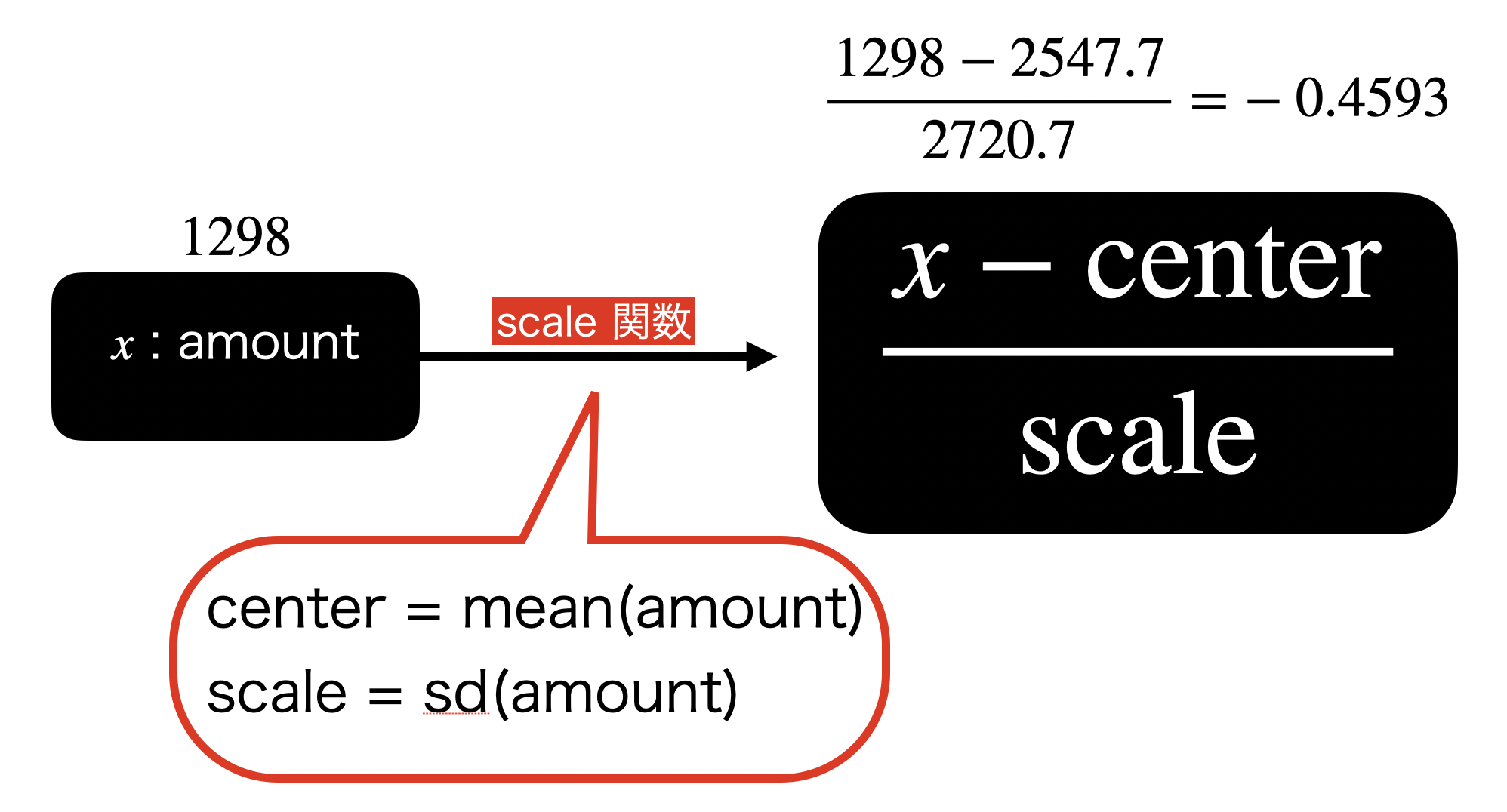
center と scale のところには計算式を入れても良い ので、実は全てこの書き方で N-1 で割った分散も R言語 で実現することが可能です。
他にも、問60 でも威力を発揮することができます。
問60 は答案で計算式を立てるので、normalizeのようにできませんがscale なら統一した書き方ができます。
Exploratory で scale 関数を使うときの注意点(データタイプの話)
大事な注意点を1つしておきます。
それは Exploratory で scale 関数を使うときは、データタイプが array になっているのでサポートされていない ことです。
この場合はヒストグラムすらも表示されません。
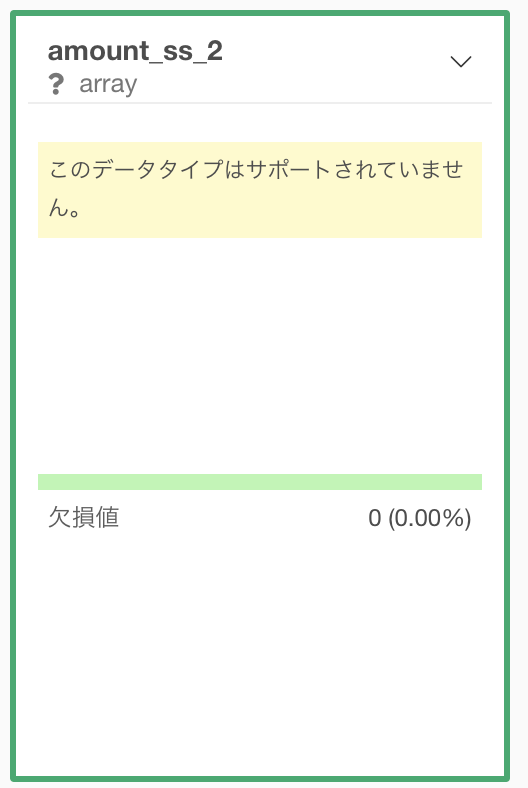
この場合は次のようにコマンドを改良しましょう。
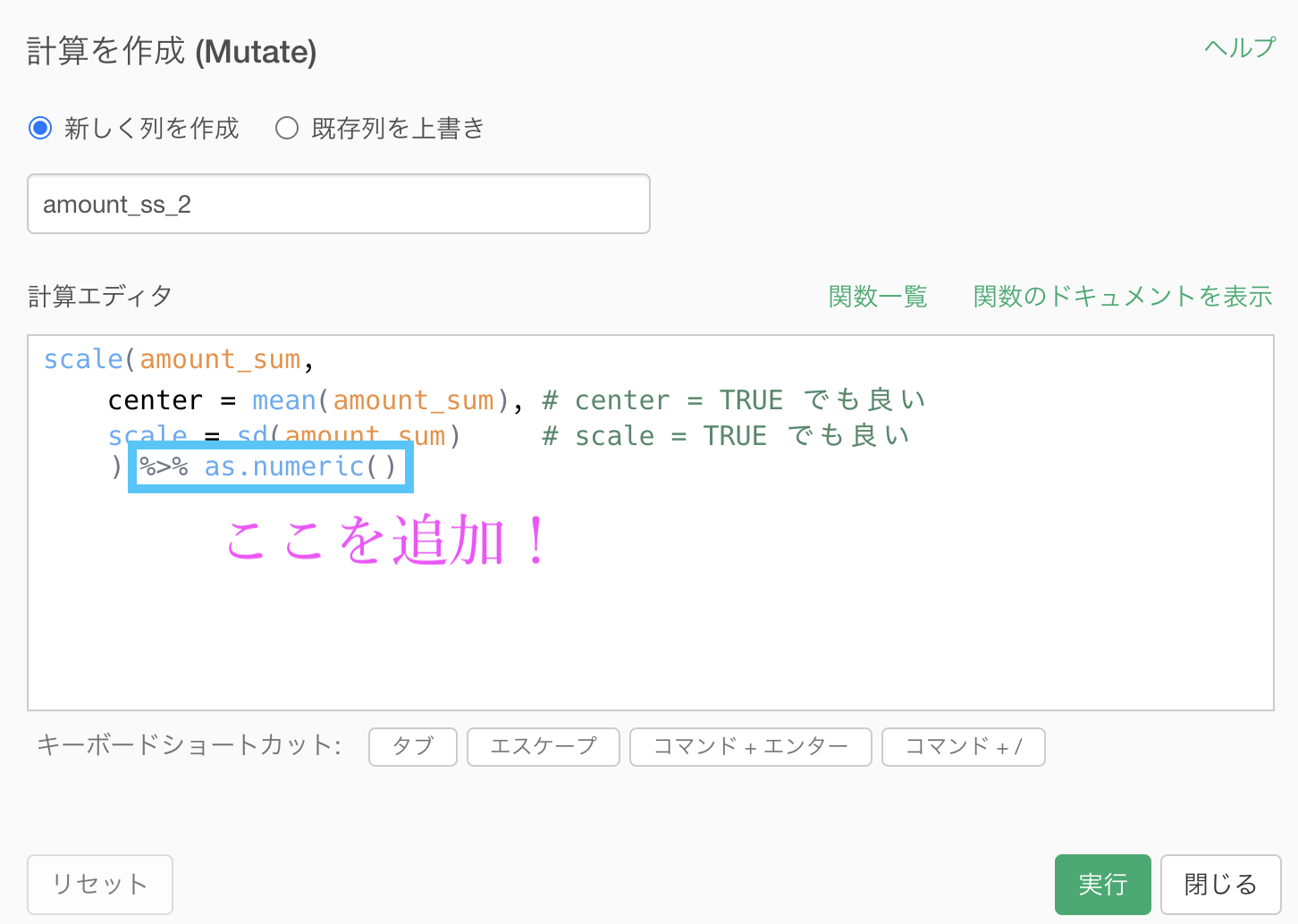
scale(...) %>% as.numeric()コマンドの解釈は「scale した後に numeric(数値)型にする」という具合です。
このようにすることでヒストグラムもきちんと描かれていますし、平均 0 、分散 1 になっていることがわかります。
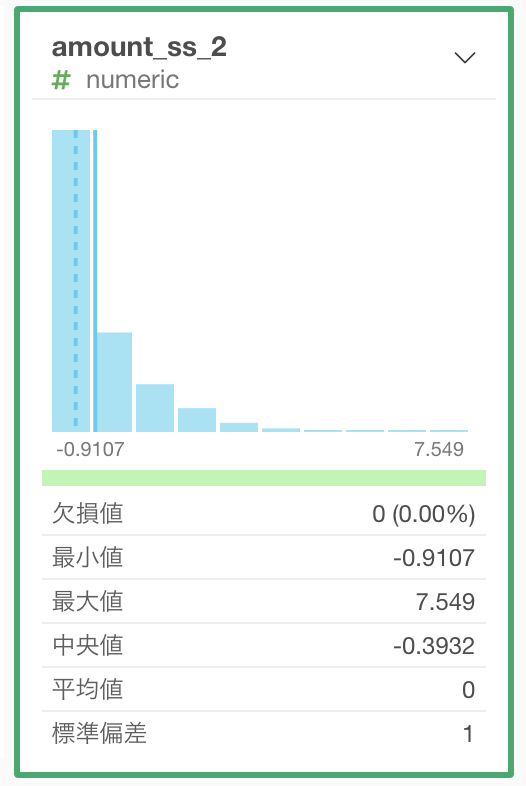
問60 では
- 答案 : 計算式を使った書き方 → 比較的簡単
- 追加の解説 : scale を使った書き方 → イメージとセットで考える
に注目しながら、やがては scale を使った書き方で、書き方を統一していけるようになると良いかと思います。
問60 : 最小値0、最大値1に変換する

答案・解説はこちら
というものです。
そもそもなんじゃそれっていうのはだんだん分かってきます。
問59 に引き続き、ここからスタートさせます。
問59 の結果から最後のステップを取り除いた状態(= 集計が終わったあと)になります。
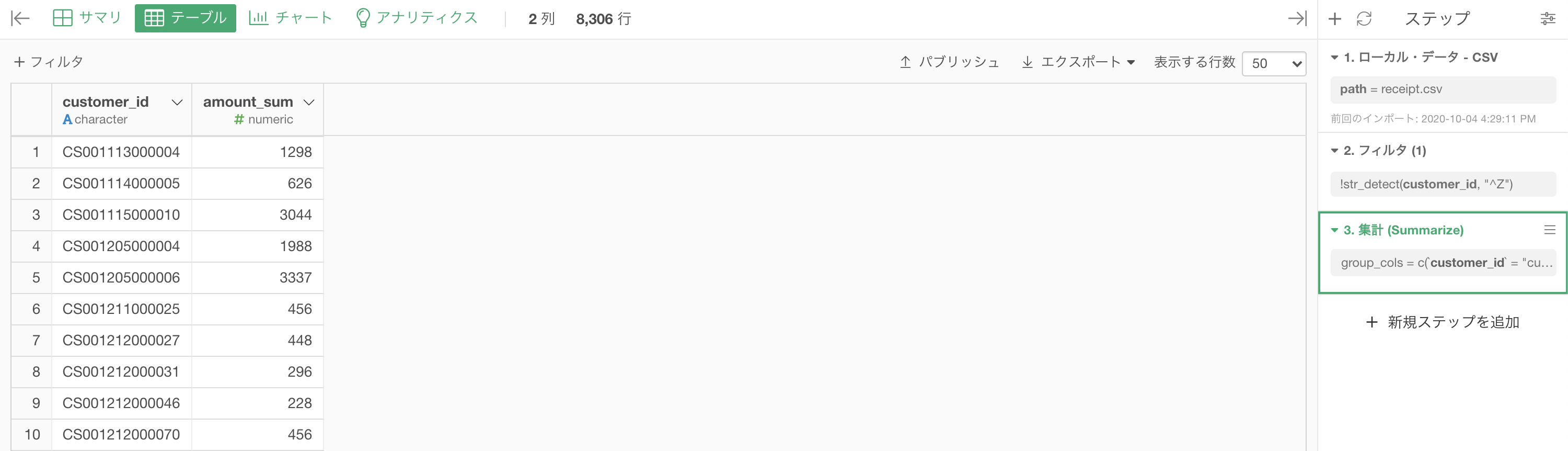
このあとは計算を作成 (Mutate) をして、このように書きます。
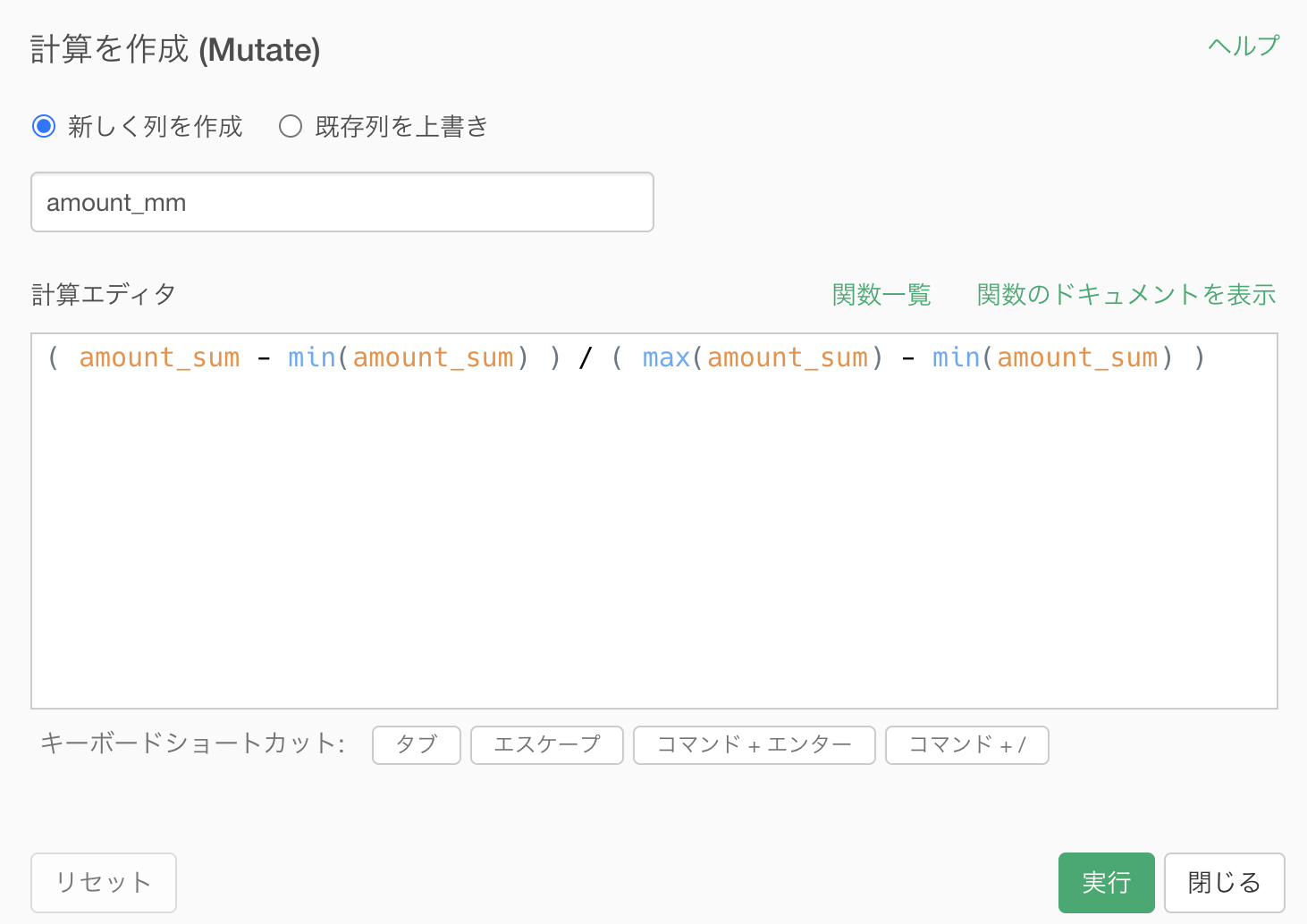 コードはこのようになっています。エラーになったらコピペなどして使ってください。
コードはこのようになっています。エラーになったらコピペなどして使ってください。
(amount_sum - min(amount_sum)) / (max(amount_sum) - min(amount_sum))ちなみに実行している計算式はこれです。 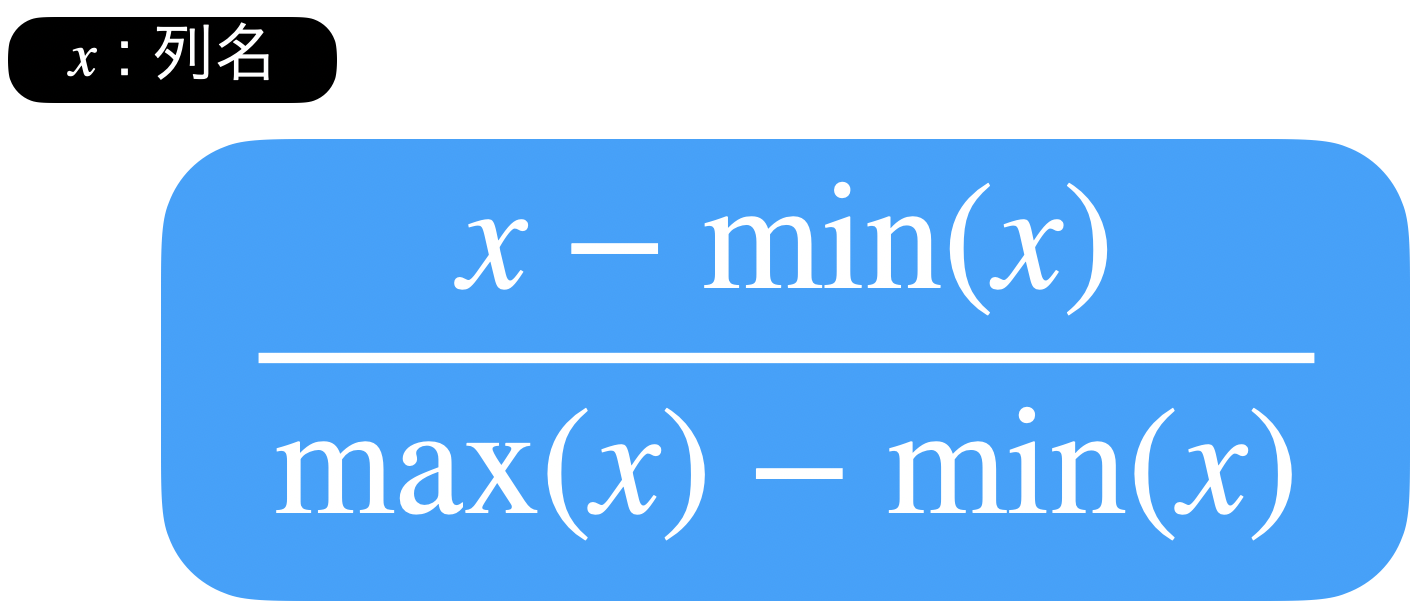
結果はこのようになります。
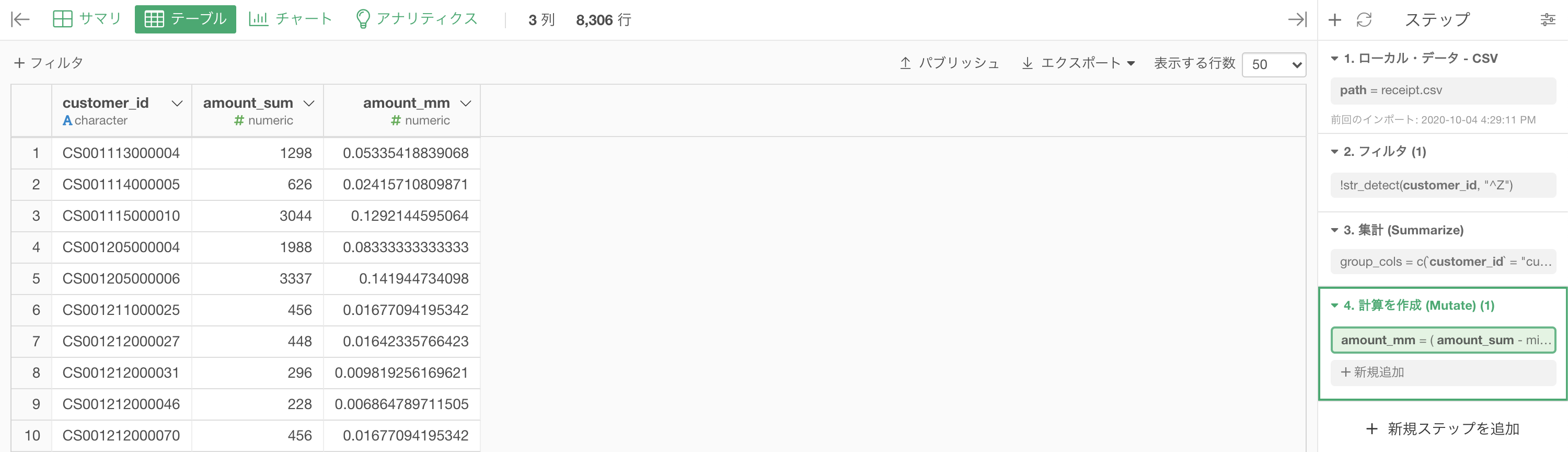
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \
groupby('customer_id').agg({'amount':'sum'}).reset_index()
df_sales_amount['amount_mm'] = preprocessing.minmax_scale(df_sales_amount['amount'])
df_sales_amount.head(10)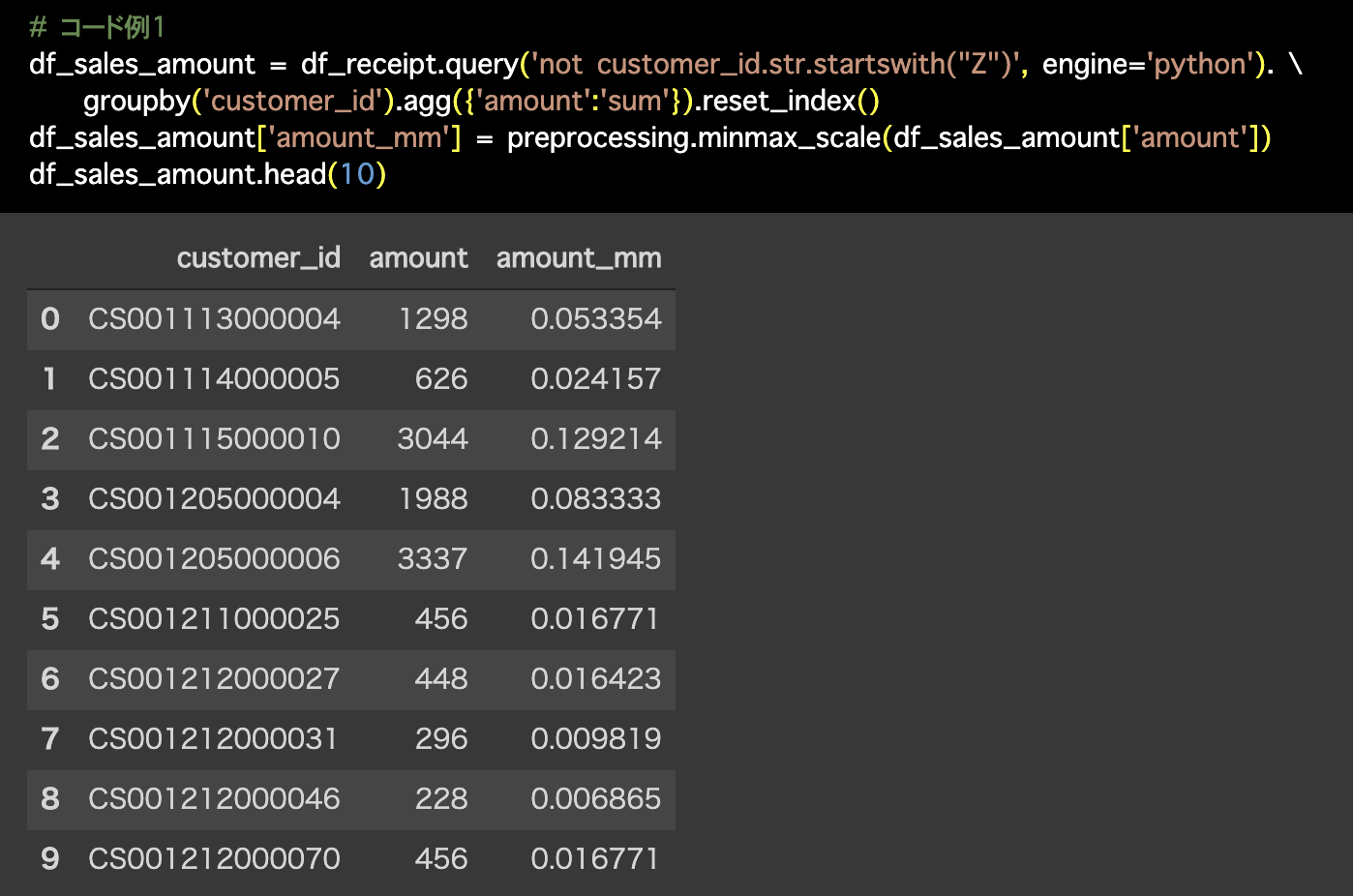
2つ目の解答コードはこのようになっています。
# コード例2(fitを行うことで、別のデータでも同じの平均・標準偏差で標準化を行える)
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \
groupby('customer_id').agg({'amount':'sum'}).reset_index()
scaler = preprocessing.MinMaxScaler()
scaler.fit(df_sales_amount[['amount']])
df_sales_amount['amount_mm'] = scaler.transform(df_sales_amount[['amount']])
df_sales_amount.head(10)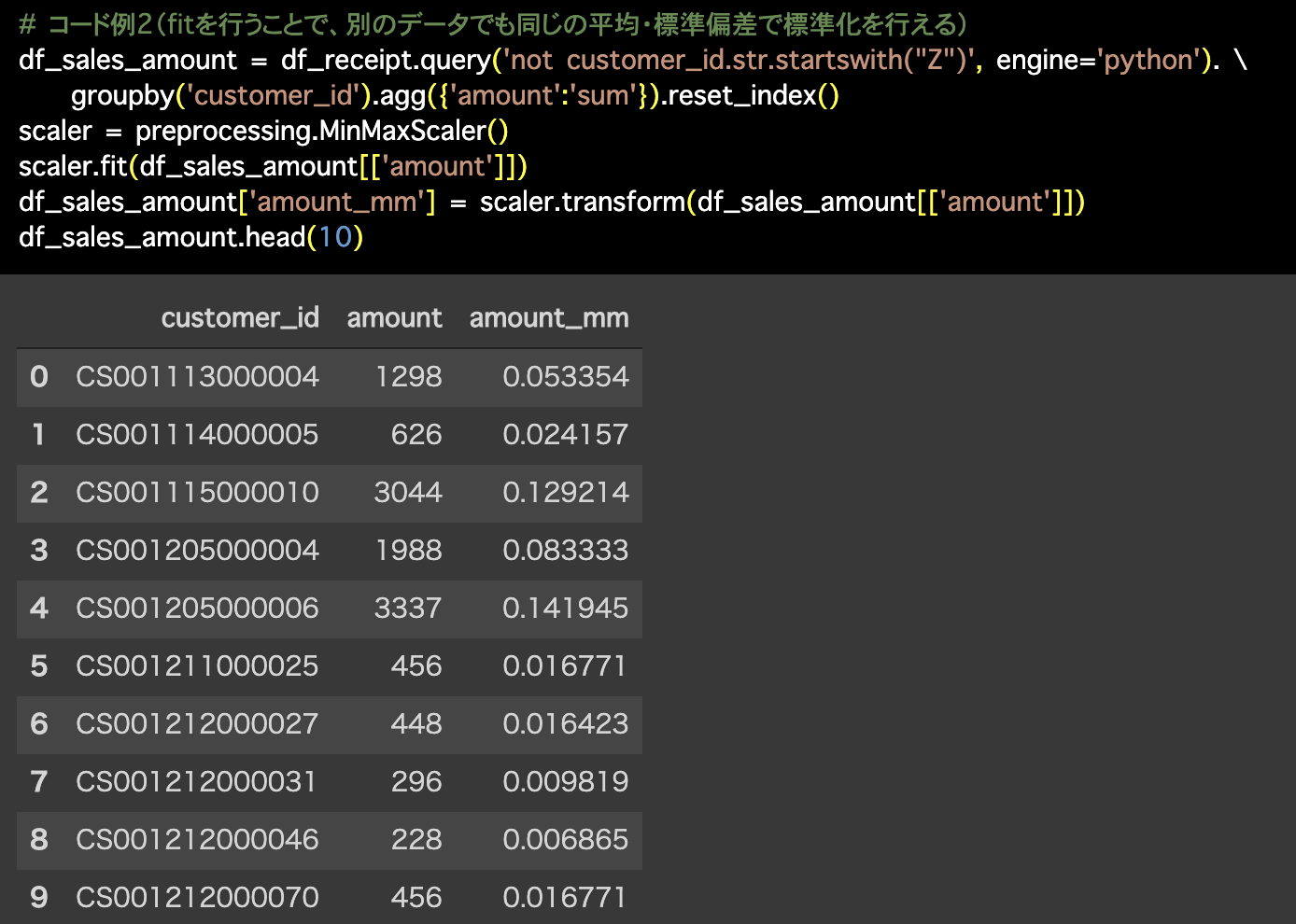
標準化 vs Min-Maxスケーリング
まず最初に言っておきますが、多くの分野で標準化が用いられます。
しかし、使い分けができなければ「突然 Min-Maxスケーリングなんて言われても...!」となることでしょう。
体感的な使い分けとしては次のような感じです。ざっくりしていて申し訳ないです。
- 標準化 : Min-Maxスケーリングじゃないとき → 料金、数量、身長、体重など
- Min-Max : 数値の取り得る範囲が予めわかっているもの → 画像データなど
数値の範囲が予めわかっているというのは結構珍しいことです。
例えば画像データは各ピクセルで 0〜255 までしか取れません。
もちろん、絶対に Min-Max じゃなきゃダメなんだ!ということではありません。
でも例えば家の価格などで考えたときに、最高級マンションはいくらでも高くなりますし、マイホームやホームレスの場合は 0円(対象外かもしれないけど)です。
ということは、外れ値や予想もしなかった大きな値のデータがある場合に Min-Max スケーリングを使うととんでもないことになります。
具体的に最高級マンション(=最大値)のところは 1 で、あとは全部 0 にちかい値 になります。
今回のデータでもそのことと同じようなことが実現できます。
非会員顧客のフィルターをなかったことにして、amount_mm(Min-Maxスケーリングした amount_sum)をヒストグラムにするとこのようになります。
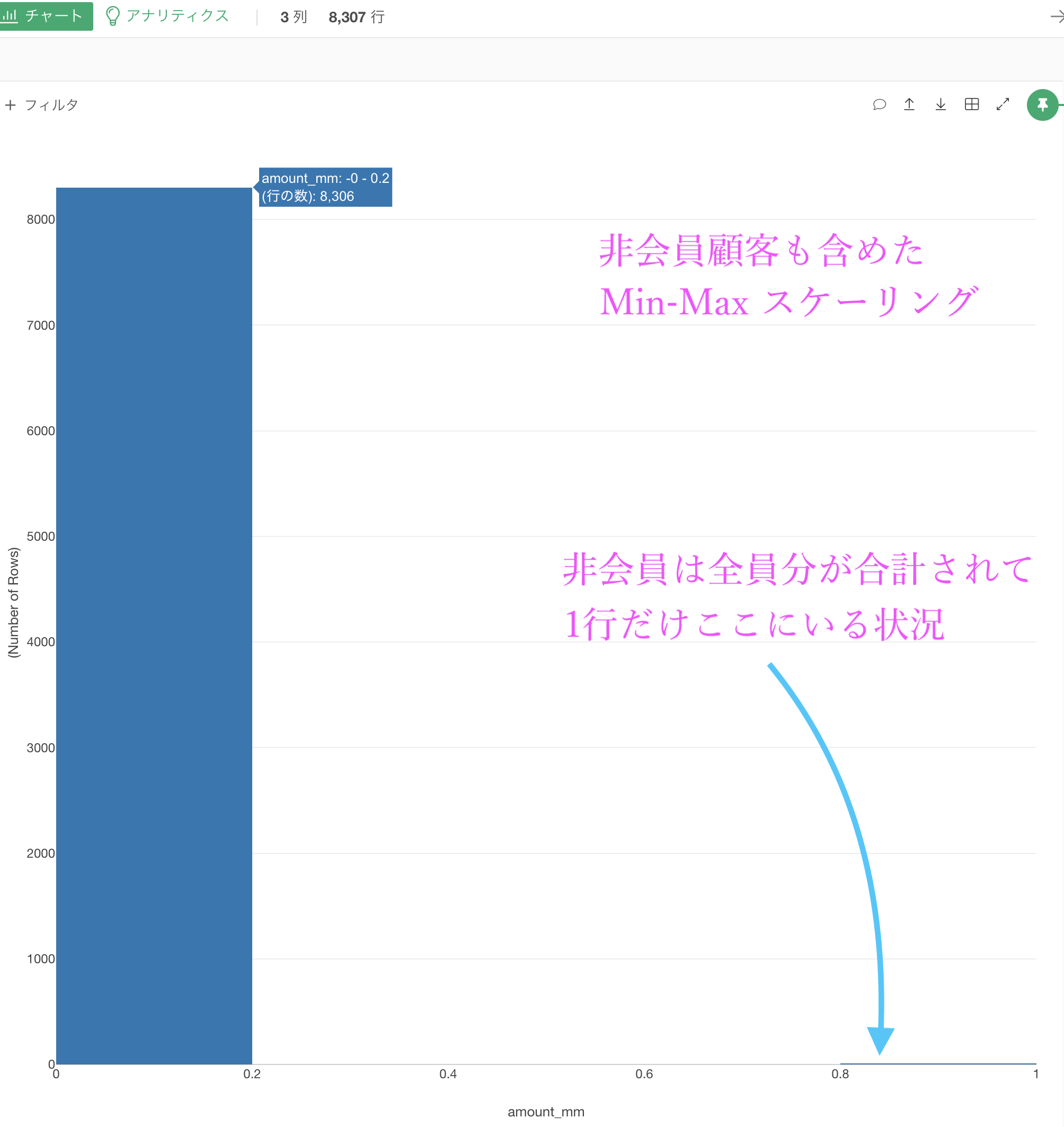
これならまだ標準化した方が良いかもしれません(それでも差が激しいので上手くいきませんが、Min-Maxスケーリングのときよりはそれぞれの値が離れます)。
同じようなグラフになるので見せませんが(汗)
scale を使った書き方はこちら
まず 問59 で述べたように、scale 関数を使った書き方を提示しておきます。
計算を作成(Mutate) した後の中身の式はこのようになります。
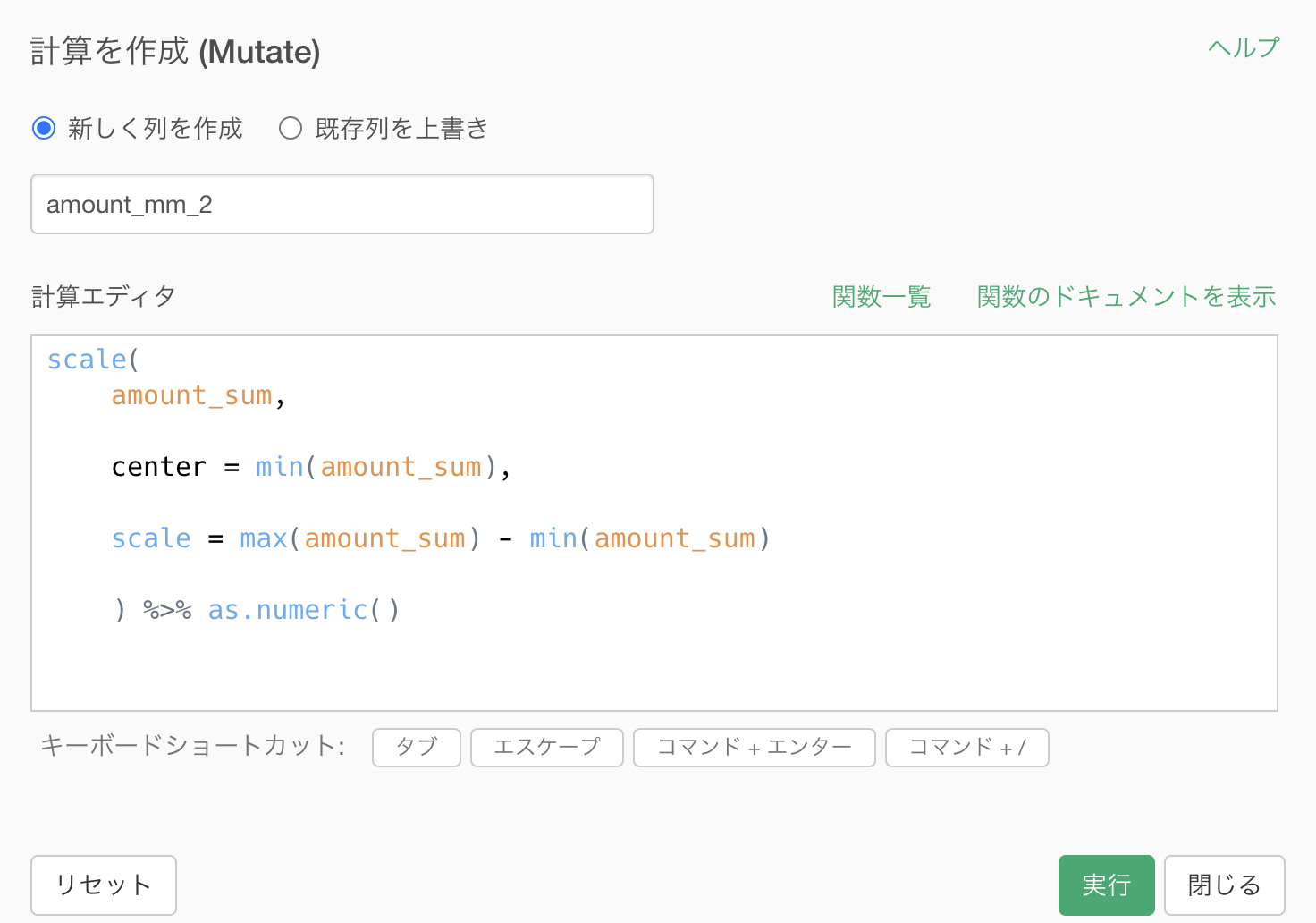
scale(
amount_sum,
center = min(amount_sum),
scale = max(amount_sum) - min(amount_sum)
) %>% as.numeric() scale のイメージ図をもう一度確認した方が良いので、改めて今回の答案とセットで載せておきます。
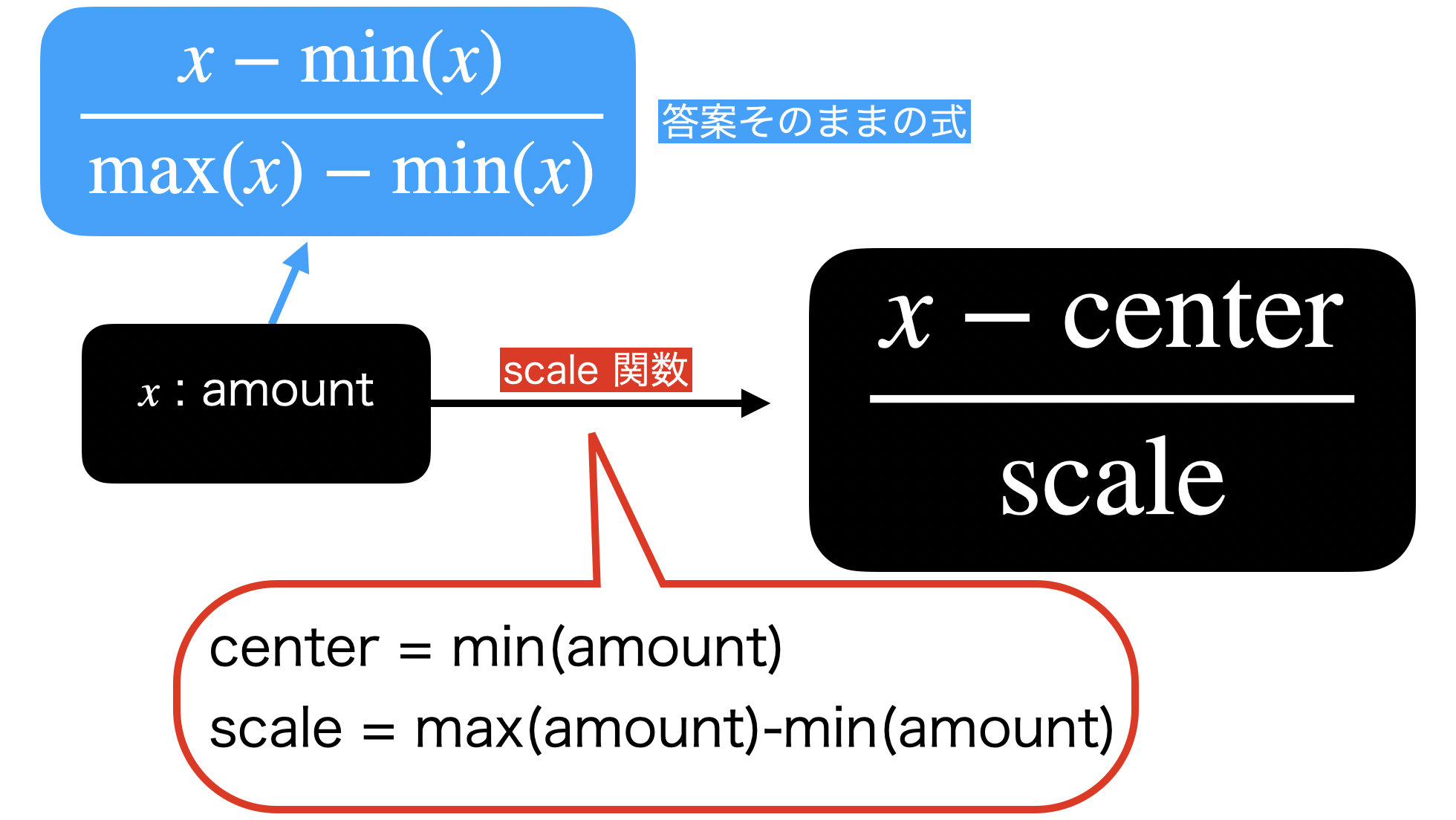
これでコマンドとイメージ(数式など)が少しでも対応つくと良いかなぁと思いっています。
とにかく scale 関数は、center と scale の位置(分子と分母の位置)に何を書くか?を決めるだけでなんでも機能 します。
平均 0、分散 1 のときは normalize 関数、最小値 0、最大値 1 のときは計算式を立てる...といったことに振り回されなくて済むことが魅力的 です。
問59 と比べても、書き方が統一しているところがメリット です。
一方、わかりやすさとしては scale 関数よりも答案の方だと思っています。
なぜなら、単純にコマンド量が多いから、他の人がパッと見ても読みにくいから です。
変換することの意味
ここで素朴な疑問です。
質問の意図・背景としては「前処理で求められたから」とか「その方がモデルが上手く動くから」という受動的な姿勢を対象にしてはいません。
そのようなモヤモヤを解決するためにを必死に考えてみましょう。
それが、どうしてスケーリングしなくてはならないか?の答えに直結するからです。
解決した・先を見たい方はこちら
例えば次のようなことを考えましょう。
・A社の価値(株価など)は、日本円にして 100 万円
・B社の価値(株価など)は、ドルにして 1 万ドルとします。
このときに、A社 と B社 を比較したいなぁと思って、単純に引き算するととんでもないことが起きます。
データの中に入れたときは気にすることができなかったかもしれませんが、単位(円なのかドルなのか)を気にしていないからです。
つまり引き算してみると
A社 - B社は
99万...円?ドル?となって変なことになります。
しかし、そこでスケーリングを行うとどうなるか?というとなので、スケーリングしたあと(人間にはちょっと見にくい数値ですが...)に引き算することは許されるのです。
なぜ単位が消えるのか?
これについては 計算式を見たときに、単位も一緒につける とわかります。
イメージを示しておきます。
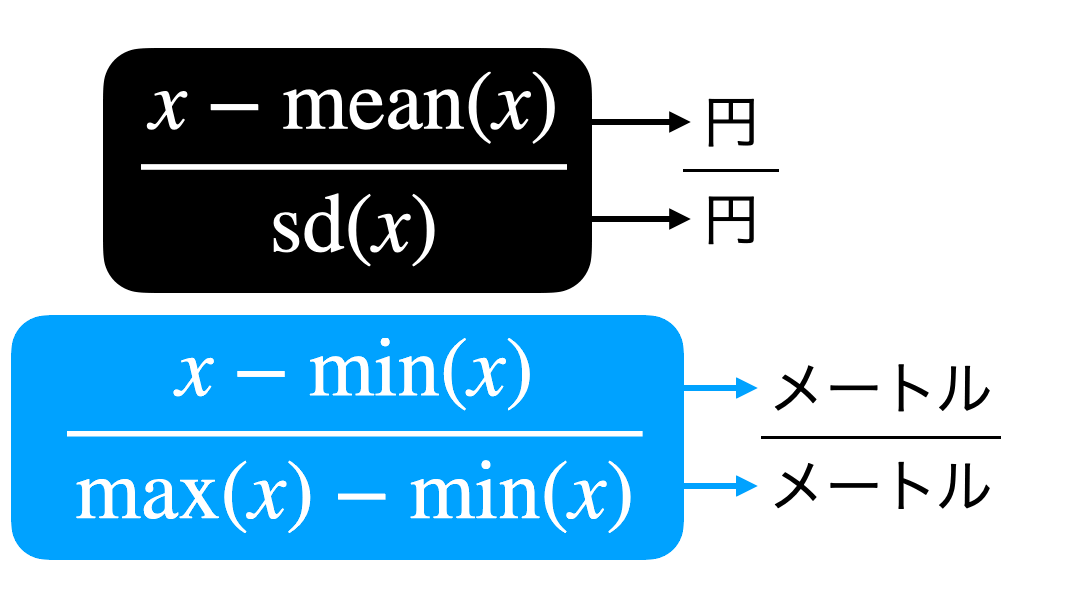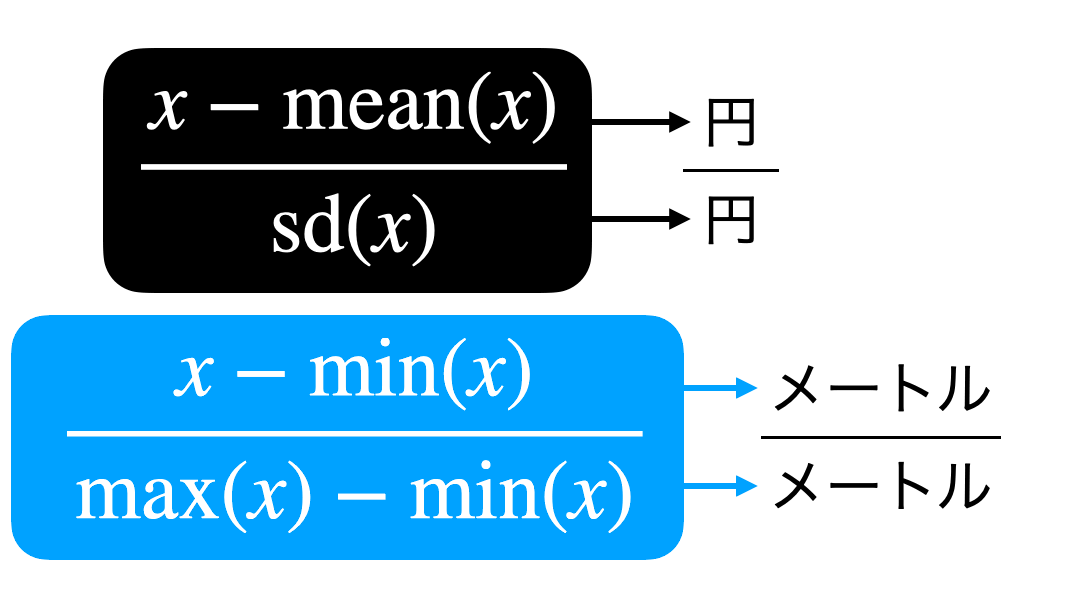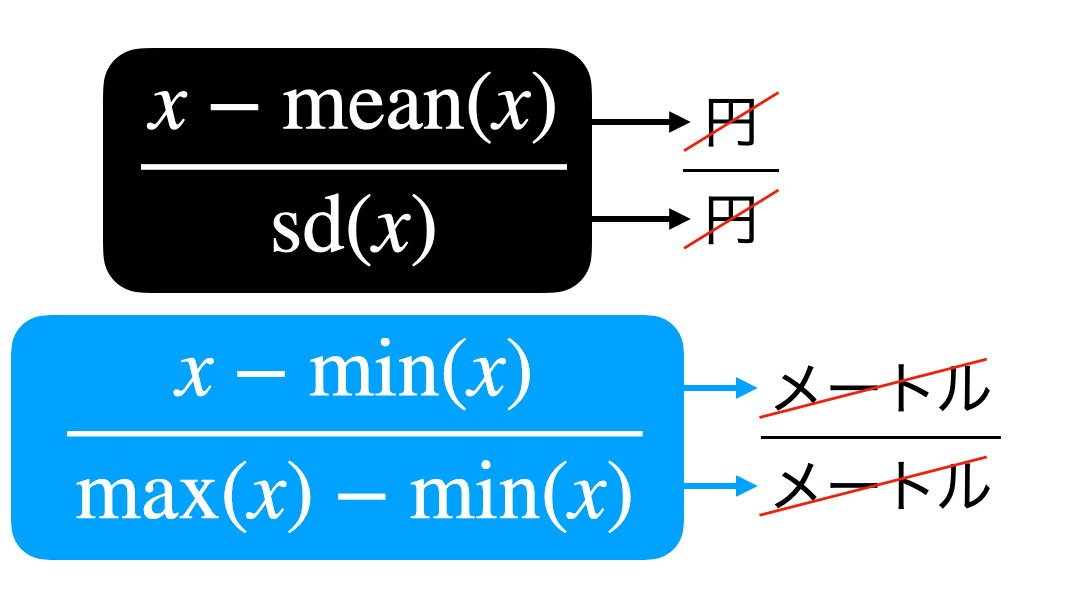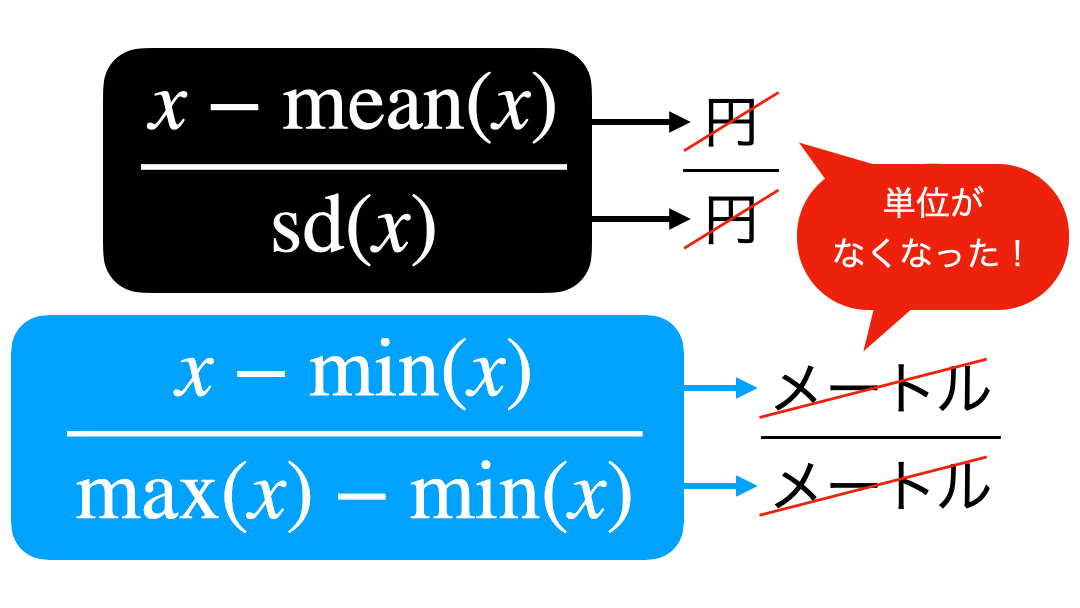
これで単位が消えてしまったけど、値はきちんと計算することができます。
その値のことを「無名数」と読んだりして、日本円だった会社とドルだった会社の比較も可能になりますし、実は偏差値なども無名数です。
偏差値って普通「50点」とか「75点」なんて言い方しませんよね?
それと同じ感覚のことをしているのです。