データサイエンティスト協会 構造化データ前処理 100 本ノック with Exploratory
問61〜問70 の答案
答案全体を通して
Exploratory では R 言語が動いていますが, 解答やコード参照の説明では Python言語 のものでやります。
SQL的な視点や考え方が入るときもその都度書きたいと思います。枠の色使いは以下のような形を意識しています。
オレンジ枠 :
あか枠 :
あお枠 :
みどり枠 :
問61 : 数値データを対数変換する(常用対数)

答案・解説はこちら
です。早速やっていきましょう。
問59 や 問60 と同じところからスタートします。
ステップを1つ消すか、あるいは集計までいきましょう。

そうすれば、あとは 計算を作成(Mutate) するだけです。
列名は amount_log10 としています。
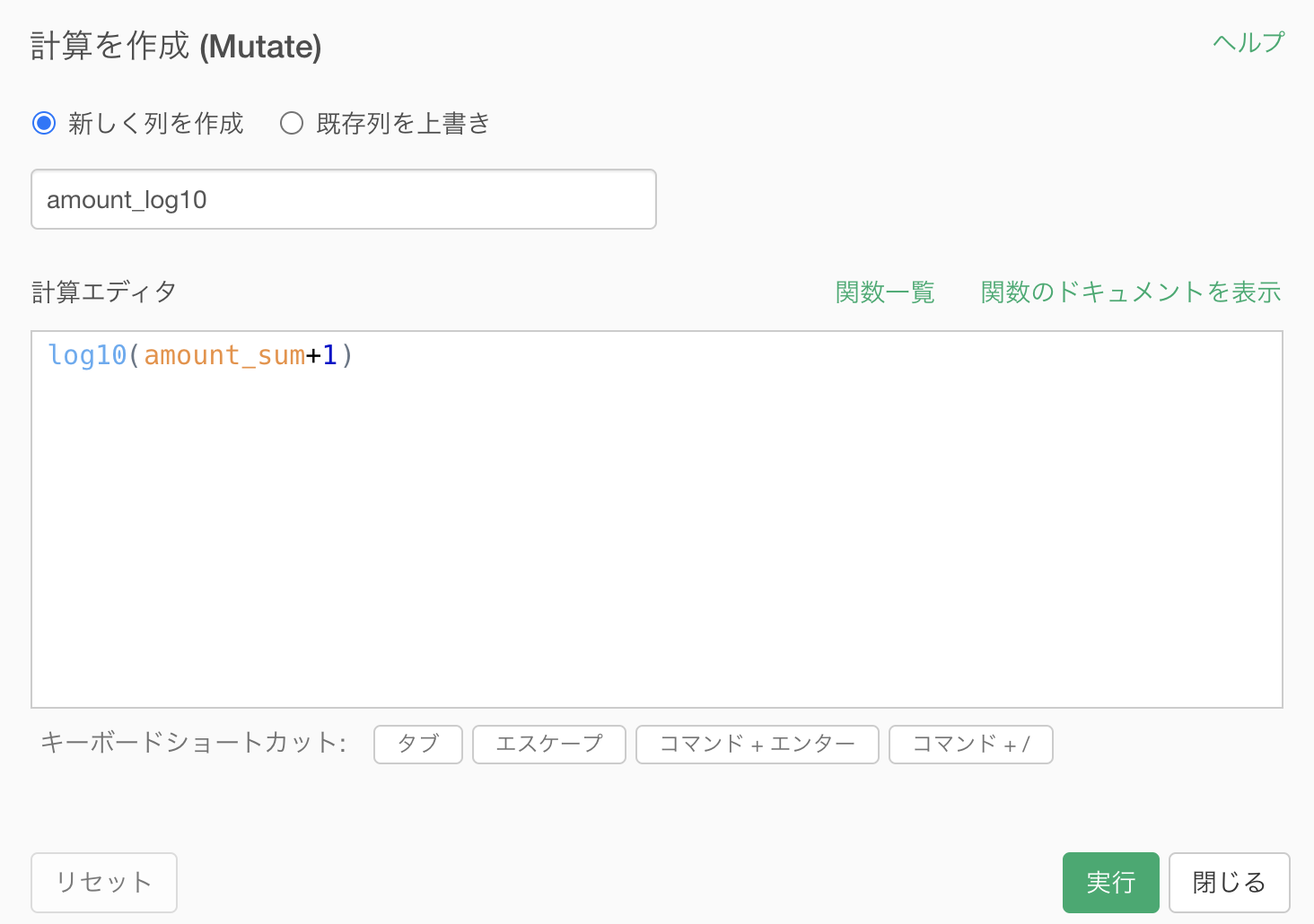
コードはこのようになっています。
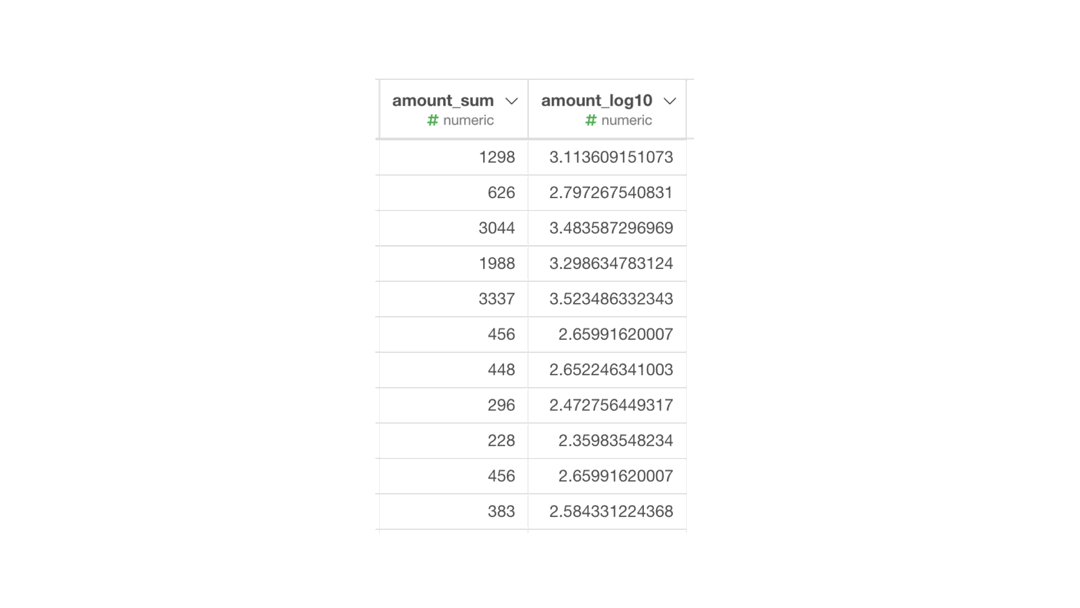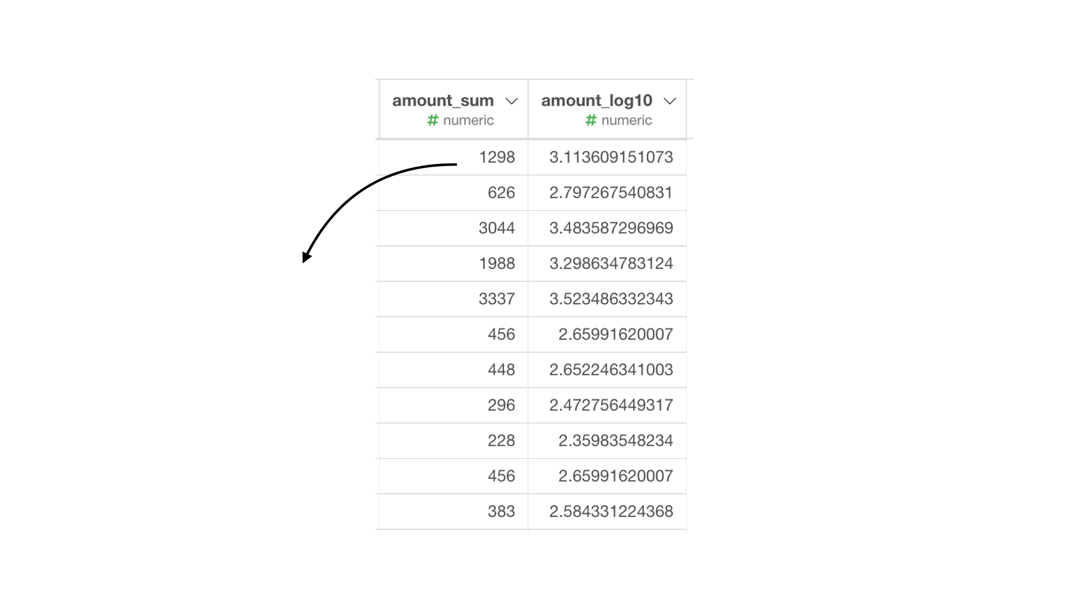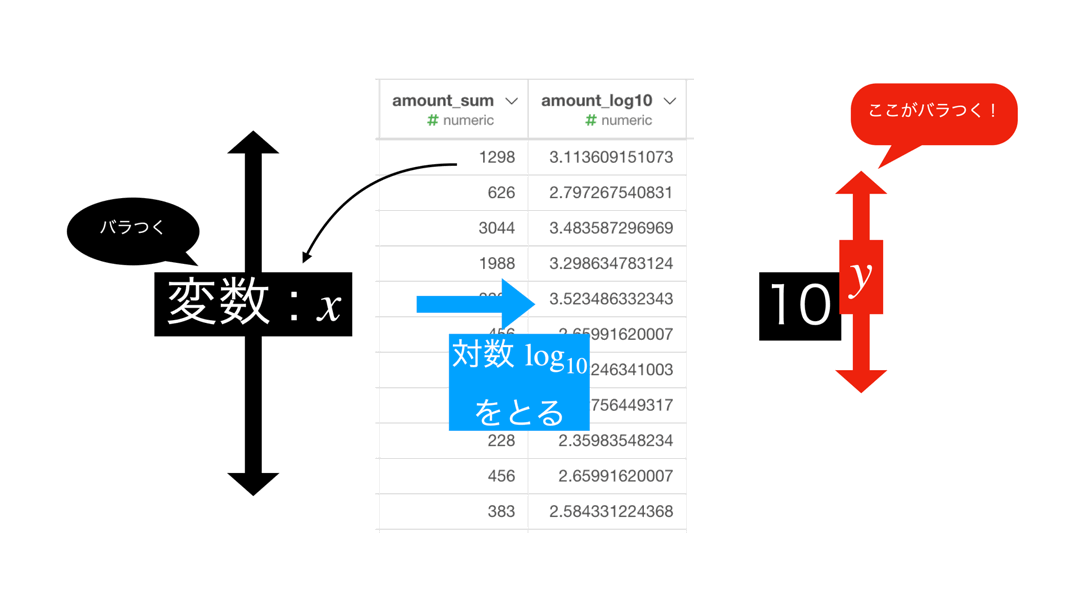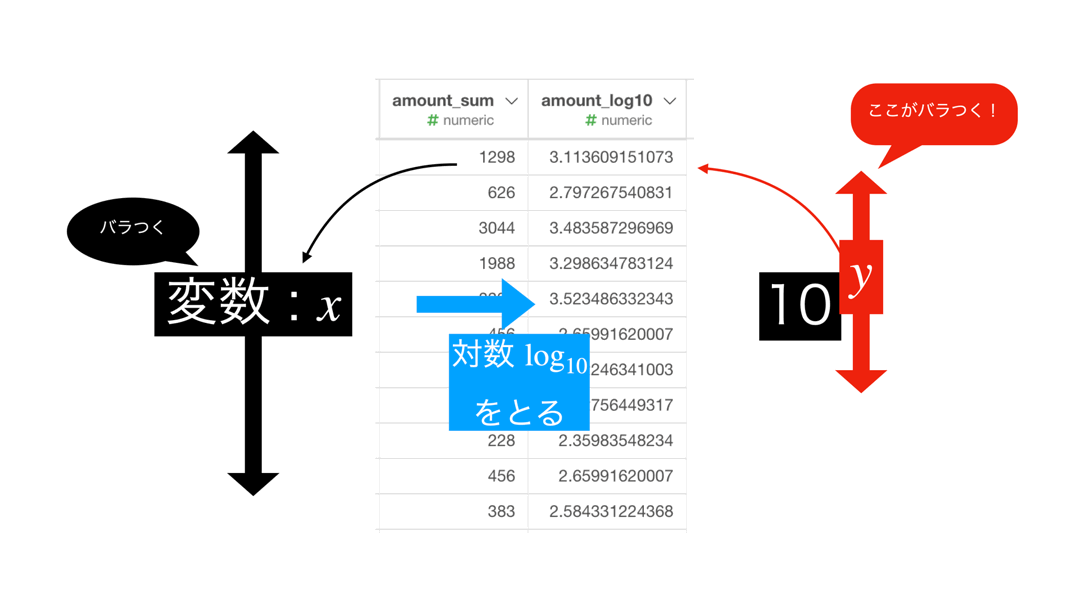
log10(amount_sum + 1)結果はこのようになります。解答と確認しましょう。
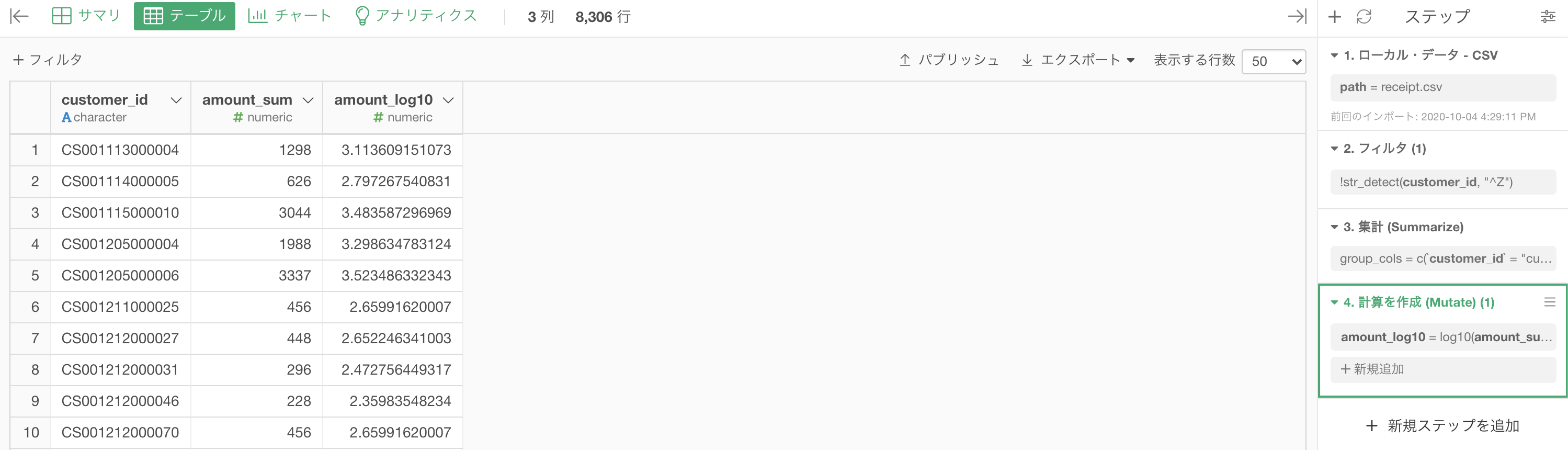
Python 解答コードはこちら
解答コードはこのようになっています。
# sklearnのpreprocessing.scaleを利用するため、標本標準偏差で計算されている
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \
groupby('customer_id').agg({'amount':'sum'}).reset_index()
df_sales_amount['amount_log10'] = np.log10(df_sales_amount['amount'] + 1)
df_sales_amount.head(10)
なんで +1 をするのか?
です。
要はこう言うことです。
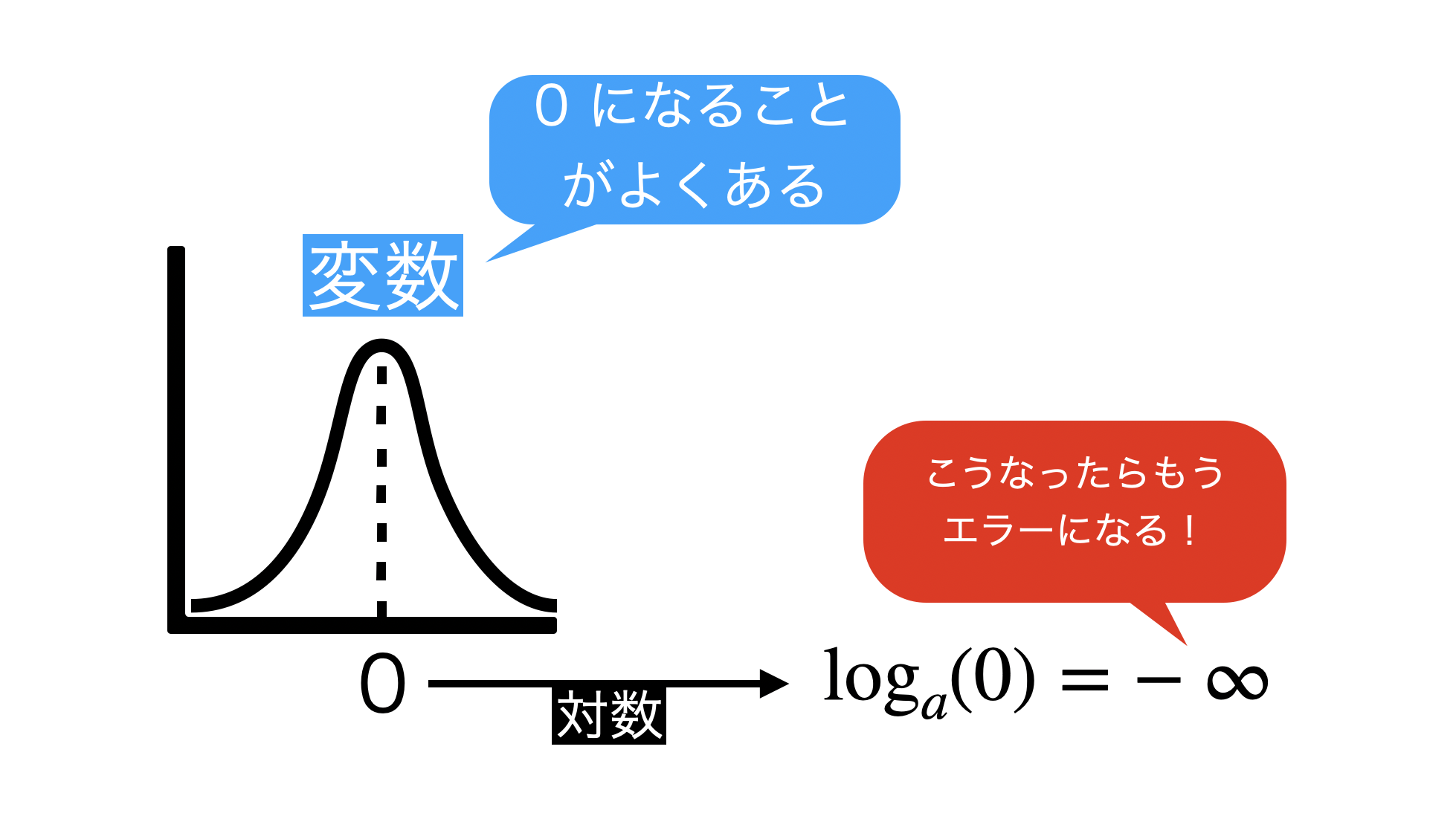
変数ってよく 0 になる(あるいはマイナスの値になる)ことが多いのですが、それを考慮せずに対数をとってしまうと不意を突かれてエラーになります。
どうしても対数を取りたいんだけど、0 になるなら +1 でズラして仕舞えば良いではないか というだけの発想なので、特に(数学的に)意味のある +1 ではありません。
これは エラーを防ぐための+1 というだけです。
ここでは「なんで log は 0 になったら計算できないのか?」といったことは、グラフを見せる程度で、数学的な説明することはしません。
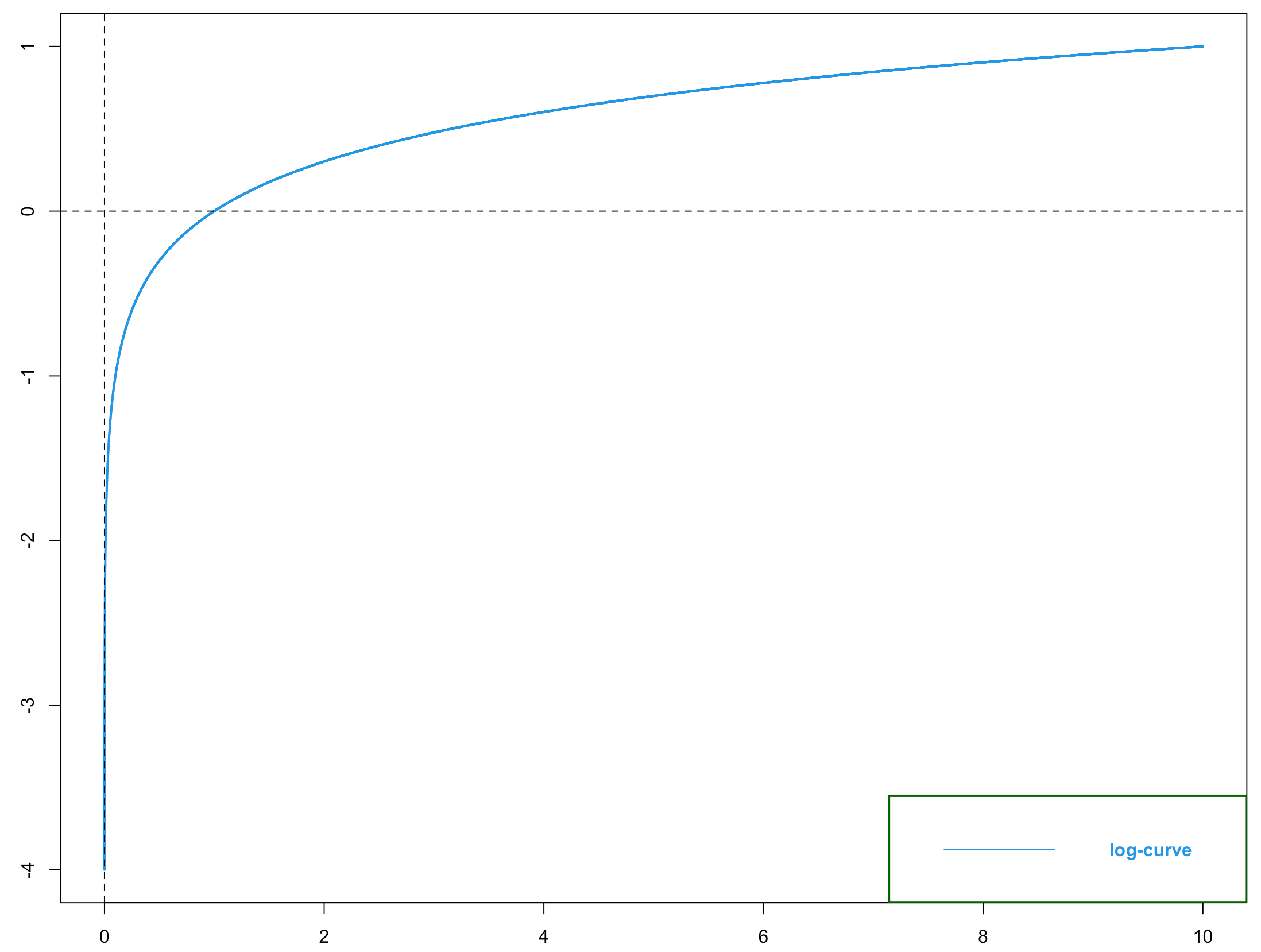
感覚的なことを言っておけば、変数+1 してから log するのは 0 で割り算して計算機でエラーになることを防ぐためのテクニックみたいなもの とでも思っておきましょう。
対数ってどこを見ているのか?
対数 log は数学的に扱いやすい・みんなも使ってる ... それはよく知られた事実なのですが、子どものように「なんで?なんで?」と聞かれて本質的な答案を言えますか?
これを言えないと対数使う資格もないかもしれませんよ?(割と本気で)
この解決の糸口はをハッキリさせておくことです。
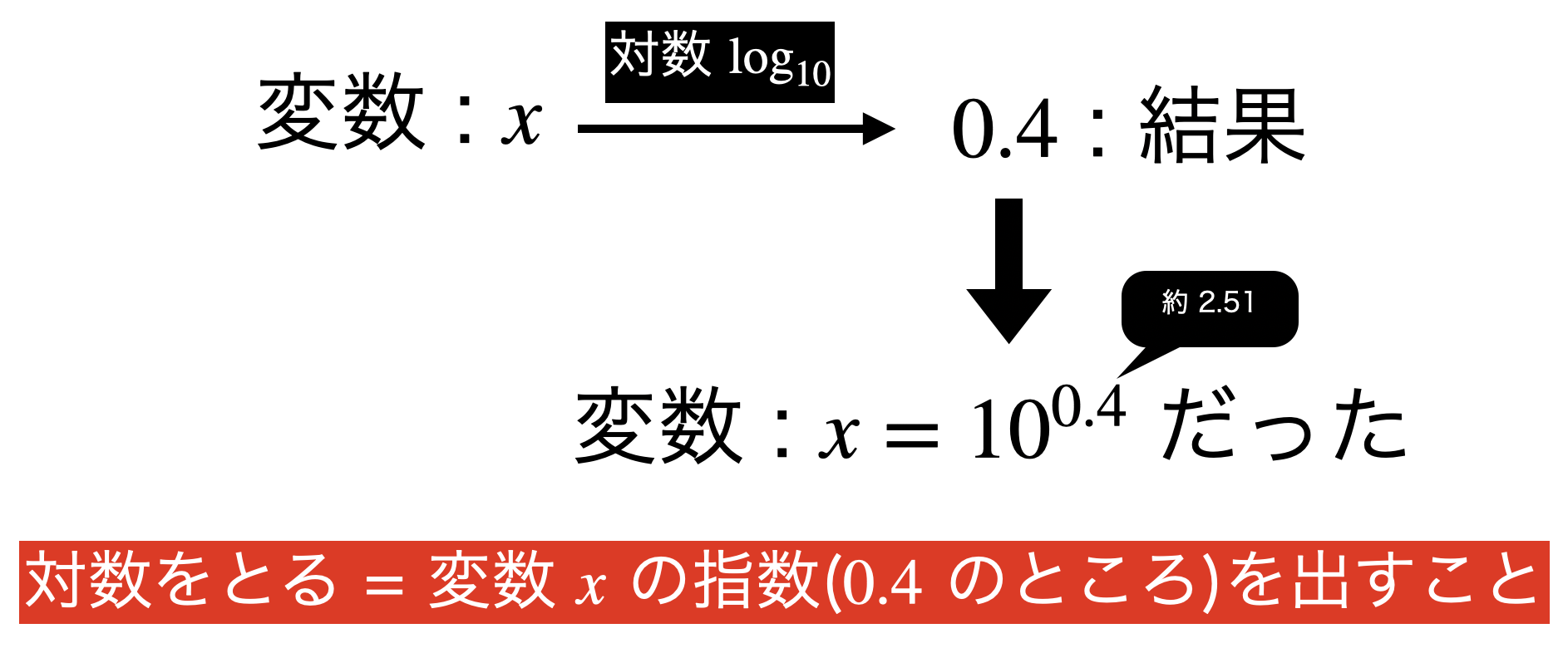
対数が見せてくれているもの
対数をとった結果で表示される数値は、この指数部分です。
つまり結果のデータで見ると、こういうことです。
というのが一般的な(数学的な?)答案かと思います。
ここから派生してというメリットも得られているだけです。
データをもらった瞬間は、私たちは「データが実は指数部分を見ないと本質的なバラつき方がわからない」という知見を得ていません。
データから「対数を取るんだね」と教えてもらうには、一度でも可視化する必要があるかもしれませんし、あるいはデータがどのように生成されたのか・先人はどのように考えて log を取ろうと考えたのかを知る必要があるかもしれませんよね。
前処理の段階では、そうするためのモチベーション作りまでしたいのは山々ですが、どうやらそこまで本質的なことはできそうもありません。
問62 も同じ流れでいきます。
問62 : 数値データを対数変換する(自然対数)

答案・解説はこちら
です。早速やっていきましょう。
問59 〜 問61 と同じところからスタートします。
ステップを1つ消すか、あるいは集計までいきましょう。

あとは 計算を作成(Mutate) するだけです。
列名は amount_loge(ログ・イーと読みます)としています。
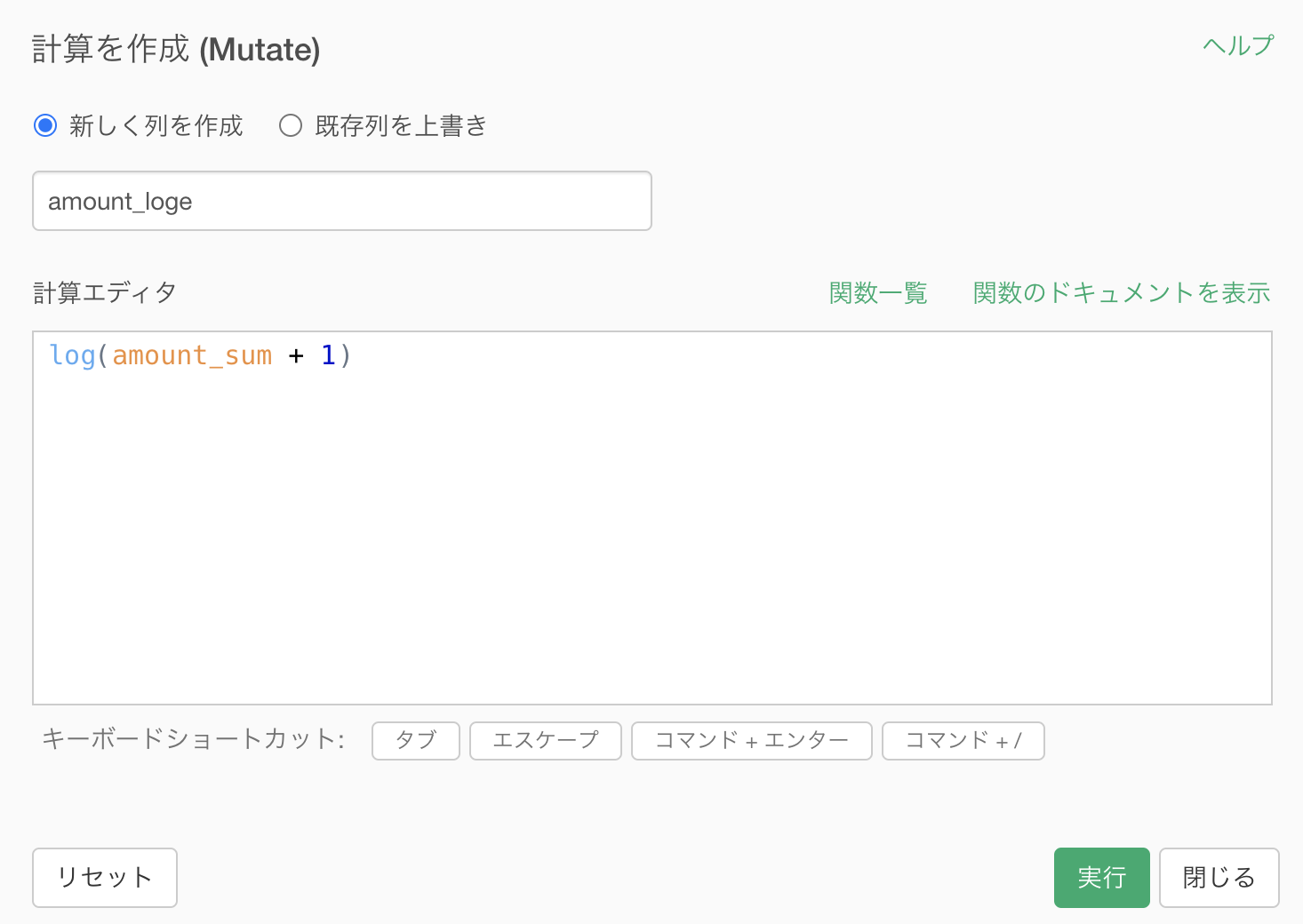
コードはこのようになっています。
log(amount_sum + 1)結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
df_sales_amount = df_receipt.query('not customer_id.str.startswith("Z")', engine='python'). \
groupby('customer_id').agg({'amount':'sum'}).reset_index()
df_sales_amount['amount_loge'] = np.log(df_sales_amount['amount'] + 1)
df_sales_amount.head(10)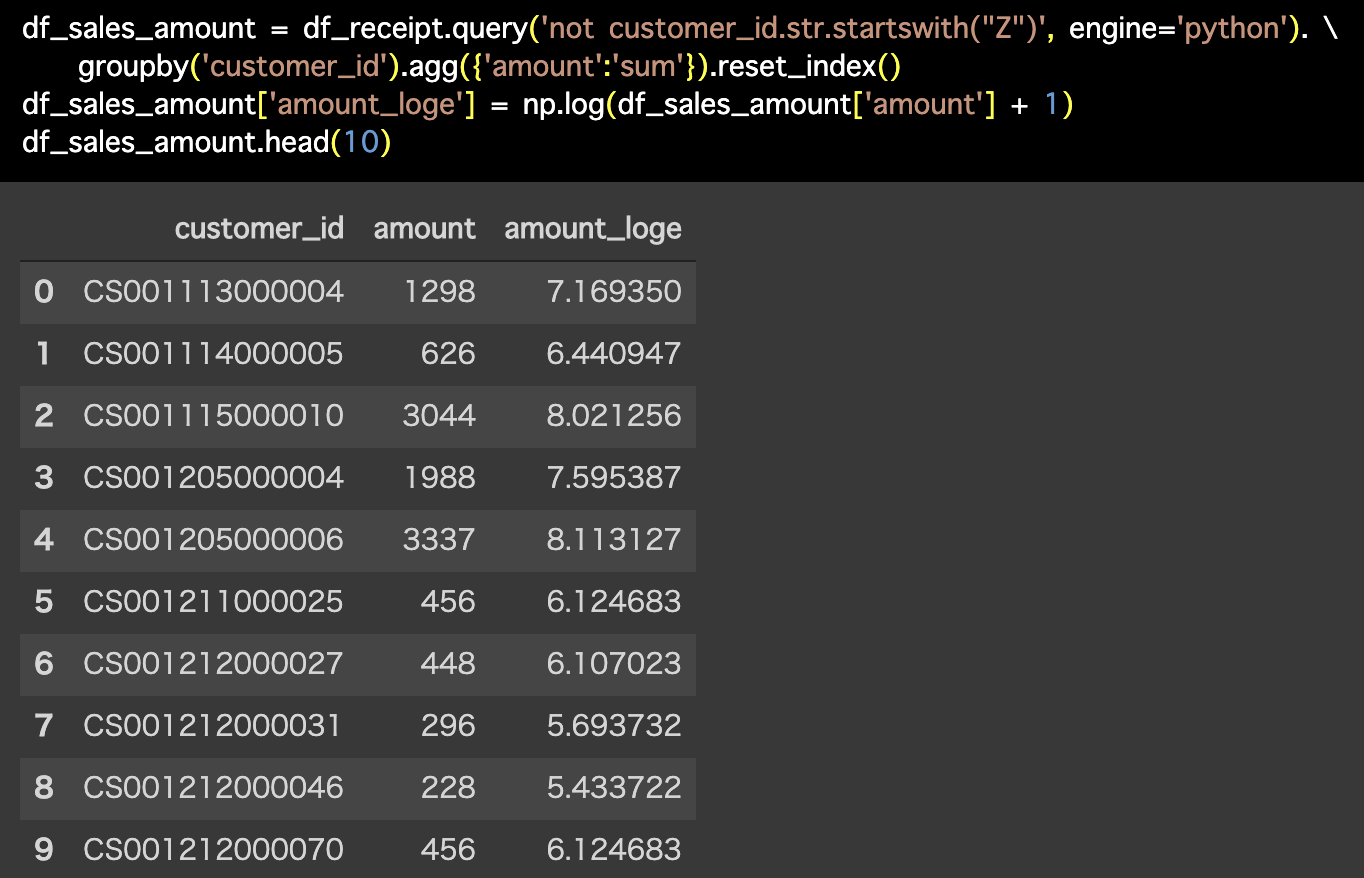
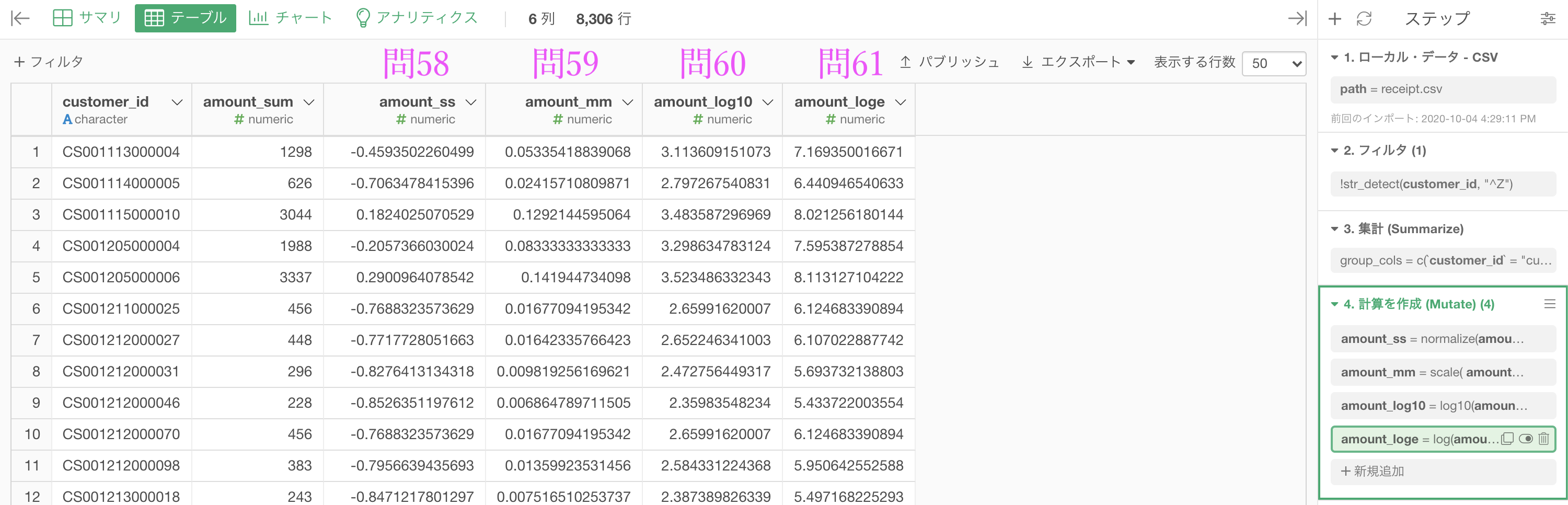
問59〜問62 までをセットで表示するとこうなる
特に「いつもこうやるんだよ」という意味ではないのですが、せっかく一貫した話が続いたので少しまとめるという意味でもやってみるのは良いことだと思います。
今回で一旦、話題は切れます。
次の話は 1列 だけではなくて 2列 に対しての計算をすることです。
問63 : 数値を引き算する

答案・解説はこちら
ということをやる点です。
問58〜問61では、1列 に対して何かをする(標準化、Min-Maxスケーリング、常用対数、自然対数)でしたが、今度は 2列 あった上で何かすることが前提です。
まずはやることのイメージをハッキリさせてから実装しましょう。
想像しながら説明を読んで欲しいのですが、2列 を計算して新しい列を作ることができれば、3列以上でも2列セットで見ていけます。
なので、1列 と 2列 から新しい列を作成することができれば、大抵のことはできるというわけなのです。
とは言っても今まで通り計算を作成 (Mutate) からやっていくだけです。
早速やっていきましょう。
ここでやることはです。df_product(商品情報)のデータを開いておきましょう。
問題文は「利益額」と難しく書いてありますが、要するに「1つ の商品が売れる = いくら利益になるか(小売店で想像して)」ということです。
それは単純に「 uni_price - unit_cost 」とすることで解決します。なぜなら
- unit_price : お店から消費者が買う場合の値段(商品棚にある値段)
- unit_cost : 仕入れ値 = お店が商品の代わりに(前もって)負担するお金
ということなので「もしこの商品が売れたらいくらの利益になっているのか?」を、この問題では知りたいから「unit_price - unit_cost」と引き算しよう!ということになります。
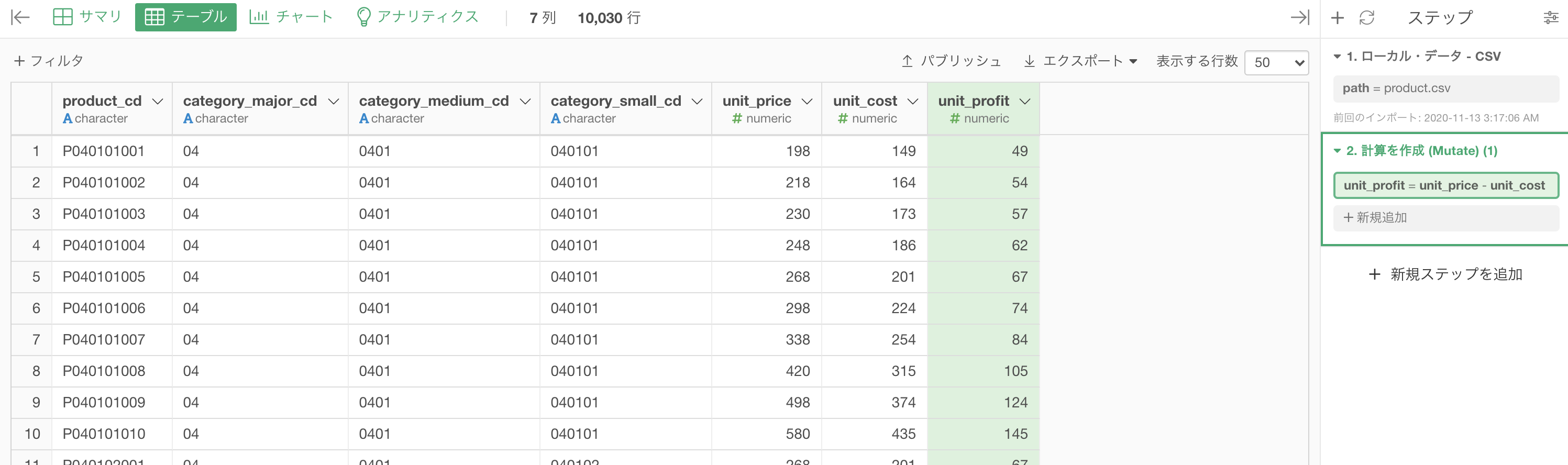
計算を作成 (Mutate) でこのように打ち込みます。
列名は unit_profit としています。
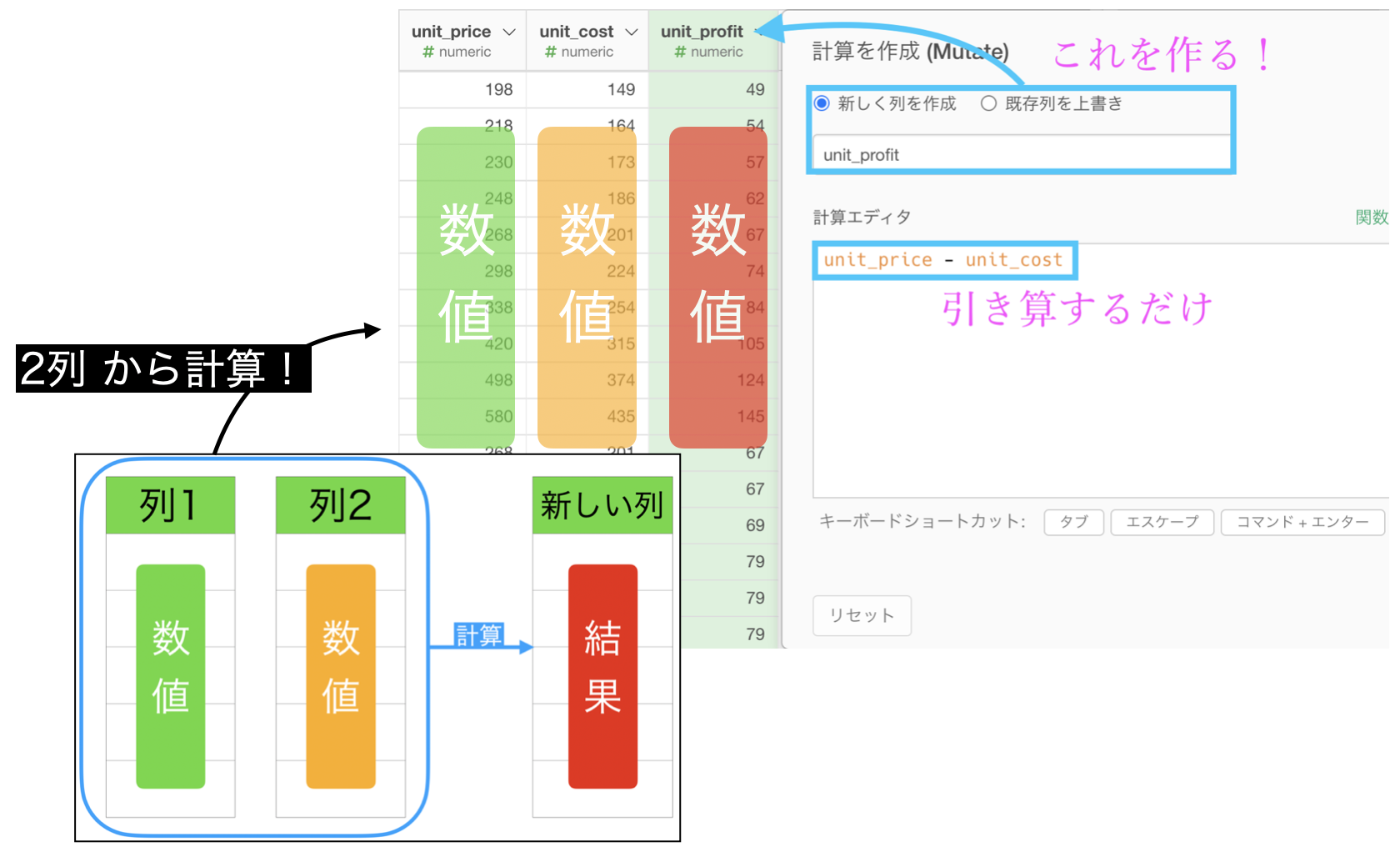
計算エディタの中身はこのようになっています。
unit_price - unit_cost 結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
df_tmp = df_product.copy()
df_tmp['unit_profit'] = df_tmp['unit_price'] - df_tmp['unit_cost']
df_tmp.head(10)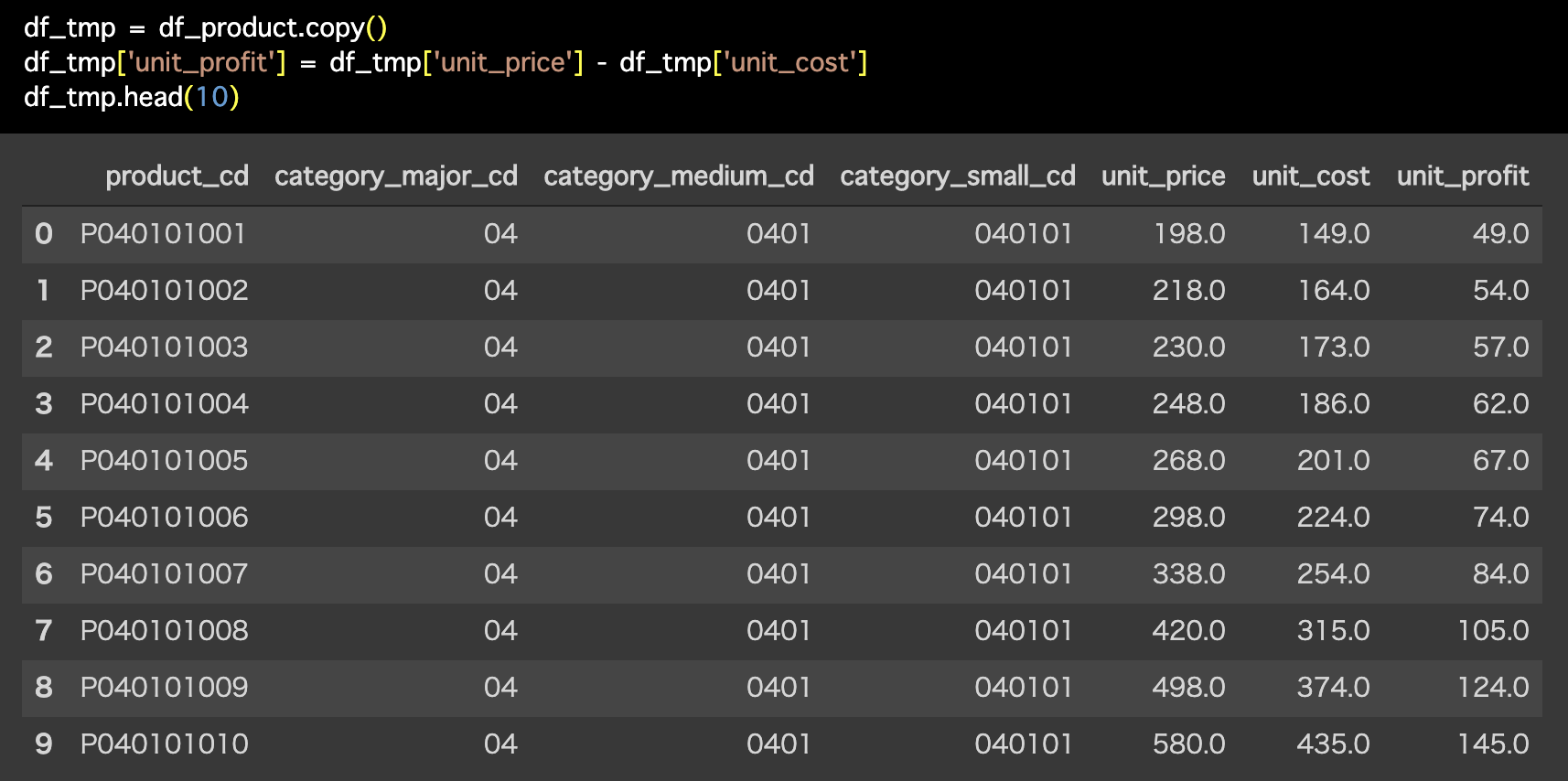
問63 の結果を引き継ぎますので、そのままにしておいてください。
問64 : 数値を割り算する

答案・解説はこちら
です。
そのあとに平均を取ることは集計で解決できるでしょう。
問題文を見るとまず「各商品の利益率」と「全体平均を算出」なので、まずは前半をなんとかします。
各商品の利益率を計算式で見る(unit は省略)とこのようになります。 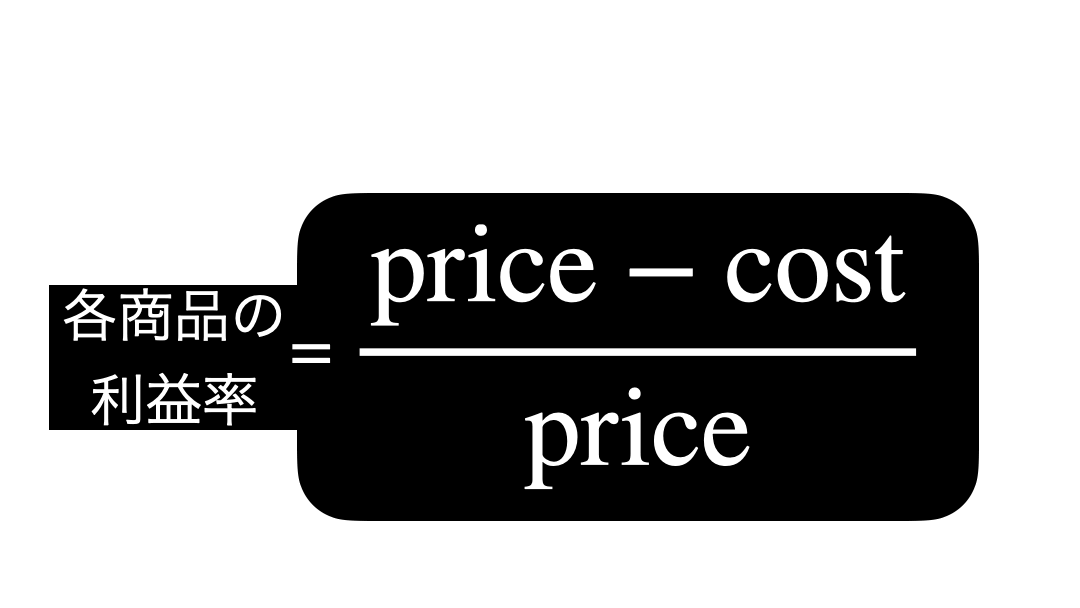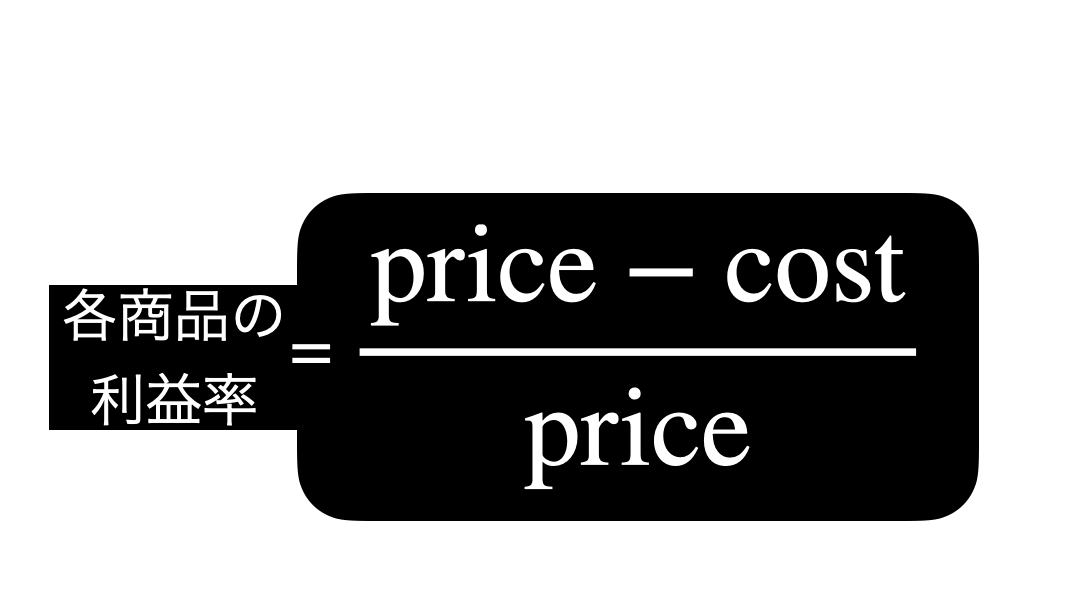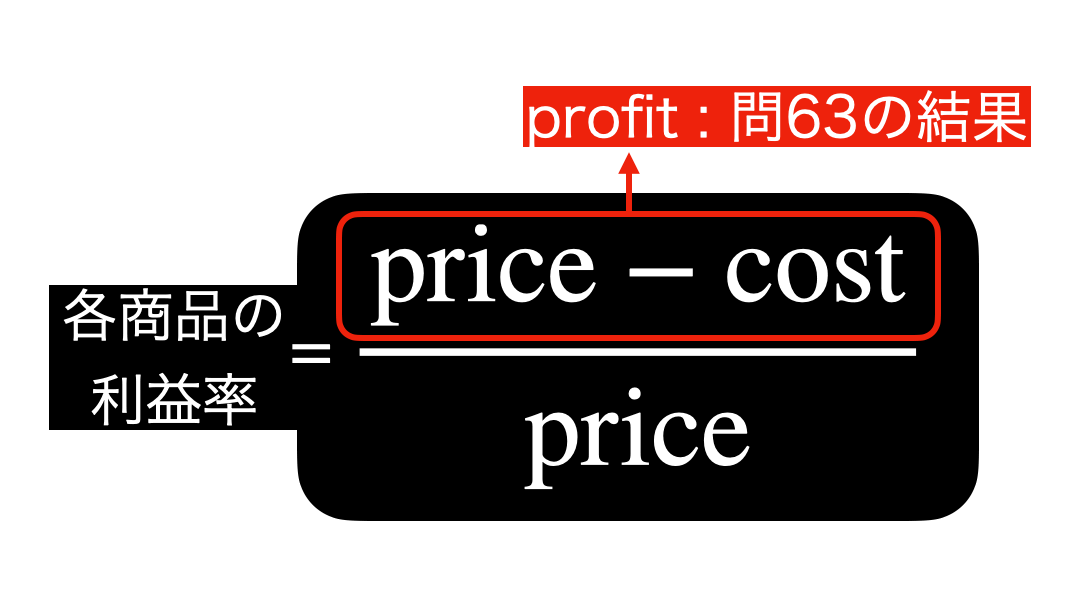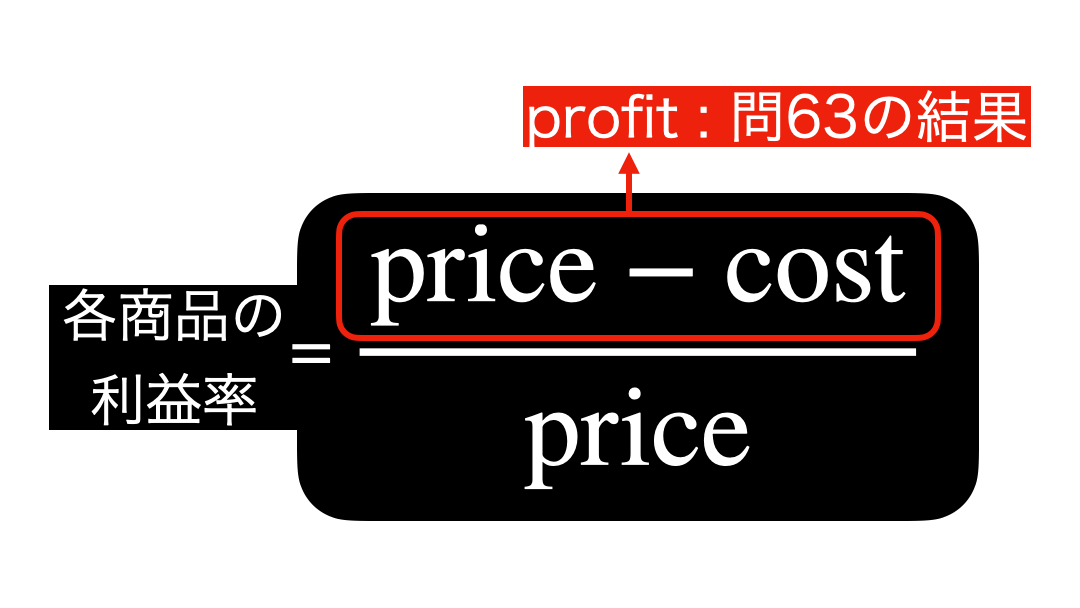 ということは結局、ただの割り算 になることがわかります。
ということは結局、ただの割り算 になることがわかります。
ただし、列同士の割り算であることには注意しましょう。
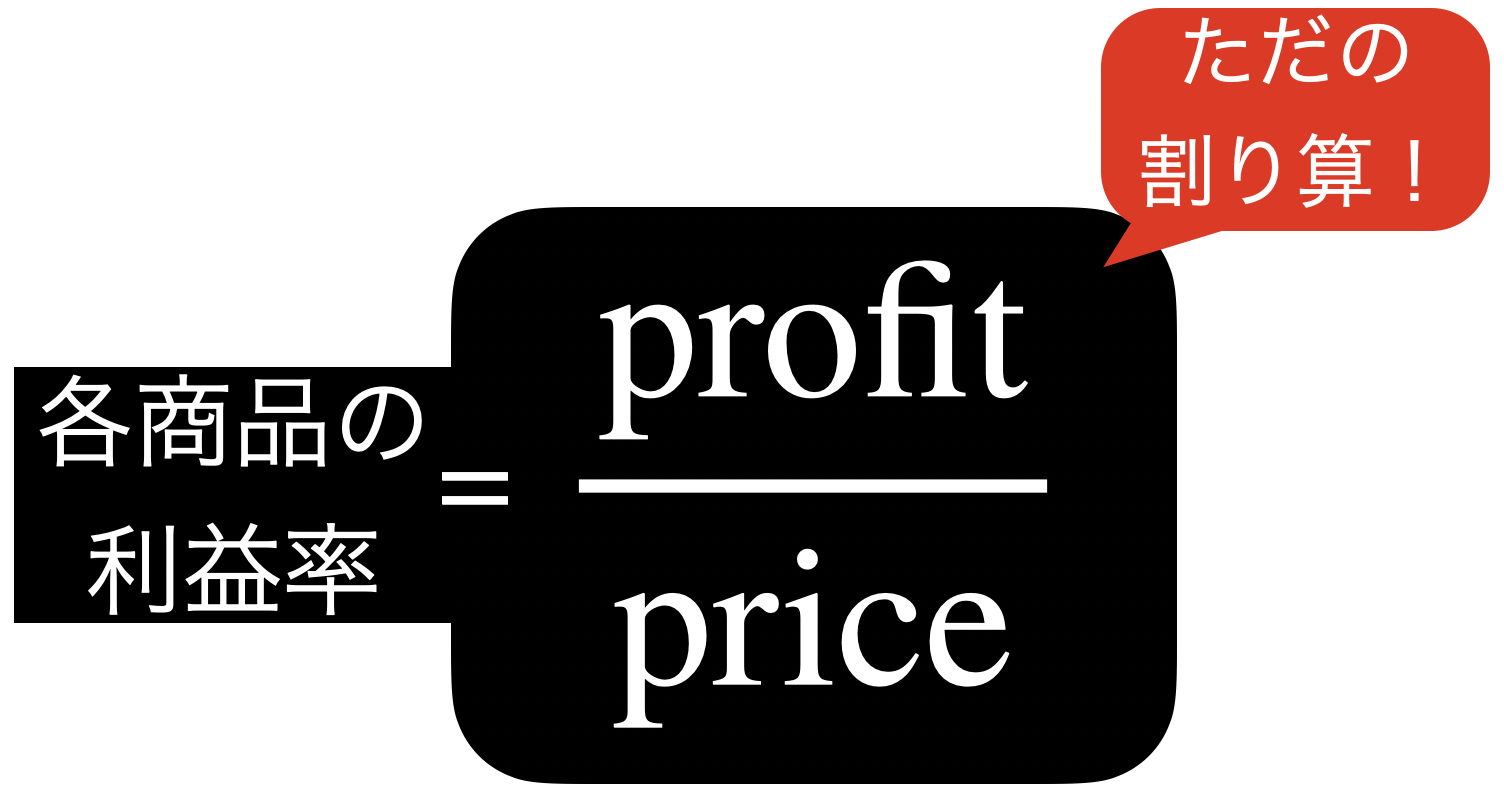
これを Exploratory で実装していきましょう。
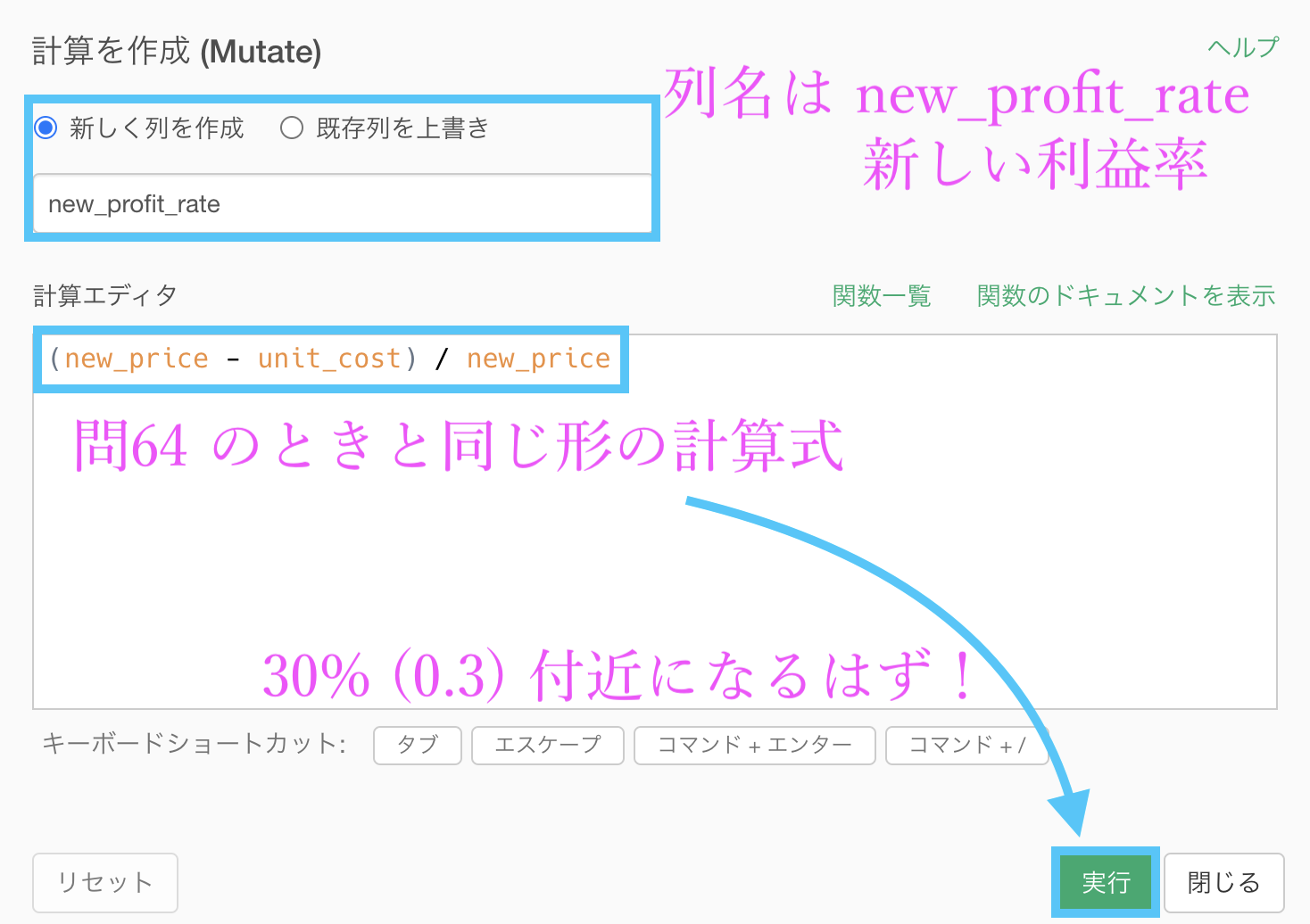
問63 の引き継ぎで、df_product にていつものように計算を作成 (Mutate) をしてから、列名を「unit_profit_rate」(商品の利益率)とします。
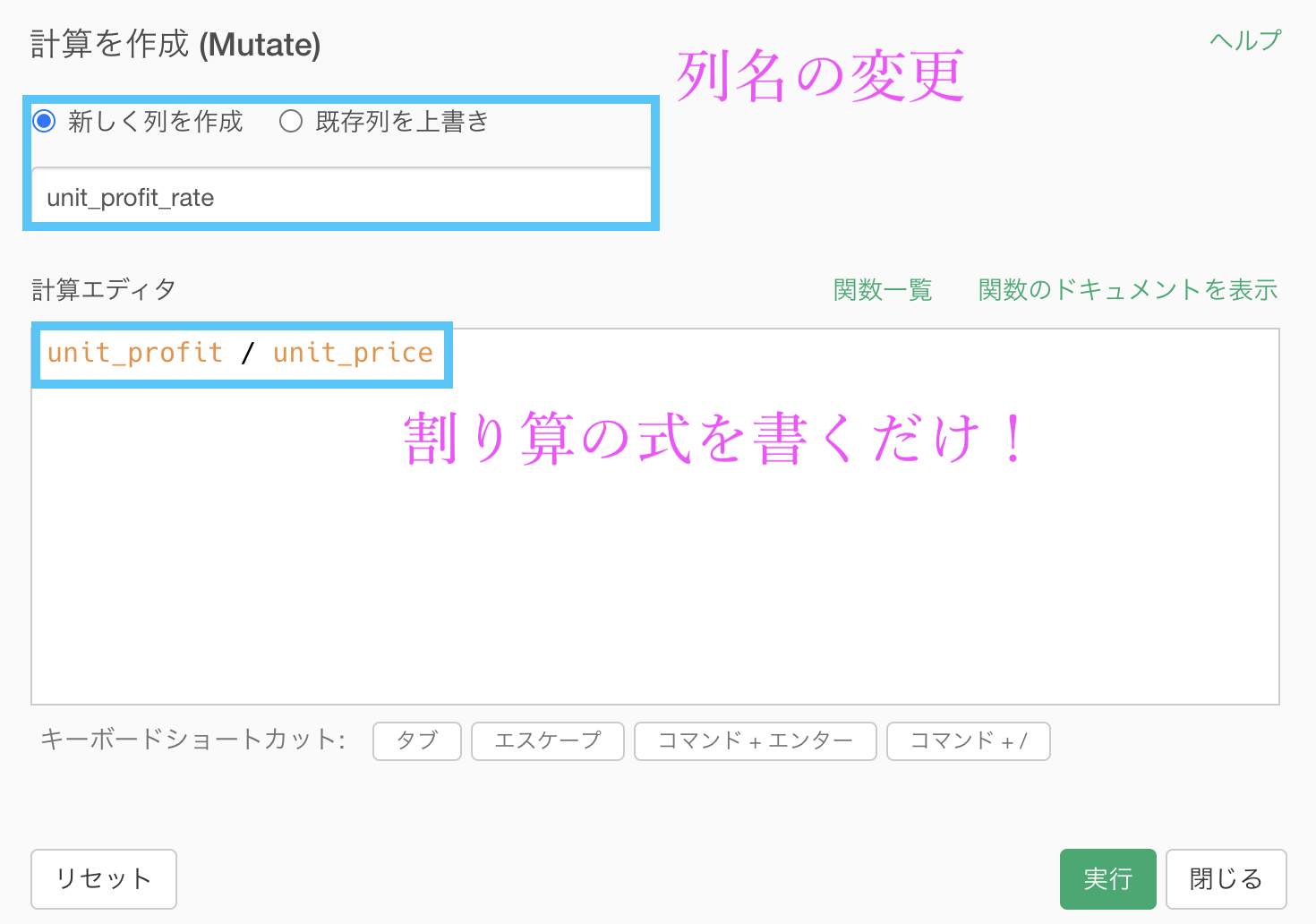
あとは計算エディタのなかに
unit_profit / unit_priceを書くだけです。
計算結果はこのようになります。
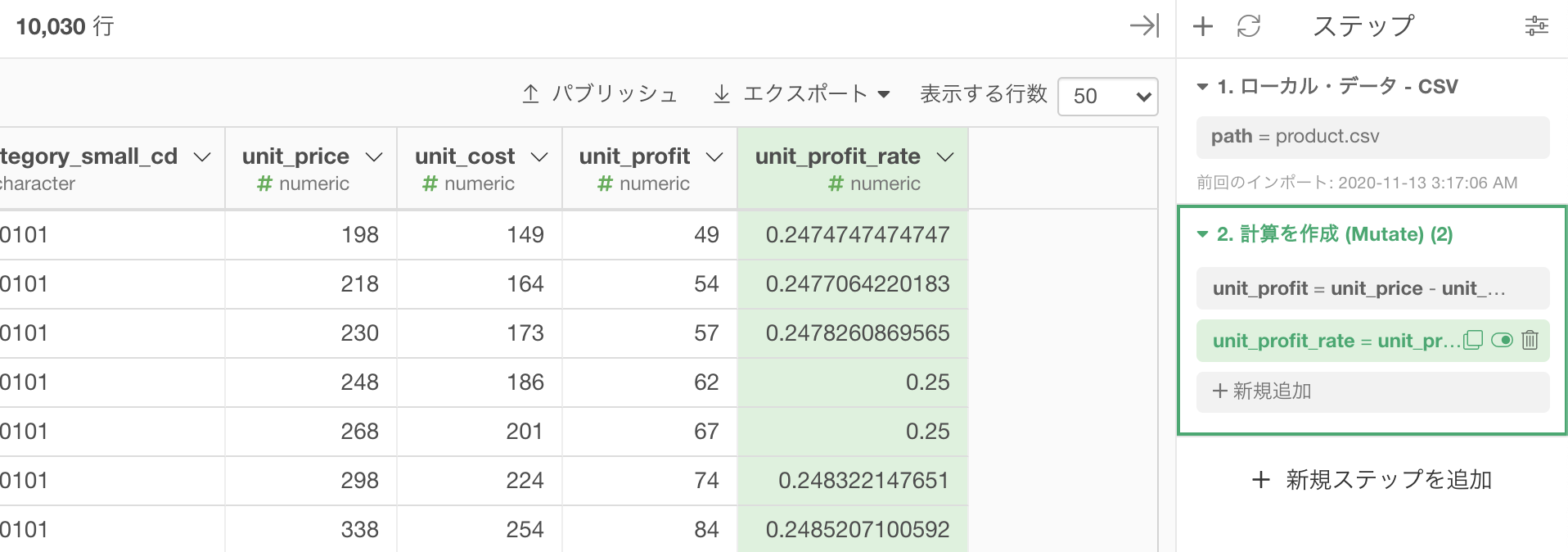
これでメインに話すこと(各商品の利益率)は終わりました。
あとは「全体平均を算出」するために集計します。
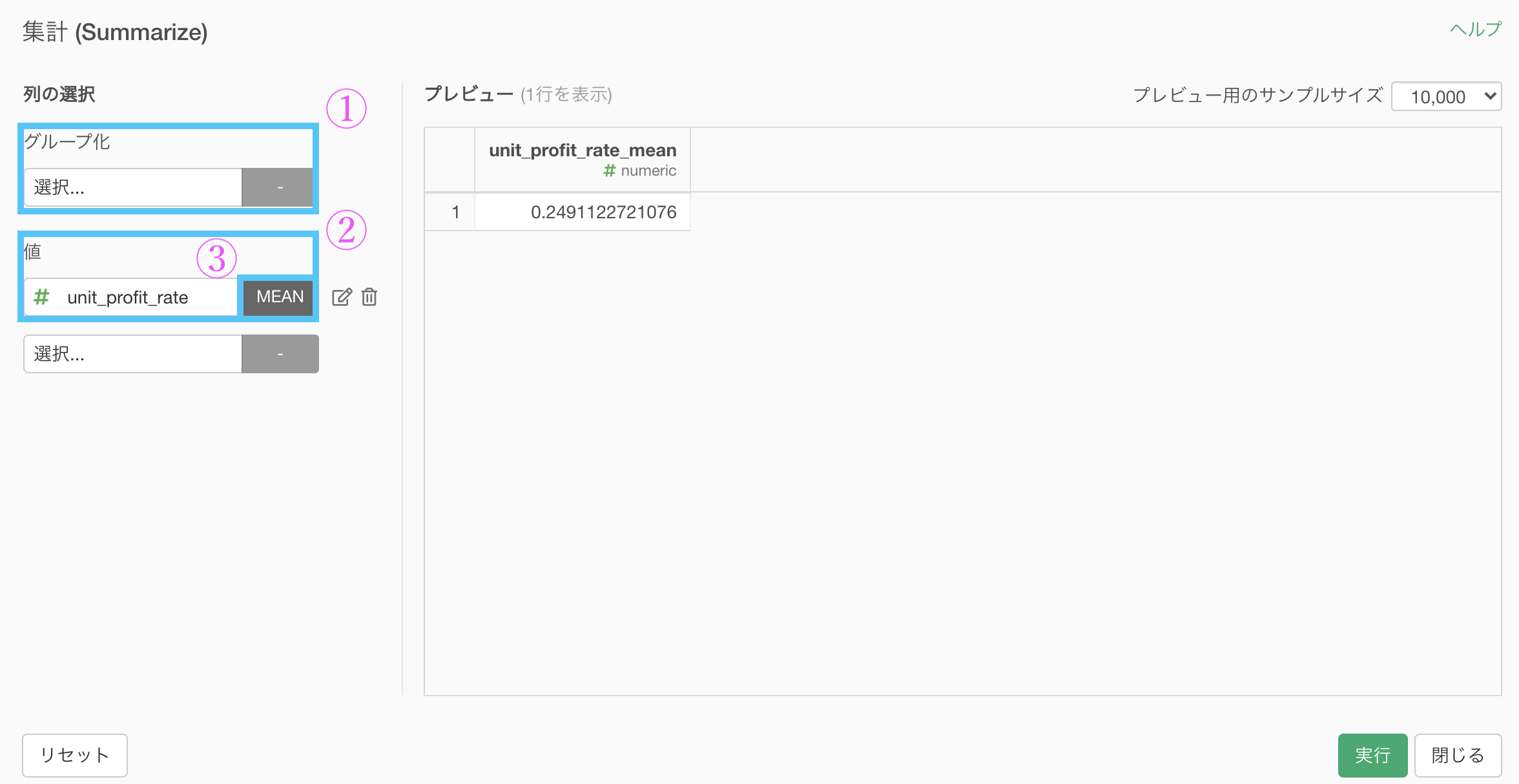
グループ化 : なし 値 : unit_profit_rate 計算 : 平均値(mean)結果はこのようになります。解答と確認しましょう。
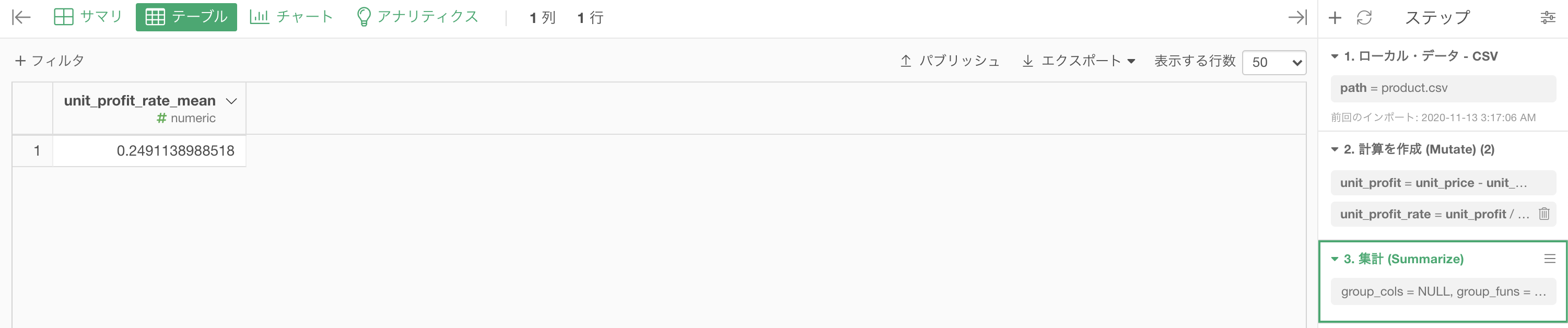
Python 解答コードはこちら
解答コードはこのようになっています。
df_tmp = df_product.copy()
df_tmp['unit_profit_rate'] = (df_tmp['unit_price'] - df_tmp['unit_cost']) / df_tmp['unit_price']
df_tmp['unit_profit_rate'].mean(skipna=True)
一応カバーしておきます
ちなみに問題文には「単価と原価にはNULLがあることに注意せよ」とありますが、答案では特に気にしていませんでした。
要するに、欠損値があるときに計算すると、上手に計算してくれず普通はエラーになるので、そこを注意してくださいね(具体的には、その欠損値は飛ばすか消去することで解決する)ということなのです。
しかし、Exploratory で集計 (Summarize) 機能を使った時点で、その注意は全くしなくて良いことになります。
計算できないところは自動で消去して計算しないので、エラーになっていないのです。
次の問題でも df_product は使いますが、問65 ではこの結果は引き継ぎませんので、ステップ処理は消して置いてください。
問65 : 除算結果に対して有効桁数以下を切り捨てる

答案・解説はこちら
ひとまず「こうやったら 問65 の答えになるよ」ということを答案にして、じゃあ「なんでその式で良いのか?」ということをあとで解説する流れにしたいと思います。
まずこの問題でやることは、unit_cost の値段からことです。
要するに、unit_price を new_price として新しくする際に、利益率30%で更新しましょうということなのです。
このことをとりあえず Exploratory で実装してみます。
重ねて言いますが、なんでそうなるのか?はあとで解説します。
まず df_product の unit_cost にて「数値関数を使う → floor」を選択します。以前にも floor(フロア)関数は出てきましたね。
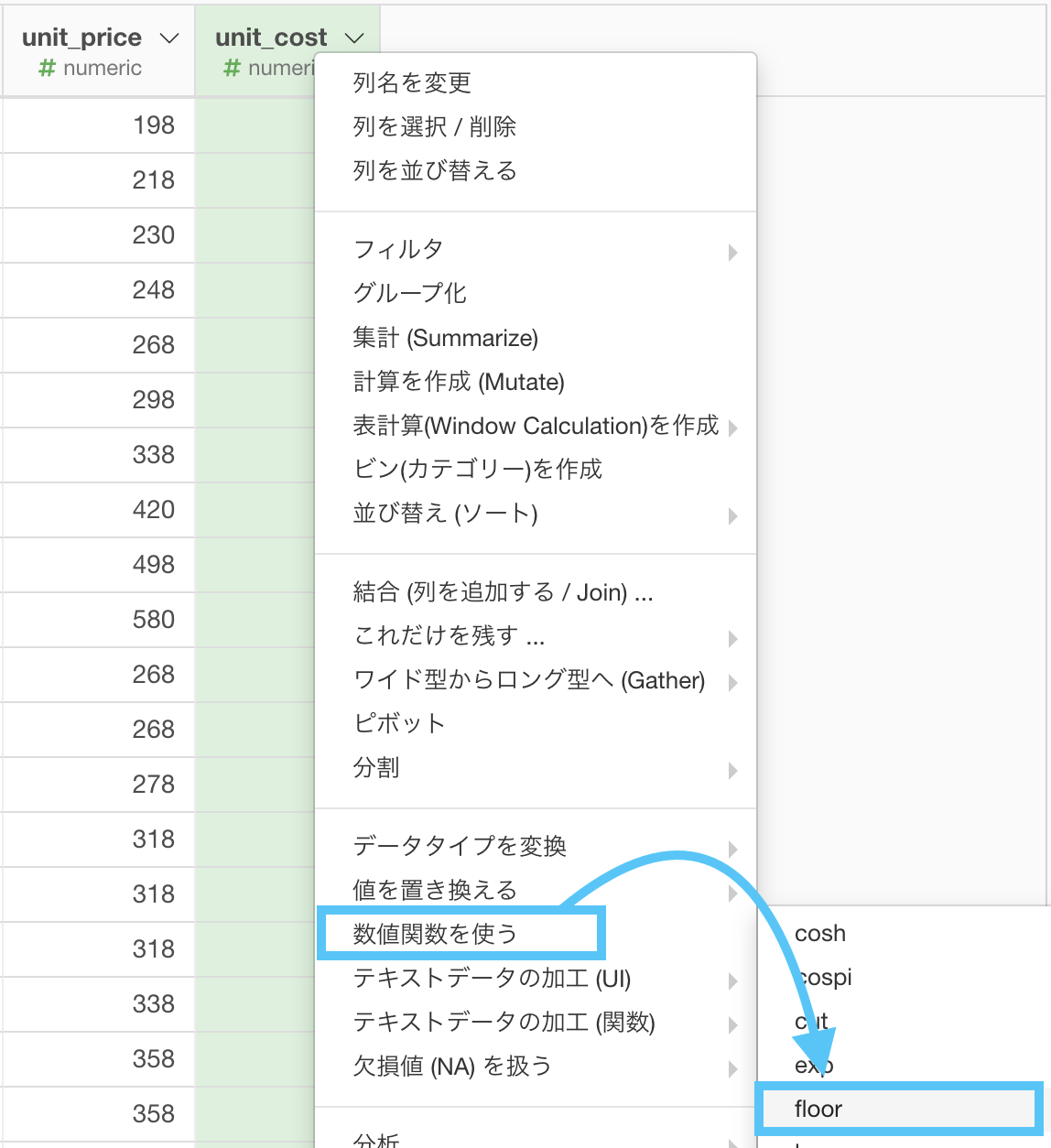
このような(計算を作成する)画面が出てきたと思います。
列名を new_price 変更します。
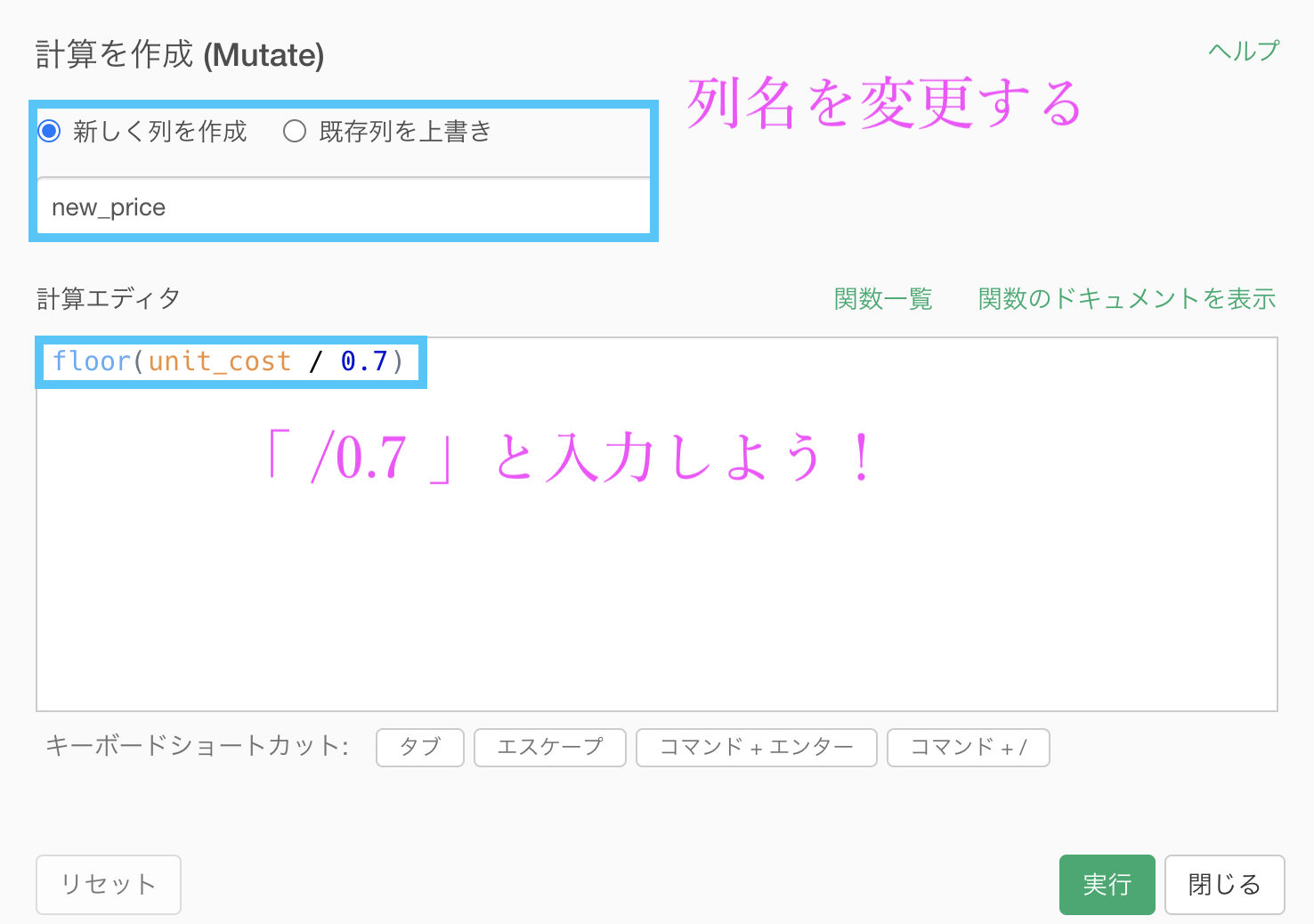
コードはこのようになっています。実質カッコの中身で「/ 0.7」を書くだけで良いです。コピペ用に書いておきます。
floor(unit_cost / 0.7)前に floor 関数を使ったときと同じくですが、計算の動き方(なんで 0.7 で割るのかはあとで解説!)はこのようになります。
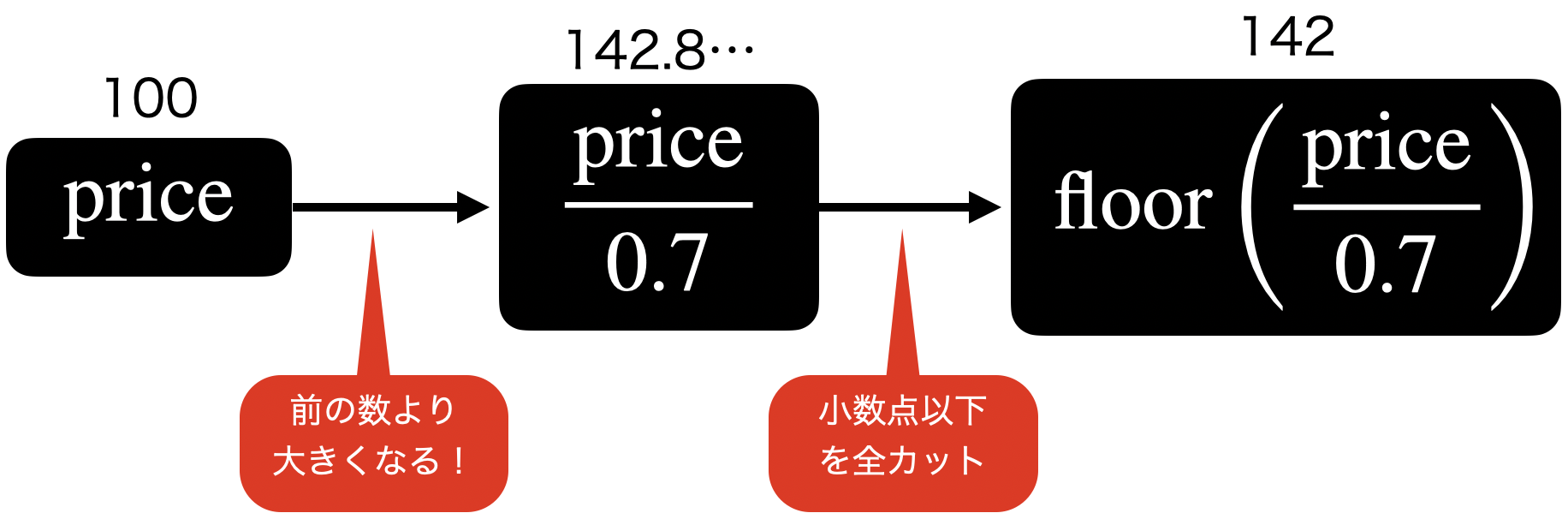
気付きのポイントとしては、前の値よりも大きくなることです。割り算って聞いたら普通は小さくなるイメージですが、0.7 で割り算するので、10倍して 7 で割るのと同じです。
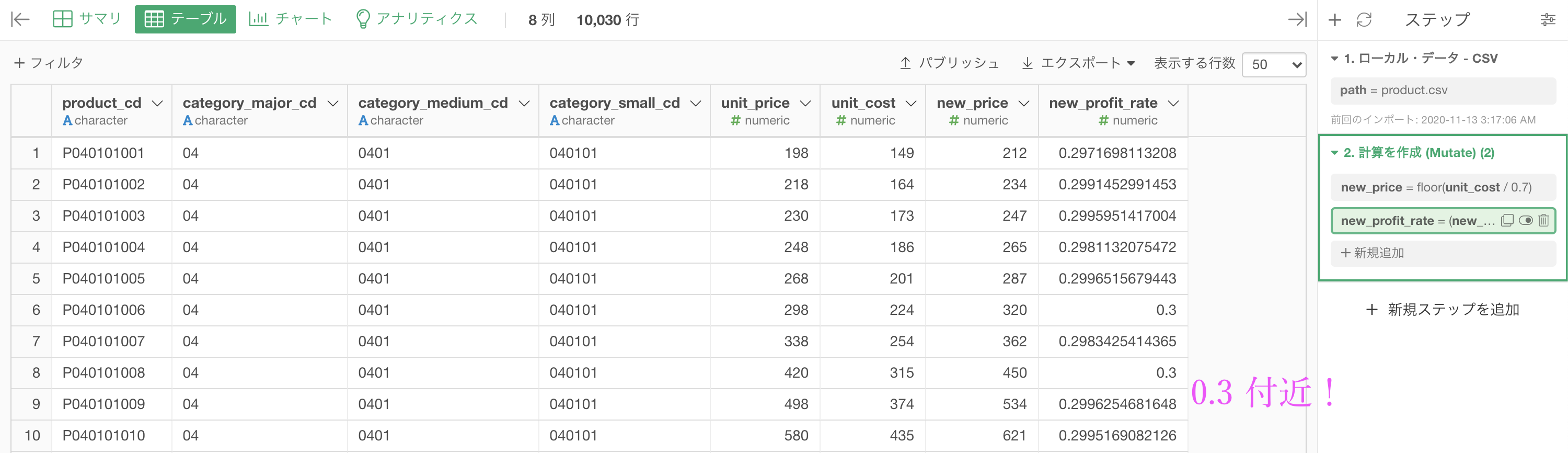
floor 関数を実行した結果はこのようになります。

この時点で問題の大体は終わっているのですが、本当にこれで利益率が 30%付近(0.3付近)になっているのか確認する必要 があります。
その際には 問64 と同じ方法を取れば良いので、次のように計算式を立てることができます。
この結果は、0.3 付近になるはずです。その確認のための実装でもあります。
結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
# math.floorはNaNでエラーとなるが、numpy.floorはエラーとならない
df_tmp = df_product.copy()
df_tmp['new_price'] = df_tmp['unit_cost'].apply(lambda x: np.floor(x / 0.7))
df_tmp['new_profit_rate'] = (df_tmp['new_price'] - df_tmp['unit_cost']) / df_tmp['new_price']
df_tmp.head(10)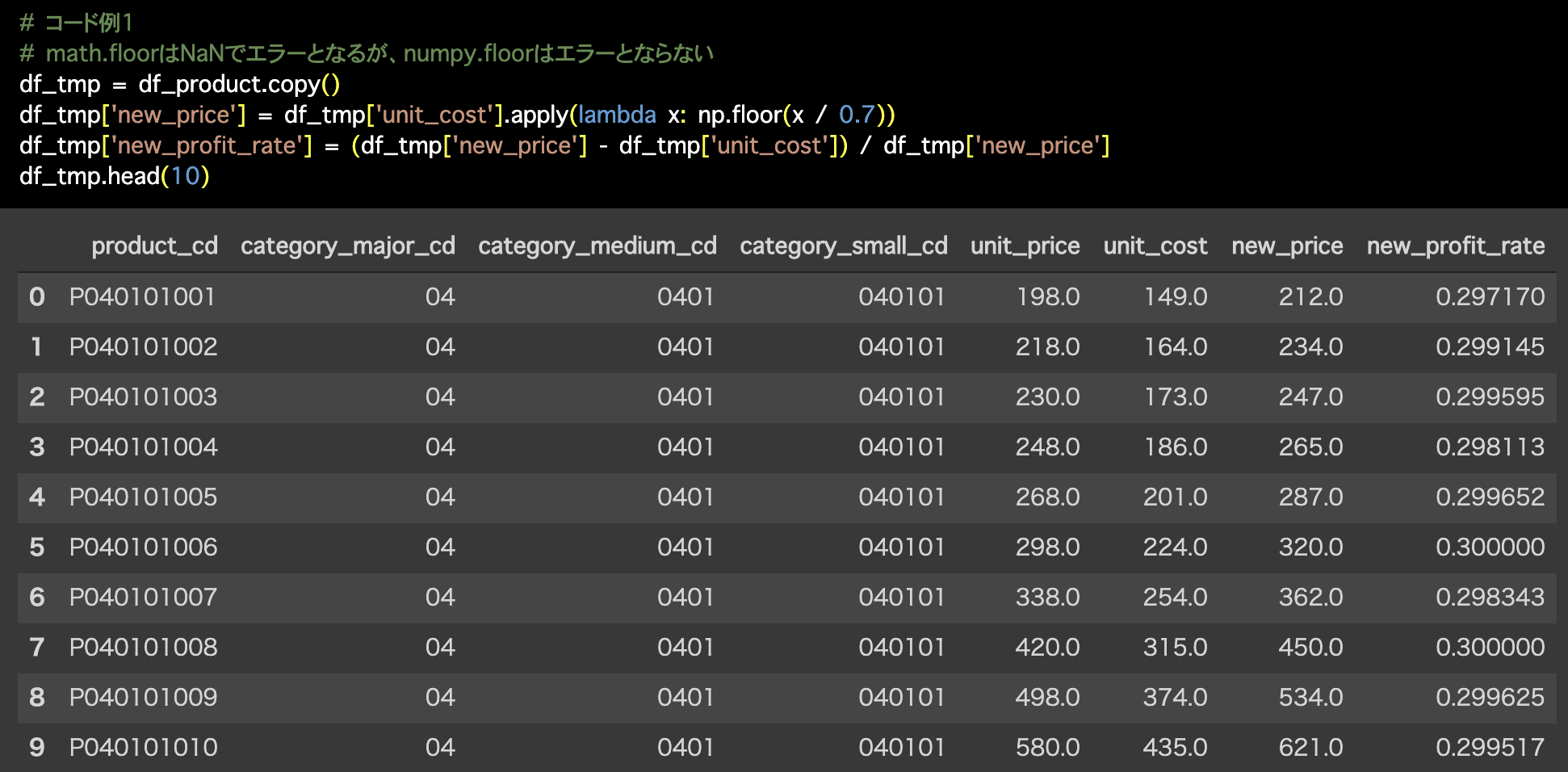
2つ目の解答コードはこのようになっています。
# コード例2
df_tmp = df_product.copy()
df_tmp['new_price'] = np.floor(df_tmp['unit_cost'] / 0.7)
df_tmp['new_profit_rate'] = (df_tmp['new_price'] - df_tmp['unit_cost']) / df_tmp['new_price']
df_tmp.head(10)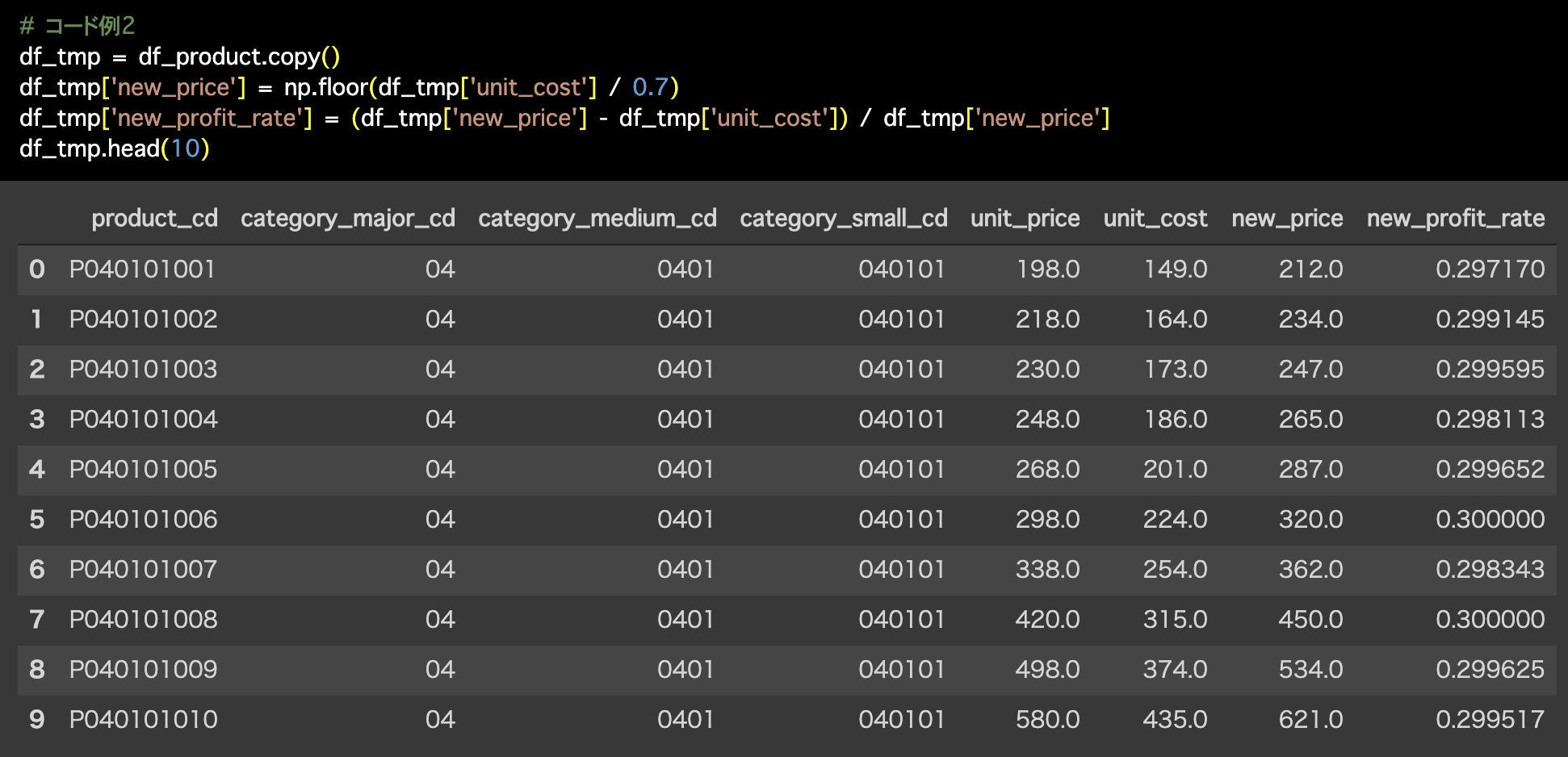
なんで 30% (0.3) なのに 0.7 で割ったのか?
先に断っておきますが、floor 関数を使った理由は単純で「価格だから整数値にする必要があったから」です。
まぁ問題文には「1円未満は切り捨てること」とあるので、それを floor 関数で実現しているだけです。
ということです。
それにはきちんとした理由があります。
まず、スタートはここからです。

です。これを真剣に考えることが解決の糸口です。
問64 での図を少し加えて、問65 のヒントになりそうなものにしました。
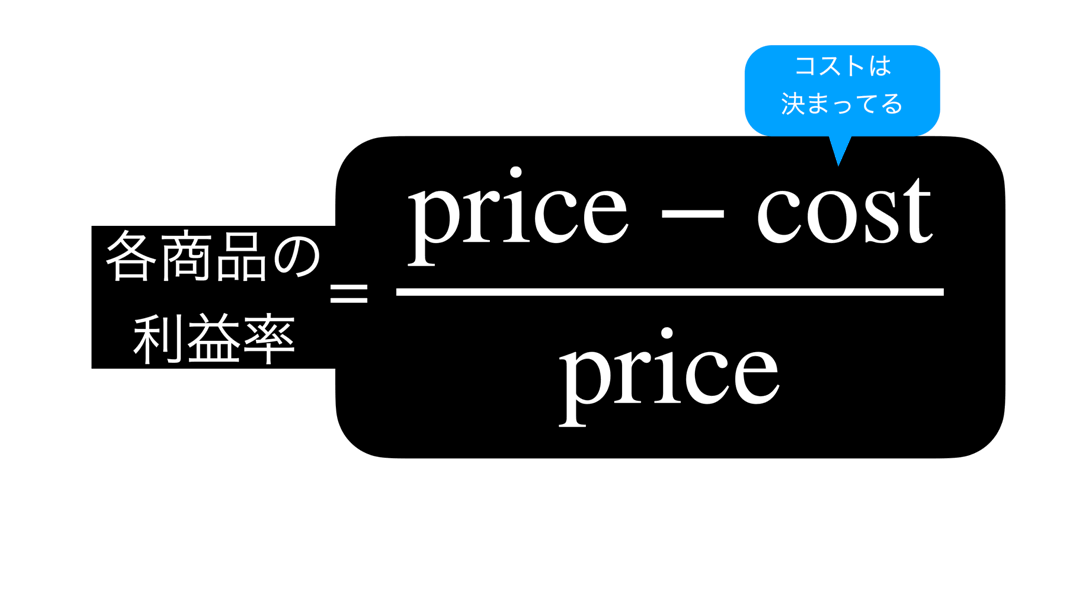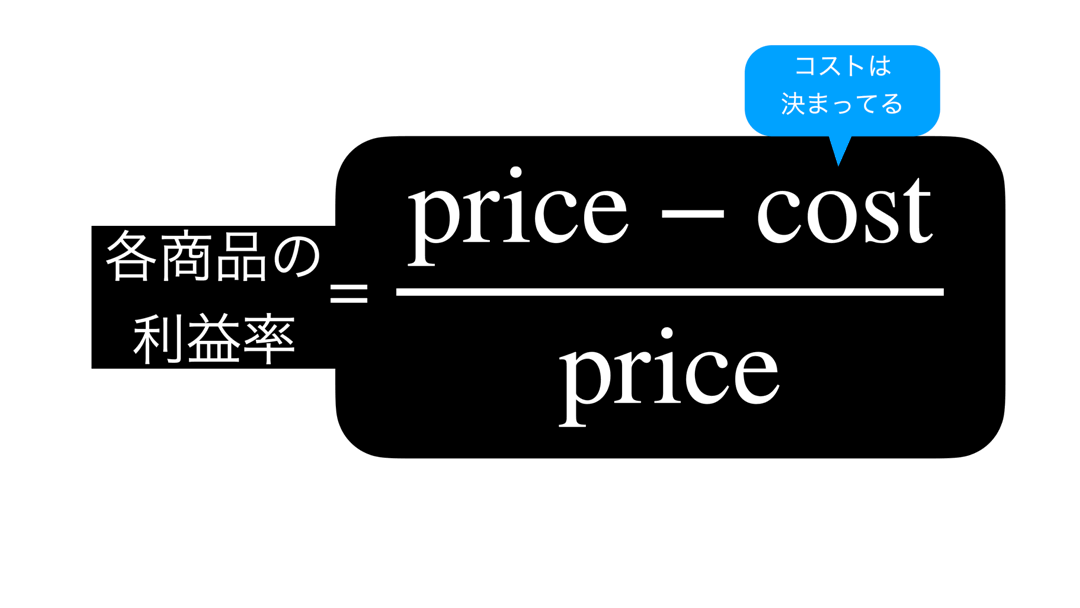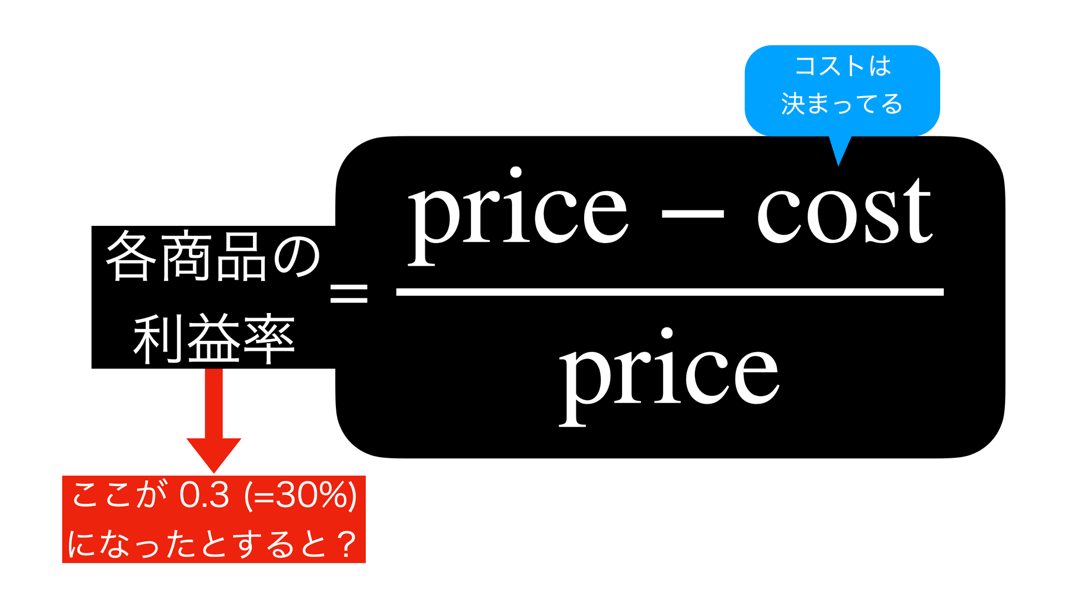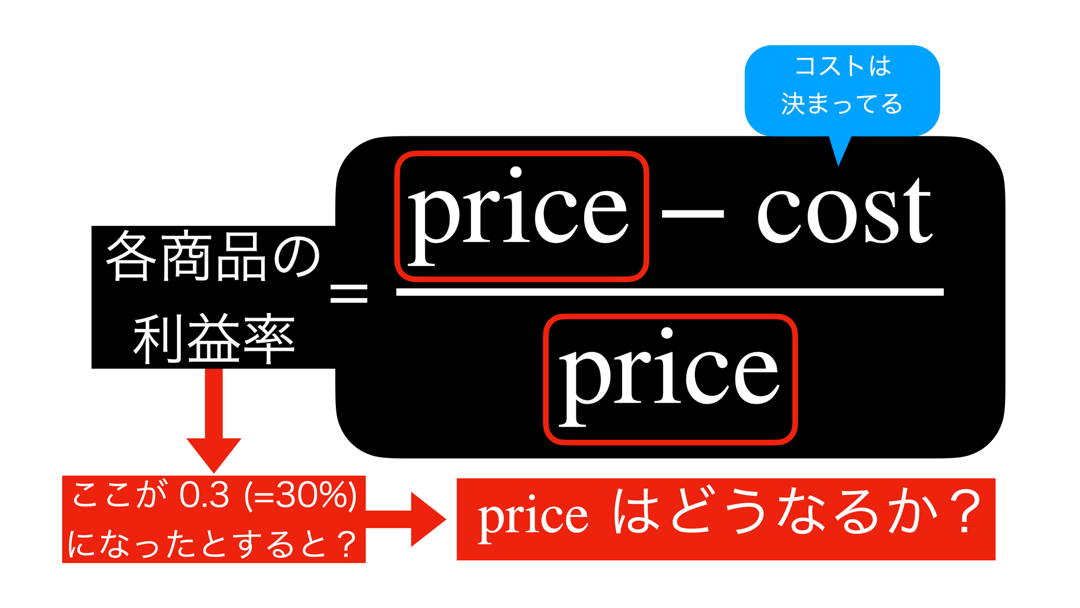
さて、ここで中学校・高校でよくやる、方程式を変形することをしましょう。
いま、price がどうなるか?をみたいので、price = ... という形を目指します。
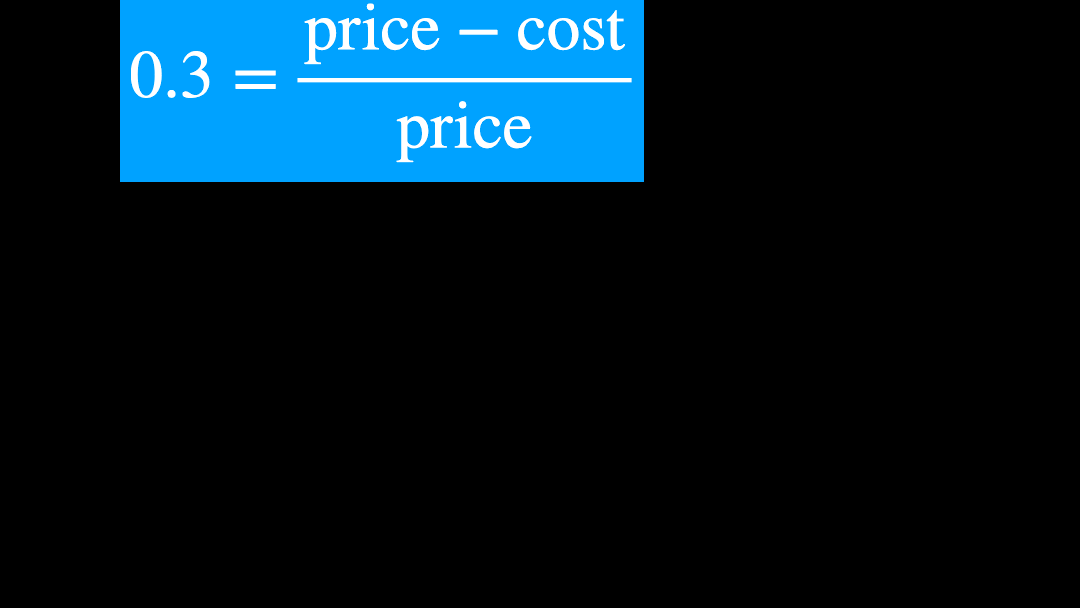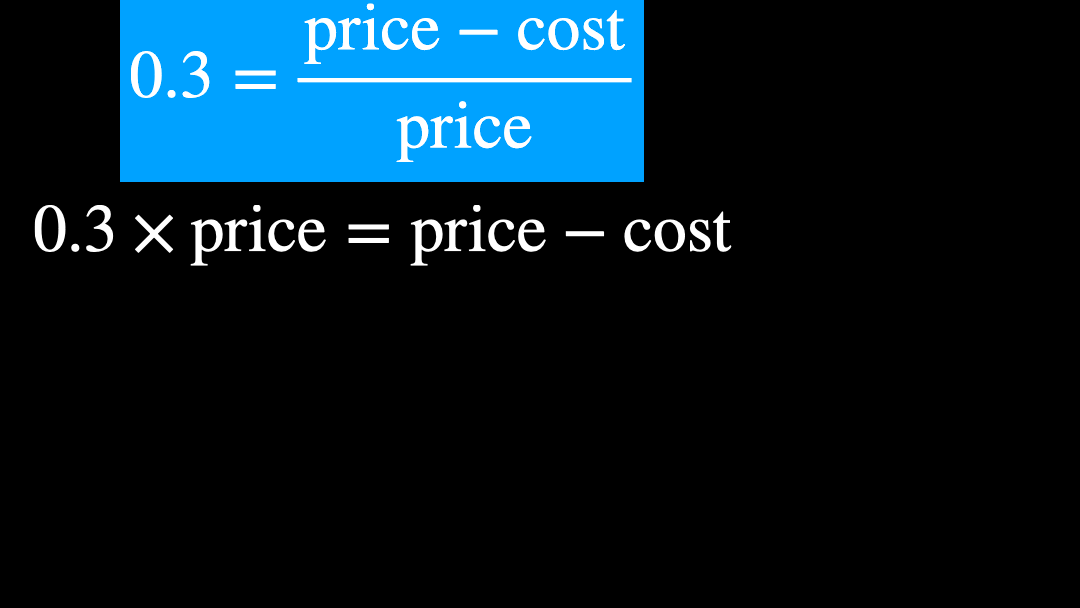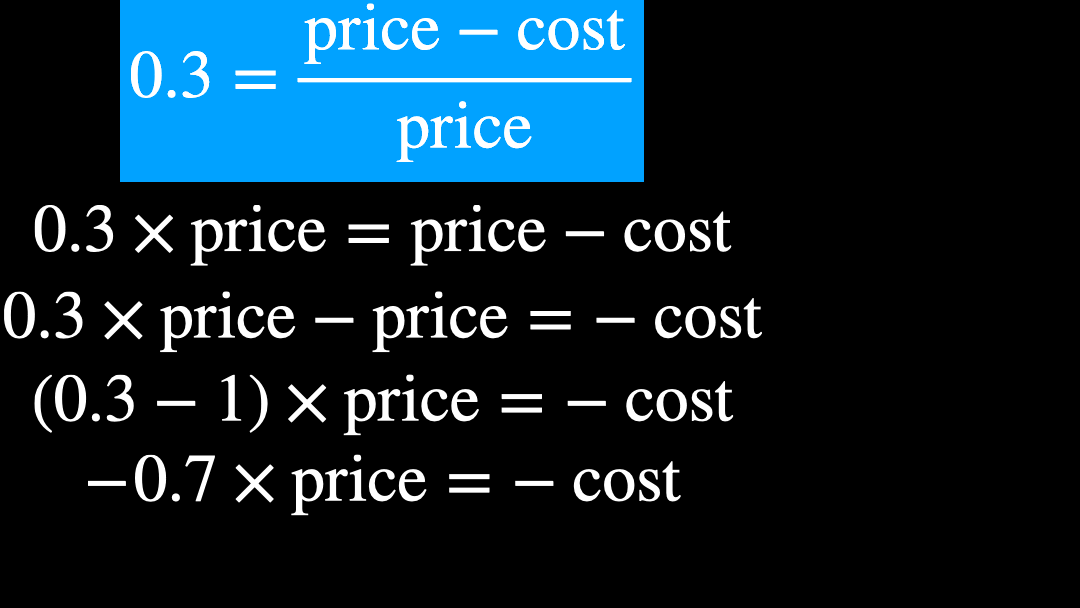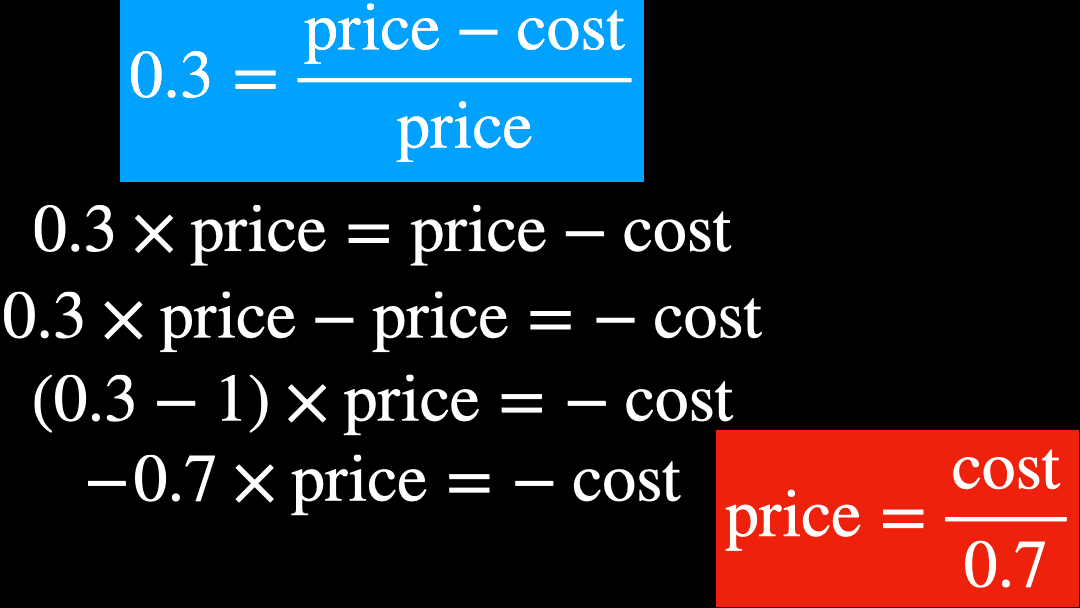
ということで、new_price の計算式で 0.7 で割り算するということと、利益率 30% ということは全く等価であることがわかりました。
単純な計算かもしれませんが、中学校や高校でやってきた程度の意味の重さではないことはよくわかるかと思います。
でも同じ計算式ですし、数学から見ればそれ以上も以下もありません。
単に意味が重たく感じているかそうでないかは数学自体とは全くの無関係だけど、でも数学を実際に使うとはこういうことかなぁと思います。
問66 と 問67 に引き継ぎますのでステップなども含めてそのままにしておいてください。
問66 : 除算結果に対して有効桁数以下を四捨五入する

答案・解説はこちら
です。
問65 では 利益率30% の新しい価格を設定するときに floor 関数を使ったことを覚えているでしょうか。
このステップで使っていたはずです。
この floor 関数は小数点以下を問答無用で消し去る(整数部分だけ残す)効果を持っています ので、要するにそれは「有効桁数以下を切り捨てる」ということ と同じです。
この類の話は3つに分類されます。
- 切り捨て → 問65(前の問題)→ floor
- 四捨五入 → 問66(今の問題)→ 今からやる
- 切り上げ → 問67(次の問題)→ 次にやる
そういうわけですので、floor 関数のところだけ変えれば問題解決ということになります。
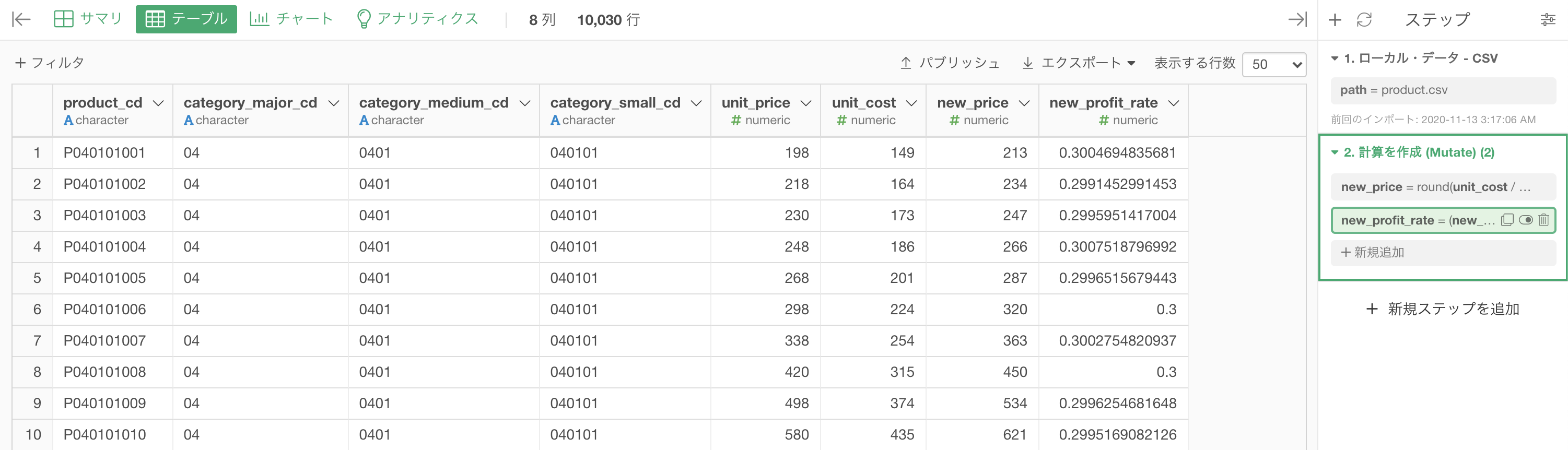
計算式を開くには、そのステップ(の中身)をクリックするのでした。 floor のところを round と書き換えましょう。
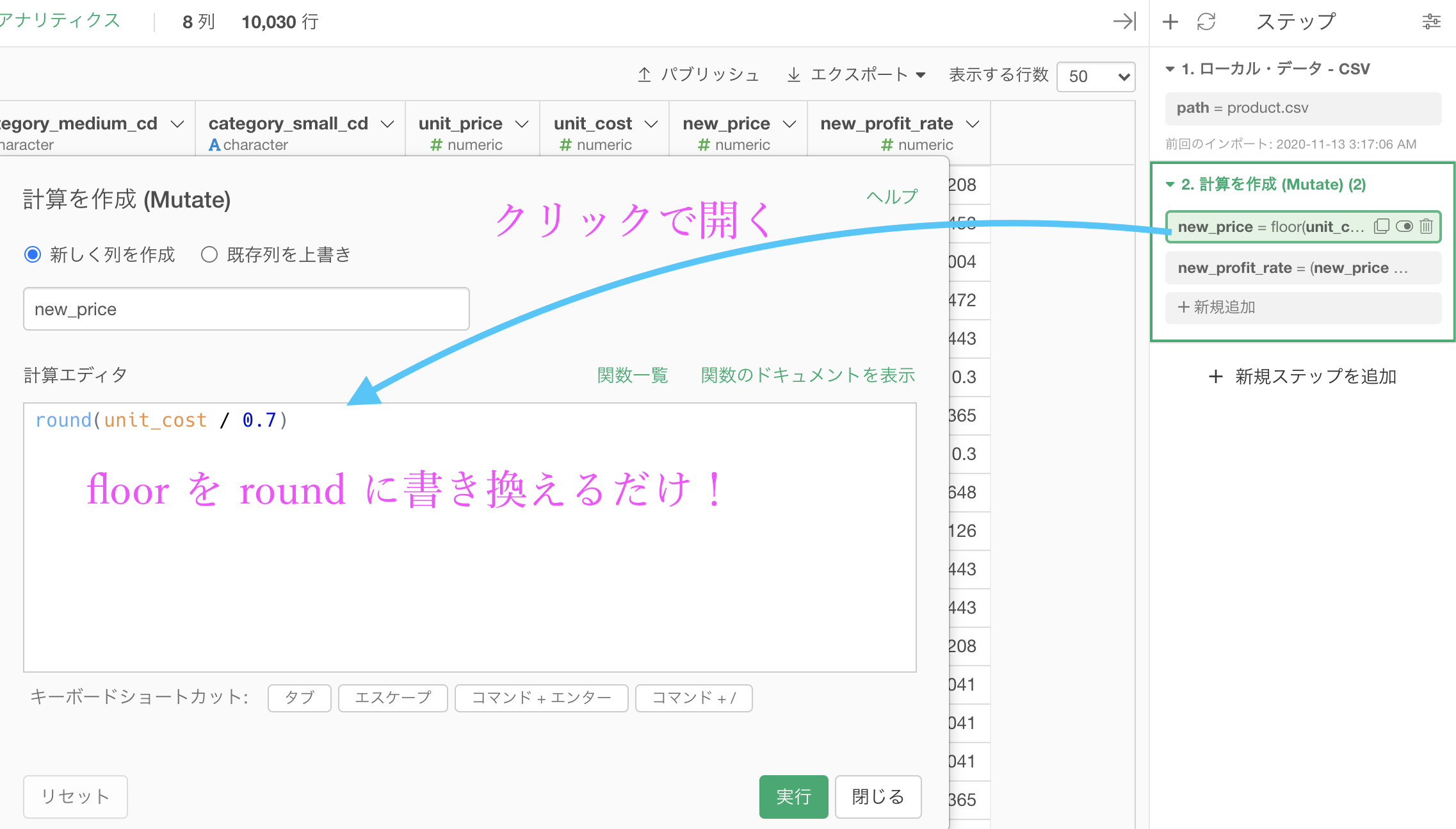
これで実行すればおしまいです。
結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
# 組み込みのroundはNaNでエラーとなるが、numpy.roundはエラーとならない
df_tmp = df_product.copy()
df_tmp['new_price'] = df_tmp['unit_cost'].apply(lambda x: np.round(x / 0.7))
df_tmp['new_profit_rate'] = (df_tmp['new_price'] - df_tmp['unit_cost']) / df_tmp['new_price']
df_tmp.head(10)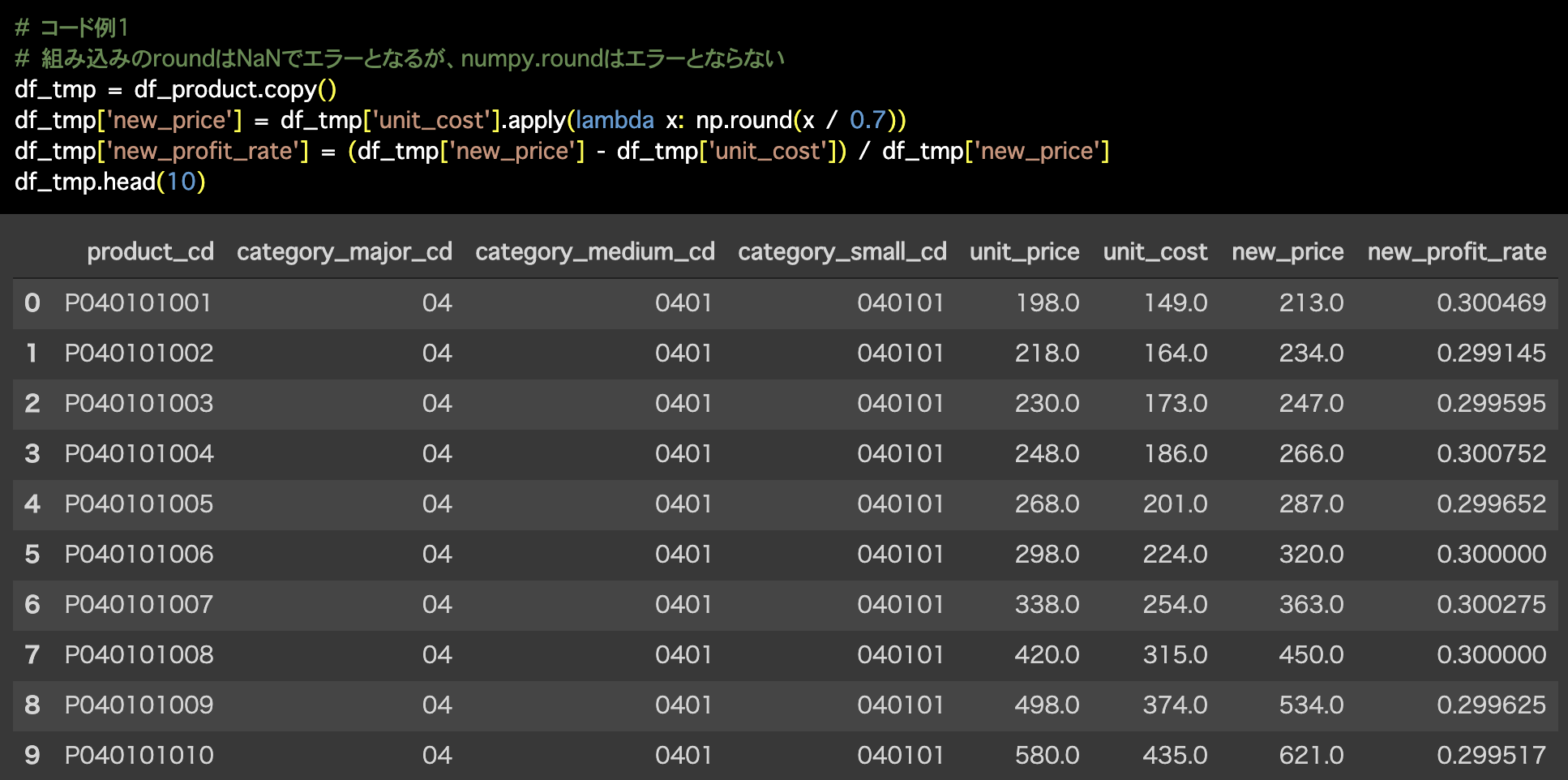
2つ目の解答コードはこのようになっています。
# コード例2
df_tmp = df_product.copy()
df_tmp['new_price'] = np.round(df_tmp['unit_cost'] / 0.7)
df_tmp['new_profit_rate'] = (df_tmp['new_price'] - df_tmp['unit_cost']) / df_tmp['new_price']
df_tmp.head(10)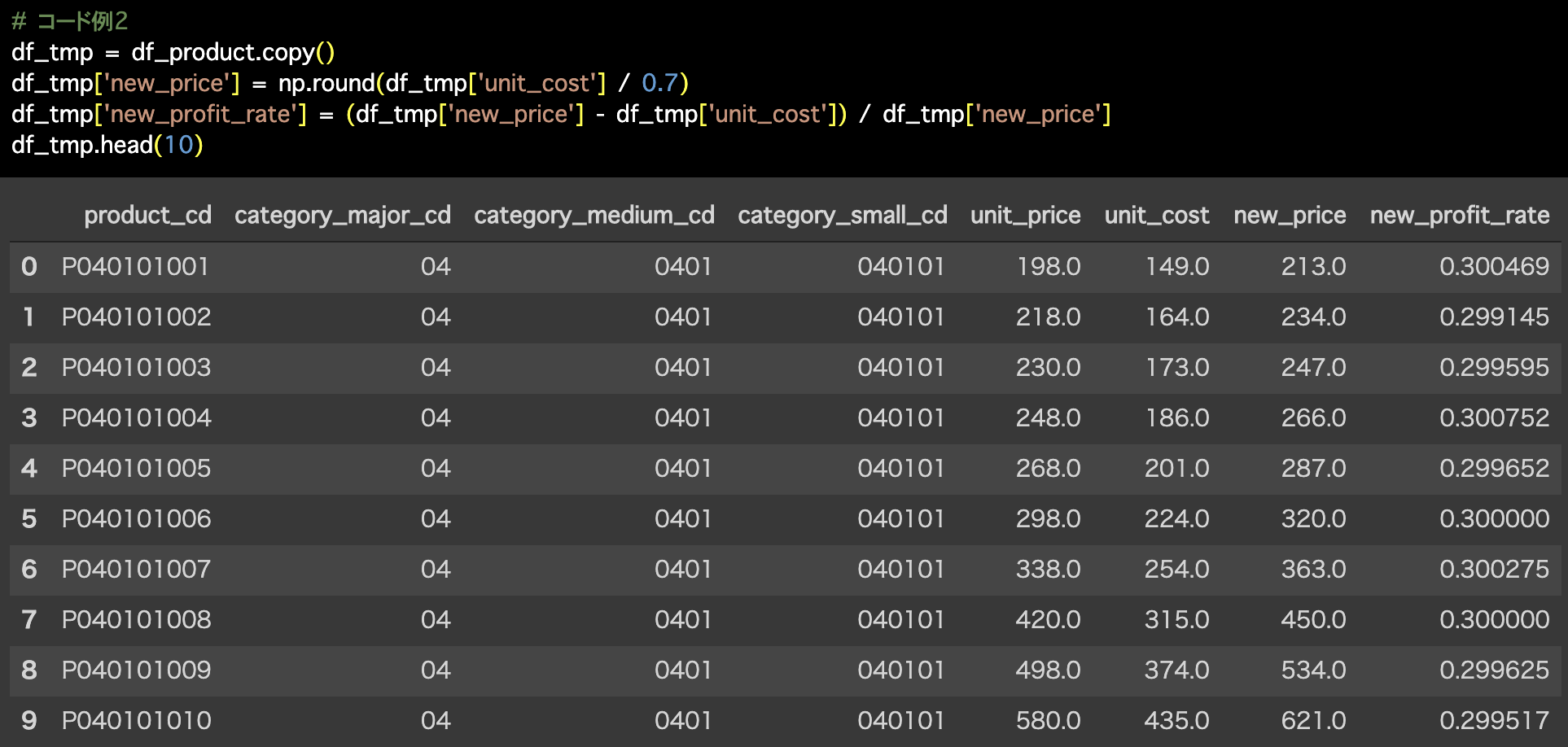
問67 : 除算結果に対して有効桁数以下を切り上げる

答案・解説はこちら
です。
これに関しての説明は 問66 でやっているので、どこが変わるのかは想像つくと思います。
一応確認しておきましょう。
- 切り捨て → 問65(話の背景)→ floor
- 四捨五入 → 問66(前の問題)→ round
- 切り上げ → 問67(今の問題)→ 今からやる
round のところを ceiling と書き換えましょう。
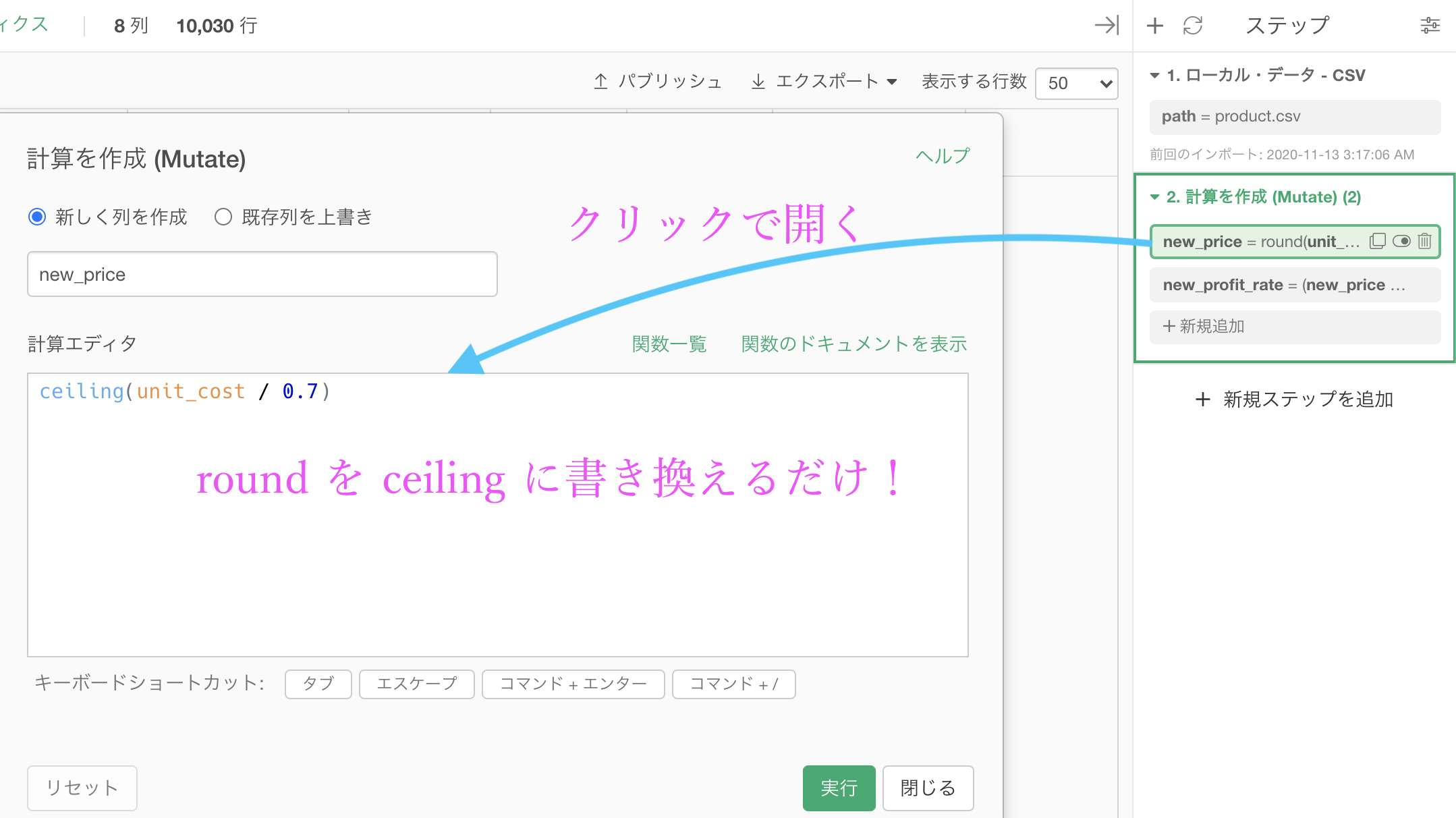
結果はこのようになります。解答と確認しましょう。
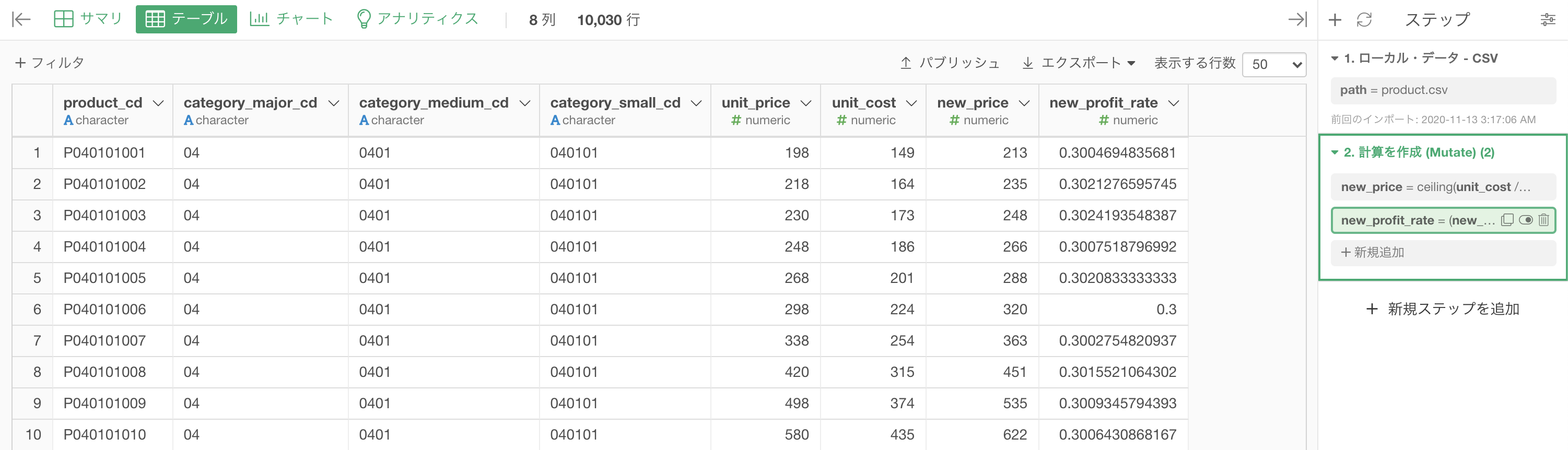
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
# math.ceilはNaNでエラーとなるが、numpy.ceilはエラーとならない
df_tmp = df_product.copy()
df_tmp['new_price'] = df_tmp['unit_cost'].apply(lambda x: np.ceil(x / 0.7))
df_tmp['new_profit_rate'] = (df_tmp['new_price'] - df_tmp['unit_cost']) / df_tmp['new_price']
df_tmp.head(10)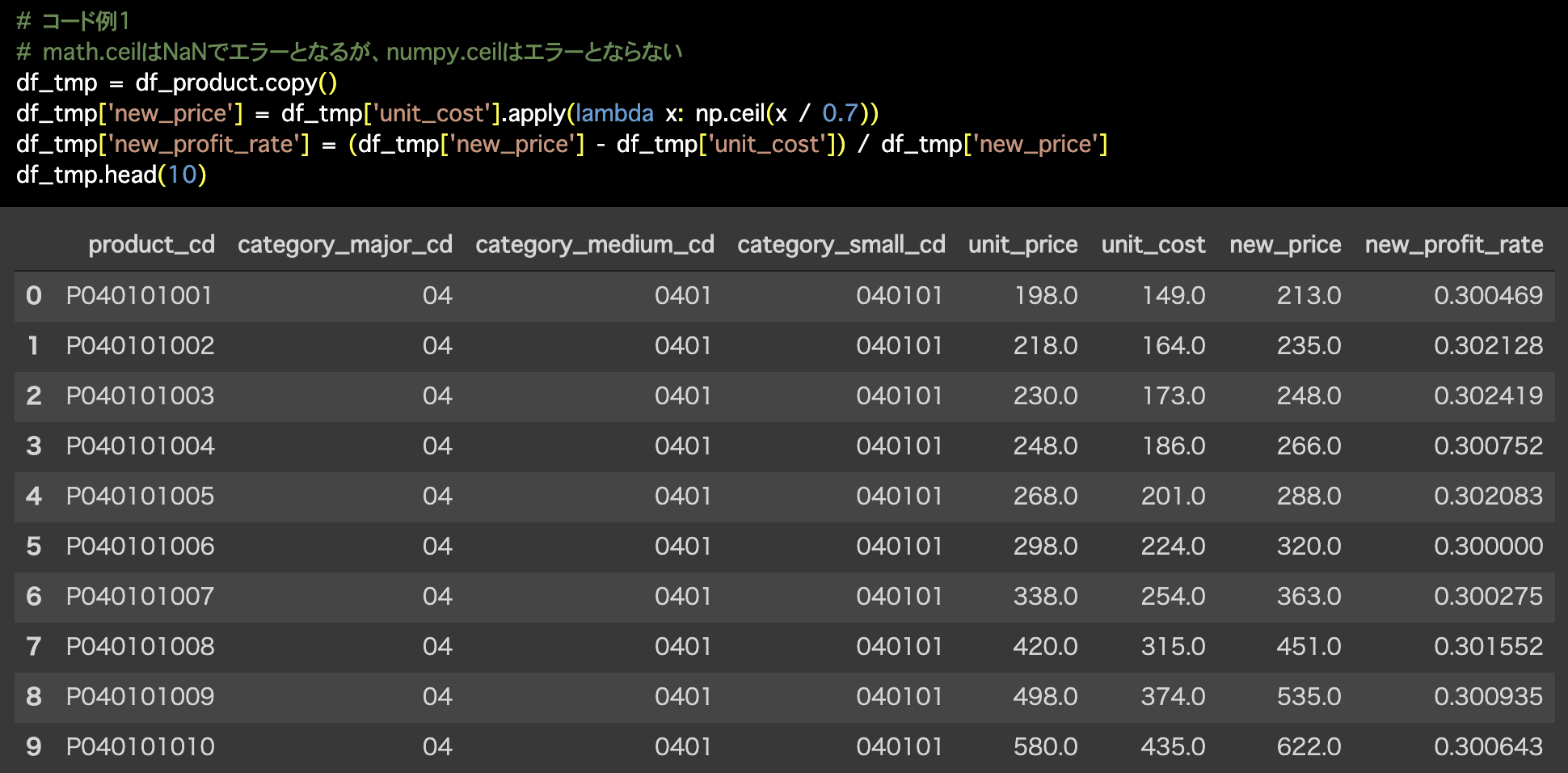
2つ目の解答コードはこのようになっています。
# コード例2
df_tmp = df_product.copy()
df_tmp['new_price'] = np.ceil(df_tmp['unit_cost'] / 0.7)
df_tmp['new_profit_rate'] = (df_tmp['new_price'] - df_tmp['unit_cost']) / df_tmp['new_price']
df_tmp.head(10)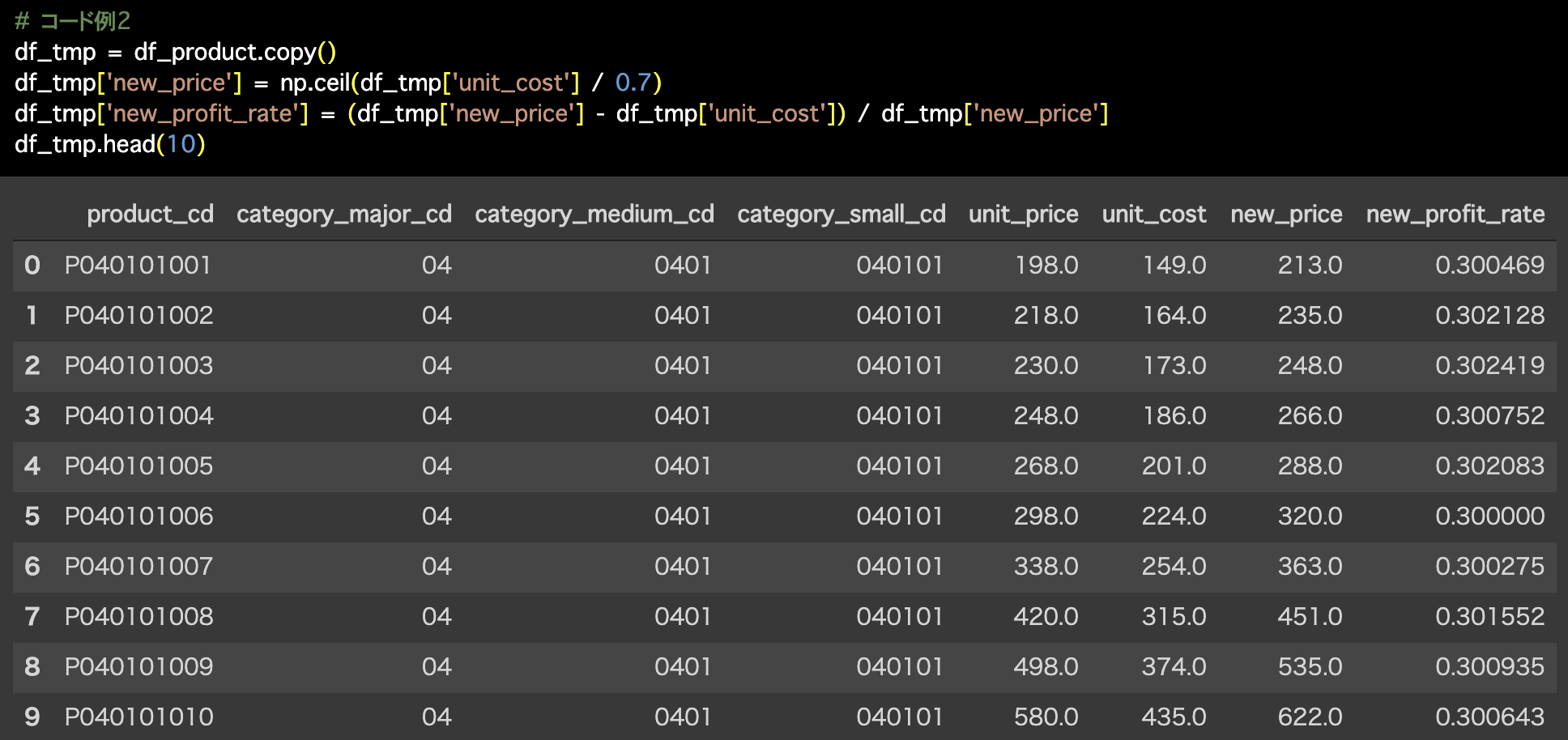
大事なことなので一旦まとめで締めましょう。
まとめ
- 切り捨て → 問65 → floor(フロア)
- 四捨五入 → 問66 → round(ラウンド)
- 切り上げ → 問67 → ceiling(セイリング)
今更ながら読み方を書いてしまい申し訳ありません。これでもう一度理解を深めていただけたら幸いです。
切り捨て、四捨五入、切り上げをするのは小数点第1位なので、3つの結果は全て整数になります。
これもワンポイントとして知っておくと良いと思います。
本番で使うときのために
今回の答案に書いたようにやれば本番でもできそうだ!と思われた方もいるかもしれませんが、意外とコマンドって忘れるもの です。
頻繁にコマンドに触れていない限りは、少しずつ忘れていって「結局また同じサイトを調べてた」なんてことが落ちです。
もちろんそれでも解決してきた方がいらっしゃるので、それが全面的に悪いとは当然思っていません。
だって、同じように解決してきましたから。
しかし、できればそのようなことは減らす努力・工夫を凝らすようにした方が良いとは思っています。
なので、ここでは「直接的に floor・round・ceiling を選択できる」ようにすることで解決を試みます。
- floor 関数
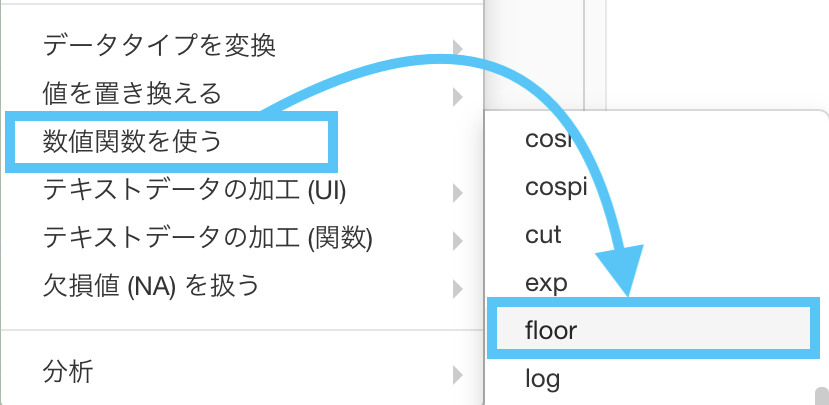
- round 関数
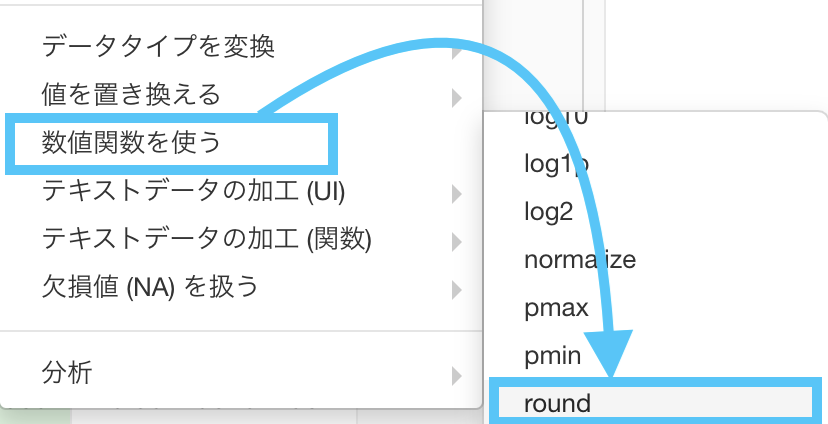
- ceiling 関数
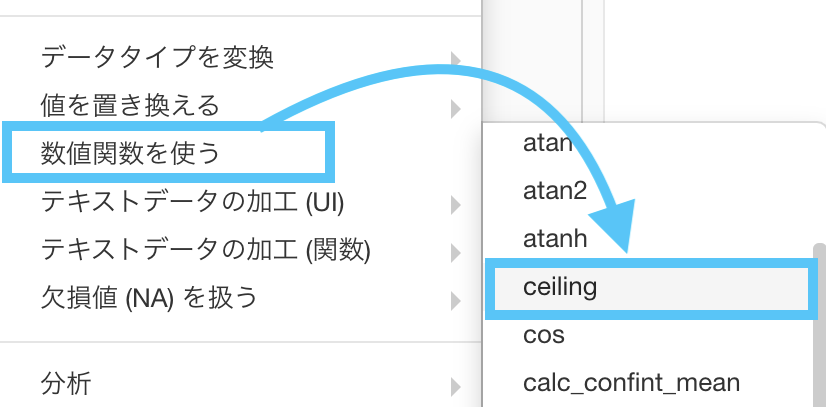
全部ステップメニューの「数値関数を使う」というところから選択できる ということさえ知っておけば、本番でも使えるかと思います。
次の問題で、どれを使えば良いのかを考えながら実装できると身に付いたと思っても良いかもしれません。
問68 : 乗算結果に対して有効桁数以下を切り捨てる

答案・解説はこちら
ことです。tax とは税金の意味です。
10% 込みとはつまり 110% の unit_price を計算するということですよね。
消費者である方が多いはずのでこの感覚は共有できると思います。少なくとも 利益率30% よりは...。
さて、早速 Exploratory で実装していきましょう。
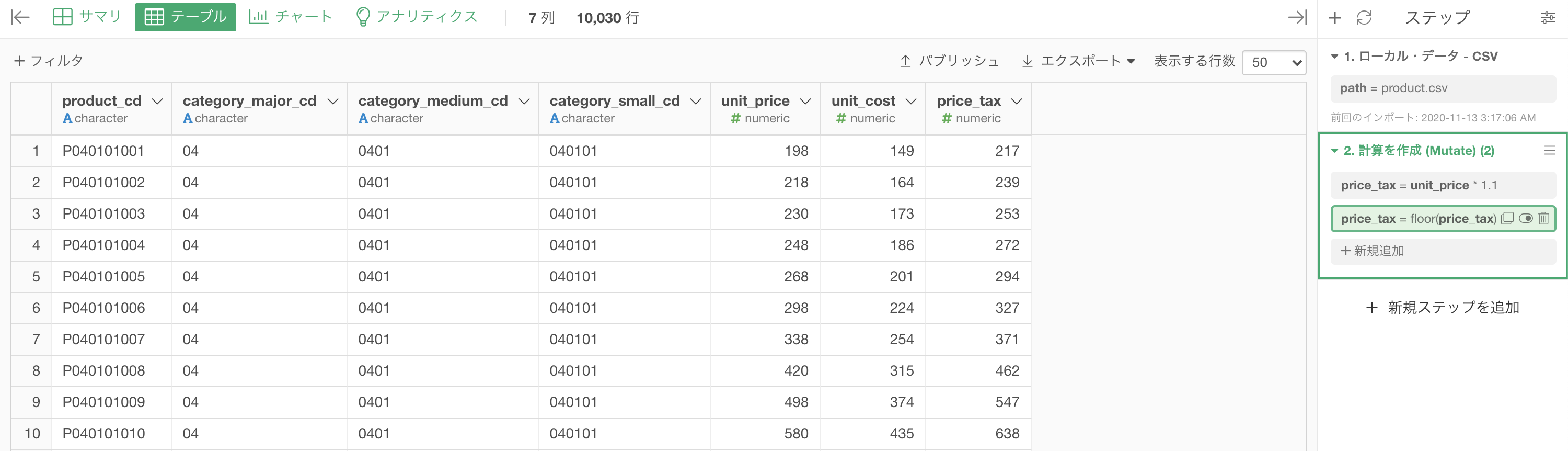
110% とは 1.1 倍することですので、計算を作成(Mutate) して以下のようにします。
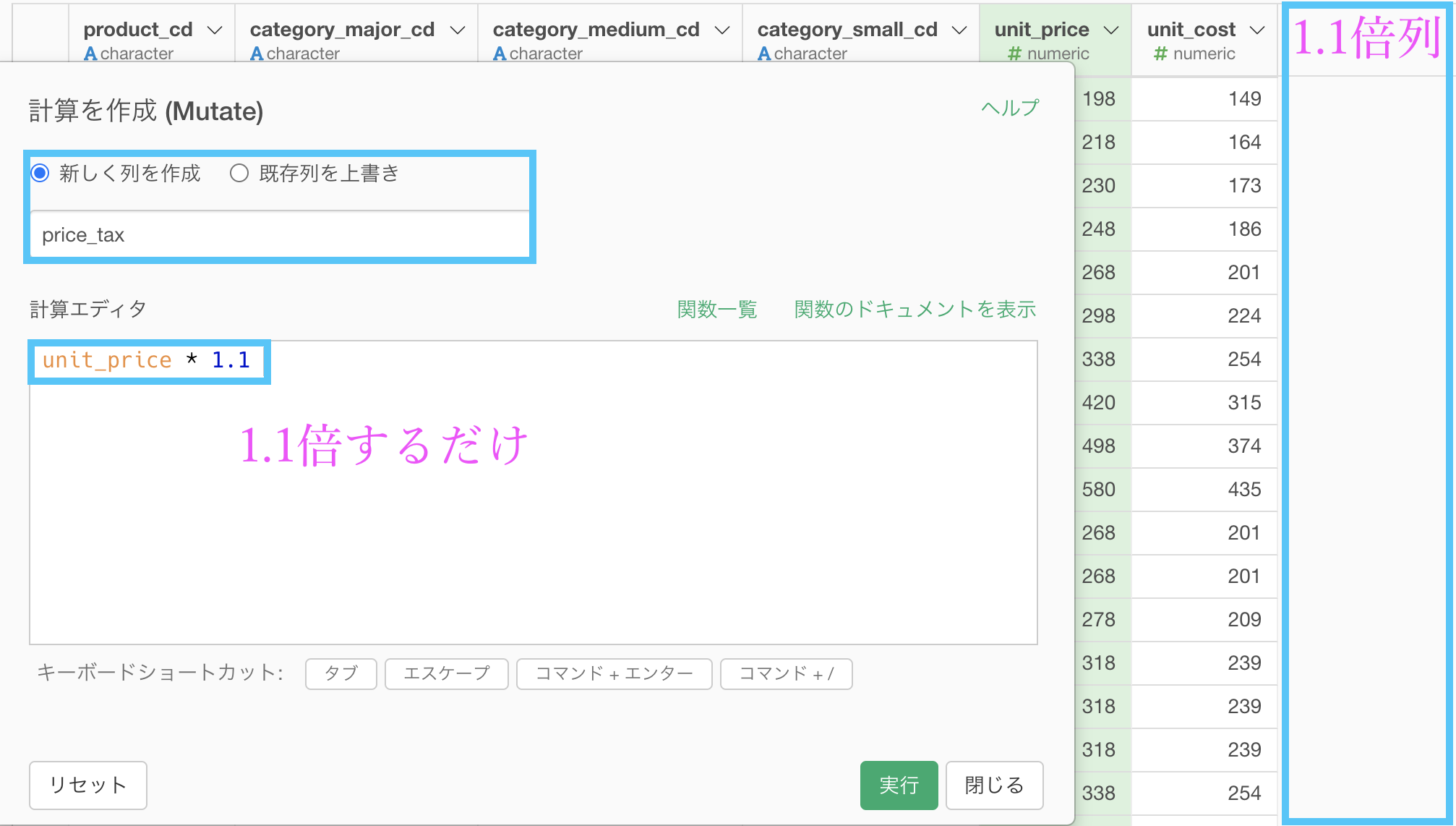
列名が price_tax の、実質 unit_price の 1.1倍 が一番右に出てきた結果になったと思います。

しかし、これでは日本円で正確に払いきることは不可能ですよね。
なぜなら 0.1円 がないからです。
そういうわけなので、ここで 問65 〜 問67 の登場 です。
今回は問題文に「1円未満の端数は切り捨て」と書いてありますので、floor 関数で小数点以下を一気に切り捨ててしまいましょう。
もう実装の仕方については良いと思いますので言葉での説明は省きます。
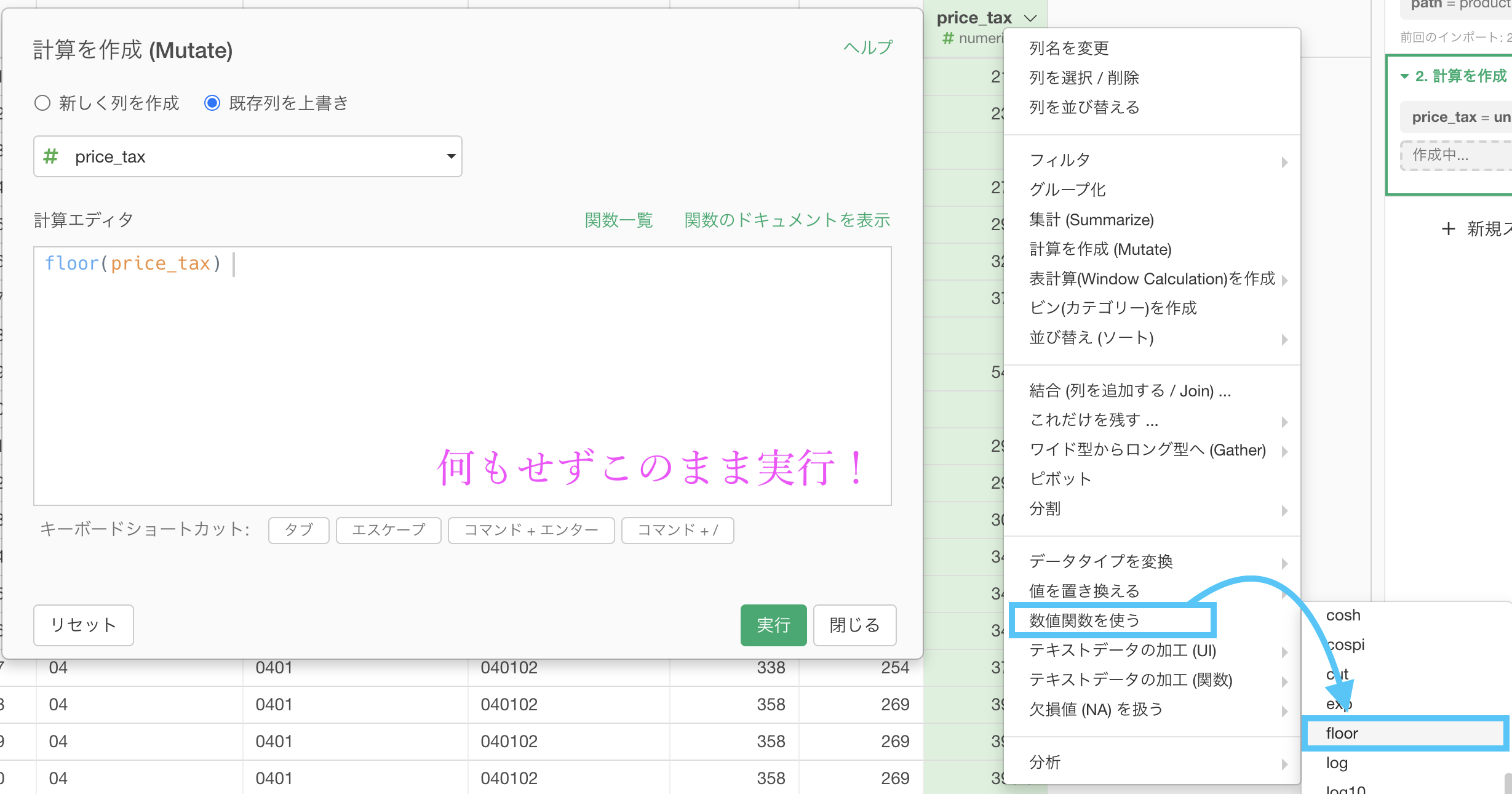
結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
# math.floorはNaNでエラーとなるが、numpy.floorはエラーとならない
df_tmp = df_product.copy()
df_tmp['price_tax'] = df_tmp['unit_price'].apply(lambda x: np.floor(x * 1.1))
df_tmp.head(10)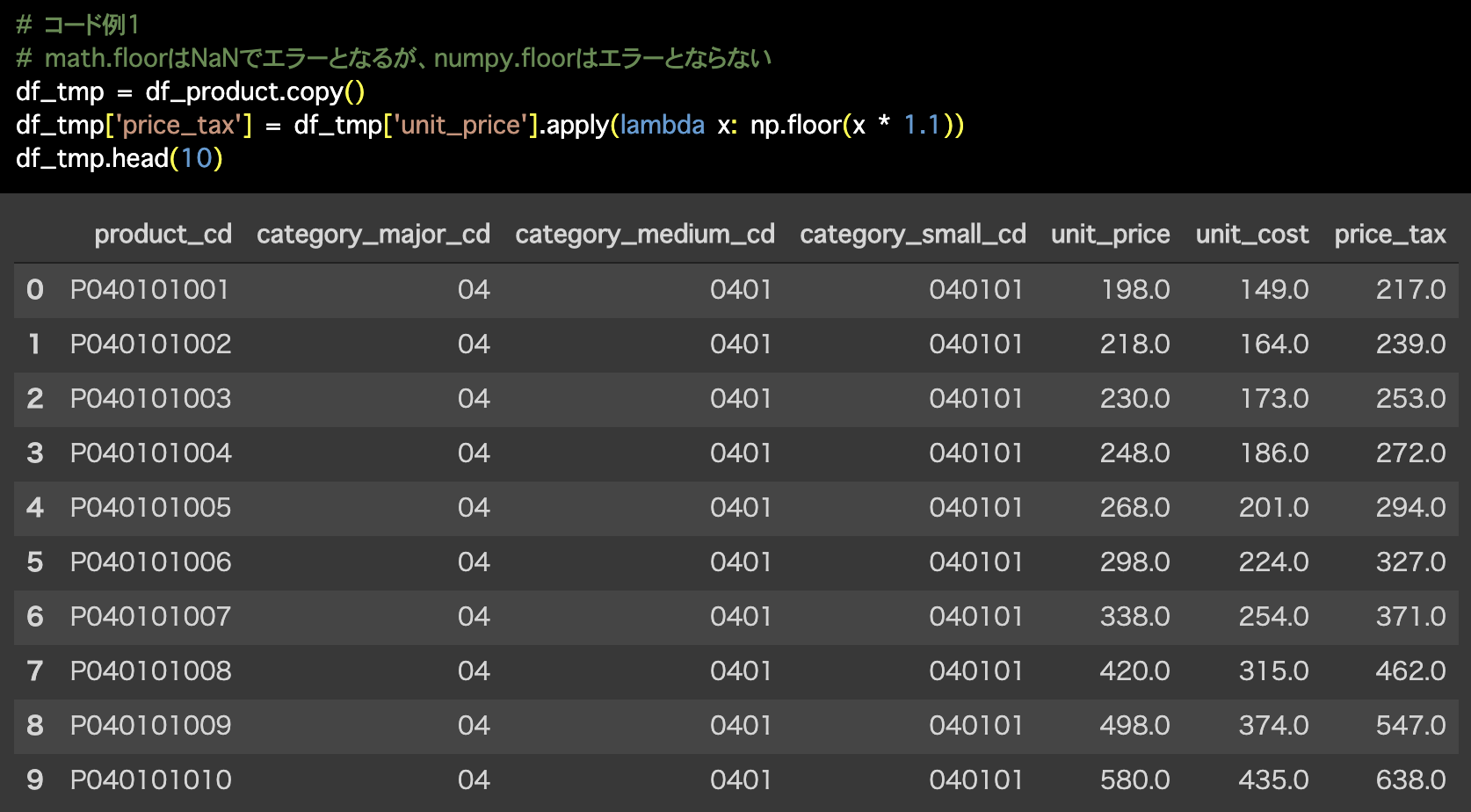
2つ目の解答コードはこのようになっています。
# コード例2
# math.floorはNaNでエラーとなるが、numpy.floorはエラーとならない
df_tmp = df_product.copy()
df_tmp['price_tax'] = np.floor(df_tmp['unit_price'] * 1.1)
df_tmp.head(10)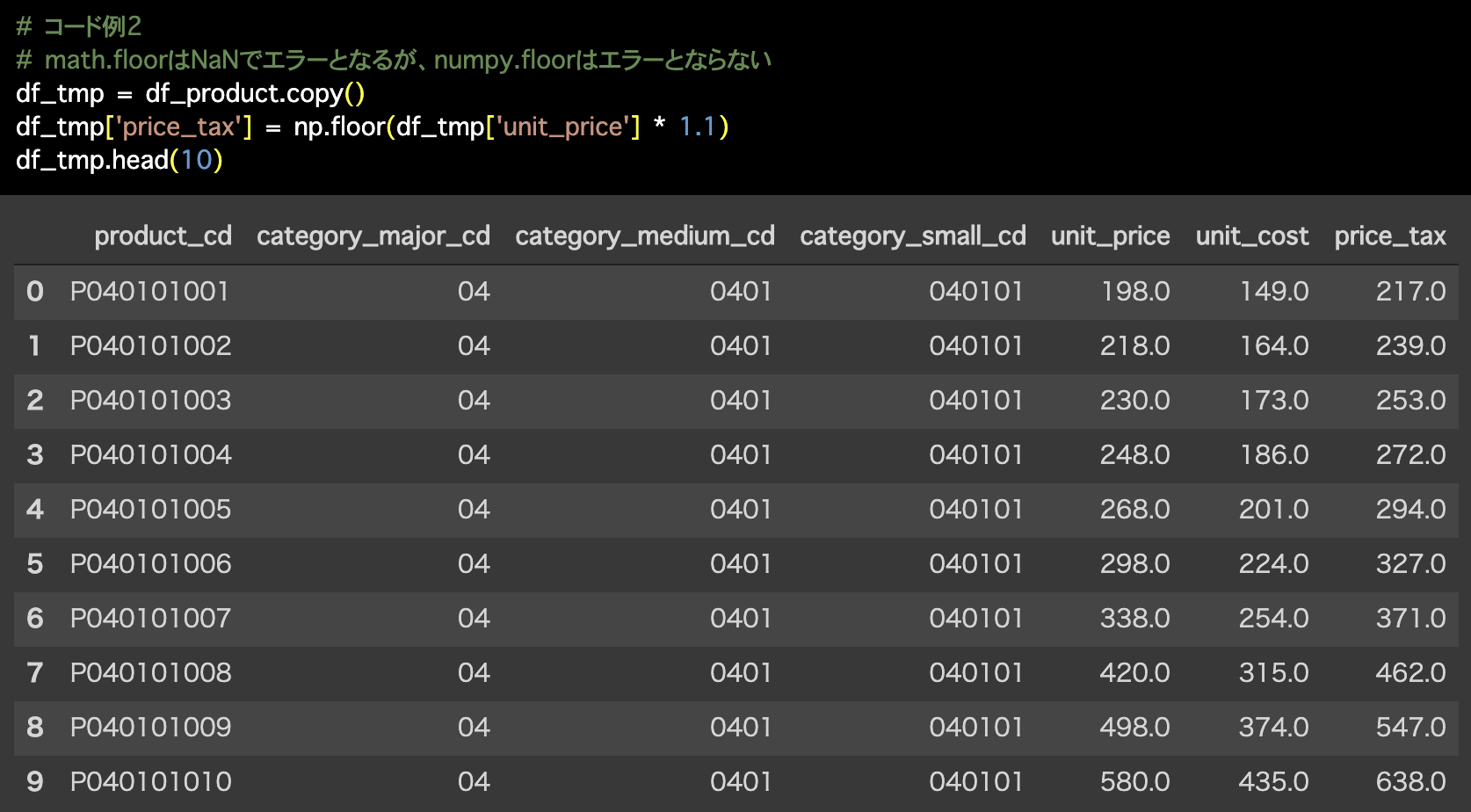
書き方いろいろ
Pythonはそこまでいろいろな書き方ができないかもしれませんが、R(あるいはExploratory)では書き方がいくつかあります。
ここでは3つほど紹介しておきましょう。どれも同じ実装ですが、時と場合によって「読みやすさ」は異なってくると思います。
また、コードが長くなるとどれが良い・人に教える際にはどれが良いということを考えると、結局は「コレ!」が無いと思います。
- 2つで書く
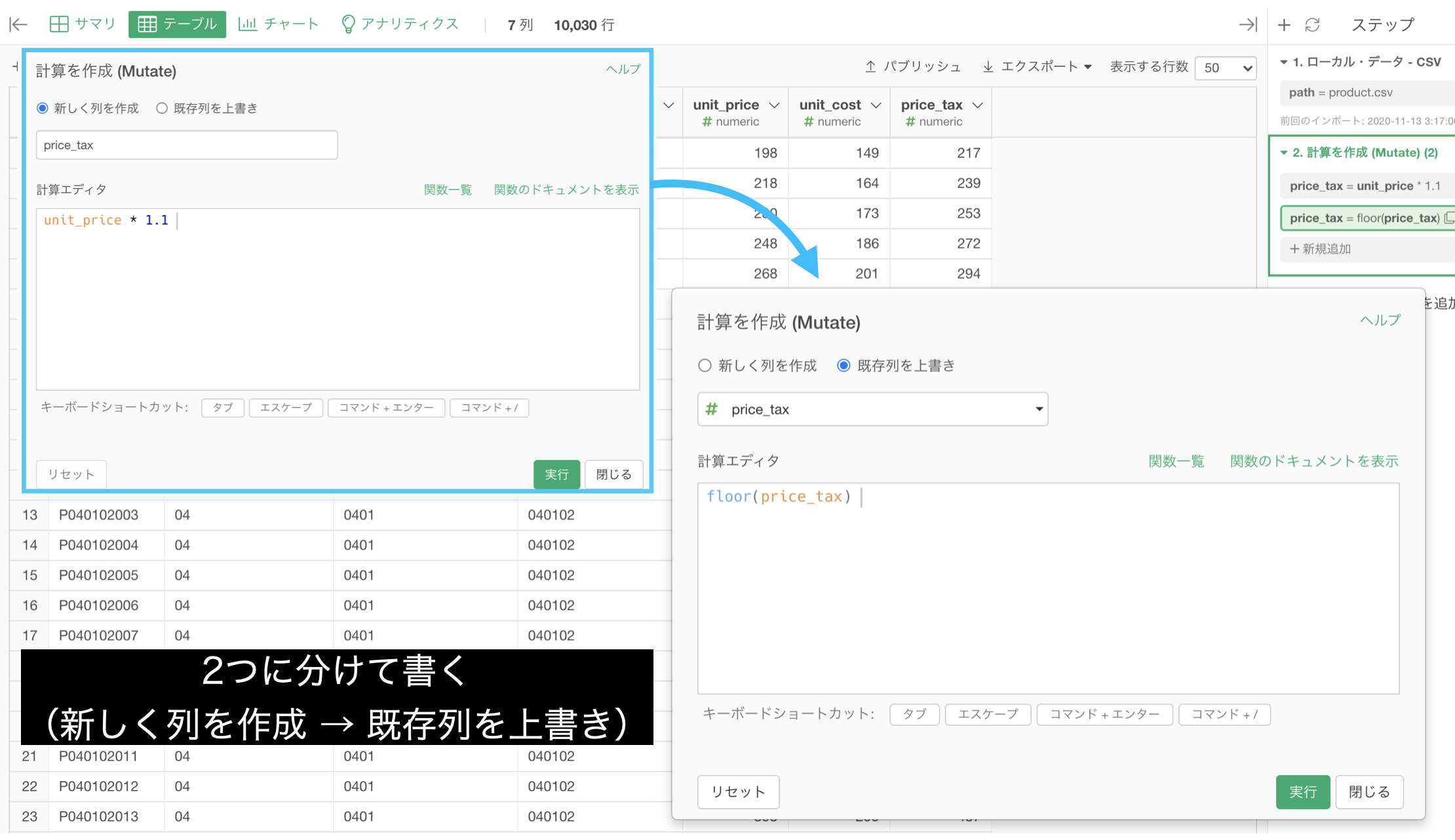
- 1つの式の中に正しく書く
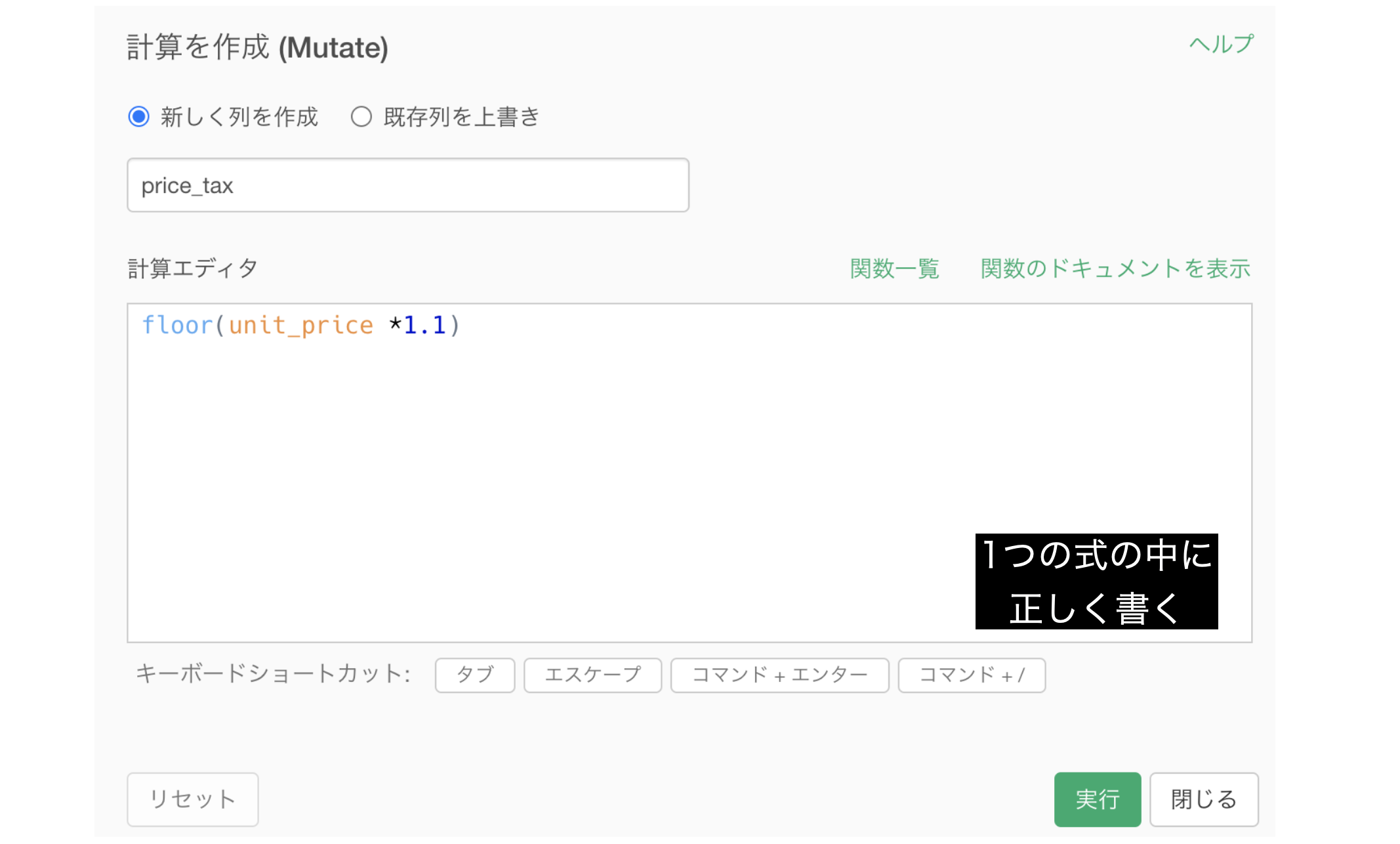
- パイプ演算子
%>%を使って書く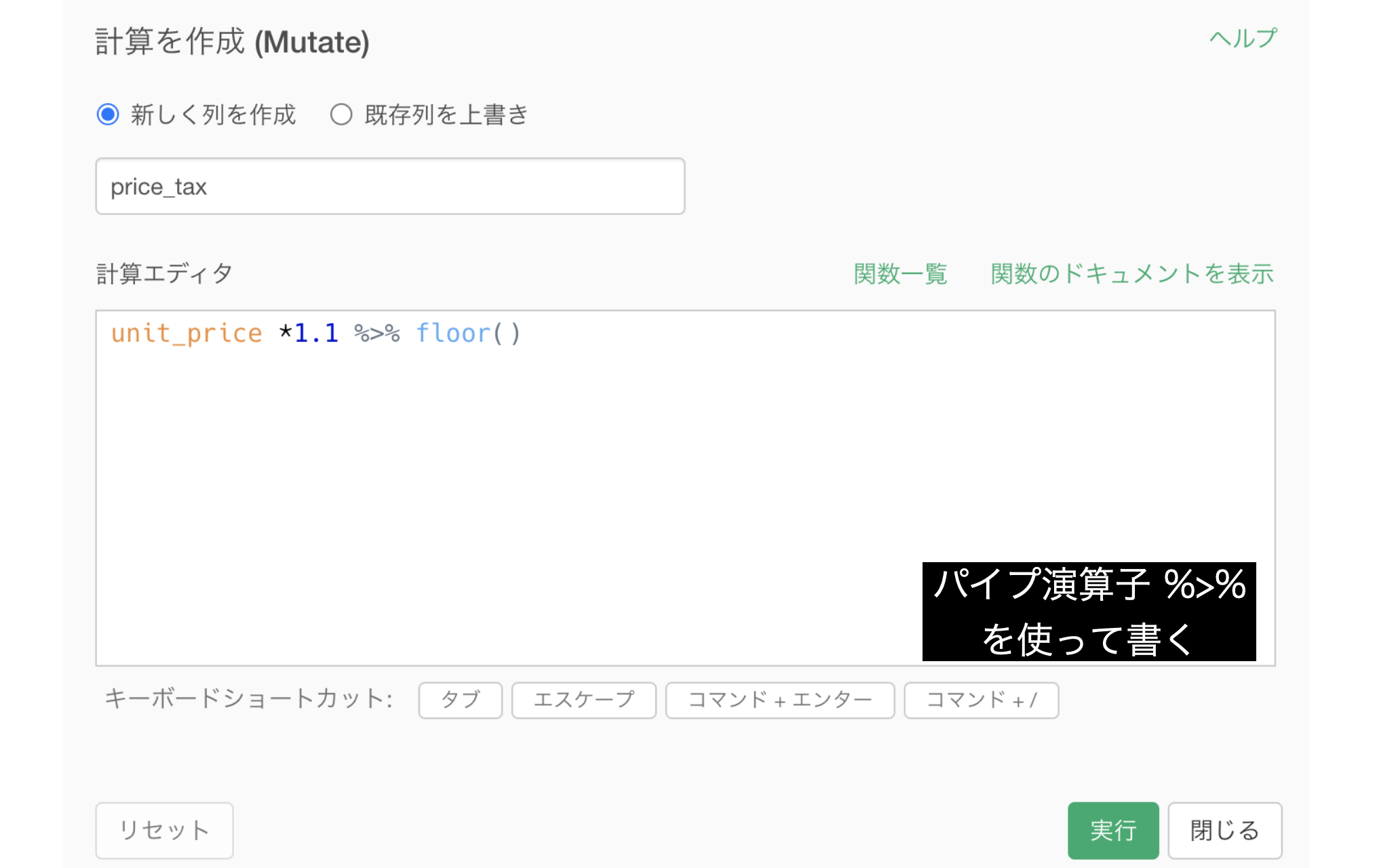
3つとも全て同じ結果になるのですが、ぜひどれもまずやってみることをオススメします。
個人的には3番目の %>% を使った書き方はオススメです。
この書き方が他の2つと異なるのは what(何を)ではなく、How(どのように)を記述していくだけだからです。
そのため、floor()のなかに 何も入っていなくても 動いています。
また、Exploratory もステップとステップの間には全て %>% を使って動いていますので、やはり 3番目 の書き方は慣れておくのが良いと思います。
いきなり 3番目 の使い方をやろうするよりかは...
すぐ慣れることは難しいと思いますが、参考文献としてもオススメとしても Rユーザのための RStudio〈実践〉入門 tidyverse によるモダンな分析フローの世界 が個人的には最初に挙げられます。

ぜひ練習してみましょう。その代わり %>% が出てくる 2章くらいまでは読み進める気力がないと門前払いされます。
個人的にはとても読みやすい本だと思います。少なくとも数学書よりは断然読みやすいでしょう。
問69 : 集計結果から割合を計算する

答案・解説はこちら
ここでやることは
です。
今までの問題で 1度以上 は経験したものがほとんどですので、チャレンジ的にやっていただいても良いかと思います。
ボキャ貧の言葉で表現しても何をしたいのかわからないかもしれませんので、今回は先に結果(イメージ)を見てから処理を行うことにしましょう。
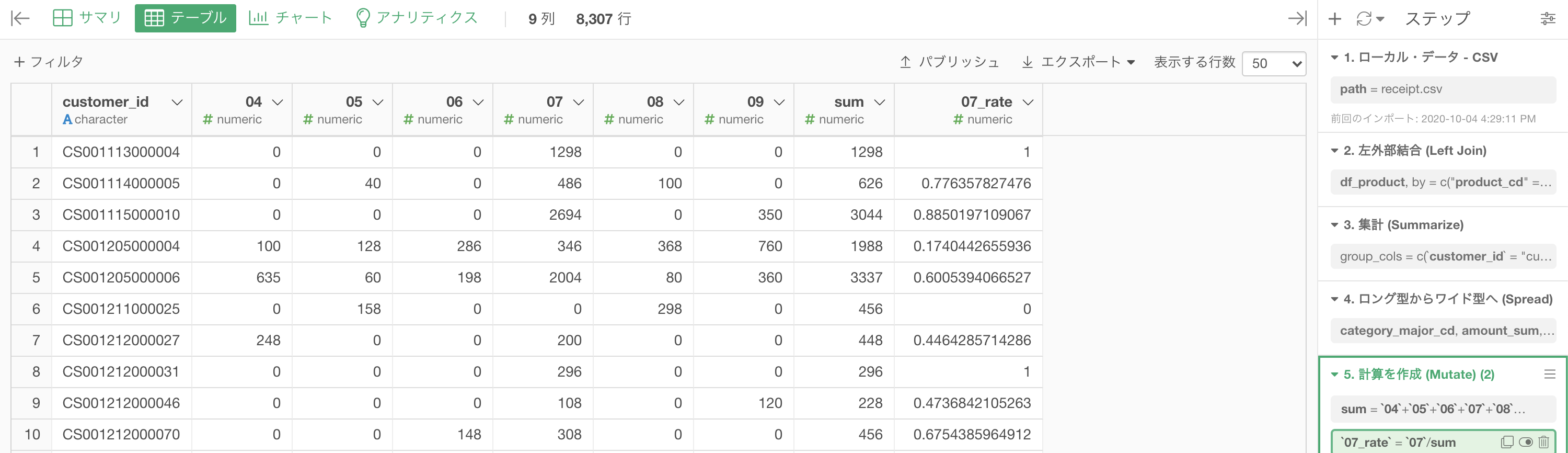
結果となるイメージはこのようになっています。
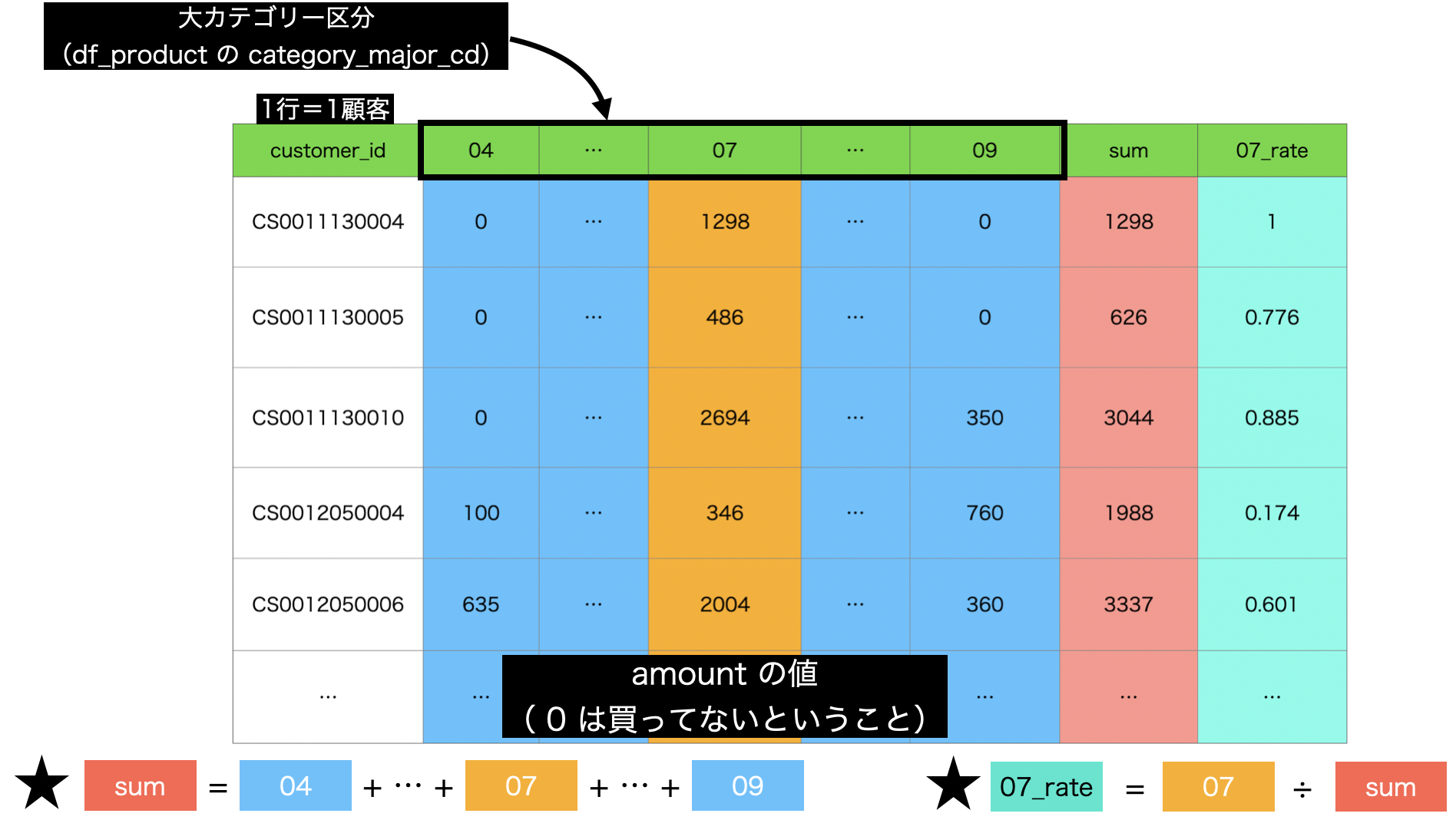
この結果を作るためにやるべきことは以下のような流れです。
- customer_id と 04 〜 09 までを頑張って作る
- sum と 07_rate(07だけの割合)を計算を作成 (Mutate) で作る
見た目で 1番目 ができれば 2番目 はすぐ終わりそう(と感じるはずです)なので、要するに前処理のメインは 1番目 ということ になります。
ではそろそろ Exploratory で実装していきましょう。
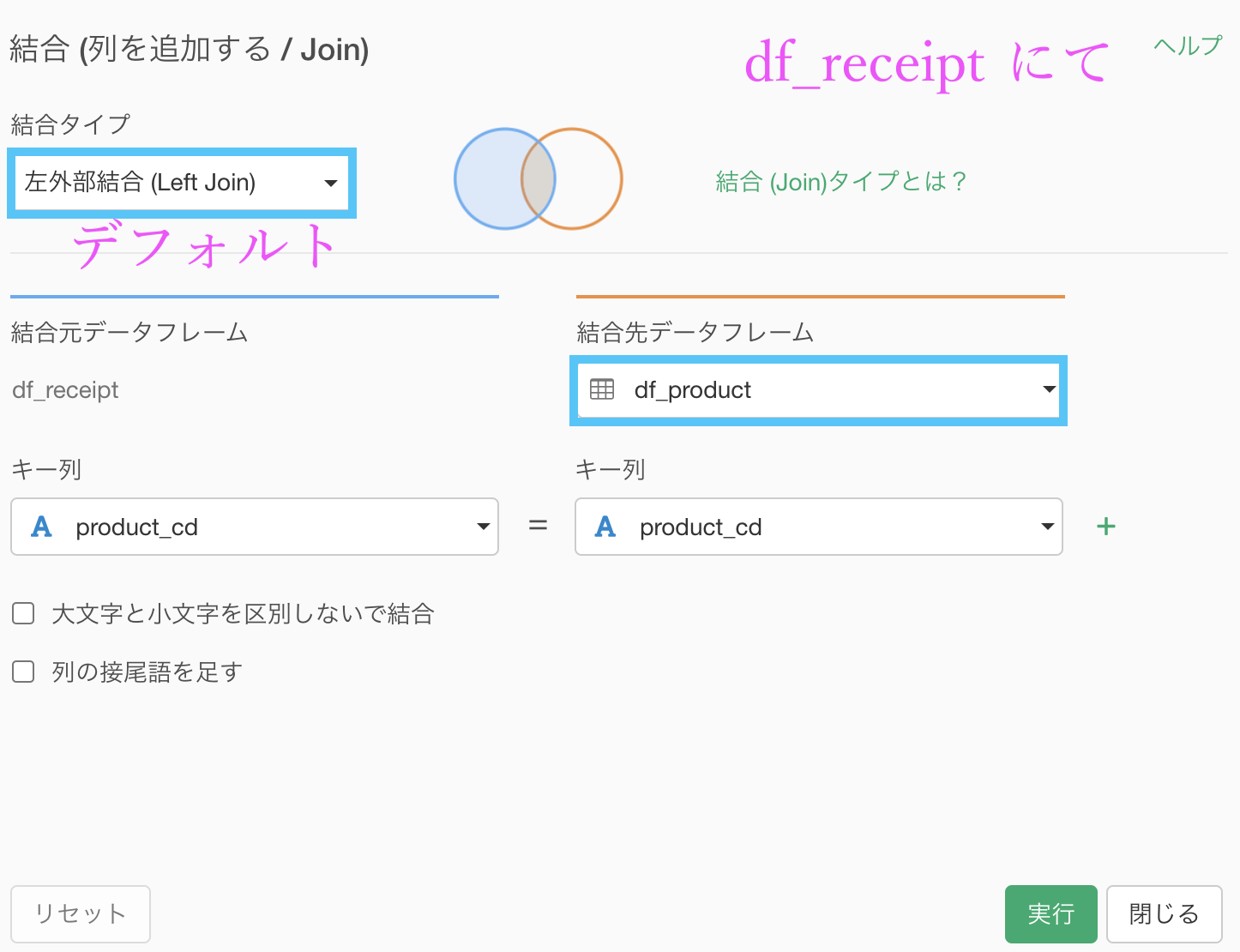
まずは問題文にあるように df_receipt と df_product を結合させましょう。
下にあるように、df_receipt を開いて df_product を左外部結合させます。
次にやることは集計 (Summarize) です。以下のように集計しましょう
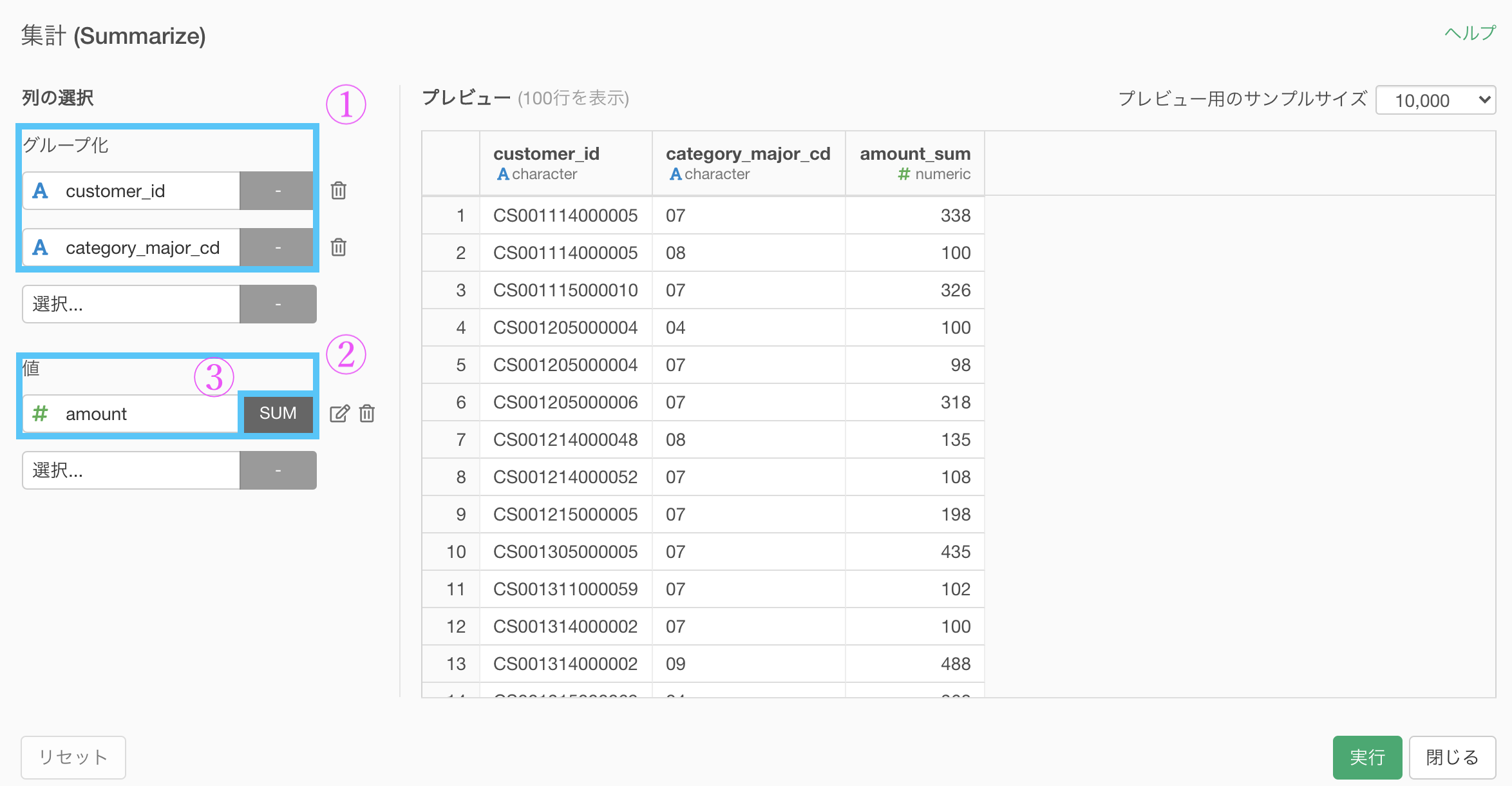
グループ化 : customer_id と category_major_cd
値 : amount 計算 : 合計(sum)少し時間はかかったかもしれませんが、以下のような画面になったかと思います。

まだゴールの形には遠いかもしれませんが、次の処理で一気にゴールに近づきます。
次の処理は「ロング型からワイド型へ (Spread) 」です。ゴールの形(特に列名)を見て、きっとワイド型にするのかな?と思った方もいるかもしれません。
以下のような操作で実行しましょう。
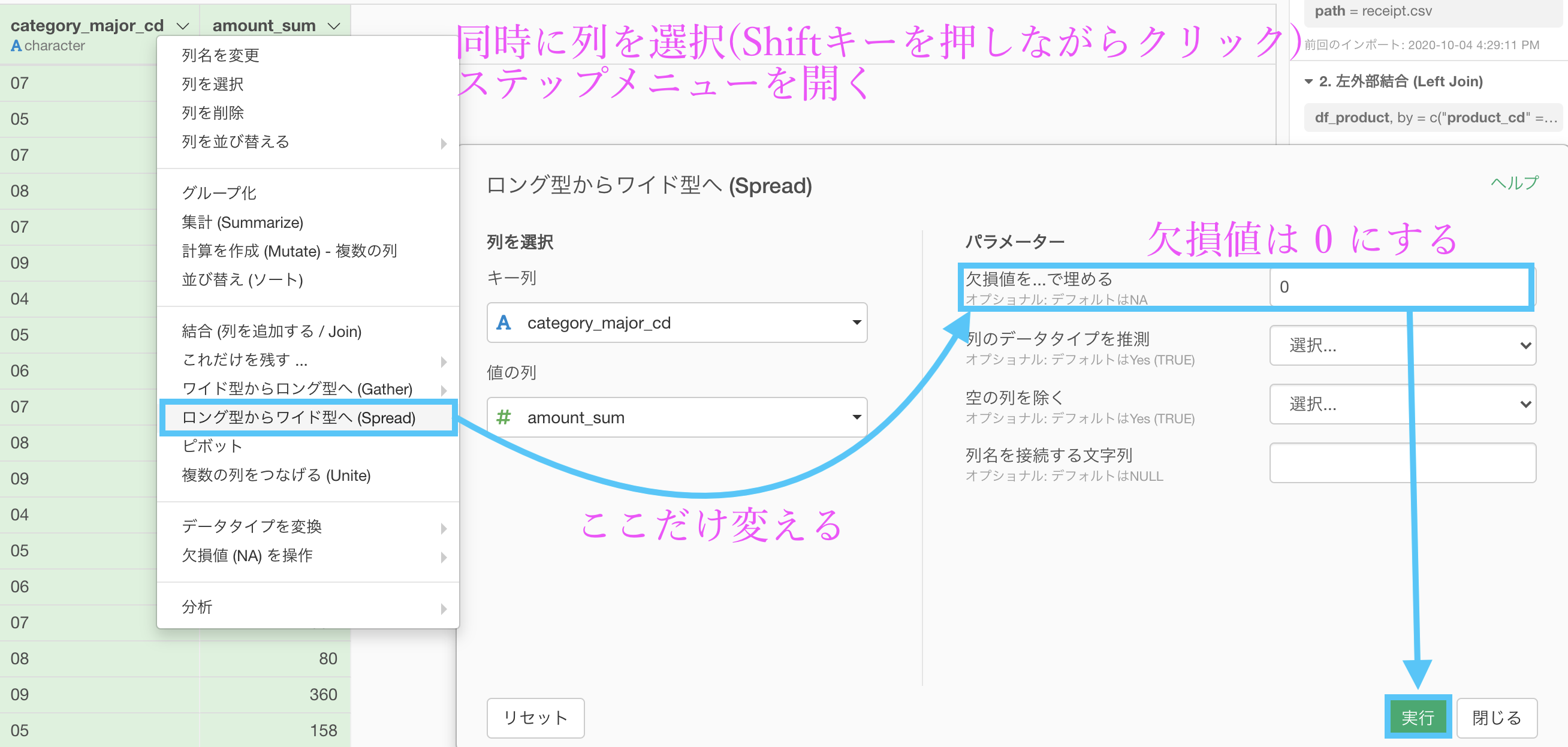
これで customer_id と 04 〜 09 までを頑張って作る処理は終わり です。
つまり、メインはほぼ終わっています。
まずは sum の列を作りましょう。
最初に見たときのように「sum」の列は 04 〜 09 までの列を(横に)足したものでした。
ステップメニューから、計算を作成 (Mutate) でいつものように計算エディタを出します。
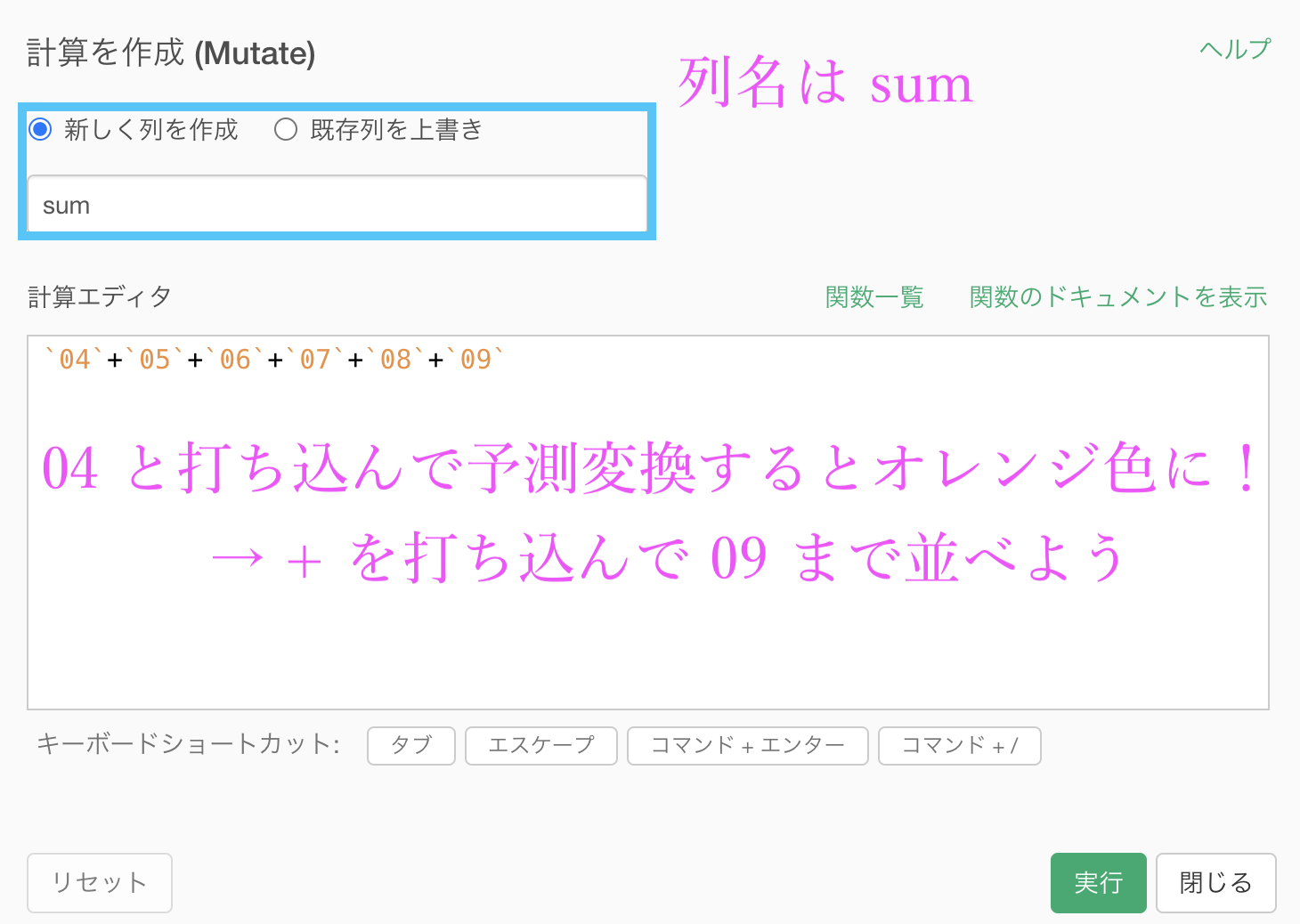
多少面倒かもしれませんが、Exploratory の計算エディタには予測変換がついていますので「04」と打ち込んだだけで列名が出てきます。
オレンジ色になったら列を選べたことになります。
あとは「 + 」を打ち込めば次の列を予測変換してくれますので、結構楽に打ち込むことができるはずです。
一応コピペ用に書いておきます。
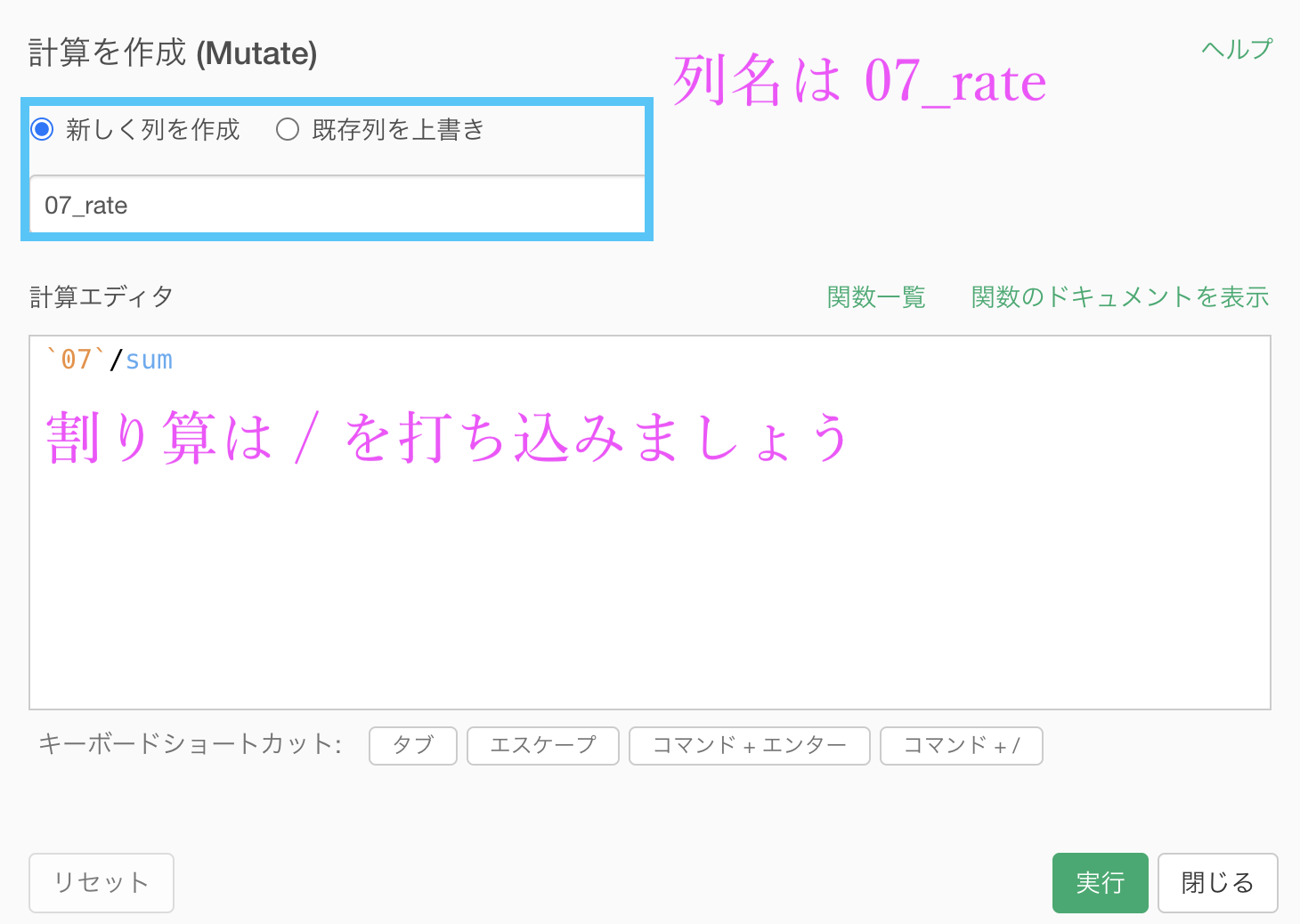
`04`+`05`+`06`+`07`+`08`+`09`これで実行したら、次は 07_rate の列を作りましょう。
07_rate は 07 ÷ sum のことでしたから、これも計算を作成 (Mutate) から計算エディタを出せば大丈夫です。
結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
1つ目の解答コードはこのようになっています。
# コード例1
df_tmp_1 = pd.merge(df_receipt, df_product,
how='inner', on='product_cd').groupby('customer_id').agg({'amount':'sum'}).reset_index()
df_tmp_2 = pd.merge(df_receipt, df_product.query('category_major_cd == "07"'),
how='inner', on='product_cd').groupby('customer_id').agg({'amount':'sum'}).reset_index()
df_tmp_3 = pd.merge(df_tmp_1, df_tmp_2, how='inner', on='customer_id')
df_tmp_3['rate_07'] = df_tmp_3['amount_y'] / df_tmp_3['amount_x']
df_tmp_3.head(10)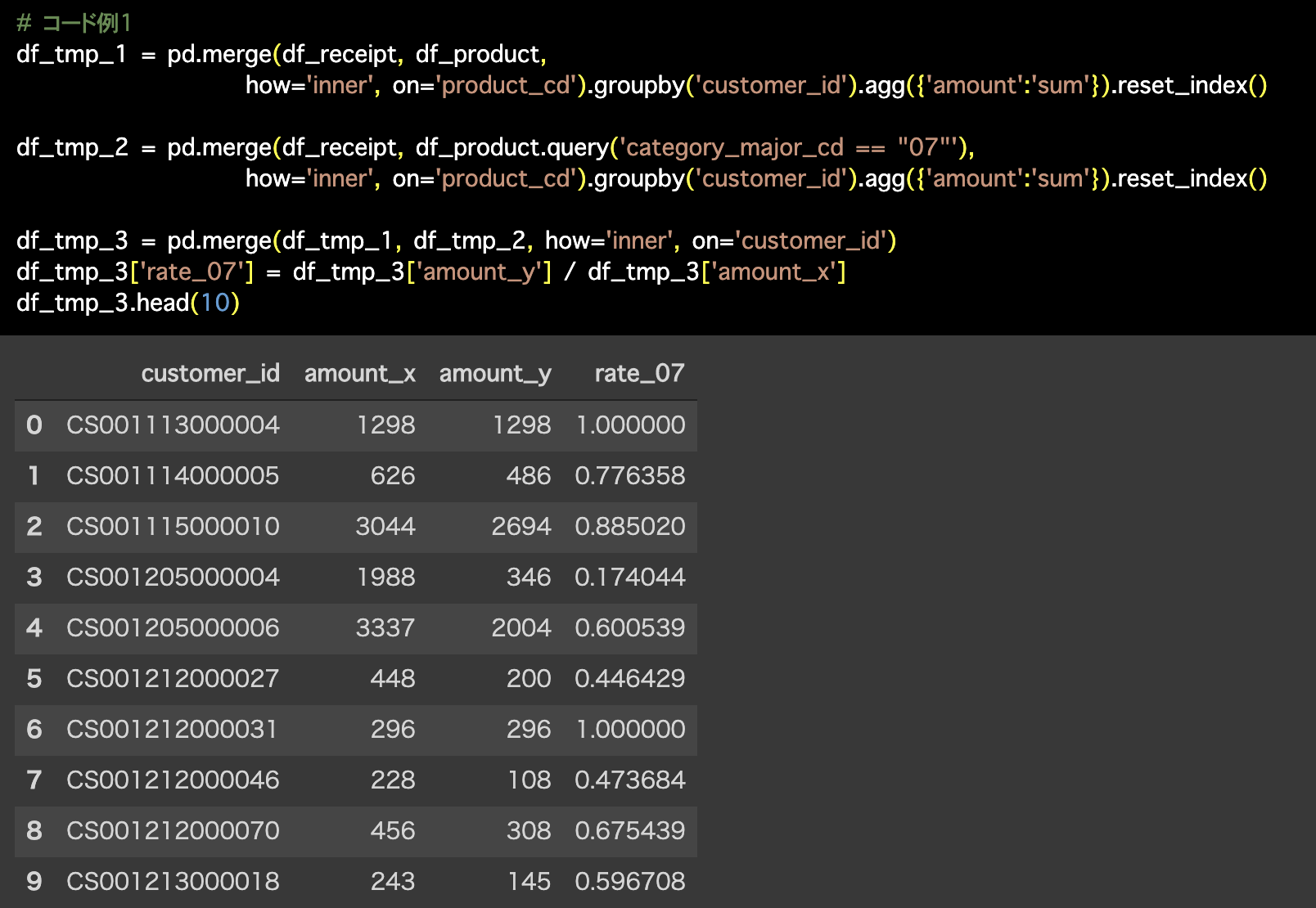
2つ目の解答コードはこのようになっています。
# コード例2
df_temp = df_receipt.merge(df_product, how='left', on='product_cd').groupby(['customer_id', 'category_major_cd'])['amount'].sum().unstack()
df_temp = df_temp[df_temp['07'] > 0]
df_temp['sum'] = df_temp.sum(axis=1)
df_temp['07_rate'] = df_temp['07'] / df_temp['sum']
df_temp.head(10)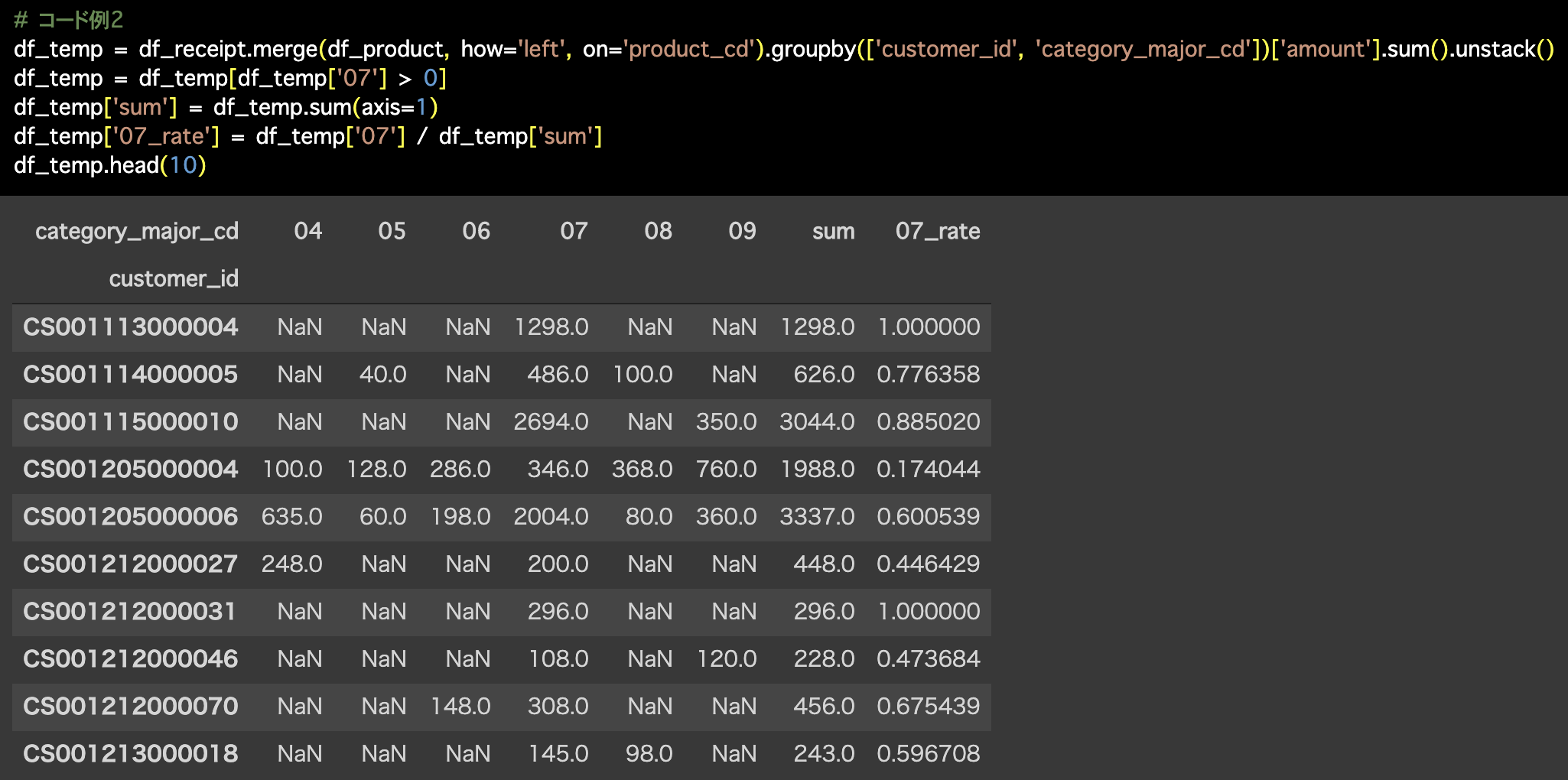
今回は コード例2 の方をカバーしましたが、実は R の解答コードにはコード例1 の方しかありませんでした。
もしかしたら追加されているかもしれませんが、答案のやり方をコード化するにしてもそこまで長くないはずです。
しかし、どうしてもこだわる人のために コード例1 の方も実装できることを説明する必要があるかもしれません。
そういう訳なので、ここの折りたたみの中に コード例1 の結果になるための実装を説明しておきます。
別解の重要性は以前の問題でも述べたと思いますので、できればこだわっていない人でも見ておくと良いと思います。
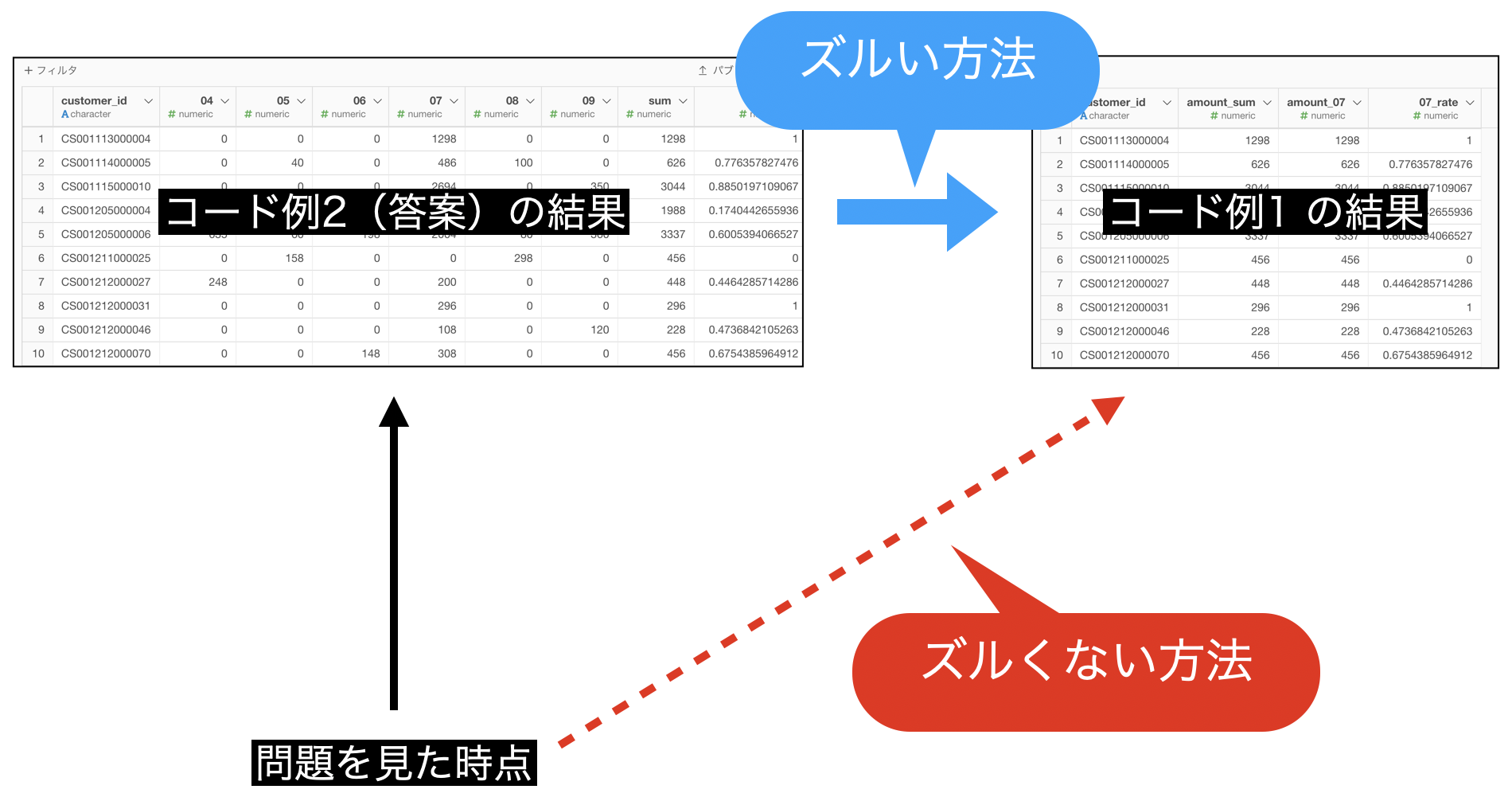
本当はズルい方法
どこがズルいのかというと、答案の結果を使うところです。
コード例1 の結果はこういうことなんだというイメージが湧きやすいので先に見ることをオススメしました。
まず答案の結果はそのままにしておいて、一番上のステップでブランチを作ってしまいます。
ブランチの名前はデフォルト(df_receipt_1)で大丈夫です。
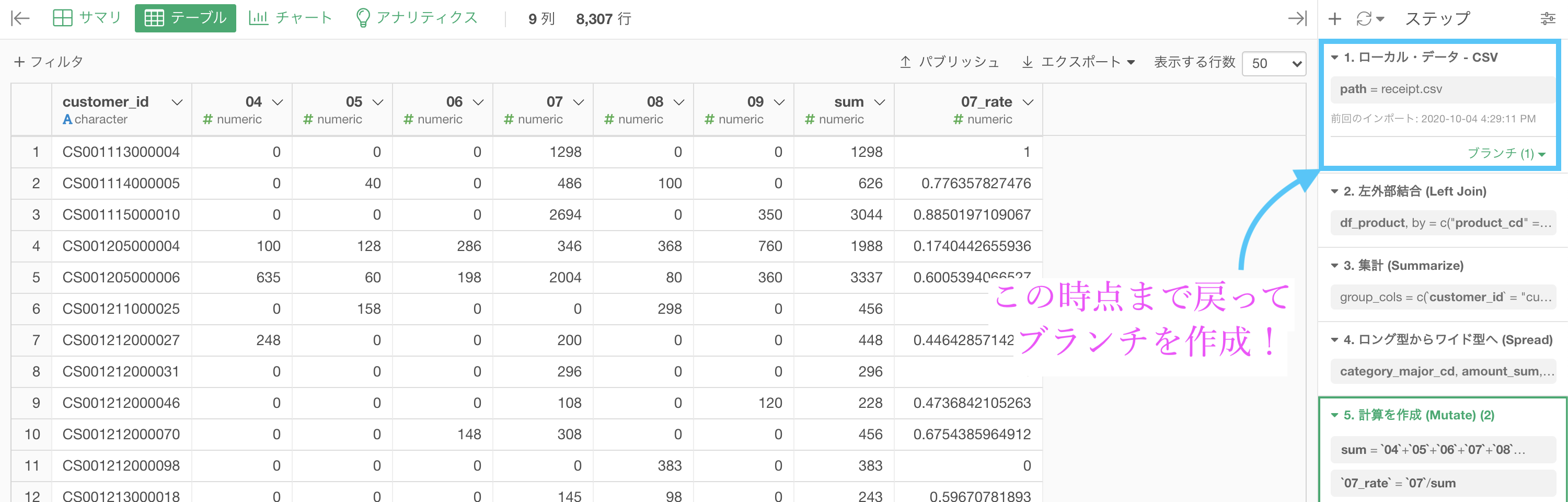
そうしたら df_receipt_1 のなかで、今まで何度もやってきた集計です。
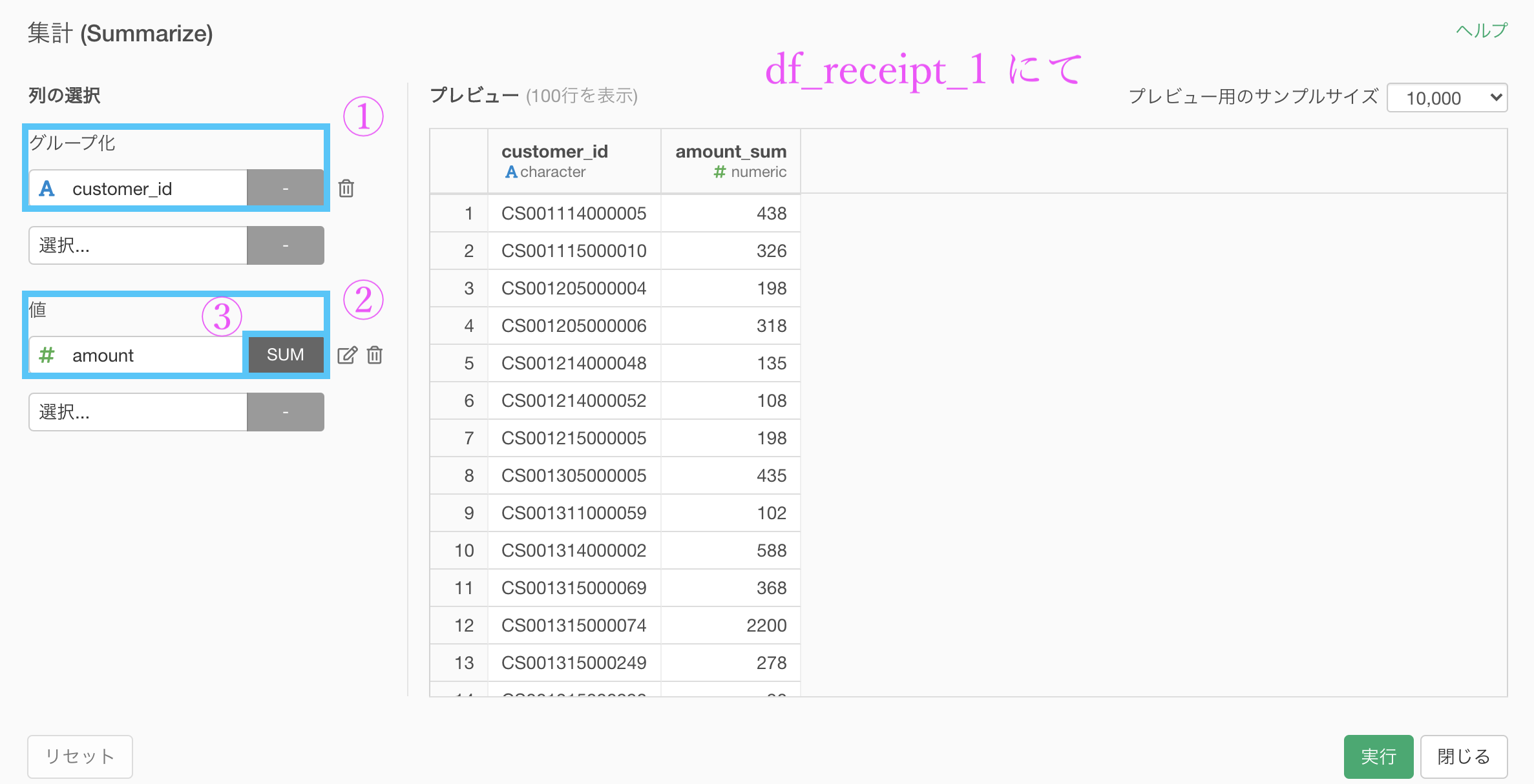
ブランチでやることはもうないので、答案の方(df_receipt)を開いて結合しましょう。
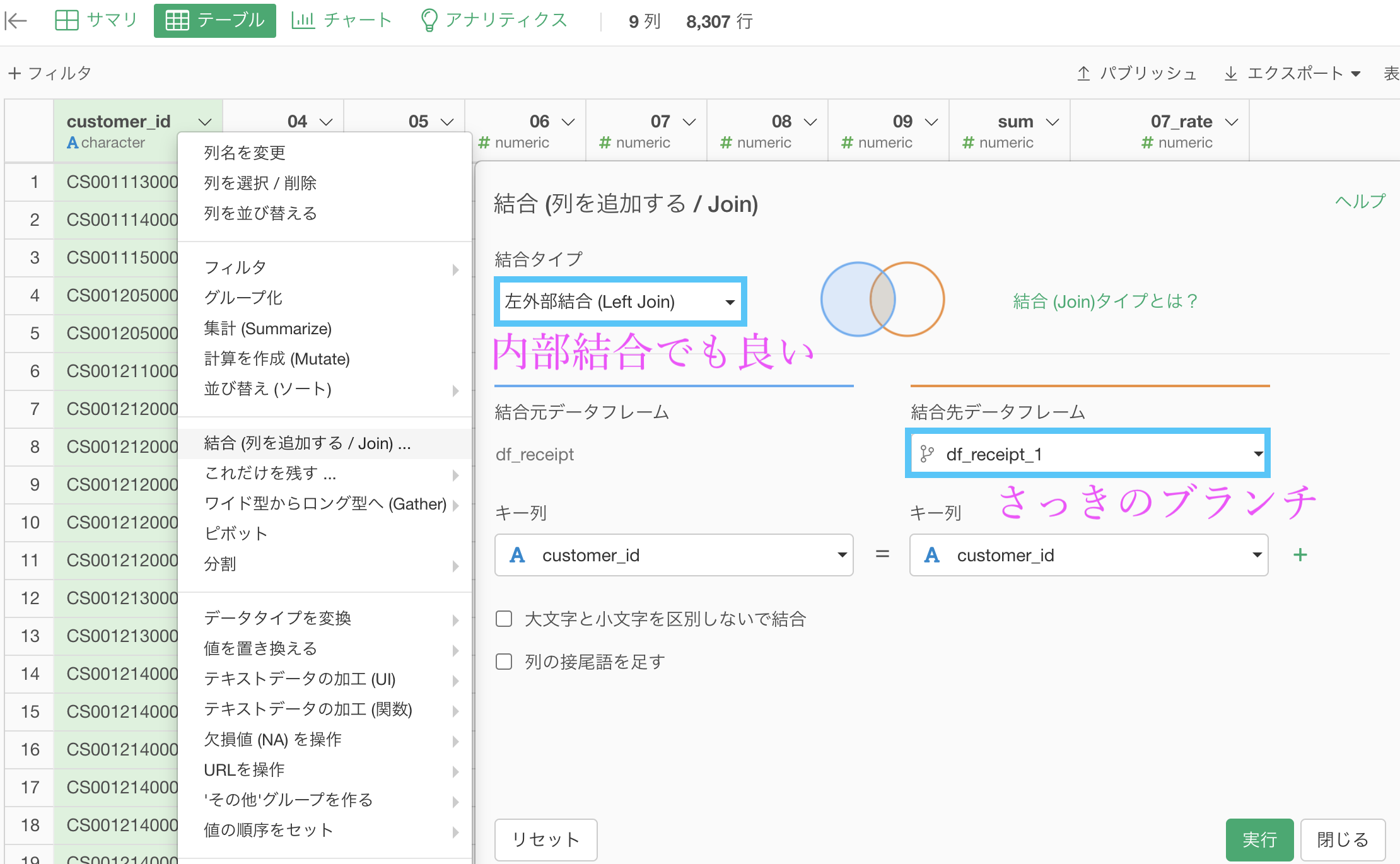
あとは列を並び替えたり、列名を変更することでこのような結果になるはずです。
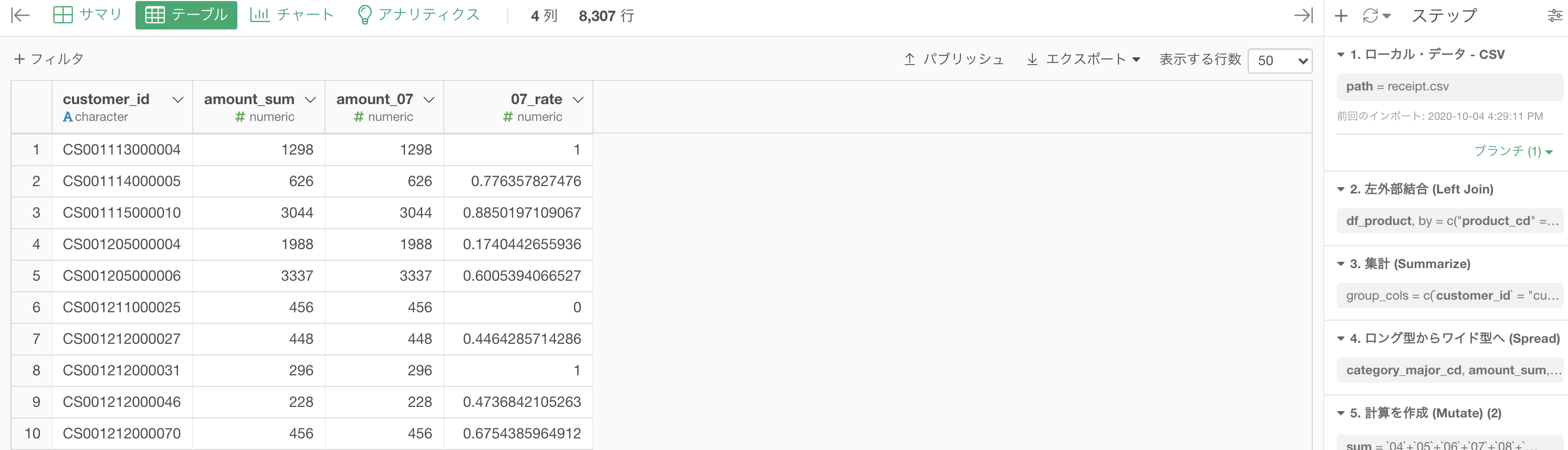
これが コード例1 の解答の結果です。
さっきも言いましたが、これのズルいところは答案の結果を使っているところです。しかし、これでわかりやすくなったと思いますが、今やったことはこのような図式にするとわかりやすいかもしれません。
長くなりすぎるので、ズルくない方法は紹介しません。余力のある人だけ自分でやってみてください。
できなくても、R の解答コードには コード例1 の結果しかないので(コードがたくさんですが)そちらを参考にしてください。
問70 : 2つの日付から経過日数を計算する

答案・解説はこちら
実は基本的に、データタイプが Date型 のものは引き算することができます。これは時間が間隔尺度と呼ばれるものだからです。
表記上はテキストデータなので、テキストデータに使う関数も使えますし、引き算もできるという欲張りなことができるデータタイプが Date型(POSIXct型) というわけ です。
それでは早速 Exploratory で実装していきます。
まずはデータを整える作業をしましょう。
df_receipt データにて、df_customer と以下のように内部結合します。
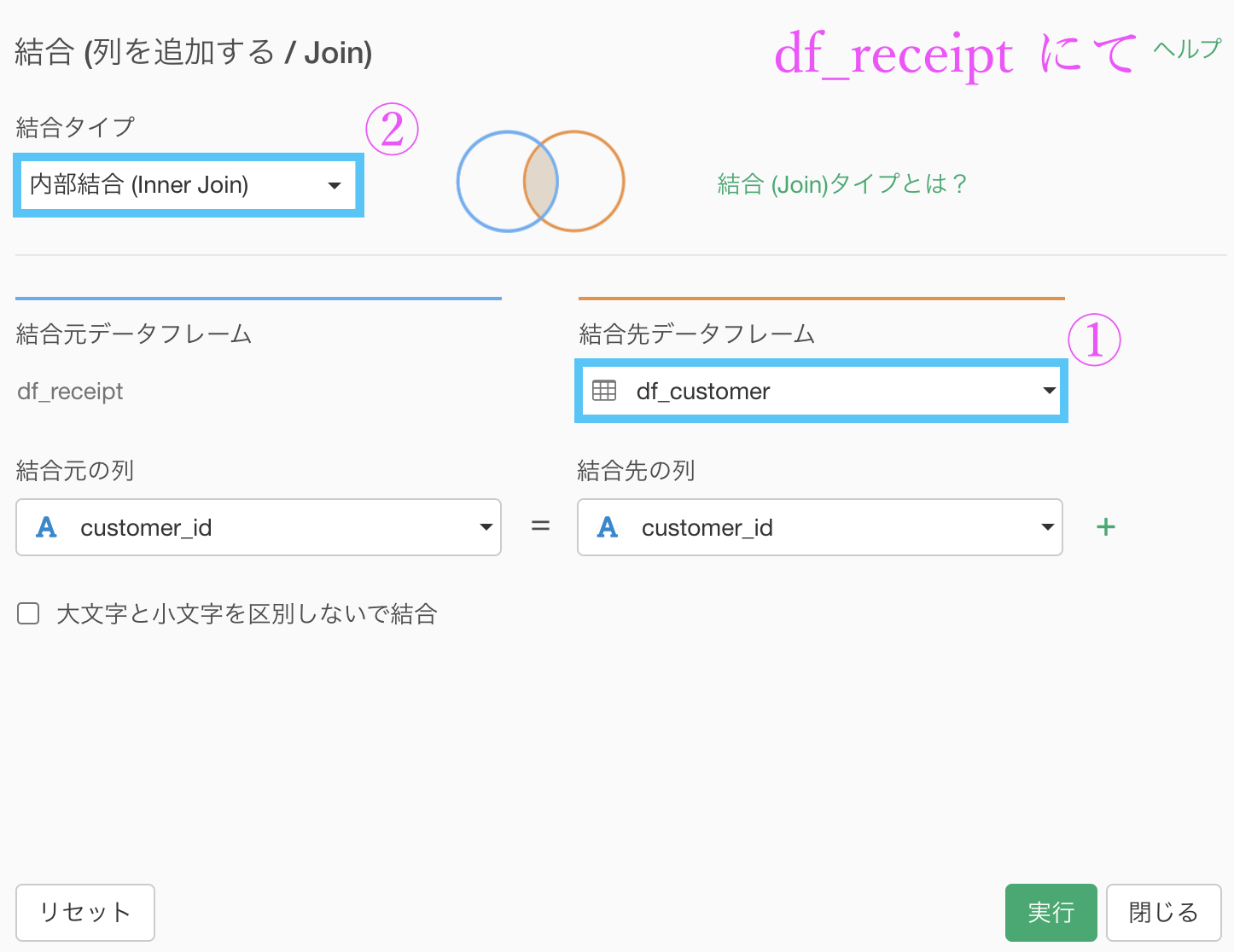
df_customer は顧客リストですので、内部結合することで非会員顧客(customer_id が Z から始まる行)も一緒に取り除くことができています。
列を選択・並び替えを行うことにより、以下のような形まで持っていきましょう。
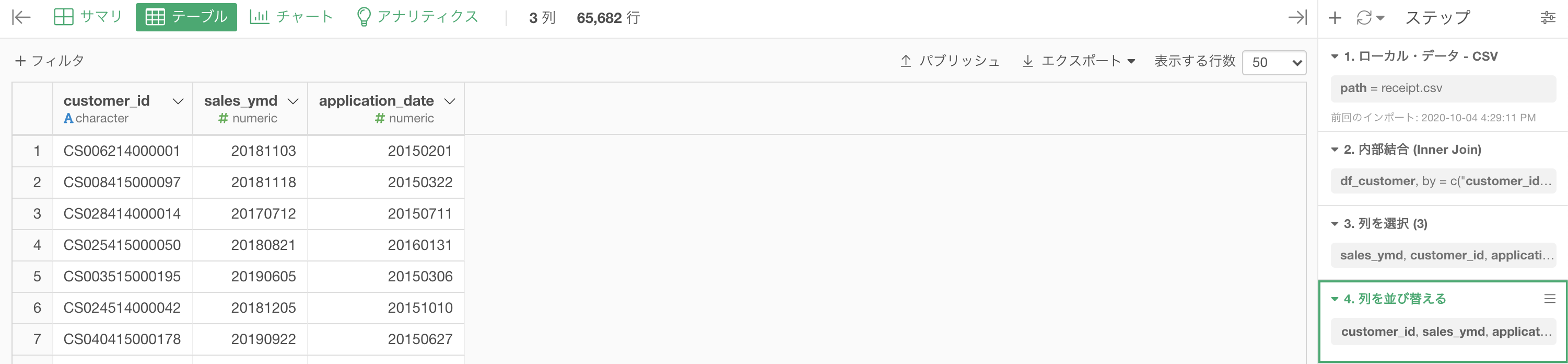
データタイプの変換をするときにもやったように、sales_ymd(お買い上げ日)と application_date(会員申し込み日)は Date型 にしましょう。
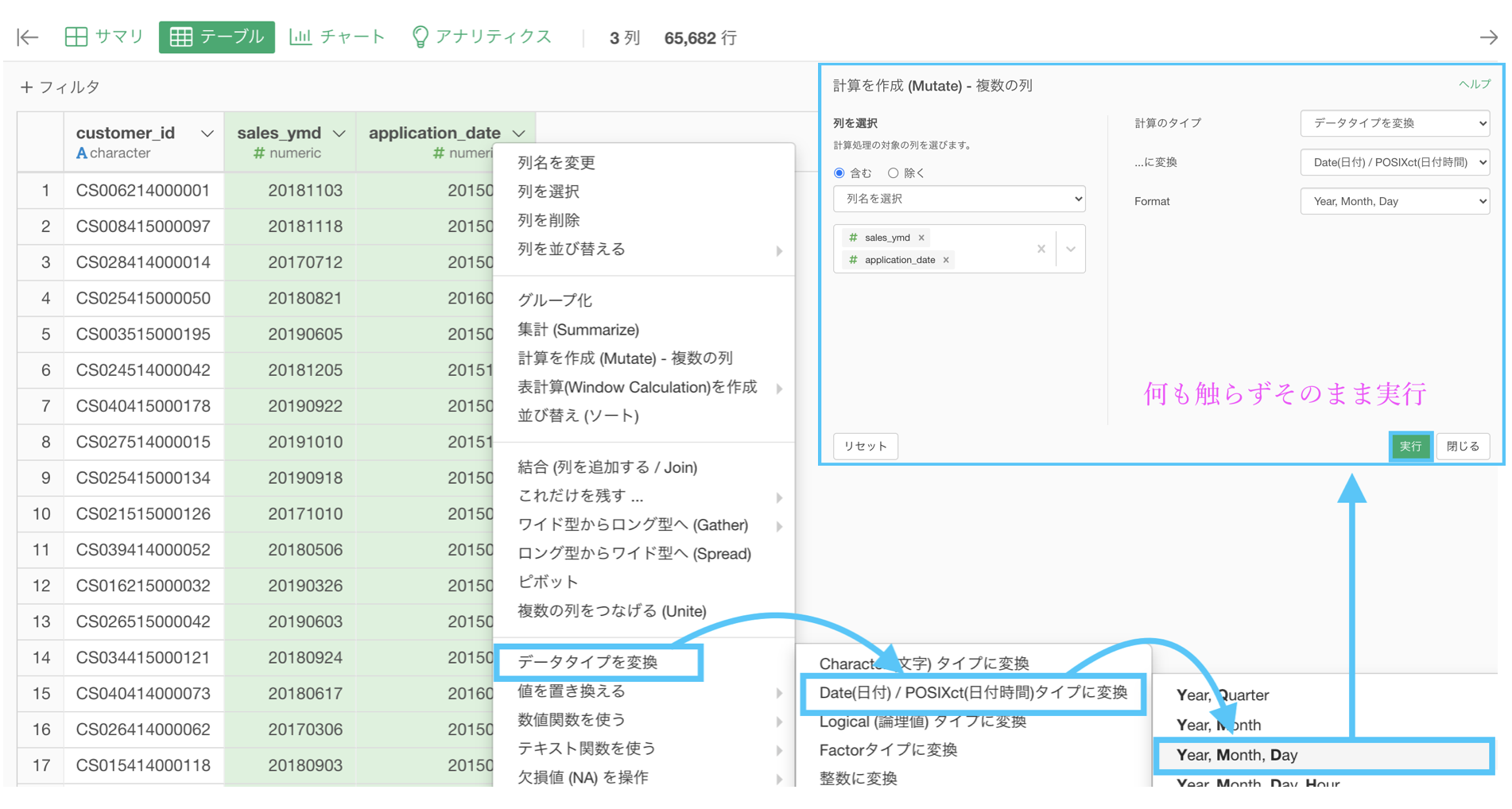
これで変換されたので、データを整える作業は終わりです。
あとは問題を解くだけです。問70 でやることはでした。
計算を作成 (Mutate) でいつものように計算エディタを開きましょう。
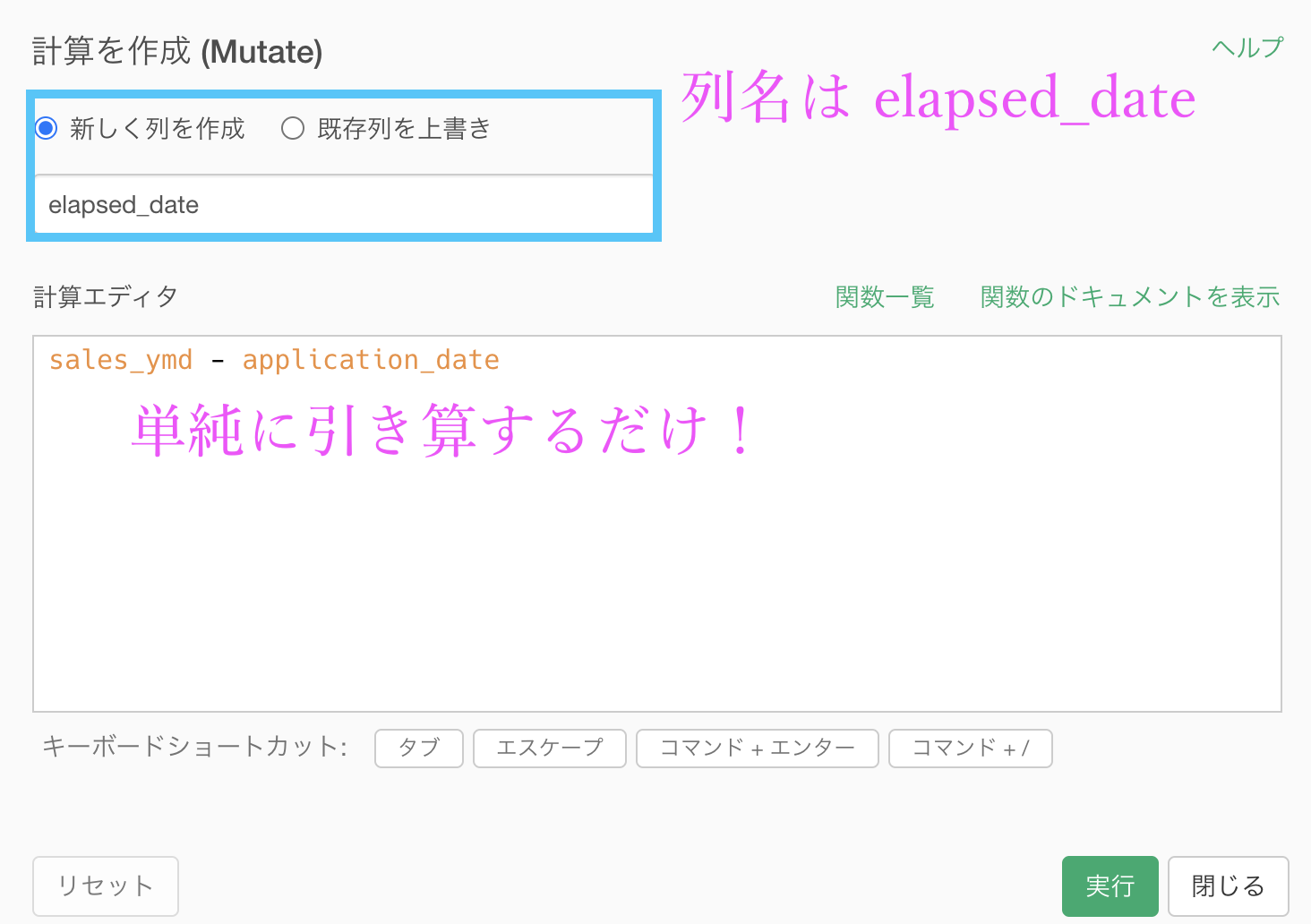
列名は elapsed_date(経過日数)としましょう。
計算エディタの中身は sales_ymd - application_dateとするだけで大丈夫です。
このような結果になったと思います。
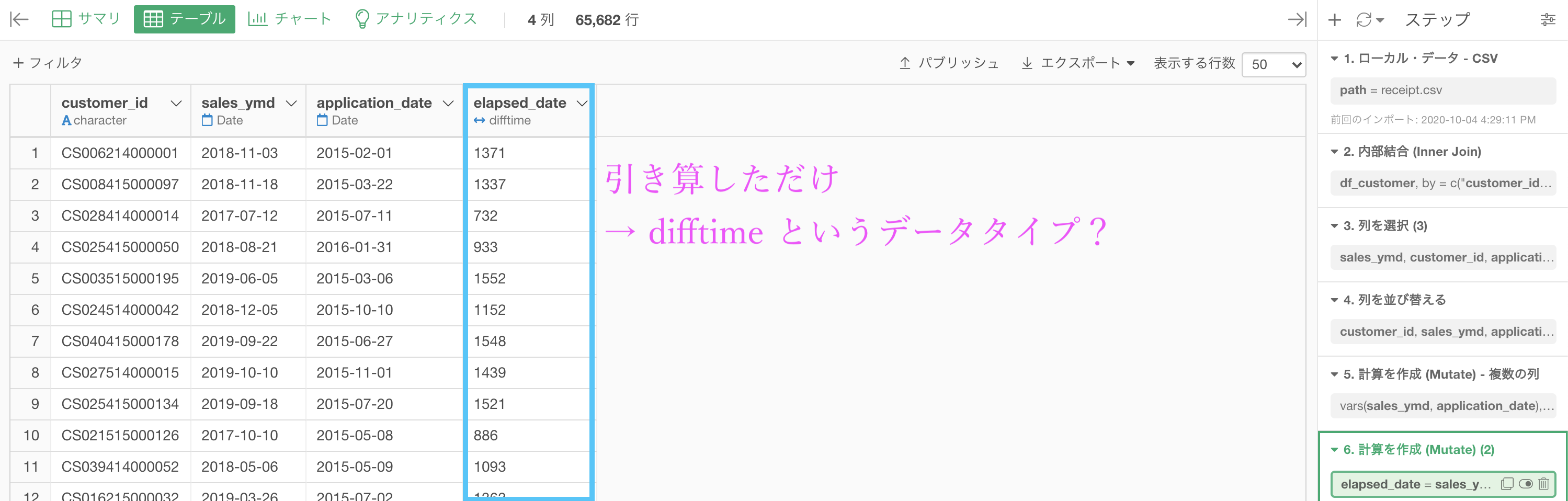
結果をよく見ると、今までみたことのない difftime(時間差)というデータタイプになっています。
この数値の結果は「日数」を表していますので、このまま解答を見れば一致しています。
しかし、今後を考えてデータタイプを変換しておきましょう。
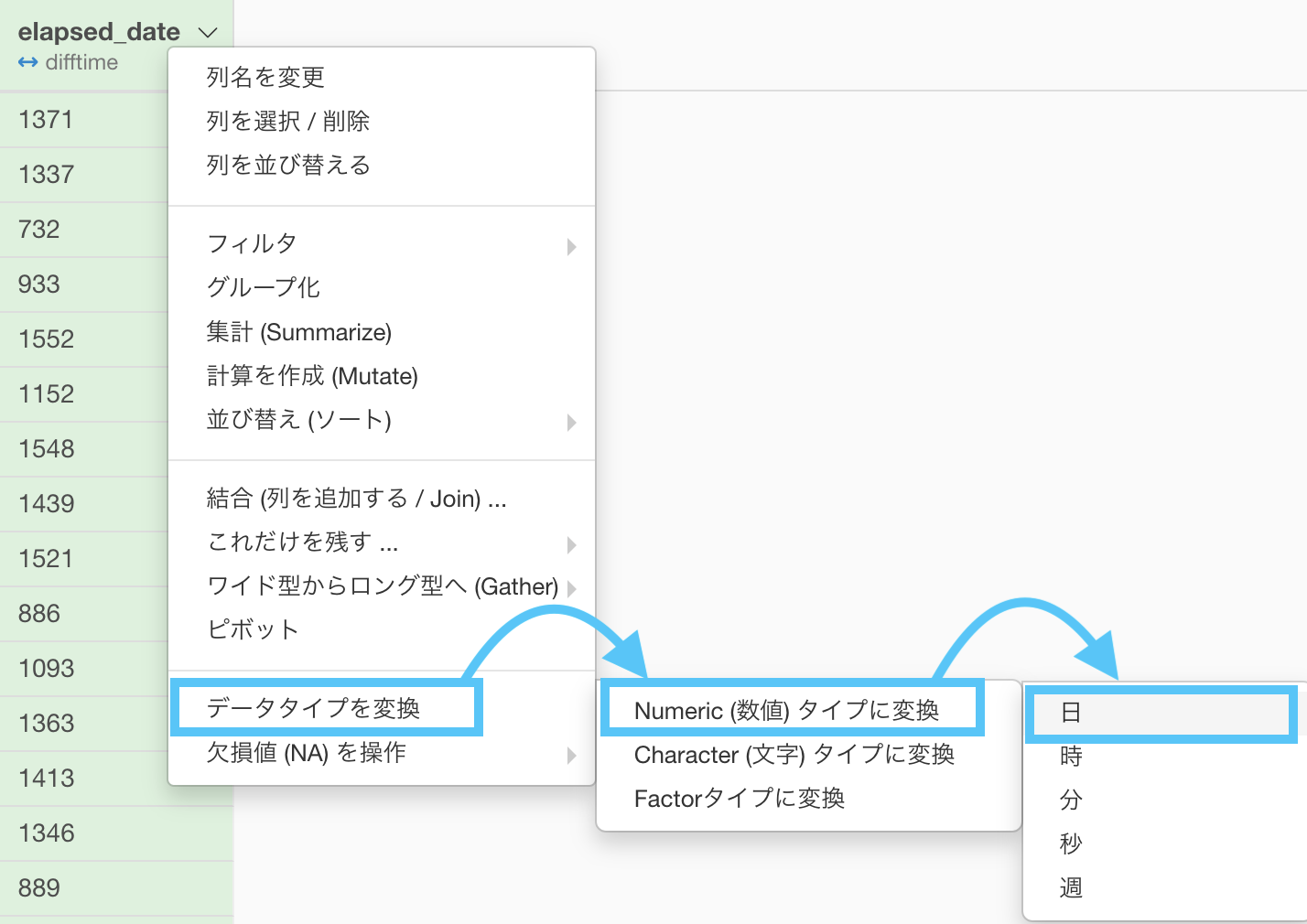
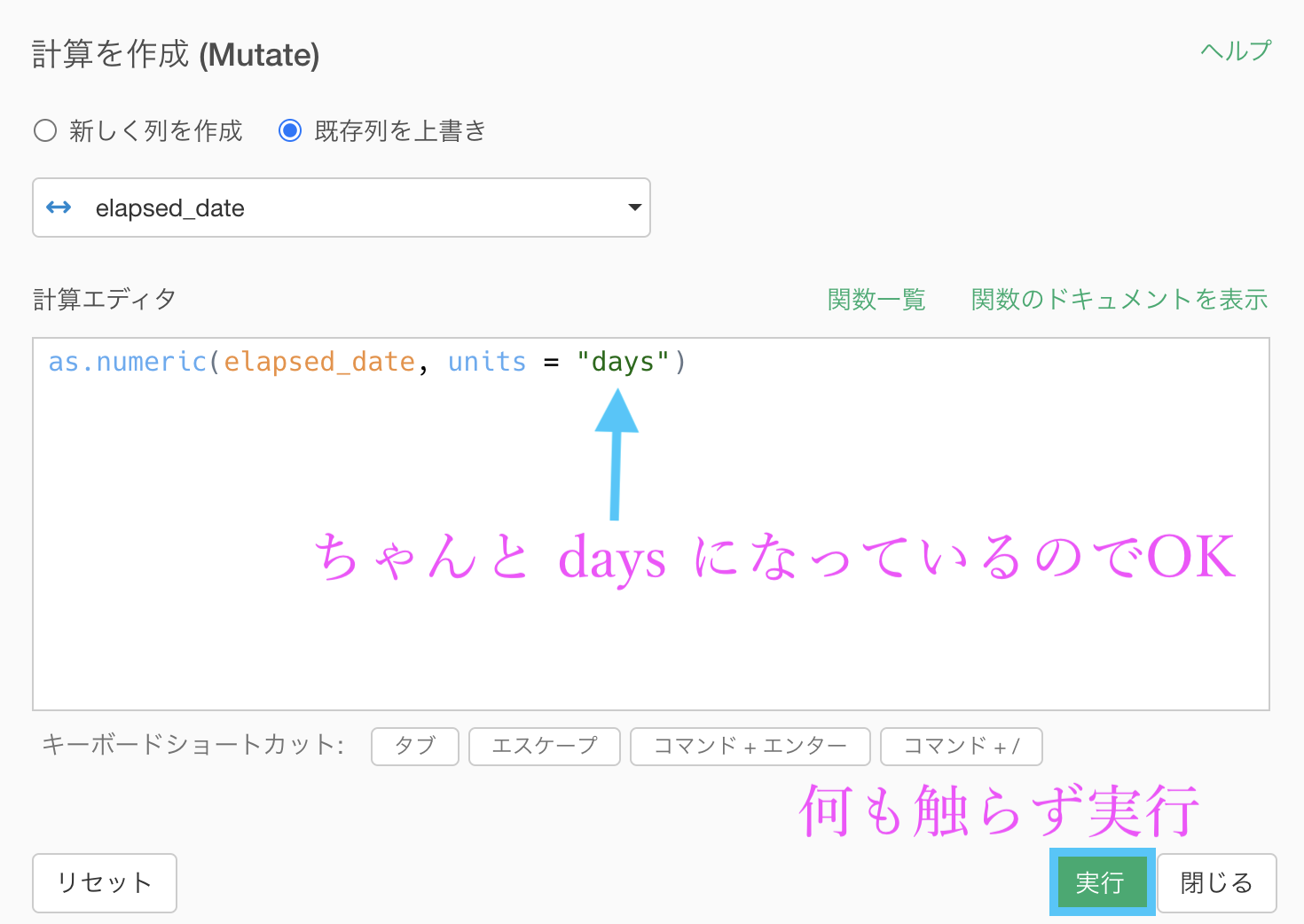
出てきた計算エディタも、何も触らず実行しましょう。
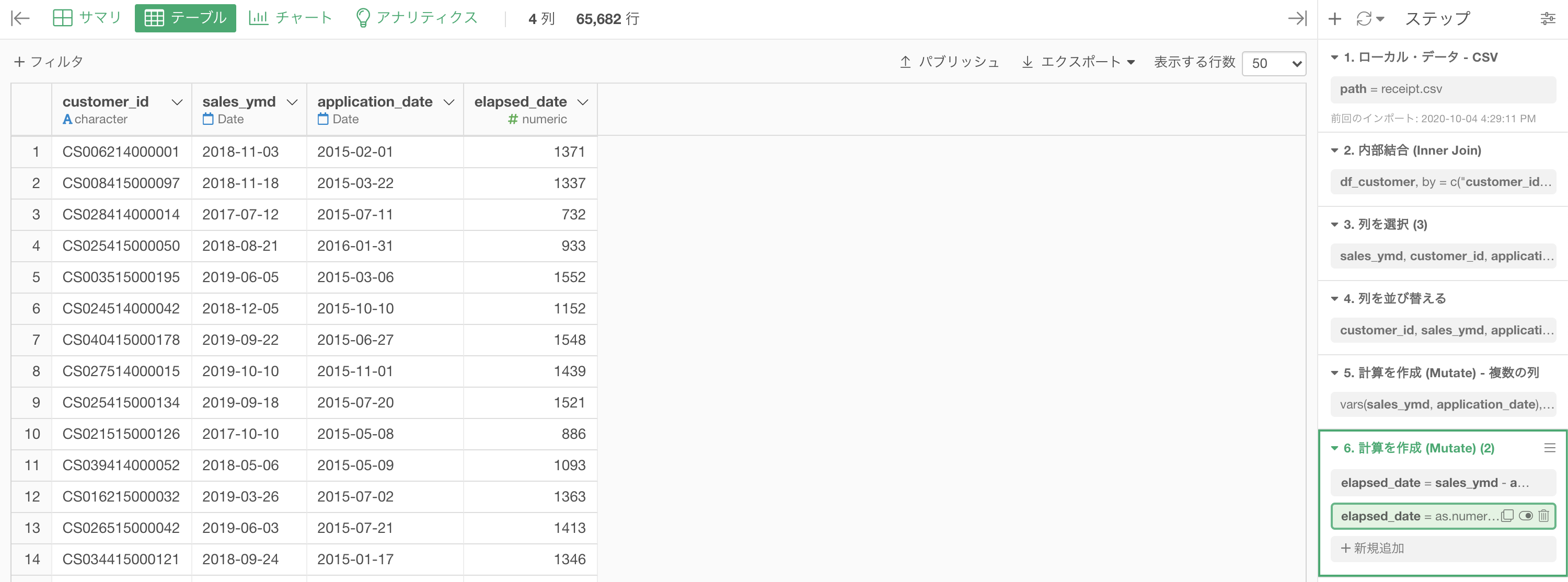
結果はこのようになります。解答と確認しましょう。
Python 解答コードはこちら
解答コードはこのようになっています。
df_tmp = pd.merge(df_receipt[['customer_id', 'sales_ymd']], df_customer[['customer_id', 'application_date']],
how='inner', on='customer_id')
df_tmp = df_tmp.drop_duplicates()
df_tmp['sales_ymd'] = pd.to_datetime(df_tmp['sales_ymd'].astype('str'))
df_tmp['application_date'] = pd.to_datetime(df_tmp['application_date'])
df_tmp['elapsed_date'] = df_tmp['sales_ymd'] - df_tmp['application_date']
df_tmp.head(10)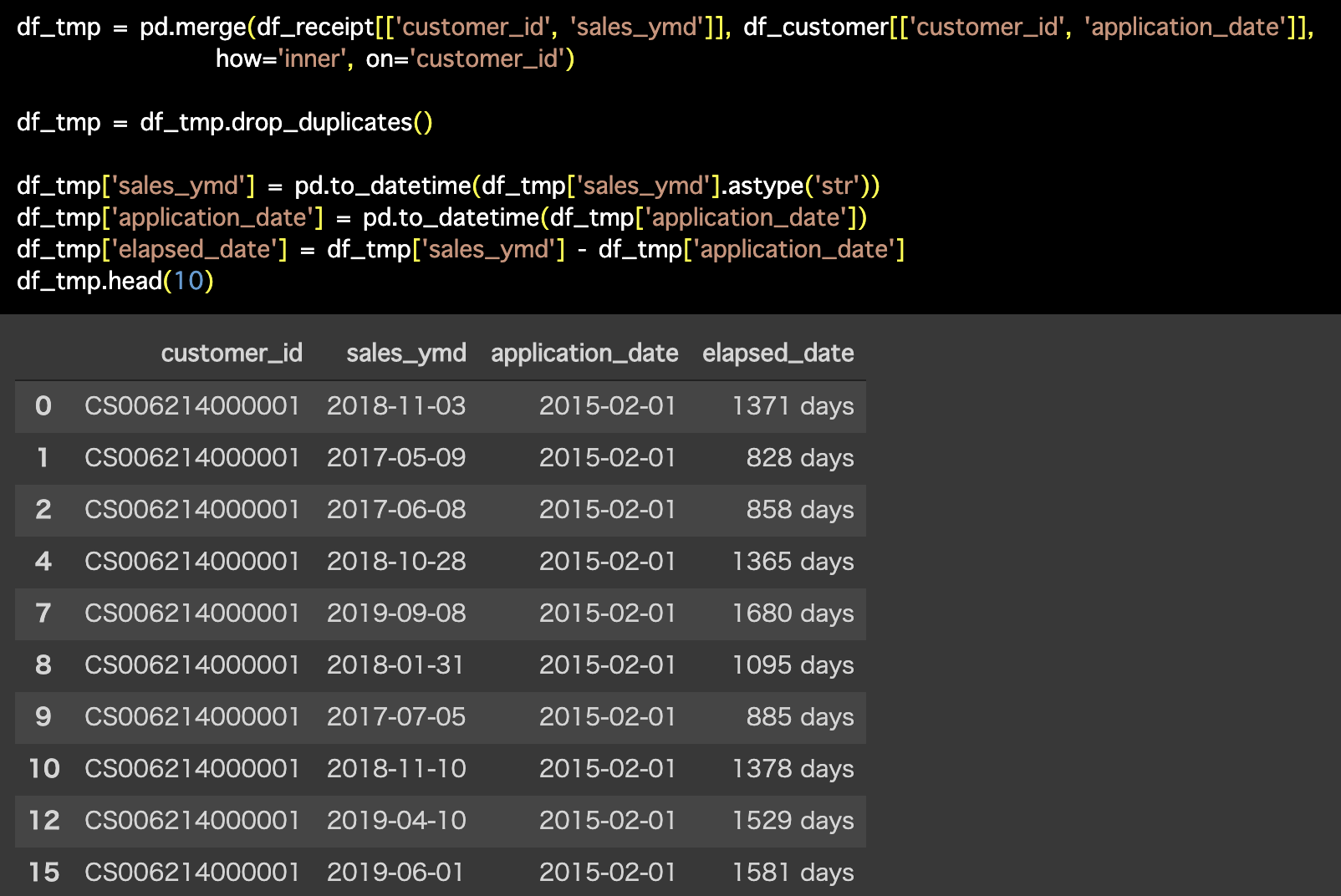
問70 と区切りが良いので次のページに移りますが、問71〜問73 は 問70 ができている前提で答案を作りますので流れは地続きです。
ちなみに週が登場しないのは、7 で割って floor関数 をかけるだけだからだと思います。五十歩百歩だと思いますけど。