Exploratory でコレスポンデンス分析やってみる
コレスポンデンス分析の数理については数量化3類などを学ぶことをオススメします。
以下のサイトなどをご覧になるとどのようなことをやっているのかを理解することができるかもしれません。カテゴリ変数に対する主成分分析とも言われています。
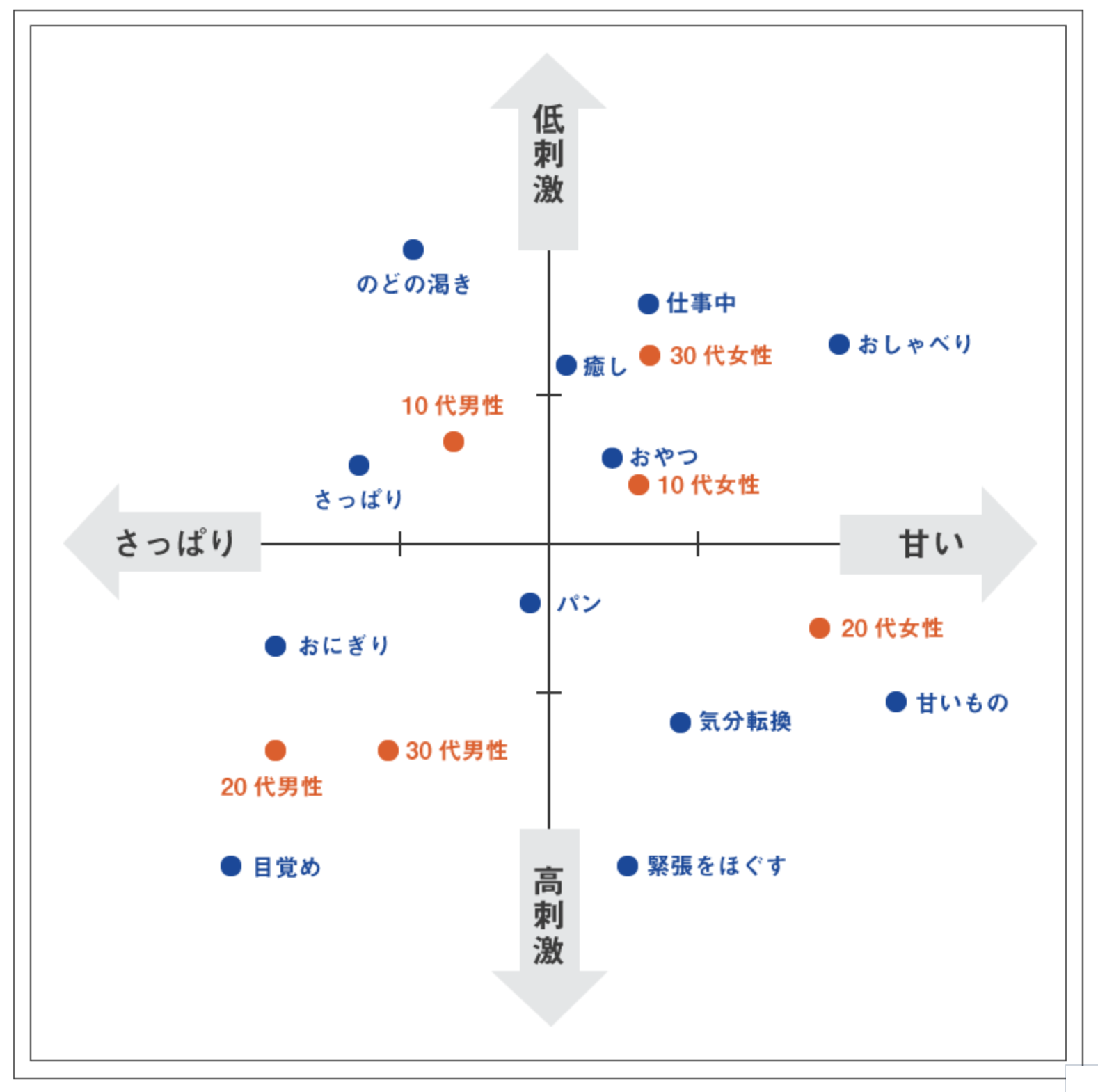
今回の目的
ここではコレスポンデンス分析を Exploratory を使って実装するやり方をご紹介します。
R コードの参考としては例えばこちらをご覧ください。
今回のデータは R の ca パッケージにある author というデータセットを用います。コレスポンデンス分析の iris データのようなものです。
使うデータ
Exploratory 上でそのデータを使用するためには、データをインポートするときに R スクリプトをクリックしましょう。
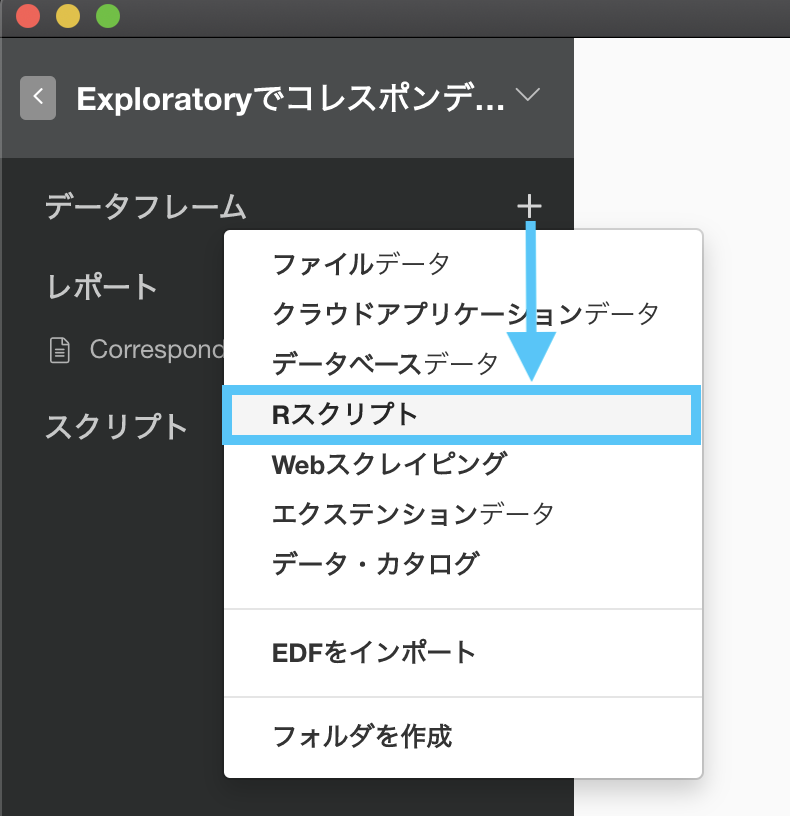
そこに以下のコードを打ち込みます。
library(ca)
author %>% as.data.frame()実行 → 保存 → 作成(名前を変更しても可)の手順でデータをインポートします。
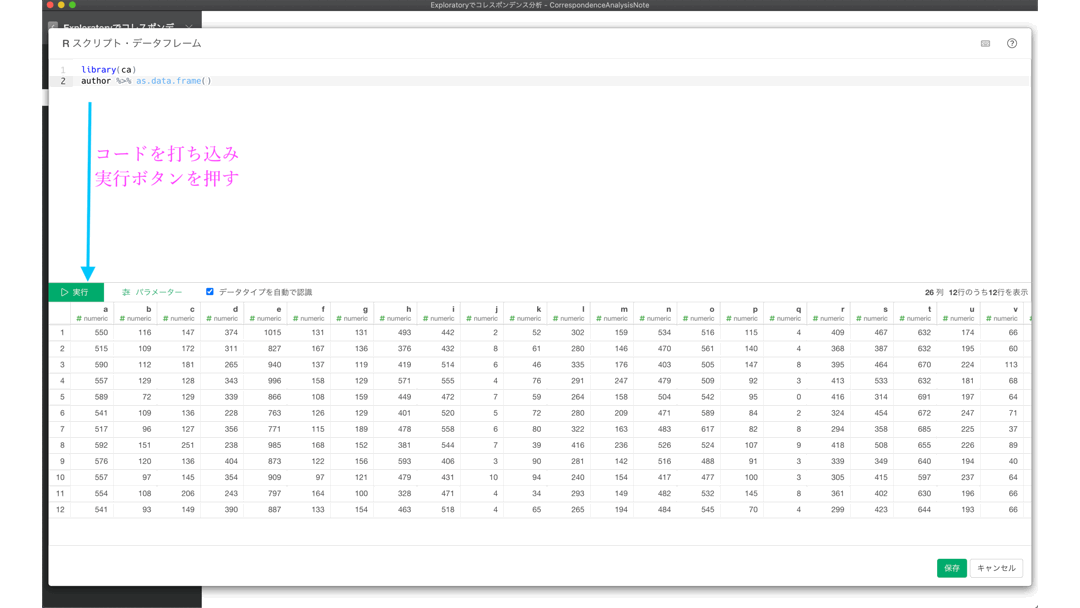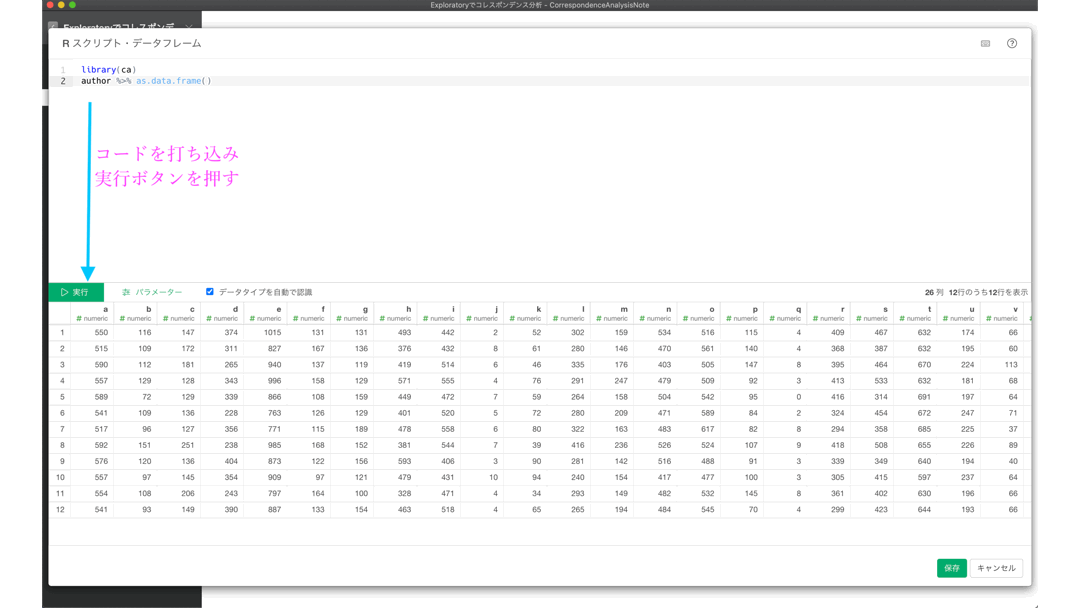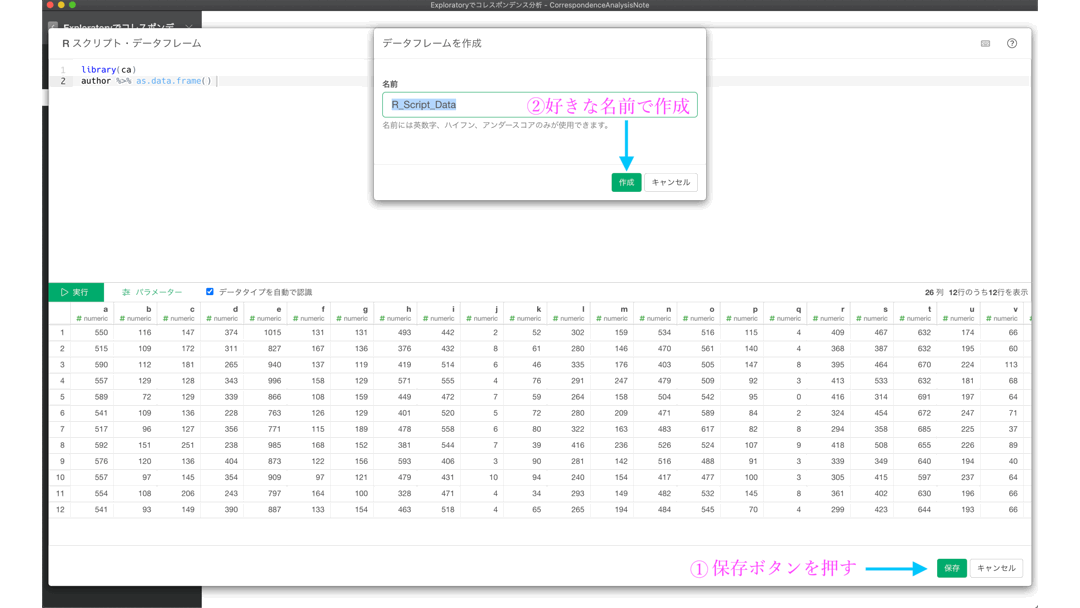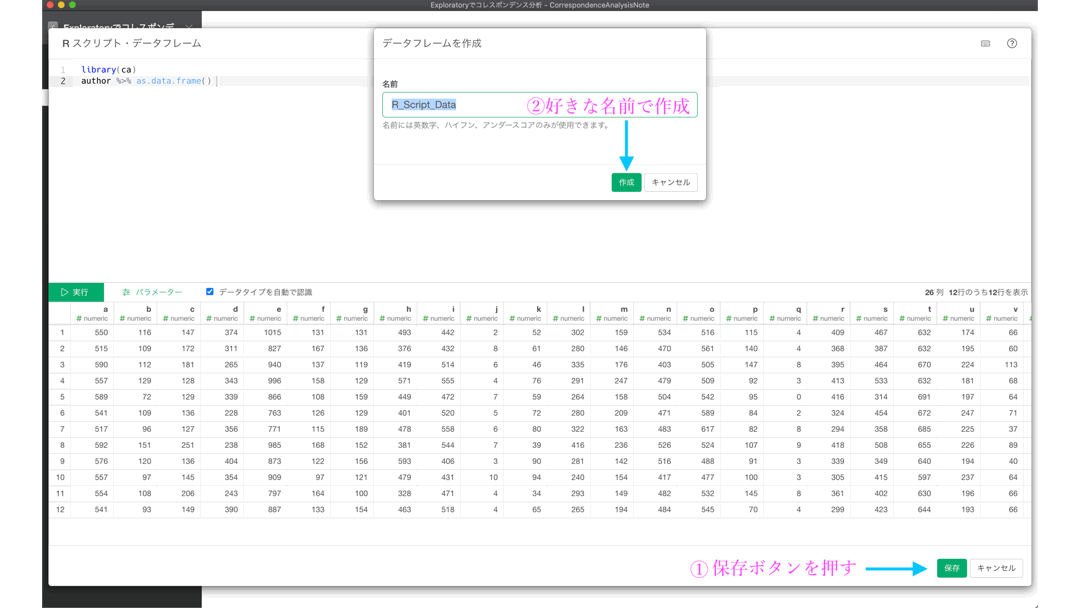
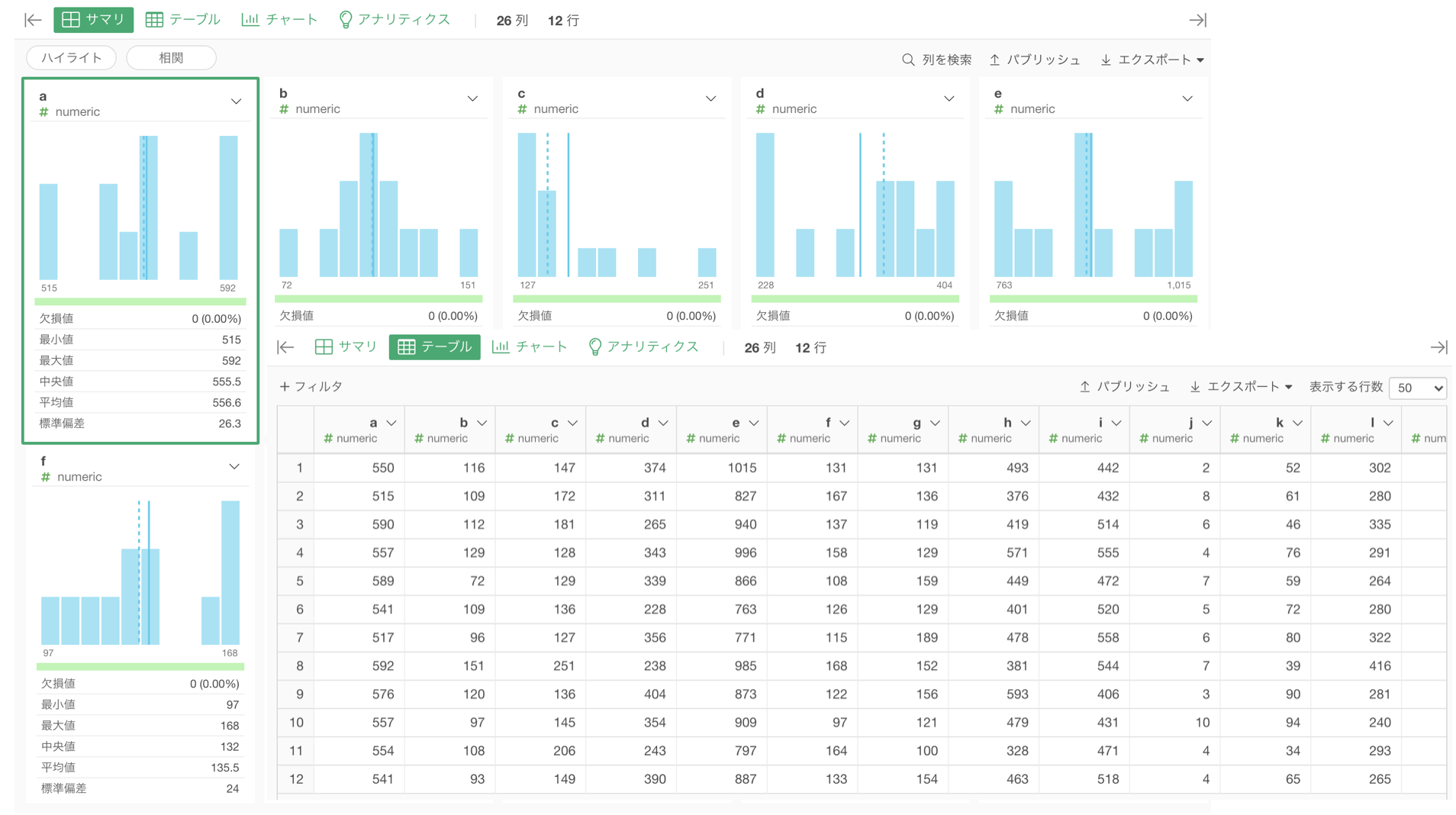
サマリーとテーブルを確認しましょう。結果は以下のようになっていると思います。
コレスポンデンス分析の実装
コレスポンデンス分析をいつものステップで一気にやるためにはスクリプトで新しく関数を作ります。
ですので、以下のようにスクリプトを作成しましょう。
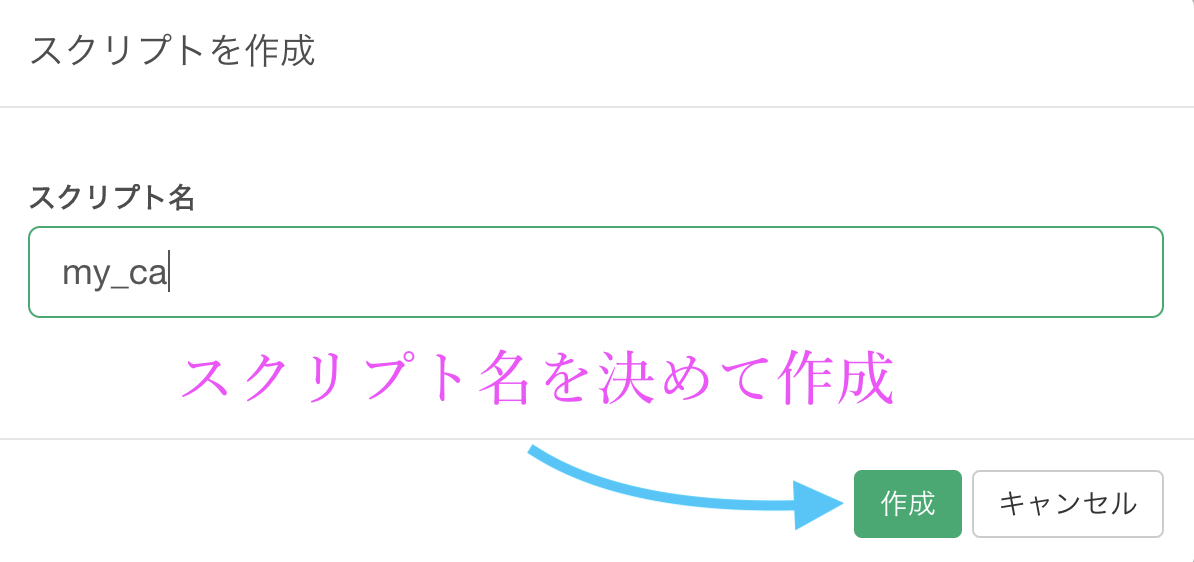
スクリプトの中に以下をコピペして保存しましょう。
my_ca <- function(tbl, dim = 2){
require(ca)
ca <- ca(tbl) # コレスポンデンス分析を実行
col_score <- ca$colcoord %>% as.data.frame() # 列スコア
row_score <- ca$rowcoord %>% as.data.frame() # 行スコア
col_names <- rownames(col_score) # 26のアルファベット
row_names <- rownames(row_score) # 12冊の小説名
col_score <- col_score %>% mutate(names = col_names) %>% mutate(ID = "col_score")
row_score <- row_score %>% mutate(names = row_names) %>% mutate(ID = "row_score")
# ID が 1列目, names が 2列目 だから
dim <- dim + 2
scores <- bind_rows(col_score, row_score) %>% reorder_cols("ID", "names") %>% .[, 1:dim]
return(scores)
}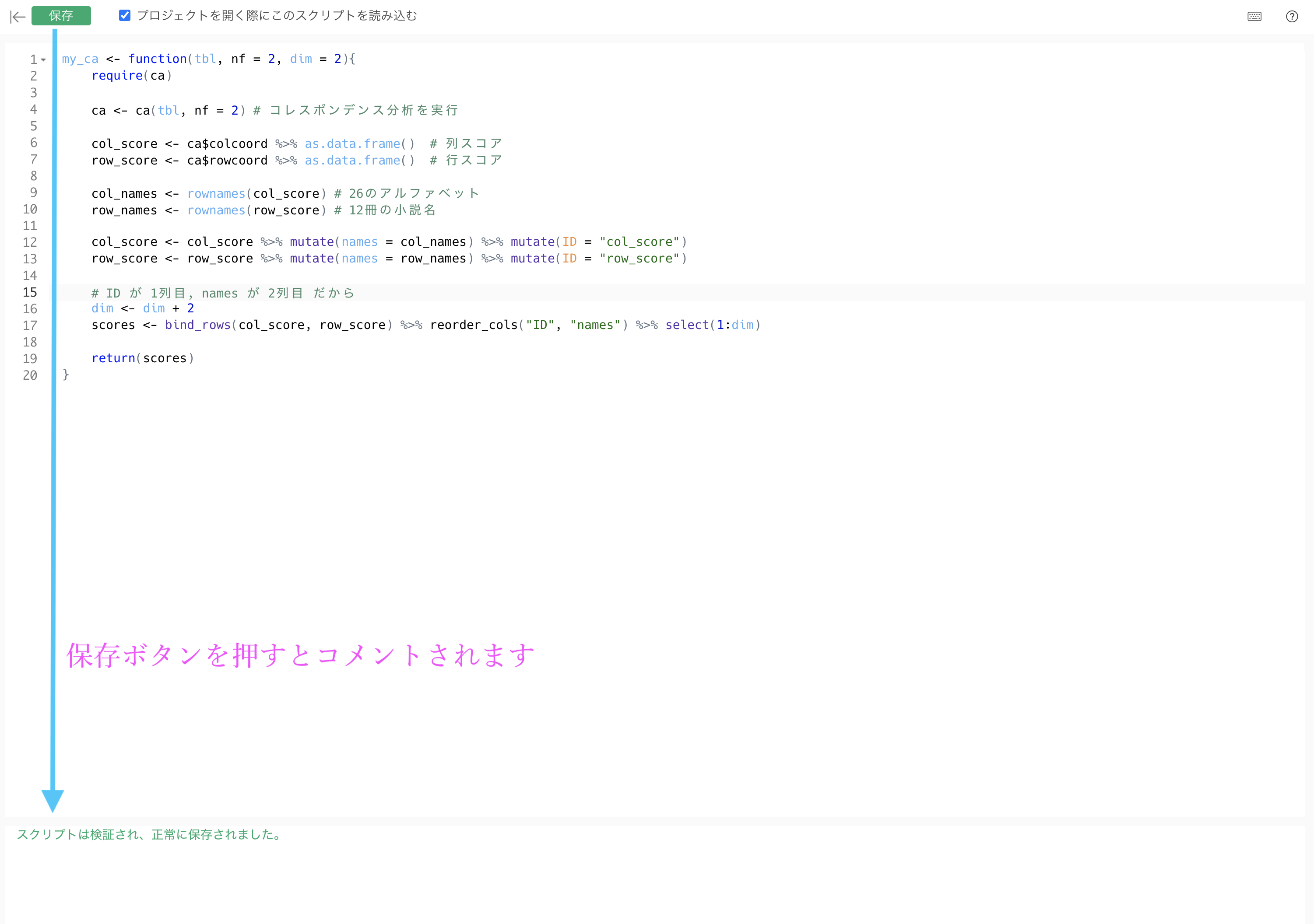 これで
これで my_ca() という関数を新しく使えるようになりました。
dim という引数は軸の数です。nf という、corresp 関数の引数と同じ意味です。
先ほどの author データに戻って、カスタムRコマンドを起動させましょう。
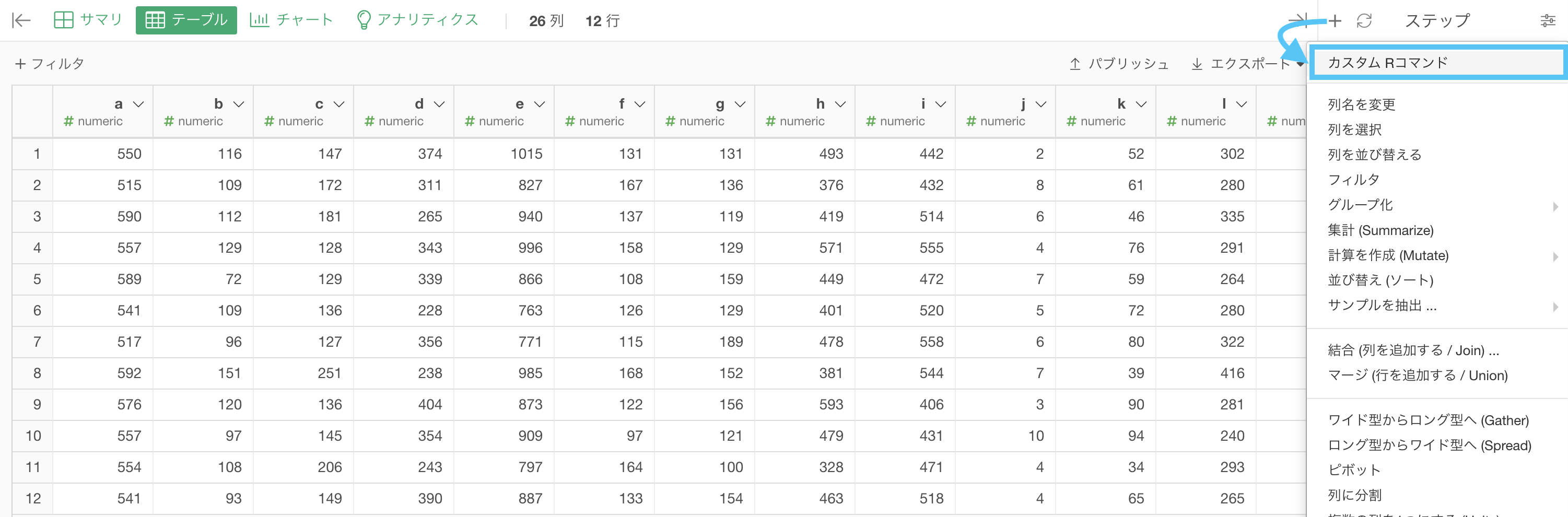
先ほど新しく作った関数 my_ca() を、とりあえずそのまま入力します。
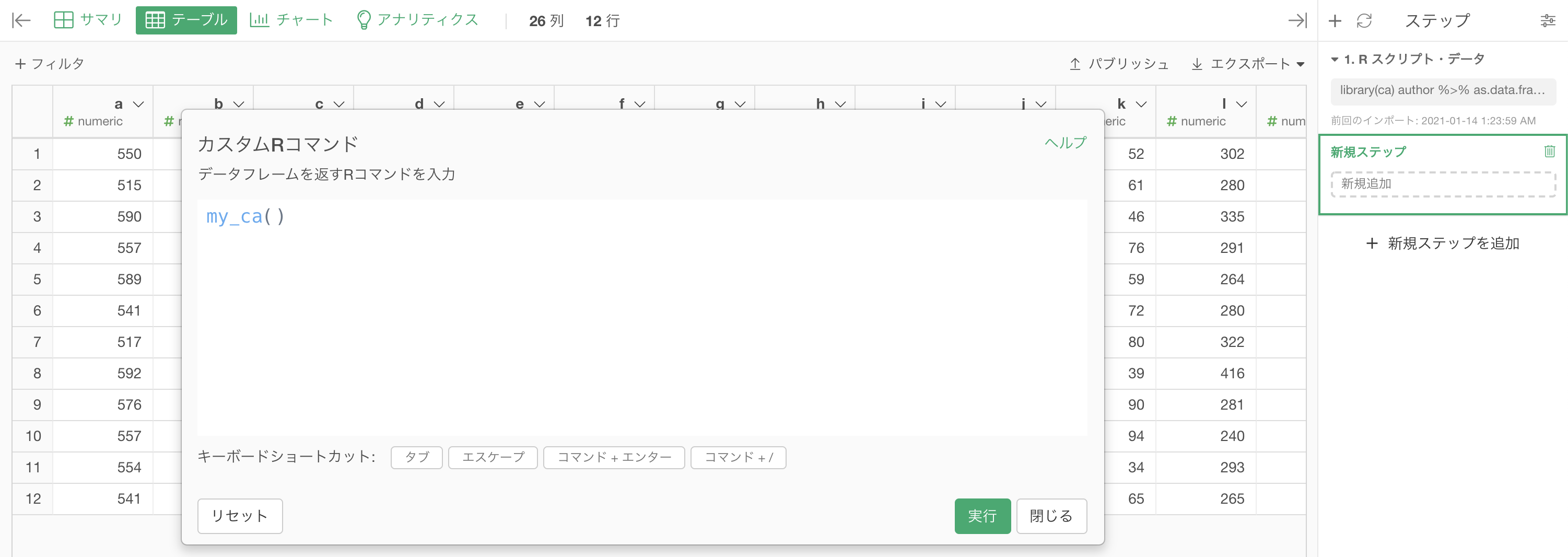
結果はこのようになったと思います。
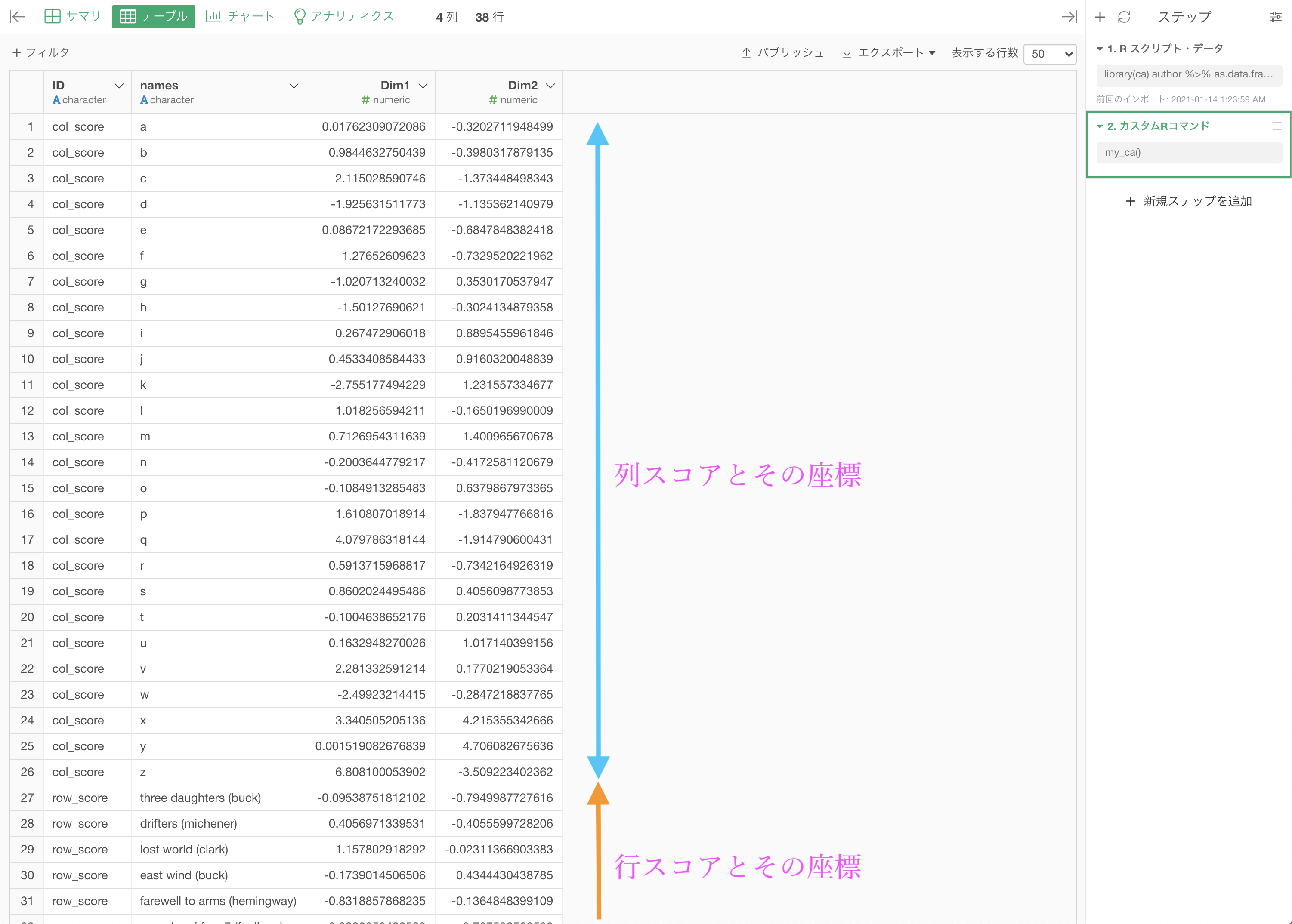
これを使って、チャートで可視化しましょう。
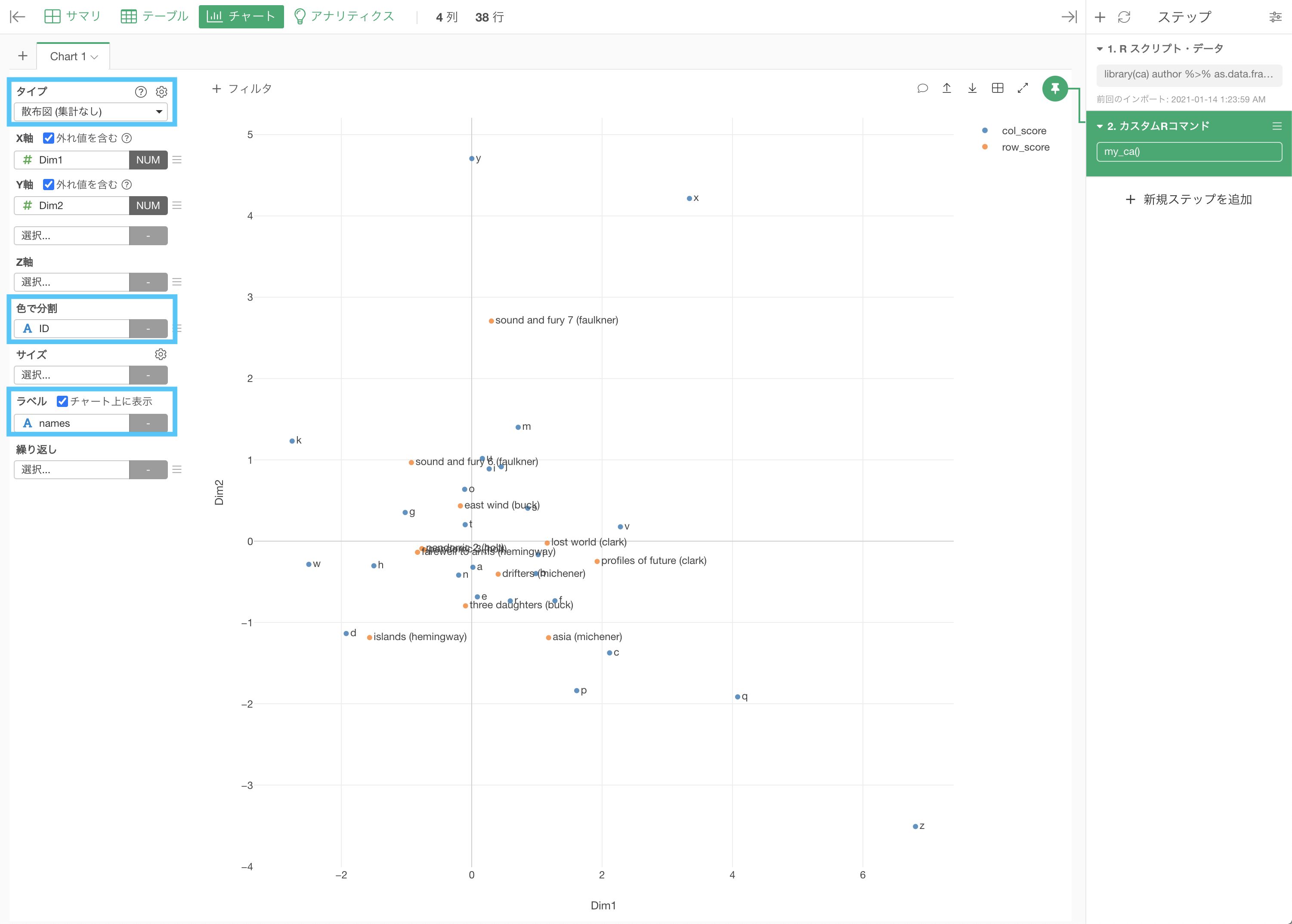
散布図(集計なし)を選びます。軸が Dim1 と Dim2 なのは察しがついていると思いますが、これだけでは何もわからないチャートになっていると思います。
きちんと「色で分割」のところに ID を入れて「ラベル」のところには「names」とし、チャート上に(チェックをつけて)表示させています。
これで対応分析の可視化はできました。
ちなみに R 言語の方でも同じ結果を得ることができます。
library(ca)
ca <- ca(author)
plot(ca)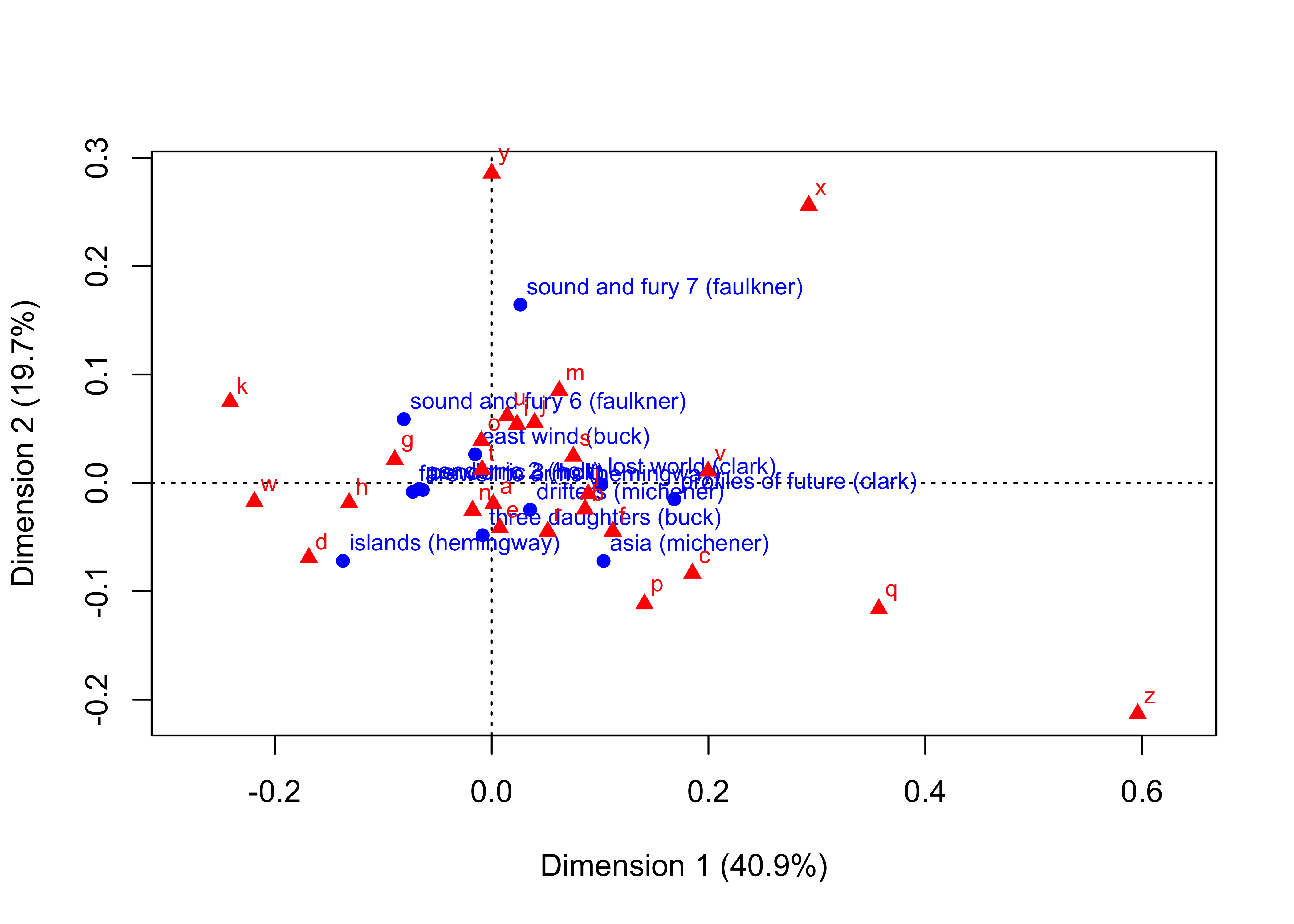
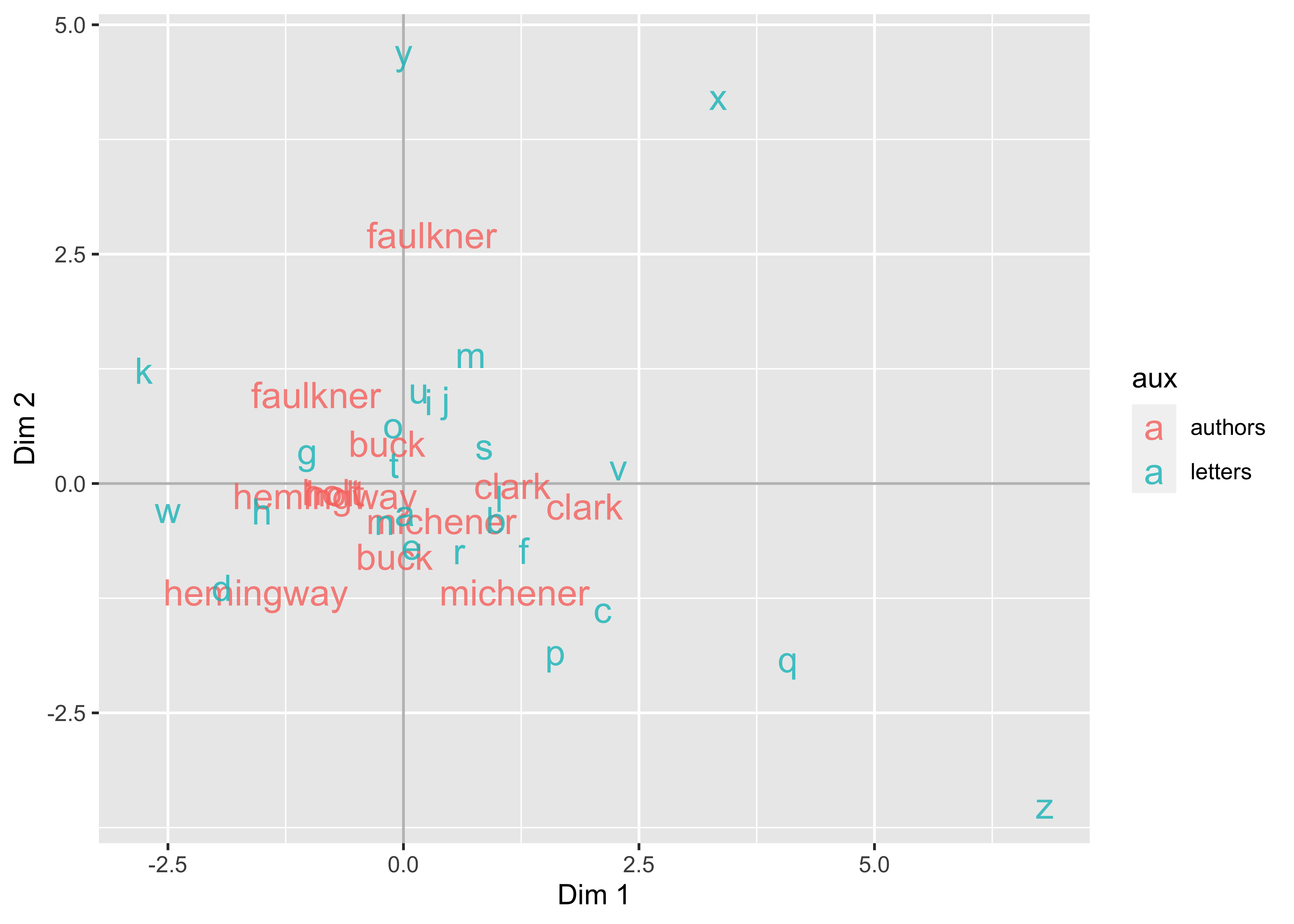
ggplot2での可視化はおまけです。
注意や備考
- たとえ処理が早くてもとにかく、よくデータを見ることはどんなときも大切だと思います。author のようなデータはある意味では特別で、
rownamesが存在していません。
Exploratory のテーブル・ビューは行の名前を見せていないからこその注意です。 - 1行 = 1レシート などの場合は、author の場合でいう小説の名前が整数値(1, 2, ...)となって可視化されるようになります。その際はチャートにするととても見辛いので、あえて欠損値にする処理を Exploratory のなかで行うなどの工夫をオススメします。
my_ca()スクリプトの中にある最初の4行程度の部分を、例えばrequire(ca) >> require(MASS)ca >> corresp
colcoord >> cscore や rowcoord >> rscore
などと変更することで、後のスクリプトのメンテナンスは必要かもしれませんが大体同じように使用することができます。- 例えば
my_ca(dim = 3)とすると 3軸目も追加することができます。その際は3次元によるコレスポンデンス分析の可視化も可能です。
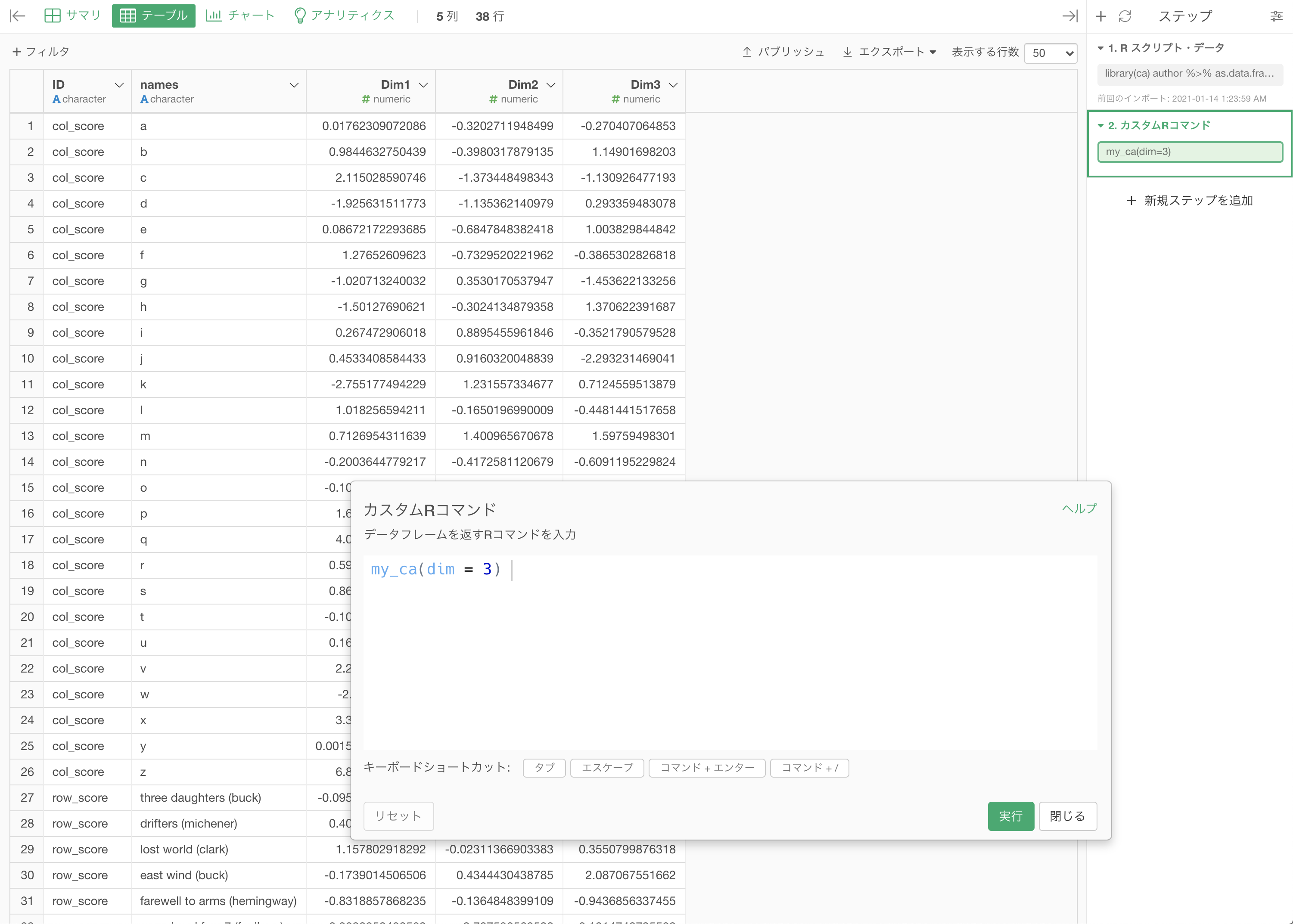
この際の可視化は以下のようになりました。あまり使用されない文字(q x z など)は外の方に行っていることもわかりますが、何よりこうも簡単にコレスポンデンス分析を3Dで可視化できることは少し面白かったのでは?^^
申し遅れました自己紹介
2021年の現在は都内の大学生です。専門は情報幾何学ですが、R 言語 や Python 言語も頑張りながら、最近は SQL に興味あります。
SNS とかやっていませんが、近いうちにまた何かできたら良いなと思います。