EDA Salon 2019年11月のまとめ
先月は、Airbnbの東京の宿泊施設データをもとに探索的にデータ分析をしてもらいました。
EDASalon発表会
12月4日に、11月のEDA Salonの発表会を行いました。
この発表会では、EDA Salonに投稿してくれた方がスピーカーとなって、テーマ設定の背景やどういった分析をしたのかを発表していただきます。
録画
zoomの調子が悪く、一部映像が途切れています。
EDASalon Award
今月のEDASalonの投稿をview数やLike数をもとにランキングにしてみました!
データの可視化賞
データの可視化賞に選ばれたのは、 Ikuyaさんの「東京でAirbnbを利用する人は何を求めている?」です!

宿泊施設名を形態素解析、ワードクラウドをつかってユーザーが好む言葉を可視化するという面白い使い方でした!
データラングリング賞
データラングリング賞に選ばれたのは、Wasabiさんの「「住所」と「1泊料金」の関係についての探索的データ分析」です!
Yahoo!リバースジオコーダAPIを使って経度緯度から正しい住所を取得するという、最高なラングリングを見せていただきました!
データ分析賞
データ分析賞に選ばれたのは、Takasunaさんの「レビュースコアを上げるアメニティはなにか」です!
ランダムフォレストで変数にあたりをつけ、線形回帰で統計的に確認、最後に可視化といった流れが非常によく、深いインサイトが得られていました!
Team Exploratory賞
Team Exploratory賞に選ばれたのは、Nakadaさんの「Airbnbに東京で部屋出すならどこが良いか?」です!
仮説の設計や、需要(検索数)と供給(宿泊施設数)という観点でデータ分析しているのが非常に面白い投稿でした!
思わず吹き出してしまった賞
思わず吹き出してしまった賞に選ばれたのは、Tanabeさんの「ジム・プール付き民泊は存在するのか!?」です!
テーマ設定も個性が表れていたんですが、何よりオチがあって最高でした!
ハイライト
EDA Salonで投稿していただいたインサイトを、もっとも印象的だったベストチャートとともに、ハイライトとして紹介していきます!
それでは早速みていきましょう!
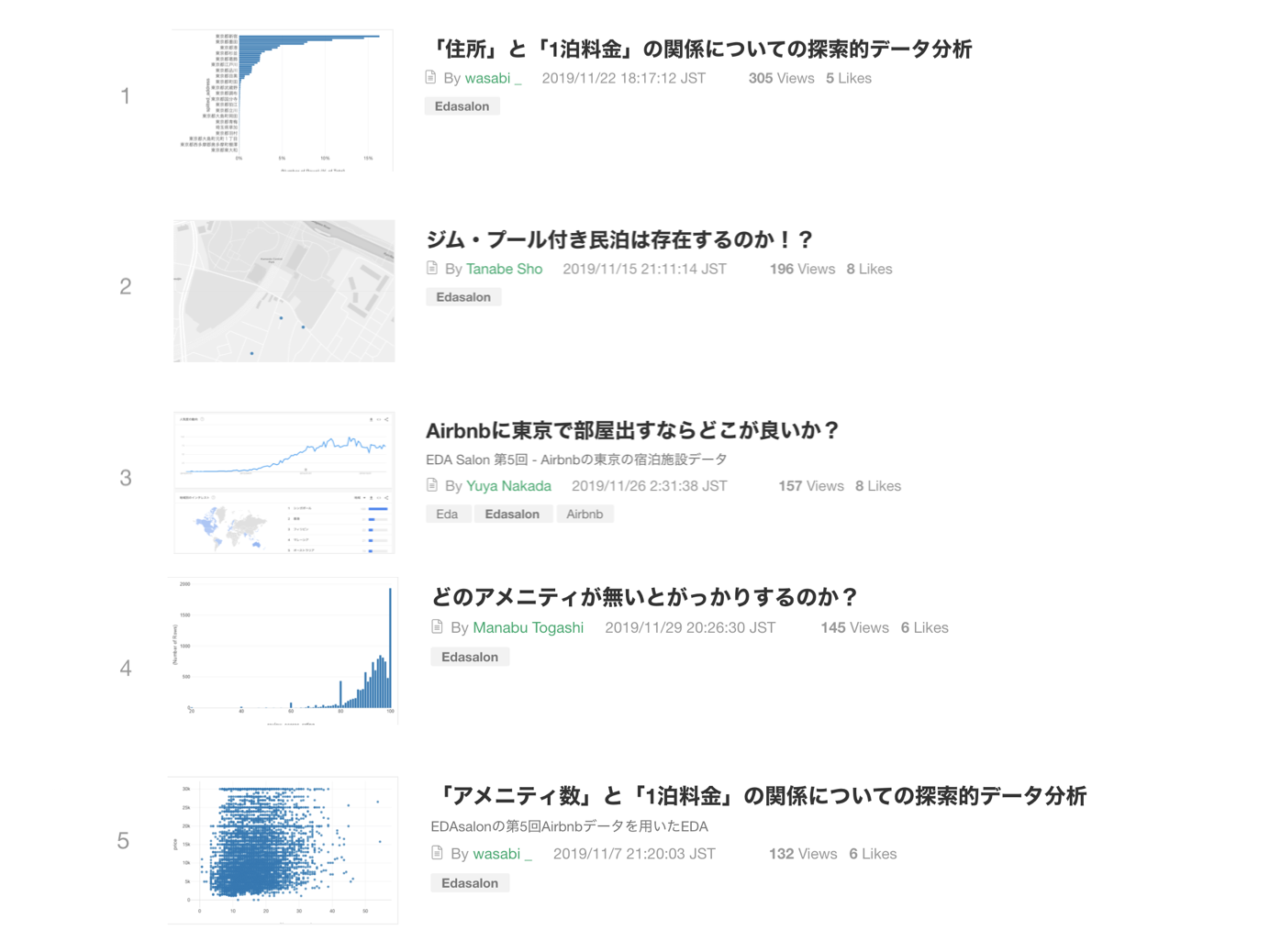
「住所」と「1泊料金」の関係についての探索的データ分析
Wasabiさんは、住所と料金の関係性について探索的にデータ分析されています。
下記は住所ごとに価格の分布を可視化した箱ヒゲ図です。
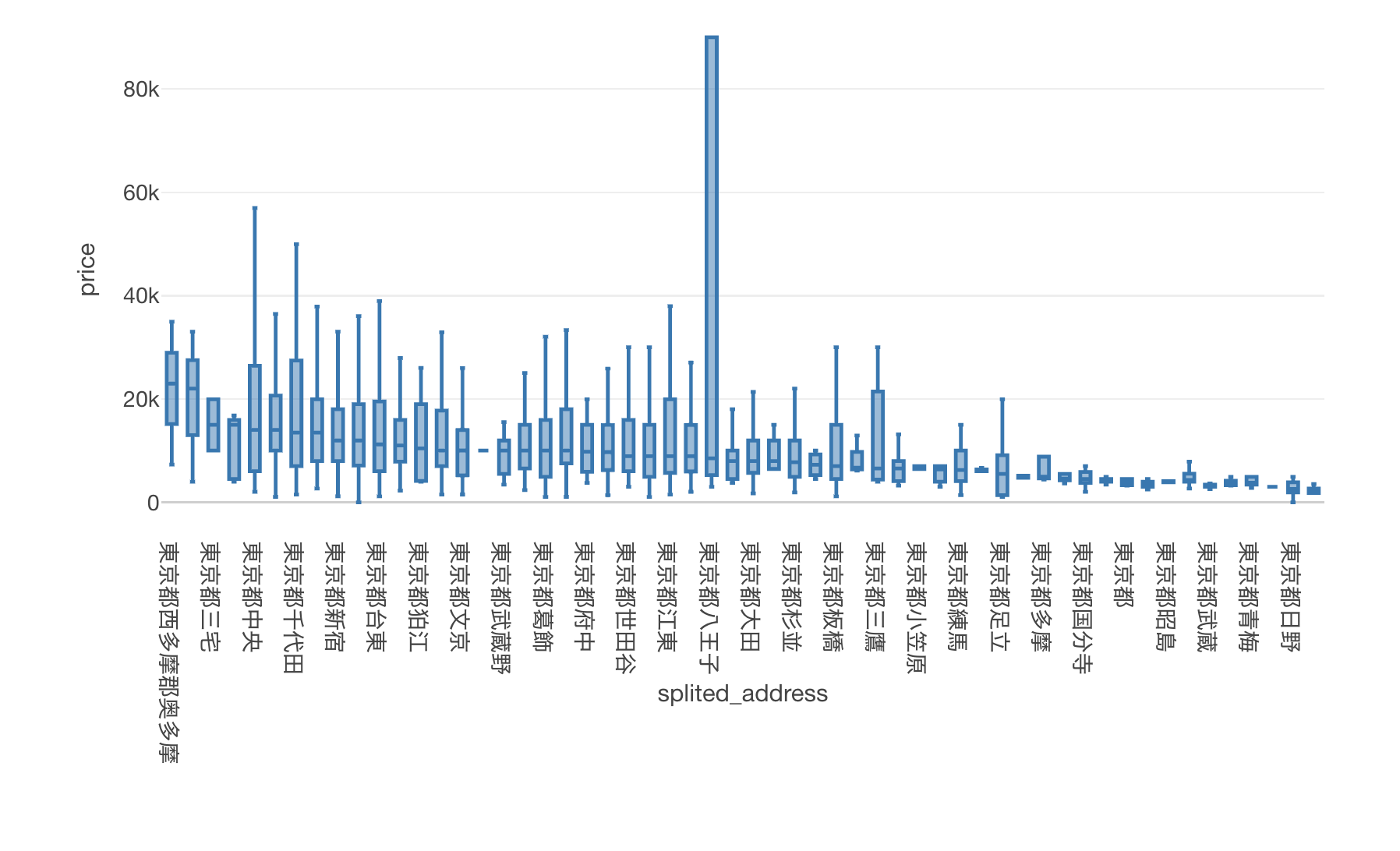
住所によって1泊料金の分布は微妙に異なることがこの箱ヒゲ図から読み取れますね!
また、今回のデータは、住所の情報が表記揺れや粒度が異なったりと、汚いデータでしたが、wasabiさんがYahooのリバースジオコーダAPIを使って、正しい住所を取得して公開していただきました。
ありがとうございます!
wasabiさんは他にも、たくさんの投稿をされているので、是非ご覧ください!どれも面白い投稿ばかりですよ!
ジム・プール付き民泊は存在するのか!?
Tanabeさんのこの投稿は、先月開催した勉強会の発表の最中に投稿していただいたものです!かなり盛り上げてくれました!
テーマは希少なアメニティは存在するのかを分析されています。
- TanabeさんのTwitter @ckEa4gqEwNBsKDy
- ジム・プール付き民泊は存在するのか!? - Link
下記は、X軸に東京23区、Y軸に希少アメニティを割り当てた格子図です。
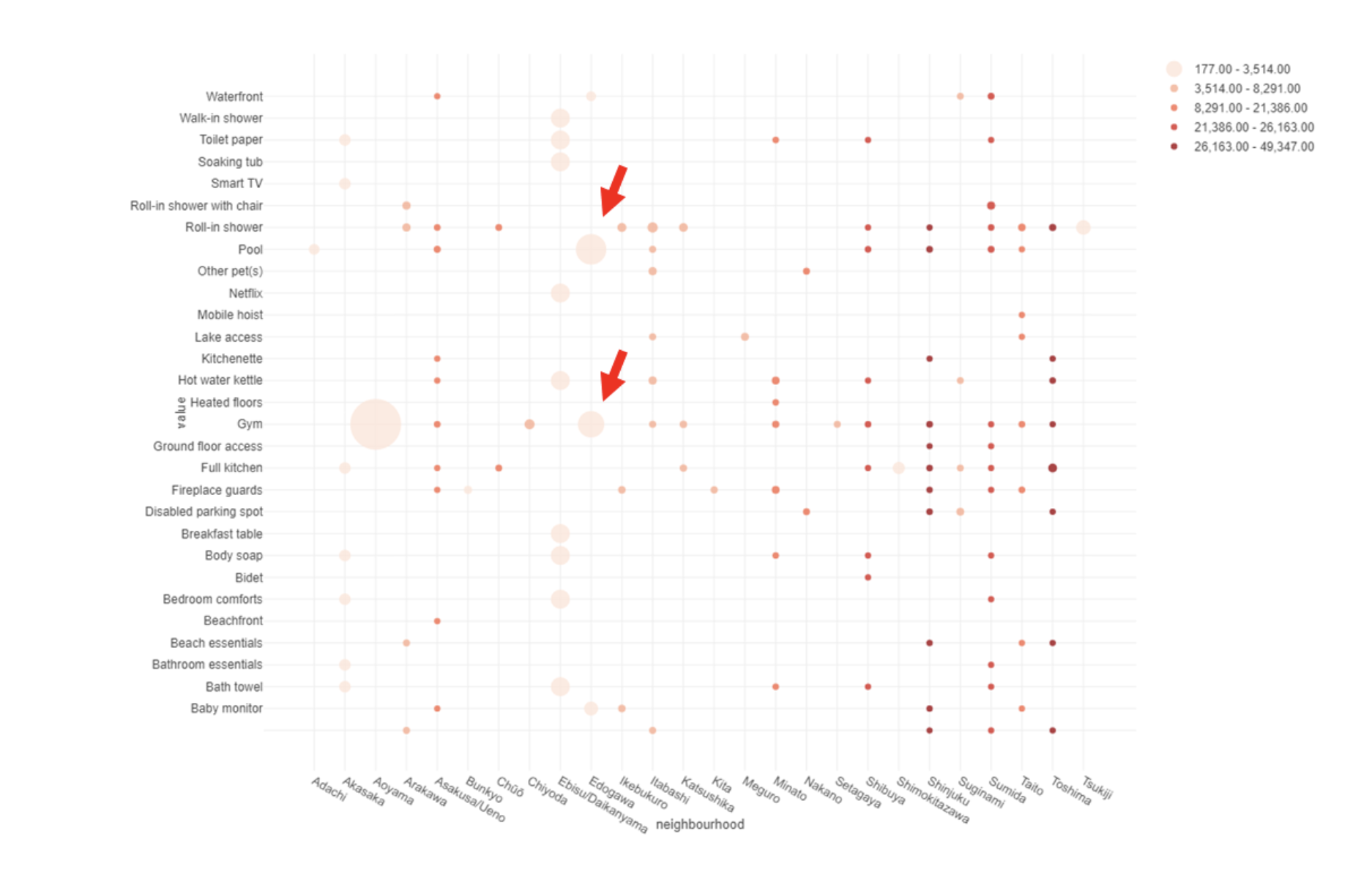
サイズが大きいほど希少アメニティの数が多く、色が濃いほど区の物件数のが多くなるようです。
これをみると、江戸川区にジム・プール月の民泊がありそうなことがわかりますね。
ここからマップでどういった特徴があるのかを分析しているんですが、オチが素晴らしいです。
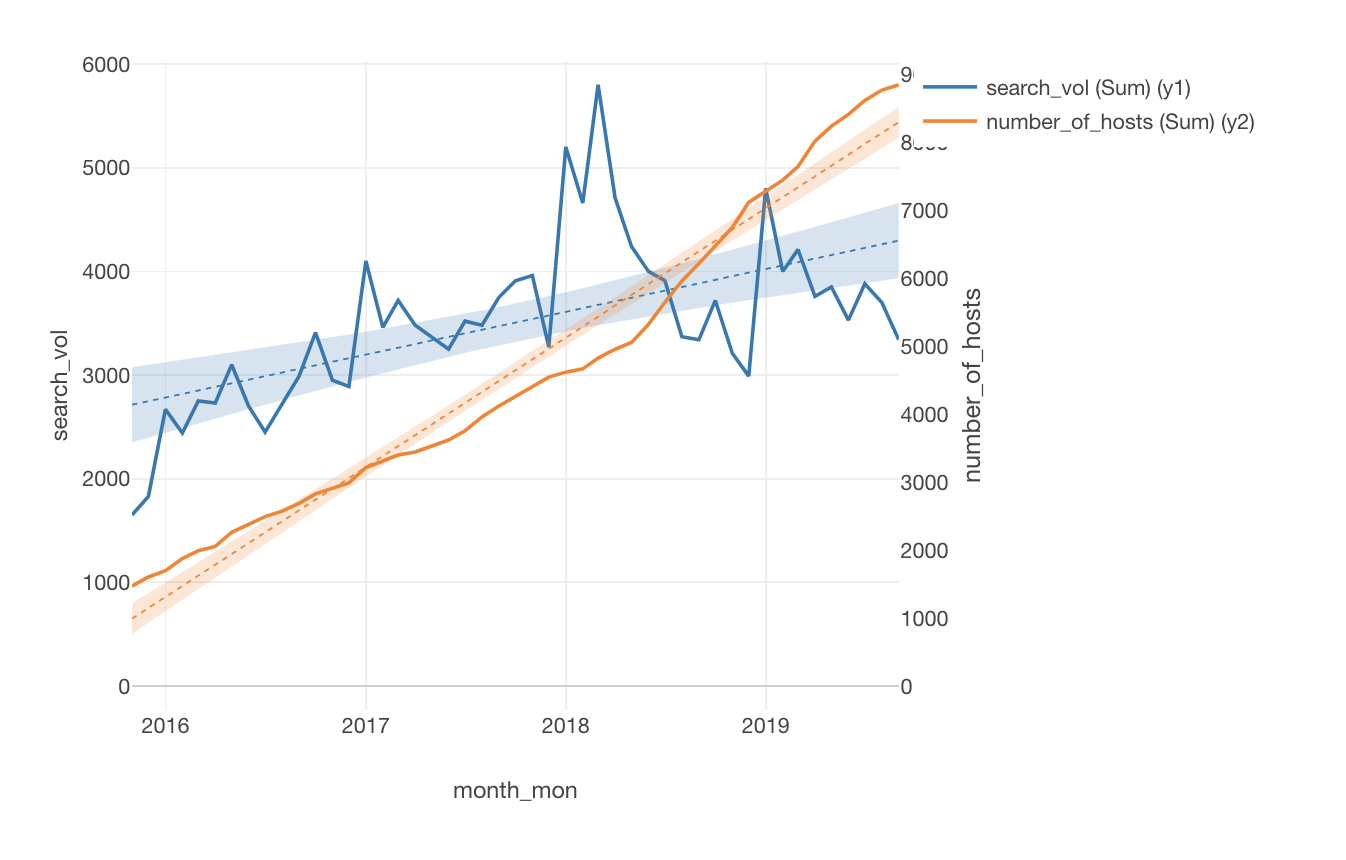
Airbnbに東京で部屋を出すならどこ良い?
Nakadaさんは、11月のデータサイエンス・ブートキャンプに参加していただきました。
今回は、自分が東京でAirbnbに部屋を出すと仮定し、その場合にどのエリアに出すのが良いのか?という視点でデータ分析しています。
- Airbnbに東京で部屋を出すならどこ良い? - Link
下記は、Y1軸にairbnb tokyoの検索数、Y2軸に宿泊施設数を割り当てたラインチャートです。
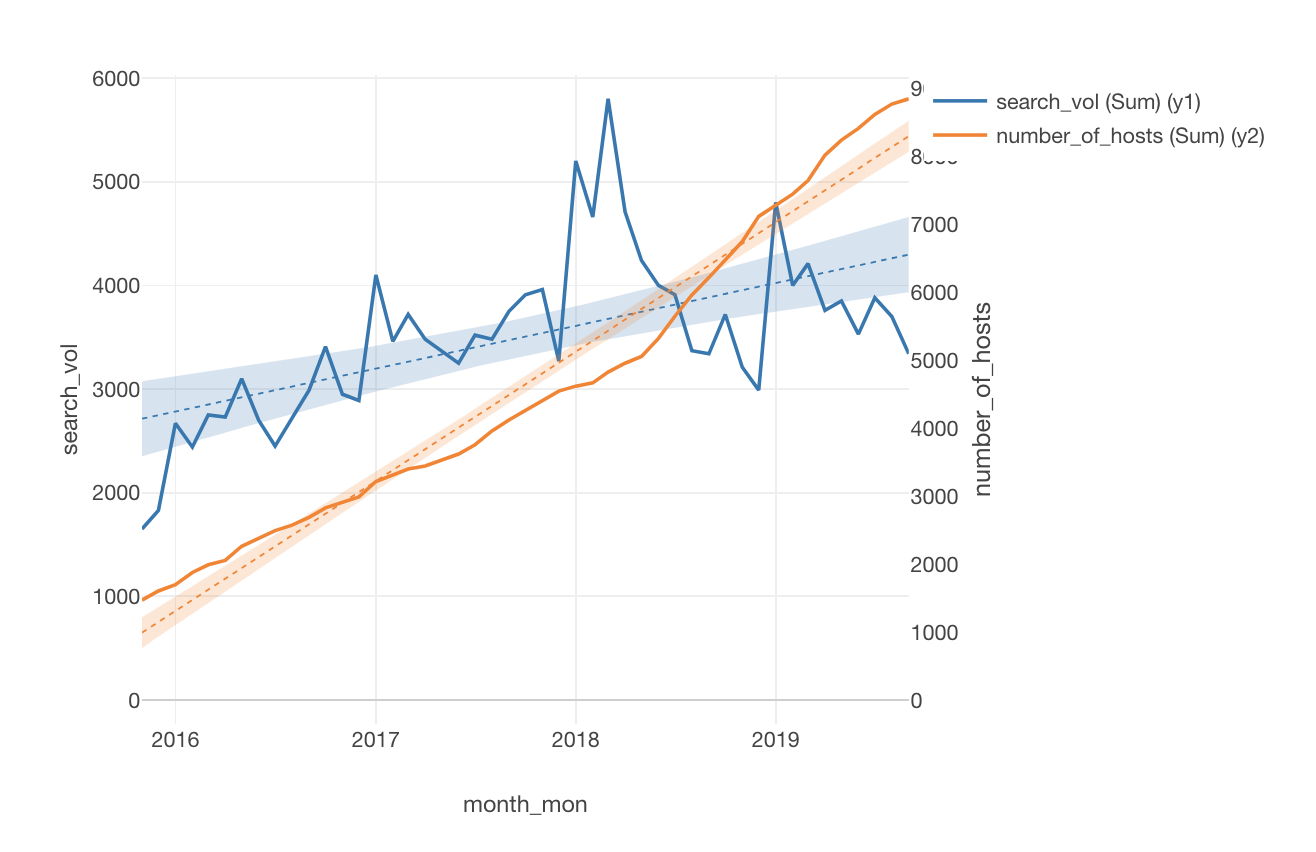
この分析の面白いところは、需要と供給という観点で分析されているところです。
供給に関しては、今回のデータにある宿泊施設の数ですが、需要に関してはGoogle Trendsを使ってエリア別の検索数を取得していました。
最初の仮説の立て方から、最後の結論、そして限界に関するコメントまで、とてもクオリティの高い分析でした!
台東区はホステルが「熱い」
Kanさんは、東京に行くときに安く泊まるにはどういった物件が良いのかということを調べてみようということで分析しています。
下記は、エリアごとに物件数を地図 - ヒートマップを使って可視化したチャートです。
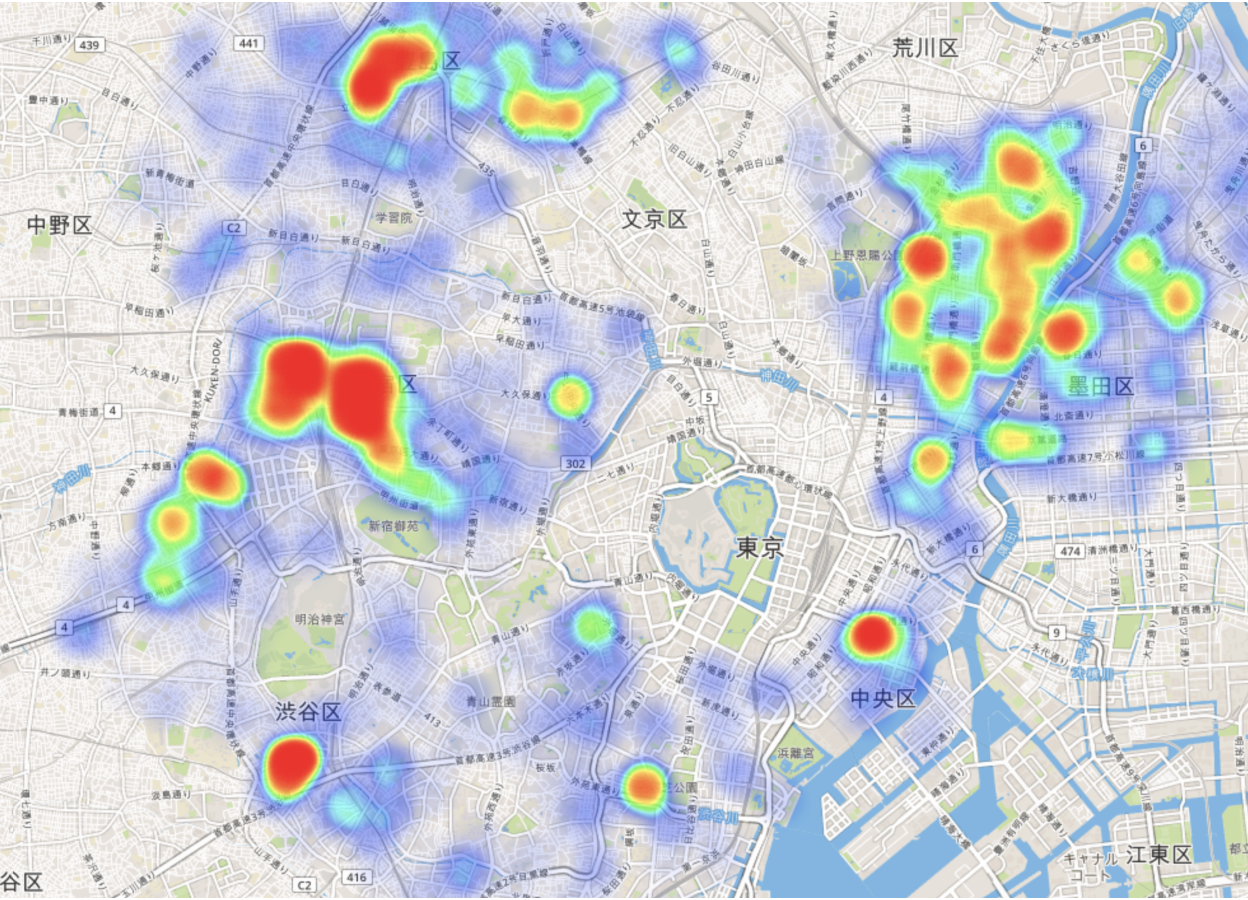
Airbnbでは、物件のタイプがホステルだと1泊の価格が安く、そして台東区がホステルの数が多くなっているようです。
分析していく中で出てきた疑問を深堀りする進め方が上手く、非常に参考になる分析でした!
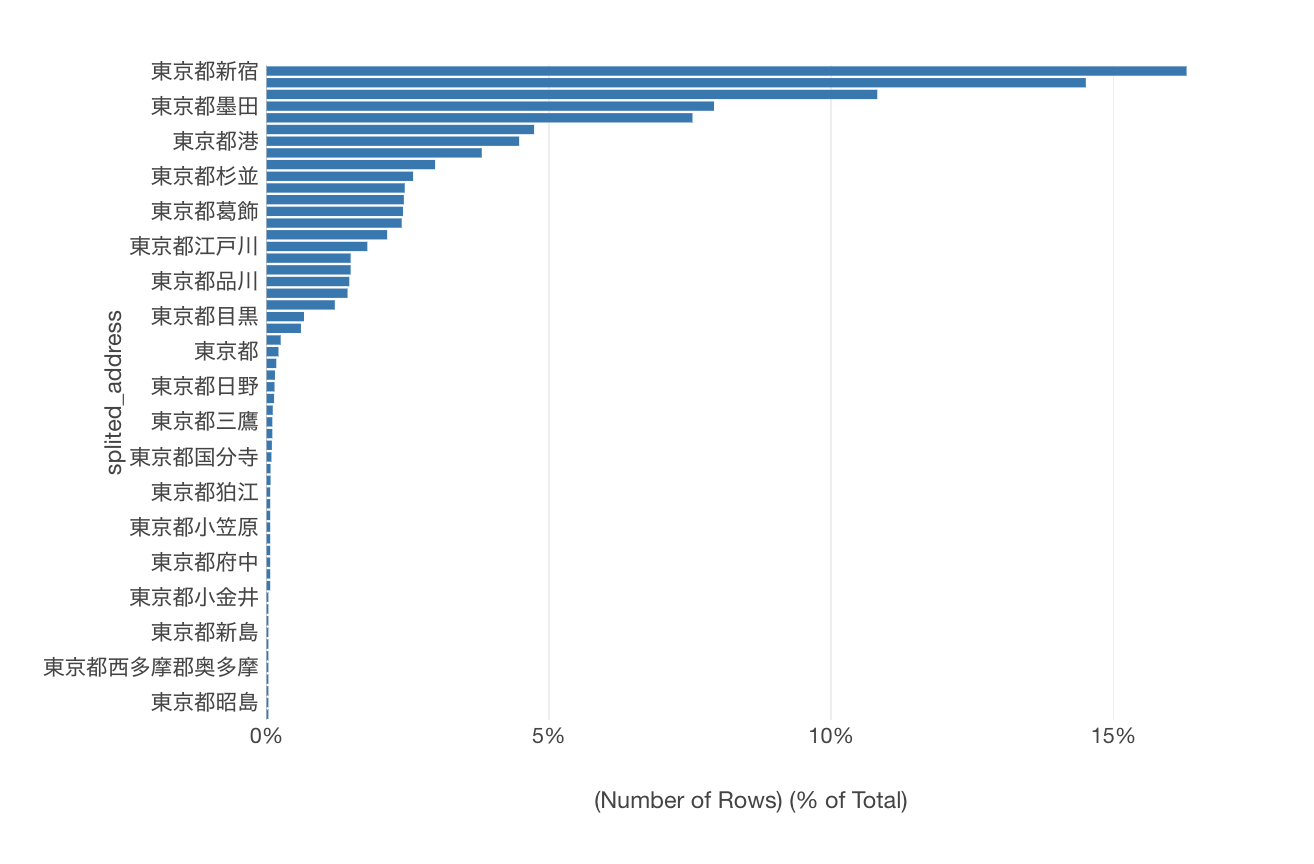
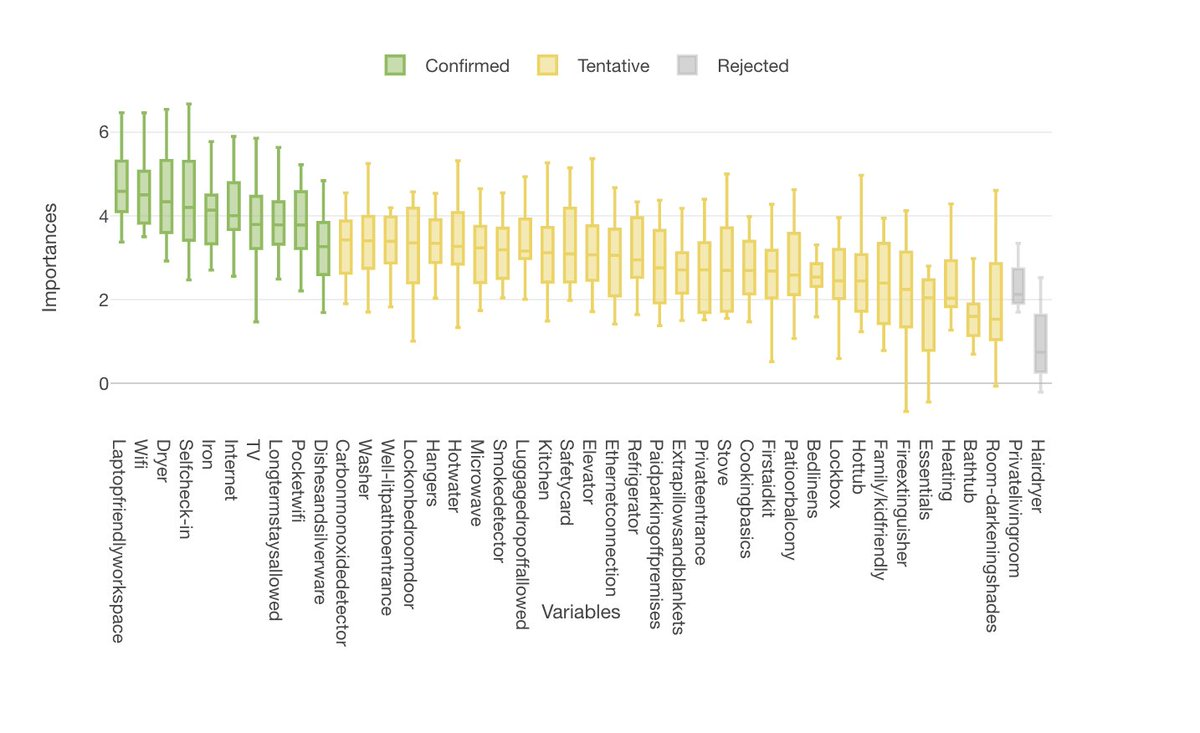
レビュースコアを上げるアメニティはなにか
Takasunaさんも、11月のデータサイエンス・ブートキャンプの参加者です!
今回は、レビューの評価とアメニティの関係性を分析されています。
- レビュースコアを上げるアメニティはなにか - Link
下記は、レビュー評価を目的変数に、予測変数にランダムフォレストで関係性がありそうだと判明したアメニティを割り当てた線形回帰の係数(有意)です。
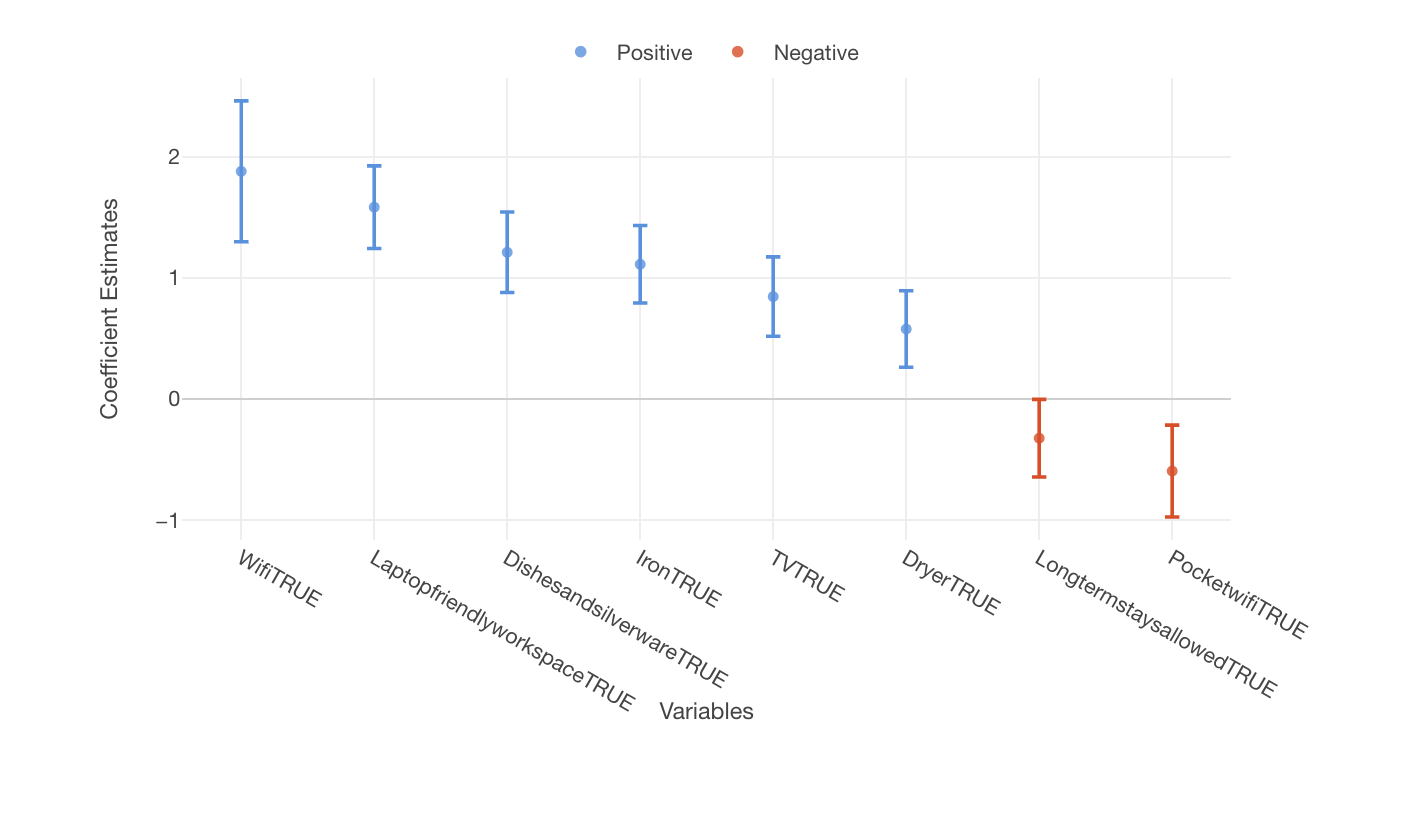
Wifiや作業スペースはレビュー評価に関係しているようですが、ポケットWifiの場合はレビュー評価が下がるという結果は面白いですね。
高砂さんは丁寧な分析をされていて、ランダムフォレストでレビュー評価に関係のありそうな変数にあたりをつけ、線形回帰でどの変数が本当に関係があるのかを深堀り。そして最後に、チャートで可視化をして直感的にわかりやすくしていました。
ExploratoryではじめてのEDA
IIMURAさんには、Exploratory Publicを使って初のEDASalonに挑戦していただきました。ありがとうございます。
- ExploratoryではじめてのEDA -Link
分析の内容としては、データにある経度緯度の情報をもとに、経度緯度マップを使って1泊料金を可視化しています。
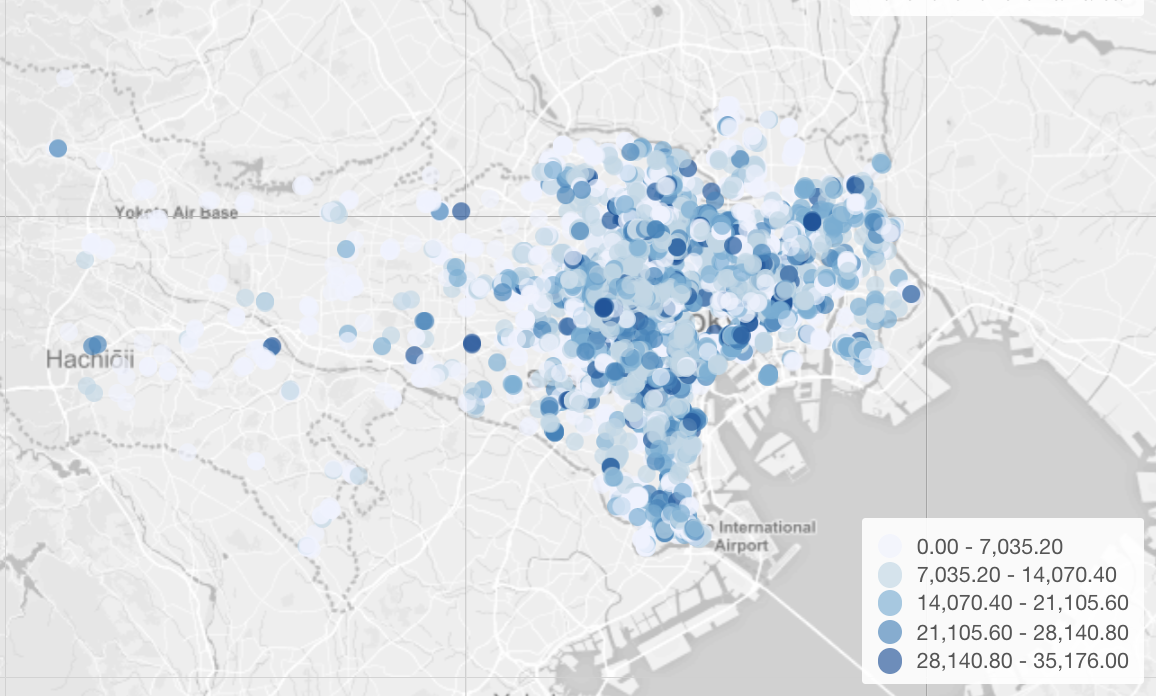
このマップを見ると、八王子などがある東京の西側では1泊料金が低い宿泊施設が多いように見えます。
どのアメニティがないとがっかりするのか?
Togashiさんは、レビュー評価とアメニティの関係について分析しています。
- TogashiさんのTwitter @TogashiManabu
- どのアメニティが無いとがっかりするのか? - Link
下記は、レビュー評価が80点以上かどうかを目的変数にして、予測変数にアメニティを割り当てたランダムフォレストです。
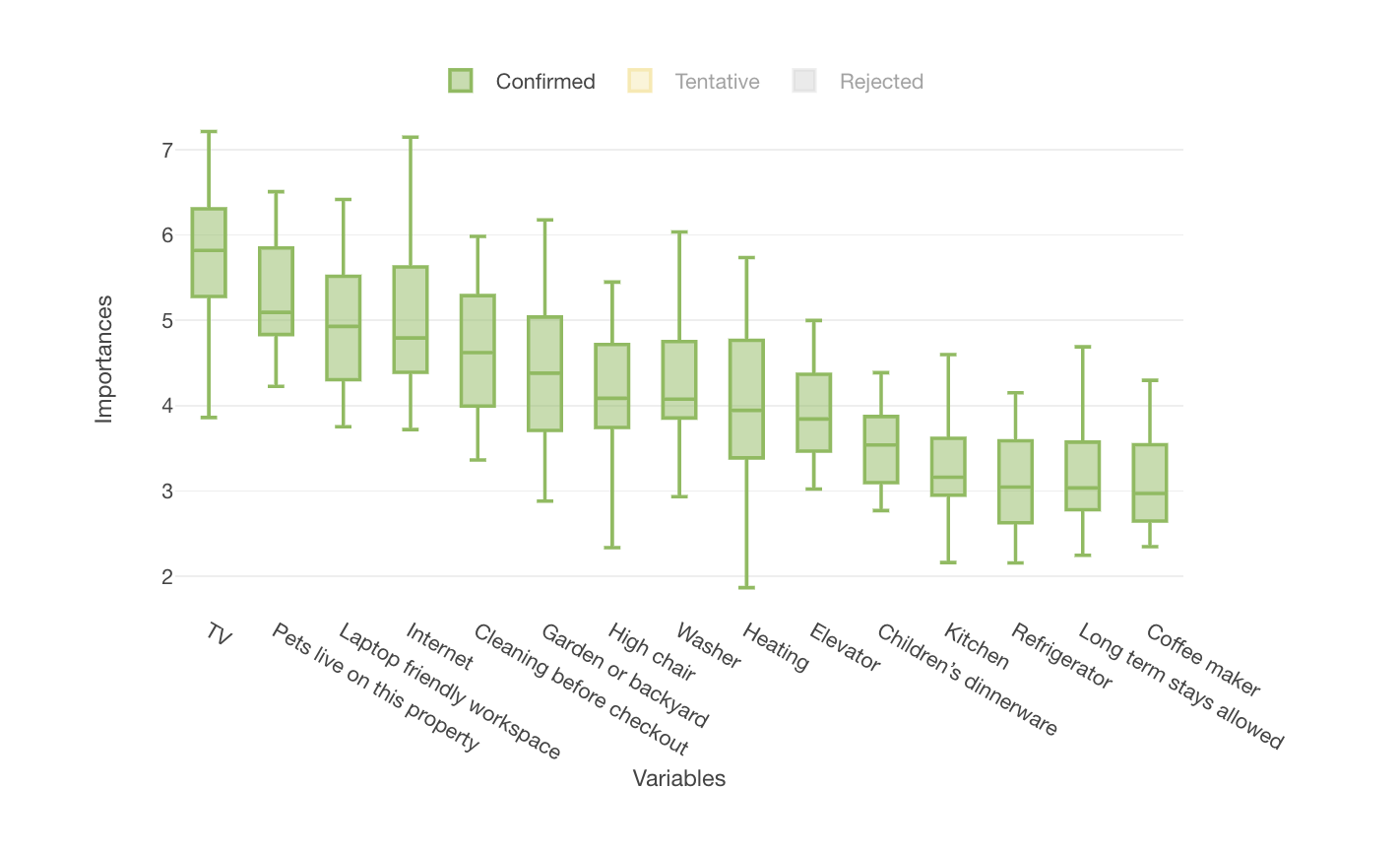
レビュー評価が80点以上の宿泊施設には、普段の生活で使用しているインターネットや冷蔵庫などの必需品が備わっていることがわかります。
東京でAirbnbを利用する人は何を求めている?
Ikuyaさんは、Airbnb を利用する人は何を求めているのかを、宿泊施設名にあるアピールポイントをヒントに分析されています。
下記はワードクラウドを使って、新宿区の宿泊施設名のアピールポイントを可視化しています。

乗降客数日本一位のターミナル駅ということで新宿駅と駅への近さについての言及が多いようです。
Airbnbの物件タイトルのテキスト分析すると好まれる言葉が発見できるという、面白い分析でした!
総評
先月は、Airbnbの東京の宿泊施設データをもとにEDA Salonに挑戦して頂きました。
異なるテーマ設定や分析がされていて、非常に面白い投稿ばかりでした。
そして、回数を重ねるごとに分析のレベルが高くなってきているのではないかと感じています。特に、分析の方向性に合わせて柔軟にデータを加工している投稿が多くなってきました。
改めて、ラングリングと可視化と、アナリティクスを駆使して探索的にデータ分析をするのは楽しいですね!
EDA Salonに挑戦してくださった皆様ありがとうございました!
次回のEDASalonでも楽しみにお待ちしています。
次回12月のお題決定!
次回のEDA Salonのお題が決まりました!
次回のEDASalonのお題は、「日本の統計データ(e-stat)」です!

今月は、データラングリング(加工)をメインにしたEDASalonとします。
データラングリングをした後は、可視化やアナリティクスをして投稿してみてください!
EDA Salonへの参加方法
Exploratoryでデータを可視化したり、分析したら、それをノートに簡単にまとめて、「EDASalon」というタグ付きでパブリッシュしてみて下さい!
EDA Salonへの参加方法の詳細は下記をご覧ください。
Exploratoryをまだ持っていない方
Exploratoryをまだお持ちでない方は、フルバージョンを30日間の無料トライアルで試すか、パブリックバージョン(Exploratory Public)を無料で使うことができるのでぜひサインアップしてみてください。