Exploratoryの使い方 Part 3 - データラングリング - AI版
このノートは、Exploratoryを効率的に使い始めることができるように作られた「Exploratoryの使い方」の第3弾、「データラングリング(データの加工)」編です。
その中でも、自然言語でデータを加工できる「AI プロンプト」を使ったバージョンとなります。もし、「Publicプラン」や「アカデミックプラン」を使っていてAI プロンプトが使えない場合、こちらから「UI版」をご覧ください。
このノートでは、AI プロンプトを使ってデータをきれいにしたり、加工、整形していくためのプロンプトの書き方やコツについて、実際にサンプルデータを使って手を動かしながら学んでいただくようにデザインされています。
所要時間は20分ほどとなっています。
1. データをインポートする
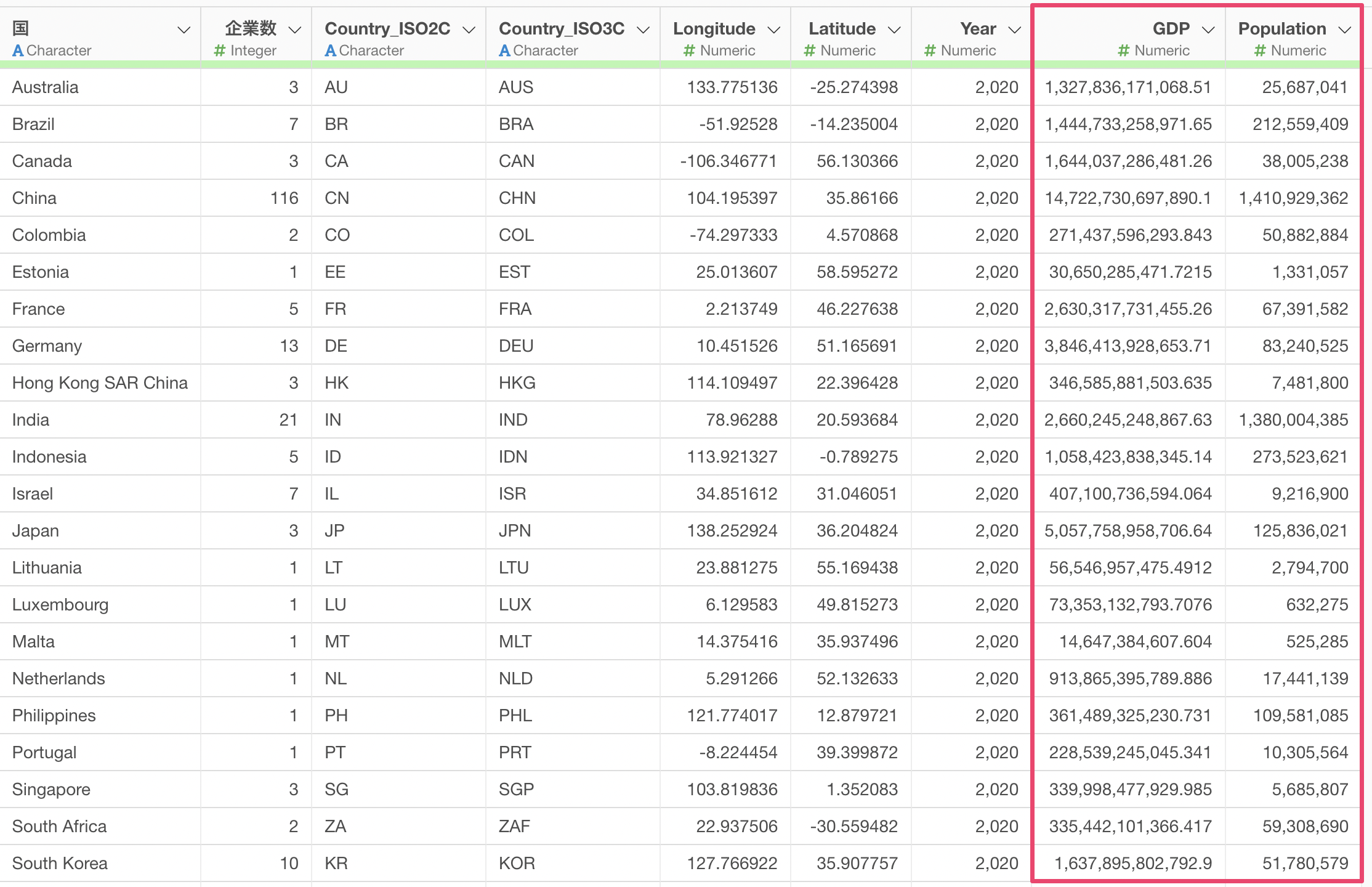
今回はサンプルデータとして以下の2つのデータを使います。
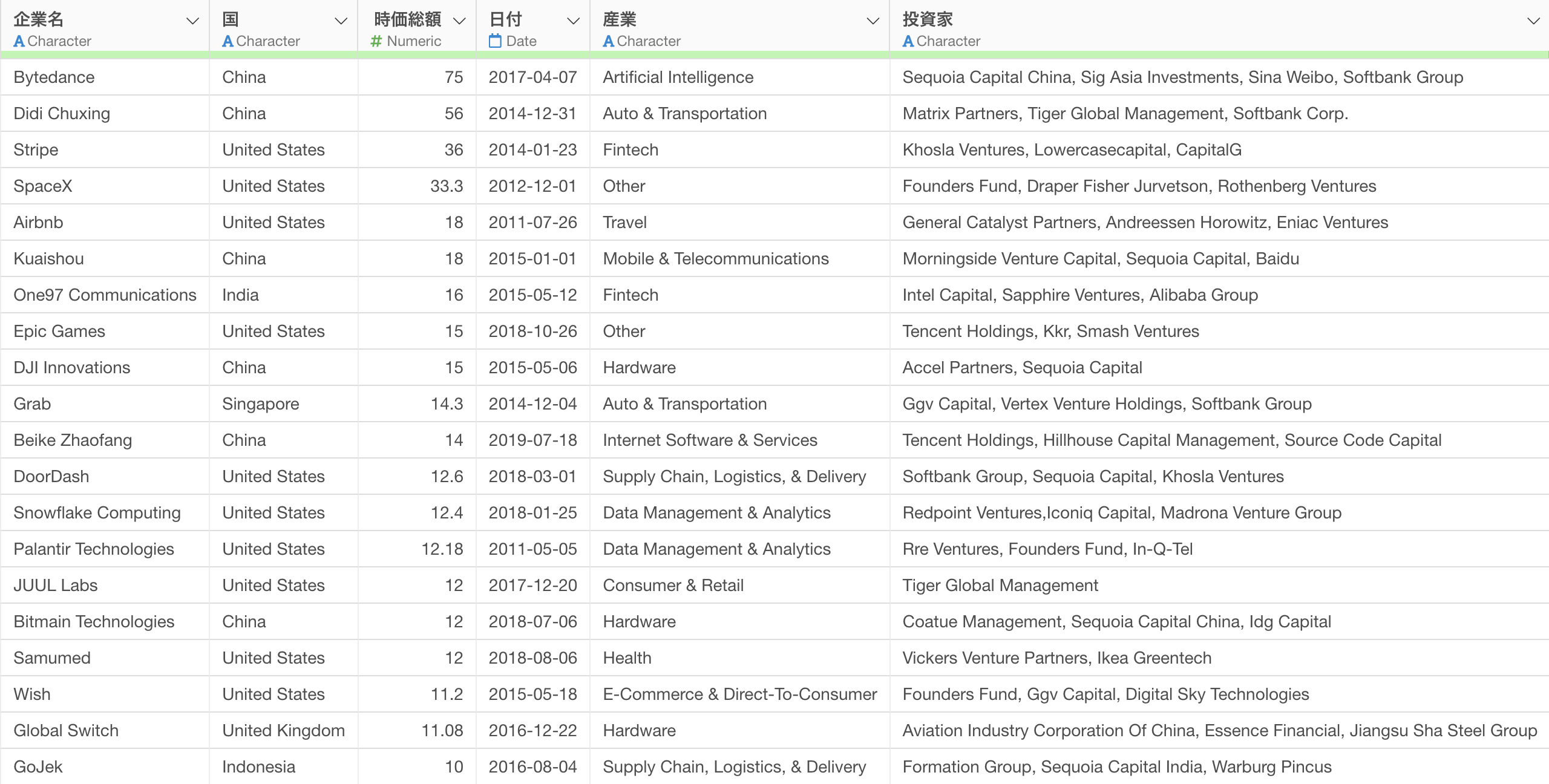
1つ目の「ユニコーン企業のデータ」は、1行が1ユニコーン企業になっており、それぞれの企業の国や時価総額などの情報が列として入っています。
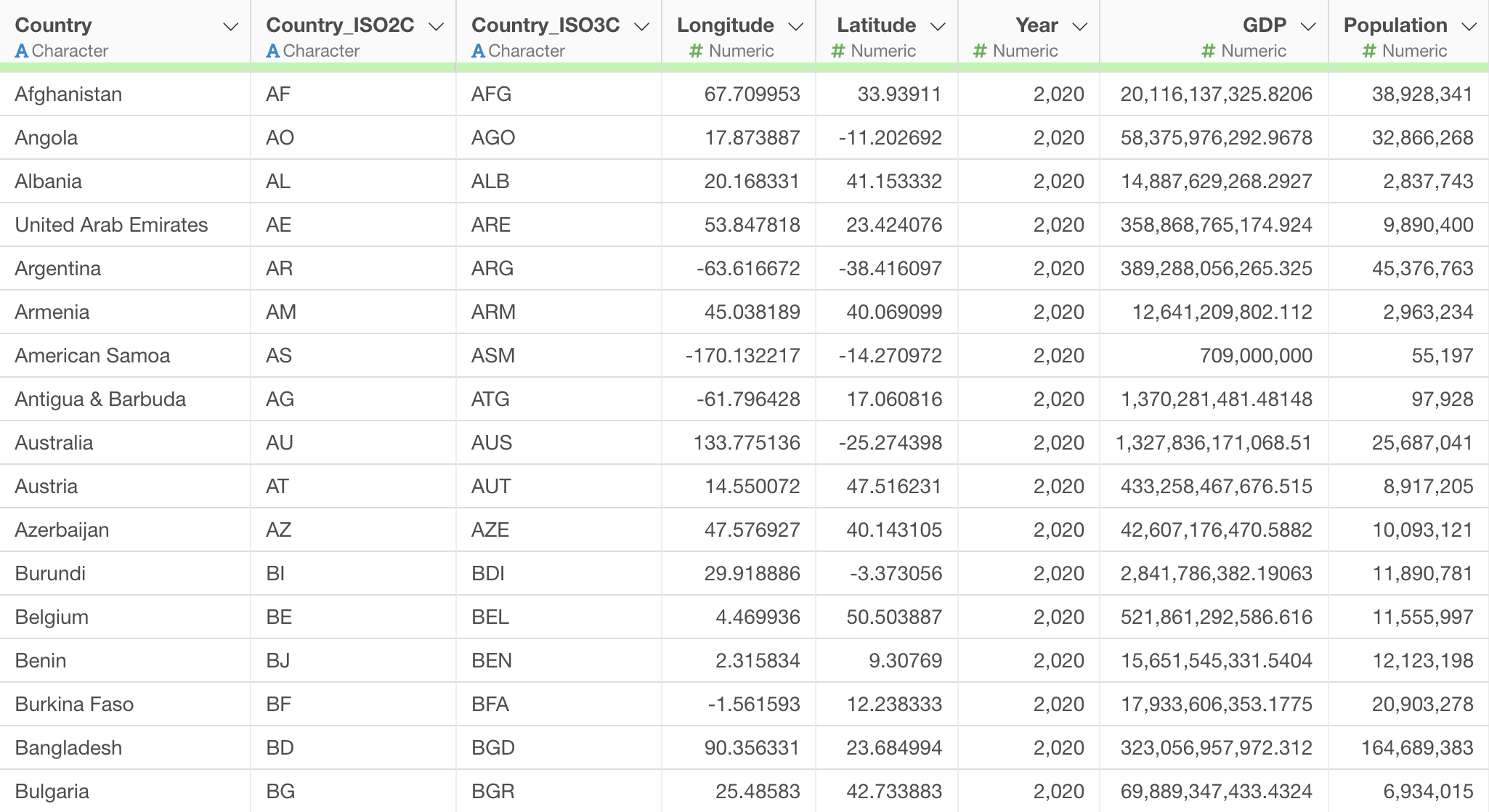
2つ目の「国別のGDPと人口データ」は、2020年における国ごとのGDPと人口の情報が列として入っています。
データをダウンロードできたら、ダウンロードしたフォルダを開き、「ユニコーン企業のデータ」と「GDPと人口データ」を2つ選択した状態で、Exploratoryの画面にドラッグ&ドロップします。
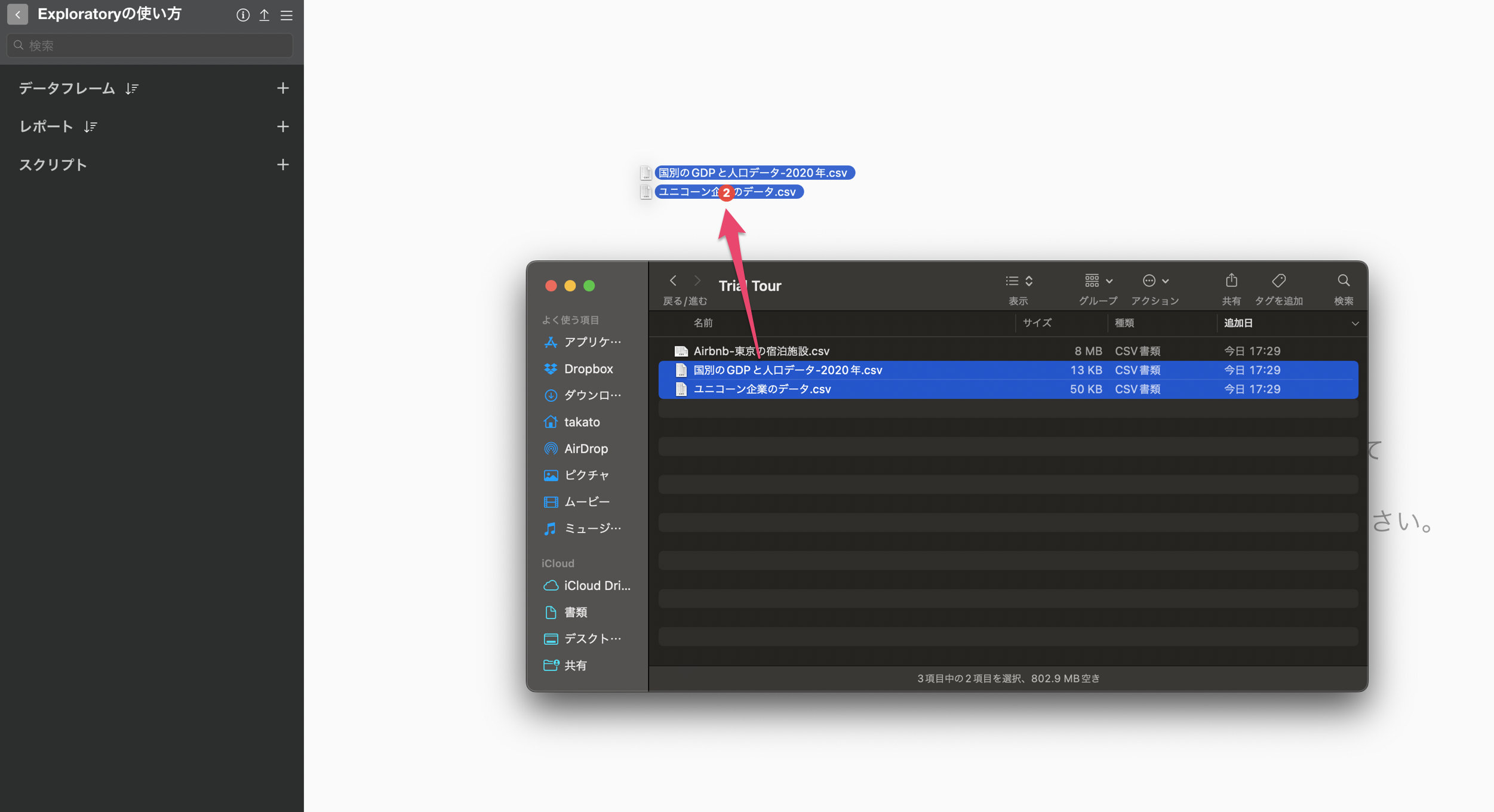
CSVファイルの選択ダイアログが表示され、2つのデータが選択されていることが確認できます。
これらは別々のデータフレームとしてインポートしたいため、通常の「インポート」ボタンをクリックします。
インポートダイアログが表示されますが、今回はインポート時の設定は必要ないため、「全てをOK」のボタンをクリックして、一気にインポートを行います。
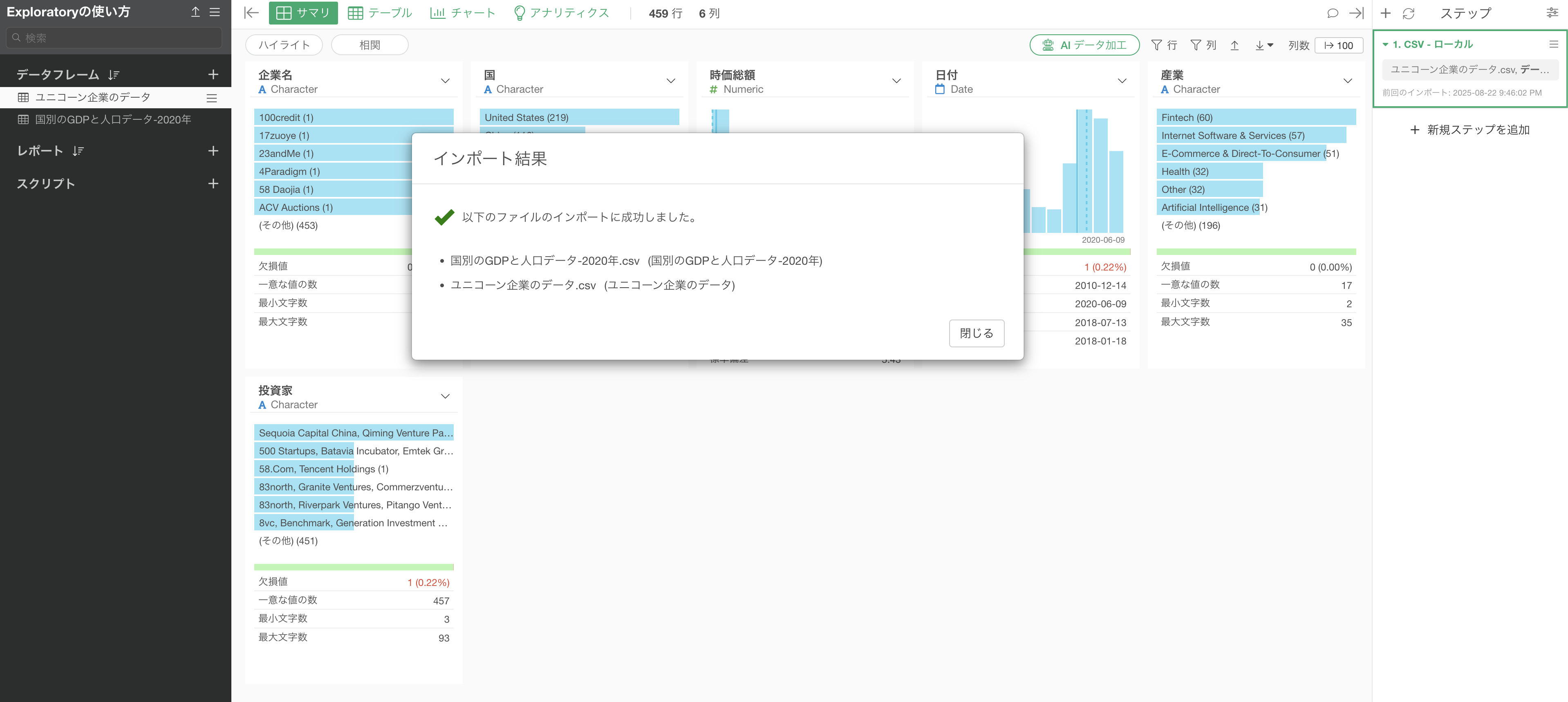
今回使用する「ユニコーン企業のデータ」と「国別のGDPと人口のデータ」という2つのデータフレームがインポートされていることが確認できます。
2. 新しい値に置換する
ユニコーン企業のデータを開き、産業ごとの企業数を可視化してみましょう。
サマリビューの産業の列から「チャートの作成」ボタンをクリックします。
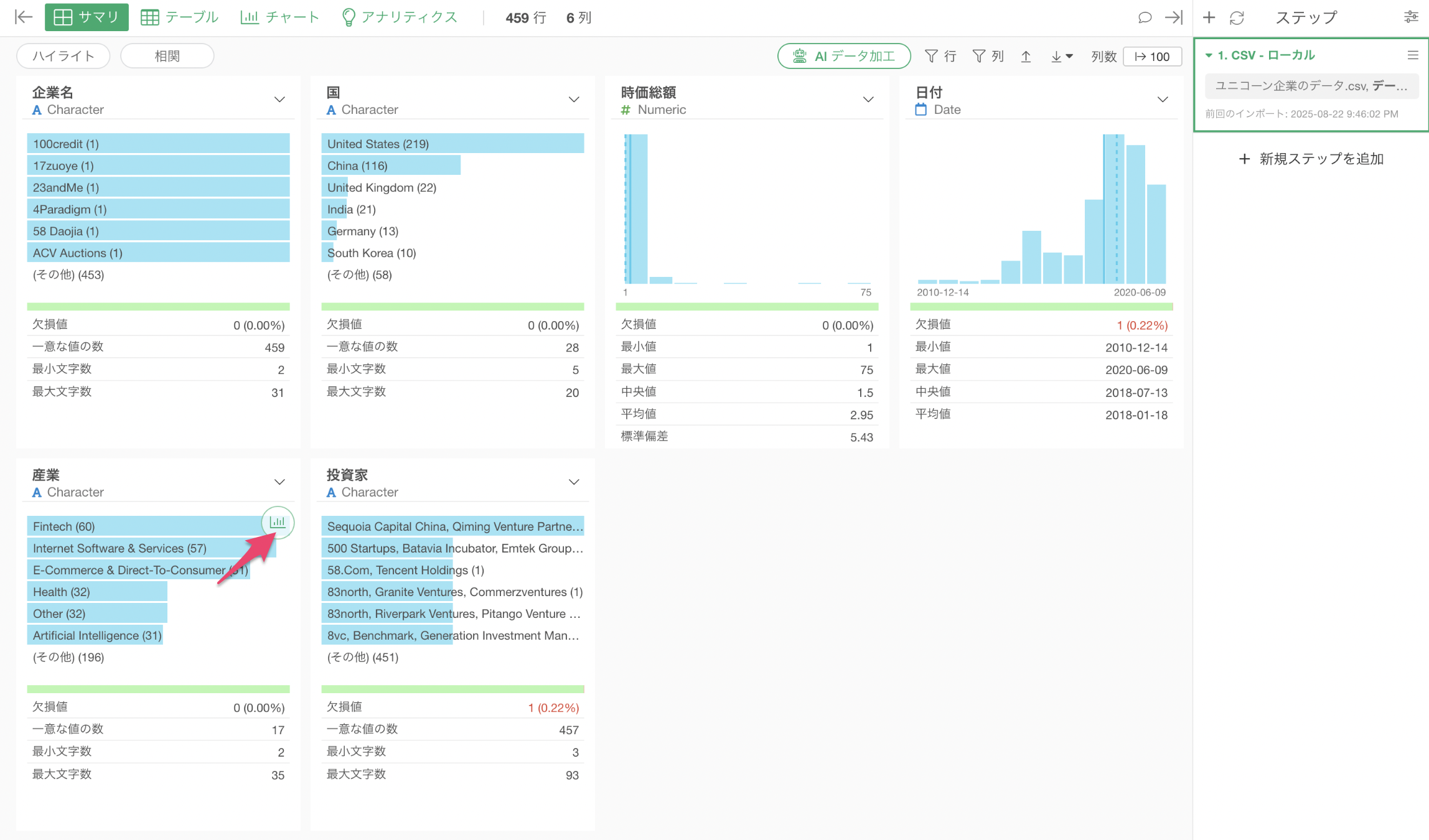
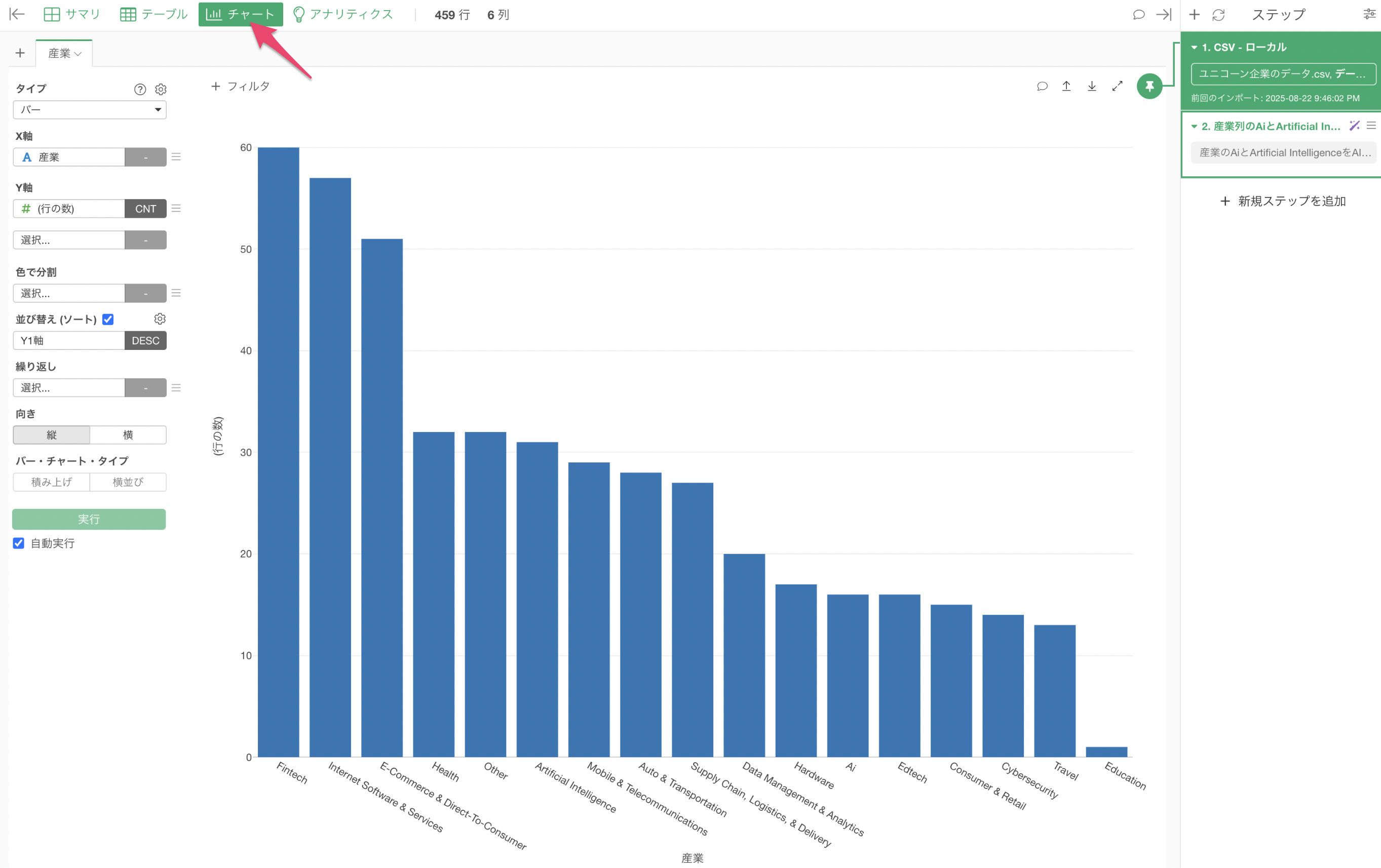
チャートビューに移り、産業ごとの行の数(企業数)を可視化することができました。
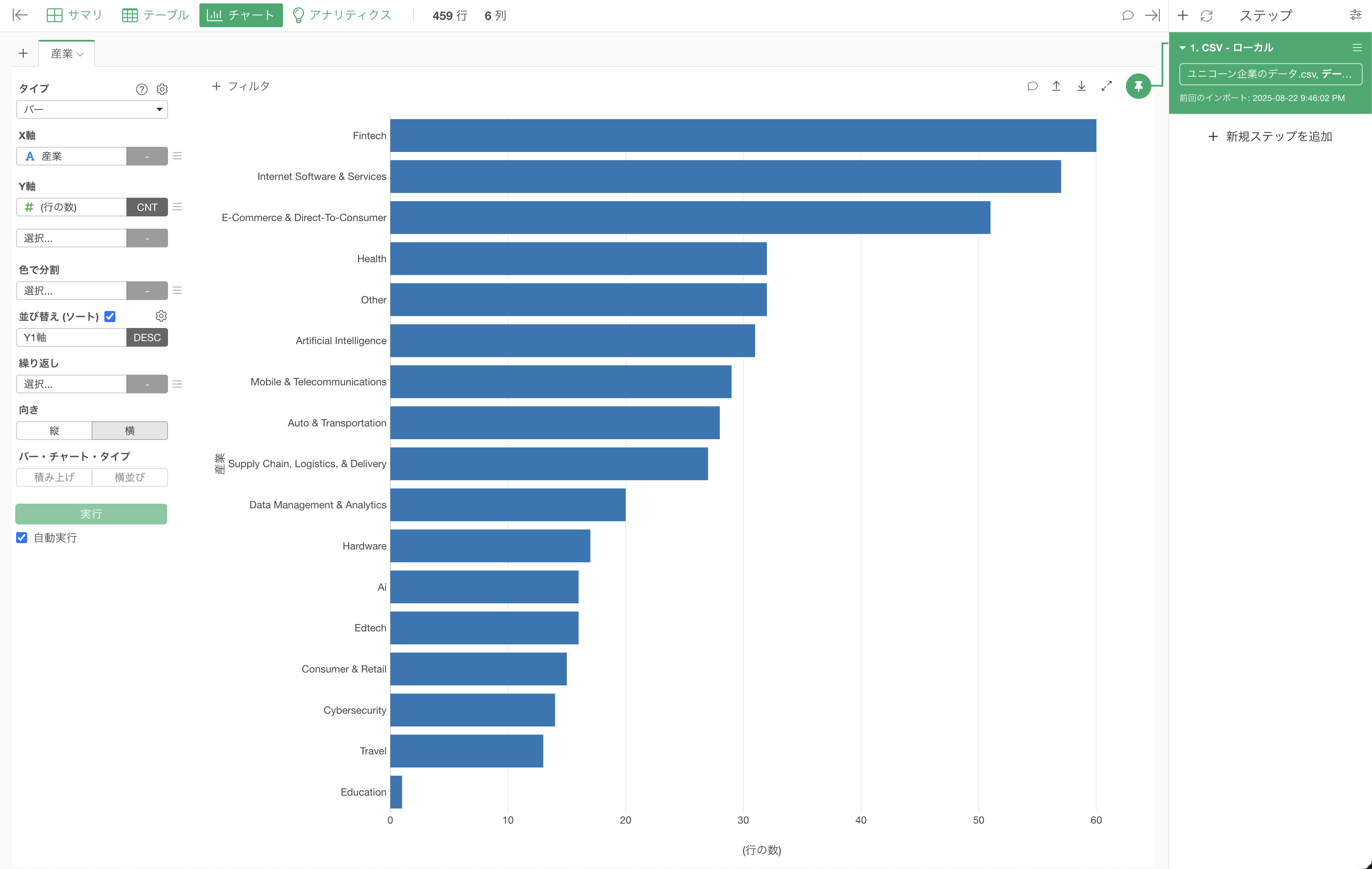
バーチャートの向きを縦にしたい場合は、向きに「縦」を選択します。
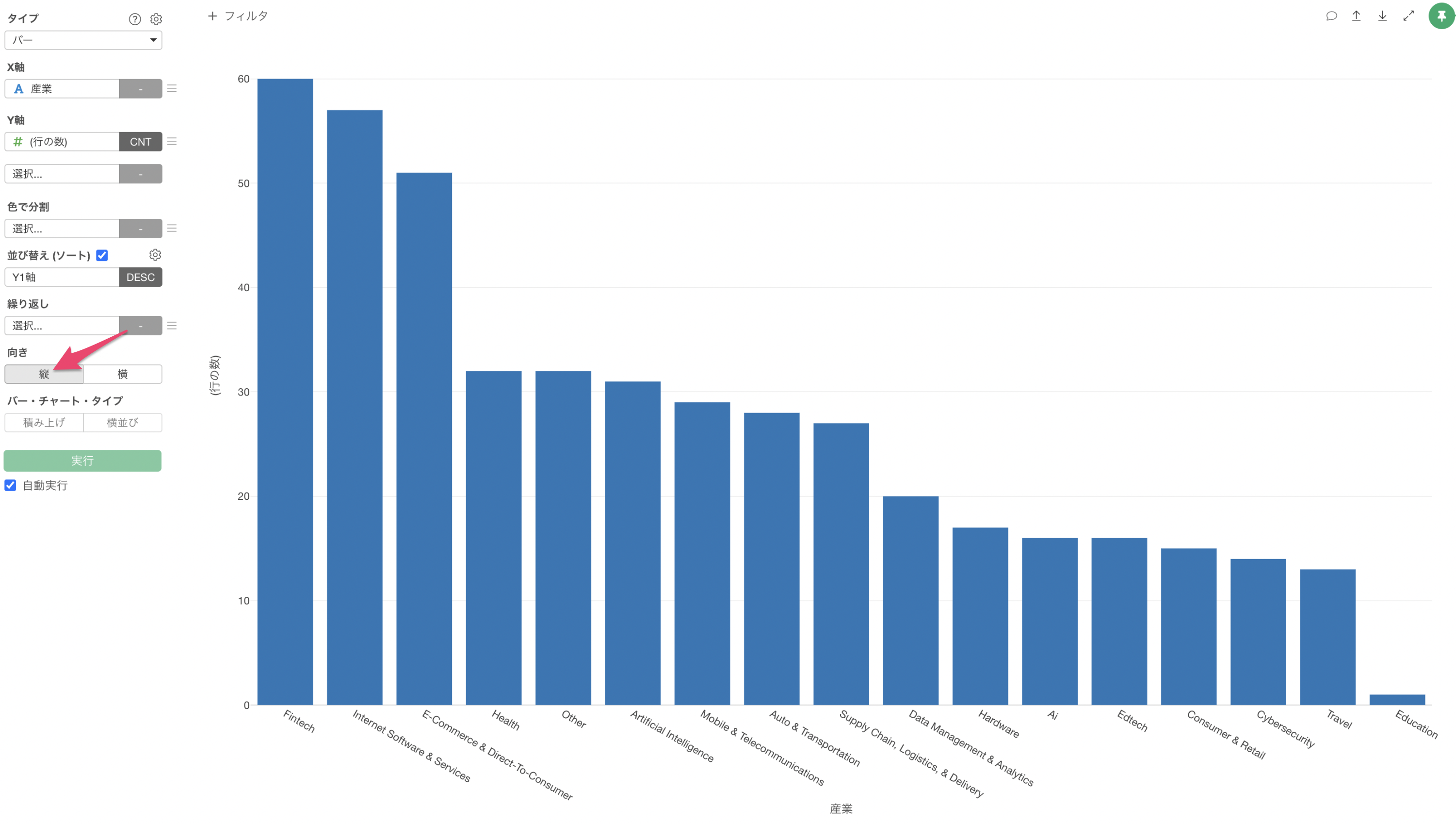
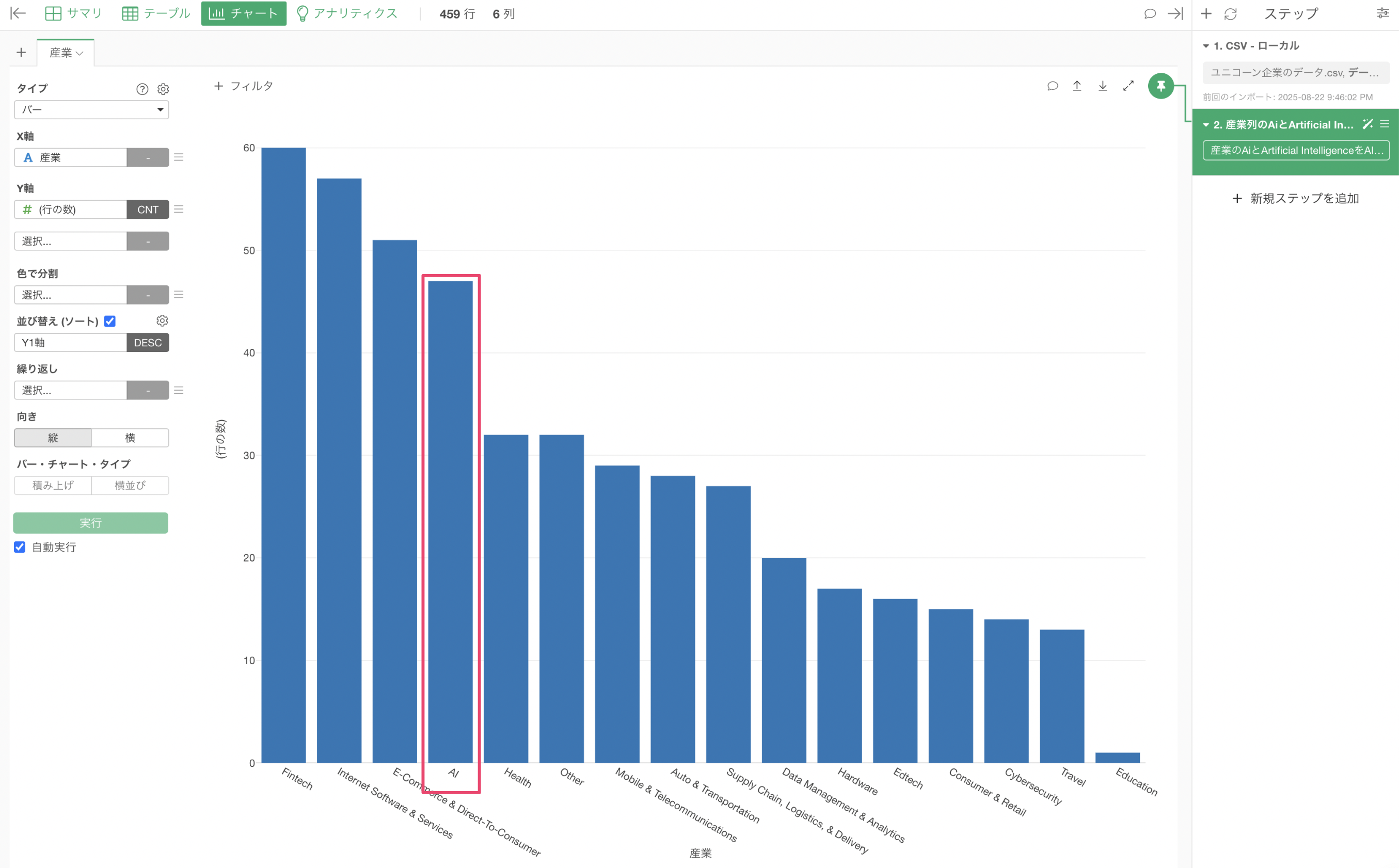
産業には「Artificical Intelligence」と「Ai」という同じ「AI」を表す値があるようです。これらは同じカテゴリーとしてカウントしたいため、どちらも「AI」に置換して表記を統一したいです。
「AI データ加工」のボタンをクリックします。
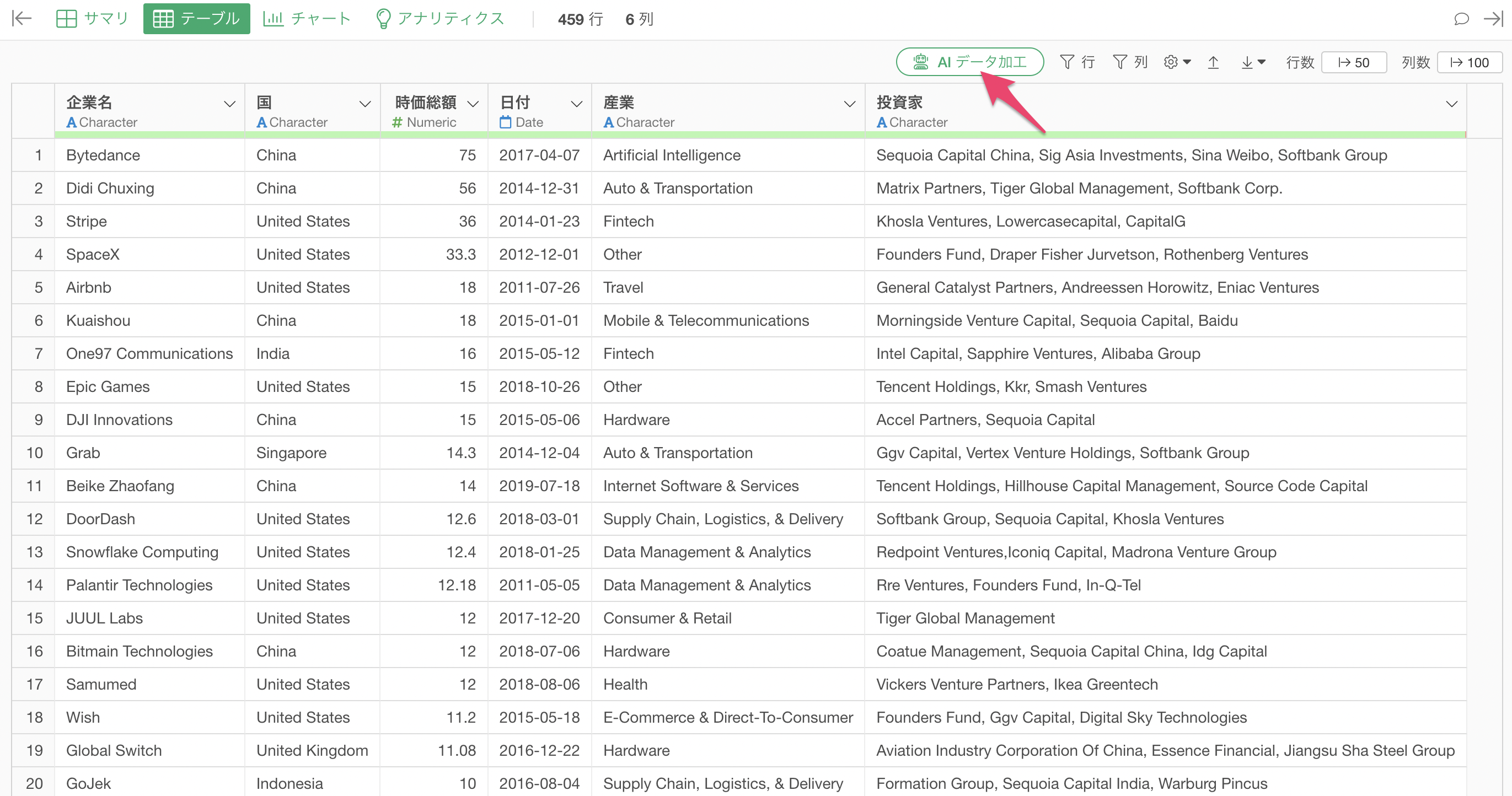
AI プロンプトのダイアログが表示されるため、プロンプトに以下を指定します。
産業のAiとArtificial IntelligenceをAIに置き換えて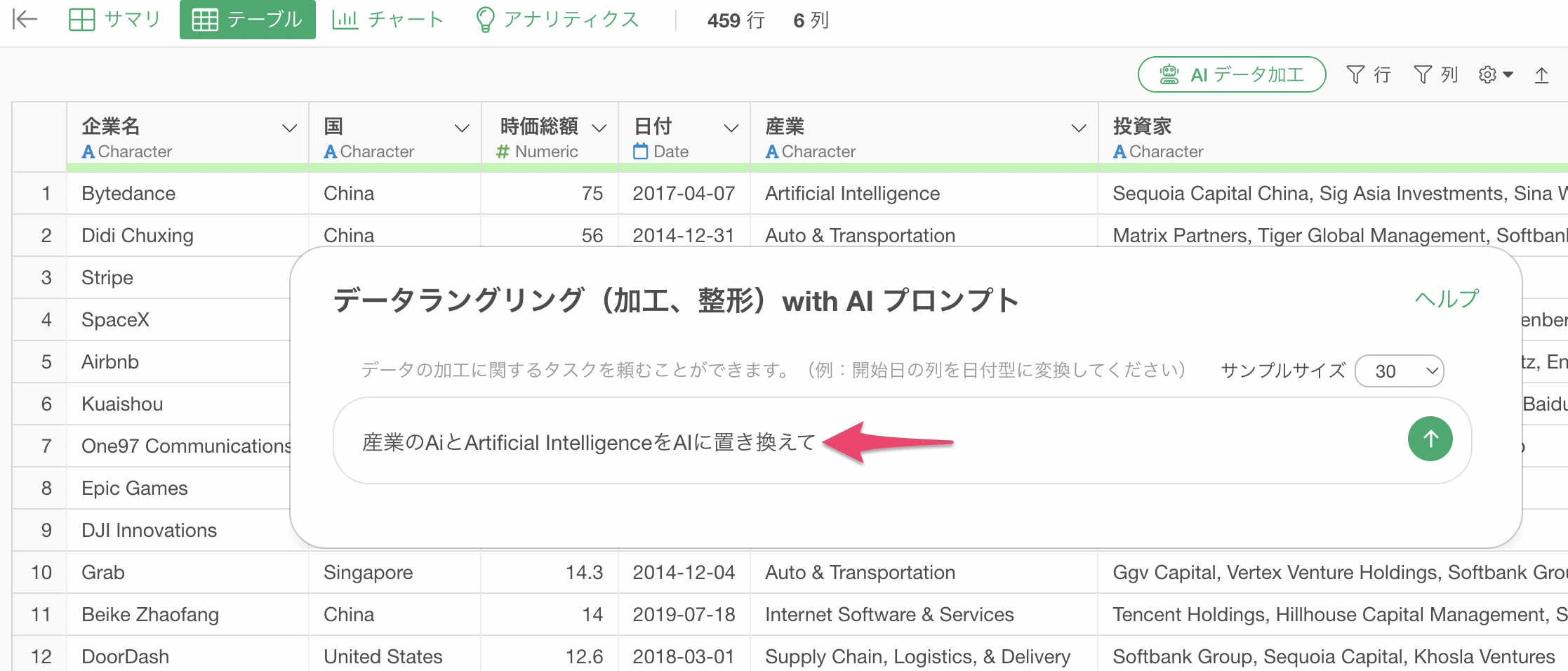
産業の「Ai」と「Artificial Intelligence」を「AI」に置き換えるためのRスクリプトがAIによって返ってきます。
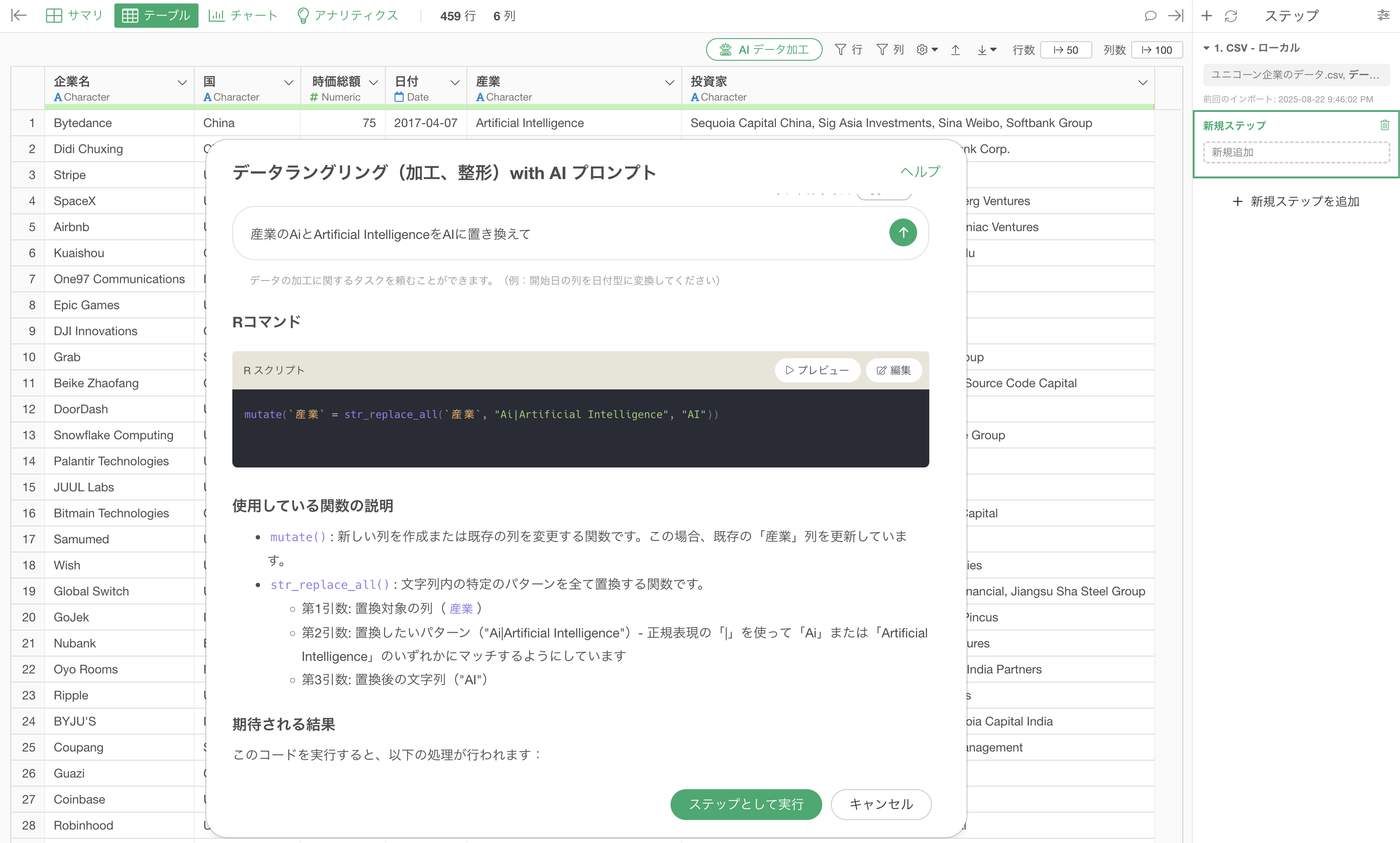
Rコマンドで使用している関数は、「使用している関数の説明」の方でどういった関数や引数が使われているのかを説明しています。また、「期待される結果」のセクションでは、このコードを実行することでどういった結果が得られるのかを説明するようになっています。
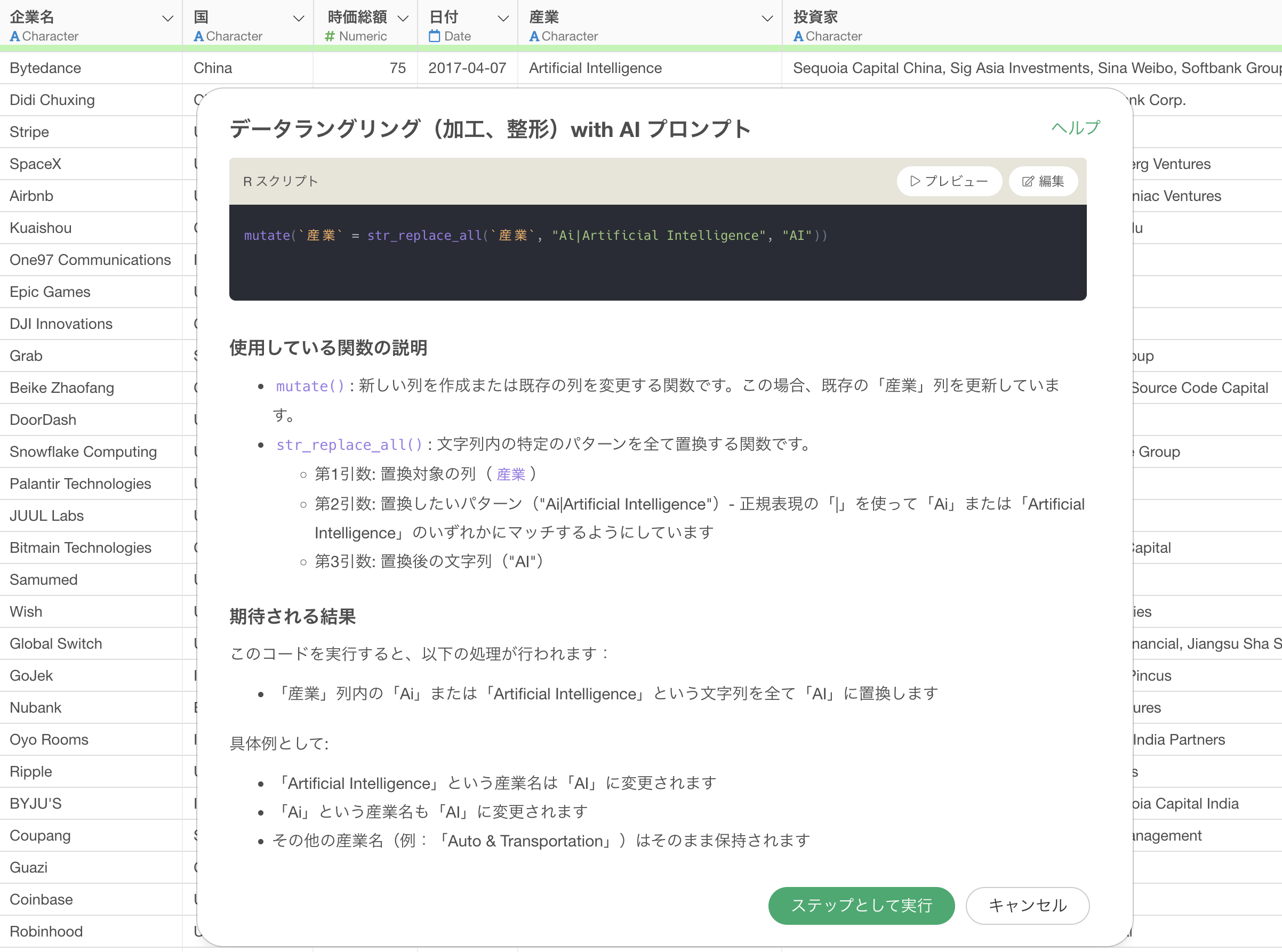 実行することで、産業の「Artificical
Intelligence」と「Ai」を「AI」に置換することができました。
実行することで、産業の「Artificical
Intelligence」と「Ai」を「AI」に置換することができました。
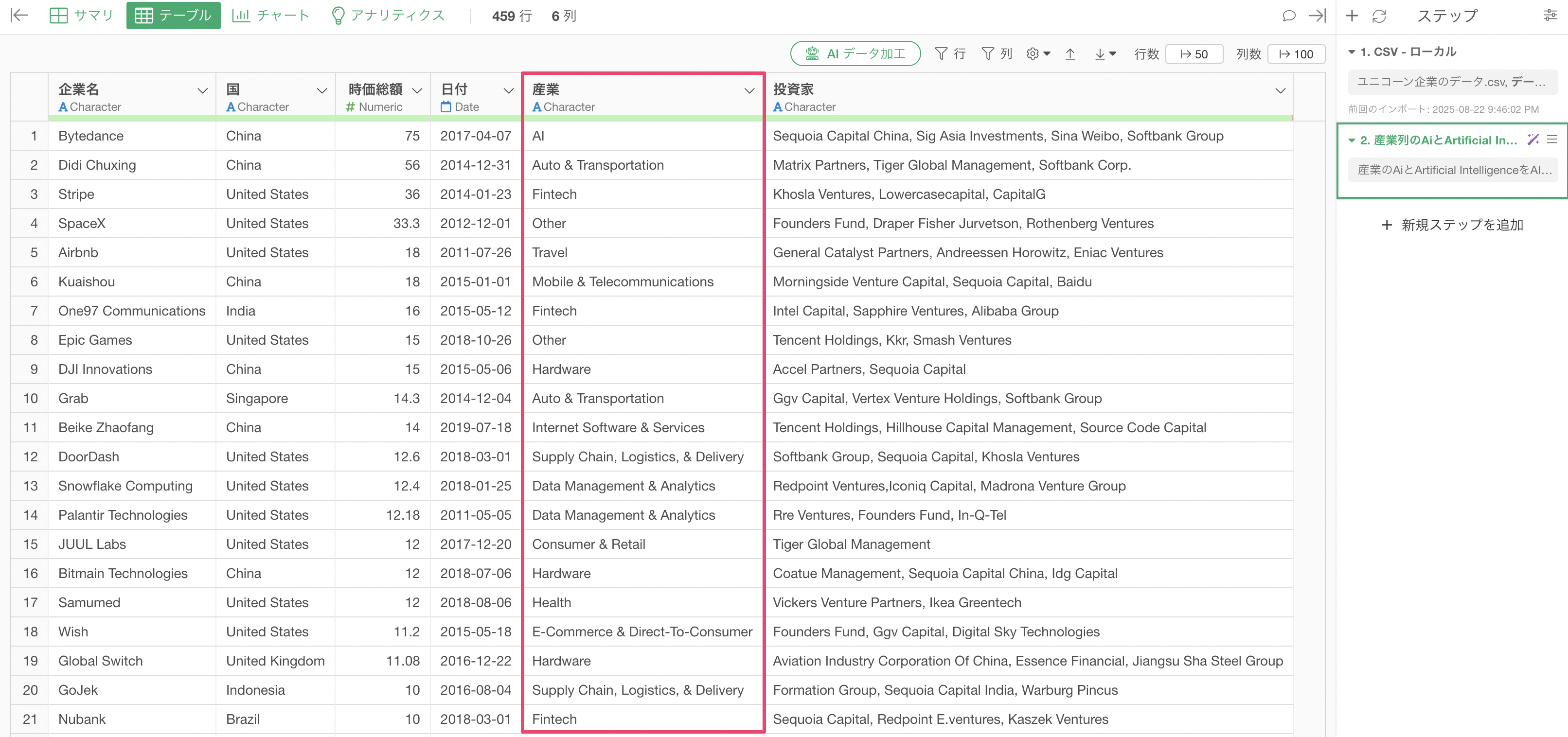
先ほどのバーチャートで結果を確認したいため、「チャートビュー」を開きます。
しかし、産業の「Artificical Intelligence」と「Ai」はまだ別々の値として表示がされているようです。
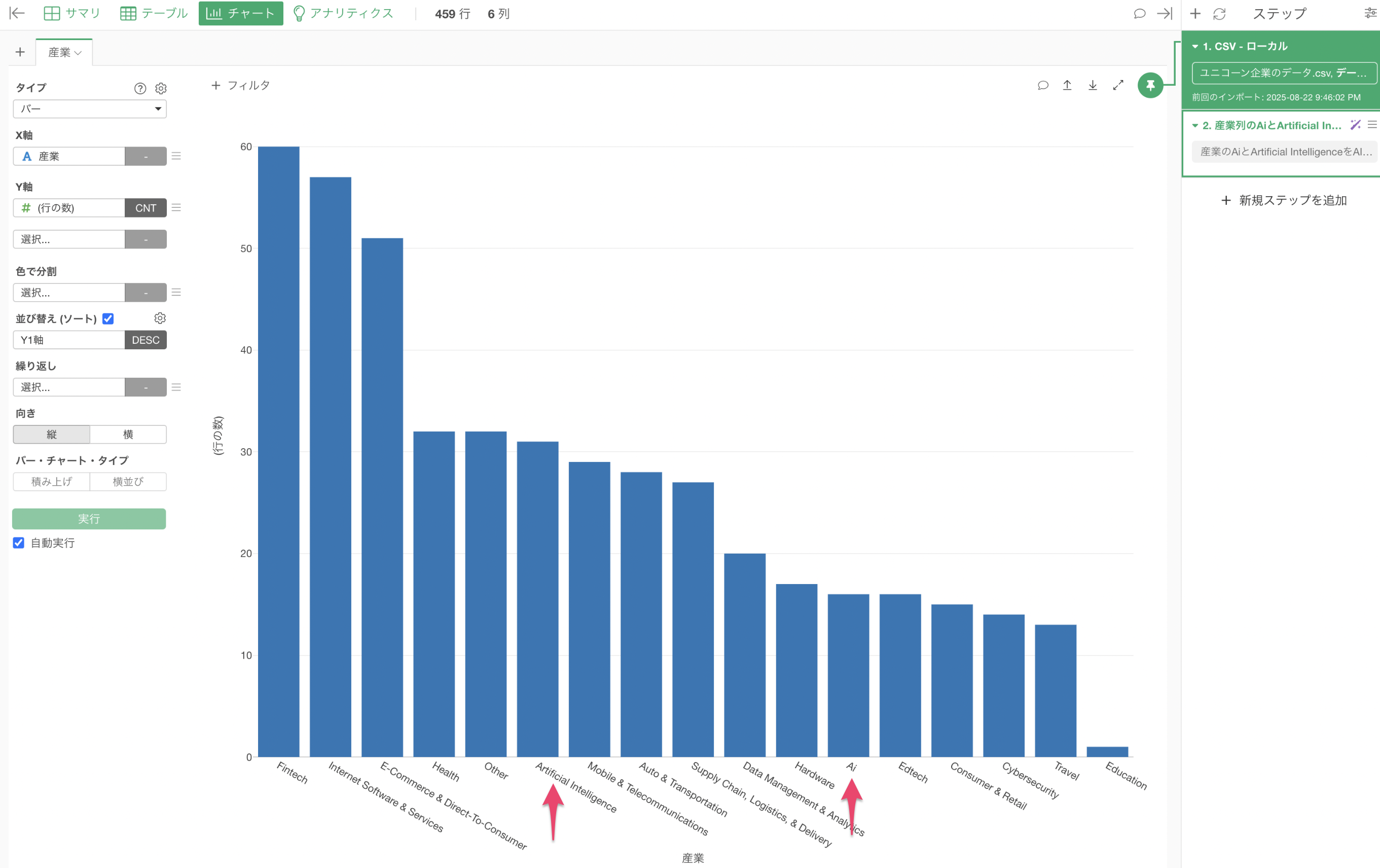
なぜなら、このチャートは、ピンが1番目のステップに「ピン付け」されたままです。ということは、この時点ではまだ産業の「Artificical Intelligence」と「Ai」を「AI」に置換する処理はされていません。
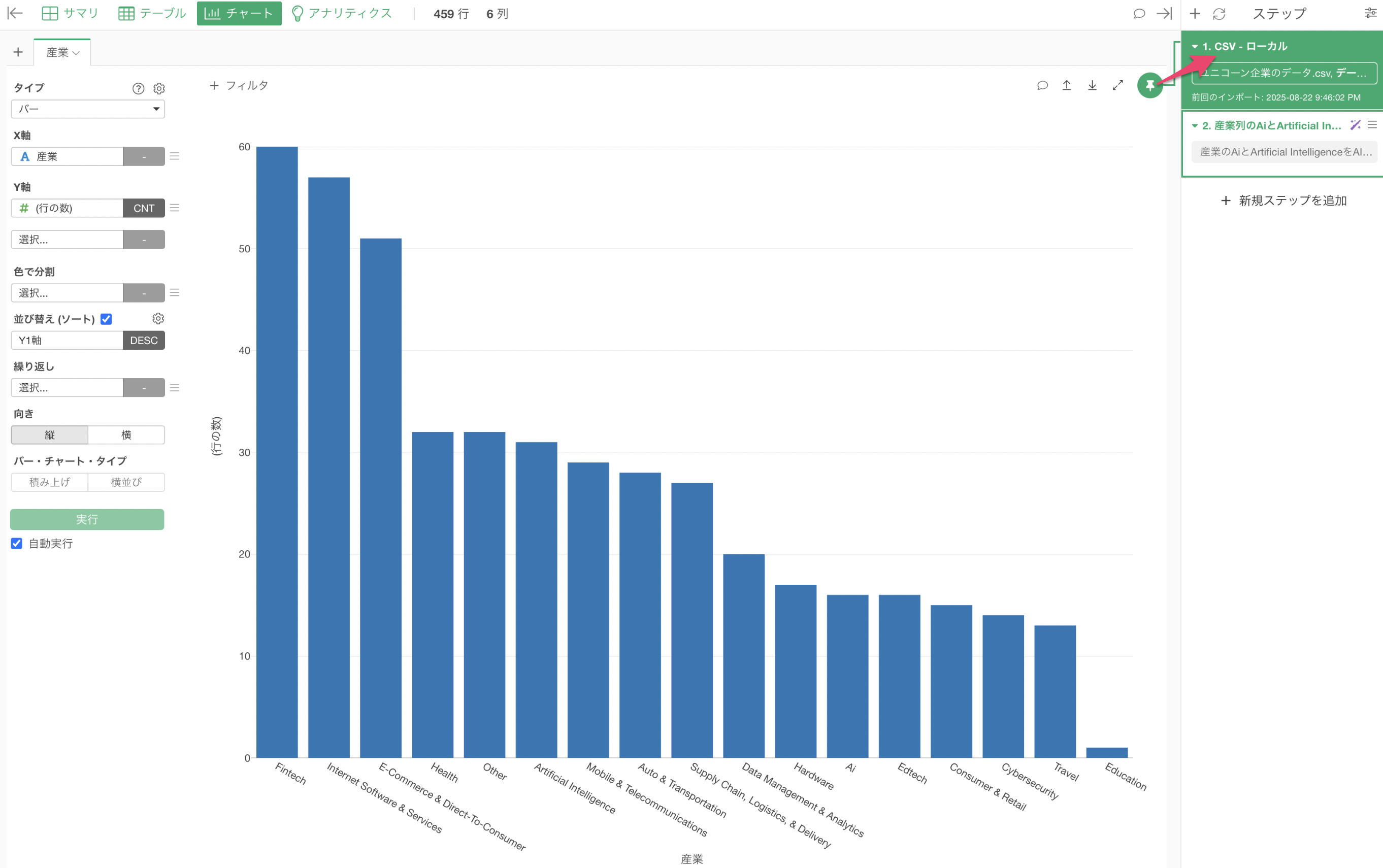
そこで、産業の値を「新しい値に置換」した2番目のステップにチャートのピン動かす必要があります。ドラッグ&ドロップでチャート・ピンを2番目のステップに動かしましょう。
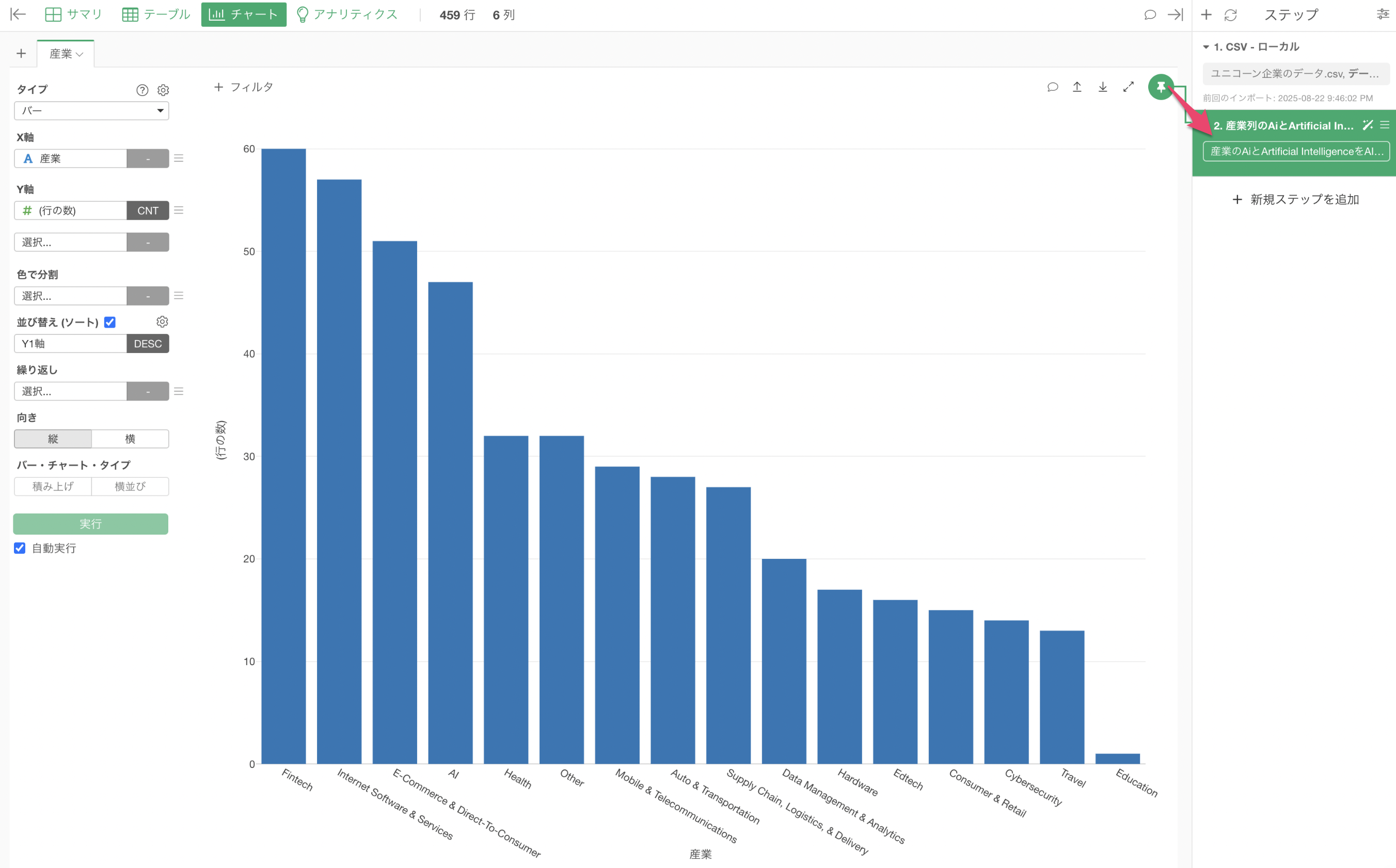
これにより、「Artificical Intelligence」と「Ai」を「AI」にまとめて一つのバーとして可視化していることが確認できます。
3.データを集計する
集計とは、「グループ」ごとに行をまとめて、グループ単位での計算を行うことを指します。
例えば、今回のユニコーン企業のようなデータであれば、下記のように「国」ごとに企業数(行の数)や時価総額の平均値を計算することです。
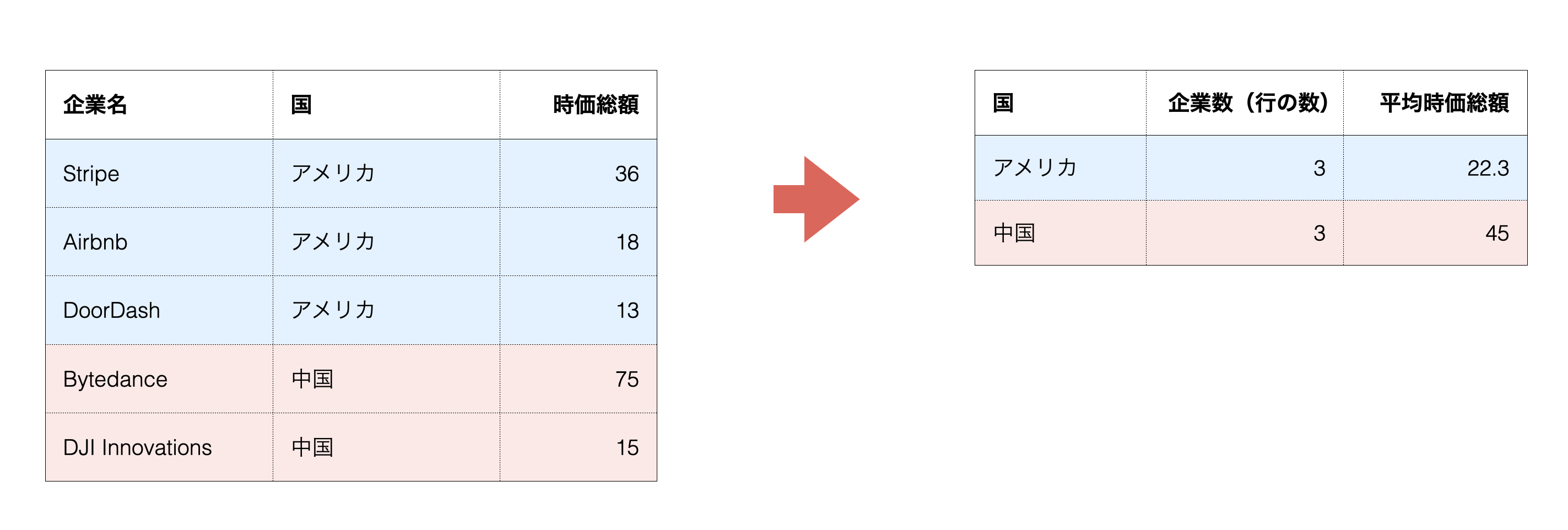
Exploratoryでは、チャートの中で集計が行われるため、基本的には可視化のために集計を行う必要はありません。しかし、集計結果をもとに、さらに計算を行いたい場合などは、事前にデータを集計する必要があったりします。
現在は1行が1ユニコーン企業のデータとなっていますが、集計をして1行1カ国にし、国ごとの企業数をデータとして作成してみましょう。
「AI データ加工」のボタンをクリックします。
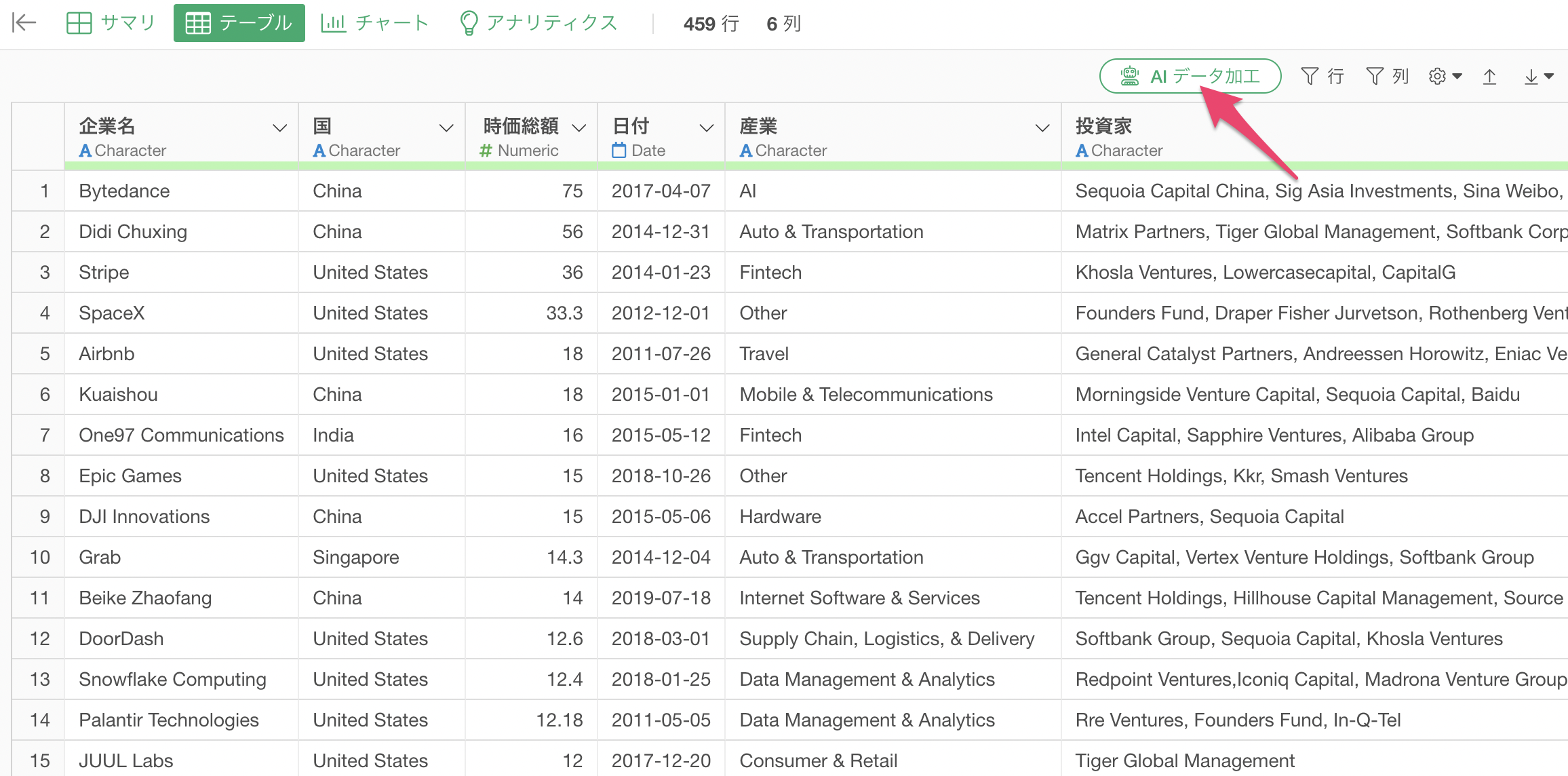
AI プロンプトのダイアログが表示されるため、プロンプトに以下を指定します。
国ごとに企業数を集計して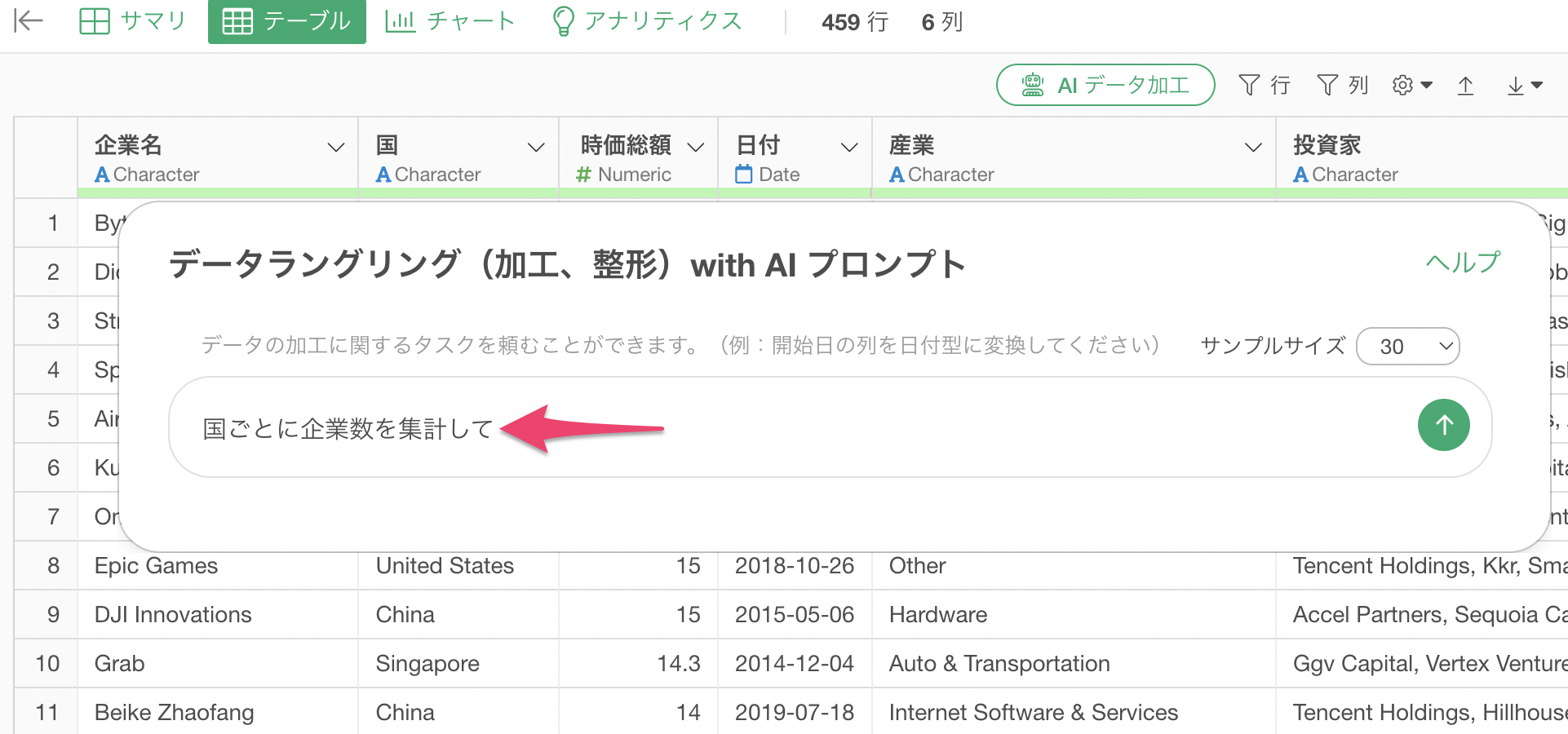
国ごとに企業数を集計するためのRスクリプトが返ってきます。
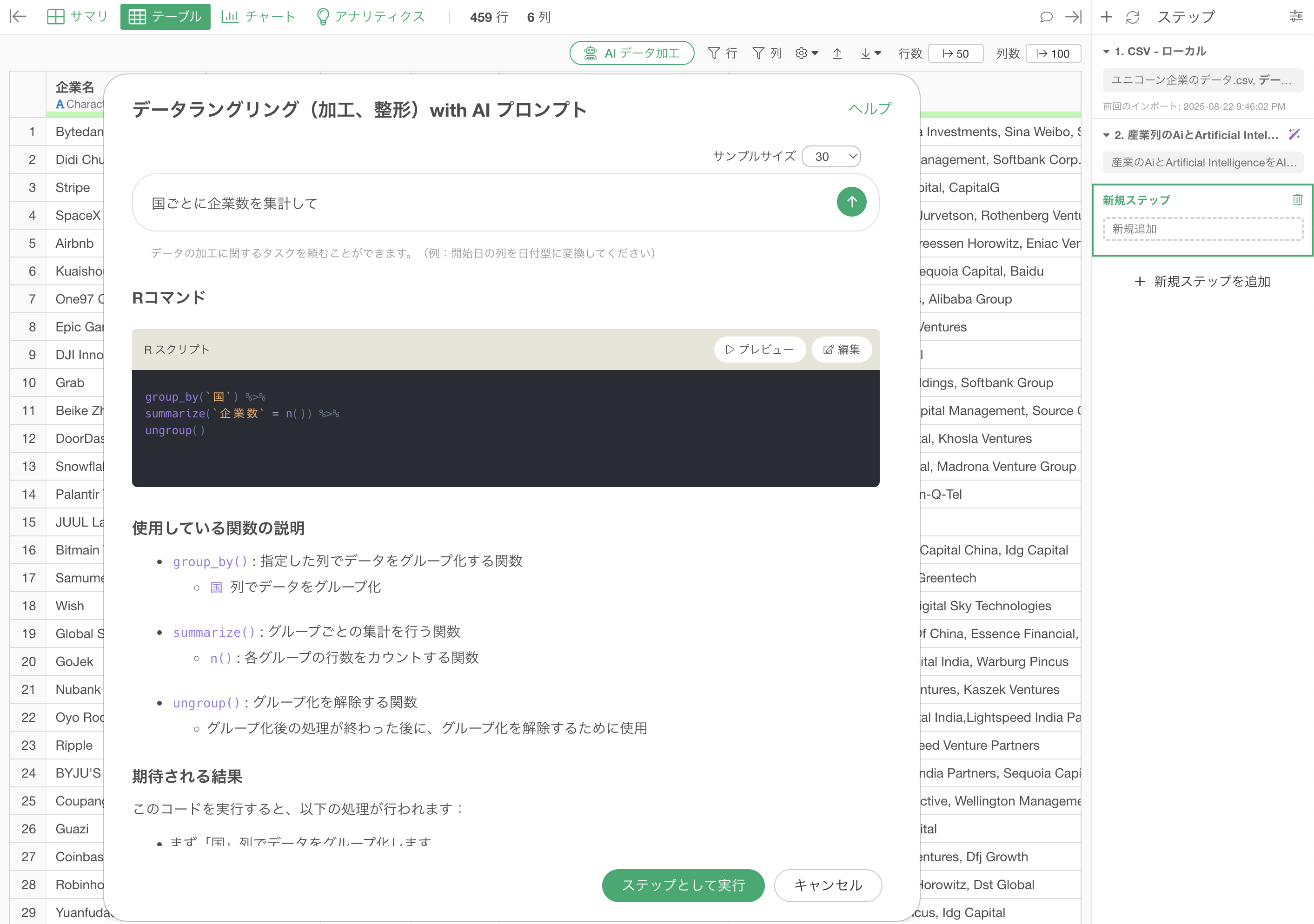
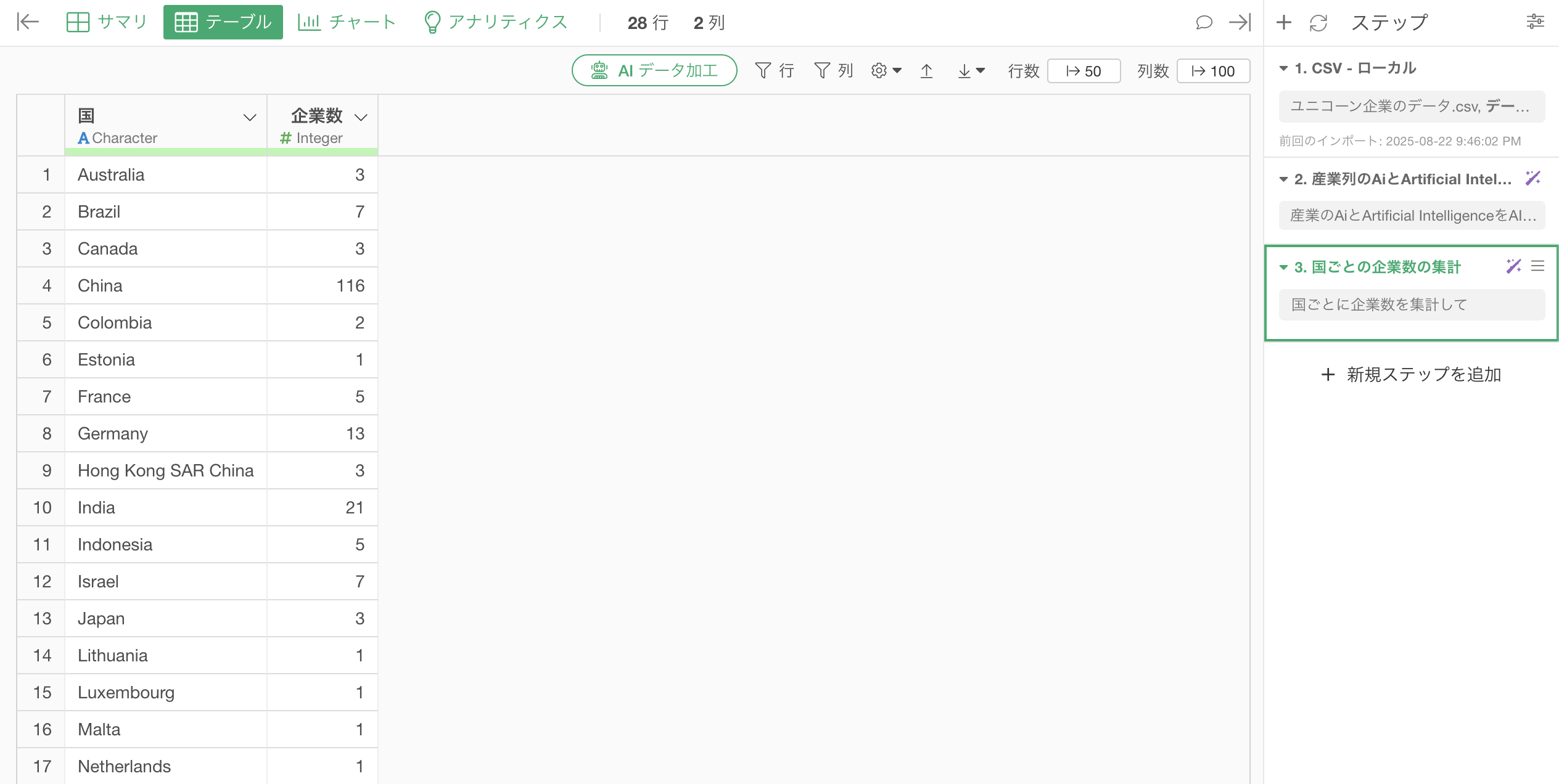
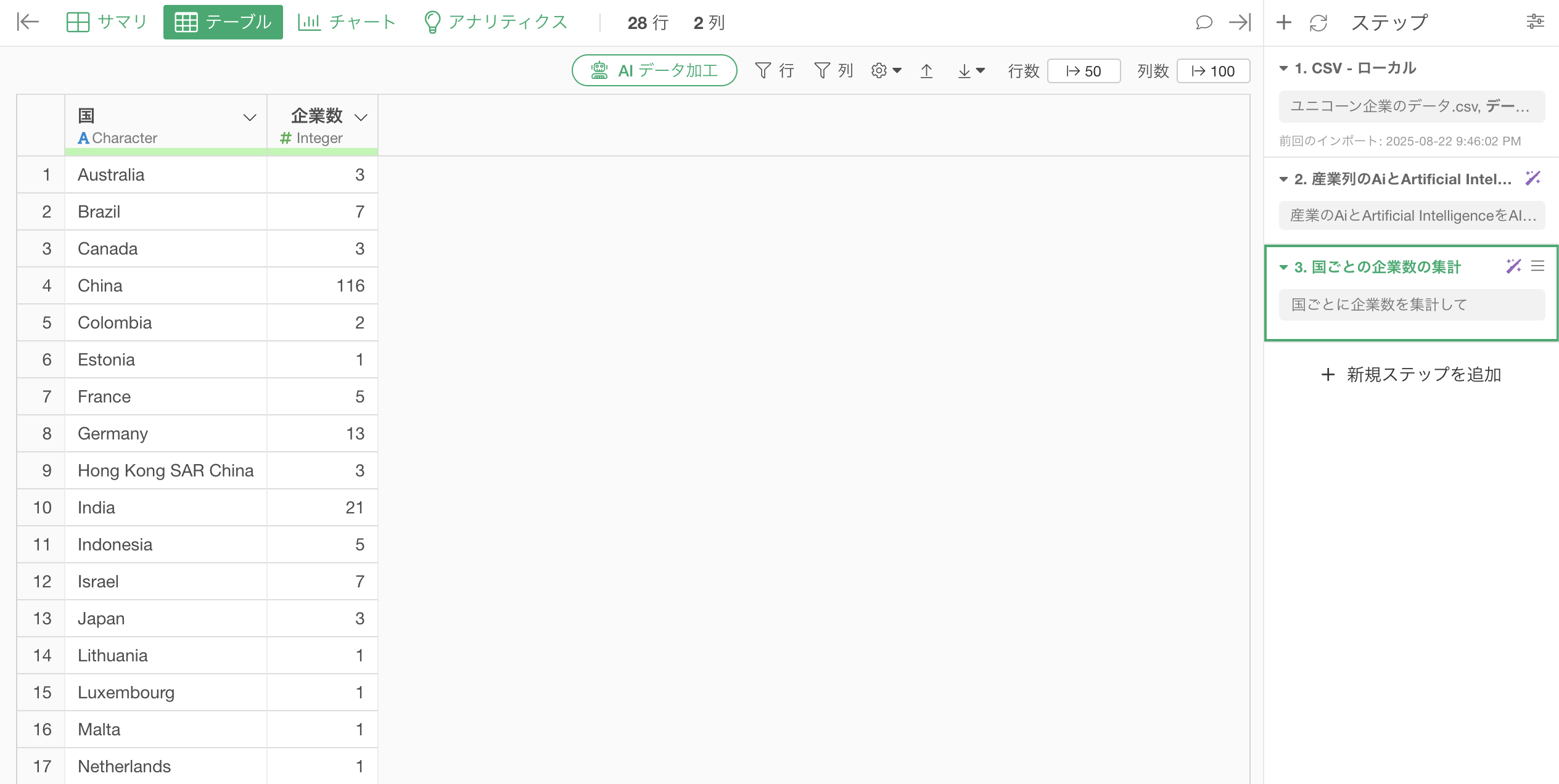
1行が1企業のデータから、1行1カ国のデータにして、国ごとのユニコーン企業数(行の数)を集計することができました。
4. 結合(列を追加)する
例えば、国ごとのユニコーン企業数とGDPとはどういった関係にあるのか調べたいとします。
ただ、ユニコーン企業のデータには、GDPの情報は列としてありません。
そこで、先程インポートしたもう一つのデータである「国別のGDPと人口データ」にある、「GDP」や「人口(Population)」のデータを、国名をキーとして、企業数のデータと結合してみます。
「AI データ加工」のボタンをクリックします。
AI プロンプトのダイアログが表示されるため、$マークを書くことで、他のデータフレームを参照することができます。
次に、プロンプトには以下のように指定します。
$国別のGDPと人口データ-2020年と結合して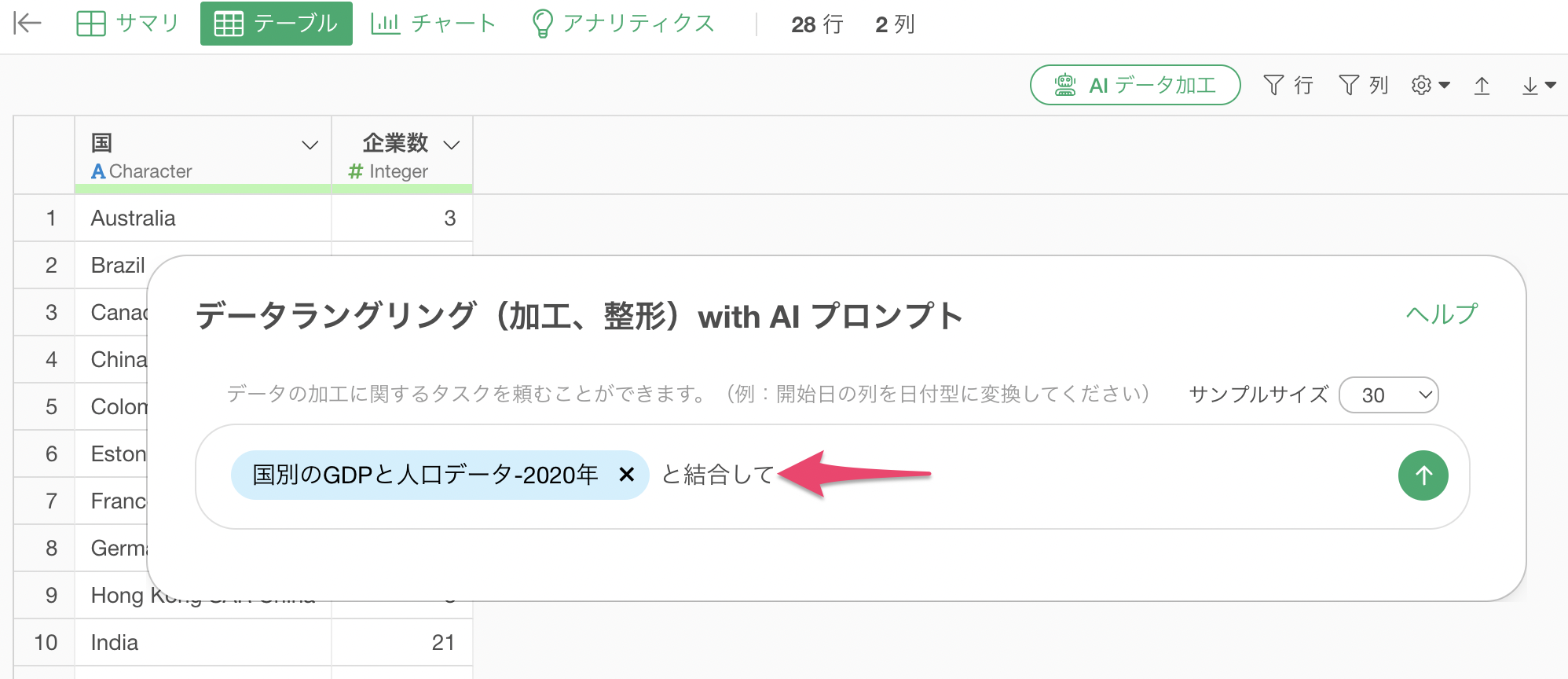
国別のGDPと人口データを結合するためのRスクリプトが返ってきます。
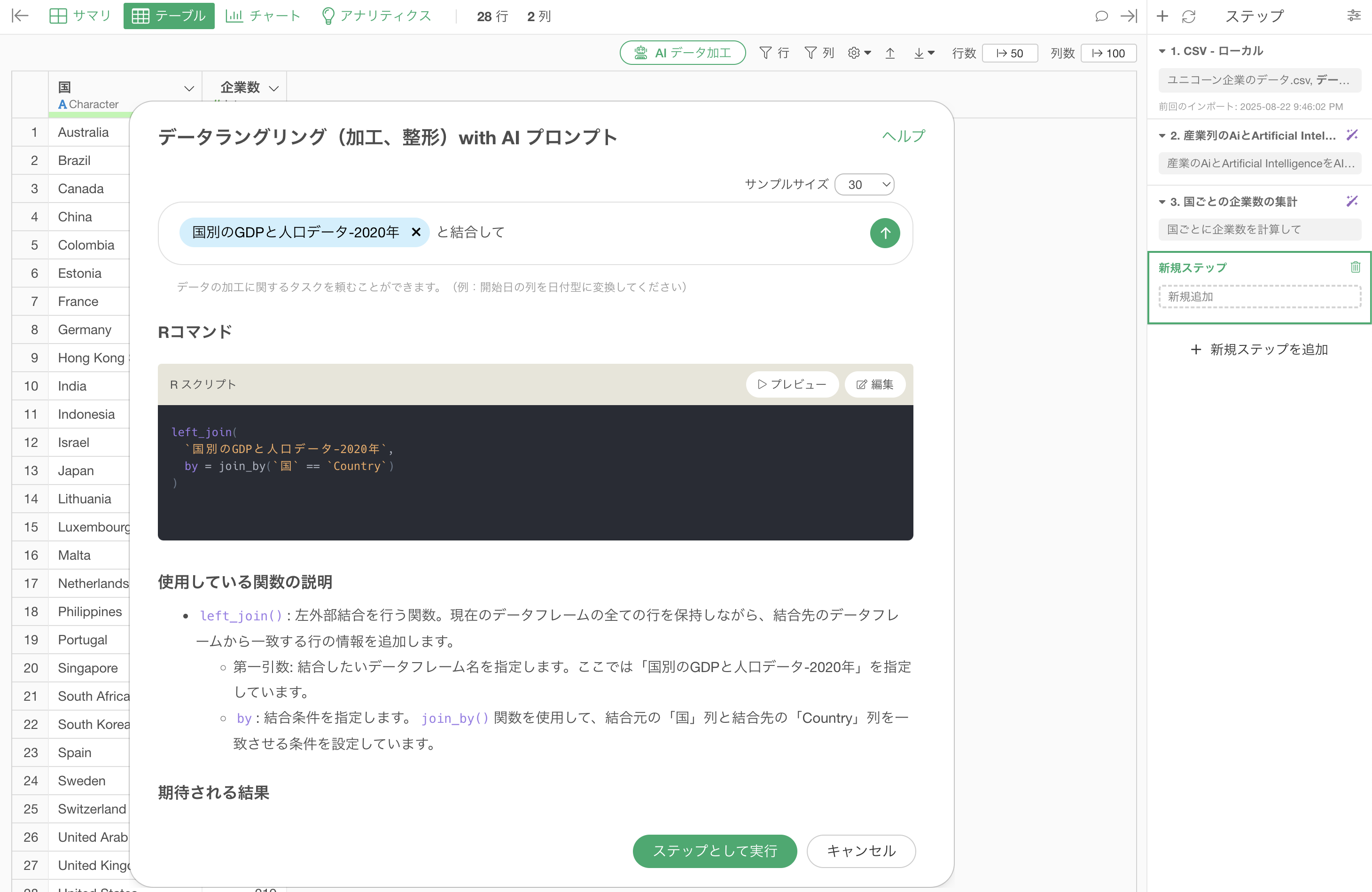
実行をすることで、ユニコーン企業のデータに国をキーとして「GDP」と「Population(人口)」などの列を結合することができました。
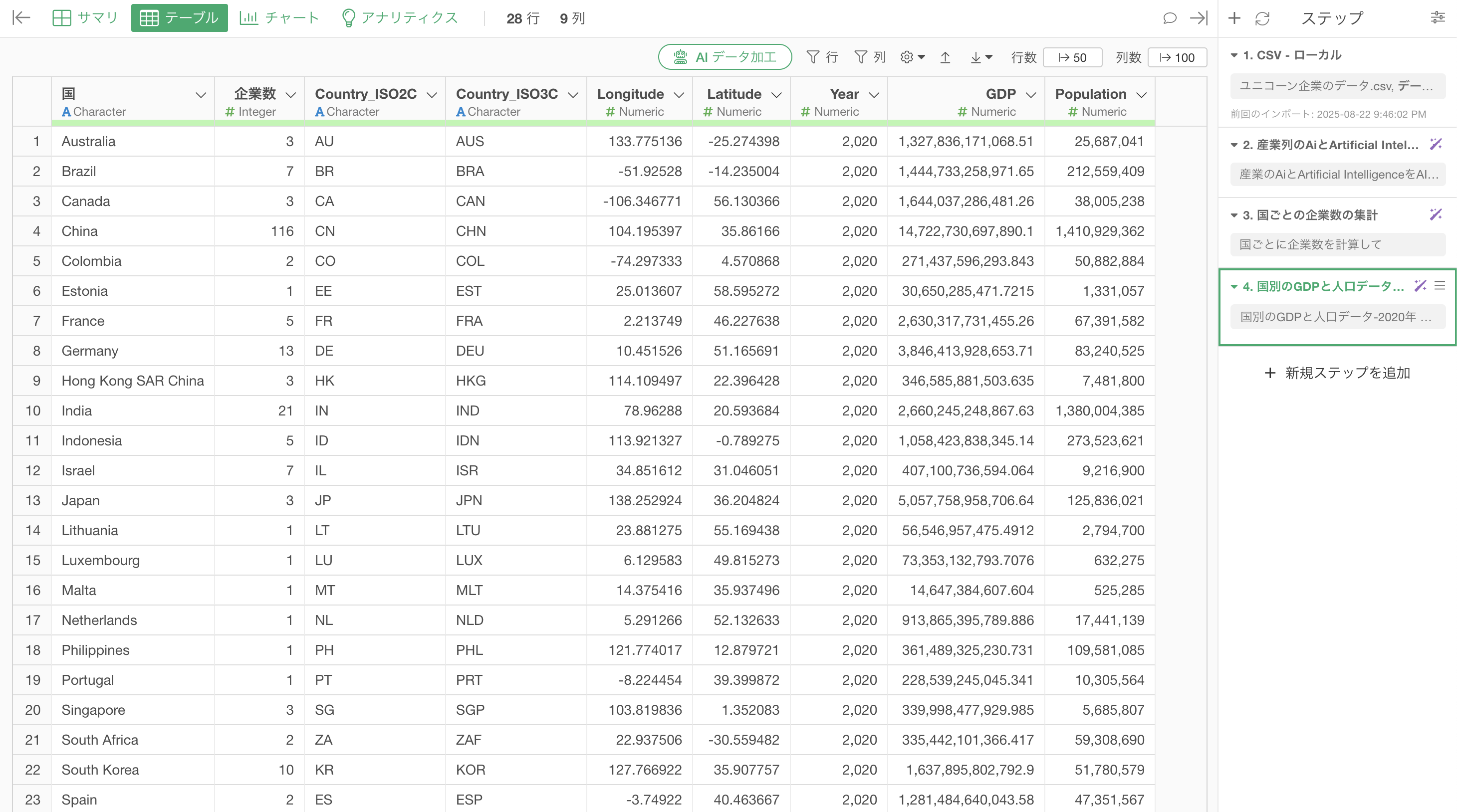
今回は、国ごとのユニコーン企業数とGDPをバーチャートを使って可視化したいです。
チャートを作成していくため、チャートビューを開きます。
新しくチャートを作成したいため、「新規チャートを追加」の「プラス」ボタンをクリックします。
新しくチャートを作成することができました。また、チャートを新しく作成したときは、「チャートピン」が現在選択されている4番目のステップに紐づいていることがわかります。
チャートのタイプに「バー」を選択します。
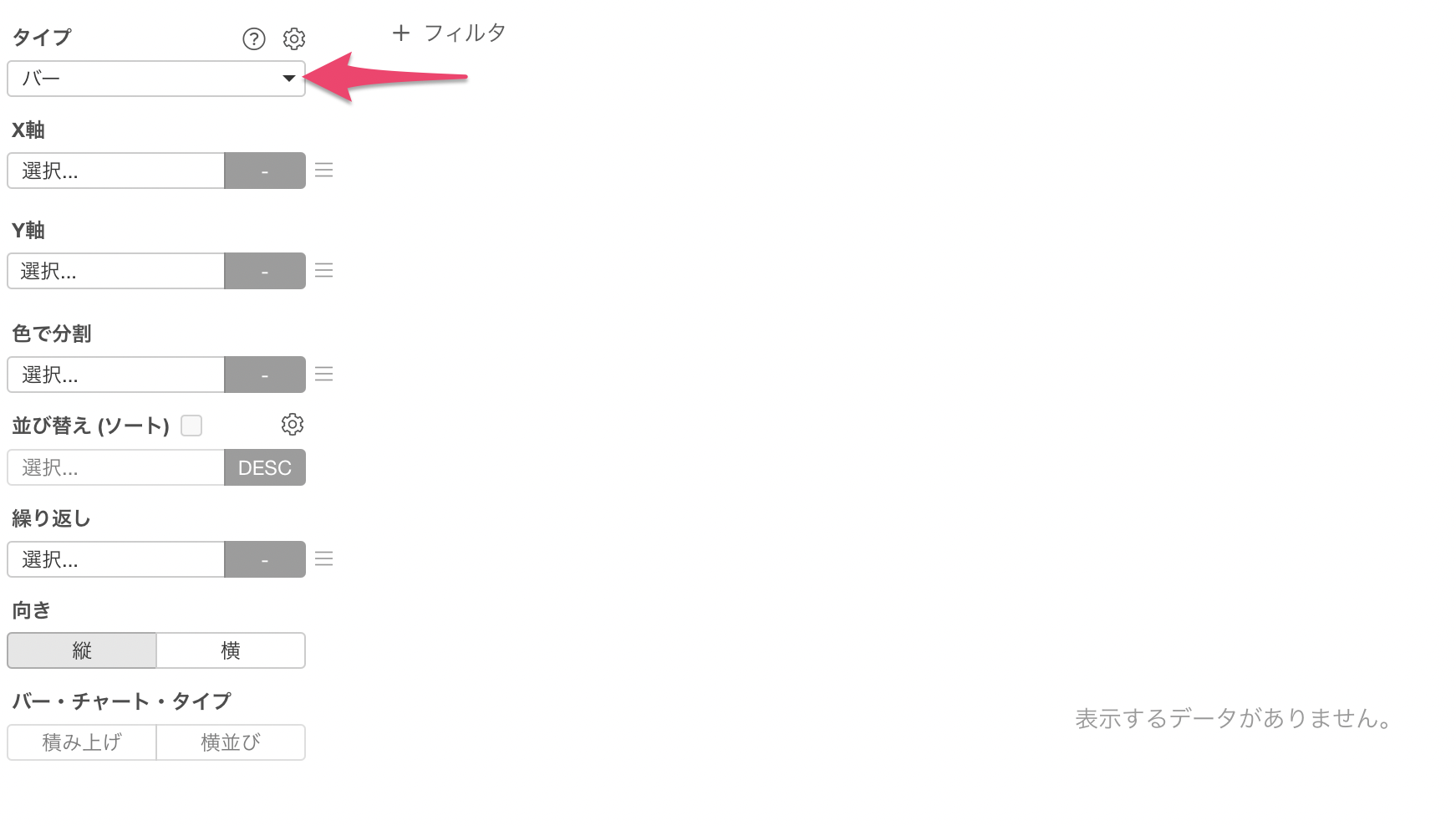
X軸に「国」を選び、Y軸には「企業数」の集計関数には「合計値(SUM)」を選択します。
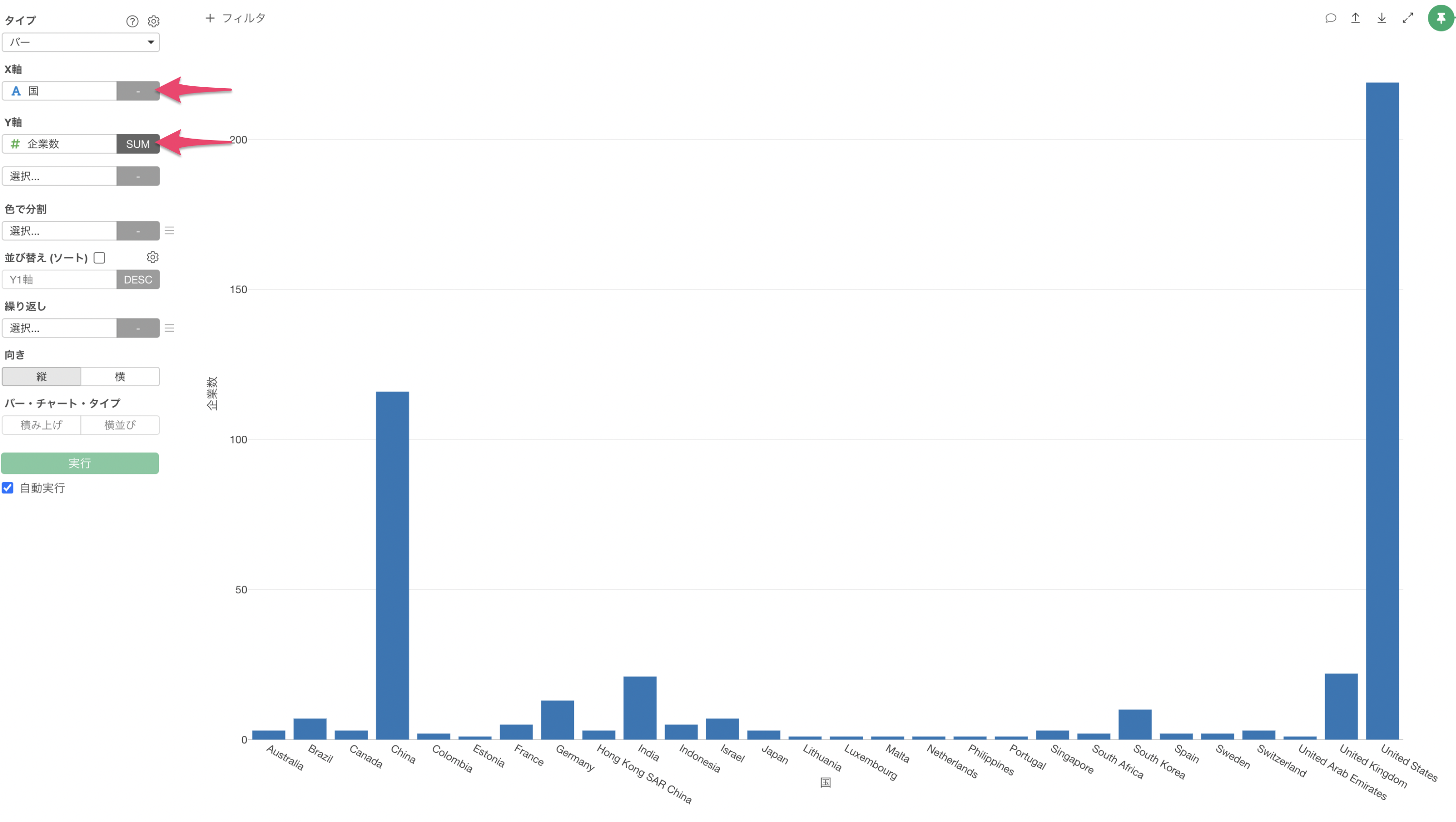
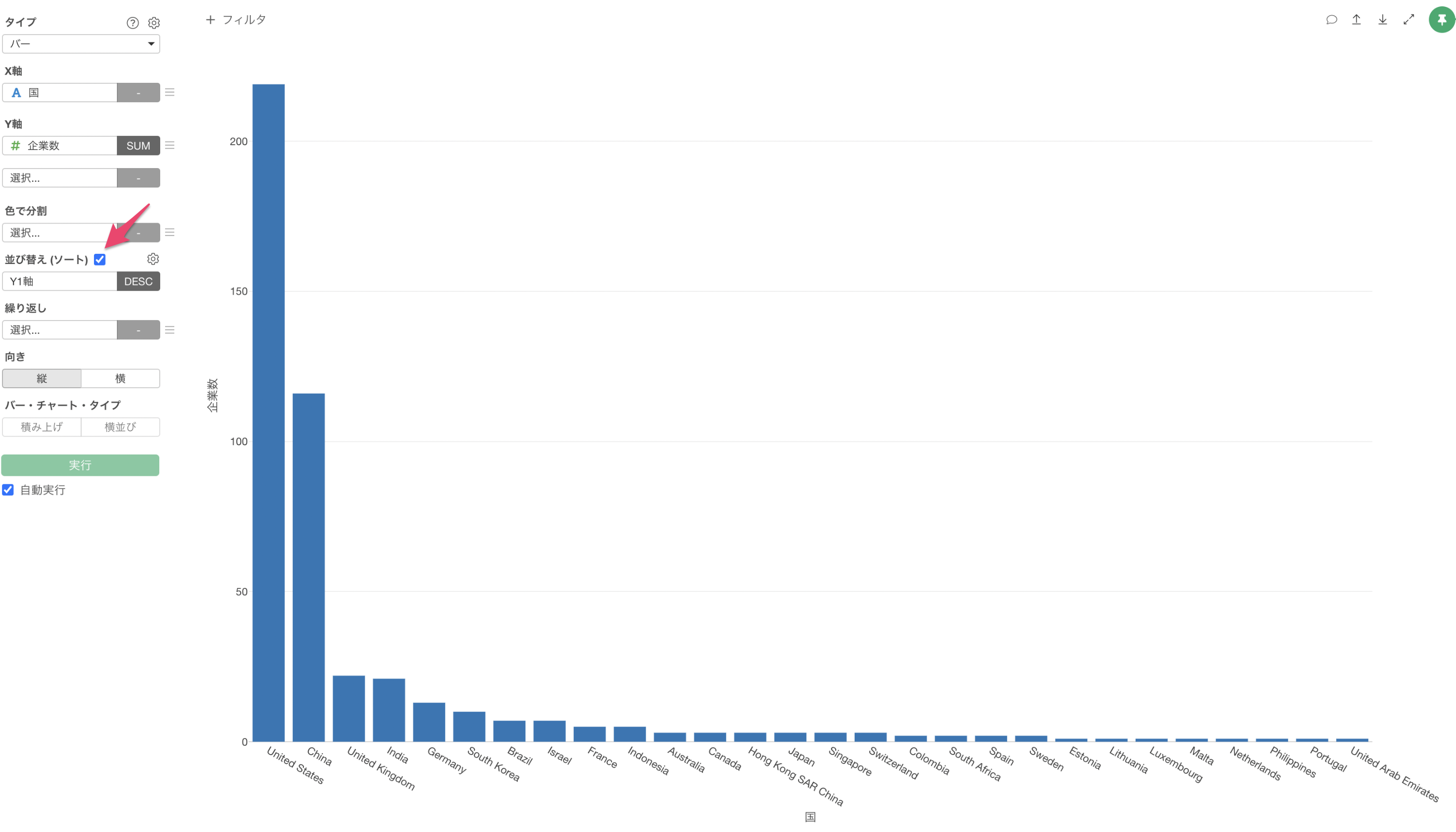
並び替え(ソート)にチェックをつけることで、企業数が多い順(降順)に国を並び替えることができます。
Y軸の2つ目の列に「GDP」を選び、集計関数には「合計値(SUM)」を選択します。
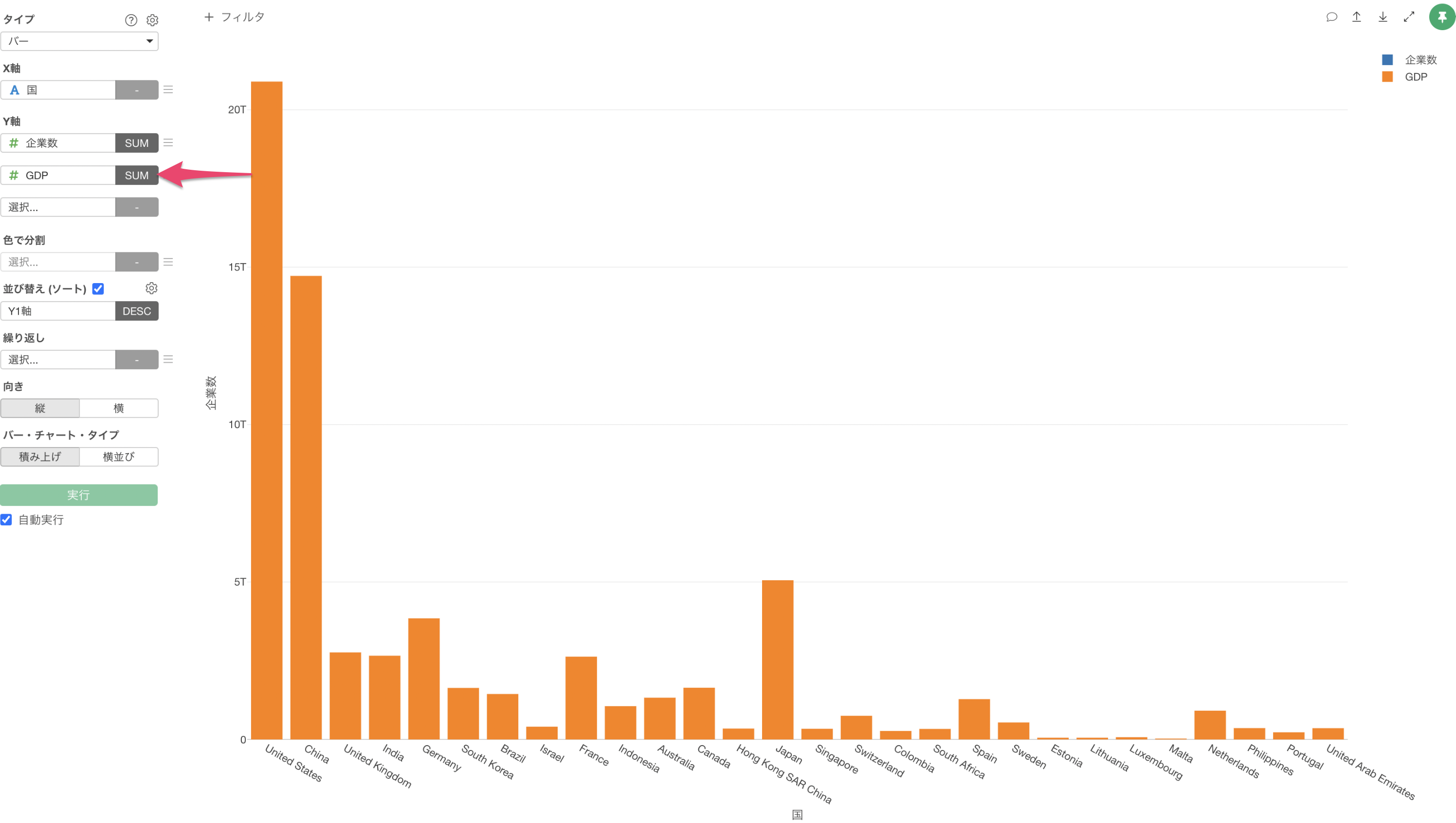
しかし、これでは「企業数」と「GDP」が同じY1軸を使用しているため、GDPを「Y2軸」に設定したいです。
Y軸の2つ目に設定した「GDP」のメニューから「Y1/Y2軸の指定」を選択します。
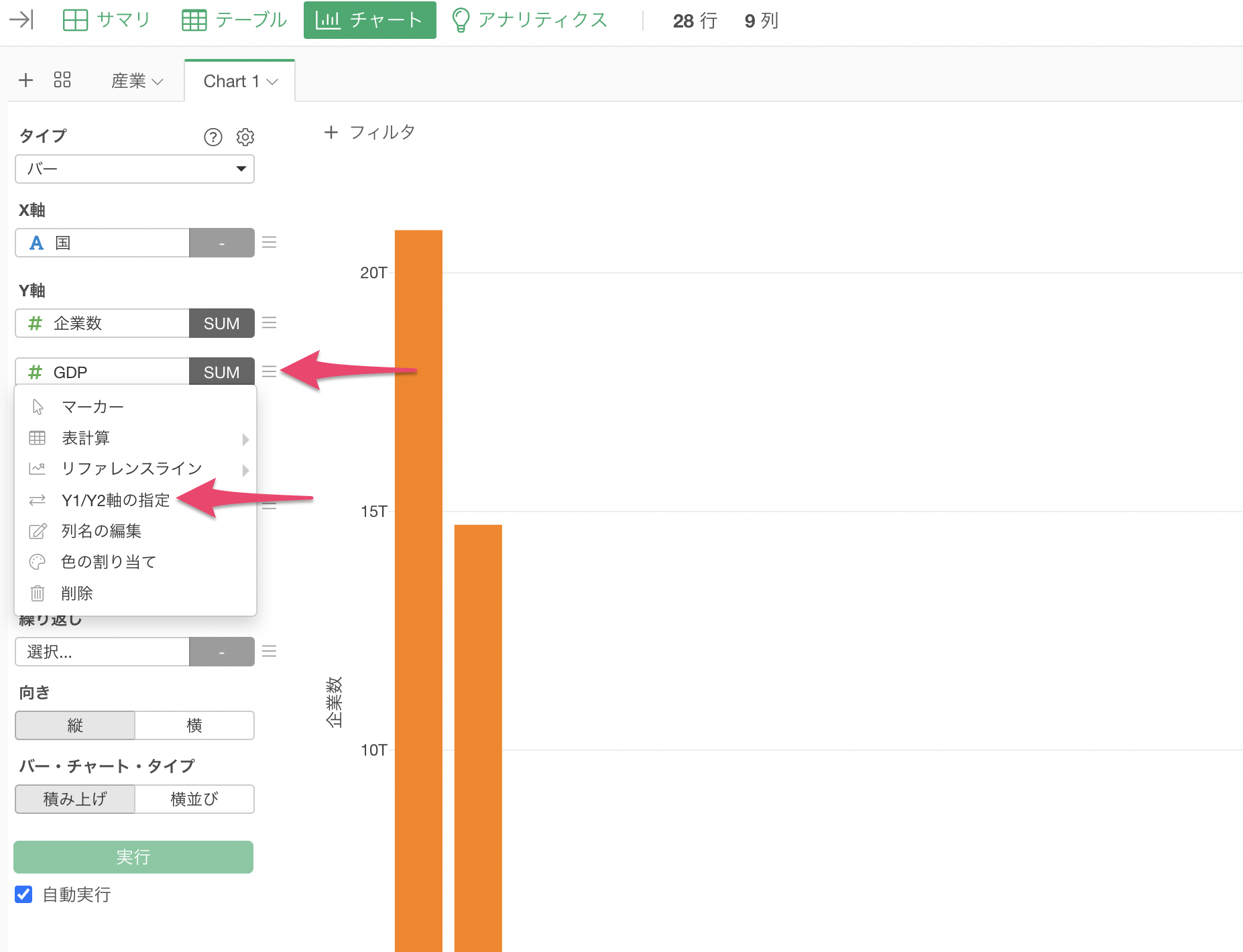
列の設定のダイアログが表示されるため、GDPの「Y2軸」にチェックをつけて適用します。
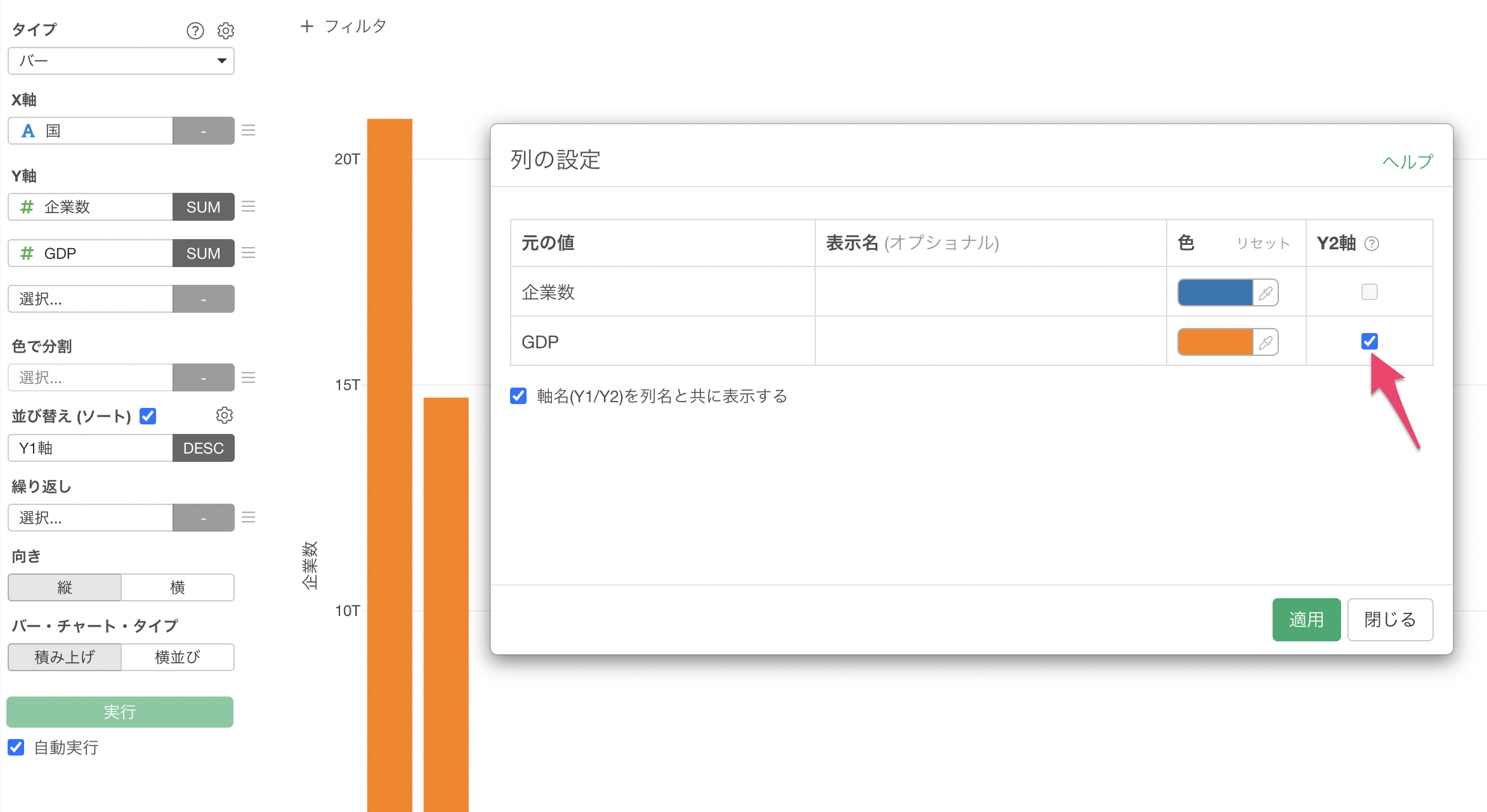
GDPの列の値を「Y2軸」に設定できました。
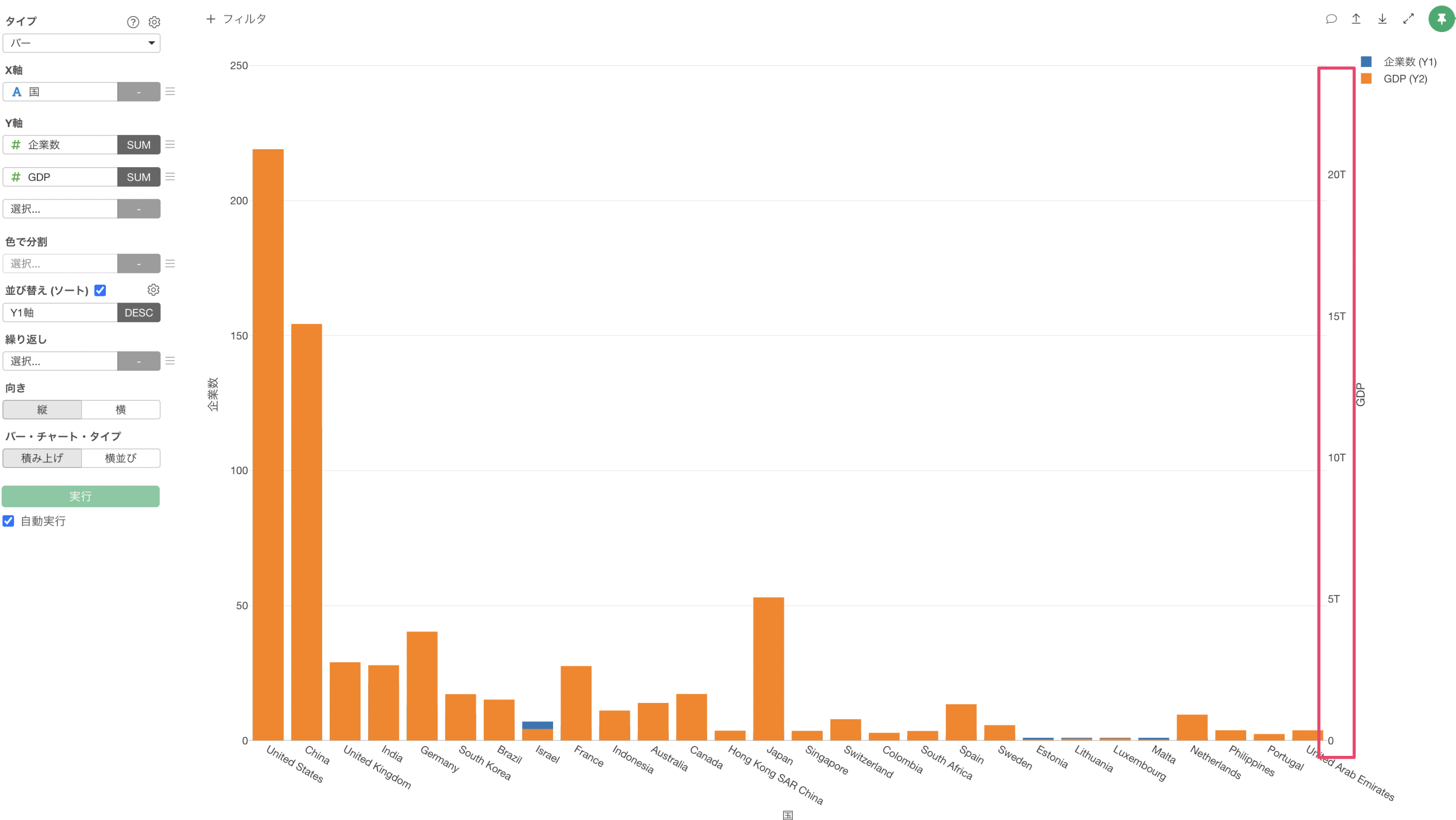
「企業数」と「GDP」のバーを横並びで表示したいため、バー・チャート・タイプに「横並び」を指定します。
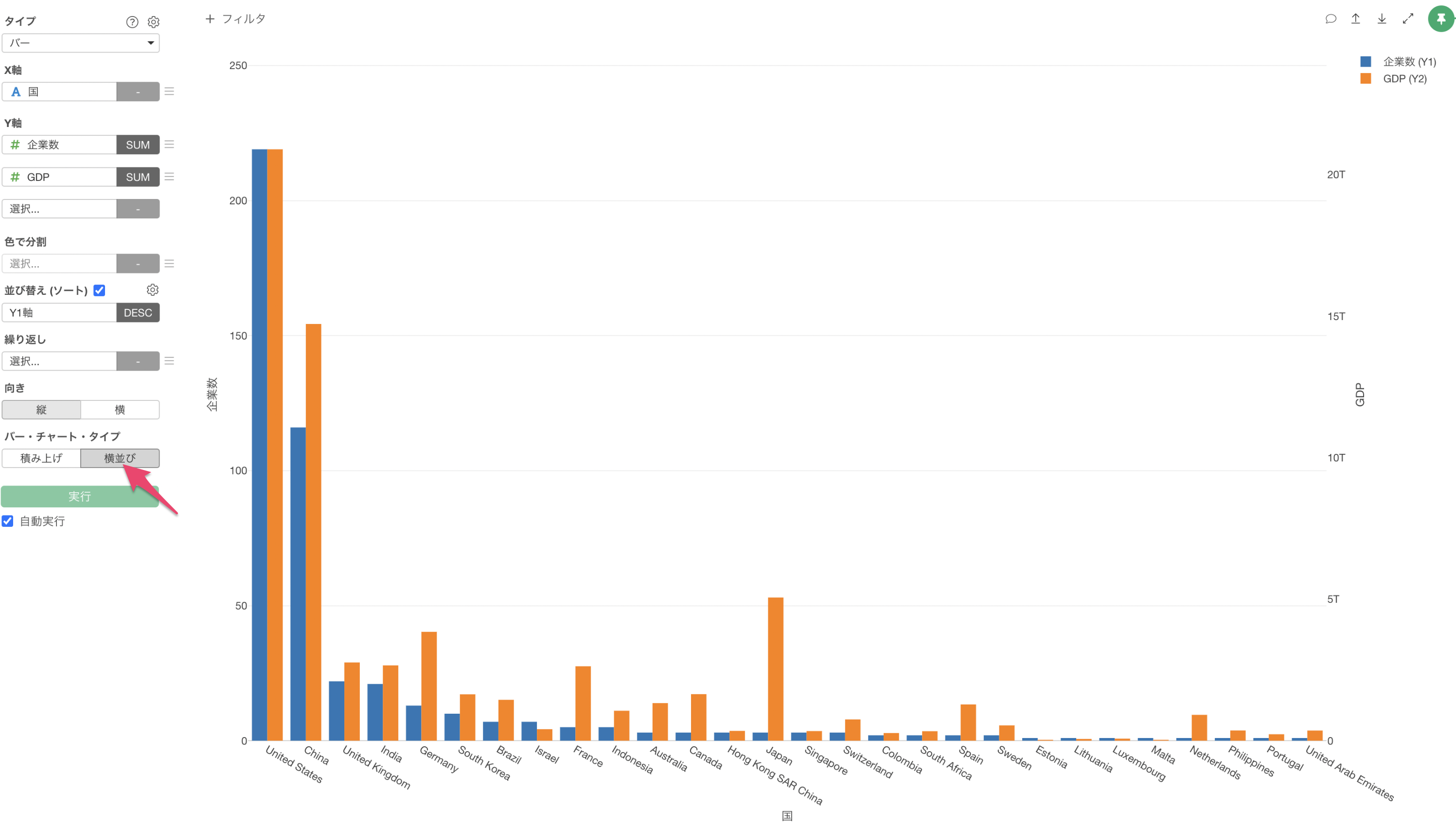
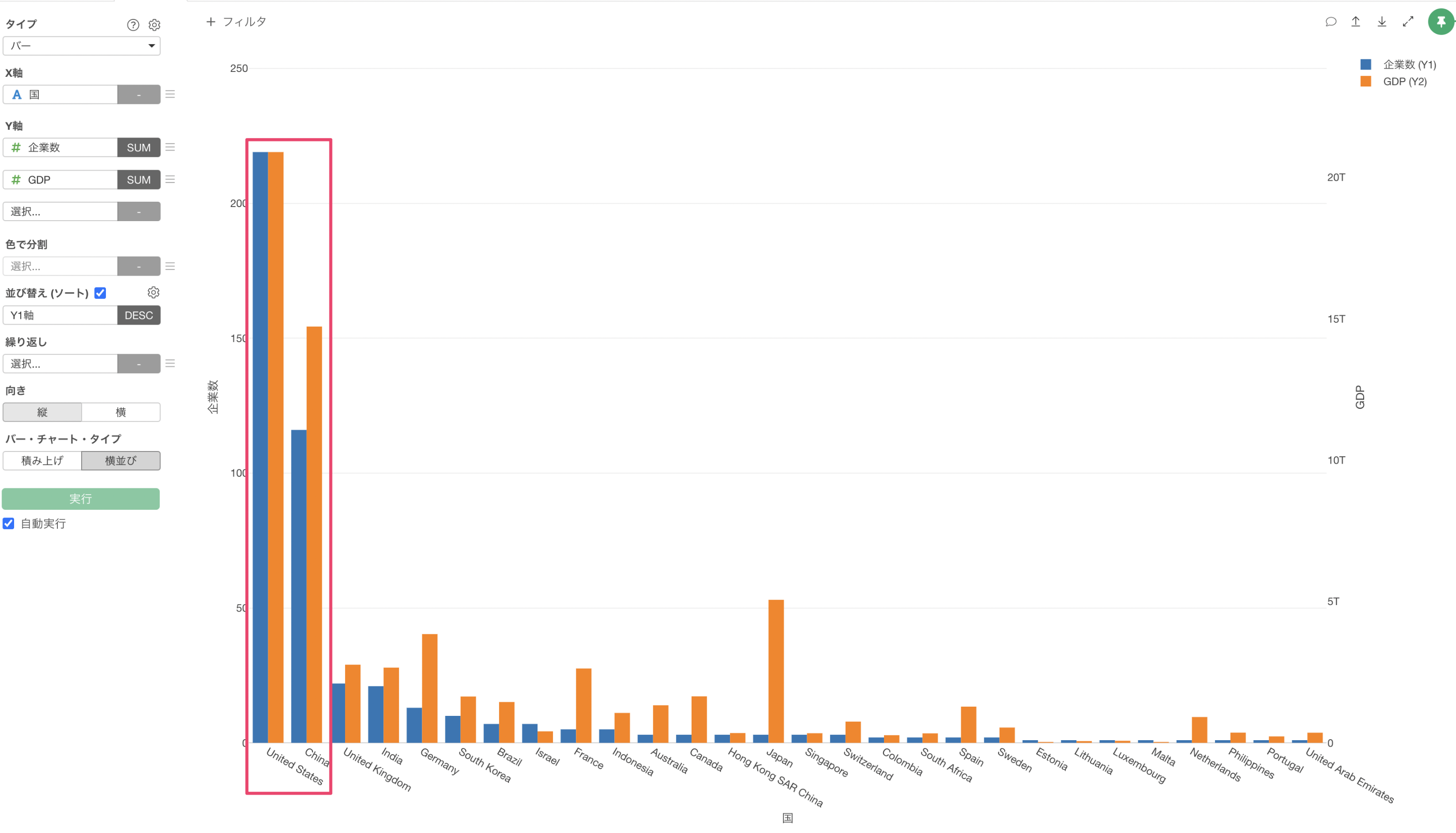
GDPが高い「アメリカ(United States)」や「中国(China)」はユニコーン企業数も多いことがわかります。
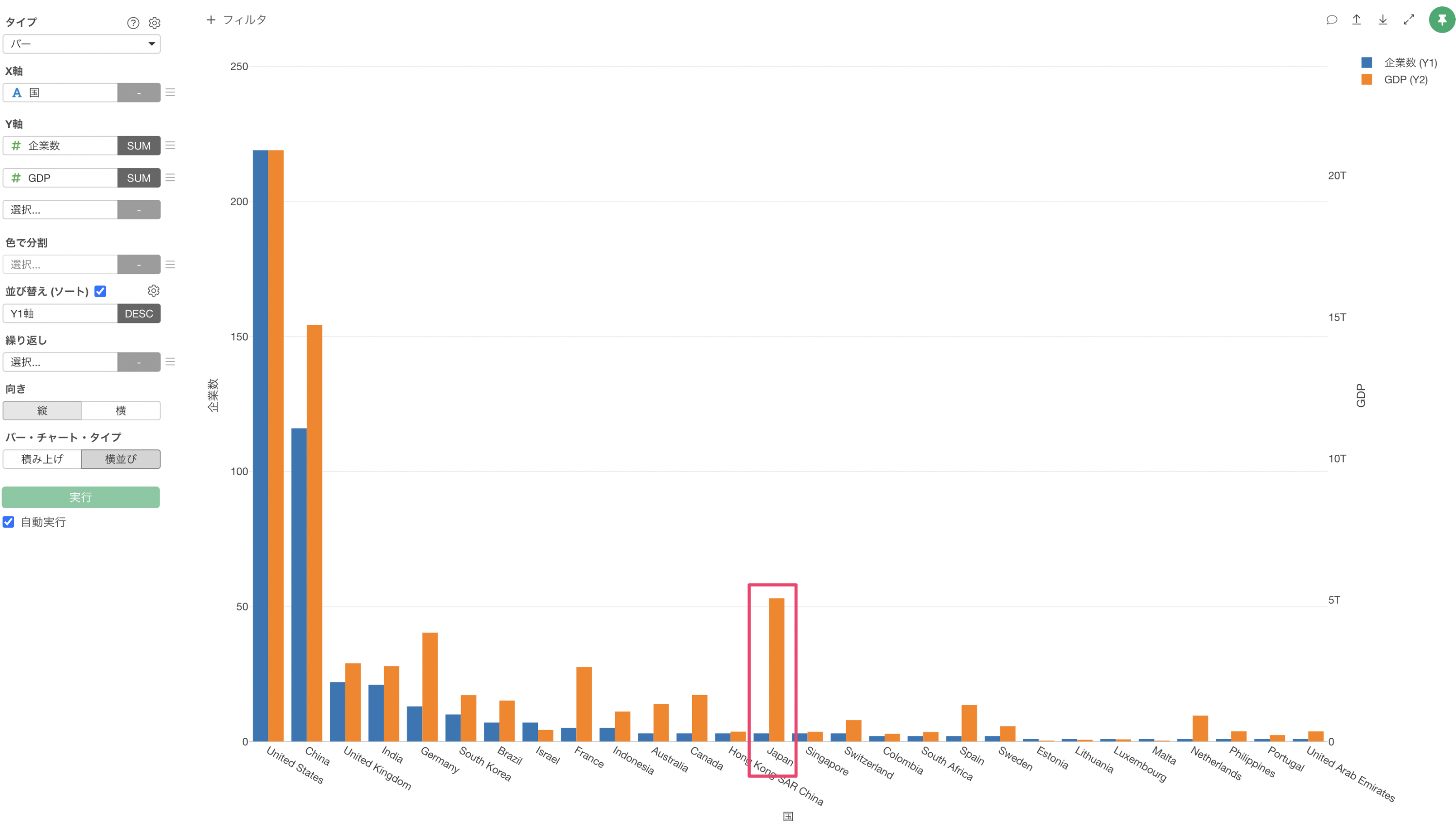
一方で、「日本(Japan)」はGDPは他の国に比べて高いですが、ユニコーン企業数は3件と少ないことがわかります。※ 2020年時点のデータを使用しています。
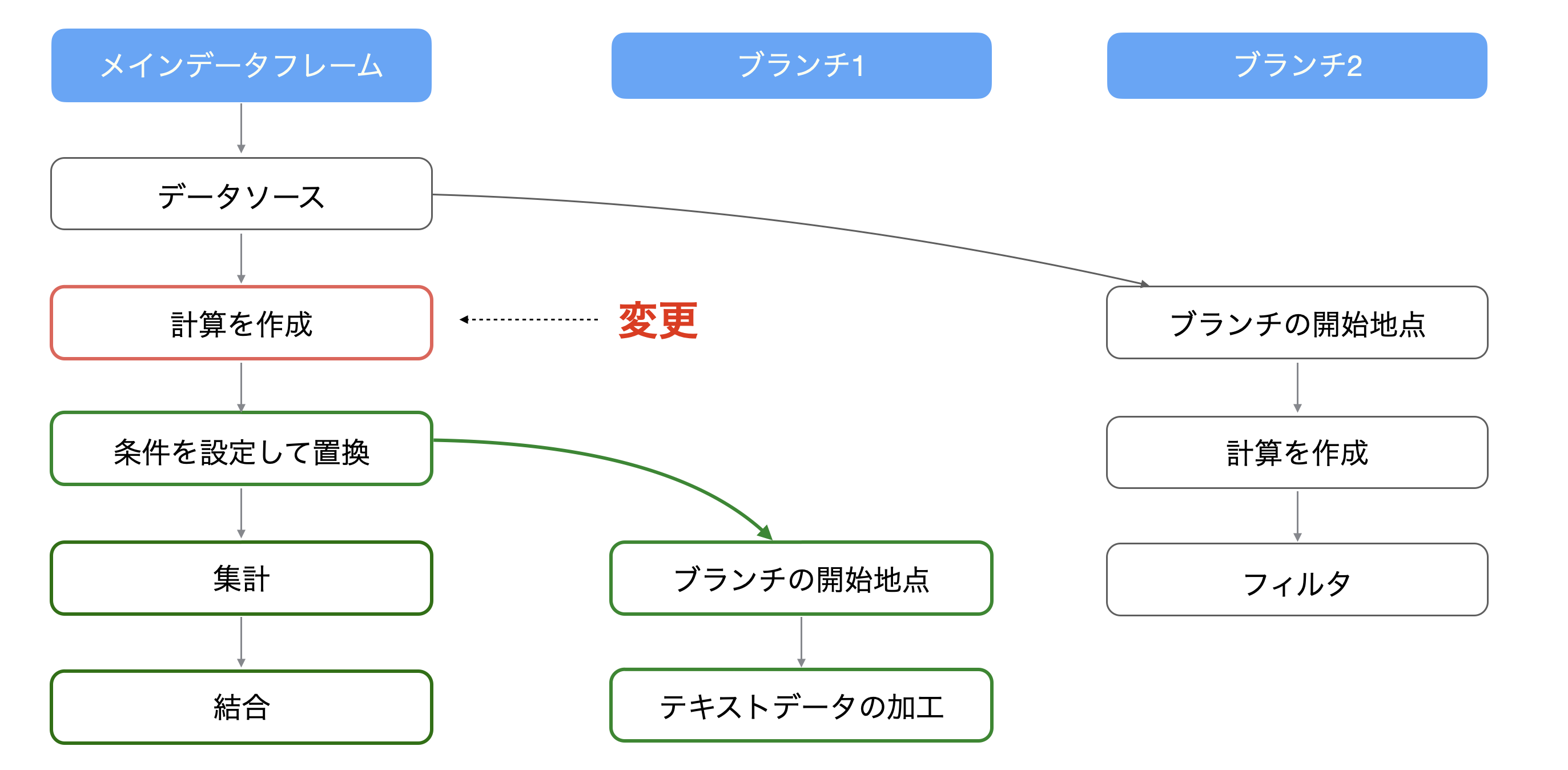
5. ブランチを作成する
データを集計したことによって、1行1企業のデータから1行1カ国のデータになってしまいましたが、1行1企業のデータを使って別のデータラングリングを行いたいことがあります。
そういった時に使えるのが「ブランチ」機能で、ブランチによってメインのデータフレームから派生させたデータフレームを作成することができます。
さらに、ブランチは複数作成することができ、どのステップからでも作ることができます。
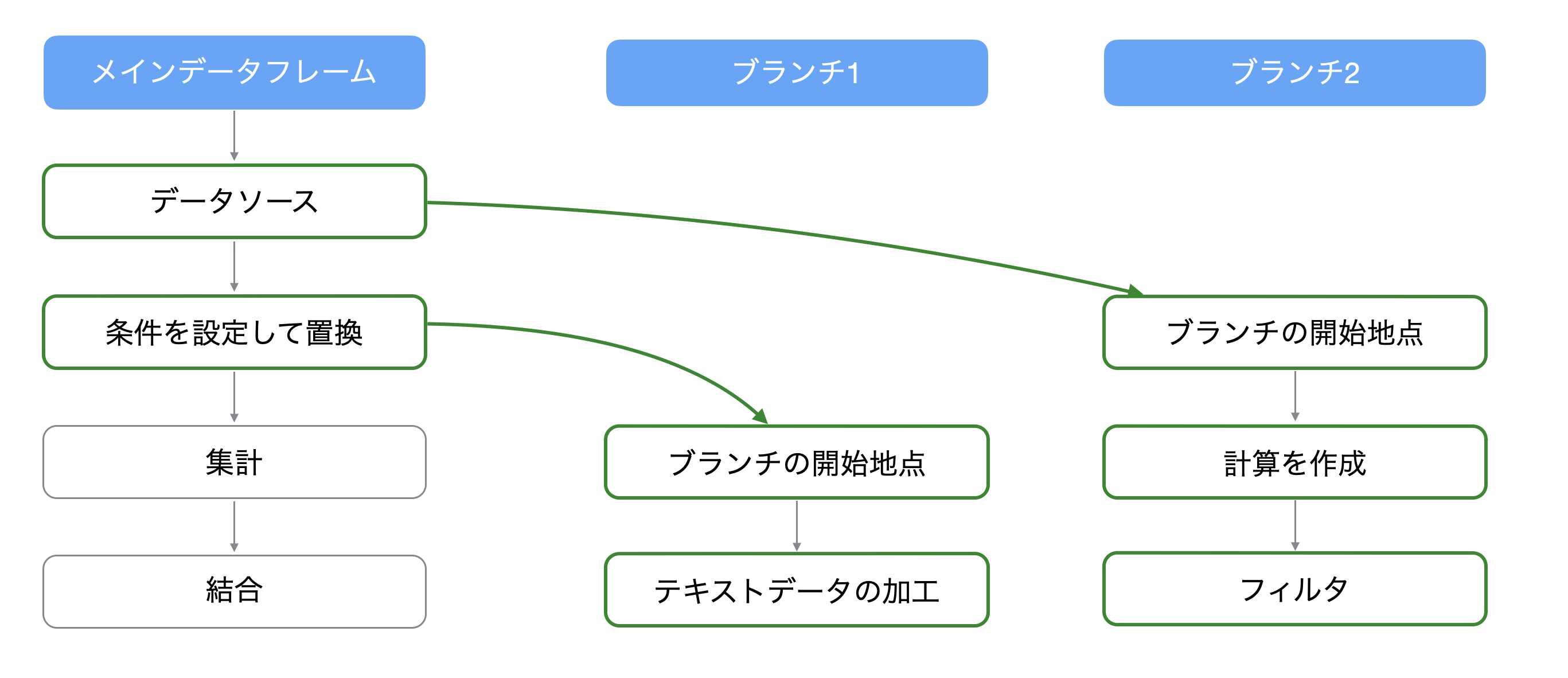
ブランチが作られた以前のステップを変更すると、それより下流に位置するステップのみが更新されるようになっています。
1行1企業のデータからブランチを作成したいため、集計をする前のステップである2番目のステップを選択します。
2番目のステップから「ブランチを作る」ボタンをクリックします。
ブランチ名に任意の名前を指定して「作成」ボタンをクリックします。
メインのデータフレームから派生した「ブランチ」データフレームを作成できました。
2番目のステップからブランチを作成したため、このデータフレームは2番目のステップまでの処理を反映して作られていることがわかります。
6. 値を複数の行に分割する
企業に複数の投資家が投資をしている場合、「投資家」の列には複数の投資家の名前がコンマ区切りで表示されます。
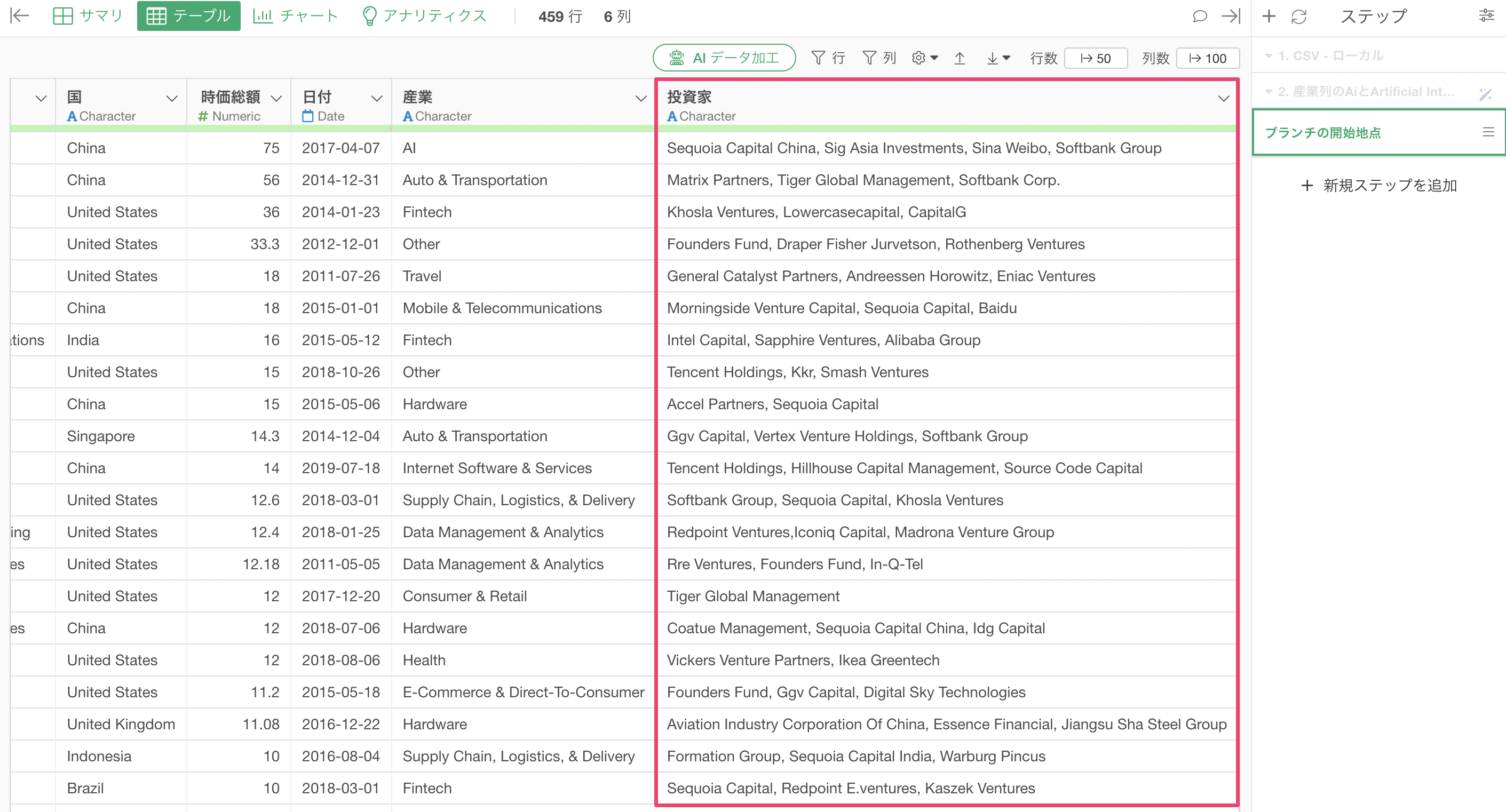
現在のように、1行1企業の状態で、企業単位での集計や可視化をしたい場合はこのままで問題ありません。
しかし、「投資家」に注目をして集計・可視化をしようとすると上手くいきません。なぜなら、1行が1投資家になっていないため、特定の投資家の件数を数えるといったことができないからです。
そのため、1行を1投資家になるように、投資家の値を複数の行に分割してみましょう。
「AI データ加工」のボタンをクリックします。
AI プロンプトのダイアログが表示されるため、プロンプトに以下を指定します。
投資家の列を行に分割して
投資家の値をカンマ区切りで行に分割するためのRスクリプトが返ってきます。
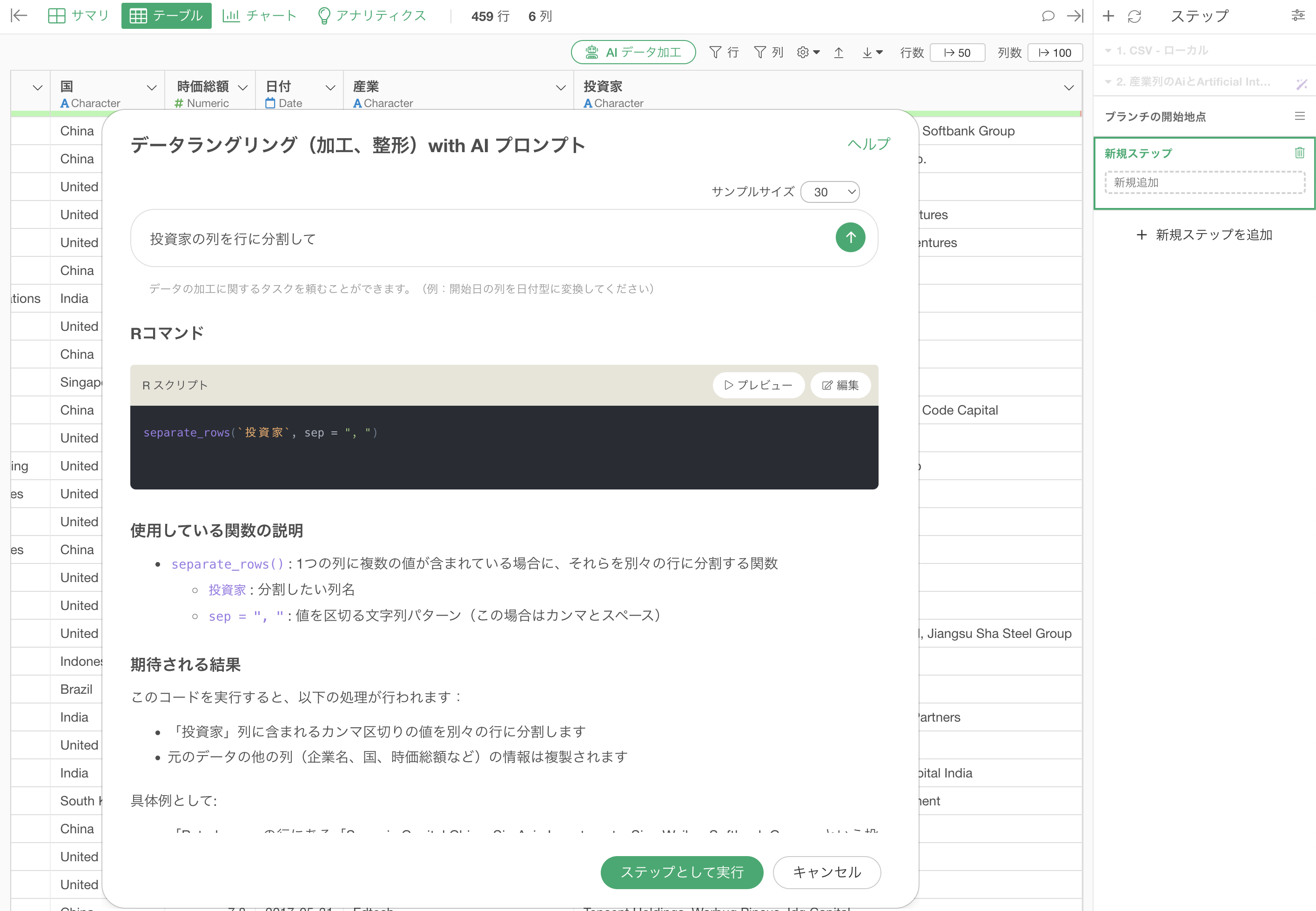
実行することで、投資家ごとに行に分割することができました。
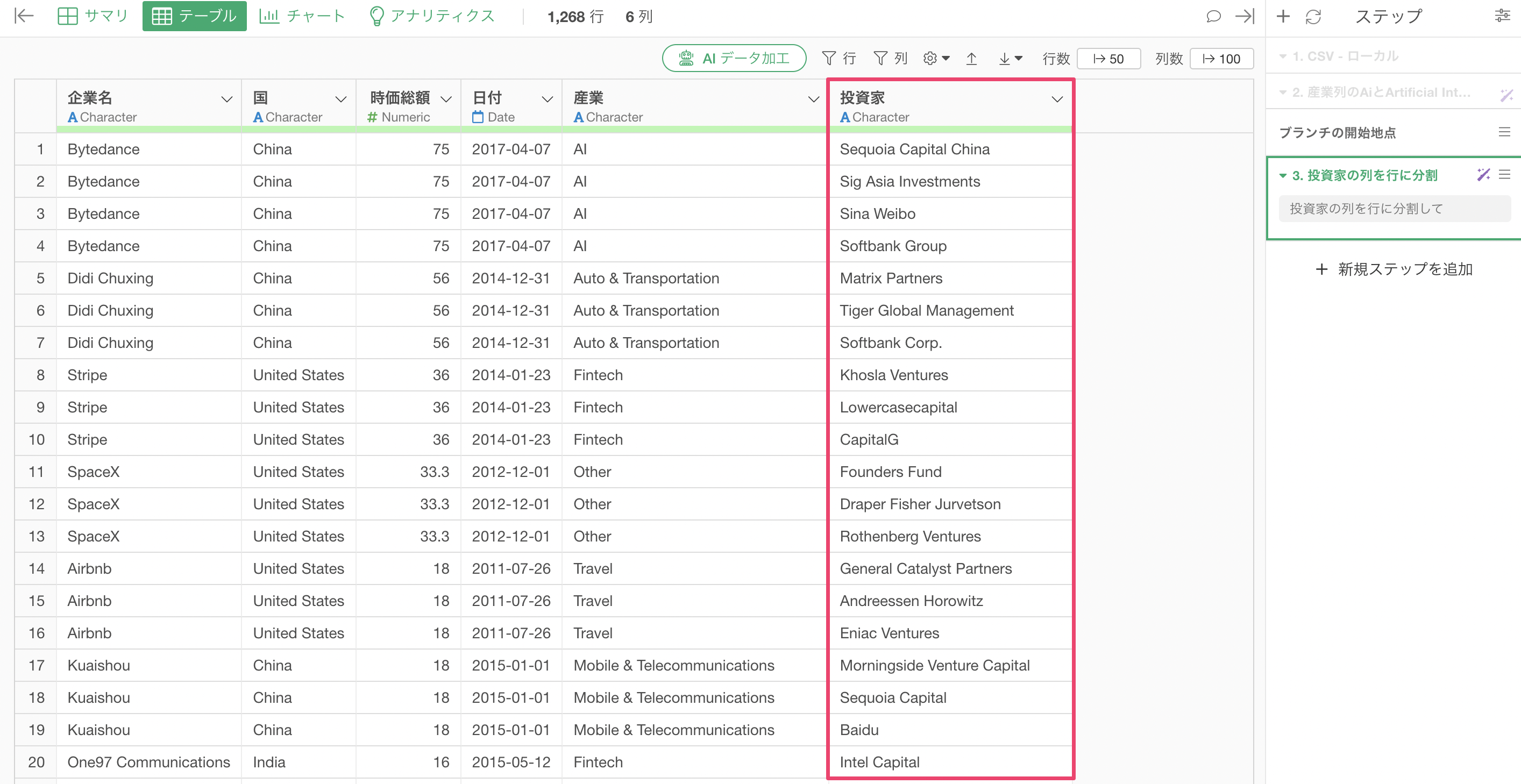
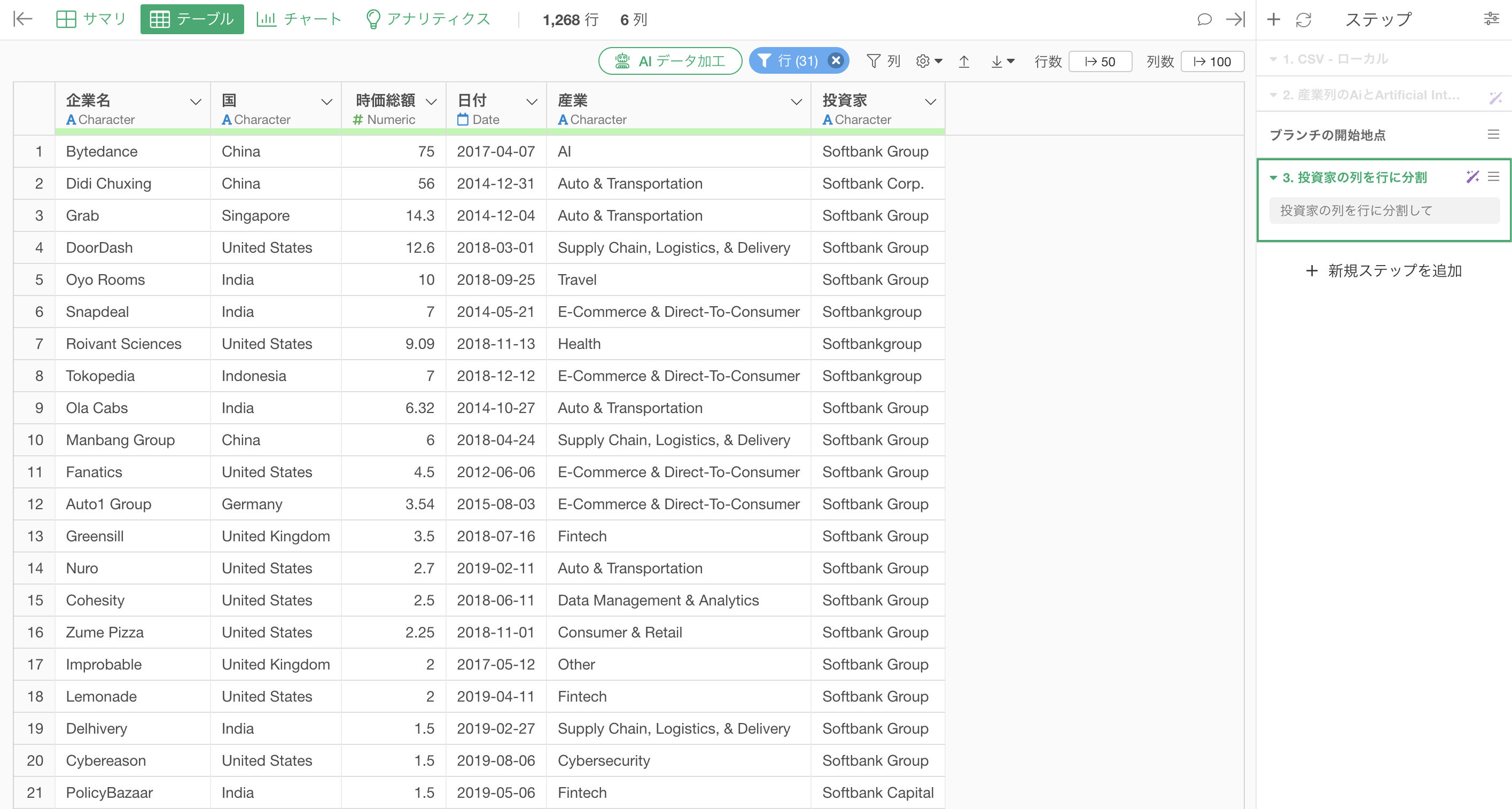
投資家ごとに行ができたことによって、複数の企業から投資を受けている企業はその分だけ行数が増えることとなります。例えば、Tiktokで有名な中国の「Bytedance」という企業は、4つの投資家から投資を受けているため、4行になっていることがわかります。
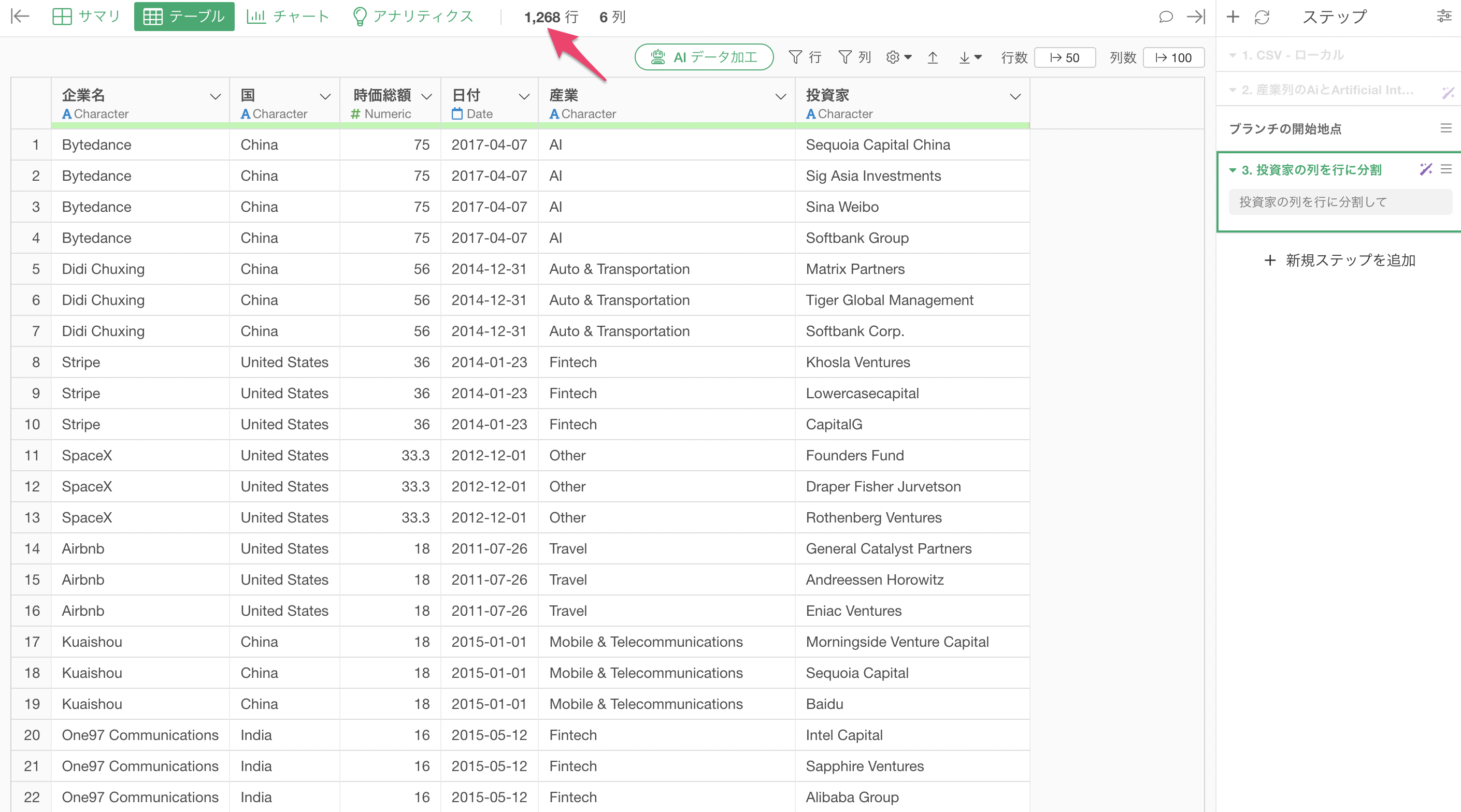
投資家ごとに行に分割したことにより、行数も「1,268行」と増えていることが確認できます。
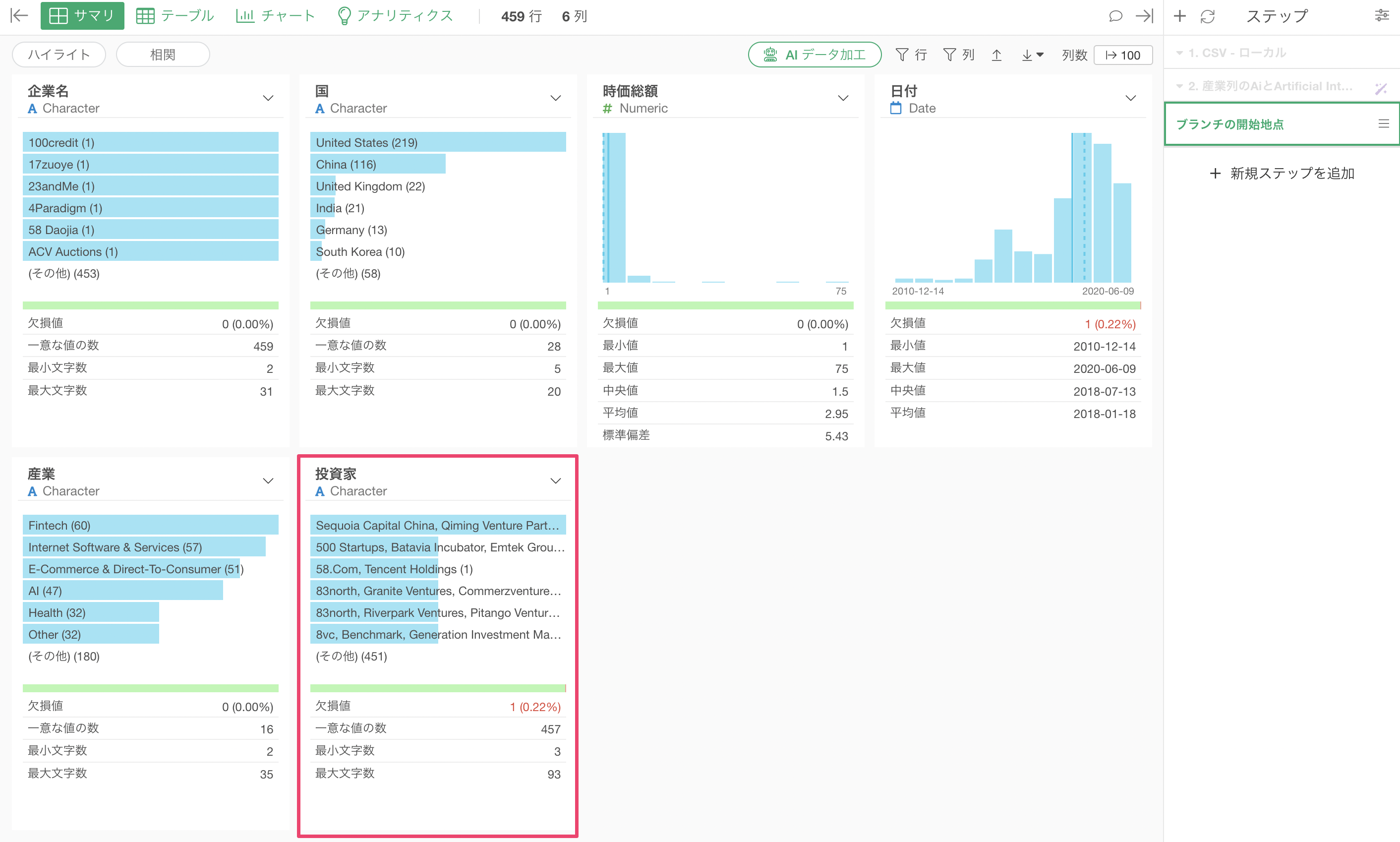
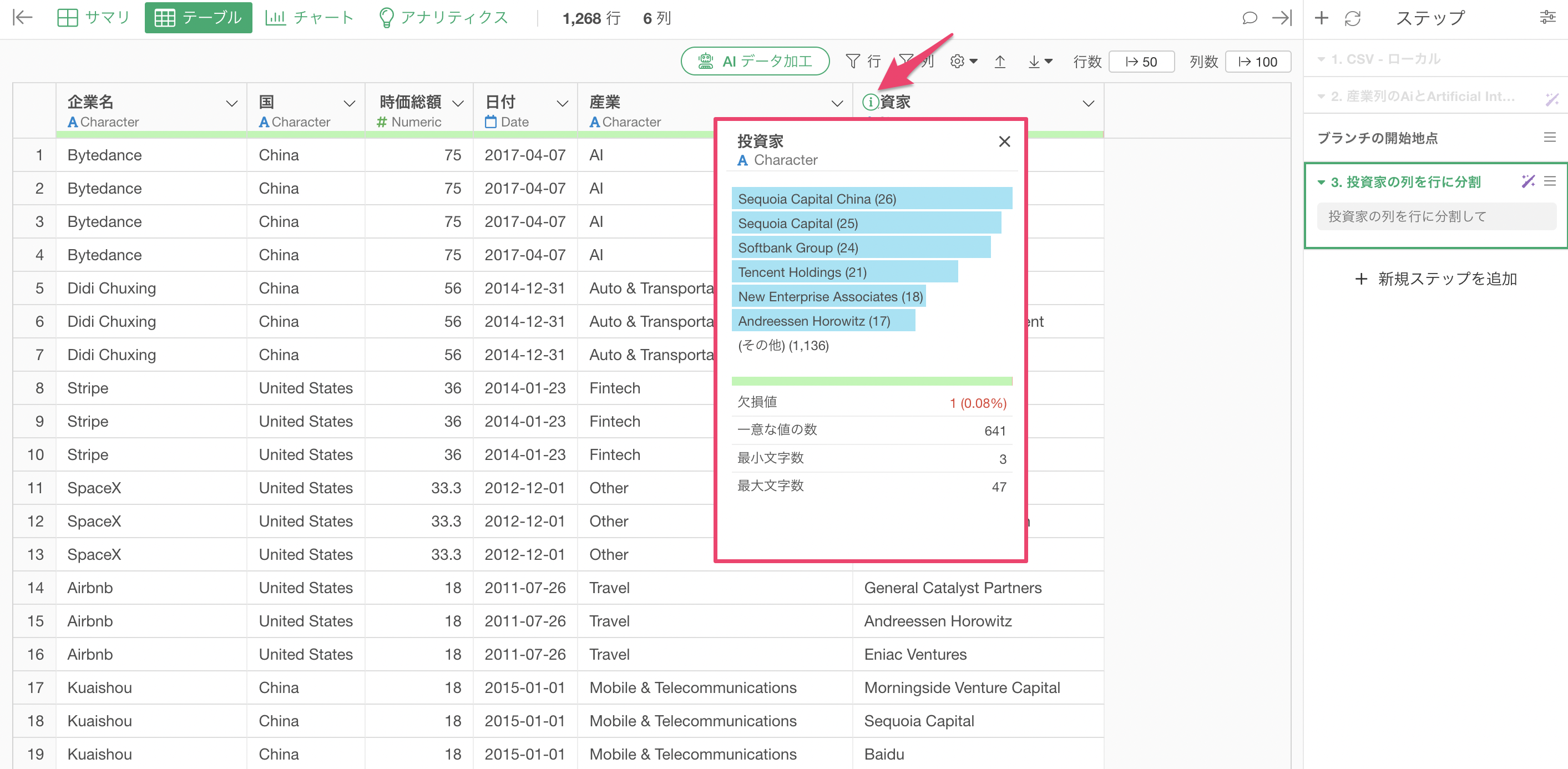
さらに、テーブルビューから投資家の列の「i」ボタンを押すことで「サマリ情報」を見ることができますが、どの投資家がより多くの企業に投資をしているのかも簡単に確認していくことが可能です。
7. テキストデータの表記揺れを整える
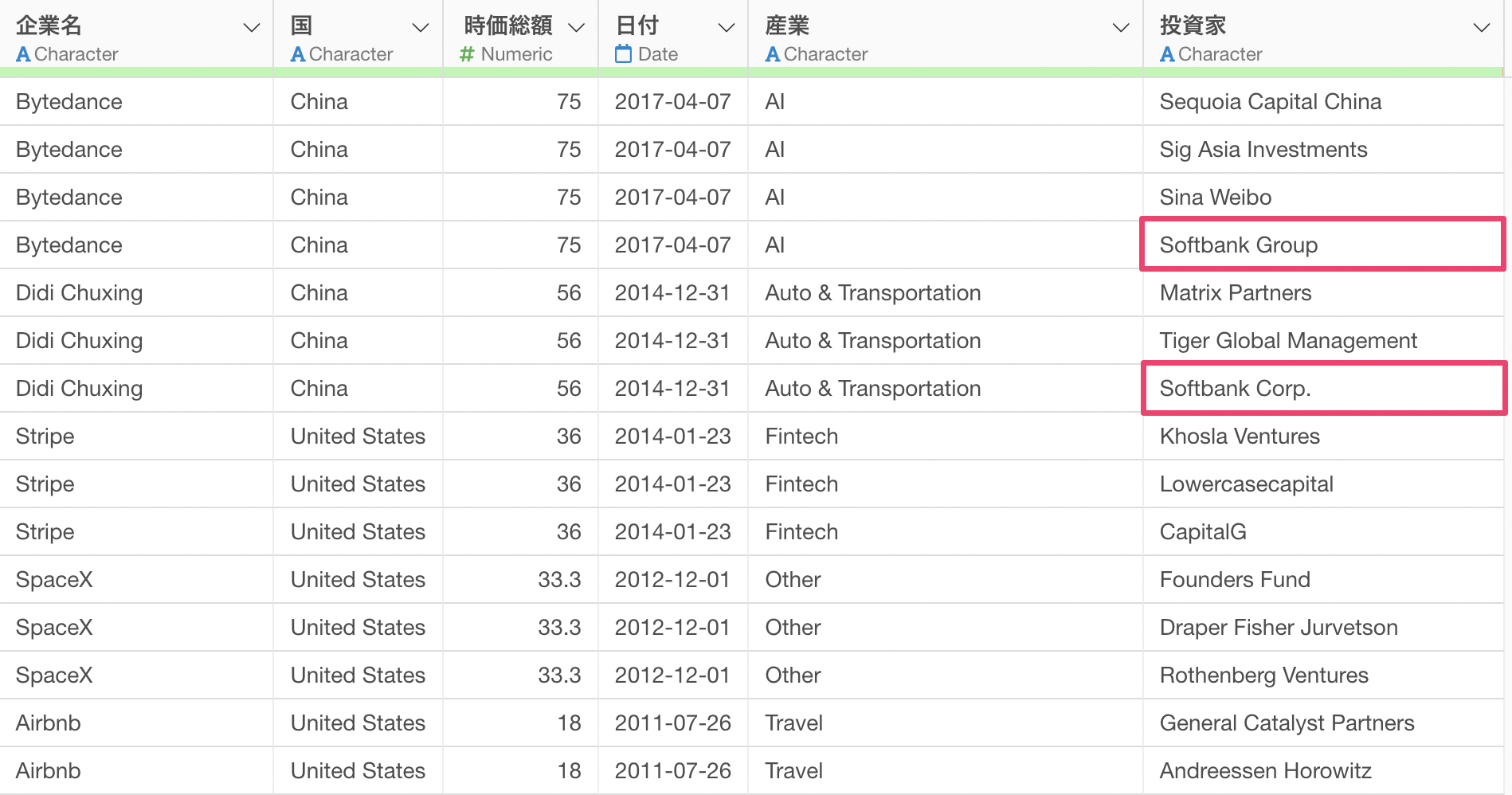
今回は投資家の中でも、日本企業である「Softbank」に注目していきたいです。
ただ、「Softbank Group」や「Softbank Corp.」といった形で同じ「Softbank」でも複数の名称に分かれてしまっています。
他にもSoftbankを含む文字としてどういったものがあるのかを調べるために、テーブルビューの「行フィルタ」を使って「Softbankを含む」データに絞り込んでいきます。
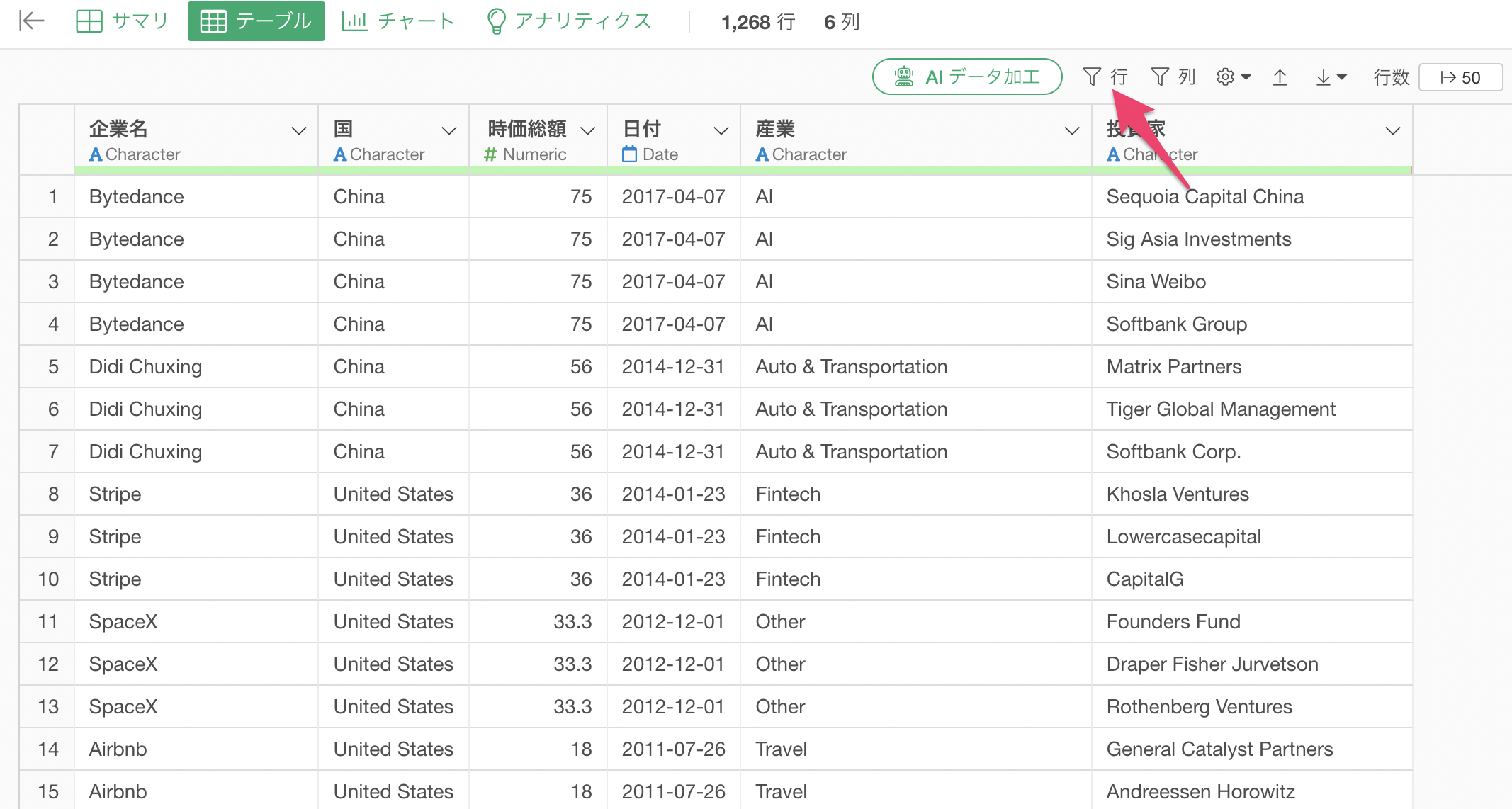
行フィルタのダイアログが表示されるため、以下のように指定します。
- 列に「Select Investors」を選択
- 演算子に「この文字列を含む」を選択
- 「softbank」と入力
- 「大文字と小文字を区別しない」をチェック
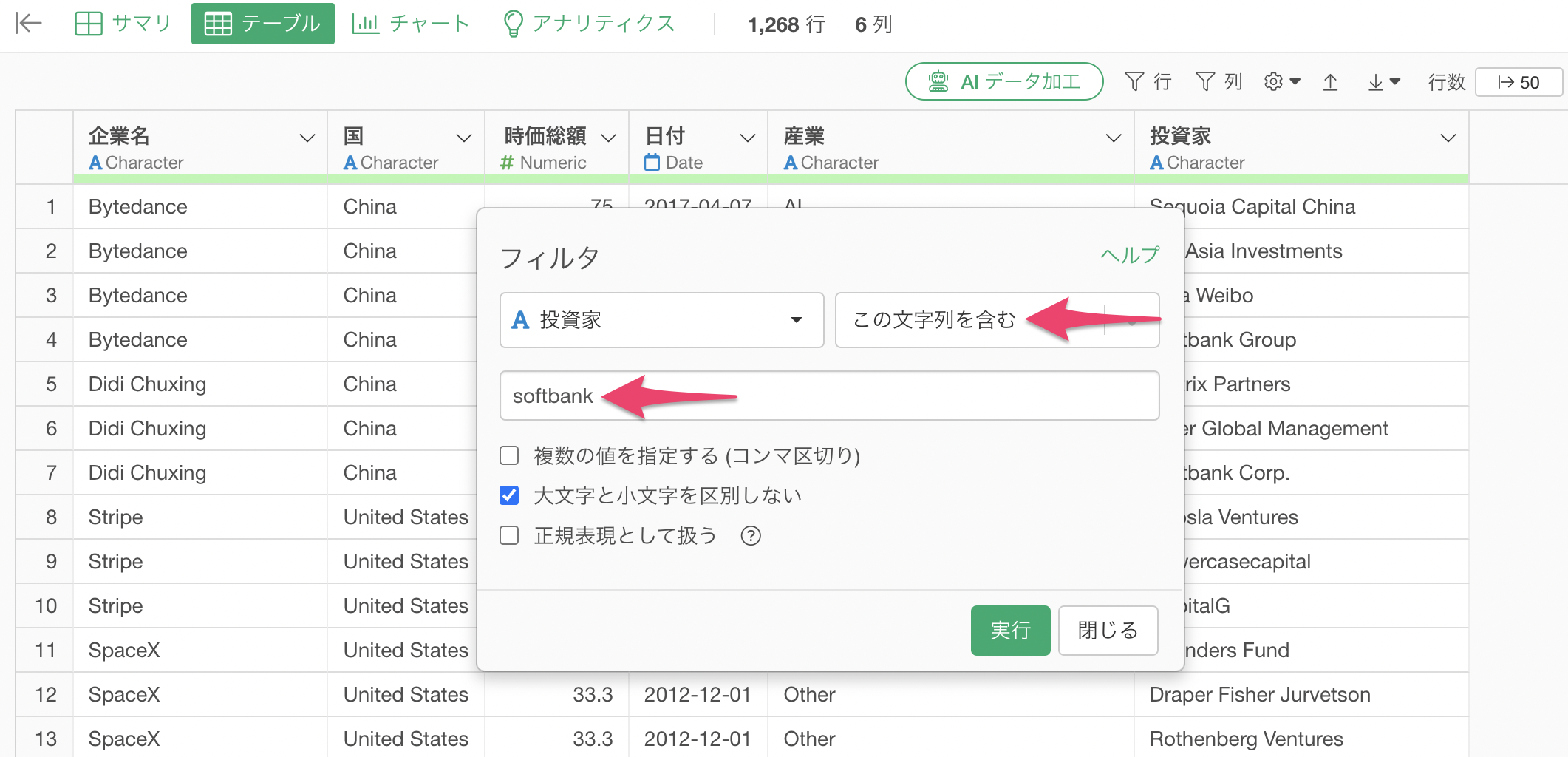
「Softbankを含む」行は31件あり、Softbankの後の表記が異なっていることがわかります。
 こういった問題をよく「表記揺れ」と呼びますが、表記揺れが起こるとデータを集計したり、可視化をする時に別々の値として認識されるために、正しい数で計上できないことに繋がります。
こういった問題をよく「表記揺れ」と呼びますが、表記揺れが起こるとデータを集計したり、可視化をする時に別々の値として認識されるために、正しい数で計上できないことに繋がります。
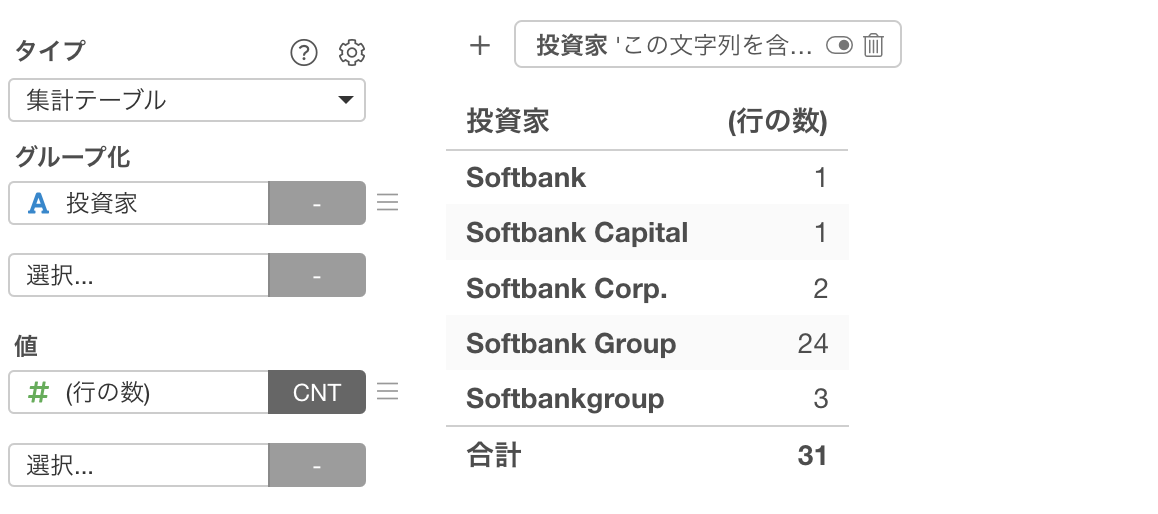
そのため、同じ意味を表す値は、同じ文字として整える必要があります。これを行うのが「テキストデータの加工」です。

「AI データ加工」のボタンをクリックします。
AI プロンプトのダイアログが表示されるため、プロンプトに以下を指定します。
投資家の列のGroup,Capital,Corp.の文字を取り除いて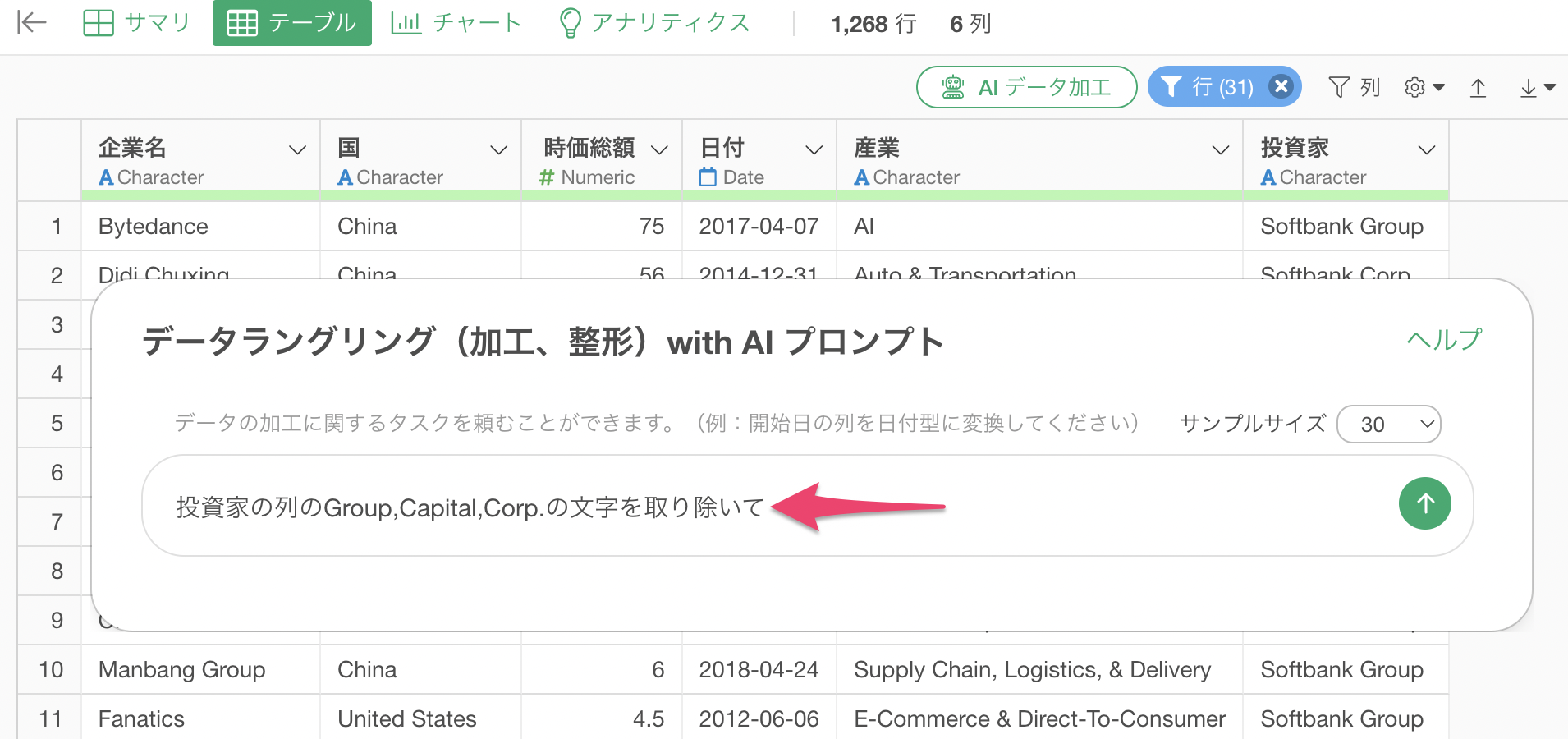
投資家の列のGroup,Capital,Corp.の文字を取り除くためのRスクリプトが返ってきます。
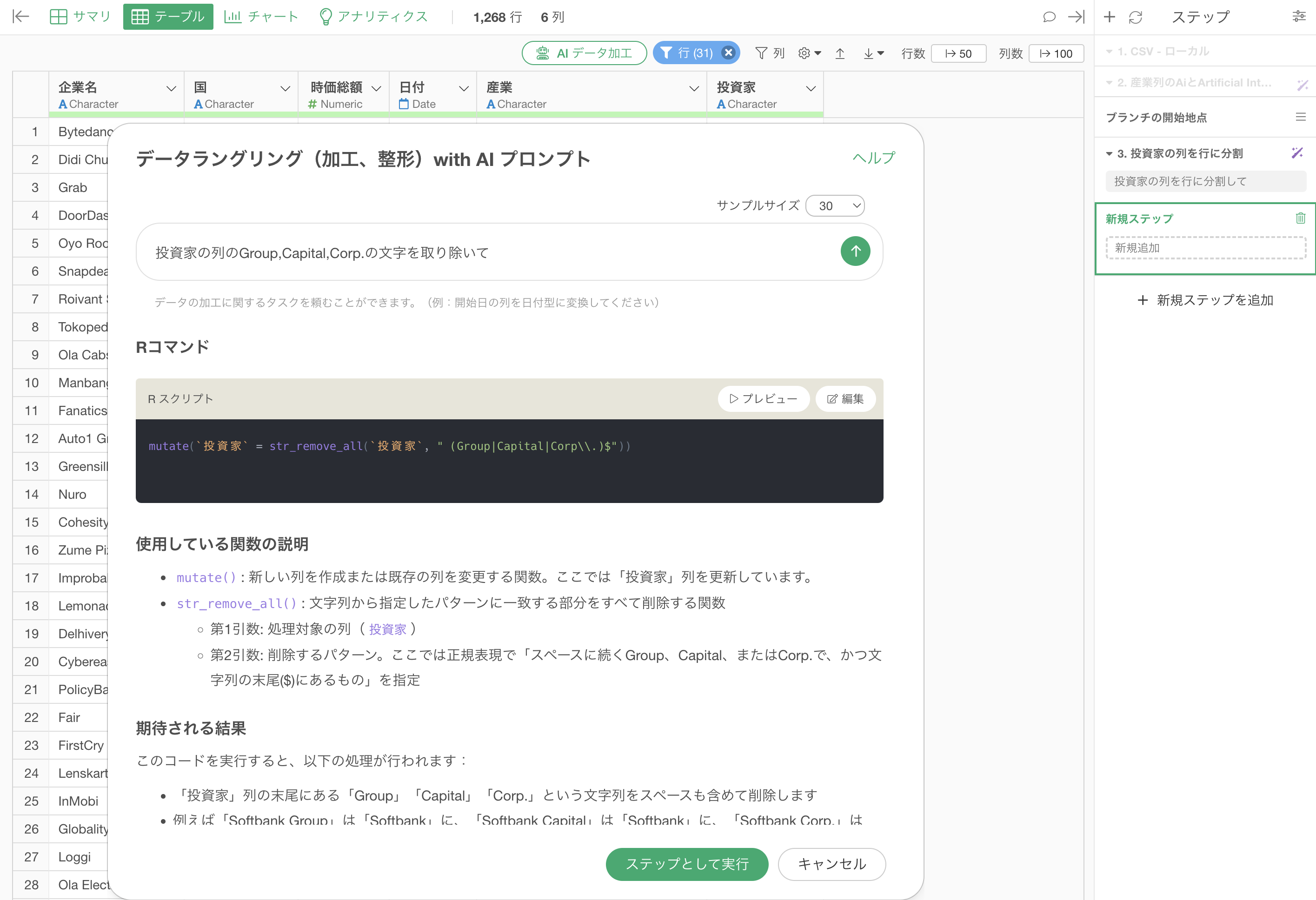
実行すること「Group」、「Capital」、「Corp.」を取り除くことはできていますが、「Softbankgroup」のgroupは取り除かれていません。
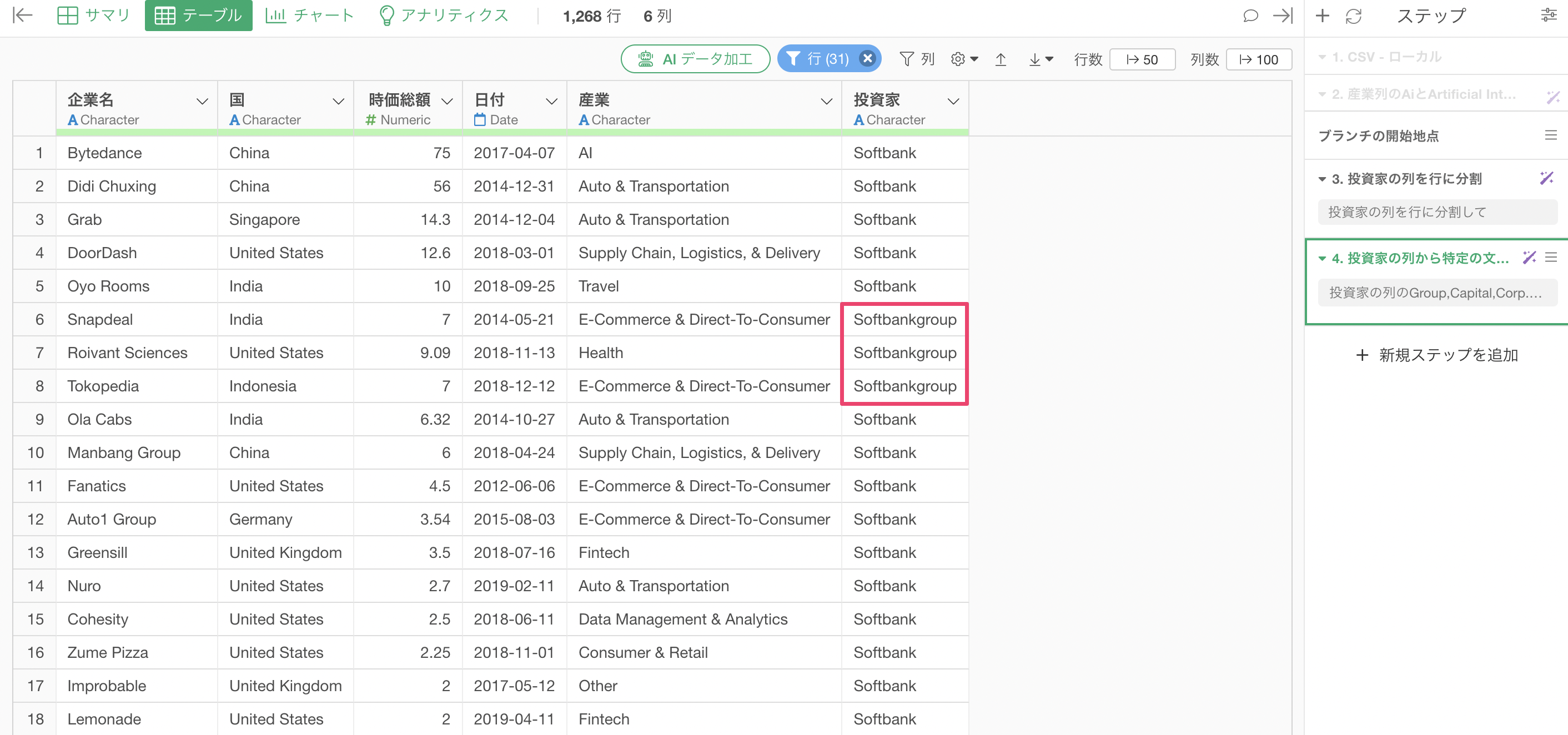
投資家の文字列を取り除いた「ステップ4」のトークンをクリックする。
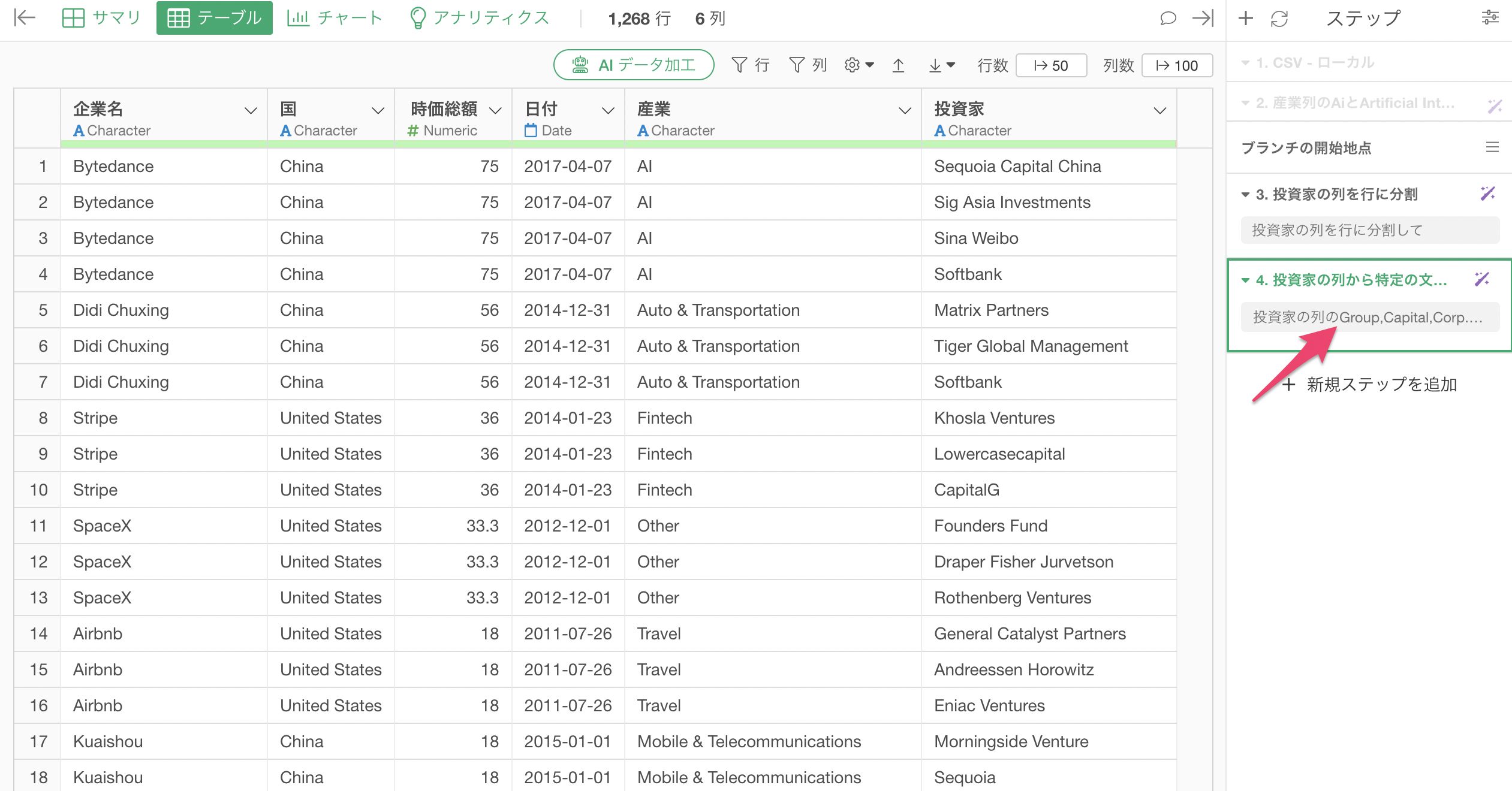
AI プロンプトのダイアログが表示されため、プロンプトを以下に変更します。この際に、値をダブルクォートで囲みます。
投資家の列の"Group","Capital","Corp."の文字を取り除いて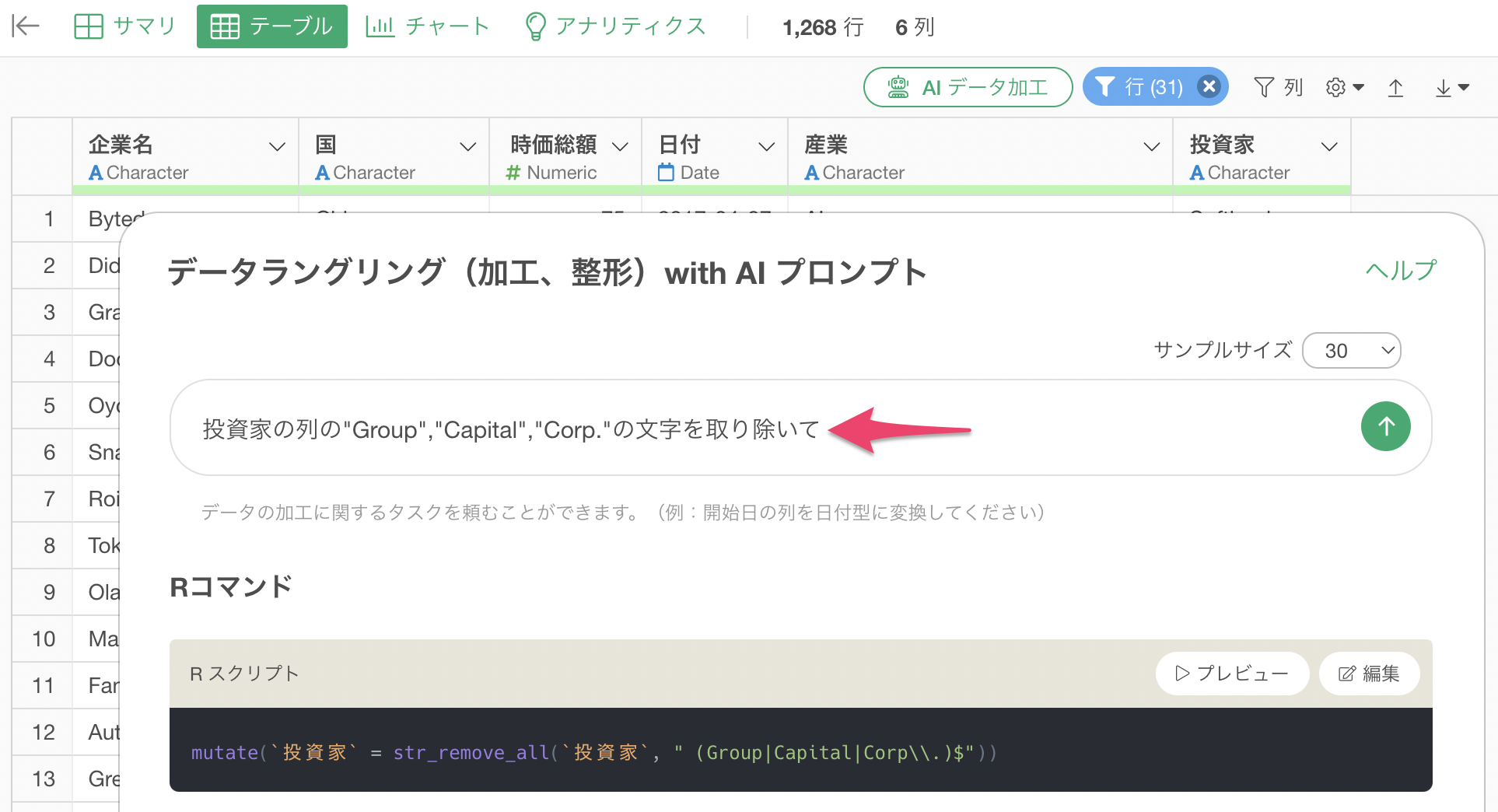
これによっていくつかの引数が追加されます。例えば、ignore_case = TRUE
によって大文字・小文字を無視して処理ができるようになります。
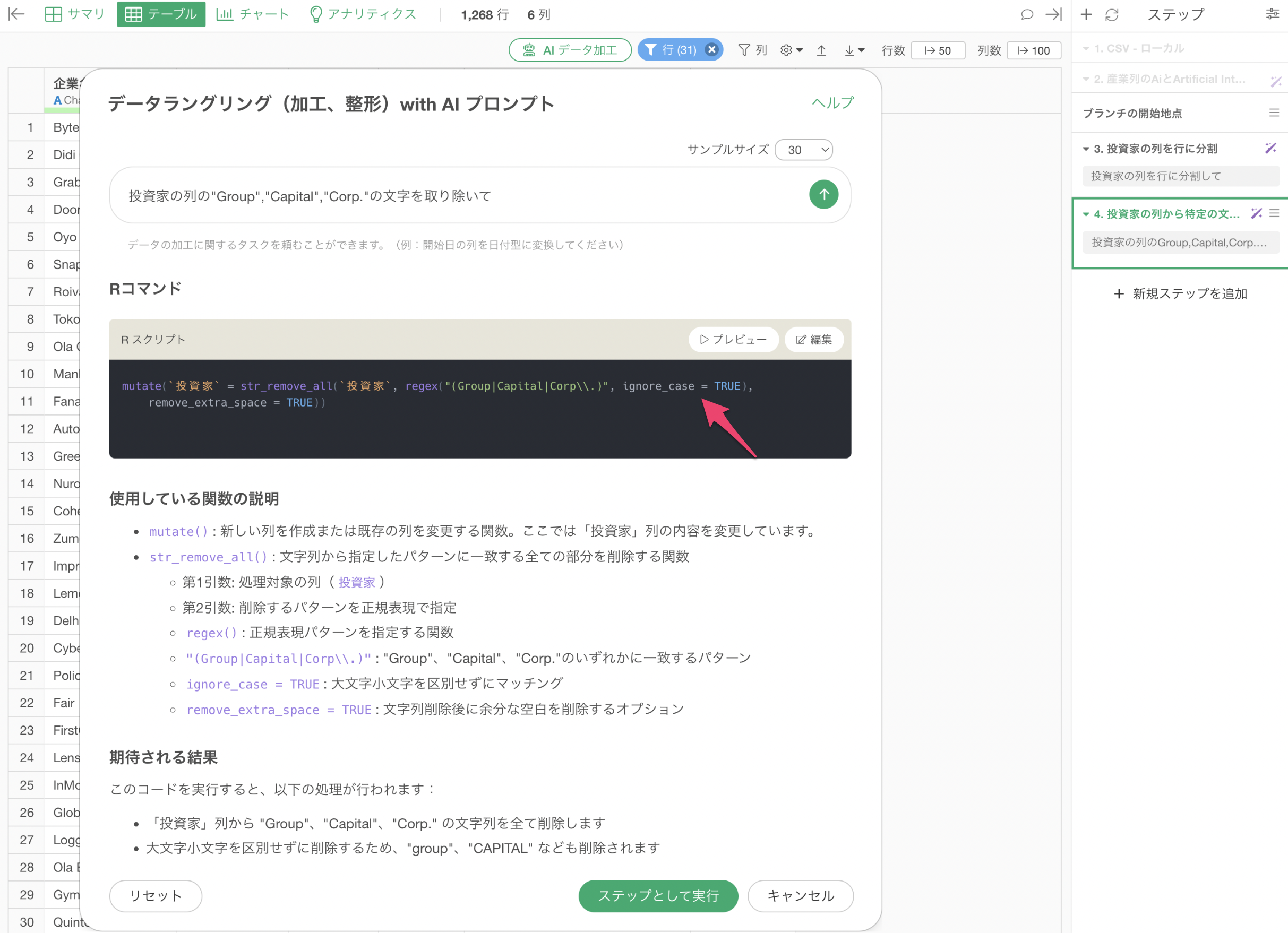
実行することで、小文字の「group」も取り除くことができている。
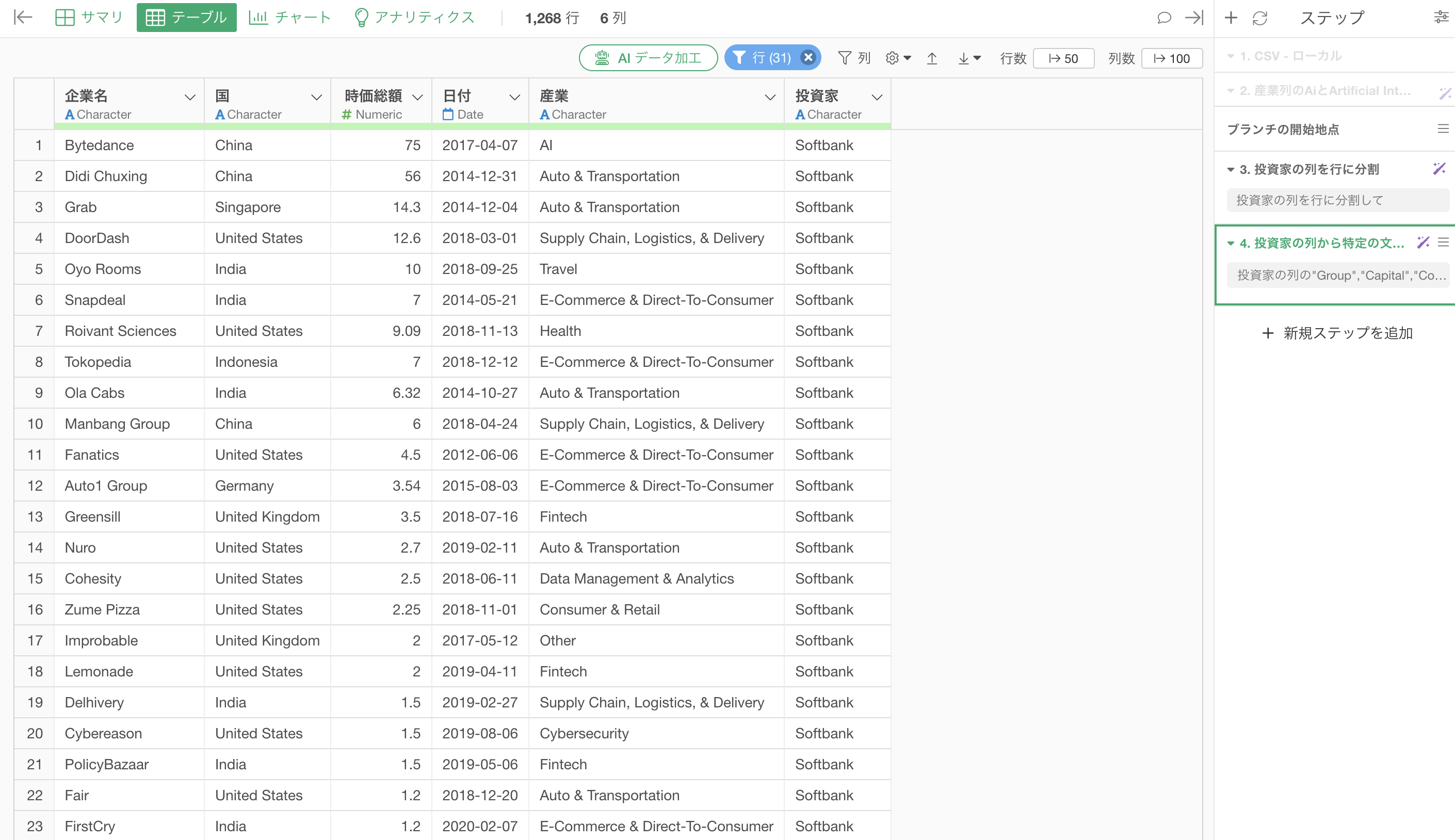
プレビューによるデバッグ
AI プロンプトで出力されたRスクリプトをプレビューをすることで、実行した際の加工結果を確認することが可能です。
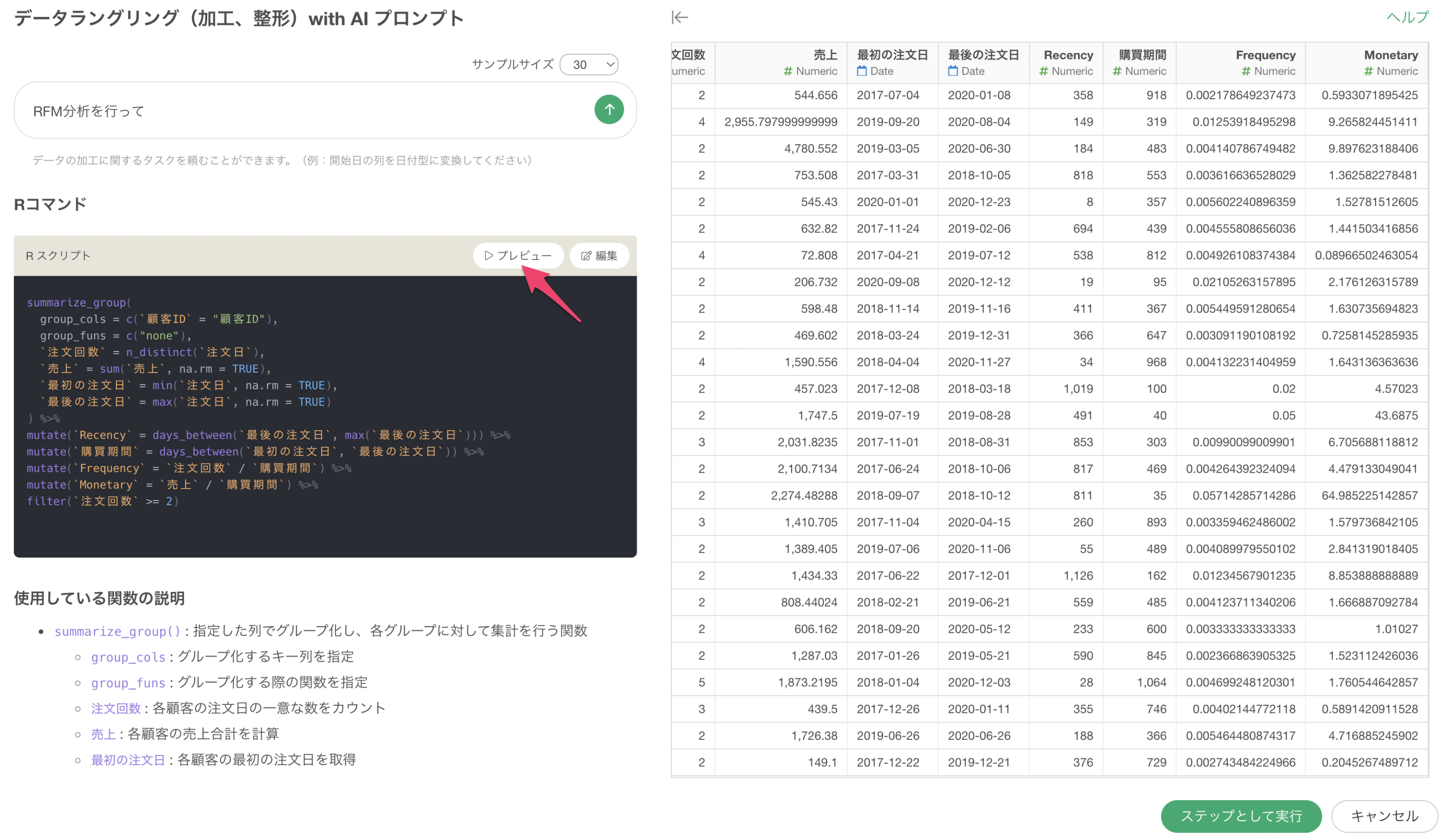 AI
プロンプトでは複数の関数をパイプ(%>%)で繋ぎ合わせたRスクリプトで出力されることがありますが、それぞれの関数での実行結果を確認するためのデバッグが可能です。
AI
プロンプトでは複数の関数をパイプ(%>%)で繋ぎ合わせたRスクリプトで出力されることがありますが、それぞれの関数での実行結果を確認するためのデバッグが可能です。
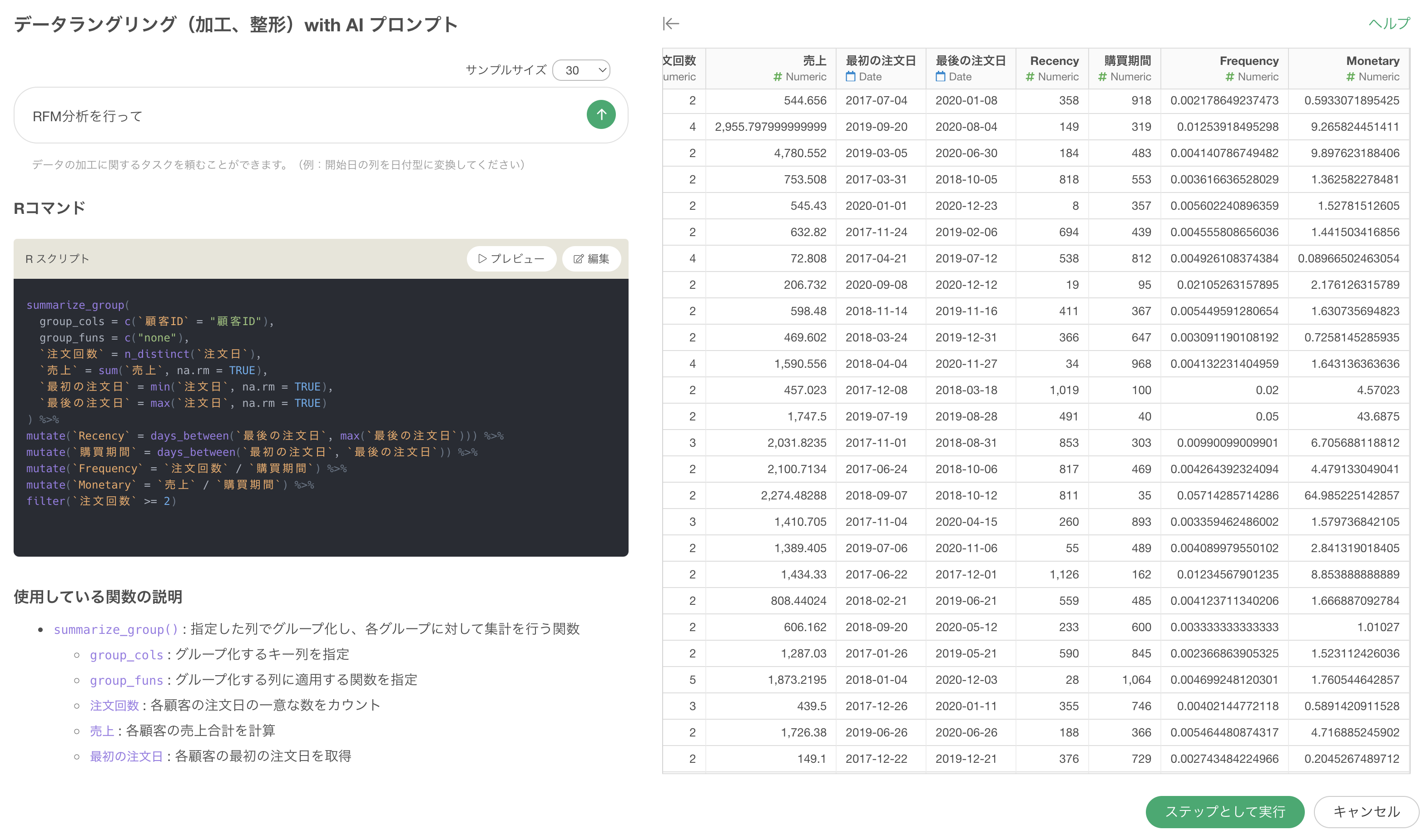
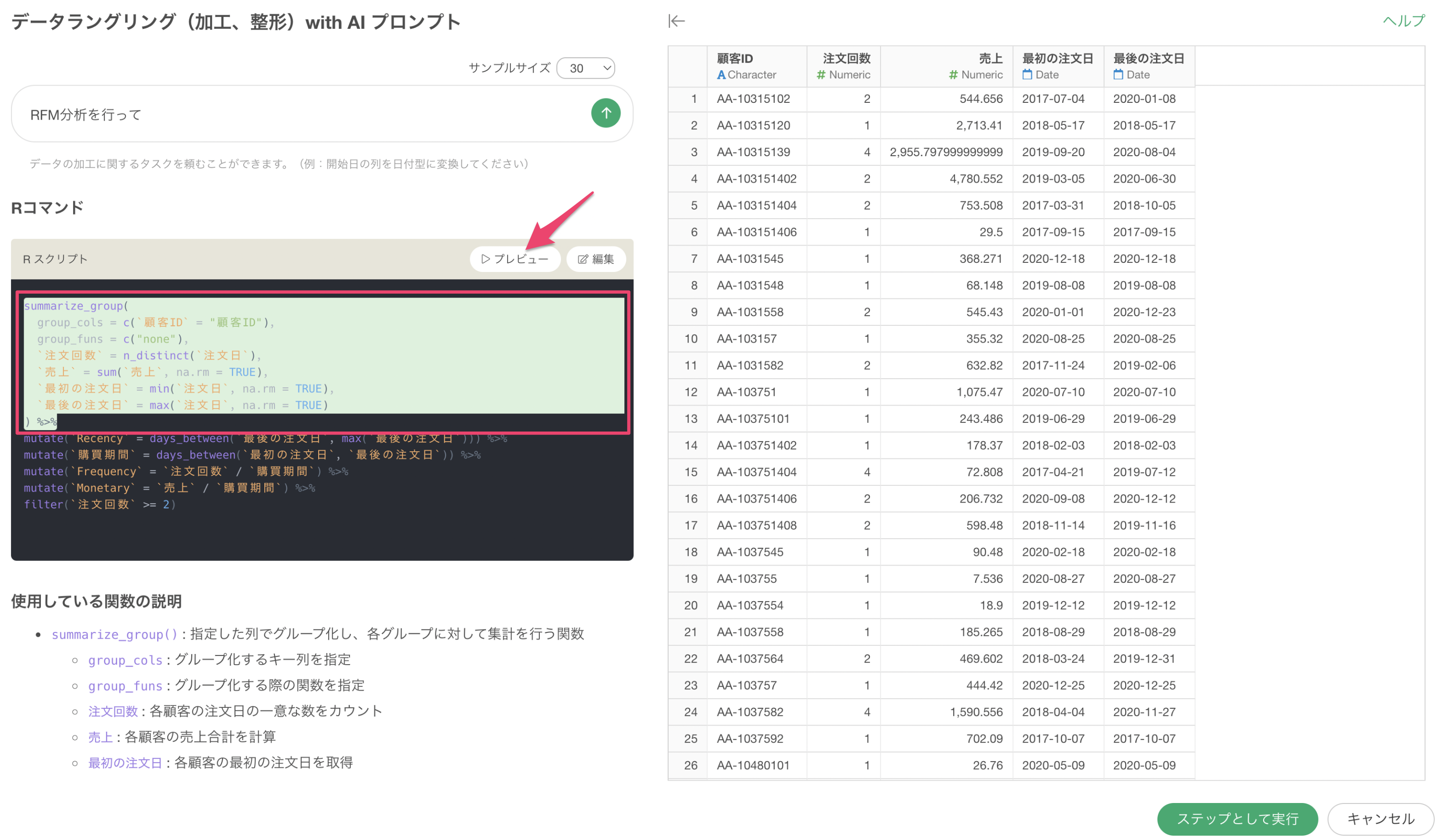
例えば、以下はRFM分析の実行のために集計をするための関数が使われていますが、見たい箇所の関数をクリックした上でプレビューをすることで、その時点までの実行結果を確認することができます。
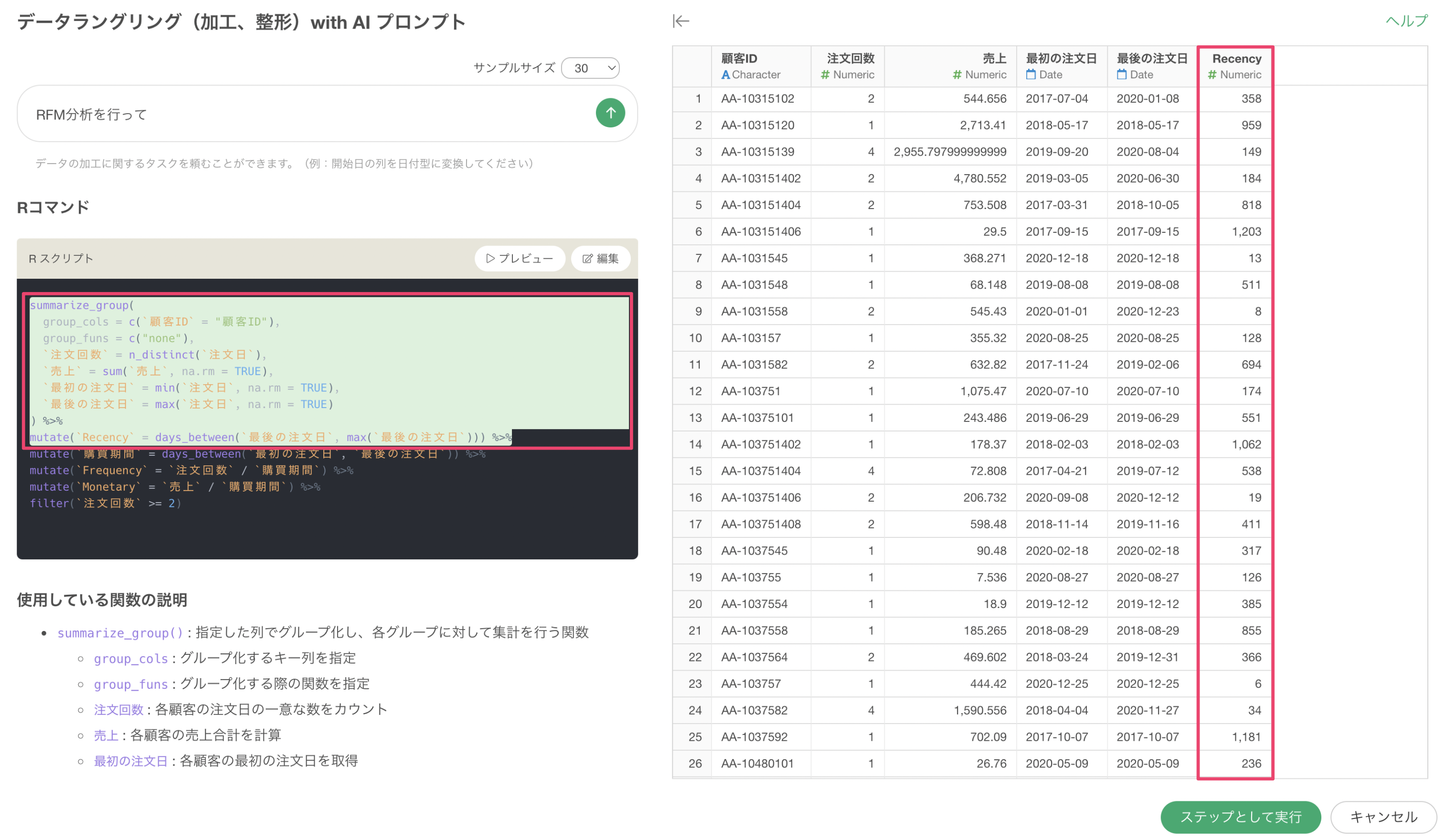
以下の場合、2つ目の計算(mutate関数)によってRecencyの列が追加されていることがわかります。
エラーが発生した時の自動修正
AI プロンプトを使った際に、稀にエラーが発生することがあります。
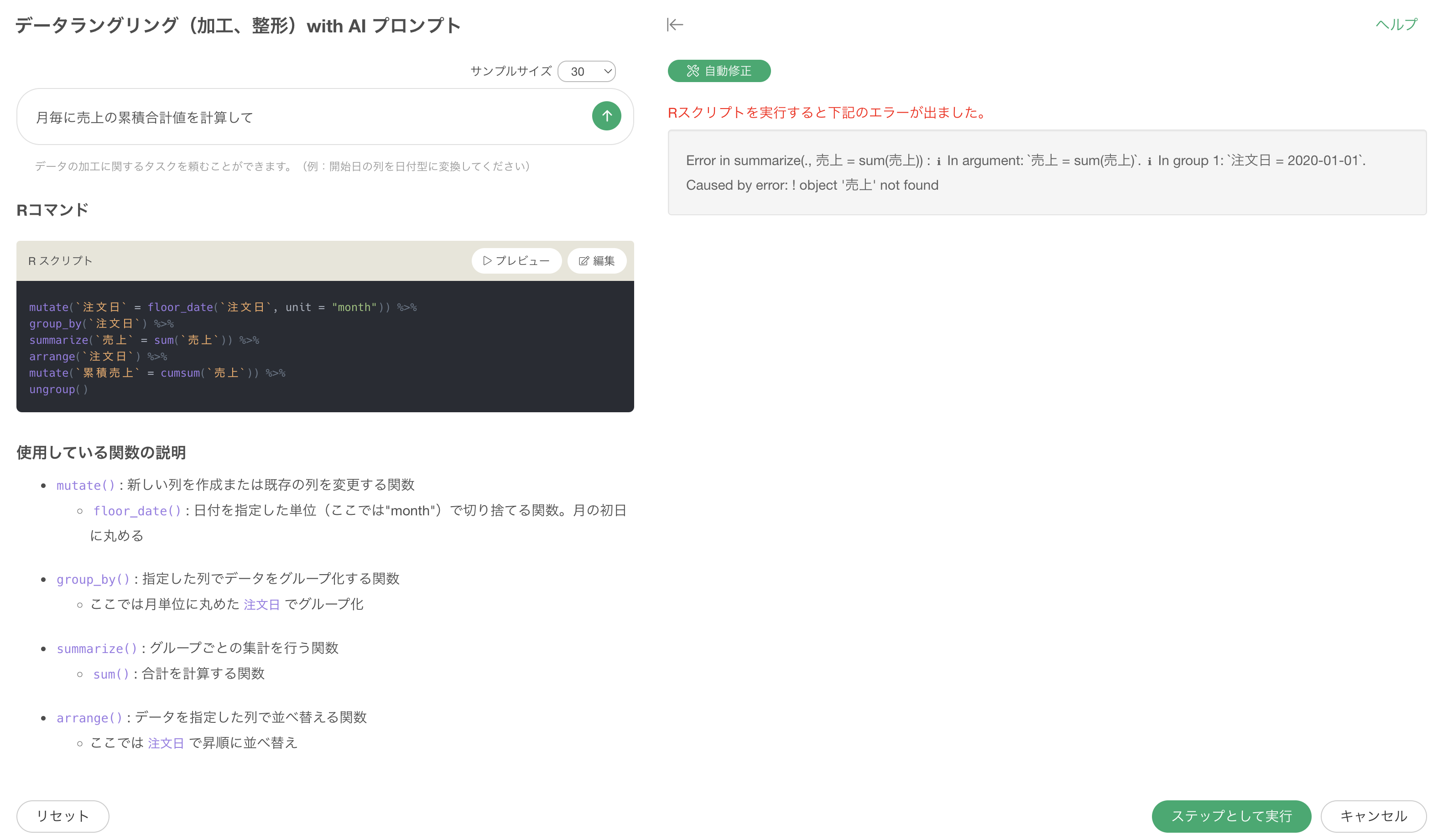
プレビューによってどういったエラーが発生しているのかを確認していくことができますが、このエラーをAIによって自動的に解決するために「自動修正」のボタンをクリックします。
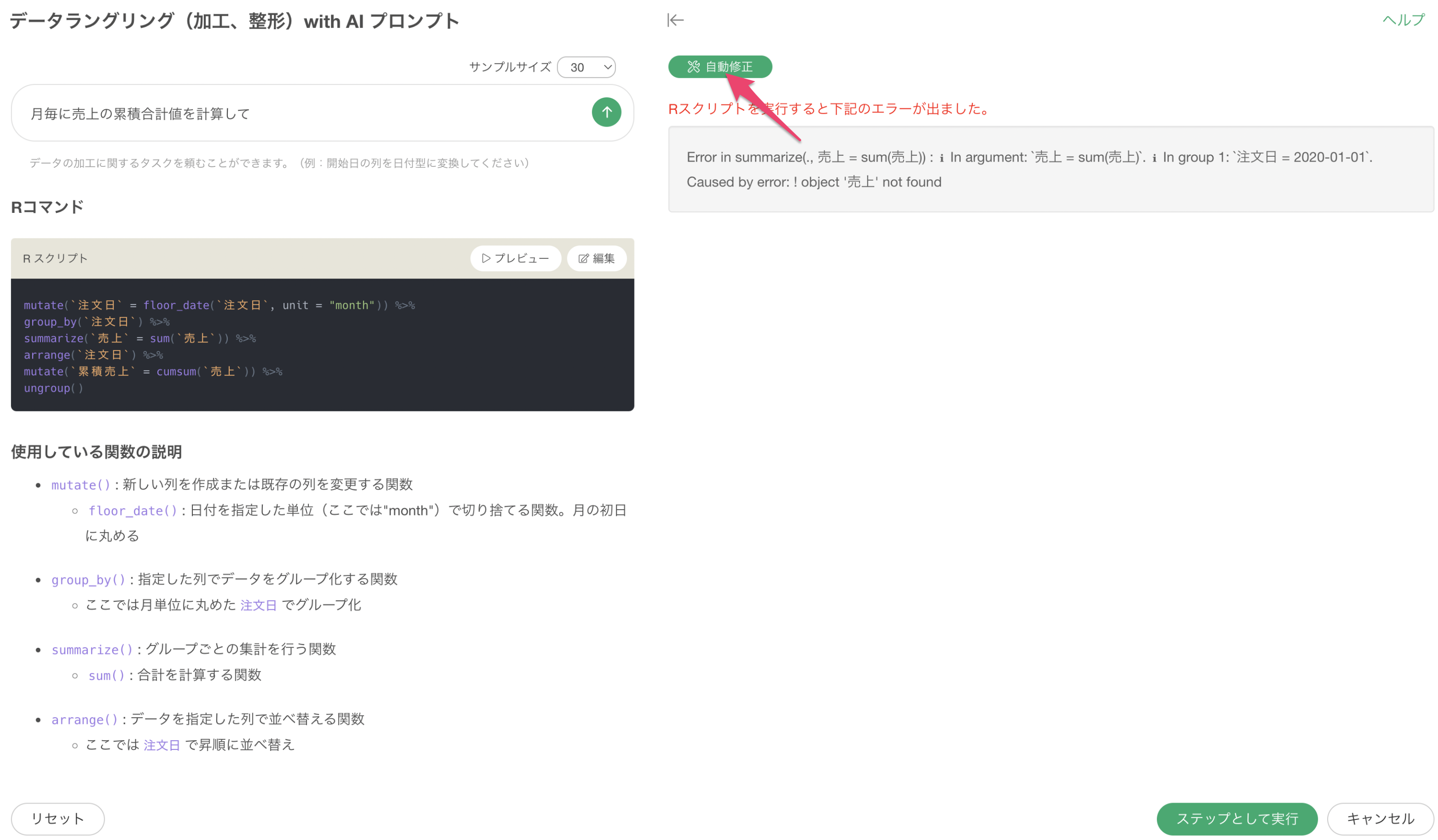
これにより、エラーの内容を元にして再度Rコマンドなどを修正した上で結果を返すことができます。
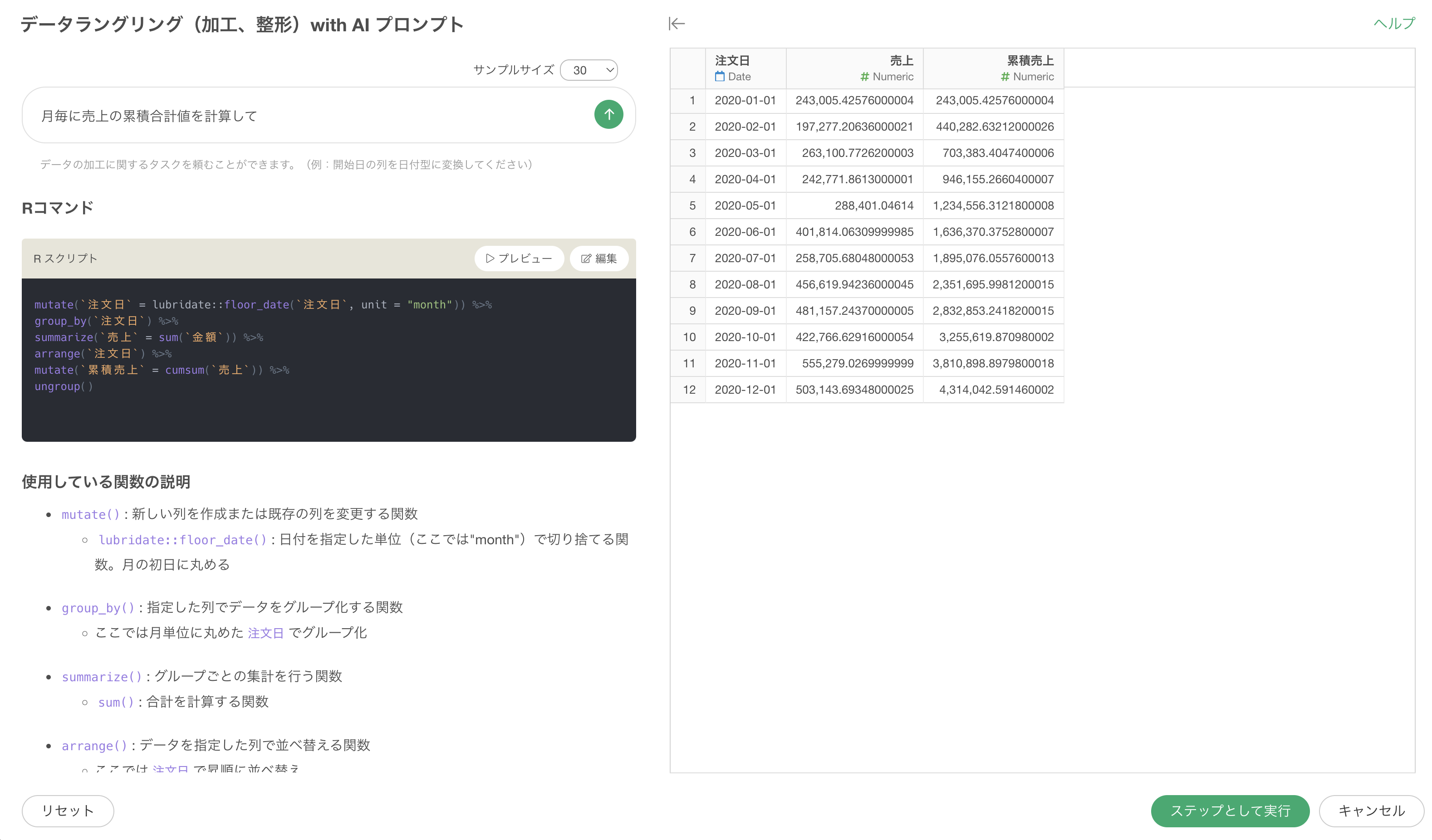
Exploratoryの使い方のデータラングリングのAIプロンプト版は以上となります!
AI プロンプトの書き方について詳しく学びたい方は、こちらの「AI プロンプトのベストプラクティス」をご覧ください。
Exploratoryの使い方シリーズ
Exploratoryの使い方シリーズの他のパートには下記のリンクからご確認いただけます。ぜひ次の「ダッシュボード」のパートも実施してみてください。