Exploratoryの使い方 Part 1 - 基礎
このノートは、Exploratoryを効率的に使い始めることができるように作られた「Exploratoryの使い方」の第1弾、「基礎」編です。
Exploratoryはデータの可視化や分析、そしてデータの加工などができるツールでたくさんのことができますが、ここではその中でもこの本でハンズオンを進めていく際に必要となる最低限の機能について実際にサンプルデータを使い、以下の9つのタスクを進めながら学んでいきましょう。
- プロジェクトを作成する
- データをインポートする
- 4つのビュー
- サマリ・ビューの使い方
- チャートを作る
- コメント機能
- 計算をする
- データラングリングのステップ
- チャートのピン機能
それでは、さっそく始めていきましょう!
1. プロジェクトを作成する
Exploratoryではデータのインポートを含め、全てのデータに関する作業はプロジェクトの中で行います。
そのため、まず最初にプロジェクトを作成します。
プロジェクトの管理画面から「新規作成」のボタンをクリックします。
任意のプロジェクト名を入力して作成ボタンをクリックします。
新しく作られたプロジェクトが開きます。

2. データをインポートする
プロジェクトを作成することができたら、次はデータをインポートしましょう。
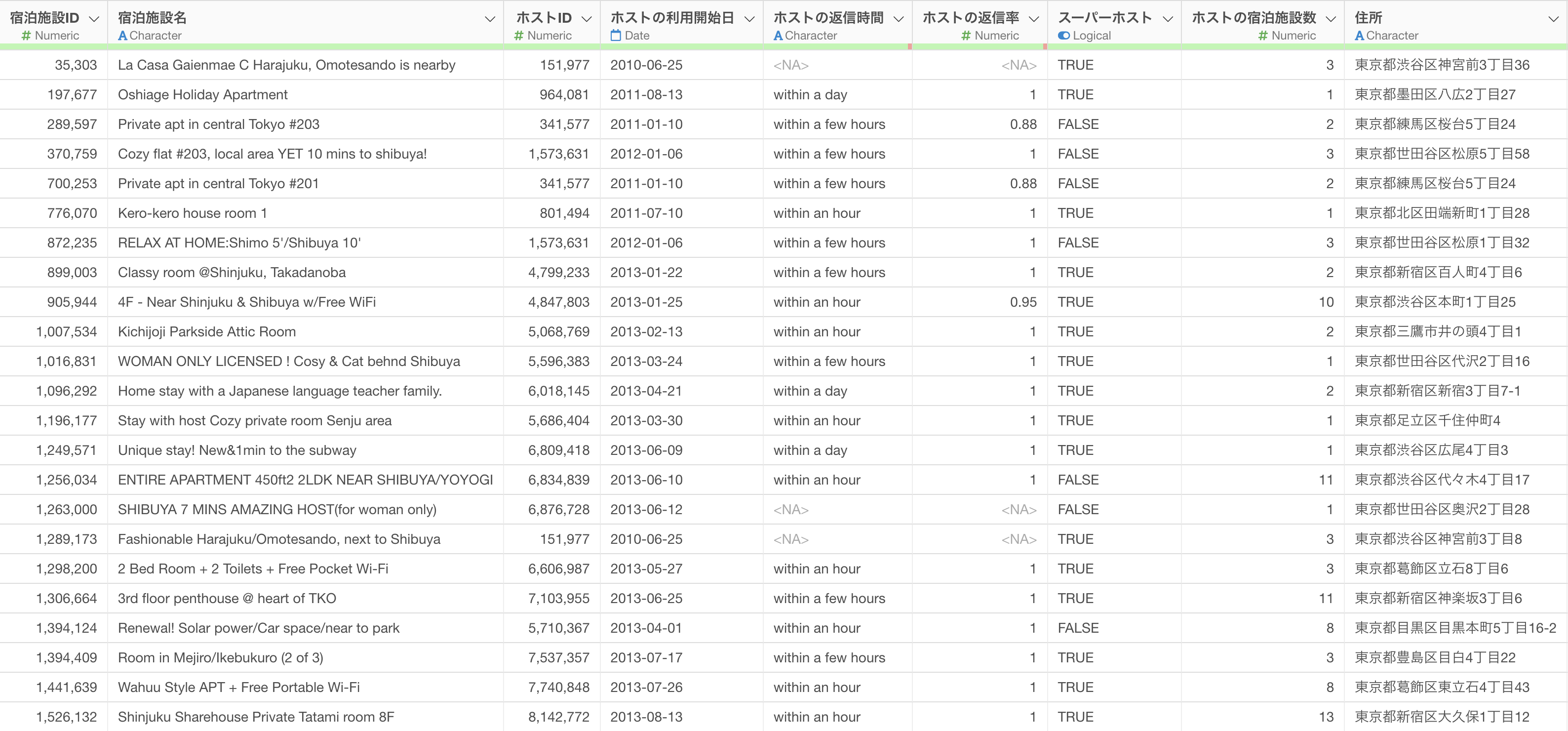
今回はサンプルデータとして「Airbnbの東京の宿泊施設」のデータを使用します。
データはこちらのページからダウンロードできます。Macをお使いの方は「CSV-UTF8」を、Windowsをお使いの方は「CSV - Shift-JIS」をダウンロードしてください。

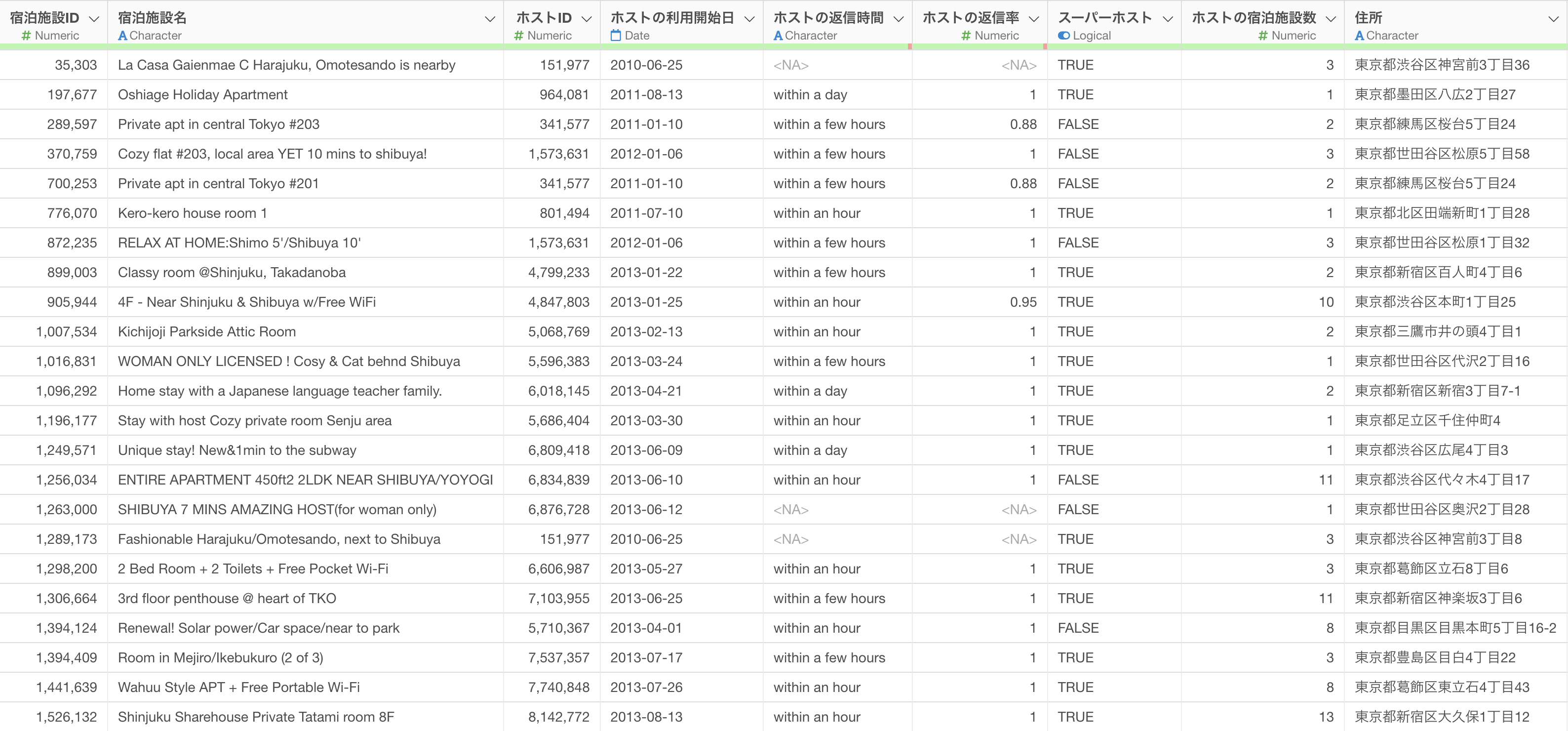
このデータは1行が1物件になっており、それぞれの物件に関する価格や広さなどの情報が列として入っています。
データをダウンロードできたら、ダウンロードしたフォルダを開き、「Airbnb-東京の宿泊施設.csv」をExploratoryの画面にドラッグ&ドロップします。
データをインポートするためのダイアログが開きますので、今回はそのまま「インポート」ボタンをクリックします。
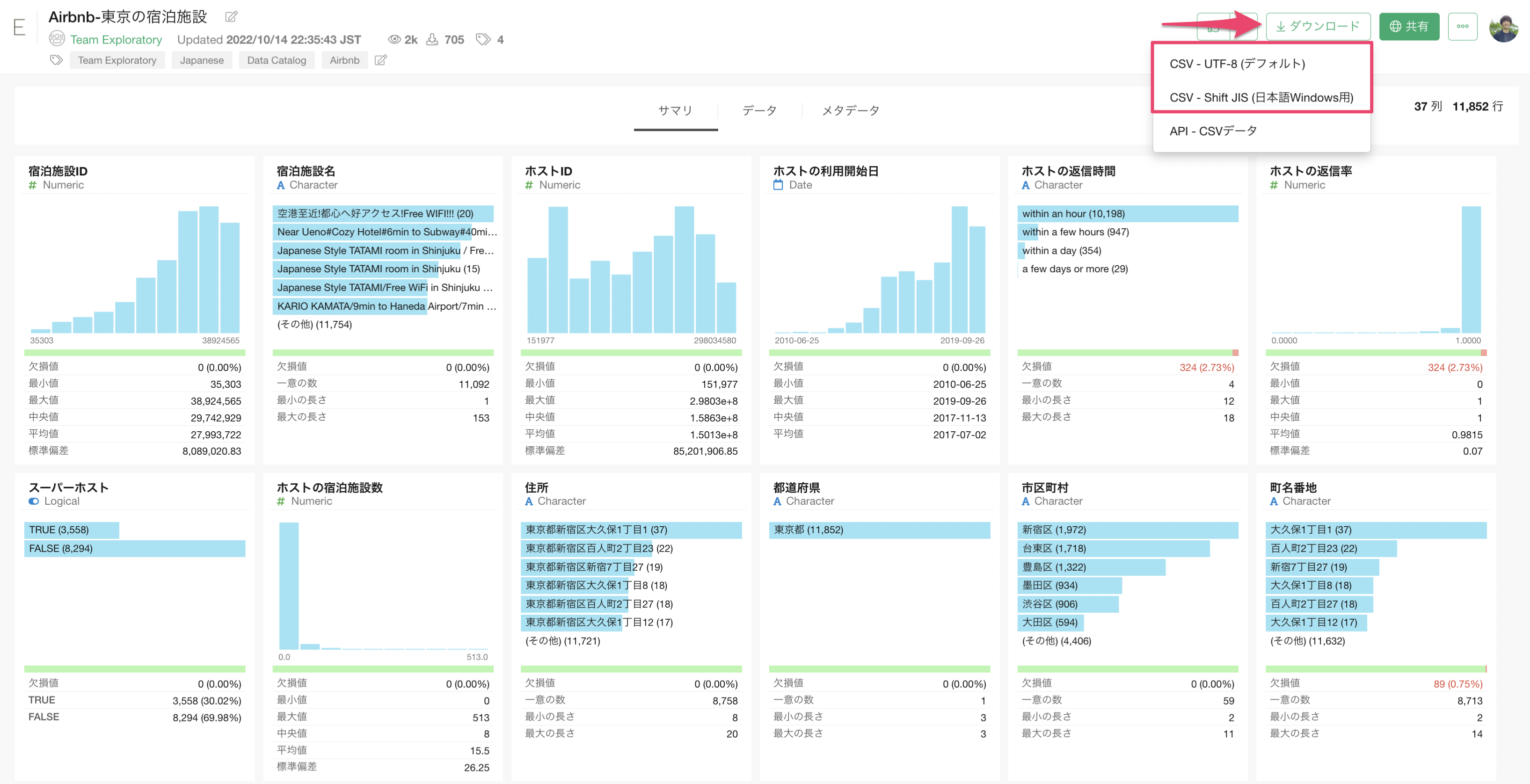 データのインポートのためのダイアログの左側には、インポート時のデータの読み取り方についての様々な設定を行うことが可能です。
データのインポートのためのダイアログの左側には、インポート時のデータの読み取り方についての様々な設定を行うことが可能です。
任意のデータフレーム名を指定して、「作成」ボタンをクリックします。
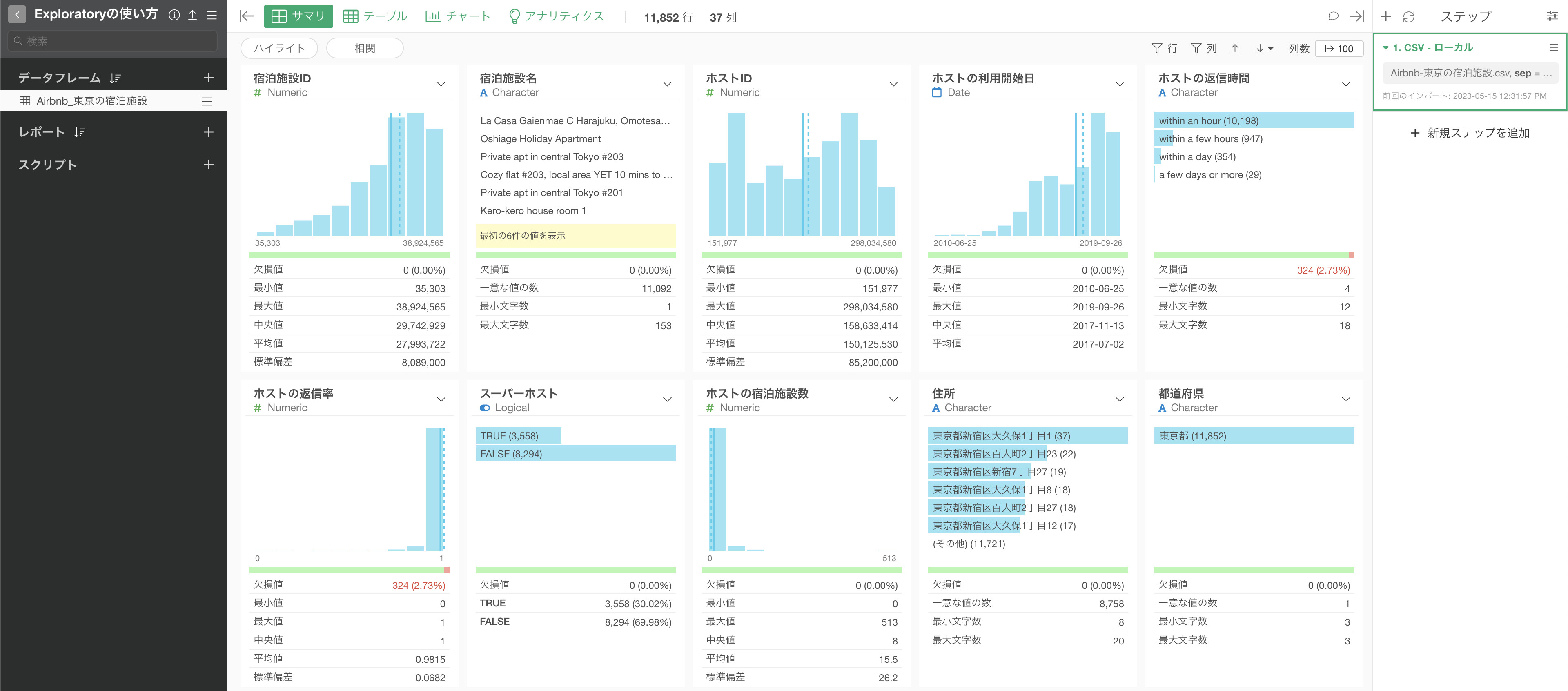
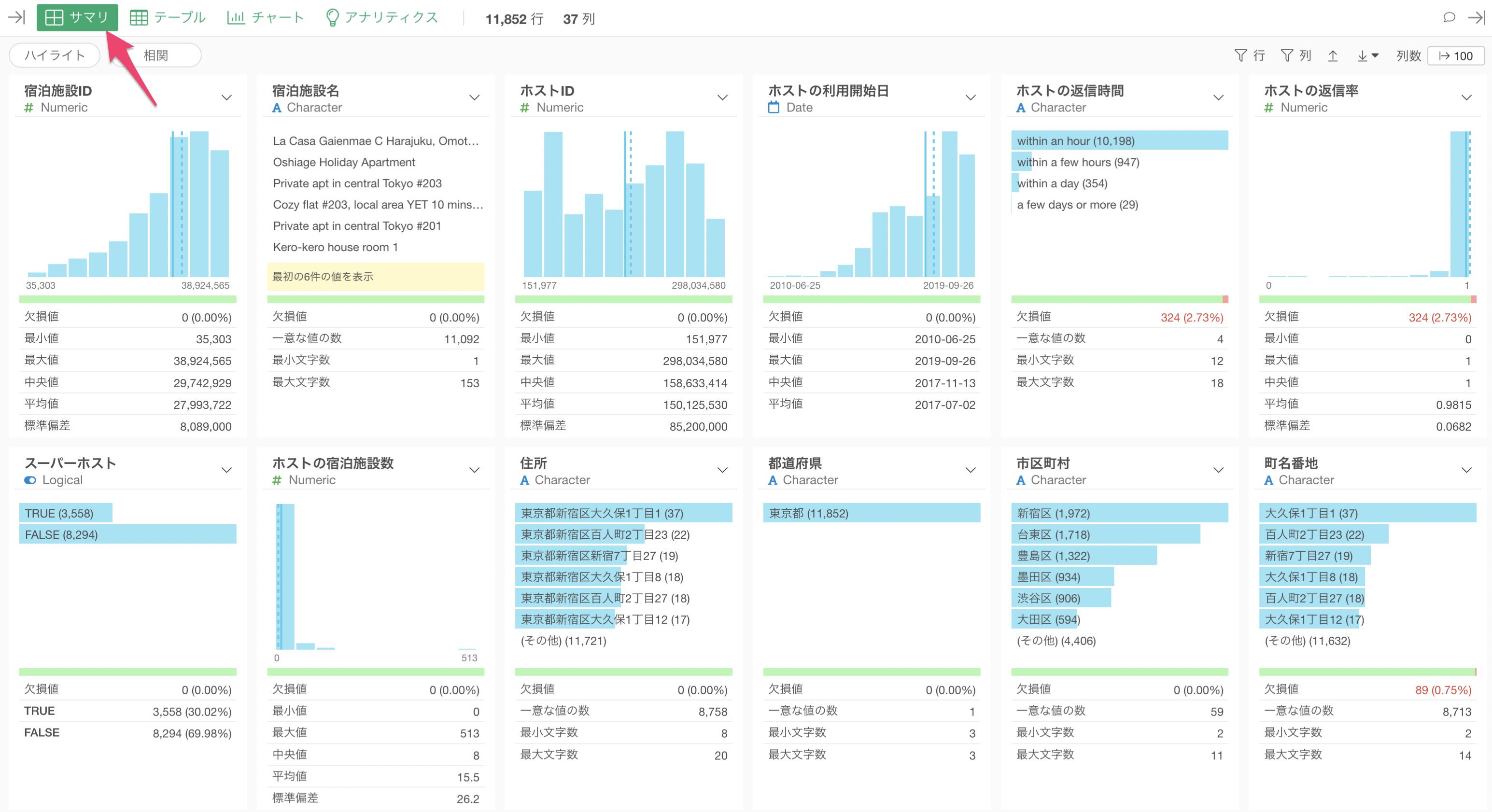
 データがインポートされると、サマリ・ビューというデータの概要を簡単に眺めることができる画面が表示されます。
データがインポートされると、サマリ・ビューというデータの概要を簡単に眺めることができる画面が表示されます。
画面の表示領域を広くしたい場合は、「サイドバーを隠す」のボタンをクリックして左側のデータフレームなどがリストされるサイドバーを隠す、またはドラッグ・アンド・ドロップでサイドバーの幅を狭めることができます。
サイドバーを隠す:
サイドバーの幅を調整する:
列数と行数
データの「列数」や「行数」は常に画面の上部に表示されるようになっています。
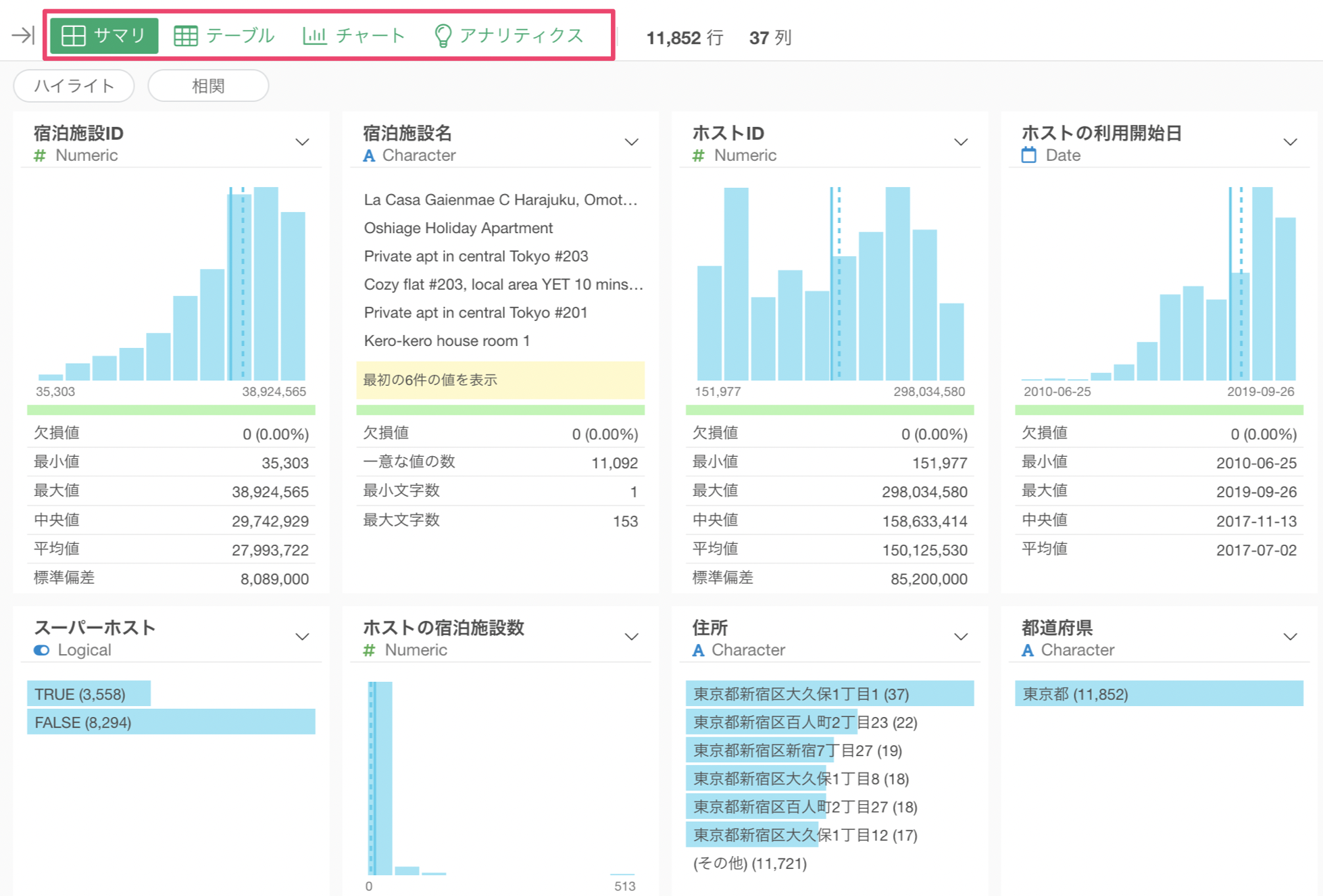
3. 4つのビュー
Exploratoryではデータをインポートすると上部に以下の4つの「ビュー(View)」メニューが表示されます。
- サマリ・ビュー
- テーブル・ビュー
- チャート・ビュー
- アナリティクス・ビュー
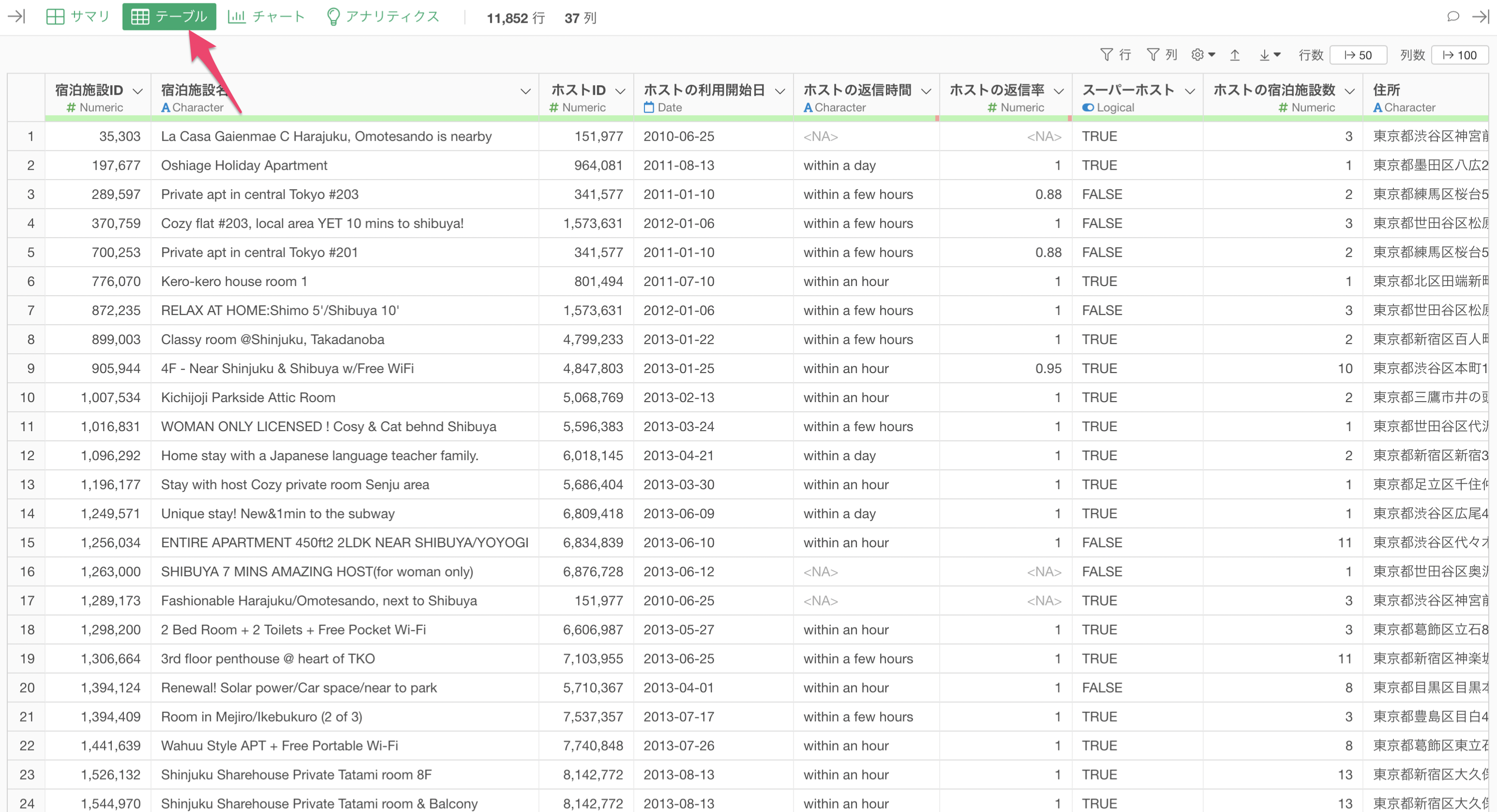
テーブルビュー
データが表形式で表示され、行単位でデータを確認できます。
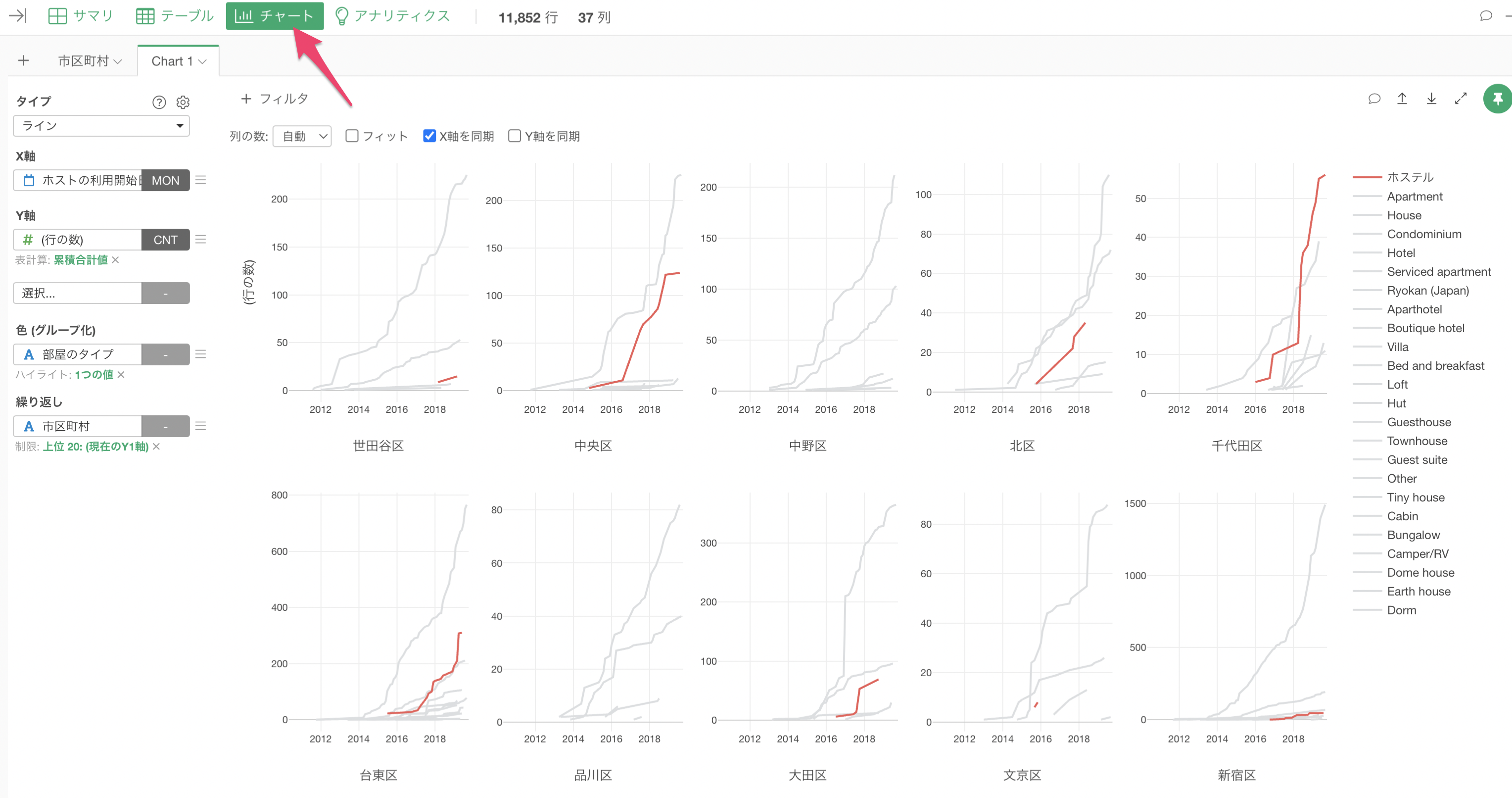
チャートビュー
チャートを使って様々な角度からデータを可視化し、データの中にあるパターンやトレンドを発見していくことができます。
アナリティクスビュー
様々な統計や機械学習のアルゴリズムを使ってデータを分析することができます。
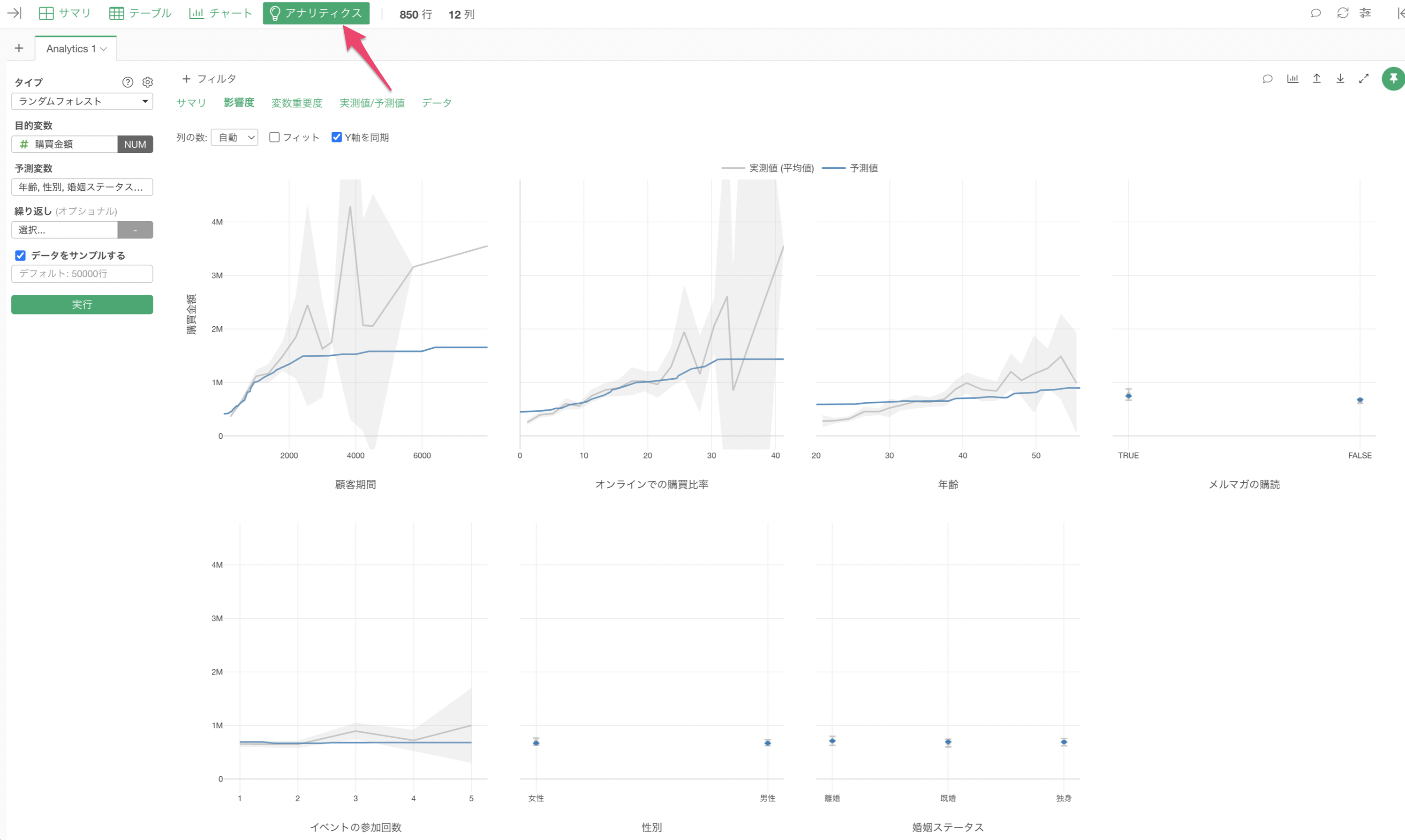 また、Exploratoryでは「ガイド付きのアナリティクス」の機能によって、分析結果を初心者でも理解できるように、各チャートの見方や分析手法に関する詳細な説明を自動的に表示されるようになっています。
また、Exploratoryでは「ガイド付きのアナリティクス」の機能によって、分析結果を初心者でも理解できるように、各チャートの見方や分析手法に関する詳細な説明を自動的に表示されるようになっています。
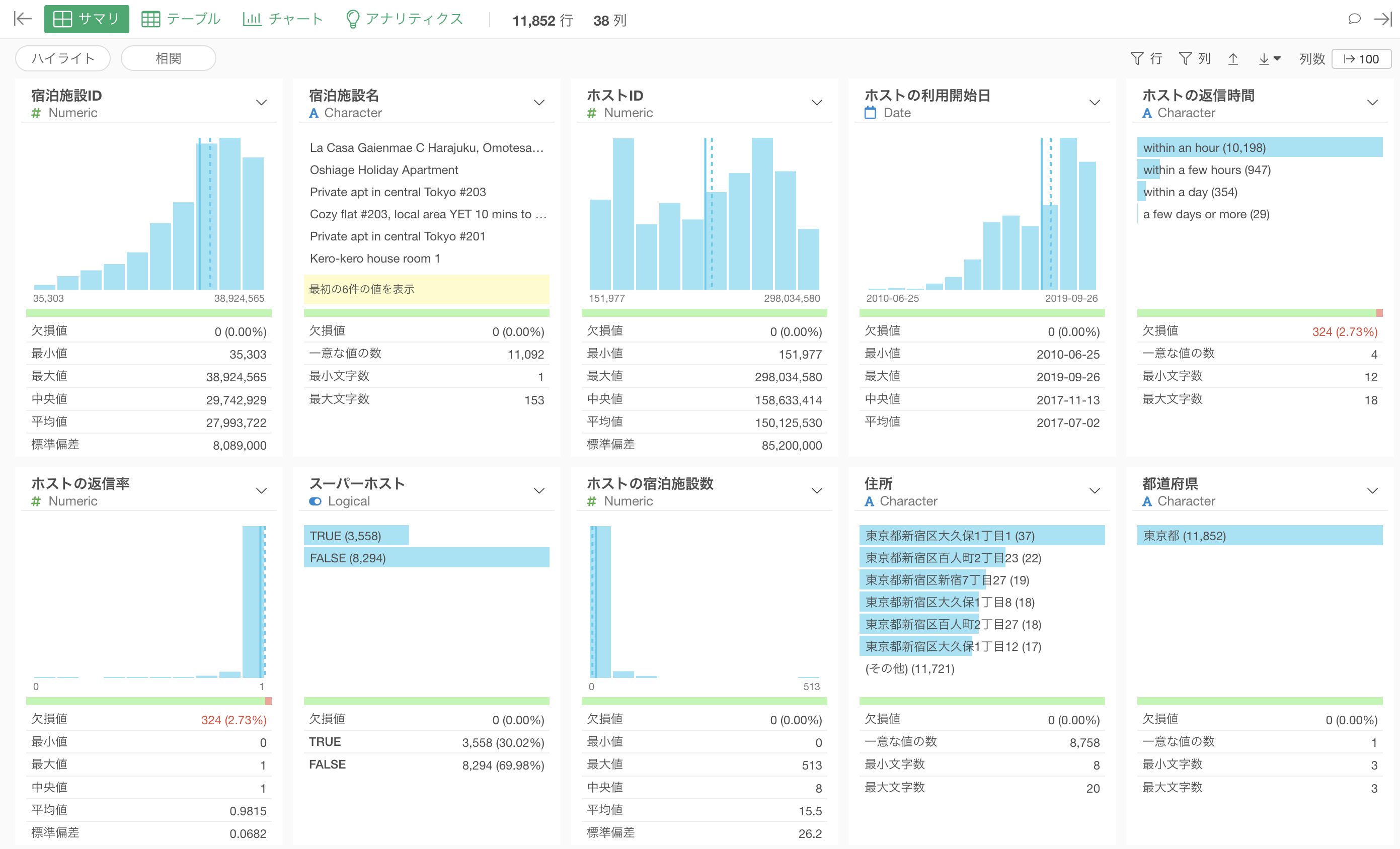
4. サマリ・ビューの使い方
サマリビューで表示される統計情報とチャートはそれぞれの列の「データ型」によって変わります。
Exploratoryでは多くのデータ型がサポートされていますが、よく使われるのは以下の5つのタイプです。
- 数値(Numeric)
- 文字列(Character)
- ロジカル(Logical)
- 日付、日付/時間(Date, POSIXct)
数値(Numeric)
数値型の列は、値を等幅(数値の範囲を均等に分ける)に10等分したバーチャートが表示されます。また、バーにマウスを重ねるとその数値の範囲に含まれる行数が表示されるようになっています。
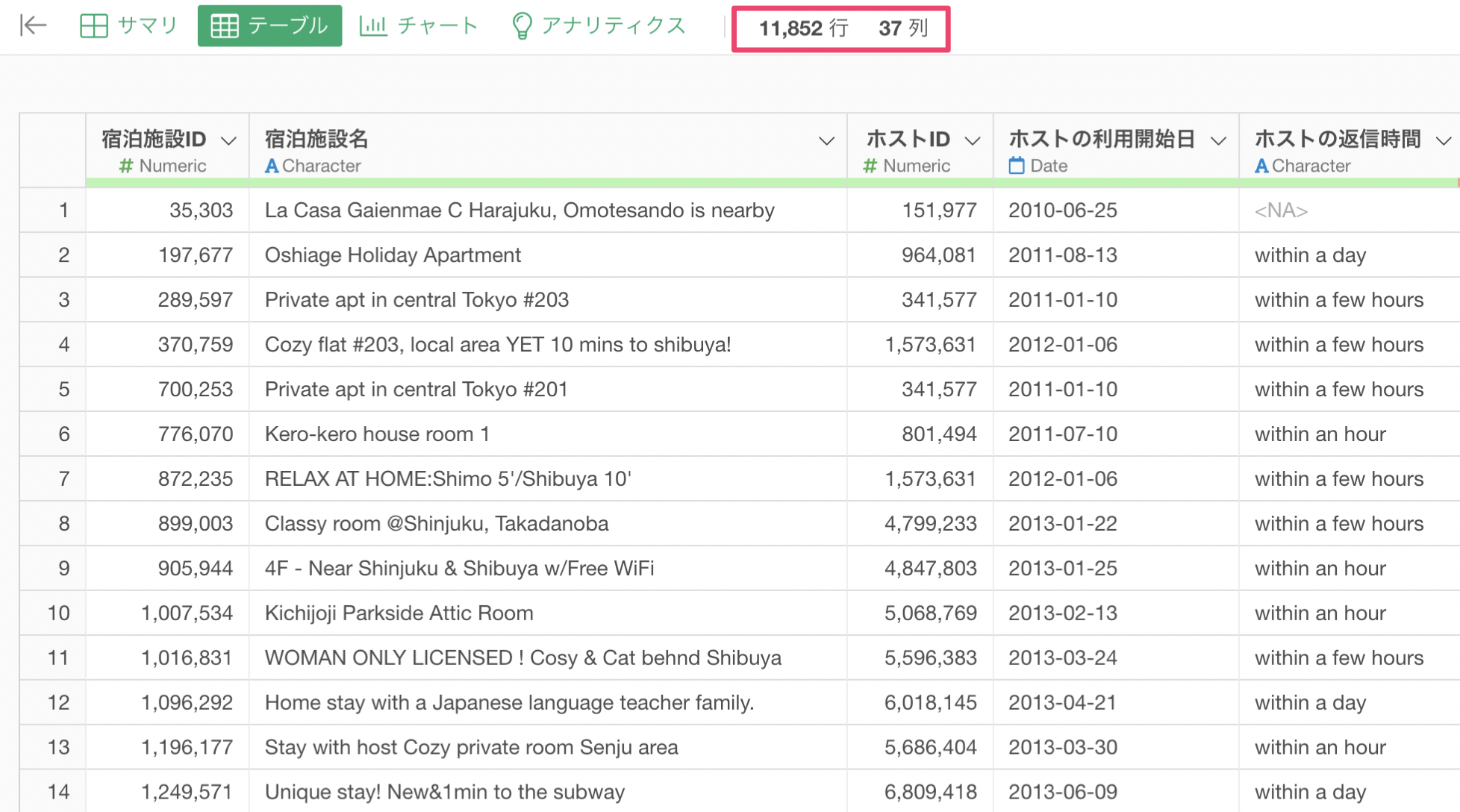
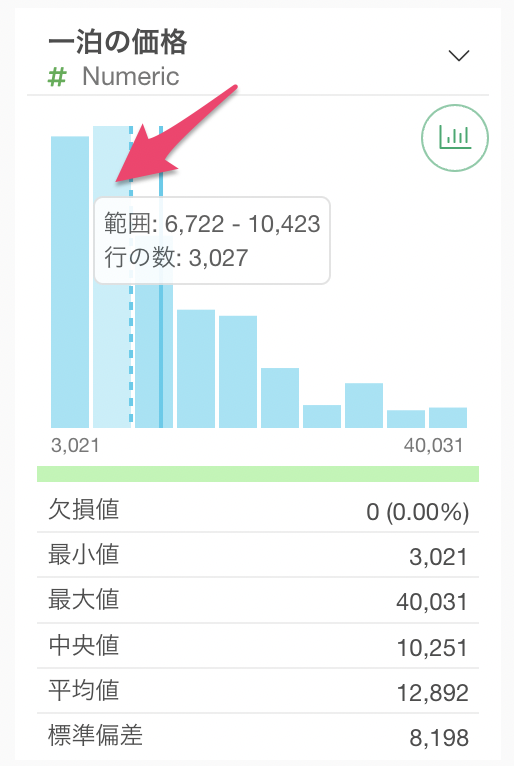
チャートの下には「平均値」や「中央値」といった数値に関する統計情報が表示されます。
文字列(Character)
文字列型の列は、出現頻度(行の数)を表す横向きのバーチャートが表示され、最も頻繁に出てくる値から順に表示しています。
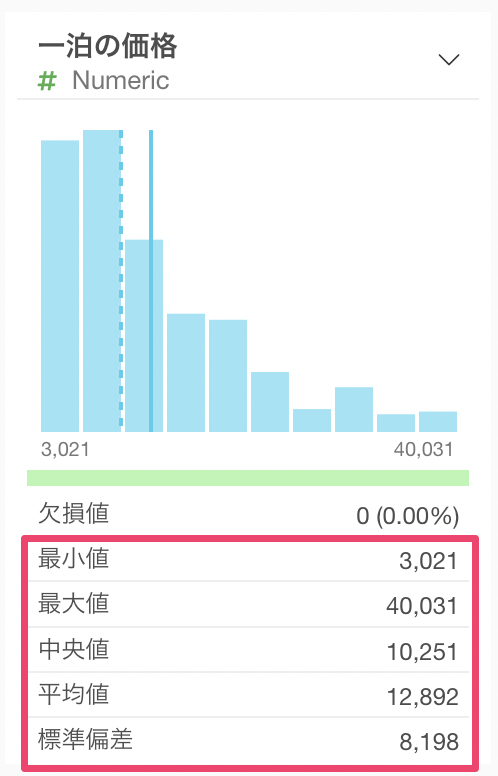
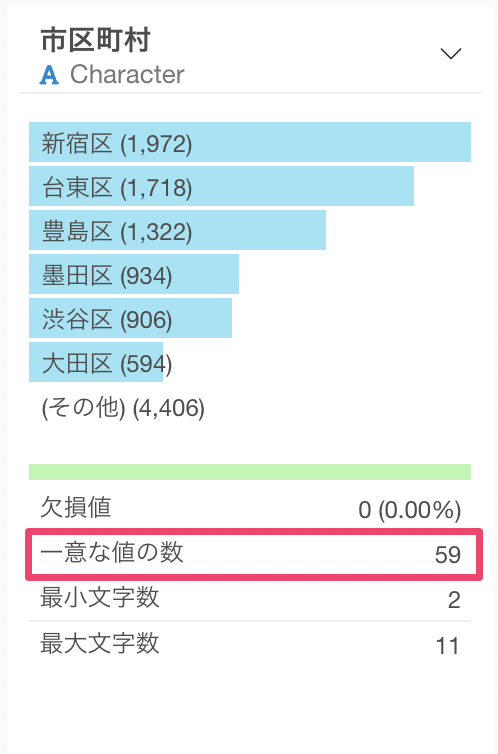
一意な値の数からは、その文字列型の列にどれだけの一意な値が存在するのかを確認できます。下記の例では、一意な値の数が59のため、59もの市区町村があることがわかります。
ロジカル(Logical)
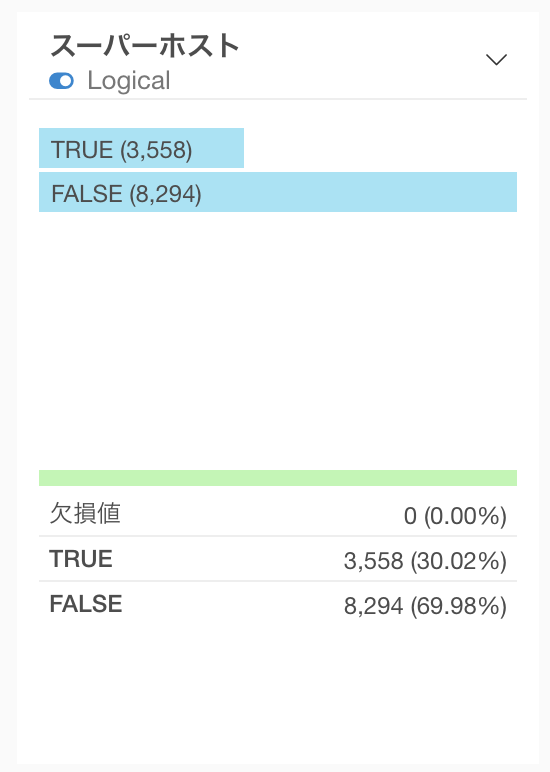
ロジカル型の列は、TRUEとFALSEの行数を表す横向きのバーチャートが表示されます。また、サマリ情報を見ることで、それぞれの比率を確認できます。
データ型をロジカル型にすることで、チャート作成時にTRUEやFALSEの割合を簡単に比較できたり、ロジカル型に適したアナリティクス(例:ロジスティック回帰)を利用したりすることができます。データ型をロジカル型にする方法については、こちらのノートをご覧ください。
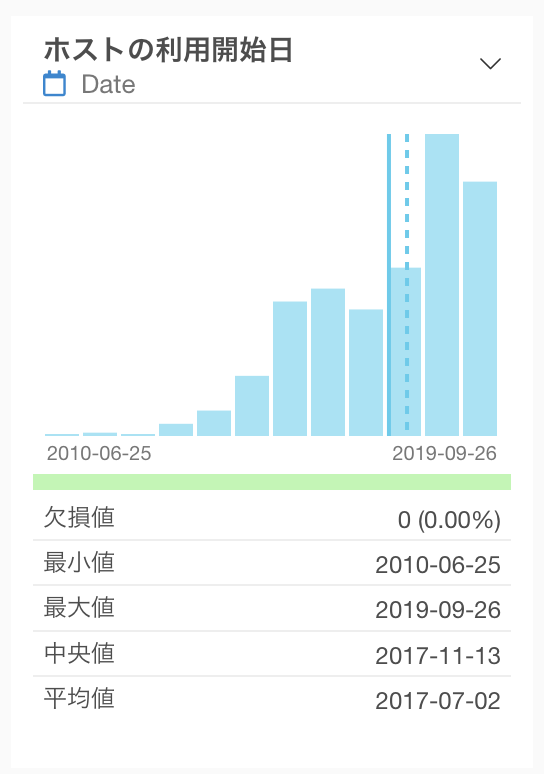
日付、日付/時間(Date, POSIXct)
日付、または日付/時間型の列は、区切られたそれぞれの期間にどれだけの行の数があるかを表すバーチャートが表示されます。また、最小値と最大値を見ることで、データの期間を確認することができます。
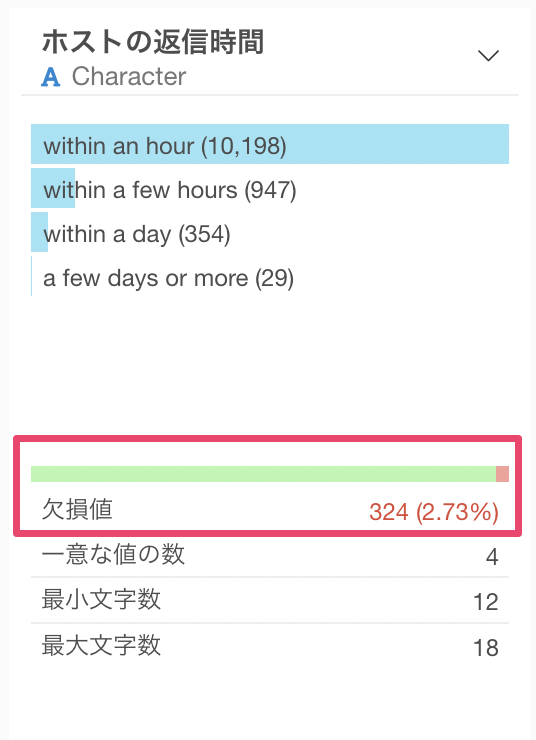
欠損値について
列に欠損値がある場合、欠損値の行数と割合が表示されます。
欠損値は値がないことを表し、テーブルビューで見ると<NA>として表示されます。
サマリビューと同様に、テーブルビューでも列名の下にある緑と赤色のバーにマウスを重ねることで欠損値の数と割合が確認できます。
5. チャートを作る
データ分析を行う際にはチャートを使ってデータを可視化することで、データの中にあるパターンを自分の目で確認することが欠かせません。また、分析した結果を他の人に伝える際にも、チャートを使って自分が伝えたいデータの中にあるパターンや傾向を効果的に伝えることが重要となります。
Exploratoryでは「チャート」ビューの下でチャートを作ることができます。
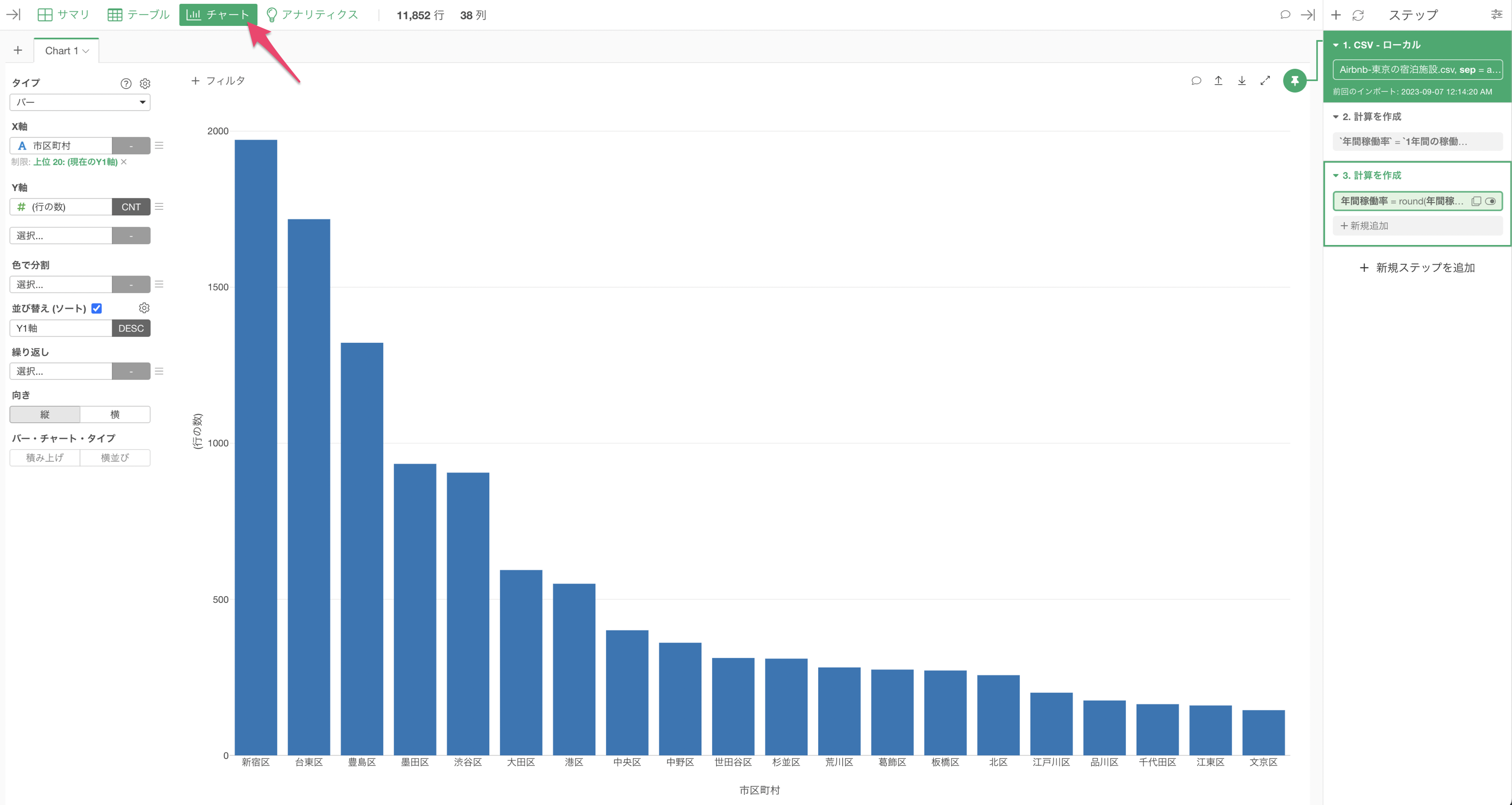
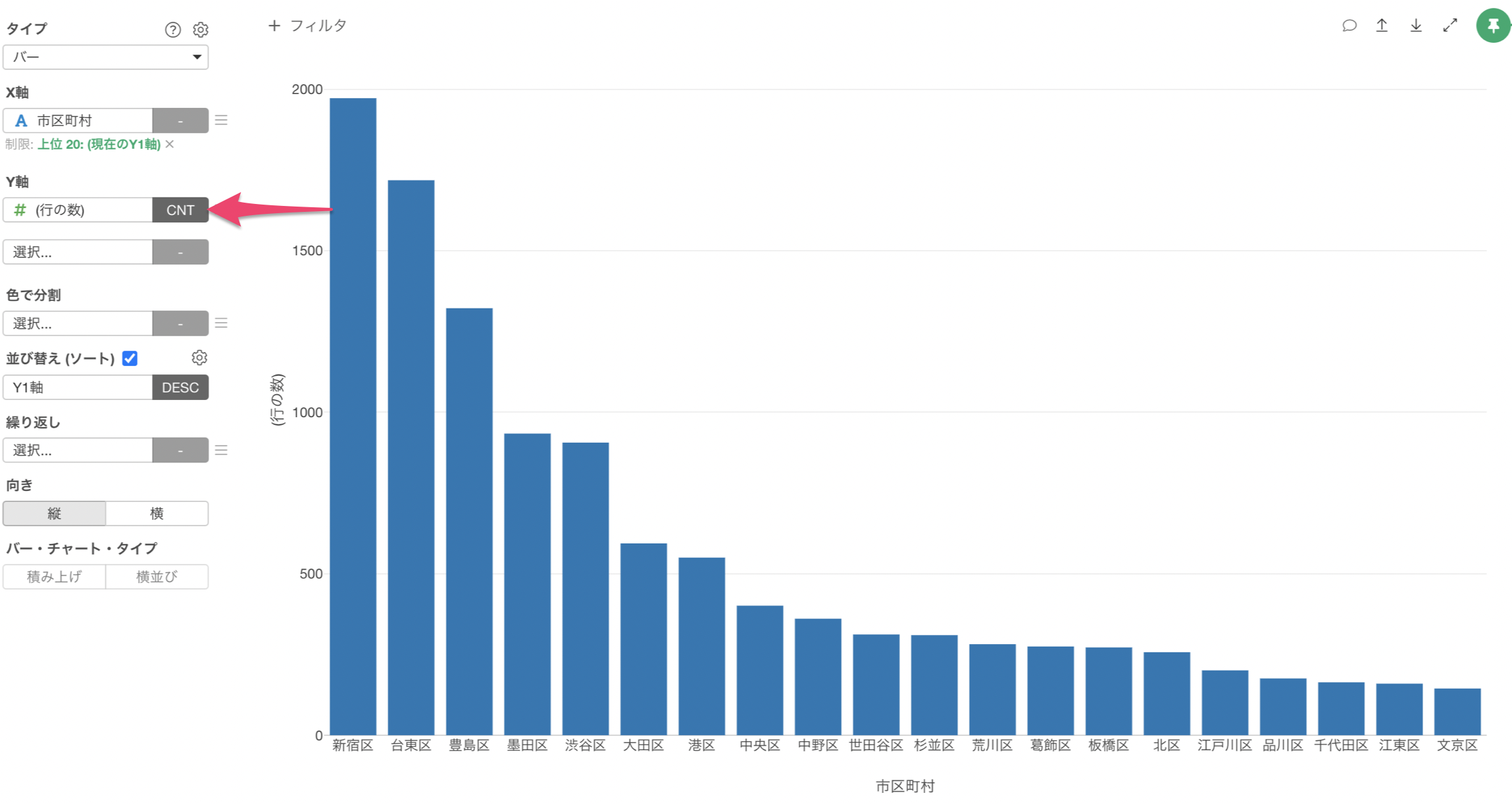
まずは、市区町村ごとの宿泊施設数(行の数)を表すチャートを作ってみましょう。
チャートビューを開き、タイプに「バー」を選択します。
X軸に「市区町村」、Y軸に「行の数」を選択します。
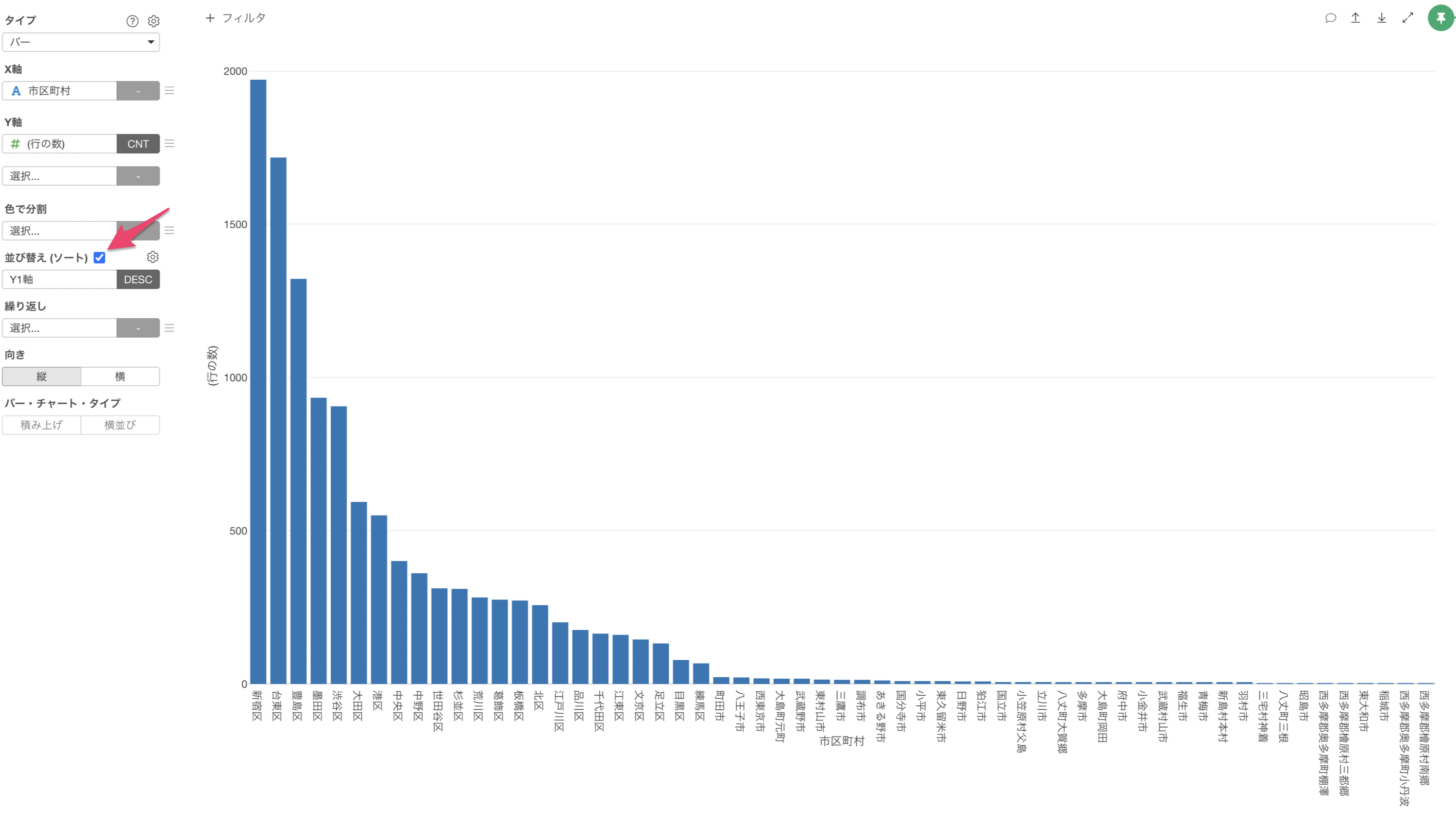
このままでは、X軸の並び順がひらがな順(漢字の場合はコード順)に並んでいて比較がしづらいため、「並び替え(ソート)」にチェックをつけます。
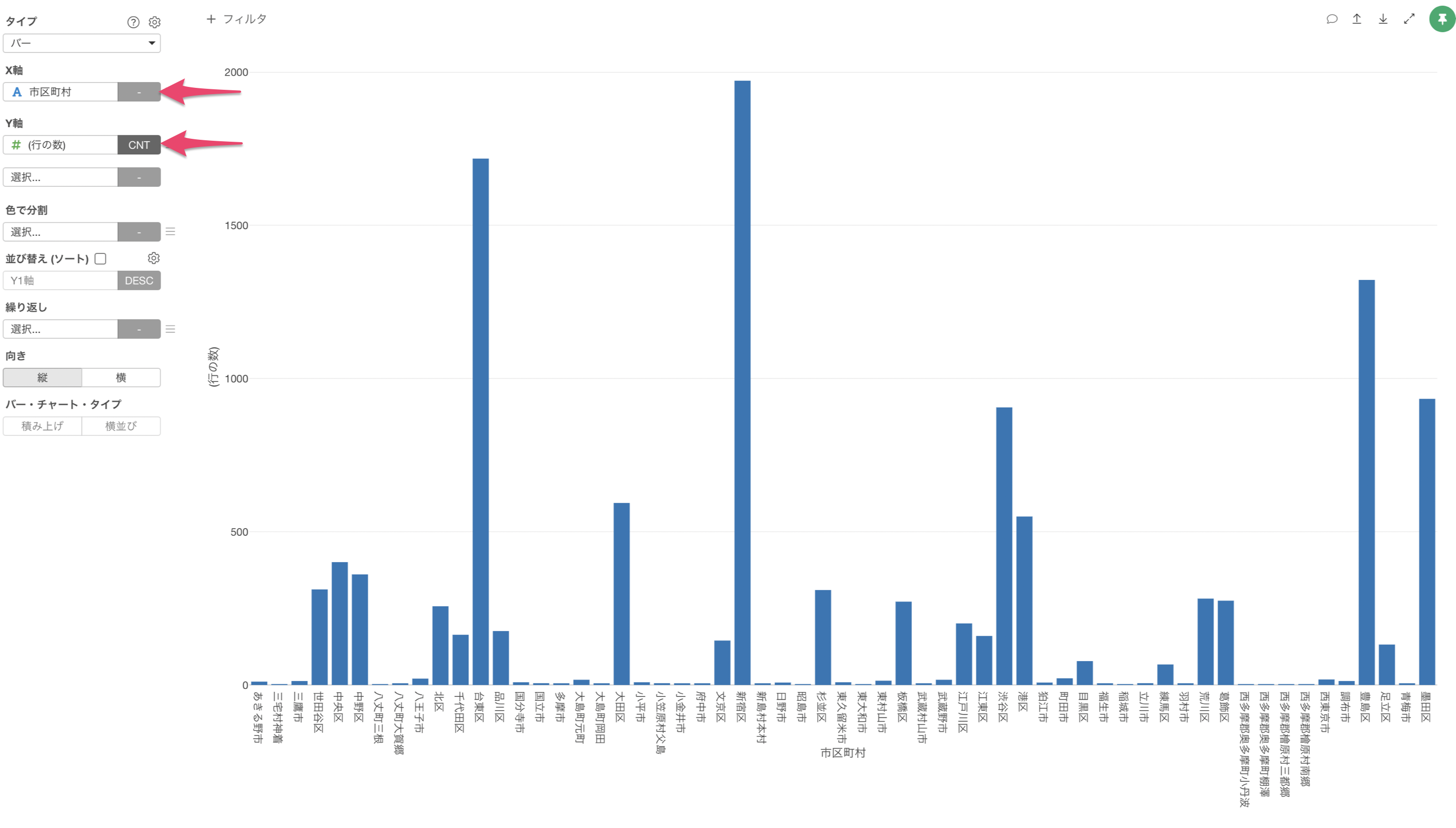 これにより、市区町村ごとの行の数(宿泊施設数)をバーチャートで可視化することができました。
これにより、市区町村ごとの行の数(宿泊施設数)をバーチャートで可視化することができました。
表示する値の制限
ところで、このデータには市区町村が59もあるためその数分のバーが表示されます。しかしほとんどの市区町村にはほとんど宿泊施設数がありません。
そこで、宿泊施設数が多い方から20の市区町村だけを表示してみましょう。
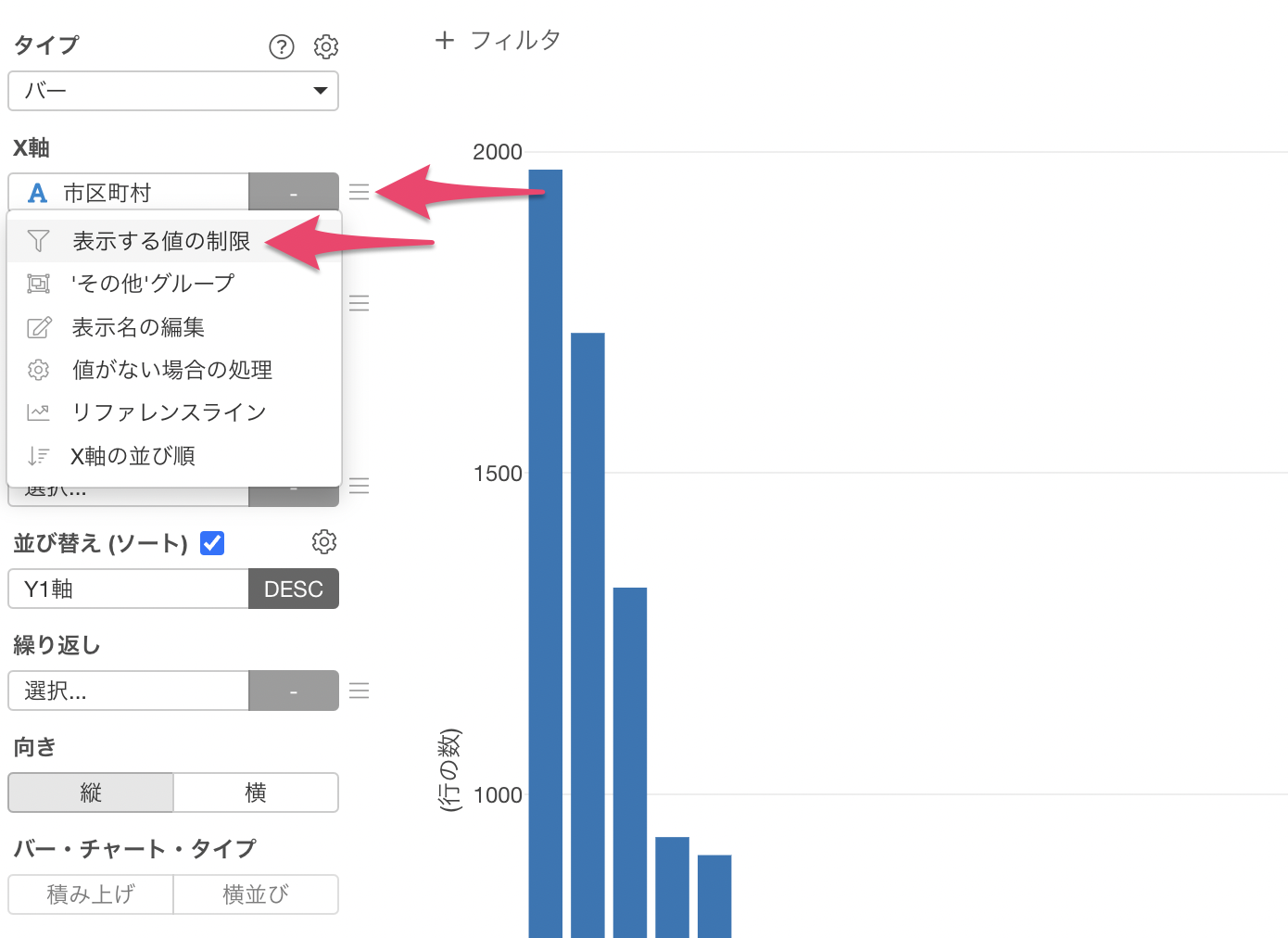
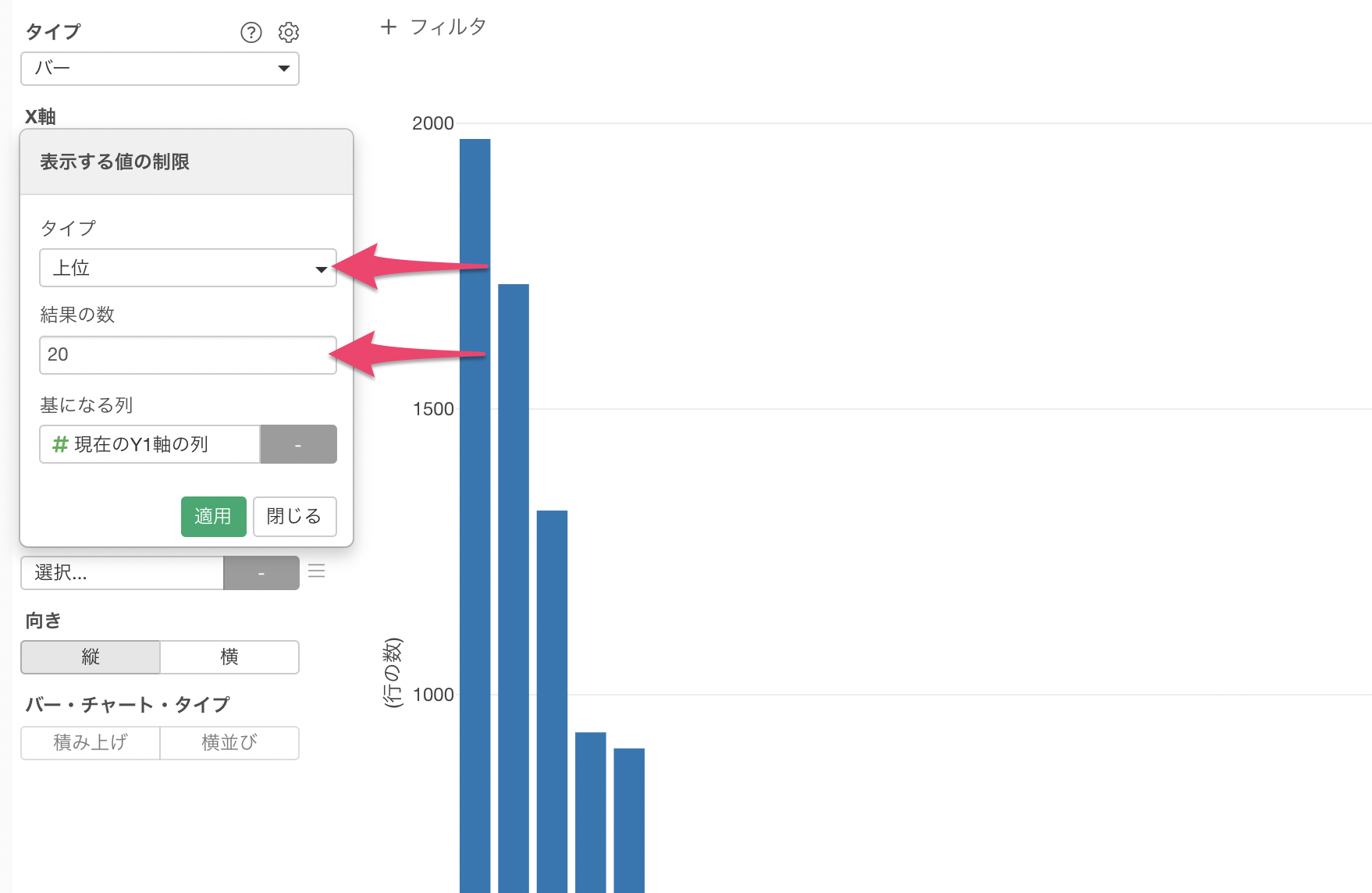
X軸のメニューから「表示する値の制限」を選択します。
タイプに「上位」を選び、結果の数に「20」を指定して適用します。
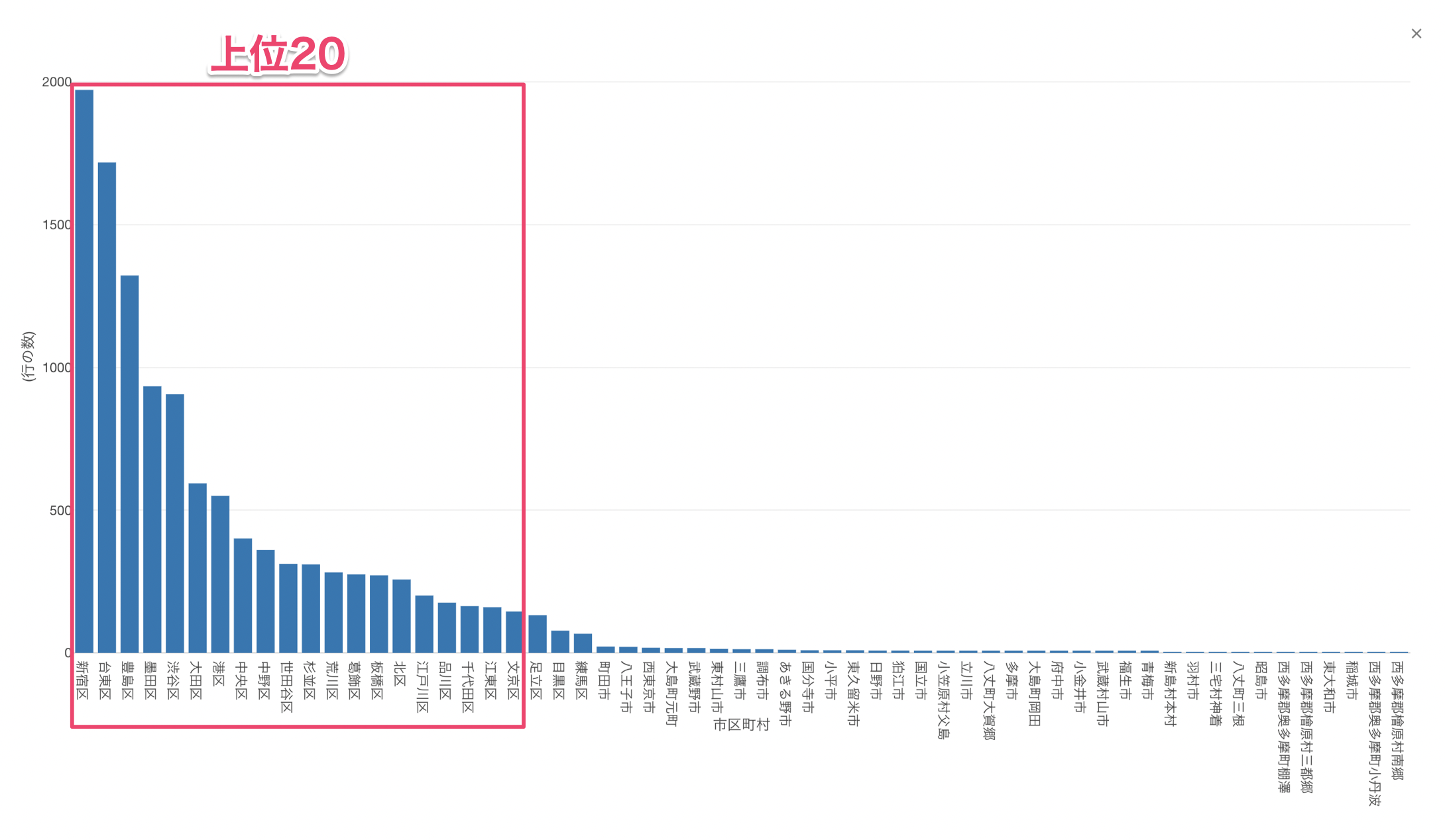
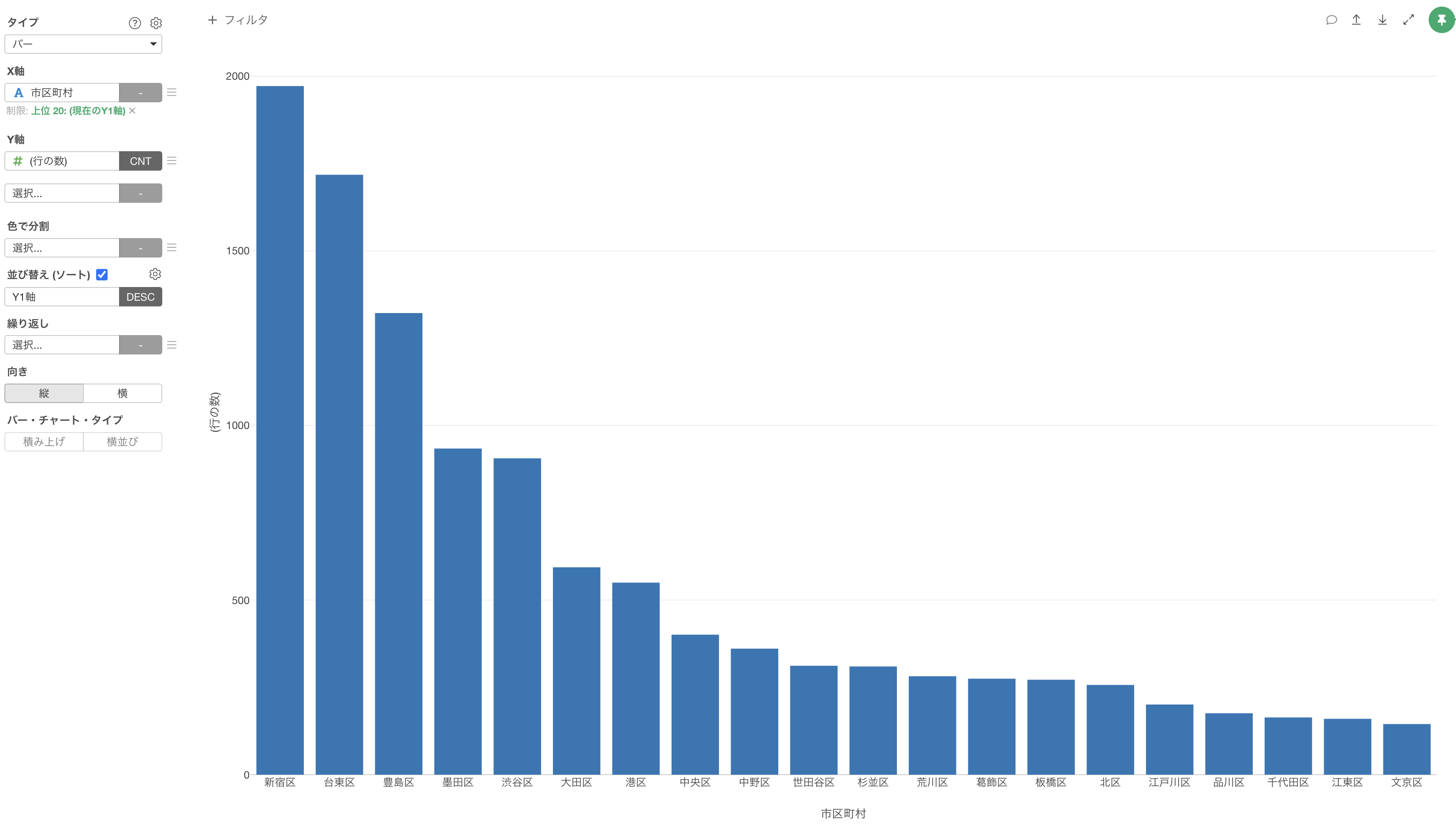
これにより、行の数、つまり宿泊施設数が多い上位20の市区町村のみを表示することができました。
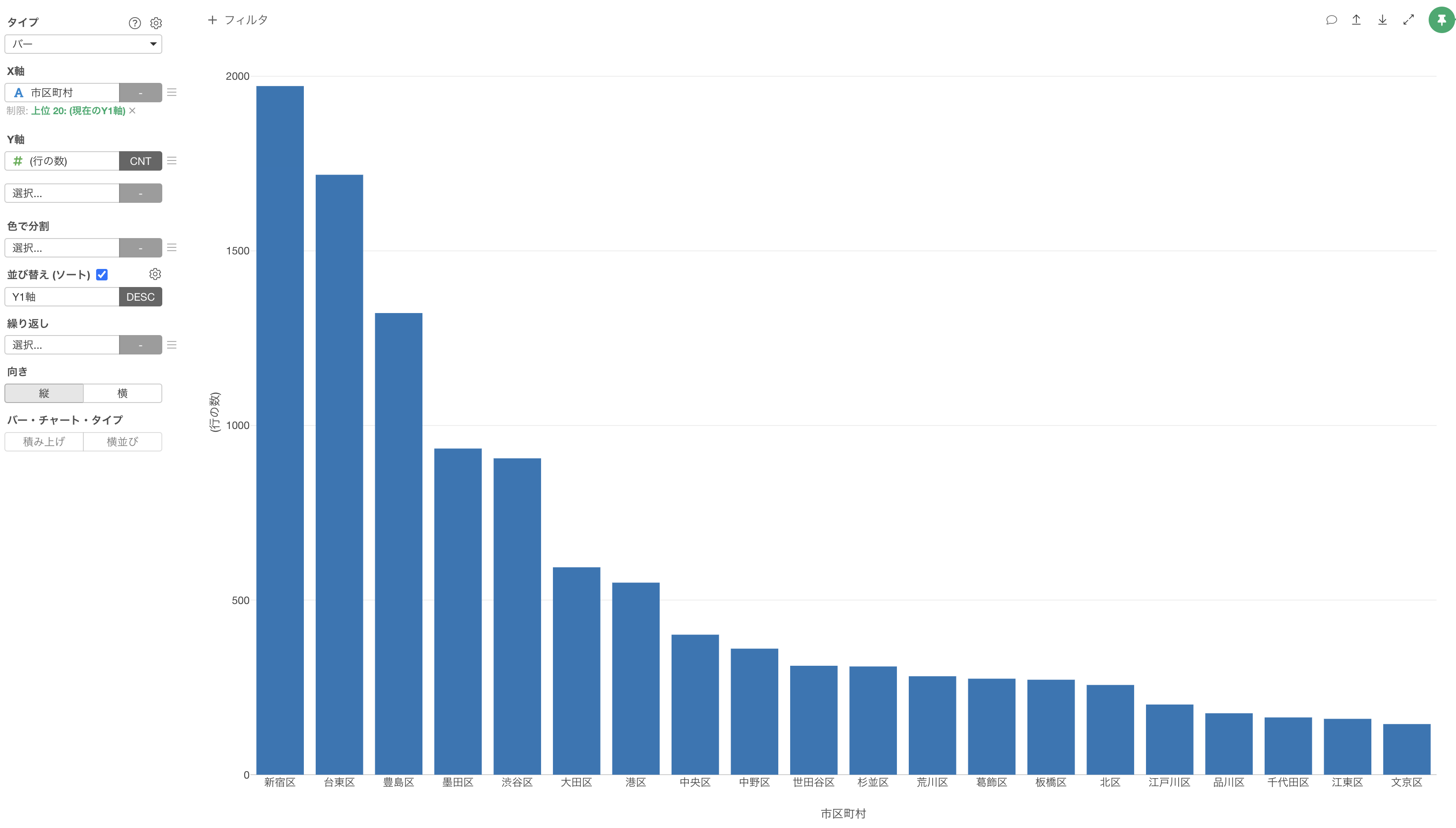
宿泊施設の数は「新宿区」が最も多く、その次に「台東区」や「豊島区」が多いことがわかります。
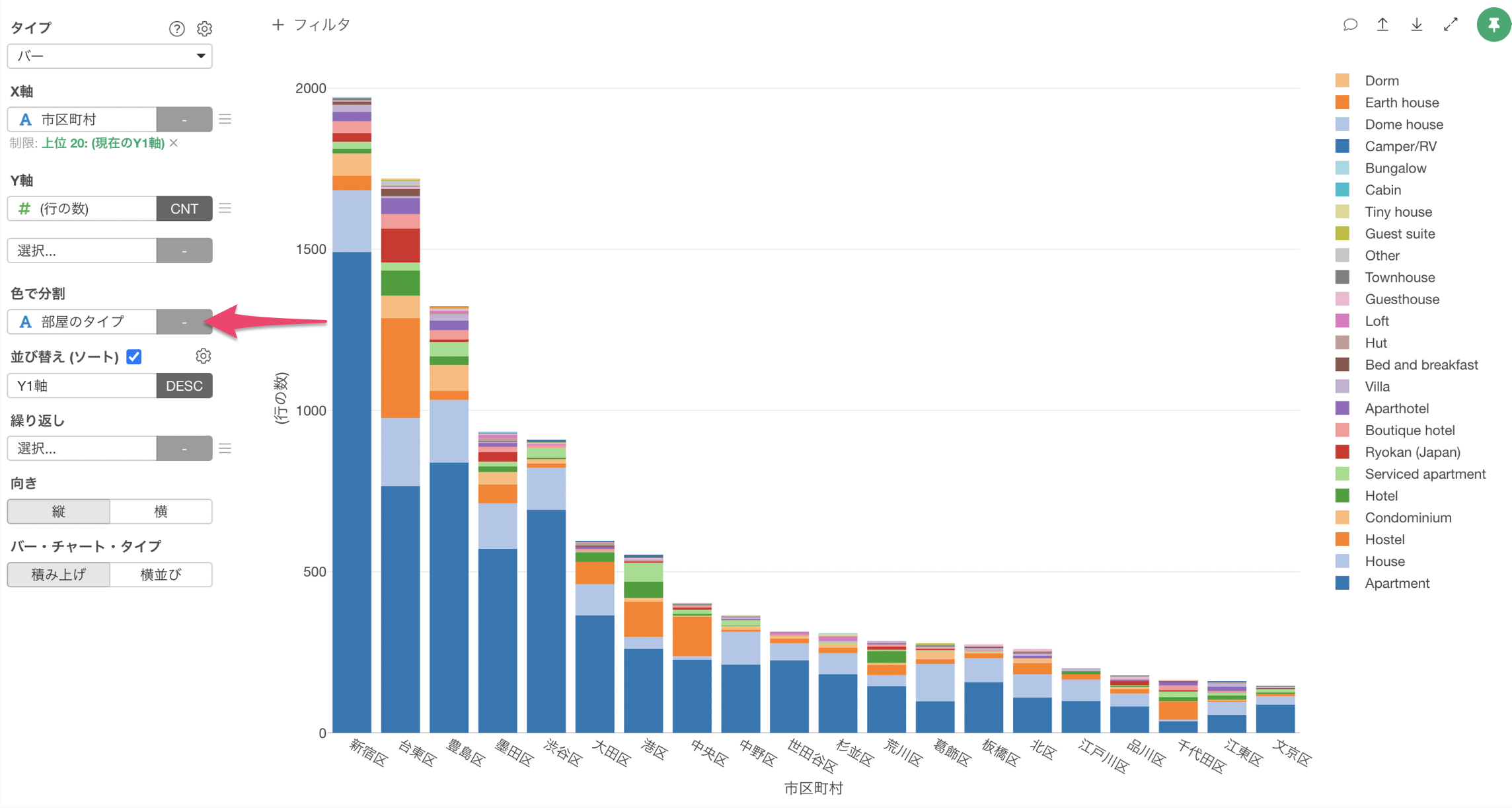
色によるグループ分け
それぞれの市区町村のバーを「部屋のタイプ(例:アパートメント)」によって分けてみましょう。
色(グループ化)に「部屋のタイプ」を選択します。
これにより、市区町村ごとの行の数のバーを「部屋のタイプ」別に色を分けて可視化することができました。
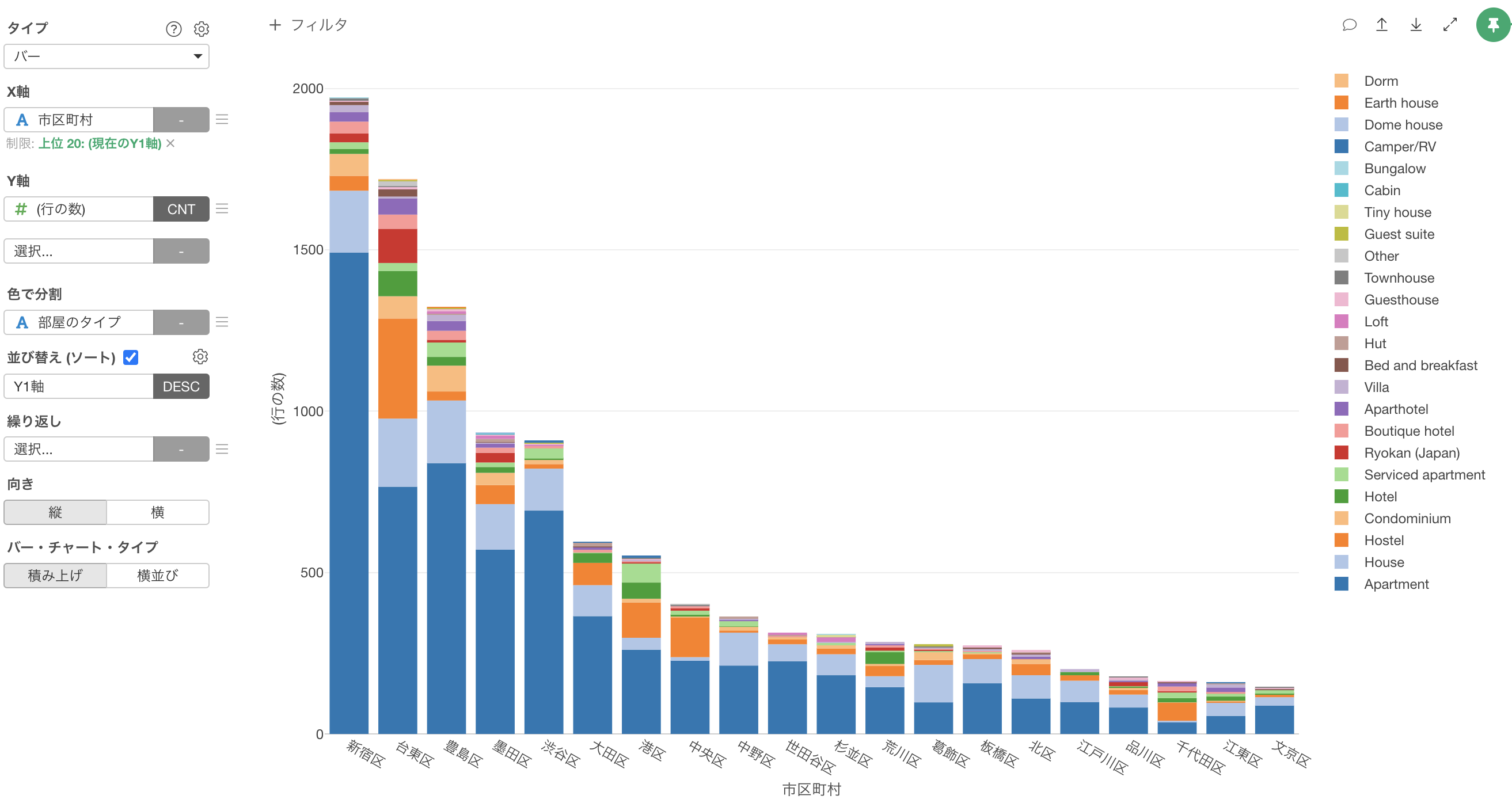
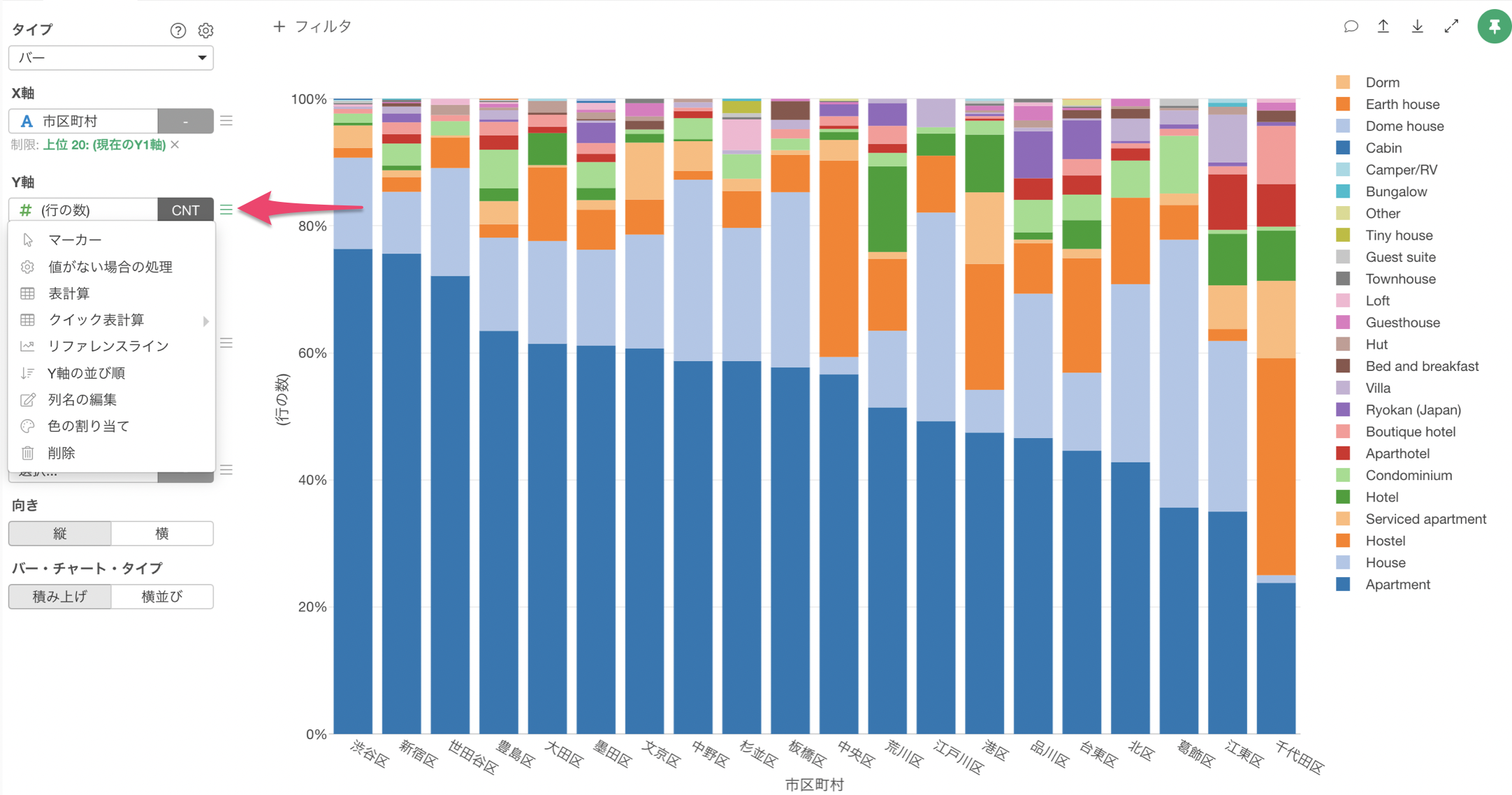
次に、全てのバーを100%にした上で、それぞれの市区町村におけるそれぞれの「部屋のタイプ」の割合を可視化してみましょう。
Y軸のメニューを選択します。
次に、「表計算」の「合計値に対する割合」を選択します。
これにより、全ての市区町村のバーを100%にして、その中での部屋のタイプの割合を可視化することができました。
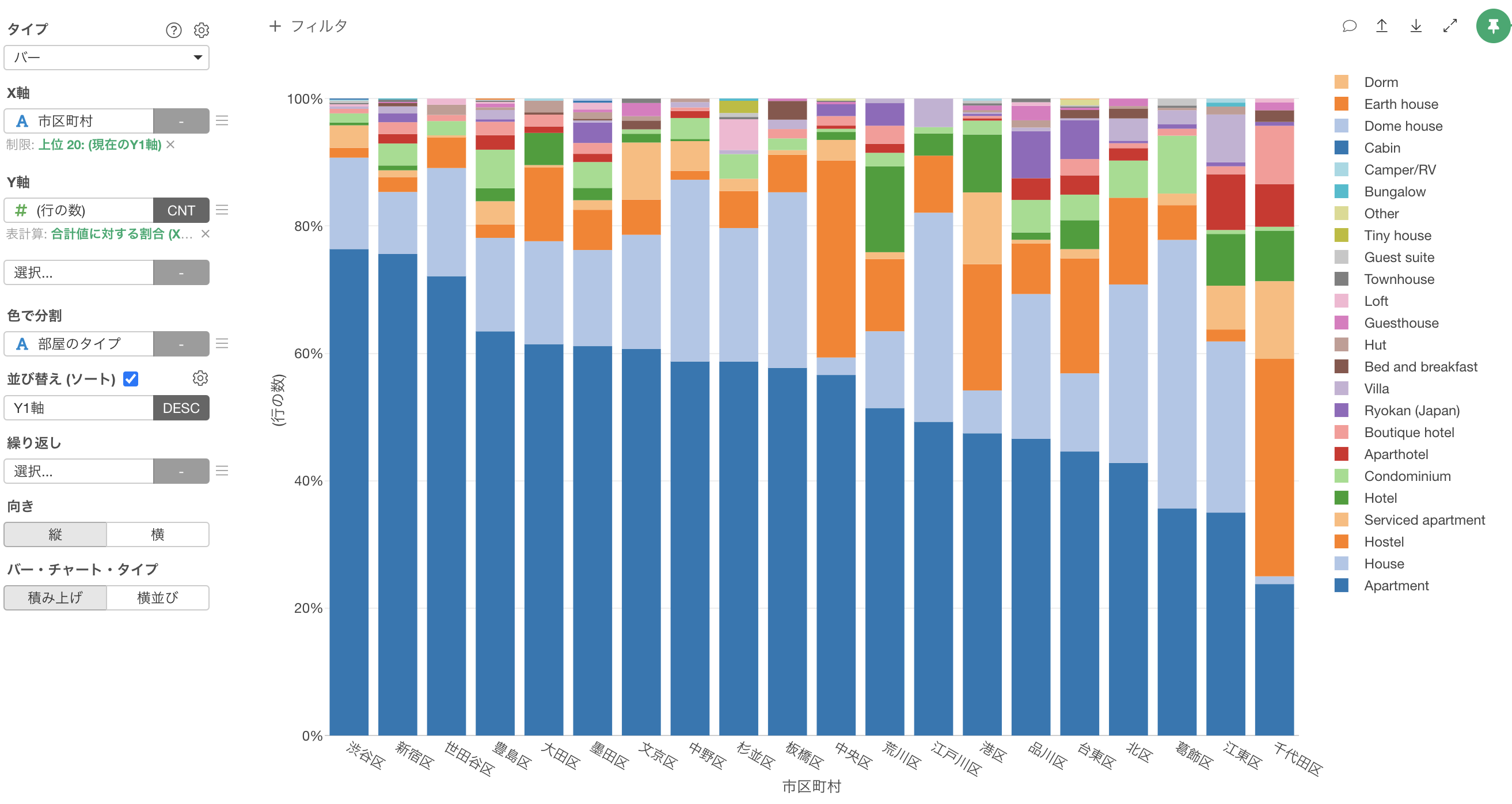
ほとんどの場合はアパートメント(Apartment)が圧倒的に多いことがわかりますが、中央区と千代田区ではホステル(Hostel)も多いことがわかります。
6. コメント機能
Exploratoryではそれぞれのチャートやデータに対してコメントを入力することができます。データを可視化したり、分析したりする際に気づいたことをコメントとして残すことで、後でレポートとしてまとめる際にこれまでに分かったことを簡単に思い出すことができるため便利な機能です。
作成したチャートについてコメントを残したい場合は、右上のコメント・アイコンをクリックして、コメント・ダイアログを開き、文章を入力することができます。
コメントを入力し「OK」ボタンをクリックすると、チャート右上のコメントアイコンが緑色で塗りつぶされた状態になります。アイコンの上にマウスを持っていくと、コメントが表示されます。
7. 計算をする
Exploratoryでは簡単に計算を行うことができ、その計算結果で元の列を上書きしたり、または新しい列として保存したりすることができます。
ここでは、「1年間の稼働日数」という列を元に「年間稼働率」を計算してみましょう。
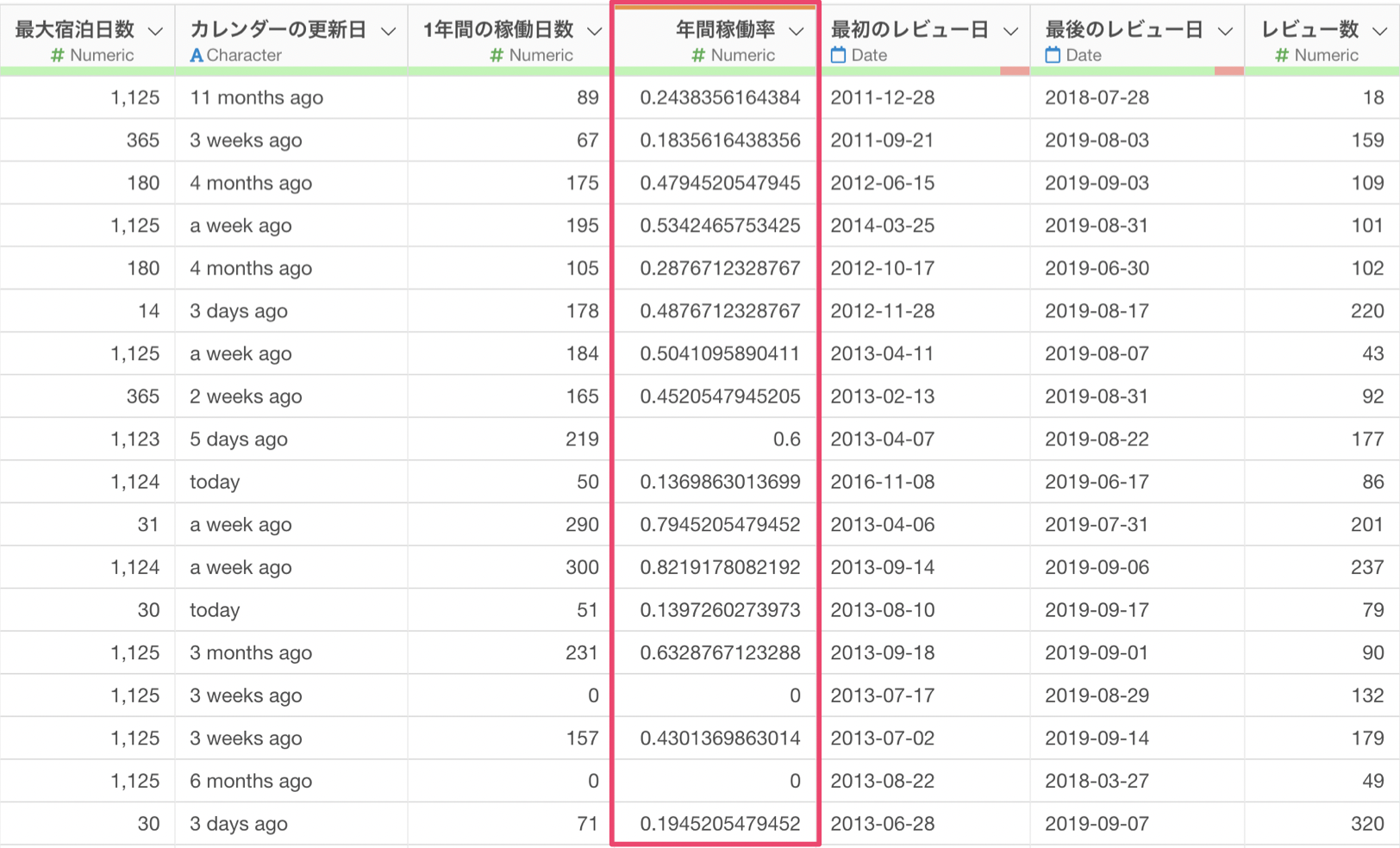
年間稼働率は1年間、つまり365日の間にどれだけの日数が稼働(使用)されていたかです。そこで、年間稼働率を求める計算式は以下のようになります。
`1年間の稼働日数` / 365ソフトウェアの世界では➗を「/(スラッシュ)」という記号を使って表します。ちなみに掛け算の場合は「*(アスタリスク)」という記号を使います。
| 四則演算 | 書き方 |
|---|---|
| 足す | + |
| 引く | - |
| 掛ける | * |
| 割る | / |
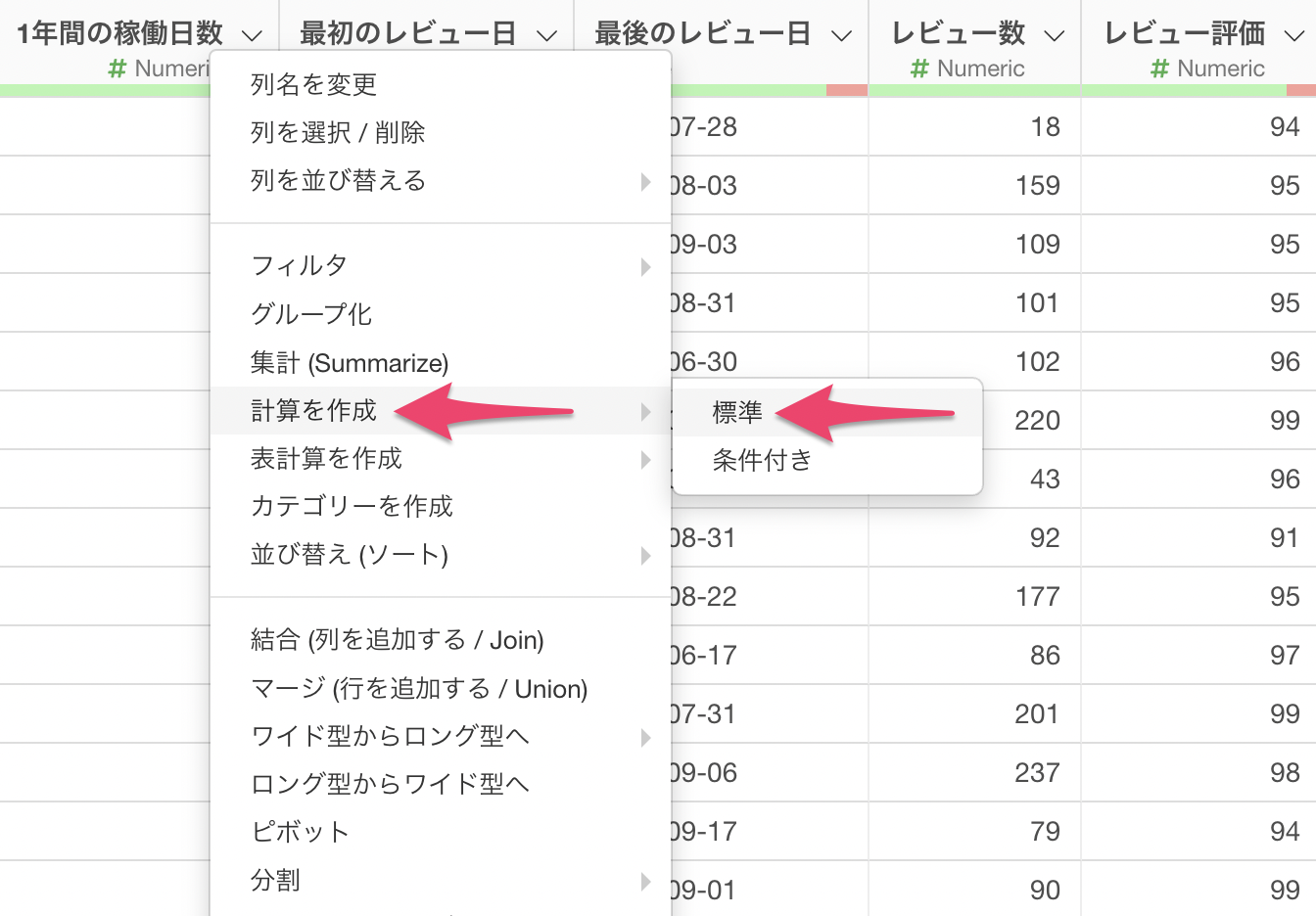
Exploratoryで計算を行う場合はそれぞれの列にある下向きの矢印アイコンをクリックすると出てくる「列ヘッダーメニュー」の中にある「計算を作成」を使います。
今回は「1年間の稼働日数」の列の値を元に計算を作成したいので、「1年間の稼働日数」列の列ヘッダー・メニューから「計算を作成」を選択し、さらに「標準」を選択します。
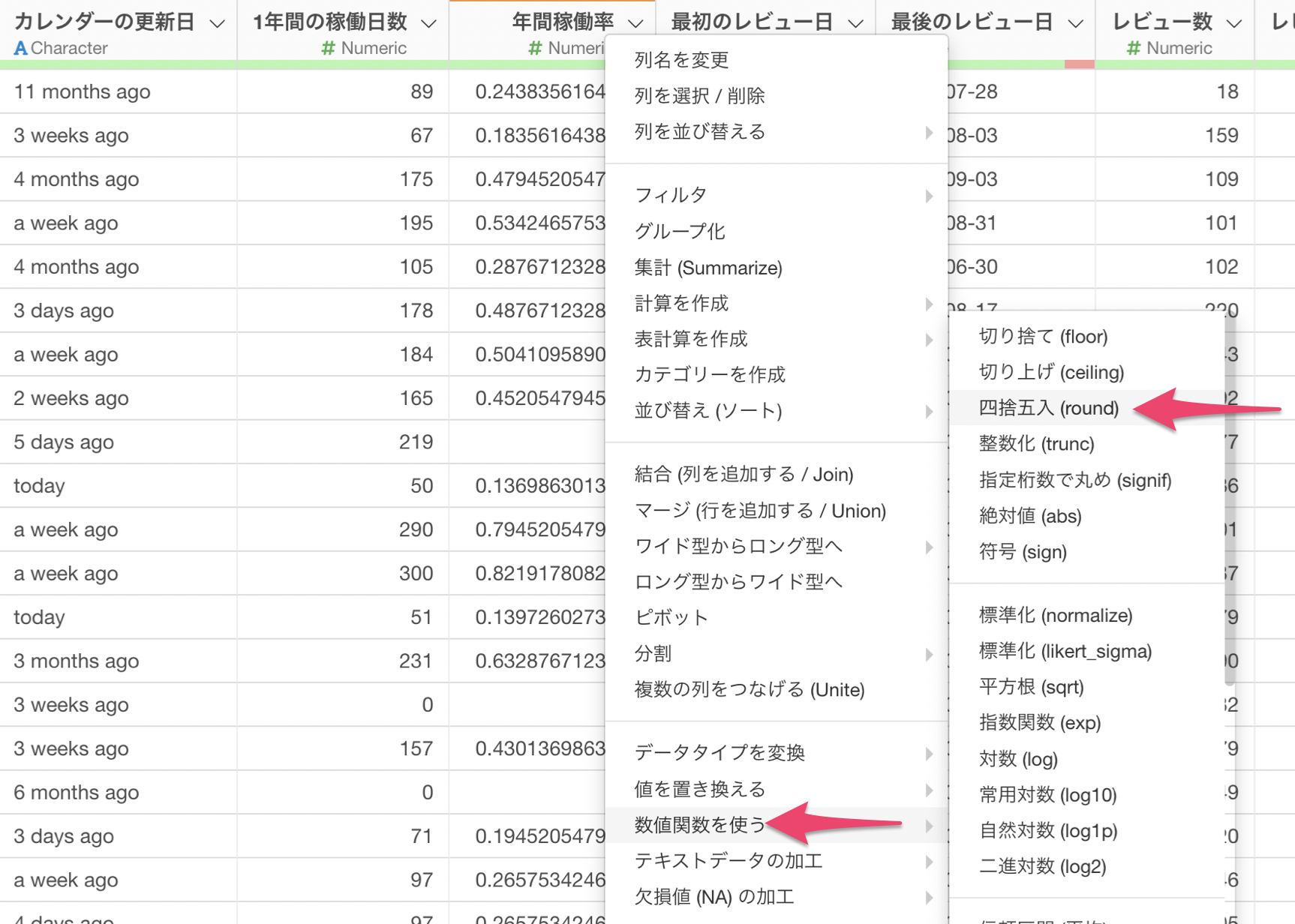
計算を作成には2つのサブメニューがありますがほとんどの場合は「標準」を使います。たまに、ある条件に合った場合にのみ特定の計算を実行したい場面がありますが、そうしたときに使えるのが「条件付き」です。条件付きの計算の詳しい使い方についてはこちらをご覧ください。
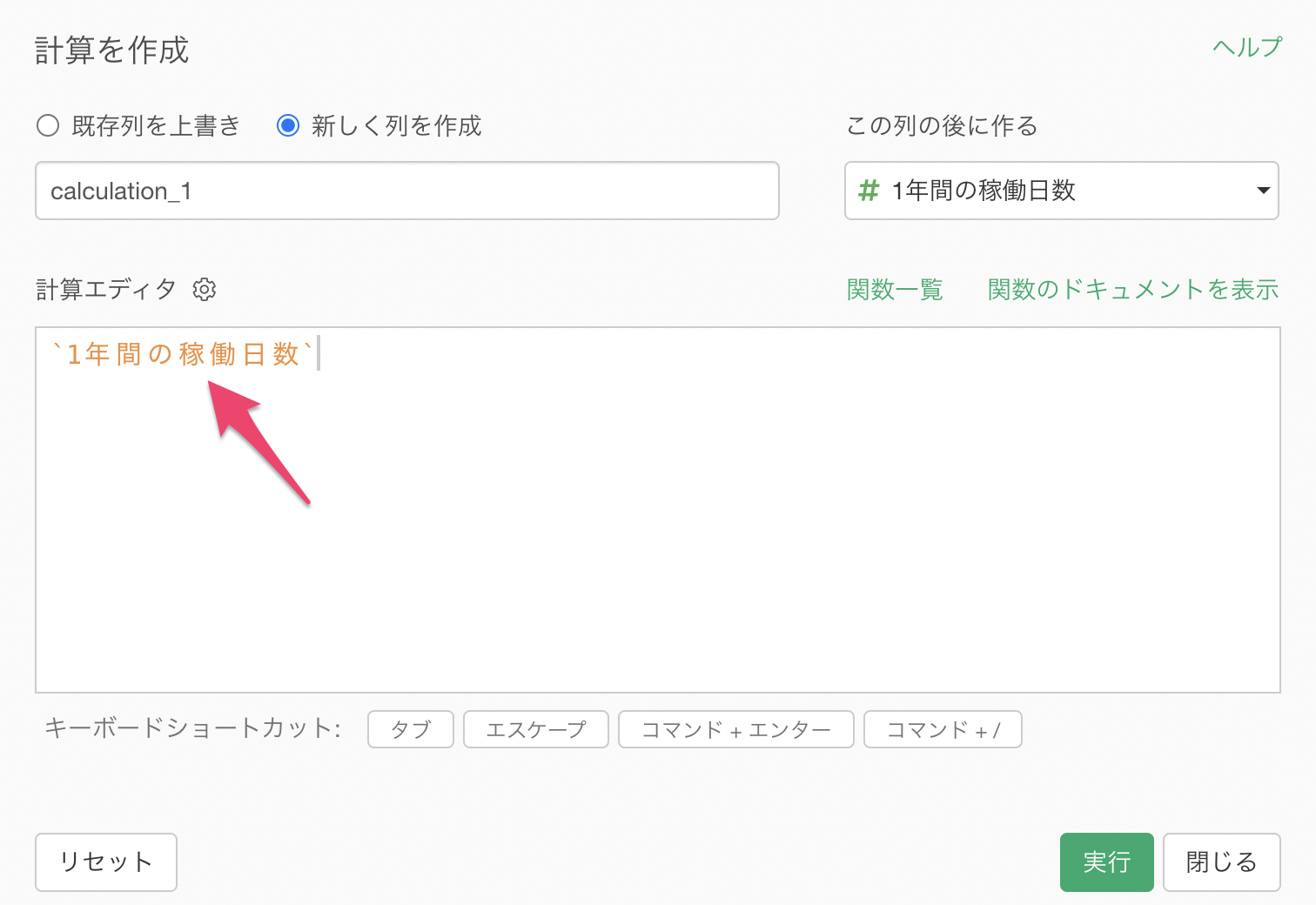
「計算を作成」のダイアログが開くと、すでに「1年間の稼働日数」という列名が計算エディタ内にすでに入力されているのが確認できます。これはこの列の列ヘッダーメニューから「計算の作成」ダイアログを開いたからです。
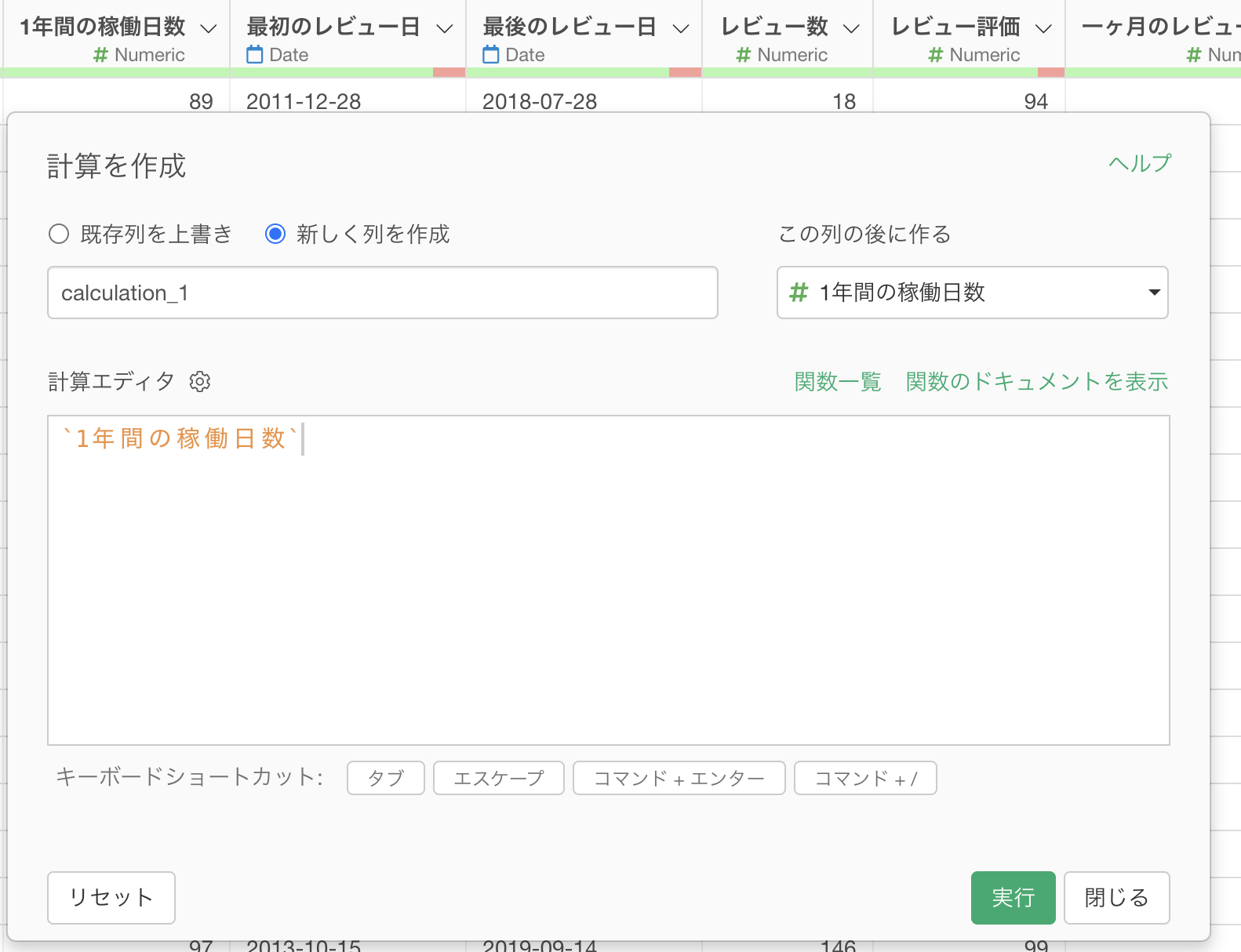
たいていの場合はそのまま列名が入力されているはずなのですが、今回は列名の最初と最後に「`(バックティック)」という記号が入力されています。これは列名が数字で始まっていたり、列名の中にスペースなどの特殊記号が入っている場合にエスケープ記号として使われます。
Exploratoryを使っている限りは、こうしたエスケープ記号は自動で入力されるため、どういう場合にこのエスケープ記号が必要になるか特に意識する必要はありません。
この「計算を作成」のダイアログの中では計算式や関数を使って自由自在に計算を行うことができます。
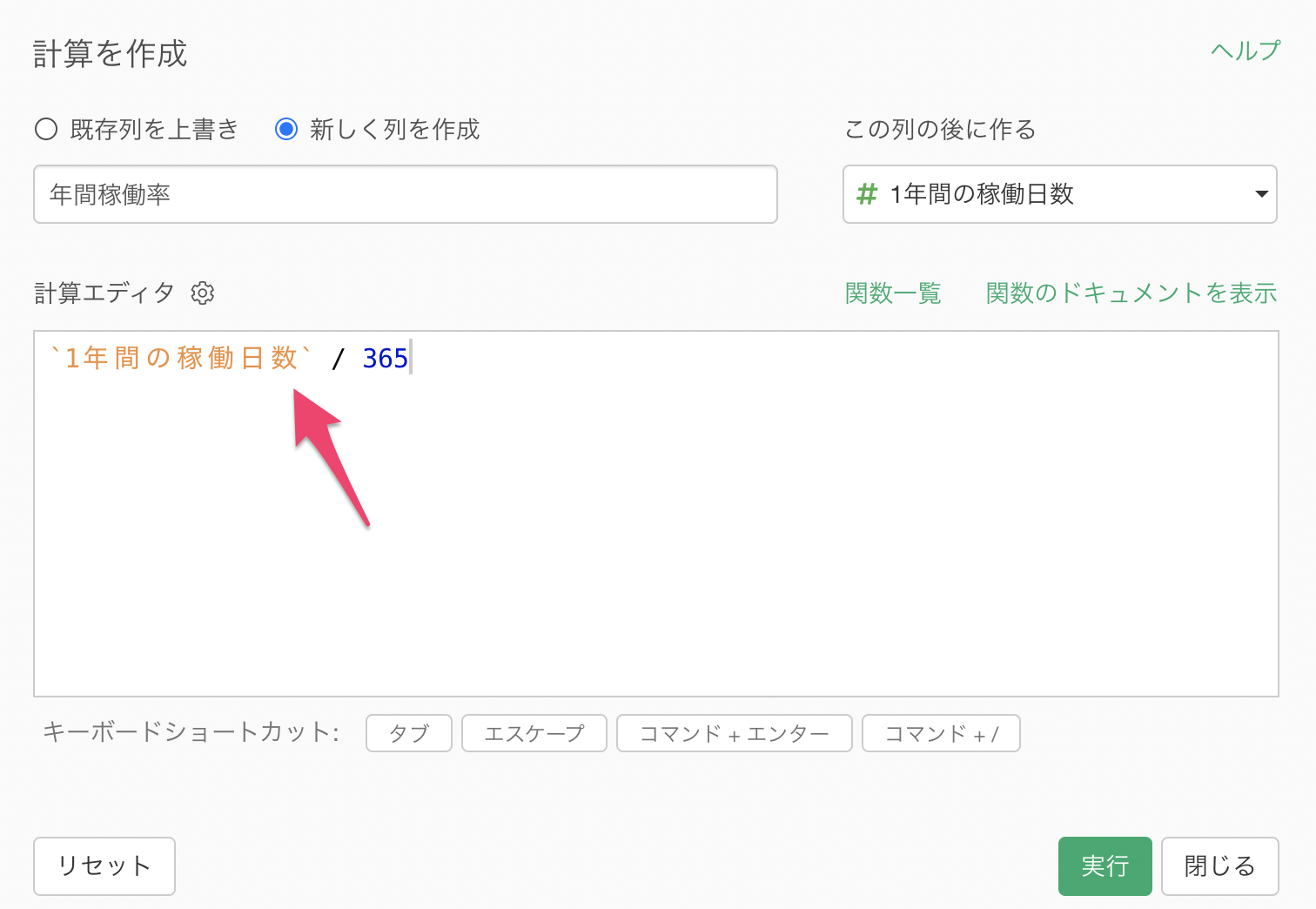
今回は年間稼働率を求めるために、計算エディタに下記の計算式を入力する必要があります。
1年間の稼働日数 / 365 すでに列名は入力されているため、ここでは/ 365
を列名「1年間の稼働日数」の後に入力するだけです。
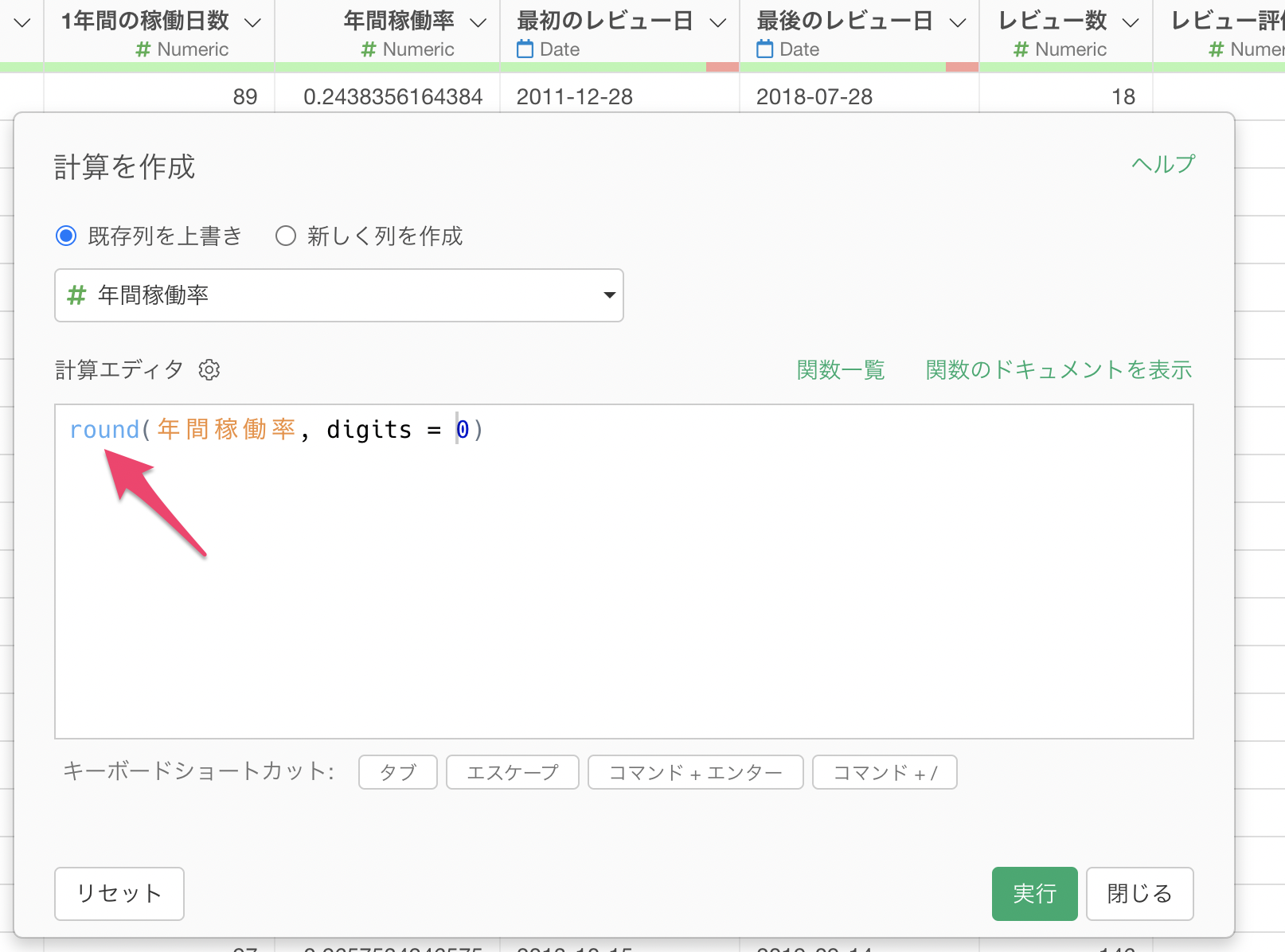
今回は計算結果を新しい列として追加したいため「新しく列を作成」が選択されていることを確認します。
確認できたら、「実行」ボタンをクリックします。すると、それぞれの行に対して「年間稼働率」が計算された列が新しく追加されます。
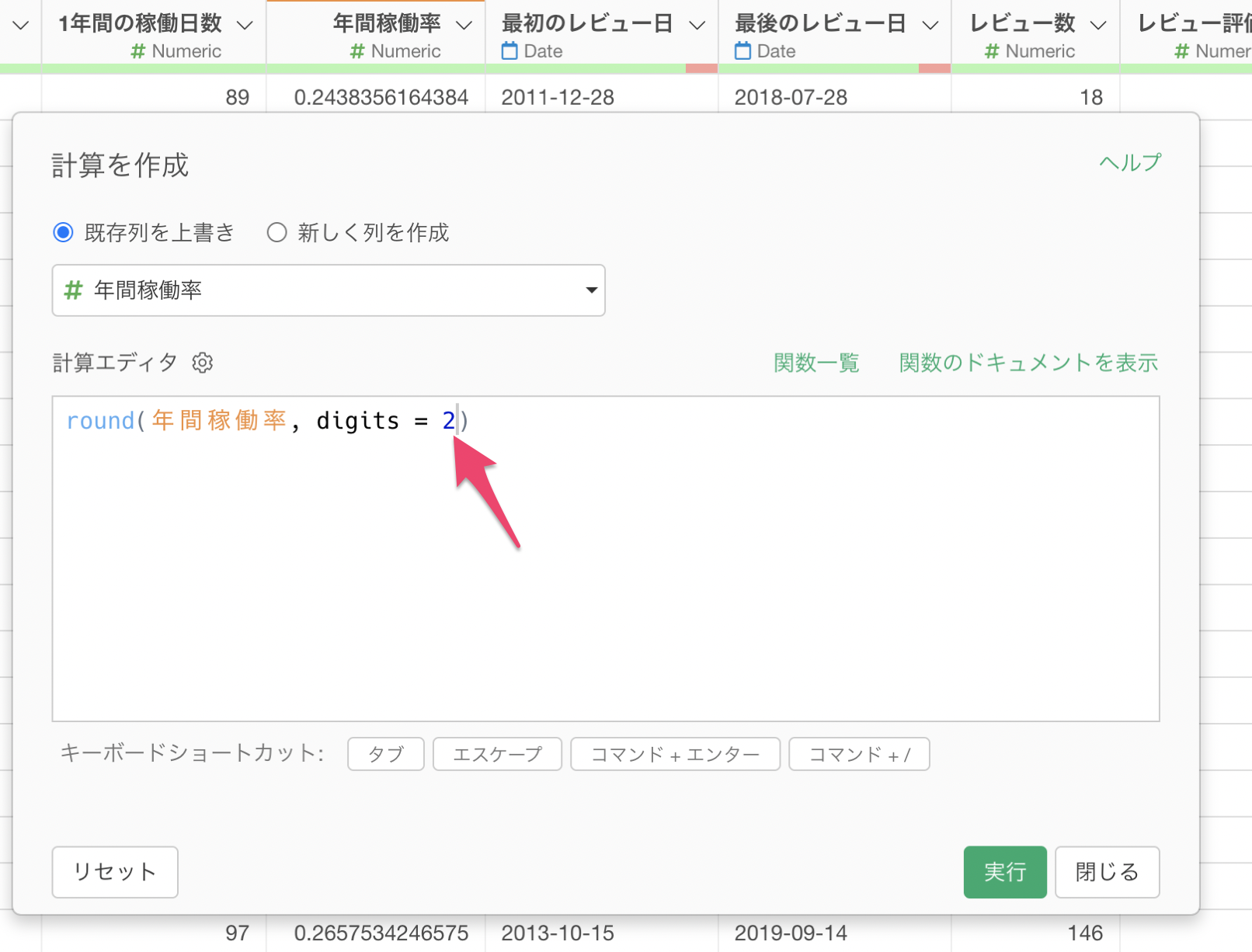
ところで、年間稼働率の値は小数点以下の桁数が多く含まれています。これらの値を見やすくするために、小数点二桁で四捨五入してみましょう。
このような四捨五入したい場合は「round」という関数を使って以下のような計算式を使うことができます。
round(年間稼働率)Exploratoryの場合は関数を覚えていなくても、列ヘッダーメニューから関数を使った計算式を自動で生成することができます。
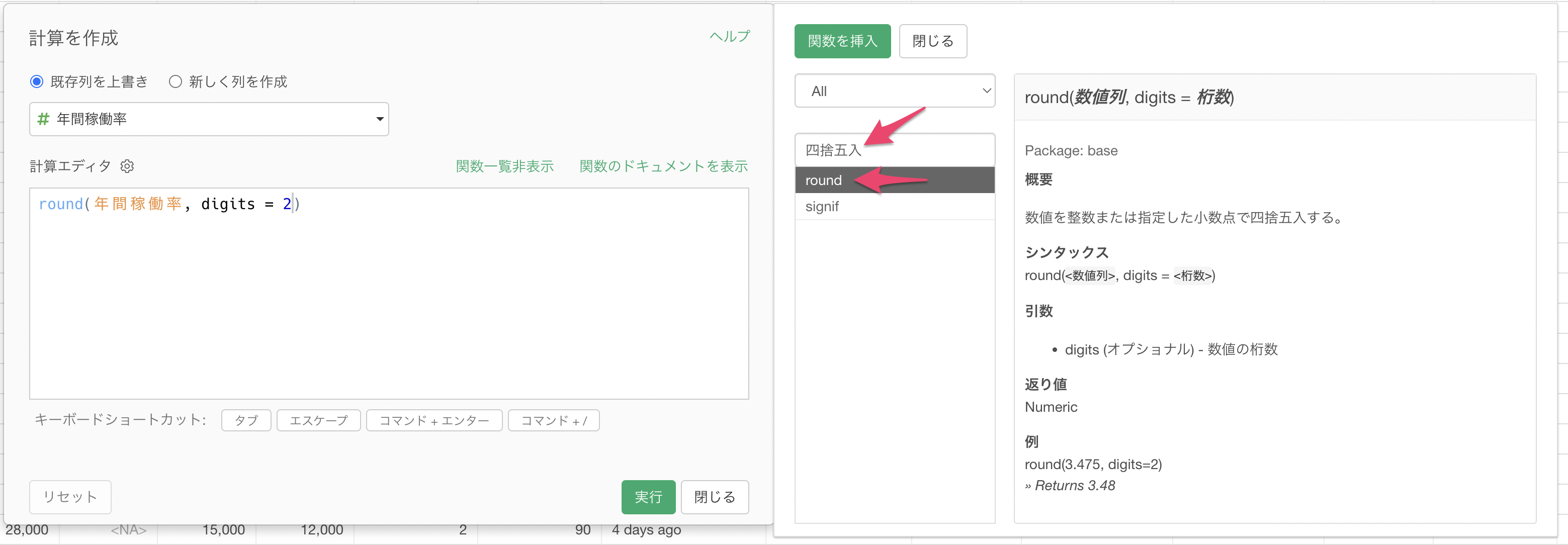
年間稼働率の列ヘッダメニューから「数値関数を使う」を選択し、その後「四捨五入(round)」を選択します。
「計算を作成」のダイアログが開き、計算エディタには四捨五入のための「round」関数を使った計算式が既に入力されています。
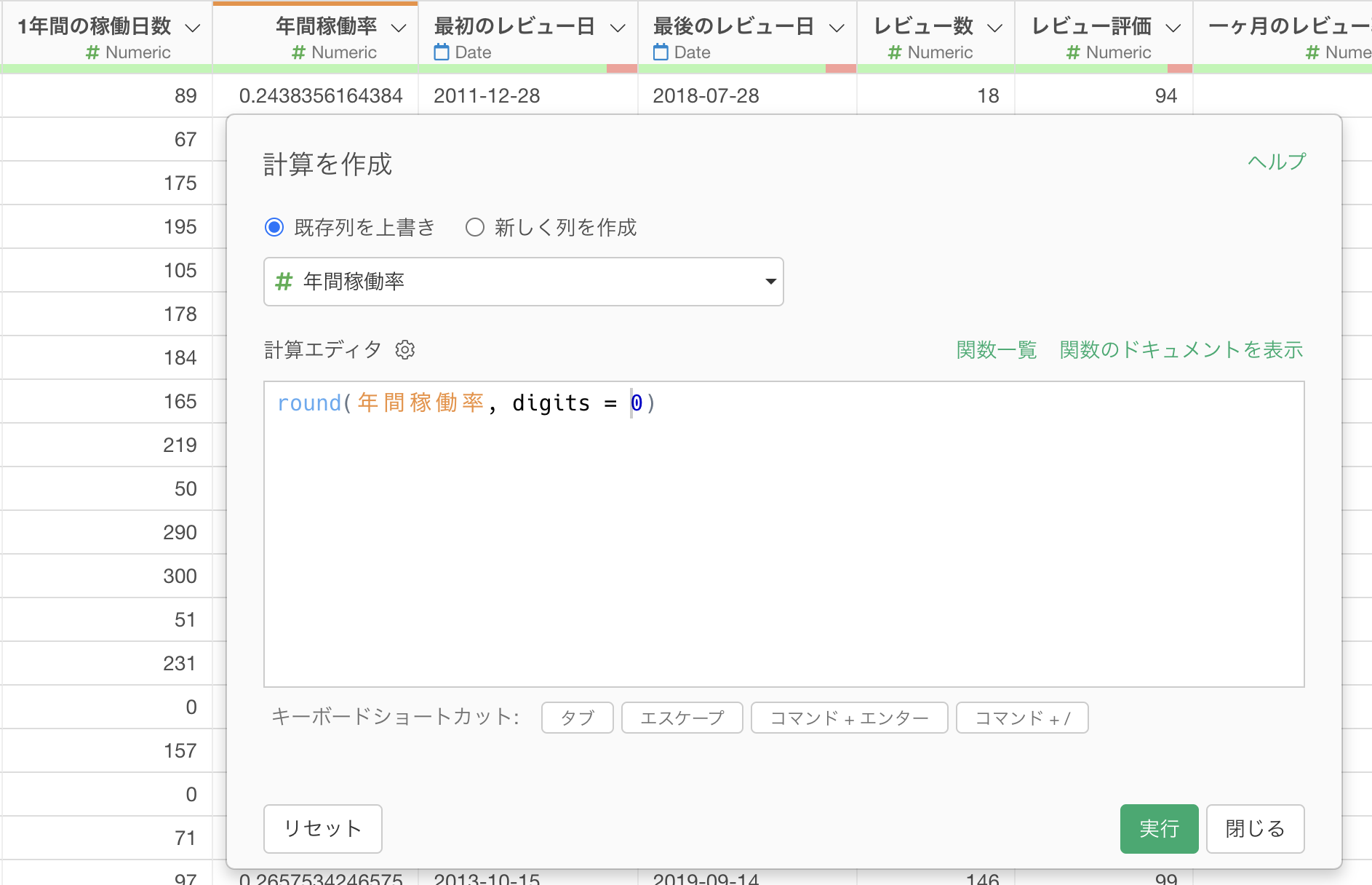
今回は小数点二桁で四捨五入したいため、digitsに小数点二桁を意味する「2」を指定します。
今回は計算結果を新しい列として追加するのではなく、既存の列「年間稼働率」を上書きしたいため「既存列を上書き」を選択した上で「実行」ボタンをクリックします。
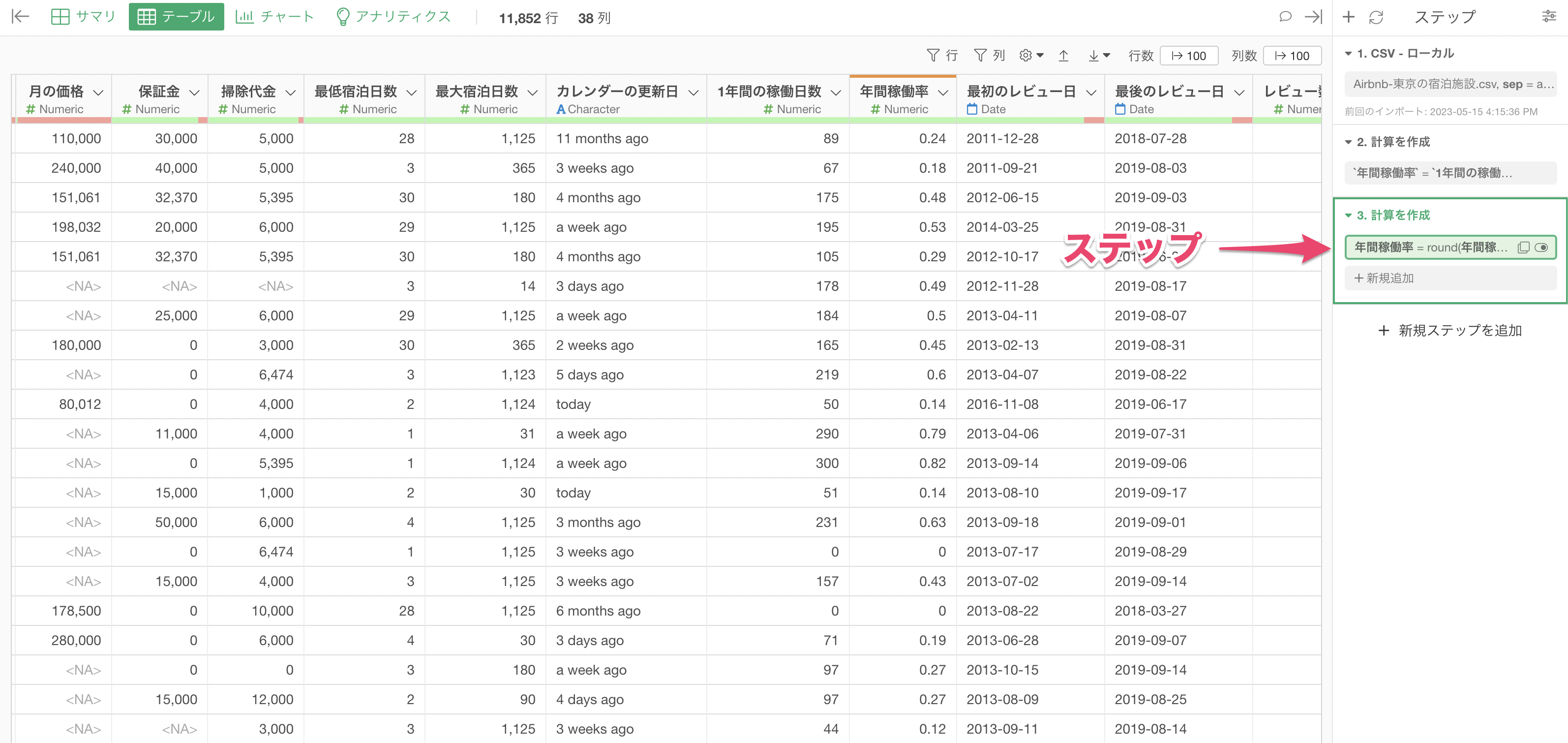
「年間稼働率」の値を小数点二桁で四捨五入した結果が表示されているのが確認できます。
今回紹介したように、たいていの場合は列ヘッダーメニューにあるメニューを選択することで関数やそれに伴う引数は自動で入力されるため、それぞれの関数を覚えていなくても簡単に使い始めることができます。
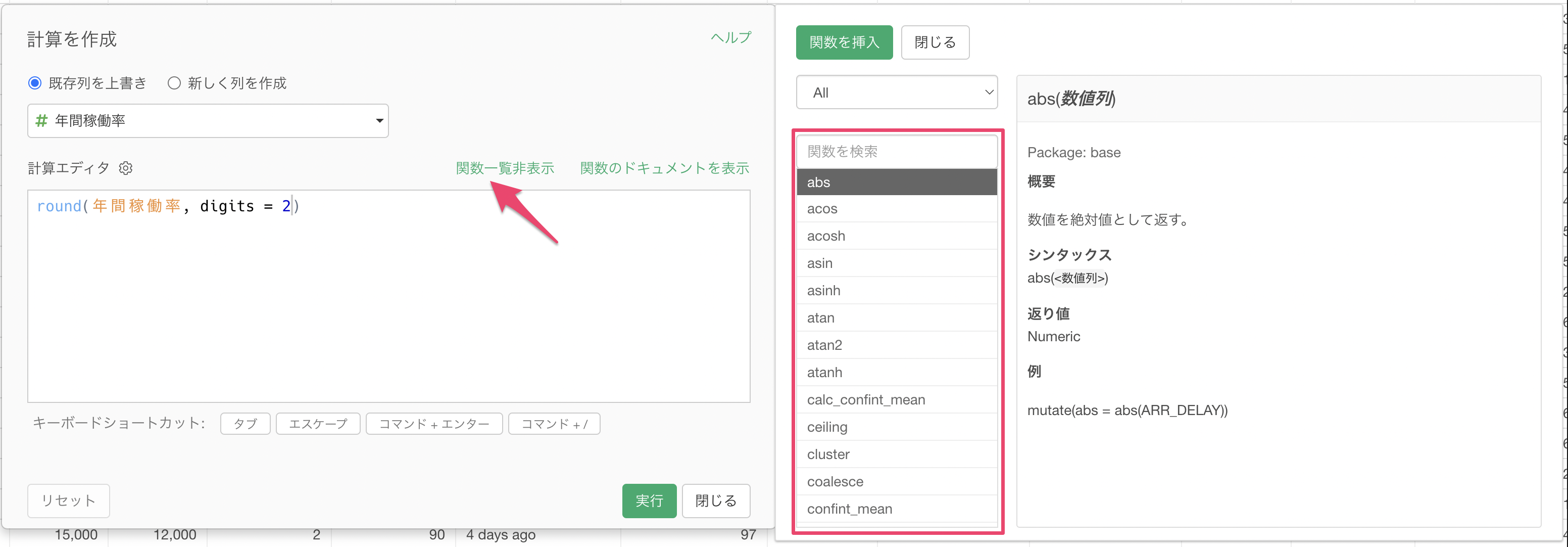
それでもまれに列ヘッダーメニューにない関数を使いたい場合もあります。その場合は「計算を作成」のダイアログ内にある「関数一覧」をクリックすることで、関数名や使い方を調べることができます。
例えば、検索ボックスに「四捨五入」と入力をすると、先ほど使用したround関数が表示されます。
8. データラングリングのステップ
これらの計算などのデータの加工をしていくと、それらの処理は自動的に右側に「ステップ」として記録されていきます。
既存のステップを編集したい場合はトークンをクリックします。すると該当のダイアログが表示されます。
なお、ステップのコメントアイコンをクリックすると、ステップの名称を変更したり、ステップにコメントを残すことが可能です。
ステップにコメントを追加すると、コメントを追加したステップのコメントアイコンが緑色で塗りつぶされ、コメントアイコンにマウスカーソールを重ねると、入力したコメントが表示されるようになります。
ステップについて詳しく知りたい方は、こちらをご参照ください。
9. チャートのピン機能
先ほど計算した「年間稼働率」の平均値を「市区町村」ごとに表すチャートを作ってみましょう。
チャートビューに戻り、前に作ったバーチャートを開きます。
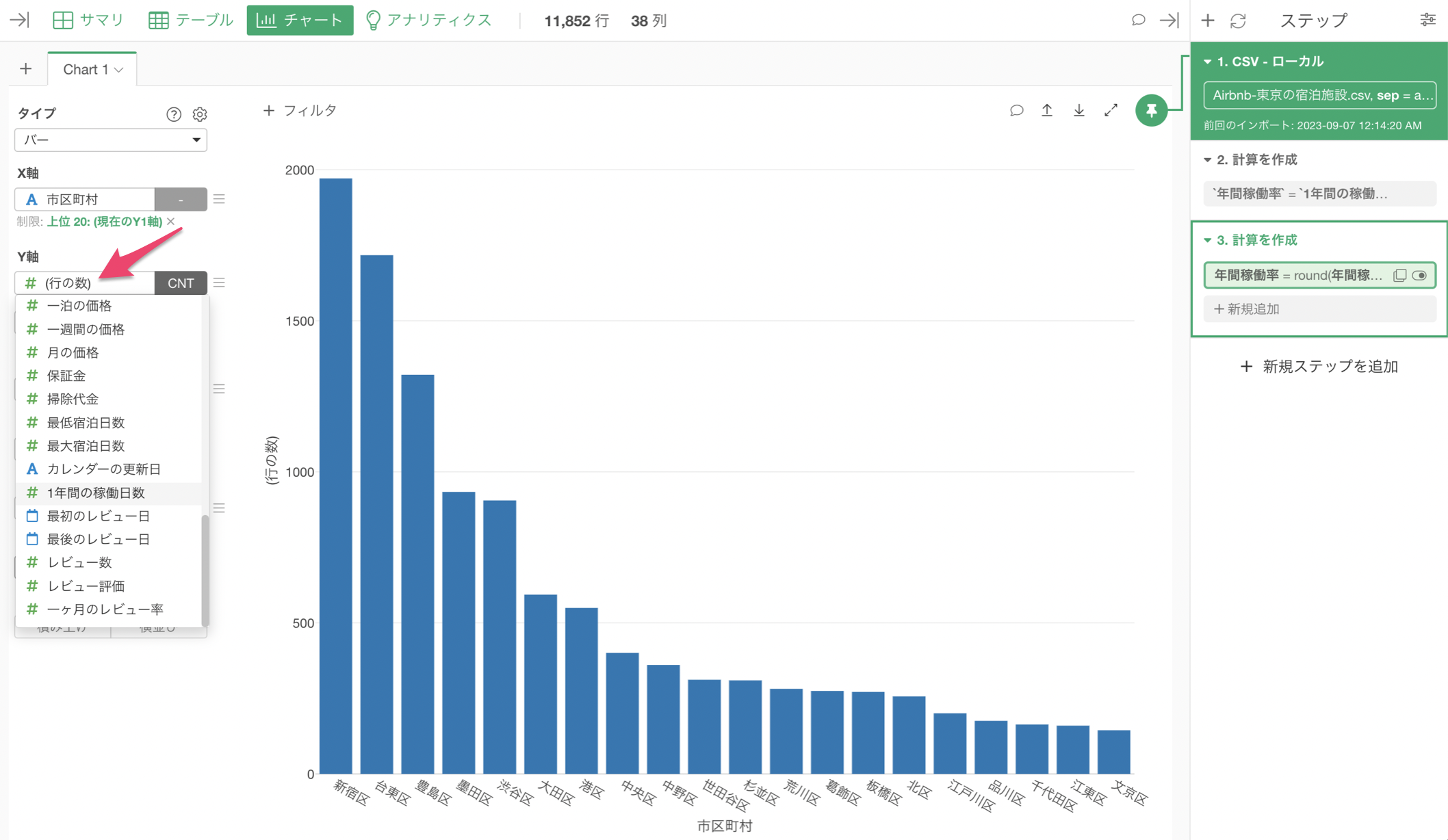
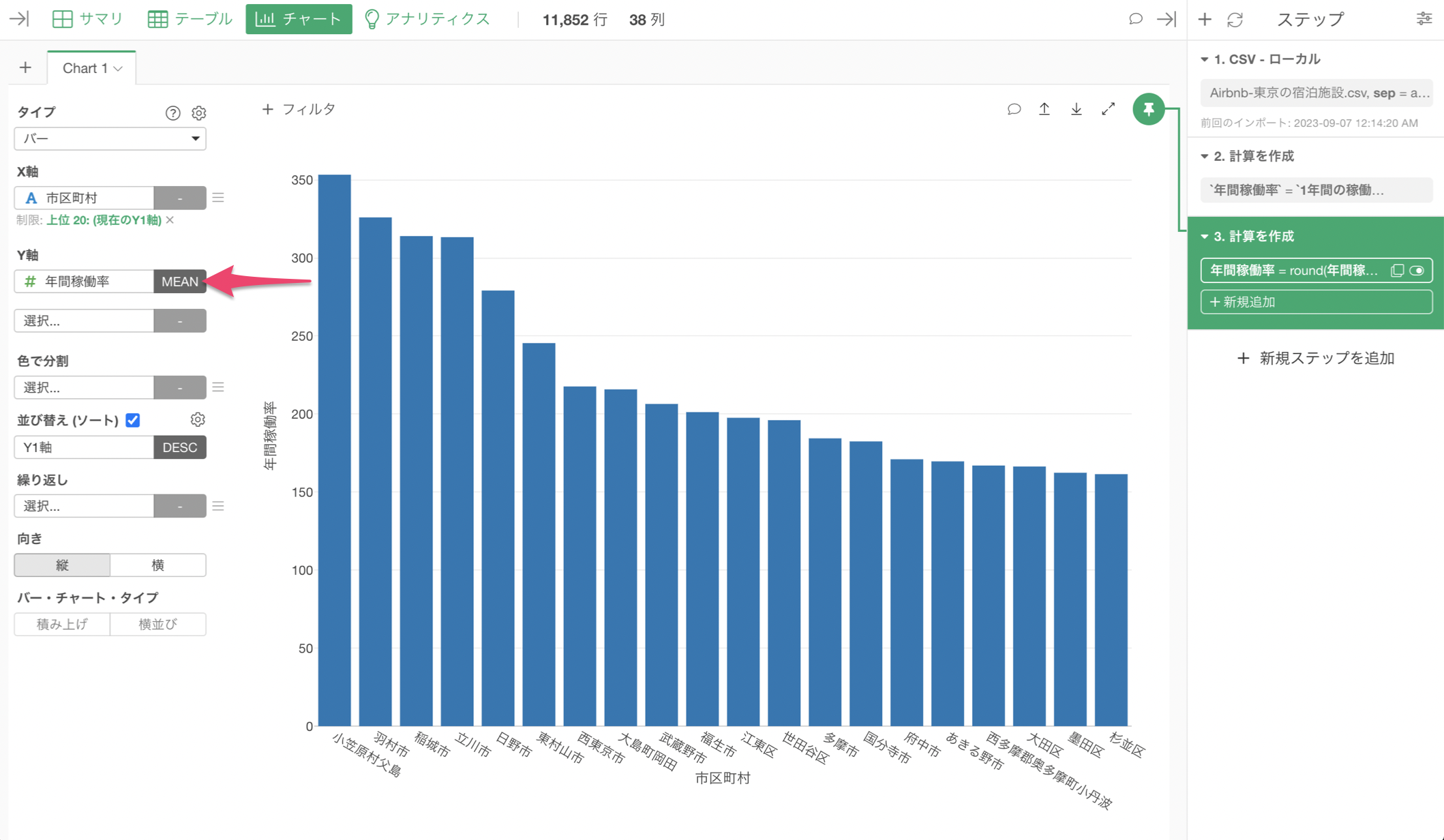
Y軸を「年間稼働率」の列に変えたいところですが、「年間稼働率」が表示がされていません。
Exploratoryでは、チャート・ピンという機能があり、それぞれのチャートは「ピン付け」されているデータラングリングのステップのデータを可視化するようになっています。
このチャートは、ピンが1番目のステップに「ピン付け」されたままです。ということは、この時点ではまだ「年間稼働率」の列はできていません。
そこで、「年間稼働率」や「四捨五入」をした3番目のステップにチャートのピン動かす必要があります。ドラッグ&ドロップでチャート・ピンを3番目のステップに動かしましょう。
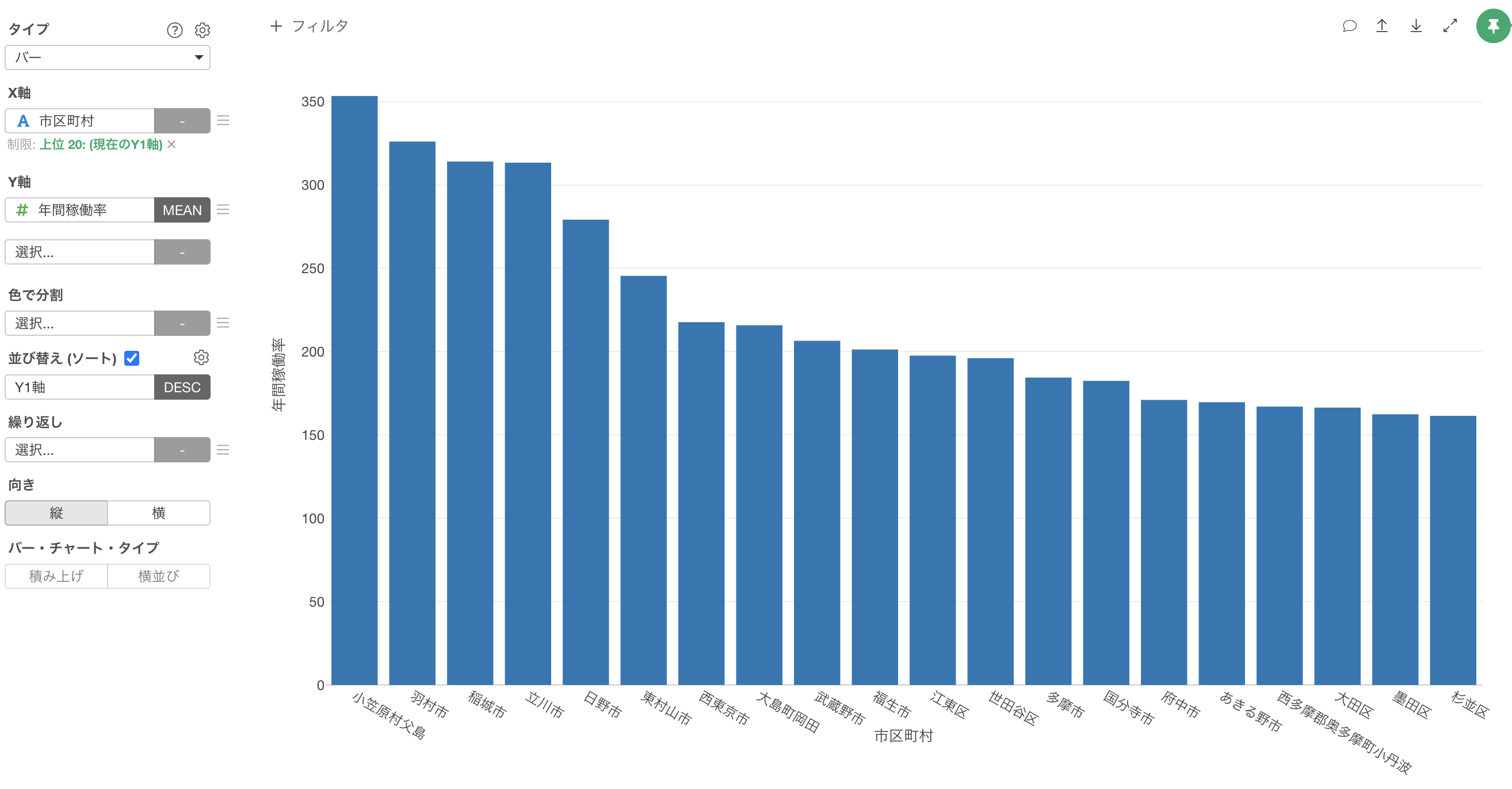
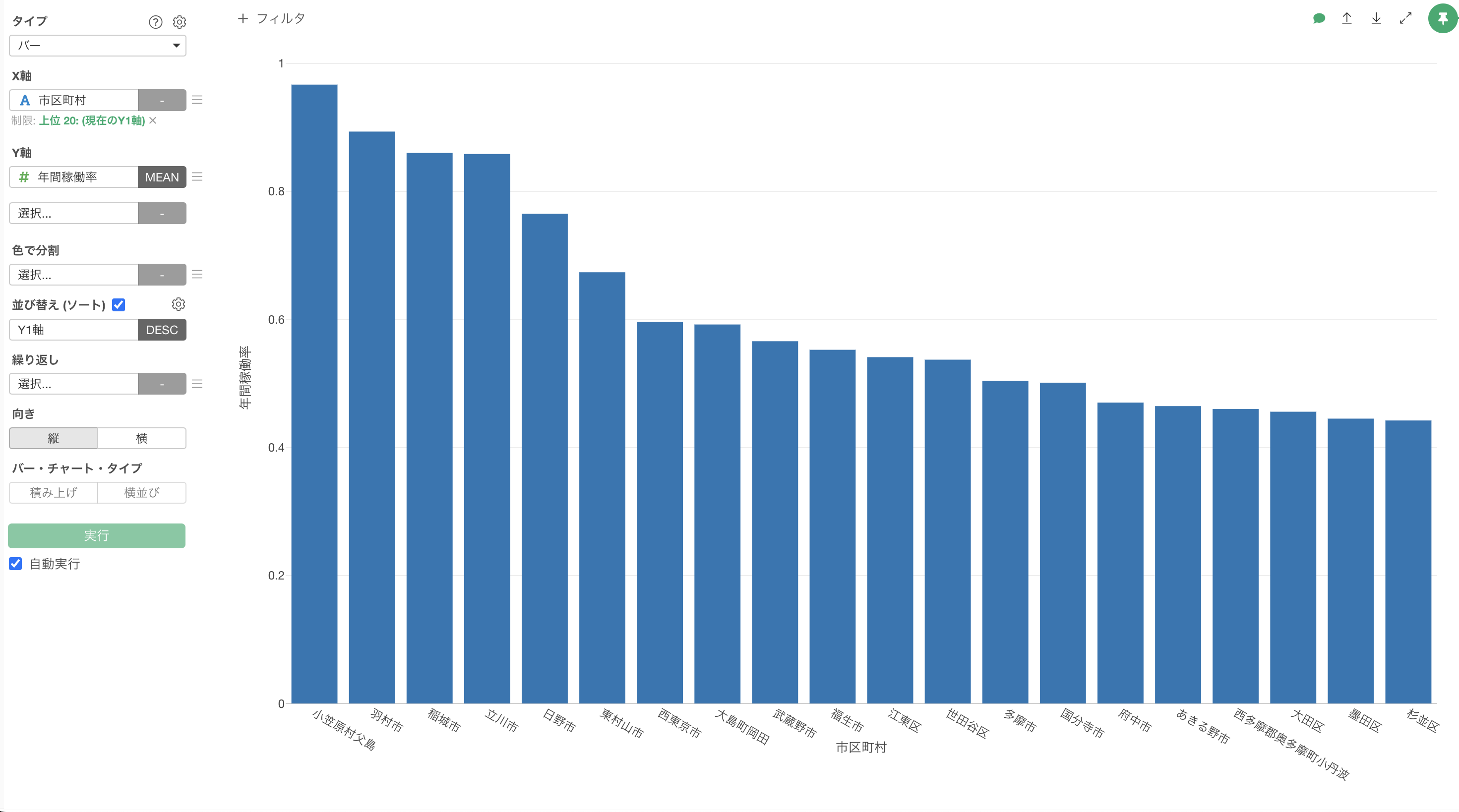
これにより、Y軸に「年間稼働率」の列が選択できるようになります。集計関数には平均値(MEAN)を選択します。
年間稼働率の平均値が高い上位20の市区町村を可視化することができました。「小笠原村父島」や「羽村市」などが年間稼働率の平均値が高いようです。
Exploratoryの使い方の基礎版は以上となります!
Exploratoryの使い方シリーズ
Exploratoryの使い方シリーズの他のパートには下記のリンクからご確認いただけます。ぜひ次の「可視化」のパートも実施してみてください。