テキスト分析 - トピックモデル(LDA)の紹介
このノートでは、テキスト分析 - トピックモデル(LDA)についてご紹介します。
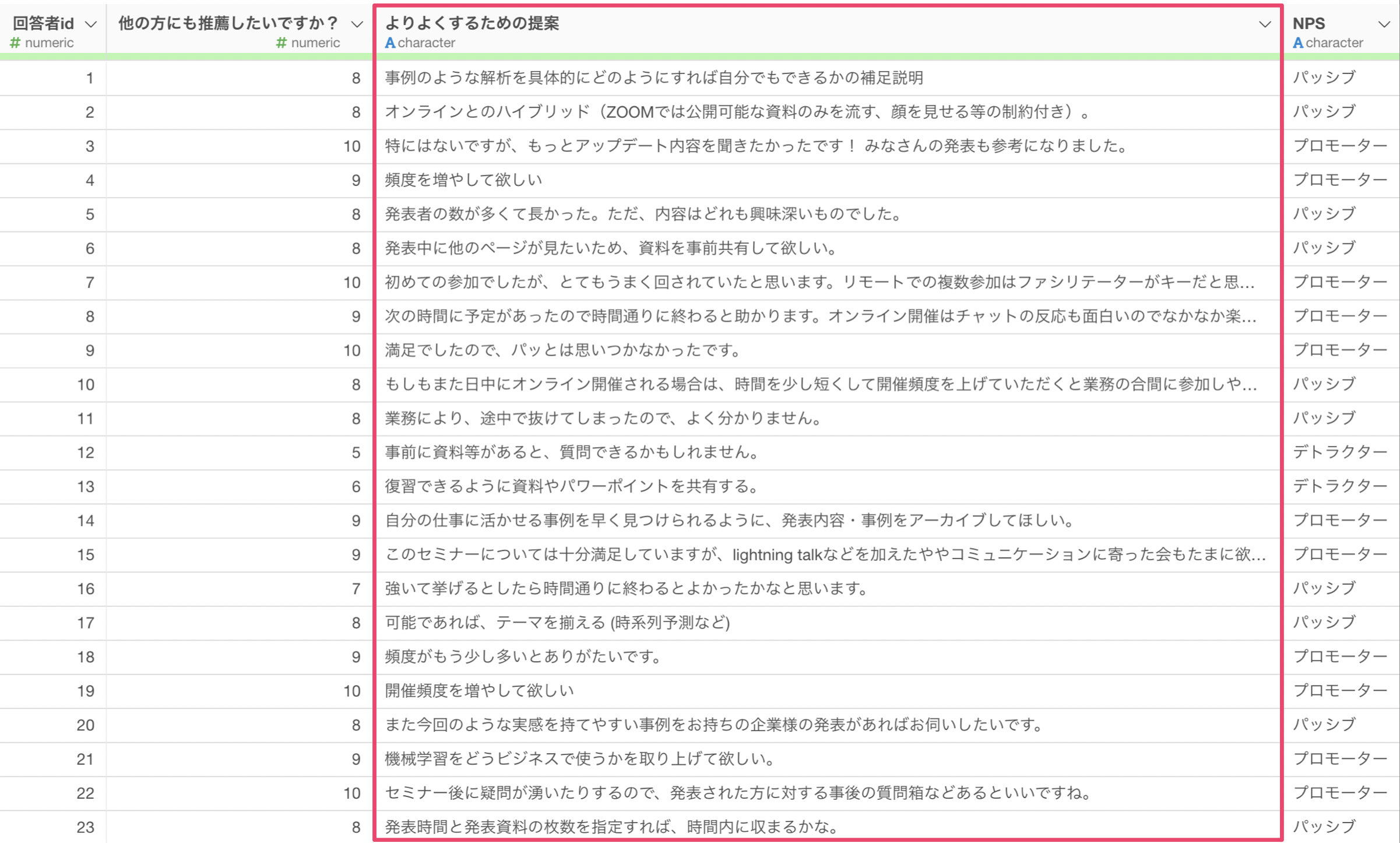
アンケートでは、5段階評価などではわからない回答者が持っている具体的な考えを引き出すために、自由記述の質問を設定することはよくやることの一つです。
しかし、自由記述のテキストのように定性データの解釈は人によって異なるため、全体的な特徴や傾向を客観的に捉えにくいために、うまく活用しきれないという声をよく耳にします。
今回紹介するトピックモデルを使うことで、文章の中で似たような単語が使われている傾向からいくつかのグループ(トピック)に分け、どういった文章があるのかを把握することができるようになります。
トピックモデルでは、それぞれの文章で使われている単語を元にして、それぞれの文章でのトピックごとの確率を出します。トピックの確率が高い単語や文章を見ることで、そのトピックは政治である、スポーツであるといった形で判断していくことができます。

必要なデータ
テキスト分析 - 単語のカウントを実行するためには、自由記述のテキストの列が必要です。さらに、一緒に使われる単語の組み合わせを知りたい場合は、1行が1観察対象(例:1行が回答者)となっている必要があります。

テキスト分析 - トピックモデルを実行する
アナリティクスビューを選び、タイプに「テキスト分析」の「トピックモデル(LDA)」を選択します。
テキストの列に「よりよくするための提案」を選択します。
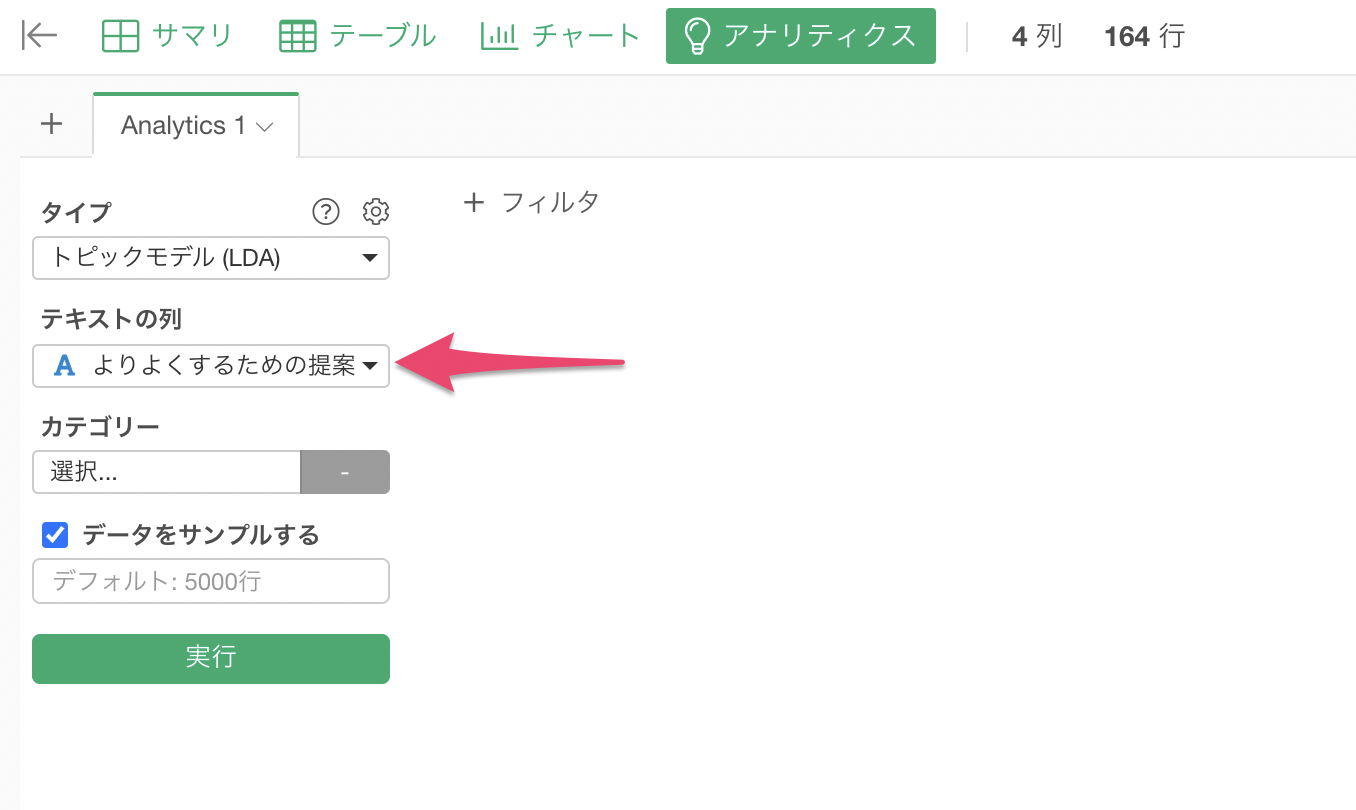
もしデータが「5000行」以上の場合、全てのデータを使いたい場合は「データをサンプルする」のチェックを外してください。しかし、データの行数によっては実行までに時間がかかってしまうために、デフォルトでは「5000行」でサンプルされていることになります。
設定ができたら、「実行」ボタンをクリックします。
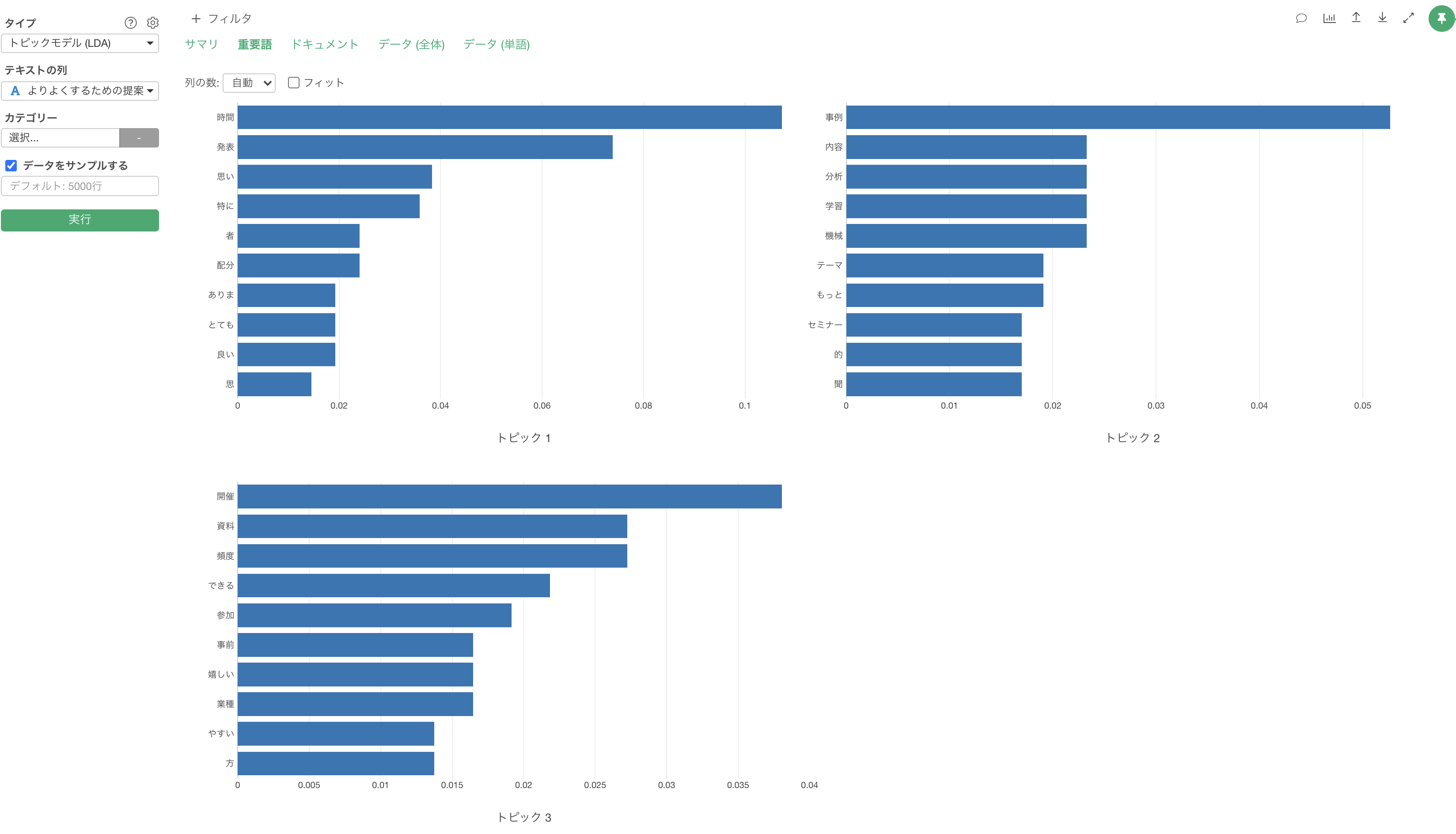
テキスト分析の「トピックモデル」が実行されました。
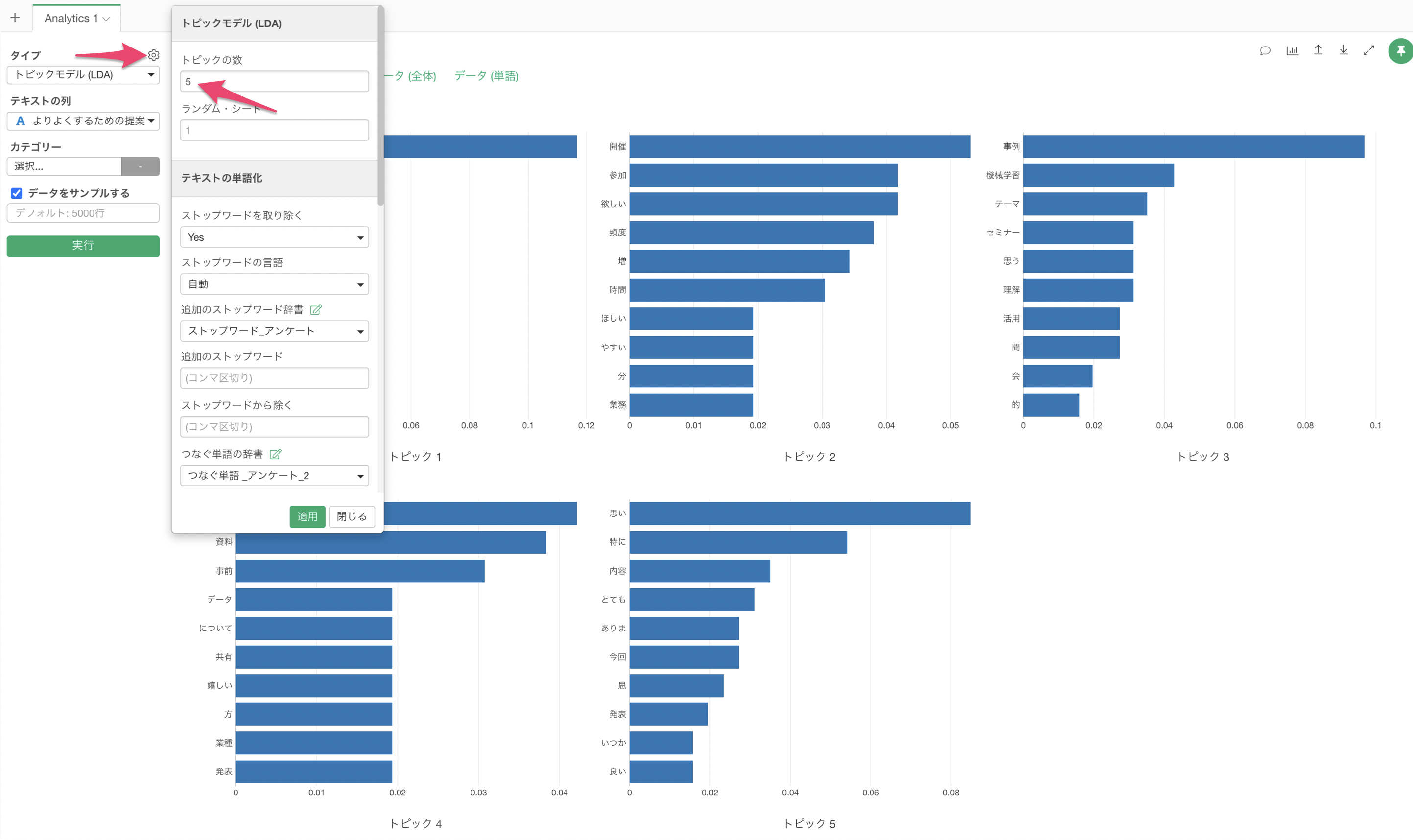
トピックの数を増やしたい場合は、プロパティから変更することができます。
結果の解釈
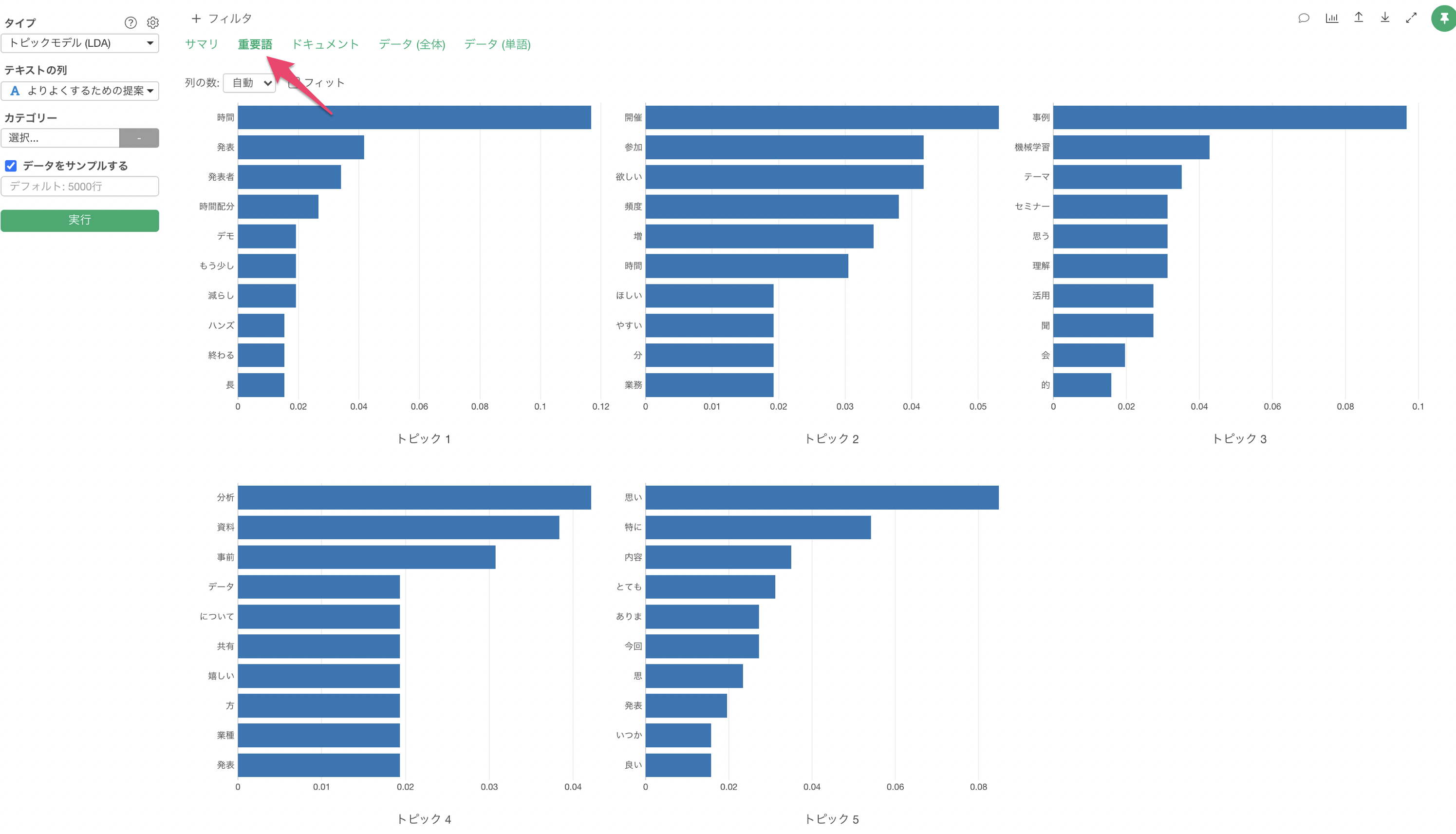
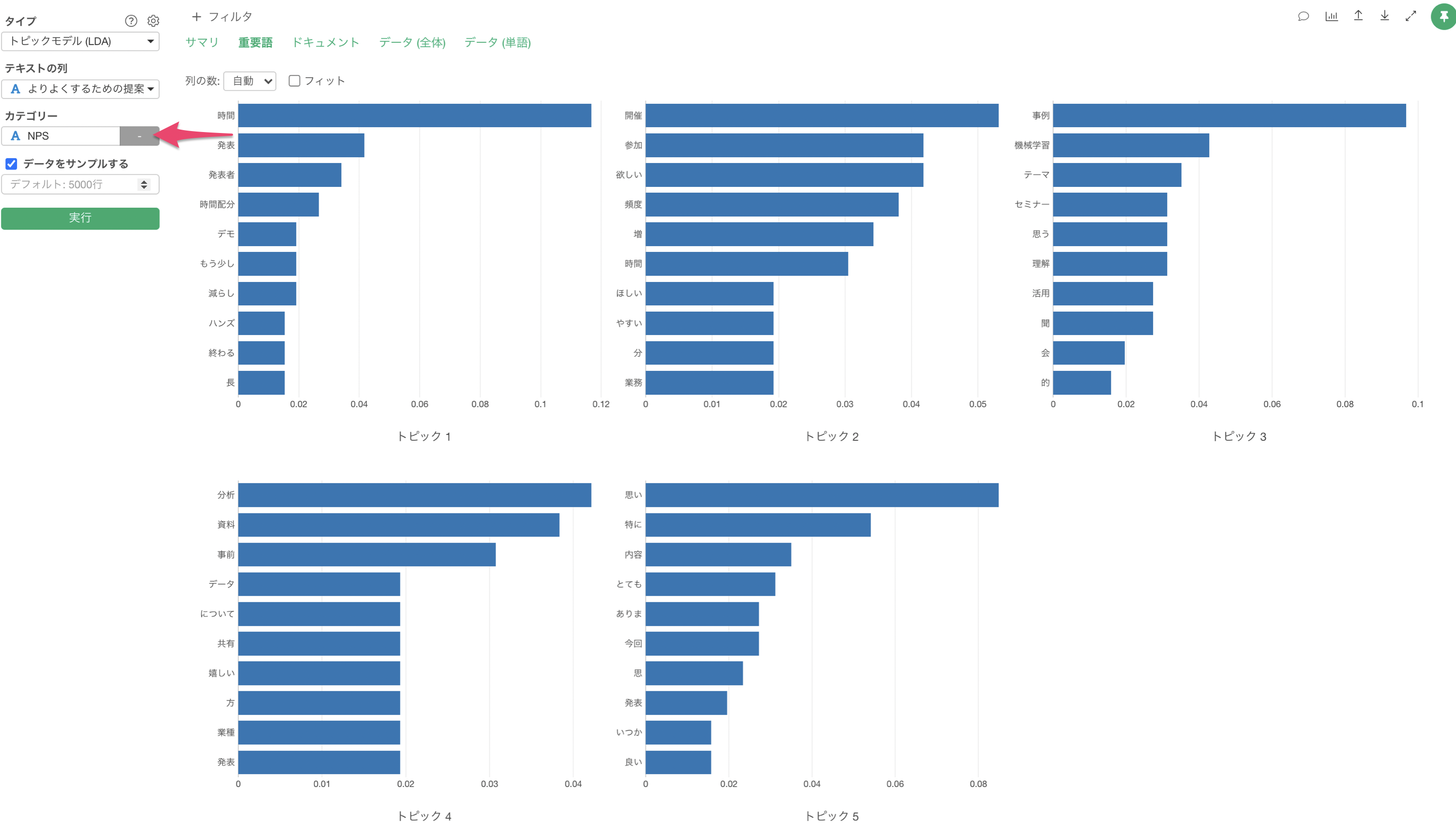
重用語
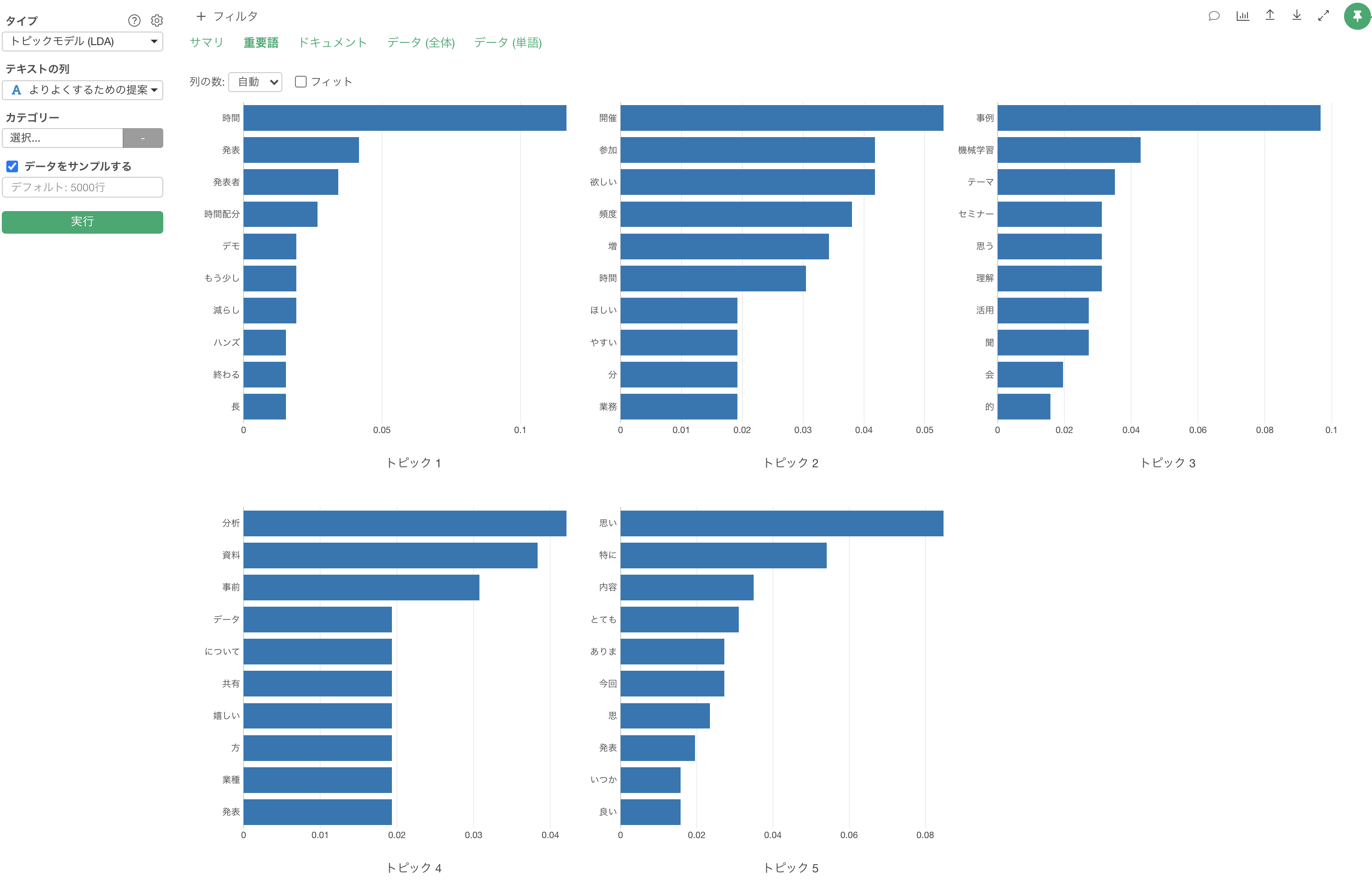
「重要語」のタブでは、それぞれのトピックごとで、そのトピックの確率が高い重要となる単語がバーチャートとして表示されます。
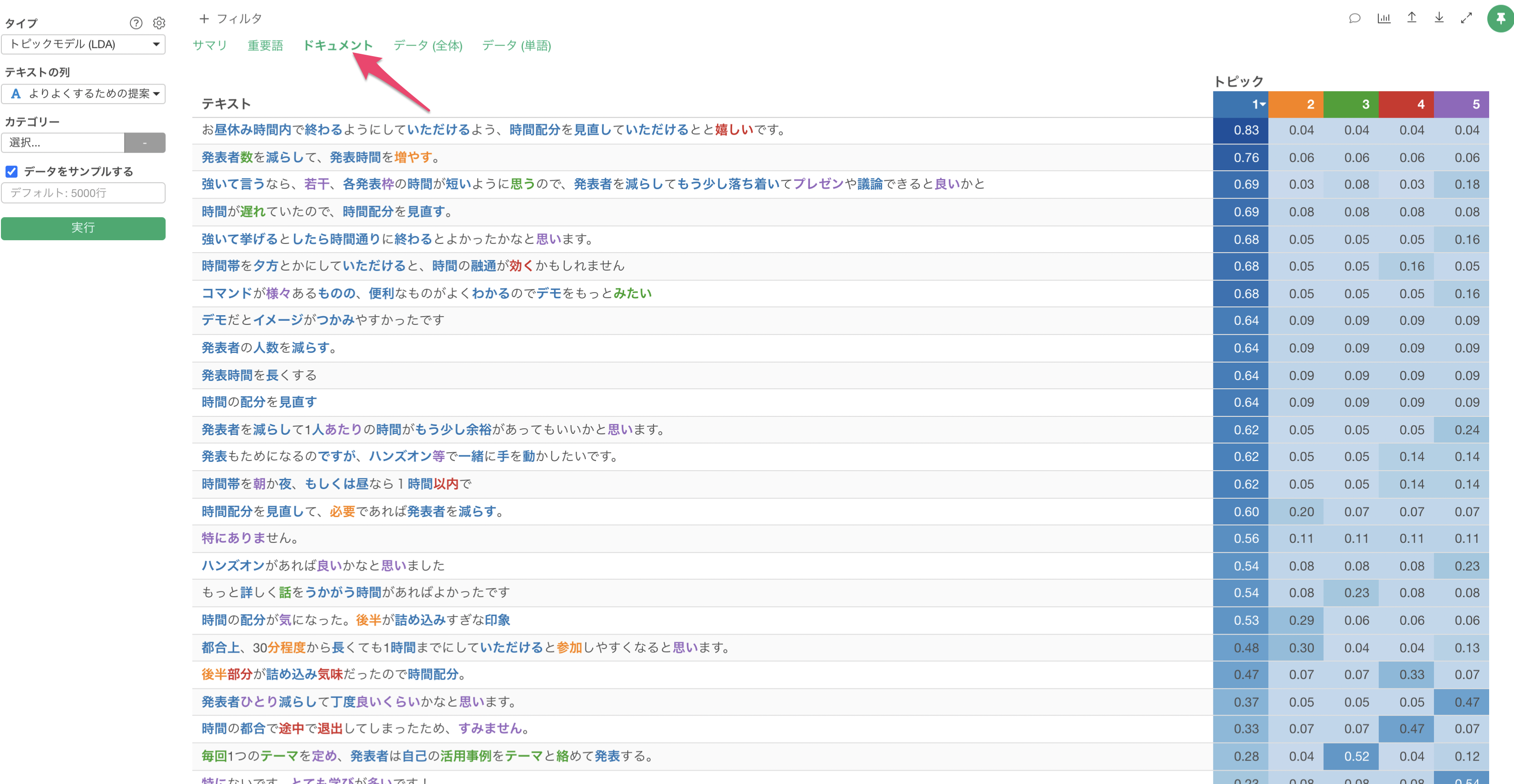
ドキュメント
「ドキュメント」のタブでは、元データが表示され、トピックの確率が高い単語はそのトピックの色で表示されます。
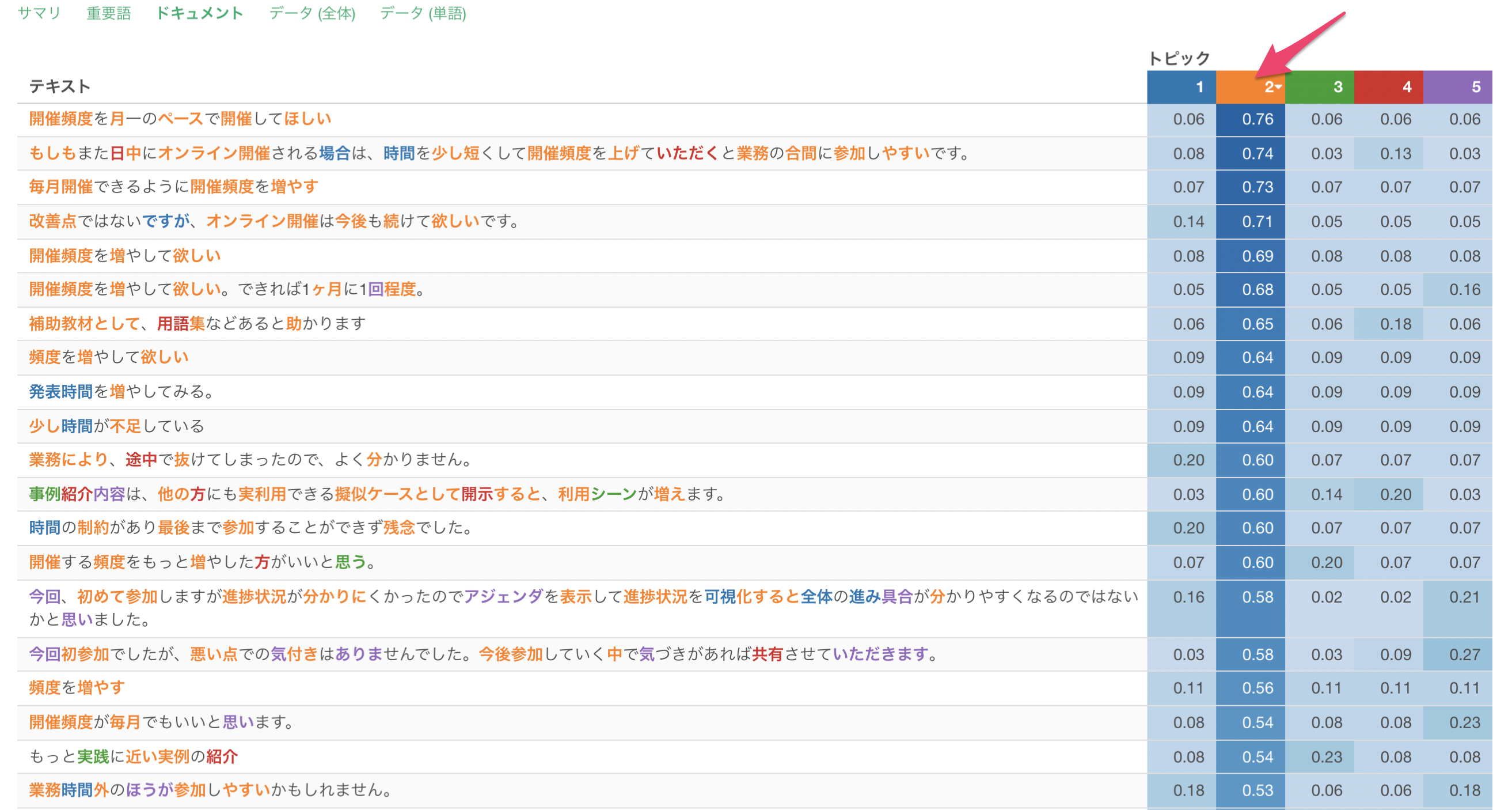
もしトピック2の確率が高いテキストを確認したい場合は、トピック2の列をクリックすることで、ソートを行うことができます。
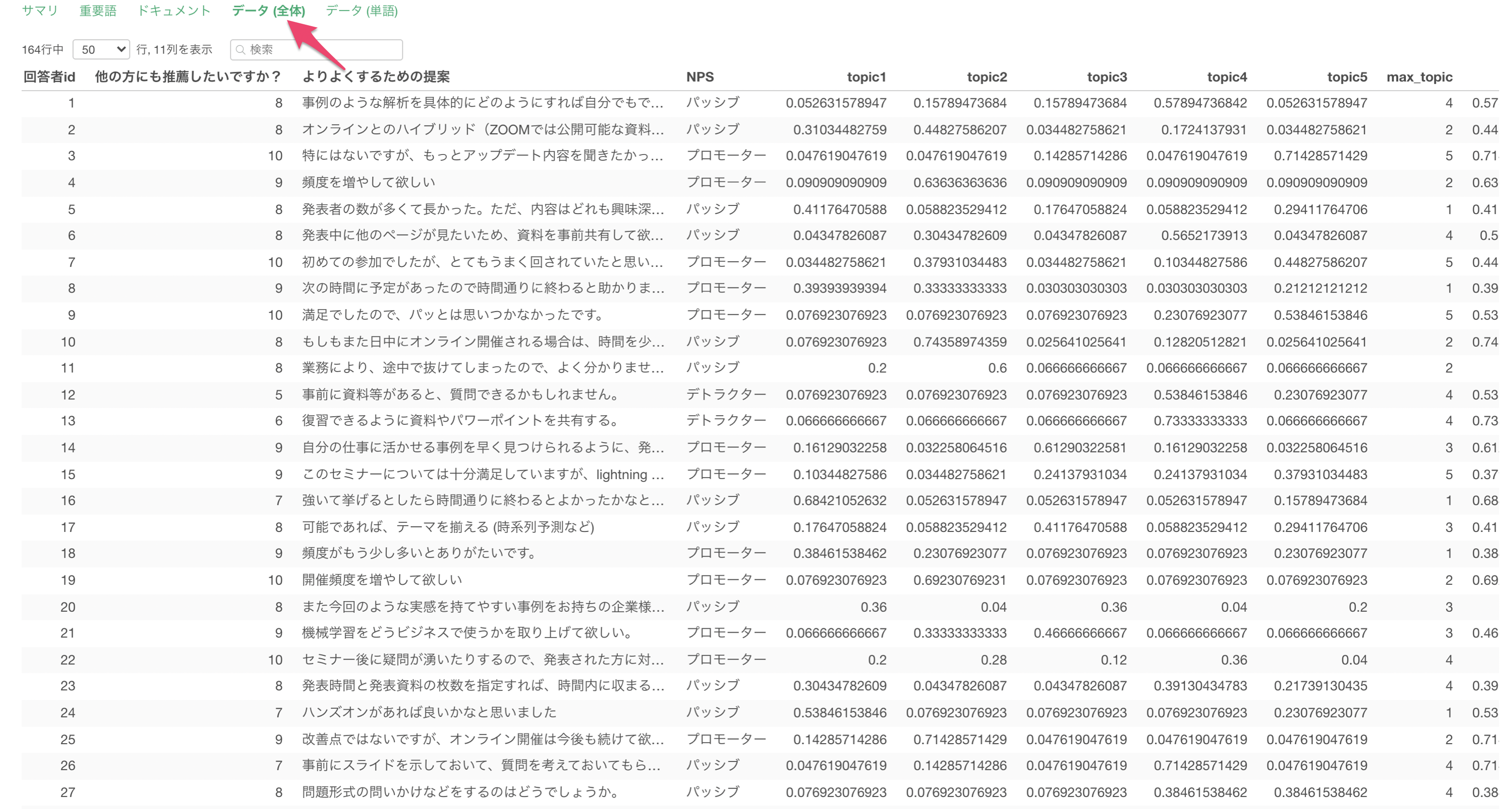
データ(全体)
「データ全体」のタブでは、元のデータでの文章ごとのトピックの確率をテーブル形式で確認できます。また、それぞれの文章の中で最も確率が高かったトピックをmax_topicとなっています。
サマリ
「サマリ」タブでは、それぞれのトピックごとにどれだけの行数があるのかを確認できます。文章ごとのトピックの選定は、文章の中で最も確率が高かったトピックであるmax_topicをもとにしています。

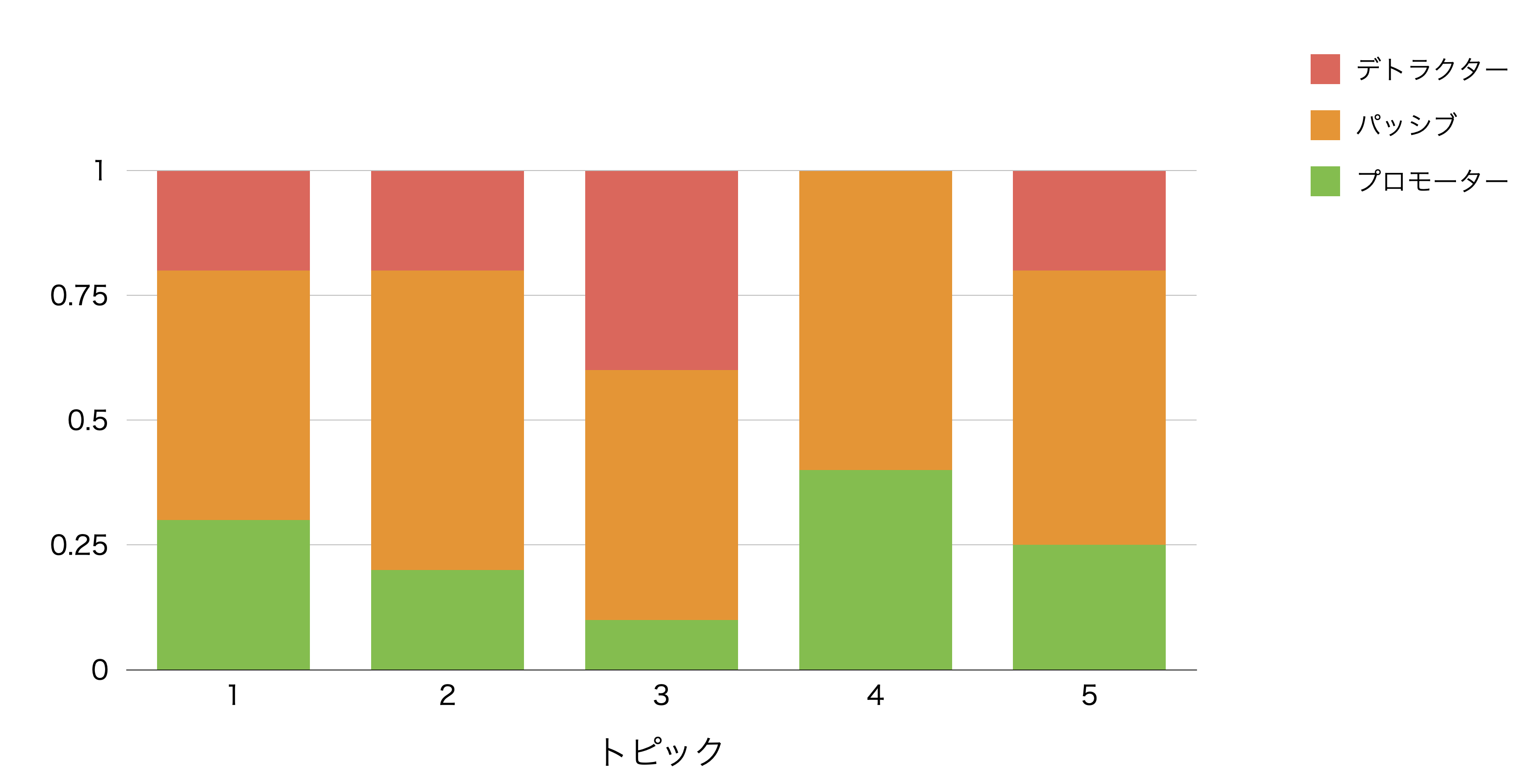
トピックごとのカテゴリーの関係の可視化
データの中に性別や年代などのカテゴリーの列がある場合、それぞれの単語でカテゴリーの比率を見ていくことができます。
例えば、今回のデータにはNPSといったカテゴリー列があります。

そこで、トピックごとにNPSグループ(カテゴリー)の比率を調べていきたいです。
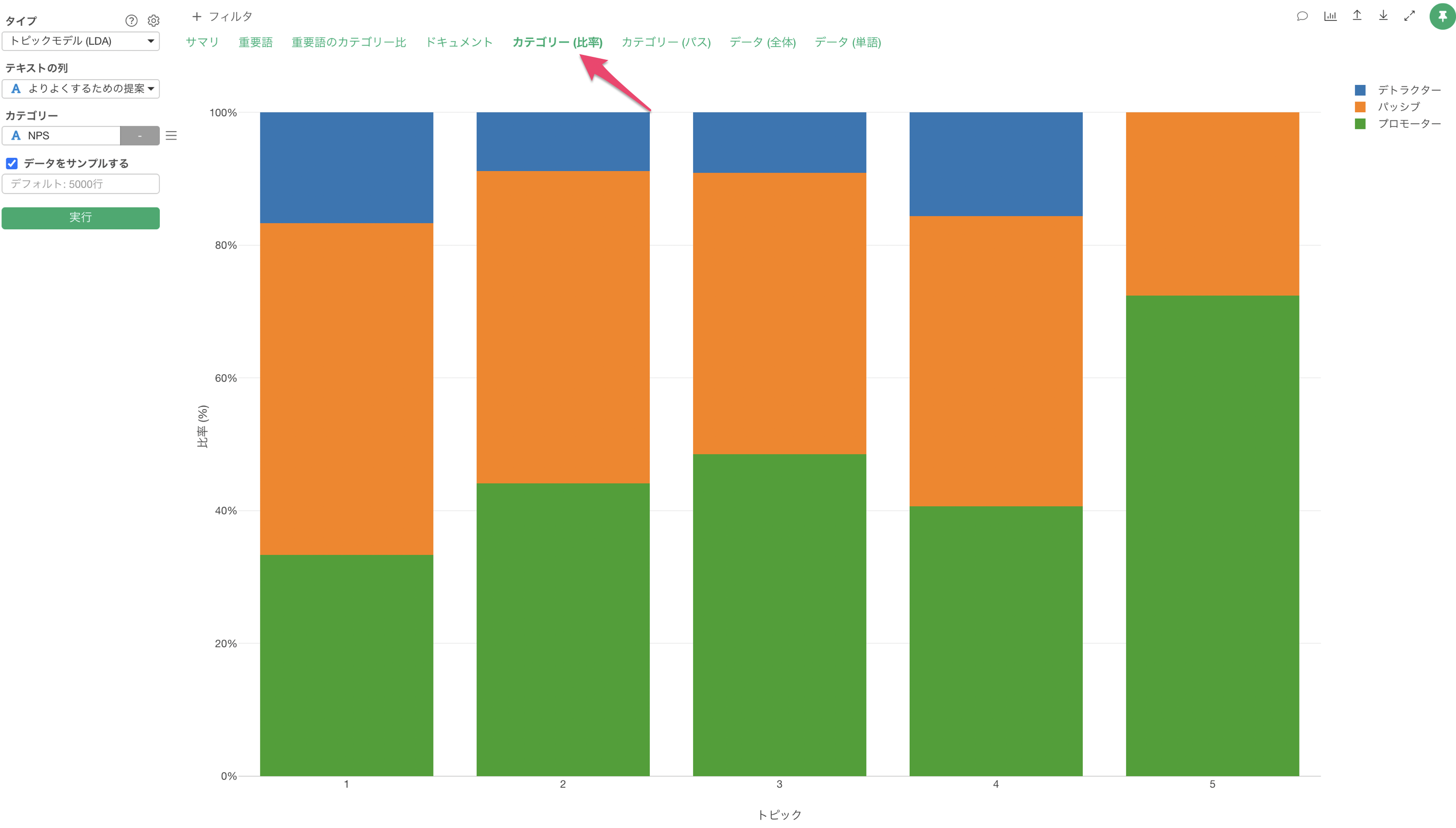
「カテゴリー」に「NPS」の列を選択して実行します。
「カテゴリー比率」タブより、それぞれのトピックごとのカテゴリーの比率を確認できます。今回の場合はNPSグループの比率が可視化されています。
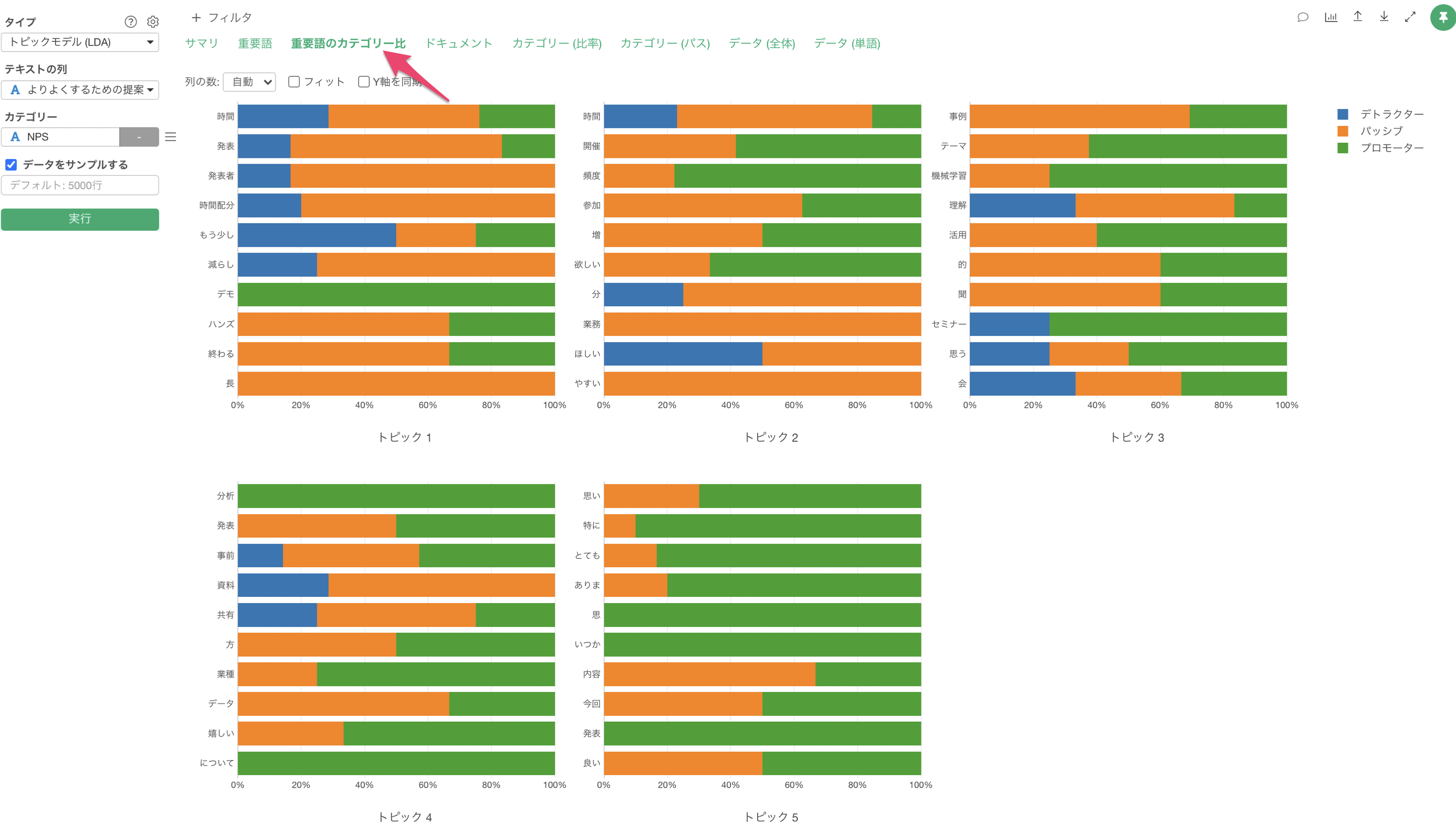
「重用語のカテゴリー比」タブからは、トピック別の重用語ごとにカテゴリーの比率を確認できます。
ストップワード、つなぐ単語の辞書の設定
Exploratoryでは、あまりにも一般的な単語でそれぞれの文章を特徴づけることがない「ストップワード」や、分かれてしまう単語を一つの単語として扱える「つなぐ単語」を辞書として登録して使うことができます。
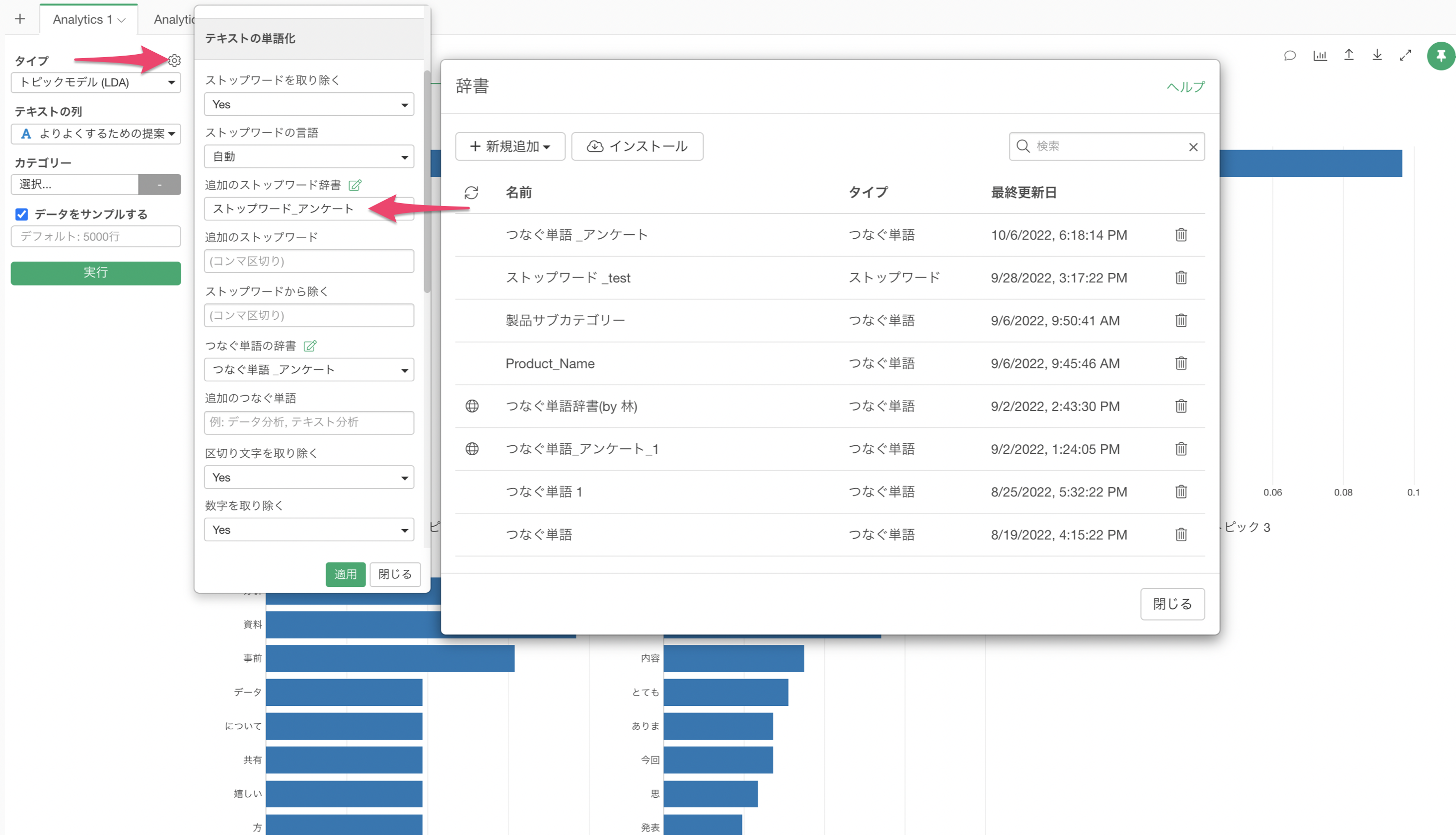
辞書では下記のように、1行ごとに単語を入力して登録することができます。
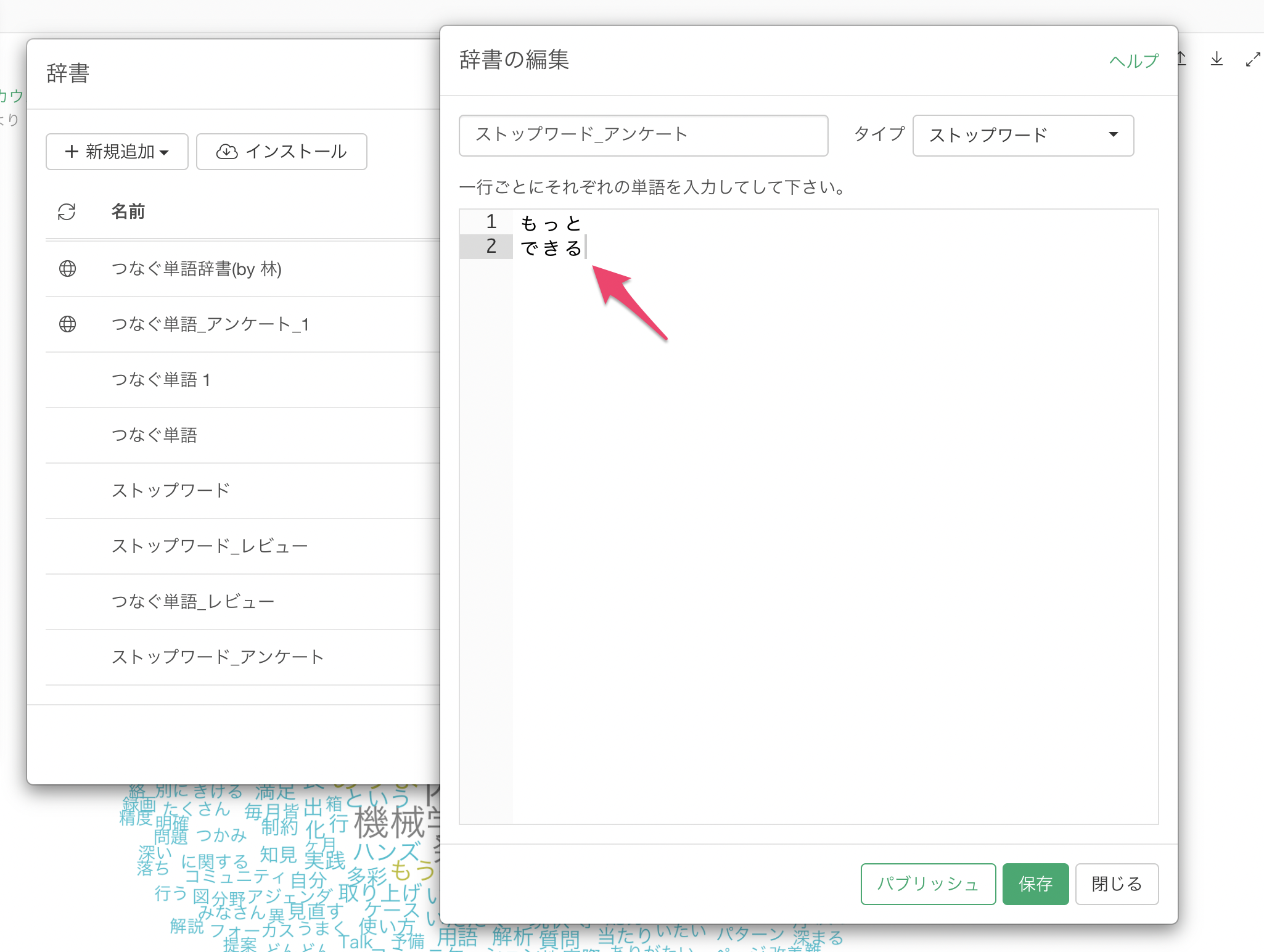
さらに、辞書はExploratoryサーバーにパブリッシュして、チームメンバーや他の人たちにも共有することができます。
辞書の詳しい使い方については、こちらの資料をご参照ください。
参考資料
テキスト分析に関する参考資料は下記をご覧ください。
テキスト分析 - トピックモデルに関するよくある質問
Q: トピックモデルを実行しても「参照データが更新されています。実行をクリックしてください。」というメッセージが表示され、結果が表示されない
トピックモデルを実行して際に、添付画像のように「参照データが更新されています。実行をクリックしてください」というメッセージが表示され、結果が表示されないことがあります。

このような状態のときは、元のデータフレームに、添付画像のようにトピックモデルが実行結果を生成する際に利用する「topic1(数字)」「max_topic」「topic_max」といった列が含まれている可能性があります。
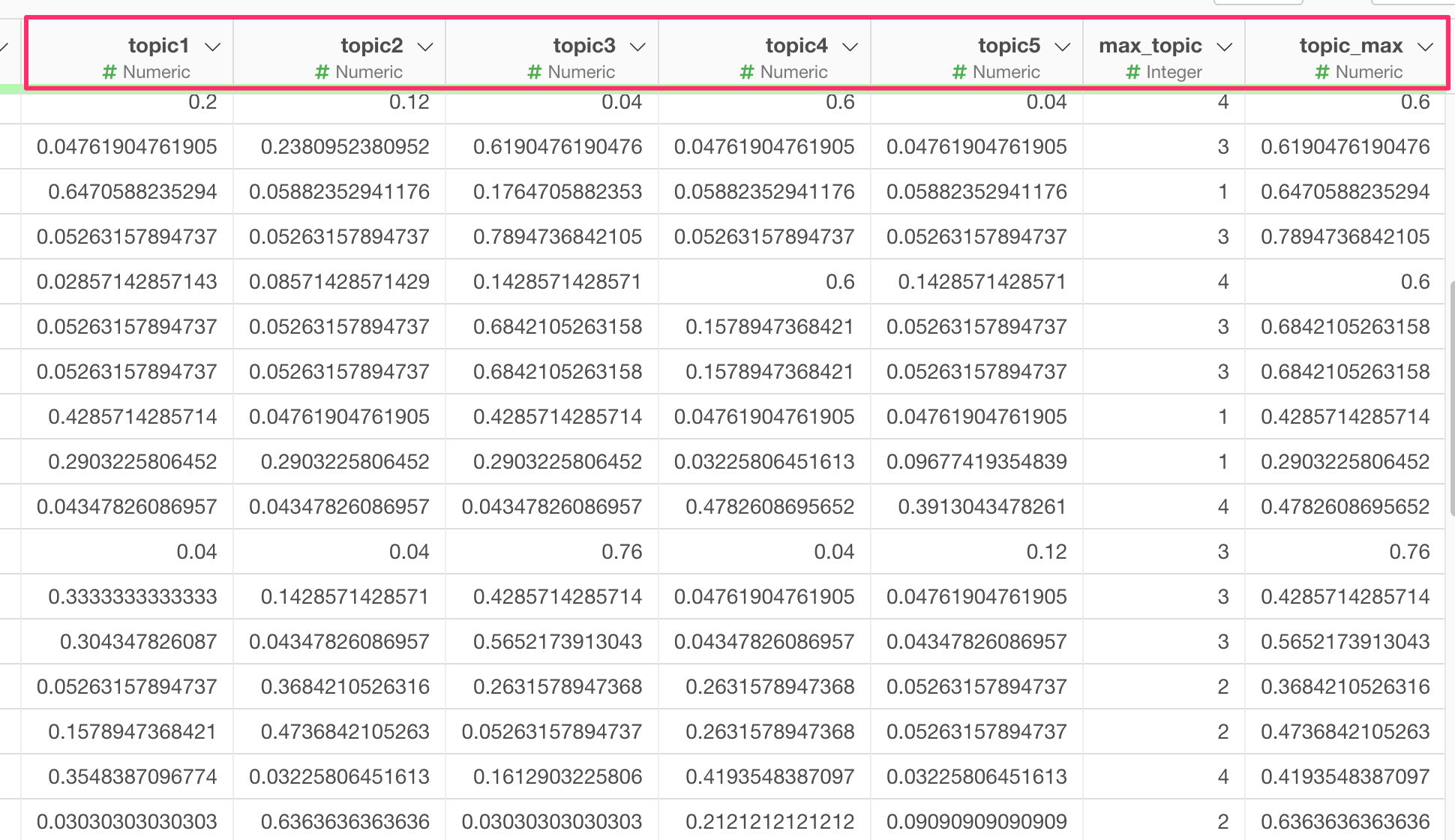
そこで、もし「topic1(数字)」「max_topic」「topic_max」という列名を含むデータフレームを使って、トピックモデルを実行したいときには、該当の列を別の列名に変更するか、それらの列を削除いただくことで、こちらの問題は解消されます。
Q: トピックモデルで「学校」、「教育」といった単語が含まれている文章を1つのトピックに強制的にまとめることはできますか。
トピックモデルでは、一緒に使われている単語の傾向が高いものを元にトピックをまとめているため、「学校」や「教育」といった単語を使っている際に、他の単語も似ている傾向があれば1つのトピックにまとまりますが、他に使われている単語が異なったりデータ量が少ない場合は異なるトピックになることがあります。
そのため、特定の単語が同じトピックにまとまるように意図的に調整することはアルゴリズムの性質上できないようになっております。
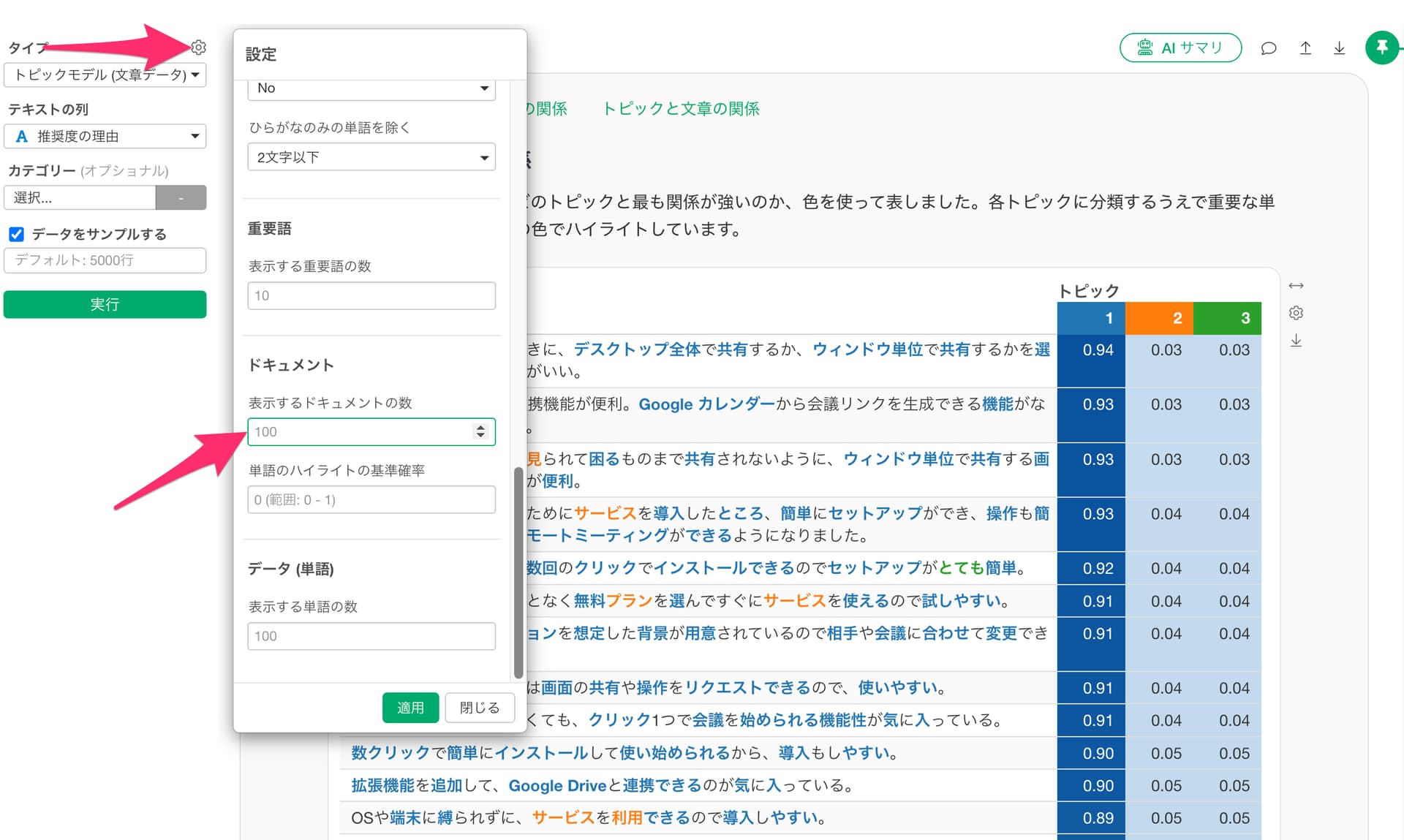
Q: トピックと文章の関係のチャートで100件以上の文章を表示させたい。
トピックと文章の関係のチャートの表ではデフォルトで100件の文章が表示されます。
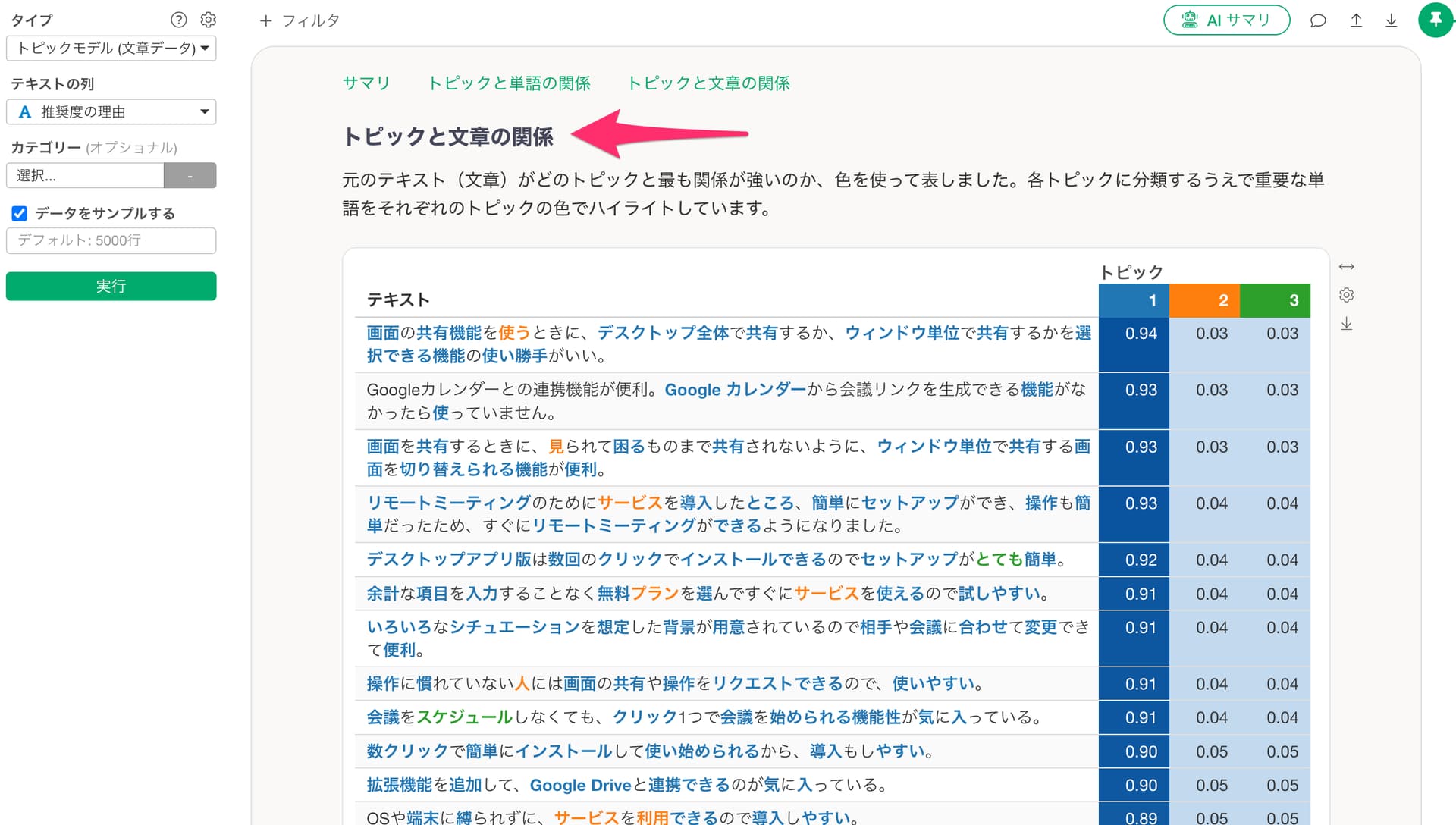
100件以上の文章を表示させたい場合は、チャートの設定ボタンをクリックし、「表示するドキュメントの数」に表示させたいドキュメント数を入力してください。
アンケートデータ分析トレーニング
様々な形のアンケートデータからビジネスや顧客サービスの改善につながるインサイトを掘り出すための分析手法を効率的に身に着けていただくためのトレーニングを開催しています!
アンケートデータは持っているが活用しきれていない、分析または可視化の手法を効果的に学びたいと行った方は、ぜひご参加を検討下さい!
<a href=“https://exploratory.io/survey-data-training-jp” class=“btn btn-primary” target=“_blank”> 詳細はこちら</a>