データの基礎
こちらのノートでは、データ分析をするうえで欠かせないExploratoryの基礎や「データタイプ」について紹介いたします。
1. プロジェクトを作成する
Exploratoryではデータのインポートを含め、全てのデータに関する作業はプロジェクトの中で行います。
そのため、まずはプロジェクトを作成します。
プロジェクトの管理画面から「新規作成」のボタンをクリックします。
任意のプロジェクト名を入力して作成ボタンをクリックします。
新しく作られたプロジェクトが開きます。

2. データをインポートする
プロジェクトを作成することができたら、次はデータをインポートしましょう。
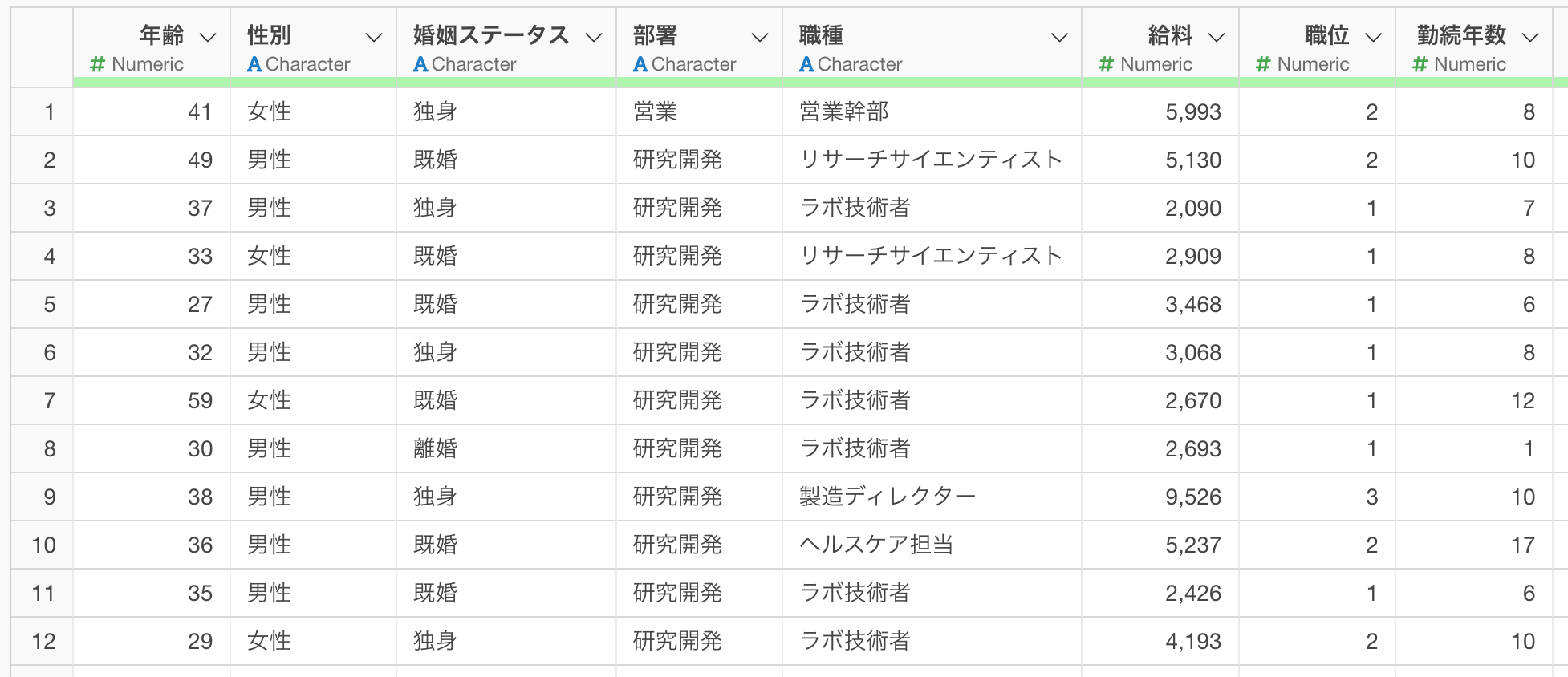
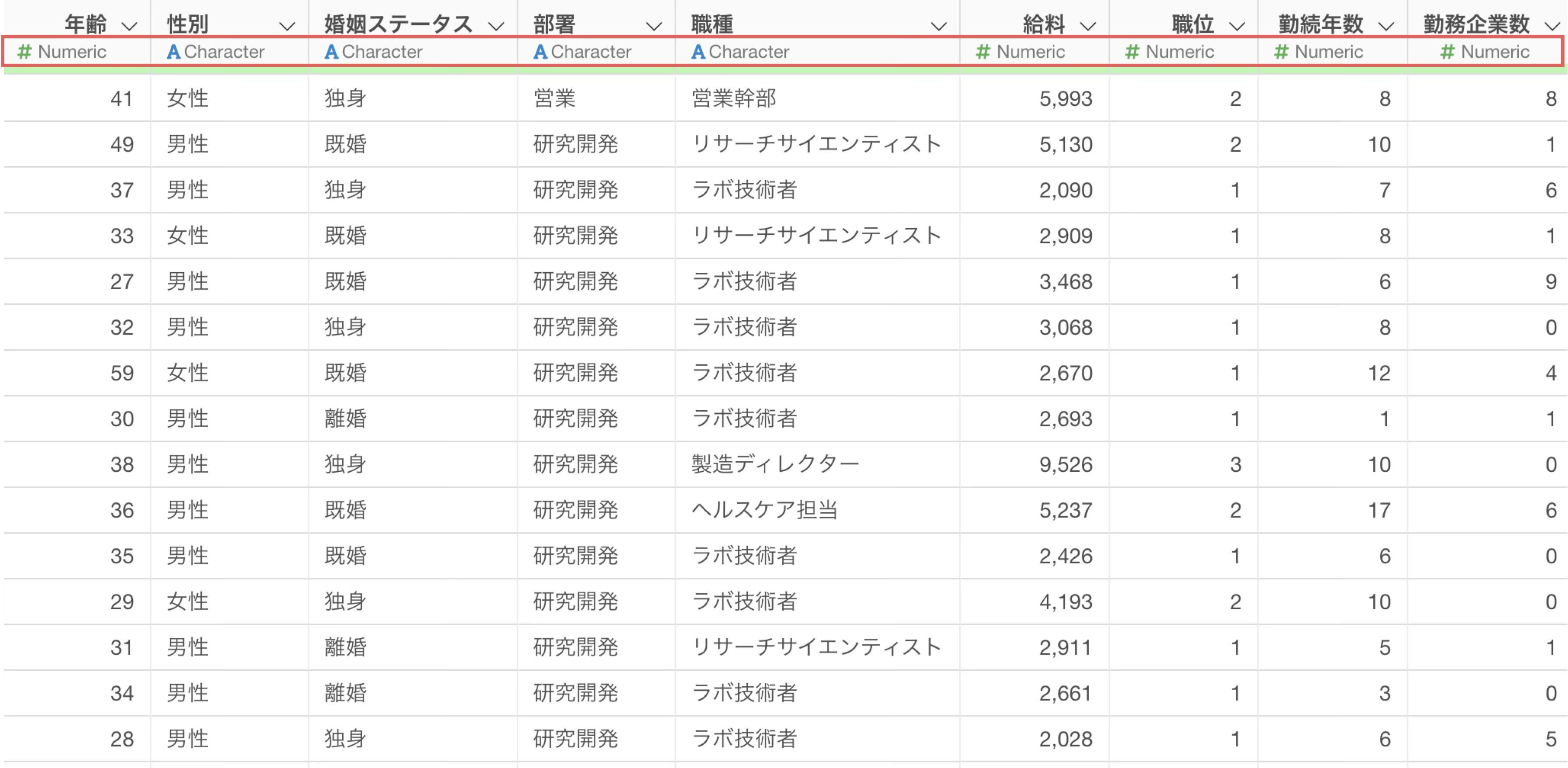
今回は、1行が1人の従業員を表しており、年齢・性別・勤続年数・給料・職種・離職状況などの情報が含まれているデータを利用します。
データはこちらのページからダウンロードできます。
Macをお使いの方は「CSV-UTF8」を、Windowsをお使いの方は「CSV - Shift-JIS」をダウンロードしてください。
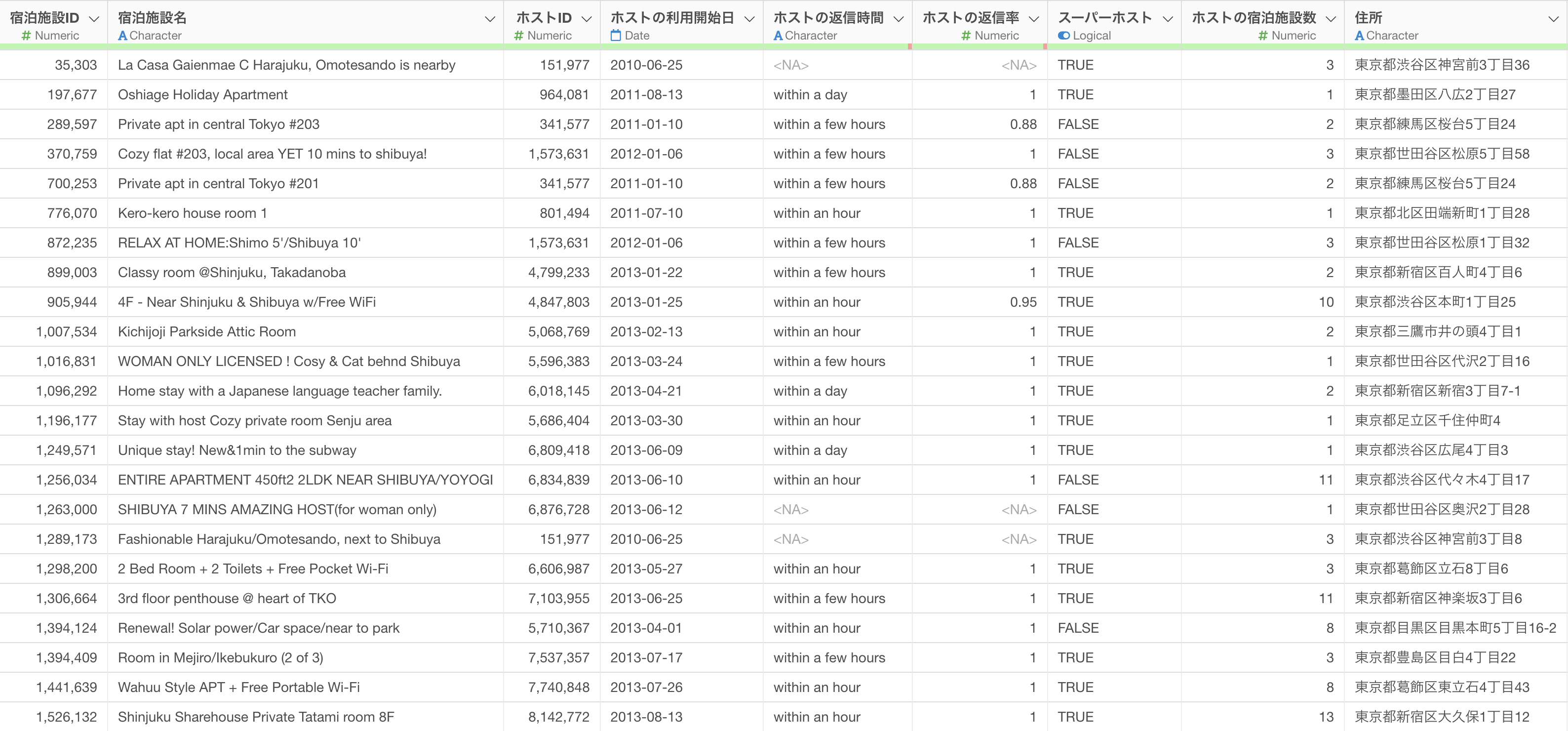
このデータは1行が1人の従業員を表しており、それぞれの従業員に関する情報が列として入っています。
データをダウンロードできたら、ダウンロードしたフォルダを開き、Exploratoryの画面にファイルをドラッグ&ドロップします。
するとデータをインポートするためのダイアログが開きますので、今回はそのまま「インポート」ボタンをクリックします。
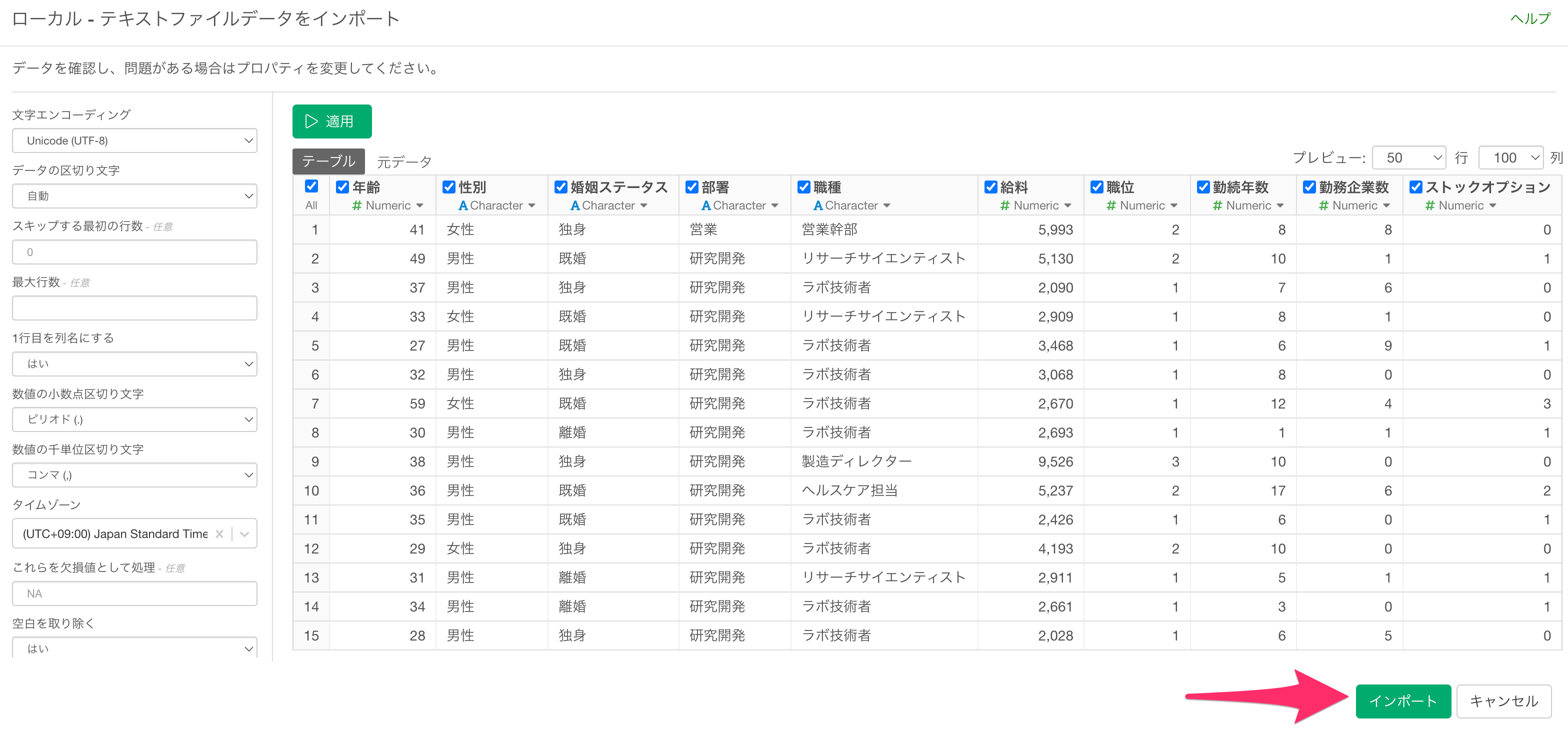
データのインポートのためのダイアログの左側には、インポート時のデータの読み取り方についての様々な設定を行うことが可能です。
任意のデータフレーム名を指定して、「作成」ボタンをクリックします。
データがインポートされると、サマリ・ビューというデータの概要を簡単に確認できる画面が表示されます。
画面の表示領域を広くしたい場合は、「サイドバーを隠す」のボタンをクリックして左側のデータフレームなどがリストされるサイドバーを隠す、またはドラッグ&ドロップでサイドバーの幅を狭めることができます。
サイドバーを隠す:
サイドバーの幅を調整する:
列数と行数
データの「列数」や「行数」は常に画面の上部に表示されるようになっています。
3. 4つのビュー
Exploratoryではデータをインポートすると上部に以下の4つの「ビュー(View)」メニューが表示されます。
- サマリ・ビュー
- テーブル・ビュー
- チャート・ビュー
- アナリティクス・ビュー
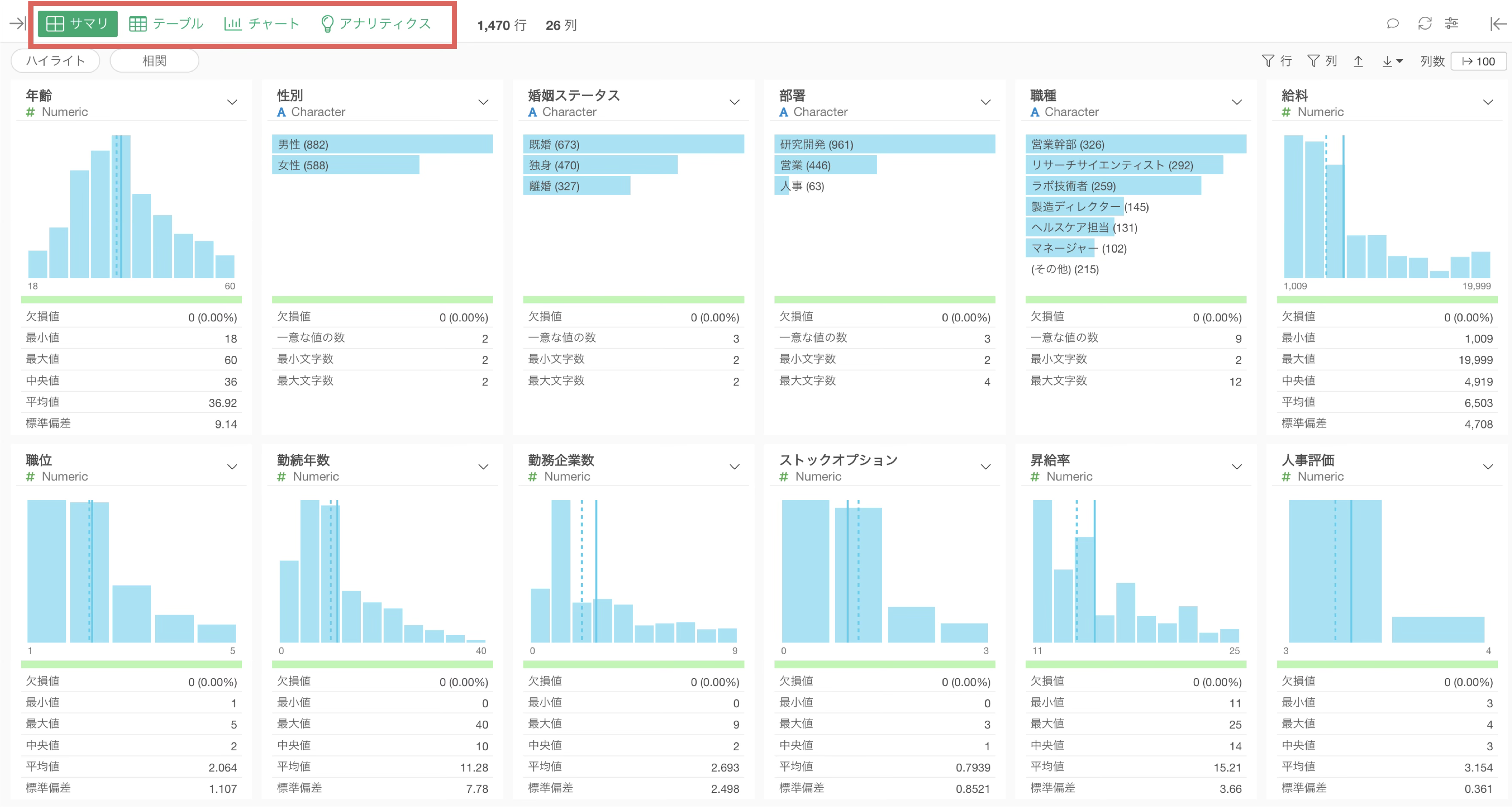
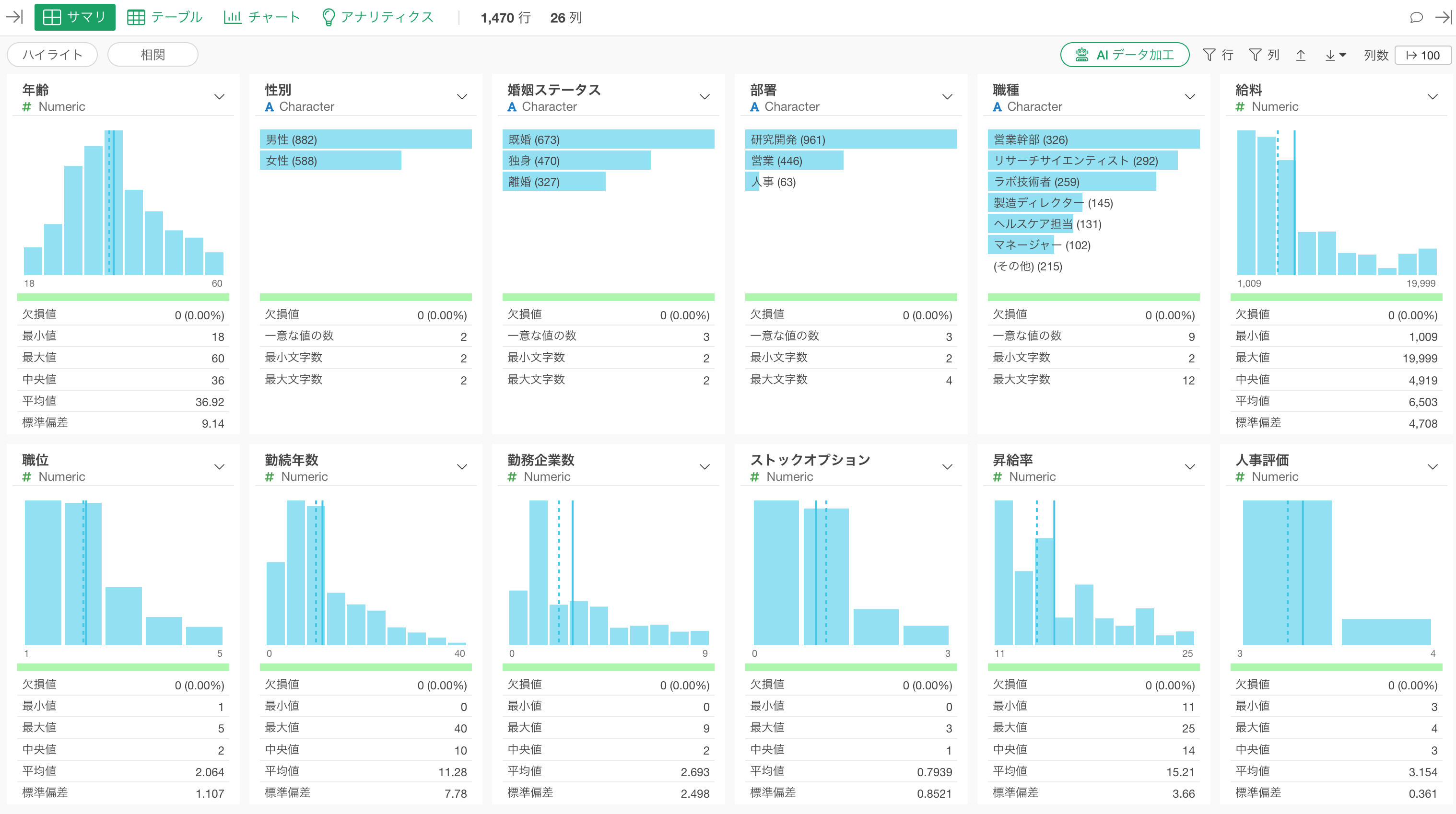
サマリ・ビュー
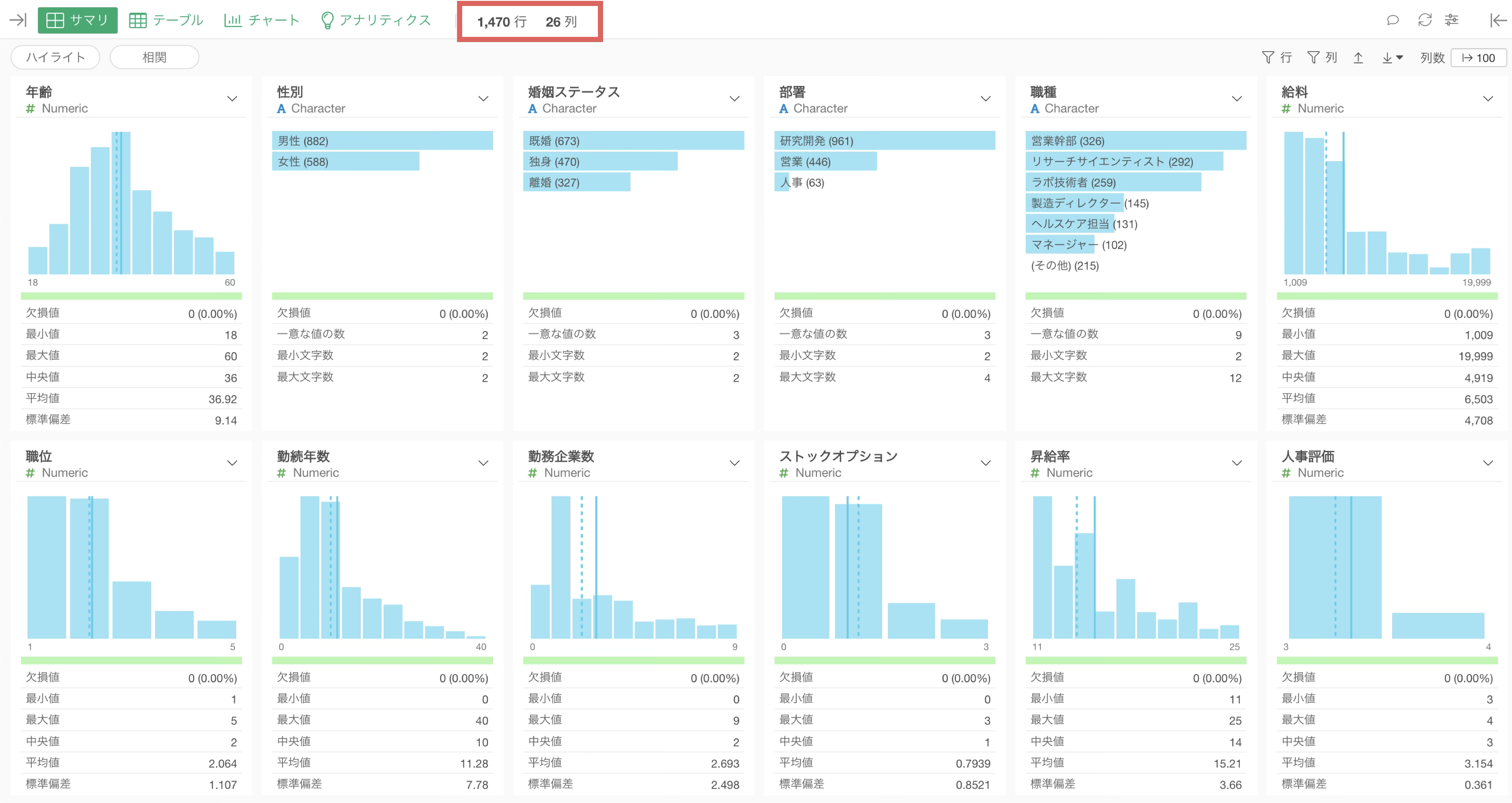
各列の統計情報(数値の指標)とデータの分布を描いたチャートが自動的に生成されます。
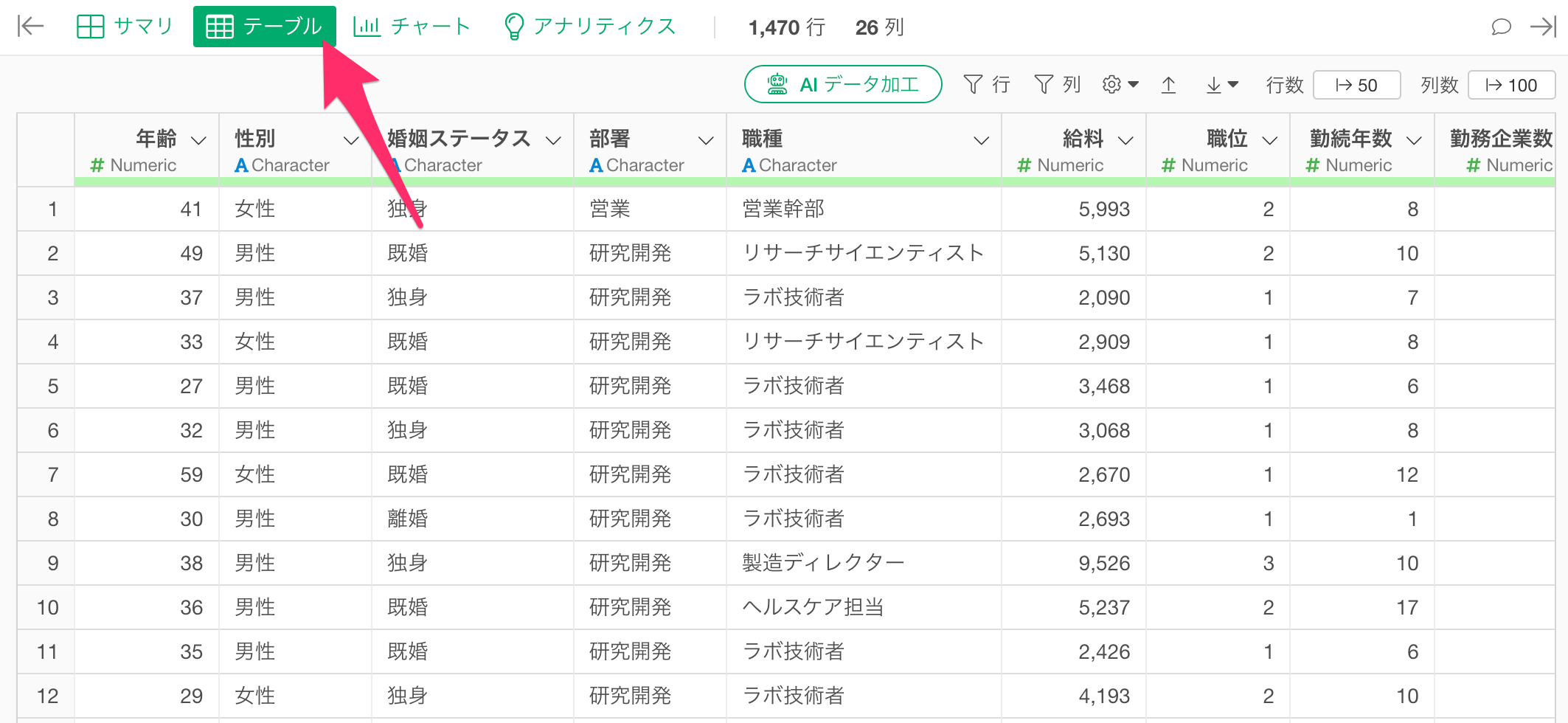
テーブル・ビュー
データが表形式で表示され、行単位でデータを確認できます。
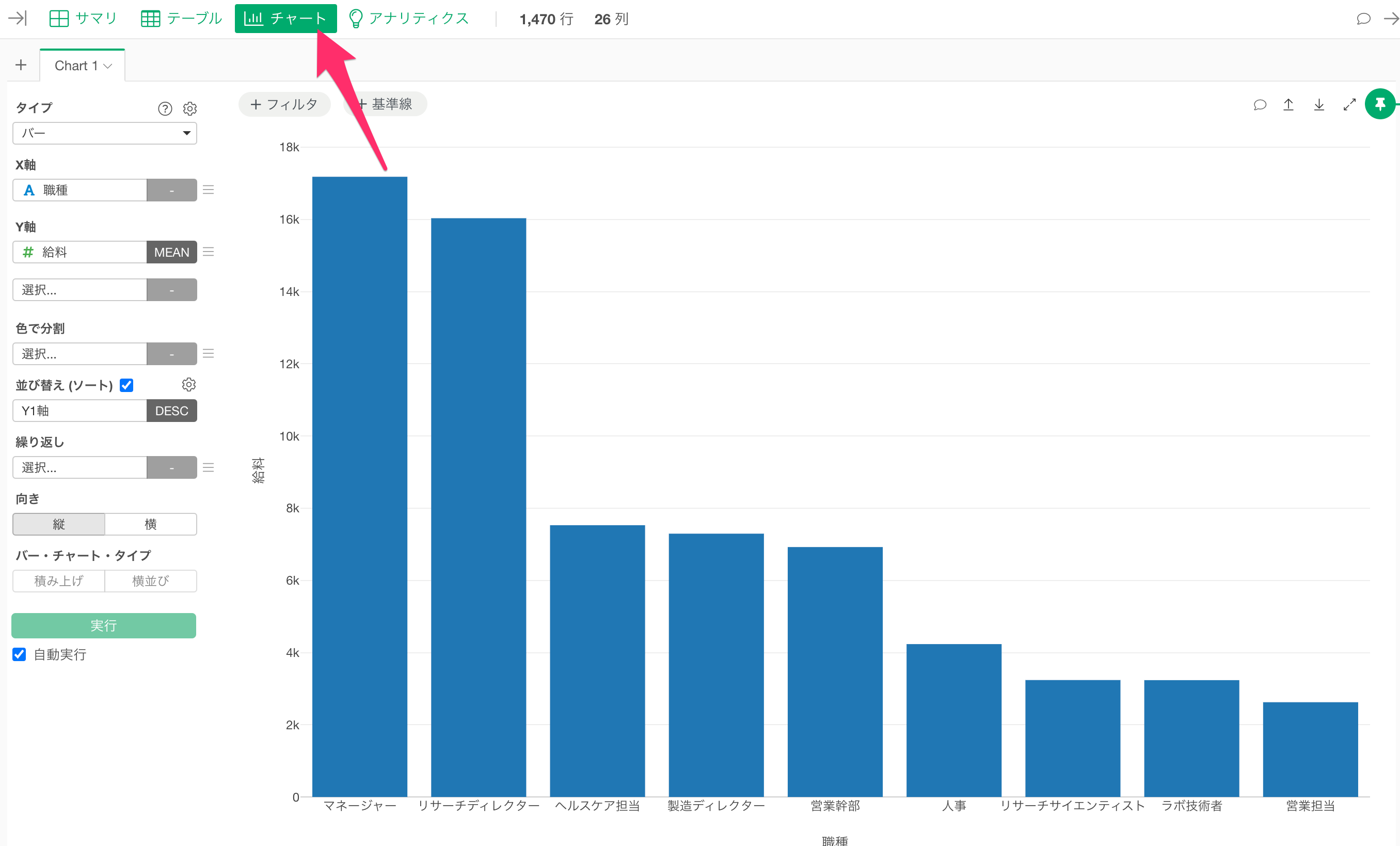
チャート・ビュー
チャートを使って様々な角度からデータを可視化し、データの中にあるパターンやトレンドを発見していくことができます。
アナリティクス・ビュー
様々な統計や機械学習のアルゴリズムを使ってデータを分析することができます。
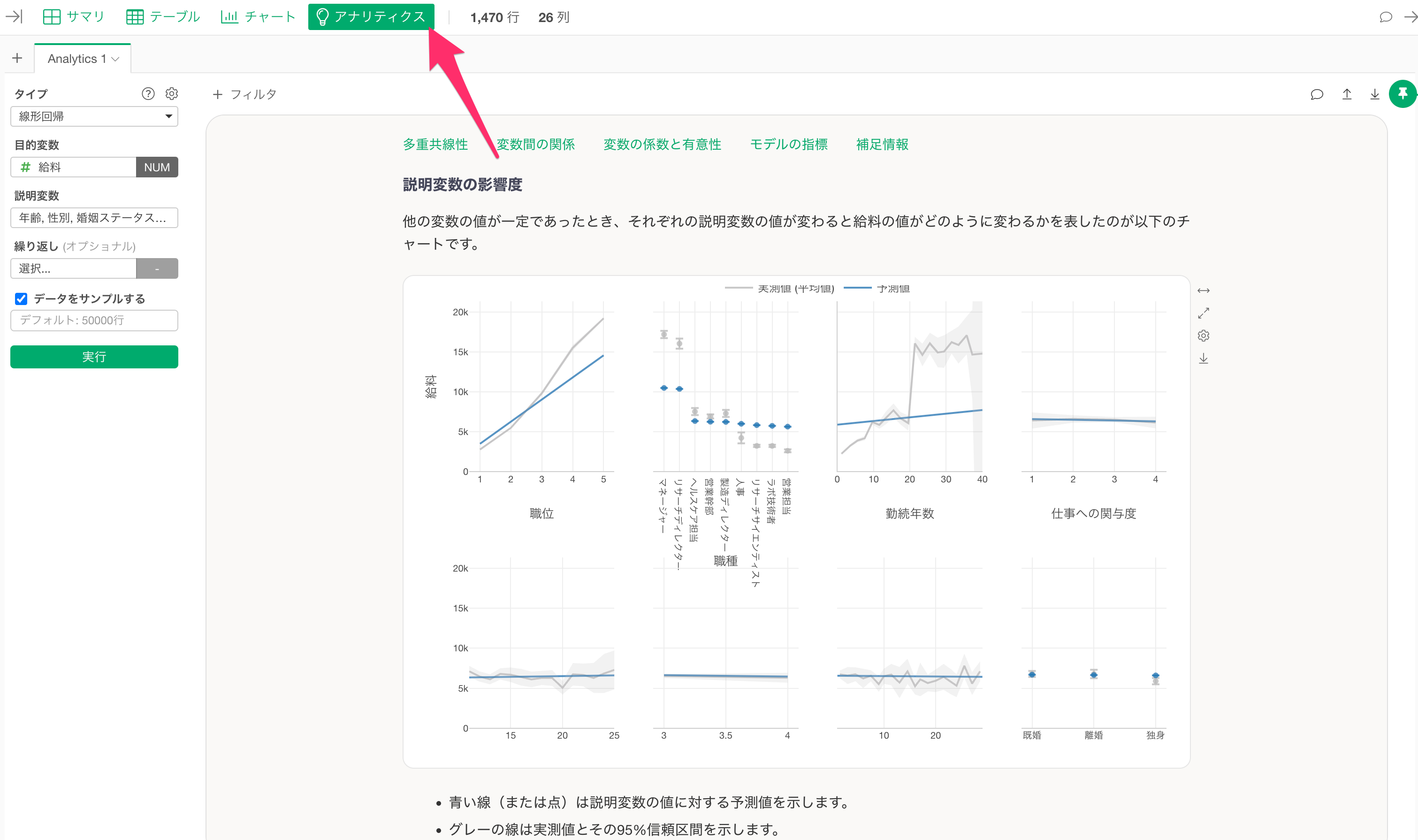
また、Exploratoryでは「ガイド付きのアナリティクス」の機能によって、分析結果を初心者でも理解できるように、各チャートの見方や分析手法に関する詳細な説明を自動的に表示されるようになっています。
4. データ型
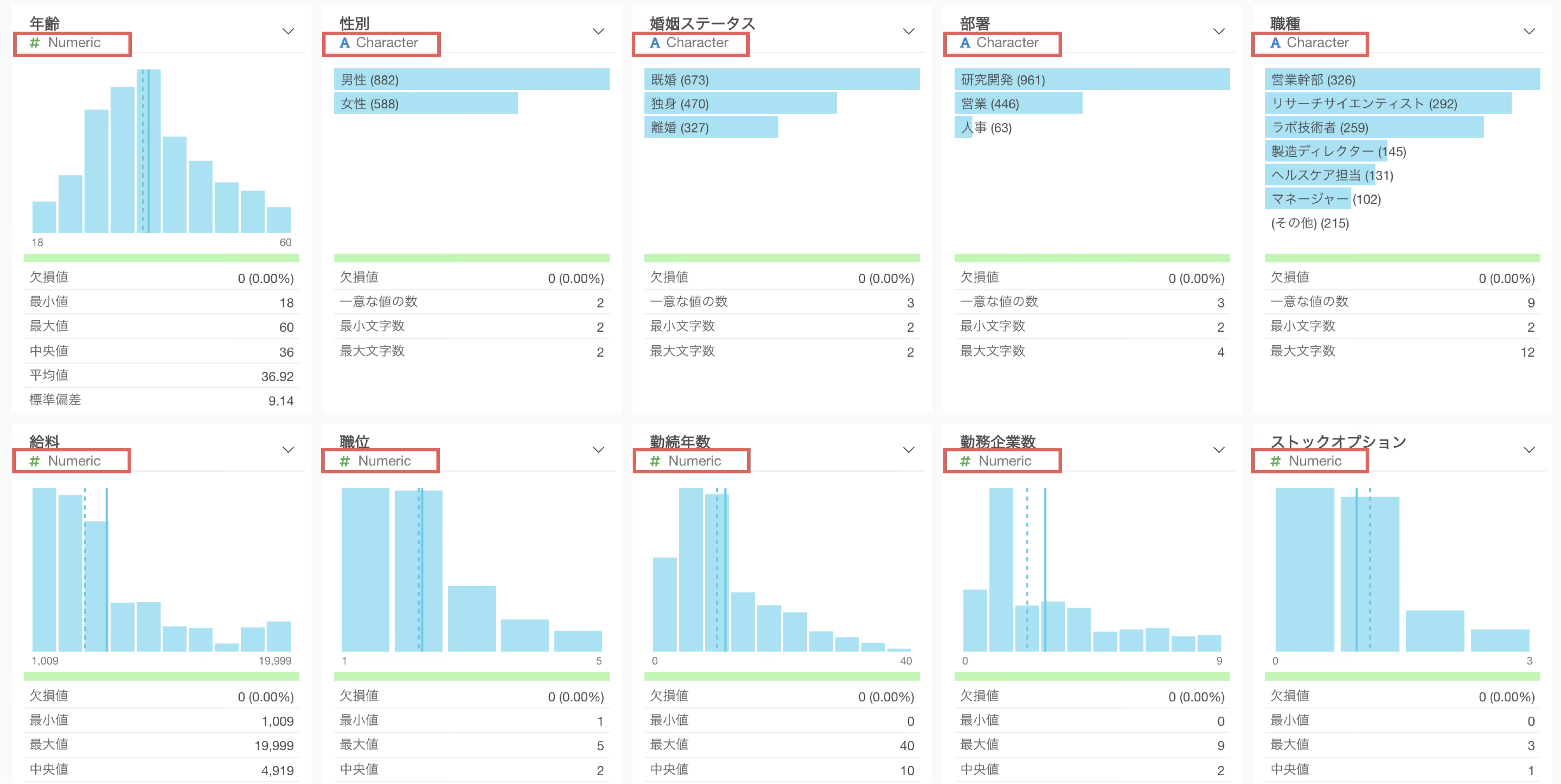
サマリ・ビューやテーブル・ビューで表示される統計情報とチャートはそれぞれの列の「データ型」によって変わります。
データ型は、その列に入っているデータの「種類」を表しています。データ型によって、使える分析手法やチャートの描き方が変わってきますので、分析を始める前にきちんと確認・設定しておくことが重要です。
サマリ・ビュー
テーブル・ビュー
Exploratoryでは多くのデータ型がサポートされていますが、よく使われるのは以下の5つのタイプです。
- 数値(Numeric)
- 文字列(Character)
- 順序つきカテゴリー(Factor)
- ロジカル(Logical)
- 日付、日付/時間(Date, POSIXct)
数値型(Numeric)
数値型はその名のとおり、数値のデータを表します。数値型には次の2つの特徴があります。

- 連続性がある: 数値は0、10、20、30と独立して存在するのではなく、その間にも10.1、10.2、10.3…と連続した値が存在します。
- 順序関係がある: 20は30より小さい、50は40より大きい、というように大小関係が明確です。
数値型の列は、値を等幅(数値の範囲を均等に分ける)に10等分したバーチャートが表示されます。また、バーにマウスを重ねるとその数値の範囲に含まれる行数が表示されるようになっています。
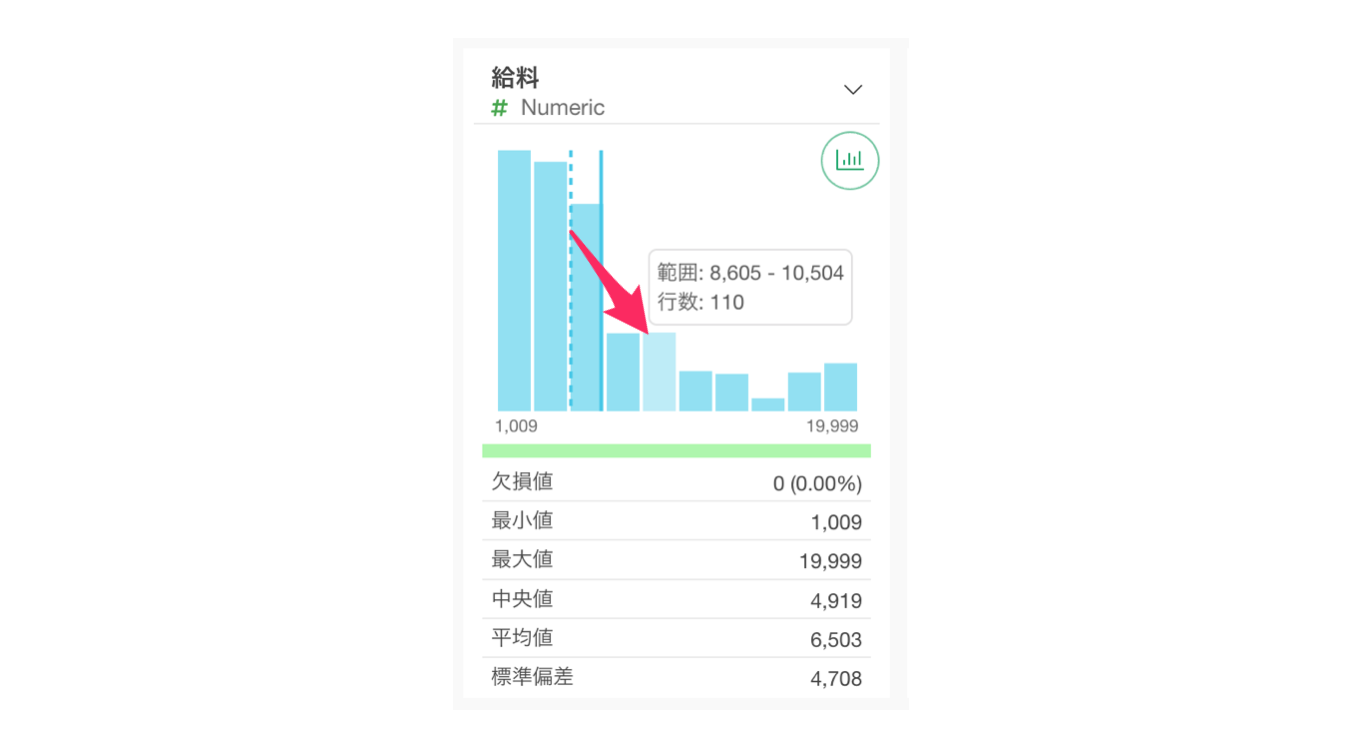
サマリ・ビューのヒストグラムでは、実線で「平均値」が、点線で「中央値」が表されます。
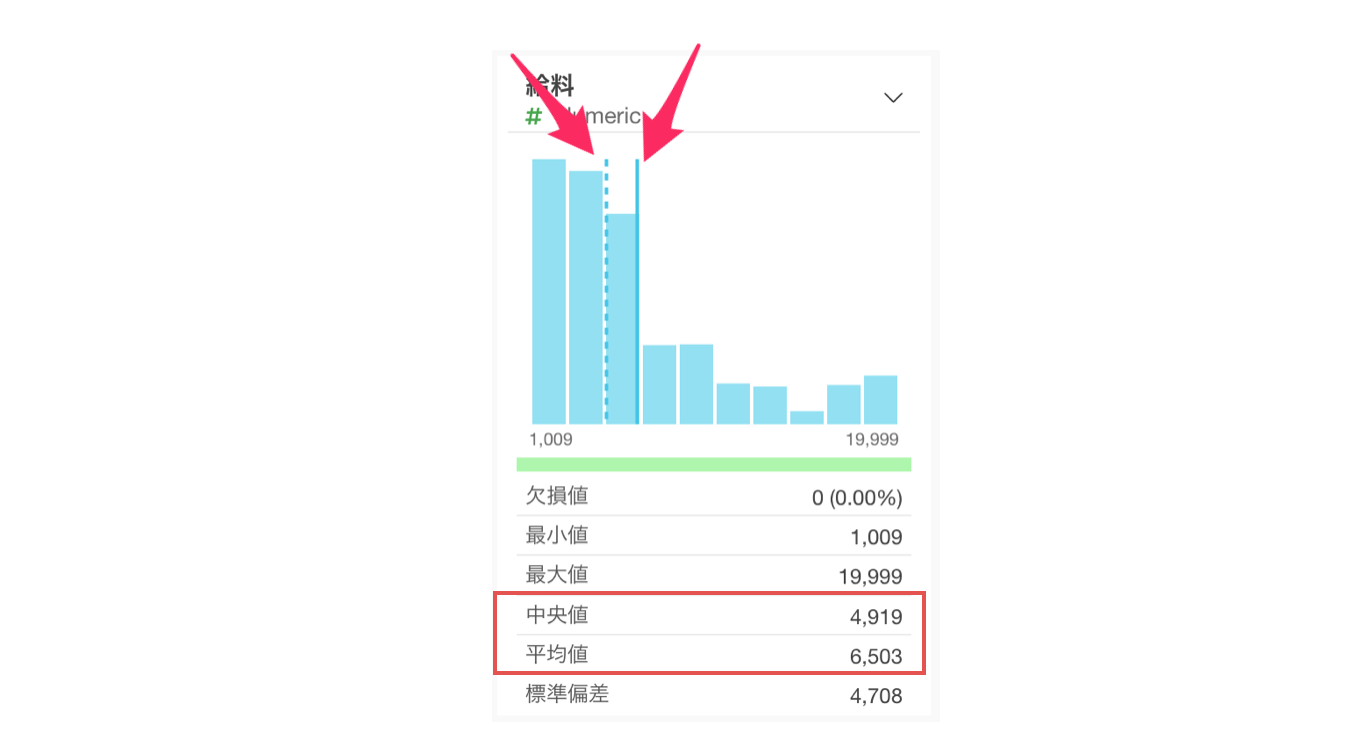
チャートの下部では「値の範囲」や「代表値」を確認できます。
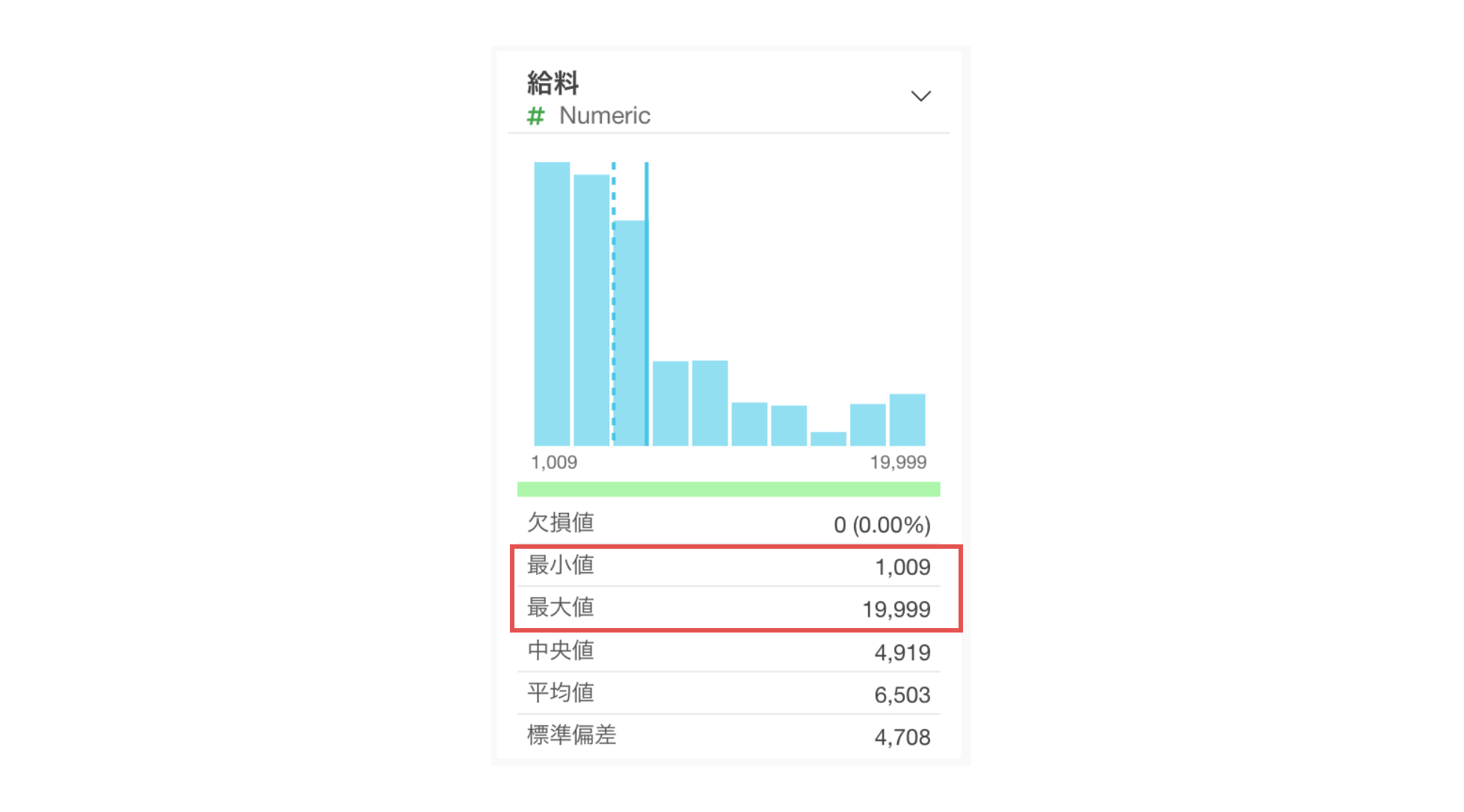
例えば、今回のデータのサマリ・ビューを確認すると、給料の最小値は1,009ドル、最大値は19,999ドルであることがわかります。
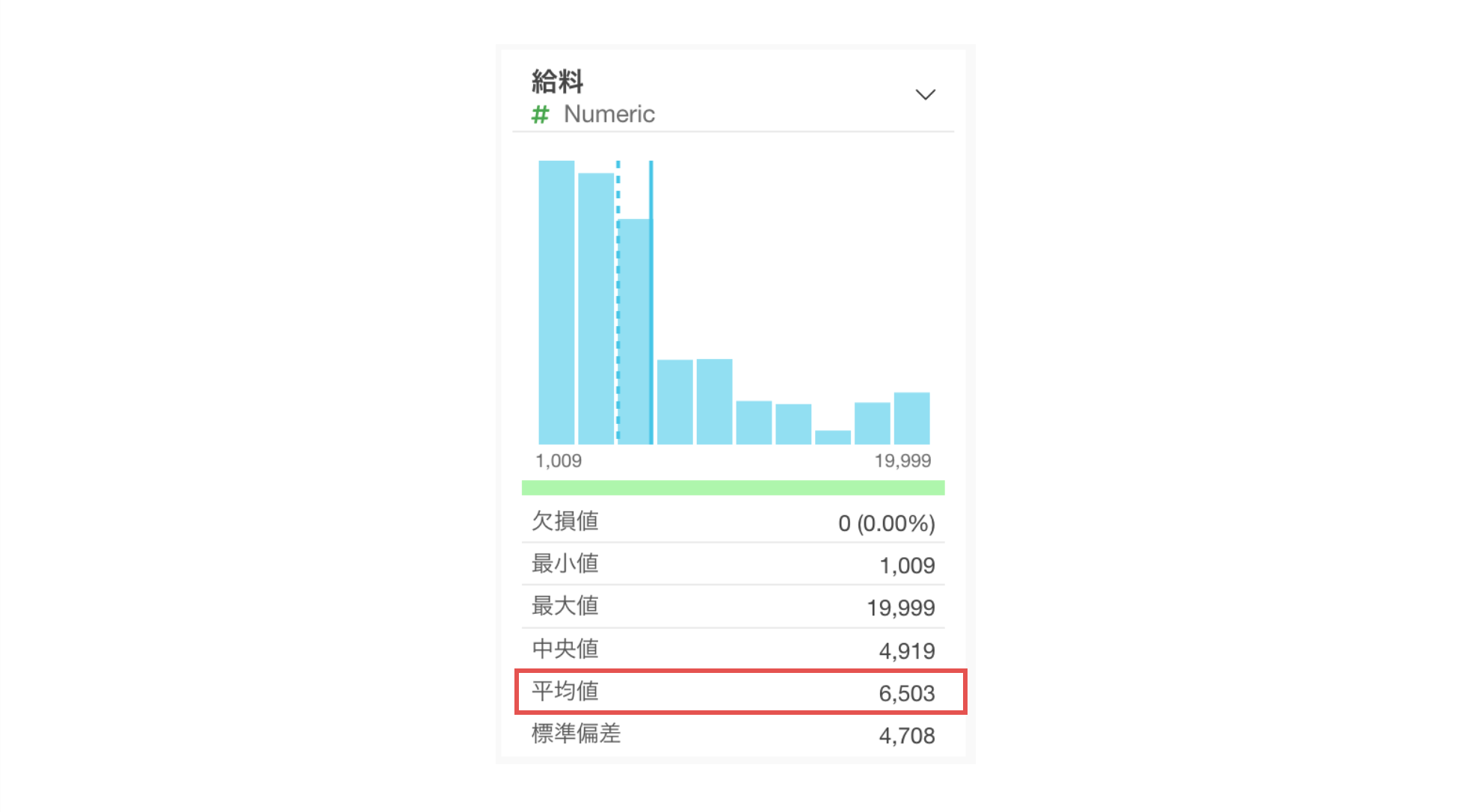
また給料の平均値が6,503ドルということもわかります。
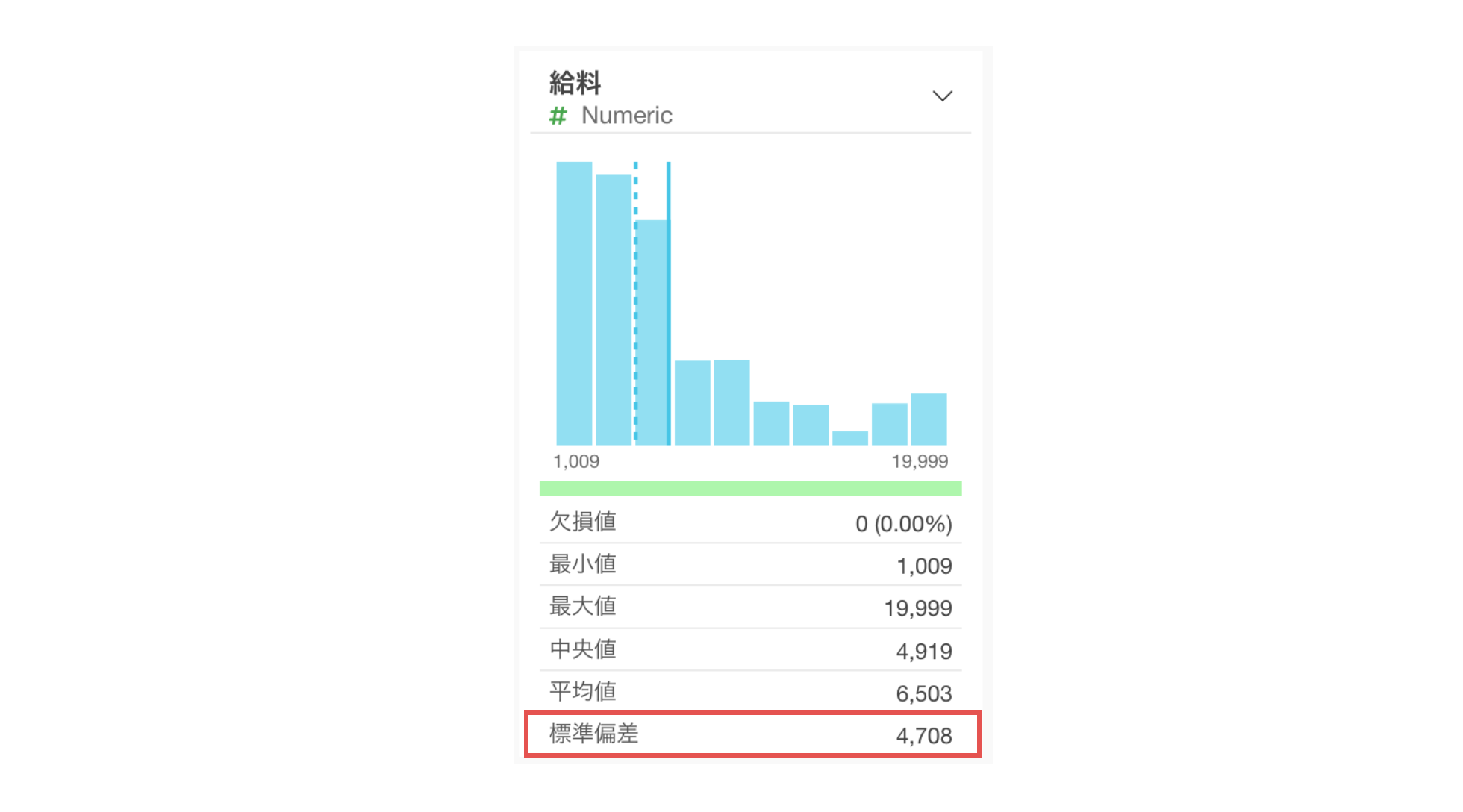
標準偏差は、データのばらつきの大きさを表す指標です。数値が大きいほど、データが平均値から大きく広がっていることを意味します。
カテゴリー型(Character)
カテゴリー型は、文字列のデータを表します。

カテゴリー型には数値型とは異なる以下のような特性があります。
- 連続性がない: 例えばカリフォルニア州とニューヨーク州の間に何かが連続しているわけではありません。それぞれのカテゴリーは独立した別の値です。
- 順序関係は必ずしもない: 職種や婚姻ステータスなどのカテゴリーには、基本的に大小関係や順序はありません。
カテゴリー型の列は、サマリ・ビューで行の数を表す横向きのバーチャートが表示されます。
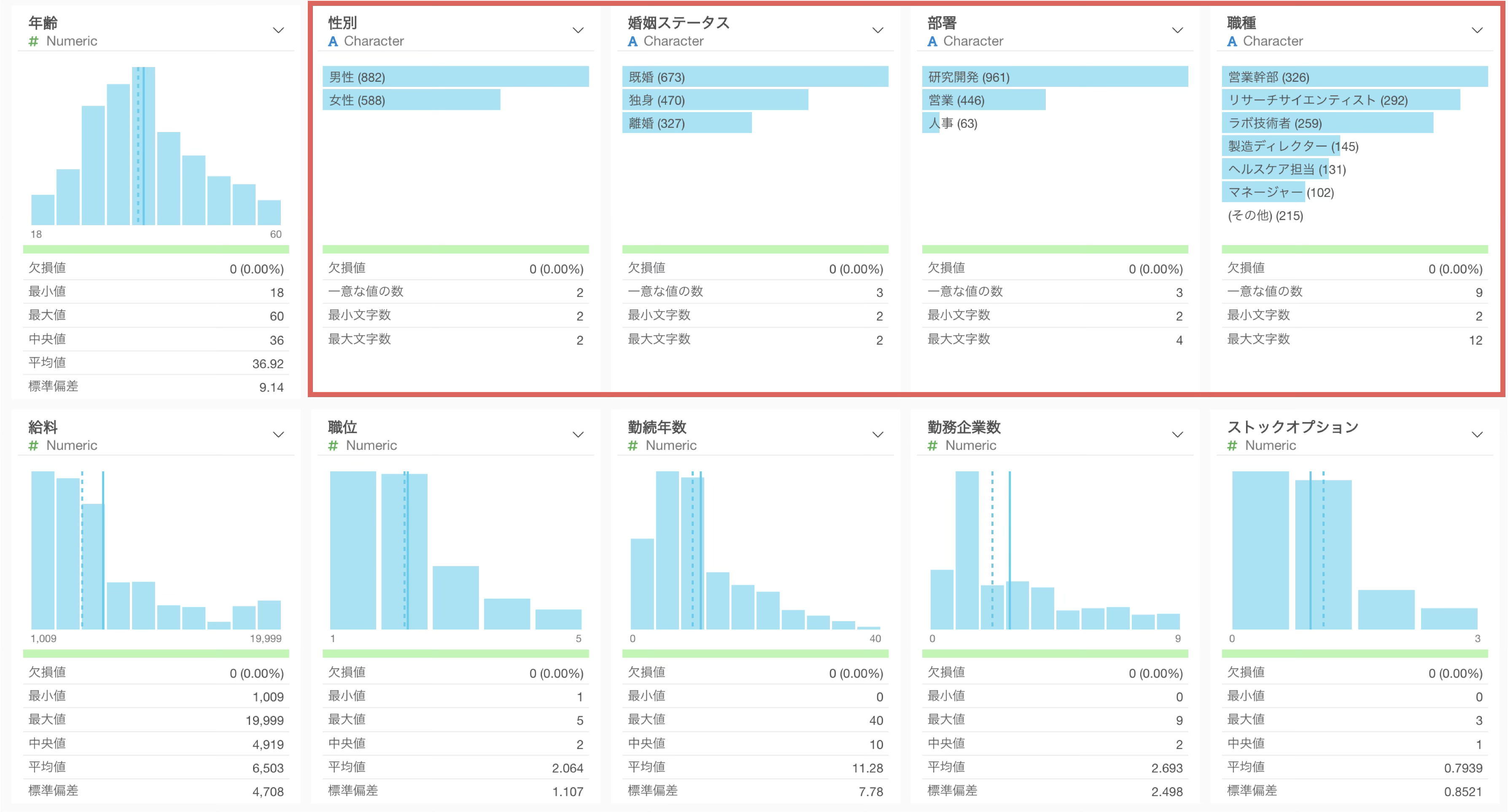
最も頻繁に出てくる値から順番に上から表示されますが、スペースの都合上、6番目以降の値は「その他」にまとめられます。
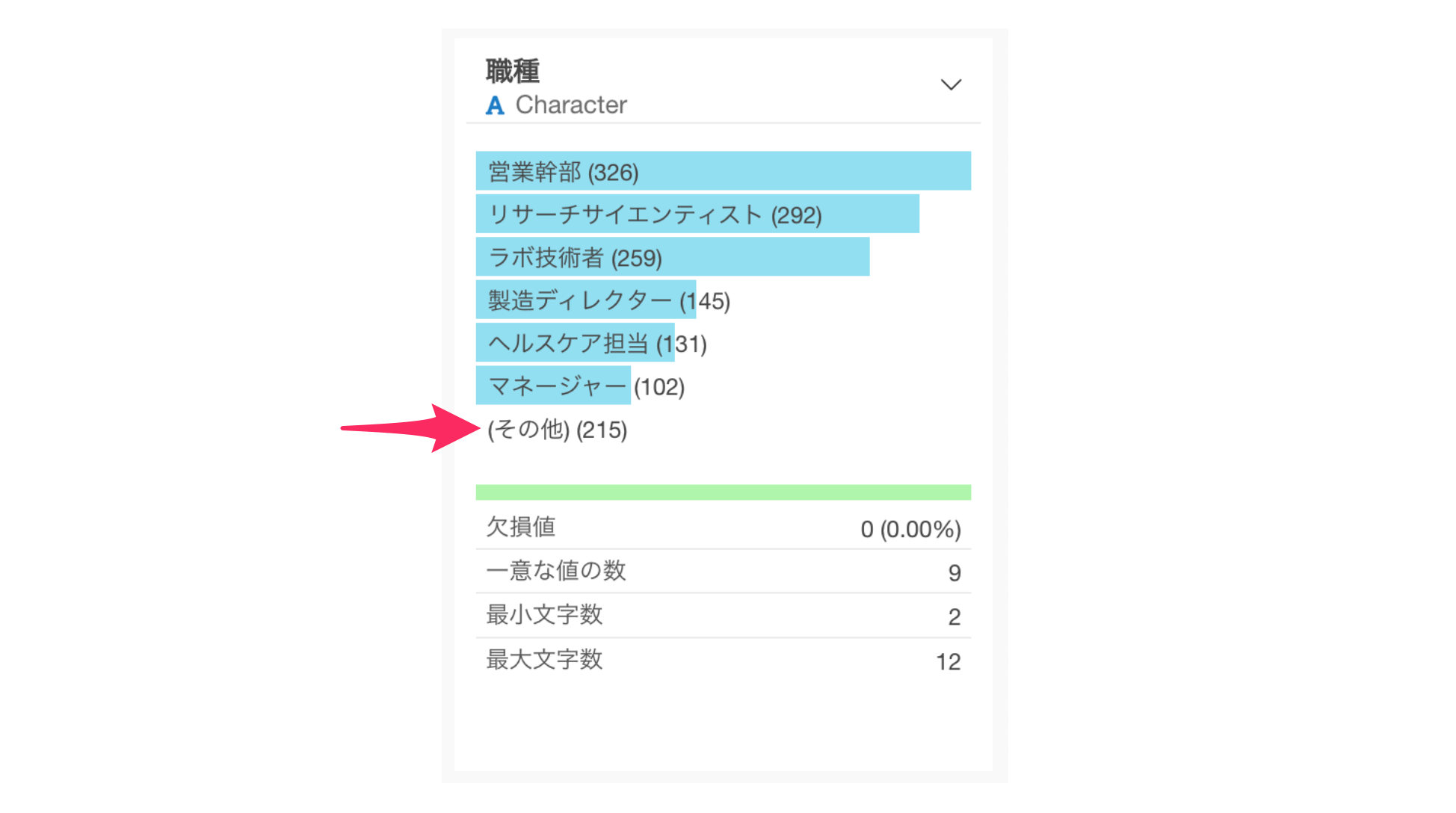
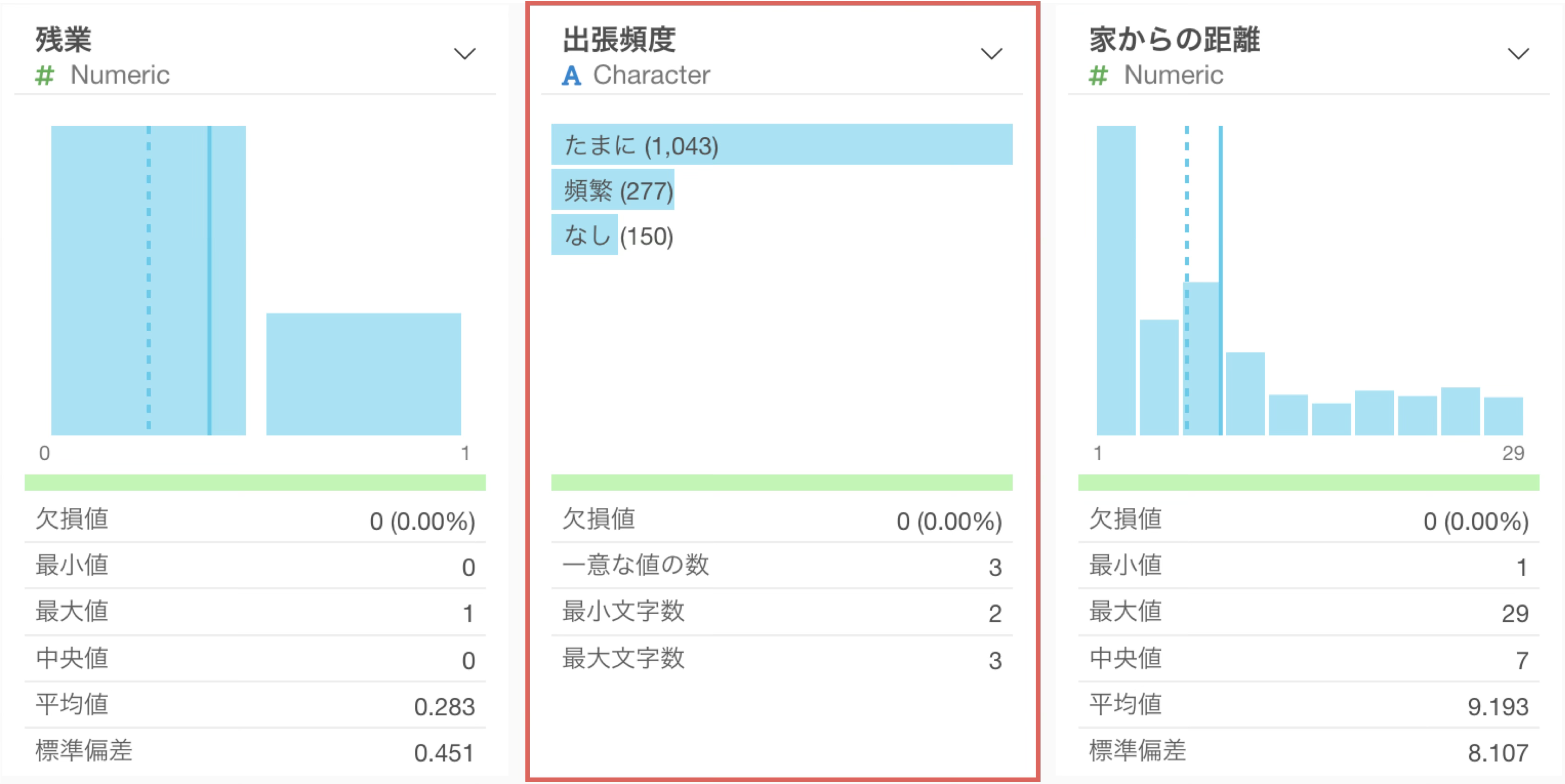
サマリ・ビューでは「一意な値の数」も確認できます。
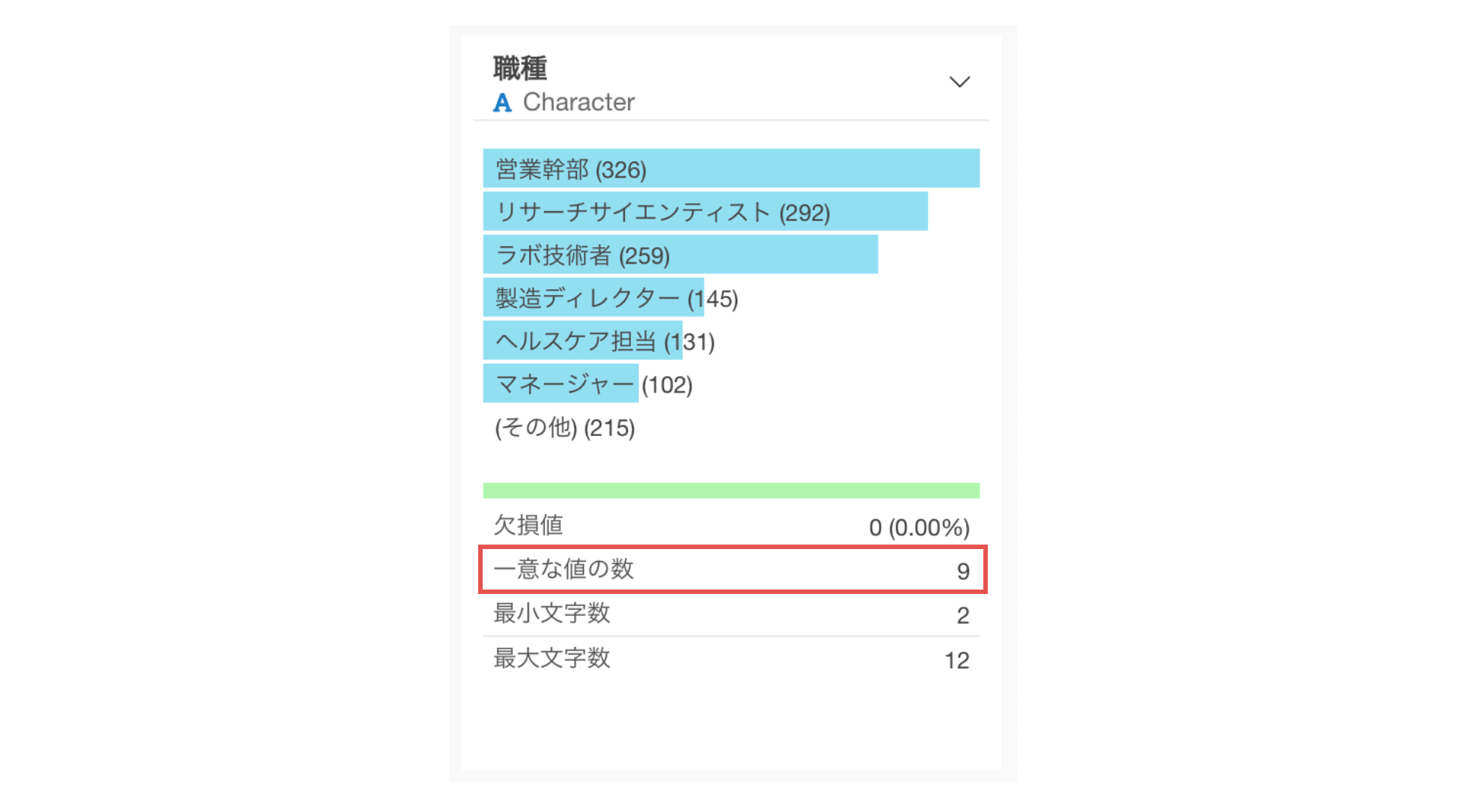
これはこの列にいくつのパターン(カテゴリー)が存在するかを示しています。職種の一意な値の数は9ですので、このデータには9種類の職種があることがわかります。
順序つきカテゴリー(Factor)
順序つきカテゴリー(Factor)は、カテゴリー型の特殊なパターンです。
「小・中・大」や「なし・たまに・頻繁」のように、文字列でありながら内在的に順序関係を持っているデータを表します。
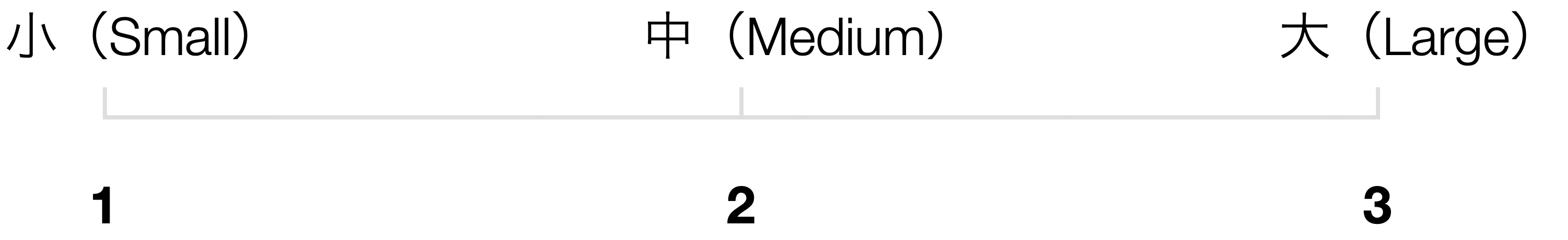
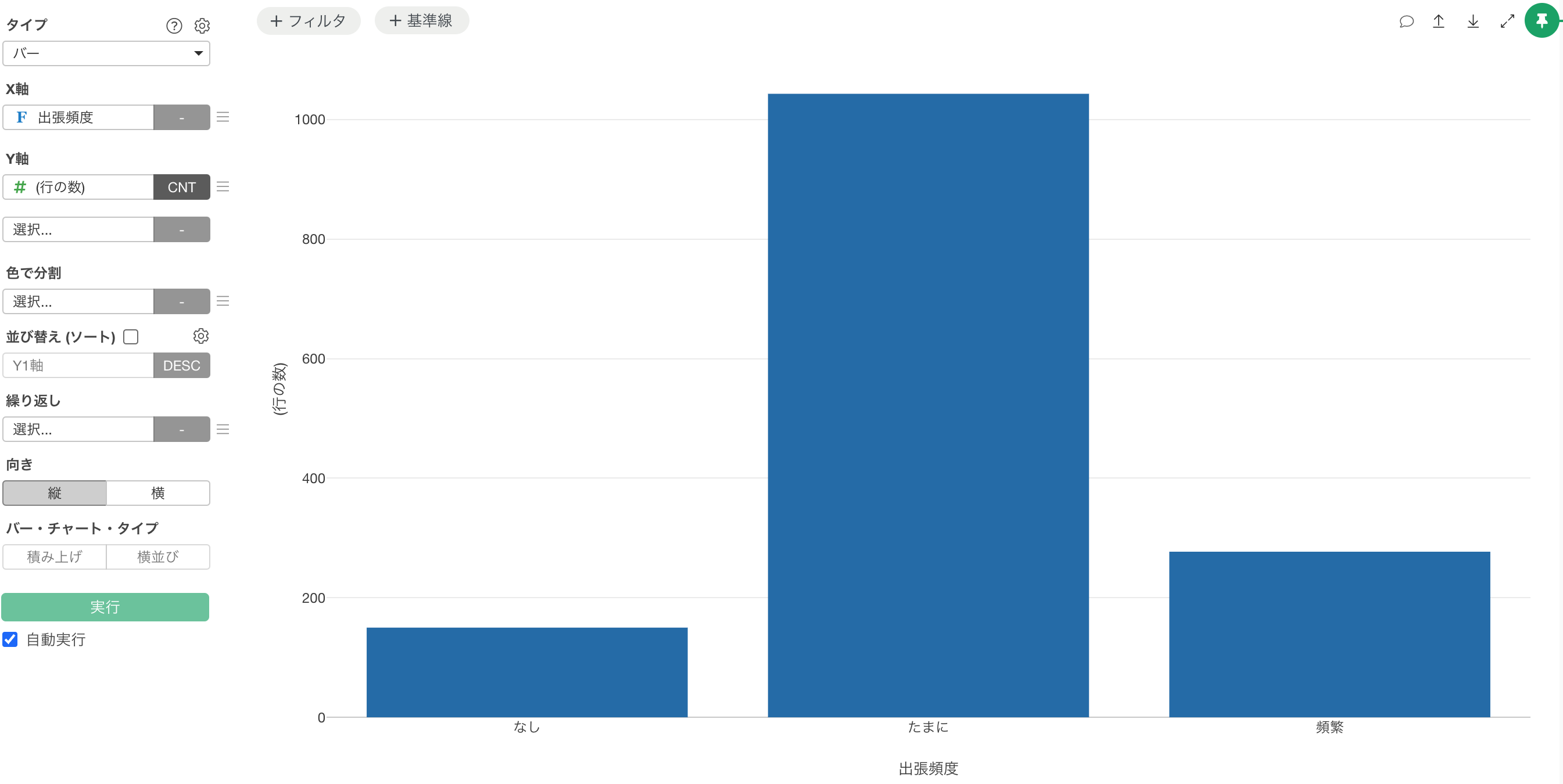
例えば、バーチャートで「出張頻度」の列をX軸に選択すると、X軸は「たまに」、「なし」、「頻繁」の順で表示されます。
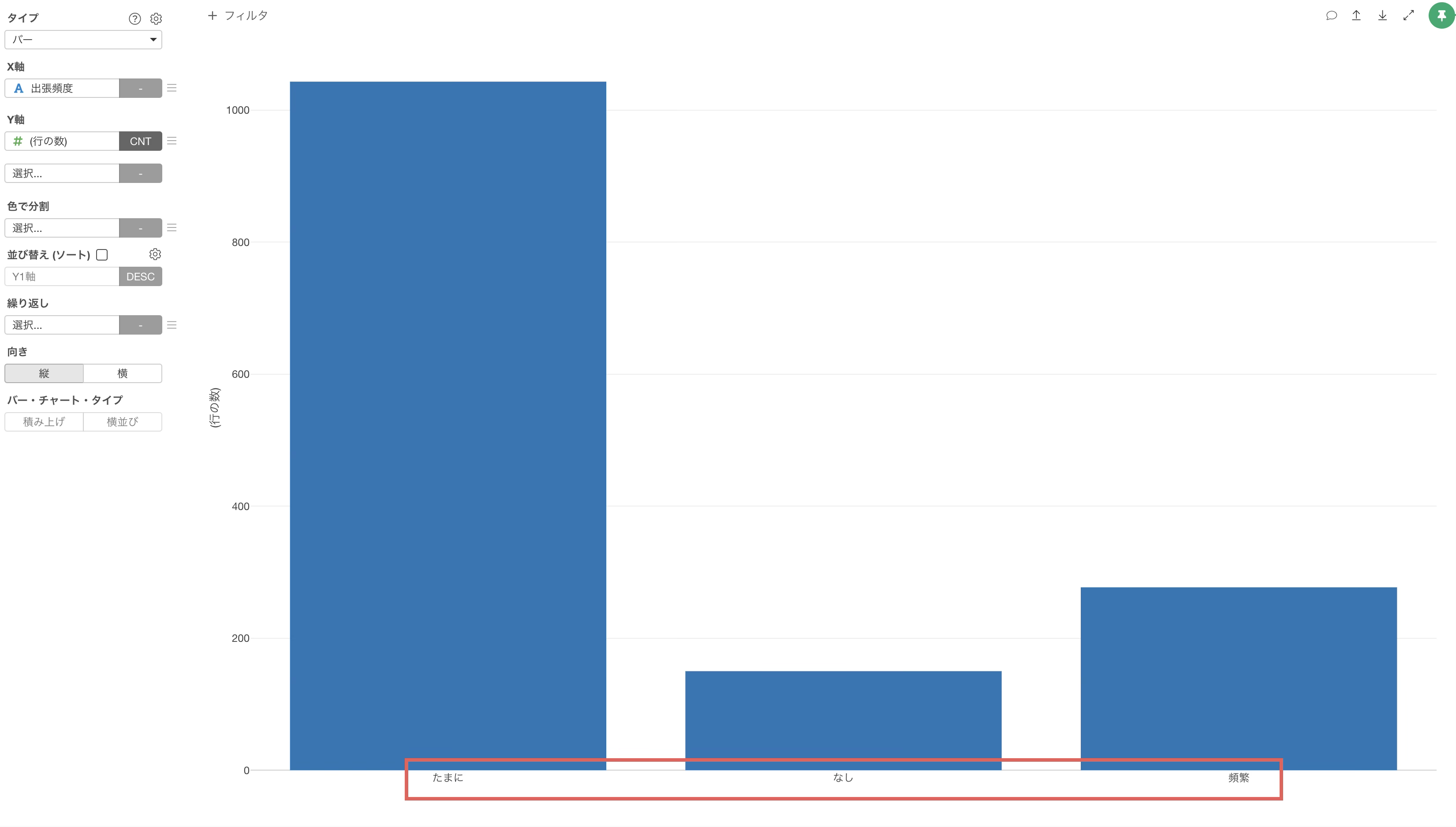
このような順番は、私たちが直感的に思い浮かべる「なし → たまに → 頻繁」という並びとは異なります。
こういった「内在的に順序関係があるカテゴリーデータ」に対して、Factor型として順序を指定しておくと、チャートで常に意図した順番で表示できるようになります。
カテゴリー型では列に値だけが格納されますが、順序つきカテゴリー型では、値に加えて「レベル」という順序情報を持たせることができます。

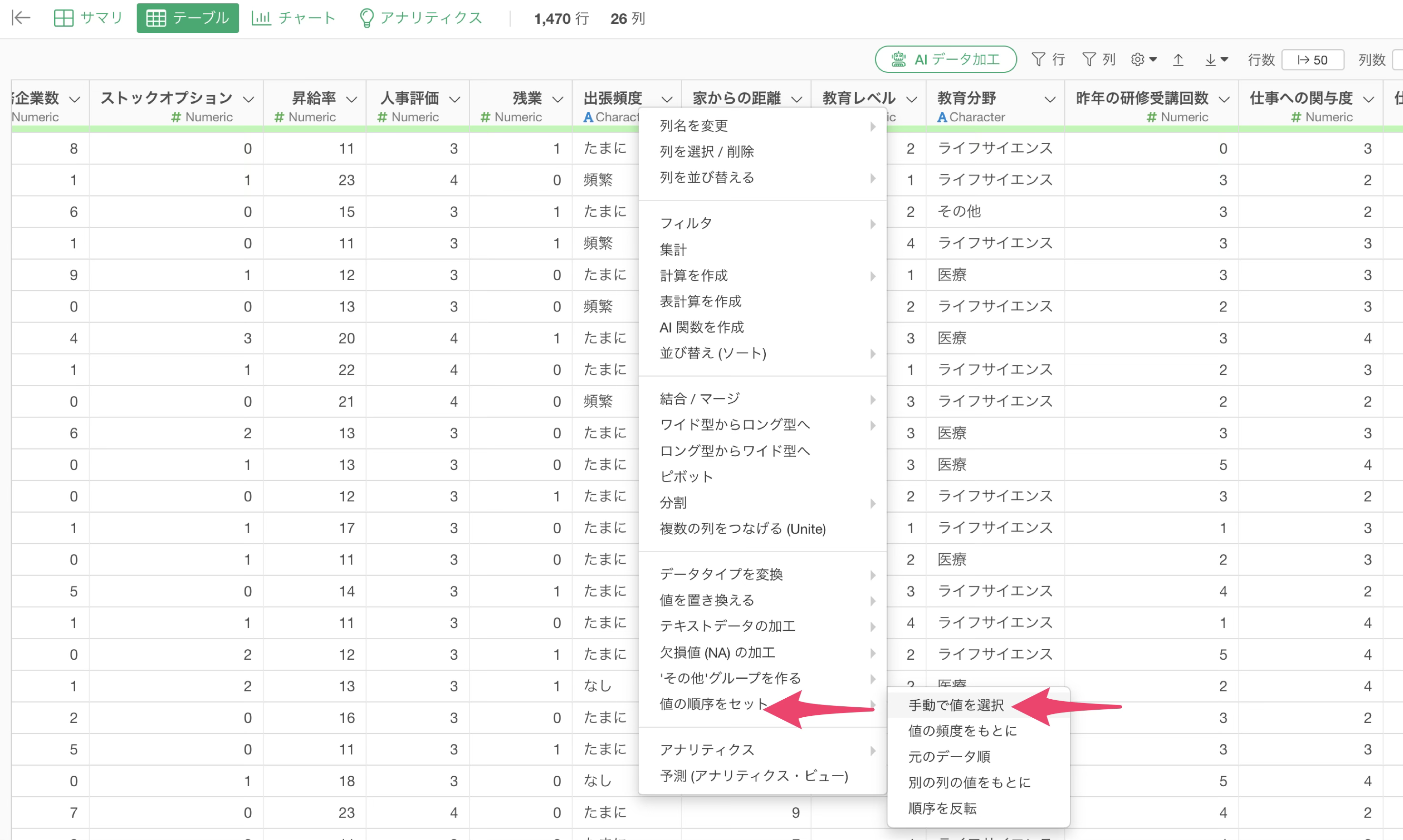
ここからは、サマリ・ビューに戻り、「出張頻度」列を順序つきカテゴリー型に変更します。
「出張頻度」の列ヘッダーメニューをクリックして、「値の順序をセット」から「手動で値を選択」を選択します。
すると、「計算を作成」ダイアログが開き、値に順序を設定するためのfct_relevel
という関数が自動的に設定されます。
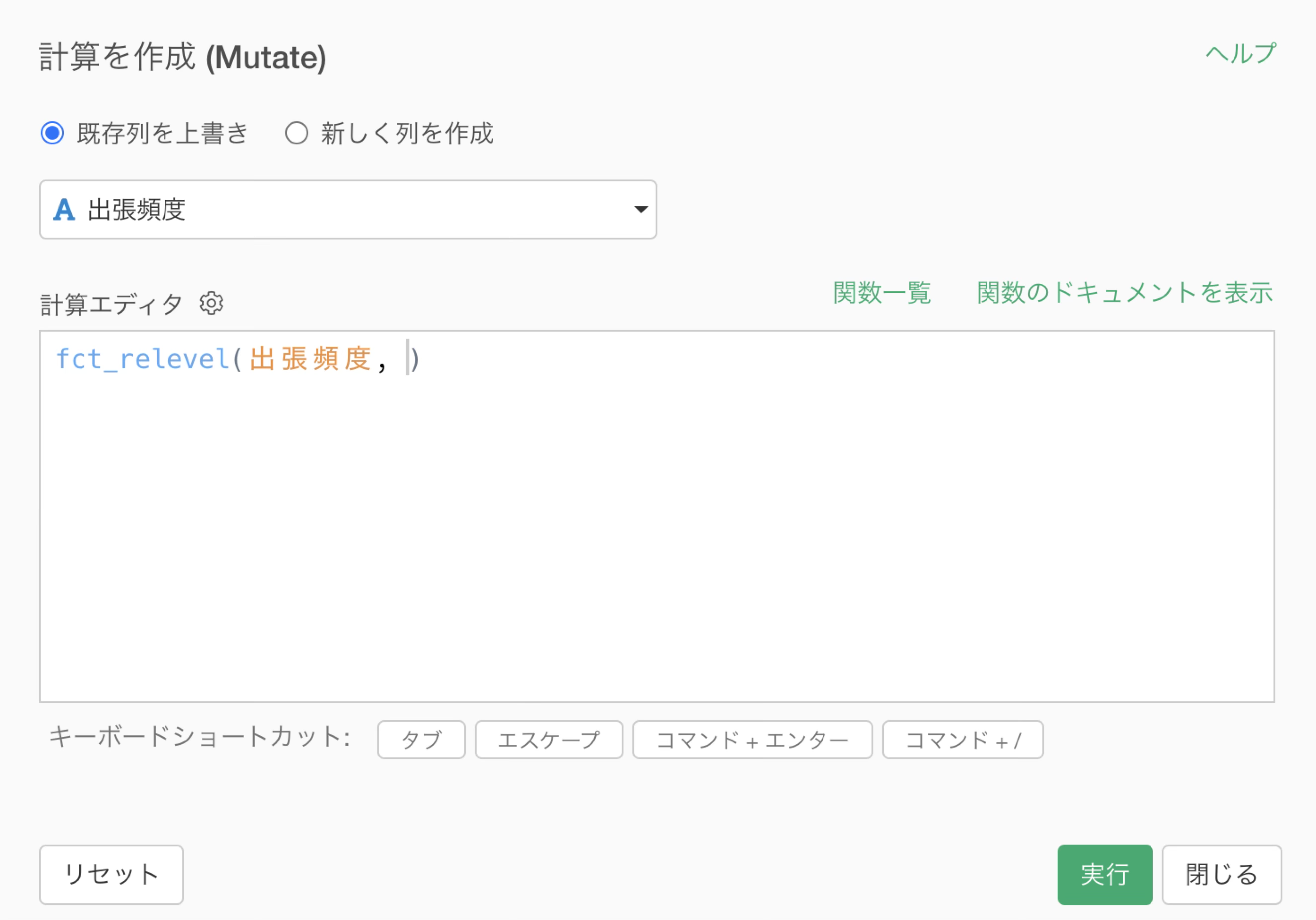
指定した列の値がドロップダウンで表示されるので、カンマ区切りで以下のように順番を指定します。
fct_relevel(出張頻度, "なし", "たまに", "頻繁")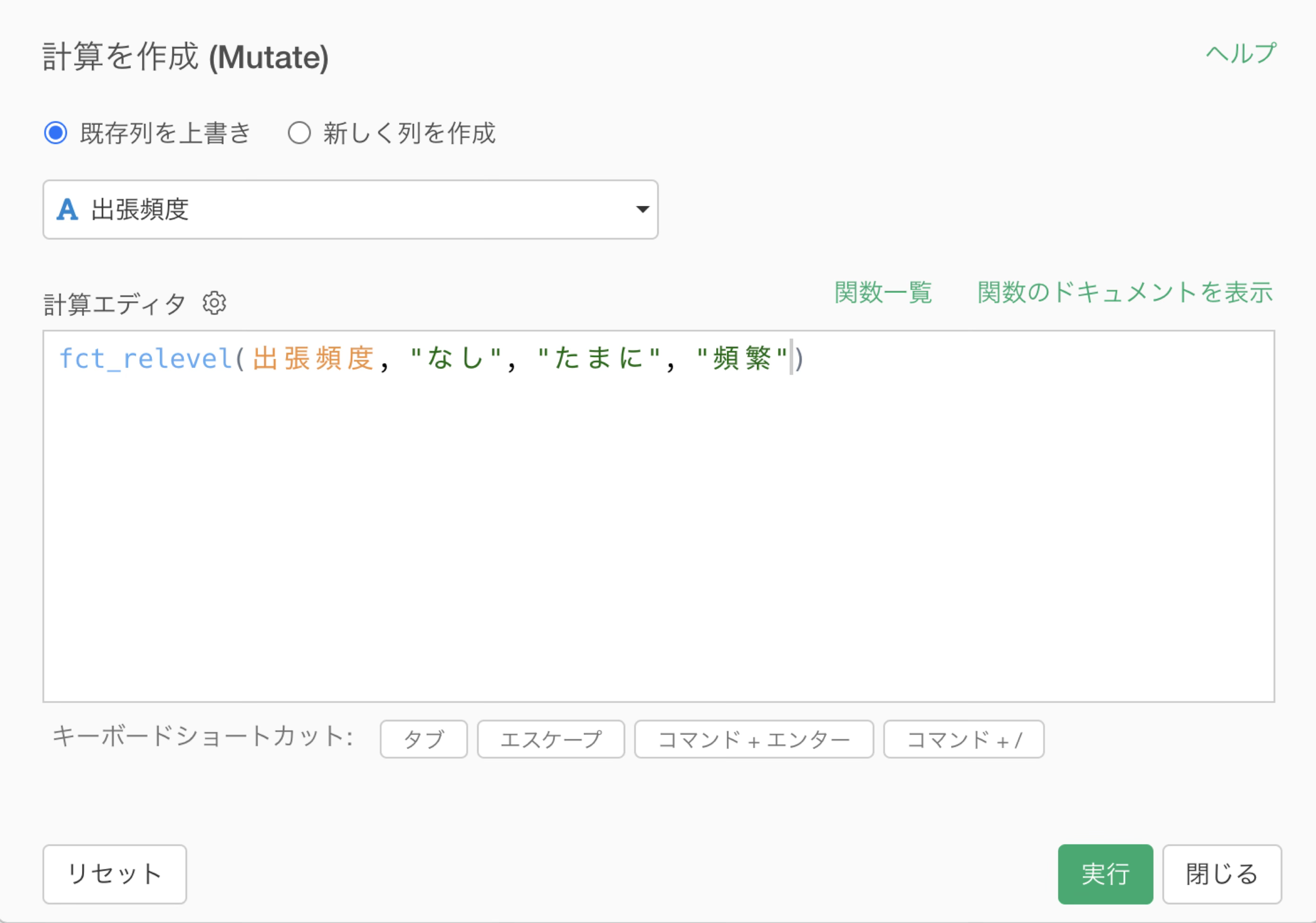
「実行」ボタンをクリックすると、ステップが追加されます。
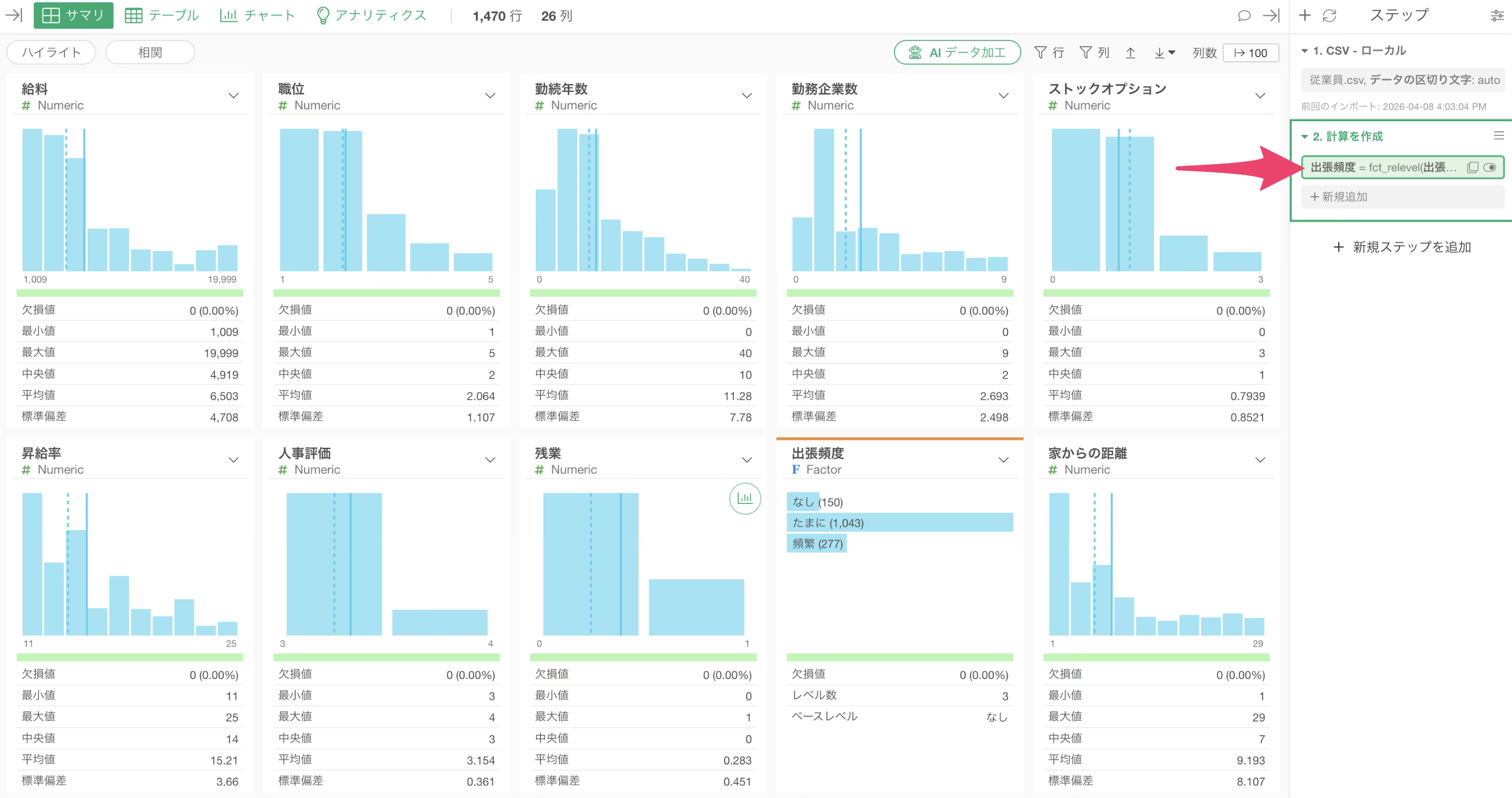
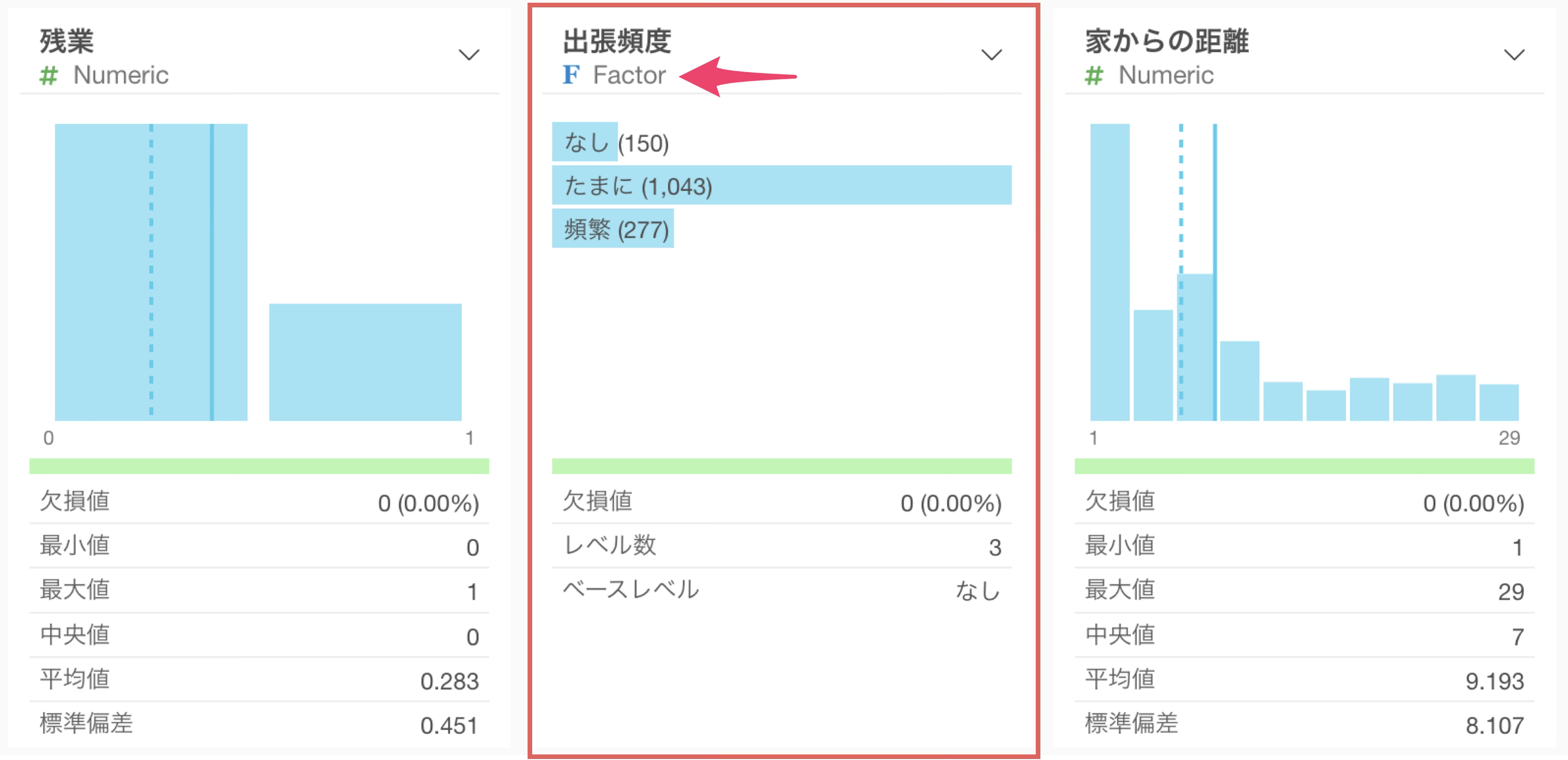
また「出張頻度」列のデータタイプがCharacter型からFactor型に変わったことが確認できます。
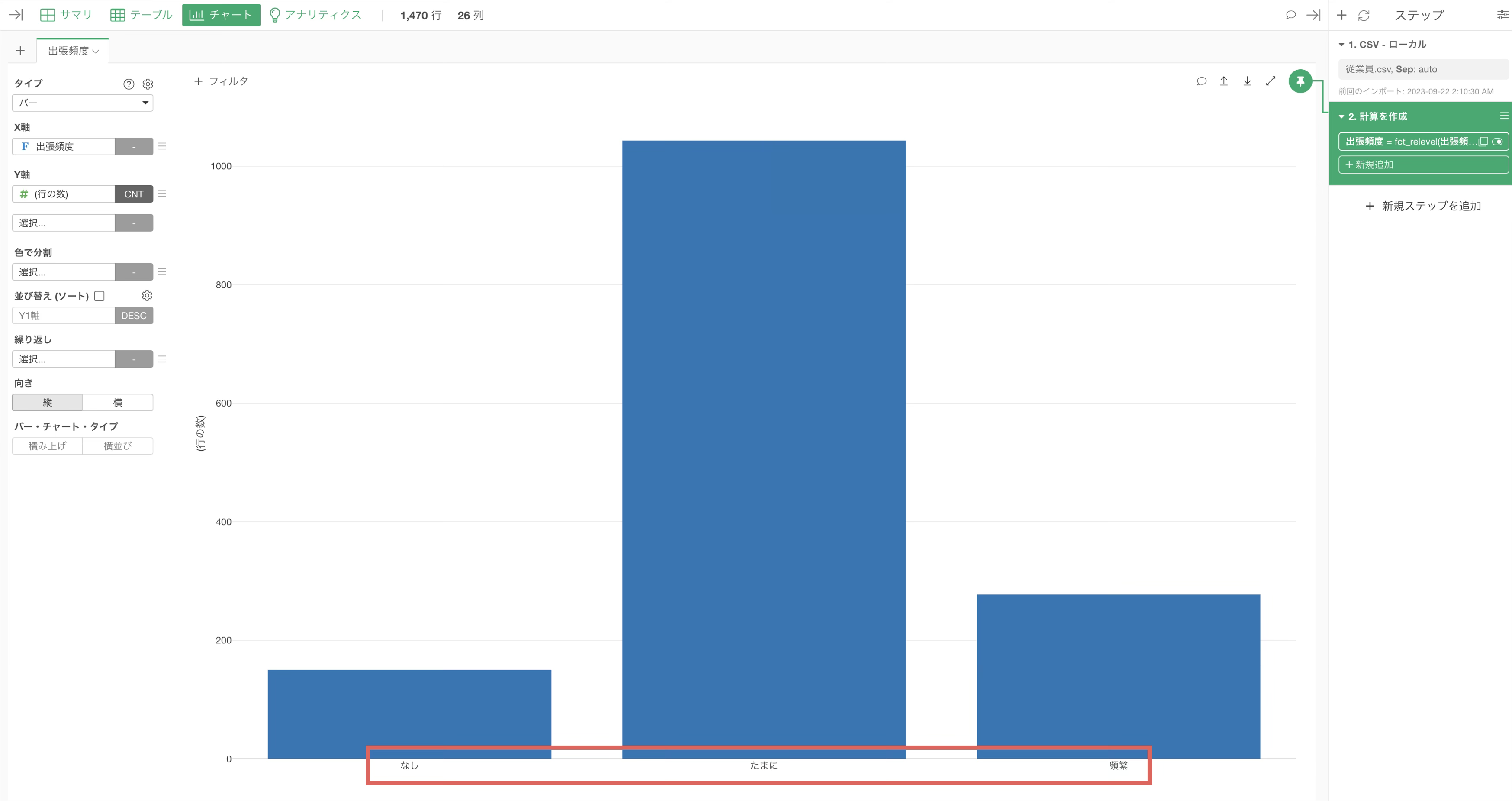
設定した順に値が表示されます。
サマリ・ビューからバーチャートの作成ボタンをクリックします。
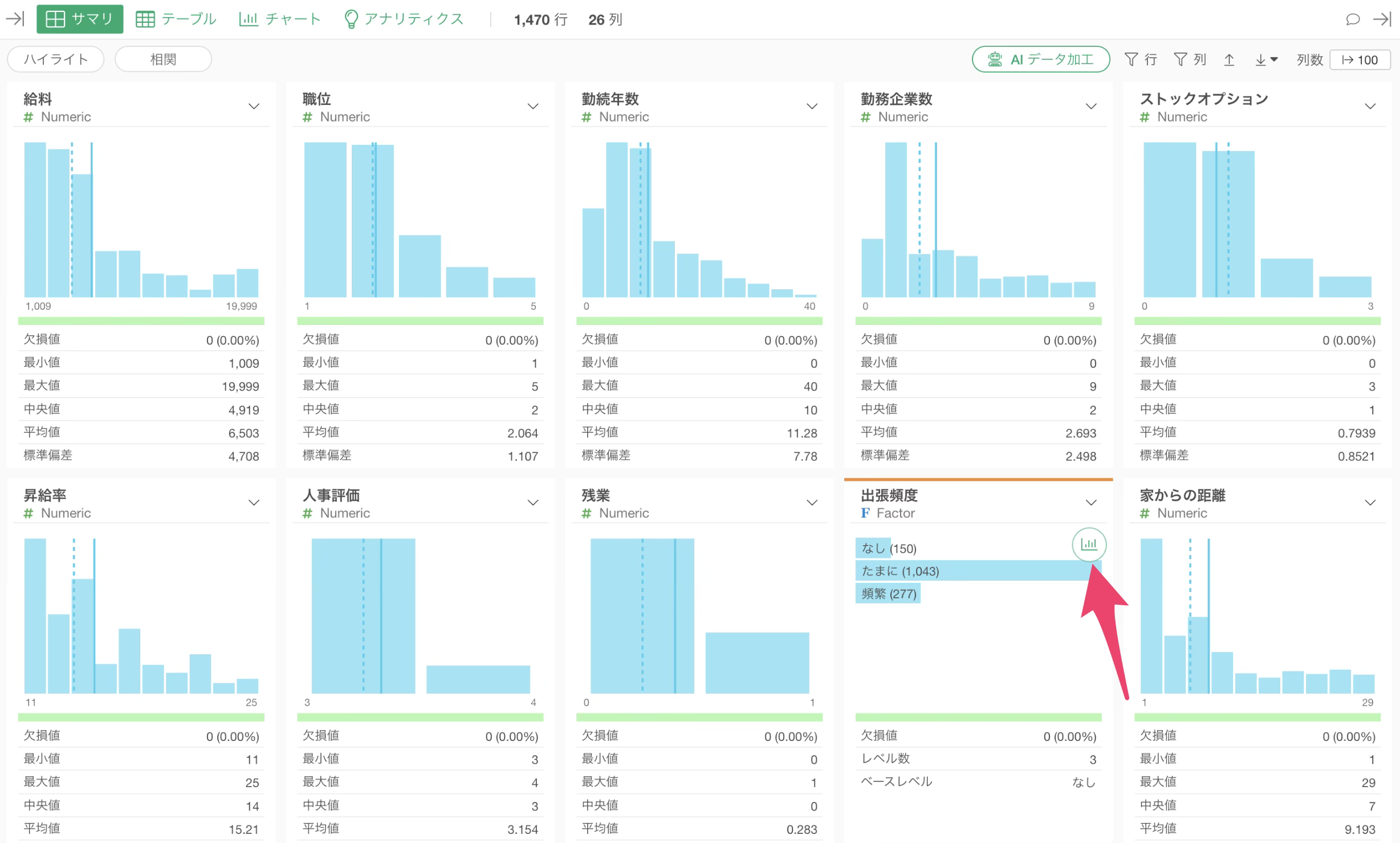
すると横向きのチャートが作成されるので、向きを「縦」に変更します。
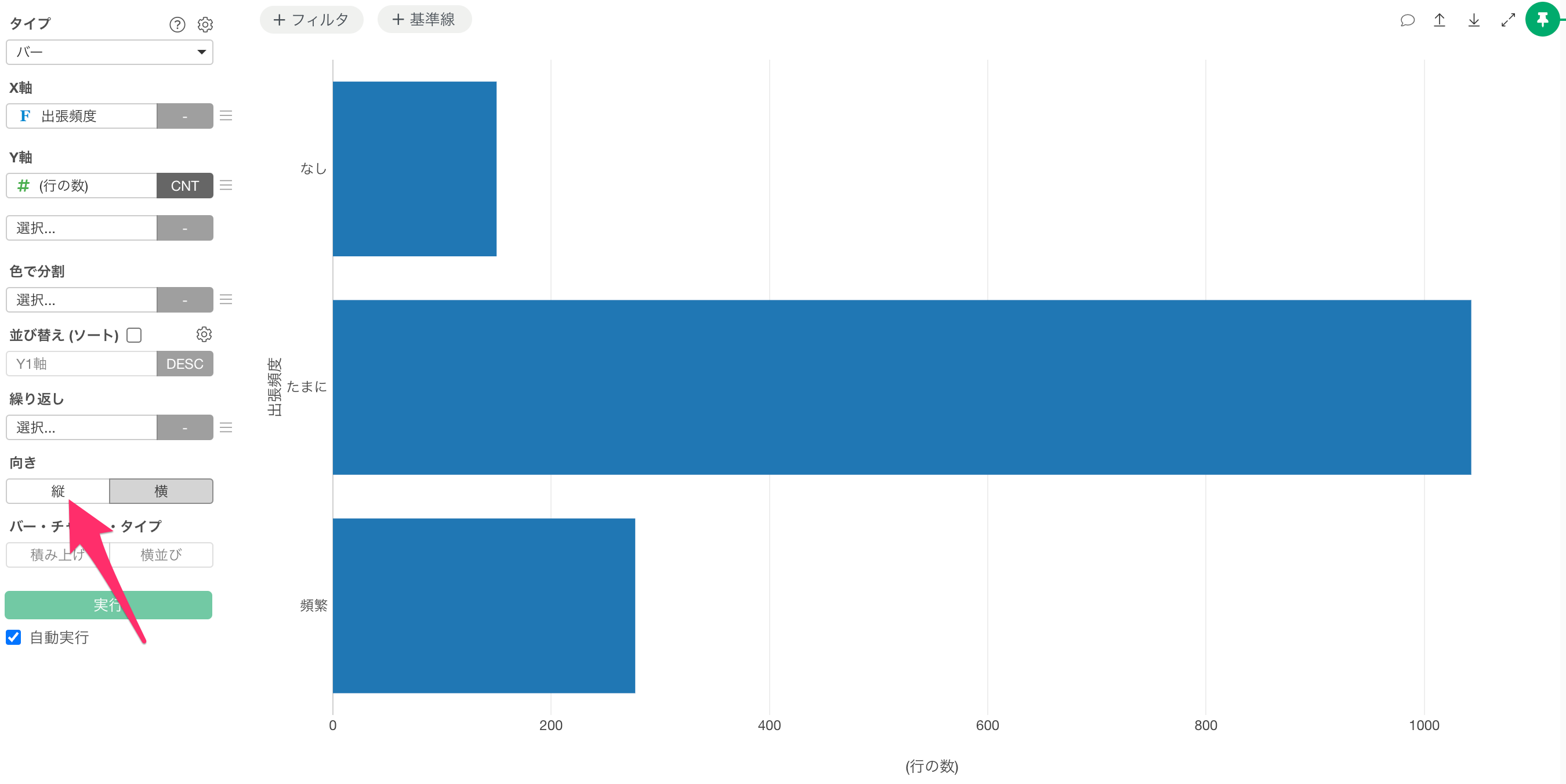
指定した順序で、出張頻度の値が表示されました。
ロジカル(Logical)
ロジカル型は、TRUEまたはFALSEの2つの値しか取らない特殊なカテゴリーです。

「離職したかどうか」「残業しているかどうか」のように、2択の情報を表すデータに適しています。
カテゴリー型(Character型)のYes/Noといった値をそのままチャートに使うことはできますが、ロジカル型に変換しておくと次のようなメリットがあります。
- TRUEかFALSEの2つの値しか入らないようにできる。
- TRUEの数やTRUEの割合を簡単に集計することができる。
- ロジカル型のデータに対応するアナリティクス(例:ロジスティック回帰など)を使用することができる。
今回の従業員データの「離職」列は現在Character型(Yes/No)になっているので、ロジカル型(TRUE/FALSE)に変換します。
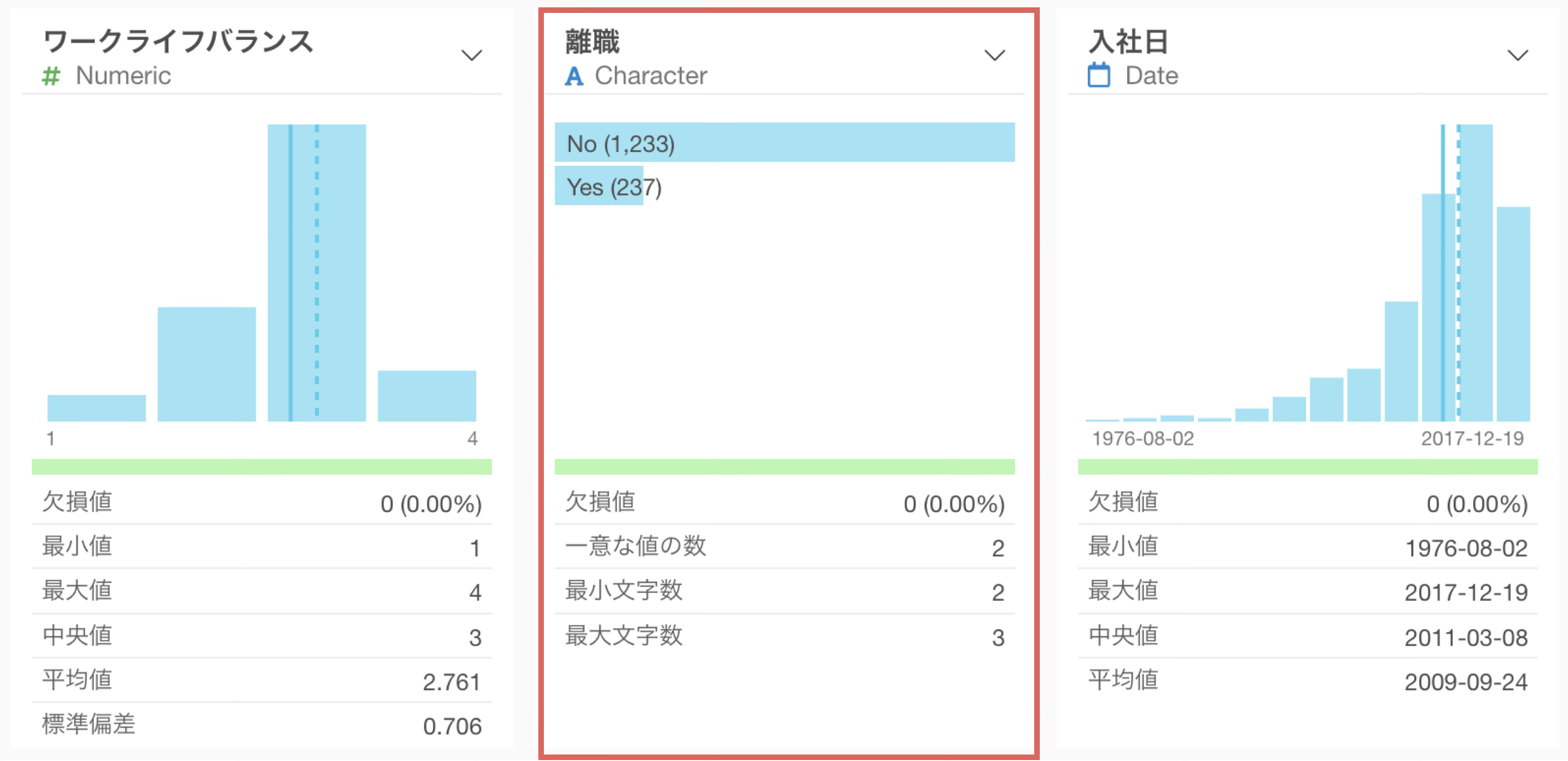
「離職」の列ヘッダーメニューから「データタイプを変換」の「Logical(論理値)型に変換」を選択します。
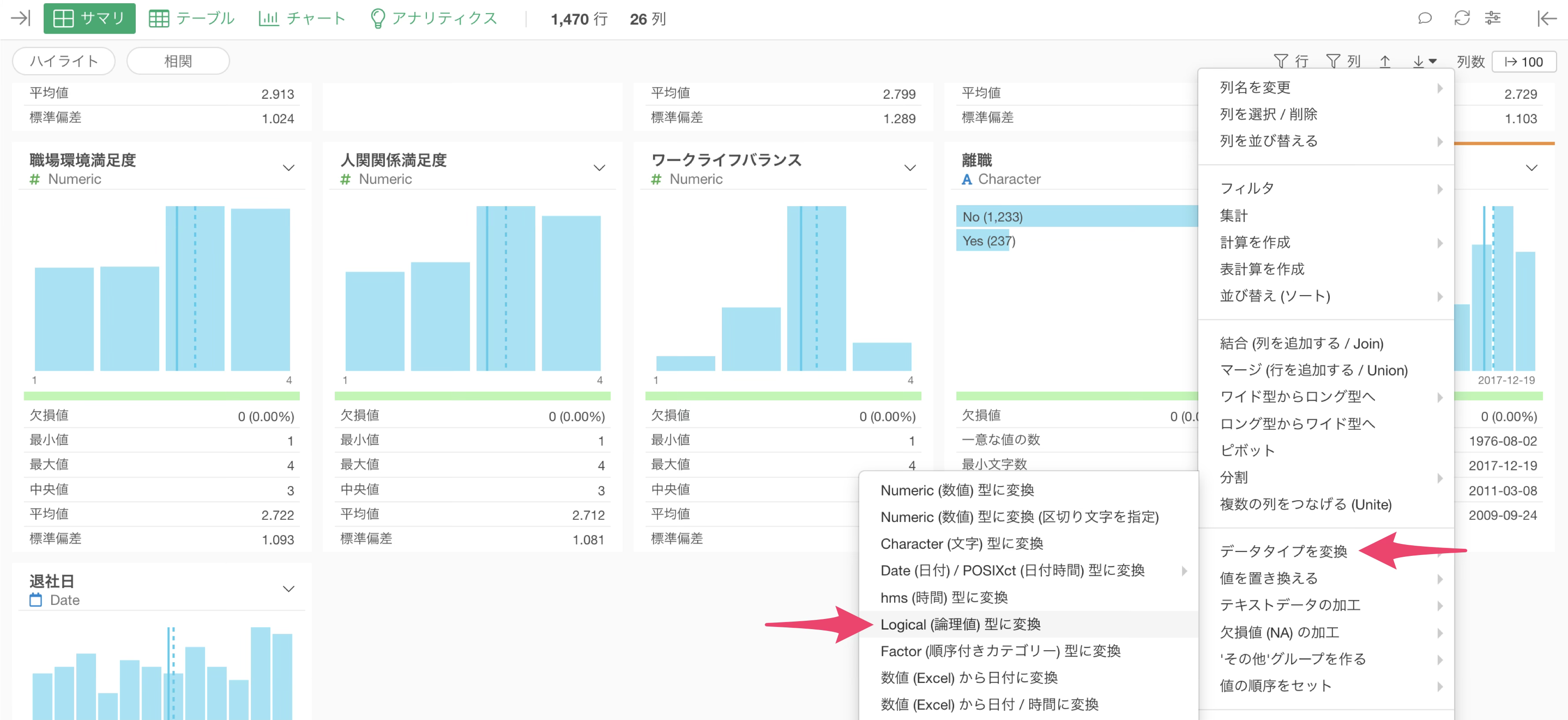
すると、「計算を作成」ダイアログが表示され、str_logical(離職)
という関数が自動的に設定されます。
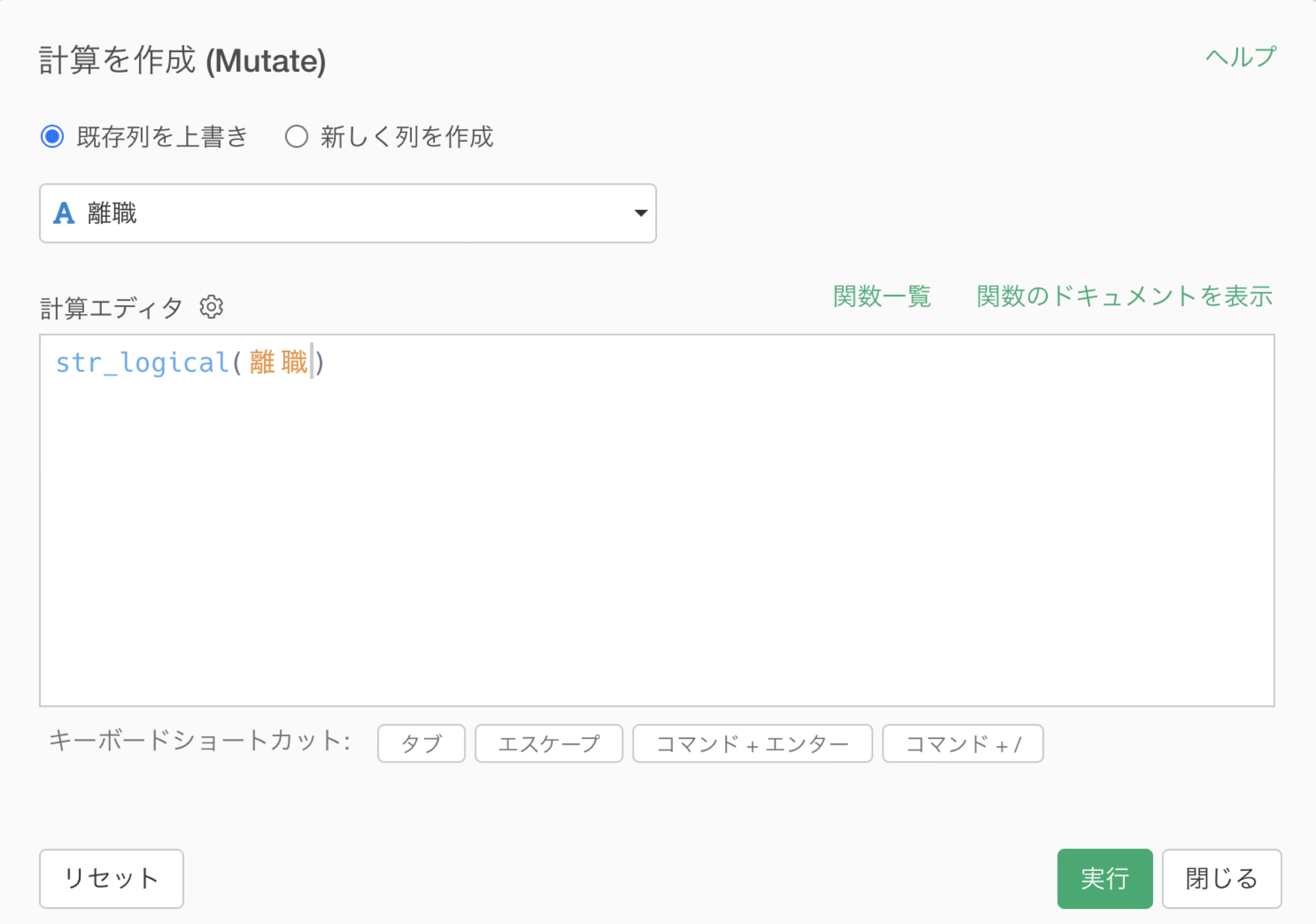
str_logical
は文字列(String)をロジカル型に変換する関数で、「Yes」は「TRUE」に、「No」は「FALSE」に自動変換されます。
なお、str_logical関数は値が「1」のときに「TRUE」、「0」のときには「FALSE」を返す特徴があります。

「実行」ボタンをクリックすると、新しいステップが追加され、「離職」列のデータタイプがLogical型に変わります。
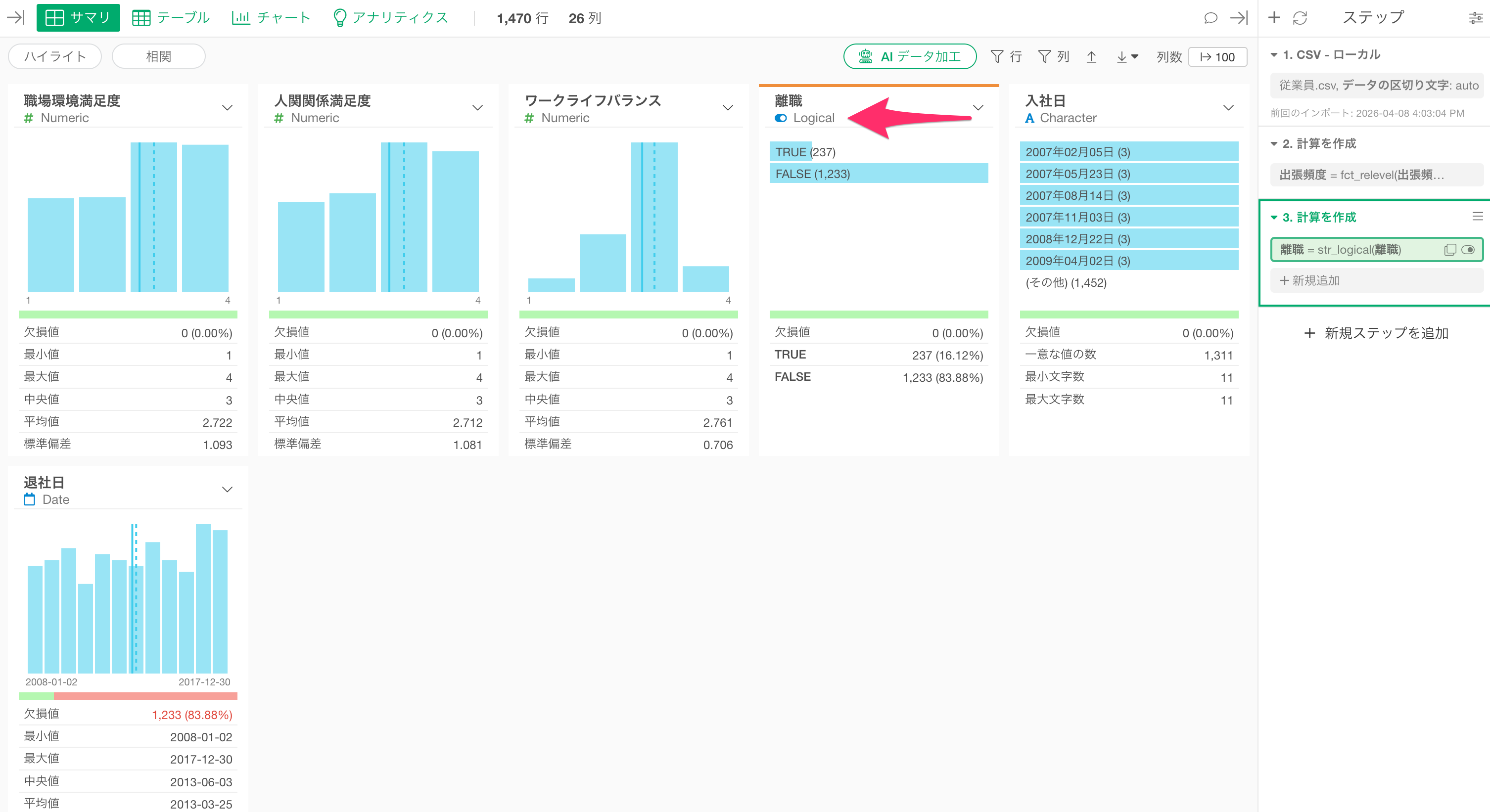
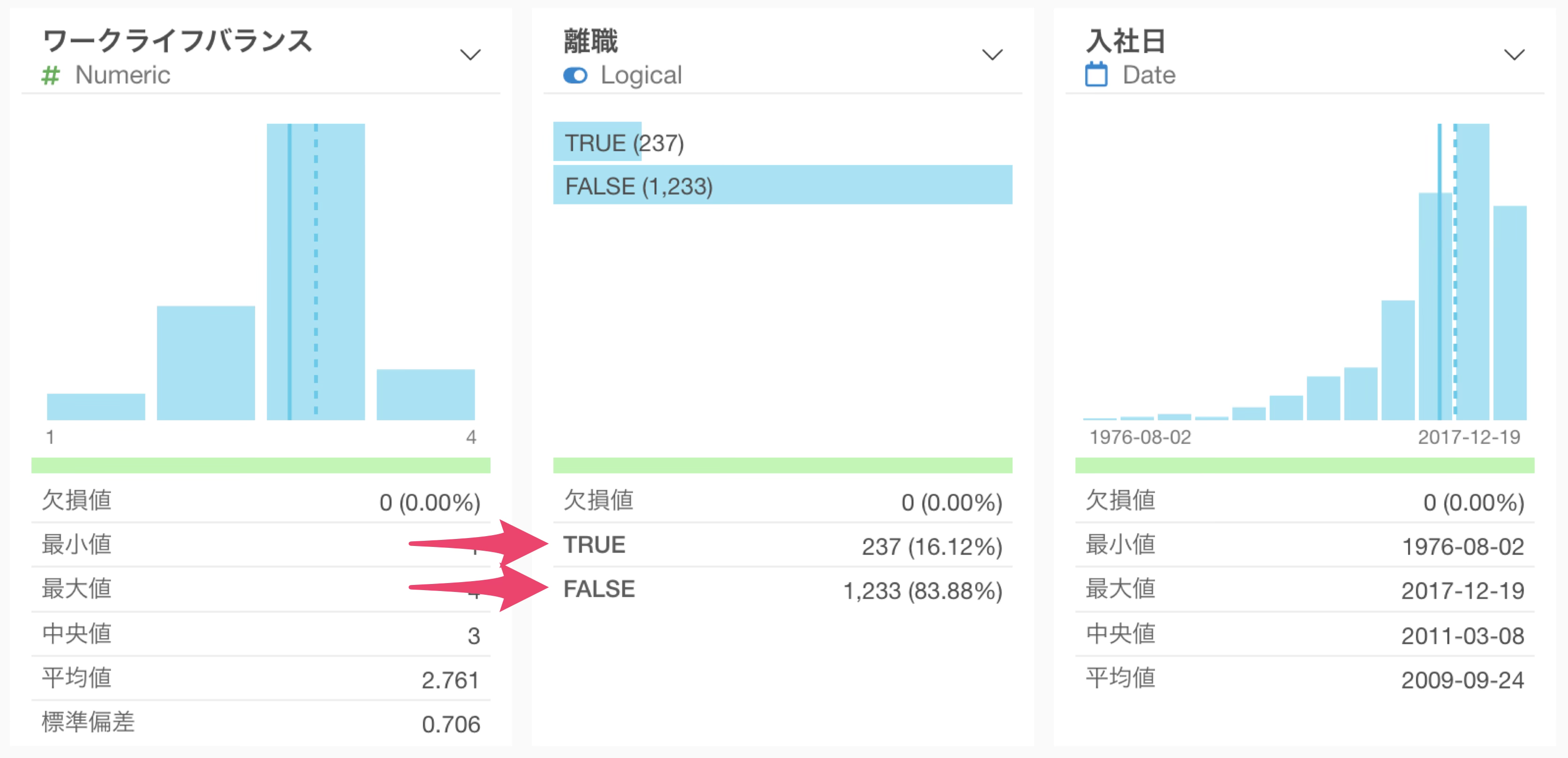
サマリを確認すると、TRUEとFALSEの割合を確認できます。
日付、日付/時間(Date / POSIXct)
日付型は、データの中に日付や時間の情報が含まれる場合に使います。
Exploratoryでは、日付のみのデータには「Date型」、日付に時間情報も含まれる場合には「POSIXct型」を使用します。
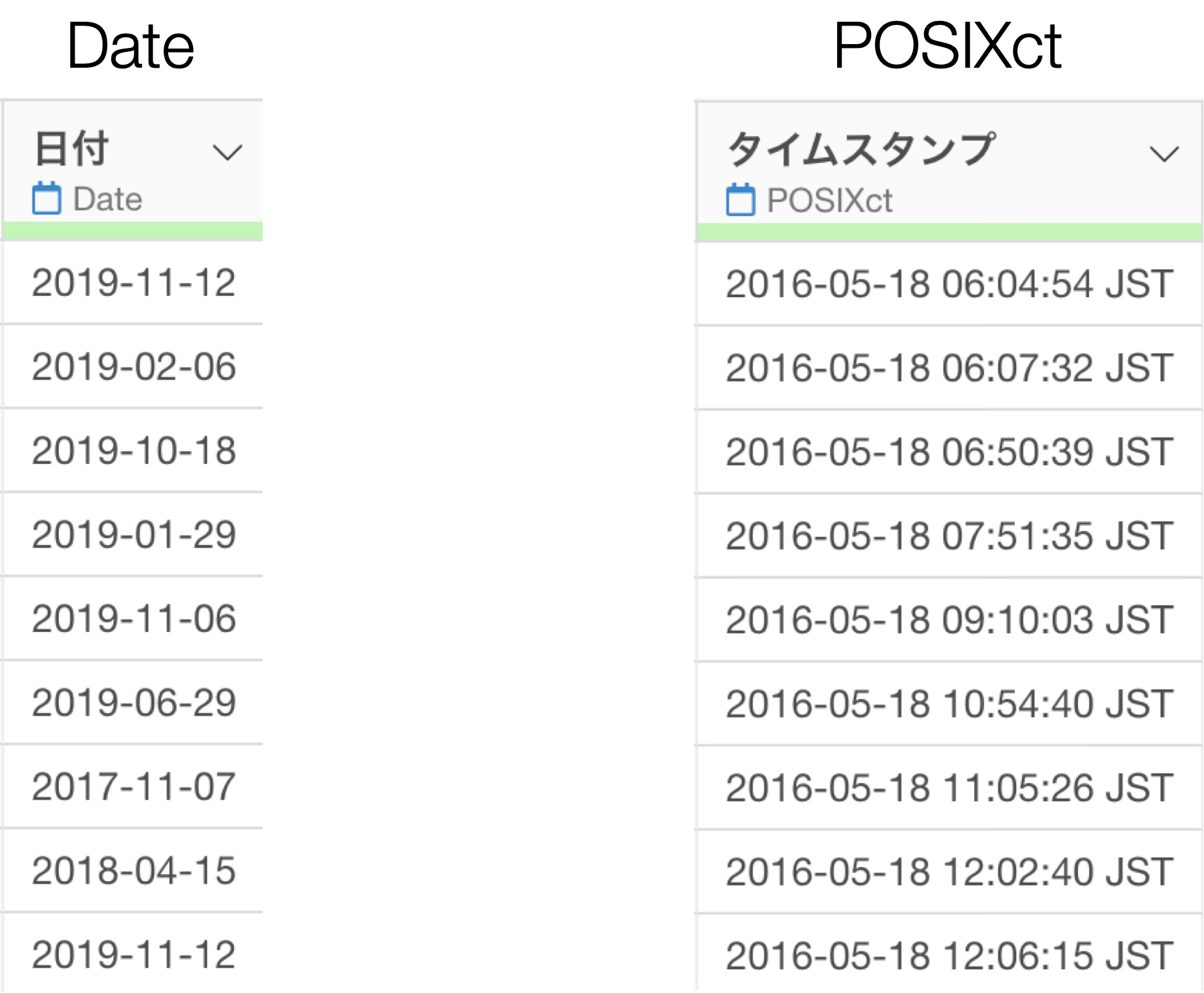
両者は数値と同様に「連続性がある」「順序関係がある」という特性があります。

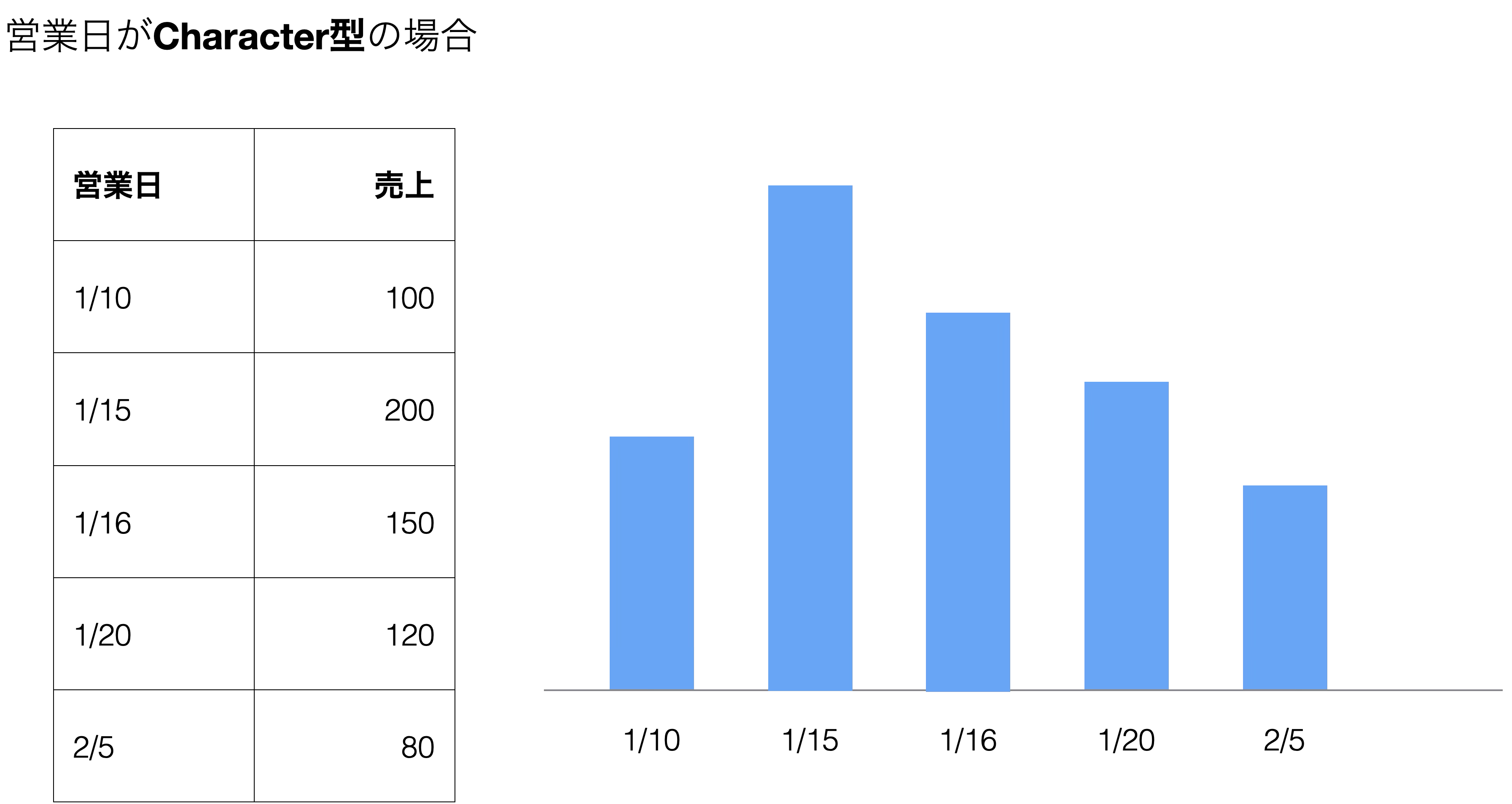
また、入社日のような日付データが文字列型(Character型)になったままだと、チャートで可視化する際に問題が生じます。
例えば、日付が文字列型の場合、「1/10」「1/15」「1/16」はそれぞれ別々の文字列として扱われ、日付同士の間隔や順序は考慮されません。
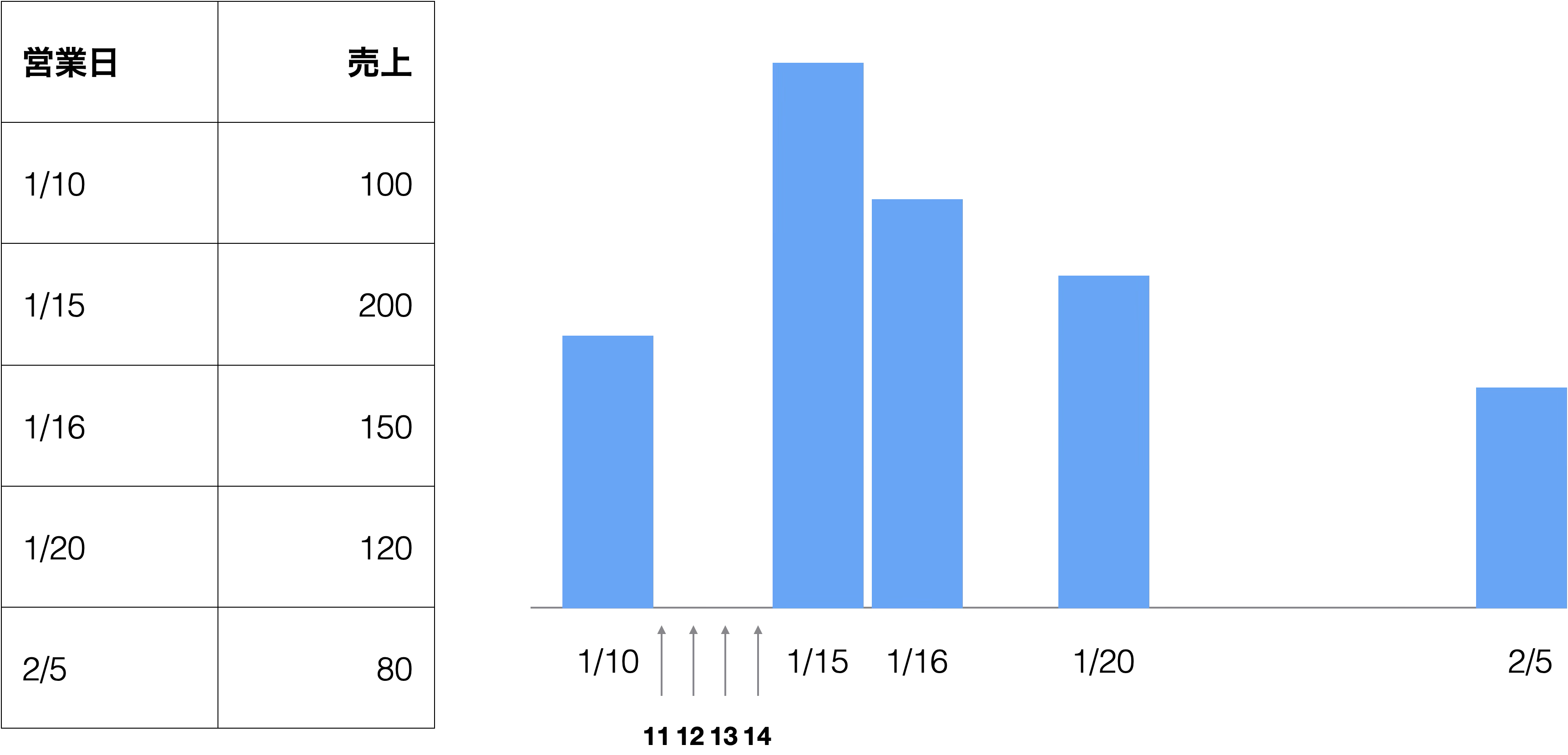
一方、Date型に変換されていると、日付の間隔(1/10と1/15は5日、1/15と1/16は1日など)が正しく反映されたチャートが描けるようになります。
日付型や日付/時間型に変換するときに重要なのが、「元のデータの並び順」です。
これは日付型や日付/時間型に変換するときに、年(Year)・月(Month)・日(Day)・時(Hour)・分(Minute)・秒(Second)の頭文字を使って並び順を指定するためです。
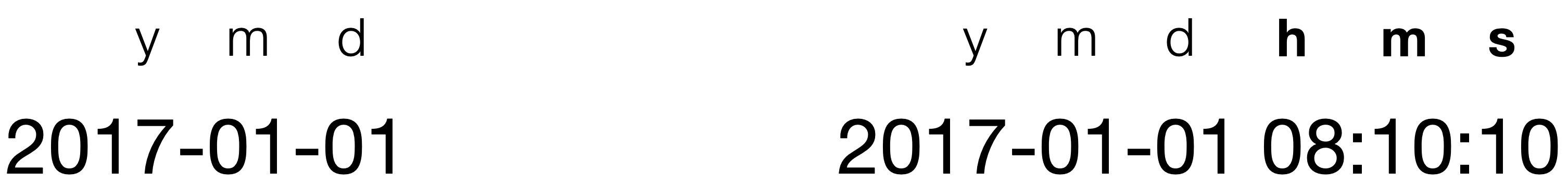
例えば、入社日のデータは年(year)、月(month)、日(day)の順番になっていますので、変換には ymd関数を使います。

もとのデータが月(month)、日(day)、年(year)の順番であればmdy関数を使います。
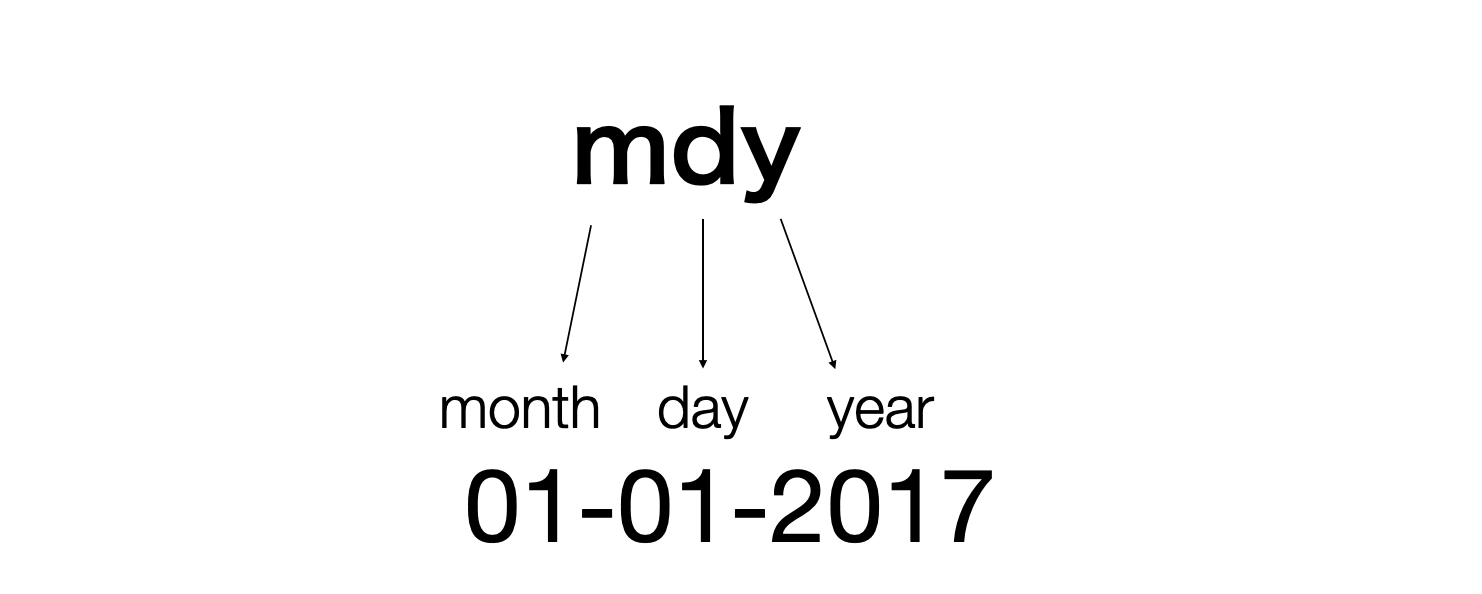
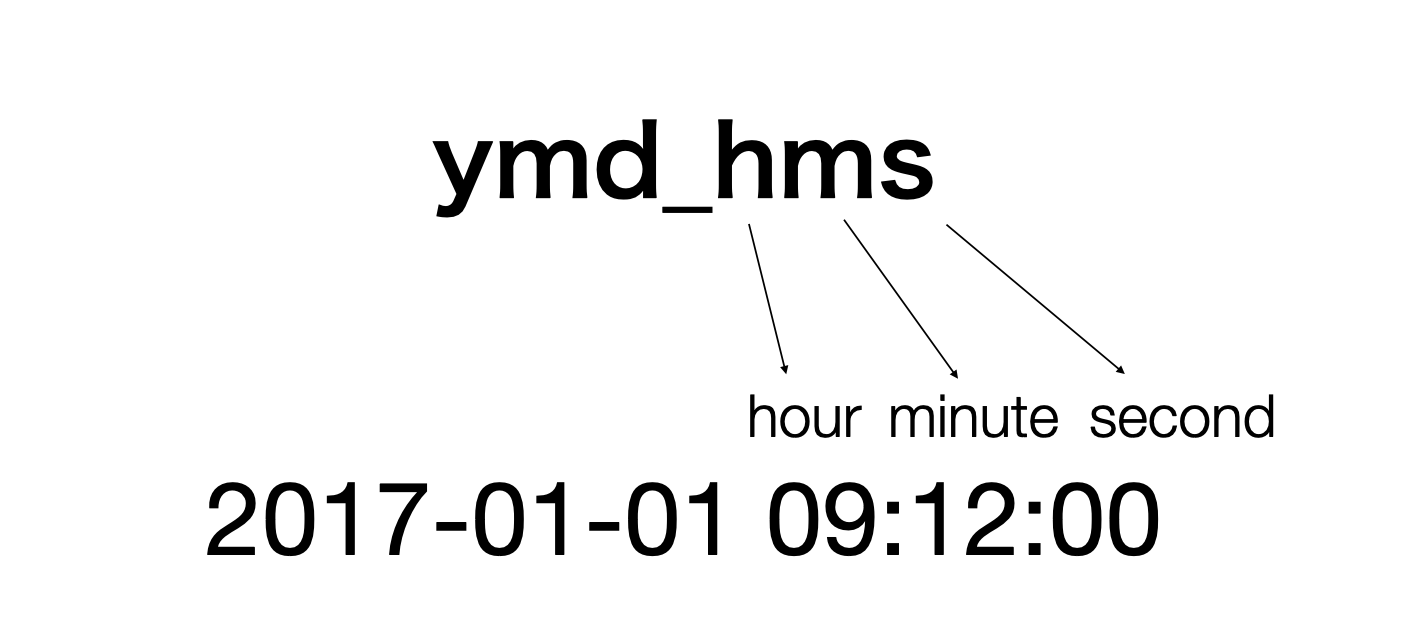
もとのデータに時間情報があり、年(year)、月(month)、日(day)、時(hour)、分(minute)、秒(second)に並んでいる場合、ymd_hms関数を使って日付時間型へ変換が可能です。
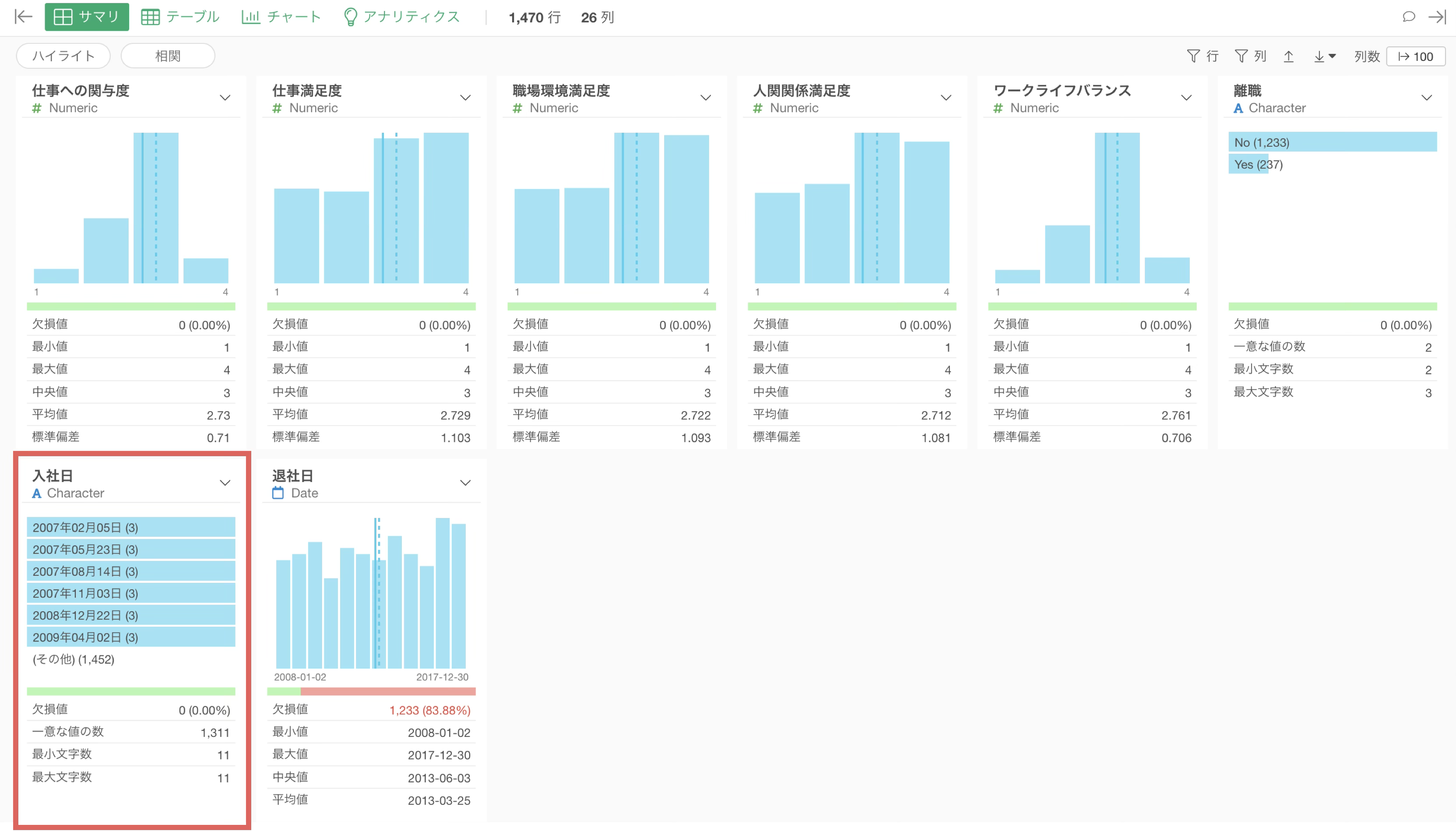
 今回の従業員データの「入社日」列はCharacter型のため、Date型に変換します。
今回の従業員データの「入社日」列はCharacter型のため、Date型に変換します。
「入社日」の列ヘッダーメニューから「データタイプを変換」、「Date(日付) / POSIXct(日付時間)型に変換」、「Year, Month, Day」を選択します。
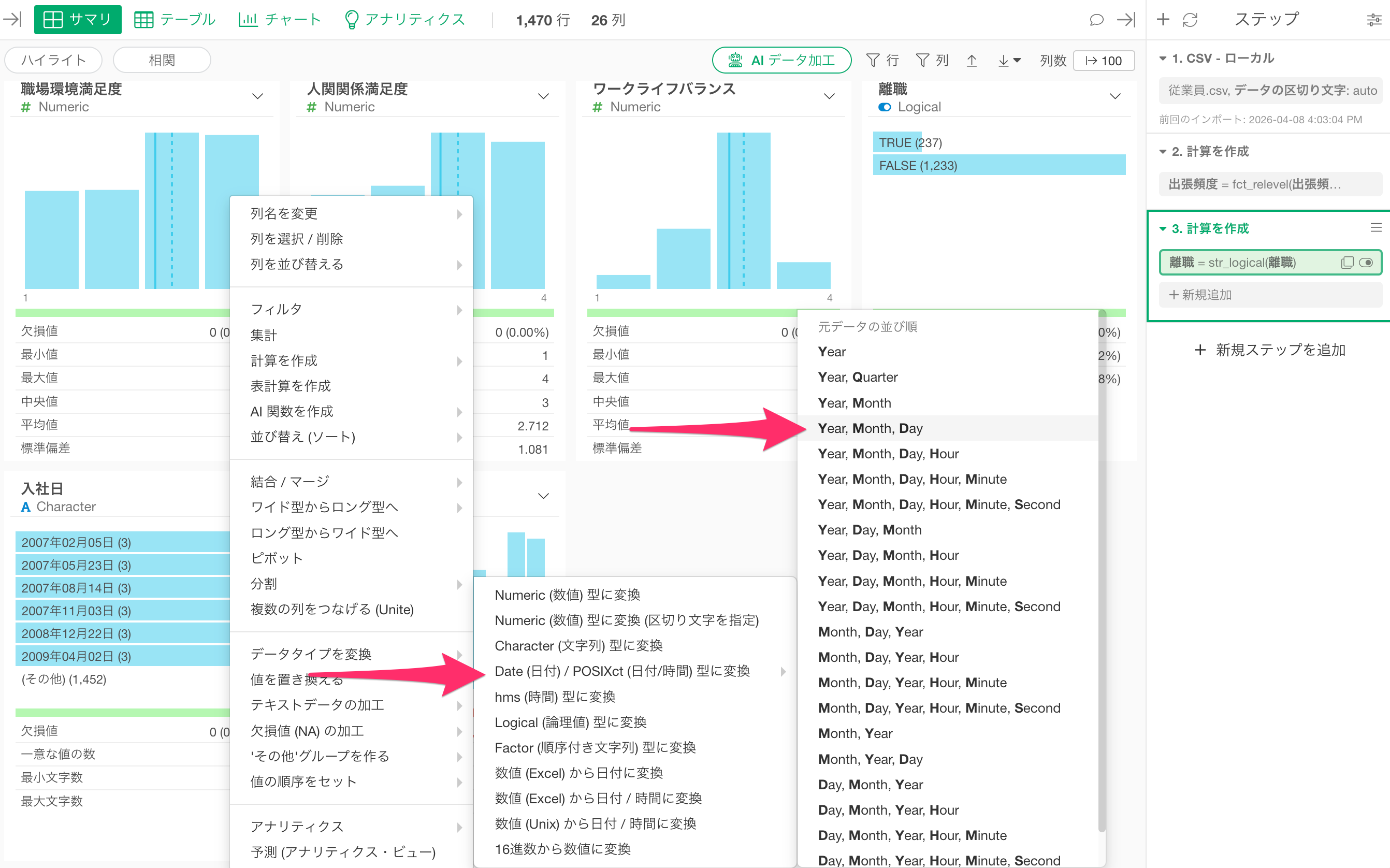
すると「計算を作成」のダイアログに日付型に変換されるための関数が設定されるので、そのまま「実行」ボタンをクリックします。
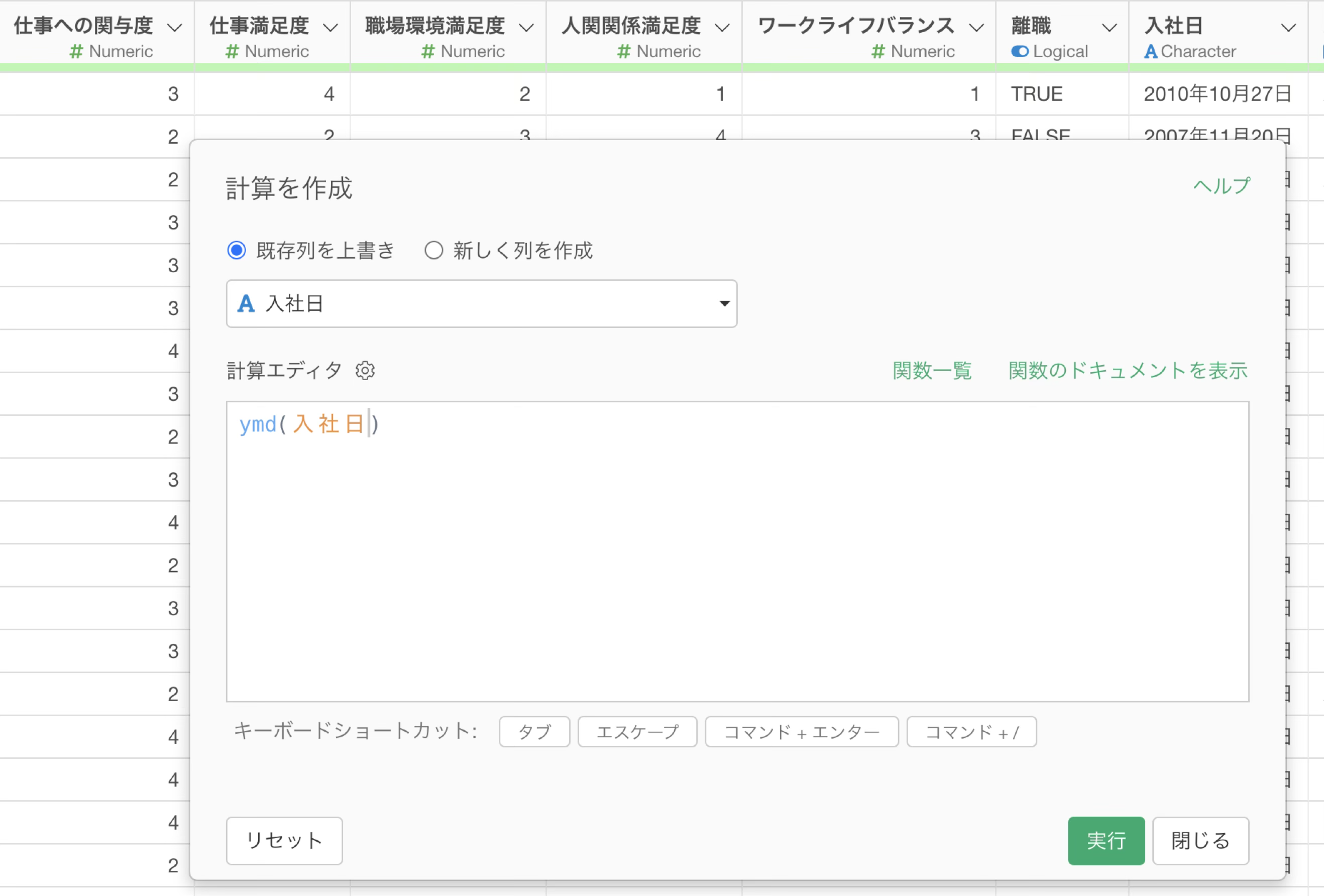
実行すると入社日列のデータタイプが Date型に変わります。
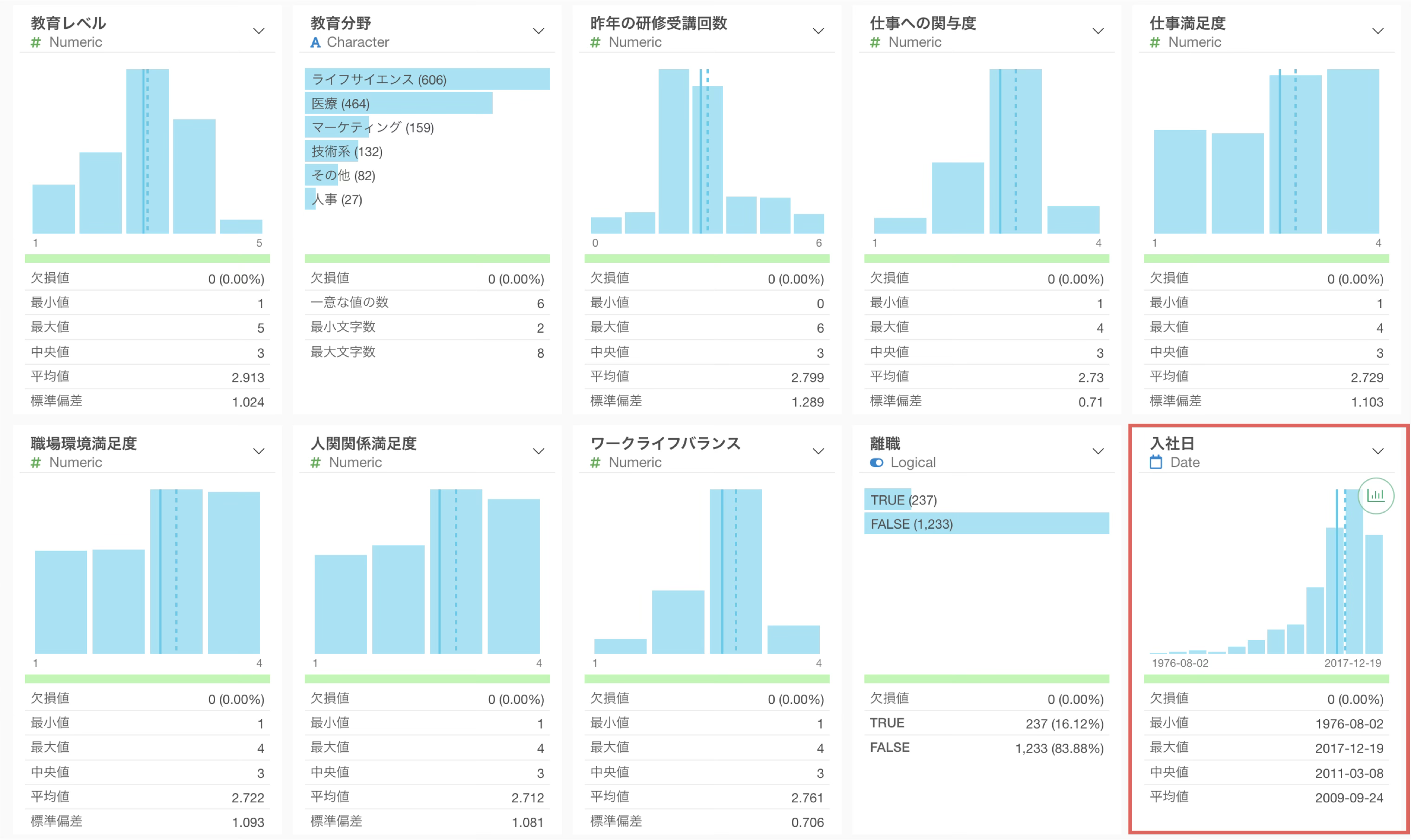
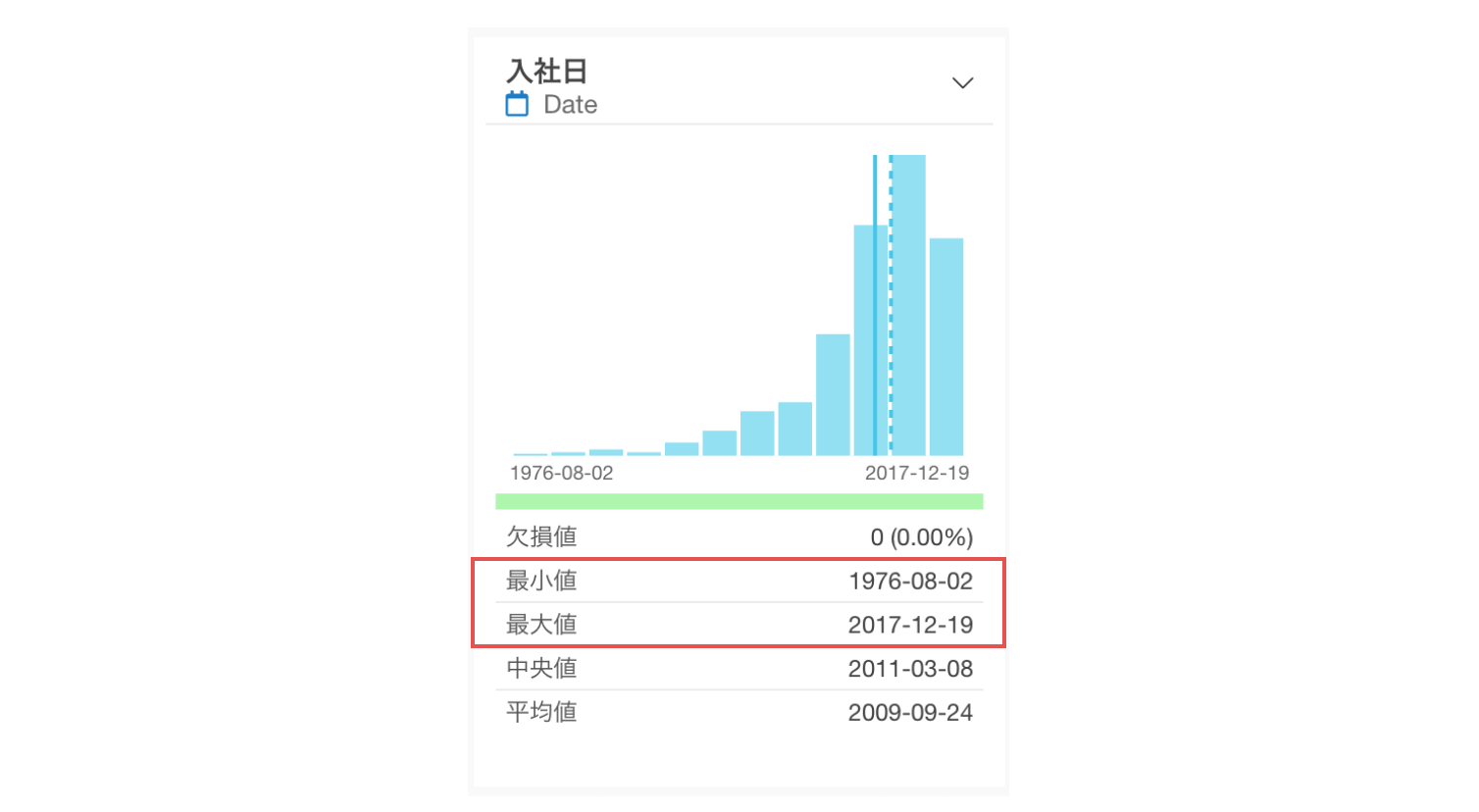
入社日をDate型に変換すると、サマリ・ビューに日付のヒストグラムが表示され、入社日の最小値(1976年8月2日)・最大値(2017年12月19日)が確認できるようになります。また、近年になるほど入社者が多くなっているトレンドも一目でわかります。
Exploratoryの基礎や「データタイプ」について紹介は以上となります!
Exploratoryの使い方シリーズ
Exploratoryを効率的に使い始められるように作られた「Exploratoryの使い方」シリーズを公開しています。ぜひご実施ください。