
こんにちは、Exploratoryの西田です。お元気ですか?
いよいよ今年も残すところ後2週間となってしまいました。こちらUSは今週末がクリスマス、来週末がNew Yearということで今週から2週間ほど多くの会社ではゆったりモードになります。私どもの方はその間を利用して、Exploratoryの次のリリースであるv4.2を仕上げてしまい、年明けとともに世の中に出そうという計画なので、ゆったりしている暇はないと言った感じです。;)
ところで、今週よりExploratoryのユーザーでなくても、このWeekly Updateを購読することができるようになりました。もちろん無料です。周りに興味のある方がいらっしゃれば、ぜひこちらの登録ページ を紹介していただければと思います。
今週は、World Economic Forum (世界経済フォーラム)より、将来の仕事はどうなっていくのか、Googleがなぜ中国にAIのリサーチセンターを開くのか、MOOC(Massive Open Online Course)の先駆けとして有名なCourseraがどのようにデータサイエンスのチームを作っていったのかということに関連した記事を紹介したいと思います。
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
将来の仕事を予測する
4 predictions for the future of work by Stephane Kasriel - Link
World Economic Forum (世界経済フォーラム)より、"将来の仕事を予測する"という記事がありました。フリーランスの人材を斡旋するプラットフォームで、Upworkという会社がシリコンバレーにありますがそこでCEOをやっているStephane Kasrielによる記事ですので、フリーランスという形態の仕事に対する強気な予測の面があるというのを割り引いて読む必要がありますが、我々データサイエンス、AIに関わる人間にとって、これからの仕事のあり方を考える際にいくつか重要な考察があるのでそちらの方を簡単にここで紹介しておきたい思います。
機会創出としてのAI
まずは、2018年は、人間か機械(AI、ロボット)かではなく、人間と機械が協力して世界の問題を解決していくということをより多くの人達がようやく認識することになる年になると予測します。
そうした上で、将来的にAIによる自動化によって仕事がなくなるというよりも、AIをどんどん活用していくことで必要になってくる仕事、そこで要求される新しいタイプのスキルが満たされないということこそが問題になると提起しています。
70年代にパーソナル・コンピューターが出てきた時に、当時の世の中はすべての仕事がコンピューターに置き換わってしまうと心配していたのと同じで、現在のAIによってすべての仕事が置き換わるというのは、現在のAIに対する理解の欠如による問題の単純化であると思います。
たしかにこれから、AIによって全ての業界、仕事がリセット(再定義)されていくことになります。しかしこうした破壊的な変化というのは多くの人間にとって実はまたとない機会なわけで、それを使いこなすことができるものには大きな果実が待っているわけです。逆にその変化の波に乗り遅れるということは、乗りこなすことができるものによって淘汰されていくことを意味しているわけです。
次のデータ、AIの10年を考えた時に、どう自己変革をしていくのか、自分たちのビジネスにとっても、さらには自分のキャリアにとっても真剣に考え直す必要があると思います。
ちなみに、70年代、パーソナルコンピュータが世の中に出てきて間もない時に行われたAppleのスティーブ・ジョブスに対するインタビューのビデオがここにありますが、当時の社会のコンピュータに対する不安というものを伺うことができます。まるで今のAIに対する世間一般の不安を表しているかようです。
才能のある人材の獲得競争は企業から都市へ
Stephaneはタレント(能力、スキルのある人材)の獲得競争は会社同士というよりも、都市同士で行われていくことになると予測します。その例として最近のアマゾンの2番めの本社の候補地の募集にまつわるエピソードを挙げています。こちらはAmazonが5000億円の投資をして作るということで、全米から200ほどの都市が手を挙げて応募しています。都市によっては、職員がアマゾンのウェブサイトで、1000個ほどの製品を買ってそれぞれに対するレビューを書いたり、ニューヨークなどはエンパイアーステートビルの夜のライトアップをアマゾンの色にしてみたりとそれぞれジェフ・ベゾス(AmazonのCEO)の注意をひこうと必死になっています。そんな中で、シリコンバレーの中心的な都市であるサンホゼの市長は、そんな競争には参加しないと強気に構えています。彼によると、アマゾンほどのスケールの企業であれば、結局は、これからのテクノロジーに強いタレントの集まる都市にこうした本社機能をおかざるをえず、そうすると自ずとその候補は限られてくるからです。(ヒント:シリコンバレー)
技術の進歩とともに、リモートで働く人はこれからもどんどん増えていくでしょう。つまり人は会社のある場所へ引っ越していくのではなく、これからのキャリアを形成していく機会が豊富で、最新のテクノロジーに触れることができ、刺激的で、楽しい場所に住みたいと思うでしょう。そして、こうしたタレントの集まる場所を企業が求めて追っかけていくことになるのです。ということで、タレントを惹き付けることのできる都市が結果的にはこれから成長していく企業を惹き付けることになるので、それぞれの都市はそういったタレントを惹き付ける努力を行うべきで、さらにそういったタレントを養成する努力を行っていくべきだというのがポイントですね。
ちなみに現在テック、AIをリードするテック企業が旧世代のテック企業に比べてどれだけ雇用を生み出す可能性があるのかを、以前にも紹介したBenedict Evansが以下のチャートにまとめています。
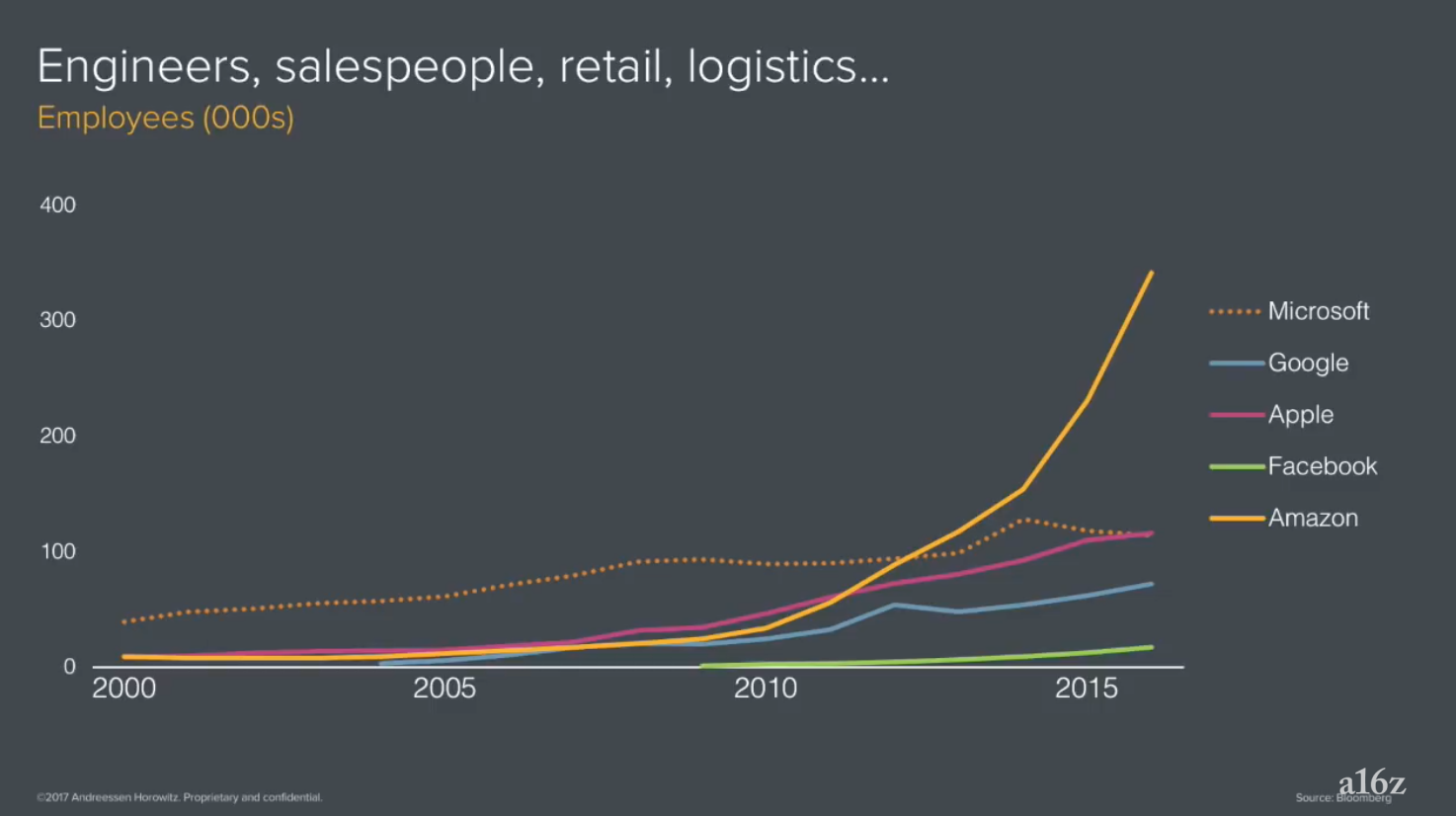
そして、すでにAIのタレントの獲得競争というのは世界中で始まっています。そちらについては以下の別の記事の中でまた触れます。
これからの10年はAIによる変革の時代です。そこで求められる人材はAIをパートナーとして問題解決をし、意志決定を行っていくことができる人間です。そしてAIを理解するための言葉がデータサイエンスなわけです。日本もどんどんこれから必要になってくるデータサイエンスのできる人間を生み出していかないと、これからのAI時代に成長していく企業がやってこないばかりか、既存の企業ですら出ていくことになってしまうのではないかと心配です。
最後に、この記事の中で紹介されていたチャートで、世界での最高の職というものがありました。それぞれのバーの長さがそれぞれの職種の年収の中央値を表し、ワークライフ・バランスがいいと思われているものから順に上から並べられています。
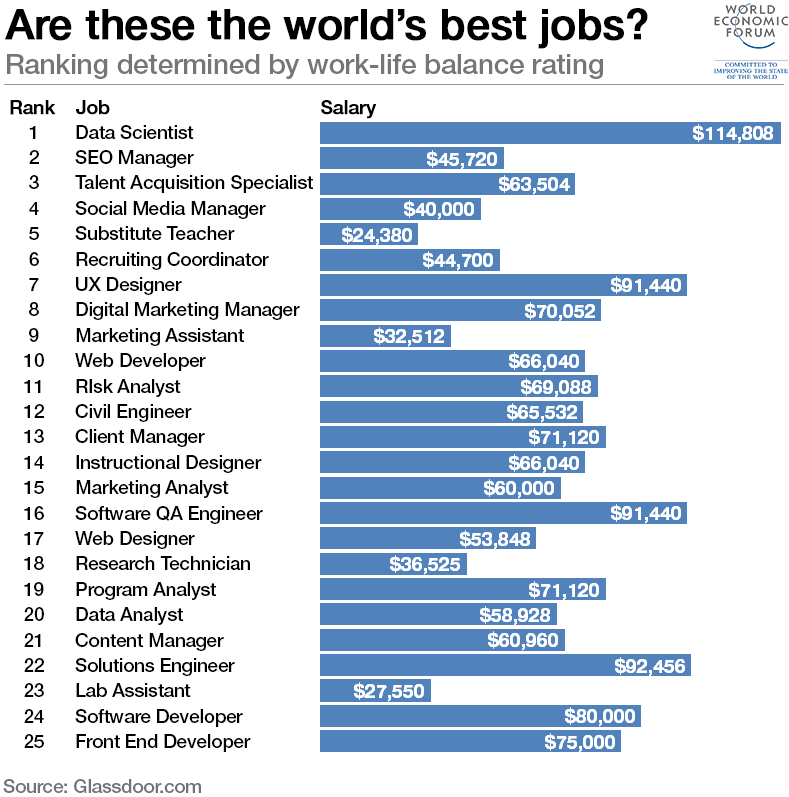
データサイエンティストがトップに来ていますが、彼らの給料が高いというのはよくいわれていることですが、ワークライフ・バランスに関してもトップにランクされているというのは知りませんでした。一緒に仕事をしているデータサイエンティストの人たちも毎日が楽しそうなので、納得ではあります。なんといっても、急激に伸びている業種というのは売り手市場ですので選択が豊富です。つまり現在の職が楽しくなければ他にたくさん仕事をする場所があるわけです。そして、イノベーションの進化の激しい波の中にいるということは、知的好奇心を毎日のようにくすぐられます。さらにまだまだ新しい業界なので、与えられた仕事を答えのあるやり方でこなしていくのではなく、もっと実験的に、クリエイティブに問題を解決していくことが求め られるわけです。私個人にとってはそれは楽しくてしょうがないと言った感じですが、そう思っているデータサイエンティストの人たちは実際多いと思います。
なぜGoogleはいまさら中国にオフィスを開くのか
Why Google is opening office in China? AI Talent? - Link
先週、Googleが中国の北京にAIのリサーチセンターを立ち上げるという発表がありました。Googleといえば、その昔中国のインターネットに対する検閲への抗議として中国から撤退していますが、戻ってくるようです。これからのAIの世界での中国の重要性を無視できないということでしょう。
その中国ですが、以前にも紹介したMcKinseyの”Artificial intelligence: The next digital frontier?”というレポートによると世界の6つのAIハブのうちの2つを抱えています。
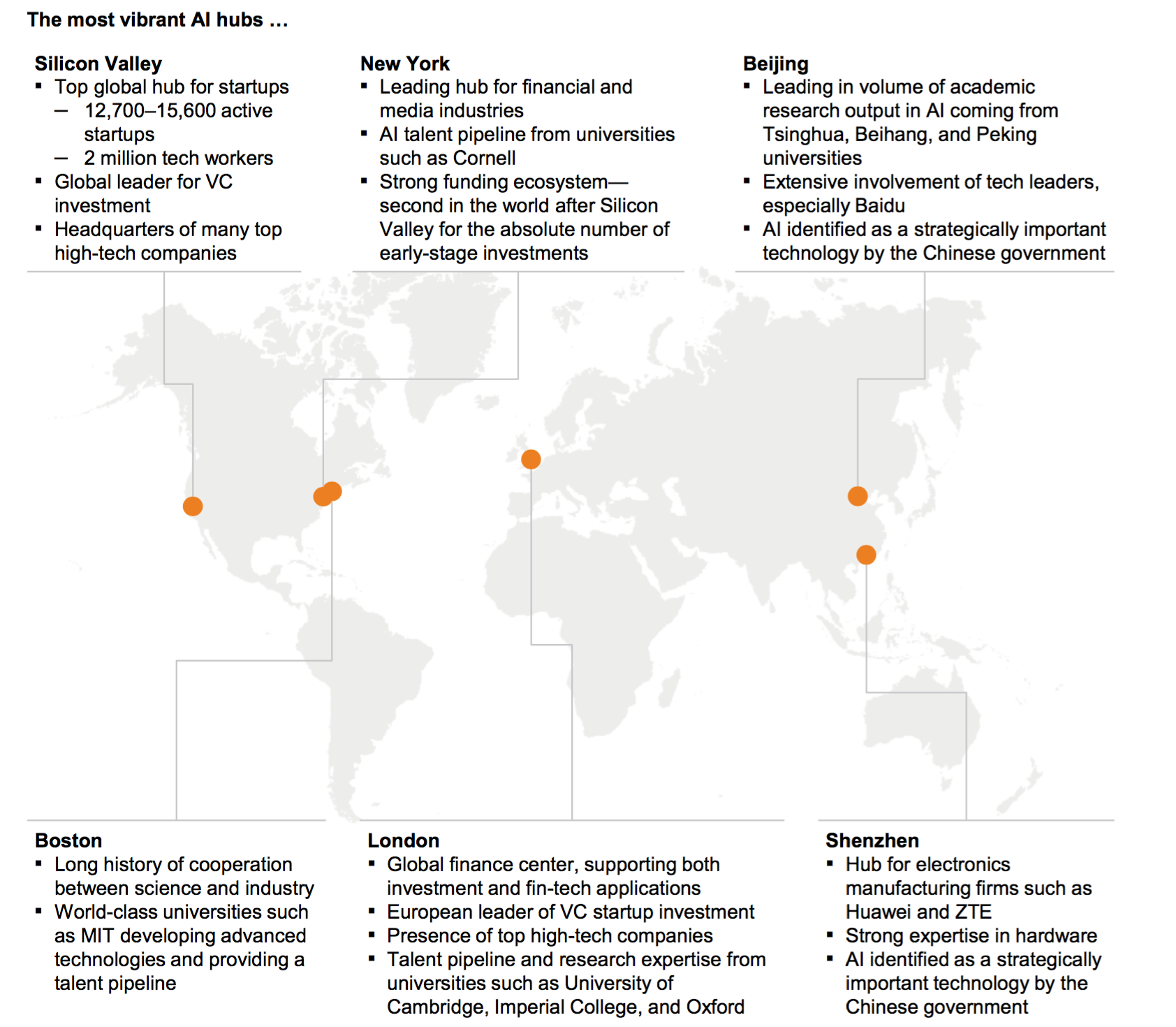
こちらはたまたまそうなっというのではなく、国家の意思です。AIは中国にとって長期的に、さらに戦略的に重要な柱の一つとして位置づけられているので、この分野には莫大な投資が行われいます。
今年の夏に中国の国家成長に関する計画が提示されましたがAIに関しても強気な目標を立てています。まずは2020年までにAI分野でトップクラスの国と同等のレベルに追いつく、2025年までにAIの技術に関して大きなブレイクスルーを生み出す、2030年までにAIが中国の経済の基盤となるとのことです。(参考:China's AI Awakening)
以前ここでも紹介した、AI業界のスーパースターで、もとGoogle BrainやBaiduなどでチーフ・サイエンティストをやっていたAndrew Ngによると、中国政府のこうしたビジョンが与える影響というのは非常に大きく、今までの歴史からするとそれは到達されるであろうとのことです。
そして、たまたま先週、そのAndrew Ngが彼の新しいスタートアップであるLanding.aiの発表を行っていました。こちらはAIを様々な業界に導入していく支援をするコンサルティングの会社のようですが、まずは製造業からということで、Foxconnを戦略的パートナーに迎えAIの本格的な導入を支援していくようです。中国政府のビジョンを、こういうかたちで民間、しかもスタートアップが中心となって実現していく姿勢は素晴らしいですね。
ちなみに、中国の示すビジョンとその投資もすごい規模ですが、AIにとっての石油とも言うべきデータの規模も中国をAIの世界で優位に立たせる理由です。市民のプライバシーというものが保証されず、政府がうんといえばどんなデータでも誰からでも取ることができるわけです。例えば、機械学習を使った顔認識の技術を使って市民を監視するといったことは既に行われています。このことと、単純に人口が多いことから来る大量のデータが入手可能だという事実は、他の国には太刀打ちできません。
ところで、最後にGoogleにまた話を戻しますが、グーグル・クラウドのチーフ・サイエンティストのFei-Fei Liが今回のアナウンスメントの中でも強調していたことですが、"GoogleはAIファーストの会社"ということをGoogleのエグゼクティブ・クラスの人たちから最近よく聞きます。数年前はモバイル・ファーストという言葉がシリコンバレーの多くの会社で言われていましたが、現在はそのAI版だということです。実際、Google、Facebook、Apple、Amazonなどといった企業はAIをインターネット、ソーシャル、モバイルに続く破壊的なシフトであると捉えています。最近のシリコンバレーの会社はイノベーターのジレンマにはまって新しい変革の波に乗り遅れたIBM、Microsoftといった巨人の失敗から学んでいるので、現在とてつもない規模での勝ち組といえど、こうした変革に適応できるように生まれ変わることができないと新しく出て来る会社に淘汰されていくことを自覚しています。こうしてAIファーストというメッセージが出てくるわけです。
Courseraでは、どうデータサイエンス・チームを作っていったのか?
How to structure a data science team? by Chuong Do - Link
CouseraというMOOC(Massive Open Online Course)のトレンドの先駆けであるオンライン教育のプラットフォームがありますが、そこで最近までデータサイエンスチームのトップをやっていたChuong Doが、Couseraがどうやってデータサイエンスのチームを作っていったのかをQuoraというQ&Aサイトでまとめていました。
タイプA vs. タイプB
まずはデータサイエンティストといっても、大きく分けて二つのタイプがあります。まずは、タイプAとよばれる分析タイプで統計的な分析を通してデータからビジネスの意志決定に役立つインサイトを得ることを主な仕事とします。もう一つはタイプBとよばれるビルダー・タイプで予測モデルやアルゴリズムを作ってそれをデータプロダクト(例:レコメンデーション、チャットボットなど)としてユーザーに使ってもらうことを主な仕事とします。それぞれに要求されるスキル、経験がけっこう違います。
特にスタートアップのような場合は仕事の内容を細かく定義することは結局は時間の無駄になりますが、少なくともこの違いを知っておくのは、データサイエンスに関わる人材の採用と育成の際に役立つと思います。
一般的にデータサイエンティストの人たちは会社の中で一つのチーム、部署としてまとまっています。それはそうした人材の採用と育成は、データサイエンスの事情がわかる人たちによって一つにまとめられたチームで行うほうが効率がいいからです。しかし、社内でのデータサイエンス関連のプロジェクトを成功させるためには、データサイエンティストをビジネス部門に配置し、そこのチームの一員として活動させるほうが効率がいいことがよくあります。これをembedding(埋込み型)と言います。
ただ、このembeddingは社内のデータサイエンティスト同士のつながりが薄くなってしまい、彼らがそれぞれのチームの中で孤立していくことにもなってしまいます。そこで、Courseraでは2人から4人ほどのデータサイエンティストからなるクラスターと呼ばれる小さいチームを作り、そうしたチーム単位でいくつかのビジネスやプロダクトを担当するチームと協力して仕事を行うパートナーシップの形成に力を入れているようです。
データサイエンスチームの所属先
データサイエンスチームの所属というのは企業によって様々です。LinkedInのような企業では、データサイエンスチームはエンジニアリングを担当する組織の一部ですし、Couseraのような企業ではプロダクトを担当する組織の一部ですし、以前紹介したStitchFixのような企業ではCEOに直接レポートします。そして、先ほどにも挙げた、タイプA、タイプBのデータサイエンスチームを別々に作り、それぞれが別の組織にレポートするという場合もあります。Instacartがこのパターンです。
ただ、どの組織に最終的にレポートすることになったとしても、組織を横断して協業できる体制を最初から意識して作っておくことが重要です。なぜなら、データサイエンスプロジェクトの成功は、様々な他の部門の人間との協力関係なくしてはありえないからです。
成功への外部要因
他の部門との協業というと、まずはデータインフラを用意、整備できるエンジニアリングのサポートが重要になります。
そして、データプロダクトを作ることにおいての複雑さを理解しているプロダクトマネージャーと開発マネージャーが必要です。一般的なソフトウェアの開発であれば要件を削って製品を期日までにリリースするということがよくありますが、データプロダクトの開発の場合は要件のスコープを簡単に削ることはできません。というのも、開発した予測モデルが、決められた予測精度を出せるまではリリースすることができないからです。そこで、開発を行う前の要件を決める段階で、プロダクトマネージャーや開発マネージャーと言った人間が、何が機械学習のアルゴリズムを使ってできるのか、何ができないのか、その前提条件とは何なのかなどを理解している必要があります。
そして最後に忘れてはならないのが、CEOを始めとした重役レベルの人間が社内の人間にデータを使って意志決定をさせていることです。データサイエンスのプロジェクトが社内で成功するかどうかは、組織全体がデータドリブンな文化を作れるかどうかにかかっています。
以上が簡単なまとめですが、最後に私の方から一言付け加えさせていただきたいと思います。
データサイエンスはまだまだ新しい領域で、毎日凄まじいスピードで進化しています。そもそもデータサイエンスとは何か、データサイエンティストとは何なのかという議論さえ未だに起きています。しかし、いちばん重要なのは、最終的にデータサイエンスを使って何の問題を解決したいのかをはっきりさせることです。それがあって初めて、そうした問題を解決するためにどうデータとアルゴリズムを使えるのか、そのためにどういった人材が必要なのか、そういった人材を成功させるにはどういったチームを作っていくべきなのかという質問の順番で答えていくことができます。
チームの構成だとか仕事の定義と言った技術的なことにとらわれるのではなく、こうした本質的なことを絶えず考えながら、実験的にデータサイエンスのプロジェクトを行っていくことで、自分たちの組織にうまくはまるデータサイエンスのチームを作っていければいいのではないかと思います。今まで私が会ってきたどんな企業も試行錯誤を繰り返しながらデータサイエンスのチームを作っていっています。そして、どこも未だに完璧な答えというのは見つけ出していないというのが現実です。
興味深いデータ
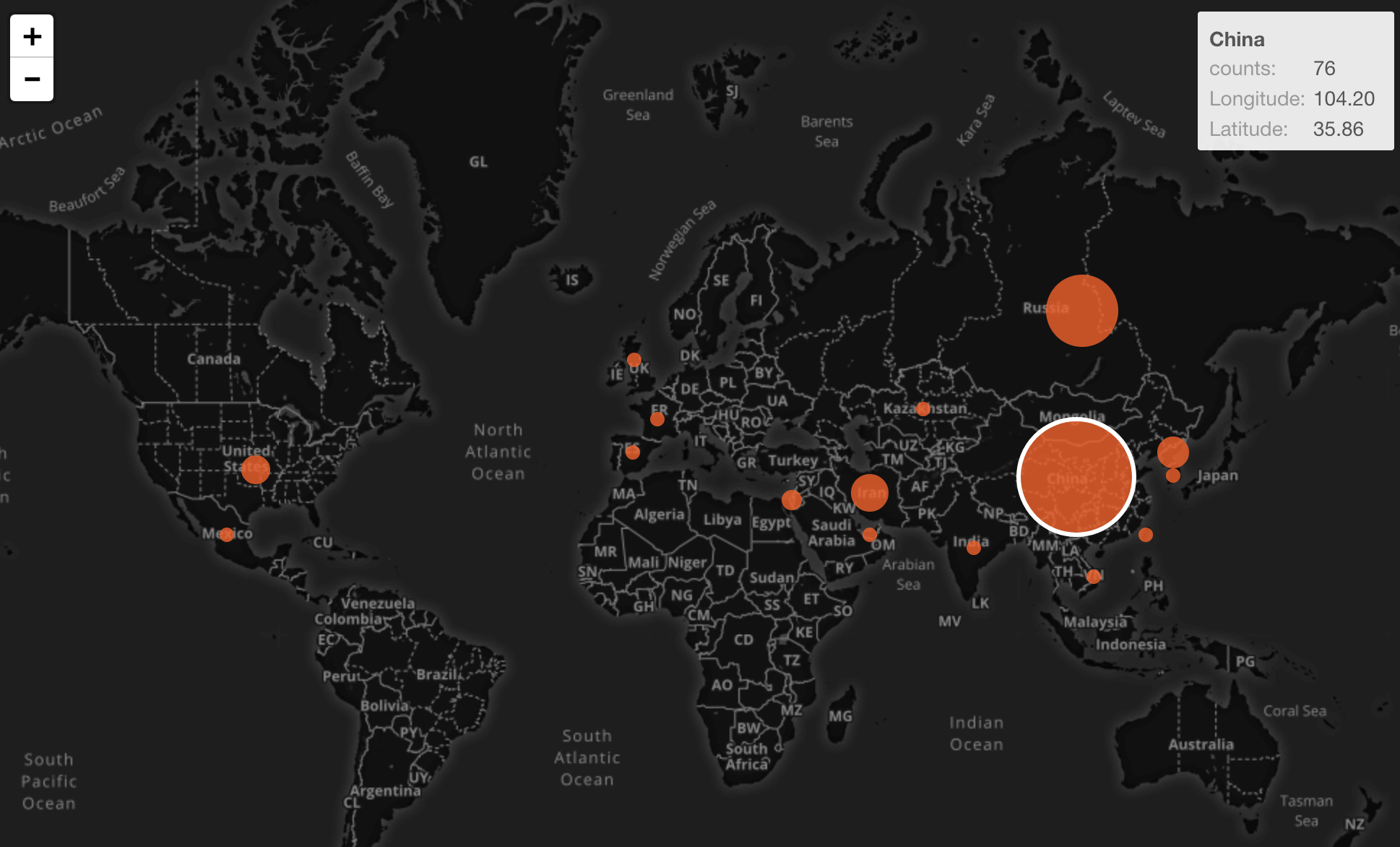
アメリカの警察による銃の使用に関するデータ
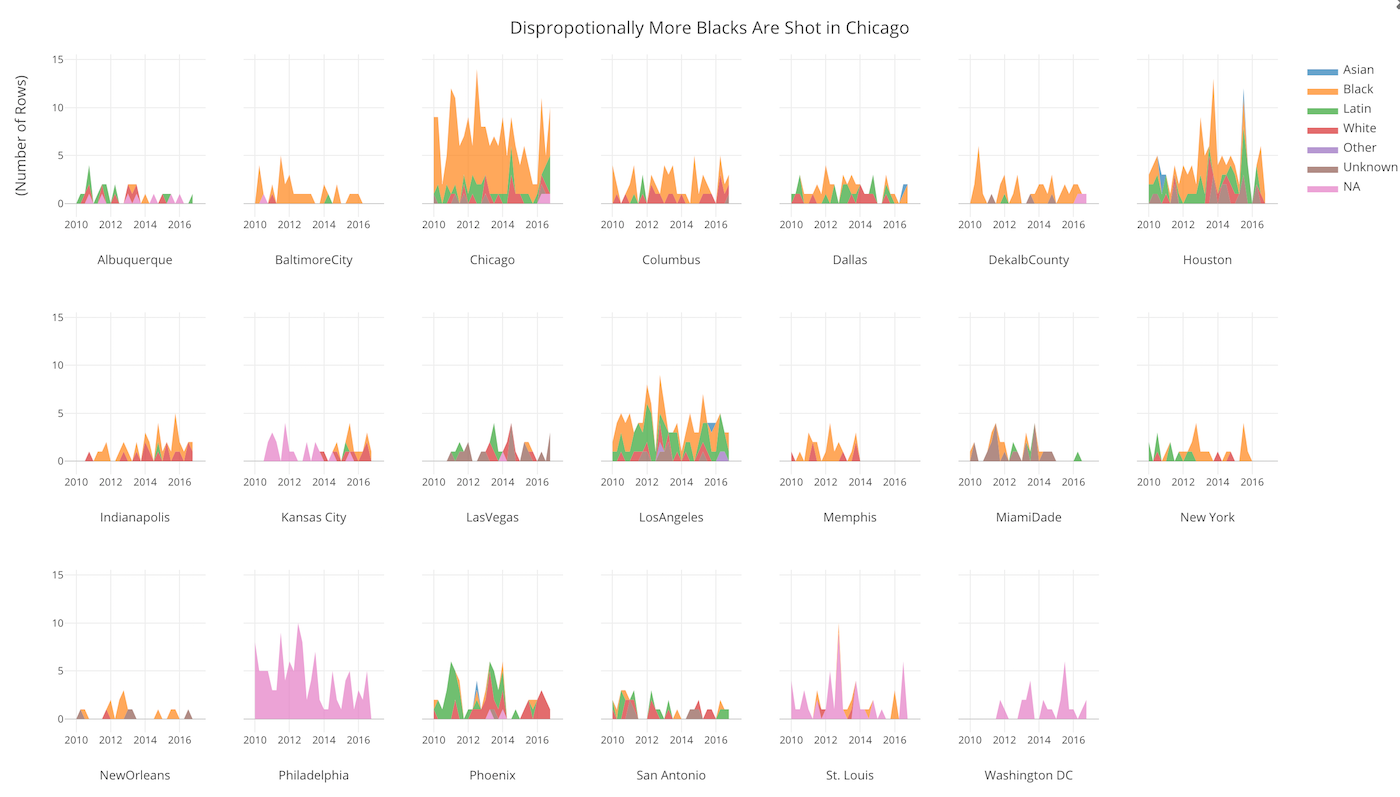
こちらにVICEという比較的新しいオンラインメディアがありますが、そこが9ヶ月かけて、アメリカ全国の規模の大きい警察組織(Top50)に所属の警察官による一般市民に対する銃の発砲に関するデータを集めて公開しています。2010年から2016年までのデータです。撃たれる人の人種構成に地域によって差が見られますが、上記のチャートのようにシカゴでは黒人の割合が特に大きいのわかります。上記のリンクから2013年の人口調査によるそれぞれの都市の人種構成のデータもダウンロードできますが、そこから導き出されるシカゴの黒人の比率と比べても、特別に高いのがわかります。
分析しやすいようにラングリングしたものをこちらにEDFとして共有していますので、そのままExploratoryにインポートしていろいろ探索してみてください。
ブログ記事 from Team Exploratory
英語になりますが、先週データラングリングに関する記事を書きました。日付データを扱ってるとたまに出くわすことのある’歯抜け’問題を解決するための方法です。
- Populating Missing Dates with Complete and Fill Functions in R and Exploratory - Link
What Are We Working On?
以前よりたくさんのユーザーからリクエストいただいておりました、ダッシュボード。いよいよ次のバージョンから出てきます!
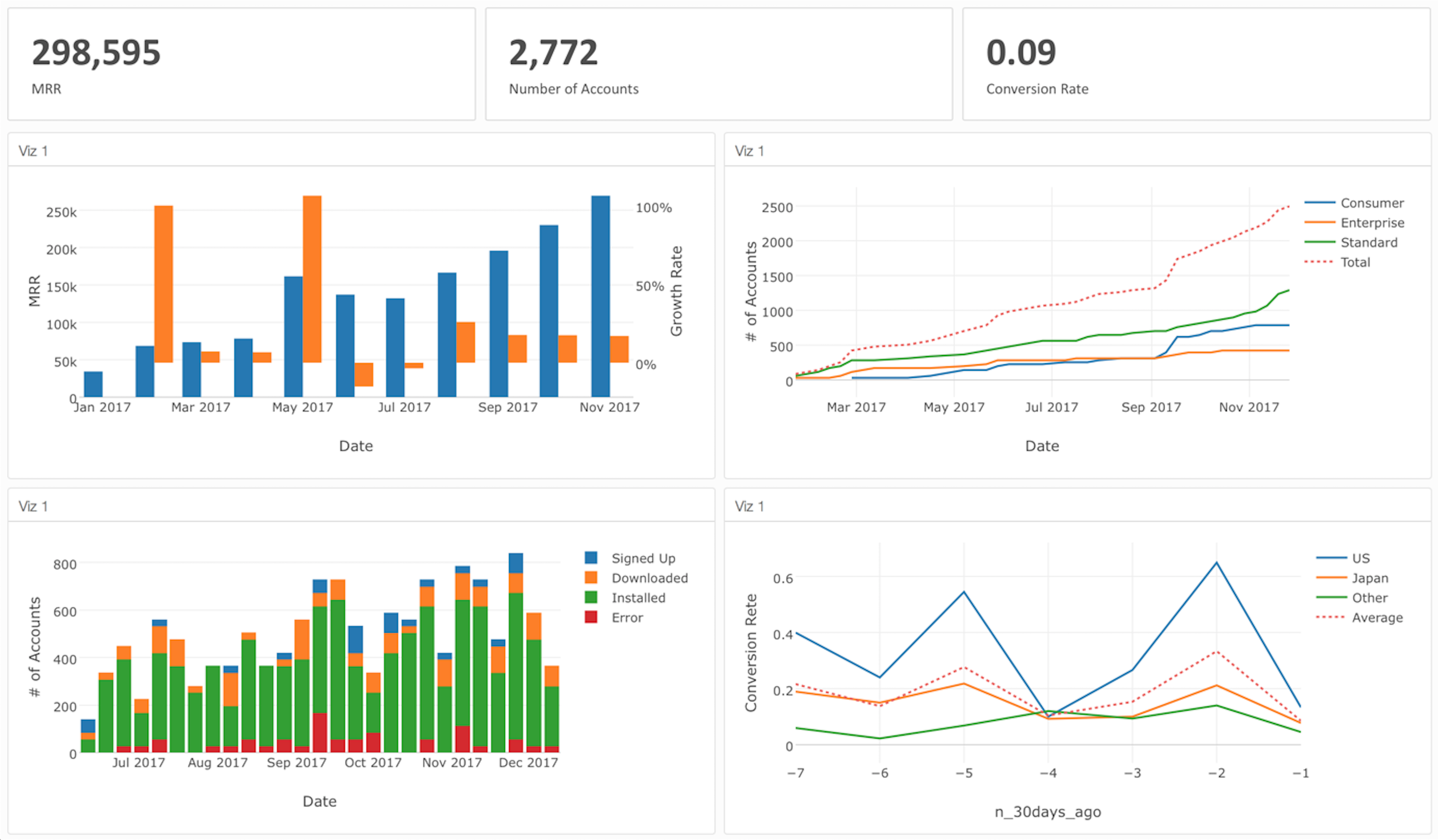
こちらは、UIから簡単に作れて、さらにExploratory CloudかExploratory Collaoboration Serverの方にパブリッシュすることによって毎日、毎時間更新するようスケジュールすることもできます。
データサイエンス・ブートキャンプ・トレーニング
先週もお伝えしましたが、来年1月の中旬のデータサイエンス・ブートキャンプの方の残りの席があと僅かとなっておりますので、参加をご検討されている方はお早めにお申し込みくださいませ。詳しくはこちらのブートキャンプ・ホームページをご覧ください。
それでは、今週は以上です。
素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory's Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちらより (https://exploratory.io/tag/weekly%20update%20-%20japanese) どうぞ!来週より自動的に週一度、私が皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを配信いたします。