
こんにちは、Exploratoryの西田です。
日本はずいぶん寒くなってきたと聞きますが、こちらサンフランシスコの方も朝は摂氏5度くらいといったかんじで、どんどんと冬の足音が近づいてきているようです。
ところで、当初は今年いっぱいでこのシリーズを終える予定でしたが、多くの方からいただいたリクエストもあり、急遽、私どものデータサイエンス・ブートキャンプ・トレーニングを1月の16、17、18日の日程で開催することになりました。すでに日本では3回ほど行いましたが、そこでいただいたフィードバックや私達が感じた気づき等をもとに、トレーニングの教材、ならびにトレーニングで使うExploratory Desktopの方も絶えず改善、進化していっています。この場を借りて、これまでにブートキャンプに参加された方たちには、熱く御礼を申し上げたいと思います。
これまでに参加されていない方でデータサイエンスを本格的に学んでみたい方、2018年こそはデータサイエンスを始めてみたい方は、プログラミングなしでデータサイエンスを始めることのできるこちらのブートキャンプ・トレーニングへの参加をぜひご検討いただければと思います。詳細はこちらです。
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
「今後はすさまじい伸び」国内AI市場、6年間で15倍以上の成長見込み─IDC調べ
日本でもいよいよAI・機械学習の市場が盛り上がってきているようです。
16年の市場規模はユーザー支出額ベースで158億8400万円と推定。21年には2501億900万円まで拡大する見込みという。
ちなみに、同じIDC(グローバル)によると、北米(アメリカ、カナダ)だけで去年(2016年)すでに$6.2 billion(約7000億円)、世界では2020年には$18.2 billion(約2兆円)となるようです。(リンク)
これらのAIを使う企業の支出額ベースに対して、AI分野への投資という観点では、McKinseyのレポート”Artificial intelligence: The next digital frontier? ”によると2016年だけで、世界で2兆円から3兆円ほどとなっています。これはGoogleのようなシリコンバレーの企業、またはBaiduのような中国の企業が牽引しています。このうち90%はR&D、残りが買収等に使われているようです。
IDCは同市場を「自然言語処理と言語解析を使って質問に応答し、機械学習をベースにレコメンドなどを行う技術」と定義。カスタマーサポートなどで顧客に自動応答するチャットボットやECサイトなどで購入履歴に応じた商品をレコメンドするなどのシステムを想定し、「汎用的なAIでなく、あくまで人間を補助する“弱いAI”と考えてもらっていい」という。
なにも、ここまで特定の分野に絞って狭く定義しなくてもいいのではないかと思います。人間の全ての意思決定は予測、もしくは予測に基づいていますが、現在はその予測の部分を私達の勘や推測に頼って行っています。その予測の部分を自動化して置き換える、もしくは側面から支えることができるものがAIだと思います。ですので、AIを直接使って恩恵を受けるのは何もウェブサイトにやってくる顧客だけではなく、企業の中で意思決定を行う者、製造現場で意志決定を行う者、医療の現場で意思決定を行う者、学問の場で意志決定を行う者、さらには車を運転する時に意志決定を行うもの(ドライバー)などとなるわけで、すでにAIをパートナーとして使いこなすことでこうした意志決定をより効率的に行っている人たち、企業、サービスが多く出始めているといういう認識を持つべきだと思います。そして、これこそがAI・機械学習の真価であり、可能性だと思います。
さらに、上記のコメントでは異様に自然言語処理を強調していますが、この分野でのここ最近の飛躍的な発展は確かに目を見張る物がありますが、画像認識、動画認識の分野での発展の方にこそ現在は大きな進化が見られると思います。参考までに、前述のMcKinseyのレポートによるAI・機械学習のジャンル別の投資規模を示したチャートがこちらになりますが、こちらの方がよりシリコンバレーで肌で感じることのできる現実だと思います。
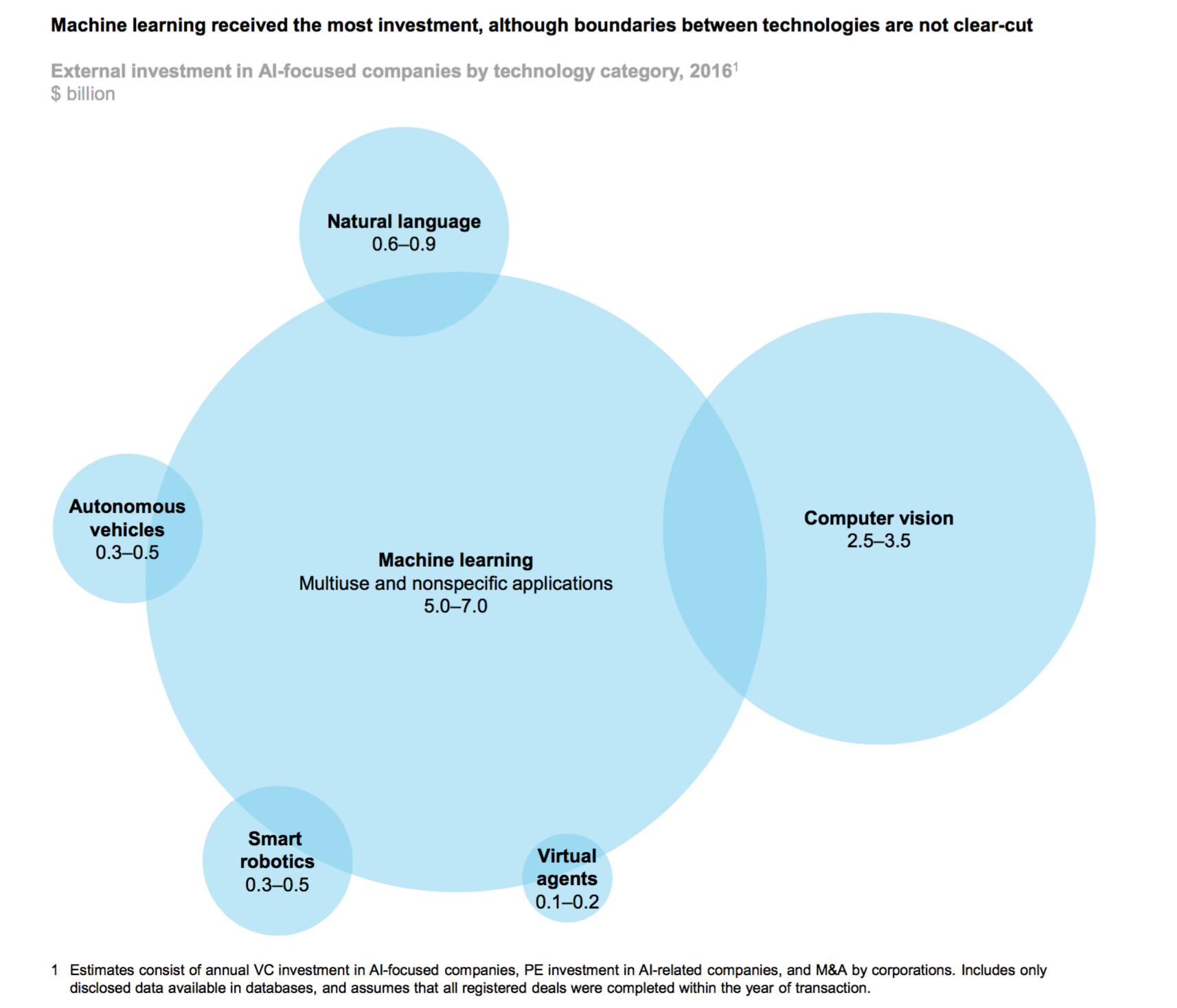
ところで同じMcKinseyのレポートでは世界のAIハブとして以下の都市、地域を上げています。
- Silicon Valley
- New York
- Boston
- London
- Beijing
- Shenzhen
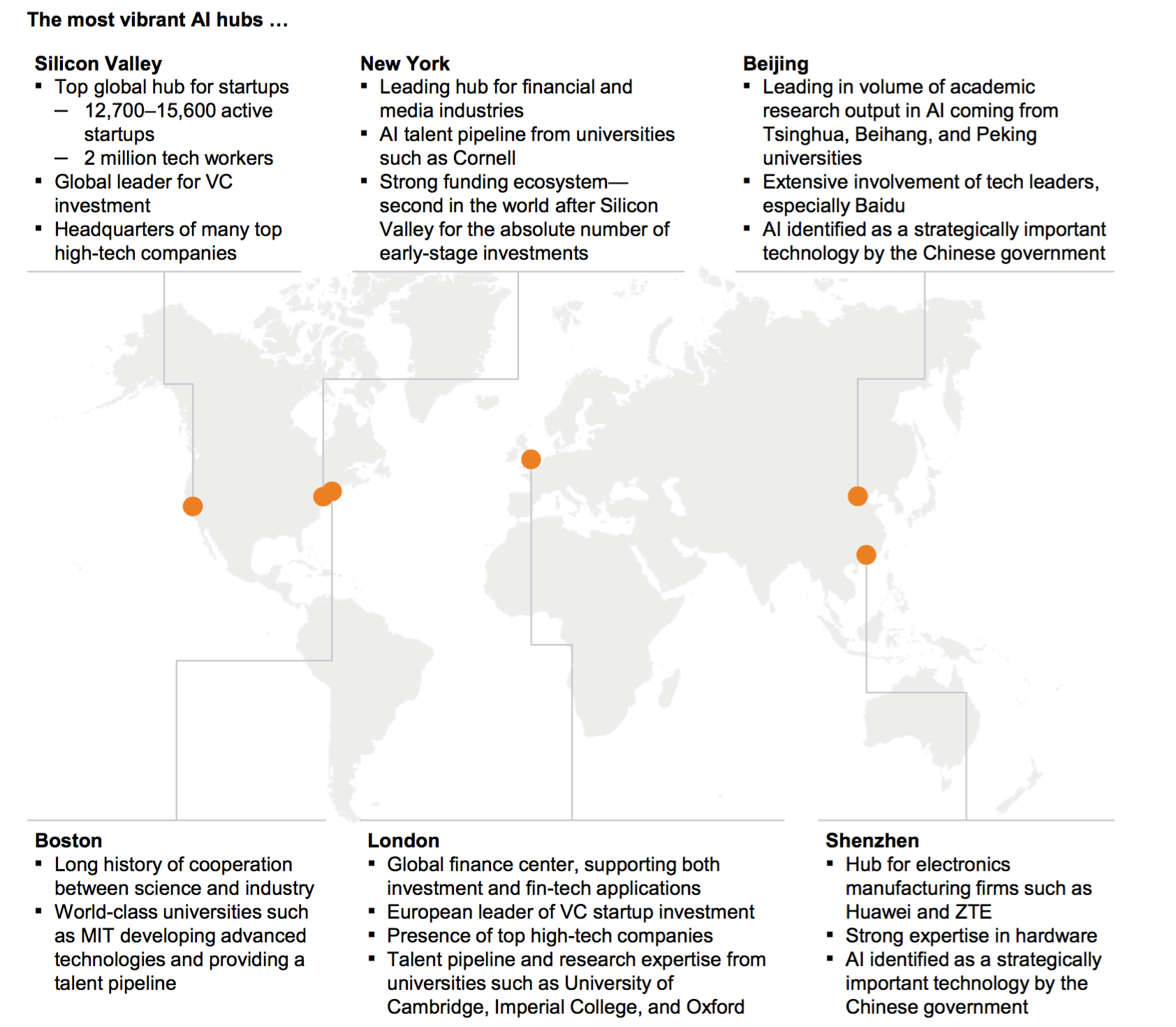
こういった、特に今の時代のものづくりであるいわゆるソフトウェア関連では日本ではなく中国がアジアを代表することが多いですが、それにしてもここに日本の都市、特に東京がないという現実は危機感を持つべきだと思います。東京はその経済規模、世界中で活躍する企業の本社の密集度、優秀な人材と大学のような研究機関の多さからしても、ここにある6つの都市、地域に対してまったく引けを取らないはずですので、次の10年で最も重要なAI・データの分野での革新にもっと貢献できるはずですし、もっとリーダーシップもとれるはずです。
フランスのパリのように年老いた人々が昔を懐かしむような観光都市になってしまうのでなく、今を生きる都市として、次の10年を見据えて世界をリードしていくことのできる国、都市となるよう、私達も側面からではありますが、積極的に支援していくことができればと思っております。
CheXNet: ディープラーニングを使ってレントゲン医師並に胸部のレントゲン写真から肺炎の症状を見つけ出す
CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning - Link
私達のCheXNetモデルはレントゲン写真を入力すると、肺炎であるかどうかの確率と肺炎の症状を示すヒートマップのイメージを出力することのできる、121レイヤーのConvolutional Neural Networkです。
いよいよレントゲン医師よりも正確に肺炎を診断できるAIが、Andrew Ngのチームによって開発されたようです。彼はもともと、GoogleでGoogle Brainチームを作り、オンライン教育のCourseraを作り、その後BaiduでAIの開発を率いていたAI・機械学習業界のスーパースターですが、現在はBaiduを離れ、様々なAI関連のプロジェクトに関わっています。
以前、McKinseyの“Where machines could replace humans—and where they can’t (yet)”というレポートで、USでは平均で年収3000万円から4000万円稼ぐレントゲン医師のような複雑な仕事もいづれはAIによって置き換えることが可能だと言っていましたが、いよいよそれが現実になってきたようです。
ただ、こうしてAIが既存の仕事を奪うというようなコンテクストだと不必要な不安を煽ってしまいますが、実際はレントゲン医師がこうしたAIをツール、もしくはパートナーとして使うことによって、彼らの仕事をさらに効率化させることができるということの方が重要だと思います。現在はそもそもレントゲン医師のサービスは世界の3分の1の人たちにしかアクセスすることができません。それは供給が需要に追いついていないからです。それ故、こうした技術の発展はその供給側の生産性を上げることになり、それによって世界中の多くの人がこうしたサービスにアクセスすることができるようになるわけです。これこそが、このCheXNetのプロジェクトにも実は多くのレントゲン医師が関わっている理由です。
60年台、70年台に冷蔵庫よりも大きいメインフレームのコンピュータが企業に入ってきたときにも、これからの仕事はコンピュータによって置き換わってしまうという不安があったと聞きますが、今のAIによるトランスフォーメーションはそれに近い状態ではないでしょうか。ただ、当時もそうでしたが、そうした新しい技術をチャンスだととらえ、使いこなすことができる企業、人間が、その後さらに飛躍し、勝ち残っていくことになるのですから、AIをこれからの10年の最も重要なパートナーだと捉え、そのAIとの対話の手段であるデータサイエンスをもっと多くの人にどんどんと学んでいってほしいものです。
AIがソフトウェア開発を置き換える
”Software is eating the world“というA16ZのMarc Andreessenによって提唱されたフレーズを、私達もこの20年ほど実際に毎日のように目の当たりにしてきましたが、今度はそのソフトウェア開発そのものが、AIによって置き換わり始めているということに関する2本の記事が先週出てきて話題になっていました。
Software 2.0 by Andrej Karpathy - Link
まずは、TeslaでAI部門のディレクターであるAndrej Karpathyからです。
これまでのソフトウェアの開発では、コンピュータに私達が欲しい結果、または動作を出力させるための指令をプログラミング言語という形で書いて来たのに対して、Software 2.0という新しい世界ではニューラルネットワークのウェイトという形でそうした指令を書いていきます。ただ実際にはその何百万ともなるウェイトを書くのは不可能に近いので、ラベルの付いたデータをAIのアルゴリズムに渡して、欲しい条件を満たすようにコンピュータに最適なウェイトの設定を探させることになります。
実は、世界中の多くの問題というのはプログラムを書くよりもデータを集めることで解決するほうがはるかに簡単であったりするのです。明日の多くのプログラマーの人たちは複雑なソフトウェアのレポジトリを管理し、複雑なプログラムを書き、その実行環境を分析することはなくなるでしょう。その代わりに、ニューラルネットワークに食べさせるデータを集め、クレンジングし、加工し、ラベルを付け、分析、可視化することになるのです。
つまり、これからのソフトウェアを作っていく人たちというのは今まで私達の知っているソフトウェア・エンジニアというよりは、データサイエンティストの人たちになるということです。
もうすでにAIによって置き換わり始めている分野として以下を挙げています。
- Visual Recognition
- Speech recognition
- Speech synthesis
- Machine Translation
- Robotics
- Games
そしてこの多くがGoogleによって目覚ましい成果をすでにあげています。数年前にGoogleで働く友人がイメージの検索のアルゴリズムをDeep Learningのモデルに置き換えるプロジェクトをやっていましたが、その成果に非常に興奮していたのを思い出します。
Deep Learning is Eating Software by Pete Warden - Link
こちらはGoogleのリサーチ・エンジニア、Pete Wardenによるもので、前出の記事での議論をさらに発展させたものです。
これは、こうして言葉にするとあまりドラマティックだと感じられないかもしれませんが、どうやってソフトウェアを開発するかという観点では、根本的、ラディカルな変化です。複雑に絡み合ったロジックを書き、それを変更、修正していくのではなく、ソフトウェアの開発者というのはAIのモデルをトレーニングする先生となり、トレーニングするためのデータの収集家となり、そのトレーニングの結果の分析者となるのです。これは私が学校で学んだプログラミングとは全く違います。しかしこのことで私が興奮する理由は、今までは、プログラミングというハードルのために関わることのできなかったはるかに多くの人たちが、ソフトウェアの開発に関わることができることになるからです。
そうは言っても、全てのソフトウェア開発が置き換わるわけではないかもしれませんし、そこまで行くにはいろいろな障害もあるでしょう。ただいずれ多くのソフトウェアがそうやって開発されていくのは間違いないと思います。
なんといっても、そうしたAIによって書かれるソフトウェアというのは人間が書くものよりもクオリィティが高いわけですから。
私はこうした破壊的な変化にものすごく興奮してしまいます。というのは、“Software is eating the world”というのは、世の中がさらに便利になり、さらに多くの人たちにその恩恵が行き届くということで、私は素晴らしいことだと思っていたのですが、ただその世界を食べていっている主体がどうしてもソフトウェア・エンジニアの多い、またはそうしたソフトウェアを開発していくことに適した文化のあるシリコンバレーから出てくる企業に限られてしまっていたのは問題だと感じていたからです。
このソフトウェア開発における革命は、こうした現状をある意味リセットすることができます。そしてこれまでのソフトウェア革命の担い手としての主体が変わってくる可能性があります。これはシリコンバレーの外の世界にとってはたいへん大きなチャンスです。ソフトウェアの開発に求められるスキルとデータサイエンティストに求められるスキルは、もちろん共通している部分はありますが、根本的な部分でかなり違います。ですので、データの分析に秀でた人材を多く擁する地域、都市こそが次の10年のAI・データによる革新に大いに貢献できるチャンスがあるのです。
“Software is eathing the world”という、ソフトウェア革命はこれからもまだ続きます。ただし、そのソフトウェアを作り出す担い手がソフトウェアエンジニアからデータサイエンティストの手に移っていくということです。それはつまり、これからの未来をデータサイエンティストが作っていくということなのです。
これは、非常に興奮しますね!
機械学習の時代に企業はどうやって前に進んでいくべきか
How companies can navigate the age of machine learning by Ben Lorica - Link
先ほどのIDCの記事にもあるように日本でもこれからますます、AI・機会学習を使ったデータサイエンスのプロジェクトが増えていくと思います。全ての意志決定の予測の部分をAI・機械学習を使って効率化していこうとするものですから、まさに様々な業種、業界での取り組みがいっそう活発になります。そうした時に企業は機械学習のプロジェクトにどのように取り組んでいくべきなのでしょうか。O’Reilly(テック系最大手の出版社)のチーフ・データサイエンティストのBen Loricaからのアドバイスがこちらにまとめられています。
AI・機械学習のプロジェクトを成功させる上でのボトルネック
データサイエンスのプロジェクトを行っていく中でいろいろな問題に遭遇してしまいます。その中でも技術的な面からのトップ3は以下に挙げられています。
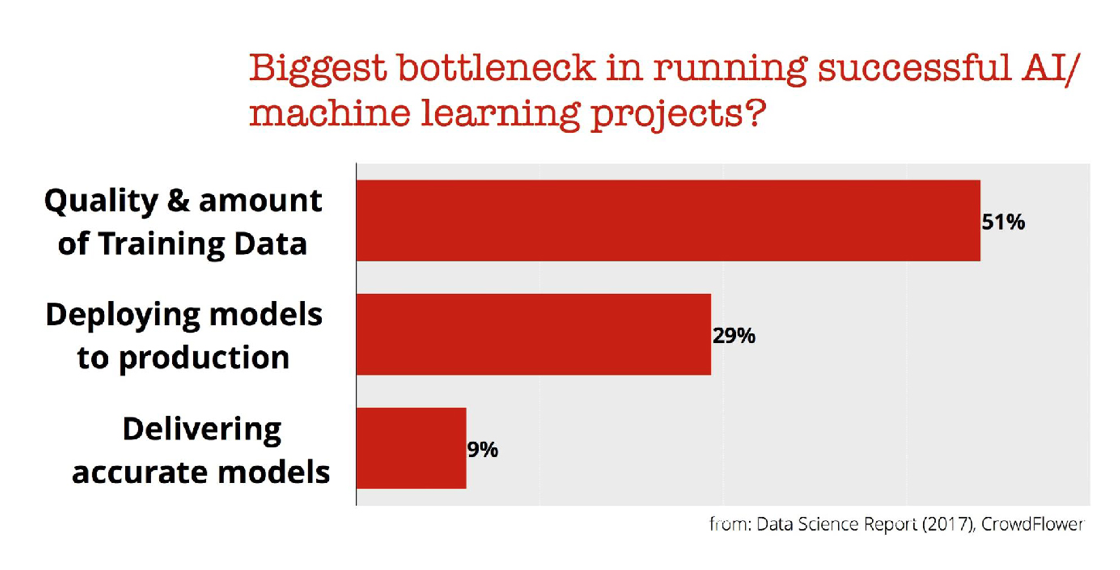
やはりダントツで、データのクオリィティと量がトップです。結局、AI・機械学習を使ったプロジェクトが成功するか失敗するかはデータのクオリィティと量に大きく左右されます。パターンを見つけ出すために必要な量のデータがない、データはたくさんあるが、肝心な部分が収集できていなかった、収集されてはいるけど、技術的、もしくは社内の政治的な理由でアクセスできない、データが不完全である、人間によるミスで間違っている、データのフォーマットがデータが出て来る場所によって違うなどと、上げればきりがないほどデータの量とクオリィティに関しては様々な問題があります。
このデータのクオリィティの問題は、私どものデータサイエンス・ブートキャンプに参加された皆さんにとってはすでにおなじみですが、これこそが私達のトレーニングではデータ・ラングリング(データの加工)に時間をかける理由です。データサイエンティストの80%ほどの時間はデータラングリングに費やされているというのは共通した認識ですし、意味のある分析成果を効率的に求めるのであれば、結局はデータを自分で取ってきて、自分でクレンジングし、加工し、自由自在に操ることが必要となります。残念ながらこのスキル無しではどんなAI・機械学習のアルゴリズムも、ただの机上の空論で終わってしまうというのが現実です。
データサイエンス業界の物凄いスピードでの進化
ここ最近のデータサイエンスの世界の進化は非常に速く、私達でもついていくのが大変です。新しい技術、アルゴリズム、ツールが毎日のようにオープンソースとして出てきます。今日のやり方が明日になると廃れてしまうといったことが平気であります。著者のBenは、例えば今後5年ほどこの業界の進歩が全く止まってしまったとしても、企業にとってはすでにあるそうしたツールに追いつくだけでしばらくは忙しいだろう推測します。
まだまだ進化は始まったばかり
ここ最近のこの業界の進化は目を見張る物がありますが、研究者や理論家でさえまだよく分かってないものがたくさんあります。私たちはまだ、トライアル・アンド・エラー(試しては失敗)の時代にあるのです。
こう言われると何だか、エジソンが電球を発明するために様々な実験を繰り返していた時代を思い出します。
予測モデルの作成とは、機械学習のアルゴリズムの世界を探検、探索しているようなものです。企業はそうした探索(exploration)を規律に乗っ取り効率的に行なっていく必要があります。これは、データまたは機械学習のモデルを再現することが可能なパイプラインを管理し、実験に関するメタデータを保存し、コラボレーションのためのツールを用意し、最新のリサーチの結果を利用することができる仕組みを持つことを意味します。
この世界で先を行っている会社はデータサイエンティストに複数の機械学習のライブラリを使わせます。会社公認の一つか二つのライブラリだけを使わせるような企業がまだありますが、それはとんでもないことです。データサイエンティストは絶えず様々なことを試し続ける必要があり、そのためには彼(彼女)らに様々なライブラリを使わせるべきなのです。
私が日本にいる間に、幾つかの会社ではいまだにオープンソースの世界でのデータサイエンスの進化の恩恵に預かることのできないSASやSPSSといったプライベートなテクノロジーしか使わせてもらえないという話を聞きましたが、こういう時代にあって、それはたいへん恐ろしいことだと思います。勘違いを通り越して、その会社の未来にとっては犯罪のレベルだと思います。
AI/機械学習・カンパニーとなるには、データ、エンジニアリング、モデルの作成に関わるチャレンジを解決していくことのできるツールとプロセスが必要になります。企業は様々な製品やサービス部門で機械学習をようやく使い始めました。ツールはこの先もどんどん良くなっていくでしょうし、ベスト・プラクティスもようやく出てきはじめているようです。
日本ではよく、他の会社の事例を聞きたいという方が多いですが、まずは自分たちで積極的に勉強しながらやり始めることが今はものすごく重要です。まだ新しい分野であり、さらには進化と変化のスピードがものすごく速いので、自分たちにあった手法やプロセスを自分たちで探索的に作っていくしかないからです。そして、ここでなまけてしまうと、つまり他の人たちがやってうまくいくのを待ってそれをコピーしようとしていると、せっかくのAI・データの波に乗り遅れ、取り残されてしまい、思わぬところからやってくるAI/データ先進企業によって淘汰されてしまうことになります。これは、インターネット、モバイルですでに起きたことです。こちらに関しては、”データサイエンスのすゝめ — シリコンバレーに全てを飲み込まれる前に”という記事の中でも述べましたので、よろしければぜひご参照下さい。
興味深いデータ
USの出産に関するデータ
Natality(出産率) - Link
1969年から2008年までのUSの50州およびワシントンDC、ニューヨークでの赤ちゃんの出生に関するデータがCDCによって集められ、さらにこちらのGoogle BigQueryの方でパブリックデータとして公開されています。生まれたときの赤ちゃんの体重、性別、人種、妊娠期間、お母さんが妊娠中にアルコール、タバコを消費していたかなどの情報が入ってます。
有名人による性犯罪のデータ
High-profile sexual assault timelines - Link
ここ最近大きなセクシャル・ハラスメントのスキャンダルに発展しているUSの有名人 - Harvey Weinstein(映画プロデューサー), Bill O’Reilly(FoxNews政治番組のホスト), Roger Ailes(FoxNews/CEO), Donald Trump(えーっと、誰でしたっけ?), Bill Cosby (コメディアン) - による被害にあった被害者の名前、事件が起きた年、そして告発の年がこちらのGoogle SheetにAxiosのRebecca ZisserとLazaro Gamioによってまとめられ、日々明らかになってくる事件をリアルタイムで更新していっています。
Kaggleに公開されているパブリックデータ
Data sets at Kaggle - Link
これまでのトレーニングに来られた方はすでに知っていると思いますが、Kaggleというデータサイエンスのコンテストが行われる場所があります。ここにはたくさんデータ分析の練習を行うためのパブリックデータがありますので、ぜひチェックしてみて下さい。
ブログ記事 from Team Exploratory
少し古い記事になりますが、人気のあった過去のブログポストです。
What Are We Working On?
引き続きv4.2の開発作業を進めています。v4.2のテーマはチャート機能の強化ですが、そのうちの一つの機能としてリファレンス(参照)・ラインが簡単に描けるようになります。
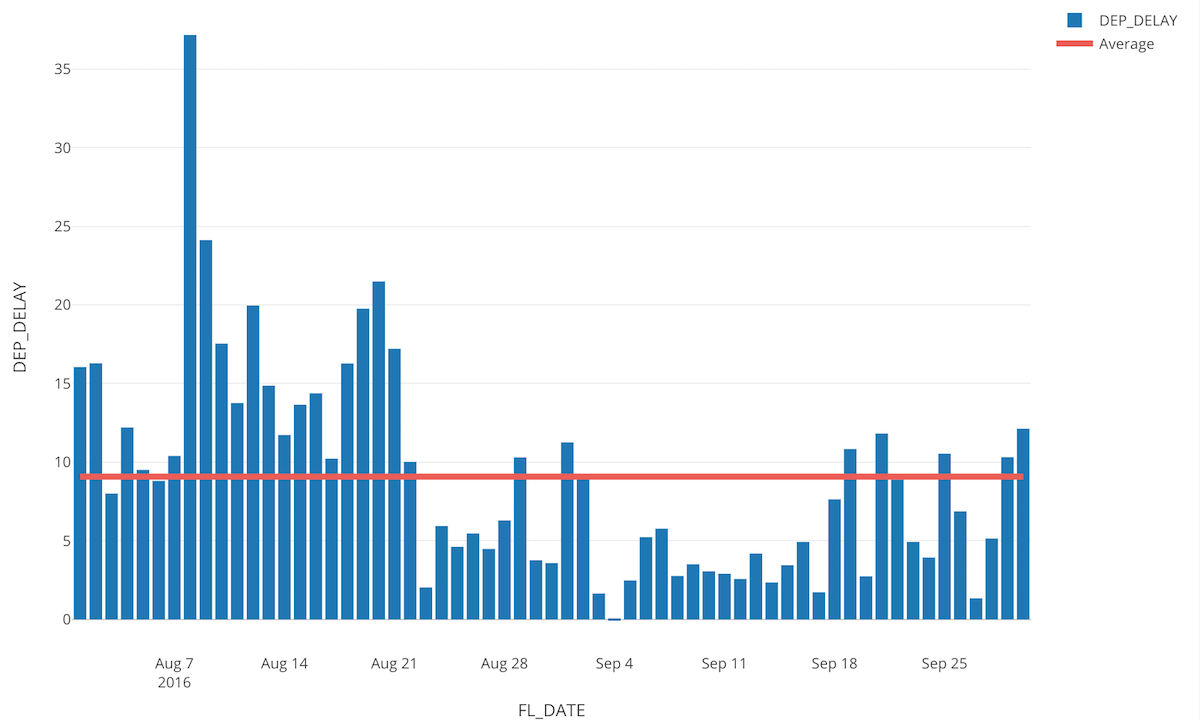
こちらは、上のように全体の集計値(例えば平均)を描くこともできますし、もしくはそれぞれのX軸ごとの集計値を描くこともできます。
データサイエンス・ブートキャンプ・トレーニング
冒頭にも申し上げましたが、好評につき1月の中旬に急遽ブートキャンプを行うことになりました。ご興味のある方、またはお知り合いに興味のあるそうな方がいらっしゃれば、ぜひお声おかけいただければと思います。詳しくはこちらのブートキャンプ・ホームページをご覧ください。
それでは、今週は以上です。
素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)