
こんにちは、Exploratoryの西田です。
先週のWeekly Updateでもお伝えしたように、AIが今まで以上に多くのビジネスに採用され、世間一般の認知も上がることでどんどんと私達の身の回りに浸透していきます。ただ、ここでいうAIとは機械学習のことであって、一般の人達が想像する、ターミネータなどの映画に出てくるいわゆるインテリジェンスを持った機械・コンピュータとしてのAIとは違うということで、一般の方達とお話するときには誤解が生じたままで噛み合わない議論となってしまうことがあります。そこで、最近はAGI(Artificial General Intelligence/汎用的なAI)という言葉がもっと何でもできてしまうAIを表す言葉として使われ始め、機械学習としてのAIはそのままAIとして使われ始めています。ですので、ここでも単にAIという言葉が出てきた際には機械学習としてのAIだと思っていただければと思います。
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
ちょうどNew York TimesのほうからおもしろいAIの説明能力に関する記事がでてきたので、まずはそちらから。
AIに自分自身を説明させることができるのか?
Can A.I. Be Taught to Explain Itself? - 11/21 - Link
先週お伝えした、レントゲン写真から肺炎を診断するAIを含め、多くの分野でAIのアルゴリズム、手法がどんどん発展していっています。ただ、たとえどんなに正確に予測できるようになったとしても、最終的には人間が意志決定を行わなければいけません。そしてその意志決定の際に、AIがどうやってその予測結果を出してきたのかが人間に分かる形で説明されない限りは、結局は使われることがありません。
実はEU(European Union)ではすでに、ここ10年ほどに渡って練られてきたEuropean Union’s General Data Protection Regulationというのが来年より施行されます。この中には条項22というのがあって、説明を求める権利というのを要求しています。EU市民はAI/機械学習のアルゴリズムによって下された決定に対して訴えを起こし、さらに人間による介入を求めることができます。AIによる自動運転の世界がもうすでに来ているわけですから、もっともだと思います。ただ適用範囲がどこまでおよぶのかがはっきりしません。例えば、Googleがどうしてサーチの結果を決めているのか、Facebookがどうやってニュース・フィードに出てくるポストの順位を決めているかということなどもこの範疇に入ってくる可能性があります。
さらに、どのレベルまでの説明を求められるのかなど、詳細はまだはっきりしていないようです。ただこうした公的機関による法によって、現在すでに使われている多くのブラックボックスになっているAIのモデルの作り方、使い方を見直す必要が出てきてるわけです。
そもそも、人間は確実性と原因(理由を使って予測するのに対して、AIは確率と相関をもとに予測するので、どのようにその予測結果を説明するかというのは、そんなに簡単にAIを知らない人間が期待するほどには直感的にならないかもしれません。そこで、まったく違ったアプローチが必要になるでしょう。
この人間と機械の意志決定の仕方の違い、さらにこれからはどんどん機械が我々人間に置き換わってより多くの意志決定を行っていくという現実が、機械による予測の仕組みにもっと透明性を持たせ、XAI (eXplainable AI / 説明可能なAI)という新しい研究の成果を求めています。
このAIがどうやって予測を行っているか説明させたいというのは、最近の機械学習のモデルがどんどん複雑になってきているからという背景があります。特に最近のディープラーニングのモデルは使ってる人たちでも実際に作られたモデルの中でどういう特徴が抽出されて、それがどのように予測の結果に使われているのかよく分からなかったりするのですが、これはディープラーニングだけでなく、データサイエンスの世界で一般的によく使われる集団学習系のランダム・フォレストやXGBoostなどの機械学習のアルゴリズムであっても同じ問題があります。このことを、ブラックボックス化されているといいますが。これは以下のようなときに問題になります。
例えば、新しく病院にやって来る患者が緊急治療が必要か、それともそのまま家に返してしまってもいいかを予測するモデルを、病院の患者のデータをもとに作るとします。この時、喘息と肺炎を患っている患者の多くがその後すぐに回復して退院しているデータがあったとします。このデータをもとにAIに予測モデルを作らせると、AIは喘息と肺炎を患って病院にやってきた患者をそのまま何もせずに家に返してしまっても問題ないと判断するかもしれません。ところが、よく調べてみると喘息と肺炎を患っている患者は看護師や医師によってすぐに危ないと判断されるために緊急治療をうけていたので、そのせいでデータ上はすぐに回復すると見えてたわけです。この時に、医者がAIがどうやってこの患者を診断しているのかが分かれば、例えAIが危なくないと判断したときでも、医者のそれまでの経験を使って軌道修正することができます。
そして、これこそが私どもが繰り返し言っている、人間とAIはパートナーになるべきだという理由の一つです。AIは人間よりもデータに隠されたパターンを客観的に認識するのが得意です。そしてそこから予測モデルを作るのも得意です。ただ、自分自身の経験・常識、ドメイン知識をもとに、そうやって提示された予測の結果をどうやって使うかを判断するのは人間の方が得意です。
ところで、この記事にも書いてありましたが、こういうAIの予測の仕組みを説明するためにデータの可視化を使うという話になるとついついその予測の結果をいかにわかりやすく見せるかに注意が行ってしまうことがありますが、そうではなく、なぜ、どうやってその予測の結果に行き着いたかを知りたいわけですね。Whatではなく、Whyのほうが重要なわけです。
”あなたの提示してるソリューションはどれも役に立たないわ。また別のレコメンデーションを可視化するなんていうのが必要なんじゃないわ。私が決断をするめにはそれを正当化しなくてはいけないのよ。”
ちなみに、ここでコメントしているこの記事の中に出てくるアナリストはCIA、NSCといったUSのいわゆるインテリジェンス(諜報)機関の人です。つまりだれがテロリストなのかという情報をもとに、例えばアフガニスタン、イラク、イエメンといった国で無人機を飛ばしてそういったテロリストを暗殺したりしている組織なわけです。AIがどんなに正確に予測しようがしまいが、最終的にその予測をもとにした意志決定に責任を追うのは人間で、その人間には法的、そして道徳的責任がつきまとうわけです。その情報が間違っていたではすまないようなオペレーションを行っているわけですから、AIがなぜそういった結果を出してるのかが使う方の人間にわからないのであれば、結局はそういったAIは使われることがなくなるのです。
ただこうした時にどんどん前に進んでいくのがアメリカです。こうしたインテリジェンス機関が75ミリオンUSD(約83億円)を投資して、民間企業、スタートアップ、研究機関とともに、このXAIの研究・開発をすでに行いはじめています。
この分野の発展に関してはこれからも目を離せませんが、Exploratoryの次期バージョンでもこの機械学習のモデルの説明の部分に関して新しい機能が追加されます。そちらについては、終わりの方にある、”What are we working on”をご覧ください。
人間と機械はチームを組んだ時により良い結果を出せる
More Evidence That Humans and Machines Are Better When They Team Up - Link
人間とAIのパートナーという点では最近、MITのコンピュータ・サイエンスとAIの研究所のディレクターであるDaniela Rusによる最近の講演をもとにした記事がありました。
AIが人間のスキルを補足する事に関する大きな可能性はよく聞きますが、そのリサーチ自体は余り進んでいません。ハーバード大学の研究者たちは、AIだけよりもAIが人間と組むことでもっと良い成果を生み出すことができることを証明しました。
現在のいわゆるAIはまだ余りにも制限がたくさんあるので、せいぜいは退屈で繰り返しになるような作業を置き換えることがほとんどでしょう。こうして、人間はもっと興味深いクリエイティブな仕事に時間をさけるわけです。
100万件以上のネット中立性の規制撤廃を訴えるコメントはフェイク
More than a Million Pro-Repeal Net Neutrality Comments were Likely Faked by Jeff Kao - 11/23 - Link
先週こちらでは米連邦通信委員会(FCC)がインターネットの中立性を守るための規制を撤廃する方針を正式に発表したニュースに対する怒りと失望で大いに盛り上がっておりました。これは、インターネットの接続プロバイダーがどのウェブサイトをユーザーにアクセスしやすくするかどうかを決められることに道を開くということで、これまでのインターネットを基盤とした新しいサービス・製品によって新しいイノベーションが生まれ、新しいビジネスが生まれて行くという流れに逆行することであって、あまりにもばかげていると言うしかありません。
FCCというのは連邦政府の一機関であるのでパブリックの意見を広く集め、それを考慮する義務があり、今回の決定も広く集めた意見を参考にしたとあるのですが、そのパブリックの意見というものの多くがボット、つまりはコンピューターに自動的に生成させたものだったようだというのが、そのデータを自然言語処理のメソッドを使って分析したJeff Kaoというデータサイエンティストによって解明されています。
それによると、FCCに送られた2200万以上のコメントのうちのたったの800,000(3%から4%)件のコメントだけが本当にユニークなコメントらしいです。そして、そうしたユニークなコメントの99%がネットの中立性を保つための規制に賛成(つまり現状維持)とのことです。
例えば、一つのスパムキャンペーンは130万件にのぼるコメントを、盗み出したIDを使ってユニークなグラスルーツのように見えるコメントとしてFCCに送ったようです。
アメリカの政治システムの根幹である市民による民主主義がこうしたスパムやフェイクニュースによって揺れているというひどい例です。ただ、一般市民がこうした不正をデータとデータサイエンスを使って暴き出していくことができるというのは大変素晴らしいと思います。現代のシャーロック・ホームズのようでかっこいいですね。そしてこうしたダイナミズムがある限り、こうした混乱の時を乗り越えてアメリカは前に進んでいくのでしょう。
興味深いデータ
ファイナンシャル関連のデータ
もしかしたらまだ知らない人が多いかもしれませんが、こちらにQuandlというファイナンシャル関連のデータを提供しているサービスがあります。オルタナティブ・データと言って、有料のデータもあるのですが、株価などの一般的なデータは無料で取ってくることができます。 そして、Exploratoryのユーザーの方は実はそこからものすごく簡単にデータを取ってくることができます。詳しくはこちらのブログポスト(申し訳ありませんが英語版です。)の方に書いてありますが、簡単な操作としては以下のようになります。
1.エクステンション・データのダイアログを開ける

2.Quandlのインポート・データのボタンを押す(まだインストールされてない場合は新規追加よりインストール)
3.Quandlからコピーしてきたコードを貼り付ける
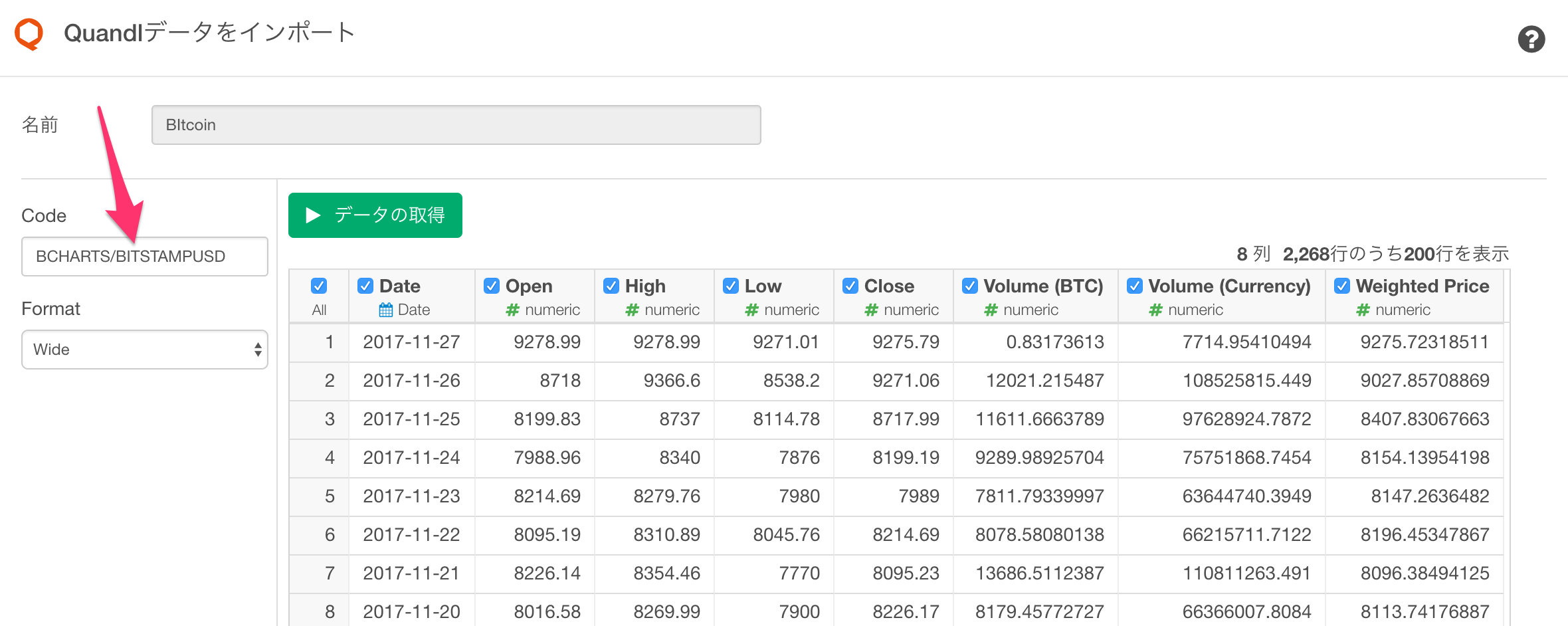
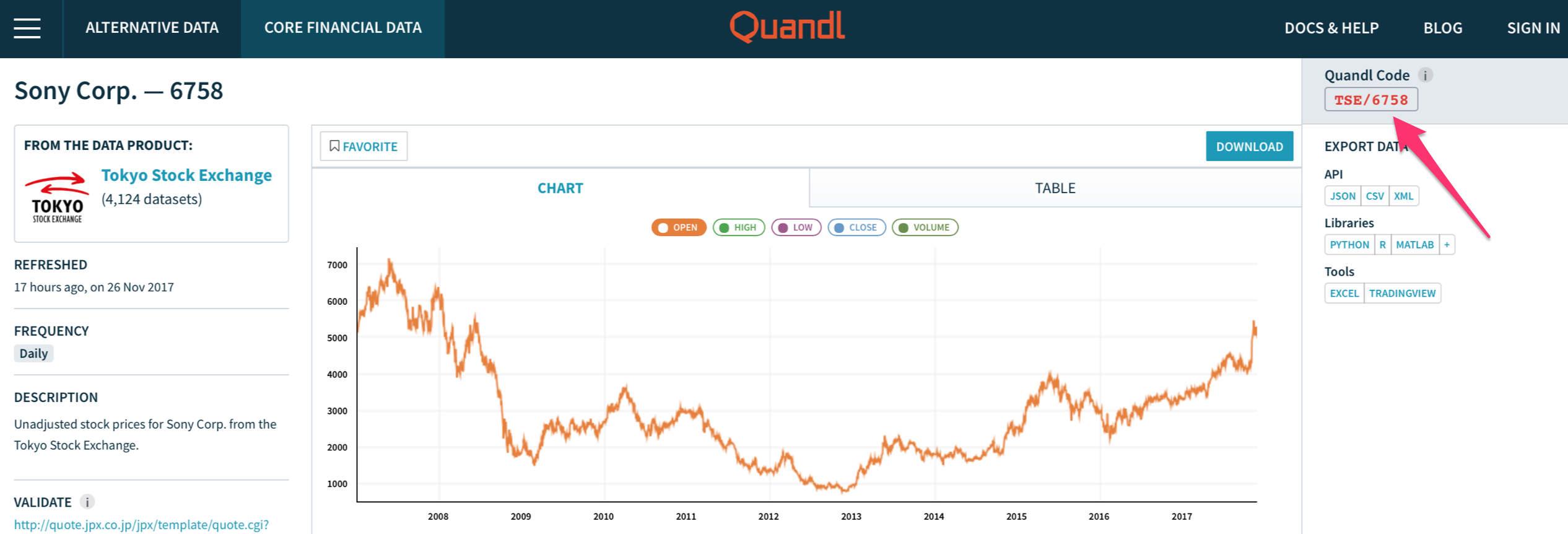
コードの方はQuandlで欲しいデータのページを開いたら、右上の方にあります。以下はソニーの株価(TSE/6758)の例です。
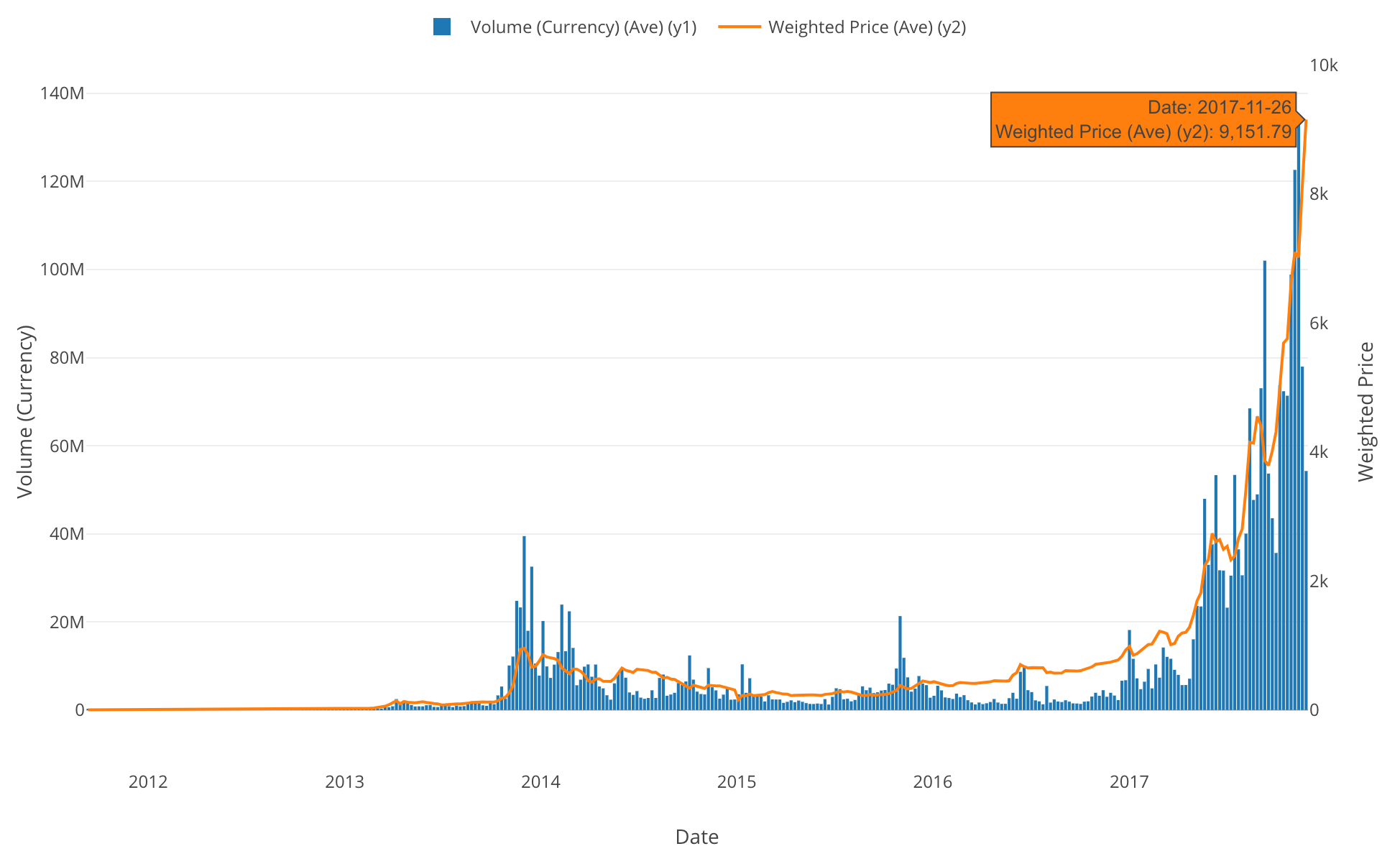
ビットコインの取引に関するデータ
先週末はビットコインの価格がいよいよ$9,000を超えてきたということで色々騒がれていましたが、上記のQuandlというデータサービスから様々なビットコインの取引に関するデータも簡単に取ってくることができるので、是非自分の手で確認してみて下さい。
例えば以下のようなデータを、それぞれのコードを入力すると取ってくることができます。
- Bitcoin Markets (bitstampUSD) - BCHARTS/BITSTAMPUSD
- Bitcoin Miners Revenue - BCHAIN/MIREV
- Bitcoin api.blockchain Size - BCHAIN/BLCHS
以下はBitstampでのUSドルとの交換レート(BCHARTS/BITSTAMPUSD)とブロックチェーンの取引量のトレンドを週単位で表したチャートです。
都道府県別のお風呂に関する聞き取り調査のデータ
2012年とかなり古いのですが、ウェザーニュースによる日本人のお風呂に関する聞き取り調査が都道府県別にまとめられています。
http://weathernews.com/ja/nc/press/2012/120124.html
このページからスクレイピングしてそのままデータをとってくることができますが、それなりに分析しようとするとやはりデータラングリングする必要があります。ということでこちらに私の方で軽くラングリングしたものを共有しておきましたのでよろしければどうぞ。
次のセクションに私の軽い分析ノートもあります。
ブログ記事 from Team Exploratory
お風呂好き調査の結果 - 島根県と沖縄県はお風呂が嫌い by Kan - Link
前述のウェザーニュースによるお風呂好き調査のデータを簡単に分析して、K-meansのクラスタリングのアルゴリズムを使って都道府県をセグメントにわけてみました。よろしければ、参考までに。
What Are We Working On?
先週もお伝えしたように、次期バージョンの主なテーマはチャート機能の強化ですが、アナリティクスの方も色々と新機能を追加しています。その中でも個人的に気に入っているのが、変数重要度の結果からさらにインサイトを掘ることができる、Local Estimated Effectsというものです。ランダム・フォレストのアルゴリズムを使った変数重要度では、どの変数が予測結果にどれほど貢献しているのかというのがわかりますが、これを使うと、さらにそれぞれの変数の中の値がどのように影響しているのかということがわかります。
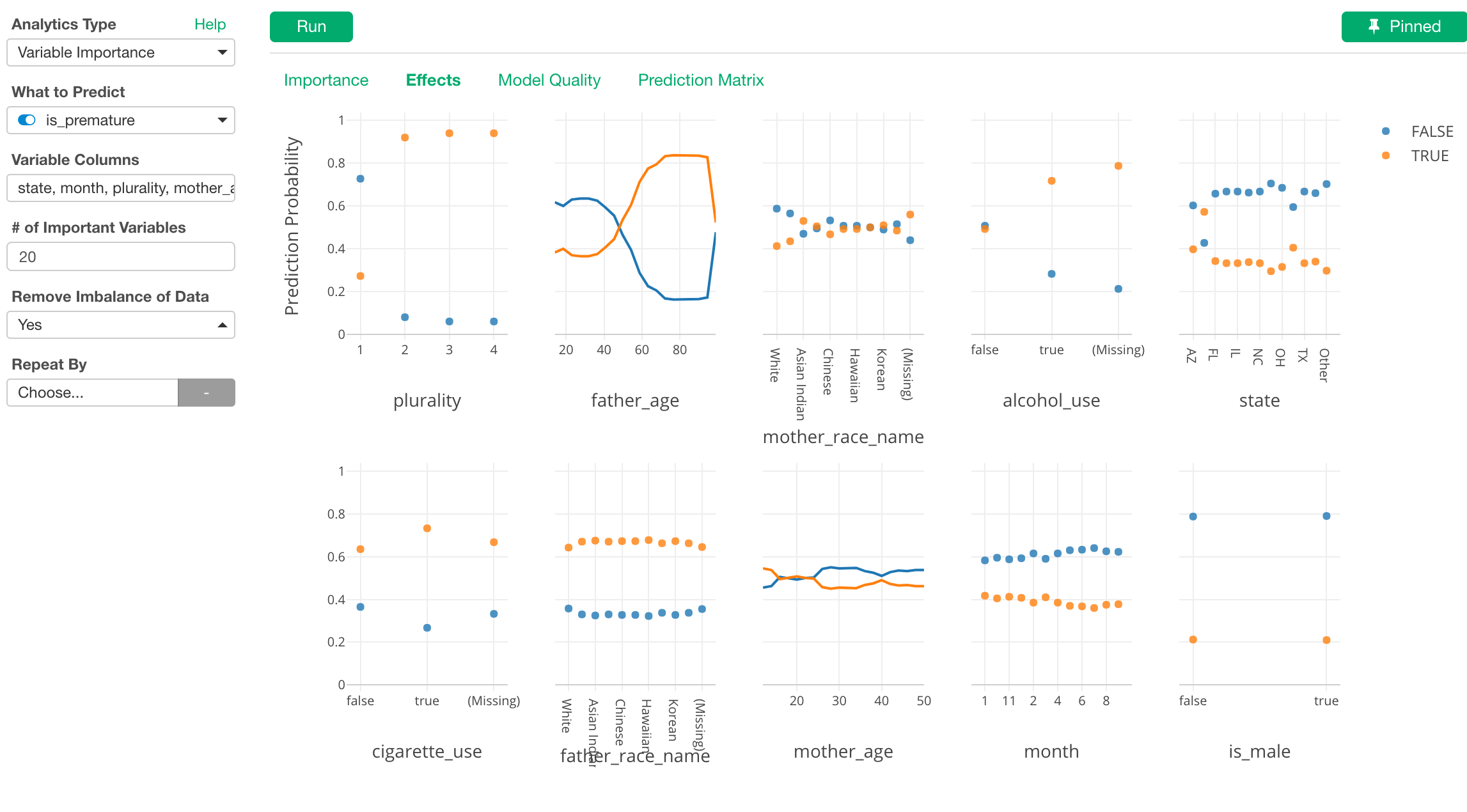
例えば、どの変数(列)が赤ちゃんが早産になるのに影響するのかを分析しようとした時に、上のLocal Estimated Effectsのチャートの一番最初のplurality(双子、三つ子など)を見ると、双子、三つ子、四つ子になるとそうなる可能性が高まることがわかり、さらにその次のfather_age(父親の歳)を見ると父親が50歳を超えると早産の可能性が高まることがわかります。
さらにこうした予測のクオリィティを上げるために、不均衡なデータをバランスの取れたものにするための渋い仕組みも入ってきます。
機械学習のアルゴリズムを使うことで、Exploratory Data Analysis(探索的データ分析)をもっと効率的に行うことができます。今回の記事にもあったように、AIの出してくる予測の結果そのものよりも、こうして何がそういう結果を導き出すのかというインサイトこそが実際のビジネスの場面では使いやすいですし、実際に行動を起こすことにつながる意志決定がしやすいのではないかと思います。
データサイエンス・ブートキャンプ・トレーニング
先週もお伝えしましたが、1月の中旬にデータサイエンス・ブートキャンプを行います。ご興味のある方、またはお知り合いに興味のあるそうな方がいらっしゃれば、ぜひお声おかけいただければと思います。詳しくはこちらのブートキャンプ・ホームページをご覧ください。
それでは、今週は以上です。
素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)