
こんにちは、Exploratoryの西田です。
すっかりご無沙汰しております。10月の終わりに日本にデータサイエンス・ブートキャンプのトレーニングを兼ねて2週間ほど行っていたのですが、その間こちらのWeekly Updateの方がすっかり滞ってしまいました。申し訳ありません!
来日の際は、これまでのブートキャンプに参加していただいた多くの皆様と勉強会でお会いでき、その後の懇親会で楽しく熱い時を一緒に過ごすことができたことに、この場を借りて改めてお礼申し上げます。

舟山さん(LT-S)による講義
参加できなかった方は、次回はぜひご参加下さい!こちらの勉強会はブートキャンプに参加されてない方でも事前に問い合わせいただければオープンです!
それでは、さっそく今週も行ってみましょう。
最近の興味深い英文の記事
テック業界勝ち組のスケール
The scale of tech winners by Benedict Evans - 10/12 - URL
こちらは、“Software is eating the world”を提唱しているA16Zの気鋭のアナリストBenedict Evansによる、テック業界の勝者であるGAFA(Google, Apple, Facebook, Amazon)がどれだけのスケールを持っているかということに関する分析です。
まずは、こちらのチャート。年間売上のトレンドですがGAFAを足した売上は一時代前の勝者であったWintel(Windows - Microsoft / Intel)の売上の3倍、IBMの6倍となっています。
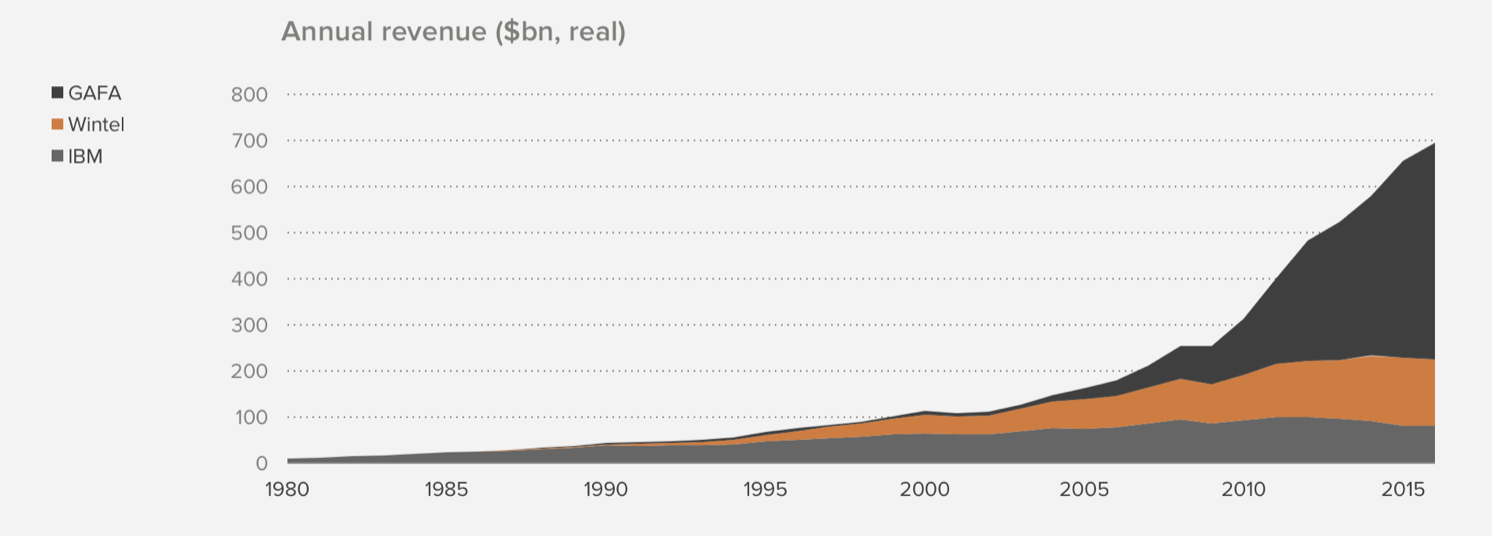
Wintelは、90年台に仕事してた人はよく知っていると思いますが、当時PC時代を牛耳っていた2つの企業です。IBMはPC時代の前、メインフレーム時代を牛耳っていた企業です。
個人的にはこちらのチャートが驚きました。これはそれぞれの会社が雇ってる従業員の数ですが2012年の時点でAmazonがすでにMicrosoftを追い越し、2016年の時点でAppleがさらに追い越しています。
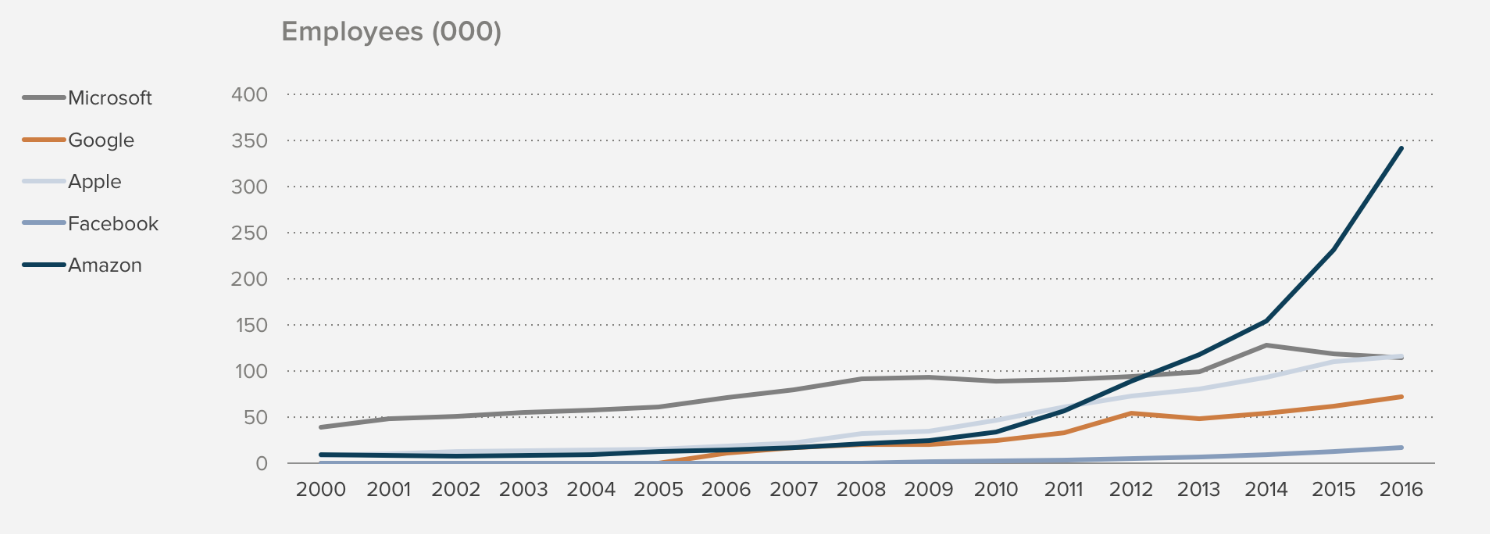
こうした新しいテック企業の成長を見るとき、ついつい売上とか市場価値という方に目を奪われてしまいますが、こうして実際に私達の日常に影響してくる雇用というかたちでも成長の成果が現れてきます。日本でも以前に活躍していたソニー、パナソニックといった日本を代表するような会社以上に人を雇用できるような新しいテック企業がでてくるといいと思います。
そして既存の広告、メディア業界にとって厄介なのはこちらのチャートです。
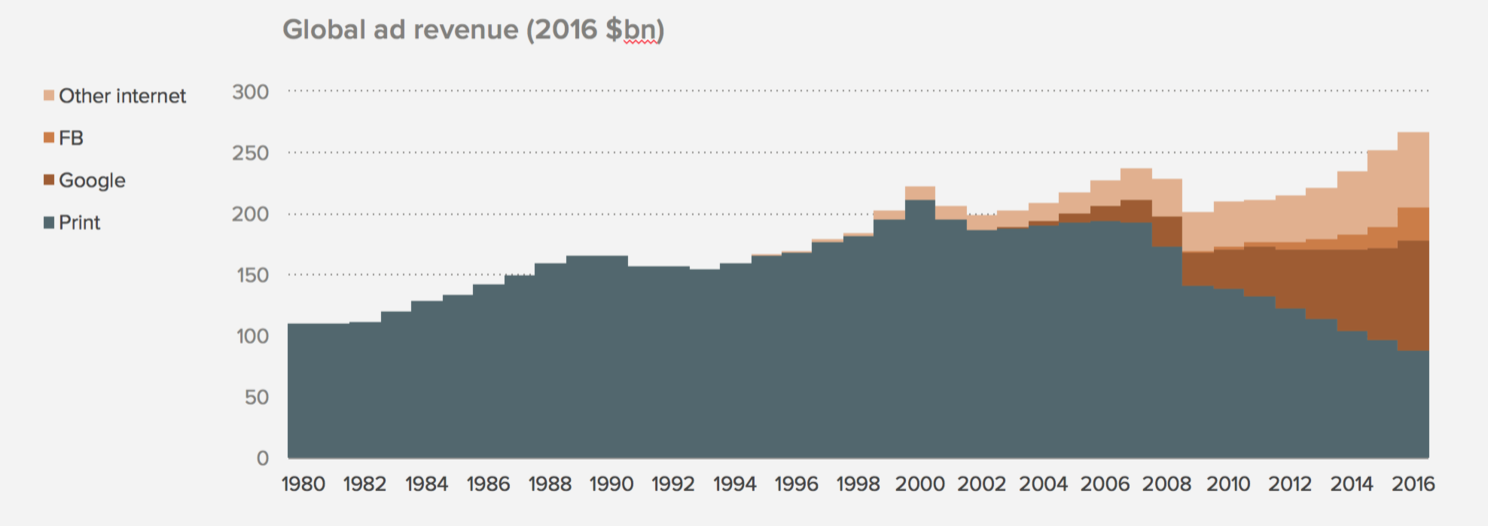
“Internet eats print ads, Google (& Facebook) eats digitl ads”とありますが新聞、雑誌などのプリントベースの広告はすでにデジタル(インターネット)に売上を取られていますし、さらにそのデジタルの成長もほとんどをGoogleとFacebookに取られてしまっているようです。
そして、日本の家電メーカーや、そういった製品を作るスタートアップにとってやっかいなのは、この部分だと思います。
すでにGoProやSonosスピーカーにすでに起こったように、ただスマホのサプライチェーンの波に乗っているだけで、クラウド、ソフトウェア、エコシステム、ネットワーク効果などをもってテクノロジーのスタックの上の方に上がっていくストーリーが描けていないと、結局はコモディティ化するウィジェットを作ってるたくさんのうちの一つのメーカーで終わってしまいます。
そして、GAFAがなぜ今日のような破壊的な変化の時代にあっても強いのかに関する洞察です。
Google、Facebook、Amazonはまだ創業者によって経営されていて、彼らはストリート・ファイターのようにアグレッシブです。これらの会社はすでに20年以上もの歴史があります。彼らはMicrosoft、Yahoo、AOL、MySpaceに何が起こったのかを理解しているので、彼らは自分たちをディスラプト(破壊)することを厭わないし、行動を起こします。
モバイルへのシフトは根本的、構造的な脅威だったわけですが、それがFacebookを抱え込みでなく、逆にアンバンドル(解体)へと導きました。創業者のザッカーバーグは会社の価値の10%を使ってインスタグラム、Whatsupなどのそれ以前の時代とは違う単体でのサービスを提供する会社を買収し、さらに、よくある大きな会社によるイノベーティブなスタートアップの買収と違って、それらの買収した会社をそのまま枯れさせることはありませんでした。
GAFAの行動力は他とは桁外れに違います。彼らは今までMicrosoftが行ってきたようなことより、遥かに多くの、そして桁外れに大きなことができます。Chris Dixonが言うところの‘super-evolved organisms’というやつです。彼らはどこから脅威がやってくるかということに関して、今までの会社に比べて遥かに敏感ですし、さらにもっと素早く反応し対処する能力があります。
ノキアはたった10年前はモバイル機器の市場の半分を握っていたのに、すべてを失いました。IBMはまだメインフレームの市場を握っていますが、そんなものは誰も気にしません。変化がどこからやってくるかはほとんど誰にも予測できませんが、それは確実にやって来ます。GAFAはそのことにものすごく敏感です。Googleは全てを実験します。Appleは車やMixed Realityのプロジェクトをすでにやっています。FacebookはInstagram、WhatsApp だけでなく Oculusも買収しました。ただ、Microsoftも20年前からモバイル機器をやっていたのですが、今となってはWindowsMobileを潰してしまう運命となりました。そしてPCはメインフレームのように時代から取り残されてしまうことをすでに認めていますし、これからはIBMのように、せいぜい他の会社によって形作られていく市場に対応していくしか先はないのです。
この先、スマホに比べ10倍のスケールで成長するといったテクノロジーが現れることはもうないでしょう。モバイルはPCに比べ10倍に大きい市場を作りましたし、PCはメインフレームよりも遥かに大きな市場となったわけです。それは、単純に世界中の50億人がスマホを手にすることによりますが、それはこの世に存在する全ての人間(大人)の数だからです。それでも、この先また何か破壊的なものは現れるでしょう。ただそれが何なのかということは現段階では分かりません。ただ、何も変わらないということはないというのは、歴史を振り返ると明らかでしょう。
トーマス・ピケティのデータは信頼できるのか?
Is Piketty’s Data Reliable? by Alex Tabarrok - 10/18 - URL
富の不均衡に関して世界的に大きな論争を起こしたフランスのトーマス・ピケティによる’21世紀の資本’という本がありますが、その中で使ったデータ、さらにそのデータの分析の仕方にいろいろ問題があったという指摘が出始めています。
今までもPhillip Magness、Robert Murphyによって言われていたり、 FTのChris Giles、Ferdinando Giugliano によって指摘されていたりしましたが、いよいよ経済史で権威もあるRichard Sutchによっても指摘されることとなっています。
20世紀の上位1%のデータはひどいくらいに操作され、上位10%に関しては実証的なサポートが欠け、どうやってデータを平滑化して平均をとったのか明らかでなく、データに関するドキュメントが十分でなく、さらにエクセルを使ったエラーは、鬱陶しいを通り過ぎている。こうしたこと全てが、不均衡な富のダイナミクスに関する間違った像を提供することになってしまっている。
ピケティの推論は、経済、社会、政治のアクターがどのように何が正しいことかそうでないのかを判断することに対して、不平等が与えるインパクトを理解しようとするものにとっては何の助けにもならない。
ただ、著者は別に富の不均衡が存在しないと言っているのではなく、(むしろそれが存在し、問題であるという結論は同じ)そうした結論に行き着く過程に間違いがあると指摘しています。
データの再現性というのは私達のようにビジネスでデータを使う人間にとっても重要ですが、こうした学術の場面でもそれが社会的に与えるインパクトが大きいだけに特に注意して責任を持って取り組んでいただきたいものです。ただ、残念ながら実はこうした問題はノーベル賞を取るような学者であってもよく犯してしまうことです。どうしても結果を出さなくてはいけないというプレッシャーから、ついつい都合のいいデータだけを使う、もしくはそうしたデータを作ってしまうというものから、もっと単純にエクセルの中での技術的な間違いと言うものもあります。トーマス・ピケティはこの全てのパターンの間違いを犯しているようですが。
ところで、このエクセルでの間違いというのは、多くの学術論文でもよく見られ、これまでにもよく指摘されています。これは単純にエクセルのバグのために間違った数字が計算されているというのもたまにありますが、ほとんどは人間が犯してしまう間違いというものです。それはエクセルの中で行った分析というのはその分析のプロセス、ステップというのを後から追跡することがそのデザイン上ほとんど不可能であるため、そうした間違いが発見されにくいということが本質的な問題だと思います。ですので、最近はアカデミアの世界でもRなどの言語を使って分析がされることが推奨されています。Rであればデータの再現性を確かにするために、後から誰でも再現可能なスクリプトを残すことができるからです。そしてこのことが、Exploratoryが世界中のアカデミアに受け入れられている理由の一つでもあります。(Exploratoryだと、右側のステップに当たる部分です。)
あまりにも多くのスタートアップがデータ分析するときに犯す4つの失敗パターン
The Four Cringe-Worthy Mistakes Too Many Startups Make with Data by Amanda Richardson - 10/26 - URL
こちらシリコンバレーのスタートアップでホテルを直前に予約する時に人気のあるHotel Tonightというスタートアップがありますが、そこのアマンダ・リチャードソンがスタートアップがデータを使うときによくハマる間違いを4つにまとめています。これはもちろんスタートアップに限らず、どのようなサイズの会社でも、とくに新しいデータ分析のプロジェクトを始める時によく見られる失敗パターンだと思います。
間違い1:ゴール(何を達成したいのか)でなく指標から始めてしまう。
ほんとによくあるのですが、多くのチームが、しっかりと筋の通った計画をもたずに、リアルタイム分析やデータレークといったジャングルの中で目的を見失ってしまい、特に目的があるわけでもなくただデータを堀りだして、何かストーリーを探し出すのに時間を費やしてしまっています。そうではなく、調べる必要のある具体的な質問や仮定から始めるべきです。
多くの場合製品をリリースすると、”どうなってる?”といった曖昧な質問をします。そうではなく、私達の製品のリリースの目的は何なのか、それはコンバーションを上げることなのかもしれませんし、顧客の入ってくるトップ・ファネルを増やすことなのかもしれませんし、ボトム・ファネルを動かすことなのかもしれません。または、ユーザー、一人あたりの売上を伸ばすことなのかもしれません。
こうした問題に対応するために、アマンダは次の提案をしています。
まずは、ゴールを紙の上に書き出すことで、やっているうちにぶれないようにします。全ての新しいプロジェクトが始まる前にこれをやるべきです。昔からある、SMART(Specific, measurable, achievable, relevant, and timely)(具体的、計測可能、到達可能、意味がある、時間の指定)というフレームワークを使うといいでしょう。そして、うまくいってるかどうかを判断するためのスコア・カードを作ります。
だれもが自分たちを褒めたいという願望があるので、データの中から自分たちに都合のいい指標を見つけてきてしまうものです。例えば、最初は自分たちのゴールは初めて使うユーザーの数を10%伸ばすことだったはずが、そのかわりにリピート・ユーザーが使う回数が30%伸びていたとすると、急に私達は“リピート・ユーザーが30%成長した!”と喜んでしまいがちです。こうして当初のゴールを見失ってしまうわけです。
データを扱ってる人に、ある製品やフィーチャー(機能)の調子はどうなのかっていう質問をすると、大抵の場合、たくさんの興味深いインサイトが答えとして帰ってきます。しかし、最も気にすべき重要な指標をこうした副次的な情報のせいで曖昧になってしまわないように気をつけて下さい。
この四半期の最も重要なゴールを考えてみて下さい。簡潔に定義された指標を持っていますか?
間違い2:パーソナライゼーションの横行
ユーザーは今までの参照履歴から何かをレコメンドされるのを期待しているのではなく、時、場、目的をわけまえたレコメンドを期待しています。ですので、意味のあるレコメンデーションなどといったパーソナライゼーションは作るだけでものすごく時間もかかるし、ものすごいデータも必要です。これはスタートアップには最初のころはないものです。
写真のストリームを提供しているようなサービスであればこうしたレコメンデーションは早い時期に作る必要があるかもしれませんが、B2Bの経費精算のサービスを作っているのであれば、パーソナライゼーションが必要になることはまずないでしょう。
間違い3:専門のデータサイエンティストを雇ってしまう
データサイエンスとは独立した仕事ではなく多くのスキルを集めたものです。分析や戦略が独立した仕事ではなく多くのスキルを集めたものなのといっしょです。チームの全ての人間が戦略的であるべきで、全ての人間が分析(データに限らず)することができるべきです。
Hidden Figures(邦題:ドリーム)という映画を見た人ならば知っているかもしれませんが、昔、NASAで有人宇宙飛行計画のミッションに参加していた女の人達はコンピューターと呼ばれていました。当時は限られた専門の人のみがコンピュータを使って計算処理を行うことを仕事としていました。もちろん、今では誰もがそうしたことを行い、誰もが持っているスキルの一つです。そうやって世界は進化していくものです。現在のデータサイエンスはまさにそうした局面にあると思います。
もっと多くの人がデータを使って意思決定を行うことができるべきですし、そのことに責任を持つべきです。
よくある間違いは、技術はあるがビジネスのセンスが全くないデータサイエンティストを雇ってしまうことです。そして、そうした人たちをビジネスに関するディスカッションが普段行われている場所から隔離した上で、彼らにたくさんの質問を次から次へと浴びせてしまうのです。こうした環境では、どんなにスキルのあるデータサイエンティストでも成功できません。こうして、彼らの行う分析の結果や提案が、机上の空論か意味のないものとなってしまうのです。
さらに、そうしている間にたくさんの優れたビジネスに関する質問は待ち行列に埋もれてしまっています。多くの人がデータサイエンティストの人たちの空き時間を待っていますが、そうではなく、どうやってこの質問に対する答えを自分で探し出せるのか?という風に考えるべきです。すべての人がデータ分析ができるような教育を受けて、それがサポートされていると感じることのできる環境を作ることで、あなたの組織はもっと成功するのです。
間違い4:最新のツールのおっかけ
データの世界は特に進化が早いので、毎日のように新しい技術、製品、ツールが出てきますが、アマンダは、それらを追いかけ続けるのではなく、全てのデータチームが彼らの組織に提供すべき3つのシンプルなものを提案しています。
一つにまとまったダッシュボード
すでに述べましたが、最も重要な指標、誰も変えることのできないゴールに基づいた指標をダッシュボードに載せるべきです。これはどんなフォーマットでも構いません。Google Docのドキュメントでもいいのです。組織の全ての人が見える形で定期的に提供するというところに意味があります。
アクセスすることのできるデータ
もしあなたのチームの全ての人たちにアナリティカル(分析)な思考ができるようになって欲しいのなら、彼らが簡単にデータにアクセスできる環境を用意するべきです。マーケティングであれば顧客の属性に関するデータかもしれませんし、製品であればコンバーションに関するものかもしれませんし、またエンジニアリング(IT)であればサーバーの稼働時間に関するものかもしれません。
フレキシブル(柔軟)なツールセット
一つのソリューションが全ての問題、全ての人にとって十分ということはないので、柔軟にそれぞれの人が仕事をしやすいツールを使わせるべきです。
興味深いデータ
USで市場に出回っている銃器はどこから来たのか - URL
連邦政府司法省の一部門であるBureau of Alcohol, Tobacco, Firearms and Explosives (ATF)がFBIや地域の警察と協力して、アメリカに出回っている銃器がどこから来たのかを追跡しています。そちらのデータを毎年公表しているのですが、こちらのページからダウンロードできます。
こちらに、さくっとデータラングリングして可視化したものがあるので、ぜひEDFをインポートしてExploratoryの中で再現していただければと思います。
BIS (Bank for International Settlements/国際決済銀行)データ
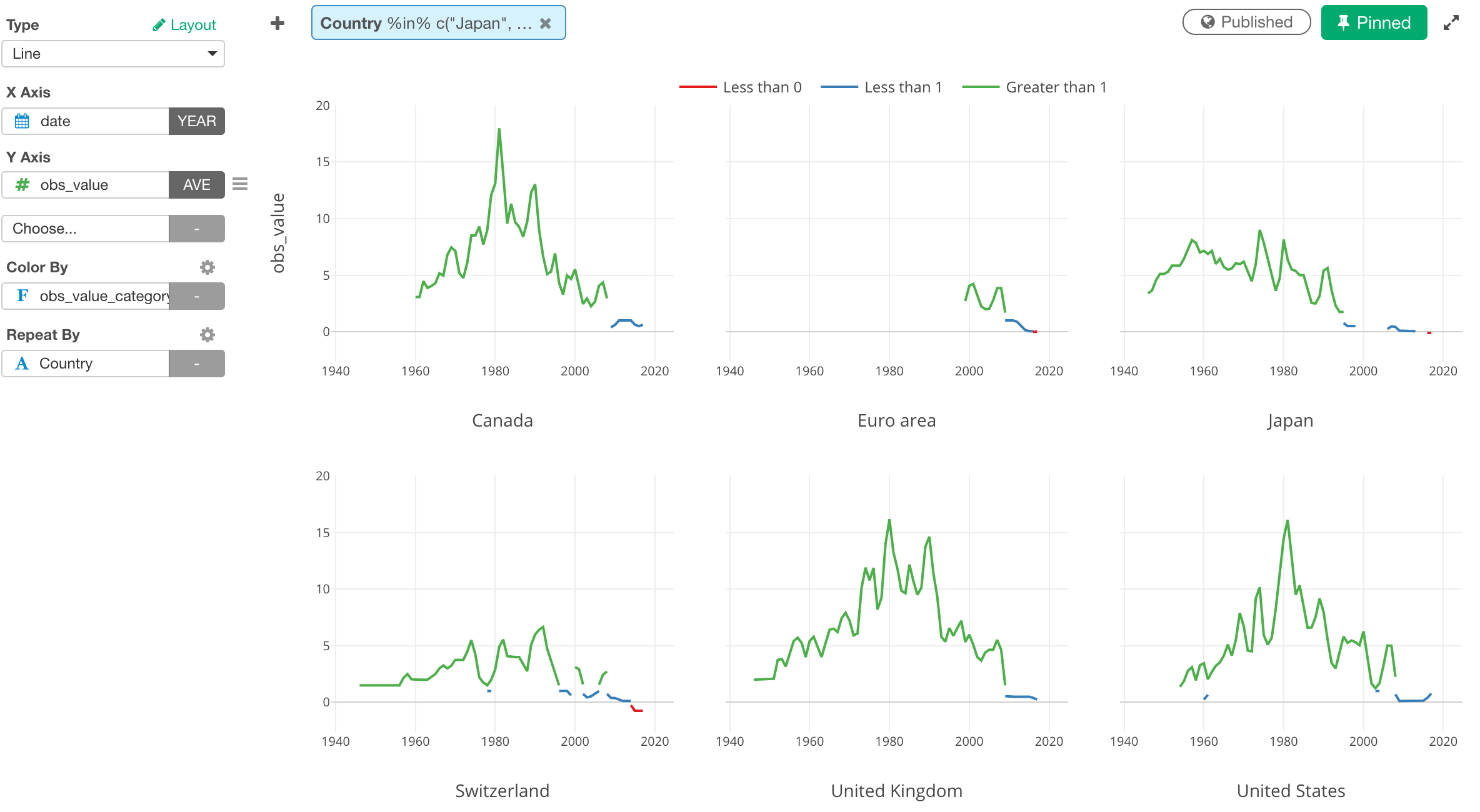
Eric PerssonがBISから簡単にデータをとってくることができる便利なRパッケージ、BIS(名前そのまんまです。😁)を作ってくれています。これを使って、例えば政策金利、物価、グローバル流動性の指標などのデータを取ってくることができます。詳しくはこちらのVignettes(ビンエット、使い方ガイド)にありますが、私の方でさくっと政策金利のデータを取ってきて、ラングリング、可視化したものがこちらにありますので、興味ある方はEDFをダウンロード、インポートしてどのようにExploratoryの中で使えるか見ていただければと思います。使う前にBISのRパッケージをインストールしておく必要があります。RパッケージのインストールはUIから簡単にできます。詳しくはこちらの方にあります。
ブログ記事 from Team Exploratory
What Are We Working On?
現在v4.2の開発を猛ピッチで進めています。今回も引き続きアナリティクス・ビューへのおもしろい追加がありますが、日本にいる際にExploratoryのユーザーの方たちとのディスカッションの中から出てきたチャート関連のエンハンスメントが主なリリースのテーマです。そんな中でも、Exploratoryのユーザーには昔からのミステリーであった(?)、“何でパイチャートがないの?”という質問にようやく終止符を打つ時が来ました。😁
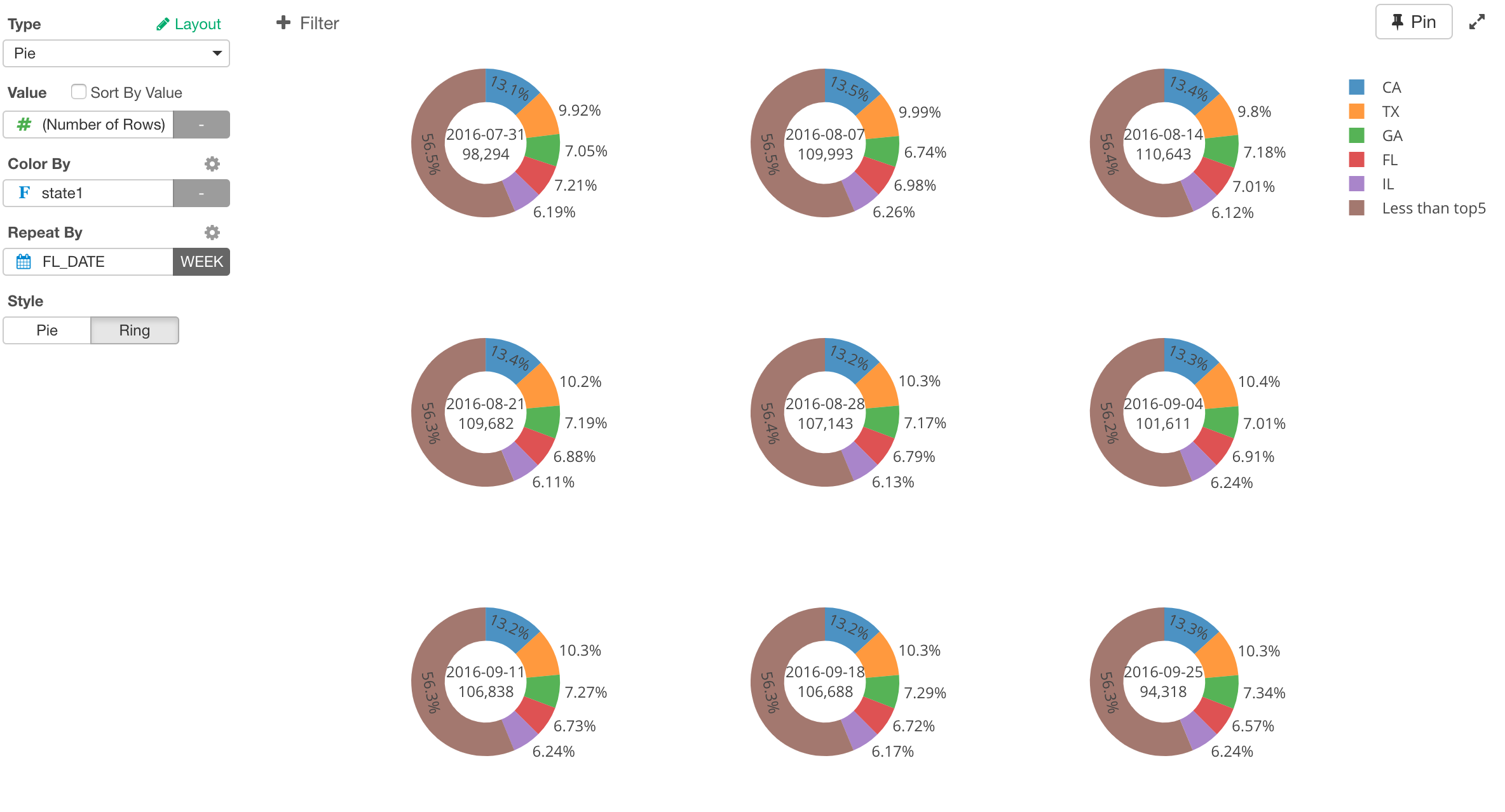
過去のアーカイブ
過去のWeekly Updateがこちらにアーカイブとしてありますので、もし周りにも興味のある人がいらっしゃったらぜひ共有してみてください。
それでは、素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)