生成AIモデルとプロンプトが拓く、テキストデータ分析の新時代
2023年の ChatGPT 3.0 の登場以来、生成AIはあらゆる業界に大きなインパクトをえました。 もちろん データサイエンス も例外ではありません。
この生成AIがどのようにデータサイエンスを変えたかを話す前に、そもそもデータサイエンスとは何かということを整理しておきましょう。もちろん、聞く人によって様々な意見があるのは承知ですが、シンプルに言えば以下の3つが交わる領域です。
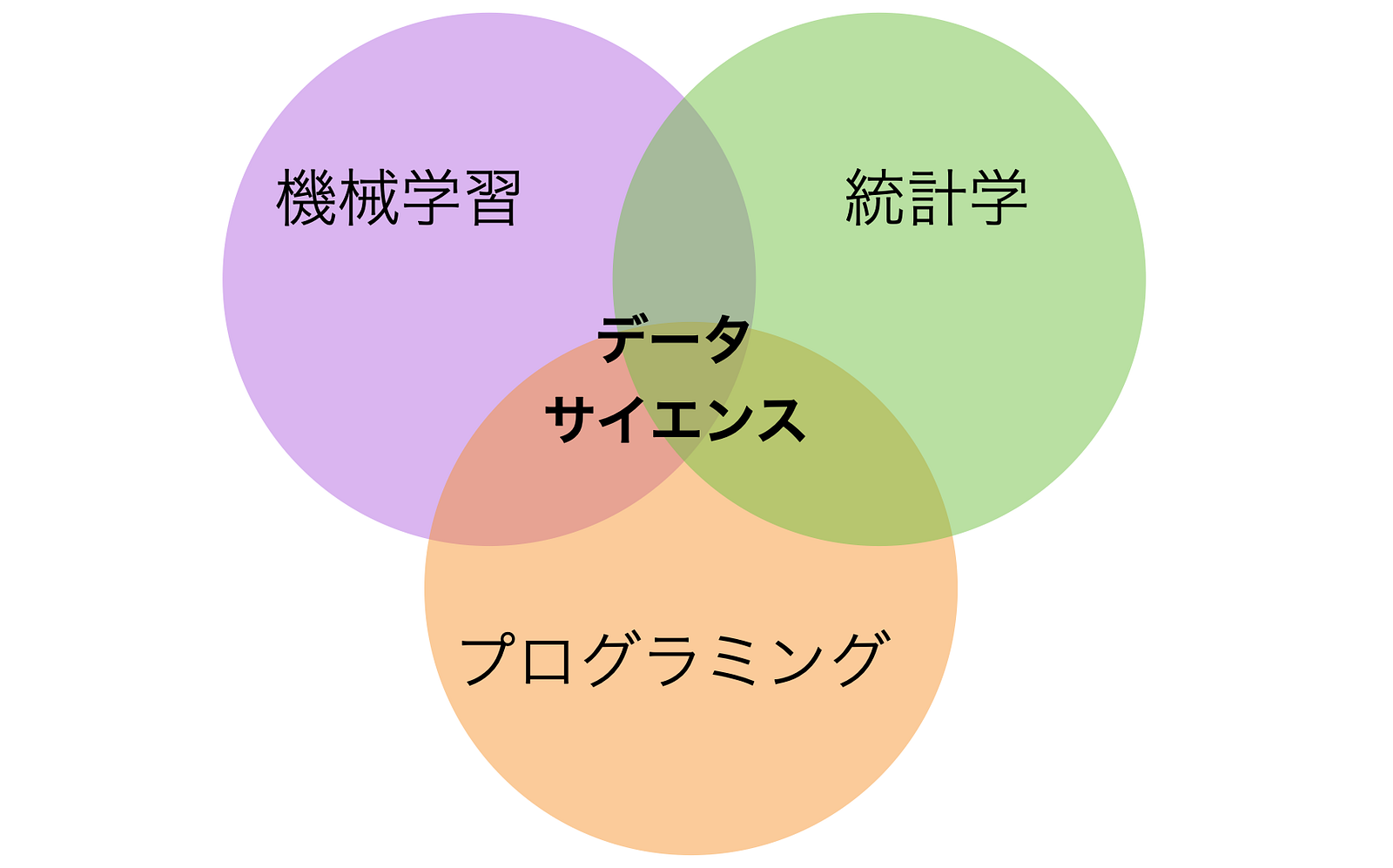
データサイエンスの誕生
もともとデータサイエンスという言葉が出てくる前は、同じような仕事をしていた人たちは統計学者と呼ばれていました。私も、昔から知っていた統計学者である知人があるとき、何かのカンファレンスで出会うと、名刺が「データサイエンティスト」に変わっていたことを今でも覚えています。
データサイエンスとはそれまでの統計学と何が違うのかというのは当時よく議論になったことですが、それは大まかに言ってしまえば、プログラミングと機械学習でした。当時、オープンソース・コミュニティで急速に進化してきたRとPythonというデータ分析やデータの処理に強いプログラミング言語の出現によって、誰もが高度なアルゴリズムやモデルに無料でアクセスできるようになりました。
さらに、当時インターネットやモバイルから膨大なデータが生成されることで、こうしたビッグデータを使った高精度な機械学習、深層学習モデルが続々と生まれました。
それまでは、こうしたアルゴリズムやモデルを使うためには高い市販のソフトを購入するか、または自前で一から作ると言ったことをしなくてはいけなかったのですから、ある意味「アルゴリズムやモデルの民主化」とも呼べるものでした。
それまでは、データ分析と言えば統計ソフトを使うという常識が、こうしたオープンソースのプログラミング言語や機械学習モデルの誕生によって、大きく変わってしまったのです。そして、これら3つが交わるものをデータサイエンスと呼び始めることになったのでした。
機械学習 -> 生成AI
しかし、2023年にChatGPT3.0がリリースされると、業界は再び大きく揺れました。チャット形式で会話できるだけでなく、 トレーニングデータに含まれていない最新の文書でも解釈し、要約や分類、Q&A ができる という性能が明らかになったのです。
それまでは、例えばテキストデータのセンチメントを分析したいと言った場合、データサイエンティストが自分で大量のテキストデータを集め、その大量データを元に機械学習または深層学習モデルを作り、精度改善のためのチューニングを行った上で、センチメントを予測していたものでした。
しかし、そんなことができるのはデータサイエンスの知識があり、膨大な量のデータが用意でき、プログラミングができる一部の人達だけでした。
そんなとき、生成AIで使われるGPT(Generalized Pre-Trained Transformer)モデルが出てくると、それが必要なくなってしまいました。
GPTなどの大規模言語モデル(LLM)は、世界中のありとあらゆるデジタル化されたデータを元にすでにトレーニングされた超巨大モデルであり、世の中にあるどんな文字(またはイメージやビデオ)情報でもそれを解釈するために必要な能力を持ったものでした。そのため、モデルが見たことないはずの文章データをAIに渡すと、そうした文章データを要約したり、分類したり、そのセンチメントをスコアリングしたりできるのでした。
全てがそうだとは限りませんが、特にテキスト(または画像)データを大量に読み込ませたモデルを時前で作るという時代は終わりを遂げてしまったのでした。(普段のビジネスでてにするよう比較的小さなデータであったり、数値データに関する場合は、現在のところ生成AIモデルよりも、自前の統計学習、または機械学習モデルの方が予測精度がいいです。これは、GPTがもともとテキストやピクセルといったデータに特有な高次元のデータにおけるパターンを認識するのを得意とするアーキテクチャであることが関係しています。)
プログラミング -> プロンプト
そして、この生成AIがデータサイエンスに与えた大きな影響としてもう1つ重要な点のが、そうしたモデルへのアクセス、そして予測精度を上げるための「チューニング」に関してです。それまでは主にPythonなどのプログラミング言語を書くことで自前の機械学習や深層学習モデルを作り、その予測精度を上げるためにパラメーターを変えたりしてチューニングを行ったものでし。
しかし、この新しいAIモデルの場合、その結果の精度を上げるために私たちが使うのはプログラミング言語を書くこともなければ、パラメーターを変えたりしてチューニングすることもありません。
私たちは、その予測精度、つまりより良い出力を得るために行うために使うのは、プロンプトであり、そこで使うのは、私たちが普段の日常会話で使う日本語などの言語です。
つまりプログラミング経験があるかないかに関わらず、誰もが世界最先端レベルのモデルを“使いこなせる”ようになった のです。
つまり、データサイエンスにおける機械学習が生成AI(GPT)に変わり、プログラミングがプロンプトに変わってしまったのです。これらと、統計学を合わせたものが新しいデータサイエンスと言えるでしょう。

もちろん、統計学自体も、生成AIの登場によって大きく影響を受けたことには変わりません。しかし、統計学自体がAIによってなにか別のものに変わってしまったり、または無くなってしまうということにはなりませんでした。ただ、統計学の実行や解釈がAIによるサポートによってしやすくなったというのが、現在の状況です。
AIモデル + Exploratory
さて、テキストデータや文字列情報をそれまでのどんなモデルより適切に「解釈」した上で、期待したような結果を返してくれる生成AIですが、自分のデータをChatGPTなどに投げて分析させたみると、思ったようにうまくいかないことがよくあります。実際にやったことがある人であれば経験したことがあると思います。
例えば、アンケートの自由記述のようなテキストデータが数百、または数千行あったとします。こうしたデータをAIに渡し、それぞれの文章のセンチメントをスコアリングさせたり、または分類させたりすると、一部はうまくいっているのですが、途中からいい加減な結果が出力されることがよくあります。
渡したデータを、私たち人間が期待するように全て見たうえで、全てに対して答えを生成しているという保証がないのです。そのため、データの量が多くなると答えが不安定になってしまったり、またAIに渡すデータを事前に加工しなくてはいけなかったり、何百、何千行というデータに対して帰ってきた結果が正しいのか判断つかなかったりといったことがおきます。また、どんなプロンプトを書けばよいのかというのも多くの人にとっては大きなチャレンジとなります。
- 行数が多いと、途中から結果が雑になる
- 全データを本当に読んだか保証がない
- プロンプトの書き方が難しい
- 結果が正しいか検証できない
- 前処理が必要だが、AIはやってくれない
Exploratory v14 の新機能「AI関数」
そこで、自分のデータに対して、1行ずつ確実にAI処理を適用できる この課題を解決するために、Exploratory v14 からAI 関数を追加しました。
これは、Exploratory に取り込んだデータに対して、
- 予測
- 分類
- スコアリング
- 翻訳
- 名寄せ
- テキスト生成
などを 1行ずつ確実に実行 できる機能です。
もちろん、この関数を作るために必要なのは、関数でもプログラミング言語でもありません。行いたい処理を普段の言葉でプロンプトの中に指示するだけです。そして、実行すれば、各行に対してプロンプトの指示に従った結果が返ってきます・
AI関数の使い方
使い方は簡単です。列ヘッダーメニューから「AI関数を作成」を選択し、

Exploratoryにインポートしたデータに対し、AIモデルに、スコアリングや予測などのやりたい計算を自分の言葉で話しかけるようにプロンプトに入力するだけです。後はAIモデルがデータを適切に解釈し、指示された計算処理を行ってくれます。
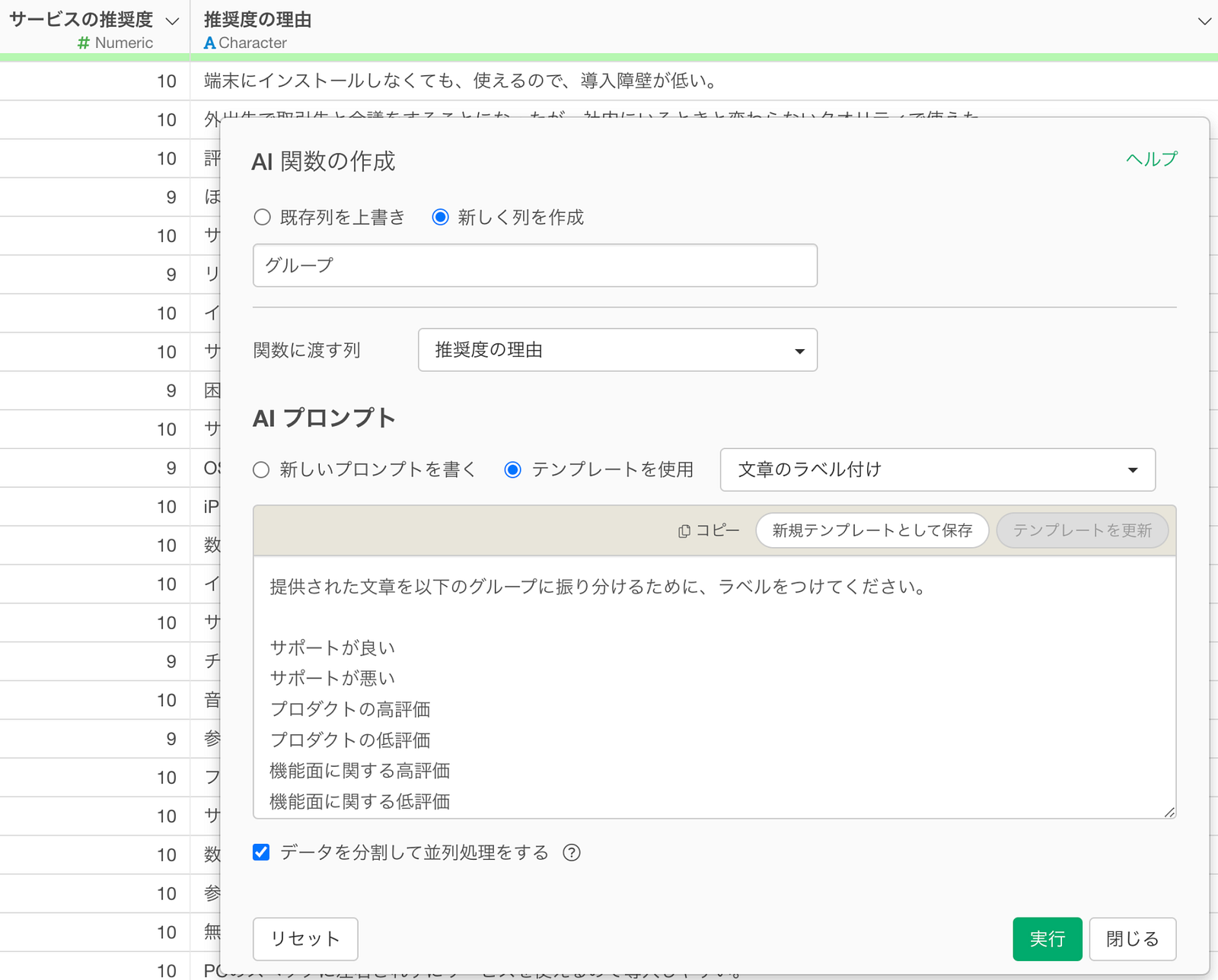
例えば、以下はテキストデータを9つのグループに分類したい場合の例です。

また、テキストデータのセンチメントをスコアリングしたい場合、以下のようなプロンプトを入力するだけです。

AI関数を使えば、他にも様々なことができるようになります。例えば、
- 文章のセンチメントのスコアリング
- 名寄せ — 表記揺れの修正
- 電話番号から国籍の判定
- 文章の翻訳
- メールアドレスから会社情報(業種・規模など)を補完
- 属性情報を元にメール文書の自動生成
といったこともできるようになります。
ExploratoryのAI関数を使うメリット
Exploratoryの中にデータを取り込み、AI関数を使うのは以下のようなメリットがあります。
前処理の自由度が高い
- AI に渡す前に、自由に加工できる
結果を視覚的に検証できる
- チャートやサマリビューで直感的にチェック可能
さらに次の分析につなげられる
- 結果をそのままアナリティクス機能で深堀り
高速処理
- 内部でデータを自動分割し、並列処理
結果の安定性が高い
- 全行に対して確実に処理が行われるよう最適化
プロンプトの再利用が簡単
- テンプレートとして保存し、関数のように使い回し可能
加工と可視化、そして分析(アナリティクス)が得意なExploratoryの中で、自分のデータに対して直接生成AIモデルを使ってテキストデータに対してスコアリング、分類、予測などができるようになれば、より多くの人たちにとってデータサイエンスがさらに身近になり、ビジネスの改善、より良い意思決定につながるのではないかと思います。
AIプロンプト・テンプレート
ところで、一度作ったプロンプトへの指示はテンプレートとして保存し、後で使い回すことも可能です。
プロンプトのサンプル集
自分で好きなようにプロンプトを書くことができるとは言っても、最初の慣れないうちはどういったプロンプトを書けば良いか戸惑ってしまうかもしれません。
そこで、いくつかの例をこちらのAI関数・ギャラリーページに用意しました。各ページにはプロンプトのテキストの例だけでなく、サンプルデータもダウンロードできるようになっておりますので、ぜひお試しください!
やりたいことをプロンプトで記述するだけで、複雑なアルゴリズムやモデルを組むことなく、データに“意味”を加えることができます。
今回追加された「AI関数」に関しては、こちらのポストで詳しく解説しておりますので、ぜひご参照ください。
AI 関数を試す!
ぜひExploratory最新版をこちらよりダウンロードし、「AI 関数」を試してみてください!
Exploratoryのアカウントをまだお持ちでない方は、ぜひこちらよりサインアップした上でお試しください。最初の30日は無料トライアル(お試し)期間となっています!
すでにトライアル期間が過ぎてしまったが、この新しいバージョンを試してみたいという方は、最新版Exploratoryを起動すると上がってくるダイアログの方にトライアル期間延長のリンクがありますので、そちらよりご連絡ください。
もし質問やフィードバックなどありましたら、ぜひこちら(support@exploratory.io)までご連絡ください!