Exploratory v15 をリリースしました! 🎉
今回のリリースのテーマは、AI時代の信頼できるデータ分析を支える3つのRです。
- Readability:データ加工の内容が読みやすいこと
- Reproducibility:分析結果を再現できること
- Reliability:データと分析結果を信頼できること
AIによって、チャートやレポートを作ることはますます簡単になっています。
しかし、どれだけきれいなダッシュボードやレポートが自動生成されたとしても、その元となるデータがどのように作られたのかが分からなければ、結果を安心して使うことはできません。
「この数字はどこから来たのか?」 「どのような加工や集計が行われたのか?」 「データが変わっても、同じ分析を再現できるのか?」
AI時代のデータ分析では、こうした問いに答えられることが、これまで以上に重要になります。
そこでExploratory v15では、データ加工の可読性、再現性、信頼性を高めるための新機能を追加しました。
主な新機能は以下です。
- データ加工の流れを可視化する ステップ・ダイアグラム
- データ加工の内容を自然言語で説明する AIステップ・サマリ
- 加工プロセス全体をまとめる データ加工ドキュメントの自動生成
- データの変更によるエラーを修正する データ加工エラーの自動修正
- チャートとアナリティクスに対応した AIサマリ
- サマリ・ビュー、チャート、テーブル、パフォーマンスの改善
データ分析を支える3つのR - 可読性(Readability)、再現性(Reproducibility)、そして信頼性(Reliability)については、こちらのブログ記事で別途詳しく説明していますので、ぜひご覧ください。
<Link>
それでは、Exploratory v15に追加された新機能を簡単に紹介します。
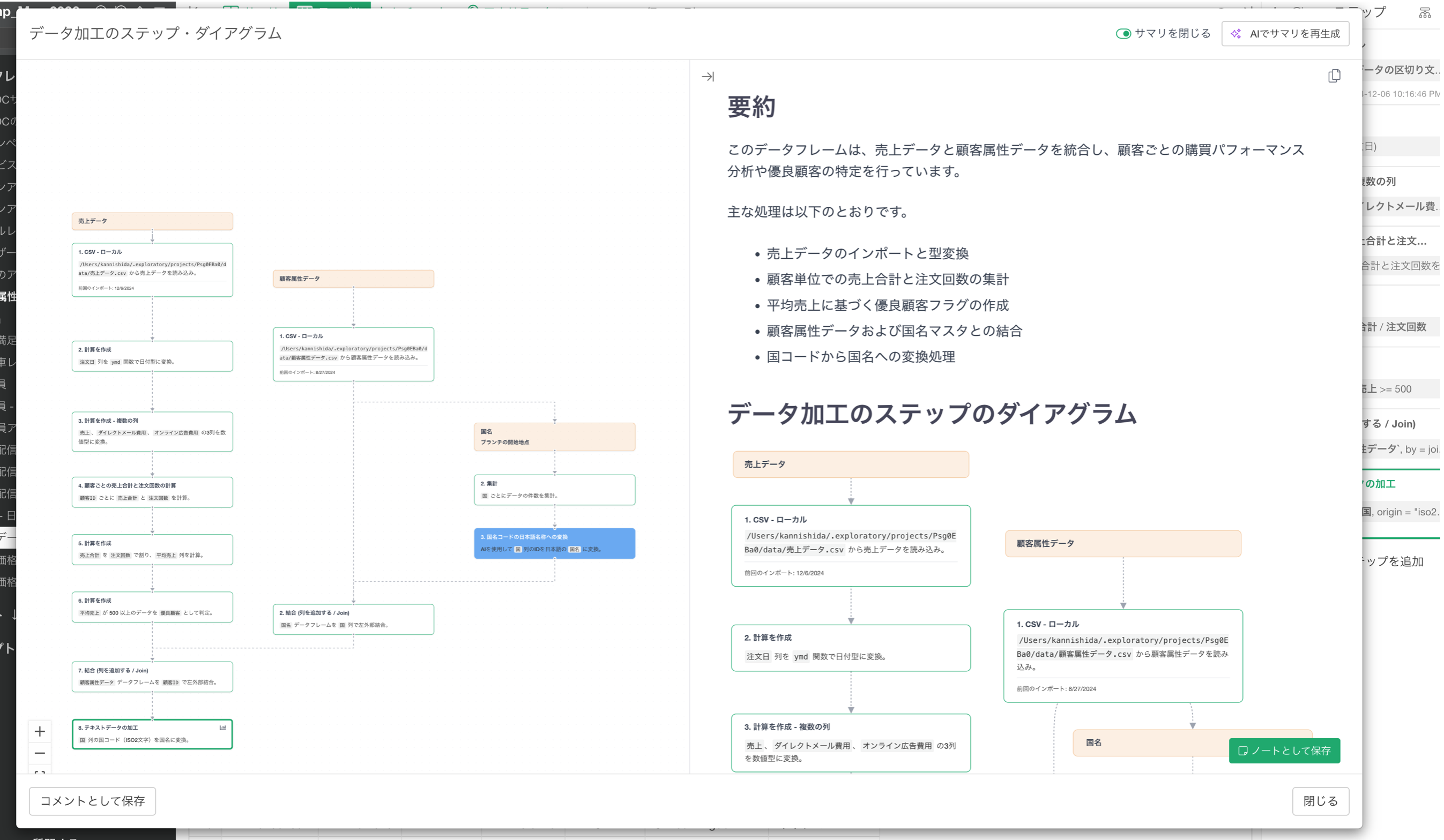
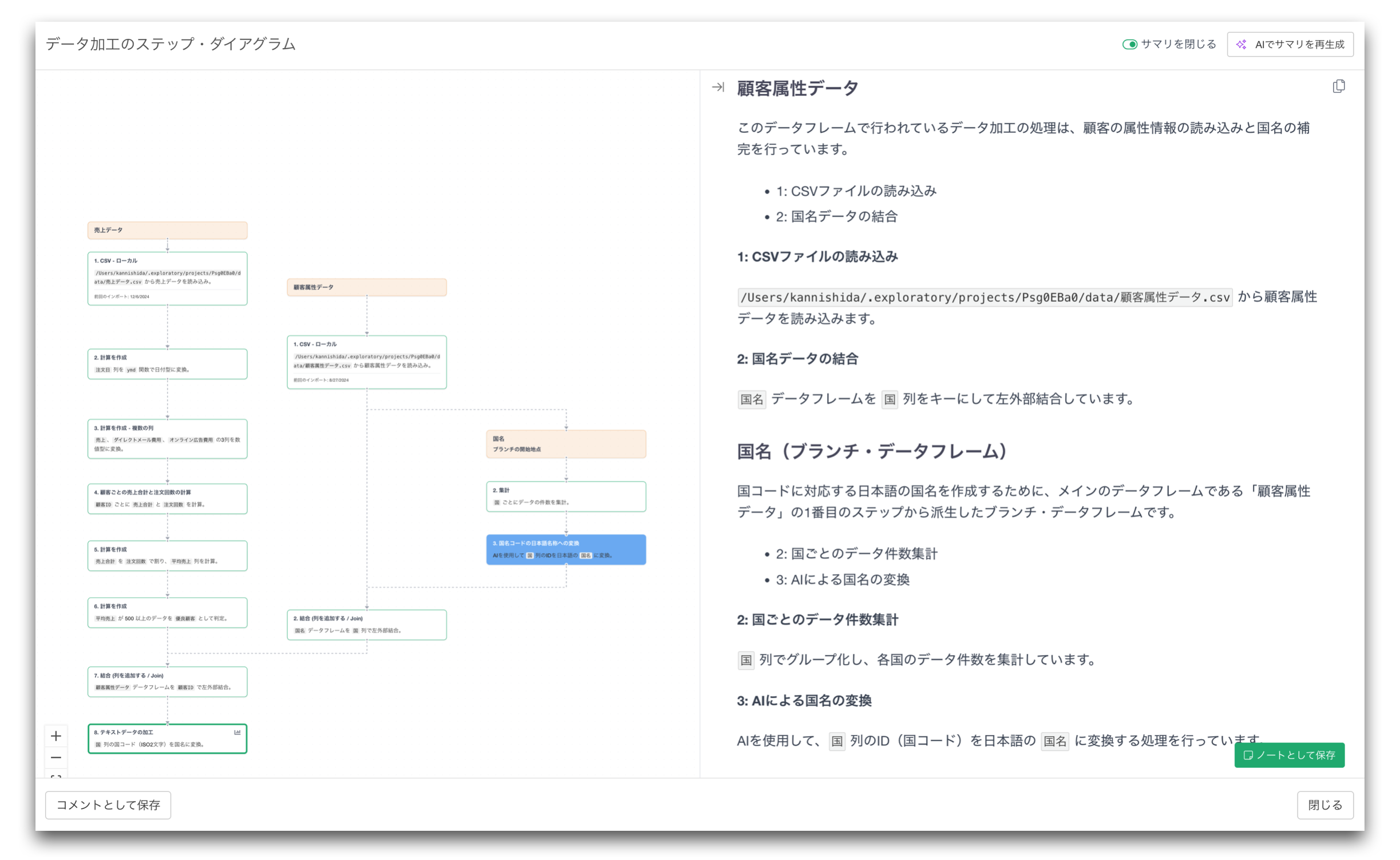
データ加工の流れを可視化するステップ・ダイアグラム
データ加工の流れを視覚的に確認できる ステップ・ダイアグラム を追加しました。
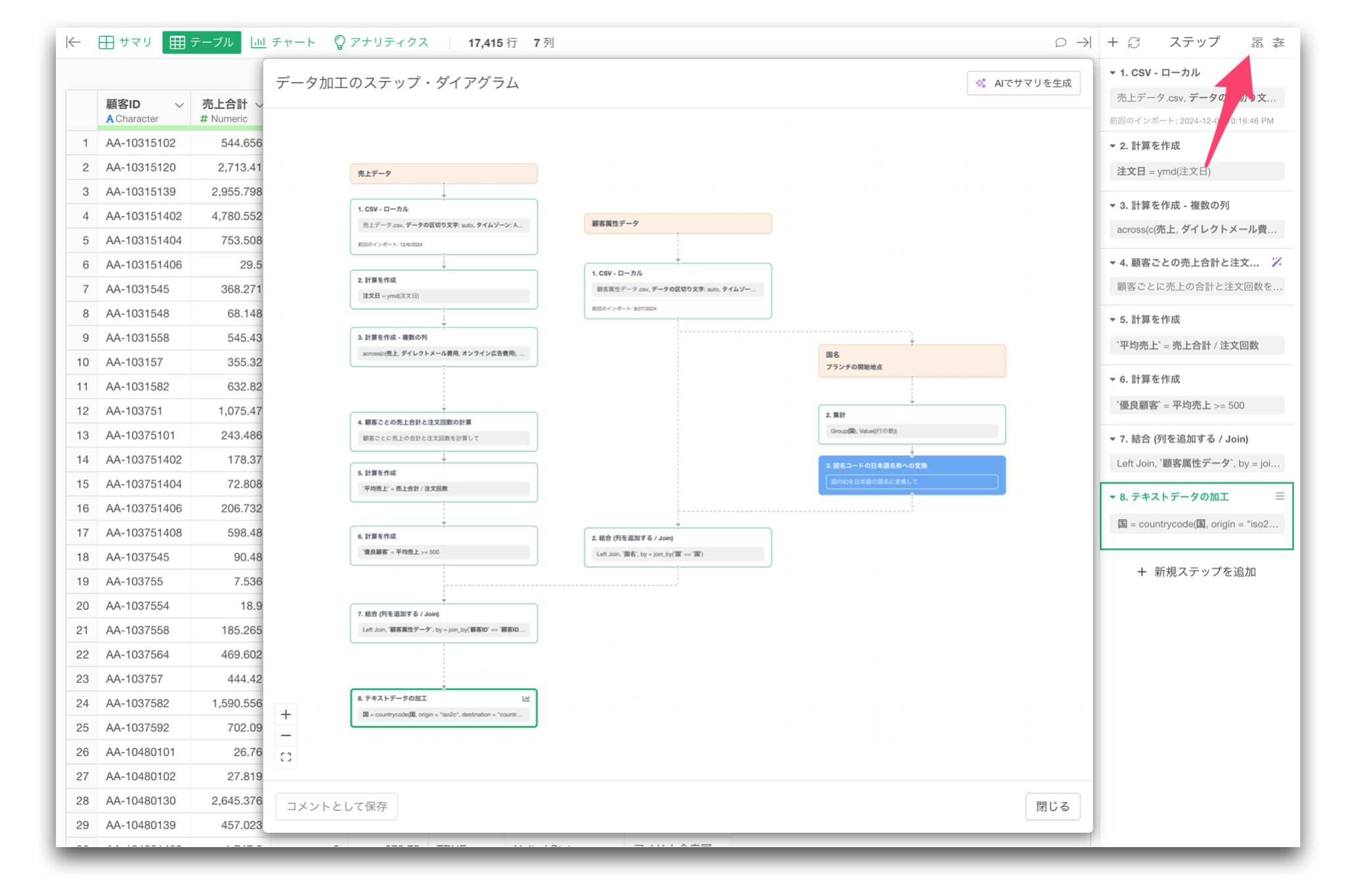
これまでExploratoryでは、各データフレームごとに加工ステップを確認することができました。しかし、実際の分析では、複数のデータフレームを組み合わせることがよくあります。
例えば、
- 顧客データ
- 注文データ
- 商品データ
- キャンペーンデータ
を結合し、加工し、そこからKPIやチャートを作成するようなケースです。
このような場合、最終的なダッシュボードやノートに表示されている数字が、どのデータから来て、どのように加工され、どのように計算されたのかを理解するには、複数のデータフレームをまたいで処理の流れを追いかける必要があります。
ステップ・ダイアグラムを使うと、この流れを一目で確認できます。
- どのデータフレームが元になっているのか
- どこでブランチされたのか
- どこで結合されたのか
- どの加工ステップを経てチャートやダッシュボードにつながっているのか
こうしたデータ加工の流れを、視覚的に理解できるようになります。
そのような場合、データ加工のステップの上部にある「ステップ・ダイアグラム」のボタンをクリックすることで、この流れを視覚的に確認できます。
さらに、ステップ・ダイアグラムはダッシュボードやノートに埋め込まれたチャートやナンバー(指標)からも開くことができます。
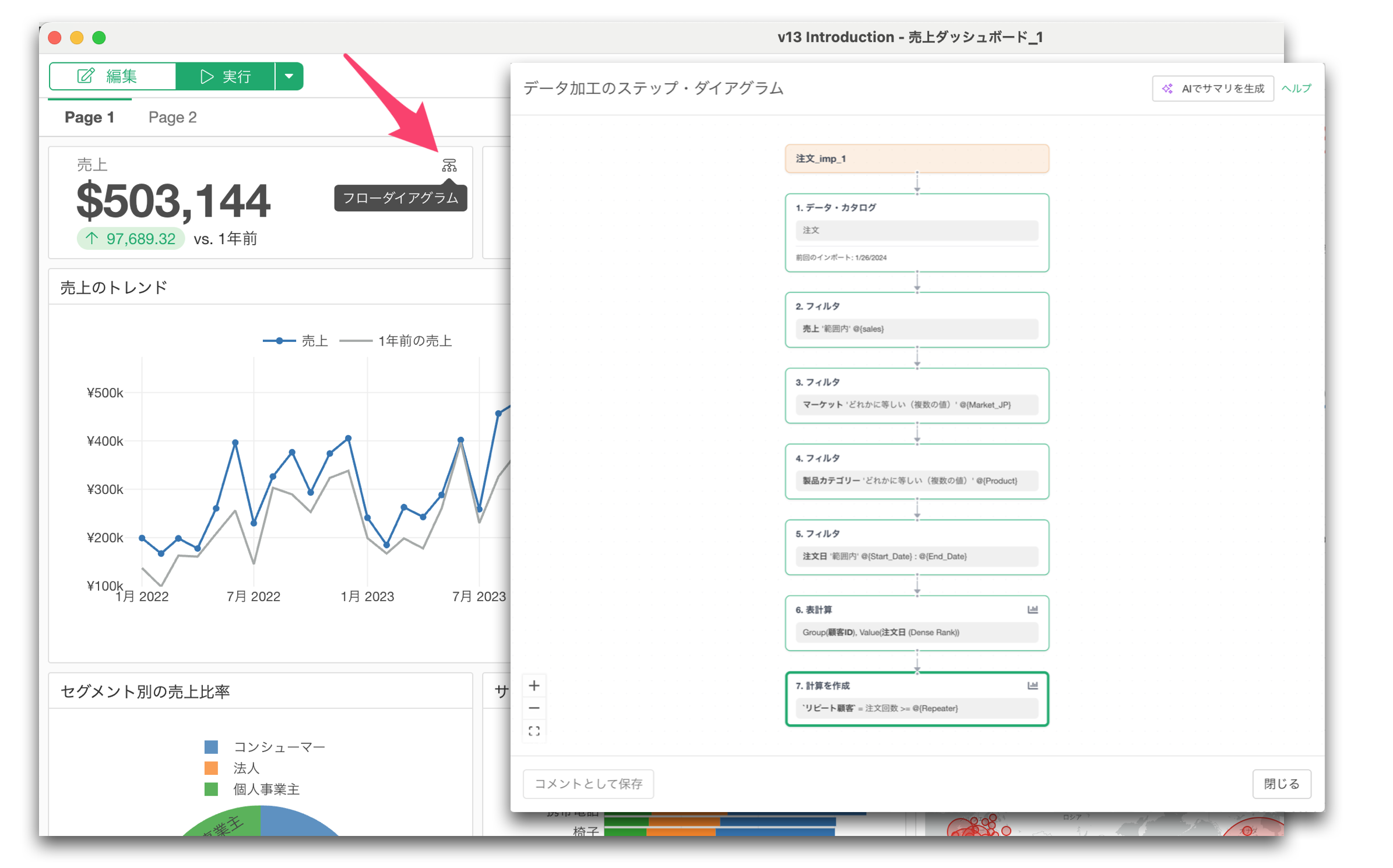
これにより、例えばダッシュボードを見た際に、そこで出力されている数値やチャートのデータがどのように作られたのかを確認することが簡単にできるようになります。
AIによるステップ・サマリ生成
ステップ・ダイアグラムでは、各データ加工ステップの内容を自然言語で説明する AIステップ・サマリ も生成できます。
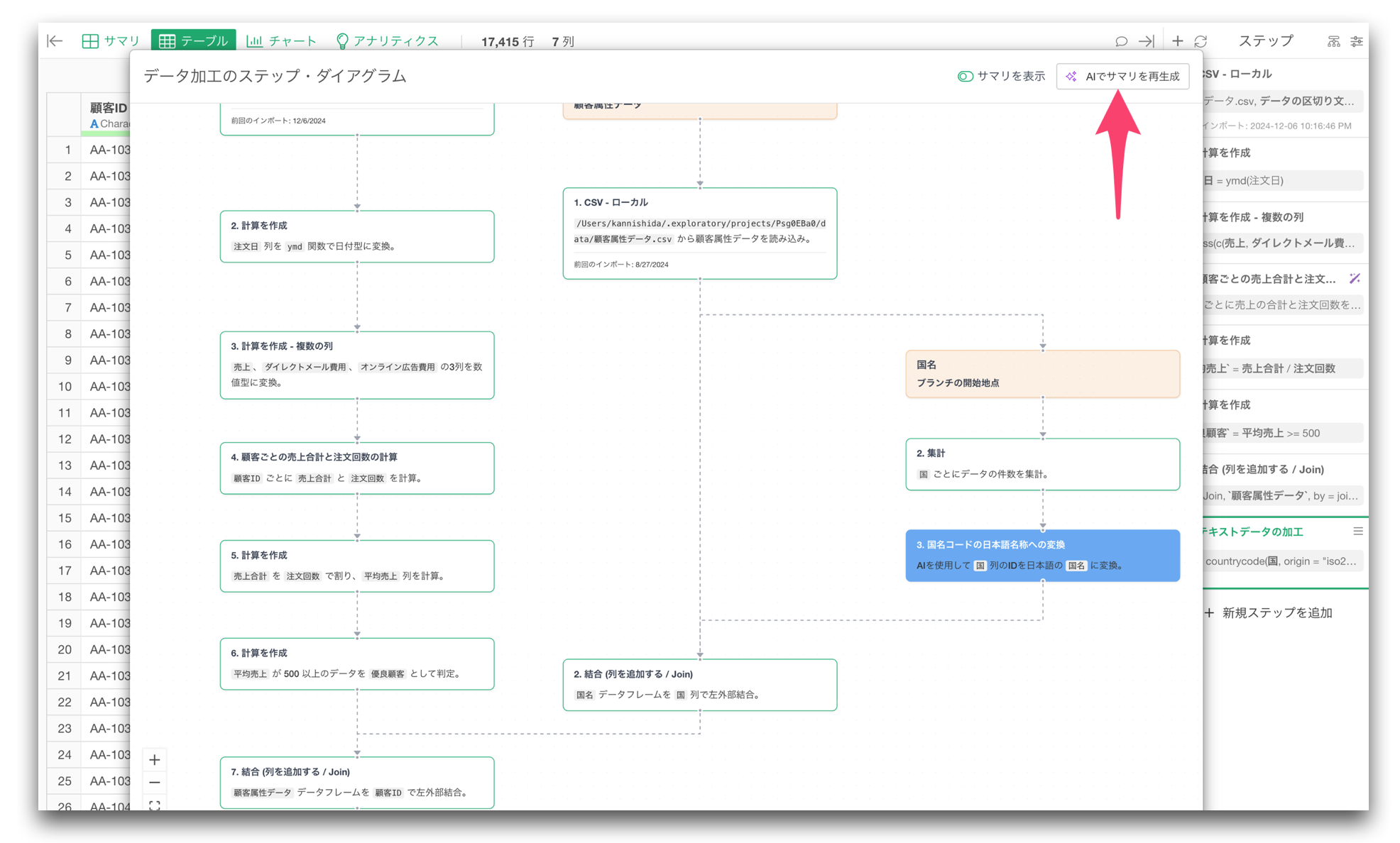
これにより、データ加工の各ステップで何が行われているかを、直感的に理解できるようになります。
例えば、次のような形で、各ステップで何が行われているのかを説明します。
- 「注文日から月の情報を抽出しています」
- 「顧客IDを使って顧客データと注文データを結合しています」
- 「地域ごとに売上を集計しています」
- 「購買回数が2回以上のデータのみに絞り込み」
これにより、データ加工の各ステップの細かい設定に詳しくないユーザーでも、データ加工の内容を理解しやすくなります。
また、チームで分析を共有するときにも、単にチャートや数字を見せるだけでなく、
「この数字は、このようなデータ加工を経て作られています」
と説明しやすくなります。
これは、分析結果への信頼を高めるうえでとても重要です。
データ加工ドキュメントの自動生成
さらに、データ加工のプロセス全体を1つのドキュメントとしてまとめる「ドキュメント生成」機能も追加しました。
さきほどの「AIによるサマリの生成」機能を使うと、各ステップの説明だけでなく、データ加工プロセス全体の要約と、各ステップの詳細を含むドキュメントが自動生成されます。
生成されるドキュメントでは、一連のデータ加工処理が意味のあるまとまりとごに整理されます。
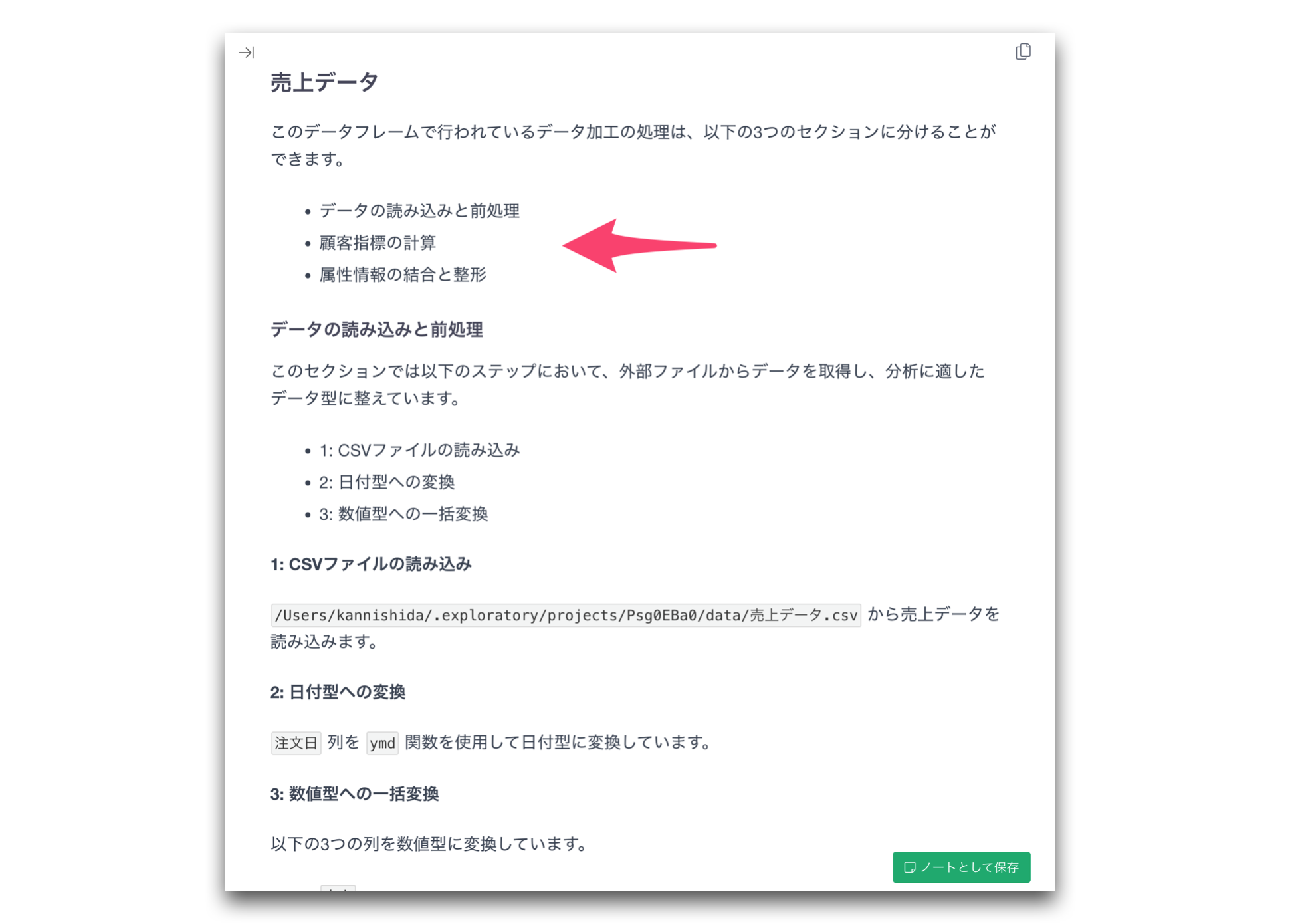
例えば、
- データの読み込みと前処理
- 顧客指標の計算
- 属性情報の結合と整形
といった形で、データ加工の流れを読みやすく説明します。
また、生成されたドキュメントを、そのままExploratoryのノートとして保存することで、自分の目的に合わせて編集したり、チームメンバーと共有したりできます。
この機能は、特に次のような場面で役立ちます。
- 分析プロジェクトの引き継ぎ
- チーム内でのレビュー
- レポート提出時の補足資料
- 分析結果の説明
- データ加工プロセスの監査や確認
これまで、分析レポートやダッシュボードは共有できても、その裏側にあるデータ加工の文脈(コンテクスト)まで共有するのは簡単ではありませんでした。というのも、それをドキュメントとして整理するのは時間がかかる作業だったからです。
しかし、この「データ加工のドキュメント生成」機能によって、これからは分析結果だけでなく、その結果がどのように作られたのかという文脈も、簡単に共有することができるようになります。
データ加工エラーの自動修正
Exploratoryにとって、「データ分析や加工の再現性」は今から10年前にv1を作ったときから、重要なコンセプトでした。
Exploratoryでは、データ加工の処理が右側に一連のステップとして記録されます。さらにそれら一連のステップ間の関係、他のデータフレームとの関係、チャートやアナリティクスとの関係、それらすべてを自動的に裏で管理することで、データ分析やレポート(ダッシュボードやノート)作成の再現性を保つようにデザインされています。
しかし、再現性を保つことは簡単ではありません。
なぜなら、現実のデータはよく変わるからです。
例えば、次のようなケースがあります。
列名が変わる
以前は Order Date
という列名だったものが、新しいデータでは Order_Date や
注文日
という名前に変わっている。その結果、後続のステップで「列が見つからない」というエラーが起きる。
データ型が変わる
以前は日付型としてインポートされていた列が、新しいCSVやExcelファイルでは文字型としてインポートされてしまう。その結果、月の抽出や日付計算などのステップが動かなくなる。
列名を変更したことで後続処理が壊れる
データ加工の途中で列名を分かりやすく変更したところ、後続のステップやチャートが古い列名を参照していたためにエラーになる。
こうした問題は、実際のデータ分析の現場ではよく起こることで、実際Exploratoryのチャット・サポートに飛んでくる問題のトップは、こうしたデータ加工のステップに関するエラーです。
そこでv15では、データ加工のエラーに対して、AIが原因を分析し、修正案を提案する データ加工エラーの自動修正 機能を追加しました。
この機能は、単にエラーメッセージを分析するだけではありません。エラーが発生したステップの前後のデータ加工処理との整合性も見ながら、どのような修正を行えば最適な形で現在のデータ加工の流れを保てるのかを分析し、その上で、現実的な修正案を提案するようにデザインされています。
例えば、
- 似た列名を持つ新しい列を見つけて、参照先を修正する
- 必要なデータ型変換ステップを追加する
- 新しく変更された列名に合わせて、後続ステップの参照を更新する
といった修正が可能になります。
ユーザーは、エラーに直面したときに「自動修正」を実行し、AIが提案する修正内容を確認したうえで、適切な修正を適用できます。
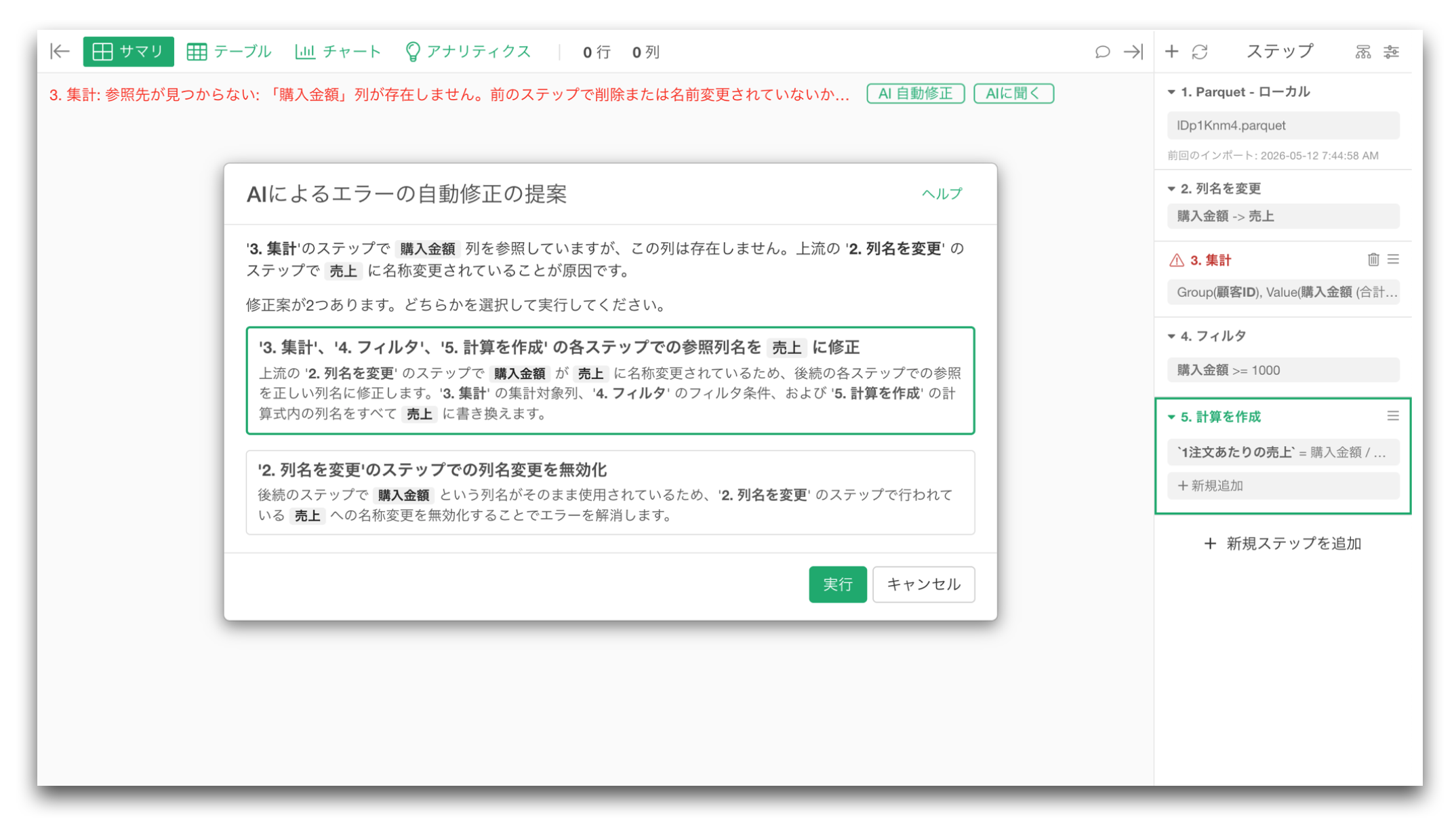
これにより、データが変わっても、分析プロセスをより安心して維持できるようになります。
AI サマリ for チャート & アナリティクス
Exploratory v15では、AIサマリ機能を大きく拡張しました。
これまで一部のアナリティクスでサポートされていたAIサマリが、v15からはすべてのアナリティクス・タイプ、そしてすべてのチャート・タイプで利用できるようになります。
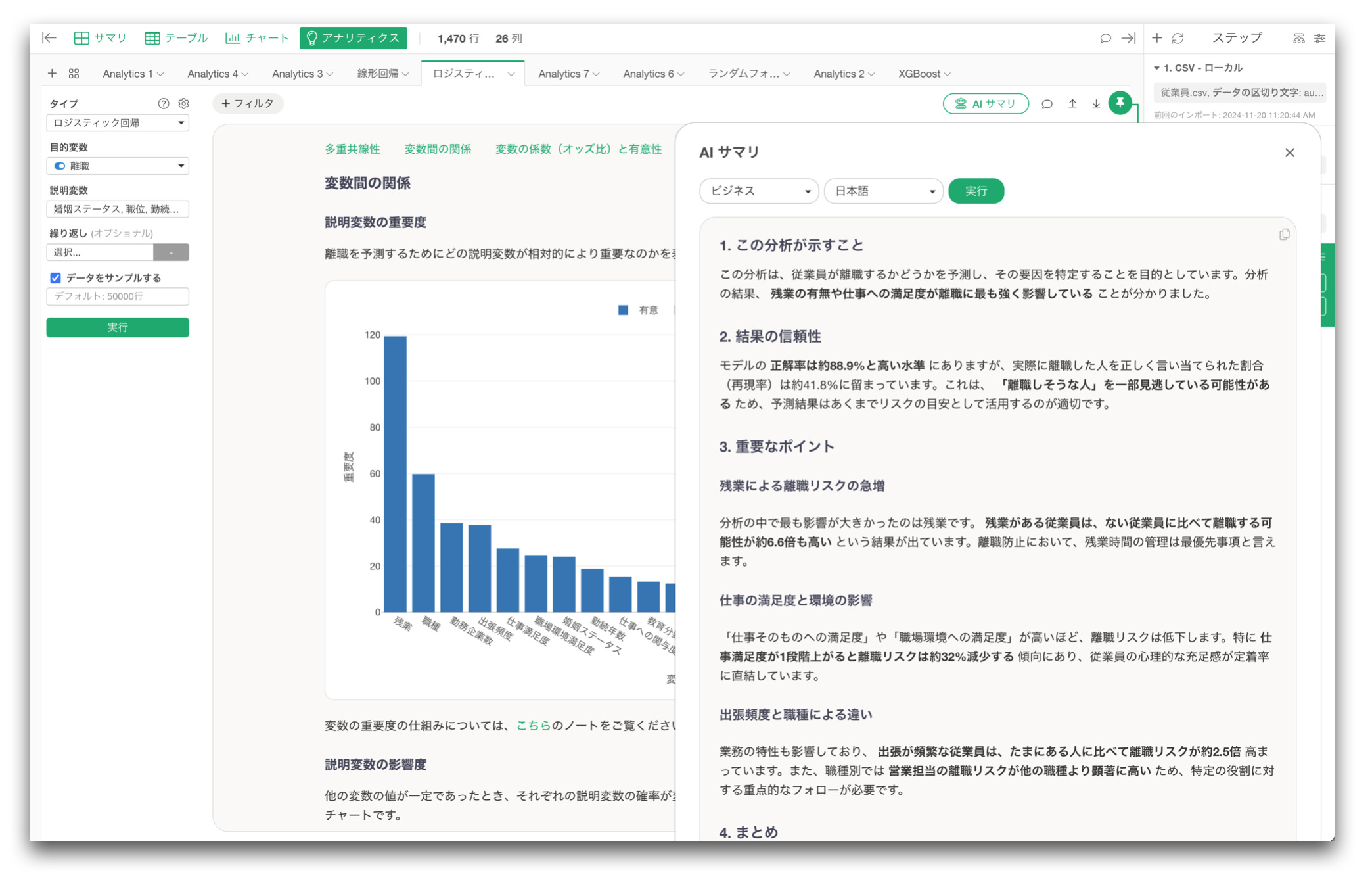
アナリティクス
Exploratoryのアナリティクスでは、分析結果のレポートが自動生成されます。
ただし、分析結果には多くの情報が含まれるため、最初にどこを見ればよいのか、何が重要なのかをつかみにくいこともあります。
AIサマリを使うと、分析結果の重要なポイントを先に把握できます。
そのうえで、詳しいレポートを読むことで、より効率的に分析結果を理解できるようになります。
チャート
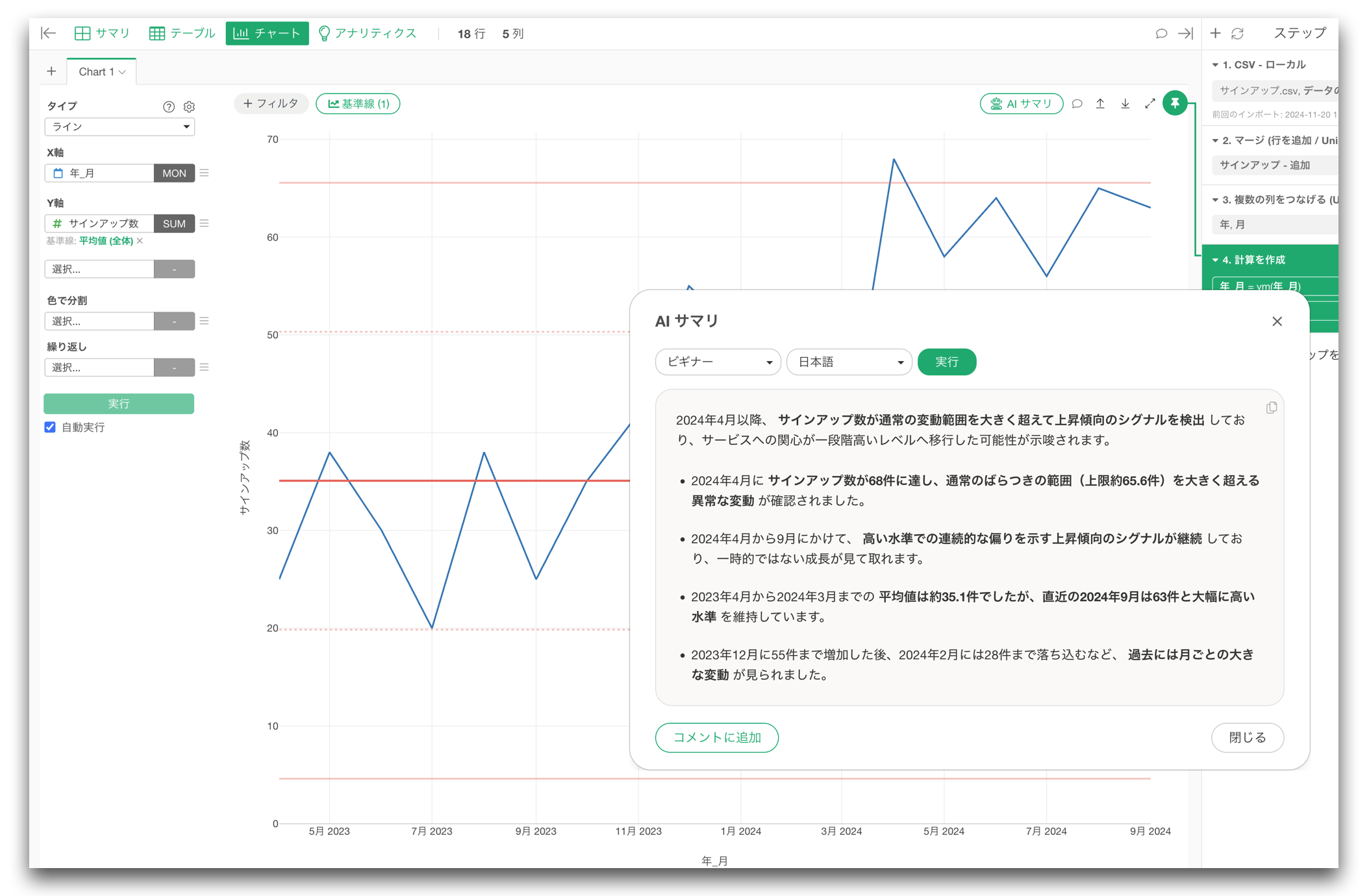
チャートのAIサマリでは、チャートから読み取れるパターンやトレンドを、分かりやすく説明します。
チャートの種類によっては、統計的な示唆も説明します。
例えばXmRチャートでは、通常のばらつきを超えた特別な変動、つまりシグナルが出ているかどうかをAIが説明します。これにより、チャートを見るだけでは見落としがちなポイントにも気づきやすくなります。
サマリ・ビューの機能強化
サマリ・ビューにもデータ理解をより効率的にするための機能を追加しました。
よりインタラクティブな操作
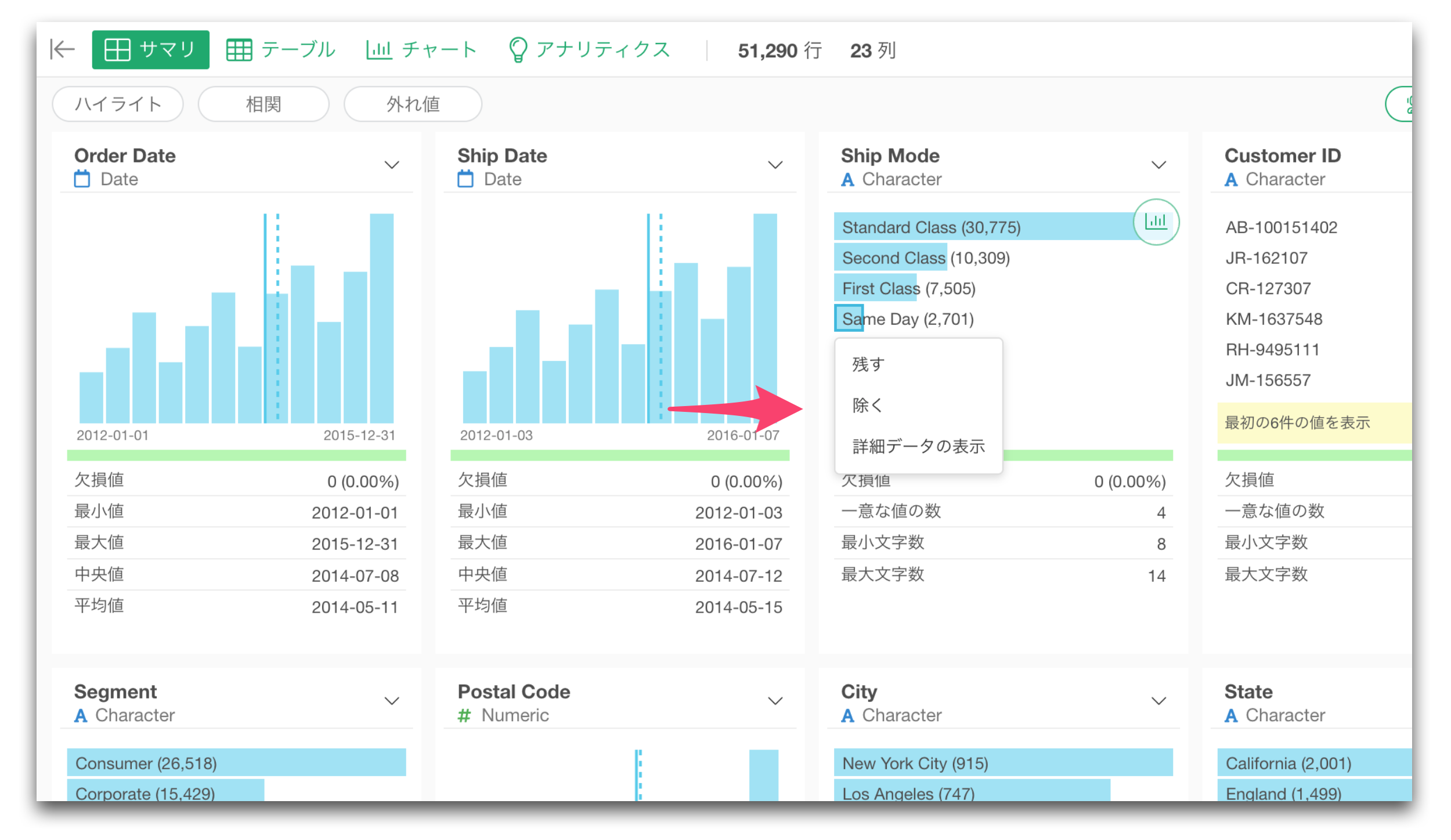
チャートのバーを選択(クリック)し、選択された値に関連するデータのみを残したり、または除いたりできるようなりました。
また、選択した値に関連する詳細データもサマリ・ビュー内でそのまま表示できるようになりました。
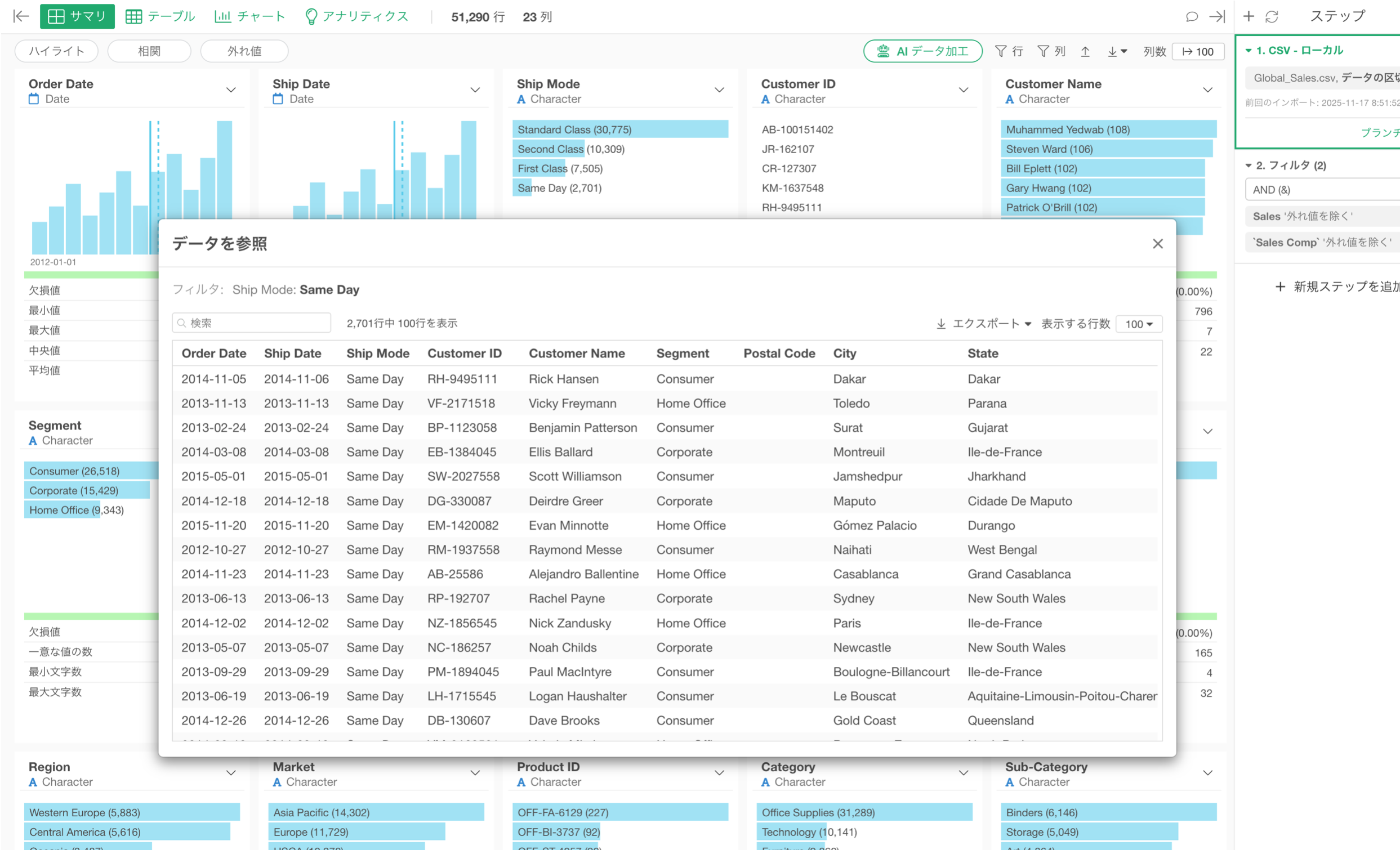
これにより、データの分布を確認しながら、気になる値をすぐに掘り下げることができます。
外れ値の分析
データ分析において、外れ値(はずれち、Outlier / 他のデータ全体の分布から大きく外れた、極端に大きな値または小さな値)の扱いが非常に重要です。
外れ値は、単なる入力ミスのこともあります。 一方で、ビジネス上重要な異常や、注目すべき顧客、商品、イベントを示していることもあります。
そこで、ある変数(列)の外れ値が、他の変数とどのように関係しているのかを、視覚的に素早く分析するために、「外れ値分析」機能をサマリ・ビューに追加しました。
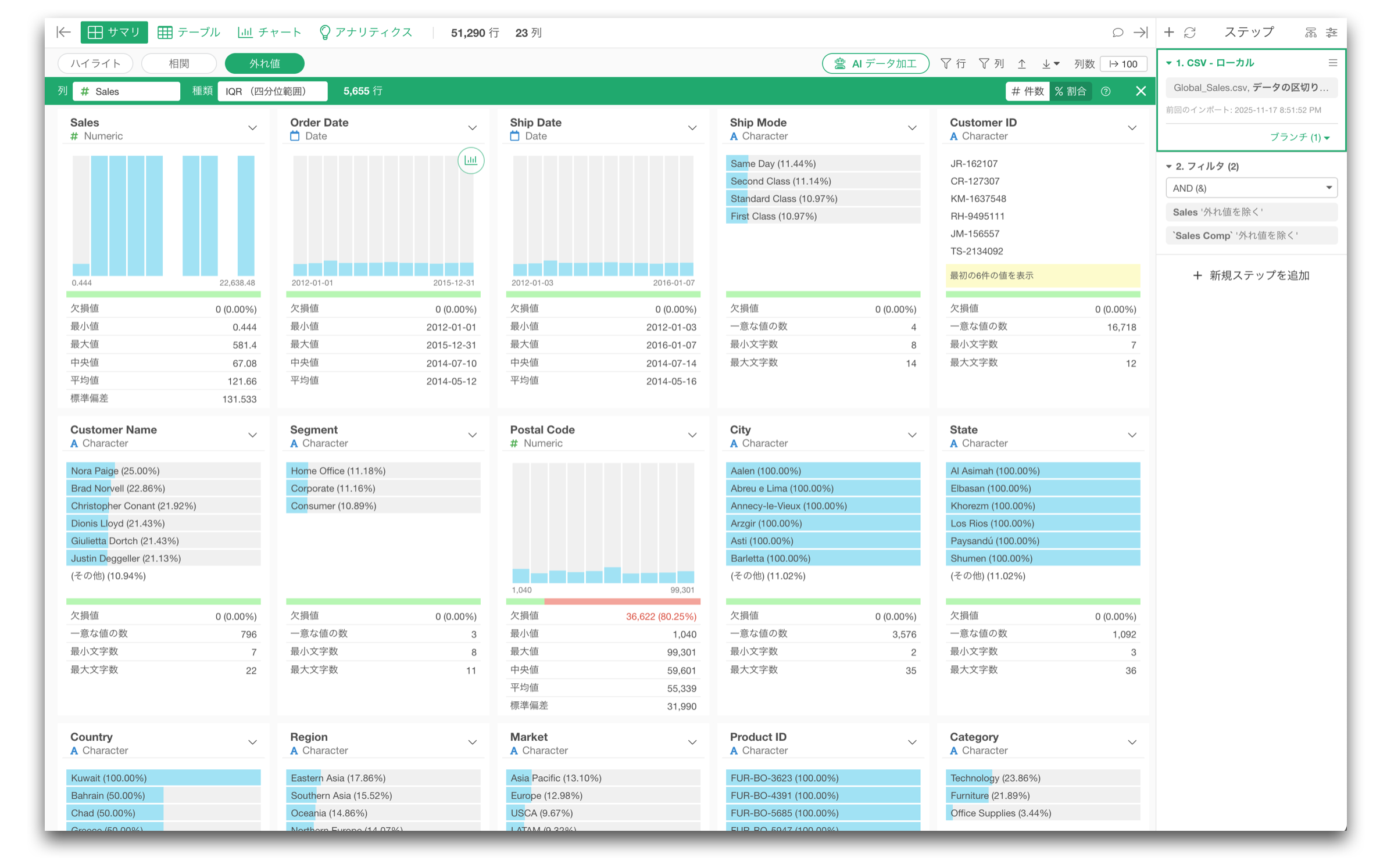
「外れ値」のボタンをクリックして、目的となる変数を選ぶと、その変数における外れ値が他の変数のどのあたりのデータと関係しているかを可視化できるようになります。
チャート
様々なタイプのチャート作れる、カスタム・チャート
Exploratory v15では、チャート・ビューの中で直接Rコードを書いてチャートを作成できる カスタム・チャート 機能を追加しました。
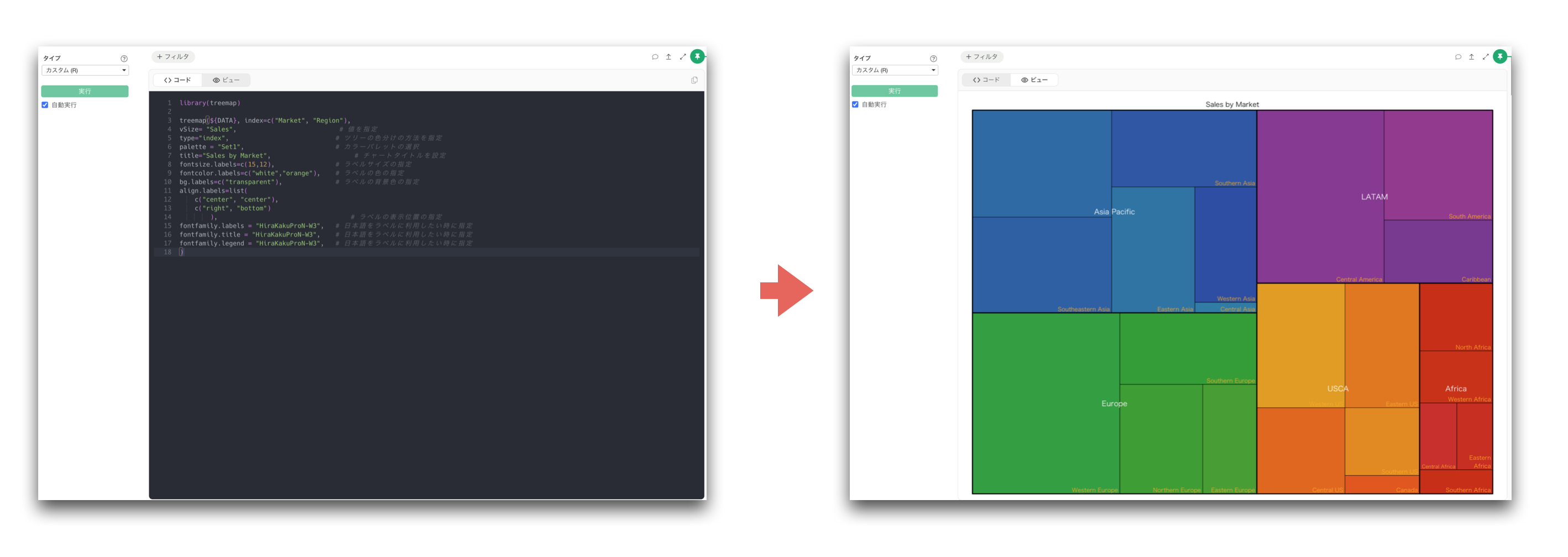
Rは統計分析に強い言語として知られていますが、実は可視化にも非常に優れています。
Rの豊富なパッケージを活用することで、標準のチャートタイプだけでは表現しきれない、さまざまな可視化を作ることができます。
カスタム・チャートを使うことで、Exploratoryの中でより柔軟なチャート表現が可能になります。
カスタム・チャートの作り方についてはこちらのノートをご覧ください。
ドラッグ・アンド・ドロップでテーブルの列幅の変更
ピボットテーブル、集計テーブル、テーブルの列幅をドラッグ・アンド・ドロップで変更できるようになりました!
これにより、長い列名や値を見やすく表示したり、レポートやダッシュボードに合わせて表の見た目を調整したりしやすくなります。
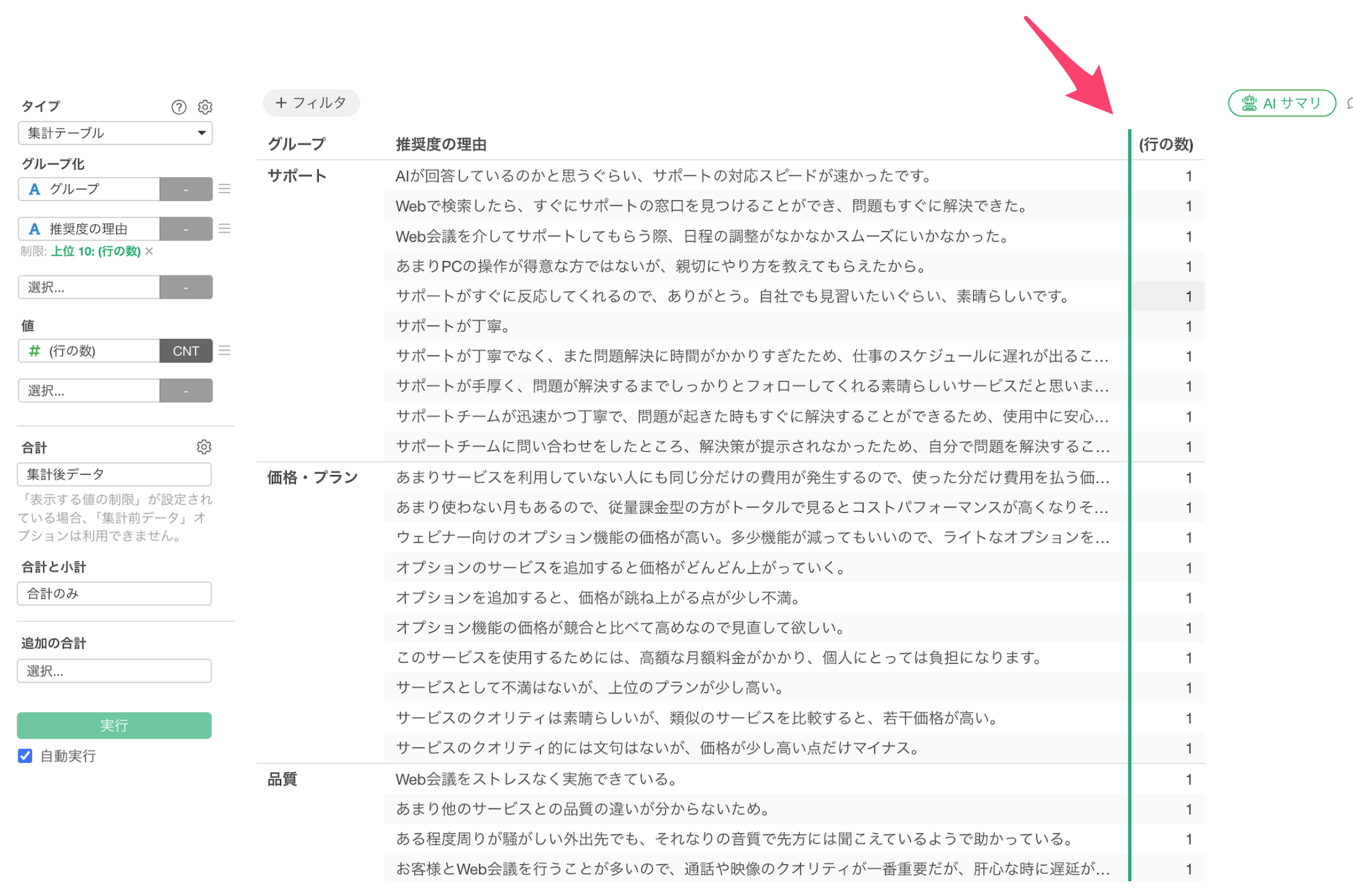
また、アナリティクス・ビューに表示されるテーブル(表)の列幅もドラッグ・アンド・ドロップで変更できるようになりました。

日々テーブルを使うユーザーの方にとっては、使い勝手が大きく向上する改善だと思います。
パフォーマンスの改善
Exploratory v15では、パフォーマンス面でも改善を行いました。
主に次の2つです。
- Exploratory本体の起動
- ノート・エディターとダッシュボードの起動
特に、プロジェクト数が多い環境では、Exploratoryの起動がよりスムーズになります。
また、基盤となるRをv4.5にアップグレードしたことにともない、dplyrパッケージもv1.2にアップグレードしました。
これにより、以下の関数を使ったデータ加工や計算のパフォーマンスが大きく改善されます。
- case_when()
- if_else()
これらの関数はExploratoryでは「条件付きの計算」ステップで使われています。これらの関数を使った処理のスピードは最大で30倍早くなります。詳しくは、以下のブログ記事をご覧ください。
Exploratoryの新機能のハイライトは以上となります。他にも多くの機能強化とバグの修正が入っております。そちらについてはリリースノートの方をご覧ください。
Exploratory v15をお試しください
Exploratory v15では、AI時代の信頼できるデータ分析を支えるために、多くの新機能を追加しました。
特に、今回のリリースでは、データ加工の流れを見える化し、その内容を説明し、ドキュメント化し、エラーが起きたときには修正を支援する機能を強化しています。
AIが分析やレポート作成を支援してくれる時代だからこそ、その元となるデータがどのように作られたのかを理解し、再現し、信頼できることが重要となります。
そういった意味で、Exploratory v15は「信用できる分析」に向けた大きなマイルストーンだと思っています。
ぜひ最新バージョンをダウンロードしてお試しください。
👉 Exploratoryをダウンロードする
https://exploratory.io/download
まだアカウントをお持ちでない方は、こちらから30日間の無料トライアルを始めることができます。
👉 無料トライアルを始める