Exploratory v15.5リリース:CatBoost、シルエット法、比率検定など、アナリティクス機能を大幅強化
こんにちは、Exploratoryの西田です。
このたび、Exploratory v15.5をリリースしました。
バージョン番号としてはマイナーリリースですが、今回のv15.5ではアナリティクス機能に大きな強化が入っています。
機械学習、クラスタリング、統計検定といった、データからより深いインサイトを得るための機能が大きく広がりました。
特に今回のリリースでは、単に分析手法を増やすだけでなく、次のような点を重視しています。
- より高精度な機械学習モデルを使えるようにすること
- パラメーター設定をわかりやすくし、モデル改善に取り組みやすくすること
- クラスタリングの結果をより客観的に評価できるようにすること
- A/Bテストや仮説検定など、実務でよく使う統計検定をより自然に行えるようにすること
AIが分析を支援してくれる時代だからこそ、その土台となるモデルや統計的な判断を、分析者自身が理解し、納得しながら使えることがますます重要になっています。今回のv15.5は、そのための大きな一歩となるリリースです。
機械学習モデルにCatBoostを追加
今回のリリースでは、新しい機械学習モデルとして CatBoost を追加しました。
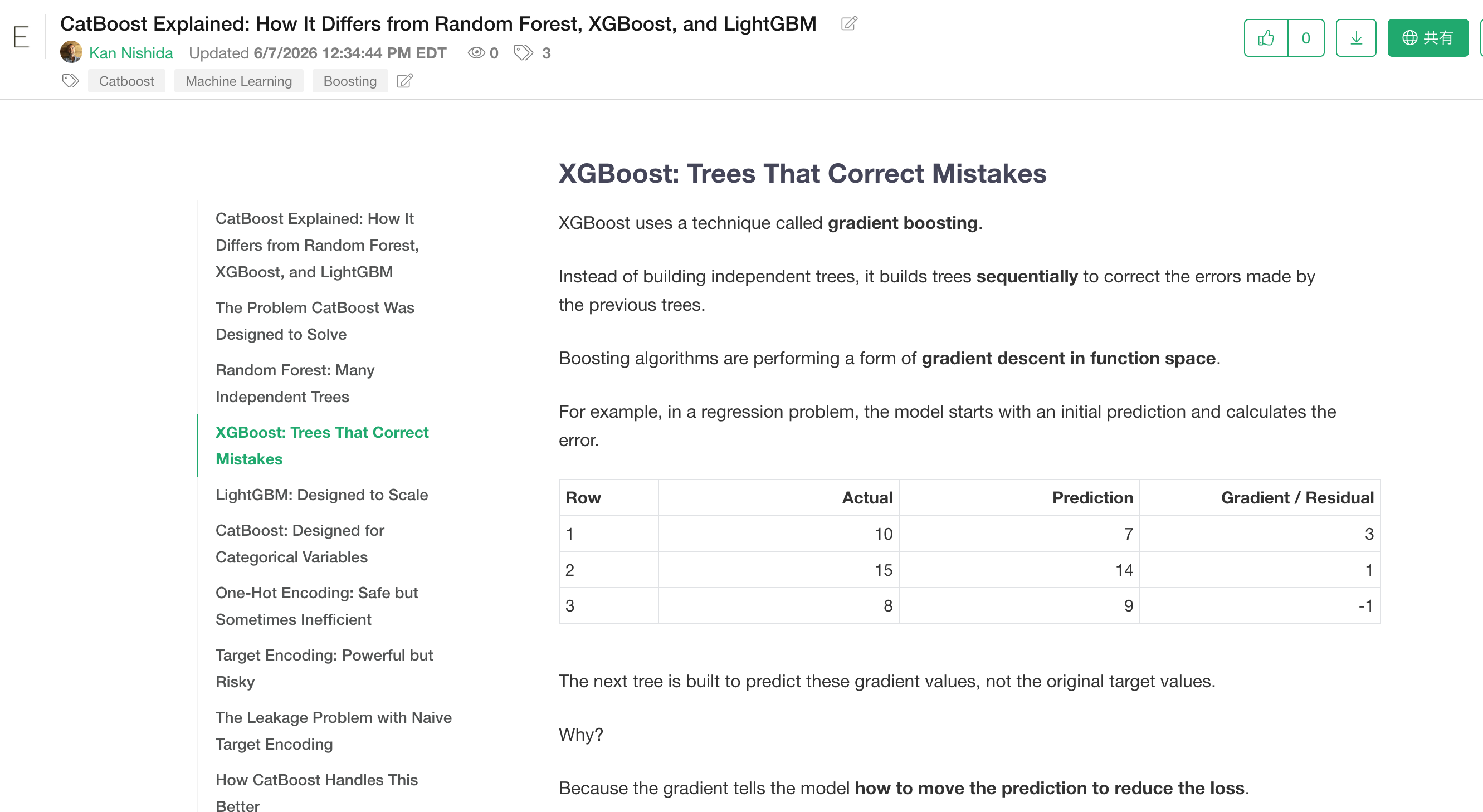
CatBoostは、XGBoostやLightGBMと同じく、ブースティング系の機械学習モデルです。
近年、データサイエンスの世界では、特にカテゴリ変数の扱いに強いモデルとしてよく使われるようになっています。
ビジネスデータでは、数値だけでなく、地域、商品カテゴリ、顧客タイプ、流入チャネル、職種、業種など、多くのカテゴリ変数が含まれます。CatBoostは、こうしたカテゴリ変数を含むデータに対して、強力な選択肢となります。
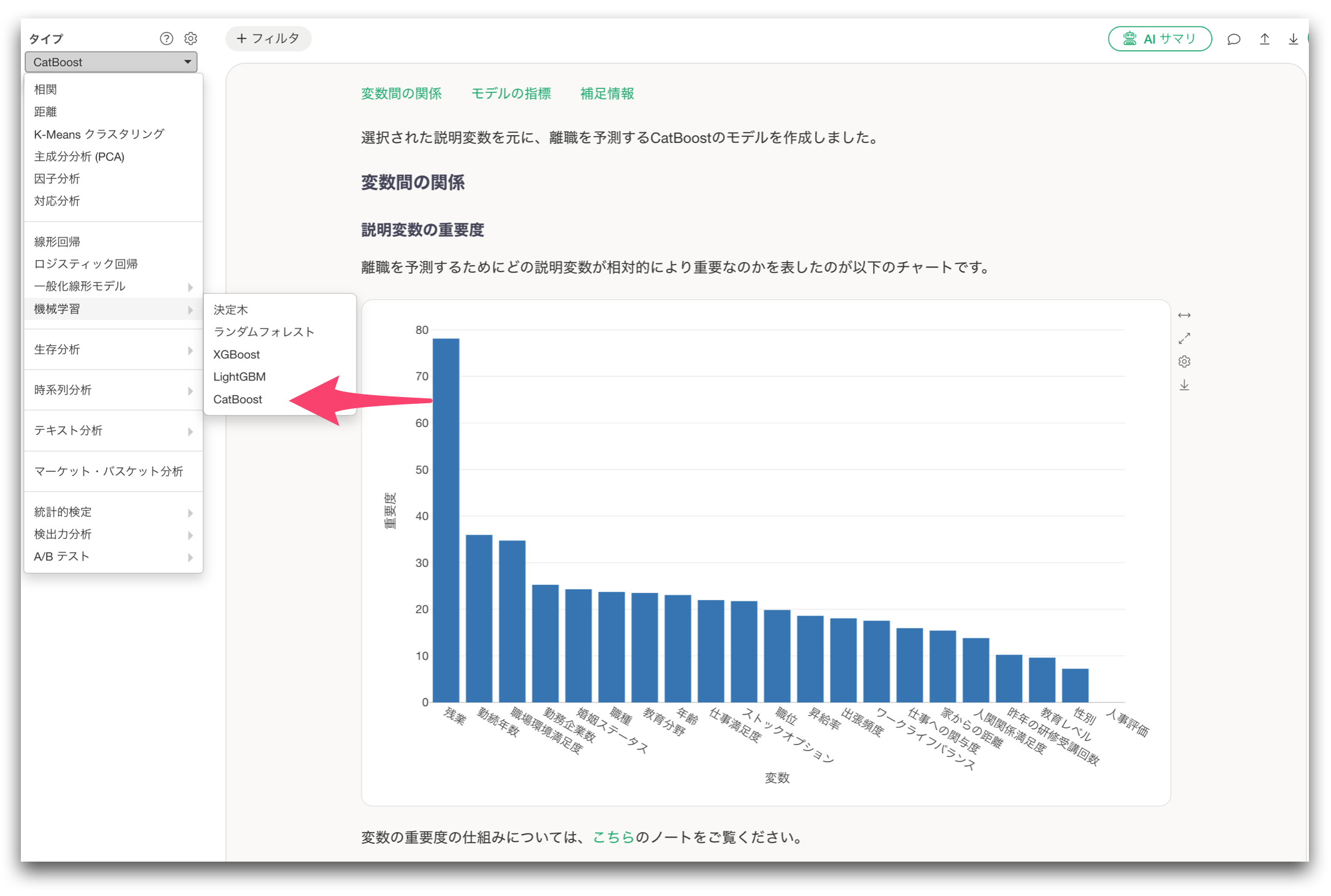
ExploratoryではすでにXGBoost、LightGBMをサポートしていますが、今回CatBoostが加わったことで、目的やデータの性質に応じて、複数の高精度な機械学習モデルを比較できるようになりました。
予測精度を高めたい場合や、カテゴリ変数を多く含むデータを扱う場合には、ぜひCatBoostも試してみてください。
機械学習モデルのパラメーター設定UIをリデザイン
機械学習モデルでは、モデルの性能を高めるためにパラメーターの調整が重要になります。
しかし、XGBoost、LightGBM、CatBoost、ランダムフォレストなどのモデルには多くのパラメーターがあり、それぞれが何を意味しているのか、どの値を選べばよいのかがわかりにくいという問題がありました。
そこで今回のリリースでは、機械学習モデルのパラメーター設定UIを大幅にリデザインしました。
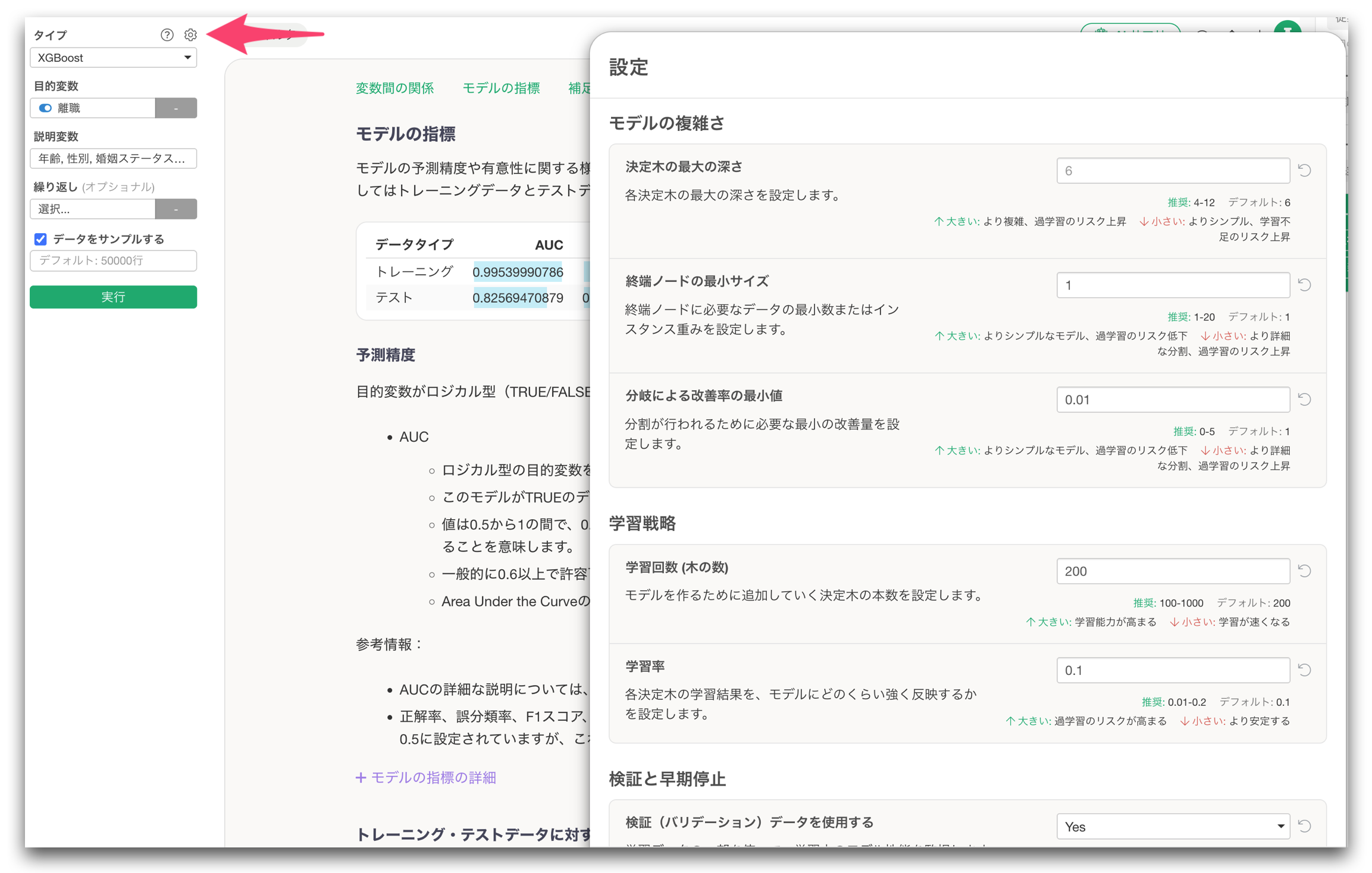
各パラメーターを、その役割や目的ごとにグループ分けし、機械学習モデル間でできるだけ一貫した並びになるように整理しています。
これにより、たとえば以下のような観点でパラメーターを探しやすくなりました。
モデルの複雑さを調整するもの
学習の進み方を調整するもの
行や列のサンプリングを調整するもの
過学習を抑えるためのもの
検証データや早期停止に関するもの
さらに、それぞれのパラメーターには、推奨値やヒントを表示するようにしました。
たとえば、「値を大きくすると何が起きやすいのか」「小さくするとどういう影響があるのか」といった情報を見ながら設定できるため、パラメーターの名前に詳しくなくても、モデル改善に取り組みやすくなっています。
機械学習モデルは、ただ作るだけではなく、結果を見ながら調整していくことが重要です。今回のUI改善によって、そのチューニング作業をより直感的に行えるようになっています。
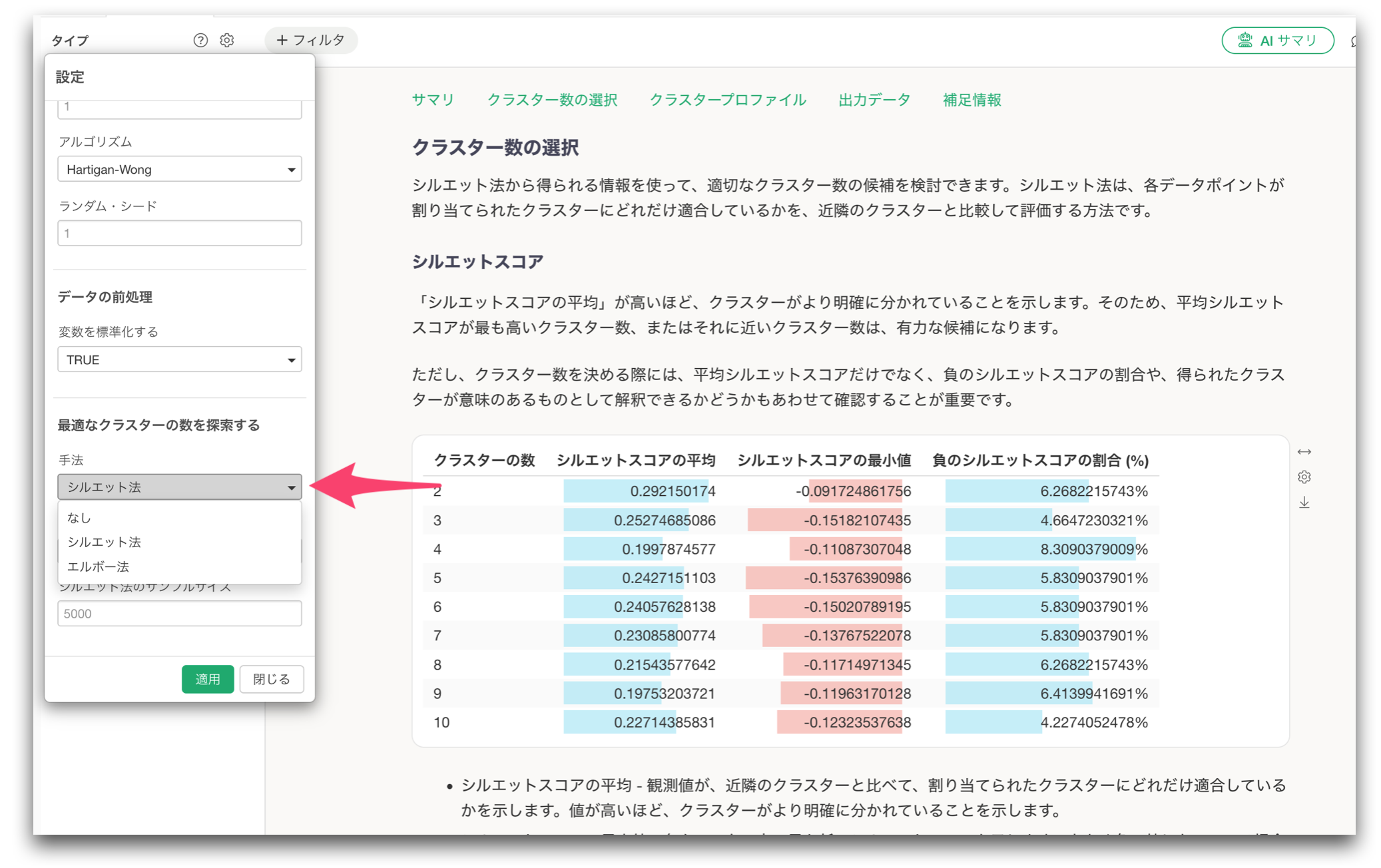
K-Meansクラスタリングにシルエット法を追加
K-Meansクラスタリングでは、あらかじめクラスターの数を決める必要があります。
しかし、「いくつのクラスターに分けるのがよいのか」は、実際には判断が難しい問題です。
これまでExploratoryでは、クラスター数を選ぶ方法としてエルボー法をサポートしていました。エルボー法はよく使われる方法ですが、チャート上で「肘(エルボー)」にあたるポイントがはっきり見えないこともあり、その場合は判断が曖昧になりがちです。
そこで今回のリリースでは、新たにシルエット法を追加しました。
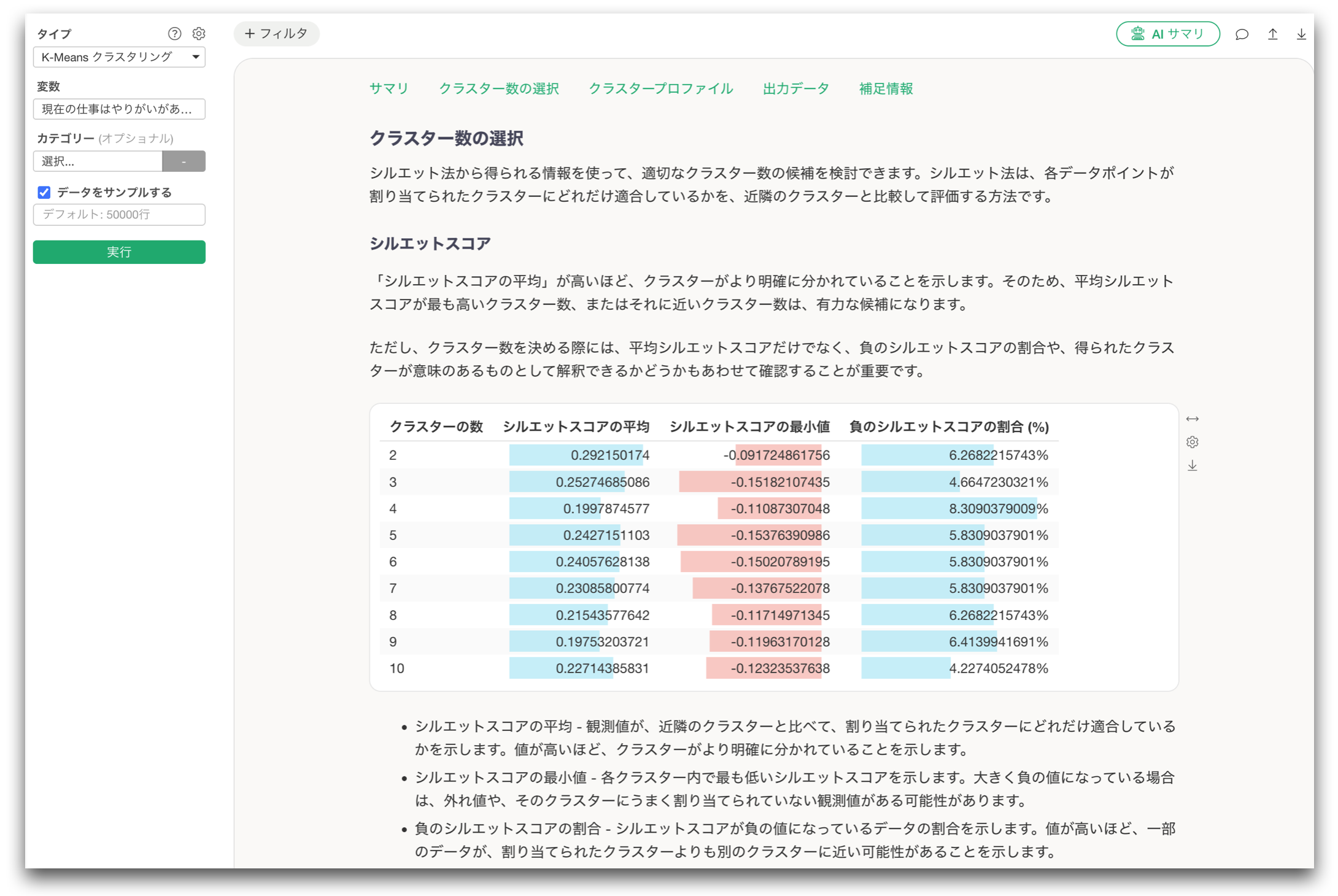
シルエット法では、それぞれのデータが、割り当てられたクラスターにどれだけよく属しているか、そして他のクラスターとどれだけ分離しているかを評価します。
その結果として得られるシルエットスコアを見ることで、クラスターの数をより定量的に判断できます。
さらにExploratoryでは、平均シルエットスコアだけでなく、負のシルエットスコアの割合も確認できるようにしています。平均スコアが高くても、負のシルエットスコアを持つデータが多い場合、そのクラスター分けには注意が必要です。見かけ上はよく見えるものの、一部のデータがうまく分類されていない可能性があるためです。
このように、平均シルエットスコアと負のシルエットスコアの割合を組み合わせて見ることで、より現実的にクラスター数を判断できるようになります。
また、最適なクラスター数を選ぶためだけでなく、各クラスターごとのシルエットスコアもサマリ表に表示するようにしました。

これにより、どのクラスターがよくまとまっているのか、逆にどのクラスターは分離が弱いのかを確認できます。
今回のリリースから、K-Meansクラスタリングではシルエット法がデフォルトになります。もちろん、エルボー法もこれまで通りサポートされていますので、必要に応じて設定から切り替えることができます。
2標本の比率検定を追加
今回のリリースでは、2標本の比率検定を追加しました。
これは、2つのグループの間で、Trueの比率に統計的に有意な違いがあるかどうかを調べるための検定です。
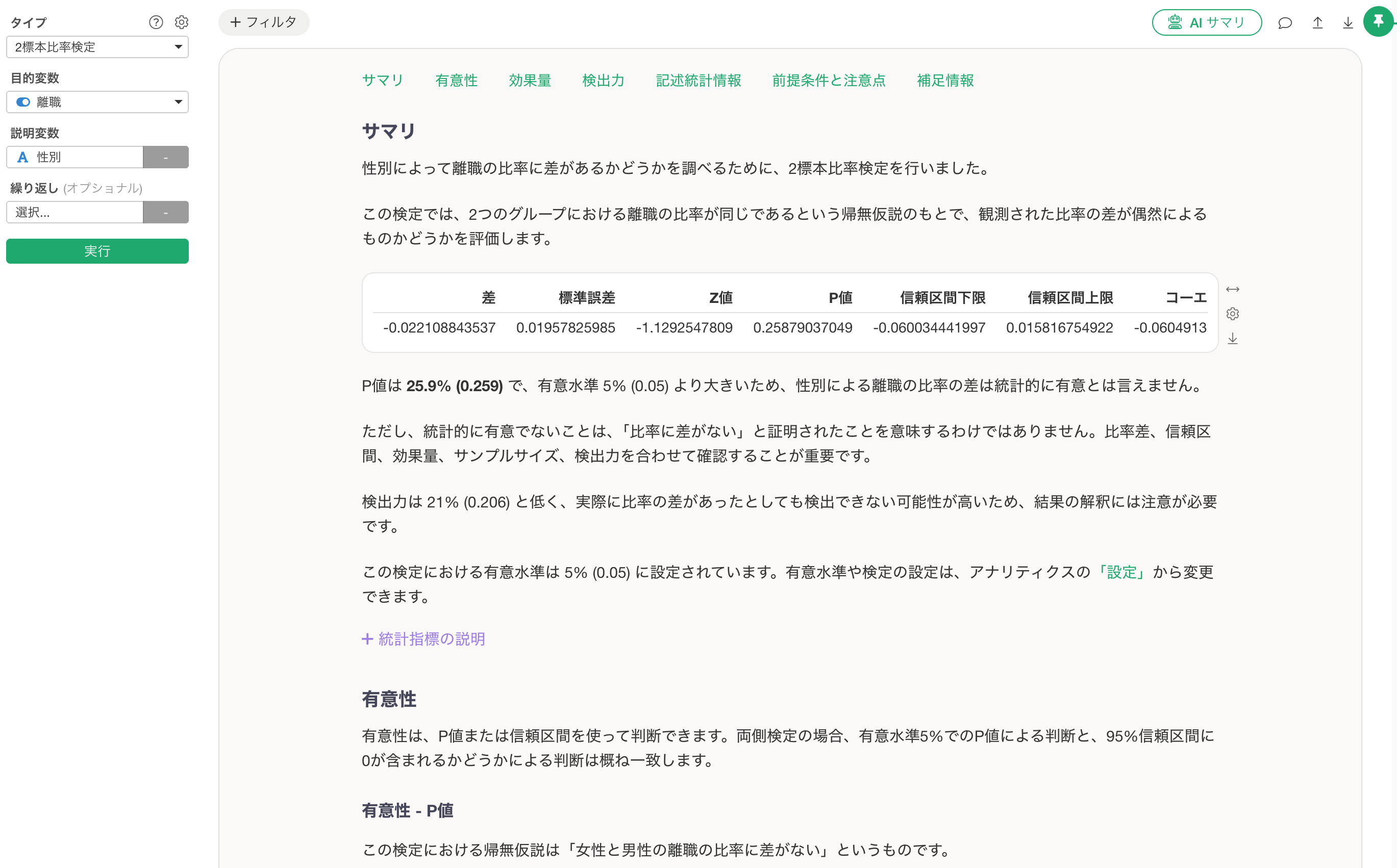
たとえば、次のような場面で使うことができます。
- A/Bテストで、コンバージョン率に差があるかを調べる
- 2つの顧客グループで、購入率に差があるかを調べる
- 2つの施策間で、クリック率や離脱率に違いがあるかを調べる
- 男女や年代など、2つのグループ間で回答率に差があるかを調べる
これまでも、複数グループ間の比率の違いを調べる方法としてカイ二乗検定を使うことができました。
一方で、A/Bテストのように「2つのグループの比率を直接比較したい」というケースでは、2標本の比率検定の方が目的に合っています。 今回この検定が追加されたことで、マーケティング、プロダクト分析、アンケート分析などでよく使われる比率の比較を、より自然に行えるようになりました。
1標本の比率検定と1標本のt検定を追加
今回のリリースでは、1標本の検定として、以下の2つも追加しました。
- 1標本の比率検定
- 1標本のt検定
これらは、手元のデータの比率や平均が、あらかじめ設定した仮説的な値と比べて、統計的に有意に異なるかどうかを調べるための検定です。
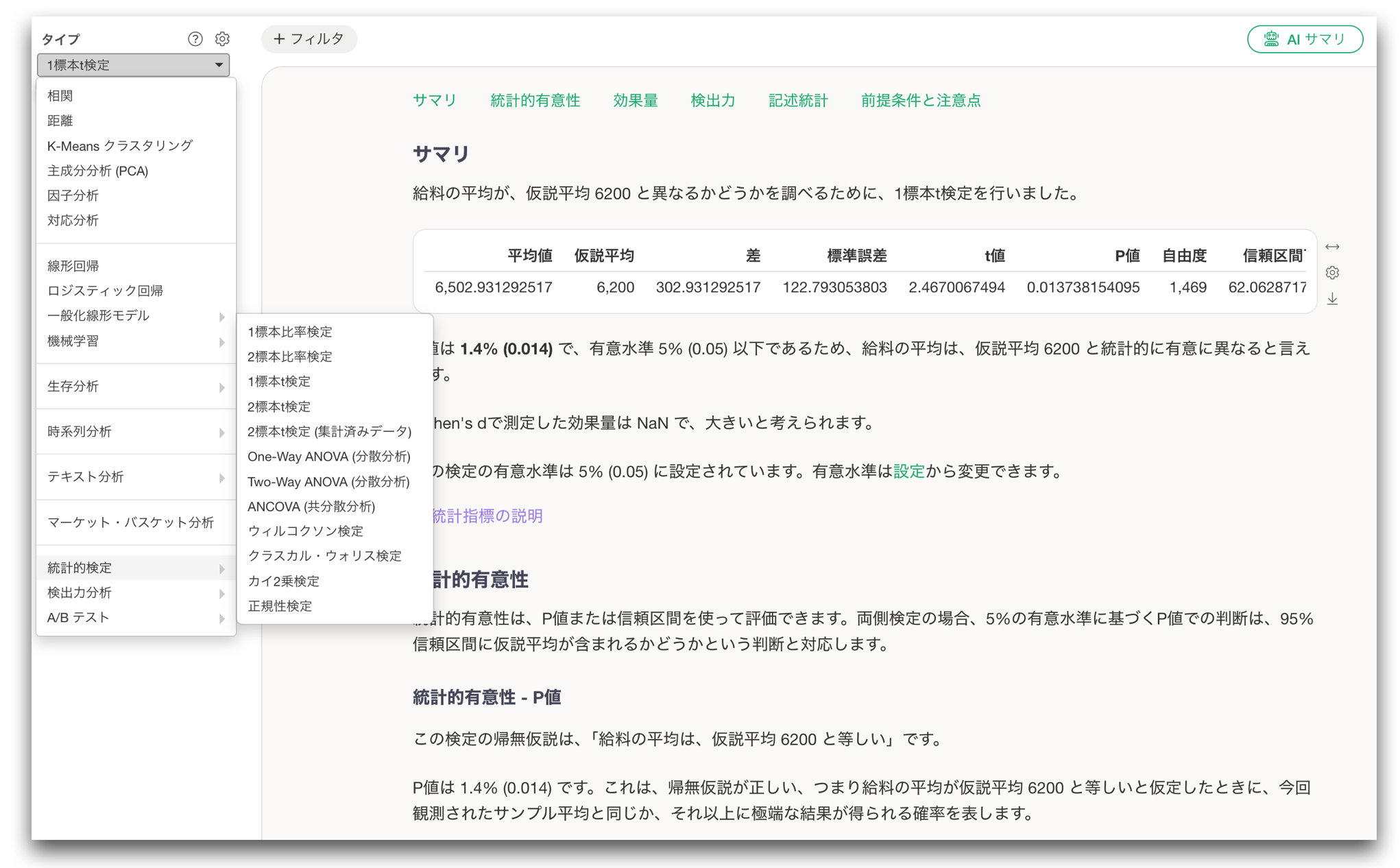
たとえば、1標本の比率検定では、次のような問いを調べることができます。
- コンバージョン率は目標値の10%を上回っているか
- 回答者の満足率は期待値の80%と違いがあるか
- 不良率は許容値の5%を超えているか
1標本のt検定では、次のような問いを調べることができます。
- 平均売上は目標値を上回っているか
- 平均満足度は基準値と違いがあるか
- 平均処理時間は想定値より短くなっているか
これにより、「2つのグループを比較する」だけでなく、「現在のデータが目標値や基準値と比べてどうなのか」を統計的に確認できるようになります。
なお、今回のリリースにあわせて、これまで「t検定」として表示されていたt検定は、名称の一貫性を保つために 2標本のt検定として表示されるようになりました。
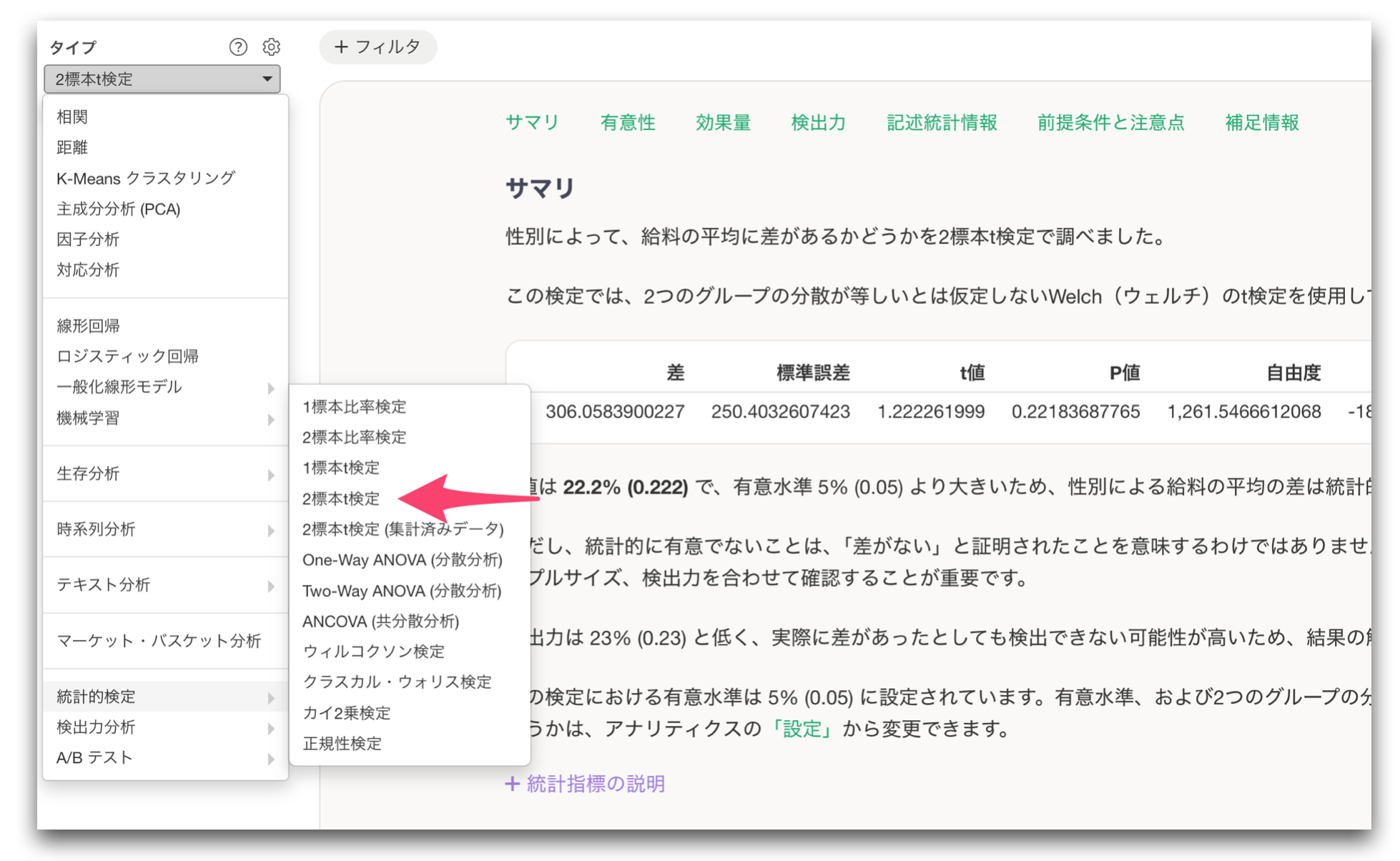
ノート:表の列幅を設定
今回のリリースでは、ノート機能にも改善が入っています。
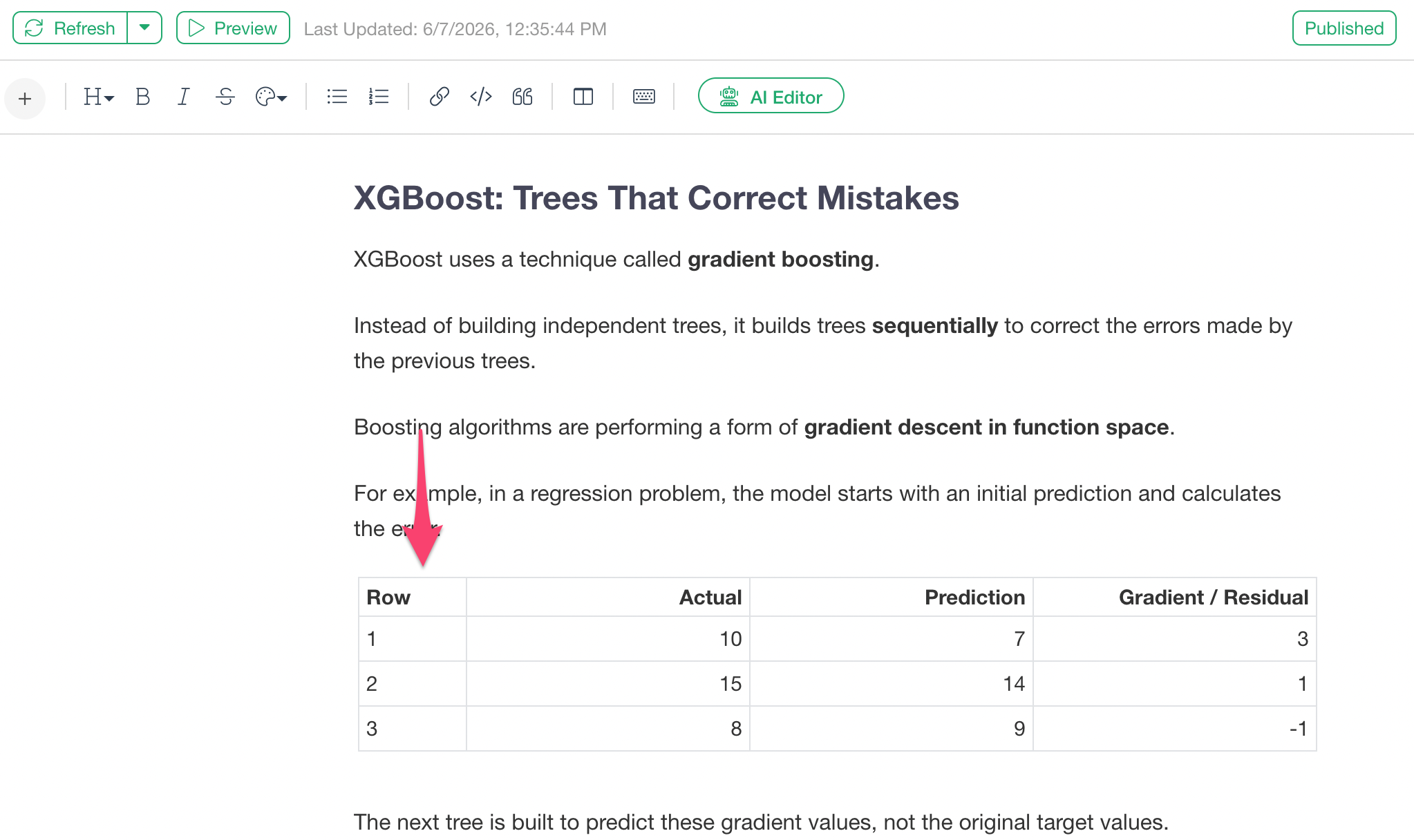
ノートエディターでは、表を使って分析結果や説明を整理することができます。今回、その表の列幅をマウスで調整し、その幅をパブリッシュ後のノートにも反映できるようになりました。
ノートエディター:
パブリッシュされたノート:
 これにより、表の中のテキストが読みやすくなるように列幅を調整しやすくなりました。
これにより、表の中のテキストが読みやすくなるように列幅を調整しやすくなりました。
Exploratory v15.5の主な新機能
今回のExploratory v15.5では、主に以下の機能を追加、改善しました。
- 機械学習モデルにCatBoostを追加
- 機械学習モデルのパラメーター設定UIをリデザイン
- K-Meansクラスタリングにシルエット法を追加
- クラスターごとのシルエットスコアをサマリに追加
- 2標本の比率検定を追加
- 1標本の比率検定を追加
- 1標本のt検定を追加
- ノートで表の列幅を設定できるように改善
その他にも、多くのバグ修正と改善が含まれています。詳しくは以下のリリースノートをご覧ください。
Exploratory v15をお試しください
Exploratory v15では、AI時代の信頼できるデータ分析を支えるために、多くの新機能を追加しています。
v15.0では、データ加工の流れを見える化し、その内容を説明し、ドキュメント化し、エラーが起きたときには修正を支援する機能を強化しました。
それらの新機能については以下のセミナーの録画、またはブログ記事をご覧ください。
そして今回のv15.5では、アナリティクス機能を大きく強化しています。
データをきれいに加工し、その流れを再現可能にするだけでなく、そこから機械学習、クラスタリング、統計検定を使って、より深いインサイトを得られるようになりました。
AIが分析やレポート作成を支援してくれる時代だからこそ、分析者自身が、モデルがどのように作られているのか、どのような設定が結果に影響するのか、そして統計的な結果をどう解釈すべきなのかを理解できることが重要です。
Exploratory v15.5は、分析者にとっての「AI時代の信頼できるデータ分析基盤」を作るうえで、重要なマイルストーンだと考えています。
ぜひ最新バージョンをダウンロードしてお試しください。
👉 Exploratoryをダウンロードする
https://exploratory.io/download
まだアカウントをお持ちでない方は、こちらから30日間の無料トライアルを始めることができます。
👉 無料トライアルを始める