
こんにちは、Exploratoryの西田です!
こちらは先週、これが民主主義を世界に対して声高に叫ぶ国の選挙なのかというくらいひどい選挙が終わったと思ったら、次はカリフォルニアの山火事です。私の住むサンフランシスコのすぐ北にあるミルバレーは火災が起きている場所からはだいぶ離れているので、ぜんぜん大丈夫です。ただ連日空が白く煙たく、毎日キャンプファイアーをしているような匂いが充満しています。
ところで、先週お伝えしたとおり、ようやくExploratory v5.0が正式にリリースされました。そこで、今週の金曜日の午前9時(日本時間)にv5.0の新機能の紹介のためのオンライン・セミナーを急遽行います。ユーザー・エクスペリエンスが以前のバージョンに比べてけっこう変わっているので、特にExploratoryのユーザーの方はぜひ参加してみてください。案内は下の方にあります。
私達のフォーカスは現在その次のリリースであるv5.1にすでに向けられていますが、こちらは、できれば次の数週間以内に出したいなと思っています。
先月の中旬にブートキャンプとアナリティカル・シンキングのトレーニングのために日本に行っておりましたが、今回もトレーニングを通して多くの新しい仲間に出会うことができました。こうして「データ」を通して様々なバックグランドを持った多くの人たちに出会うことができるというのは、今までの人生の中で最高な時であるなと実感しております。
ところで次回のブートキャンプは1月です。席の方はまだ若干空きがありますので、データサイエンスの手法やデータ分析をゼロから体系的にいっしょに学びたいという方は、この機会にご検討下さい!
それでは、今週のWeekly Update、さっそくいってみましょう!
最近の興味深い英文の記事
なぜデータ・ドリブン(データがドライブする)ではなくて、データ・インフォームド(データを理解した上で)であるべきか。
Why you should be data-informed and not data-driven - Link
ビジネスでデータを使い始めるとついついはまってしまう罠として、データに対する盲目な信仰というものがあります。つまり、データが言っているのだから、それは絶対だというものです。これは特にエクセルやBIなどのデータの可視化ツールを使っている人たちによく見られます。例えばバー・チャートで、東部地域と西部地域の売上を見て、東部のほうがいいから東部の方にもっと投資すべき、もしくは西部に対してもっとテコ入れしなくてはいけないと思ってしまったりするわけです。
ただ、データにはばらつきがあるものなので、これはたまたま今月がそうだったのかもしれなく、来月には逆の結果がでるかもしれません。ですから、こうした結果に対して一喜一憂するのではなく、そうした結果が特殊要因(アクションを取るに値する特別なことが起きている)によるものなのか、一般要因(個別に対処できる問題というよりも、システムを変更する必要があるような問題)にあるのかを統計の手法などを使いながら検証する必要があります。さらにそこで見えていないデータは何なのかを含めた、前提となっている背景への理解が必要です。
つまり、データを意思決定に役立てていこうとするのはすばらしいわけですが、ある程度のデータや統計に対するリテラシー、さらに業務知識などを活かすことで、データに踊らされるのではなく、人間の弱さ(勘と経験にはたくさんの勘違いがあります。)を補うためにデータを使うのだという前提でデータを使いこなすことによってはじめて、ビジネスの向上につながるよりよい意思決定ができるようになります。
このことをわかりやすく説明するために、最近私のまわりではデータ・ドリブンとは別にデータ・インフォームドという言葉が良く使われるようになってきています。
今回は、FacebookのWhatsApp部門のグロースのトップであるUzma Barlaskarがこのことに関してわかりやすくまとめていたので、こちらのノートに一部を翻訳してまとめました。
機械学習を使いこなす
Getting Better at Machine Learning - リンク
機械学習だけでなく、データ分析一般に言えることですが、やり始める前に、まずは解決したい問題をはっきりと定義することが非常に重要です。ここのステップが曖昧になってしまうとその後の分析のステップで、時間と労力はたくさんかかってしまうわりに、ビジネスの意思決定に影響を及ぼすほどの結果はまったく得られないということが起きてしまいます。
AirbnbのデータサイエンティストであるRobert Changが、実際のビジネスの場面で機械学習を使いこなすには、学校やKaggleなどのコンテストなどで学ぶ技術的なスキルや理論を超えて、もっと実践的なフレームワークが必要だということで、以下のステップをもとにしたフレームワークを紹介しています。
- 問題の定義
- データの収集
- モデルの構築
- 製品化
- フィードバック・ループ
実はこれって、昔からあるCRISP-DM(Cross-industry standard process for data mining)というデータマイニングの世界では有名なフレームワークにものすごく近い感じもしますが、それをAirbnbの実際のプロダクト、Airbnb Plusという事例を使って説明しているのが面白いと思います。
今回はその中でも、私が一番重要だと思う、問題の定義に関する部分を簡単に紹介します。
Airbnb Plusとういうハイ・クオリティ(高品質)なレンタルの家を探すためのプロダクトがあります。たくさんの社員はこのPlusに合うような家を探すのに情熱を持っていますが、それをスケールさせるのは難しいです。私達のチームは人間による評価と機械学習を組み合わせることで高い価値がありそうな家を探します。こうした、人間による評価と機械学習による予測の両方が必要になるような問題は最近よく出てきます。
人間が家を評価することで、データにラベル付がされます。すでに家に関する属性データ(価格、ブッキング、レビューなど)はあるので、このラベルデータと属性データを混ぜて、最初の家を評価するためのモデルを作るためのトレーニングデータとします。
まずは、これだけでも私達の作業の効率化という点では大きく役立ちました。
しかし、この製品がどんどん進化していくに従い、このアプローチには限界があるのもわかってきました。特に私達がどういった家をPlusとするのかという定義が変わってくるに従い、モデルが予測の結果として出してくるラベルに対する意味付けも変わってきました。
こうしてビジネスが成長するに伴い、モデルがデータとして使ったり、結果として出してくるラベルがどんどんと陳腐化してくるのです。つまり、私達が実際にやろうとしているのは、どんどんと変わってくるような答えを予測しようということなのです!
そこで、問題の定義の仕方を再考する必要があります。最終的には、1つの学習のタスクをいくつかの独立したタスクに切り分けることにしました。一つ一つの物件が高い潜在的な価値があるかないかを判断する代わりに、意味が変わることのないような高い品質の根拠となる属性を予測することにフォーカスすることにしました。例えば、高い品質の物件かどうかのラベルをつけるのではなく、問題を以下の数式のように定義しました。
home_high_potential = f(style, design, ...)ここでのfは、人間がそれぞれの予測結果をもとに最終的な判断をするために使うルール(条件)をもとにしたアプローチをコード化したと思ってください。
問題を定義するには深い業務知識、問題を分解する能力、たくさんの辛抱強さが多くの場面で必要になってきます。もっとも簡単に獲得できるトレーニングデータが私達がどういった問題を定義するのかということをドライブ、つまり影響を与えてしまうようなことがあってはいけません。問題を定義してから、それでは、どういったデータがその解決に必要なのかを考えるべきなのです。このことは機械学習の世界で効率的に問題を解決していくために最初につけるべき重要なスキルです。
サッカーの世界にもアナリティクスが
How data analysis helps football clubs make better signings - リンク
「サッカーはデータを適用するには複雑すぎて、あまりにも自由度が高いとよく言われたものでした。しかし、最近はそういったことはあまり聞かなくなってきました。」と、サッカーのデータ分析企業の1つであるStatsBomのCEOであるTed Knutsonは言います。
ここ10年ほどの間にもっとサイエンスの力を使ったオペレーションが出てきました。それはチームの試合結果に影響を及ぼすだけではなく、どうやって新しい選手を雇うのにお金を使うかにも影響を与えてきました。
サッカーのアナリティクス時代はイベント・データと言って試合中の全てのボールに触れるアクションに関する詳細の情報を集めるところから始まりました。2006年には、ロンドンのOpta Sportsというチームは全てのパス、シュート、タックル、ドリブルの時間と場所をボタンを押しながら記録していました。
その後、「期待されるゴール(expected goals)」というシュートが得点になる可能性を、ゴールからの距離と角度をもとに計算するシステムが使われ始めました。このコンセプトは2017年にプレミア・リーグの代表的なTV番組である「Match of the Day」で紹介された時に多くの人達に知られることになりました。
選手レベルのデータの最も大きなインパクトは選手の獲得(リクルート)と維持(リテンション)です。
クラブは自分たちが理想とするような選手のプロファイルに統計的にマッチする選手たちのリストを、自分たちの本拠地を離れることなしに、作ることがとができます。
リクルートに関する分野で活躍する企業の1つに21st Clubというのがありますが、彼らのツールは、選手の試合中のアクションと彼らのチームの総合的なパフォーマンスのレベルの関係を計算し、それを持ってそれぞれの選手に得点をつけます。クラブ側はそのデータを使って雇いたいと思っている選手がチームの総合的なパフォーマンスをより良くするのかそうでないのかを見極めることができます。
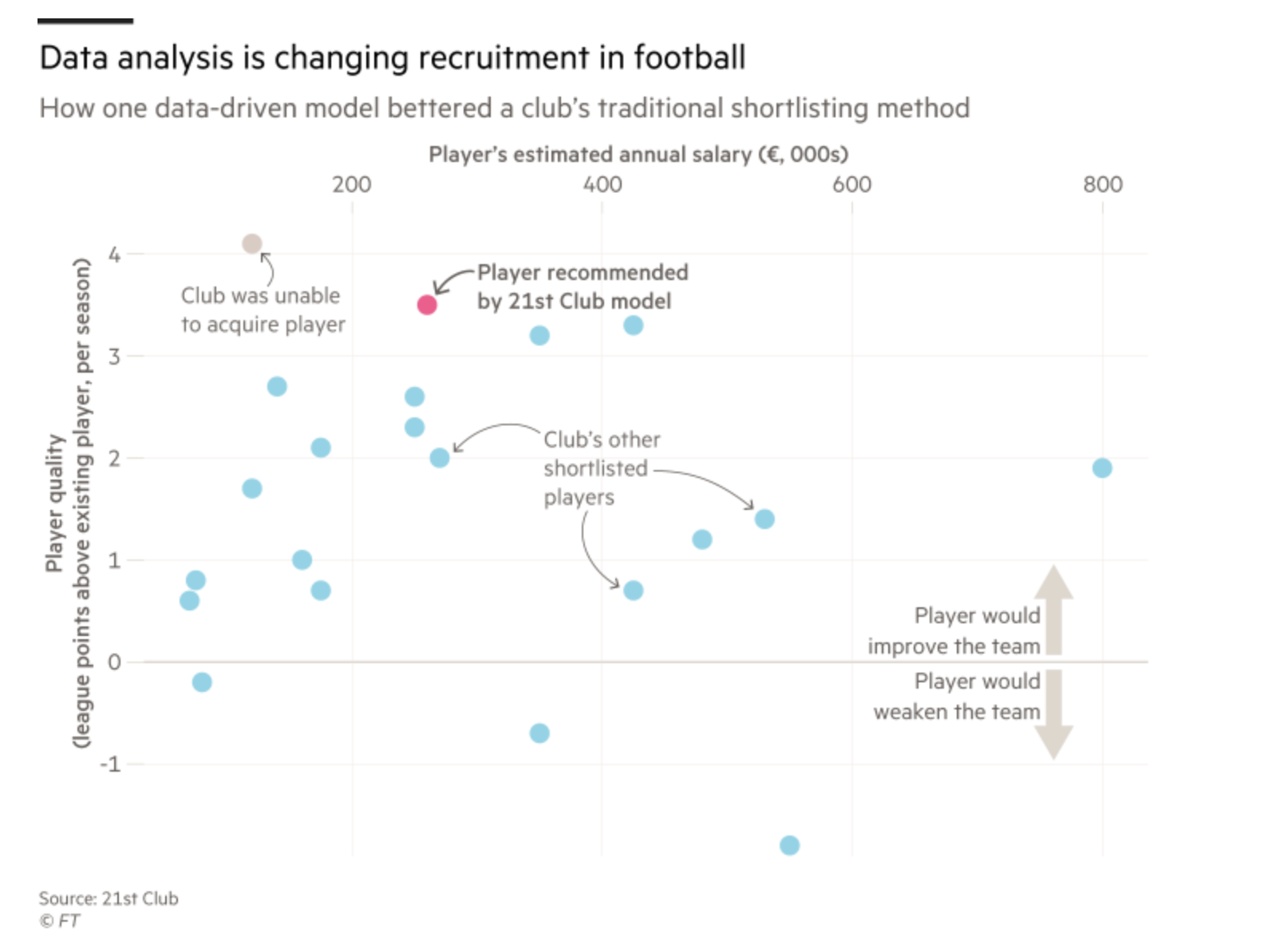
FCバルセロナというクラブのデータサイエンティスト、Javier Fernándezは、コーチ陣がほんとうに知りたい質問の多くが、彼らの持っているイベントのデータではカバーできていないことに気づきました。コーチの人たちはスペースについてよく話をするのです。スペースを作れ、スペースに入れ、といった具合です。そこで、試合中のスペースを理解するためのもっと細かなデータが必要だということに気づきました。
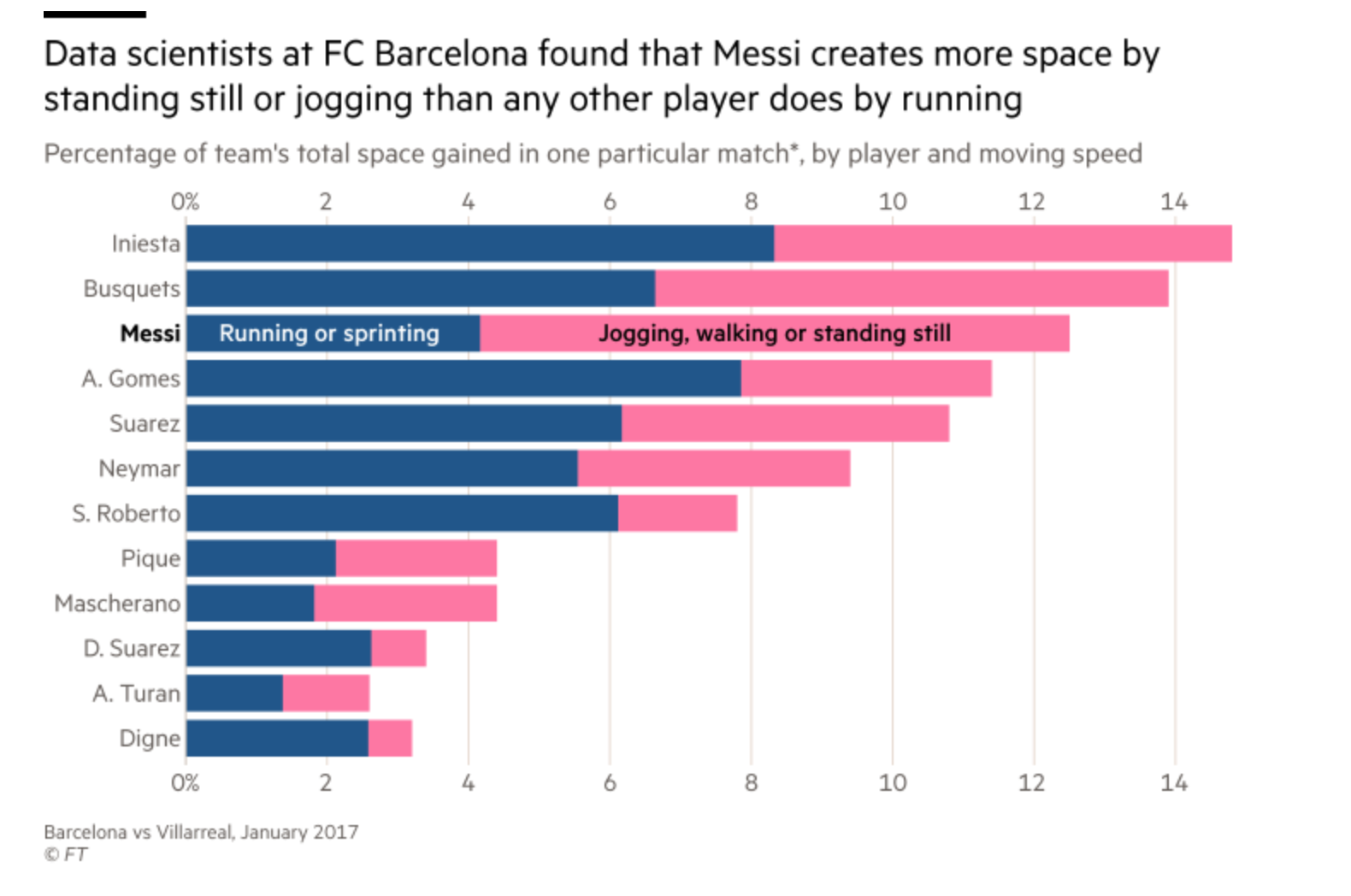
データサイエンティストは「ゴースティング(ghosting)」という手法を開発しました。これはある状況において選手がどういった行動を取るかをアルゴリズムが予測するというものです。
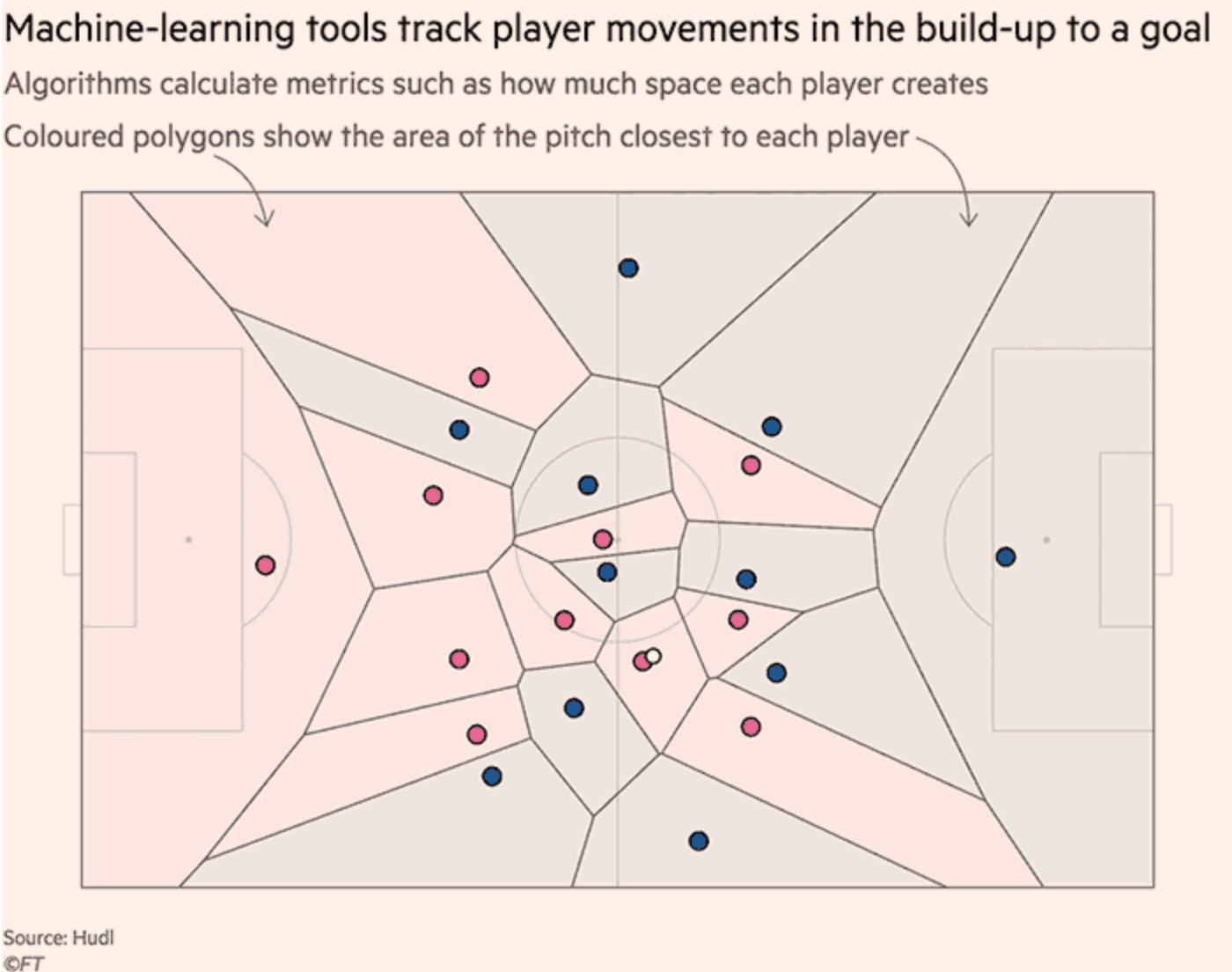
「相手が混乱するような特定のシナリオを見つけます。例えば30秒ほど相手が体制を立て直すのにかかるとします。」
とは、STATSというアナリティクスの会社でAIサイエンティストをやっているPaul Powerの言葉です。
「この30秒にフォーカスしたトレーニングをすればいいのです。」
こうした手法は選手のリクルートにも大きな価値を発揮します。
ヨーロッパのデータプライバシーの規制は結局GoogleやFacebookをより有意にするだけだった
Study: Google is the biggest beneficiary of the GDPR - リンク
GDPRというEU市民の個人データを保護するための規制がありますが、それが施行された今年の5月25日以降いったいどういう変化があったのかを調べた結果、広告界の巨人である、GoogleやFacebookといった企業をむしろより優位にさせているということがわかったようです。
ミルトン・フリードマンが昔、政府による規制の問題とは、規制そのものではなく、その法律を作る人達が規制しようとする業界、対象のものに対して持っている理解が、その業界のプレーヤーに比べてあまりにも浅いことだ、と言っていたことを思い出します。
規制を作る側は、そこで、業界の専門家に助言を求めるわけですが、そうした専門家は結局その業界の大手からやってきます。そこで、そうした巨人たちは自分たちに都合のいいような法律に書き換えてしまうので、結局は規制というのは既存の巨人たちによる独占を守り、新しいプレーヤーの新規参入を難しくするためのものになってしまうというのです。
規制が守ろうとしているのは一般市民でもあるにも関わらず、実際に守ることになってしまうのは既存の大手企業であるというのはなんとも皮肉な話だというのがポイントなのですが、その最新の事例がGDPRとして起きているわけです。
このGDPRにしろ、これから様々な地域で出てくるデータやAIに対する政府による規制はこうした運命から逃れられないのではないでしょうか。
WhoTracks.meというサービスからのデータを使って、広告トラッカーがGDPRの施行前の一ヶ月間と施行後の一ヶ月間でどれくらい使われているのかを比べてみました。WhoTracks.meのデータは50万ほどのウェブサイトと3億ほどのページロードをもとにしています。
以下が、その違いです。
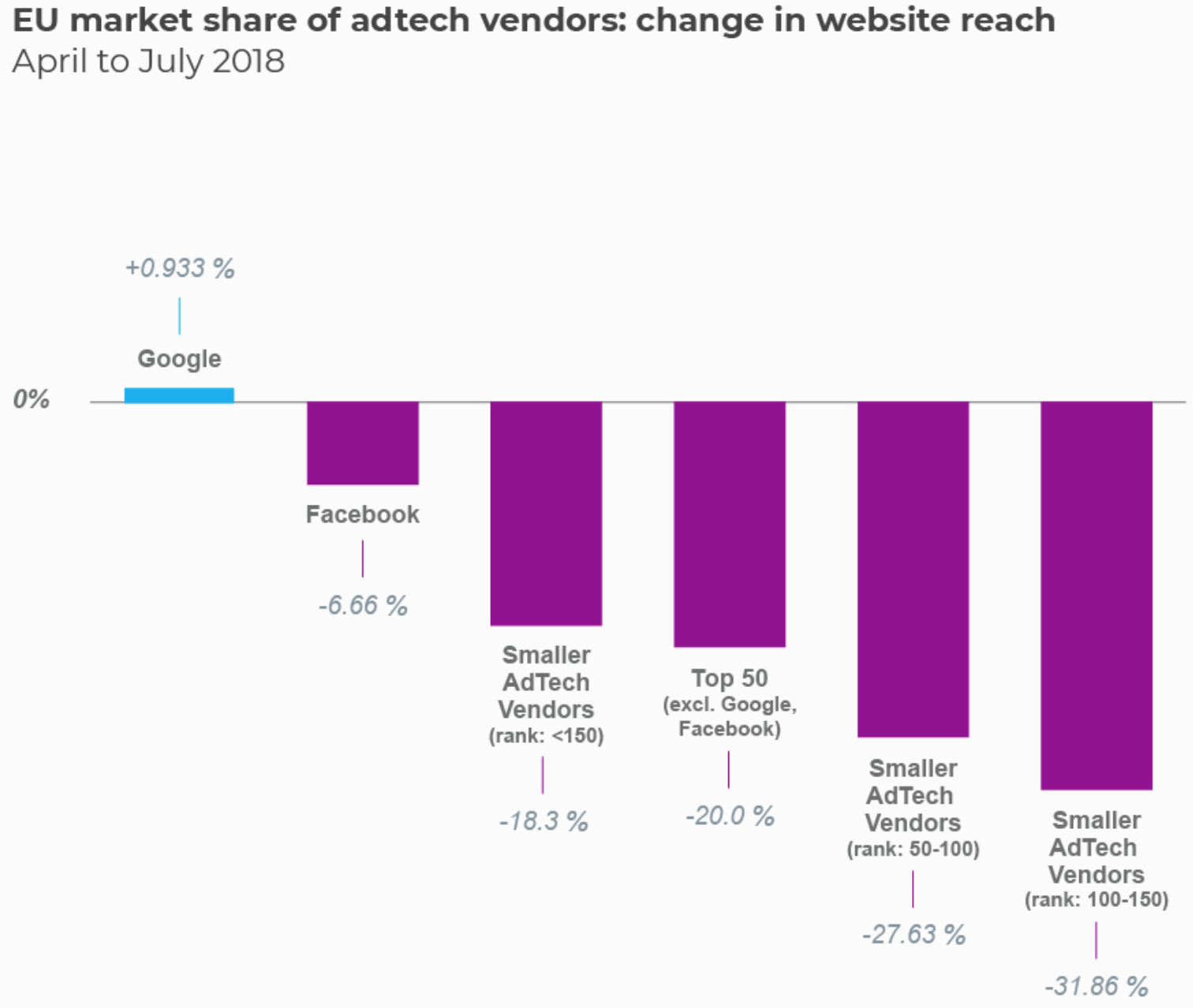
この違いは明らかです。
規模の小さいアドテック企業はかなりのリーチを減らすことになりました。(リーチは市場シェアの目安になります。)18%から31%ほどが減ってしまったことになります。Facebookも7%ほどですが少し失っています。それとは対象的に、Googleは1%ほどですが増加しています。
これにはいくつかの要因が考えられるでしょう。
- Googleなどの大きなアドテックの企業は新しい法律に準拠するために大きなリソースを使うことができた。
- Googleは独占的な地位を使ってパブリッシャーに広告トラッカーの数を減らすように促した。これがアドテックの会社が減った理由である。
- ウェブサイトのオーナーは、罰則にあうリスクをなくすために、規制に準拠していることを証明するのに大変な小さい広告会社を使うのを止めてしまった。
ひとつ確かなのは、GoogleはGDPRから間接的な恩恵を受けているということです。このことはヨーロッパのオンライン広告の市場は以前よりさらに少ない企業に集中され、多くの広告主は市場のシェアを失うことになりました。
GoogleはGDPRに関する不確実さを逆に自分たちの利益とし、市場での立ち位置をさらに強化することができました。逆に、多くの小さな競争相手はGDPRが施行されて以降、急激に市場におけるシェアを失いつつあります。
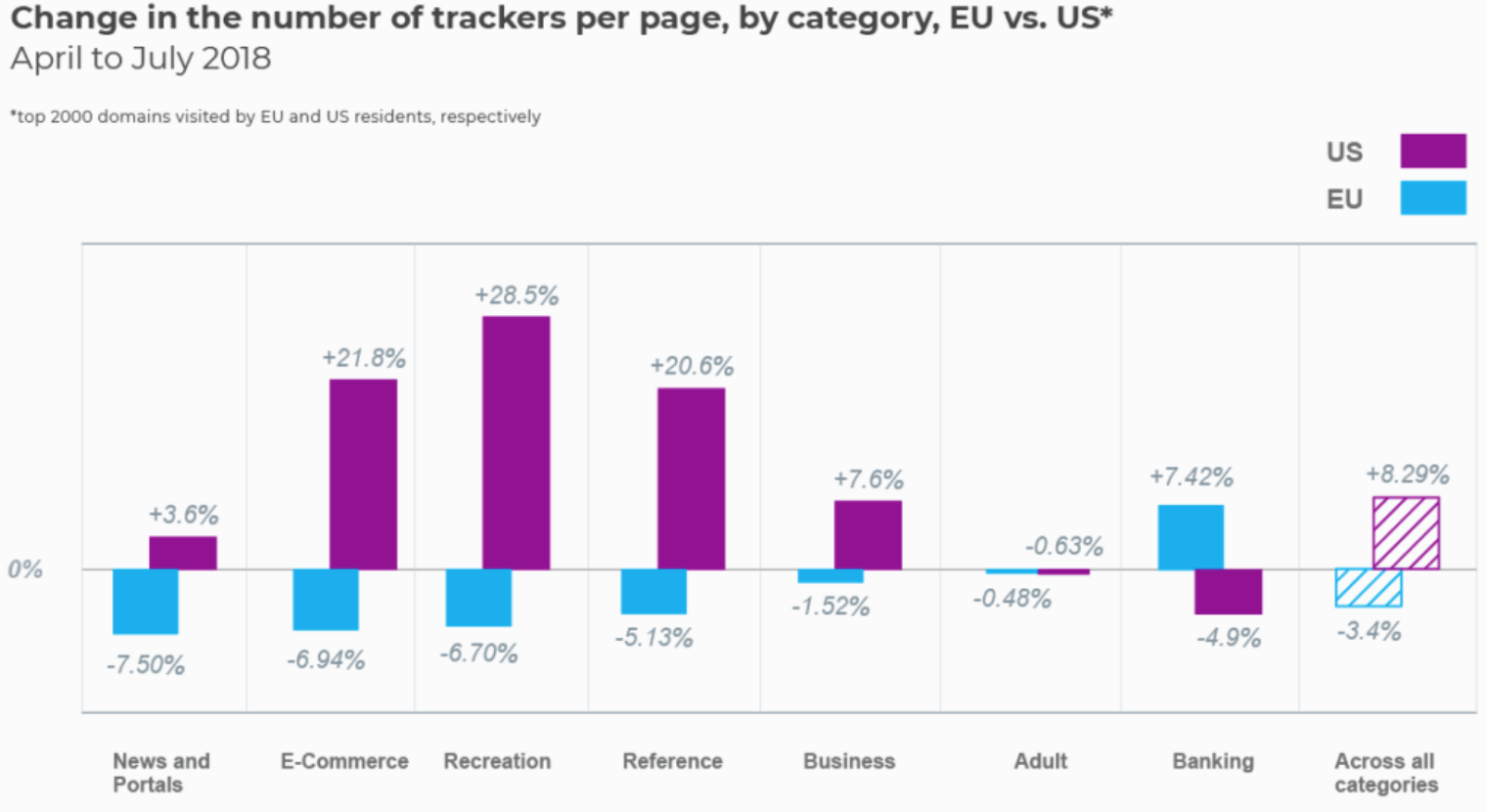
最終的には、ユーザーは自分たちのプライバシーを守るためには、GDPRのような法律や規制に頼るべきではないということです。そのかわりに、自分たちはどういったデータを誰に提供しているのかについて理解しておくべきです。GhosteryやCliqzといったアドブロッカーのツールを使って個人のデータが第三者にかってに転送されるのを防ぐといった技術的なソリューションもあります。
Quote of the Week
“Data! data! data! I cannot make bricks without clay.”
データ!データ!データ!粘土なしにレンガは作れない!
What Are We Writing?
最近、以下の記事をTeam Exploratoryより出しました。
What Are We Working On?
Exploratory v5.1
実は、v5.0に入れる予定だったが間に合わなかったといういくつかの機能があります。例えば、ダッシュボードやノートにパラメーターをつけてインタラクティブにするといった機能などです。
これらを入れたv5.1を次の数週間以内に出したいと思っています。先週はそのための基盤づくりに集中していました。今週から残りの開発作業に入っていきます。
おもしろいリリースになると思うので楽しみにしておいてください!
Exploratoryユーザー勉強会
先週もお伝えしましたが、これまでのブートキャンプに来られた方たち主催の勉強会が、今週の木曜日、11月15日の夜に開催されます!
Exploratory v5.0の紹介ウェビナー
冒頭でも述べたように、Exploratory v5.0の新機能の紹介のためのオンライン・セミナーを今週の金曜日の朝9時(日本時間)に行います。特にExploratoryのユーザーの方たちはぜひ参加してみてください。もちろん、だれでも参加できます!
データサイエンス・ブートキャンプ、1月開催!
次回ブートキャンプは来年1月です!まだ若干空きがありますので、データサイエンスの手法やデータ分析をゼロから体系的にいっしょに学びたいという方は、この機会にぜひご検討下さい!
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。