
こんにちは、Exploratoryの西田です!
いよいよクリスマスが近づいてきました。クリスマスの木を切ってきて飾ったり、ジンジャーハウスを作ったりと、だんだんと家もクリスマスな感じになってきて楽しい季節です。
USではクリスマスの日に親戚など家族そろって膨大な量のギフトの交換会が行われますが、そのためのギフトショッピングがけっこうたいへんだったりします。これだけオンラインで何でもできる時代で、さらにAIの時代なはずなのに、まだ実店舗へ行ってそれぞれの人へのギフトを手作業で選んでいくというのはちょっと不思議なかんじですね。
ところで、今週の水曜日、19日の午前9時-10時(日本時間)にオンラインセミナーをやります。今回はK-Meansというデータを類似性をもとにグループ分けする時に使うアルゴリズムの使い方の紹介です。こちらに詳細があります。
また、この1月の日本でのデータサイエンス・ブートキャンプの週末版は若干まだ空きがありますので、ビジネスの現場で使えるデータサイエンスの手法を、プログラミングなしで一から体系的に学びたい方は、この機会に参加をご検討ください!
それでは、今週のWeekly Update、さっそくいってみましょう!
最近の興味深い英文の記事
2018年の世界のAIトレンドをまとめたAIインデックス
主にUSですがAIに関する政策研究者たちが毎年AIに関するトレンドをまとめたAIインデックスというレポートを出していますが、その最新版である2018年のものが最近リリースされました。
去年は北米中心でしたが、今年はヨーロッパ、中国に関するトレンドもカバーされています。主に、投資、雇用、論文、特許、スタートアップ、ビジネス、政治の分野でのAIのトレンドです。
統計のモデルと機械学習のモデル、どう使い分ければよいのか
以前、「結局、機械学習と統計学は何が違うのか?」というポストの中で「統計と機械学習の違い」について、手法や技術的な側面から簡潔に説明していた記事を紹介しました。
今回は、もう一歩先に進んで、それでは、統計と機械学習のモデルがあった時、どう使い分ければいいのか」について簡潔にまとめられていた記事、“Road Map for Choosing Between Statistical Modeling and Machine Learning” を紹介したいと思います。
イギリスの若いCEOはデータスキル不足が心配
社内のデータスキル不足の心配をしているのは、何も日本だけではありません。こちらの記事によると、イギリスでも、71%のCEOはこのことを深刻なリスクだと捉えているようです。
ただ、年齢層によっての差も明らかなようです。
25歳から34歳までのCEOの84%はデータこそが大きなリスクだと捉えているのに対して、55歳以上では半分ほどしか同じように捉えていないとのことです。
三分の一のCEOは朝起きて最初と寝る前にビジネスのアナリティクスをチェックすると回答しています。この習慣は若い人たちになるともっと顕著です。25歳から24歳のCEOの54%がそうすると回答しているのに対し、45歳以上ではその比率は5%まで落ちています。
もっと経験豊かな高年層の人たちに比べて、若いCEOの人たちはデータに対する態度がまったく違います。彼らはデジタル時代にキャリアをスタートしているので、そうした環境を積極的に使いこなすことで柔軟な仕事環境を構築していっています。
そして彼らはデータを正しく理解できていないことによる失敗を恐れているのです。
中国のAIの野望を支えるデータのラベル付け工場
上記でも述べましたが、機械学習、AIは答えがはっきりと決まっているような画像認識などで大きな成果を発揮します。しかしそのためには正確なラベル付けの作業が欠かせません。例えば様々なタイプのバナナの写真を「バナナ」、たくさんあるりんごの写真を「りんご」といったように人間が大量の画像ファイルに対して事前にラベル付けしてあげる必要があります。
そして、この作業がバカにならないほど大変だったりするので、画像認識という点に関しては、ユーザーがせっせとタグ付けしてくれる写真共有サービスを無料で提供しているGoogleやFacebookがこの分野では強かったりするします。そしてこうしたラベル付けがスタートアップのような新参者には結構辛かったりします。
ところが、中国ではそういったラベル付けを安い人件費を利用して大量に行うようなサービスがどんどんと出てきているようです。
このことが中国にとってのアメリカに対するAI分野での競争優位となるのではないかという記事がニューヨーク・タイムズから出ていました。
- How Cheap Labor Drives China’s A.I. Ambitions - Link
「以前はマシンというのは天才だと思っていたけど、今は私達がいるからマシンが天才としてふるまえるのだとわかりました。」
とは、そうしたサービスを提供する企業で働く24歳のHouとうい女性のコメントです。
中国はみなさんも知っているように、プライバシーというものが欧米に比べてゆるいので、企業は個人のデータをほかの国に比べて収集しやすいです。さらに、そもそも政府がふだんから監視カメラを使って様々な情報を収集しているので、データに関しては、石油の世界でのサウジアラビアのような存在です。
そして、そういったラベル付けをするサービスを提供する会社が精油所というわけで、この人たちが中国がAIに関して世界で1番になるという野望をかなえるための燃料となるわけです。
Quote of the Week
“The greatest enemy of knowledge is not ignorance, it is the illusion of knowledge.”
知識にとっての最大の敵は無知ではなく、知識を持っているという幻想だ。
by Stephen Hawking
What Are We Writing?
最近、以下の記事をTeam Exploratoryより出しました。
What Are We Working On?
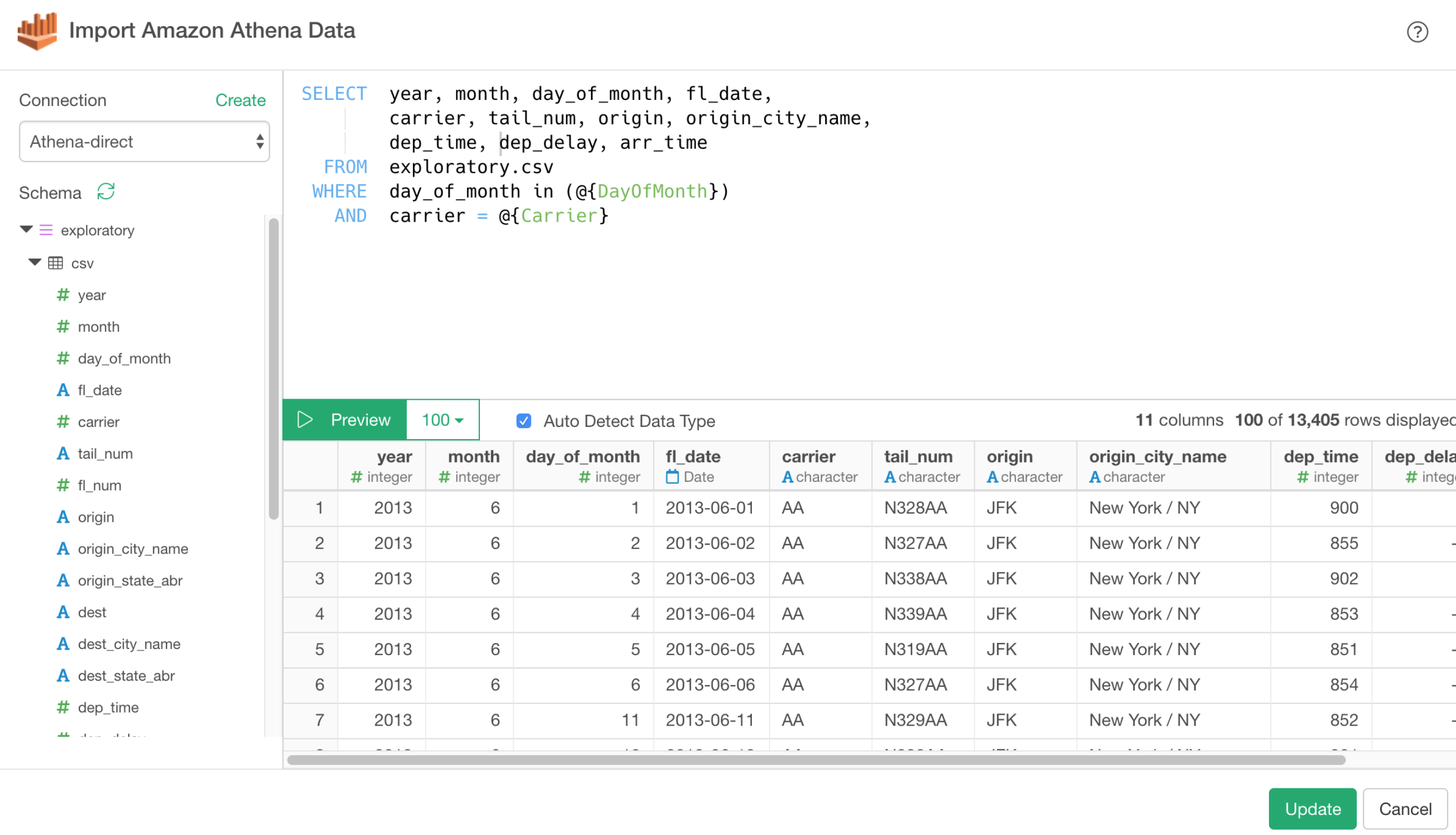
AWS S3 Athena、テラデータのサポート
v5.1からAWS S3 Athenaとテラデータがビルトインでサポートされます!
これまでも、RカスタムスクリプトやODBCデータソースを使って接続することができたのですが、次のリリースからはもっと簡単に接続してデータを取ってくることができるようになります。
もちろん、v5.1から入ってくるパラメーターの方も、Athena、テラデータのSQLの中で使うことができるようになります!💪
Exploratoryオンライン・セミナー
次回のオンライン・セミナーは2018/12/19(水) 午前9時-10時(日本時間)です。
今回はK-Meansというデータを類似性をもとにグループ分けする時に使うアルゴリズムの使い方の紹介です。こちらに詳細があります。
データサイエンス・ブートキャンプ、1月開催!
次回ブートキャンプは来年1月です!週末版の方にまだ若干空きがありますので、データサイエンスの手法やデータ分析をゼロから体系的にいっしょに学びたいという方は、この機会にぜひご検討下さい!
それでは、今週は以上です。素晴らしい一週間を!
西田, Exploratory/CEO
KanAugust(Twitter)
こちらのExploratory’s Weekly UpdateはExploratoryのユーザー以外の方も無料で購読できます。まだEmailを登録されていない方はこちら よりどうぞ!皆さんのお役に立つと思うデータサイエンス関連のニュースをまとめたものを週一度配信いたします。