
Hi there!
It’s Kan from Exploratory.
It’s been a long time! ;) We have been super busy with Data Science training classes over the last few weeks. But it’s been a lot of fun and it’s been a great pleasure to have met many data passionates around the world. This is why I love what I do! ;) Now we are back at the development of Exploratory v4.4 based on all the feedback we got during the training classes, the fun continues. 😁
Now, two things.
First, we have released Exploratory v4.3 last week. 🎉 Take a look at the release announcement blog post. There are a lot of improvements and bug fixes.
Second, now that we have finished our 2nd Data Science Booster training, we have opened the enrollment for the next Booster in June. As always, we have a student discount (50% off). If you are interested in learning how to analyze data with various Data Science methods, sign up today!
Now, here’s this week’s update!
What We Are Reading
What worries me about AI - Link
François Chollet, an author of a very popular Deep Learning framework Keras and an AI researcher@Google, has written a very insightful post about what AI can actually do to manipulate us when it’s used with Social Network data. The fact that AI at Social Network can decide what information it feeds us and can monitor how we behave, we can easily fall into the object of what machine learning algorithms can train. And that’s what we are seeing already.
AI is rapidly changing the types and location of the best-paying jobs - Link
Former US Treasury secretary: Here’s how to prepare for the future of work - Link
As the pace of the technical advancements becoming much faster and faster, it’s becoming harder for existing education systems to keep up for meeting the demands of a new type of skills required for the next generation workers. Given many of the data scientists have learned many of their current skills at their spare times or through their side projects, how to develop the skills we need is in each individual’s hands. But of course, this won’t scale and will create even more economic inequality. Now, who is going to fix this?
4 Years of Data Science at Schibsted Media Group - Link
Alex Svanevik, a data science manager at Schibsted Media Group, has shared what he learned from working as a data science manager over the last four years. Among many useful insights, I personally like that he’s encouraging to have a baseline for prediction models. Sometimes, a simple logistic regression can produce as good quality prediction as other more complicated algorithms would do. If it’s same, then go for the simpler one! ;)
Others
- The next cold war is here, and it’s all about data - Link
- Getting Value from Machine Learning Isn’t About Fancier Algorithms — It’s About Making It Easier to Use - Link
- The Day the Algorithm Died - Link
- How the AI cloud could produce the richest companies ever - Link
- An executive’s guide to AI - Link
Quote of the Week
Live as if you were to die tomorrow. Learn as if you were to live forever.
Mahatma Gandhi
What We Are Writing
Here is the release announcement blog post for Exploratory v4.3.
And, if you haven’t read yet, here are the three episodes of “A Beginner’s Guide to Linear Regression ” series.
- A Beginner’s Guide to EDA with Linear Regression — Part 1 - Link
- A Beginner’s Guide to EDA with Linear Regression — Part 2 - Link
- A Beginner’s Guide to EDA with Linear Regression — Part 3 - Link
I’ll be publishing another three episodes soon, stay tuned!
Also, Hide from Team Exploratory has recently published these two practically useful posts.
- Creating Dashboard with Exploratory - Link
- How to Write Data Wrangling Result Back to Amazon Redshift DB in R and Exploratory - Link
Also, make sure to check our Community page. Not only we answer the questions, but also we share some useful tips there.
What We Are Working On
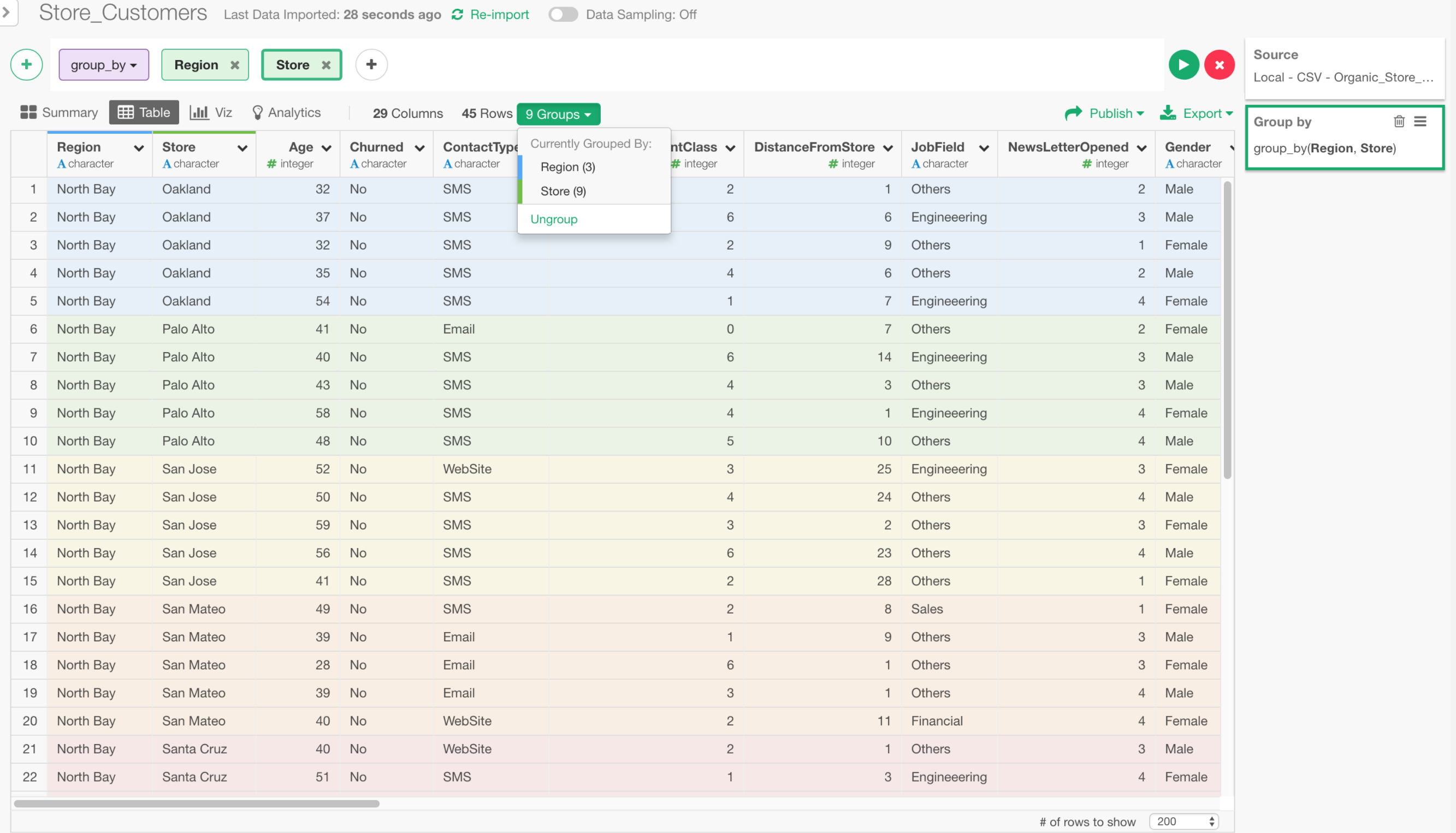
When you use Group By to group the data frame, you can do all sorts of amazing things with Summarize, Mutate, Filter, Fill, Expand, and even building models.
But, right after the Group By step, you won’t see much change in the view, which confuses many people who are new to this ‘dplyr’ data wrangling grammar.
We’re trying to improve this experience for the next release (v4.4) and here is where we are. Let me know if you have any feedback or suggestion!
Data Science Booster Training
As mentioned at the beginning, we have just scheduled our next Data Science Booster Training in June and opened the enrollment. As always, we have a student discount (50% off). If you are interested in learning Data Science without programming, sign up today!
That’s it for this week.
Have a wonderful week!
Kan CEO/Exploratory
This is a weekly email update of what I have seen in Data Science / AI and thought were interesting, plus what Team Exploratory is working on.